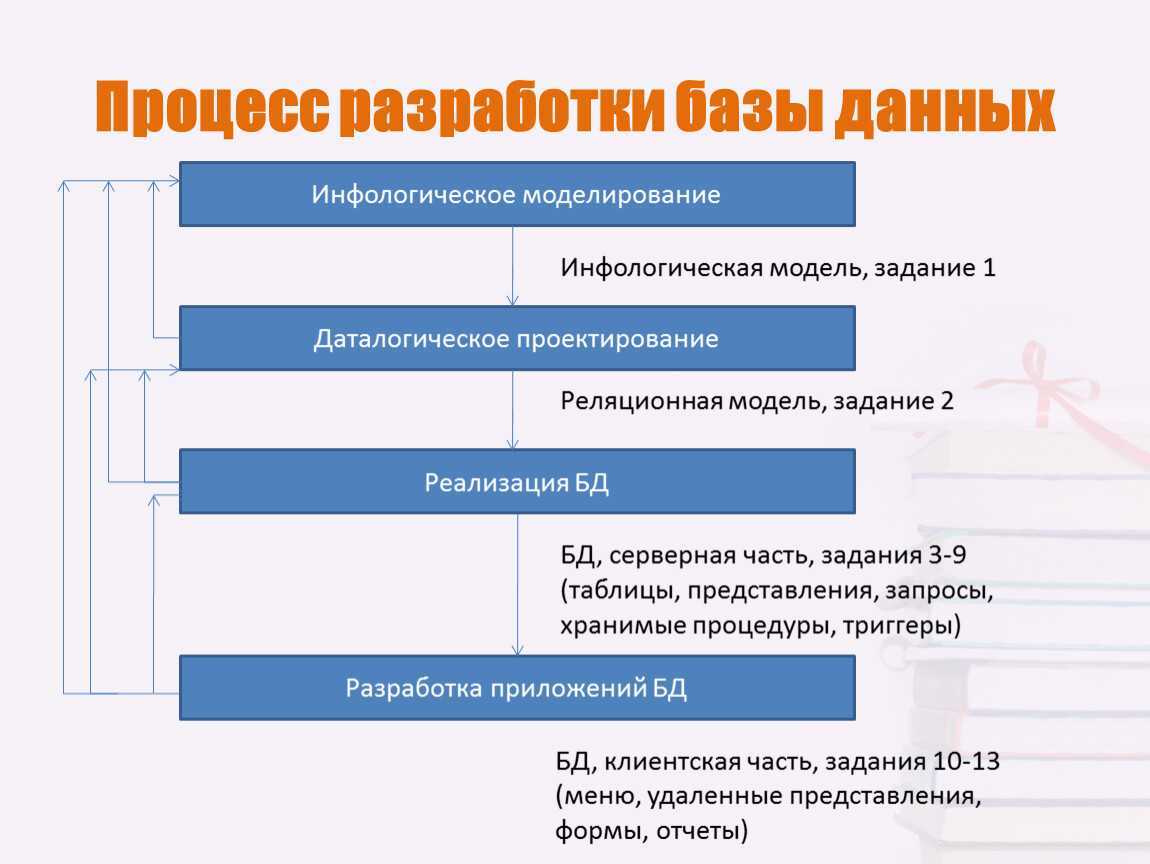
Содержание проектирования баз данных и этапность
Замысел проектирования основывается на какой-либо сформулированной общественной потребности. У этой потребности есть среда её возникновения и целевая аудитория потребителей, которые будут пользоваться результатом проектирования. Следовательно, процесс проектирования баз данных начинается с изучения данной потребности с точки зрения потребителей и функциональной среды её предполагаемого размещения. То есть, первым этапом становится сбор информации и определение модели предметной области системы, а также – взгляда на неё с точки зрения целевой аудитории. В целом, для определения требований к системе производится определение диапазона действий, а также границ приложений БД.
Далее проектировщик, уже имеющий определённые представления о том, что ему нужно создать, уточняет предположительно решаемые приложением задачи, формирует их список (особенно, если в проектной разработке большая и сложная БД), уточняет последовательность решения задач и производит анализ данных. Такой процесс – тоже этапная проектная работа, но обычно в структуре проектирования эти шаги поглощаются этапом концептуального проектирования – этапом выделения объектов, атрибутов, связей.
Создание концептуальной (информационной модели) предполагает предварительное формирование концептуальных требований пользователей, включая требования в отношении приложений, которые могут и не быть сразу реализованным, но учёт которых позволит в будущем повысить функциональность системы. Имея дело с представлениями объектов-абстракций множества (без указания способов физического хранения) и их взаимосвязями, концептуальная модель содержательно соответствует модели предметной области. Поэтому в литературе первый этап проектирования БД называется инфологическим проектированием.
Далее отдельным этапом (либо дополнением к предыдущему) следует этап формирования требований к операционной обстановке, где оцениваются требования к вычислительным ресурсам, способным обеспечить функционирование системы. Соответственно, чем больше объем проектируемой БД, чем выше пользовательская активность и интенсивность обращений, тем выше требования предъявляются к ресурсам: к конфигурации компьютера к типу и версии операционной системы. Например, многопользовательский режим работы будущей базы данных требует сетевого подключения с использованием операционной системы, соответствующей многозадачности.
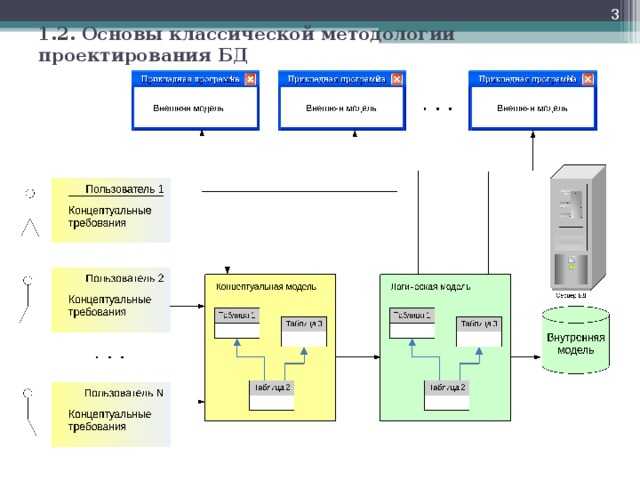
Следующим этапом проектировщик должен выбрать систему управления базой данных (СУБД), а также инструментальные средства программного характера. После этого концептуальную модель необходимо перенести в совместимую с выбранной системой управления модель данных. Но нередко это сопряжено с внесением поправок и изменений в концептуальную модель, поскольку не всегда взаимосвязи объектов между собой, отражённые концептуальной моделью, могут быть реализованы средствами данной СУБД.
Это обстоятельство определяет возникновение следующего этапа – появления обеспеченной средствами конкретной СУБД концептуальной модели. Данный шаг соответствует этапу логического проектирования (создания логической модели).
Наконец, финальным этапом проектирования БД становится физическое проектирование – этап увязки логической структуры и физической среды хранения.
Таким образом, основные этапы проектирования в детализированном виде представлены этапами:
- инфологического проектирования,
- формирования требований к операционной обстановке
- выбора системы управления и программных средств БД,
- логического проектирования,
- физического проектирования
Ключевые из них ниже будут рассмотрены подробнее.
Физическое проектирование БД
На следующем этапе физического проектирования БД логическая структура отображается в виде структуры хранения БД, то есть увязывается с такой физической средой хранения, где данные будут размещены максимально эффективно. Здесь детально расписывается схема данных с указанием всех типов, полей, размеров и ограничений. Помимо разработки индексов и таблиц, производится определение основных запросов.
Построение физической модели сопряжено с решением во многом противоречивых задач:
- задачи минимизации места хранения данных,
- задачи достижения целостности, безопасности и максимальной производительности.
Вторая задача вступает в конфликт с первой, поскольку, например:
- для эффективного функционирования транзакций нужно резервировать дисковое место под временные объекты,
- для увеличения скорости поиска нужно создавать индексы, число которых определяется числом всех возможных комбинаций участвующих в поиске полей,
- для восстановления данных будут создаваться резервные копии базы данных и вестись журнал всех изменений.
Всё это увеличивает размер базы данных, поэтому проектировщик ищет разумный баланс, при котором задачи решаются оптимально путём грамотного размещения данных в пространстве памяти, но не за счёт средств защиты базы дынных, куда входит как защита от несанкционированного доступа, так и защита от сбоев.
Для завершения создания физической модели проводят оценку её эксплуатационных характеристик (скорость поиска, эффективность выполнения запросов и расхода ресурсов, правильность операций). Иногда этот этап, как и этапы реализации базы данных, тестирования и оптимизации, а также сопровождения и эксплуатации, выносят за пределы непосредственного проектирования БД.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
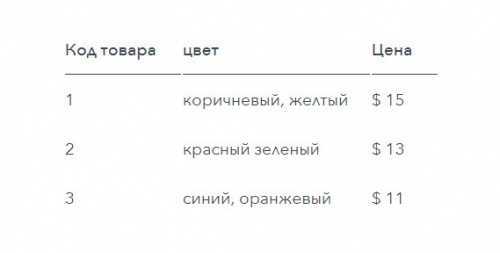
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:
Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:
Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.





В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:
В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:
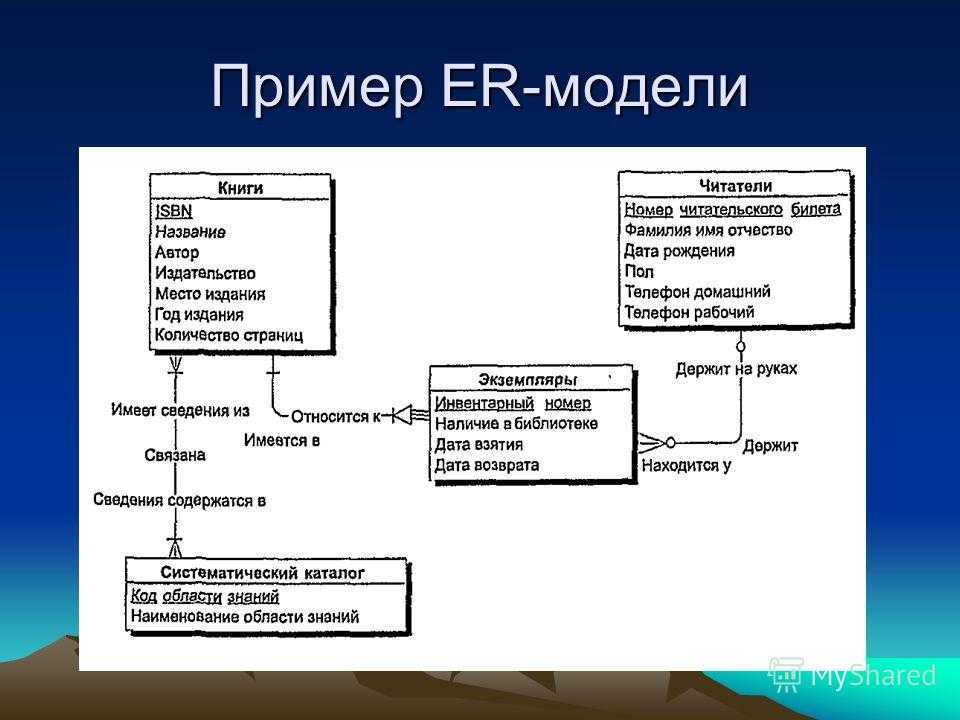
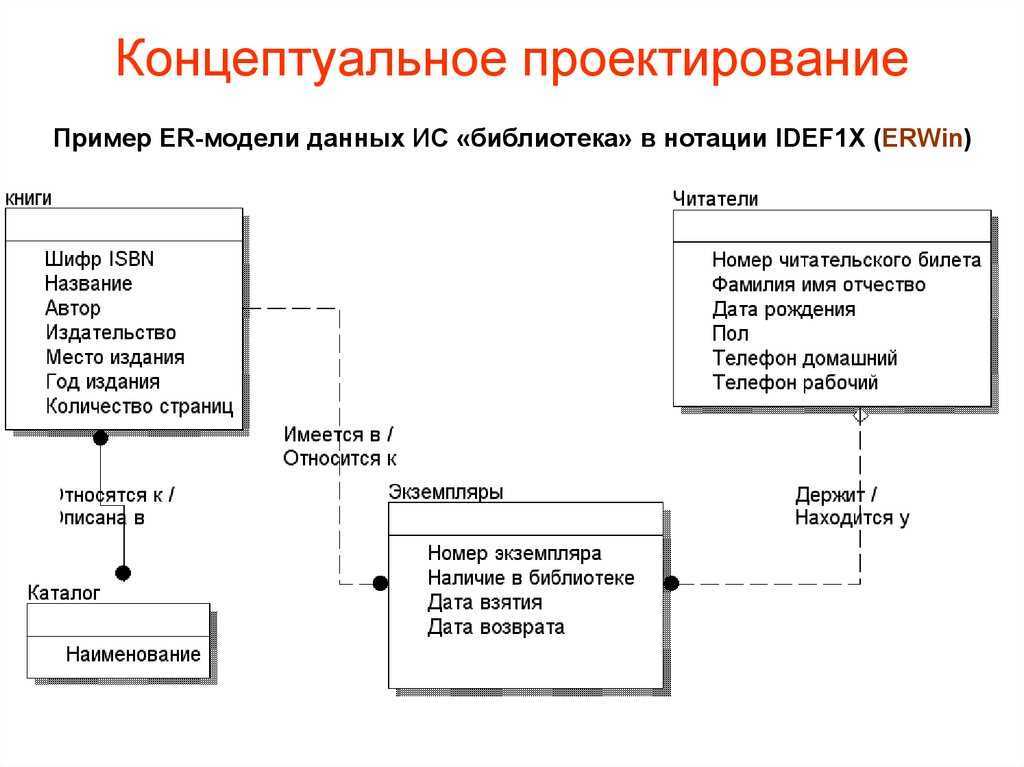
Инфологическое проектирование
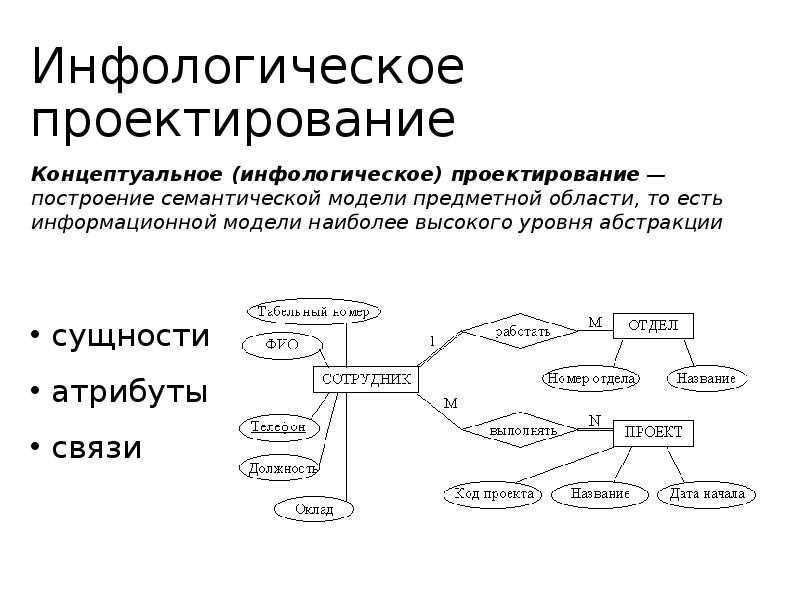
Идентификация сущностей составляет смысловую основу инфологического проектирования. Сущность здесь – это такой объект (абстрактный или конкретный), информация о котором будет накапливаться в системе. В инфологической модели предметной области в понятных пользователю терминах, которые не зависят от конкретной реализации БД, описывается структура и динамические свойства предметной области. Но термины, при этом берутся в типовых масштабах. То есть, описание выражается не через отдельные объекты предметной области и их взаимосвязи, а через:
- описание типов объектов,
- ограничения целостности, связанные с описанным типом,
- процессы, приводящие к эволюции предметной области – переходу её в другое состояние.
Инфологическую модель можно создавать с помощью нескольких методов и подходов:
- Функциональный подход отталкивается от поставленных задач. Функциональным он называется, потому что применяется, если известны функции и задачи лиц, которые с помощью проектируемой базы данных будут обслуживать свои информационные потребности.
- Предметный подход во главу угла ставит сведения об информации, которая будет содержаться в базе данных, при том, что структура запросов может не быть определена. В этом случае в исследованиях предметной области ориентируются на её максимально адекватное отображение в базе данных в контексте полного спектра предполагаемых информационных запросов.
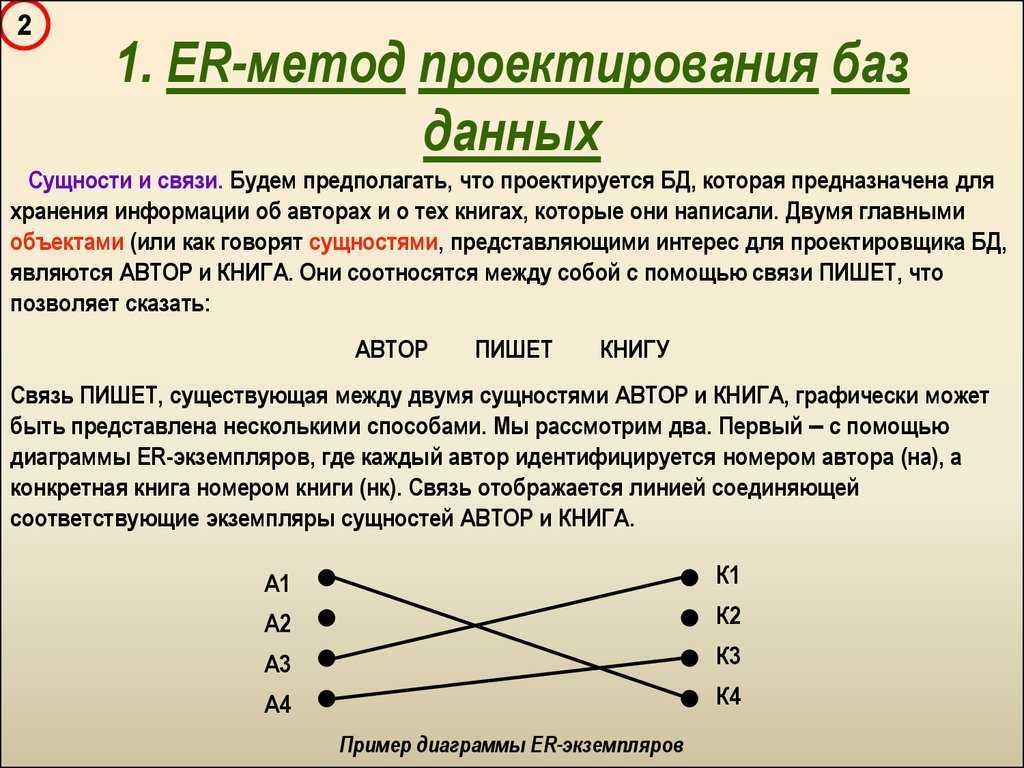
- Комплексный подход по методу «сущность-связь» объединяет достоинства двух предыдущих. Метод сводится к разделению всей предметной области на локальные части, которые моделируются по отдельности, а затем вновь объединяются в цельную область.
Поскольку использование метода «сущность-связь» является комбинированным способом проектирования на данном этапе, он чаще других становится приоритетным.
Локальные представления при методическом разделении должны, по возможности, включать в себя информацию, которой бы хватило для решения обособленной задачи или для обеспечения запросов какой-то группы потенциальных пользователей. Каждая из этих областей содержит порядка 6-7 сущностей и соответствует какому-либо отдельному внешнему приложению.
Зависимость сущностей отражается в разделении их на сильные (базовые, родительские) и слабые (дочерние). Сильная сущность (например, читатель в библиотеке) может существовать в БД сама по себе, а слабая сущность (например, абонемент этого читателя) «привязывается» к сильной и отдельно не существует.
Для каждой отдельной сущности выбираются атрибуты (набор свойств), которые в зависимости от критерия могут быть:
- идентифицирующими (с уникальным значением для сущностей этого типа, что делает их потенциальными ключами) или описательными;
- однозначными или многозначными (с соответствующим количеством значений для экземпляра сущности);
- основными (независимыми от остальных атрибутов) или производными (вычисляемыми, исходя из значений иных атрибутов);
- простыми (неделимыми однокомпонентными) или составными (скомбинированными из нескольких компонентов).
После этого производится спецификация атрибута, спецификация связей в локальном представлении (с разделением на факультативные и обязательные) и объединение локальных представлений.При числе локальных областей до 4-5 их можно объединить за один шаг. В случае увеличения числа, бинарное объединение областей происходит в несколько этапов.
В ходе этого и других промежуточных этапов находит своё отражение итерационная природа проектирования, выражающаяся здесь в том, что для устранения противоречий необходимо возвращаться на этап моделирования локальных представлений для уточнения и изменения (например, для изменения одинаковых названий семантически разных объектов или для согласования атрибутов целостности на одинаковые атрибуты в разных приложениях).
MVCC — MultiVersion Concurrency Control
zr1(y)yyy
Как это работает?
- Когда мы пошли исполнять транзакцию t1, имеется чтение x, т.е. самой изначальной версии.
- Дальше в t2 мы начинаем записывать y другой версии, потому что он был изменен.
- В транзакции t1, которая началась раньше, чем мы начали записывать y, до сих пор видно предыдущую версию y, поскольку t2 еще не завершилась, и мы и спокойно начать с ней работать.
- Поскольку транзакция t1 заканчивается раньше, чем w2(y2), то произойдет перечитываниеy,и после этого в транзакции t 2 выполнится нормальная работа, а другая транзакция просто нормально завершится.
yw2yt1xy
- В MySQL он внутри InnoDB,
- В PostgreSQL это отдельная директория, которая наконец в версии 10 стала называться WAL вместо PGX-Log;
- В Oracle это называется Redo Log;
- В DB2 — WAL.
Вместо предисловия
Полистал я несколько рекомендованных ссылок (в том числе три «местных»), а именно:
- Проектирование баз данных: новые требования, новые подходы
- Аномалии в реляционных базах данных
- Кризис баз данных и проблема выбора
- Базы данных: достижения и перспективы на пороге 21-го столетия
- Реализация ядра безопасности в информационной системе
- Словарь метаданных документно-ориентированной информационной системы
- Управление качеством данных на основе алгоритмов нечеткого поиска
- Двадцать лет практики обучили нас, что иногда нормализованные таблицы это правильно, а иногда нет; базы данных будущего должны предоставлять такой выбор.
- Большинство организаций сейчас хранят больше данных на десктопах, чем в своих БД. Этими данными на десктопах, часто хорошо структурированными по своей природе, управляет все, что угодно, но не системы управления базами данных.
- Сегодня объектно-ориентированные базы данных поддерживают один стиль навигации; сетевые СУБД и ISAM — другой. Реляционные базы данных, с другой стороны, обеспечивают запросы и операции на множествах. Высокоуровневые процессоры запросов могут ориентироваться либо на операции со множествами, либо на навигацию указателей или на то и другое. Пользователь может выбирать.
- Поэлементный навигационный стиль и вычисления, основанные на запросах и ориентированные на множества одинаково нужны. Часто подход, основанный на запросах, — наилучший путь первоначального указания множества записей, в то время как навигационные операции — единственный путь дальнейшей работы с полученными в результате данными в манере достаточно развитой, чтобы удовлетворить потребностям сложных приложений. Чем раньше мы избавимся от необходимости выбора, тем лучше.
- SQL и надстраиваемые над ним языковые формы более высокого уровня хороши для доступа к традиционным записям данных. Когда речь идет о мультимедийных данных, то здесь часто необходимы совершенно другие формы пользовательских интерфейсов.
- Одной из самых актуальных задач является создание методики проектирования хороших схем реляционных БД. Вопрос о проектировании «хороших» схем реляционных баз данных изучается в литературе уже свыше двадцати лет. К сожалению, к настоящему моменту так и не появилось общепринятой на практике методики проектирования схем. Проектирование схем БД превращается в искусство. Его результаты полностью зависят от опыта и мастерства проектировщика.
- Средств для работы с абстрактными типами данных в реляционных СУБД практически нет
Определение атрибутов
Атрибут представляет свойство, описывающее сущность. Атрибуты часто бывают числом, датой или текстом. Все данные, хранящиеся в атрибуте, должны иметь одинаковый тип и обладать одинаковыми свойствами.
В физической модели атрибуты называют колонками.
После определения сущностей необходимо определить все атрибуты этих сущностей.
На диаграммах атрибуты обычно перечисляются внутри прямоугольника сущности. На рисунке вы найдете пример базы данных «Дома», только теперь для сущностей из этой базы определены некоторые атрибуты.
Для каждого атрибута определяется тип данных, их размер, допустимые значения и любые другие правила. К их числу относятся правила обязательности заполнения, изменяемости и уникальности.
Правило обязательности заполнения определяет, является ли атрибут обязательной частью сущности. Если атрибут является необязательной частью сущности, то он может принимать NULL-значение, иначе — нет.
Также вы должны определить, является ли атрибут изменяемым. Значения некоторых атрибутов не могут измениться после создания записи.
И, наконец, вам нужно определить, является ли атрибут уникальным. Если это так, то значения атрибута не могут повторяться.
Дополнение 3. Обязательность моделей данных предметной области
Насколько обязательным этапом является составление моделей данных предметной области?
Концептуальная модель данных предметной области, с моей точки зрения, должна быть всегда. В отдельных случаях она может не документироваться в виде артефакта и существовать только в голове членов команды — например, если в проектировании участвует только системный аналитик и для него это не первый проект в данной предметной области. Но такой подход имеет много недостатков — тот же bus factor и т.д. Желательно её документировать.
Необходимость составления логической модели данных предметной области, с моей точки зрения, зависит от уровня детализации документа содержащего требования (как бы он ни назывался — ТЗ, SRS, FRD и т.д.).
Если документ достаточно верхнеуровневый, то достаточно концептуальной модели данных предметной области. Если документ подробный, то нужна также и логическая модель данных предметной области.
Если работы по созданию приложения были начаты на основе верхнеуровневых требований (содержащих только концептуальную модель данных), то составление логической модели данных предметной области может быть избыточным: может быть достаточно только логической модели данных приложения.
Получается следующая схема:
Процесс моделирование данных с учетом дополнений №1, №2 и №3
Денормализация
Денормализация — это умышленное изменение структуры базы, нарушающее правила нормальных форм. Обычно это делается с целью улучшения производительности базы данных.
Теоретически, надо всегда стремиться к полностью нормализованной базе, однако на практике полная нормализация базы почти всегда означает падение производительности. Чрезмерная нормализация базы данных может привести к тому, что при каждом извлечении данных придется обращаться к нескольким таблицам. Обычно в запросе должны участвовать четыре таблицы или менее.
Стандартными приемами денормализации являются: объединение нескольких таблиц в одну, сохранение одинаковых атрибутов в нескольких таблицах, а также хранение в таблице сводных или вычисляемых данных.
4.9
18
Голоса
Рейтинг статьи
Добавление индексов и представлений
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.

Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
Принципы проектирования баз данных
Выбор подходов к проектированию баз данных (БД) зависит от следующих факторов:
- сложность проекта;
- технологические и экономические возможности (каким оборудованием располагает проект, сколько времени будет длиться разработка, сколько сотрудников в ней будут участвовать);
- корпоративная IT-культура (какие операционные системы и инструменты применяются разработчиками: например, если организация-заказчик предпочитает продукцию компании Microsoft, то, скорее всего, будут выбраны такие инструменты, как Microsoft Access или Microsoft SQL Server, если у заказчика принято использовать ПО категории OpenSource, то, скорее всего, будут задействованы такие продукты, как MySQL, PostgreSQL и т.п.).
Проектирование начинается со сбора информации о предметной области. В ходе серии интервью с заказчиком следует выяснить, учет каких категорий объектов предполагается вести в БД, как они взаимосвязаны между собой, насколько они многочисленны.
Замечание 1
Для малочисленных объектов с жестко заданной номенклатурой целесообразно создавать не отдельные таблицы, а ограничения, проверяющие соответствие вводимых данных на соответствие диапазону значений.
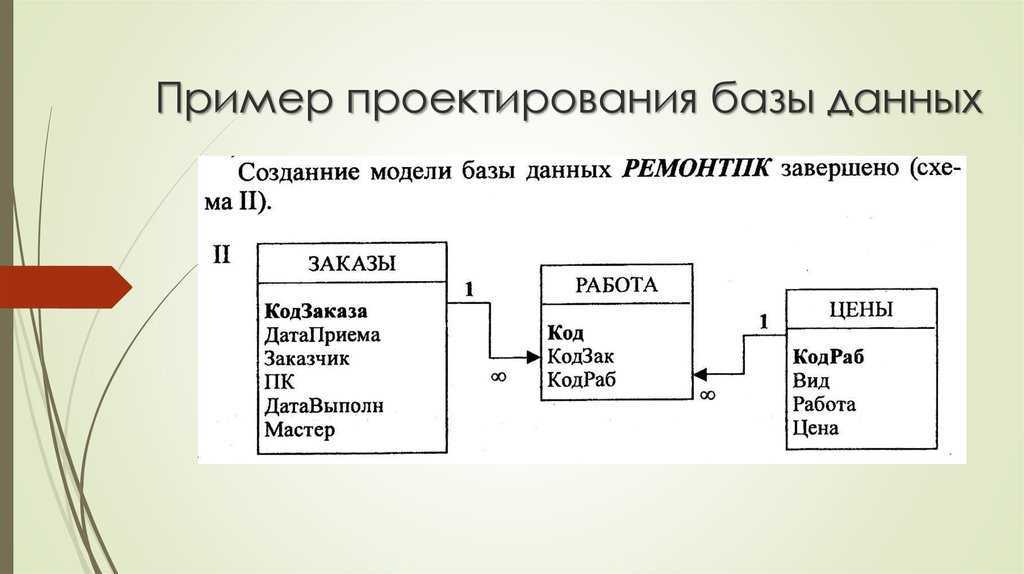
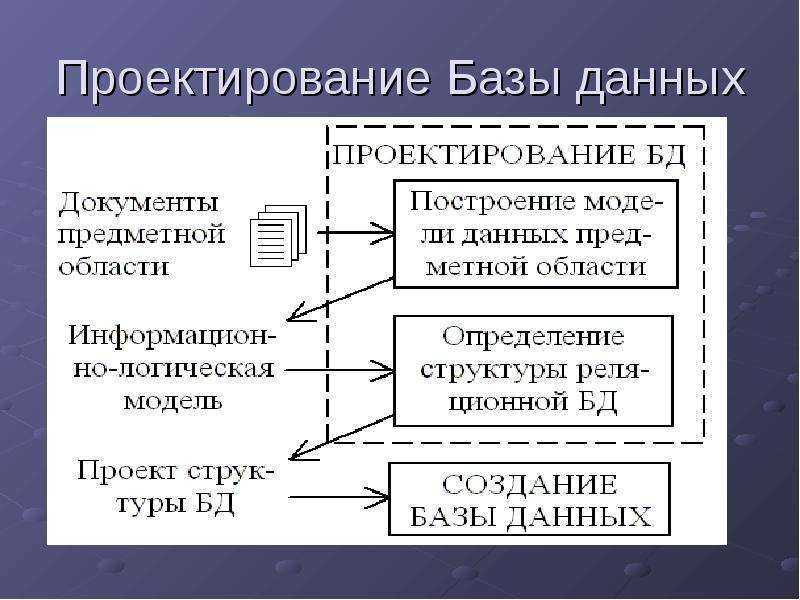
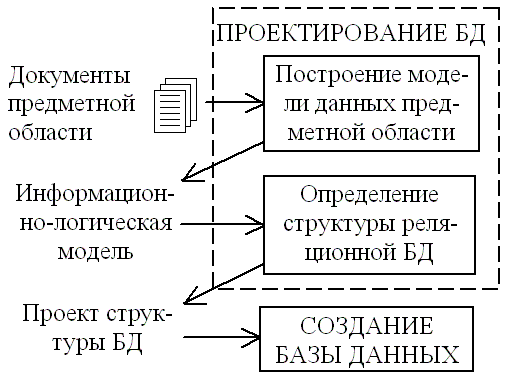 Рисунок 1. Этапы проектирования базы данных. Автор24 — интернет-биржа студенческих работ
Рисунок 1. Этапы проектирования базы данных. Автор24 — интернет-биржа студенческих работ
Следующим этапом проектирования БД может стать подготовка серии диаграмм UML, результатом которой становится диаграмма классов. Между ними устанавливаются связи типов «один-к-одному», «один-к-многим», «многие-к-многим».
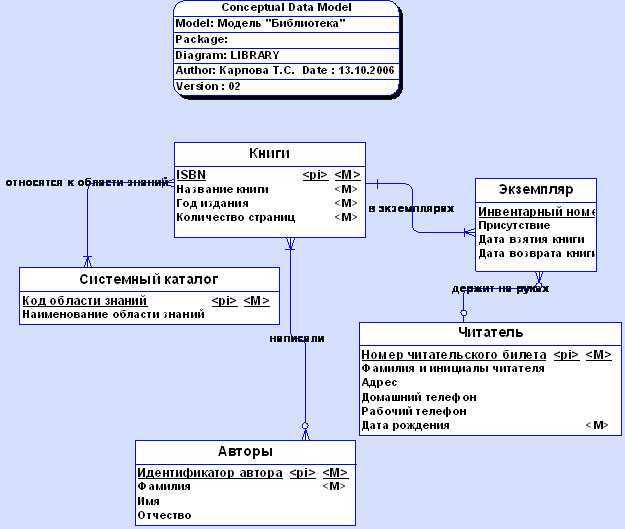 Рисунок 2. Диаграмма классов как промежуточный этап проектирования БД. Автор24 — интернет-биржа студенческих работ
Рисунок 2. Диаграмма классов как промежуточный этап проектирования БД. Автор24 — интернет-биржа студенческих работ
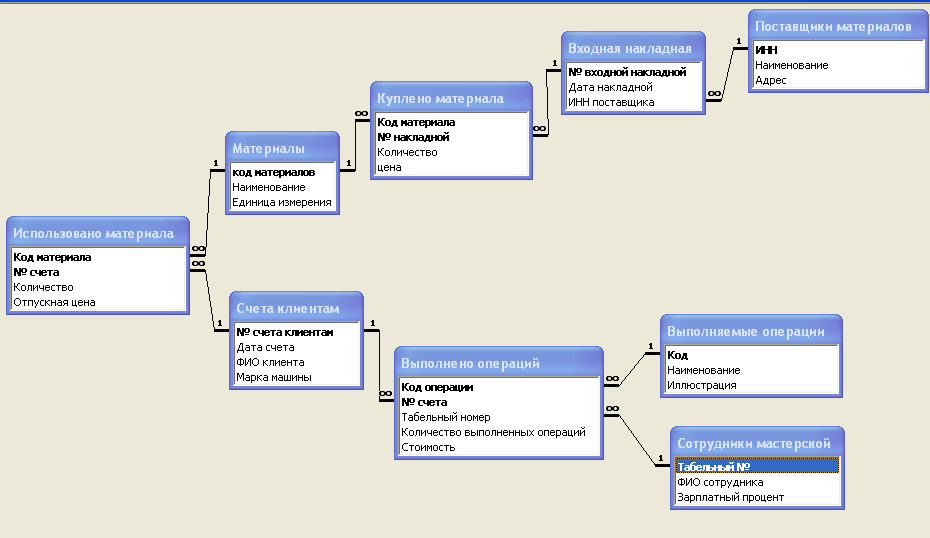
Получив необходимую информацию, можно приступать к созданию таблиц реляционной БД. Для этого могут использоваться как визуальные средства (например, в Microsoft Access), так и текстовые запросы, выполняемые непосредственно на языке SQL.
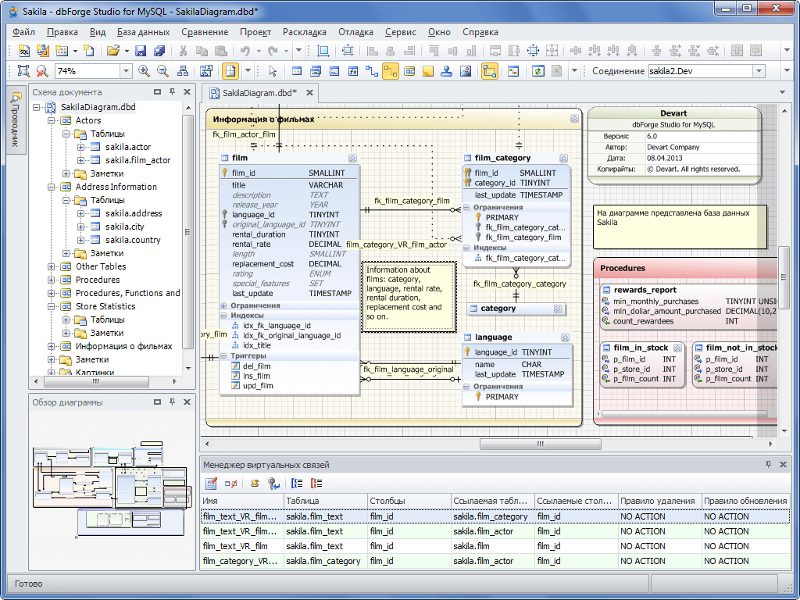 Рисунок 3. Визуальный дизайнер для баз данных MySQL. Автор24 — интернет-биржа студенческих работ
Рисунок 3. Визуальный дизайнер для баз данных MySQL. Автор24 — интернет-биржа студенческих работ
Результат эксперимента
Первый тест – как меняется время, затрачиваемое на заполнение списка друзей. Результат – на графике ниже.
Варианты 3-5 ожидаемо показывают практически константное время «бизнес-операции», которое не зависит от роста размера сети и неотличимую разницу в производительности.
Вариант 2 показывает тоже константную, но чуть худшую производительность, причем практически ровно в 2 раза относительно вариантов 3-5. И это не может не радовать, так как соотноситься с теорией – в этом варианте количество операций ввода-вывода в/из HBase как раз в 2 раза больше. Это может служить косвенным свидетельством, что наш тестовый стенд в принципе дает неплохую точность.
Вариант 1 так же ожидаемо оказывается самым медленным и демонстрирует линейный от размера сети рост времени, затрачиваемого на добавление одно друга.
Посмотрим теперь результаты второго теста.
Варианты 3-5 опять же ведет себя ожидаемо – константное время, не зависящее от размера сети. Варианты 1 и 2 демонстрируют линейный рост времени при росте размера сети и схожую производительность. Причем вариант 2 оказывается чуть медленнее – по всей видимости из-за необходимости вычитки и обработки дополнительной колонки «count», что при росте n становится более заметным. Но я все же воздержусь от каких-либо выводов, так как точность данного сравнения относительно невысока. Кроме того, данные соотношения (какой вариант, 1 или 2, быстрее) менялись от запуска к запуску (при этом сохраняя характер зависимости и «идя ноздря в ноздрю»).
Ну и последний график – результат тестирования удаления.
Здесь опять же без сюрпризов. Варианты 3-5 осуществляют удаление за константное время.
Причем, что интересно, варианты 4 и 5, в отличии от предыдущих сценариев, показывают заметную чуть худшую производительность, чем вариант 3. По всей видимости, операция удаления строки – более затратная, нежели операция удаления колонки, что в целом логично.
Варианты 1 и 2, ожидаемо, демонстрируют линейный рост времени. При этом вариант 2 стабильно медленнее варианта 1 – из-за дополнительной операции ввода-вывода по «обслуживанию» колонки count.
Общие выводы эксперимента:
- Варианты 3-5 демонстрируют бОльшую эффективность, так как они использует преимущества HBase; при этом их производительность отличается друг относительно друга на константу и не зависит от размера сети.
- Разница между вариантами 4 и 5 не была зафиксирована. Но это не значит, что вариант 5 не следует использовать. Вполне вероятно, что используемый сценарий эксперимента с учетом ТТХ тестового стенда не позволил ее выявить.
- Характер роста времени, необходимого на выполнение «бизнес-операций» с данными, в целом подтвердил полученные ранее теоретические выкладки для всех вариантов.
Подготовка эксперимента
Вышеизложенные теоретические рассуждения хотелось бы проверить на практике – это и было целью возникшей на долгих выходных задумки. Для этого необходимо оценить скорость работы нашего «условного приложения» во всех описанных сценариях использования базы, а также рост этого времени с ростом размера социальной сети (n). Целевым параметром, который нас интересует и который мы будем замерять в ходе эксперимента, является время, затраченное «условным приложением», на выполнение одной «бизнес-операции». Под «бизнес-операцией» мы понимаем одну из следующих:
- Добавление одного нового друга
- Проверка, является ли пользователь А другом пользователя Б
- Удаление одного друга
Таким образом, с учетом обозначенных в изначальной постановке требований, сценарий проверки вырисовывается следующий:
- Запись данных. Сгенерировать случайным образом исходную сеть размером n. Для большего приближения к «реальному миру» количество друзей у каждого пользователя – так же случайная величина. Замерить время, за которое наше «условное приложение» запишет в HBase все сгенерированные данные. Потом полученное время разделить на общее количество добавленных друзей – так мы получим среднее время на одну «бизнес-операцию»
- Чтение данных. Для каждого пользователя составить список «личностей», для которых надо получить ответ, подписан ли на них пользователь или нет. Длина списка = примерно кол-ву друзей пользователя, причем для половины проверяемых друзей ответ должен быть «Да», а для другой половины – «Нет». Проверка производится в таком порядке, чтобы ответы «Да» и «Нет» чередовались (то есть в каждом втором случае нам придется перебирать все колонки строки для вариантов 1 и 2). Общее время проверки затем разделить на количество проверяемых друзей для получения среднего времени на проверку одного субъекта.
- Удаление данных. Удалить у пользователя всех друзей. Причем порядок удаления – случайный (то есть «перемешиваем» изначальный список, использовавшийся для записи данных). Общее время проверки затем разделить на количество удаляемых друзей для получения среднего времени на одну проверку.
Сценарии необходимо прогнать для каждого из 5 вариантов моделей данных и для разных размеров социальной сети, чтобы посмотреть, как меняется время с ее ростом. В рамках одного n связи в сети и список пользователей для проверки должны быть, естественно, одинаковыми для всех 5 вариантов.
Для лучшего понимания ниже привожу пример сгенерированных данных для n= 5. Написанный «генератор» дает на выходе три словаря ID-шников:
- первый – для вставки
- второй – для проверки
- третий – для удаления
Как можно заметить, все ID, большие 10 000 в словаре для проверки – это как раз те, которые заведомо дадут ответ False. Вставка, проверка и удаление «друзей» производятся именно в указанной в словаре последовательности.
С учетом вычислительной мощности конкретного ноутбука экспериментально был выбран запуск для n = 10, 30, …. 170 – когда общее время работы полного цикла тестирования (все сценарии для всех вариантов для всех n) было еще более-менее разумным и умещалось во время одного чаепития (в среднем 15 минут).
Тут необходимо сделать ремарку, что в данном эксперименте мы в первую очередь оцениваем не абсолютные цифры производительности. Даже относительное сравнение разных двух вариантов может быть не совсем корректным. Сейчас нас интересует именно характер изменения времени в зависимости от n, так как с учетом указанной выше конфигурации «тестового стенда» получить временные оценки, «очищенные» от влияния случайных и прочих факторов, очень сложно (да и такой задачи не ставилось).
Эпилог
Проведенные грубые эксперименты не следует воспринимать как абсолютную истину. Есть множество факторов, которые не были учтены и вносили искажения в результаты (особенно хорошо эти флуктуации видны на графиках при небольшом размере сети). Например, скорость работы thrift, который используется happybase, объем и способ реализации логики, которая у меня была написана на Python (не берусь утверждать, что код был написан оптимально и эффективно использовал возможности всех компонент), возможно особенности кэширования HBase, фоновая активность Windows 10 на моем ноутбуке и т.п. В целом можно считать, что все теоретические выкладки экспериментально показали свою состоятельность. Ну или как минимум опровергнуть их таким вот «наскоком в лоб» не получилось.
В заключении — рекомендации всем, кто только начинает проектировать модели данных в HBase: абстрагируйтесь от предыдущего опыта работы с реляционными базами и помните «заповеди»:
- Проектируя, идем от задачи и шаблонов манипуляции с данными, а не от модели предметной области
- Эффективный доступ (без full table scan) – только по ключу
- Денормализация
- Разные строки могу содержать разные колонки
- Динамический состав колонок
Итого
-
Необходимо различать модель данных предметной области и модель данных приложения.
-
Концептуальная модель данных — всегда для предметной области, физическая модель данных — всегда для приложения, логическая модель данных — может быть как для предметной области, так и для приложения.
-
Логическая модель данных приложения зависит от типа СУБД (например, реляционная СУБД и документная СУБД), но не от конкретной СУБД (для PostgreSQL и для Oracle может использоваться одна модель). Физическая модель данных приложения зависит и от типа СУБД, и от конкретной СУБД.
-
-
В зависимости от специфики проекта может составляться различный набор моделей данных.
-
Почти всегда должны составляться: концептуальная модель данных предметной области и одна из логических моделей данных (предметной области или приложения).




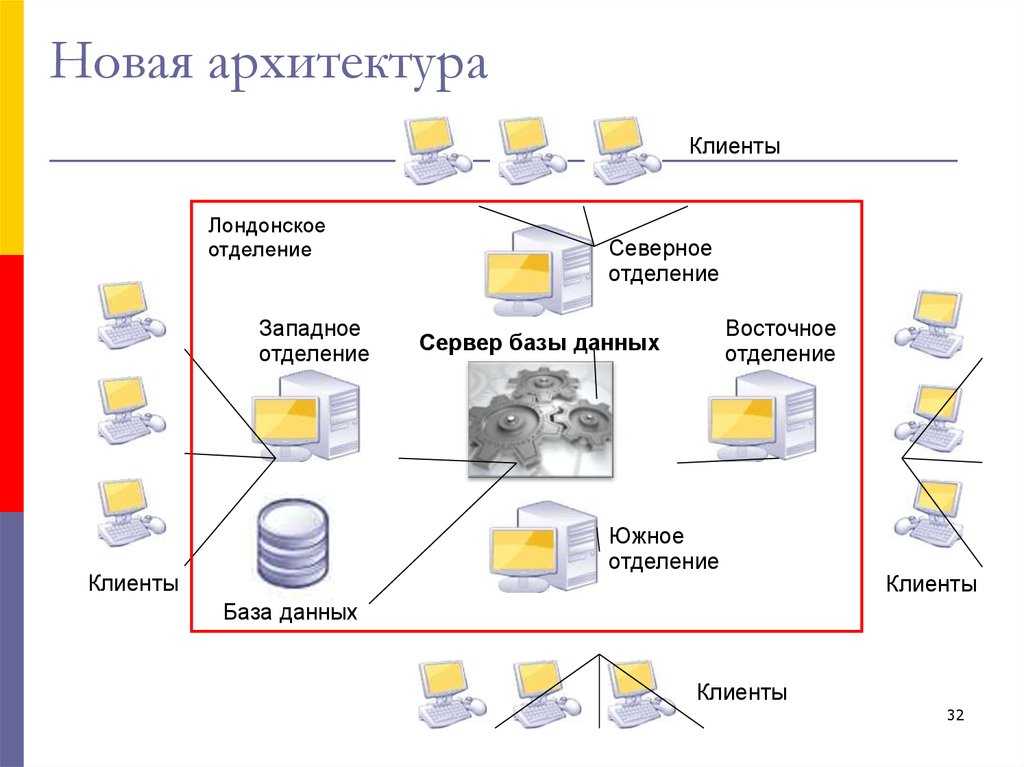
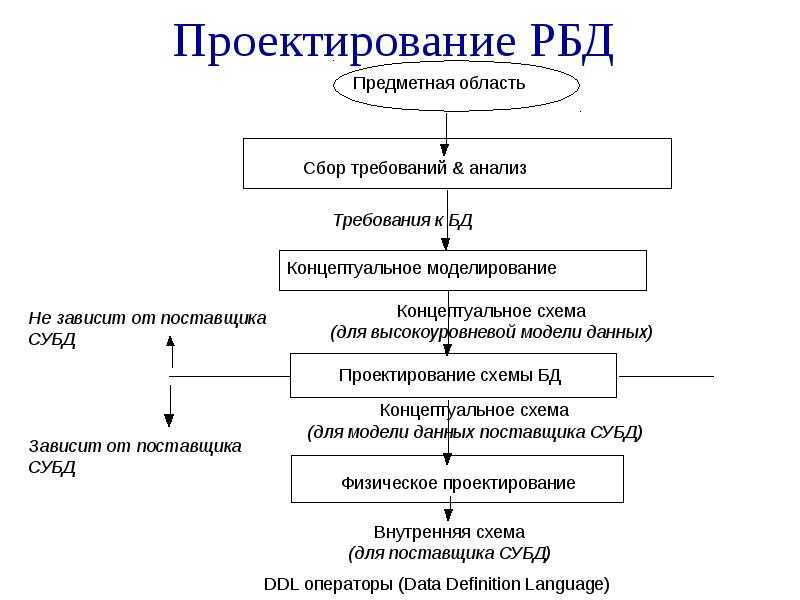
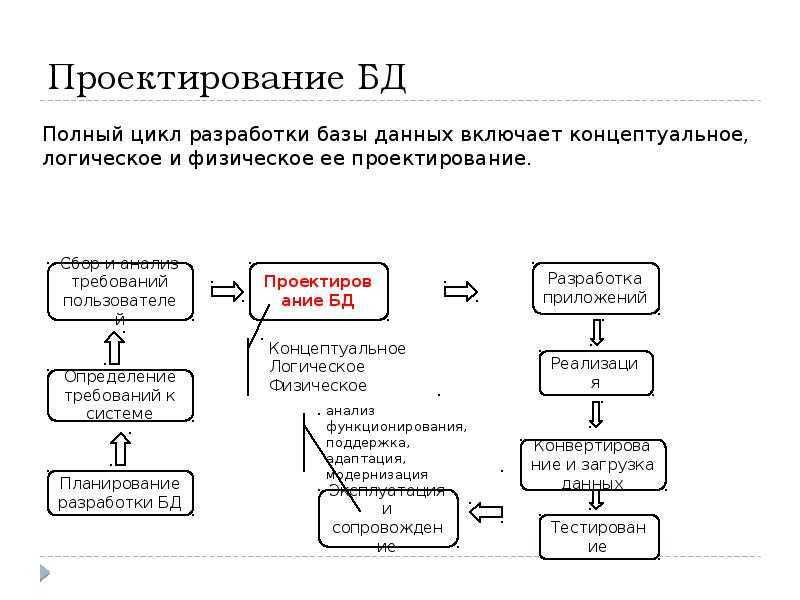
Мой личный набор, который я использую в большинстве проектов — концептуальная модель данных предметной области и логическая модель данных приложения.
В моих конкретных условиях он оказался оптимальным по отношения «полученная польза / затраченные усилия».
А какие виды моделей данных составляете вы в своих проектах?
P.S. Дополнение 4. Модель данных микросервиса
Модель данных предметной области никак не зависит архитектуры, в том числе наличия или отсутствия микросервисов. Но как организован переход от логической модели к физической в случае микросервисной архитектуре?
Как это было у нас. На этапе сбора требований «по классике» были составлены концептуальная и логическая модели данных предметной области.
После того, как на этапе проектирования были выделены микросервисы и определены зоны их ответственности, была сделана «нарезка» логической модели предметной области — какой микросервис будет хранить какие сущности. Это нужно для того, чтобы передать этот кусок модели (вместе с иными требованиями) той подкоманде, которая будет заниматься микросервисом. Приложение было большим, подкоманд много, некоторые из них субподрядные. Давать всем общую модель было избыточно.
Одна и та же сущность предметной области при «нарезке» могла попасть сразу в несколько микросервисов: например, сведения об организациях были нужны практически во всех микросервисах (с разным реквизитным составом).
Как назвать эту модель? С одной стороны, она остаётся логической моделью предметной области — сущности это понятия предметной области, а не таблицы, уровень детализации соответствует логической модели. С другой стороны, она уже частично привязана к реализации — то есть определён микросервис, в котором эта сущность будет имплементирована.
Таким образом, между логической моделью предметной области и моделью данных приложения (неважно, логической или физической) может существовать еще один промежуточный этап — «логическая модель данных предметной области, планируемая к реализации в рамках компонента архитектуры приложения»