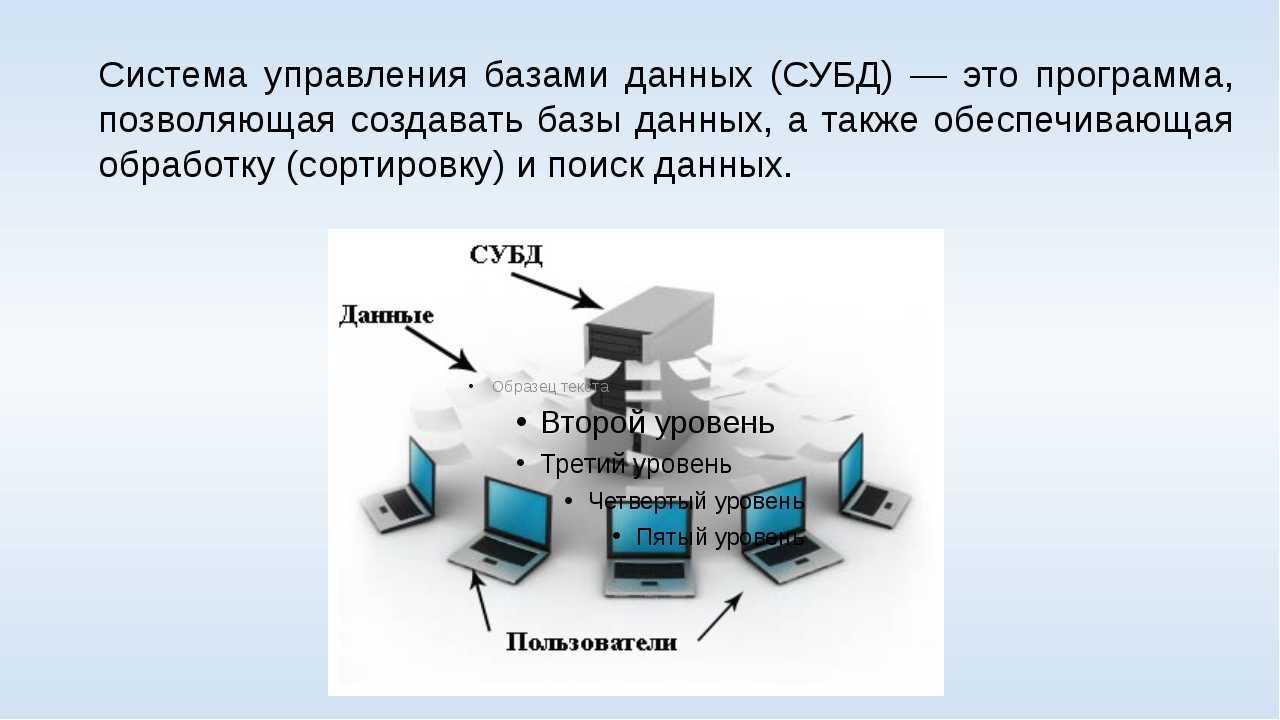
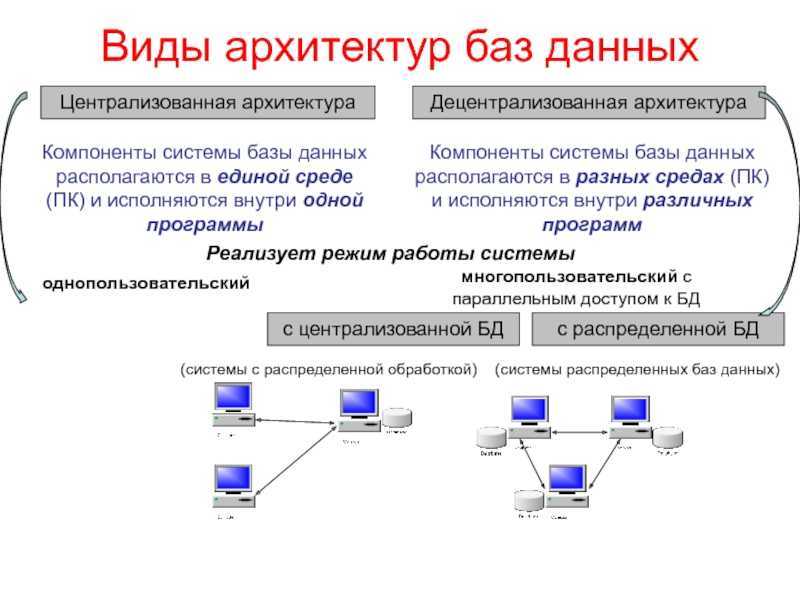
Характеристики
- Базы данных в коллекции логически взаимосвязаны друг с другом. Часто они представляют собой единую логическую базу данных.
- Данные физически хранятся на нескольких сайтах. Данные на каждом сайте могут управляться СУБД независимо от других сайтов.
- Процессоры на сайтах подключены через сеть. Они не имеют многопроцессорной конфигурации.
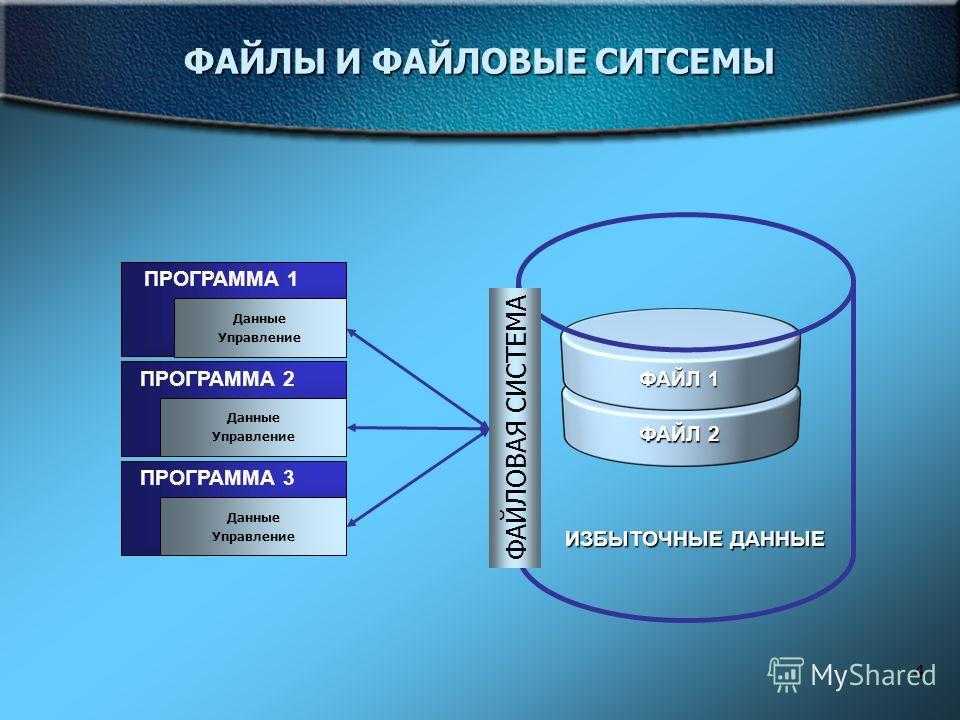
- Распределенная база данных не является слабо связанной файловой системой.
- Распределенная база данных включает обработку транзакций, но она не является синонимом системы обработки транзакций.
Базы данных в коллекции логически взаимосвязаны друг с другом. Часто они представляют собой единую логическую базу данных.
Данные физически хранятся на нескольких сайтах. Данные на каждом сайте могут управляться СУБД независимо от других сайтов.
Процессоры на сайтах подключены через сеть. Они не имеют многопроцессорной конфигурации.
Распределенная база данных не является слабо связанной файловой системой.
Распределенная база данных включает обработку транзакций, но она не является синонимом системы обработки транзакций.
Безопасность[править]
На данном этапе развития современных вычислительных комплексов существует проблема создания унифицированного, эффективно использующего ресурсы и предоставляющего гибкие настройки безопасности и конфиденциальности управляющего программного обеспечения. Всякий раз при построении нового большого суперкомпьютера, задача выбора ПО для управления и мониторинга решается практически с нуля. Особенно это актуально для компаний, предоставляющих машинное время в аренду, поскольку ни бесплатного, ни коммерческого комплексного пакета ПО такого класса пока не существует.
С точки зрения эффективности использования, имеется несколько вариантов решения задачи мониторинга, управления узлами и компонентами суперкомпьютера, создания и управления очередями заданий. Что касается вопросов безопасности суперкомпьютеров, их решение либо не происходит вообще (нет обеспечения безопасности/конфиденциальности), либо всё сводится к разграничению доступа к файлам и данным на уровне пользователей операционной системы, назначению прав доступа к хранилищам и иным компонентам суперкомпьютера, а передача всех данных по открытым каналам происходит с шифрованием данных (используя технологию SSL). Такой под ход, в частности, в среде Linux не избавляет от следующих ситуаций (если не вносить модификацию в исходные тексты ядра и утилит ОС):
- практически любой пользователь может узнать кто, когда и какое время использует узлы суперкомпьютера;
- практически любой пользователь может узнать, кто в данный момент находится на управляющем узле суперкомпьютера и какие процессы запускает, какие программы использует (при наличии нескольких управляющих узлов – только на том, на который пользователь вошёл);
- при определённых навыках, пользователь может узнать что, кем и где запущено на вычислительных узлах суперкомпьютера (только в том случае, если разграничение доступа на узлы суперкомпьютера сделано стандартным для ОС Linux способом);
- при использовании стандартных коммерческих вычислительных пакетов на суперкомпьютере, практически любой пользователь может получить доступ к временным данным других пользователей (только в случае, если сам пользователь не позаботится о сохранности своих данных).
Помимо названных, существует ещё несколько ситуаций, в которых возможна утечка конфиденциальной информации при работе на «стандартном» суперкомпьютере под управлением ОС Linux.
Рис. 2.1 ER-диаграмма концептуальной модели.
Выявленные атрибуты сущностей приведены в таблице 2.
Таблица 2.2 Атрибуты сущностей и связей
|
Тип сущности(связи) |
Атрибут |
Домен |
Обязатель-ность |
|
|
BOOK |
id |
Целое |
Да |
|
|
name |
Символьный |
|||
|
author |
Символьный |
|||
|
year |
Целое |
|||
|
izdat |
Символьный |
Да |
||
|
info |
Символьный |
|||
|
type |
Целое |
|||
|
cost |
Целое |
|||
|
PARTNER |
id |
Целое |
Да |
|
|
fio |
Символьный |
Да |
||
|
phone |
Символьный |
|||
|
address |
Символьный |
|||
|
sell |
Целое |
|||
|
book_id |
Целое |
|||
|
ZAKAZ |
id |
Целое |
Да |
|
|
klient |
Целое |
Да |
||
|
book |
Целое |
|||
|
kolvo |
Целое |
|||
|
POKUPATEL |
id |
Целое |
Да |
|
|
name |
Символьный |
Да |
||
|
phone |
Символьный |
Да |
||
|
address |
Символьный |
Да |
||
|
TYPE |
id |
Целое |
Да |
|
|
type |
Символьный |
Да |
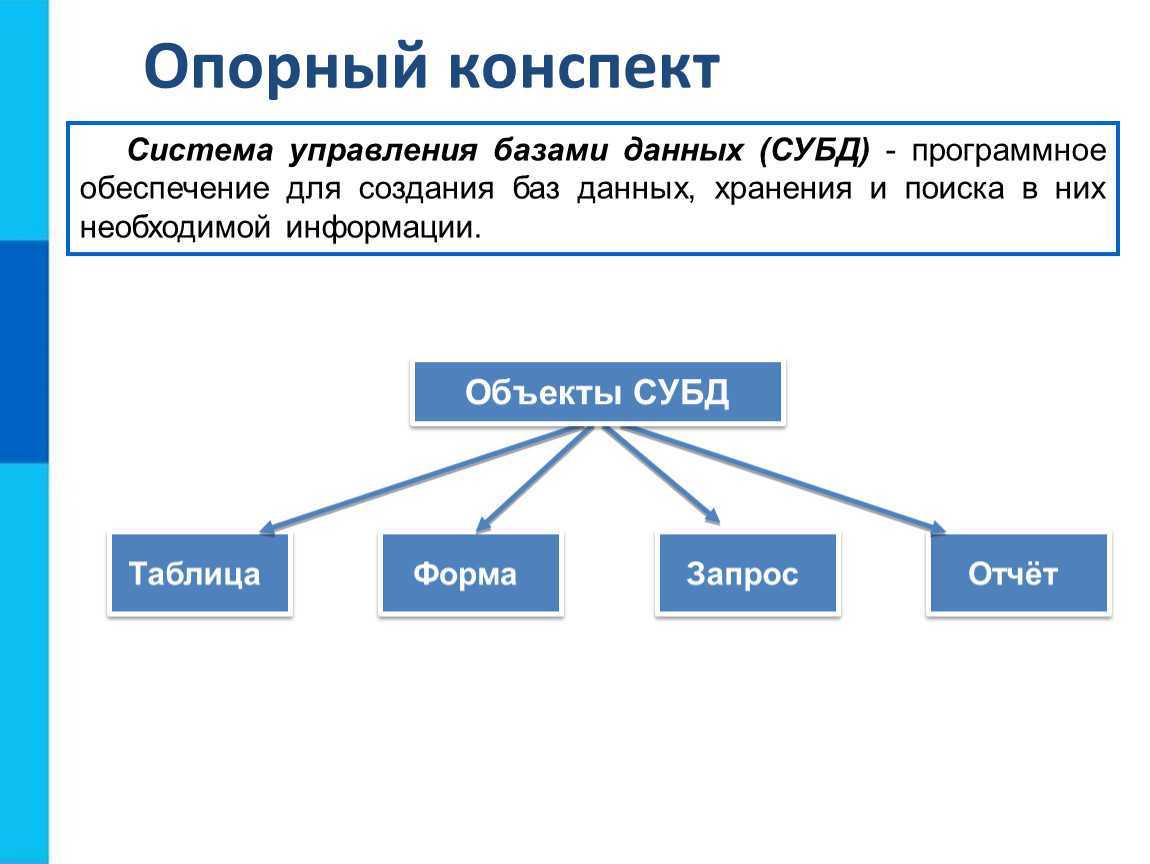
Определим атрибуты, являющиеся потенциальными и первичными ключами.
Для этого из таблицы 2.2 выберем возможные потенциальные ключи. Затем из них выберем первичные ключи.

![Распределённые базы данных (основные понятия и определения) [реферат №6936]](https://robotrackkursk.ru/wp-content/uploads/2/0/9/2093fec99693cef18c95083254ee8b06.jpeg)
Составим таблицу первичных и альтернативных ключей (табл. 2.3).
Таблица 2.3 Первичные и альтернативные ключи
|
Сущность |
Первичный ключ |
Альтернативный ключ |
|
|
BOOK |
id |
nazvanie |
|
|
PARTNER |
id |
fio, phone |
|
|
ZAKAZ |
id |
||
|
POKUPATEL |
id |
name, phone |
|
|
TYPE |
id |
type |
3.1 Построение физической модели данных на языке SQL средствами СУБД MySQL
Теперь наша задача — построить таблицы основываясь на логической модели базы данных. Правила перевода из логической модели данных в физическую следующие:
Объекты становятся таблицами в физической базе данных
Атрибуты становятся колонками (полями) в физической базе данных. Для каждого атрибута выбирается свой тип данных.
Уникальные идентификаторы становятся колонками, не допускающими значение NULL. В физической базе данных они называются первичными ключами (primary key).
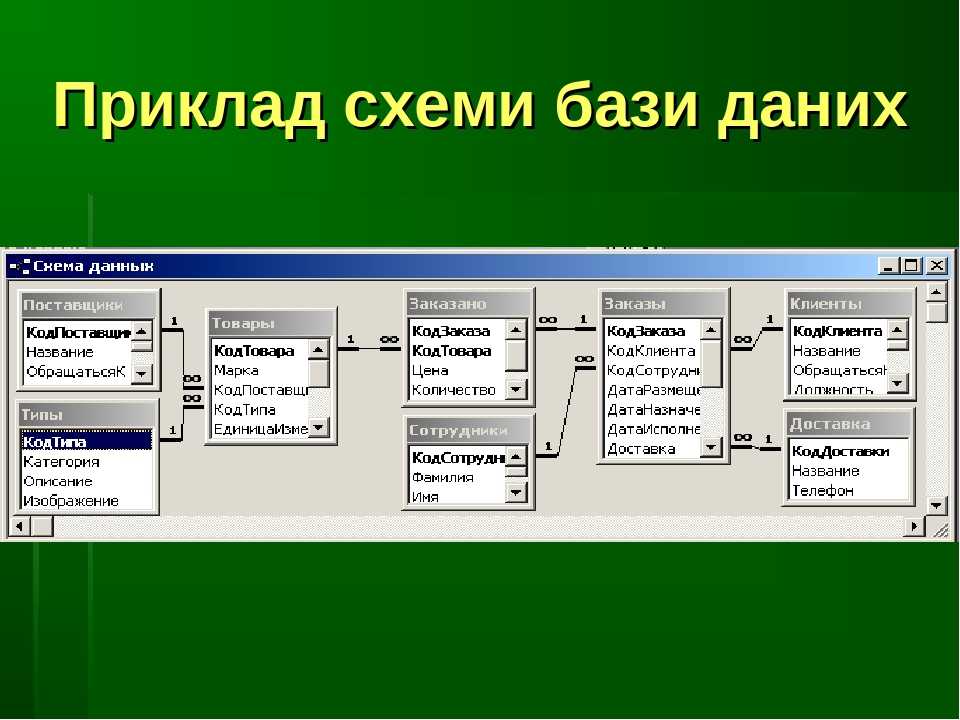
Схема таблиц базы данных представлена на рис. 3.1.
Рис. 3.1 Схема таблиц для базы данных книжного магазина
Теперь необходимо перевести все эти таблицы в SQL. В общем случае модели данных разрабатываются таким образом чтобы не зависеть от конкретной базы данных. Поэтому разработанную физическую модель данных можно применить к любой СУБД. В нашем случае это будет MySQL. MySQL — компактный многопоточный сервер баз данных. MySQL характеризуется большой скоростью, устойчивостью и легкостью в использовании.
В базе данных MySql таблицы создаются с помощью sql-запроса (см. приложение 1).
Используемые источники
http://www.inf.vspu.ac.ru/umm_chul/files/pido/lection2.pdf
https://docplayer.ru/30187268-Raspredelennye-bazy-dannyh-vvedenie.html
https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D1%91%D0%BD%D0%BD%D0%B0%D1%8F_%D0%B1%D0%B0%D0%B7%D0%B0_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85
https://coderlessons.com/tutorials/akademicheskii/izuchite-raspredelennuiu-subd/raspredelennaia-subd-raspredelennye-bazy-dannykh
- My home town
- Особенности перевода текстов официально-делового и научного стилей (Перевод официально-деловых текстов)
- Family
- Семья и ценности
- Видо-временные формы группы Perfect (Meaning of Perfect Forms.)
- Exercise II. Indicate the type of climax.
- Классификация преступлений в международном праве (Классификация преступлений в международном праве)
- Международный коммерческий арбитраж в РФ: общая характеристика
- Семейное право и «Домострой». (Источник)
- Система международного права (Юридический )
- Нейросети
- Западноевропейское искусство XIX века
Бедствия распределенных баз данных
Ниже приведены некоторые неприятности, связанные с распределенными базами данных.
Потребность в сложном и дорогом программном обеспечении — DDBMS требует сложного и часто дорогостоящего программного обеспечения для обеспечения прозрачности данных и координации на нескольких сайтах.
Затраты на обработку — даже простые операции могут потребовать большого количества сообщений и дополнительных вычислений для обеспечения единообразия данных на всех площадках.
Целостность данных. Необходимость обновления данных на нескольких сайтах создает проблемы целостности данных.
Затраты на неправильное распределение данных. Отзывчивость запросов во многом зависит от правильного распределения данных. Неправильное распределение данных часто приводит к очень медленному ответу на пользовательские запросы.
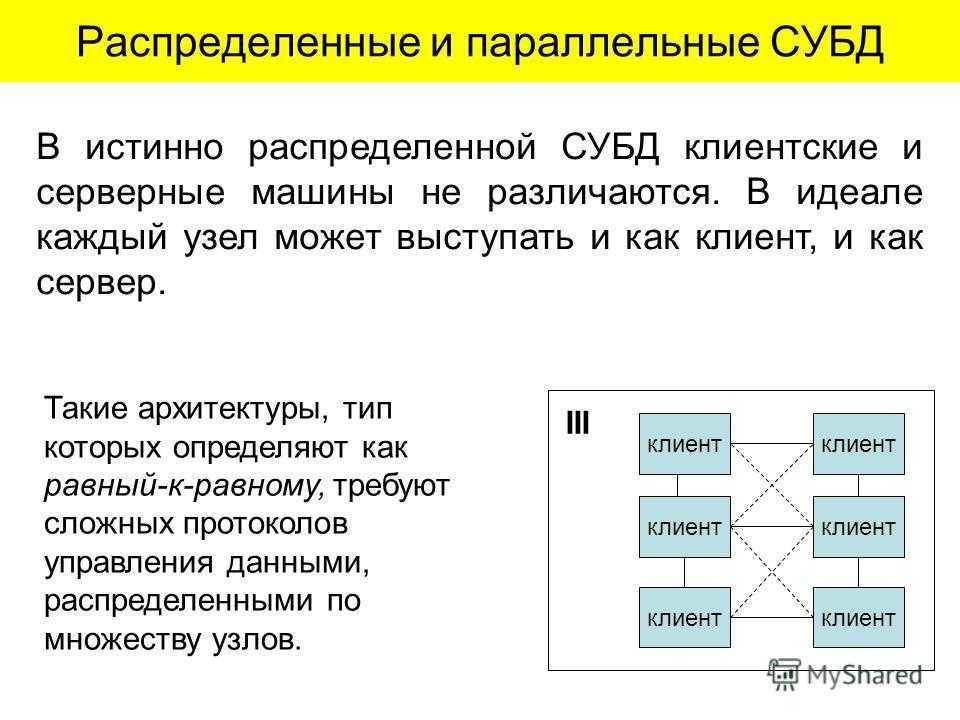
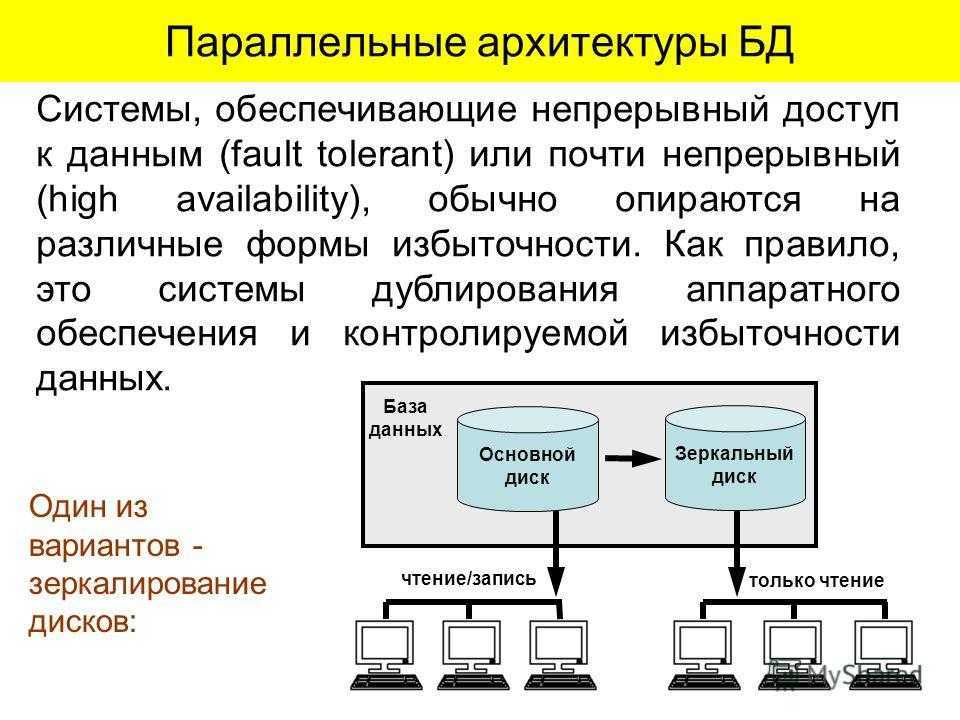
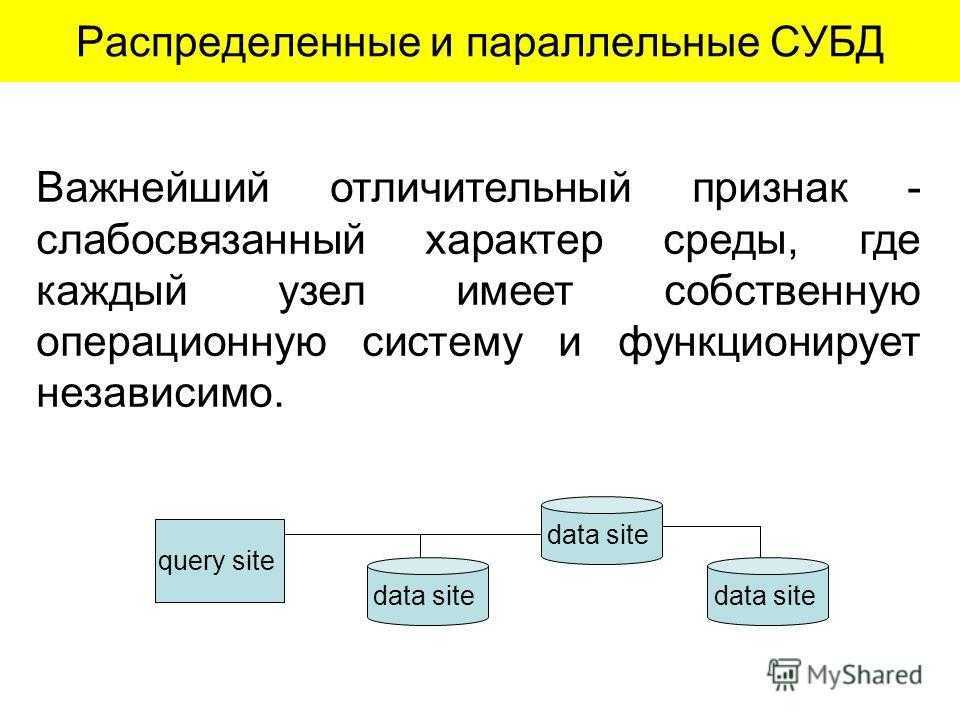
Распределенные или параллельные?[править]
Перед тем как начать изучение различных видов разветвления вычислительных процессов необходимо разобраться в базовых понятиях. Часто термин «распределенные вычисления» путают с термином «параллельные вычисления», иногда их ошибочно считают синонимами. Давайте разберемся чем отличаются эти два понятия.
|
Распределенные вычисления — способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров, объединённых в параллельную вычислительную систему. Википедия |
|
Параллельные вычисления — такой способ организации компьютерных вычислений, при котором программы разрабатываются как набор взаимодействующих вычислительных процессов, работающих параллельно. Википедия |
Таким образом распределенные вычисления не могут производится на одной вычислительной машине, а параллельные вычисления могут производиться как на одной (многопоточность), так и на нескольких машинах. Возможность выполнения параллельных вычислений в распределенных системах и приводит к частому заблуждению, что это одно и тоже.
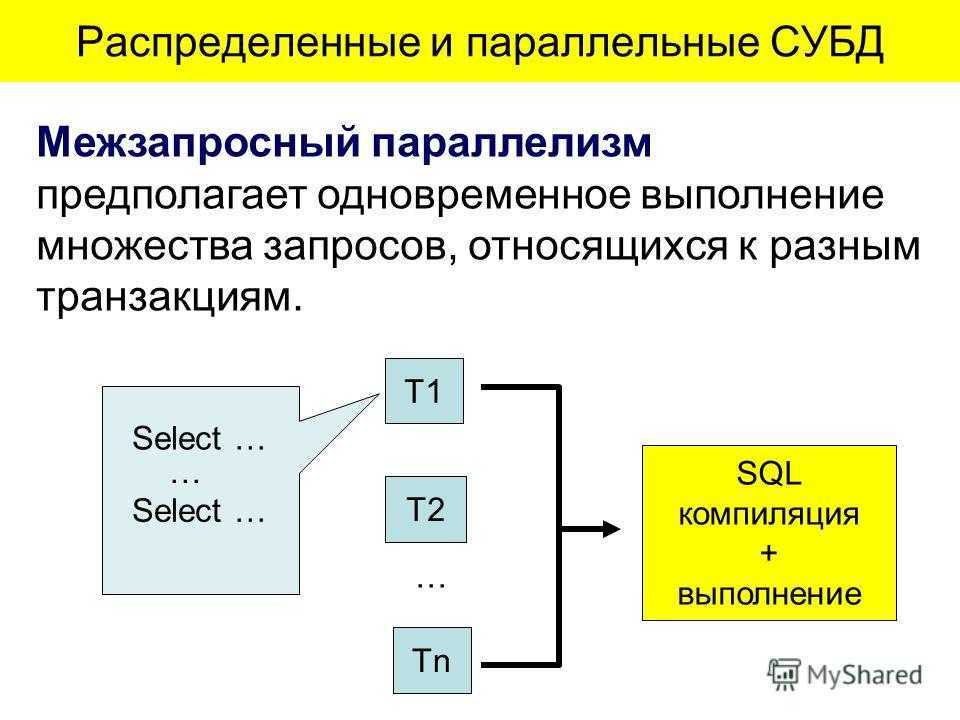

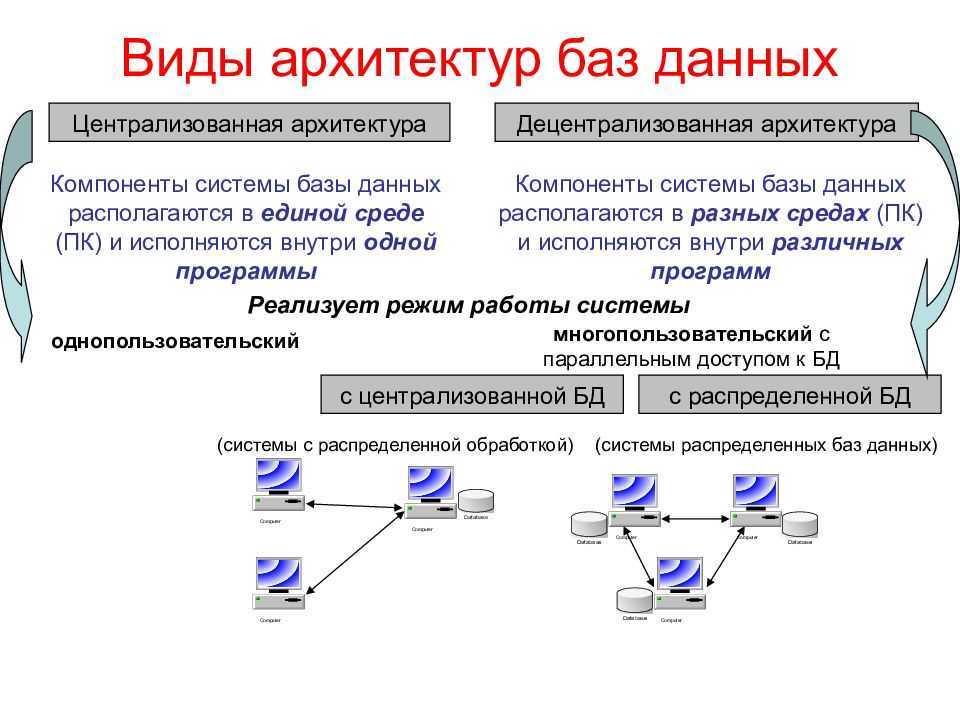
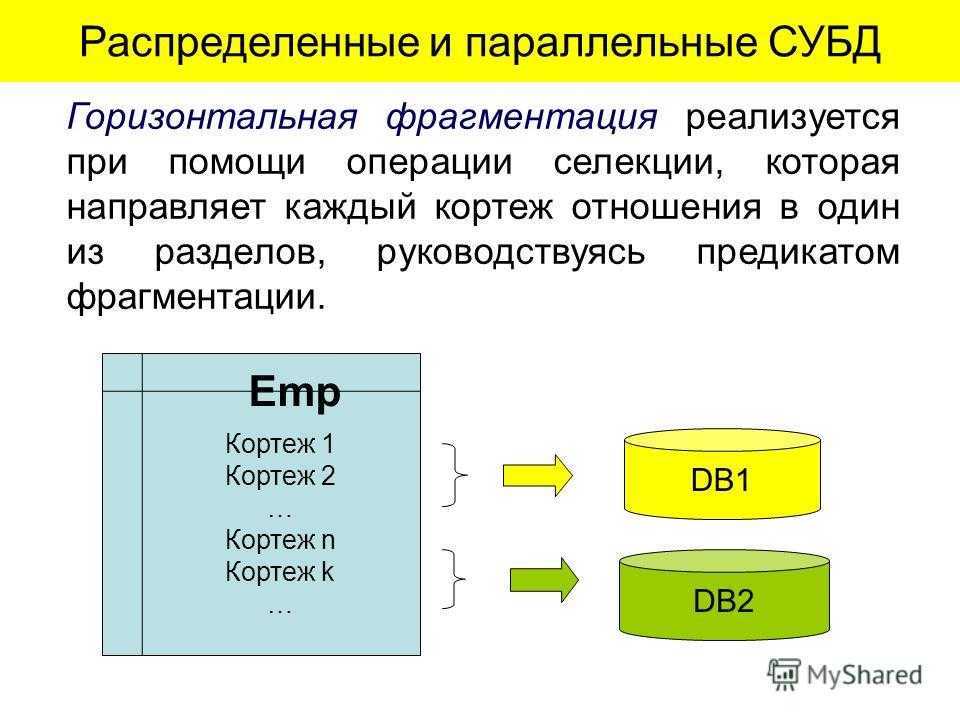
![Распределённые базы данных (основные понятия и определения) [реферат №6936]](https://robotrackkursk.ru/wp-content/uploads/4/4/0/4402acdedaee9486b550f600786c3295.jpeg)
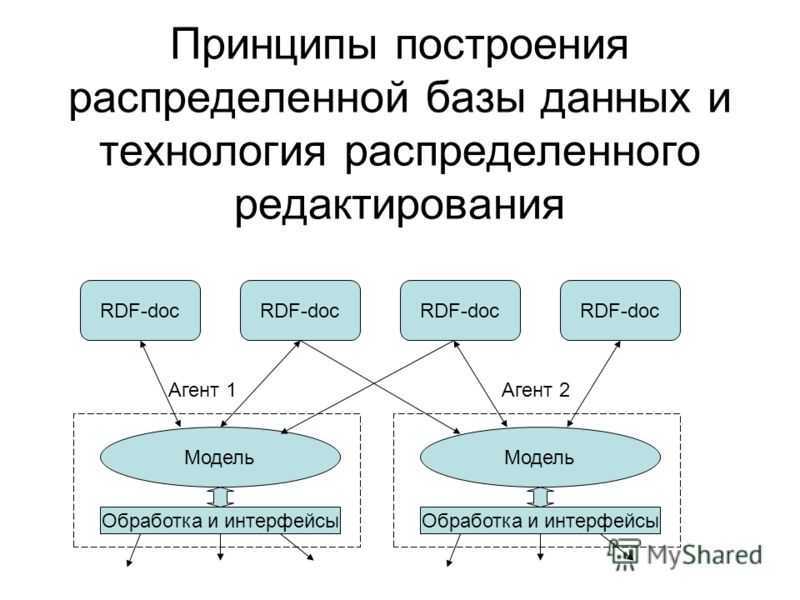
|
Распределенная система — это набор независимых компьютеров, представляющиеся их пользователям единой объединенной системой. Эндрю Таненбаум |
|
Параллельные вычисления — вычисления, которые можно реализовать на многопроцессорных системах с использованием возможности одновременного выполнения многих действий, порождаемых процессом решения одной или многих задач. Словарь по кибернетике |
Явление открытых (добровольных) вычислительных систем (англ. volunteer computing) следует выделить в отдельную тему и рассматривать как практическую реализацию систем распределенного вычисления. Такие вычислительные системы (сети) чаще всего строятся на базе, так называемых GRID систем (сетей), в русском языке иногда называются как системы метакомпьютинга (матавычисления).
Мульти базовые системы
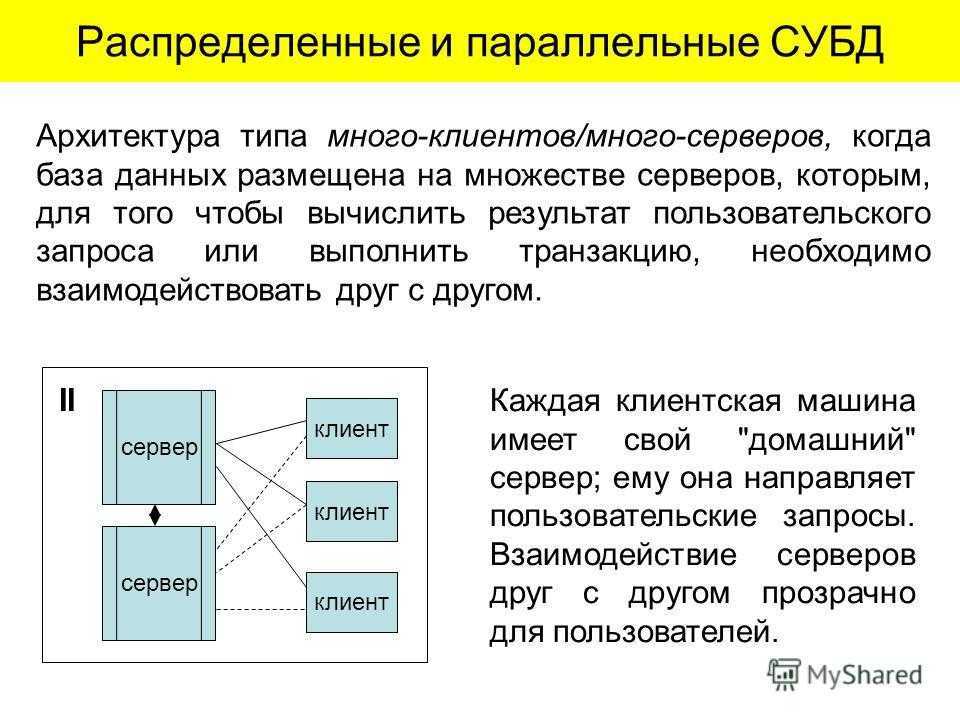
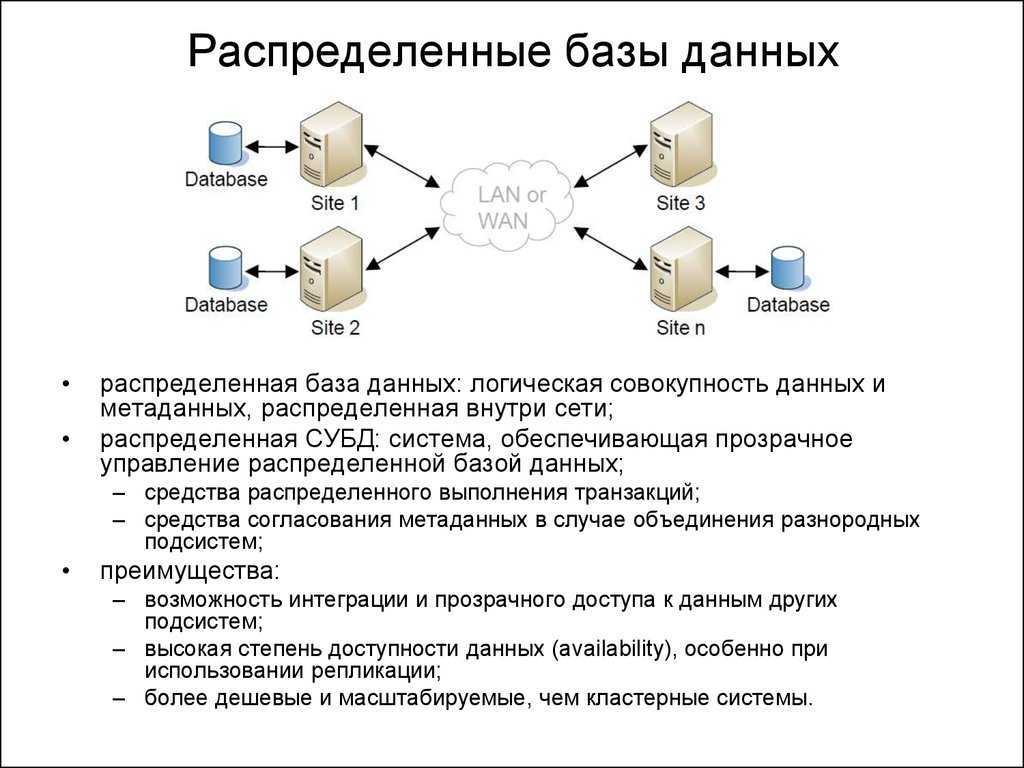
Одной из разновидностей, распределенных СУБД являются мульти базовые системы.
Мульти базовая система – распределенная система управления базами данных, в которой управление каждым из узлов осуществляется совершенно автономно.
В мульти базовых системах предпринимается попытка интеграции таких распределенных систем баз данных, в которых весь контроль над отдельными локальными системами целиком и полностью осуществляется их операторами. Полная автономия узлов позволяет не вносить какие- либо изменения в локальные СУБД. Следовательно, мульти базовые СУБД требуют создания поверх существующих локальных систем дополнительного уровня программного обеспечения, предназначенного для предоставления необходимой функциональности.
Мульти базовые системы позволяют конечным пользователям разных узлов получать доступ и совместно использовать данные без необходимости физической интеграции существующих баз данных. Они обеспечивают пользователям возможность управлять базами данных их собственных узлов без какого-либо централизованного контроля, который обязательно присутствует в обычных типах РСУБД. Администратор локальной базы данных может разрешить доступ к определенной части своей базы данных посредством создания схемы экспорта, определяющей, к каким элементам локальной базы данных смогут получать доступ внешние пользователи.
Говоря простыми словами, мульти базовая СУБД является такой СУБД, которая прозрачным образом располагается поверх существующих баз данных и файловых систем, предоставляя их своим пользователям как некоторую единую базу данных. Такая поддержка глобальной схемы позволяет пользователям на основании этой схемы строить запросы и модифицировать данные. Мульти базовая СУБД работает только с глобальной схемой, тогда как локальные СУБД собственными силами обеспечивают поддержку данных всех их пользователей. Глобальная схема создается посредством интеграции схем локальных баз данных. Программное обеспечение мульти базовой СУБД предварительно транслирует глобальные запросы и превращает их в запросы и операторы модификации данных соответствующих локальных СУБД. Полученные после выполнения локальных запросов результаты сливаются в единый глобальный результат, предоставляемый пользователю. Кроме того, мульти базовая СУБД осуществляет контроль за выполнением фиксации или отката отдельных операций глобальных транзакций локальных СУБД, а также обеспечивает сохранение целостности данных в каждой из локальных баз данных. Программы мульти базовой СУБД управляют различными шлюзами, с помощью которых контролируют работу локальных СУБД.
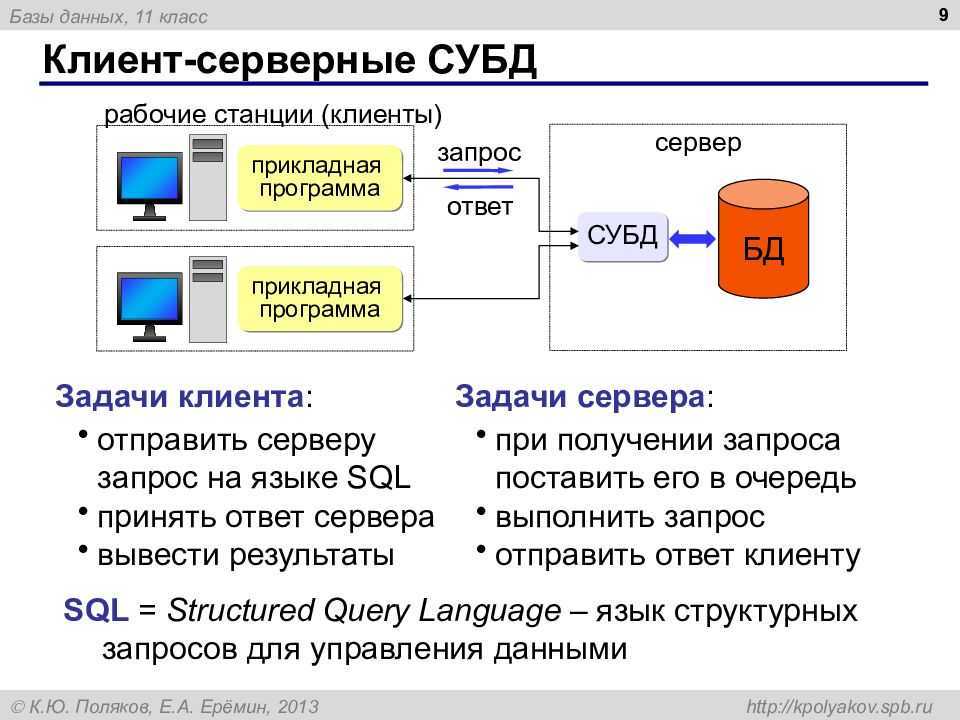
1.5 12 правил Дейта для распределенных СУБД
В 1987 г. К. Дейт опубликовал свои правила для распределенных баз данных. Ниже приведены эти 12 правил .
1. Локальная автономность. Локальные данные должны находиться под локальным владением и управлением, включая функции безопасности, целостности, представления данных в памяти. Исключением может быть ситуация, когда ограничения целостности охватывают данные нескольких узлов или когда управление распределенной транзакцией осуществляется некоторым внешним узлом.
2. Никакой конкретный сервис не должен возлагаться на какой-либо специально выделенный центральный узел. Соблюдение этого правила, т.е. принципа децентрализованности функций РаСУБД, позволяет избежать узких мест.
3. Непрерывность функционирования. Система не должна останавливаться в случае необходимости добавления нового узла или удаления в распределенной среде некоторых данных, изменения определения метаданных и даже (что довольно сложно) осуществления перехода к новой версии СУБД на отдельном узле.
4. Независимость от местоположения. Пользователи и приложения не обязаны знать о том, где физически располагаются данные.
5. Независимость от фрагментации. Фрагменты (называемые также разделами) данных должны поддерживаться и обрабатываться средствами РаСУБД таким образом, чтобы пользователи или приложения могли бы вообще ничего не знать об этом. Более того, РаСУБД должна уметь обходить при обработке запросов фрагменты, не имеющие к ним отношения (например, РаСУБД должна быть достаточно интеллектуальной, для того чтобы определять, можно ли исключить при обработке запроса тот или иной фрагмент в силу того, что запрос не содержит ссылок на хранящиеся в этом фрагменте столбцы).
6. Независимость от тиражирования. Те же принципы независимости и прозрачности относятся и к механизму тиражирования, который обсуждается ниже.
7. Распределенная обработка запросов. Обработка запросов должна производиться распределенным образом. В следующем разделе мы рассмотрим некоторые архитектурные принципы реализации РаСУБД и различные модели, в рамках которых возможна распределенная обработка запросов.
8. Управление распределенными транзакциями. На распределенные базы данных необходимо распространить механизмы управления транзакциями и управления одновременным доступом. Эта проблема включает выявление и разрешение тупиковых ситуаций, прерывания по истечении временных интервалов, фиксацию и откат распределенных транзакций, а также ряд других вопросов.
9. Независимость от оборудования. Одно и то же программное обеспечение РаСУБД должно выполняться на различных аппаратных платформах и функционировать в системе в качестве равноправного партнера. Как уже обсуждалось выше, на практике достичь этого исключительно сложно, поскольку многие поставщики поддерживают множество платформ. Это ограничение преодолевается с помощью модели многопродуктовых сред.
10. Независимость от операционных систем. Эта проблема тесно связана с предыдущей, и она также решается аналогичным образом.
11. Независимость от сети. Узлы могут быть связаны между собой с помощью множества разнообразных сетевых и коммуникационных средств. Многоуровневая модель, присущая многим современным информационным системам (например, семиуровневая модель OSI, модель TCP/IP, уровни SNA и DECnet), обеспечивает решение этой проблемы не только в среде РаБД, но и для информационных систем вообще.
12. Независимость от СУБД. Локальные СУБД должны иметь возможность участвовать в функционировании РаСУБД.
Очевидно, что, хотя крайне желательно было бы иметь системы, удовлетворяющие всем 12 правилам, нереально ожидать реализации этих требований в рамках хотя бы одного продукта даже в ближайшие годы. И действительно, за время, прошедшее с момента опубликования правил Дейта, эта цель так и не была достигнута.
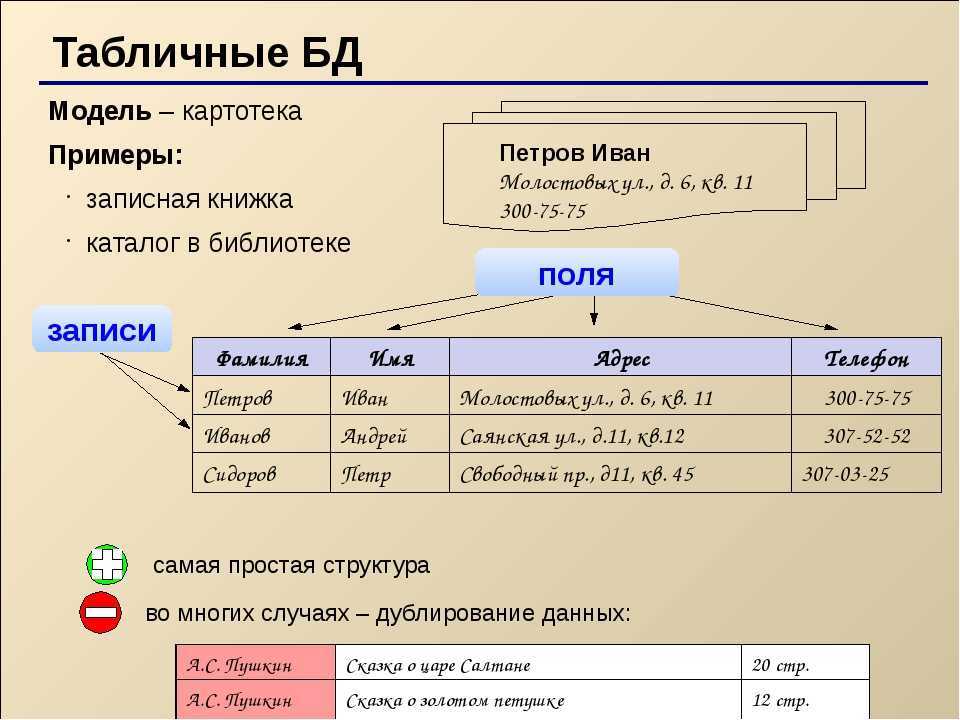
Выводы
![Распределённые базы данных (основные понятия и определения) [реферат №6936]](https://robotrackkursk.ru/wp-content/uploads/5/4/a/54a0b38357bcf403d071a999c6d95bc1.jpeg)