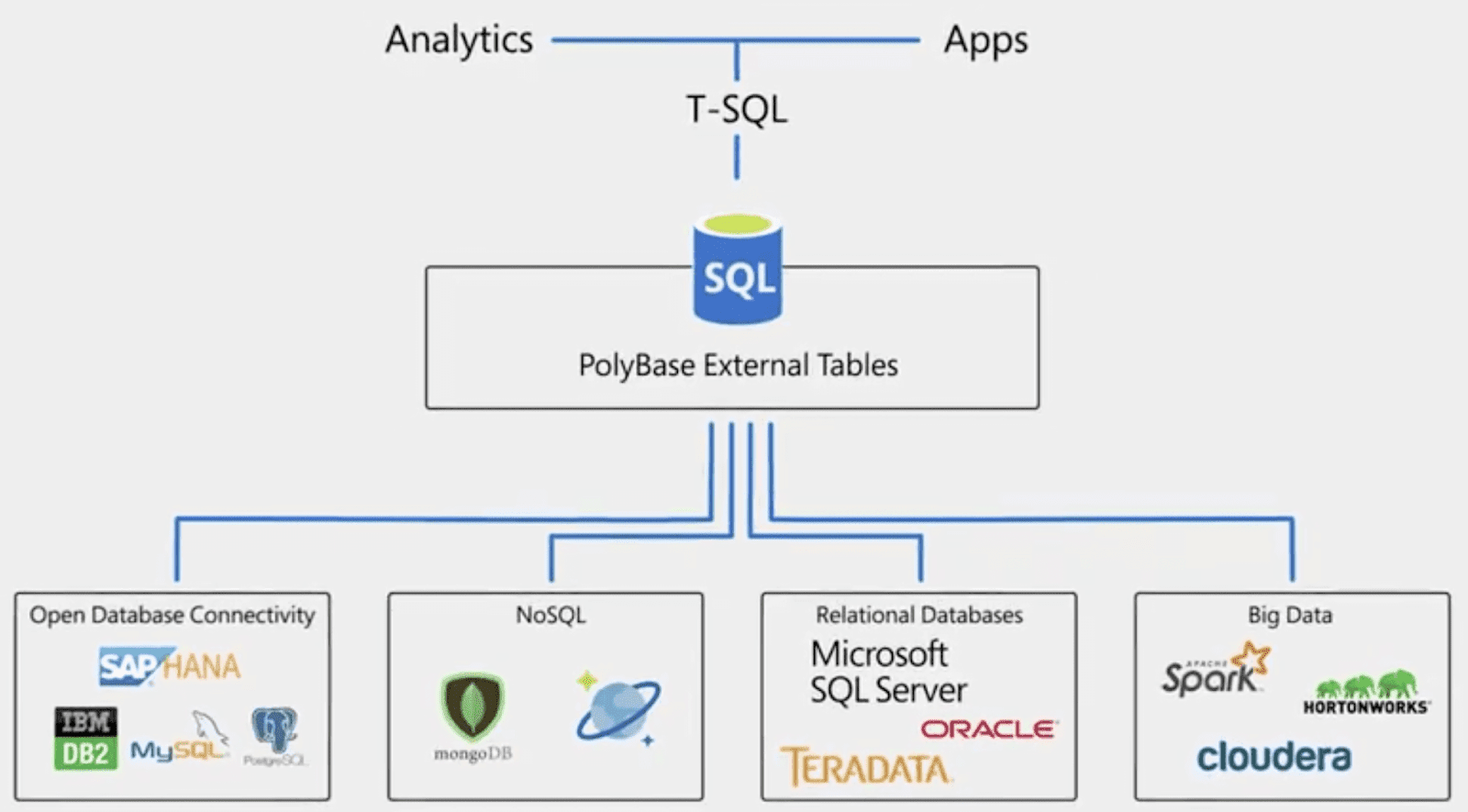
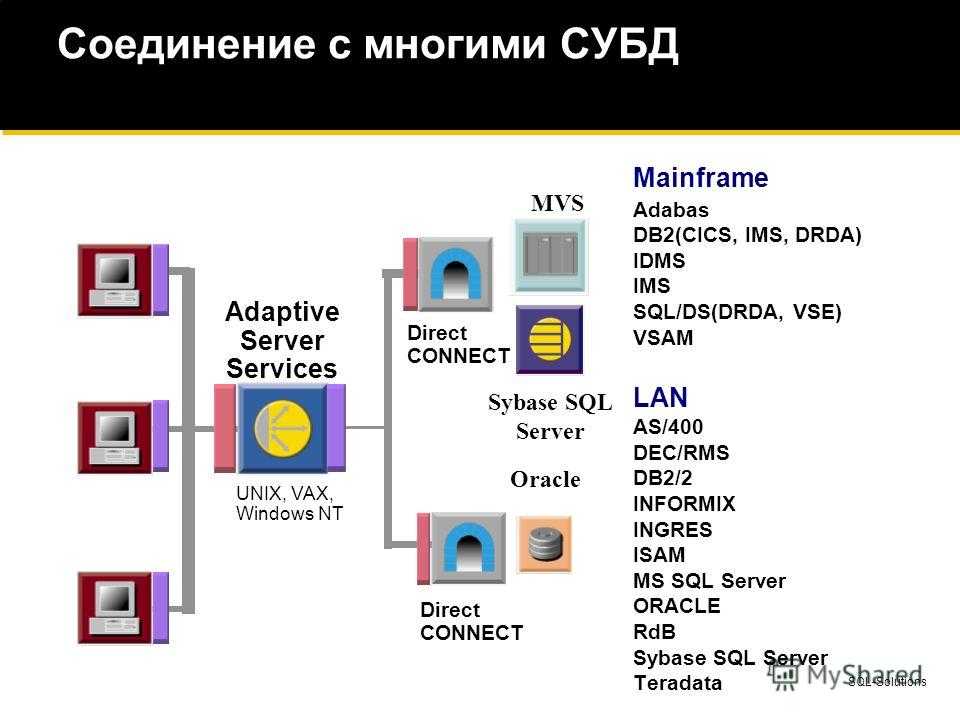
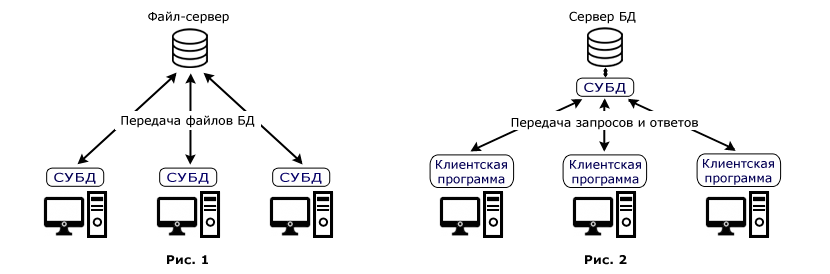
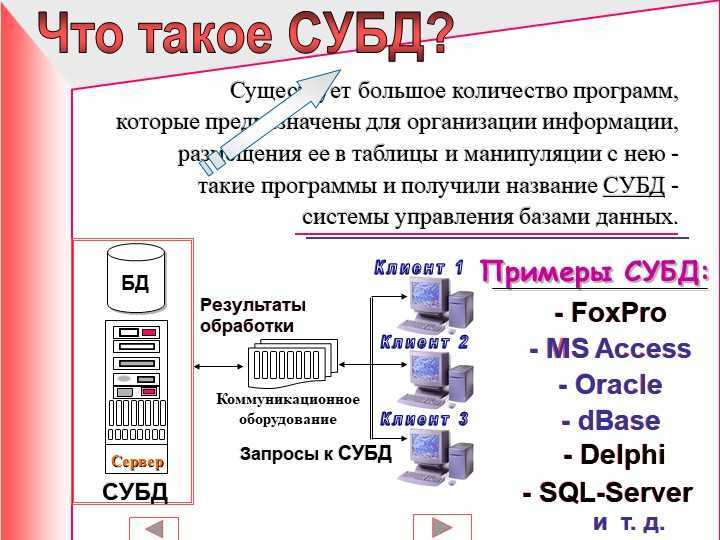
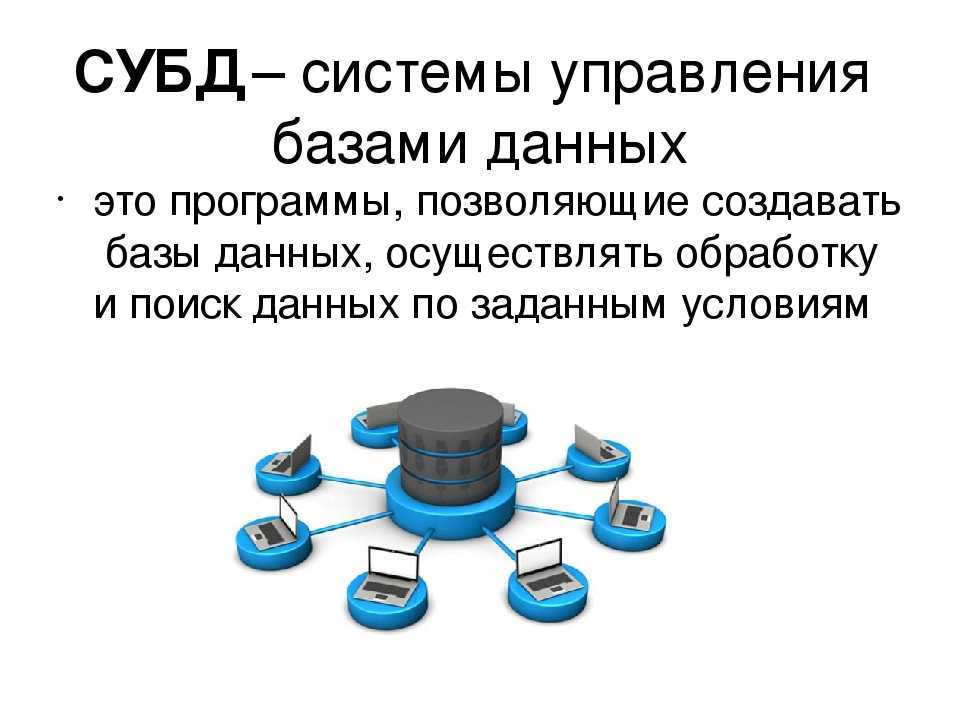
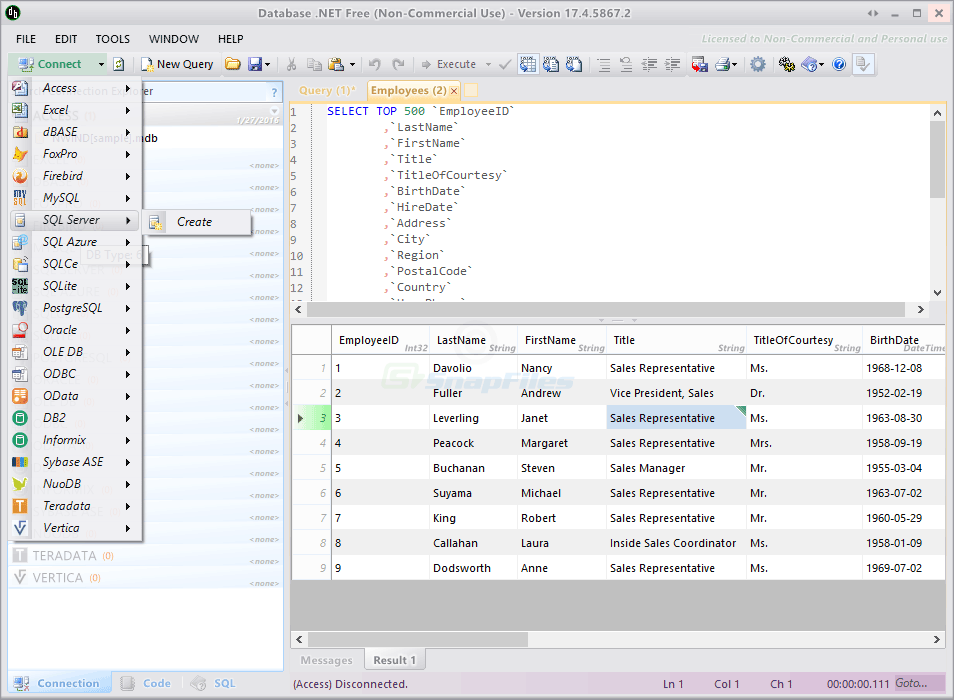
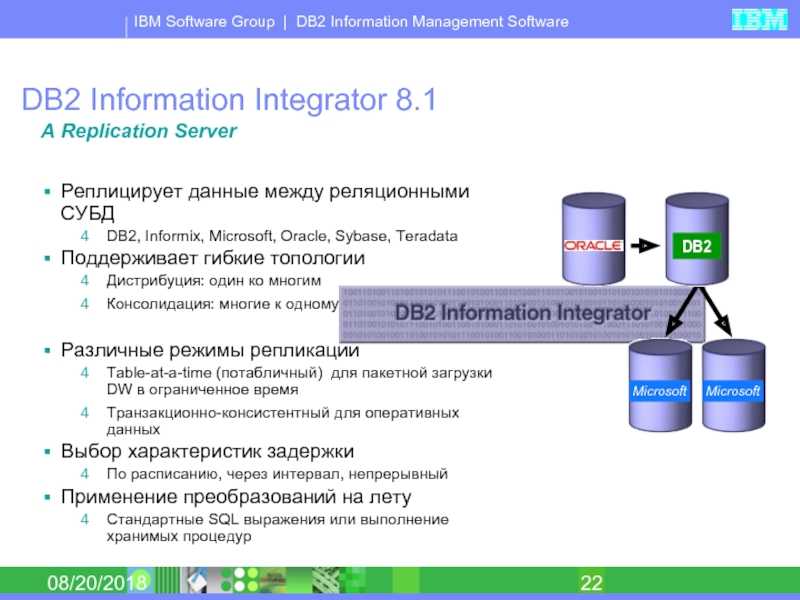
Дополнительные возможности подключения
Кроме подключения к серверу СУБД в «Форсайт. Аналитическая платформа»
реализован ряд альтернативных драйверов, позволяющих подключаться к источникам
данных. Подключение осуществляется через объект репозитория «База данных».
| Тип драйвера | Описание | Комментарии |
|
OLE DB |
Поддерживается подключение к различным источникам данных
Примечание. |
Требуется установка OLE DB драйверов в операционной системе. Поддерживается выполнение только запросов, команд СУБД. Создание |
|
DB2 |
Поддерживается работа с реляционными базами данных. Примечание. |
Требуется установка клиентской части СУБД. |
|
Greenplum/Pivotal HD Hawq/Arenadata DB |
Поддерживается подключение к источникам данных на базе программно-аппаратного Примечание. |
Требуется установка ODBC драйвера в операционной системе. |
|
HP Vertica |
Поддерживается подключение к аналитической СУБД HP Vertica Примечание. |
ODBC драйвер доступен на официальном сайте Vertica. Работа с СУБД HP Vertica осуществляется с учетом следующих ограничений:
|
|
Generic ODBC |
Поддерживается подключение к различным источникам данных Примечание. |
Требуется установка ODBC драйверов в операционной системе. Поддерживается выполнение только запросов, команд СУБД. Создание |
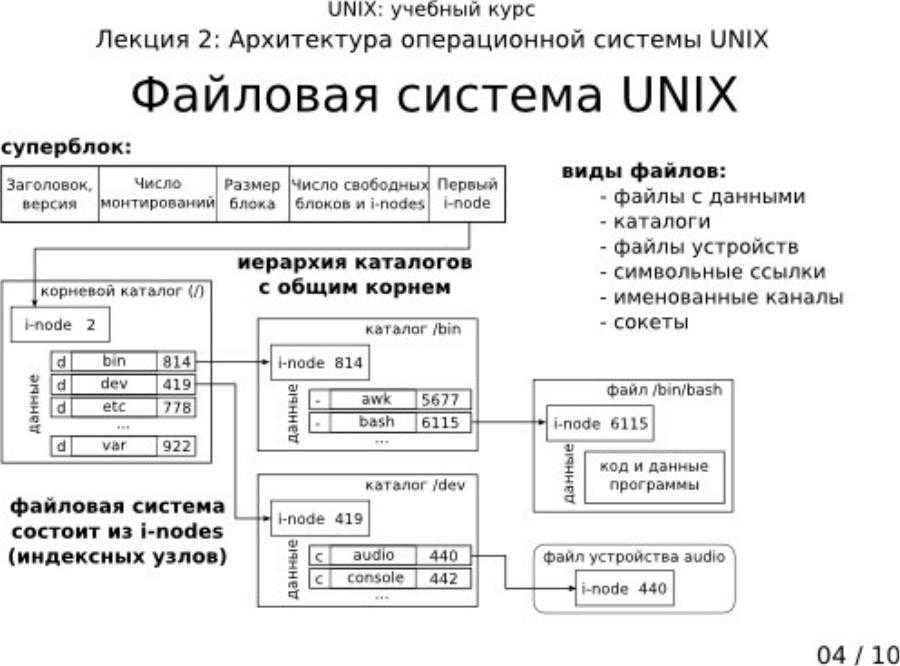
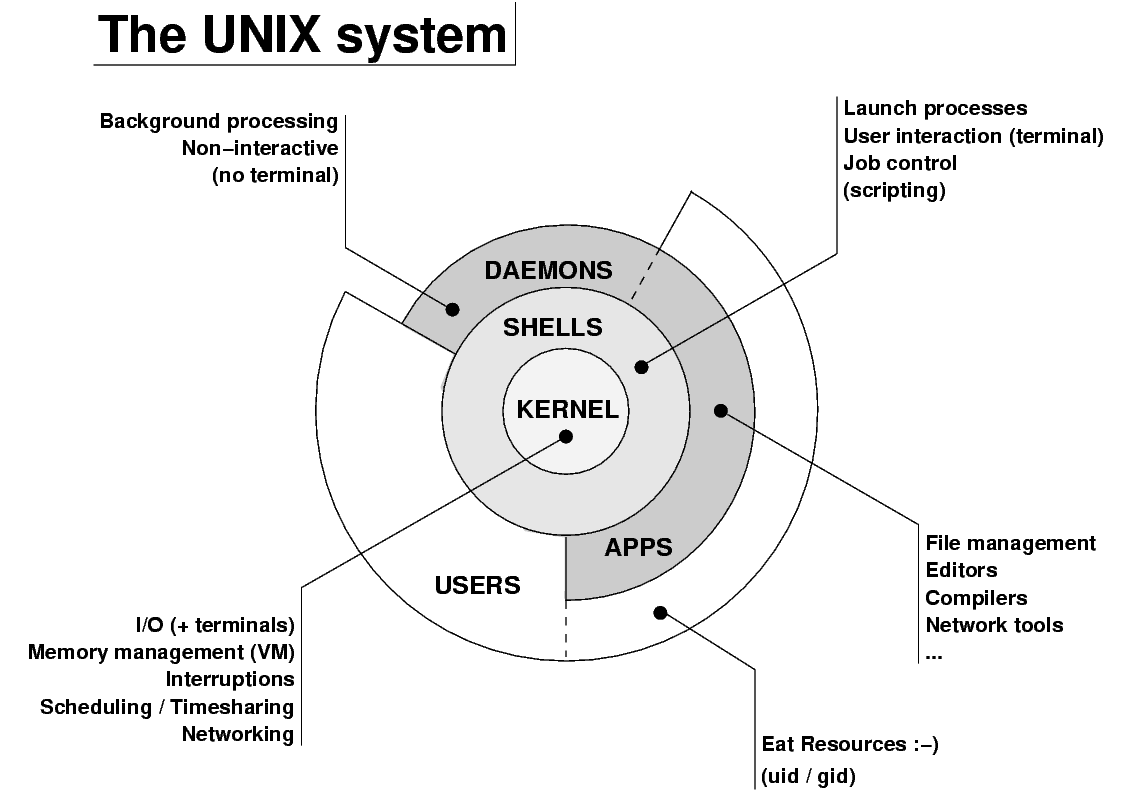
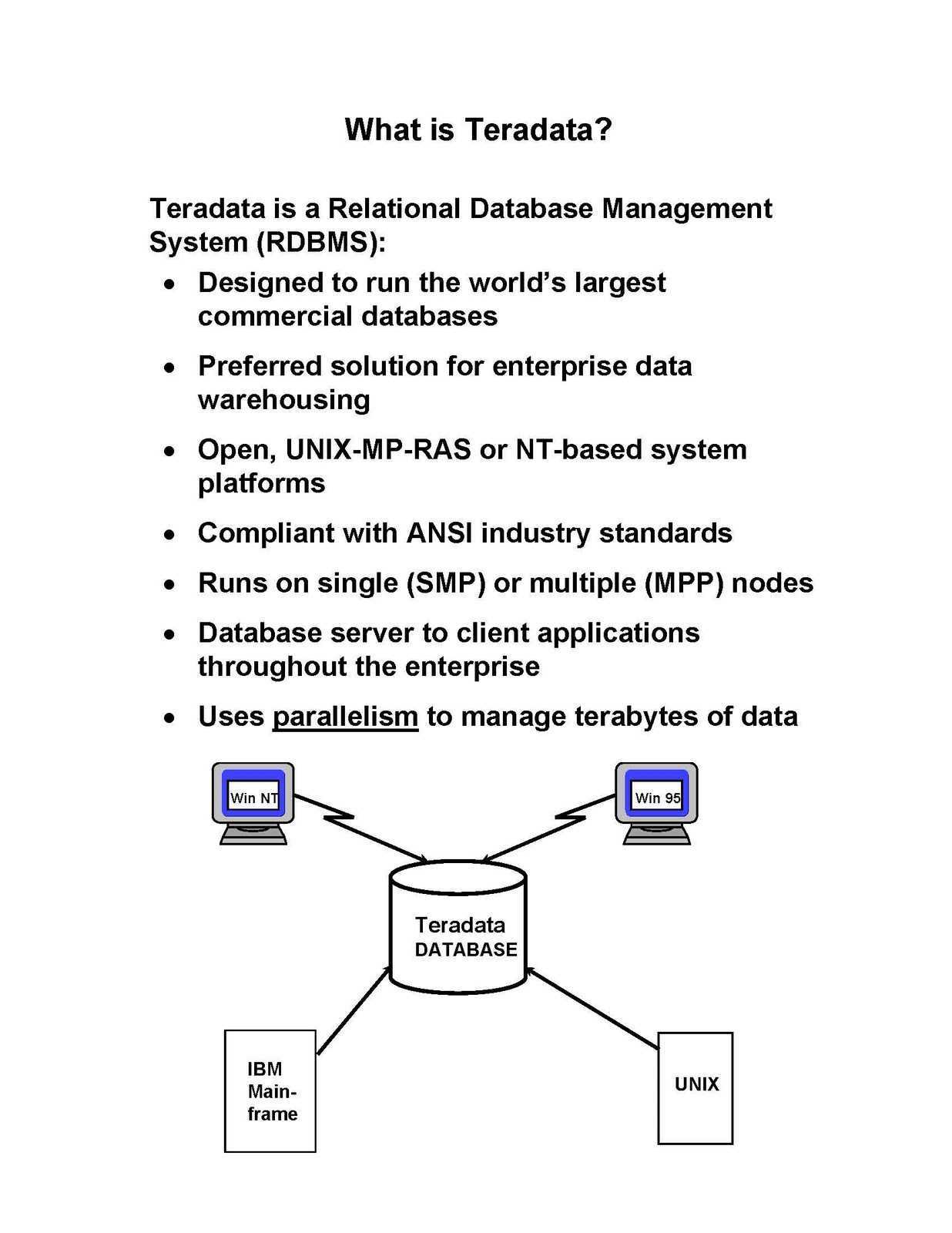
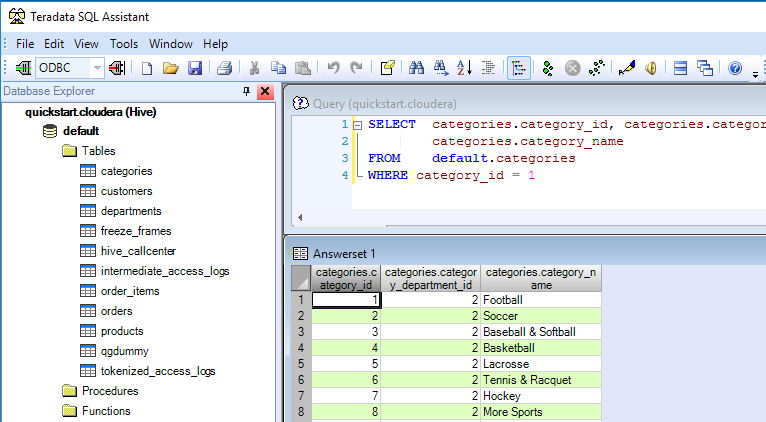
СУБД Teradata для OC UNIX
СУБД Teradata для OC UNIX
С объявлением выпуска СУБД Teradata для ОС UNIX на машине WorldMark 5100 начинается самый драматический этап в истории постоянного совершенствования продукта, со времен первого выпуска в 1984 году. С появлением СУБД Teradata для ОС UNIX на машине WorldMark 5100 были сняты все ограничения, накладываемые мощностью аппаратных платформ, таким образом были полностью реализованы возможности архитектуры СУБД Teradata. Использование СУБД Teradata для ОС UNIX сразу же улучшило соотношение цена/производительность в три раза по сравнению с системой 3600. Система включает: автоматическое добавление/удаление процессоров при почти 100%-ой степени надежности системы; непрерывную масштабируемость от SMP через кластерные системы к MPP; поддержку дисковых массивом через шину SCSI и новую масштабируемую межпроцессорную шину (BYNET). В системе реализованы: виртуальные процессоры; 20-кратное увеличение хэш-корзин (hash buckets) для поддержки баз данных объемом свыше 100ТБ; работа с данными в блоках от 4КБ до 32 КБ, наличие доли свободного пространства в блоках данных и возможность освобождения страниц памяти, используемые для значительного улучшения работы систем с переменной нагрузкой; использование уже откомпилированных шагов по выполнению SQL запросов; автоматическое восстановление фрагментации; глобальное планирование приоритетов; локальная журналирование измененных строк; настраиваемые пользователем размеры кэша для наборов данных; увеличенные размеры кэша для поддержки большинства сложных SQL-запросов к промышленным базам данных; улучшенные формулы оптимизации запросов; улучшенная обработка битовых образов (bit maps); обработка ситуаций полного отключения питания; поддержка гигабайтов энергонезависимой памяти в системе; более быстрый доступ к данным по значению неуникального первичного индекса; более быстрая система передачи сообщений между процессами; и, наконец, увеличенная производительность при распределении строк.
Завтра
И это только начало. Дальнейшие усовершенствования возможностей, функций, производительности и готовности СУБД Teradata во второй половине 90-х годов будут идти в ускоренном режиме. Соединения BYNET, мощность систем NCR WorldMark и базовая архитектура параллельного программного обеспечения позволят СУБД Teradata сохранить и укрепить позиции лидера в области промышленных реляционных СУБД, систем поддержки принятия решений и приложений для хранилищ данных.
Архитектура программного обеспечения СУБД Teradata
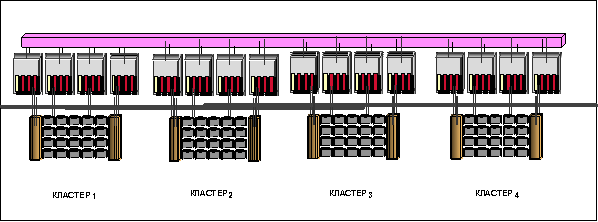
Секрет мощности СУБД Teradata кроется в ее архитектуре. Архитектура Teradata уникальна в своем роде. Разработанная для поддержки очень больших баз данных (Very Large Databases — VLDB), с которыми работают различные приложения по поддержке принятия решений (Decision Support — DSS) и приложения хранилищ данных (Data Warehousing — DW), СУБД Teradata построена на архитектуре «ничего не разделяется», с тщательно проработанным многомерным параллелизмом. Никакая другая СУБД в мире не может сравниться по мощности с СУБД Teradata.
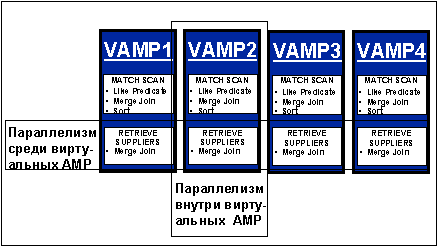
В архитектуре Teradata нет ничего однопотокового
При проектировании любых особенностей или утилит всегда принимался во внимание аспект параллелизма. С появлением версии СУБД Teradata для ОС UNIX был сделан значительный скачок вперед
Теперь Teradata работает на 32-х битовых современных машинах NCR серии WorldMark, 4700, 5150 и 5100. В системе параллельно выполняются все SQL операторы, форматирование, восстановление, загрузка и извлечение данных, управление приоритетами, инсталляция и обновление программного обеспечения, отладка, управление производительностью, доступ к словарям, блокировки, соединения таблиц, и все остальные задачи. Архитектура Teradata достаточно быстро расширяется, в то время как конкуренты при проектировании своих систем преодолевают каждый 100-гигабайтный барьер, и их системы никогда не смогут выдержать реальную нагрузку хранилищ данных.
Масштабируемость
Масштабируемость включает в себя несколько аспектов ИТ-инфраструктуры, таких как обработка увеличения объема данных и транзакций, а также увеличение многомерных данных, количество пользователей, управление рабочей нагрузкой, сложность запросов и объем и т. Д.
Teradata — это Линейно масштабируемый означает, что емкость базы данных может быть увеличена путем добавления большего количества узлов в инфраструктуру, а когда объем данных увеличивается, производительность не изменяется.
Система разработана для многомерной масштабируемости и обеспечивает более надежные модели масштабирования и масштабирования, чем Oracle. Хотя Oracle имеет хорошую масштабируемость, узкие места, как известно, происходят с подсистемой хранения, и у нее есть одна из лучших скоростей обработки данных, но только до определенного предела. Например, если большинство запросов известны, а используемые данные меньше 600 ТБ, тогда Oracle может быть подходящим, но если данные, как ожидается, увеличатся выше этого, то Teradata — лучший выбор.
параллелизм
Teradata имеет безусловный параллелизм , тогда как Oracle имеет условный. Это дает Teradata преимущество с OLAP, поскольку производительность является исключительной для достижения единого ответа быстрее, чем непараллельная система. Параллелизм использует несколько процессоров, работающих вместе для быстрого выполнения задачи.
Чтобы использовать аналогию с тем, как работает параллелизм, подумайте о очереди в оживленном торговом магазине, при этом одна очередь разветвляется на отдельные очереди для каждого. Линия движется быстрее, а не одна очередь и одна до. Чем эффективнее параллельная загрузка, тем лучше производительность системы.
Teradata имеет параллельность во всей своей системе, включая архитектуру, сложную обработку и загрузку данных. Настройка запросов не требуется для параллельной обработки запросов, и Teradata не зависит от ограничений диапазона столбцов или ограниченного количества данных, в отличие от Oracle.
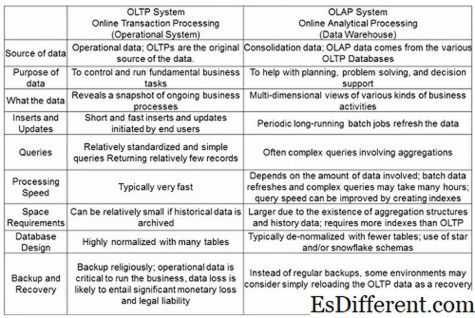
OLTP и OLAP
Реляционные системы управления базами данных (РСУБД) могут быть классифицированы как Онлайн-обработка транзакций — OLTP а также Онлайн-аналитическая обработка — OLAP.
OLTP является транзакционным и предоставляет данные для хранилищ данных, а OLAP предназначен для анализа данных.
«А хранилище данных представляет собой базу данных, содержащую данные, которые обычно представляют историю бизнеса организации. Данные в хранилище данных организованы для поддержки анализа, а не для обработки транзакций в реальном времени, как в онлайновые системы обработки транзакций (OLTP).
OLAP технология позволяет эффективно использовать хранилища данных для онлайн-анализа, обеспечивая быструю реакцию на итеративные комплексные аналитические запросы.”
Хотя Teradata ориентирована на OLAP и Oracle для OLTP, Oracle может запускать как OLTP, так и OLAP-базы данных на той же платформе, которую Teradata не поддерживает. Производительность дает Oracle преимущество перед Teradata в большинстве смешанных сценариев рабочей нагрузки.
Транзакции содержат один или несколько операторов SQL, выполняемых в базе данных для выполнения задач, при сохранении целостности данных. Транзакции взаимозависимы для управления и обработки данных, которые добавляются или удаляются из базы данных.
Oracle адаптирован для обработки транзакций из-за своей архитектурной гибкости (с помощью RDBMS объекта), тогда как OLAP Teradata является мощным средством для обработки данных обрезки и обработки данных (история данных OLTP) для анализа без необходимости перемещения или реструктуризации данных.
Oracle в основном используется как онлайн-приложение для управления вставками, обновлениями и удалениями во время транзакций, тогда как Teradata является Хранилище данных, которое хранит большие данные для аналитики, и нет транзакций в реальном времени.
Teradata — хорошая комбинация между аппаратным и программным обеспечением, производящее устройство для конечных пользователей, однако Oracle запустила свой OLAP Exadata Server в 2008 году. Это был ответ Oracle на полное устройство базы данных.
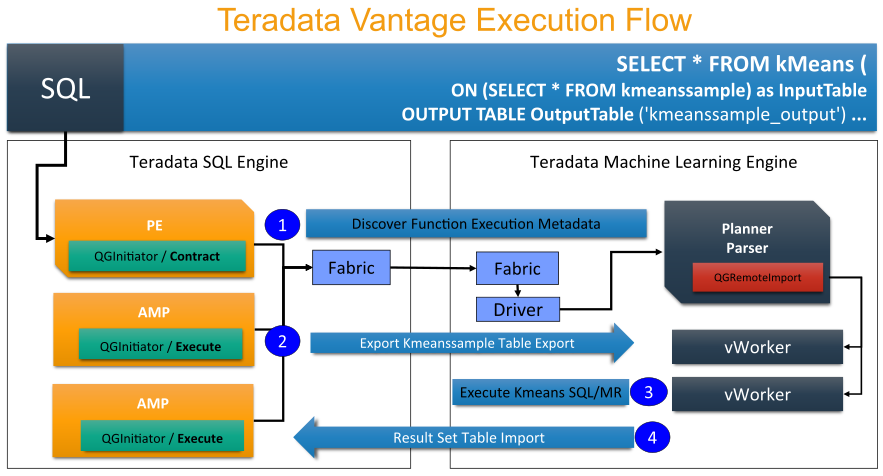
Оба требуют значительных инвестиций и более подходят для очень больших баз данных, требующих большой производительности при сложных запросах.
Сводный список идентификаторов
Ниже приведен список идентификаторов драйверов, которые могут использоваться
для настройки различных объектов репозитория. Идентификаторы используются
различными свойствами при настройке объектов с помощью макросов на Fore,
а также при создании списка репозиториев в файле Metabases.xml
и списка пользовательских драйверов в файле Drivers.xml:
| Идентификатор | Драйвер СУБД |
| ORCL8 | Oracle указанных выше версий |
| MSSQL2008 | Microsoft SQL Server 2008 |
| MSSQL2012 | Microsoft SQL Server 2012\2014\2016\2017 |
| MSSQL2012ODBC | Microsoft SQL Server (ODBC) |
| OLEDB(ODBC HIVE) | OLE DB (ODBC HIVE) |
| OLEDB(DB2) | OLE DB (DB2) |
| OLEDB(ODBC) | OLE DB (ODBC) |
| OLEDB(VISTADB) | OLE DB (VISTADB) |
| OLEDB | OLE DB провайдер |
| DB2 | Реляционная базы данных DB2 |
| TRDT | Teradata указанных выше версий |
| POSTGRES | PostgreSQL/Postgres Pro указанных выше версий |
| POSTGRES(NO_LO) | Greenplum/Pivotal HD Hawq |
| VERTICA | HP Vertica версии указанных выше версий |
| ODBC | Generic ODBC |
Примечание.
Для различных объектов репозитория список доступных для использования
драйверов может отличаться.
См. также:
Системные
требования к серверу баз данных | Системные
требования
Справочная
система
от 28/11/2022,
ООО «ФОРСАЙТ»,
Сравнительная таблица
| Составная часть | Teradata | оракул |
| Архитектура | · Недоступно ничего
· Реляционная модель · Узлы имеют несколько Parsing Engines и ядра базы данных, называемые Процессами модуля доступа |
· Общий доступ
· Объектно-реляционная модель · Совместная общая память с общим диском / слабосвязанной памятью · Архитектура БД для баз данных нескольких узлов |
| OLAP | Конфигурация системы и необходимая конфигурация не требуются. | Установка и настройка OLAP являются техническими и сложными. |
| OLTP | Невозможно. | Разработанная система. |
| Операционная система | · Windows
· Linux · UNIX |
· Windows
· Linux · UNIX · Mac OS X · Z / OS |
| параллелизм | Безусловное «Всегда включено», разработанное с самого начала. | Условные и непредсказуемые |
| Таблицы базы данных | Таблицы, созданные в базах данных и дисках, управляются самим Teradata. | Таблицы, созданные в табличных пространствах
принадлежащих к схеме, и имеют параметры использования пространства. |
| Объекты базы данных | · Курсор
· Внешняя рутина · Функция · Процедура · Спусковой крючок |
· Домен данных
· Курсор · Внешняя рутина · Функция · Процедура · Спусковой крючок |
| Использование индекса | Традиционно не используют много индексов, поскольку параллельная архитектура фокусируется на требованиях производительности пропускной способности. | Положитесь на индексы, поскольку рабочие нагрузки OLTP нуждаются в быстрых путях доступа. |
| Интерфейс | · SQL | · SQL
· GUI |
| Типы данных | ||
| строка | · CHAR
· CLOB · VARCHAR |
· CHAR
· CLOB · VARCHAR · NCHAR · NVARCHAR |
| двоичный | · BYTE
· VARBYTE |
· BFILE
· LONGRAW · RAW |
| Дата / время | · ВРЕМЯ
· ДАТА · TIMESTAMP |
· ДАТА
· TIMESTAMP |
| Общий рейтинг пользователей (обзор ИТ-станции) | В третьих | Первый |
Инструментарий аналитиков
- Удобство инструмента в использовании и поддержке
- Применимость в задачах Data Science
- Максимальная возможность использования вычислительных ресурсов кластера Hadoop, а не серверов приложений или компьютера исследователя
- Python + Anaconda. В качестве среды используется iPython/Jupyter
- R + Shiny. Исследователь работает в desktop или web-версии R Studio, Shiny применяется для разработки web-приложений, которые заточены на использование алгоритмов, разработанных в R.
- Spark. Для работы с данными используются интерфейсы для Python (pyspark) и R, настроенные в средах разработки, указанных в предыдущих пунктах. Оба интерфейса позволяют задействовать библиотеку Spark ML, которая дает возможность обучать ML-модели на кластере Hadoop/Spark.
- Данные в Impala доступны через Hue, Spark и из сред разработки с помощью стандартного интерфейса ODBC и специальных библиотек типа implyr
- Используйте лучшие практики. Если бы мы не имели ETL-подсистемы, метаданных, версионного хранения и понятной архитектуры, то не осилили бы эту задачу. Лучшие практики окупают себя, хотя и не сразу.
- Помните об объемах данных. Большие данные могут создавать технические сложности в совсем неожиданных местах.
- Следите за новыми технологиями. Новые решения появляются часто, не все они полезны, но иногда встречаются настоящие жемчужины.
- Больше экспериментируйте. Не стоит доверять только маркетинговым описаниям решений – пробуйте сами.
Кстати, о том, как наши аналитики использовали машинное обучение и данные банка для работы с кредитными рисками, вы можете почитать в отдельном посте.