Советы будущим специалистам
Стать специалистом в рассмотренной области – дело не из простых. Москва и другие регионы России на данный момент предлагают довольно мало ВУЗов, в которых учат на специалистов пор «большим материалам».
Можно воспользоваться следующими вариантами развития событий:
- отыскать зарубежный ВУЗ, где обучают на BigData Engineer;
- посетить специализированные курсы с выдачей сертификата по упомянутому направлению.
Чтобы добиться успеха, придется интересоваться IT и математикой, а также информатикой. Знания программирования тоже окажутся не лишними.
Внимание: в России для обучения на BigData Engineer и изучения технологии Big Data чаще всего используются специализированные курсы. Они проводятся как оффлайн, так и онлайн
Вот некоторые из таких профессиональных курсов:
«Промышленный ML на больших данных«;
«Data Engineer«.
Как стать специалистом в «отрасли»
Знать о характеристиках больших данных, а также уметь работать с ними должны специально обученные люди. Их так и называют – специалисты по BigData.
Самообразование в данном случае никак не поможет. Это не программирование, которому можно обучиться «с нуля» собственными силами. В ВУЗах России пока тоже не слишком часто предлагают соответствующее направление. Но выход есть.
Для того, чтобы разбираться в Big Data и стать настоящим специалистом, можно выбрать один из следующих вариантов развития событий:
- пройти обучение за рубежом по большим данным;
- отдать предпочтение специализированным курсам;
- найти ВУЗ в РФ, который поможет стать Big Data Engineer.
Выбор не такой уж большой. В основном люди отдают предпочтение курсам. Они бывают как дистанционные, так и «очные». Первый вариант пользуется большим спросом, нежели второй. Для успешного обучения требуются базовые знания информатики и IT-технологий. Проще всего освоиться в соответствующей отрасли будет инженерам, а также «технарям» и «айтишникам».
Теперь ясно, что такое Big Data, для чего и как они применяются. Стать специалистом в этой перспективной сфере может каждый, но для этого придется изрядно постараться. Большой труд окажется вознагражден достойно.

5.4. Гибридная архитектура NUMA
Главная особенность гибридной архитектуры NUMA (nonuniform memory access) – неоднородный доступ к памяти.
Суть этой архитектуры – в особой организации памяти, а именно: память физически распределена по различным частям системы, но логически она является общей, так что пользователь видит единое адресное пространство. Система построена из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти осуществляется в несколько раз быстрее, чем к удаленной. По существу, архитектура NUMA является MPP (массивно-параллельной) архитектурой, где в качестве отдельных вычислительных элементов берутся SMP (симметричная многопроцессорная архитектура) узлы. Доступ к памяти и обмен данными внутри одного SMP-узла осуществляется через локальную память узла и происходит очень быстро, а к процессорам другого SMP-узла тоже есть доступ, но более медленный и через более сложную систему адресации.
Гибридная архитектура совмещает достоинства систем с общей памятью и относительную дешевизну систем с раздельной памятью.
В структурной схеме компьютера с гибридной сетью (рис. 5.7) три процессора связываются между собой при помощи общей оперативной памяти в рамках одного SMP-узла. Узлы связаны сетью типа «бабочка» (Butterfly).
Впервые идею гибридной архитектуры предложил Стив Воллох, он воплотил ее в системах серии Exemplar. Вариант Воллоха – система, состоящая из восьми SMP-узлов. Фирма HP купила идею и реализовала на суперкомпьютерах серии SPP. Идею подхватил Сеймур Крей (Seymour R. Cray) и добавил новый элемент – когерентный кэш, создав так называемую архитектуру cc-NUMA (Cache Coherent Non-Uniform Memory Access), которая расшифровывается как «неоднородный доступ к памяти с обеспечением когерентности кэшей». Он ее реализовал на системах типа Origin.
Рисунок 5.7 – Структурная схема компьютера с гибридной сетью
Организация когерентности многоуровневой иерархической памяти
Понятие когерентности кэшей описывает тот факт, что все центральные процессоры получают одинаковые значения одних и тех же переменных в любой момент времени. Действительно, поскольку кэш-память принадлежит отдельному компьютеру, а не всей многопроцессорной системе в целом, данные, попадающие в кэш одного компьютера, могут быть недоступны другому. Чтобы этого избежать, следует провести синхронизацию информации, хранящейся в кэш-памяти процессоров.
Для обеспечения когерентности кэшей существует несколько возможностей:
— использовать механизм отслеживания шинных запросов (snoopy bus protocol), в котором кэши отслеживают переменные, передаваемые к любому из центральных процессоров и при необходимости модифицируют собственные копии таких переменных;
— выделять специальную часть памяти, отвечающую за отслеживание достоверности всех используемых копий переменных.
Наиболее известными системами архитектуры cc-NUMA являются: HP 9000 V-class в SCA-конфигурациях, SGI Origin3000, Sun HPC 15000, IBM/Sequent NUMA-Q 2000. На сегодня максимальное число процессоров в cc-NUMA-системах может превышать 1000 (серия Origin3000). Обычно вся система работает под управлением единой ОС, как в SMP. Возможны также варианты динамического «подразделения» системы, когда отдельные «разделы» системы работают под управлением разных ОС. При работе с NUMA-системами, так же, как с SMP, используют так называемую парадигму программирования с общей памятью (shared memory paradigm).
5.5. Параллельная архитектура PVP с векторными процессорами
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах.
Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько узлов могут быть объединены с помощью коммутатора (аналогично MPP). Поскольку передача данных в векторном формате осуществляется намного быстрее, чем в скалярном (максимальная скорость может составлять 64 Гбайт/с, что на 2 порядка быстрее, чем в скалярных машинах), то проблема взаимодействия между потоками данных при распараллеливании становится несущественной. И то, что плохо распараллеливается на скалярных машинах, хорошо распараллеливается на векторных. Таким образом, системы PVP-архитектуры могут являться машинами общего назначения (general purpose systems). Однако, поскольку векторные процессоры весьма дорого стоят, эти машины не могут быть общедоступными.
Наиболее популярны три машины PVP-архитектуры:
1. CRAY X1, SMP-архитектура (рис. 5.8). Пиковая производительность системы в стандартной конфигурации может составлять десятки терафлопс.
2. NEC SX-6, NUMA-архитектура. Пиковая производительность системы может достигать 8 Тфлопс, производительность одного процессора составляет 9,6 Гфлопс. Система масштабируется с единым образом операционной системы до 512 процессоров.
3. Fujitsu-VPP5000 (vector parallel processing), MPP-архитектура (рис. 5.9). Производительность одного процессора составляет 9.6 Гфлопс, пиковая производительность системы может достигать 1249 Гфлопс, максимальная емкость памяти – 8 Тбайт. Система масштабируется до 512 процессоров.
Парадигма программирования на PVP-системах предусматривает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
За счет большой физической памяти (доли терабайта) даже плохо векторизуемые задачи на PVP-системах решаются быстрее на машинах со скалярными процессорами.
|
Рисунок 5.8 – CRAY SV-2 |
Рисунок 5.9 – Fujitsu-VPP5000 |
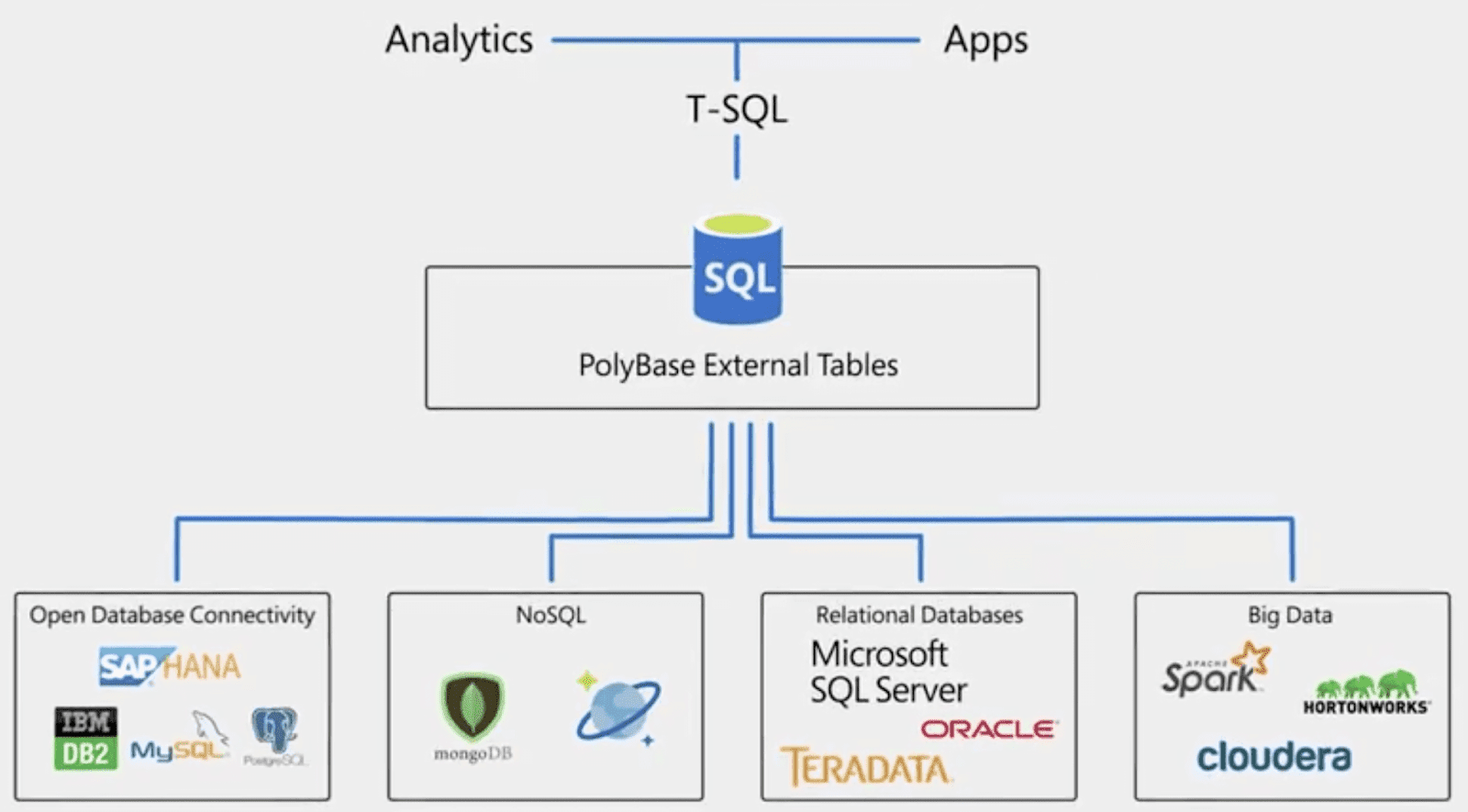
MapReduce
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи. Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.










2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce(). Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Актуальность и перспективы
Big Data вызывает немало вопросов. Эта область сегодня развивается весьма стремительно, но люди задумываются – а стоит ли вообще углубляться в соответствующую сферу деятельности. Ведь для того, чтобы добиться успеха в качестве аналитика «больших данных», придется изучить и усвоить немало информации.
Ответ однозначен – да. В России, Америке и других развитых странах вместе с «большими сведениями» с 2015 года началось развитие так называемого «блокчейна». Это – отличное дополнение изученного термина, обеспечивающее защиту и конфиденциальность электронных материалов.
Статистика показывает – инвестициями в Big Data занимаются почти все существующие крупные и известные корпорации. Кто-то — больше, кто-то – меньше. Анализ соответствующих данных помогает обнаруживать различные скрытые схемы. Они потребуются при разработке наиболее эффективных и инновационных технологий и бизнес-проектов. А если учесть не только то, какие определение имеет Big Data, но и перспективы развития IT, можно сделать вывод – большие данные со временем окажутся еще более ценными.
Прогнозирование времени функционального отказа
Как только мы установили, что зарождающийся отказ (потенциальный сбой) существует на активе, и что последствия отказа будут таковы, что их следует избегать, следующий вопрос, который возникает, это «сколько у нас остается времени, прежде чем произойдет критический отказ» или, точнее, «сколько у нас времени для предотвращения этого критического отказа». Здесь мы вступаем в область прогнозирования, и технологии обработки больших данных могут как раз помочь в получении ответа. В настоящее время те, кто знаком с ремонтами, ориентированными на надежность (RCM), скорее всего, знают, что одним из ключевых параметров является PF-интервал (см. рис. 2) — это временной интервал от точки Р (точка, в которой мы можем впервые обнаружить существование потенциального отказа или зарождающегося дефекта) до точки F (точка, в которой этот отказ неизбежно произойдет). PF-интервал важен по двум причинам. Первая заключается в том, что если мы проводим периодические проверки состояния активов, мы должны проводить их с периодичностью меньше времени PF-интервала, чтобы быть в состоянии принять необходимые меры и избежать последствий функциональных отказов. Вторая заключается в том, что PF-интервал говорит нам, как быстро мы должны принять необходимые меры для предотвращения технических сбоев в будущем
Обратите внимание, что появление «Интернета вещей», в котором все больше и больше параметров состояния оборудования регистрируются в режиме реального времени, а не через периодические проверки, дает нам возможность выбирать точку потенциальных отказов (точка P на рис. 2) как можно ближе к точке F и при этом избежать последствий отказа
Так мы можем реализовывать стратегии профилактики отказов «точно в срок», тем самым продлевая срок службы компонентов
Это особенно важно для техники, такой как карьерные самосвалы и дорожные грузовики, где интервал времени между периодическими работами обычных проверок может быть довольно большим. Так как же определить, каков PF-интервал на самом деле? В настоящее время большинство организаций оценивают PF-интервал (за исключением, возможно, для особо важных видов отказов) методом экспертных оценок
Это часто происходит в режиме мозгового штурма на тему «как долго прослужит подшипник, пока его не заклинит?» Учитывая, что эти оценки могут быть неточными, обычно принимаются более консервативные оценки PF-интервала, что приводит к излишне частым проверкам. Прогнозная аналитика в сочетании с мониторингом состояния в режиме реального времени и технологией «Интернета вещей» может позволить нам оценить PF-интервал с большей точностью путем сбора информации о том, как состояние оборудования изменяется с течением времени в рамках текущей оценки PF-интервала. Затем технология больших данных может позволить нам определить дополнительные факторы, которые могут влиять на реальный PF-интервал для конкретного отказа, на определенную часть оборудования, с учетом конкретных условий эксплуатации. Например, измеряя электрическую нагрузку на электродвигатель с одновременной фиксацией информации о вибрации, мы можем определить влияние нагрузки на двигатель и скорость его износа от точки P до точки F. Как отмечалось ранее, основным препятствием для применения более сложных прогностических аналитических методов является недостаточность данных, потому что на практике мы редко доводим оборудование до точки F, так как последствия этого могут быть слишком велики. Но без этой информации мы должны делать лишь предположения на основе взвешенных данных о потенциальных отказах.
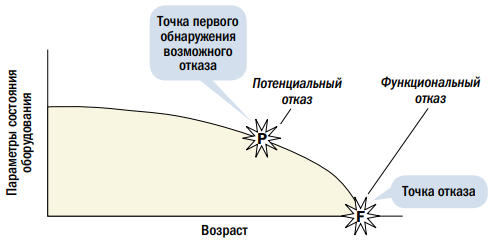
Рис. 2. Прогнозирование времени функционального отказа
История вопроса и определение термина
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Что такое суперкомпьютер?
Суперкомпьютеры выполняют массовую параллельную обработку данных, при которой задачи разбиваются на части и одновременно обрабатываются тысячами процессоров. Это их главное отличие от обычных компьютеров, которые последовательно решают задачу за задачей. Если воспользоваться аналогией, то это все равно что подойти к кассам в супермаркете с полной тележкой и разделить товары между несколькими друзьями. Каждый оплатит свою часть отдельно, после чего вы встретитесь у выхода и снова сложите продукты в одну тележку. Чем больше друзей, тем быстрее можно завершить параллельную обработку — по крайней мере, в теории.










«Если система настроена правильно, то какую бы задачу вы ни поставили суперкомпьютеру, он справится с ней гораздо быстрее, чем компьютер с меньшим количеством процессоров или одним процессором. Для некоторых вычислений домашнему ноутбуку понадобились бы недели или даже месяцы, но если вы сможете настроить эффективную параллельную обработку данных, то это займет не больше дня», — объясняет исследователь из Политехнического института Ренсселера Джоан Росс, которая недавно вернулась из Аргоннской национальной лаборатории, где она проработала шесть месяцев.
По словам Росс, обработке данных способны помешать некорректные параметры программы. Например, расчеты могут идти стремительно при работе четырех процессоров, но замедлиться при подключении пятого.
Что такое цифровая экономика?[править]
Хозяйственная деятельность, в которой ключевым фактором являются данные в цифровом виде +
Стадия развития технологий интернет, концепция вычислительной сети физических предметов («вещей»), оснащенных встроенными технологиями для взаимодействия друг с другом или с внешней средой и объединяющая целый стек технологий
Общий подход к цифровой трансформации и внедрению управления на основе данных на промышленном предприятии
Подход к цифровой трансформации компании, основанный на решении использовать современные технологии и практики проектной работы
Направление, в котором стартапы, инновационные компании и само государство оцифровывают государственные продукты и услуги, используя новые технологии
Классификация
BigData обладают собственной классификацией. Условно принято разделять все большие сведения на несколько групп:
- Структурированные. Они обладают структурой таблиц, а также отношений. Сюда можно отнести Excel, а также документы CSV.
- Полуструктурированные. Еще называются слабоструктурированными. Сведения, не обладающие строгой табличной составляющей и отношениями. Имеют разнообразные маркеры, при помощи которых в реальной жизни удается отделить семантику и обеспечение иерархии полей и записей. Пример – электронные материалы о письмах по e-mail.
- Неструктурированные. Не имеют никакой четкой организации и структуры: текст на естественном языке, аудиодорожки, видеоролики, изображения.
Работа с большими данными производится только при помощи специальных технологий. Но перед тем, как браться за них, требуется понимать общие принципы анализа, а также особенности BigData.
Внимание: не стоит путать Big Data с базами данных. Это совершенно разные понятия
Второй элемент относительно небольшой по сравнению с рассматриваемым термином.
Актуальность и перспективы
Big Data вызывает немало вопросов. Эта область сегодня развивается весьма стремительно, но люди задумываются – а стоит ли вообще углубляться в соответствующую сферу деятельности. Ведь для того, чтобы добиться успеха в качестве аналитика «больших данных», придется изучить и усвоить немало информации.
Ответ однозначен – да. В России, Америке и других развитых странах вместе с «большими сведениями» с 2015 года началось развитие так называемого «блокчейна». Это – отличное дополнение изученного термина, обеспечивающее защиту и конфиденциальность электронных материалов.
Статистика показывает – инвестициями в Big Data занимаются почти все существующие крупные и известные корпорации. Кто-то — больше, кто-то – меньше. Анализ соответствующих данных помогает обнаруживать различные скрытые схемы. Они потребуются при разработке наиболее эффективных и инновационных технологий и бизнес-проектов. А если учесть не только то, какие определение имеет Big Data, но и перспективы развития IT, можно сделать вывод – большие данные со временем окажутся еще более ценными.
Меняем правила игры
Итак, мы можем видеть, что «Интернет вещей» и большие данные потенциально представляют огромные возможности для улучшения надежности оборудования и сокращения затрат на его техническое обслуживание. В недавнем прошлом для считывания информации с оборудования, оснащенного датчиками контроля состояния, применялись стационарные посты, к которым техника подъезжала для передачи данных. Теперь же, с появлением относительно дешевых беспроводных технологий, необходимость проводных сетей для съема информации с датчиков и контроллеров отпадает. В сочетании с возможностями «Интернета вещей», интерфейсов «машина — машина», облачных технологий обмена данными и мощных серверов процесс совместного использования больших данных ускорился и упростился. Значительное увеличение инвестиций в области проектирования новых датчиков и разработки современных платформ для моделирования прогнозов по отказам добавляет уверенности в быстром развитии этих технологий. Информация от датчиков, приводов, параметров управления и оперативных данных, накопленных данных SCADA-систем, прогнозных данных может обеспечить следующее:
- визуализацию данных,
- панели ключевых показателей,
- сигналы предупреждения для операторов,
- автоматическое вмешательство,
- прогнозы по времени отказа оборудования.
В некоторых случаях информация может быть автоматически передана в систему АСУ ТОиР для завершения цикла управления и формирования заказа на работу. Системы, разработанные для обеспечения автоматизированного технического обслуживания, могут обеспечить следующие потенциальные выгоды:
- повышенную надежность активов,
- уменьшение времени на ТОиР,
- увеличение коэффициента использования оборудования,
- повышение безопасности и качества продукции,
- раннее обнаружение незначительных отклонений,
- снижение эксплуатационных расходов,
- контроль развивающихся дефектов на основе разных источников данных,
- снижение нагрузки на обслуживающий персонал за счет автоматизированной диагностики,
- некоторые системы претендуют на возможность предсказывания остаточного ресурса машин,
- усовершенствованный анализ коренных причин отказов (RCA),
- удаленный доступ к данным.
Успешное внедрение прогнозного ТОиР может быть связано с двумя ключевыми областями (табл. 1).
- Организационно-интегрированный подход на всех уровнях организации.
- Достаточность модели и данных — необходимо сбалансировать точность и устойчивость выводов в расчетной модели для обеспечения высокого качества данных.
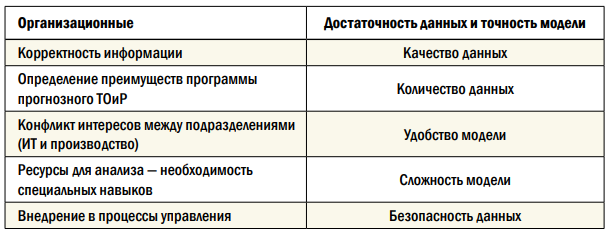
Таблица 1. Области успешного внедрения прогнозного ТОиР
Summit
Суперкомпьютер Summit, созданный американской компанией IBM для Национальной лаборатории в Окридже. Технику ввели в эксплуатацию летом 2018 года, заменив модель Titan, которая считалась самой производительной американской СуперЭВМ. Разработка лучшего современного суперкомпьютера обошлась американскому правительству в 200 млн долларов.
Устройство потребляет около 15 МВт электроэнергии – столько, сколько вырабатывает небольшая ГЭС. Для охлаждения вычислительной системы используется 15,1 кубометра циркулирующей по трубкам воды. Сервера IBM расположены на площади около 930 кв.м – территория, которую занимают 2 баскетбольные площадки. Для работы суперкомпьютера используется 220 км электрокабелей.
Производительность компьютера обеспечивается 9216 процессорами модели IBM POWER9 и 27648 графическими чипами Tesla V100 от Nvidia. Система получила целых 512 Гбайт оперативной и 250 Пбайт постоянной памяти (интерфейс 2,5 Тбайт/с). Максимальная скорость вычислений – 200 Пфлопс, а номинальная производительность – 143,5 Пфлопс.
По словам американских ученых, запуск в работу модели Summit позволил повысить вычислительные мощности в сфере энергетики, экономическую конкурентоспособность и национальную безопасность страны. Среди задач, которые будут решаться с помощью суперкомпьютера, отмечают поиск связи между раковыми заболеваниями и генами живого организма, исследование причин появления зависимости от наркотиков и климатическое моделирование для составления точных прогнозов погоды.
Что следует знать бизнесу о HPC?
Высокопроизводительные вычисления позволяют обрабатывать данные и выполнять сложные вычисления на высокой скорости и в плотных конфигурациях. HPC опирается на параллельную обработку, что повышает эффективность работы приложений, скорость и надежность. Благодаря HPC мы получаем открытия в науке, промышленности, экономике, финансах, общественных институтах, медицине, обороне и безопасности.
HPC используются в промышленности для улучшения продуктов, снижения затрат, уменьшения времени на разработку новых решений. По мере того, как объемы собираемых больших данных растут, увеличивается потребность в их анализе и обработке. И здесь высокопроизводительные вычисления HPC окажутся как нельзя кстати.
Исторически суперкомпьютеры и кластеры были ориентированы на высокопроизводительные вычисления, связанные с решением глобальных научных проблем, стоящих перед человечеством.
Так сформировался вычислительный профиль HPC, подразумевающий выполнение интенсивных вычислений за минимальное время. Многие вычисления разбиваются на несколько параллельных задач, но для обмена данными здесь требуется сетевая инфраструктура с низкими задержками. Для оценки вычислительной производительности HPC используют количество выполняемых операций с плавающей запятой в секунду (FLOPS), причем современные суперкомпьютеры достигли уровня PetaFLOPS и нацеливаются на уровень экзафлопсов (EFLOPS).
Intel планирует вместе с Министерством энергетики США построить первый экзафлопный суперкомпьютер Aurora около Чикаго. Система будет работать в Аргоннской национальной лаборатории. Интересно здесь то, что все компоненты суперкомпьютера изготовлены Intel. Что верно для процессоров (4-е поколение Xeon Scalable, Sapphire Rapids) и ускорителей GPU (Ponte Vecchio, Xe-HPC). Будет использоваться Intel Optane DC Persistent Memory.
Данные — новая нефть
В прошлом бизнес часто использовал упомянутый принцип «храни и игнорируй». Но сегодня данные превратились в новую нефть, они являются топливом для инноваций, повышения конкурентоспособности и успеха бизнеса. То есть данные для бизнеса представляют такую же ценность, как для ученого или исследователя.
Поэтому многим организациям нужны ИТ-решения, сочетающие высокопроизводительные вычисления с анализом данных. Что смещает баланс от чистых вычислительных систем на высокопроизводительный анализ данных. Подобная конвергенция приводит к появлению новых решений не только в науке и исследованиях, но также в коммерции, в сфере обработки информации, системах поддержки принятия решений, финансового анализа, видеонаблюдения в рознице, майнинга данных.
Алгоритмы интенсивной обработки данных оперируют с крупными базами данных, содержащими массивные объемы информации (например, о клиентах компании или результатах торгов на бирже). Эти базы могут накапливаться многие годы, но игнорировать их больше нельзя. Быстрый рост хранимых объемов данных неизбежно приводит к необходимости использовать HPC.
В результате мы получаем большое количество приложений, работающих на высокопроизводительных архитектурах, способных обрабатывать большие объемы данных. Чтобы можно было управлять большими объемами разнообразных данных, были разработаны специальные инструменты и библиотеки, визуализирующие результаты расчетов суперкомпьютера. Причем для вывода данных в визуально понятном виде после моделирования и симуляции могут потребоваться ресурсы суперкомпьютера. Здесь продолжается процесс конвергенции HPC, AI/ML/DL и больших данных. Поэтому требуется новая гибкая и открытая высокопроизводительная архитектура и экосистема конвергентных вычислений.
Обзор методологии
1. Собираем требования
В качестве источника могут выступать результаты опросов стейк-холдеров, анализ бизнес-целей проекта и историй использования
При этом важно конкретизировать, что имеет в виду клиент. Например, не просто «безотказная работа сайта», а «допустимый период простоя – 30 минут в месяц».
Далее мы оцениваем важность требований по двум критериям:
- ценность для бизнеса;
- степень влияния на архитектуру.
Уровни важности оцениваем по шкале HML (high, medium, low — высокий, средний, низкий). Таким образом, каждое требование будет иметь двухбуквенное сочетание
Архитектурно значимые пункты имеют обозначения HH, HM, HL, MH, MM. Стоит отметить, что большое число требований HH означает высокие риски на проекте.








2. Проектируем архитектуру
Мы проектируем архитектуру ПО, исходя из наиболее значимых атрибутов качества.
Это рекурсивный процесс, в ходе которого система декомпозируется на более мелкие подсистемы.
ADD — первый метод, который концентрируется на атрибутах качества и способах их достижения. Важным вкладом ADD было признание того, что анализ и документация являются неотъемлемой частью процесса проектирования. Этот метод успешно применяется более 15 лет.
Сейчас актуальная версия ADD — 3.0, итеративная. Согласно ей, проектирование выполняется поэтапно в течение всего времени разработки системы, в каждом спринте. В ней по шагам описано руководство по тем задачам, которые необходимо выполнить в рамках каждой итерации.
Для чего используются суперкомпьютеры
Как мы сказали выше, раньше суперкомпьютеры служили в военных целях — с их помощью происходила разработка ядерного оружия. Сегодня же мощь таких машин используются во многих науках и направлениях.
«Числодробилки» могут моделировать производственные условия и разрабатывать более совершенные продукты в областях от нефтегазовой промышленности до фармацевтики. Задумывались ли вы, как мы получаем точные прогнозы погоды? Верно, благодаря суперкомпьютерам. Ещё, к примеру, с их помощью удаётся быстро обрабатывать миллионы историй болезней и диагнозов, выявлять новые закономерности, рассчитывать вариации химических соединений для создания новых препаратов.
Из других сфер применения:
- проектирование в машиностроении;
- фармацевтика;
- физика;
- метеорология;
- криптография;
- биология;
- искусственный интеллект;
- нейросети и так далее.
О сборе и обработке
В рассматриваемой и столь большой области приходится задумываться над тем, как собирать данные и обрабатывать их. «С ходу», «просто так» справиться с поставленной задачей не получится. Связано это с тем, что Big Data требует наличия большого пространства, а также ресурсов у задействованных устройств.
С развитием технологий в мире начали появляться и внедряться специальные подходы, которые значительно упрощают перечисленные манипуляции. Вот основные инструменты, задействованные в соответствующей сфере:
- HPPC – большой суперкомпьютер с открытым исходным кодом. Называется DAS. Обрабатывает данные в режиме реального времени или в «пакетном состоянии». Все зависит от ситуации и настроек.
- Hadoop – одна из первых и самых больших технологий обработки Big Data. Ориентирован на «пакетную» работу. Реализация осуществляется через несколько машин, которые после проводят масштабирование сведений до большого количества серверов.
- Storm – удобная и универсальная система, предлагающая обработку в режиме реального времени. Подключает Eclipse Public License. Имеет открытые исходные коды.
Нет смысла использовать сразу все перечисленные инструменты. В зависимости от возможностей и потребностей специалисты выбирают те или иные варианты.