Денормализация
Денормализация — это умышленное изменение структуры базы, нарушающее правила нормальных форм. Обычно это делается с целью улучшения производительности базы данных.
Теоретически, надо всегда стремиться к полностью нормализованной базе, однако на практике полная нормализация базы почти всегда означает падение производительности. Чрезмерная нормализация базы данных может привести к тому, что при каждом извлечении данных придется обращаться к нескольким таблицам. Обычно в запросе должны участвовать четыре таблицы или менее.
Стандартными приемами денормализации являются: объединение нескольких таблиц в одну, сохранение одинаковых атрибутов в нескольких таблицах, а также хранение в таблице сводных или вычисляемых данных.
4.9
18
Голоса
Рейтинг статьи
Ключи
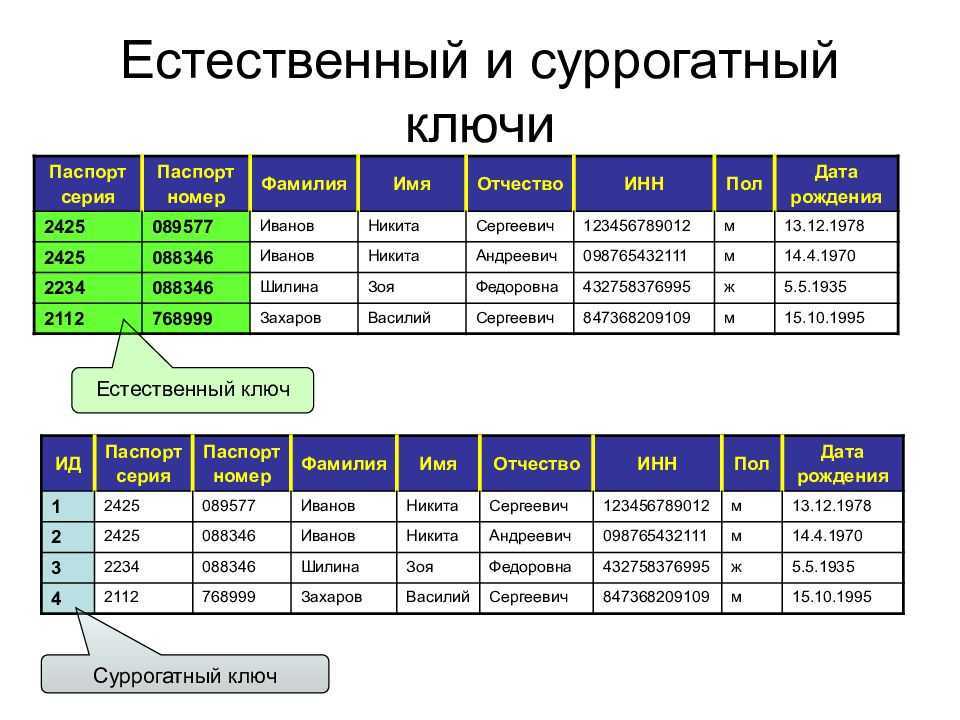
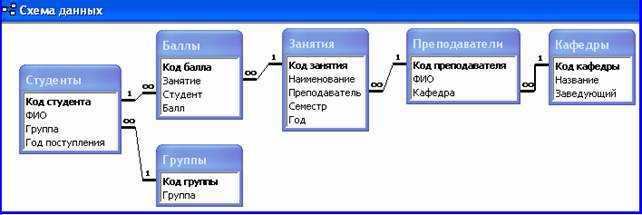
Ключом (key) называется набор атрибутов, однозначно определяющий запись. Ключи делятся на два класса: простые и составные.
Простой ключ состоит только из одного атрибута. Например, в базе «Паспорта граждан страны» номер паспорта будет простым ключом: ведь не бывает двух паспортов с одинаковым номером.
Составной ключ состоит из нескольких атрибутов. В той же базе «Паспорта граждан страны» может быть составной ключ со следующими атрибутами:
фамилия, имя, отчество, дата рождения. Это — как пример, т. к. этот составной ключ, теоретически, не обеспечивает гарантированной уникальности записи.
Также существует несколько типов ключей, о которых рассказано далее.
Возможный ключ
Возможный ключ представляет собой любой набор атрибутов, однозначно идентифицирующих запись в таблице. Возможный ключ может быть простым или составным.
Каждая сущность должна иметь, по крайней мере, один возможный ключ, хотя таких ключей может быть и несколько. Ни один из атрибутов первичного ключа не может принимать неопределенное (NULL) значение.
Возможный ключ называется также суррогатным.
Первичные ключи
Первичным ключом называется совокупность атрибутов, однозначно идентифицирующих запись в таблице (сущности). Один из возможных ключей становится первичным ключом. На диаграммах первичные ключи часто изображаются выше основного списка атрибутов или выделяются специальными символами. Сущность на рисунке имеет как ключевые, так и обычные атрибуты.
Альтернативные ключи
Любой возможный ключ, не являющийся первичным, называется альтернативным ключом. Сущность может иметь несколько альтернативных ключей.
Внешние ключи
Внешним ключом называется совокупность атрибутов, ссылающихся на первичный или альтернативный ключ другой сущности. Если внешний ключ не связан с первичной сущностью, то он может содержать только неопределенные значения. Если при этом ключ является составным, то все атрибуты внешнего ключа должны быть неопределенными.
На диаграммах атрибуты, объединяемые во внешние ключи, обозначаются специальными символами. На рисунке изображены две связанные сущности (Дома и их Хозяева) и образованные ими внешние ключи (ведь один человек может владеть больше, чем одним домом).
Ключи являются логическими конструкциями, а не физическими объектами. В реляционных базах данных предусмотрены механизмы, обеспечивающие сохранение ключей.
Области применения файлов
После этого краткого экскурса в историю и возможности систем управления
файлами рассмотрим возможные области их применения. Конечно, прежде всего
файлы применяются для хранения текстовых данных: документов, текстов программ
и т. д. Такие файлы обычно образуются и модифицируются с помощью различных
текстовых редакторов. Структура текстовых файлов обычно очень проста: это
либо последовательность записей, содержащих строки текста, либо последовательность
байтов, среди которых встречаются специальные символы (например, символы
конца строки).
Файлы с текстами программ являются входными параметрами компиляторов,
которые, в свою очередь, формируют файлы, содержащие объектные модули.
С точки зрения файловой системы, объектные файлы также обладают абсолютно
стандартной структурой — последовательности записей или байтов. Система
программирования накладывает на эту структуру более сложную и специфичную
для этой системы структуру объектного модуля. Подчеркнем, что логическая
структура объектного модуля неизвестна файловой системе, эта структура
поддерживается программами системы программирования.
Аналогично обстоит дело с файлами, формируемыми редакторами связей (компоновщиками
выполняемых программ) и содержащими образы выполняемых программ. Логическая
структура таких файлов остается известной только редактору связей и программе-загрузчику,
являющейся компонентом операционной системы.
Заметим, что в отмеченных выше случаях вполне достаточно тех средств
защиты файлов и синхронизации параллельного доступа, которые обеспечивают
системы управления файлами. Очень редко возникает потребность параллельной
модификации файлов, и как правило, каждый пользователь может обойтись своей
частной копией.
Другими словами, файловые системы обычно обеспечивают хранение слабо
структурированной информации, оставляя дальнейшую структуризацию прикладным
программам. В перечисленных выше случаях использования файлов это даже
хорошо, потому что при разработке любой новой прикладной системы, опираясь
на простые, стандартные и сравнительно дешевые средства файловой системы,
можно реализовать те структуры хранения, которые наиболее естественно соответствуют
специфике данной прикладной области.
Файловые системы и базы данных, или В любом деле требуется правильно подобранный инструмент
Думаю, что многим читателям эта лекция покажется тривиальной. Вот еще,
вздумали объяснять, как устроены и как используются магнитные диски и как
устроена файловая система ОС UNIX. Однако поверьте, что очень часто довольно
трудно понять, какой механизм управления данными во внешней памяти необходим
и достаточен для решения конкретной прикладной задачи. Если раньше приходилось
сталкиваться с ситуацией, когда возможности файлов переоценивались, то
теперь сплошь да рядом применяют базы данных в случаях, для которых вполне
достаточно файлов. Поэтому кажется полезным еще раз перечислить возможности
и альтернативные решения файловых систем, показать наиболее типичные области
их применения и отметить те ситуации, когда эти возможности оказываются
недостаточными для организации прикладных систем.
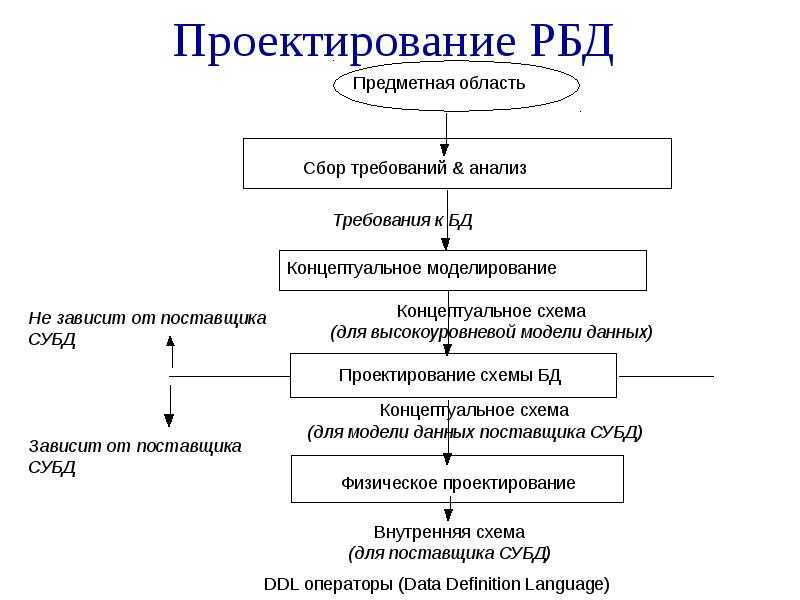
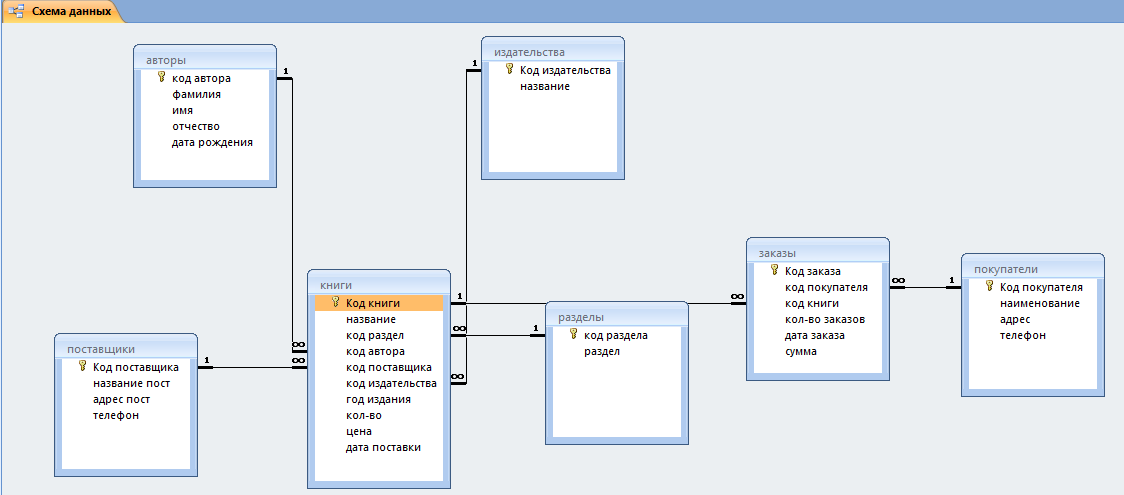
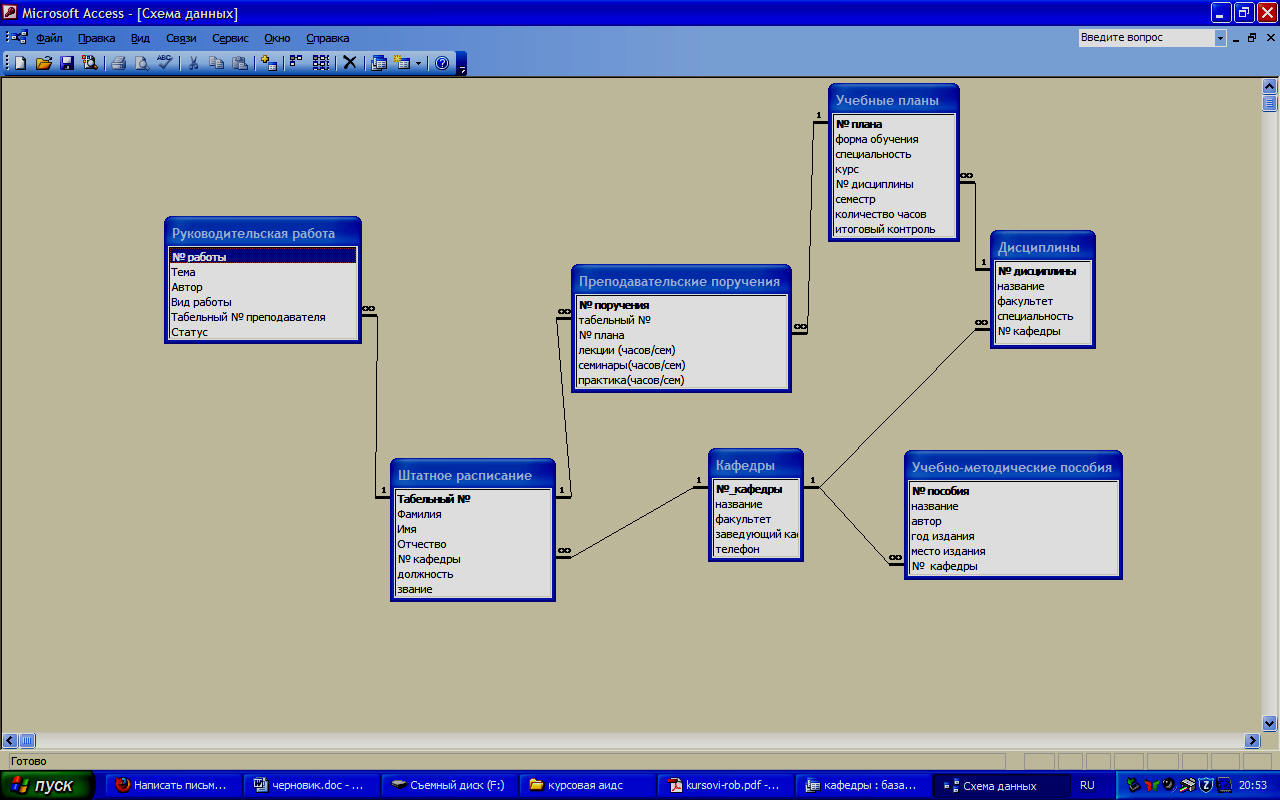
Как проектируют базы данных
Обычно современные СУБД содержат
средства, позволяющие создавать таблицы и ключи.
Существуют и утилиты, поставляемые отдельно от
СУБД (и даже обслуживающие несколько различных
СУБД одновременно), позволяющие создавать
таблицы, ключи и связи.
Еще один способ создать таблицы, ключи
и связи в базе данных — это написание так
называемого DDL-сценария (DDL — Data Definition Language; о нем
мы поговорим чуть позже).
Наконец, есть еще один способ, который
становится все более и более популярным, — это
использование специальных средств, называемых CASE-средствами (CASE означает Computer-Aided
System Engineering). Существует несколько типов
CASE-средств, но для создания баз данных чаще всего
используются инструменты для создания диаграмм «сущность-связь» (entity-relationship diagrams, E/R
diagrams). С помощью этих инструментов создается так
называемая логическая модель данных, описывающая факты и объекты,
подлежащие регистрации в ней (в таких моделях
прототипы таблиц называются сущностями (entities), а поля — их
атрибутами (attributes). После установления связей между
сущностями, определения атрибутов и проведения
нормализации, создается так называемая физическая модель
данных для конкретной СУБД, в которой
определяются все таблицы, поля и другие объекты
базы данных. После этого можно сгенерировать
либо саму базу данных, либо DDL-сценарий для ее
создания.
Список наиболее популярных в настоящее время CASE-средств.
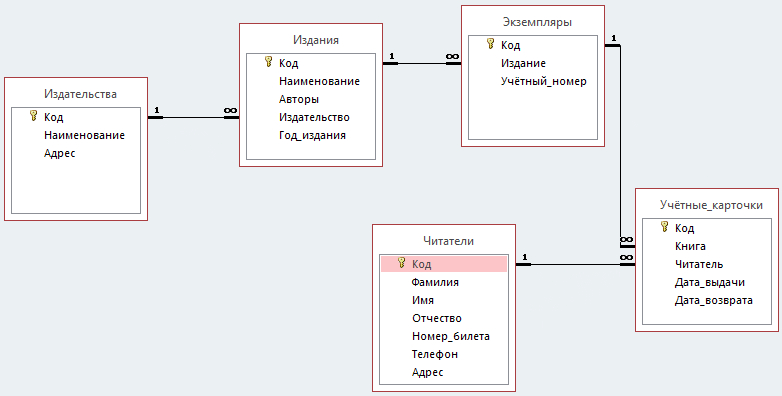
Определение атрибутов
Атрибут представляет свойство, описывающее сущность. Атрибуты часто бывают числом, датой или текстом. Все данные, хранящиеся в атрибуте, должны иметь одинаковый тип и обладать одинаковыми свойствами.
В физической модели атрибуты называют колонками.
После определения сущностей необходимо определить все атрибуты этих сущностей.
На диаграммах атрибуты обычно перечисляются внутри прямоугольника сущности. На рисунке вы найдете пример базы данных «Дома», только теперь для сущностей из этой базы определены некоторые атрибуты.
Для каждого атрибута определяется тип данных, их размер, допустимые значения и любые другие правила. К их числу относятся правила обязательности заполнения, изменяемости и уникальности.
Правило обязательности заполнения определяет, является ли атрибут обязательной частью сущности. Если атрибут является необязательной частью сущности, то он может принимать NULL-значение, иначе — нет.
Также вы должны определить, является ли атрибут изменяемым. Значения некоторых атрибутов не могут измениться после создания записи.
И, наконец, вам нужно определить, является ли атрибут уникальным. Если это так, то значения атрибута не могут повторяться.
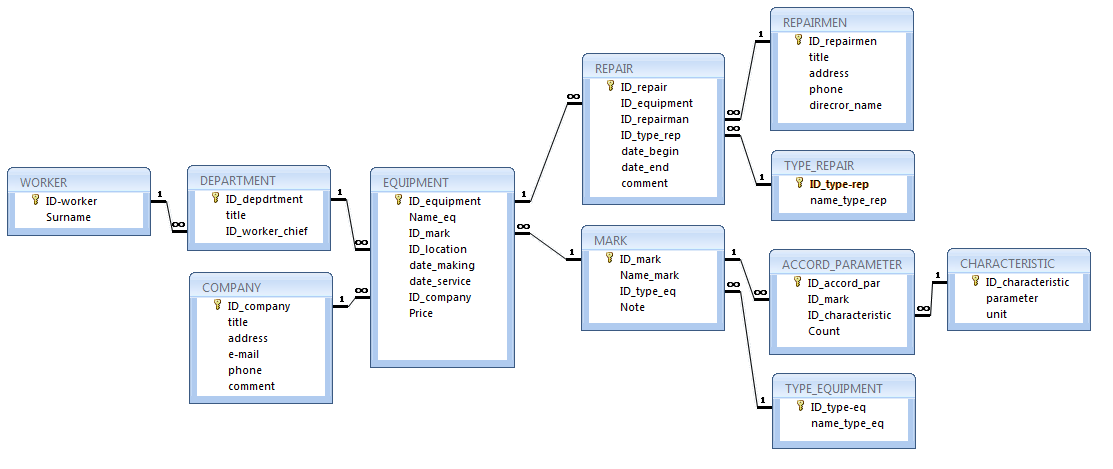
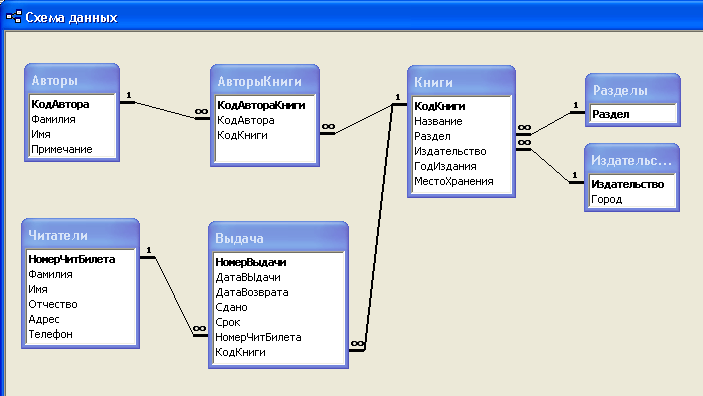
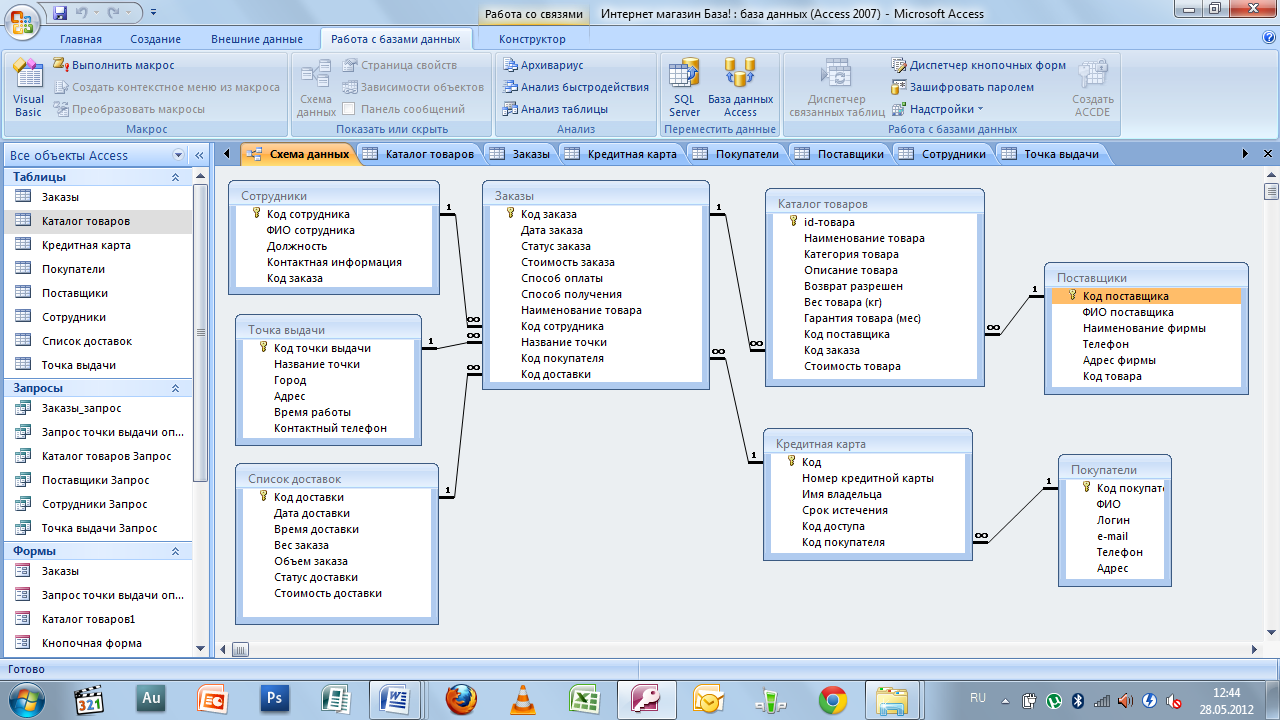
Определение сущностей
На этом этапе вам необходимо определить сущности, из которых будет состоять база данных.
Сущность — это объект в базе данных, в котором хранятся данные. Сущность может представлять собой нечто вещественное (дом, человек, предмет, место) или абстрактное (банковская операция, отдел компании, маршрут автобуса). В физической модели сущность называется таблицей.
Сущности состоят из атрибутов (столбцов таблицы) и записей (строк в таблице).
Обычно базы данных состоят из нескольких основных сущностей, связанных с большим количеством подчиненных сущностей. Основные сущности называются независимыми: они не зависят ни от какой-либо другой сущности. Подчиненные сущности называются зависимыми: для того чтобы существовала одна из них, должна существовать связанная с ней основная таблица.
На диаграммах сущности обычно представляются в виде прямоугольников. Имя сущности указывается внутри прямоугольника:
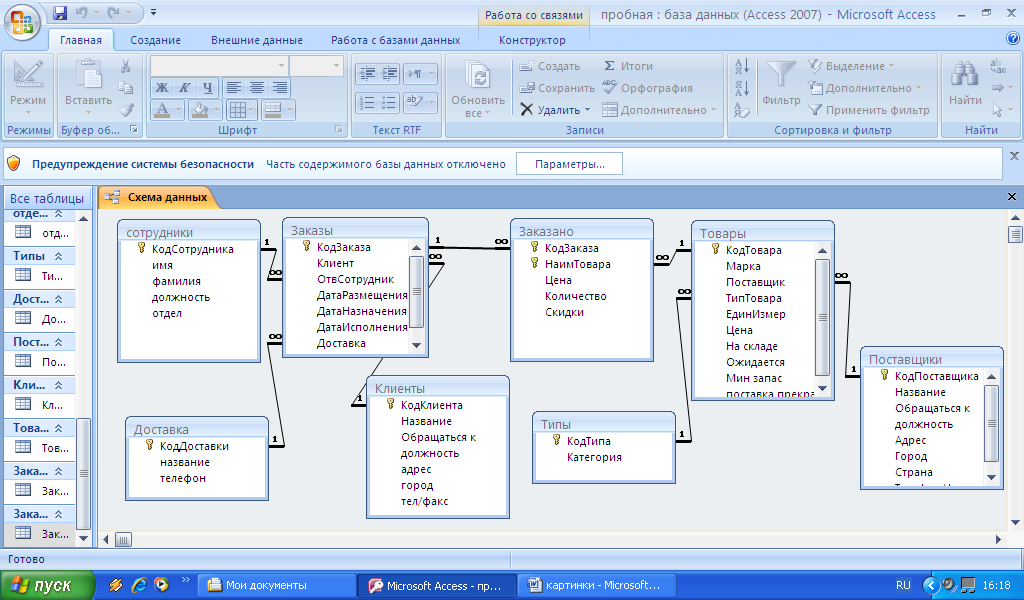
Любая таблица имеет следующие характеристики:
- в ней нет одинаковых строк;
- все столбцы (атрибуты) в таблице должны иметь разные имена;
- элементы в пределах одной колонки имеют одинаковый тип (строка, число, дата);
- порядок следования строк в таблице может быть произвольным.
На этом этапе вам необходимо выявить все категории информации (сущности), которые будут храниться в базе данных.
Определение связей между сущностями
Реляционные базы данных позволяют объединять информацию, принадлежащую разным сущностям.
Отношение — это ситуация, при которой одна сущность ссылается на первичный ключ второй сущности. Как, например, сущности Дом и Хозяин на предыдущем рисунке.
Отношения определяются в процессе проектирования базы. Для этого следует проанализировать сущности и выявить логические связи, существующие между ними.
Тип отношения определяет количество записей сущности, связанных с записью другой сущности. Отношения делятся на три основных типа, о которых рассказано далее.
Один-к-одному
Каждой записи первой сущности соответствует только одна запись из второй сущности. А каждой записи второй сущности соответствует только одна запись из первой сущности. Например, есть две сущности: Люди и Свидетельства о рождении. И у одного человека может быть только одно свидетельство о рождении.
Один-ко-многим
Каждой записи первой сущности могут соответствовать несколько записей из второй сущности. Однако каждой записи второй сущности соответствует только одна запись из первой сущности. Например, есть две сущности: Заказ и Позиция заказа. И в одном заказе может быть много товаров.
Многие-ко-многим
Каждой записи первой сущности могут соответствовать несколько записей из второй сущности. Однако и каждой записи второй сущности может соответствовать несколько записей из первой сущности. Например, есть две сущности: Автор и Книга. Один автор может написать много книг. Но у книги может быть несколько авторов.
По критерию обязательности отношения делятся на обязательные и необязательные.
- Обязательное отношение означает, что для каждой записи из первой сущности непременно должны присутствовать связанные записи во второй сущности.
- Необязательное отношение означает, что для записи из первой сущности может и не существовать записи во второй сущности.
Численные и информационные прикладные системы
Во всей истории вычислительной техники можно проследить две основных
области ее использования. Первая область — применение вычислительной техники
для выполнения численных расчетов, которые слишком долго или вообще невозможно
производить вручную. Развитие этой области способствовало интенсификации
методов численного решения сложных математических задач, развитию класса
языков программирования, ориентированных на удобную запись численных алгоритмов,
становлению обратной связи с разработчиками новых архитектур ЭВМ.
Вторая область, которая непосредственно относится к теме наших лекций,
— это использование средств вычислительной техники в автоматических или
автоматизированных информационных системах. В самом широком смысле информационная
система представляет собой программно-аппаратный комплекс, функции которого
состоят в надежном хранении информации в памяти компьютера, выполнении
специфических для данного приложения преобразований информации и/или вычислений,
предоставлении пользователям удобного и легко осваиваемого интерфейса.
Обычно такие системы имеют дело с большими объемами информации, и эта информация
имеет достаточно сложную структуру. Классическими примерами информационных
систем являются банковские системы, системы резервирования авиационных
или железнодорожных билетов, мест в гостиницах и т. д.
Вторая область использования вычислительной техники возникла несколько
позже первой. Это связано с тем, что на заре вычислительной техники возможности
компьютеров по хранению информации были очень ограниченными. Говорить о
надежном и долговременном хранении информации можно только при наличии
запоминающих устройств, сохраняющих информацию после выключения электрического
питания. Оперативная (основная) память компьютеров этим свойством обычно
не обладает. В первых компьютерах использовались два вида устройств внешней
памяти — магнитные ленты и барабаны. Емкость магнитных лент была достаточно
велика, но по своей физической природе они обеспечивали последовательный
доступ к данным. Магнитные же барабаны (они больше всего похожи на современные
магнитные диски с фиксированными головками) давали возможность произвольного
доступа к данными, но были ограниченного размера.
Эти ограничения не являлись слишком существенными для чисто численных
расчетов. Даже если программа должна обработать (или произвести) большой
объем информации, при программировании можно продумать расположение этой
информации во внешней памяти (например, на последовательной магнитной ленте),
обеспечивающее эффективное выполнение этой программы.
Но для информационных систем, в которых потребность в текущих данных
определяется конечным пользователем, наличие только магнитных лент и барабанов
неудовлетворительно. Представьте себе покупателя билета, который, стоя
у кассы, должен дождаться полной перемотки магнитной ленты. Одним из естественных
требований к таким системам является удовлетворительная средняя скорость
выполнения операций.
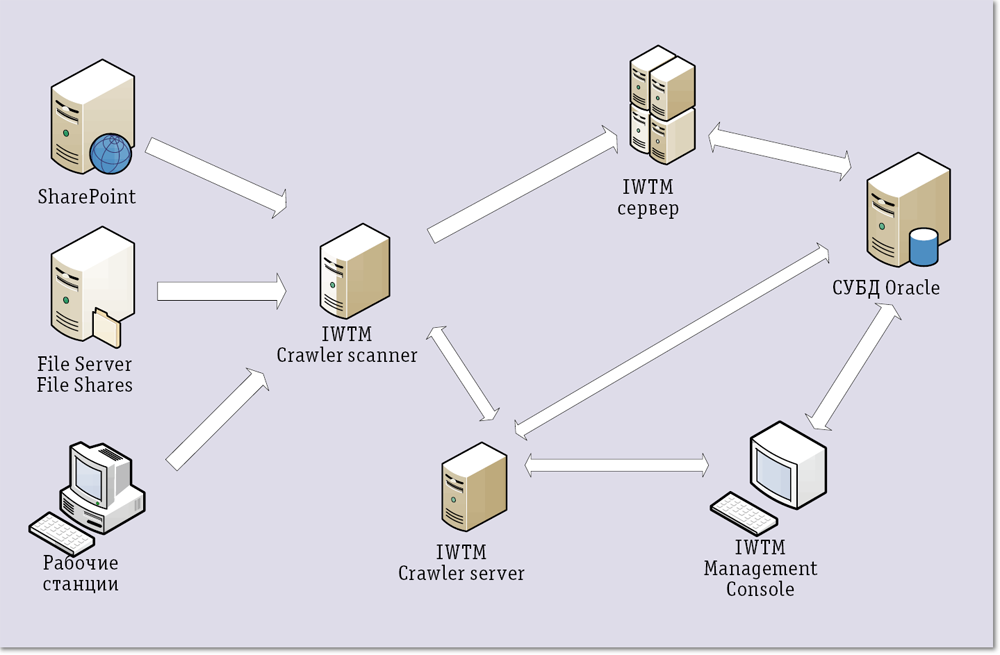
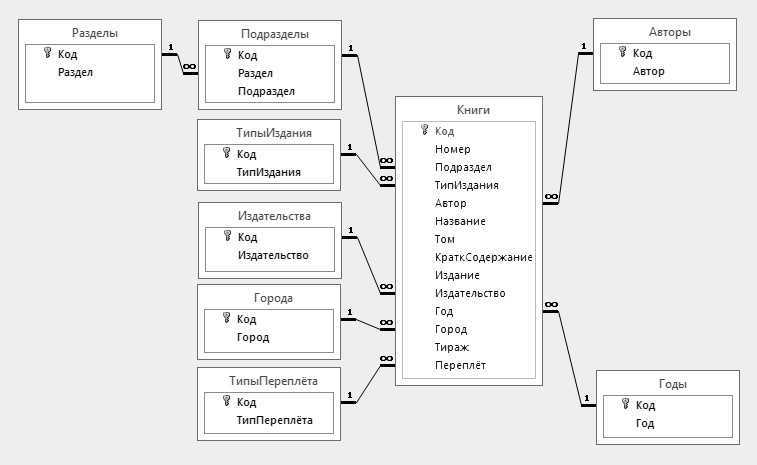
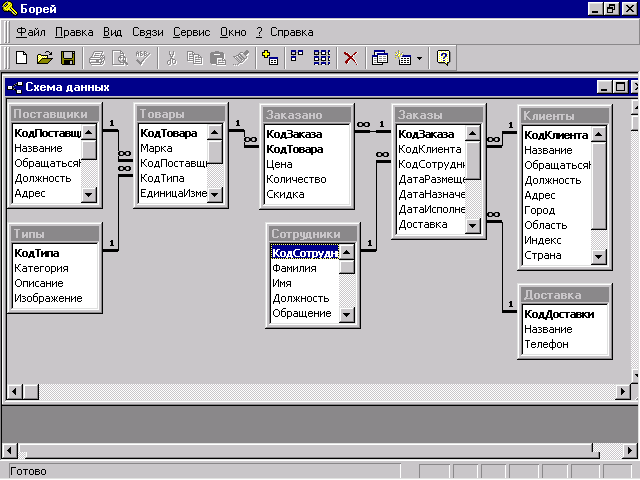
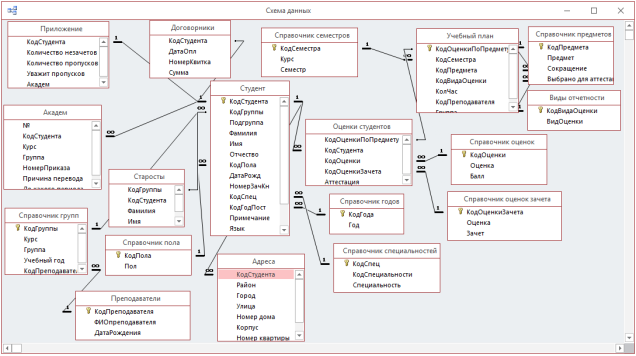
Как кажется, именно требования нечисленных приложений вызвали появление
съемных магнитных дисков с подвижными головками, что явилось революцией
в истории вычислительной техники. Эти устройства внешней памяти обладали
существенно большей емкостью, чем магнитные барабаны, обеспечивали удовлетворительную
скорость доступа к данным в режиме произвольной выборки, а возможность
смены дискового пакета на устройстве позволяла иметь практически неограниченный
архив данных.
С появлением магнитных дисков началась история систем управления данными
во внешней памяти. До этого каждая прикладная программа, которой требовалось
хранить данные во внешней памяти, сама определяла расположение каждой порции
данных на магнитной ленте или барабане и выполняла обмены между оперативной
памятью и устройствами внешней памяти с помощью программно-аппаратных средств
низкого уровня (машинных команд или вызовов соответствующих программ операционной
системы). Такой режим работы не позволяет или очень затрудняет поддержание
на одном внешнем носителе нескольких архивов долговременно хранимой информации.
Кроме того, каждой прикладной программе приходилось решать проблемы именования
частей данных и структуризации данных во внешней памяти.