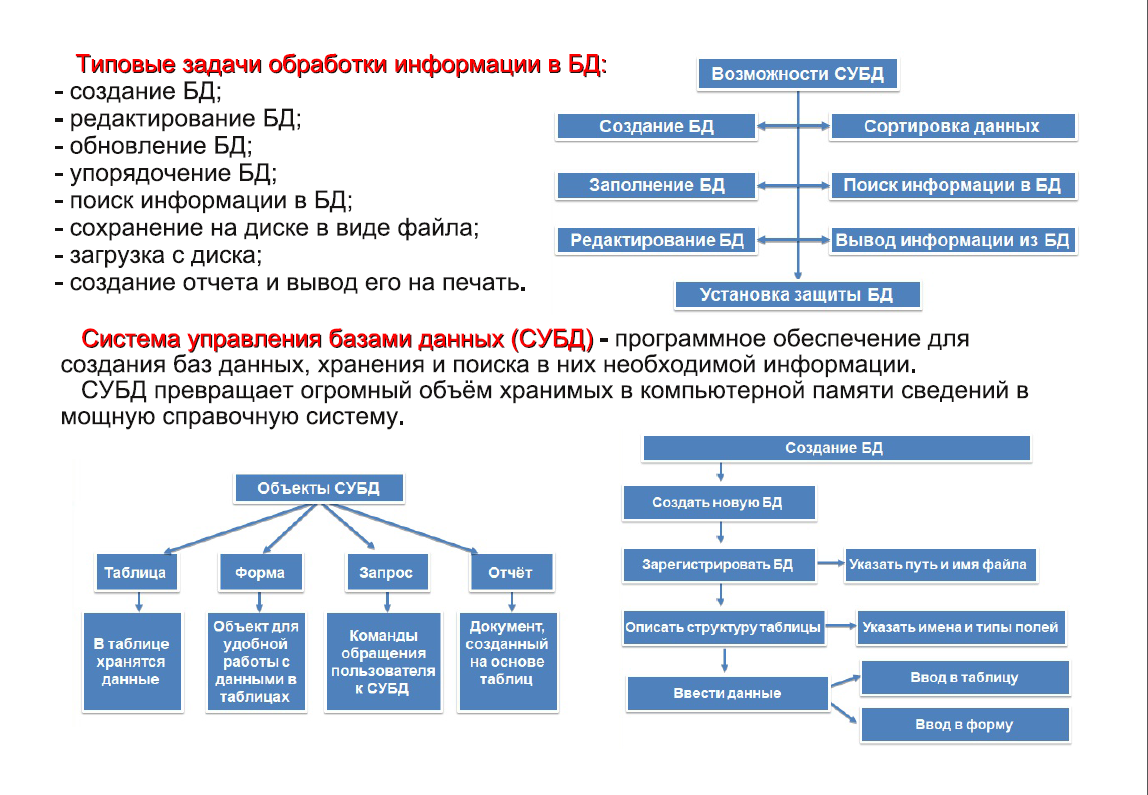
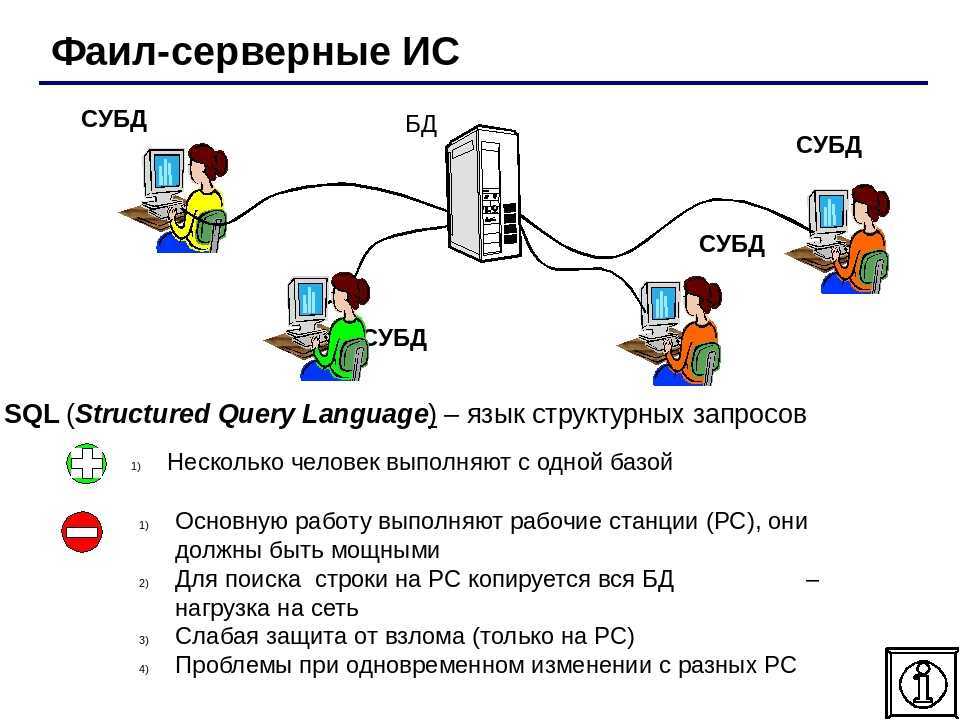
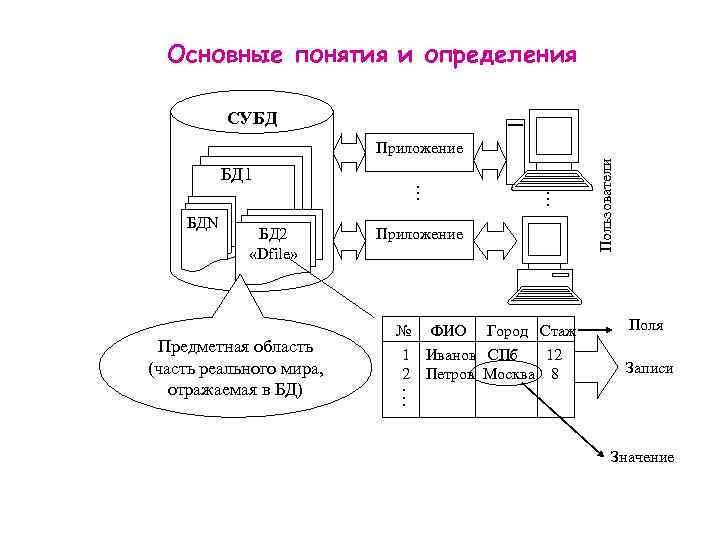
Языки манипулирования данными
Основное средство для общения с реляционными базами данных — язык структурированных запросов SQL.
Это декларативный язык. То есть инструкции в нём не идут одна за другой (не как в императивных языках). Каждый оператор SQL описывает только необходимое действие, а СУБД сама принимает решение, как его выполнить.
Например, чтобы выбрать все данные из таблицы Messages за 10.11.2020, делается запрос:
SELECT * FROM messages WHERE date = ‘10.11.2020’
Язык структурированных запросов делится на несколько частей (группы операторов) и позволяет:
- определять данные (DDL),
- манипулировать ими (DML),
- контролировать доступ к данным (DCL)
- и управлять транзакциями (TCL).
В SQL изначально нет средств для создания печатных отчётов, экранных форм и других инструментов для разработки программ. Хотя SQL сам по себе не является полноценным (Тьюринг-полным) языком программирования, но его стандарт позволяет создавать процедурные расширения. Они доводят его функциональность до полноценного языка программирования.
При этом синтаксис SQL в разных СУБД может различаться. Кое-где даже используются его отдельные диалекты, например:
- T-SQL — для работы с Microsoft SQL Server;
- на PL / SQL пишут хранимые процедуры и функции в Oracle;
- на PL / pgSQL — в PostgreSQL.
Мультимодельные СУБД на основе реляционной модели
Ведущими СУБД в настоящее время являются реляционные, прогноз Gartner нельзя было бы считать сбывшимся, если бы РСУБД не демонстрировали движения в направлении мультимодельности. И они демонстрируют. Теперь соображения о том, что мультимодельная СУБД подобна швейцарскому ножу, которым ничего нельзя сделать хорошо, можно направлять сразу Ларри Эллисону.
Автору, однако, больше нравится реализация мультимодельности в Microsoft SQL Server, на примере которого поддержка РСУБД документной и графовой моделей и будет описана.
Документная модель в MS SQL Server
О том, как в MS SQL Server реализована поддержка документной модели, на Хабре уже было две отличных статьи, ограничусь кратким пересказом и комментарием:
- Работаем с JSON в SQL Server 2016
- SQL Server 2017 JSON
Способ поддержки документной модели в MS SQL Server достаточно типичен для реляционных СУБД: JSON-документы предлагается хранить в обычных текстовых полях. Поддержка документной модели заключается в предоставлении специальных операторов для разбора этого JSON:
- для извлечения скалярных значений атрибутов,
- для извлечения поддокументов.
Вторым аргументом обоих операторов является выражение в JSONPath-подобном синтаксисе.
Абстрактно можно сказать, что хранимые таким образом документы не являются в реляционной СУБД «сущностями первого класса», в отличие от кортежей. Конкретно в MS SQL Server в настоящее время отсутствуют индексы по полям JSON-документов, что делает затруднительными операции соединения таблиц по значениям этих полей и даже выборку документов по этим значениям. Впрочем, возможно создать по такому полю вычислимый столбец и индекс по нему.
Дополнительно MS SQL Server предоставляет возможность удобно конструировать JSON-документ из содержимого таблиц с помощью оператора — возможность, в известном смысле противоположную предыдущей, обычному хранению. Понятно, что какой бы быстрой ни была РСУБД, такой подход противоречит идеологии документных СУБД, по сути хранящих готовые ответы на популярные запросы, и может решать лишь проблемы удобства разработки, но не быстродействия.
Наконец, MS SQL Server позволяет решать задачу, обратную конструированию документа: можно разложить JSON по таблицам с помощью . Если документ не совсем плоский, потребуется использовать .
Графовая модель в MS SQL Server
Поддержка графовой (LPG) модели реализована в Microsoft SQL Server тоже вполне предсказуемо: предлагается использовать специальные таблицы для хранения узлов и для хранения ребер графа. Такие таблицы создаются с использованием выражений и соответственно.
Таблицы первого вида сходны с обычными таблицами для хранения записей с тем лишь внешним отличием, что в таблице присутствует системное поле — уникальный в пределах базы данных идентификатор узла графа.
Аналогично, таблицы второго вида имеют системные поля и , записи в таких таблицах понятным образом задают связи между узлами. Для хранения связей каждого вида используется отдельная таблица.
Проиллюстрируем сказанное примером. Пусть графовые данные имеют схему как на приведенном рисунке. Тогда для создания соответствующей структуры в базе данных нужно выполнить следующие DDL-запросы:
Основная специфика таких таблиц заключается в том, что в запросах к ним возможно использовать графовые паттерны с Cypher-подобным синтаксисом (впрочем, «» и пр. пока не поддерживаются). Также на основе измерений производительности можно предположить, что способ хранения данных в этих таблицах отличен от механизма хранения данных в обычных таблицах и оптимизирован для выполнения подобных графовых запросов.
Более того, довольно трудно при работе с такими таблицами эти графовые паттерны не использовать, поскольку в обычных SQL-запросах для решения аналогичных задач потребуется предпринимать дополнительные усилия для получения системных «графовых» идентификаторов узлов (, , ; по этой же причине запросы на вставку данных не приведены здесь как слишком громоздкие).
Подводя итог описанию реализаций документной и графовой моделей в MS SQL Server, я бы отметил, что подобные реализации одной модели поверх другой не кажутся удачными в первую очередь с точки зрения языкового дизайна. Требуется расширять один язык другим, языки не вполне «ортогональны», правила сочетаемости могут быть довольно причудливы.
Документные СУБД
Документные или документно-ориентированные СУБД — это одна из наиболее популярных разновидностей NoSQL СУБД, где основной единицей логической модели данных является документ — структурированный текст, с определенным синтаксисом.
Иногда встречаются мнения что модель данных в документных БД похожа на модель данных в объектно-ориентированных базах данных. В этом есть доля правды, единственная реальная разница между ними заключается в том, что базы данных документов только сохраняют состояние, но не поведение.
Так же, само название «документо-ориентированная» подчас вводит в заблуждение, и мне встречались коллеги, которые считали, что это база для систем документооборота. Нет, это не так.
Интересно, что документные СУБД развиваются достаточно активно, и сейчас некоторые из них, в том числе, поддерживают проверку схемы.
Известными представителями таких СУБД являются CouchDB, MongoDB, Amazon DocumentDB.
Когда выбирать документную СУБД
Если нужно хранить объекты в одной сущности, но с разной структурой. Если нужно хранит структуры, включая объекты, списки и словари, особенно в формате близкому к JSON.
На самом деле область применения документных СУБД очень широкая. Их можно использовать как компактную базу данных для отдельно взятого микро-сервиса, так и для вполне масштабных решений, в качестве хранилища состояний чего-либо.
Когда не выбирать документную СУБД
Не самое лучшее решение для реализации транзакционная модели, и точно не лучший вариант для формирования отчетности.
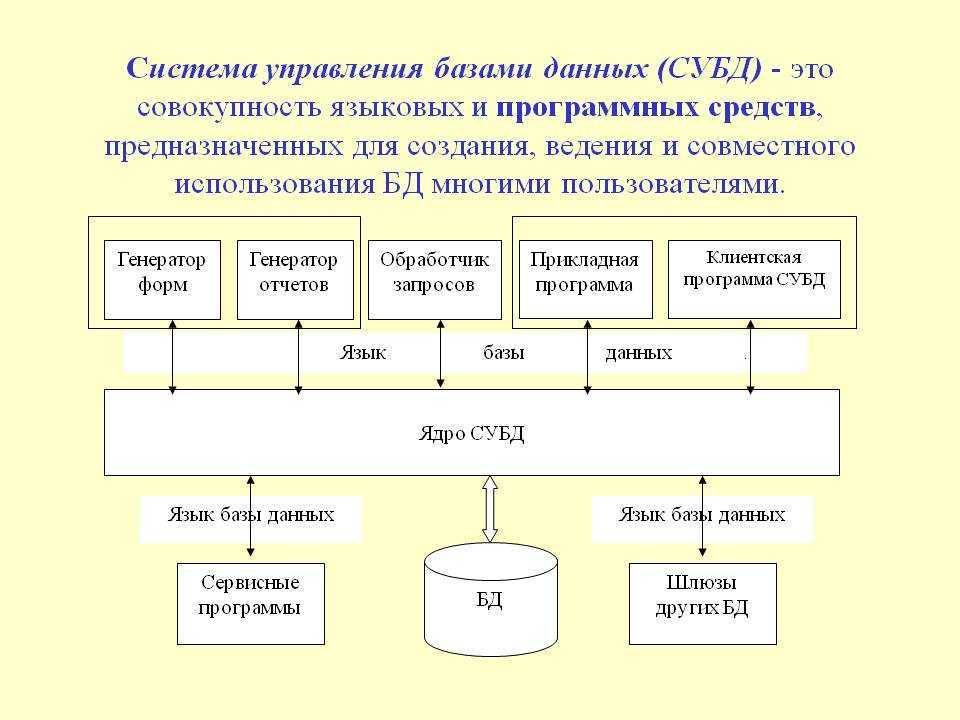
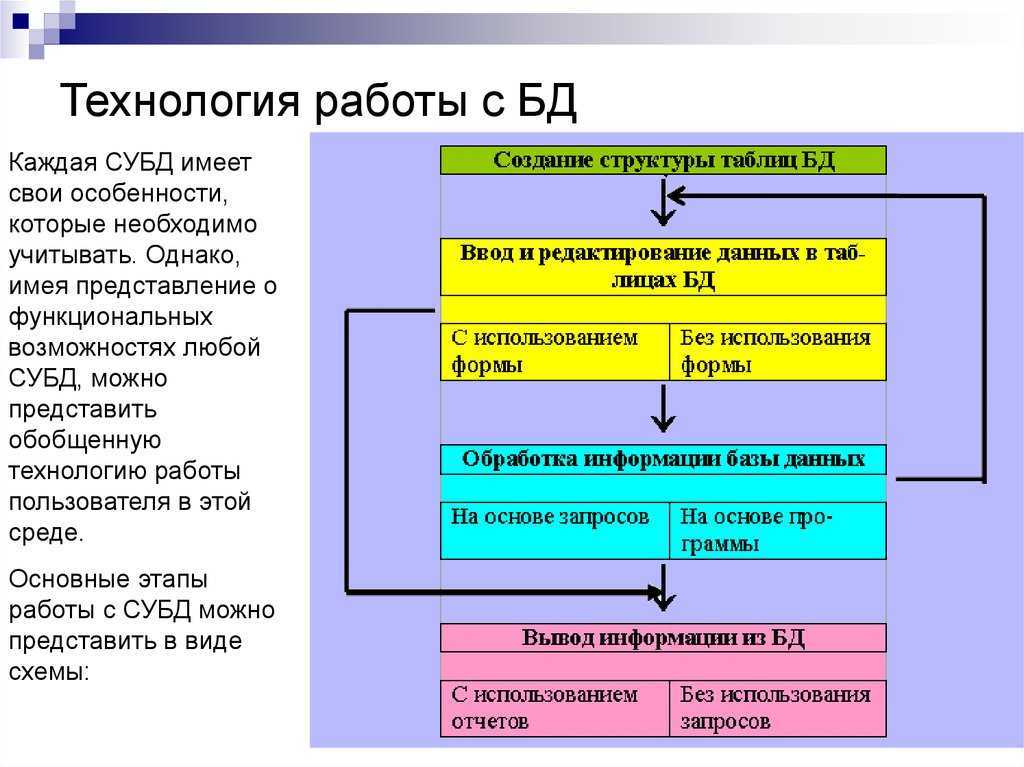
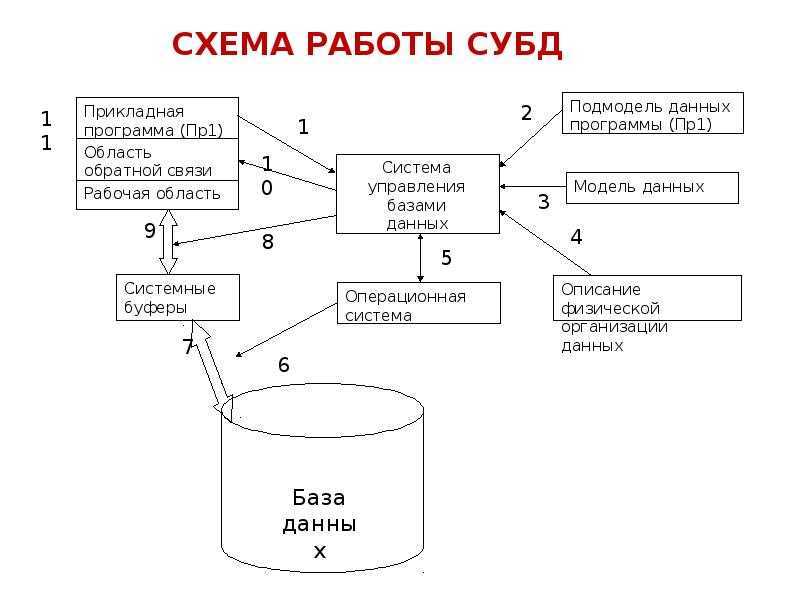
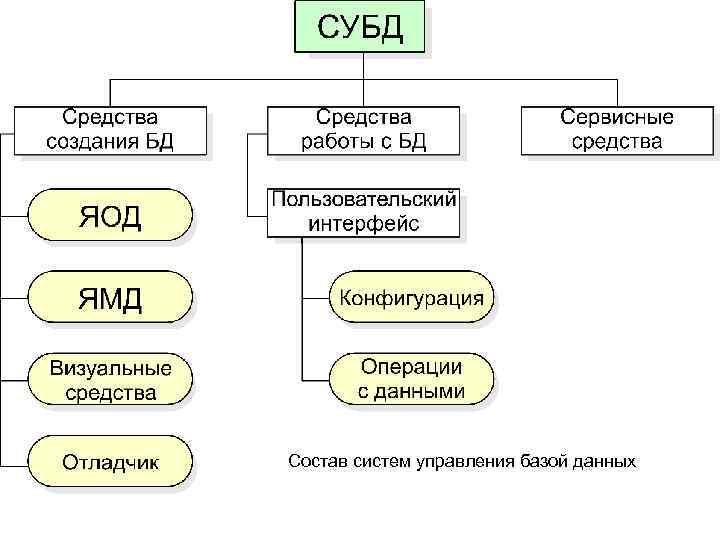
Из чего состоят системы управления базами данных
Если база — это хранилище, то СУБД — комплекс средств для обслуживания хранилища. СУБД имеет сложное устройство.
Ядро СУБД отвечает за главные операции: хранение базы, ее обслуживание, документирование изменений. Это основная часть системы.
Процессор языка или компилятор обрабатывает запросы. Обычно СУБД реляционного, объектно-ориентированного и объектно-реляционного типа поддерживают язык SQL и внутренние языки запросов.
Набор утилит предназначен для различных сервисных функций: их может быть очень много, а некоторые СУБД могут расширяться с помощью пользовательских модулей.
Устройство СУБД
1.4.Проектирование физической структуры базы данных
Модель Сущность-Связь (ER-модель) — модель данных, позволяющая описывать концептуальные схемы.
ER-модель удобна при проектировании информационных систем, баз данных, архитектур компьютерных приложений, и других систем (далее, моделей). С её помощью можно выделить ключевые сущности, присутствующие в модели, и обозначить отношения, которые могут устанавливаться между этими сущностями.
ER-модель является одной из самых простых визуальных моделей данных (графических нотаций). Она позволяет обозначить структуру в общих чертах.
СУБД, применяемая на предприятии – MS SQL Server.
На рис. 2 описана связь основных таблиц в базе данных.
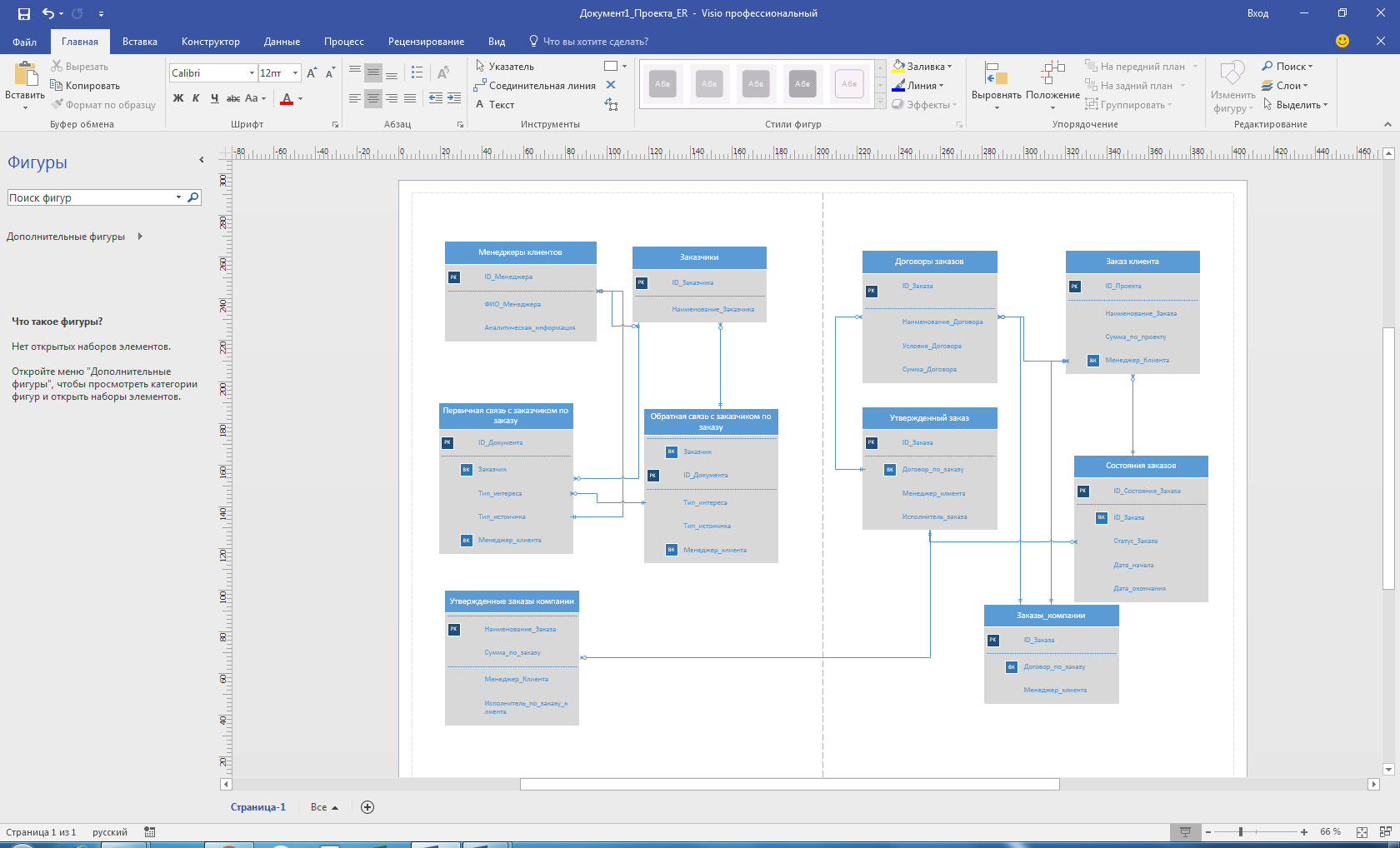
Рисунок 2 — «ER-модель» предметной области управления взаиморасчетами с клиентами компании ООО «Тат Телеком»
Описание таблиц ER-модели представлено в табл. 3-12
Таблица 3. Клиенты
|
Наименование поля |
Идентификатор поля |
Тип поля |
Длина поля |
Прочее |
|
ID_Заказчика |
IDЗаказчика |
число |
4 |
Первичный ключ – ключевое поле (PK) |
|
Наименование Заказчика |
НаименованиеЗаказчика |
строка |
Таблица 4. Договоры
|
Наименование поля |
Идентификатор поля |
Тип поля |
Длина поля |
Прочее |
|
ID_Заказа |
ID_Заказа |
число |
4 |
Первичный ключ – ключевое поле (PK) |
|
Наименование договора |
НаименоваиеДоговора |
строка |
30 |
FK1 |
|
Условия договора |
УсловияДоговора |
ХранилищеЗначений |
||
|
Сумма договора |
СуммаДоговора |
число |
Таблица 5. Заказ
|
Наименование поля |
Идентификатор поля |
Тип поля |
Длина поля |
Прочее |
|
ID_Заказа |
ID_Заказа |
число |
4 |
Первичный ключ – ключевое поле (PK) |
|
Наименование заказа |
Наименование_Заказа |
строка |
30 |
|
|
Сумма заказа |
СуммаПоЗаказу |
Число |
12 |
|
|
Менеджер клиента |
Менеджер Клиента |
Строка |
FK1 |
Таблица 6. Менеджеры клиентов
|
Наименование поля |
Идентификатор поля |
Тип поля |
Длина поля |
Прочее |
|
ID_Менеджера |
IDМенеджера |
число |
Первичный ключ – ключевое поле (PK) |
|
|
ФИО Менеджера |
ФИОМенеджера |
Строка |
30 |
|
|
Аналитическая информация |
АналитическаяИнформация |
число |
4 |
Таблица 7. Первичная связь с клиентом по заказу
|
Наименование поля |
Идентификатор поля |
Тип поля |
Длина поля |
Прочее |
|
ID_Документа |
IDДокумента |
число |
4 |
Первичный ключ – ключевое поле (PK) |
|
Наименование Заказчика |
НаименованиеЗаказчика |
строка |
||
|
Тип Источника |
ТипИсточника |
Строка |
30 |
|
|
Тип интереса |
ТипИнтереса |
Строка |
12 |
|
|
Менеджер клиента |
Менеджер Клиента |
Строка |
FK1 |
Таблица 8. Обратная связь клиента по заказу
|
Наименование поля |
Идентификатор поля |
Тип поля |
Длина поля |
Прочее |
|
ID_Документа |
IDДокумента |
число |
4 |
Первичный ключ – ключевое поле (PK) |
|
Наименование Заказчика |
НаименованиеЗаказчика |
строка |
||
|
Тип Источника |
ТипИсточника |
Строка |
30 |
|
|
Тип интереса |
ТипИнтереса |
Строка |
12 |
|
|
Менеджер клиента |
Менеджер Клиента |
Строка |
FK1 |
Таблица 9. Заказы компании
|
Наименование поля |
Идентификатор поля |
Тип поля |
Длина поля |
Прочее |
|
Наименование договора |
НаименоваиеДоговора |
строка |
30 |
FK1 |
|
ID_Клиента |
ID Клиента |
число |
4 |
FK2 |
|
Менеджер клиента |
Менеджер клиента |
Строка |
FK3 |
Таблица 10. Cостояние заказов клиента
|
Наименование поля |
Идентификатор поля |
Тип поля |
Длина поля |
Прочее |
|
|
ID_Cостояние_Клиента |
IDCостояниеКлиента |
число |
4 |
||
|
ID_Клиента |
ID Клиента |
число |
4 |
FK1 |
|
|
Статус клиента |
Статус Клиента |
строка |
30 |
||
|
Дата Начала |
ДатаНачала |
Дата |
|||
|
Дата Окончания |
ДатаОкончания |
Дата |
Таблица 11. Утвержденный заказа клиента
|
Наименование поля |
Идентификатор поля |
Тип поля |
Длина поля |
Прочее |
|
ID_Заказа |
ID_Заказа |
число |
4 |
Первичный ключ – ключевое поле (PK) |
|
Наименование заказа |
Наименование_Заказа |
Строка |
30 |
|
|
Договор клиента |
Договор клиента |
Строка |
12 |
FK1 |
|
Менеджер клиента |
Менеджер Клиента |
Строка |
Таблица 12. Утвержденные проекты компании
|
Наименование поля |
Идентификатор поля |
Тип поля |
Длина поля |
Прочее |
|
ID_Заказа |
ID_Заказа |
число |
4 |
Первичный ключ – ключевое поле (PK) |
|
Наименование клиента |
Наименование_Клиента |
строка |
30 |
|
|
Сумма клиента |
Сумма По Клиенту |
Число |
12 |
|
|
Менеджер клиента |
Менеджер Клиента |
Строка |
FK1 |
|
|
Исполнитель клиента |
Исполнитель Клиента |
Строка |
20 |
PosgreSQL
Масштабируемая объектно-реляционная база данных, работающая на Linux, Windows, OSX и некоторых других системах. В PostgreSQL 10 есть такие функции, как логическая репликация, декларативное разбиение таблиц, улучшенные параллельные запросы, более безопасная аутентификация по паролю на основе SCRAM-SHA-256.


![Выбор субд [курсовая №32036]](https://robotrackkursk.ru/wp-content/uploads/c/4/2/c422fdf46fc72796d310ec1e2286741a.jpeg)


- Разработчик: PostgreSQL Global Development Group
- Написана на C
- Используется в компаниях: Apple, Cisco, Fujitsu, Skype, and IMDb
Особенности
- Поддержка табличных пространств, а также хранимых процедур, объединений, представлений и триггеров.
- Восстановление на момент времени (PITR).
- Асинхронная репликация.
1.3. Проектирование логической структуры базы данных
Информационная модель представляет собой схему движения входных, промежуточных и результативных потоков и функций предметной области. Кроме того, она объясняет, на основе каких входных документов и какой нормативно-справочной информации происходит выполнение функций по обработке данных и формирование конкретных выходных документов. Информационная модель представлена на рис.1.
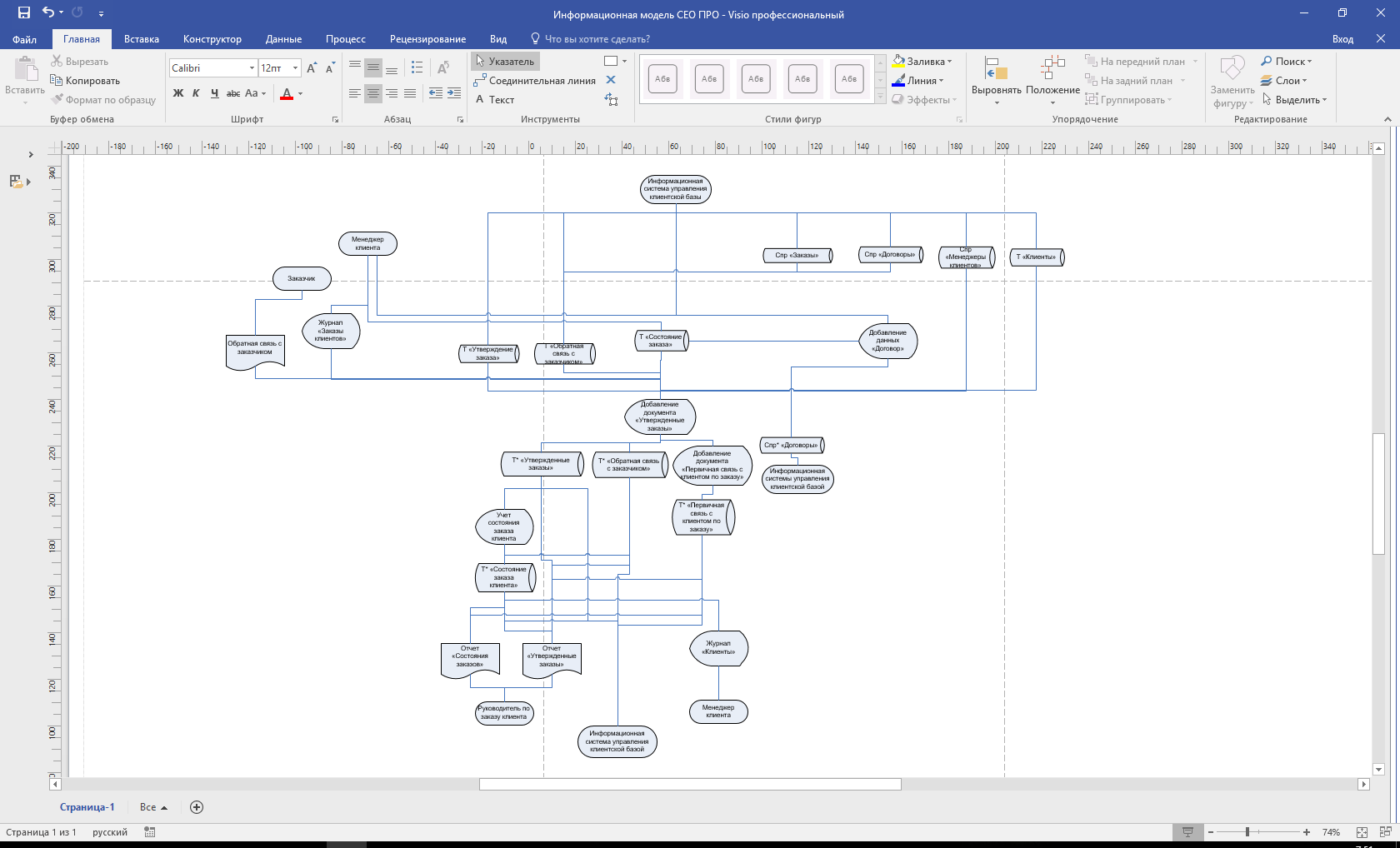
Рисунок 1. Информационная модель системы автоматизации взаиморасчетами с клиентами
Информационная модель содержит 4 области:
- Область входящей информации, в которой указаны документы, информация из которых используется в качестве входной, а также экранные формы для ввода данной информации;
- Область справочников системы, которая иллюстрирует состав справочников и таблиц базы данных;
- Область обработки информации, в которой показано, как входная информация учитывается в системе и в каких таблицах базы данных она сохраняется;
- Область формирования результатной информации, в которой приведены экранные формы и выходные документы.
Пользователь системы первоначально заполняет справочники системы исходными данными, после чего система готова к работе. Используя входные данные, пользователь формирует содержание таблиц системы. При запросе результатной информации с помощью соответствующих экранных форм хранящаяся в системе информация преобразуется в необходимый вид и представляется в виде результатных документов, которые выводятся в виде экранных форм и могут быть выведены на печать на твердый носитель.
MS SQL-сервер
Являясь полностью коммерческим инструментом, Microsoft SQL Server является одной из самых популярных реляционных СУБД. Он хорошо справляется с эффективным хранением, изменением и управлением реляционными данными. Для взаимодействия с базами данных SQL Server инженеры баз данных обычно используют язык Transact-SQL (T-SQL), который является расширением стандарта SQL.Плюсы MSSQL1) Разнообразие версий. Microsoft SQL Server предоставляет широкий выбор различных опций с различными функциональными возможностями. Например, Express edition с бесплатной базой данных предлагает инструменты начального уровня, идеально подходящие для обучения и создания настольных или небольших серверных приложений, управляемых данными. Опция разработчиков позволяет создавать и тестировать приложения, включая некоторые корпоративные функции, но без лицензии на производственный сервер. Для более крупных проектов существуют также веб-версии, стандартные и корпоративные версии с различными административными возможностями и уровнями обслуживания.2) Комплексное решение для обработки бизнес-данных. Ориентируясь в основном на коммерческие решения, MSSQL предоставляет множество дополнительных функций для бизнеса. Дополнительный выбор компонентов позволяет создавать ETL-решения, формировать базу знаний и осуществлять очистку данных. Кроме того, он предоставляет инструменты для общего администрирования данных, онлайн-аналитической обработки и интеллектуального анализа данных, дополнительно предоставляя возможности для создания отчетов и визуализации.3) Внушительная документация.4) Поддержка облачных решений. Являясь частью согласованной экосистемы Microsoft, MSSQL может быть интегрирован с Microsoft cloud, базой данных SQL Azure или SQL Server на виртуальных машинах Azure. Эти решения позволяют перенести администрирование баз данных в облако, если ваша база данных бизнес-программного обеспечения становится действительно огромной и сложной в администрировании.Минусы MSSQL1) Привязка к платформе Microsoft Windows. Выбирая MSSQL, на практике приходится автоматически выбирать ОС Windows. Несмотря на недавнее появление версий под Linux, такая связка остаётся экзотикой. 2) Высокая стоимость. Будучи в основном используемым в масштабах предприятия, MSSQL-сервер остается одним из самых дорогих решений. Говоря о цифрах, издание Enterprise в настоящее время стоит более 14 000 долларов за ядро, продаваемое в виде 2 основных пакетов.3) Высокая требовательность к аппаратным ресурсам.4) Неясные и плавающие условия лицензии. Еще одна проблема – постоянно меняющийся процесс лицензирования. Ценовую стратегия трудна для понимания.5) Сложный процесс настройки. Для тех новичков, которым приходится работать с массивными наборами данных, работа с оптимизацией запросов и настройкой производительности может оказаться проблематичной. Поскольку этот процесс не столь очевиден, он может создать существенные узкие места на ранней стадии.6) Восстановление данных после аварийного отключения питания обязательно требует участия специалиста.Сервер MSSQL является разумным вариантом для компаний с уже имеющимися подписками на продукты Microsoft. Поскольку Microsoft создает устойчивую экосистему с хорошо интегрированными сервисами, MSSQL здесь с его доступом к облаку и мощными инструментами поиска данных пригодится.
Из чего состоит СУБД
СУБД — это набор инструментов, каждый из которых способен совершать с базой данных определённое действие: считывать её, удалять элементы или обрабатывать запросы от пользователя. И чтобы все эти инструменты правильно функционировали, у СУБД должна быть хорошо прописанная архитектура.
Главные элементы СУБД — ядро, процессор, программные средства и базы данных. Поговорим о каждом из них подробнее.
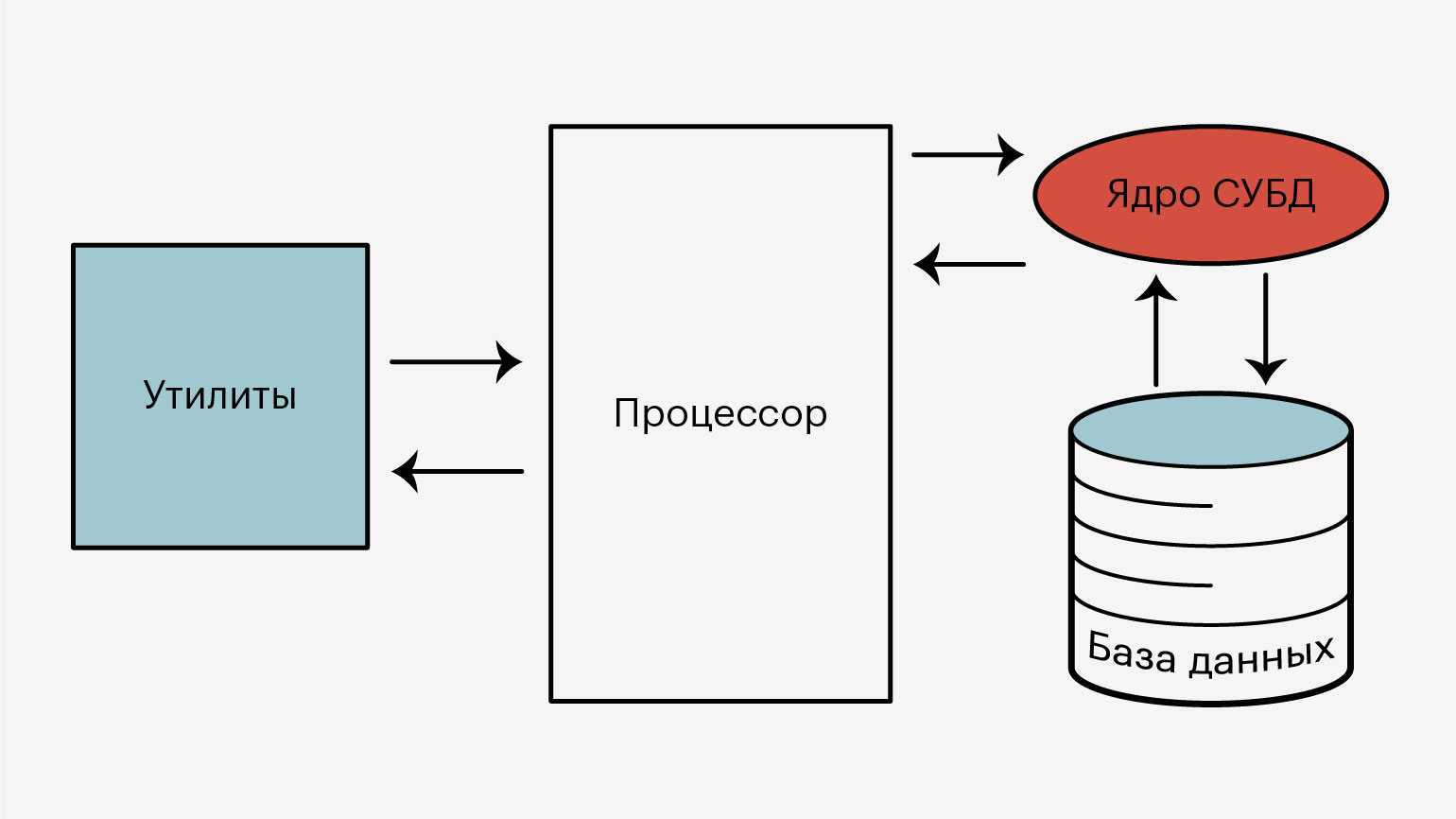
Примерное представление устройства СУБД изнутриИллюстрация: Оля Ежак для Skillbox Media
Ядро. Отвечает за работу всей системы в целом. Через него проходят все процессы обработки данных и их хранения. Ядро следит за всеми изменениями баз данных и фиксирует их.
Процессор, или компилятор. Занимается обработкой запросов от пользователей. Главная его задача — преобразовать SQL-запрос в понятные для компьютера команды, а затем вернуть результаты.
Программные средства, или утилиты. Нужны, чтобы пользователь мог вводить запросы, а администраторы могли настраивать доступ и другие необходимые параметры.
Рекомендации по выбору СУБД
Реляционные СУБД (Oracle, MySQL, Microsoft SQL Server, PostgreSQL) универсальны и подходят почти для любых задач, когда не нужно обрабатывать очень большой поток запросов и хранить слишком большие объемы данных. Когда же запросов много, возникает проблема масштабирования, с которой реляционные СУБД пока нормально справиться не могут.
Самая простая СУБД предполагает использование парадигмы «ключ-значение» (например, Redis и Memcached). Обычно такие СУБД применяют для решения задач кеширования. Отдельные СУБД данного типа позволяют перенести работу полностью в память и задать время существования записей (затем они автоматически будут удалены). Для баз данных с большим числом и сложными структурами хранимых сущностей эти СУБД неудобны.
Если необходимо хранить связи между узлами в графовой структуре БД (например, в социальной сети для описания общих интересов или родственных связей) рекомендуем обратить внимание на такие СУБД как InfiniteGraph, Neo4j, Amazon Neptune и InfoGrid. Данное ПО позволит вам построить систему оценок и рекомендаций
В колоночных СУБД используется особый способ записи информации, благодаря чему менять структуру таблиц можно очень быстро. Этот тип БД рассматривает колонку как отдельную таблицу. Если в обычной реляционной СУБД считывание данных происходит по всей строке, пока не будет достигнута нужная колонка, в колоночной СУБД считывается сразу нужный столбец. Из преимуществ колоночных СУБД можно выделить хороший процент сжатия, что заметно уменьшает занимаемое пространство. Особенностью колоночных баз и колоночных индексов является то, что для них невозможна операция промежуточной вставки или апдейта. Часто эти базы не предусматривают оператор UPDATE, только DELETE и INSERT. Применять такие колоночные СУБД как SAP IQ, Vertica, ClickHouse, Google BigQuery, InfoBright для простой выборки со статическими параметрами, где хранится менее ста миллионов строк, не имеет смысла.
Документная СУБД оптимальна в тех случаях, когда объекты предполагается помещать, например, в какое-нибудь хранилище состояний или когда записываются сложные структуры со списками и словарями (например, если вы работаете с форматом JSON). А, вот, для формирования отчетности и для реализации транзакционной модели документная СУБД это не самый лучший вариант.
MySQL

Мне нравится48Не нравится17
MySQL – бесплатная реляционная система управления базами данных. Разработку и поддержку MySQL осуществляет компания Oracle. MySQL широкое распространение получила в интернете, как система хранения данных у сайтов, иными словами, подавляющее большинство сайтов хранят свои данные в базе MySQL. Поэтому не удивительно, что MySQL занимает лидирующую строчку нашего рейтинга.
В рейтинге Stack Overflow MySQL занимает первое место, т.е. программисты больше всего задают вопросы, связанные именно с MySQL.
Во всех остальных рейтингах MySQL уверенно занимает вторую строчку, и это один из самых стабильных результатов среди всех наших сегодняшних участников. Именно поэтому MySQL и занимает первую строчку рейтинга самой популярной СУБД.
Субъективное сравнение СУБД
Следующая гистограмма (рис. 2) показывает, какой процент специалистов желает/избегает работать с конкретной СУБД.
Рис. 2. Объективная оценка удобства использования самых часто используемых СУБД.
Нереляционная СУБД Redis уже пятый год является самой любимой и востребованной СУБД, с которой удобно работать, как считают специалисты. Однако, реляционная PostgreSQL чисто символически уступает полпроцента. А такая мощная и весьма известная СУБД как IBM DB2 второй год подряд является системой, которую стремится избегать большинство.Кроме того, из практики авторы могут привести примеры практического внедрения и любопытные результаты.1) Переход с MS SQL на PostgreSQL (под Linux) оказался оправданным решением для высоконагруженных проектов (размер БД свыше 1 Тб). Это привело к повышению производительности, высвобождению ресурсов и упрощению обслуживания. В течение последних трёх лет данная тенденция остаётся неизменной. 2) Переход с MariaDB на MySQL полностью оправдывает себя, что показали примеры с несколькими веб-сайтами. Несмотря на то, что непосредственно перенос БД в другую СУБД зачастую оказывается непростым мероприятием, дальнейшая простота в обслуживании и стабильность явно того стоят.3) Дополнительное кэширование средствами Redis может дать десятикратный прирост производительности для старого высоконагруженного сайта.Из авторской практики следует привести в качестве примера один из интересных вариантов выбора и внедрения. В одном из проектов для полнотекстового поиска был применён Redisearch (надстройка над Redis), и через какое-то время стал очевидным недостаток — для Redis работает правило, что все данные должны храниться в ОЗУ. В результате пришлось менять структуру проекта и использовать ElasticSearch, благо у него более мощный язык поиска данных и репликация реализована без дополнительных настроек.4) Ещё интересный случай из авторской практики: на самом старте проекта была применена СУБД MongoDB без шардирования, а с развитием проекта оказалось, что производительности начинает не хватать. Возникла необходимость выбирать критерии шардирования. Выбор был сделан вынужденно неоптимально, т.к. к этому моменту БД успела вырасти до неудобных размеров (8 Тб). Был сделан вывод о том, что подобными вопросами следовало озаботиться при дизайне системы.5) Наконец, из опыта авторов следует упомянуть интересную ситуацию использования базовых возможностей СУБД, которые показали себя максимально эффективно. В одном из проектов была применена СУБД MongoDB в базовом варианте репликации на 3 копии. Когда произошёл серьёзный аппаратный сбой и была физически уничтожена треть кластера, на работоспособности всей системы это не сказалось ни коим образом.
Сравнение СУБД
Очень интересная гистограмма может быть построена по результатам опроса за 2021 год профессионалов, работающих в сфере ИТ (рис. 2), показывающая, какой процент специалистов хочет\избегает работать с конкретной СУБД.
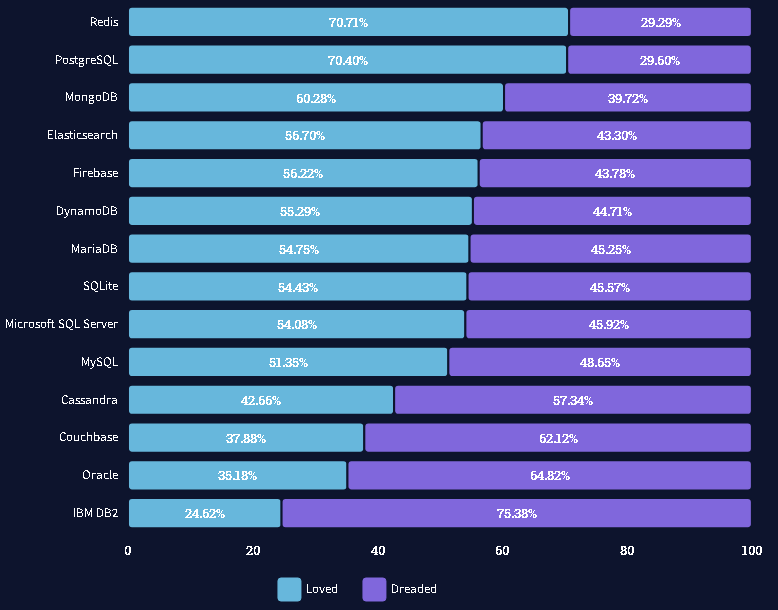
Рис. 2. Оценка удобства использования самых часто используемых СУБД.
Redis уже пятый год является самой любимой и востребованной СУБД, с которой удобно работать, как считают специалисты. Однако, PostgreSQL чисто символически уступает полпроцента. А такая мощная и весьма известная СУБД как IBM DB2 второй год подряд является СУБД, которую стремится избегать большинство.Кроме того, из собственной практики авторы могут привести примеры перехода с одной СУБД на другую.1) Переход с MS SQL на PostgreSQL (под Linux) оказался оправданным решением для высоконагруженных проектов (размер БД свыше 1 Тб). Это привело к повышению производительности, высвобождению ресурсов и упрощению обслуживания. В течение последних трёх лет данная тенденция остаётся неизменной. 2) Переход с MariaDB на MySQL полностью оправдывает себя, что показали примеры с несколькими коммерческими и образовательными веб-сайтами. Несмотря на то, что непосредственно перенос БД в другую СУБД зачастую оказывается непростым мероприятием, дальнейшая простота в обслуживании и стабильность явно того стоят.3) Дополнительное кэширование средствами Redis может дать десятикратный прирост производительности для старого высоконагруженного сайта, работающего с PostgreSQL.
Кому подходит и не подходит DBaaS
Как показывает опыт, наиболее часто к DBaaS обращаются в следующих случаях:
-
Требуются мощности для Dev- и Test-сред с оплатой по принципу Pay-as-you-go. Нередко бывает, что Production-среда в компании развернута на On-premise-серверах, но инженерам и разработчикам для тестирования приложений требуются дополнительные мощности под регулярно создаваемые и удаляемые БД. Это удобно делать в облаке, где ресурсы предоставляются по запросу и можно гибко управлять их потреблением, настраивая лимиты для каждого проекта или разработчика.
Оплачиваются при этом только используемые вычислительные мощности с посекундной тарификацией. В любой момент можно остановить неиспользуемую БД, после чего оплачиваться будет только место на диске, а не CPU и RAM.
-
Нужно быстро развернуть решение, аттестованное по 152-ФЗ. Если компания работает с персональными данными и необходимо соответствовать требованиям 152-ФЗ, использование DBaaS в аттестованном облаке может оказаться наиболее быстрым и простым решением, так как в этом случае не приходится тратить время и ресурсы на самостоятельное развертывание и аттестацию защищенного контура.
При этом зачастую компании переносят в облако только часть данных, оставляя наиболее «чувствительные» на своей стороне. Это позволяет значительно сэкономить на используемых мощностях, особенно при обработке больших объемов данных.
-
Требуется недорогое хранилище для резервных копий. В облаке MCS для хранения бэкапов баз данных можно использовать отказоустойчивое объектное хранилище S3. Хранение массивных бэкапов с редким доступом в таком хранилище обойдется намного дешевле, чем на локальных серверах. S3 позволяет хранить неограниченный объем данных без каких-либо специальных действий со стороны пользователя для увеличения объема хранения, а оплачивается только фактически использованный объем хранения.
Кроме этого, сами бэкапы автоматизированы и расписание их создания легко настраивается. При необходимости бэкапы из S3 всегда можно выгрузить в On-premise-хранилище.
-
В команде не хватает опыта самостоятельной настройки и администрирования СУБД. Установка и настройка любой СУБД требует времени, а создание отказоустойчивой системы — высокого уровня квалификации команды. Используя DBaaS, можно запустить любую БД всего за несколько минут с помощью API или UI, а также получить «из коробки» весь необходимый функционал: автомасштабирование БД по мере роста нагрузок, резервное копирование и геораспределенные реплики для большей надежности. Кроме этого, провайдеры предоставляют определенный SLA на работу своих сервисов, часто с финансовыми гарантиями.
Однако далеко не всегда DBaaS является лучшим решением
Важно учитывать, что облачные провайдеры не предоставляют Root-доступ к настройкам серверов БД: это своеобразная плата за то, что провайдер гарантирует SLA, минимизируя ошибки и гарантируя доступность сервисов. Поэтому в тех случаях, когда требуется полный контроль над системой, включая ее администрирование, On-premise-вариант выглядит предпочтительнее — разумеется, при достаточном уровне экспертности в самостоятельной установке и развертывании БД
Аналогично и в случаях, когда требуется тонкая настройка СУБД, то есть опять же нужен доступ к ее «внутренностям».
Microsoft SQL Server

Мне нравится36Не нравится28
Microsoft SQL Server – это система управления реляционными базами данных, разработанная компанией Microsoft. Ее активно используют в корпоративном секторе, особенно в крупных компаниях. И это не просто СУБД – это целый комплекс приложений, позволяющий не только хранить и модифицировать данные, но еще и анализировать их, осуществлять безопасность этих данных и многое другое.
По результатам опросов компании РУССОФТ, именно Microsoft SQL Server чаще всего используют софтверные организации.
В остальных рейтингах Microsoft SQL Server уверенно занимает третью строчку, поэтому данной СУБД мы отдаем вторую строчку нашего рейтинга.
СУПБД (система управления пространственными базами данных)
Этот тип СУБД оптимизирован для работы с объектами, определенными в геометрическом пространстве — как простыми (точки, кривые, многоугольники), так и сложными (3D-объекты, топологическое покрытие, линейные сети).
СУПБД имеет набор специальных функций для обработки создания, преобразования, измерения (расстояние, площадь, объем), вычисления (пересечение/контакт) и выбора на основе определенных критериев. И содержит специальные индексы, оптимизирующие обработку объектов, и особый стандартизированный язык SQL/MM.
Самые известные СУПБД:
- Oracle Spatial;
- Microsoft SQL;
- PostGIS;
- Spatiallite.
Когда следует выбирать СУПБД?
При создании ГИС-решений — не только для хранения, но и для работы с геометрическими объектами на уровне СУПБД.
Когда не следует выбирать СУПБД?
Для хранения геометрических объектов в качестве координат.
Выводы и заключение
Существует большое количество СУБД, не описанных в данной статье. В частности, есть функциональные СУБД отечественной разработки , которые не вошли в настоящий обзор только лишь потому, что не являются популярными с точки зрения повсеместного внедрения. Настоящая статья является сравнительным обзором самых часто используемых СУБД. Каждая СУБД по-своему хороша, но имеет и некоторые недостатки. Однозначно посоветовать правильный выбор для новых проектов или для будущего перехода не представляется возможным. Попробуем в общих чертах дать рекомендации по выбору.Для разработки интернет-мгазина логично рассмотреть СУБД Cassandra. Чтобы дополнить эту СБУД мощной поисковой системой, рационально подключить Elasticsearch.Особенность Cassandra заключается в том, что это заманчивый вариант для центров обработки данных и аналитики в реальном времени с огромными объемами данных.Говоря об аналитических инструментах без нескольких слоев данных или каталогах продукции, разумным может оказаться выбор СУБД MongoDB.Приложения Интернета вещей и архитектура микросервисов однозначно намекают на внедрение Redis. Конечно, есть и другие СУБД, которые можно рассмотреть, исходя из бизнес-модели и коммерческих потребностей.Вполне возможно, лучшей рекомендацией будет: следует выбирать ту СУБД, которая лучше всего известна, и с которой наиболее удобно работать.Известен и альтернативный подход: во многом выбор СУБД зависит от того, что за приложение планируется создать — то есть выбор осуществляет не разработчик, а сам продукт.