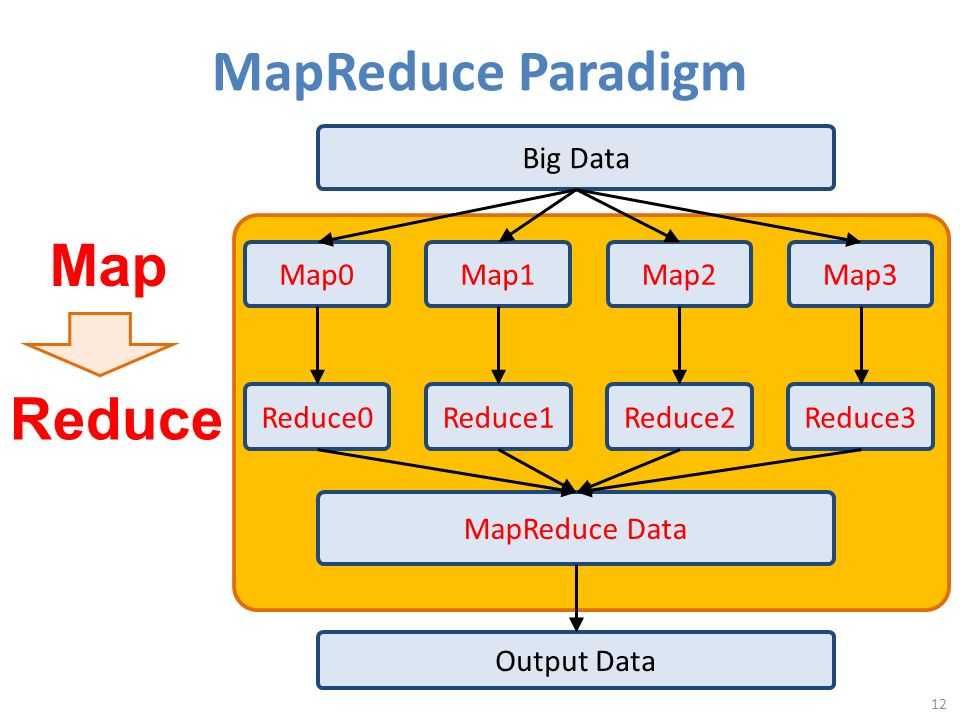
Введение в MapReduce
- MapReduce — это инфраструктура параллельных распределенных вычислений на основе JavaПриложения для обработки данных, написанные с его использованием, могут работать на больших коммерческих аппаратных кластерах для решения распараллеливаемых проблем в больших наборах данных, а обработка данных может происходить в файловых системах (неструктурированных) или базах данных (структурированных). Данные. MapReduce может использовать расположение данных и обрабатывать данные рядом с местом хранения, чтобы минимизировать накладные расходы на связь.
- Инфраструктура MapReduce организует распределенные серверы, параллельно выполняет различные задачи и управляет всеми коммуникациями и передачей данных между различными частями системы, а также может выполняться автоматически.Распараллеливание вычислительных задач,Автоматически разделить данные расчета и задачи расчетаНа узле кластераАвтоматически назначать и выполнять задачи и собирать результаты расчетовСистема будет отвечать за обработку сложных деталей нижележащих уровней многих систем, участвующих в параллельных вычислениях, таких как распределение данных, передача данных и отказоустойчивая обработка, снижая нагрузку на разработчиков.
- MapReduce по-прежнемуМодель и метод параллельного программированияМодель программирования и методология. С помощью концепции проектирования языка функционального программирования Lisp он предоставляет удобный метод параллельного программирования, который абстрагирует сложный процесс параллельных вычислений, выполняющийся в крупномасштабном кластере, в две функции: Map и Reduce, Использование функции программирования Map and Reduce для выполнения основных задач параллельных вычислений, предоставление абстрактных операций и интерфейса параллельного программирования для простого и удобного выполнения крупномасштабного программирования данных и обработки вычислений.
Обзор Hadoop MapReduce
Hadoop MapReduce – программная модель (framework) выполнения распределенных
вычислений для больших объемов данных в рамках парадигмы map/reduce, представляющая
собой набор Java-классов и исполняемых утилит для создания и обработки заданий на
параллельную обработку.
Основные концепции Hadoop MapReduce можно сформулировать как:
- обработка/вычисление больших объемов данных;
- масштабируемость;
- автоматическое распараллеливание заданий;
- работа на ненадежном оборудовании;
- автоматическая обработка отказов выполнения заданий.
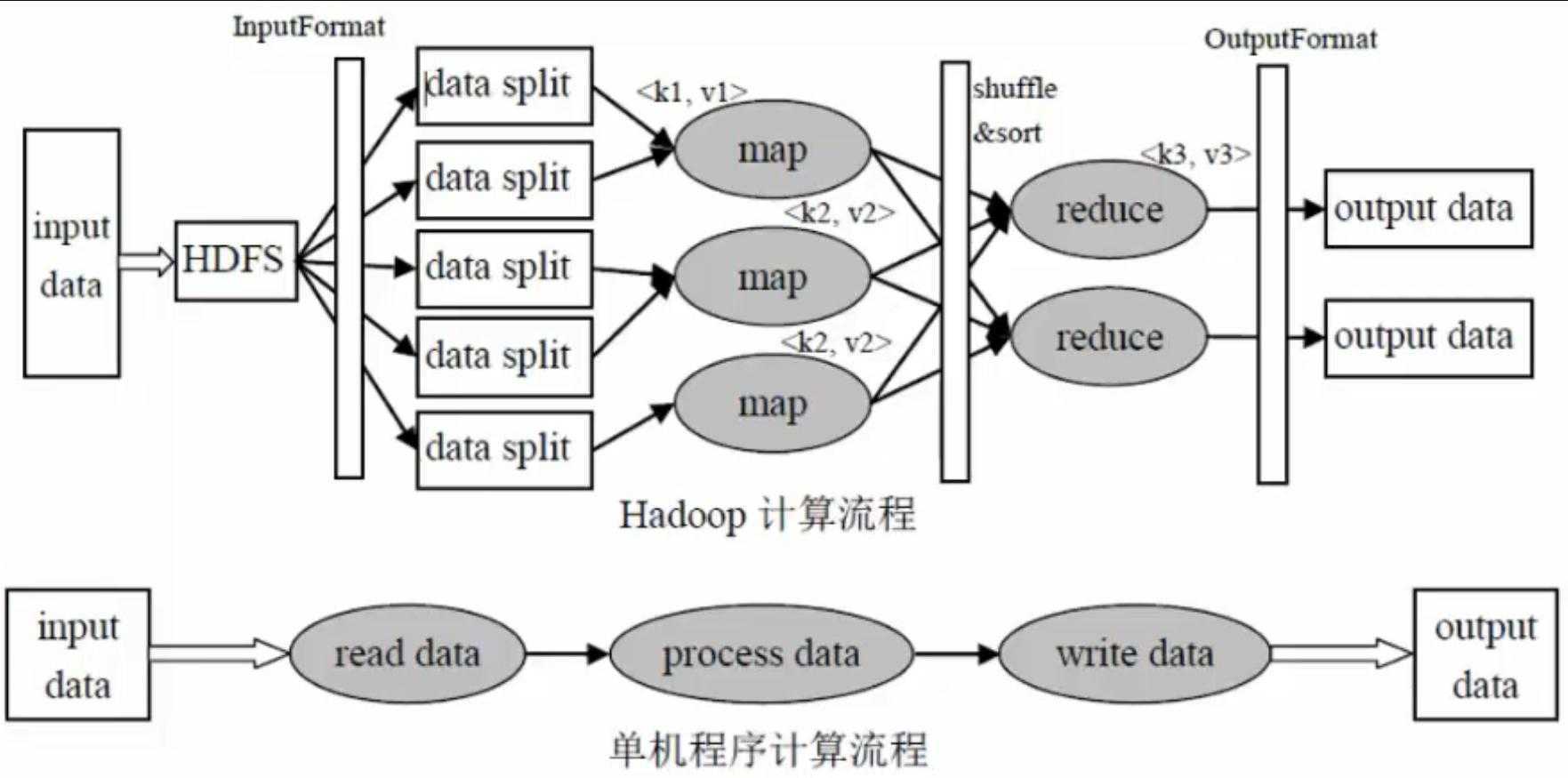
Работу Hadoop MapReduce можно условно поделить на следующие этапы:
-
Input read
Входные данные делятся на блоки данных предопределенного размера (от 16 Мб до 128
Мб) – сплиты (от англ. split). MapReduce Framework закрепляет за каждой функцией
Map определенный сплит. -
Map
Каждая функция Map получает на вход список пар «ключ/значение» <k,v>, обрабатывает
их и на выходе получает ноль или более пар <k’,v’>, являющихся промежуточным
результатом.где k’ — в общем случае, произвольный ключ, не совпадающий с k.
Все операции map() выполняются параллельно и не зависят от результатов работы друг
друга. Каждая функция map() получает на вход свой уникальный набор данных, не повторяющийся
ни для какой другой функции map(). -
Partition / Combine
Целью этапа partition (разделение) является распределение промежуточных результатов,
полученных на этапе map, по reduce-заданиям.где reducers_count — количество узлов, на которых запускается операция свертки;reducer_id — идентификатор целевого узла.
В простейшем случае,
Основная цель этапа partition – это балансировка нагрузки. Некорректно реализованная
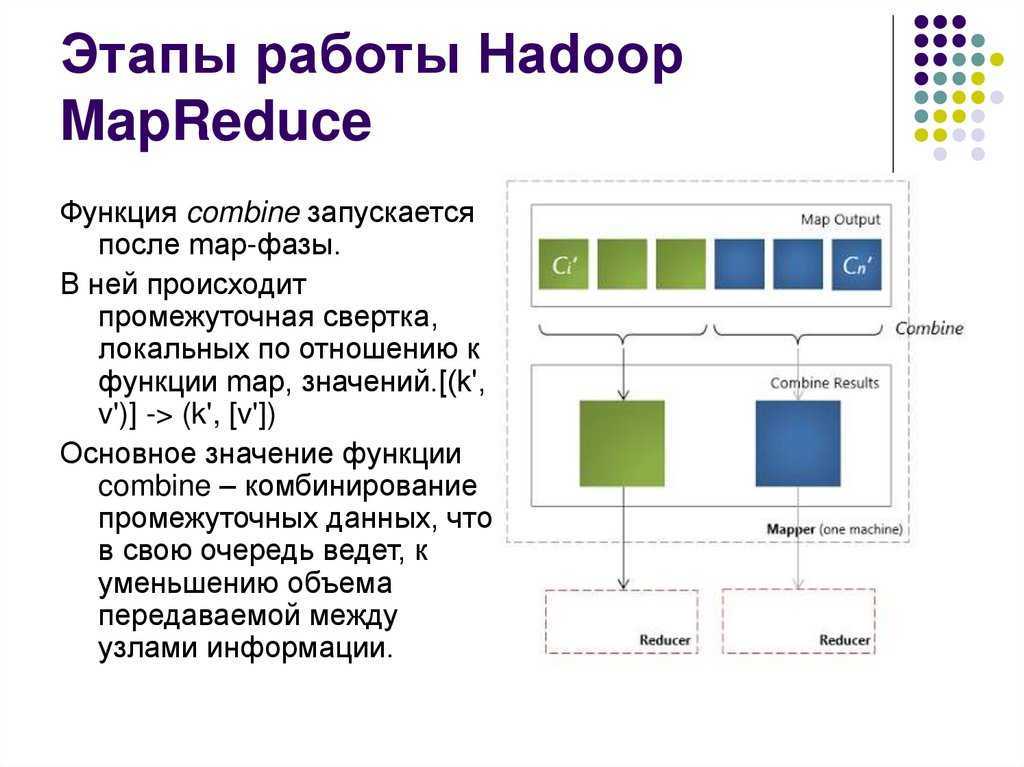
функция partition может привести к неравномерному распределению данных между reduce-узлами.Функция combine запускается после map-фазы. В ней происходит промежуточная свертка,
локальных по отношению к функции map, значений.Основное значение функции combine
– комбинирование промежуточных данных, что в свою очередь ведет, к уменьшению объема
передаваемой между узлами информации. -
Copy / Сompare / Merge
На этом этапе происходит:-
Copy: копирование результатов, полученных в результате работы функций map
и combine (если такая была определена), с map-узлов на reduce-узлы. -
Сompare (или Sort): сортировка, группировка по ключу k полученных в результате операции
copy промежуточных значений на reduce-узле. - Merge: «слияние» данных, полученных от разных узлов, для операции свёртки.
-
Copy: копирование результатов, полученных в результате работы функций map
-
Reduce
Framework вызывает функцию reduce для каждого уникального ключа k’ в отсортированном
списке значений.Все операции reduce() выполняются параллельно и не зависят от результатов работы
друг друга. Таким образом, результаты работы каждой функции reduce() пишутся в отдельный
выходной поток. -
Output write
Результаты, полученные на этапе reduce, записываются в выходной поток (в общем случае,
файловые блоки в HDFS). Каждый reduce-узел пишет в собственный выходной поток.
Разработчику приложения для Hadoop MapReduce необходимо реализовать базовый обработчик,
который на каждом вычислительном узле кластера обеспечит преобразование исходных
пар «ключ/значение» в промежуточный набор пар «ключ/значение» (класс, реализующий
интерфейс Mapper), и обработчик, сводящий промежуточный набор пар в окончательный,
сокращённый набор (класс, реализующий интерфейс Reducer) [].
Все остальные фазы выполняются программной моделью MapReduce без дополнительного
кодирования со стороны разработчика. Кроме того, среда выполнения Hadoop MapReduce выполняет следующие функции:
- планирование заданий;
- распараллеливание заданий;
- перенос заданий к данным;
- синхронизация выполнения заданий;
- перехват «проваленных» заданий;
- обработка отказов выполнения заданий и перезапуск проваленных заданий;
- оптимизация сетевых взаимодействий.
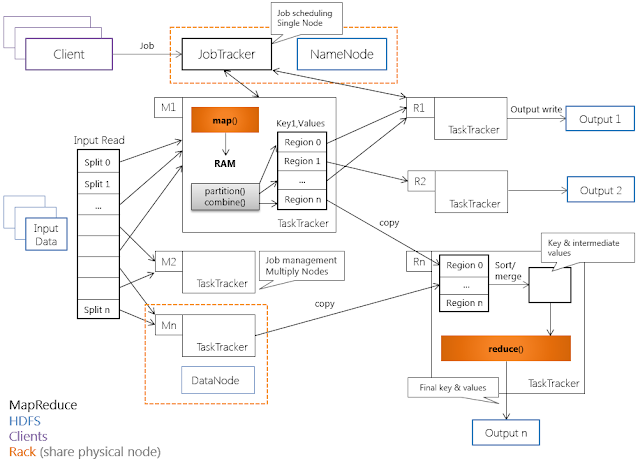
Архитектура Hadoop MapReduce
Hadoop MapReduce использует архитектуру «master-worker», где master –
единственный
экземпляр управляющего процесса (JobTracker), как правило, запущенный на отдельной
машине (вычислительном узле). Worker-процессы – это произвольное множество процессов
TaskTracker, исполняющихся на DataNode.
JobTracker и TaskTracker «лежат» над уровнем хранения HDFS, и запускаются/исполняются
в соответствии со следующими правилами:
- экземпляр JobTracker исполняется на NameNode-узле HDFS;
- экземпляры TaskTracker исполняются на DataNode-узле;
- TaskTracker исполняются в соответствии с принципом «данные близко», т.е. процесс
TaskTracker располагается топологически максимально близко с узлом DataNode, данные
которого обрабатываются.
Вышеописанные принципы расположения JobTracker- и TaskTracker-процессов позволяют
существенно сократить объемы передаваемых по сети данных и сетевые задержки, связанные
с передачей этих данных – основные «узкие места» производительности в современных
распределенных системах.
JobTracker является единственным узлом, на котором выполняется приложение MapReduce,
вызываемое программным клиентом. JobTracker выполняет следующие функции:
- планирование индивидуальных (по отношению к DataNode) заданий map и reduce, промежуточных
свёрток; - координация заданий;
- мониторинг выполнения заданий;
- переназначение завершившихся неудачей заданий другим узлам TaskTracker.
В свою очередь, TaskTracker выполняет следующие функции:
- исполнение map- и reduce-заданий;
- управление исполнением заданий;
- отправка сообщений о статусе задачи и завершении работы узлу JobTracker;
- отправка диагностических heartbeat-сообщений узлу JobTracker.
Взаимодействие TaskTracker-узлов с узлом JobTracker идет посредством RPC-вызовов,
причем вызовы идут только от TaskTracker. Аналогичный принцип взаимодействия реализован
в HDFS – между узлами DataNode и NameNode-узлом. Такое решение уменьшает зависимость
управляющего процесса JobTracker от процессов TaskTracker.
Взаимодействие JobTracker-узла с клиентом (программным) проходит по следующей схеме:
JobTracker принимает задание (Job) от клиента и разбивает задание на множество M
map-задач и множество R reduce-задач. Узел JobTracker использует информацию о файловых
блоках (количество блоков и их месторасположение), расположенную в узле NamеNode,
находящемуся локально, чтобы решить, сколько подчиненных задач необходимо создать
на узлах типа TaskTracker.
TaskTracker получает от JobTracker список задач (тасков), загружает код и выполняет его. Периодично TaskTracker отсылает JobTracker статус выполнения задачи.
Взаимодействия TaskTracker-узлов с программным клиентом отсутствуют.
По аналогии с архитектурой HDFS, где NameNode является единичной точкой отказа (Single
point of failure), JobTracker также является таковой. Принцип восстановления в узлах
JobTracker и TaskTracker описан ниже.
При сбое TaskTracker-узла JobTracker-узел переназначает задания неисправного узла
другому узлу TaskTracker. В случае неисправности JobTracker-узла, для продолжения
исполнения MapReduce-приложения, необходим перезапуск JobTracker-узла. При перезапуске
узел JobTracker читает из специального журнала данные, о последней успешной контрольной
точке (checkpoint), восстанавливает свое состояние на момент записи checkpoint и
продолжает работу с места последней контрольной точки.
Что такое MapReduce?
MapReduce — это модель программирования или программная среда в среде Apache Hadoop. Он используется для создания приложений, способных обрабатывать большие объемы данных параллельно на тысячах узлов (называемых кластерами или сетками) с отказоустойчивостью и надежностью.
Эта обработка данных происходит в базе данных или файловой системе, где хранятся данные. MapReduce может работать с файловой системой Hadoop (HDFS) для доступа к большим объемам данных и управления ими.
Эта структура была представлена в 2004 году компанией Google и популяризирована Apache Hadoop. Это уровень обработки или механизм в Hadoop, на котором выполняются программы MapReduce, разработанные на разных языках, включая Java, C++, Python и Ruby.
Программы MapReduce в облачных вычислениях работают параллельно, поэтому подходят для анализа данных в больших масштабах.
MapReduce направлен на разделение задачи на более мелкие, несколько задач с использованием функций «карты» и «уменьшения». Он сопоставит каждую задачу, а затем сократит ее до нескольких эквивалентных задач, что приведет к меньшей вычислительной мощности и накладным расходам в сети кластера.
Пример: Предположим, вы готовите еду для дома, полного гостей. Так что, если вы попытаетесь приготовить все блюда и сделать все процессы самостоятельно, это станет суете и займет много времени.
Но предположим, что вы привлекаете некоторых из своих друзей или коллег (не гостей), чтобы помочь вам приготовить еду, распределяя различные процессы на другого человека, который может выполнять задачи одновременно. В этом случае вы приготовите еду намного быстрее и проще, пока ваши гости еще в доме.
MapReduce работает аналогичным образом с распределенными задачами и параллельной обработкой, чтобы обеспечить более быстрый и простой способ выполнения данной задачи.
Apache Hadoop позволяет программистам использовать MapReduce для выполнения моделей на больших распределенных наборах данных и использовать передовые методы машинного обучения и статистические методы для поиска закономерностей, прогнозирования, выявления корреляций и многого другого.
Недостатки и альтернативы Big Data решений
Прежде всего, отметим, что для первой версии фреймворка MapReduce, реализованного в Apache Hadoop v1.0, были характерны следующие ограничения :
- предел масштабируемости кластера Apache Hadoop: не более 4K вычислительных узлов и около 40K параллельных заданий;
- сильная связанностьфреймворка распределенных вычислений и клиентских библиотек, реализующих распределенный алгоритм;
- наличие единичных точек отказа и невозможность использования в средах с высокими требованиями к надежности;
- проблемы версионной совместимости: необходимость единовременного обновления всех вычислительных узлов кластера при обновлении платформы Hadoop (установке новой версии или пакета обновлений).
Эти ограничения были устранены в новой версии MapReduce 2.0, выпущенной в 2012 году, за счет изменений в менеджере ресурсов (ResourceManager) и планировщике-координаторе приложений ApplicationMaster, а также появления YARN (Yet Another Resource Negotiator). Этот программный фреймворк выполнения распределенных приложений предоставляет компоненты и API для разработки распределенных приложений различных типов, обеспечивая распределение ресурсов в ответ на запросы от выполняемых приложений и ответственность за отслеживанием статуса их выполнения .

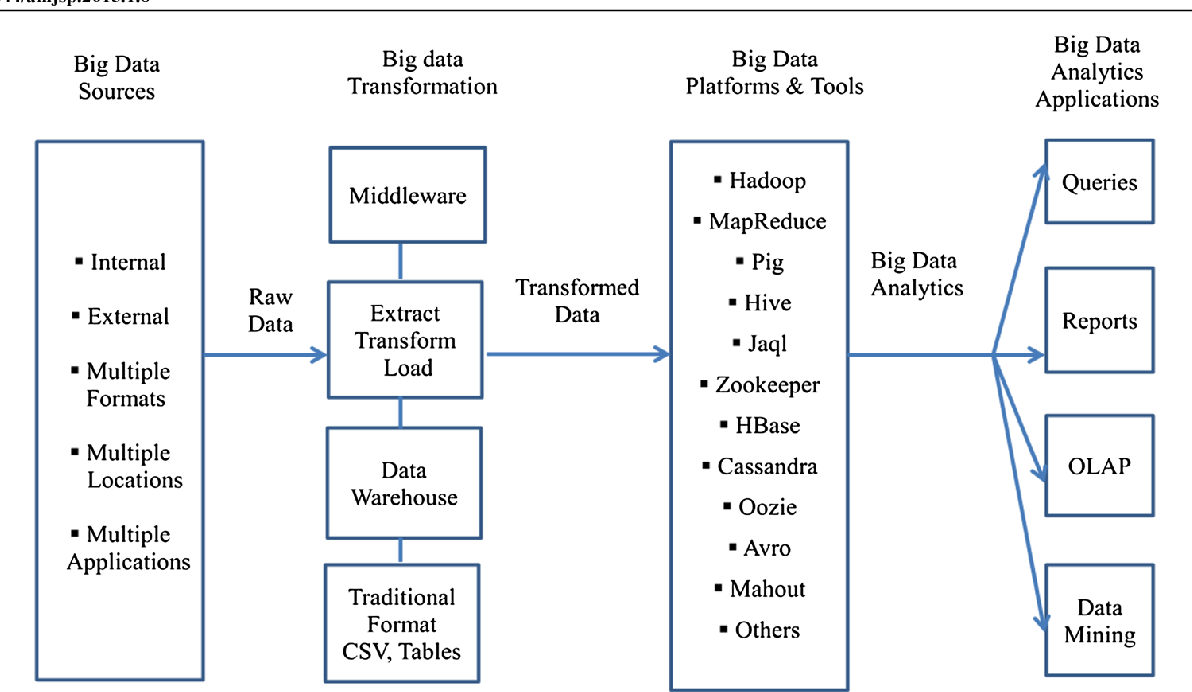
В частности, ответственность по управлению ресурсами кластера лежит на ResourceManager, а по планированию/координации жизненного цикла приложений – на ApplicationMaster. При этом каждый вычислительный узел разделен на произвольное количество контейнеров Container, содержащих предопределенное количество ресурсов: CPU, RAM и т.д., за которыми наблюдает менеджер узла (NodeManager) .
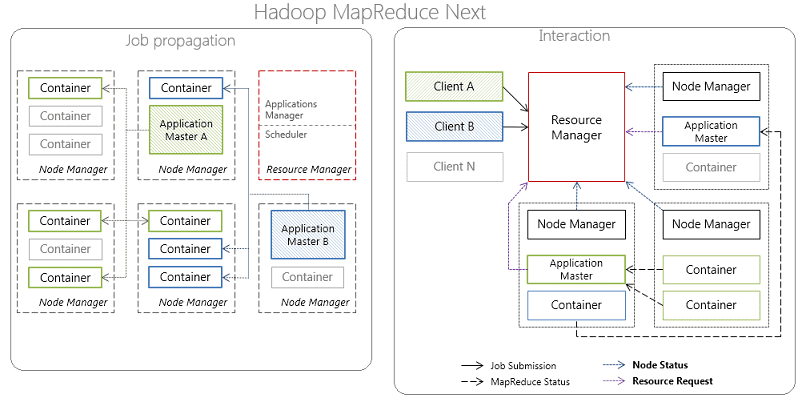
Принцип работы MapReduce 2.0
Тем не менее, эти нововведения не устранили недостатки MapReduce, обусловленные архитектурными особенностями этой вычислительной модели:
- недостаточно высокая производительность – классическая технология, в частности, реализованная в ядре Apache Hadoop, обрабатывает данные ациклично в пакетном режиме. При этом функции Reduce не запустятся до завершения всех процессов Map. Все операции проходят по циклу чтение-запись с жесткого диска, что влечет задержки (latency) в обработке информации.
- ограниченность применения – продолжая вышеотмеченный недостаток, высокие задержки распределенных вычислений, приемлемые в пакетном режиме обработки, не позволяют использовать классический MapReduce для потоковой обработки в режиме реального времени, повторяющихся запросов и итеративных алгоритмов на одном и том же датасете, как в задачах машинного обучения (Machine Learning). Для решения этой проблемы, свойственной Apache Hadoop, были созданы другие Big Data фреймворки, в частности, Apache Spark и Flink.
Например, в отличие от классического обработчика ядра Apache Hadoop c двухуровневой концепцией MapReduce на базе дискового хранилища, Spark использует специализированные примитивы для рекуррентной обработки в оперативной памяти. Благодаря этому многие задачи вычисляются значительно быстрее. Например, многократный доступ к загруженным в память пользовательским данным позволяет эффективно работать с алгоритмами Machine Learning.
Таким образом, достоинства и недостатки MapReduce обусловливают специфику прикладного использования этой вычислительной модели. В частности, эта технология не применяется в чистом виде в потоковых Big Data системах, где требуется оперативно обрабатывать большие объемы непрерывно поступающей информации в режиме реального времени. На практике такое встречается в платформах Internet of Things. Однако, если требование быстрой обработки данных не является критичным и бизнес-приложению подходит пакетный режим работы с данными, как, например, в ETL-системах или индексировании веб-страниц, MapReduce справится с такими задачами на отлично.
Источники
- https://ru.bmstu.wiki/MapReduce
- https://dic.academic.ru/dic.nsf/ruwiki/607046
- https://habr.com/ru/post/161437/
Примеры
Вот код Java для статистического случая частоты слова:
Приведенный выше код обнаружит, что при указании Mapper и Reducer также указывается класс Combiner. Combiner — это локализованная операция сокращения (поэтому мы видим, что класс WordCount загружается с помощью less), которая является последующей операцией операции map, и map На том же хосте в основном необходимо выполнить простую операцию объединения и повторения значения ключа до того, как карта вычислит промежуточный файл, чтобы уменьшить размер промежуточного файла, чтобы при переходе к Shuffle он мог снизить стоимость передачи по сети и улучшить передачу по сети. эффективность. Команда для отправки задания MR:
Например:
Приведенная выше кодовая диаграмма:
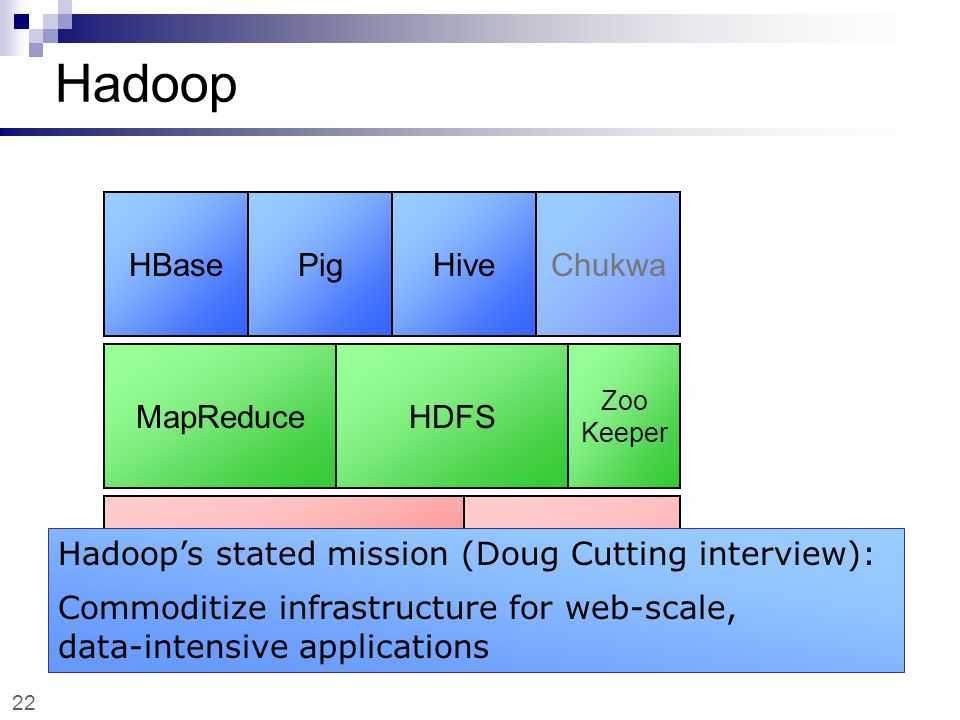
Hadoop MapReduce Classic
Hadoop
- HDFS – распределенная файловая система;
- Hadoop MapReduce – программная модель (framework) выполнения распределенных вычислений для больших объемов данных в рамках парадигмы map/reduce.
архитектуру Hadoop MapReduceструктуру HDFS
- Ограничение масштабируемости кластера Hadoop: ~4K вычислительных узлов; ~40K параллельных заданий;
- Сильная связанность
Отсутствие поддержки альтернативной программной модели выполнения распределенных вычислений: в Hadoop v1.0 поддерживается только модель вычислений map/reduce.
фреймворка распределенных вычислений и клиентских библиотек, реализующих распределенный алгоритм. Как следствие:
- Наличие единичных точек отказа и, как следствие, невозможность использования в средах с высокими требованиями к надежности;
- Проблемы версионной совместимости: требование по единовременному обновлению всех вычислительных узлов кластера при обновлении платформы Hadoop (установке новой версии или пакета обновлений);
- Отсутствие поддержки работы с обновляемыми/потоковыми данными.
Проблема
Часто в Data Science мы имеем дело с таким с огромным количеством данных, что многие методы их обработки не работают или невозможны в реализации. Огромное количество данных — это хорошо, это очень хорошо, и мы хотим использовать как можно больше.
Давайте начнем с простой задачи. Вам дан список строк, и вам нужно вернуть самую длинную строку. Это довольно легко сделать в Python:
def find_longest_string(list_of_strings):
longest_string = None
longest_string_len = 0
for s in list_of_strings:
if len(s) > longest_string_len:
longest_string_len = len(s)
longest_string = s
return longest_string
Мы перебираем строки по очереди, вычисляем длину и сохраняем самую длинную строку, пока не закончим.
Для небольших списков это работает довольно быстро:
list_of_strings = %time max_length = print(find_longest_string(list_of_strings)) OUTPUT: python CPU times: user 0 ns, sys: 0 ns, total: 0 ns Wall time: 75.8 µs
Даже для списков с более чем 3 элементами это работает довольно хорошо, здесь мы попробуем с 3000 элементами:
large_list_of_strings = list_of_strings*1000 %time print(find_longest_string(large_list_of_strings)) OUTPUT: python CPU times: user 0 ns, sys: 0 ns, total: 0 ns Wall time: 307 µs
Но что если мы попробуем 300 миллионов элементов?
large_list_of_strings = list_of_strings*100000000 %time max_length = max(large_list_of_strings, key=len) OUTPUT: python CPU times: user 21.8 s, sys: 0 ns, total: 21.8 s Wall time: 21.8 s
Это уже проблема. В большинстве приложений время ответа в 20 секунд не приемлемо. Один из способов сократить время вычислений — купить гораздо более быстрый процессор. Масштабирование вашей системы путем внедрения более качественного и быстрого оборудования называется «Вертикальное масштабирование». Это, конечно, не будет работать вечно. Во-первых, не так просто найти процессор, который работает в 10 раз быстрее. Во-вторых, наши данные, вероятно, будут увеличиваться, и мы не хотим менять наш процессор каждый раз, когда ощущаем что наш код недостаточно быстрый. Такое решение не масштабируемое. Вместо этого мы можем выполнить «Горизонтальное масштабирование»: мы разработаем наш код так, чтобы он мог работать параллельно, и он станет намного быстрее, когда мы добавим больше процессоров.

Hadoop MapReduce и что его окружает
Apache Hadoop — инфраструктура, упрощающая работу с кластерами.
Основные элементы Hadoop — это:
- распределённая файловая система (HDFS);
- метод крупномасштабного выполнения программ (MapReduce).
HDFS — распределённая файловая система Hadoop для хранения файлов больших размеров с возможностью потокового доступа к информации, поблочно распределённой по узлам вычислительного кластера. Здесь мы храним, читаем, записываем и перекладываем данные.
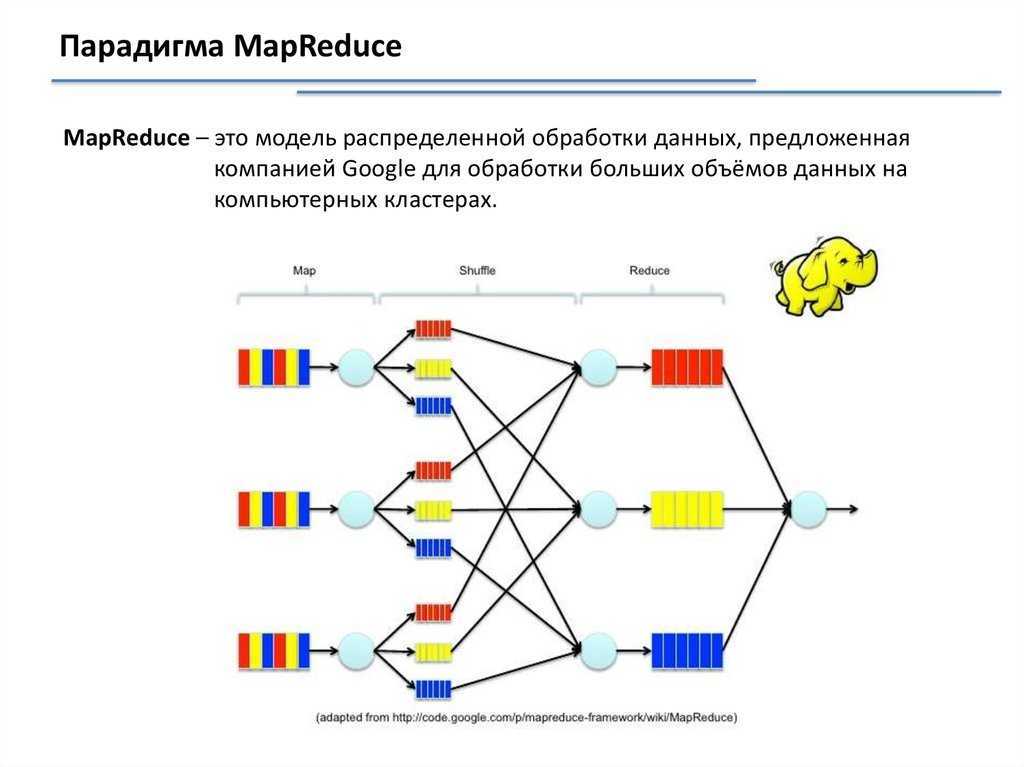
MapReduce — модель распределённых вычислений, представленная компанией Google, используемая для параллельных вычислений над очень большими, вплоть до нескольких петабайт, наборами данных в компьютерных кластерах.
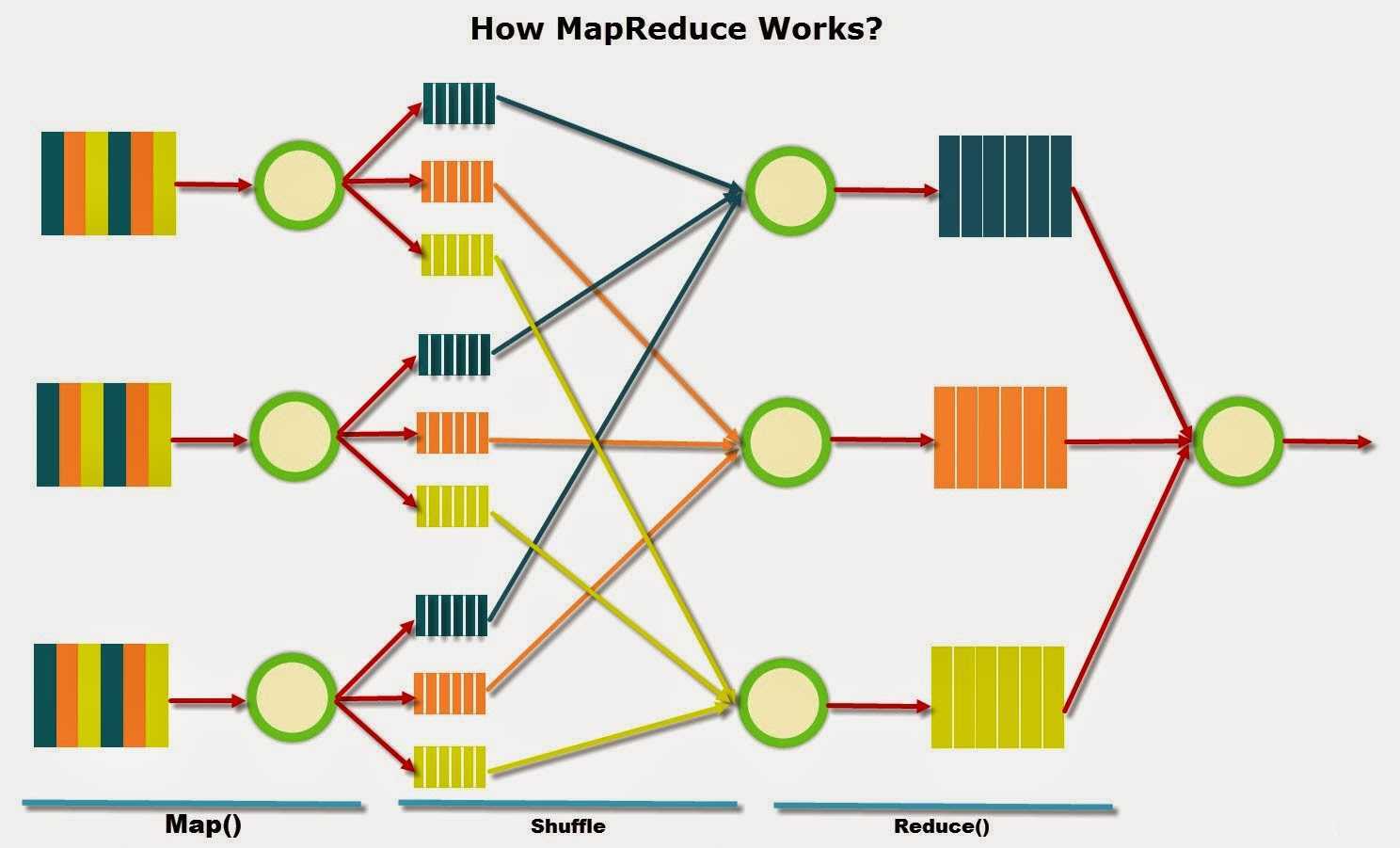
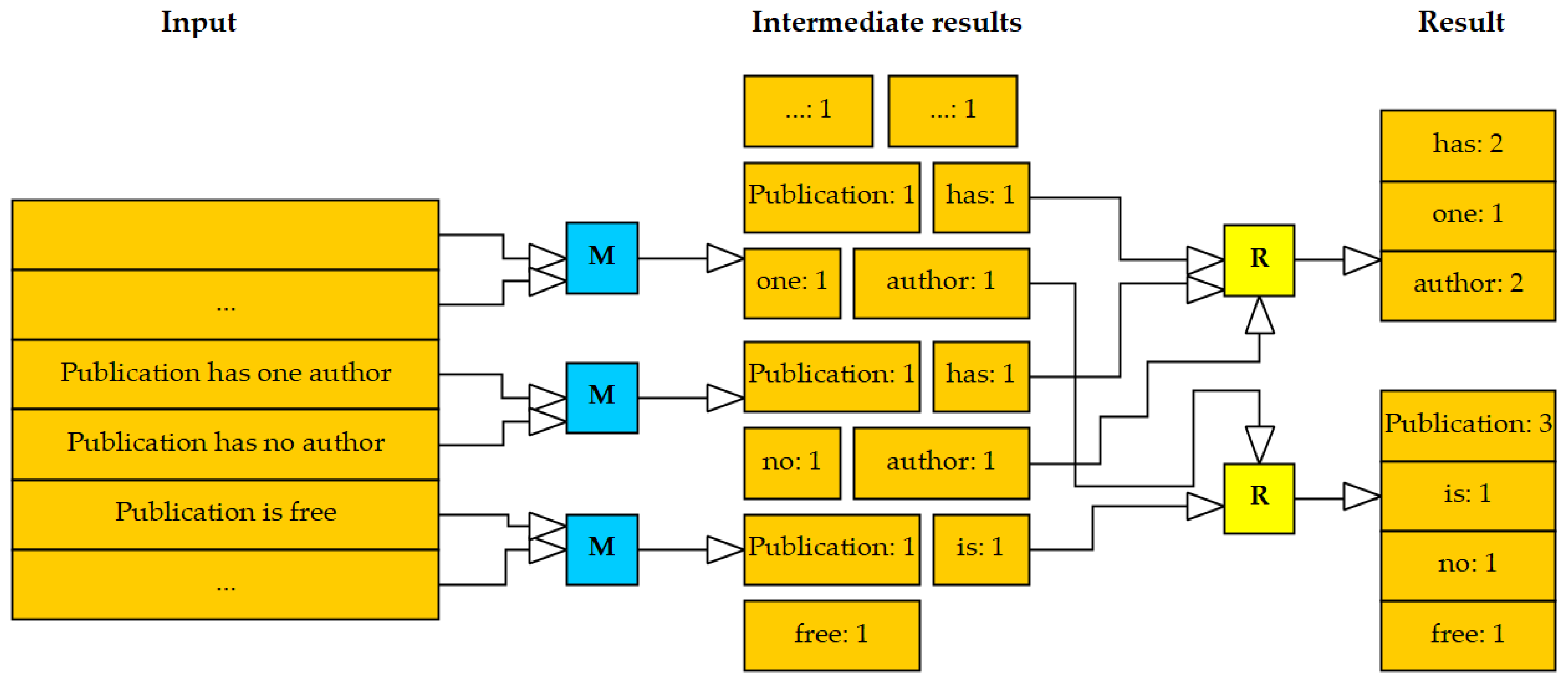
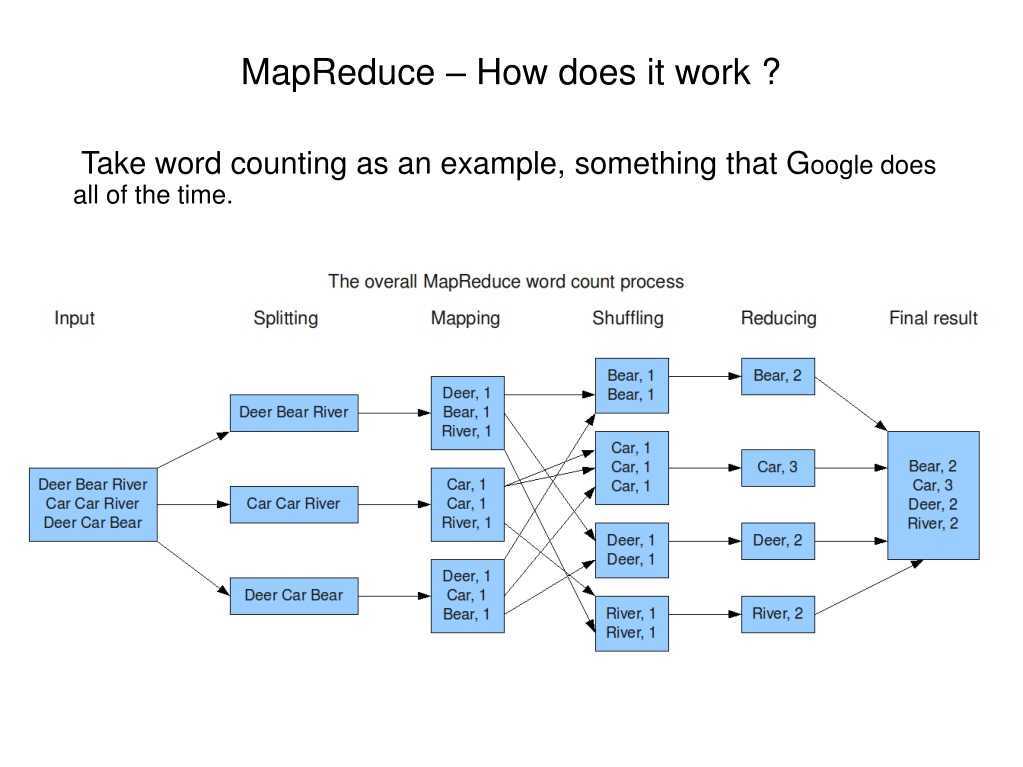
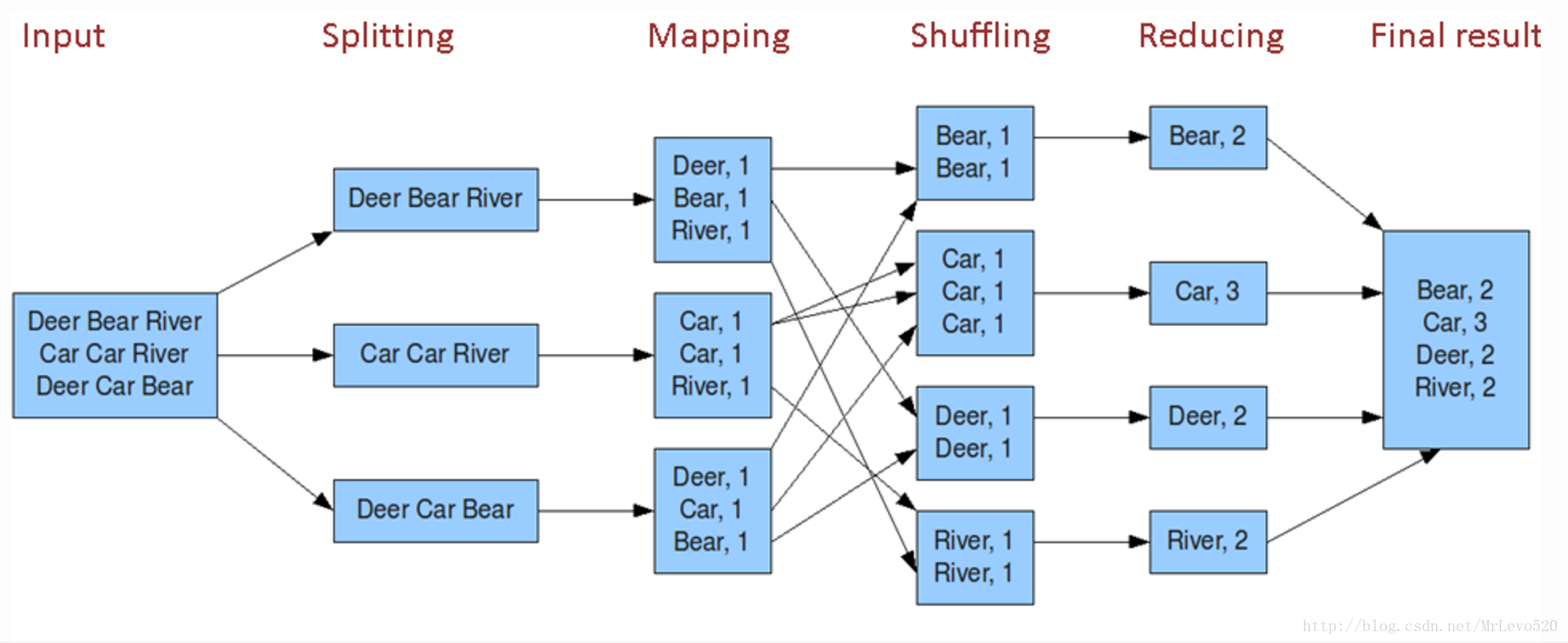
Алгоритм легко понять по аналогии
Представьте, что вам предложено подсчитать голоса на национальных выборах. В вашей стране 25 партий, 2500 избирательных участков и 2 миллиона граждан. Как это можно сделать? Можно собрать все избирательные бюллетени со всех участков и подсчитать их самостоятельно, либо приказать каждому избирательному участку подсчитать голосов по каждой из 25 партий и передать вам результат, после чего объединить их по партиям.
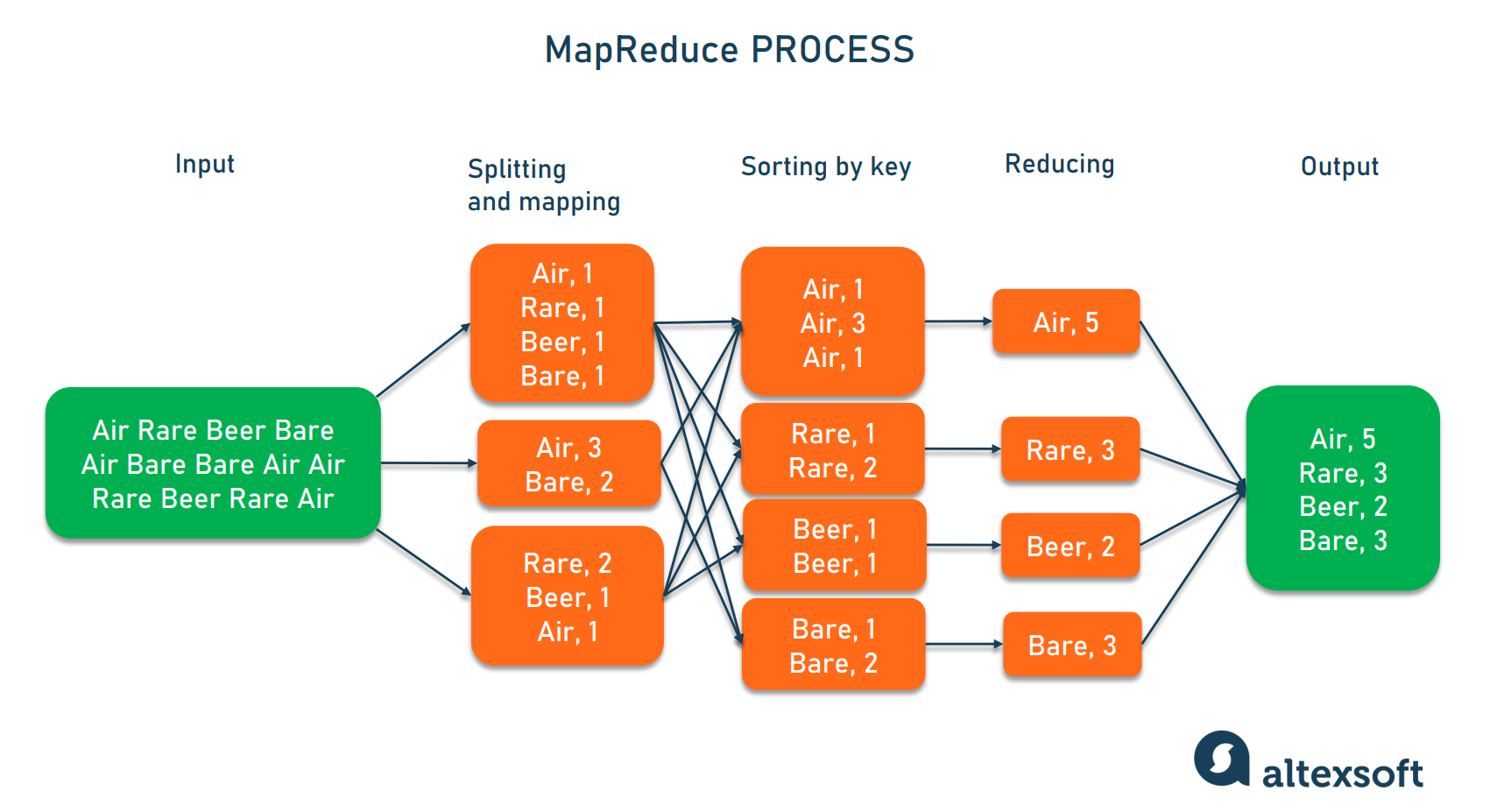
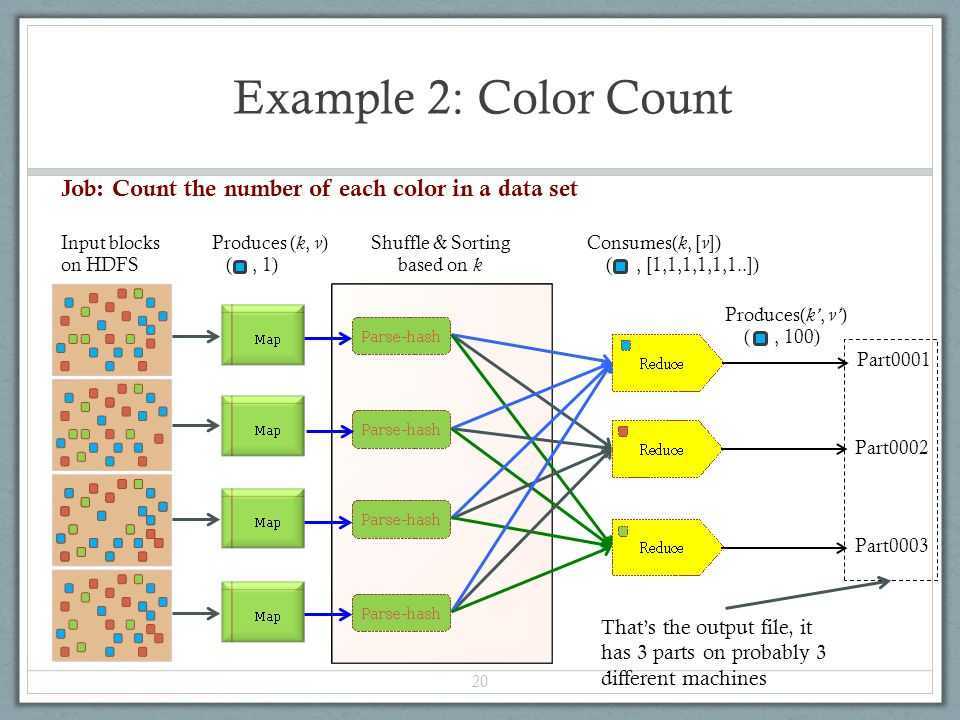
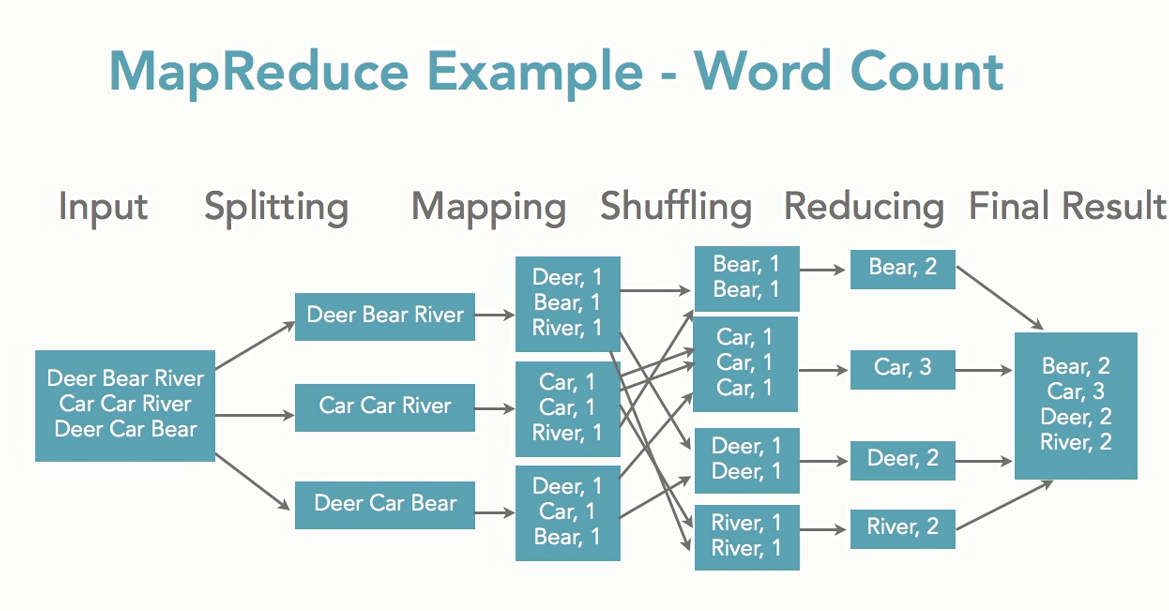
Ниже представлена схема выполнения данного алгоритма на примере подсчёта слов в выборке.
Разберём, что происходит, по этапам;
- Input — входные данные для обработки;
- Splitting — разбивка данных на порционные данные;
- Mapping — обработка этих порционных данных воркерами (вычислительными процессами) в формате ключ-значение. Для этого алгоритма ключ — слово, значение — количество вхождений данного слова;
- Shuffling — ключи сортируются, чтобы упростить обобщение данных и сделать всю работу в одном воркере, не раскидывая их по разным местам;
- Reducing — после того, как мы посчитали количество одинаковых слов на каждом отдельном воркере, объединяем их вместе.
Между этапами происходит запись промежуточных данных на диск, воркеры и данные обособлены друг от друга. Данный алгоритм отлично подходит для кластеров. Подсчёт происходит в разы быстрее, чем на одной машине.
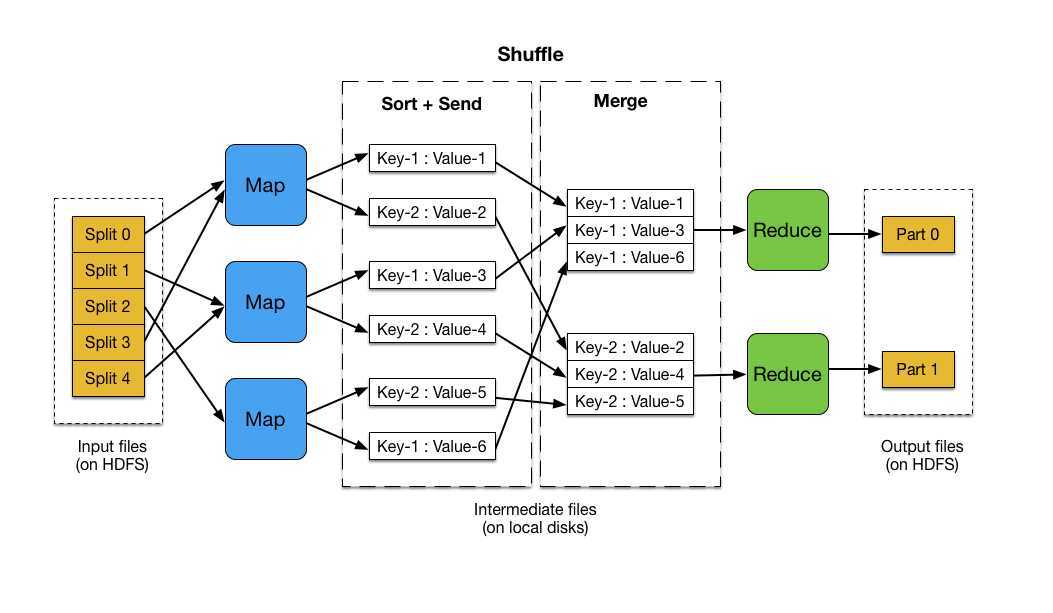
Этапы MapReduce
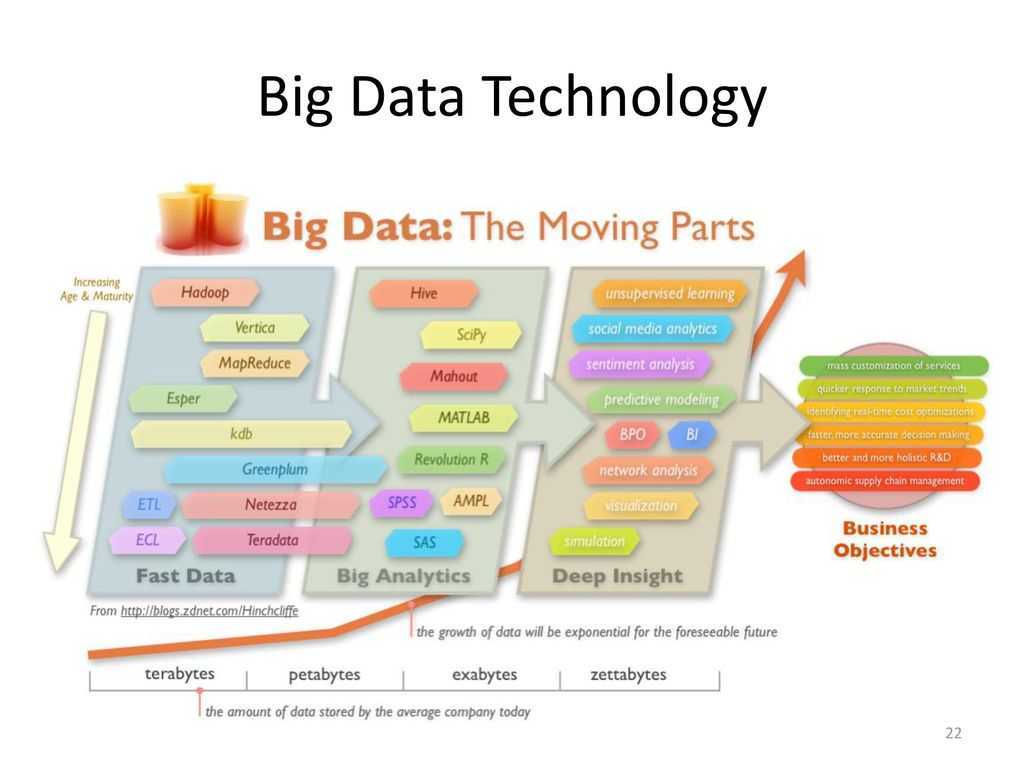
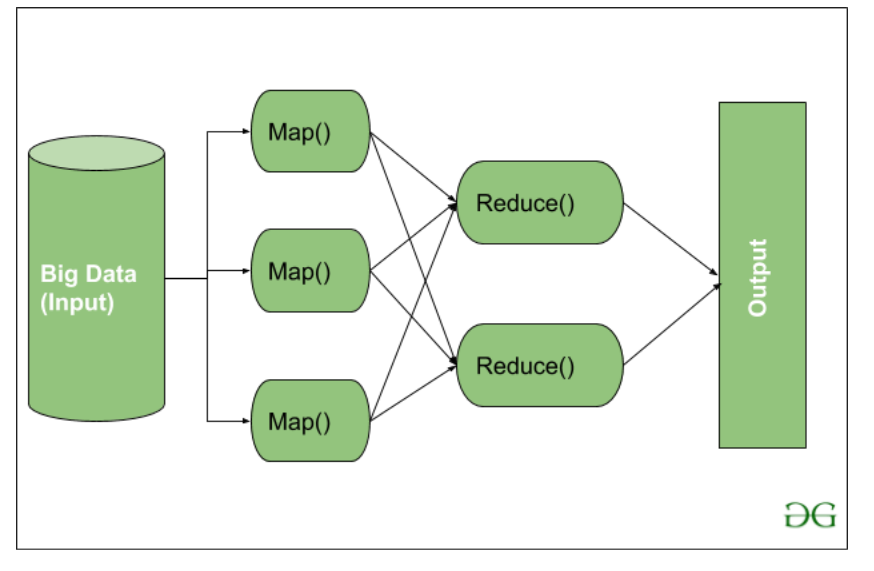
карта
На этом этапе входные данные сопоставляются с выходными или парами ключ-значение. Здесь ключ может относиться к идентификатору адреса, а значение может быть фактическим значением этого адреса.
На этом этапе есть только одна, но две задачи — сплиты и картографирование. Разделения означают подчасти или части задания, отделенные от основного задания. Их также называют входными разбиениями. Таким образом, входное разделение можно назвать входным фрагментом, потребляемым картой.
Далее выполняется задача сопоставления. Это считается первой фазой при выполнении программы уменьшения карты. Здесь данные, содержащиеся в каждом разбиении, будут переданы функции отображения для обработки и создания выходных данных.
Функция – Map() выполняется в репозитории памяти для входных пар ключ-значение, создавая промежуточную пару ключ-значение. Эта новая пара ключ-значение будет служить входными данными для функции Reduce() или Reducer.
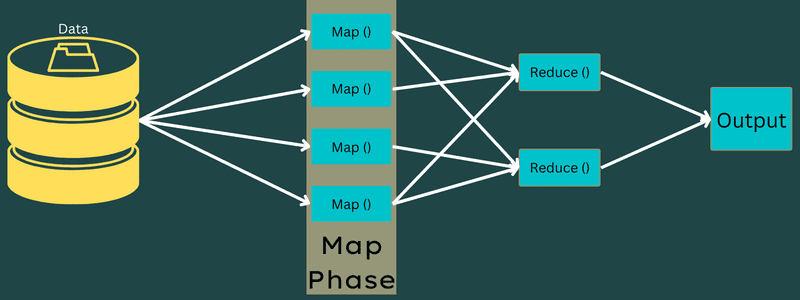
Уменьшать
Промежуточные пары ключ-значение, полученные на этапе сопоставления, работают как входные данные для функции Reduce или Reducer. Как и на этапе сопоставления, здесь задействованы две задачи — перемешивание и уменьшение.
Таким образом, полученные пары ключ-значение сортируются и перемешиваются для передачи в Редьюсер. Затем редюсер группирует или агрегирует данные в соответствии с парой ключ-значение на основе алгоритма редуктора, написанного разработчиком.
Здесь значения из фазы перетасовки объединяются для возврата выходного значения. На этом этапе подводится итог всему набору данных.
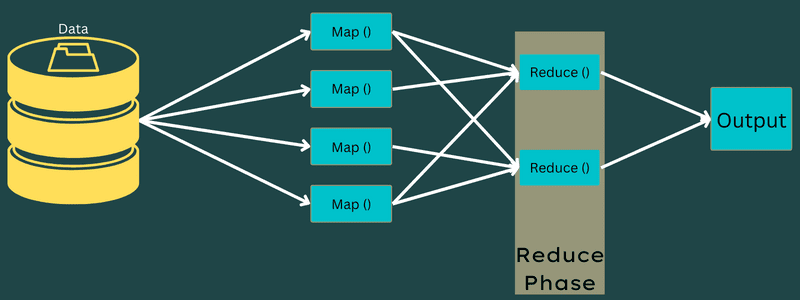
Теперь весь процесс выполнения задач Map и Reduce контролируется некоторыми сущностями. Это:
- Трекер вакансий: Проще говоря, трекер вакансий действует как мастер, который отвечает за полное выполнение отправленного задания. Средство отслеживания заданий управляет всеми заданиями и ресурсами в кластере. Кроме того, средство отслеживания заданий планирует каждую карту, добавленную в средство отслеживания задач, которое работает на определенном узле данных.
- Несколько трекеров задач: Проще говоря, несколько трекеров задач работают как ведомые, выполняя задачу в соответствии с инструкциями трекера заданий. Трекер задач развернут на каждом узле отдельно в кластере, выполняющем задачи Map и Reduce.
Это работает, потому что задание будет разделено на несколько задач, которые будут выполняться на разных узлах данных из кластера. Job Tracker отвечает за координацию задачи, планируя задачи и запуская их на нескольких узлах данных. Затем Task Tracker, сидящий на каждом узле данных, выполняет части задания и следит за каждой задачей.
Кроме того, средства отслеживания задач отправляют отчеты о ходе выполнения в средство отслеживания заданий. Кроме того, Task Tracker периодически отправляет сигнал «пульса» на Job Tracker и уведомляет их о состоянии системы. В случае любого сбоя средство отслеживания заданий может перенести задание на другое средство отслеживания задач.
Фаза вывода: когда вы достигнете этой фазы, у вас будут окончательные пары ключ-значение, сгенерированные из Reducer. Вы можете использовать средство форматирования вывода для преобразования пар ключ-значение и записи их в файл с помощью средства записи.
Инструменты интеллектуального анализа данных
Интеллектуальный анализ данных ― это не только используемые инструменты или программное обеспечение баз данных. Интеллектуальный анализ данных можно выполнить с относительно скромными системами баз данных и простыми инструментами, включая создание своих собственных, или с использованием готовых пакетов программного обеспечения. Сложный интеллектуальный анализ данных опирается на прошлый опыт и алгоритмы, определенные с помощью существующего программного обеспечения и пакетов, причем с различными методами ассоциируются разные специализированные инструменты.
Например, IBM SPSS, который уходит корнями в статистический анализ и опросы, позволяет строить эффективные прогностические модели по прошлым тенденциям и давать точные прогнозы. IBM InfoSphere Warehouse обеспечивает в одном пакете поиск источников данных, предварительную обработку и интеллектуальный анализ, позволяя извлекать информацию из исходной базы прямо в итоговый отчет.
В последнее время стала возможна работа с очень большими наборами данных и кластерная/крупномасштабная обработка данных, что позволяет делать еще более сложные обобщения результатов интеллектуального анализа данных по группам и сопоставлениям данных. Сегодня доступен совершенно новый спектр инструментов и систем, включая комбинированные системы хранения и обработки данных.
Можно анализировать самые разные наборы данных, включая традиционные базы данных SQL, необработанные текстовые данные, наборы «ключ/значение» и документальные базы. Кластерные базы данных, такие как Hadoop, Cassandra, CouchDB и Couchbase Server, хранят и предоставляют доступ к данным такими способами, которые не соответствуют традиционной табличной структуре.
В частности, более гибкий формат хранения базы документов придает обработке информации новую направленность и усложняет ее. Базы данных SQL строго регламентируют структуру и жестко придерживаются схемы, что упрощает запросы к ним и анализ данных с известными форматом и структурой.
Документальные базы данных, которые соответствуют стандартной структуре типа JSON, или файлы с некоторой машиночитаемой структурой тоже легко обрабатывать, хотя дело может осложняться разнообразной и переменчивой структурой. Например, в Hadoop, который обрабатывает совершенно «сырые» данные, может быть трудно выявить и извлечь информацию до начала ее обработки и сопоставления.
Масштабирование в Caché
Исторически InterSystems Caché имел достаточно инструментов в своём арсенале, как для вертикального, так и горизонтального масштабирования. Как мы все знаем (грустный смайл) Caché это не только сервер баз данных, но и сервер приложений, который может использовать ECP (Enterprise Cache Protocol) для горизонтального масштабирования и высокой доступности.
Особенность ECP протокола – будучи сильно оптимизированным протоколом для когерентности доступа к одним и тем же данным на разных узлах кластера, сильно упирается в производительность write daemon на центральном узле сервера БД. ECP позволяет добавить дополнительные счетные узлы с ядрами процессоров, если нагрузка на write-daemon не очень высокая, но этот протокол не поможет отмасштабировать ваше приложение горизонтально, если каждый из вовлеченных узлов порождает большую активность на запись. Дисковая подсистема на сервере БД по-прежнему будет узким местом.
На самом деле, при работе с большими данными современные приложения предполагают использование другого, или даже ортогонального озвученном выше, подхода. Масштабировать приложение горизонтально надо с использованием дисковой подсистемы на каждом из узлов кластера. В отличие от ECP, где данные приносятся на удаленный узел, мы наоборот, приносим код, размер которого предполагается малым, к данным на каждом узле, размер которых предполагается очень большим (как минимум относительно размера данных). Похожий тип партиционирования, именуемый шардингом, в будущем будет реализован в SQL движке Caché в одном из будущих продуктов. Но даже сегодня, на имеющихся в платформе средствах, мы можем реализовать нечто простое, что позволило бы нам спроектировать горизонтально масштабируемую систему, с применением современных, «модных, молодежных» подходов. Например, с применением MapReduce…