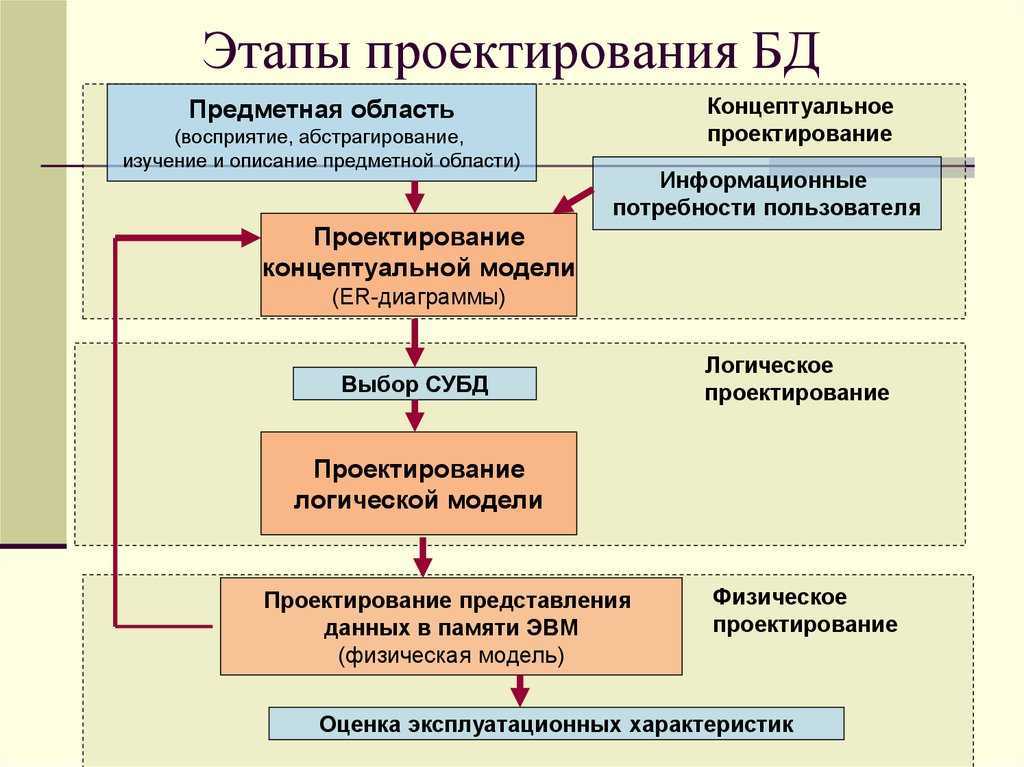
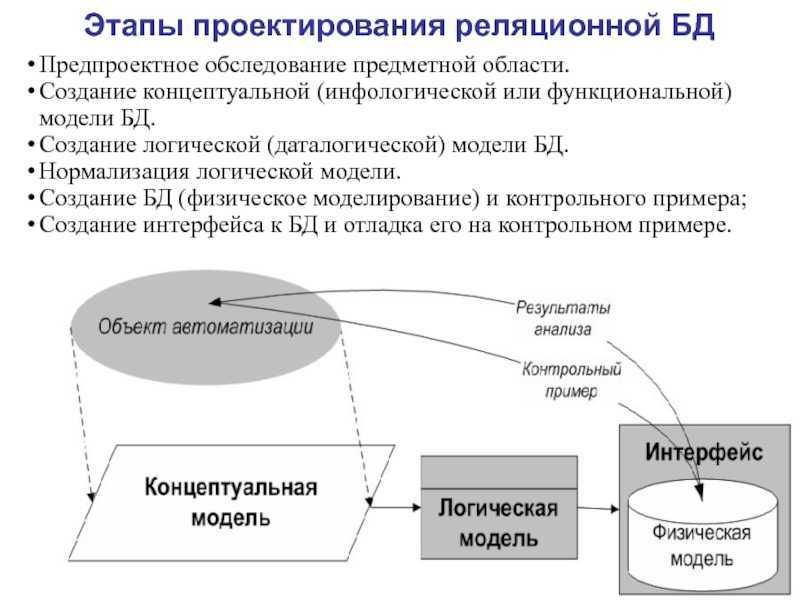
Содержание проектирования баз данных и этапность
 Замысел проектирования основывается на какой-либо сформулированной общественной потребности. У этой потребности есть среда её возникновения и целевая аудитория потребителей, которые будут пользоваться результатом проектирования. Следовательно, процесс проектирования баз данных начинается с изучения данной потребности с точки зрения потребителей и функциональной среды её предполагаемого размещения. То есть, первым этапом становится сбор информации и определение модели предметной области системы, а также – взгляда на неё с точки зрения целевой аудитории. В целом, для определения требований к системе производится определение диапазона действий, а также границ приложений БД.
Замысел проектирования основывается на какой-либо сформулированной общественной потребности. У этой потребности есть среда её возникновения и целевая аудитория потребителей, которые будут пользоваться результатом проектирования. Следовательно, процесс проектирования баз данных начинается с изучения данной потребности с точки зрения потребителей и функциональной среды её предполагаемого размещения. То есть, первым этапом становится сбор информации и определение модели предметной области системы, а также – взгляда на неё с точки зрения целевой аудитории. В целом, для определения требований к системе производится определение диапазона действий, а также границ приложений БД.
Далее проектировщик, уже имеющий определённые представления о том, что ему нужно создать, уточняет предположительно решаемые приложением задачи, формирует их список (особенно, если в проектной разработке большая и сложная БД), уточняет последовательность решения задач и производит анализ данных. Такой процесс – тоже этапная проектная работа, но обычно в структуре проектирования эти шаги поглощаются этапом концептуального проектирования – этапом выделения объектов, атрибутов, связей.
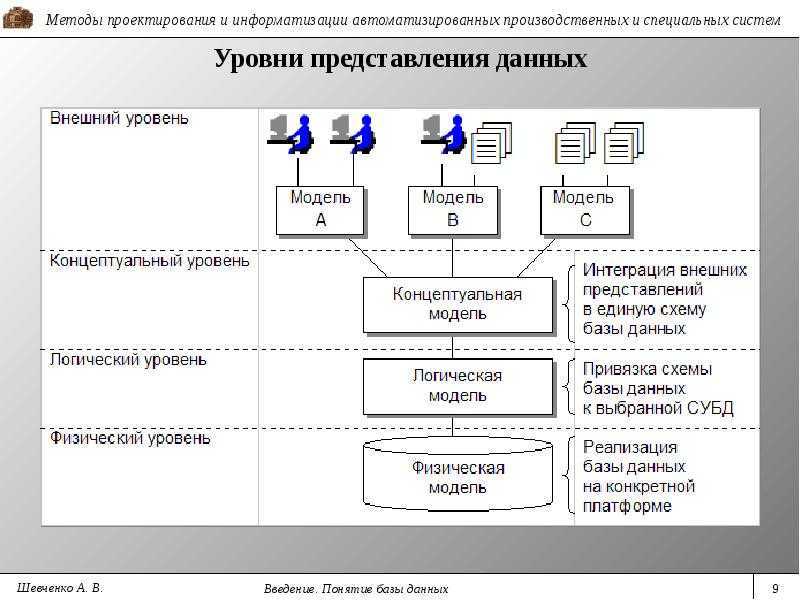
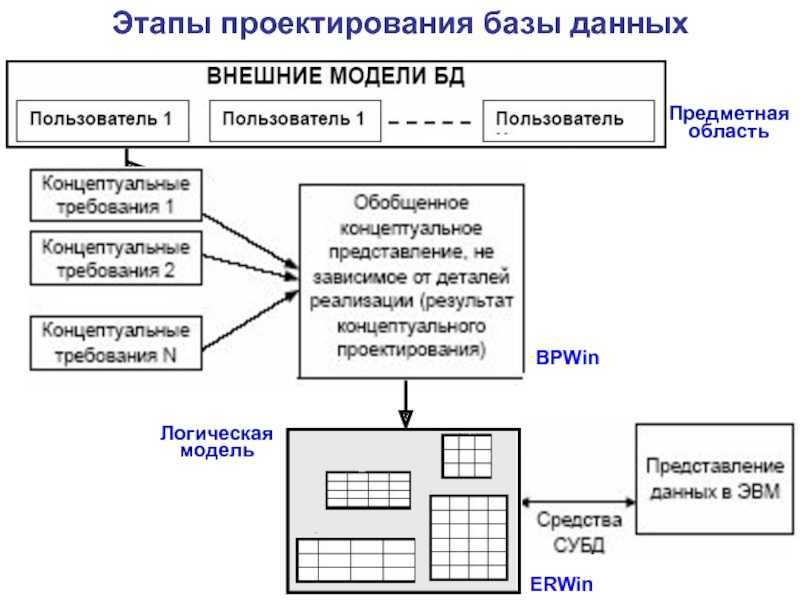
Создание концептуальной (информационной модели) предполагает предварительное формирование концептуальных требований пользователей, включая требования в отношении приложений, которые могут и не быть сразу реализованным, но учёт которых позволит в будущем повысить функциональность системы. Имея дело с представлениями объектов-абстракций множества (без указания способов физического хранения) и их взаимосвязями, концептуальная модель содержательно соответствует модели предметной области. Поэтому в литературе первый этап проектирования БД называется инфологическим проектированием.
Далее отдельным этапом (либо дополнением к предыдущему) следует этап формирования требований к операционной обстановке, где оцениваются требования к вычислительным ресурсам, способным обеспечить функционирование системы. Соответственно, чем больше объем проектируемой БД, чем выше пользовательская активность и интенсивность обращений, тем выше требования предъявляются к ресурсам: к конфигурации компьютера к типу и версии операционной системы. Например, многопользовательский режим работы будущей базы данных требует сетевого подключения с использованием операционной системы, соответствующей многозадачности.
Следующим этапом проектировщик должен выбрать систему управления базой данных (СУБД), а также инструментальные средства программного характера. После этого концептуальную модель необходимо перенести в совместимую с выбранной системой управления модель данных. Но нередко это сопряжено с внесением поправок и изменений в концептуальную модель, поскольку не всегда взаимосвязи объектов между собой, отражённые концептуальной моделью, могут быть реализованы средствами данной СУБД.
Это обстоятельство определяет возникновение следующего этапа – появления обеспеченной средствами конкретной СУБД концептуальной модели. Данный шаг соответствует этапу логического проектирования (создания логической модели).
Наконец, финальным этапом проектирования БД становится физическое проектирование – этап увязки логической структуры и физической среды хранения.
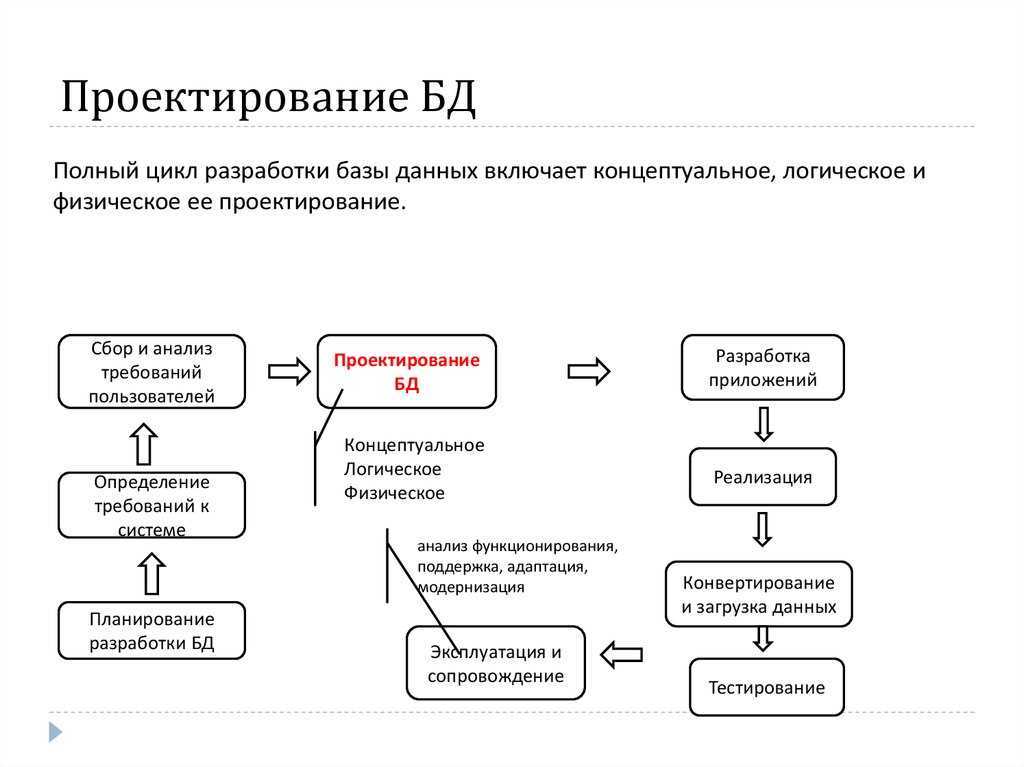
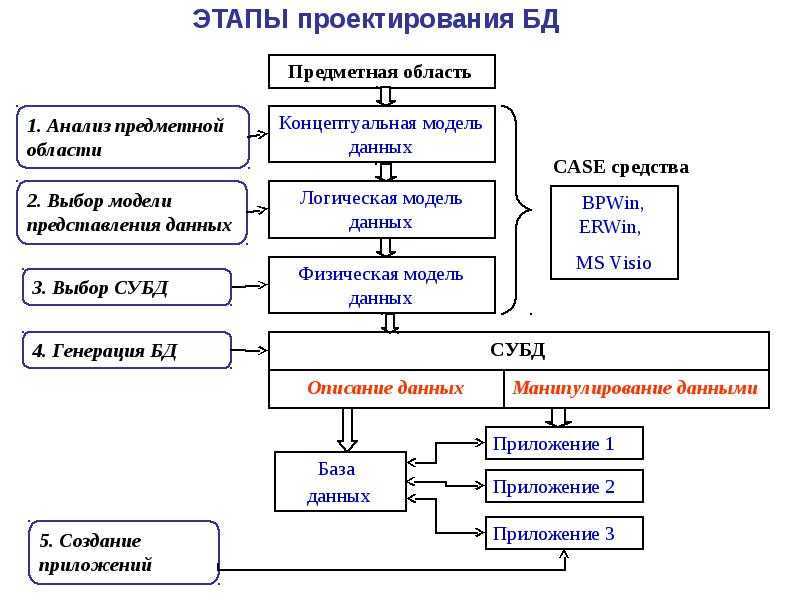
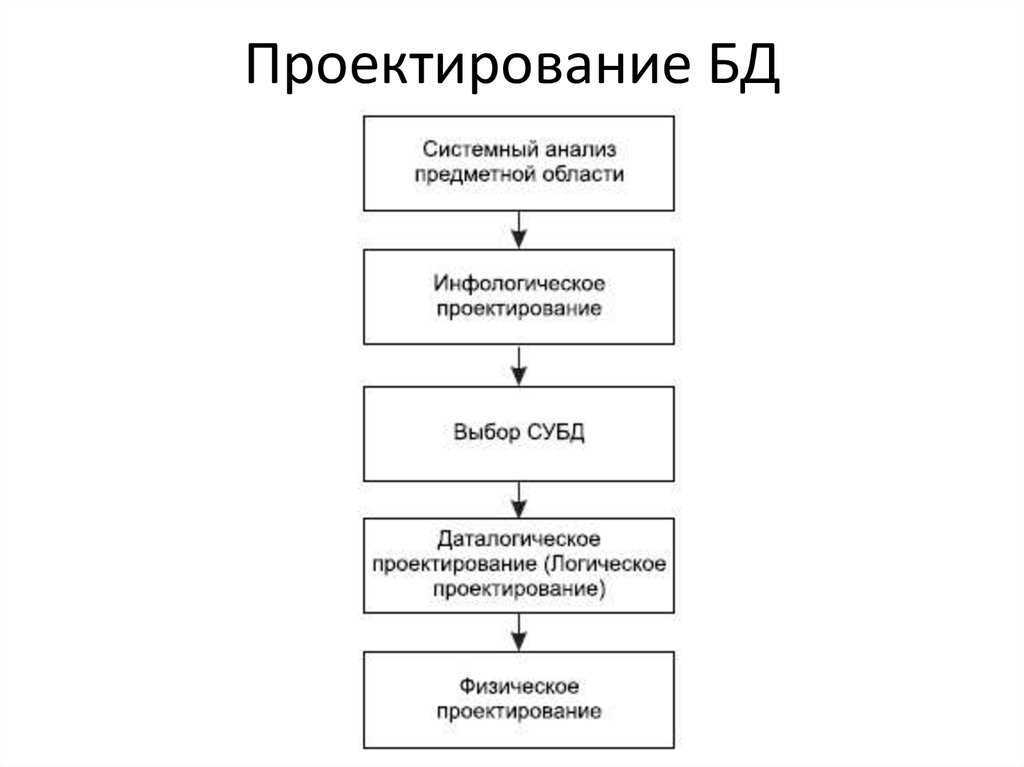
Таким образом, основные этапы проектирования в детализированном виде представлены этапами:
- инфологического проектирования,
- формирования требований к операционной обстановке
- выбора системы управления и программных средств БД,
- логического проектирования,
- физического проектирования
Ключевые из них ниже будут рассмотрены подробнее.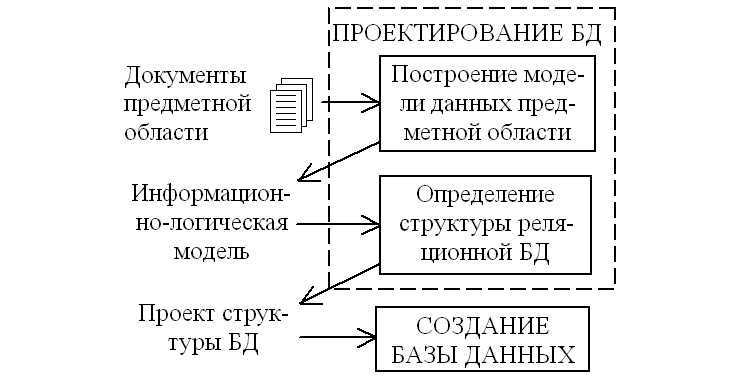
Очередные соображения на тему идеальной БД
- Поскольку идеальная БД (СУБД) должна идеально обслуживать любого клиента (при этом информационные потребности пользователей разные, и они изменяются со временем), то все разговоры о «галерах, с цепью на ноге, к другому концу которой приковано ядро» или, другими словами, о «пересечении требований, предъявляемых разными потребителями к базе» есть полнейшая глупость. Идеальная СУБД должна идеально обслуживать ЛЮБОГО пользователя. Это называется «персонификация UI» или, говоря словами для кухарки, «каждому по потребностям». Возражения?
- База данных в общем случае является многопользовательской, распределенной, мультимодельной, мультиплатформенной мультибазой данных (совокупность баз данных есть тоже база данных). Каких-либо ограничений на поддерживаемые типы данных, размеры элементов и число связей между ними, на число пользователей и компьютеров распределенной СУБД, платформы и операционные системы, количество баз данных и метаданных в мультибазе не накладывается.
- СУБД должна обеспечивать быстрый доступ к данным и высокую релевантность ответов даже при наличии ошибок в запросах и данных, а также эффективную реализацию алгоритмов обработки вновь поступающей (в произвольные моменты времени) информации, верификации БД, коррекции ошибок в данных (в т.ч. изменение структуры БД) и защиты данных. Эффективность алгоритмов не должна ухудшаться с ростом объема данных и сложности их структуры.
- СУБД построена по технологии «клиент-сервер». Клиентская часть СУБД не является ее составной частью и должна быть стандартной и аппаратно независимой (броузер). Серверная часть обеспечивает санкционированный доступ к базам данных с целью занесения, удаления, редактирования, поиска, верификации данных, а также модификации схемы БД при необходимости.
- Данные в БД могут быть любого типа (числа, строки, графика, музыка, сайты, даты, деньги — любые оцифрованные данные), и образовывать сложные типы данных, представляющих произвольные комбинации данных более простых типов (массивы, списки, деревья, отношения и т.п.).
- Данные имеют переменную структуру полей, и каждое поле может быть связано с любыми другими полями БД по разным измерениям, образуя многомерный граф произвольной сложности (мультиграф, псевдограф, циклический граф, бесконечный граф — как угодно), каждый узел которого имеет, в общем случае, переменное количество сязей с другими узлами (ребер), в т.ч. нулевое.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:
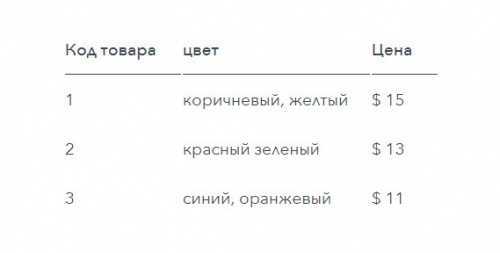
Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:

Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.




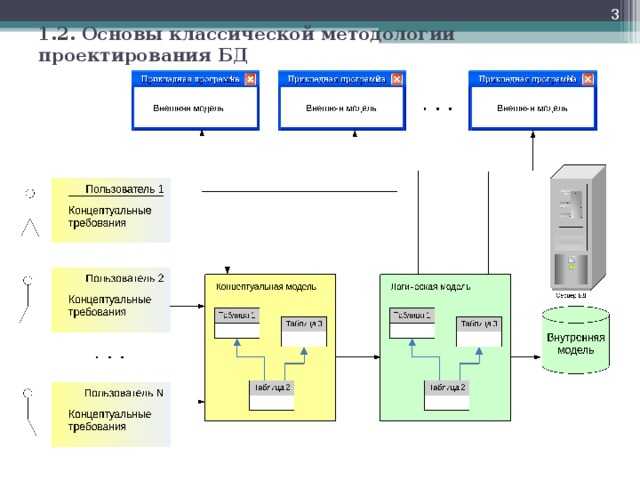

В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:
В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:
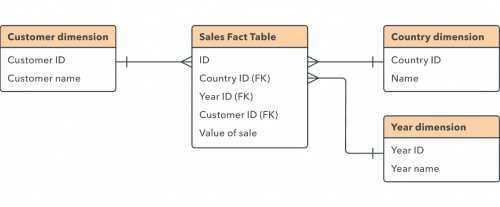
Добиваем РМД
В этот пост я намерен собрать аргументацию против сторонников РМД — практика показывает, что их даже слишком много. Впрочем, аргументации тоже немало. Вот, например:
Сделать многие приложения доступными для непрограммистов в тех случаях, когда ранее программисты были бы необходимы
Благороднейшая цель! Слова самого Кодда: «Важно помнить, что базы данных появились, чтобы приносить пользу конечным пользователям, а не для прикладных программистов, которые сегодня выступают в качестве посредников (middle-men)». И..
полностью противоположный заявленной цели результат: именно благодаря Кодду в приложения БД буквально ломанулась целая толпа посредников, благо требования к их квалификации резко снизились.
редставления самого Кодда о том, что такое RDM, неоднократно менялись в течение всей жизни. Например, Стоунбрейкер писал, что «можно видеть четыре разных версии» модели. До сих пор это понятие не имеет однозначного толкования. По-видимому, наиболее «классическим» определением следует считать Третий Манифест, поскольку Дейт писал (немного перефразировано): «Мы с Хью Дарвеном хотели, чтобы Манифест отчасти рассматривался бы как определительная формулировка, что такое реляционная модель».
Маниакальная борьба Кодда с навигацией (да и сложностью) явно обусловлена знанием о существовании концепций БД от CODASYL, стремлением избавиться от ее недостатков (как и появление 3-го Манифеста обусловлено знанием о существовании SQL, с которым Дейт энд кампани ведут борьбу не на жизнь, а на смерть). Кодд сам отвергал возможность компромисса, любую попытку объединения двух подходов, поскольку в результате «мы получаем ненужную сложность».
Авторы Третьего Манифеста прямо говорят, что «сфера их интересов — это абстрактная модель, а не вопросы реализации». Тем не менее, они указывают, что «существует ряд вопросов, на которые пока еще нет удовлетворительных ответов в доступной литературе». Даже при такой, предельно упрощенной постановке вопроса (ведь реализация абстрактных положений может оказаться неэффективной, практически непригодной, или даже вообще невозможной!), Манифест буквально пестрит фразами типа «данный вопрос требует дальнейшего изучения», «эта проблема требует дополнительного изучения», «набросок возможной модели наследования можно получить у авторов» и т.п. Иными словами, авторы открытым текстом признают, что недостаточно разбираются в проблеме — позиция, достойная всяческого уважения, рядом с которой соседствуют наивные, детские попытки «запрещать, и не пущать». Почему «РМ-предписания и запреты не могут быть предметом компромисса»? С какой стати «любые(!) основы для будущего управления данными должны твердо(!) корениться в РМД»? Кто сказал, «направления будущего развития СУБД» должны непременно базироваться на том, что было «впервые представленной миру Коддом в 1969 году»? Мир не обязан все время играть в одни и те же погремушки.
Выбор системы управления и программных средств БД
 От выбора системы управления БД зависит практическая реализация информационной системы. Наиболее значимыми критериями в процессе выбора становятся параметры:
От выбора системы управления БД зависит практическая реализация информационной системы. Наиболее значимыми критериями в процессе выбора становятся параметры:
- типа модели данных и её соответствие потребностям предметной области,
- запас возможностей в случае расширения информационной системы,
- характеристики производительности выбранной системы,
- эксплуатационная надёжность и удобство СУБД,
- инструментальная оснащённость, ориентированная на персонал администрирования данных,
- стоимость самой СУБД и дополнительного софта.
Ошибки в выборе СУБД практически наверняка впоследствии спровоцируют необходимость корректировать концептуальную и логическую модели.
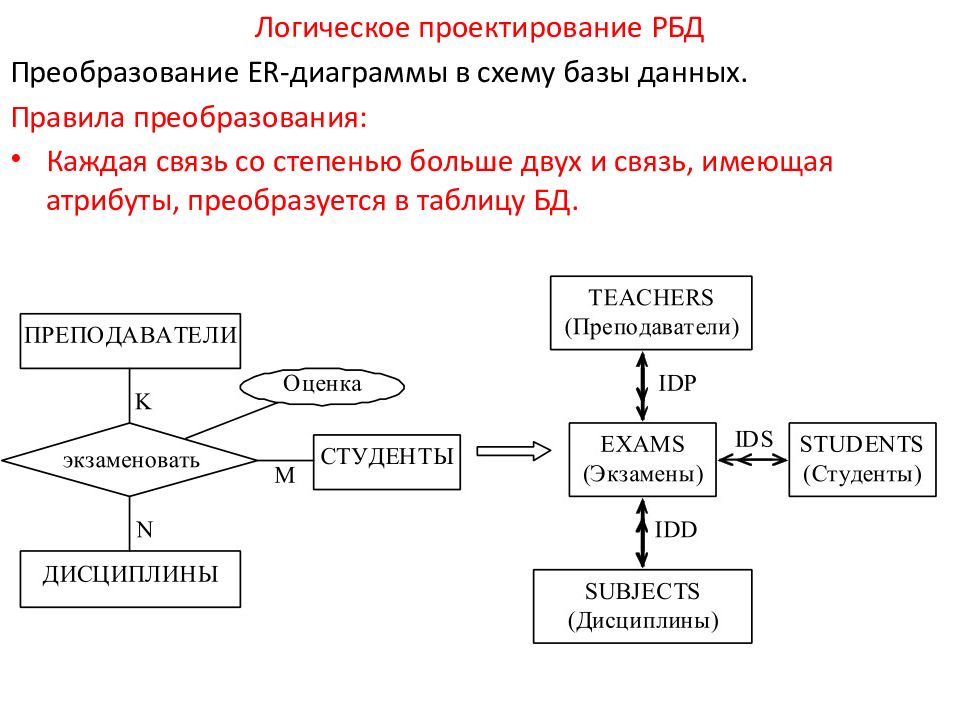
Инфологическое проектирование
Идентификация сущностей составляет смысловую основу инфологического проектирования. Сущность здесь – это такой объект (абстрактный или конкретный), информация о котором будет накапливаться в системе. В инфологической модели предметной области в понятных пользователю терминах, которые не зависят от конкретной реализации БД, описывается структура и динамические свойства предметной области. Но термины, при этом берутся в типовых масштабах. То есть, описание выражается не через отдельные объекты предметной области и их взаимосвязи, а через:
- описание типов объектов,
- ограничения целостности, связанные с описанным типом,
- процессы, приводящие к эволюции предметной области – переходу её в другое состояние.
Инфологическую модель можно создавать с помощью нескольких методов и подходов:
- Функциональный подход отталкивается от поставленных задач. Функциональным он называется, потому что применяется, если известны функции и задачи лиц, которые с помощью проектируемой базы данных будут обслуживать свои информационные потребности.
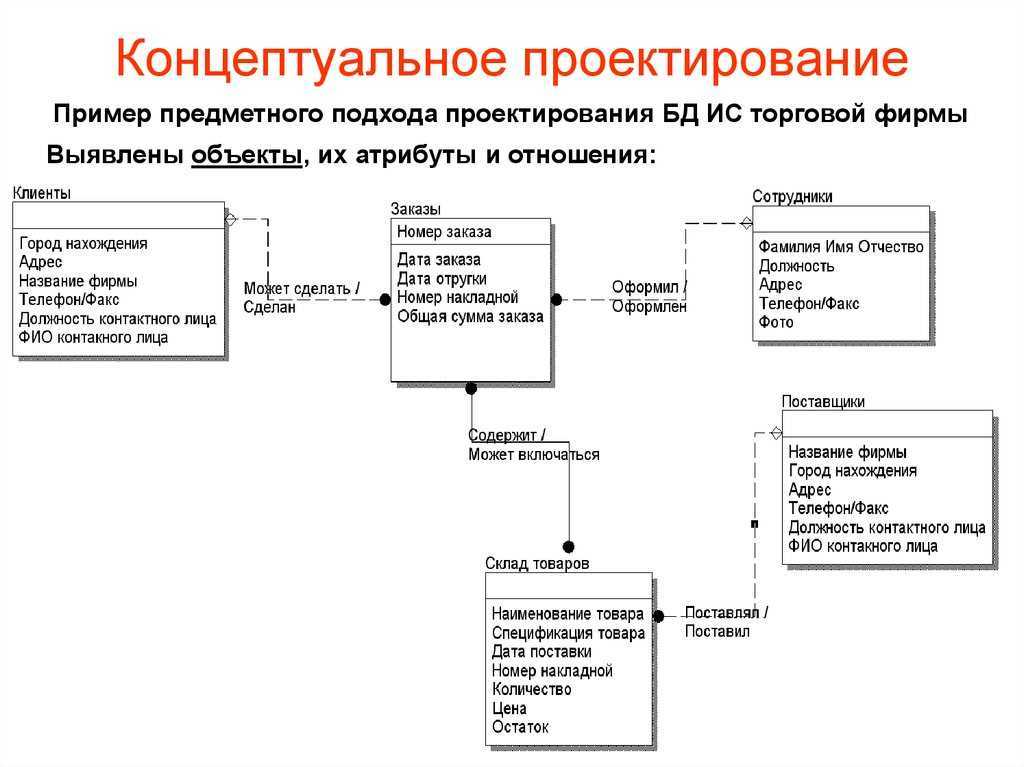
- Предметный подход во главу угла ставит сведения об информации, которая будет содержаться в базе данных, при том, что структура запросов может не быть определена. В этом случае в исследованиях предметной области ориентируются на её максимально адекватное отображение в базе данных в контексте полного спектра предполагаемых информационных запросов.
- Комплексный подход по методу «сущность-связь» объединяет достоинства двух предыдущих. Метод сводится к разделению всей предметной области на локальные части, которые моделируются по отдельности, а затем вновь объединяются в цельную область.
Поскольку использование метода «сущность-связь» является комбинированным способом проектирования на данном этапе, он чаще других становится приоритетным.
Локальные представления при методическом разделении должны, по возможности, включать в себя информацию, которой бы хватило для решения обособленной задачи или для обеспечения запросов какой-то группы потенциальных пользователей. Каждая из этих областей содержит порядка 6-7 сущностей и соответствует какому-либо отдельному внешнему приложению.
Зависимость сущностей отражается в разделении их на сильные (базовые, родительские) и слабые (дочерние). Сильная сущность (например, читатель в библиотеке) может существовать в БД сама по себе, а слабая сущность (например, абонемент этого читателя) «привязывается» к сильной и отдельно не существует.
Для каждой отдельной сущности выбираются атрибуты (набор свойств), которые в зависимости от критерия могут быть:
- идентифицирующими (с уникальным значением для сущностей этого типа, что делает их потенциальными ключами) или описательными;
- однозначными или многозначными (с соответствующим количеством значений для экземпляра сущности);
- основными (независимыми от остальных атрибутов) или производными (вычисляемыми, исходя из значений иных атрибутов);
- простыми (неделимыми однокомпонентными) или составными (скомбинированными из нескольких компонентов).
После этого производится спецификация атрибута, спецификация связей в локальном представлении (с разделением на факультативные и обязательные) и объединение локальных представлений.При числе локальных областей до 4-5 их можно объединить за один шаг. В случае увеличения числа, бинарное объединение областей происходит в несколько этапов.
В ходе этого и других промежуточных этапов находит своё отражение итерационная природа проектирования, выражающаяся здесь в том, что для устранения противоречий необходимо возвращаться на этап моделирования локальных представлений для уточнения и изменения (например, для изменения одинаковых названий семантически разных объектов или для согласования атрибутов целостности на одинаковые атрибуты в разных приложениях).
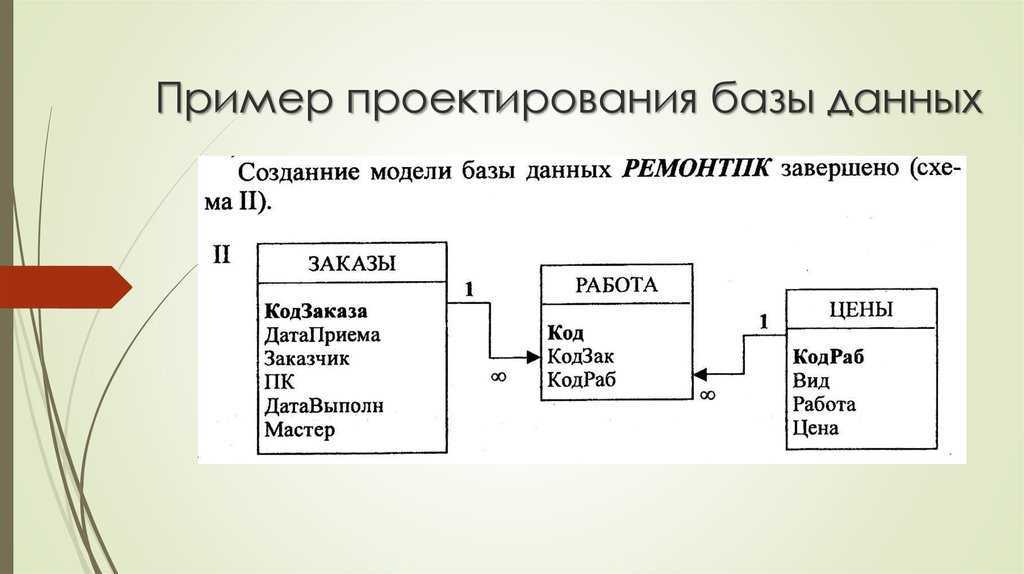
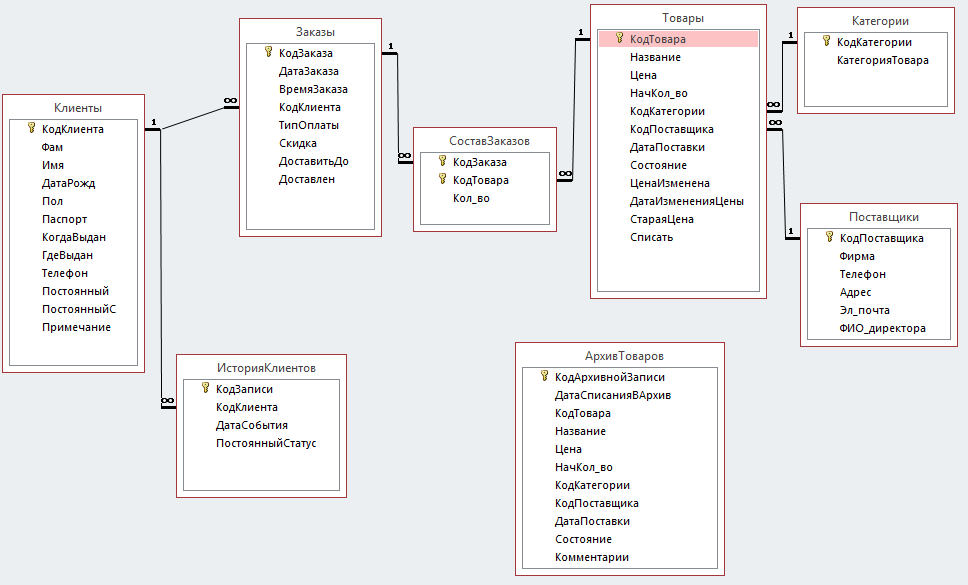
Создание взаимосвязанных таблиц
При подготовке структуры таблиц следует продумать имена колонок и типы данных, которые в них будут содержаться. Современные СУБД предоставляют широкий диапазон типов данных для хранения: числовые (цельночисленные, с плавающей точкой, двойной точности и т. п.), текстовые (char, varchar, text), календарные (дата и время), финансовые (с учетом особенностей валют) и т.п.
Кроме того, в таблицах следует установить некоторые ограничения, чтобы в записи не попадали некорректные данные. Например, если в таблице есть поле, содержащее номер пластиковой карты, то следует убедиться, что последовательность цифр, из которых он состоит, соответствует определенному шаблону.
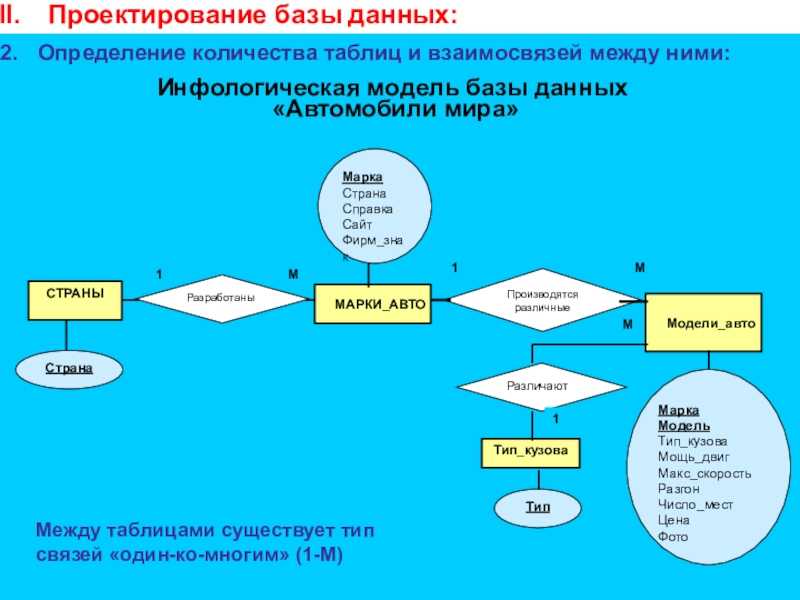


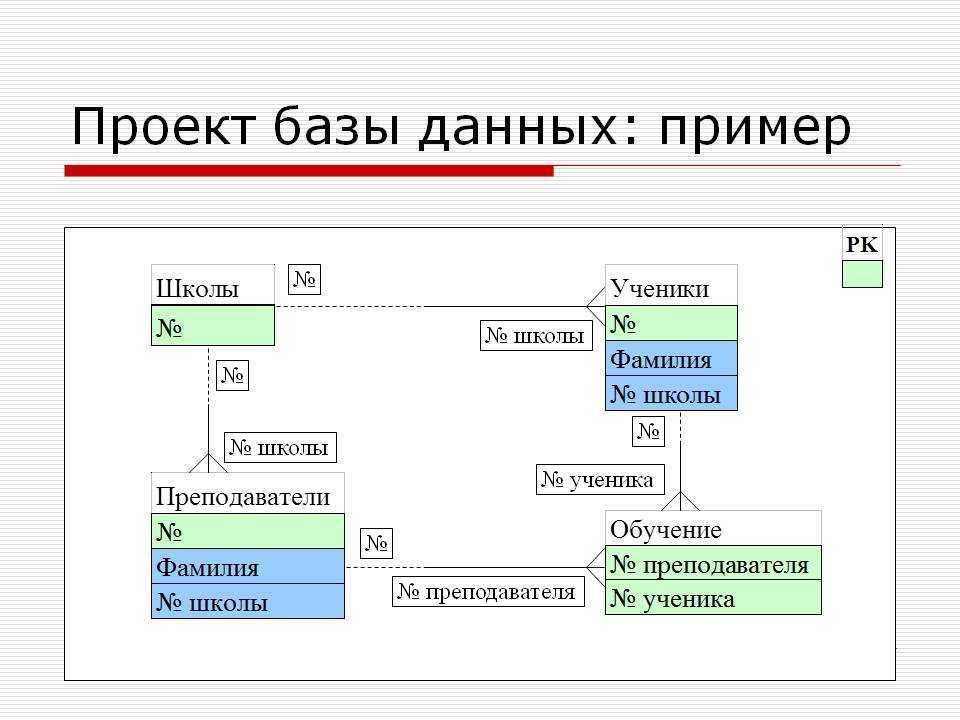
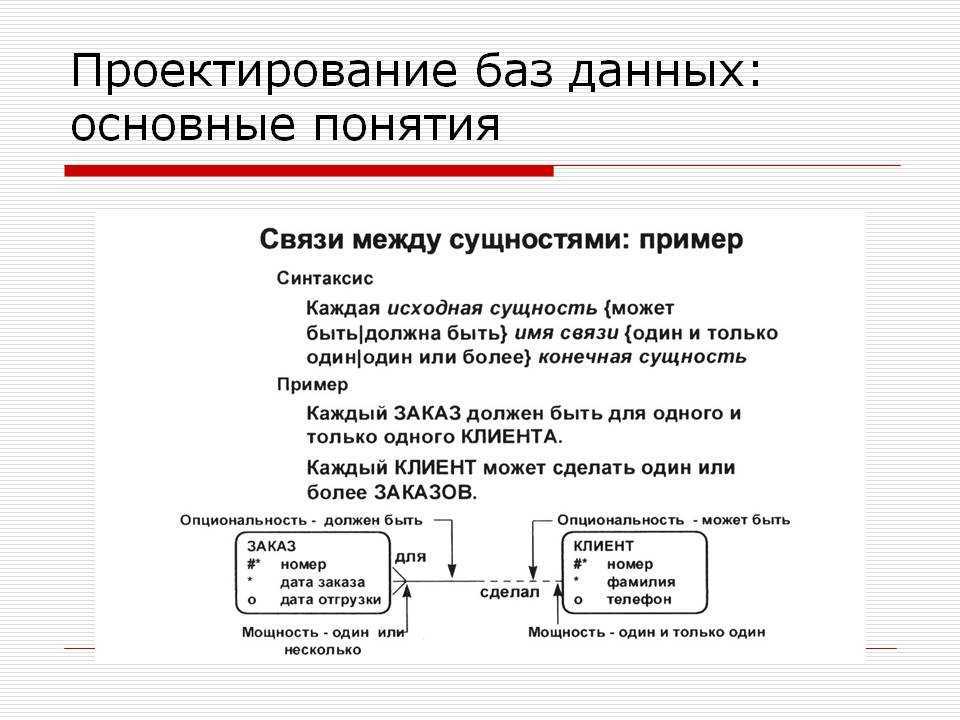
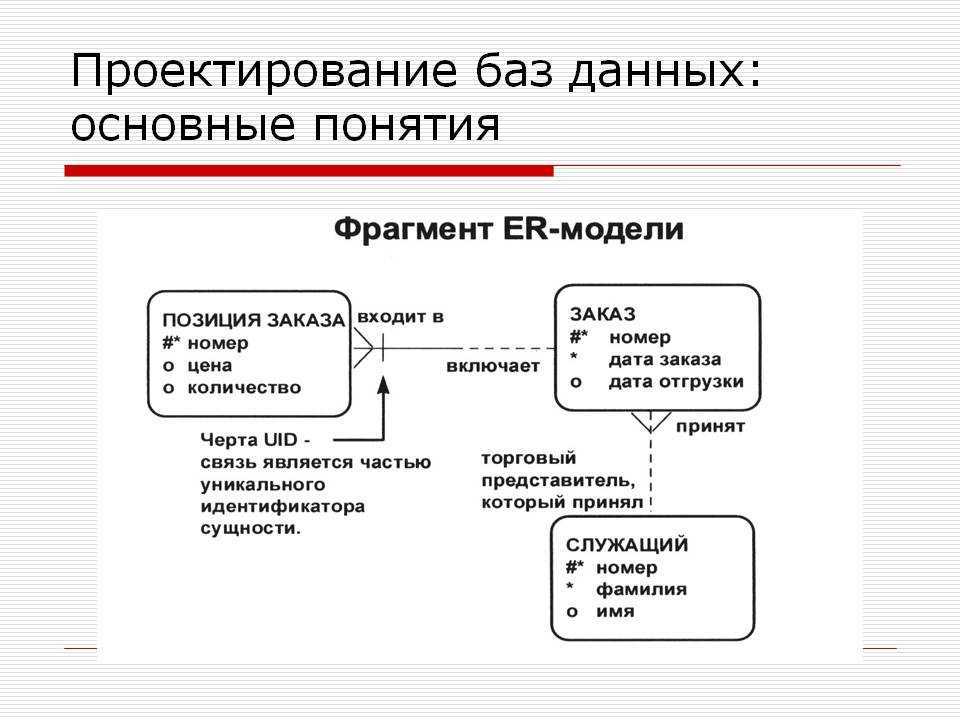
Помимо обеспечения корректного заполнения таблиц, следует позаботиться о том, чтобы они были связаны правильно. В каждой таблице формируется поле или набор полей, характеризующее запись уникальным образом. Такой идентификатор называется ключом и используется в других таблицах как внешний ключ. Например, в таблице «Водители» базы данных «Гараж» ключевым полем может стать номер водительского удостоверения. Тогда в таблице «Транспортные средства» следует создать колонку «Водитель», ссылающуюся на таблицу «Водители» и содержащую одно из значений ее колонки «Удостоверение».
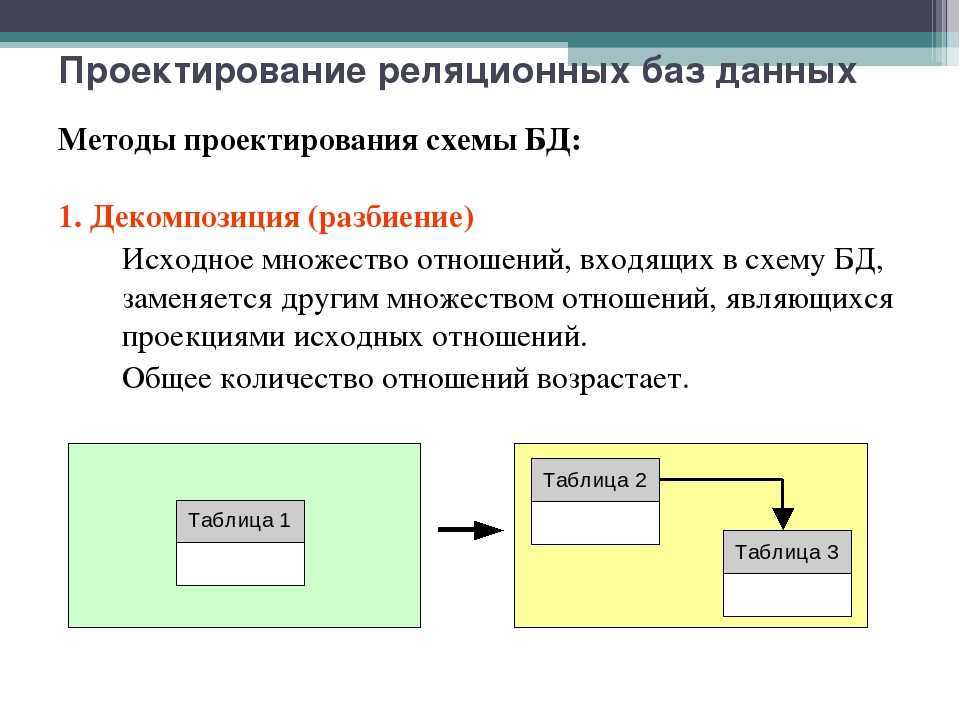
При проектировании связей между таблицами следует учитывать требования т.н. «нормальных форм».
Определение 1
Нормальная форма — свойство связи между таблицами в реляционной базе данных, свидетельствующее о наличии или отсутствии в ней избыточности. Избыточность может приводить к логическим ошибкам. Иными словами, нормальная форма — совокупность требований, которым должна соответствовать связь между таблицами.
При проектировании БД учитывается сразу несколько нормальных форм (всего их насчитывается до 7, в зависимости от методики подсчета). Свойствам нормальных форм посвящены многочисленные исследования.
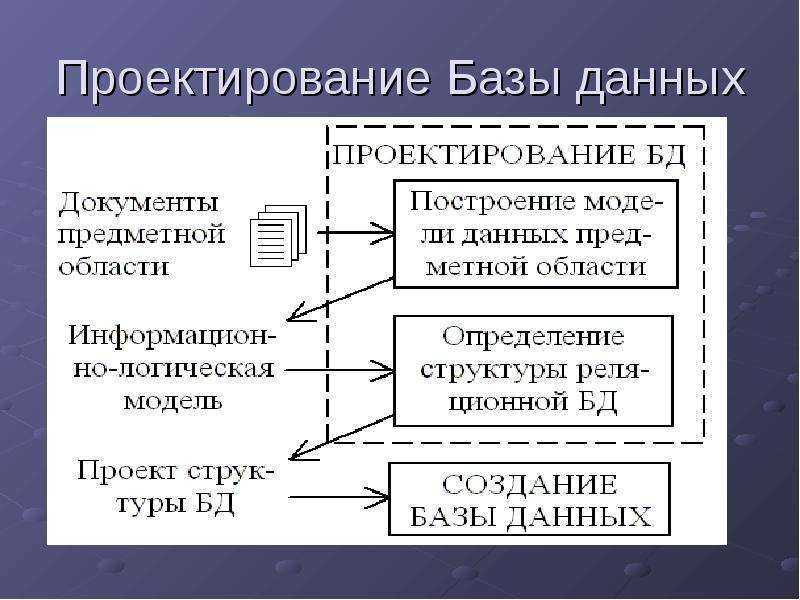
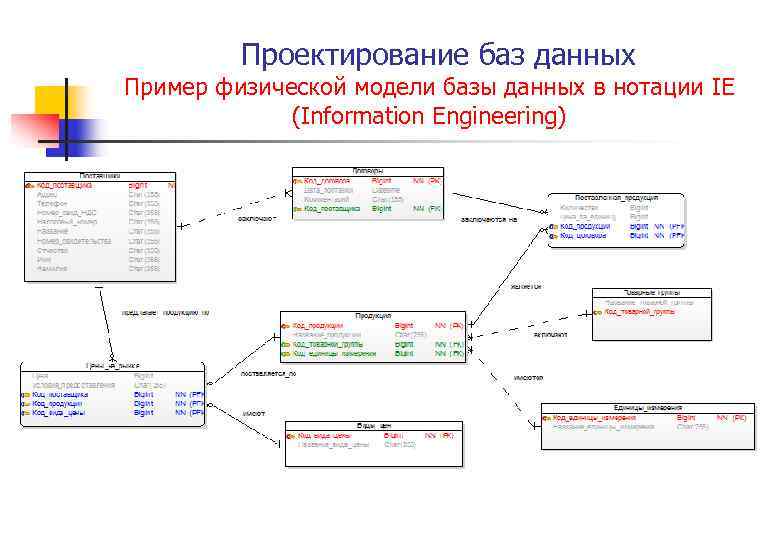
Физическое проектирование БД
На следующем этапе физического проектирования БД логическая структура отображается в виде структуры хранения БД, то есть увязывается с такой физической средой хранения, где данные будут размещены максимально эффективно. Здесь детально расписывается схема данных с указанием всех типов, полей, размеров и ограничений. Помимо разработки индексов и таблиц, производится определение основных запросов.
Построение физической модели сопряжено с решением во многом противоречивых задач:
- задачи минимизации места хранения данных,
- задачи достижения целостности, безопасности и максимальной производительности.
Вторая задача вступает в конфликт с первой, поскольку, например:
- для эффективного функционирования транзакций нужно резервировать дисковое место под временные объекты,
- для увеличения скорости поиска нужно создавать индексы, число которых определяется числом всех возможных комбинаций участвующих в поиске полей,
- для восстановления данных будут создаваться резервные копии базы данных и вестись журнал всех изменений.
Всё это увеличивает размер базы данных, поэтому проектировщик ищет разумный баланс, при котором задачи решаются оптимально путём грамотного размещения данных в пространстве памяти, но не за счёт средств защиты базы дынных, куда входит как защита от несанкционированного доступа, так и защита от сбоев.
Для завершения создания физической модели проводят оценку её эксплуатационных характеристик (скорость поиска, эффективность выполнения запросов и расхода ресурсов, правильность операций). Иногда этот этап, как и этапы реализации базы данных, тестирования и оптимизации, а также сопровождения и эксплуатации, выносят за пределы непосредственного проектирования БД.
Проектирование вспомогательных объектов реляционных БД
После создания взаимосвязанных таблиц проектировщики БД разрабатывают дополнительные средства, облегчающие работу с данными. Реализации языка SQL предусматривают такие удобные возможности, как отчеты (view), индексы, триггеры и т.д. Развитые СУБД предоставляют разработчикам множество встроенных функций для работы с текстом, числами, датами, объектами БД. БД может содержать и вновь созданные конкретно для ее целей функции.
В качестве примера рассмотрим ситуацию, когда из таблицы «Пациенты» базы данных «Поликлиника» нужно выбирать сотрудников возрастом старше 60 лет. Хранить сведения о возрасте в таблице нецелесообразно, т.к. он постоянно меняется, но можно задействовать функцию AGE, которая находит разницу между текущей датой и датой рождения. Создадим соответствующее представление (view):
Теперь, совершая запрос
, мы можем легко получить необходимую информацию.
В СУБД, ориентированных на визуальную разработку, таких, как Microsoft Access, в состав баз данных входят также формы и отчеты с удобными элементами управления и офисного форматирования. Последовательно совершенствуя запросы, формы, отчеты, насыщая базу данных новыми возможностями, разработчики стремятся сделать ее всё более эффективной для обработки данных, соответствующих заданной предметной области.
Замечание 2
Применение набирающих популярность баз данных класса NoSQL существенно сокращает время проектирования, поскольку в них для хранения данных применяются не взаимосвязанные таблицы, а принципиально другие способы, предоставляющие в ряде случаев более гибкие возможности по сравнению с SQL-инструментами.
Идеальная БД
Идеальная БД: БД, которая не вызывает ни у одного из ее многочисленных пользователей никаких иных чувств, кроме восторга.Пользователь:
- Умный Профессионал (все знает, и все умеет).
- Глупая Кухарка (ни хрена не умеет, ни хрена не соображает).
- Средний Юзер (любое промежуточное состояние).
- Любознательный Компьютер (самый активный пользователь).
Поскольку посты вроде как можно редактировать — будем пополнять и модифицировать. Если этот пост можно редактировать только мне — пишите заявки. Кстати, я хотел бы, чтобы ветка была модерируемой — мусор потихоньку вычищался, формулировки вылизывались… это возможно (я имею в виду, технически)?
Добавление индексов и представлений
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.

Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
Этапы создания базы данных
Надлежащим образом структурированная база данных:
- Помогает сэкономить дисковое пространство за счет исключения лишних данных;
- Поддерживает точность и целостность данных;
- Обеспечивает удобный доступ к данным.
Основные этапы разработки базы данных:
- Анализ требований или определение цели базы данных;
- Организация данных в таблицах;
- Указание первичных ключей и анализ связей;
- Нормализация таблиц.
Рассмотрим каждый этап проектирования баз данных подробнее
Обратите внимание, что в этом руководстве рассматривается реляционная модель базы данных Эдгара Кодда, написанная на языке SQL (а не иерархическая, сетевая или объектная модели)
Вместо предисловия
Полистал я несколько рекомендованных ссылок (в том числе три «местных»), а именно:
- Проектирование баз данных: новые требования, новые подходы
- Аномалии в реляционных базах данных
- Кризис баз данных и проблема выбора
- Базы данных: достижения и перспективы на пороге 21-го столетия
- Реализация ядра безопасности в информационной системе
- Словарь метаданных документно-ориентированной информационной системы
- Управление качеством данных на основе алгоритмов нечеткого поиска
- Двадцать лет практики обучили нас, что иногда нормализованные таблицы это правильно, а иногда нет; базы данных будущего должны предоставлять такой выбор.
- Большинство организаций сейчас хранят больше данных на десктопах, чем в своих БД. Этими данными на десктопах, часто хорошо структурированными по своей природе, управляет все, что угодно, но не системы управления базами данных.
- Сегодня объектно-ориентированные базы данных поддерживают один стиль навигации; сетевые СУБД и ISAM — другой. Реляционные базы данных, с другой стороны, обеспечивают запросы и операции на множествах. Высокоуровневые процессоры запросов могут ориентироваться либо на операции со множествами, либо на навигацию указателей или на то и другое. Пользователь может выбирать.
- Поэлементный навигационный стиль и вычисления, основанные на запросах и ориентированные на множества одинаково нужны. Часто подход, основанный на запросах, — наилучший путь первоначального указания множества записей, в то время как навигационные операции — единственный путь дальнейшей работы с полученными в результате данными в манере достаточно развитой, чтобы удовлетворить потребностям сложных приложений. Чем раньше мы избавимся от необходимости выбора, тем лучше.
- SQL и надстраиваемые над ним языковые формы более высокого уровня хороши для доступа к традиционным записям данных. Когда речь идет о мультимедийных данных, то здесь часто необходимы совершенно другие формы пользовательских интерфейсов.
- Одной из самых актуальных задач является создание методики проектирования хороших схем реляционных БД. Вопрос о проектировании «хороших» схем реляционных баз данных изучается в литературе уже свыше двадцати лет. К сожалению, к настоящему моменту так и не появилось общепринятой на практике методики проектирования схем. Проектирование схем БД превращается в искусство. Его результаты полностью зависят от опыта и мастерства проектировщика.
- Средств для работы с абстрактными типами данных в реляционных СУБД практически нет