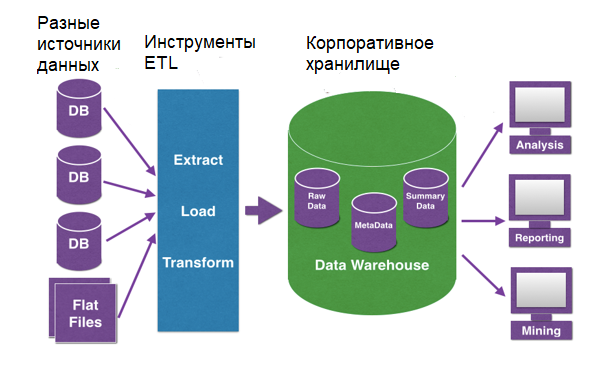
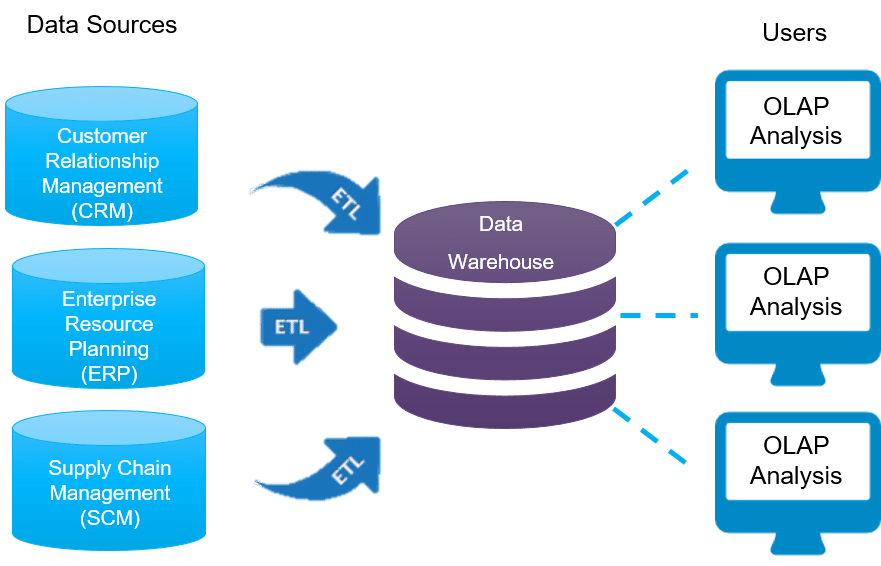
Принцип слоеного пирога или архитектура КХД
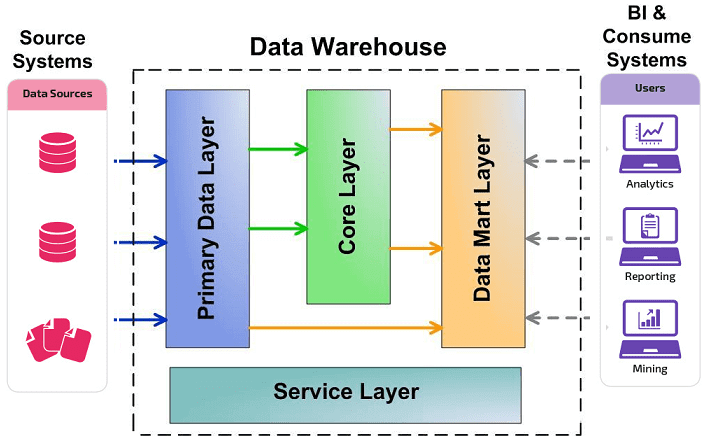
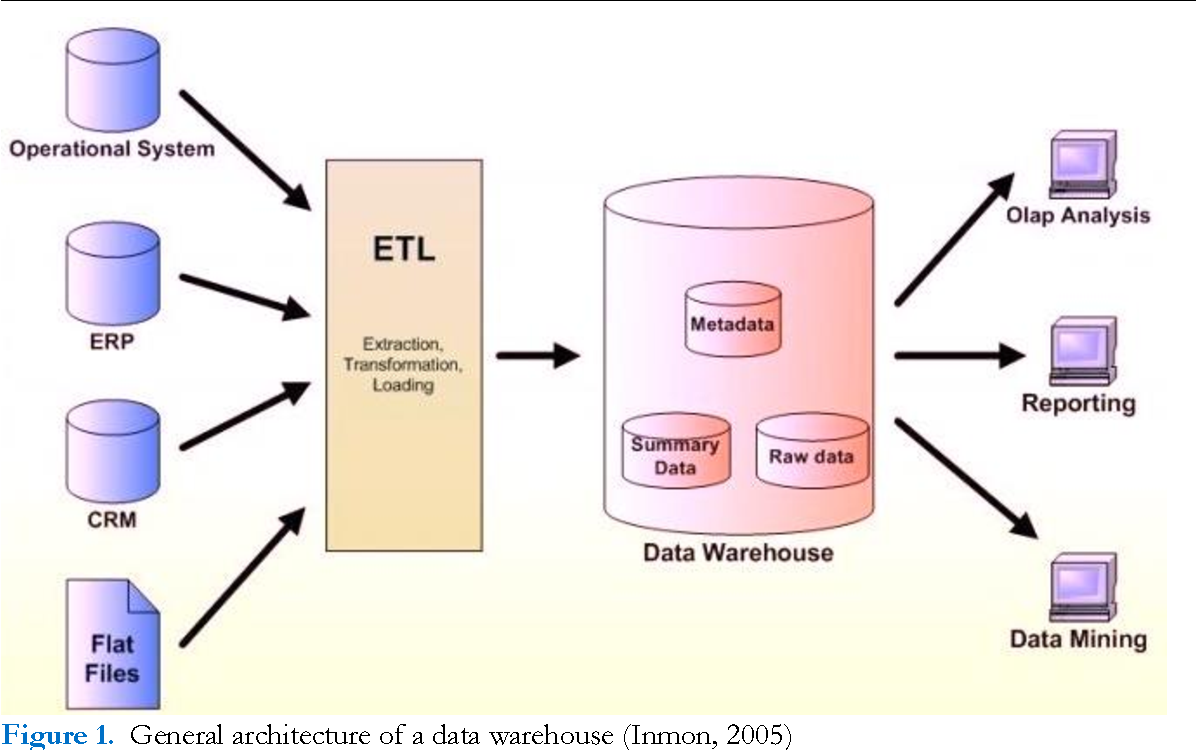
Вышеприведенное определение DWH показывает, что это средство хранения данных является реляционным. Однако, не стоит считать КХД просто большой базой данных с множеством взаимосвязанных таблиц. В отличие от традиционной SQL-СУБД, Data Warehouse имеет сложную многоуровневую (слоеную) архитектуру, которая называется LSA – Layered Scalable Architecture. По сути, LSA реализует логическое деление структур с данными на несколько функциональных уровней. Данные копируются с уровня на уровень и трансформируются при этом, чтобы в итоге предстать в виде согласованной информации, пригодной для анализа .
Классически LSA реализуется в виде следующих уровней :
- операционный слой первичных данных(Primary Data Layer или стейджинг), на котором выполняется загрузка информации из систем-источников в исходном качестве и сохранением полной истории изменений. Здесь происходит абстрагирование следующих слоев хранилища от физического устройства источников данных, способов их сбора и методов выделения изменений.
- ядро хранилища (Core Data Layer) – центральный компонент, который выполняет консолидацию данныхиз разных источников, приводя их к единым структурам и ключам. Именно здесь происходит основная работа с качеством данных и общие трансформации, чтобы абстрагировать потребителей от особенностей логического устройства источников данных и необходимости их взаимного сопоставления. Так решается задача обеспечения целостности и качества данных.
- аналитические витрины (Data Mart Layer), где данные преобразуются к структурам, удобным для анализа и использования в BI-дэшбордах или других системах-потребителях. Когда витрины берут данные из ядра, они называются регулярными. Если же для быстрого решения локальных задач не нужна консолидация данных, витрина может брать первичные данные из операционного слоя и называется соответственно операционной. Также бывают вторичные витрины, которые используются для представления результатов сложных расчетов и нетипичных трансформаций. Таким образом, витрины обеспечивают разные представления единых данных под конкретную бизнес-специфику.
- Наконец, сервисный слой (Service Layer) обеспечивает управление всеми вышеописанными уровнями. Он не содержит бизнес-данных, но оперирует метаданными и другими структурами для работы с качеством данных, позволяя выполнять сквозной аудит данных (data lineage), использовать общие подходы к выделению дельты изменений и управления загрузкой. Также здесь доступны средства мониторинга и диагностики ошибок, что ускоряет решение проблем.
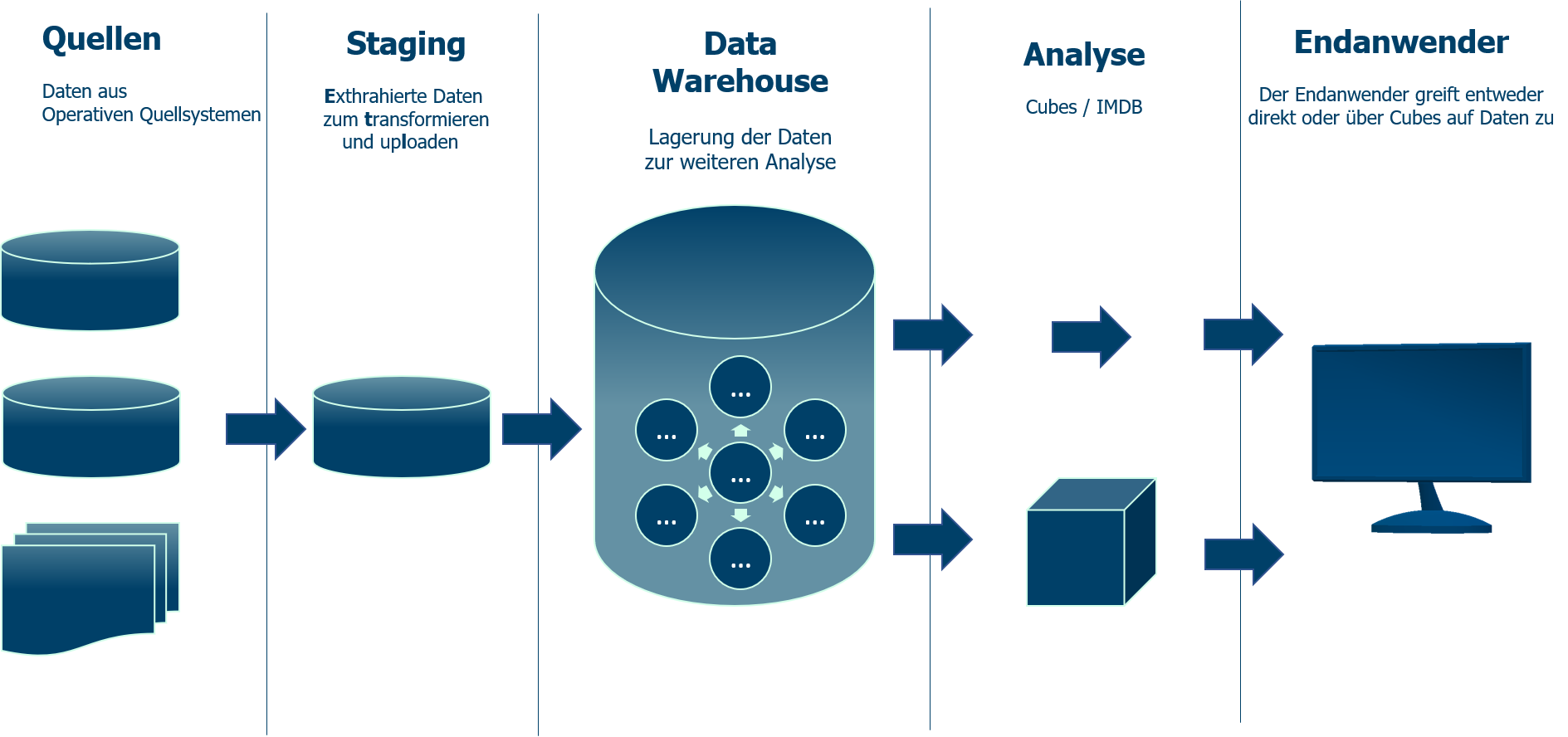
LSA — слоеная архитектура DWH: как устроено хранилище данных
Все слои, кроме сервисного, состоят из области постоянного хранения данных и модуля загрузки и трансформации. Области хранения содержат технические (буферные) таблицы для трансформации данных и целевые таблицы, к которым обращается потребитель. Для обеспечения процессов загрузки и аудита ETL-процессов данные в целевых таблицах стейджинга, ядра и витринах маркируются техническими полями (мета-атрибутами) . Еще выделяют слой виртуальных провайдеров данных и пользовательских отчетов для виртуального объединения (без хранения) данных из различных объектов. Каждый уровень может быть реализован с помощью разных технологий хранения и преобразования данных или универсальных продуктов, например, SAP NetWeaver Business Warehouse (SAP BW) .
ETL и ELT — в чем разница?
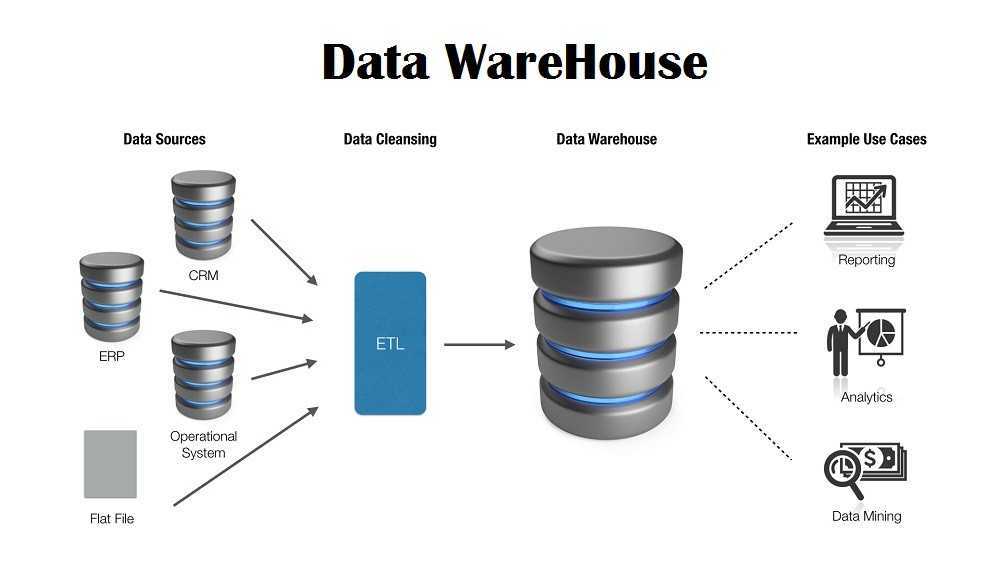
Оба подхода используют разные процессы для управления данными. Data Warehouse использует метод ETL – Extract, Transform и Load, то есть дословно переводится как «извлечение», «преобразование» и «загрузка». В свою очередь, Data Lake использует ELT — Extract, Load и Transform, то есть сначала идет «загрузка», а только потом «преобразование».
ETL использует промежуточный сервер для преобразования данных и только потом загружает их в хранилище Data Warehouse. Такой подход применяется для небольшого количества данных и вычислительных преобразований.
ELT работает с большими объемами данных и сразу грузит их в Базу данных, их преобразование происходит уже в целевой системе. Скорость загрузки данных никогда не зависит от их размера. Из минусов, ELT сложнее внедрить в систему в отличие от ETL, так как для внедрения и поддержки ELT требуются нишевые знания.
ETL не поддерживает Data Lake, с ним работает только ELT. Для быстрого и эффективного анализа данных лучше подойдет ETL, так как данные в нем уже структурированы и преобразованы. Если же нужно быстро и сразу загрузить всю необработанную информацию, следует использовать ELT, так как данные будут преобразованы уже после загрузки. ELT — относительно новая технология. Она стала возможна благодаря новым облачным хранилищам, где данные могут храниться в огромных объемах. Платформы Amazon Redshift и Google BigQuery дали возможность использовать ELT из-за их возможностей массово-параллельной обработки данных.
Что такое big data?
Отличия аналитика данных от Data ScientistОтличия аналитика данных от data scientist. Что они должны знать и уметь.
Большие данные — это огромный объем структурированной и неструктурированной информации. Также к big data относятся технологии, которые используют, чтобы собирать, обрабатывать данные и использовать их в работе.
К большим данным можно отнести поток сообщений из социальных сетей, датчики трафика, спутниковые снимки, стриминговые аудио- и видеопотоки, банковские транзакции, содержимое веб-страниц и мобильных приложений, телеметрию с автомобилей и мобильных устройств, данные финансового рынка.
Технологические компании практически никогда не удаляют собранную информацию, так как завтра она может стоить в разы больше, чем вчера. И даже сегодня она уже приносит миллиардные прибыли многим компаниям. Первые версии системы хранения больших данных Hadoop даже не имели команды «Удалить данные»: такой функции не предполагали.
Как пример — Facebook*. Компания использует информацию о поведении пользователей, чтобы рекомендовать новости, продукты внутри соцсети. Знания об аудитории повышают интерес пользователей и мотивируют посещать соцсеть как можно чаще. Как следствие — растет прибыль Facebook.
А гугл выдает результаты поиска не только на основе ключевых слов в поисковом запросе. Он также учитывает историю предыдущих запросов и интересы пользователя.
За последние годы производительность вычислительных систем сильно выросла. Это видно на графике роста количества транзисторов за последние 50 лет.
Транзистор — это полупроводниковый элемент. Из транзисторов собирают основные логические элементы, а на их основе создают различные комбинационные схемы и непосредственно процессоры. Чем больше транзисторов в процессоре — тем выше его производительность.
Закон Мура: количество транзисторов, размещаемых на кристалле интегральной схемы, удваивается каждые два года
Закон Мура: количество транзисторов, размещаемых на кристалле интегральной схемы, удваивается каждые два года График:
Благодаря высокой производительности появилась возможность обрабатывать данные с такой же большой скоростью, с которой они поступают.
Как работает дата-центр «Яндекса» в Финляндии
Видео: «Яндекс» на ютубе
Хранилище пар «ключ — значение»
Хранилище ключей и значений связывает каждое значение данных с уникальным ключом. Большинство хранилищ пар «ключ — значение» поддерживают только самые простые операции запроса, вставки и удаления. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком. В большинстве реализаций атомарной операцией считается чтение или запись одного значения.


Приложение может хранить произвольные данные в виде набора значений. Все сведения о схеме должны быть предоставлены приложением. Хранилище «ключ-значение» просто извлекает или сохраняет значение по ключу.
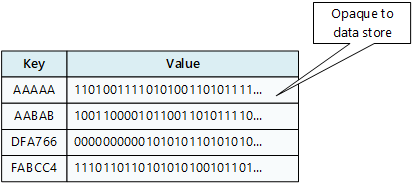
Хранилища ключей и значений оптимизированы для приложений, выполняющих простой поиск, но не подходят, если вам нужно запрашивать данные в разных хранилищах ключей и значений. Хранилища ключей и значений также не оптимизированы для запросов по значению.
Одно хранилище пар «ключ — значение» очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.
Службы Azure
- Azure Cosmos DB для таблицы и Azure Cosmos DB для NoSQL | (базовые показатели безопасности Azure Cosmos DB)
- | Кэш Azure для Redis(базовые показатели безопасности)
- Хранилище | таблиц Azure (Базовые показатели безопасности)
Рабочая нагрузка
- Доступ к данным осуществляется с помощью одного ключа, например словаря.
- Соединения, блокировки или объединения не нужны.
- Механизмы статистической обработки не используются.
- Как правило, вторичные индексы не используются.
Примеры
- Кэширование данных
- Управление сеансом
- Управления параметрами и профилями пользователя
- Рекомендации по продуктам и реклама
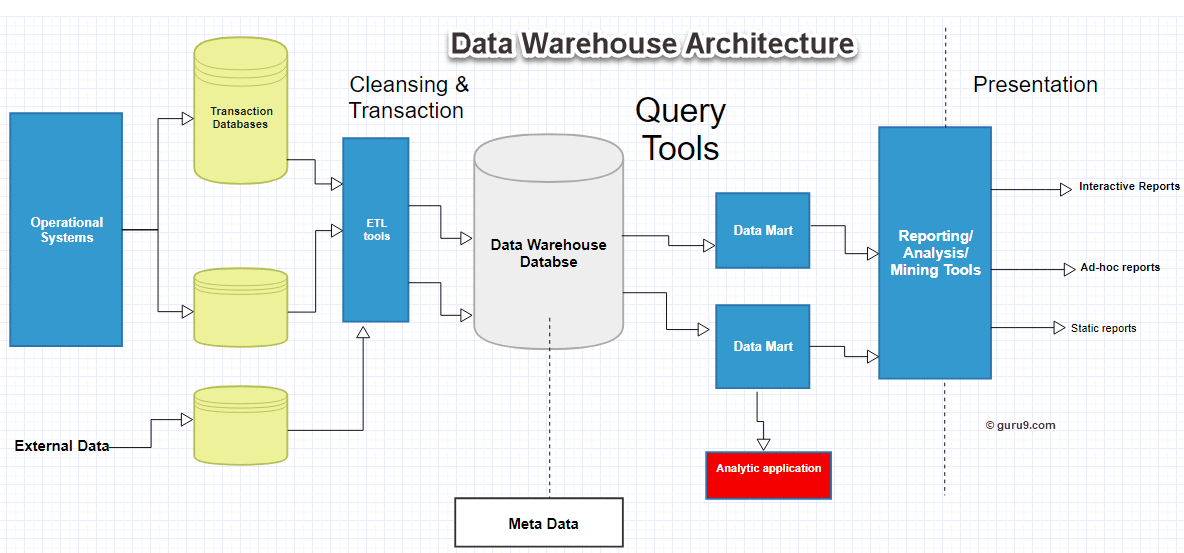
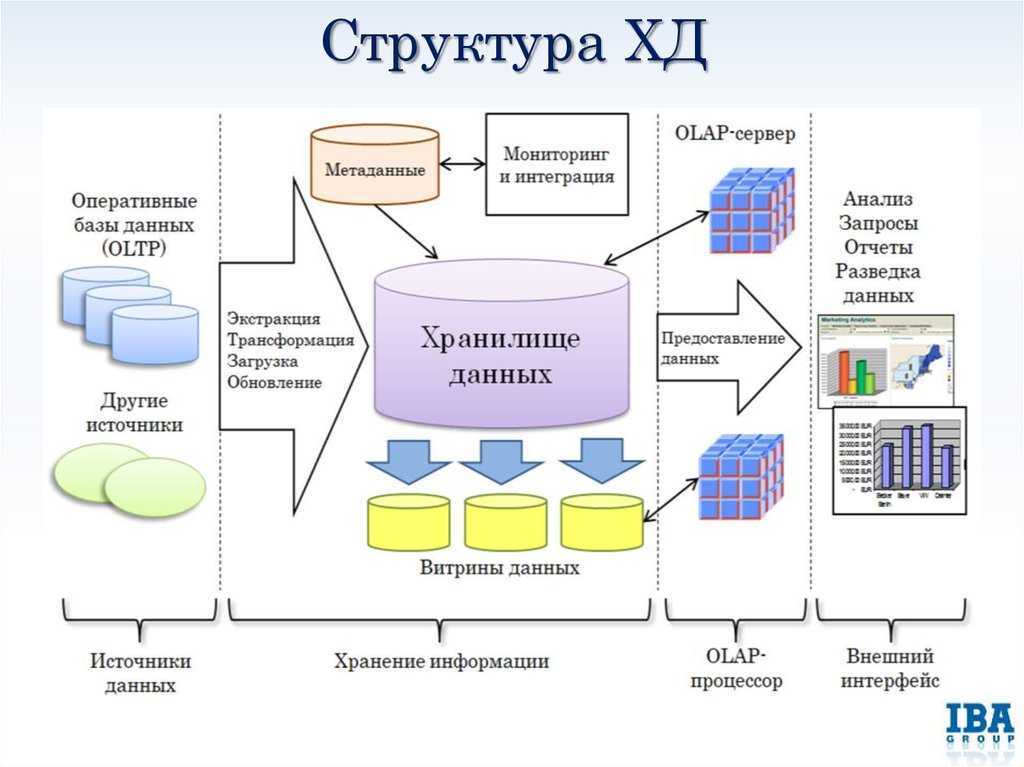
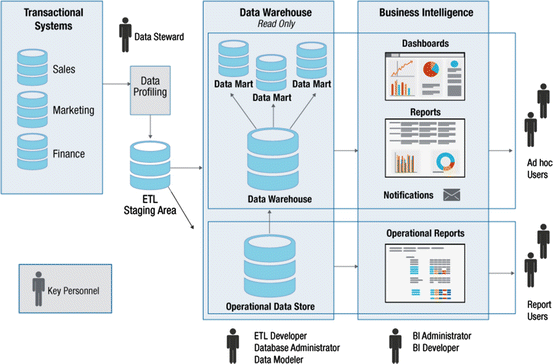
Чем отличается DWH от обычной базы данных?
Классическое применение баз данных обычно раскладывается на базы, которые находятся в рамках каких-либо OLTP-систем, т.е. систем, которые используются в качестве репозиториев, или для хранилищ данных. То есть хранилища всегда используют базы данных для своей работы, однако эти данные структурированы таким образом, чтобы их можно было максимально быстро предоставить в качестве отчётности или для построения агрегатов. Такая часть хранилища называется витриной данных. Она позволяет получить отчёт в течение 2-3 секунд, даже если дневной объём данных содержит в себе миллионы или миллиарды записей. Поэтому хранилище – это структурированная база данных, и структурирование – это отдельная часть проекта по внедрению хранилища, поскольку оно должно быть построено так, чтобы работа была быстрой, но при этом была учтена вся историчность изменений данных. Сама применимость базы данных под хранилище отличается от применимости любой другой базы данных.
Хранение данных
Под хранением обычно понимают запись данных на некоторые накопители данных, с целью их (данных) дальнейшего использования. Опустим исторические варианты организации хранения, рассмотрим подробнее классификацию систем хранения по разным критериям. Я выбрал следующие критерии для классификации: по способу подключения, по типу используемых носителей, по форме хранения данных, по реализации.
По способу подключения есть следующие варианты:
подключение дисков в сервере
дисковая полка, подключаемая по FC
По типу используемых накопителей возможно выделить:
- Дисковые. Предельно простой и вероятно наиболее распространенный вариант до сих пор, в качестве накопителей используются жесткие диски
- Ленточные. В качестве накопителей используются запоминающие устройства с носителем на магнитной ленте. Наиболее частое применение — организация резервного копирования.
- Flash. В качестве накопителей применяются твердотельные диски, они же SSD. Наиболее перспективный и быстрый способ организации хранилищ, по емкости SSD уже фактически сравнялись с жесткими дисками (местами и более емкие). Однако по стоимости хранения они все еще дороже.
- Гибридные. Совмещающие в одной системе как жесткие диски, так и SSD. Являются промежуточным вариантом, совмещающим достоинства и недостатки дисковых и flash хранилищ.
Если рассматривать форму хранения данных, то явно выделяются следующие:
- Файлы (именованные области данных). Наиболее популярный тип хранения данных — структура подразумевает хранение данных, одинаковое для пользователя и для накопителя.
- Блоки. Одинаковые по размеру области, при этом структура данных задается пользователем. Характерной особенностью является оптимизация скорости доступа за счет отсутствия слоя преобразования блоки-файлы, присутствующего в предыдущем способе.
- Объекты. Данные хранятся в плоской файловой структуре в виде объектов с метаданными.
По реализации достаточно сложно провести четкие границы, однако можно отметить:
RAID контроллер от компании Fujitsu
пример организации LVM с шифрованием и избыточностью в виртуальной машине Linux в облаке Azure
Давайте рассмотрим более детально некоторые технологии, их достоинства и недостатки.
Достоинства и недостатки облачных DWH
КХД может быть реализовано не только в локальном датацентре предприятия. Облачные вычисления, когда процесс хранения и обработки данных выполняется на стороне внешнего сервиса или платформы, занимают свою нишу и в области Data Warehouse. Основными преимуществами, которые получают компании от использования подобных решений, считаются следующие :
- быстрота развертывания за счет использования типизированных шаблонов, экономия времени на проектирование и реализацию локального продукта;
- отказоустойчивость благодаря геораспределенному реплицированию, резервному копированию и другим способам обеспечения высокой доступности, которые гарантирует облачный провайдер;
- масштабируемость, а также гибкость при подключении новых источников и потребителей данных благодаря виртуализации и открытым интерфейсам внутриплатформенного взаимодействия.
Недостатками облачных DWH-сервисов можно назвать некоторые сложности в организации ETL-процессов из-за того, что большинство технических подробностей «скрыто под капотом». Также пользователи, привыкшие к локальным решениям, могут опасаться инцидентов с нарушением cybersecurity на стороне SaaS/PaaS-провайдера. Тем не менее, облачные DWH становятся все более популярными. Например, в сентябре 2019 года отечественная компания Mail.ru Group сообщила о запуске своего облачного DWH-сервиса на базе колоночной СУБД ClickHouse, изначально разработанной другим российским ИТ-гигантом, Яндексом .
На международном рынке облачных DWH-сервисов наиболее распространены следующие решения :
- Amazon Redshift;
- Google BigQuery;
- Azure Synapse Analytics от
Эти и другие подобные DWH-сервисы имеют похожую архитектуру, основные компоненты которой мы рассмотрим далее.
Типы корпоративных хранилищ данных
Хранилище данных внутри компании
Хранилище данных на внутренних мощностях компанииинструменты интеграции данных
- дорогостоящая технологическая инфраструктура (и аппаратная, и программная)
- необходимость найма команды дата-инженеров и специалистов DevOps для создания и поддержки всей платформы данных.
Когда использовать
Виртуальное хранилище данных
Виртуальное хранилище данныхнесколько виртуально соединённых баз данных
Схема связей между абстракцией виртуального хранилища данных и исходными базами данных
- Необходимы постоянное обслуживание ПО и оборудования разных баз данных, а также затраты на них.
- Данным, хранящимся в виртуальном хранилище, всё равно нужно ПО преобразования, чтобы сделать их удобоваримыми для конечных пользователей и инструментов отчётности.
- Сложные запросы данных могут занимать слишком много времени, поскольку все необходимые элементы данных могут располагаться в двух отдельных базах данных.
Когда использовать
Модель ядра хранилища и корпоративная модель данных
Миф 1.На самом деле.Миф 2.На самом деле.Миф 3.На самом деле.Разработка модели данных – это не процесс изобретения и придумывания чего-то нового. Фактически, модель данных в компании уже существует. И процесс ее проектирования скорее похож на «раскопки». Модель аккуратно и тщательно извлекается на свет из «грунта» корпоративных данных и облекается в структурированную форму.Миф 4.На самом деле.Миф 5.На самом деле.Миф 6.На самом деле.

Слой первичных данных (или историзируемый staging или операционный слой)
очищаемый
- возможность ошибиться (в структурах, в алгоритмах трансформации, в гранулярности ведения истории) – имея полностью историзируемые первичные данные в зоне доступности для хранилища, мы всегда можем сделать перезагрузку наших таблиц;
- возможность подумать – мы можем не торопиться с проработкой большого фрагмента ядра именно в этой итерации развития хранилища, т.к. в нашем стейджинге в любом случае будут, причем с ровным временным горизонтом (точка «отсчета истории» будет одна);
- возможность анализа – мы сохраним даже те данные, которых уже нет в источнике – они могли там затереться, уехать в архив и т.д. – у нас же они остаются доступными для анализа;
- возможность информационного аудита – благодаря максимально подробной первичной информации мы сможем потом разбираться – как у нас работала загрузка, что мы в итоге получили такие цифры (для этого нужно еще иметь маркировку мета-атрибутами и соответствующие метаданные, по которым работает загрузка – это решается на сервисном слое).
- было бы удобно выставить требования к транзакционной целостности этого слоя, но практика показывает, что это трудно достижимо (это означает то, что в этой области мы не гарантируем ссылочную целостность родительских и дочерних таблиц) – выравнивание целостности происходит на последующих слоях;
- данный слой содержит очень большие объемы (самый объемный на хранилище — несмотря на всю избыточность аналитических структур) – и надо уметь обращаться с такими объемами – как с точки зрения загрузки, так и с точки зрения запросов (иначе можно серьезно деградировать производительность всего хранилища).
Сервисный слой
- область метаданных – используется для механизма управления загрузкой данных;
- область качества данных – для реализации офф-лайн проверок качества данных (т.е. тех, что не встроены непосредственно в ETL-процессы).
управляющий процесс
Проектирование и ведение моделей данных хранилища
проектировать«сущность-связь»многомерная модель
- задача построение концептуальной (логической) модели ядра — системный и бизнес анализ — исследование предметной области, углубление в детали и учет нюансов «живых данных» и их использования в бизнесе;
- задача построения модели анализа – и далее концептуальной (логической) модели витрин;
- задача построения физических моделей – управление избыточностью данных, оптимизация с учетом особенностей СУБД под запросы и загрузку данных.
- Модель данных – это не набор «красивых картинок», а процесс ее проектирования – это не процесс их рисования. Модель отражает наше понимание предметной области. А процесс ее составления – это процесс ее изучения и исследования. Вот на это тратится время. А вовсе не на то, чтобы «нарисовать и раскрасить».
- Модель данных – это проектный артефакт, способ обмена информацией в структурированном виде между участниками команды. Для этого она должна быть всем понятна (это обеспечивается нотацией и пояснением) и доступна (опубликована).
- Модель данных не создается единожды и замораживается, а создается и развивается в процессе развития системы. Мы сами задаем правила ее развития. И можем их менять, если видим – как сделать лучше, проще, эффективнее.
- Модель данных (физическая) позволяет консолидировать и использовать набор лучших практик, направленных на оптимизацию – т.е. использовать те приемы, которые уже сработали для данной СУБД.
Google BigQuery (BQ)
Что это?
Это база данных, она находится в облаке Google, точнее в Google Cloud Platform. Она поддерживает язык SQL для работы с данными. Эту технологию Google сделал специально для анализа данных. Архитектура и движок этой базы отличается от привычных MS SQL и MySQL. Колоночное хранение данных и ряд других особенностей делают все расчеты очень быстрыми. Например можно посчитать сумму продаж из розничной сети используя таблицу из 10 миллионов чеков за пару секунд.
Как все это работает?
Довольно просто: нужно зарегистрироваться в облачных службах Google, создать там проект BigQuery, загрузить данные и можно получать результаты. Попробуем для начала пройти этот процесс шаг за шагом, а потом рассмотрим более детальные вопросы по построению архитектуры.
Сколько это стоит?
Не дорого. Цены здесь: https://cloud.google.com/bigquery/pricing. Вы платите за хранение данных ($0.020 за GB, 10 GB бесплатно) и за . Пример: вы загрузили в BQ данные объемом 10 GB и ваши аналитики делают SQL запросы к ним. Допустим за один запрос они обрабатывают в среднем 1 GB данных (это объем данных в таблиц который нужно обработать что бы получить результат. Ваши аналитики за месяц сделали 1000 запросов (в сумме 1 TB данных). В итоге использование BQ в этом месяце будет для вам бесплатным — вы уложились в лимиты на бесплатное использование.
Допустим вы загрузили 100 GB данных, тогда их хранение будет стоить $1.8 в месяц. Аналитики пусть сделали 1000 запросов по 10 GB, обработка будет вам стоить $45 в месяц.
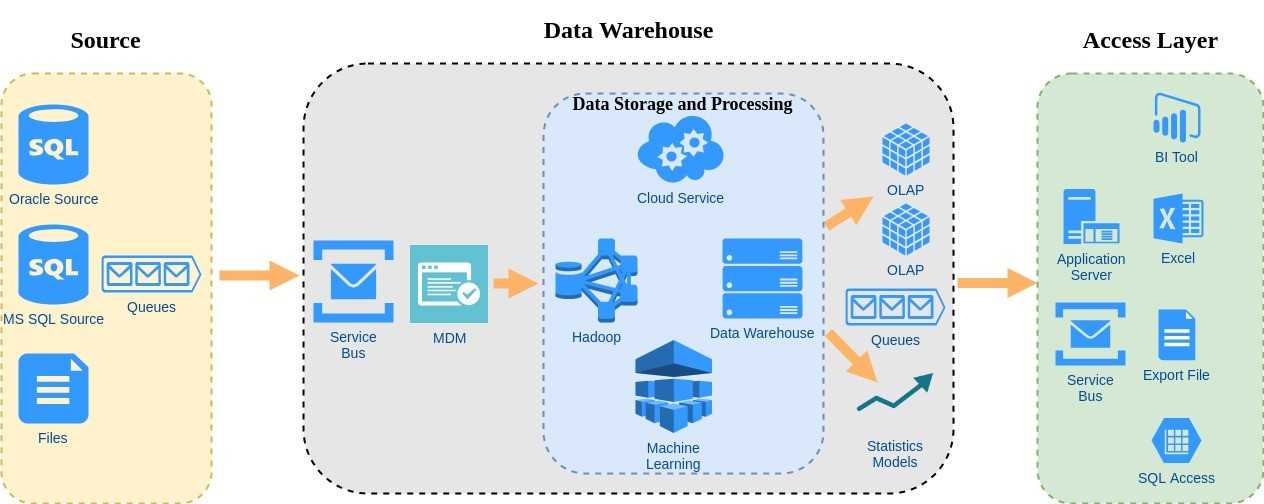
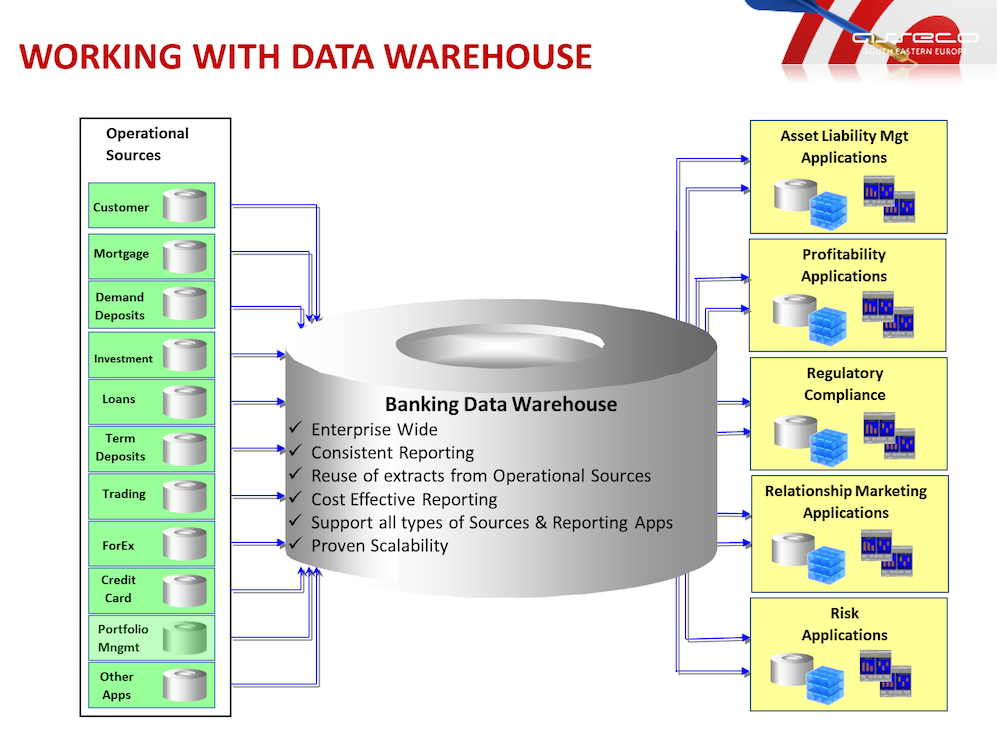
Где хранить корпоративные данные: краткий ликбез по Data Warehouse
Потребность в КХД сформировалась примерно в 90-х годах прошлого века, когда в секторе enterprise стали активно использоваться разные информационные системы для учета множества бизнес-показателей. Каждое такое приложение успешно решало задачу автоматизации локального производственного процесса, например, выполнение бухгалтерских расчетов, проведение транзакций, HR-аналитика и т.д.
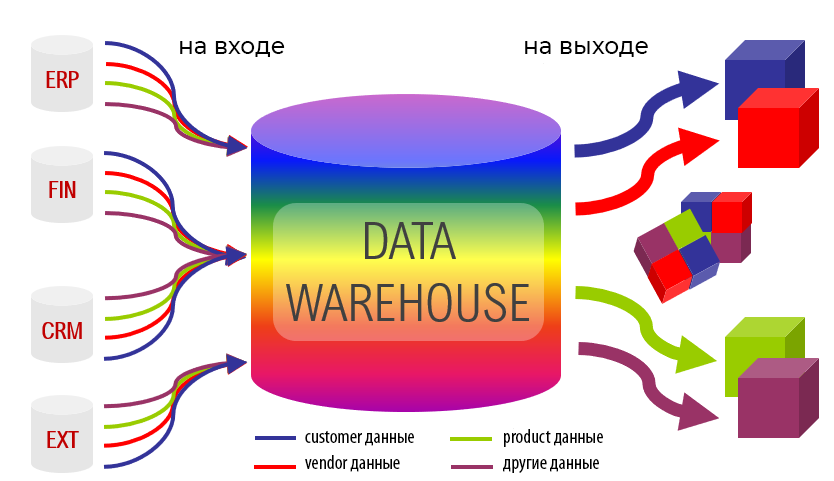
При этом схемы представления (модели) справочных и транзакционных данных в одной системе могут кардинально отличаться от другой, что влечет расхождение информации. Частично этот вопрос Data Governance мы затрагивали в контексте управления НСИ. Кроме того, большое разнообразие моделей данных затрудняет получение консолидированной отчетности, когда нужна целостная картина из всех прикладных систем. Поэтому возникли корпоративные хранилища данных (Data Warehouse, DWH) – предметно-ориентированные базы данных для консолидированной подготовки отчётов, интегрированного бизнес-анализа и оптимального принятия управленческих решений на основе полной информационной картины .
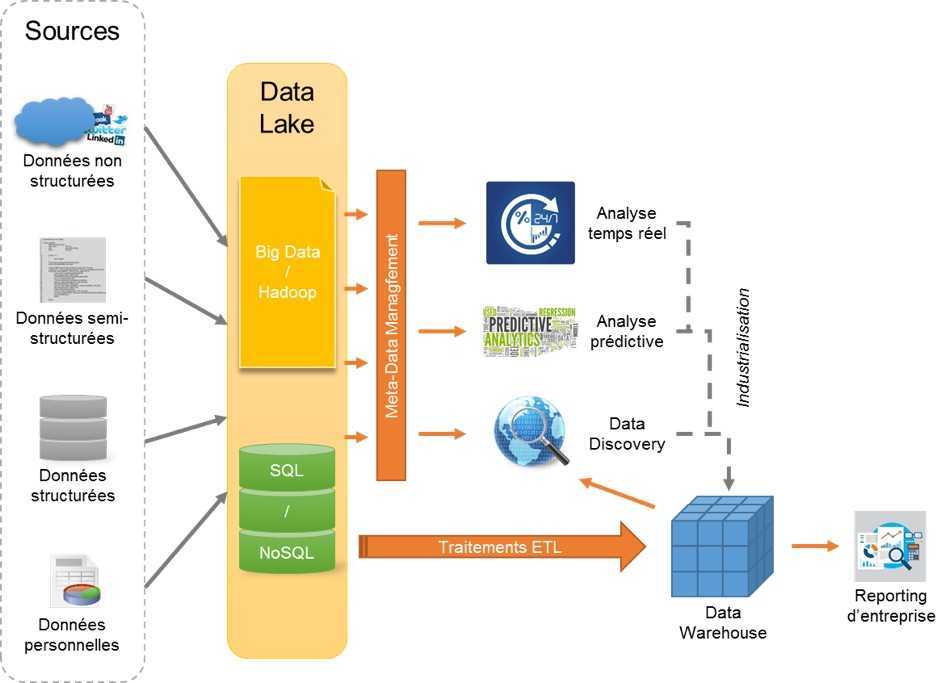
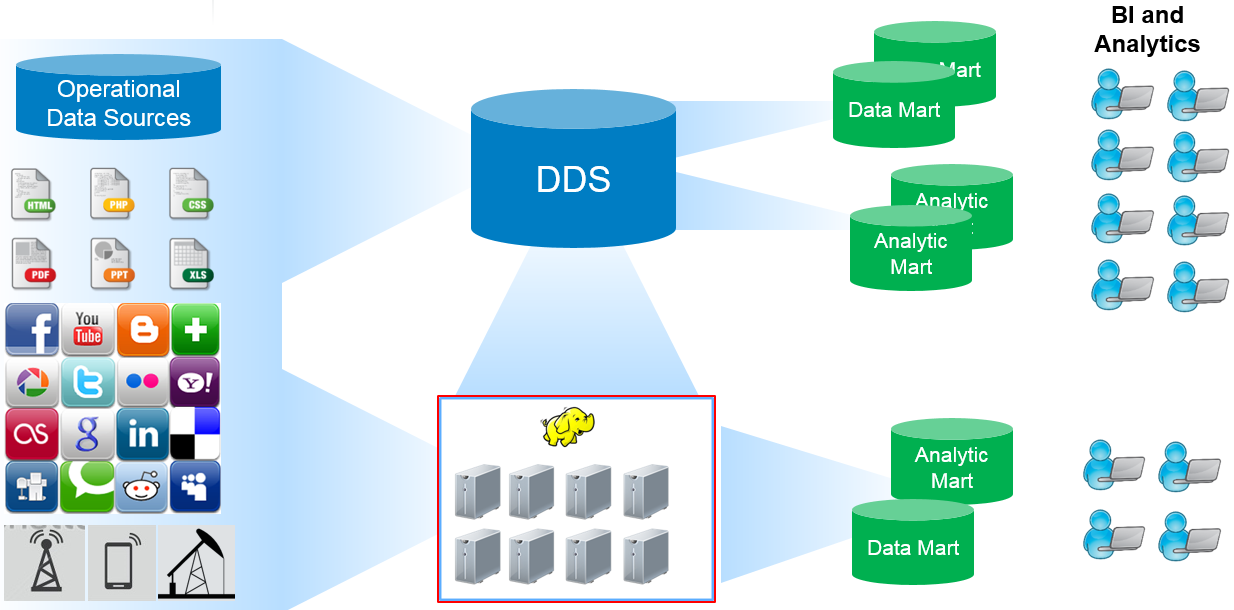
Data Lake
В отличие от подхода Data Warehouse, метод Data Lake представляет собой хранилище, где хранятся все необработанные данные в исходном формате без преобразования. Каждый элемент в Data Lake обозначен уникальным идентификатором и набором тегов метаданных. Данные могут быть неструктурированными, полуструктурированными или структурированными, они преобразуются только при запросе на использование. Из-за сложности подхода, Data Lake больше подходит для пользователей, занимающихся глубоким анализом данных и их исследованием.
По затратам средств метод Data Lake обходится намного дешевле, чем хранение данных в Data Warehouse. Также Data Lake быстрее выдает результат, так как у пользователей есть доступ к данным до их преобразования. Data Warehouse же потребует гораздо больше времени для внесения любых изменений в хранилище.
SDS
Software-defined storage — программно определяемое хранилище данных, основанное на DAS, при котором дисковые подсистемы нескольких серверов логически объединяются между собой в кластер, который дает своим клиентам доступ к общему дисковому пространству.
Наиболее яркими представителями являются GlusterFS и Ceph, но также подобные вещи можно сделать и традиционными средствами (например на основе LVM2, программной реализации iSCSI и NFS).
Пример SDS на основе GlusterFS
Из преимуществ SDS — можно построить отказоустойчивую производительную реплицируемую систему хранения данных с использованием обычного, возможно даже устаревшего оборудования. Если убрать зависимость от основной сети, то есть добавить выделенные сетевые карты для работы SDS, то получается решение с преимуществами больших SAN\NAS, но без присущих им недостатков. Я считаю, что за подобными системами — будущее, особенно с учетом того, что быстрая сетевая инфраструктура более универсальная (ее можно использовать и для других целей), а также дешевеет гораздо быстрее, чем специализированное оборудование для построения SAN. Недостатком можно назвать увеличение сложности по сравнению с обычным NAS, а также излишней перегруженностью (нужно больше оборудования) в условиях малых систем хранения данных.
DAS
Direct Attached Storage — это исторически первый вариант подключения носителей, применяемый до сих пор. Накопитель, с точки зрения компьютера, в котором он установлен, используется монопольно, обращение с накопителем происходит поблочно, обеспечивая максимальную скорость обмена данными с накопителем с минимальными задержками. Также это наиболее дешевый вариант организации системы хранения данных, однако не лишенный своих недостатков. К примеру если нужно организовать хранение данных предприятия на нескольких серверах, то такой способ организации не позволяет совместное использование дисков разных серверов между собой, так что система хранения данных будет не оптимальной: некоторые сервера будут испытывать недостаток дискового пространства, другие же — не будут полностью его утилизировать:
Конфигурации систем с единственным накопителем применяются чаще всего для нетребовательных нагрузок, обычно для домашнего применения. Для профессиональных целей, а также промышленного применения чаще всего используется несколько накопителей, объединенных в RAID-массив программно, либо с помощью аппаратной карты RAID для достижения отказоустойчивости и\или более высокой скорости работы, чем единичный накопитель. Также есть возможность организации кэширования наиболее часто используемых данных на более быстром, но менее емком твердотельном накопителе для достижения и большой емкости и большой скорости работы дисковой подсистемы компьютера.
Apple’s Mesa Data Center
Площадь: 120 тыс. м2
Расположение: Аризона, США
Mesa Datacenter был первоначально спроектирован компанией First Solar Inc., производящей солнечные панели, но в 2018 году компания Apple сообщила, что в течение следующего десятилетия потратит 2 миллиарда долларов на дальнейшее совершенствование этого объекта. Однако компания, известная своей секретностью, не стала делиться подробностями о том, что происходит внутри центра обработки данных, сославшись на безопасность, хотя известно, что в нем работают 150 человек.. Apple называет это предприятие своим глобальным центром управления данными.
С тем, чтобы обеспечить ЦОД экологически чистой энергией, Apple построила в штате Аризона солнечную электростанцию площадью 120 гектаров. Ее мощность составляет 50 МВт, что достаточно для питания 12 500 домов. Это не делает центр обработки данных на 100% зеленым, но компенсирует энергопотребление в городе Меса.
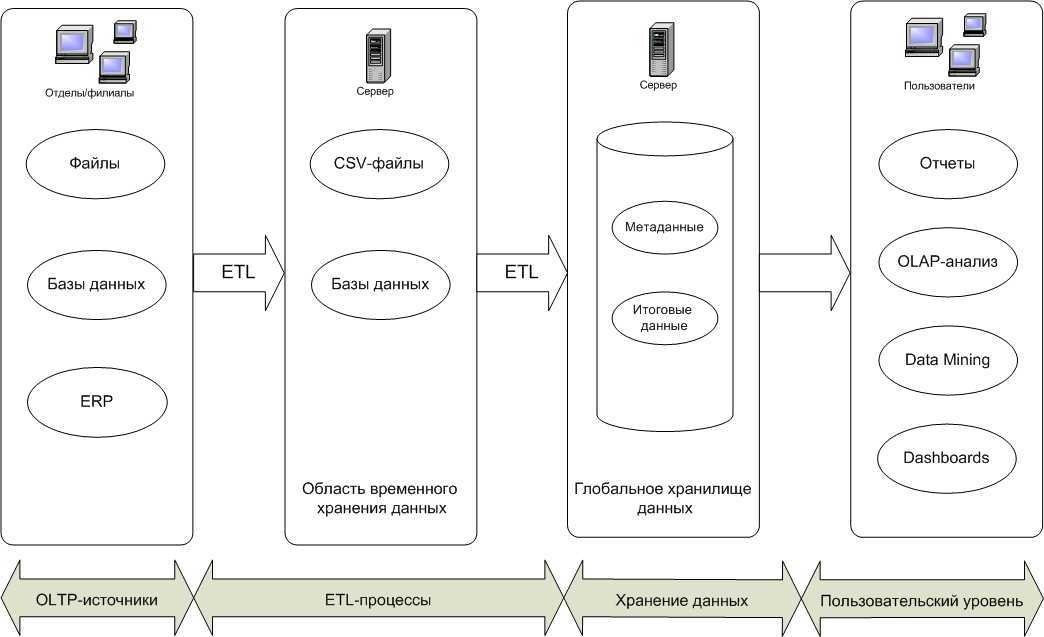
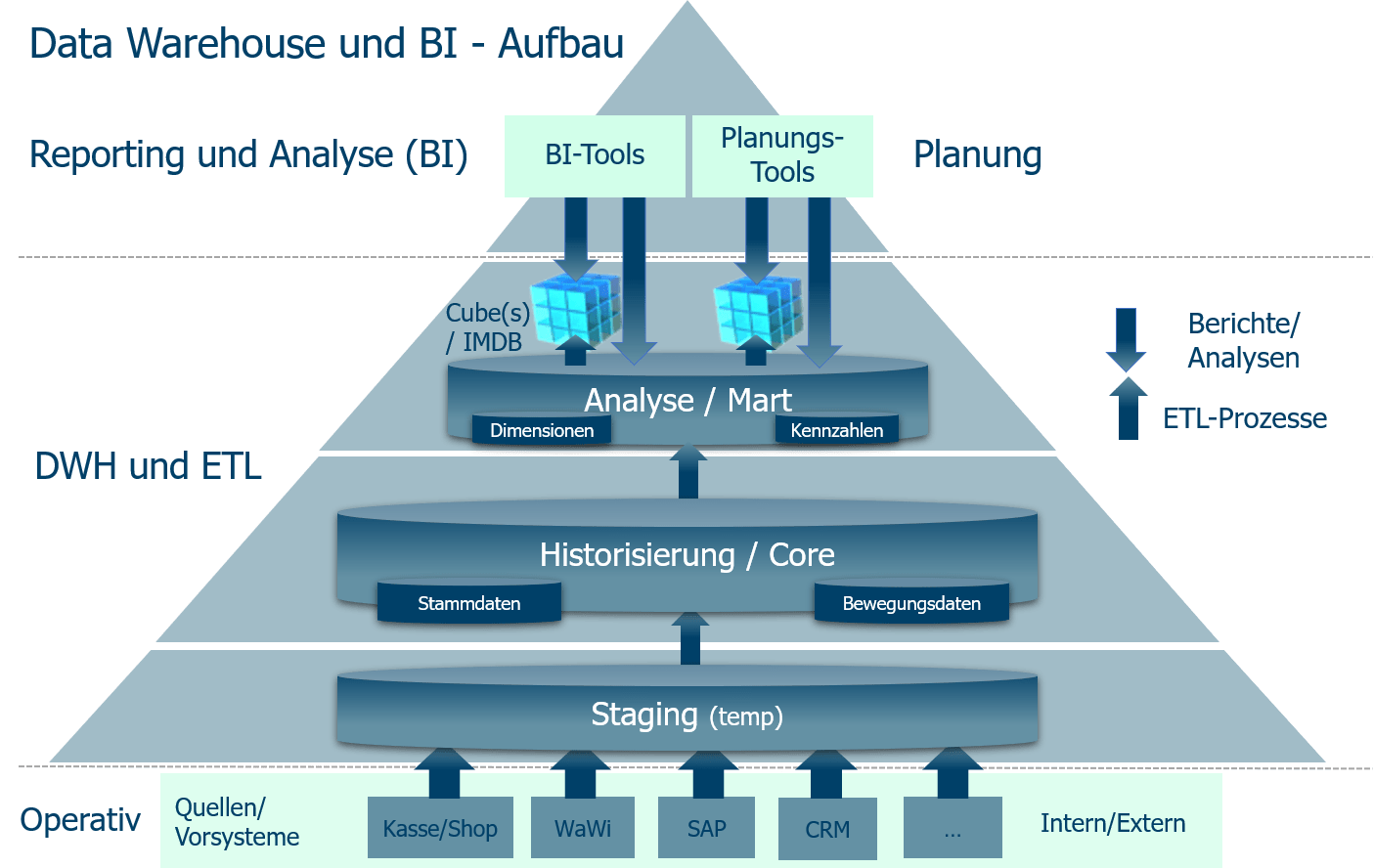
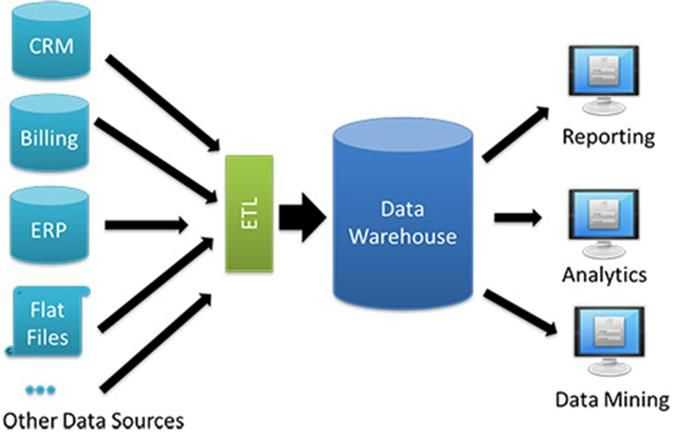
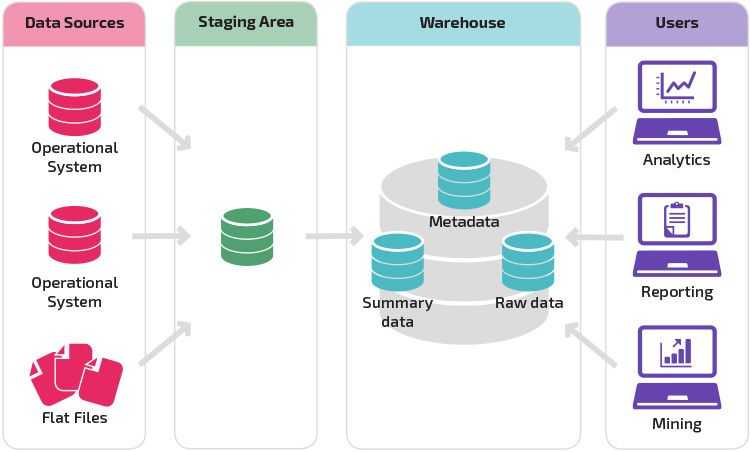
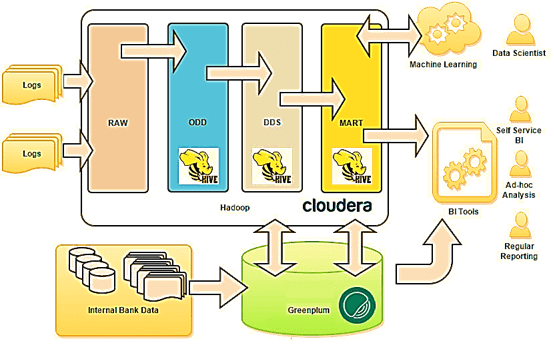
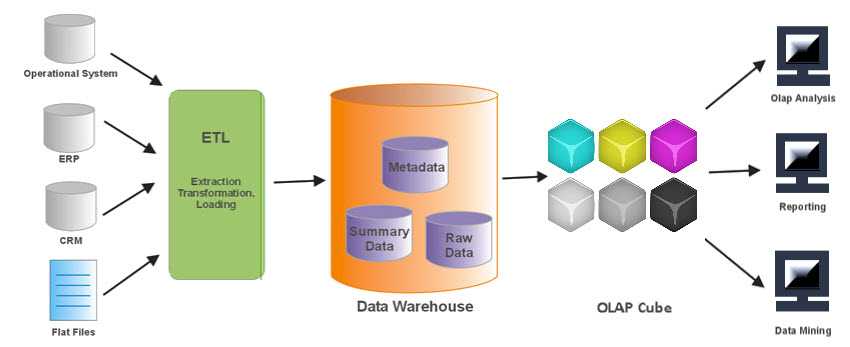
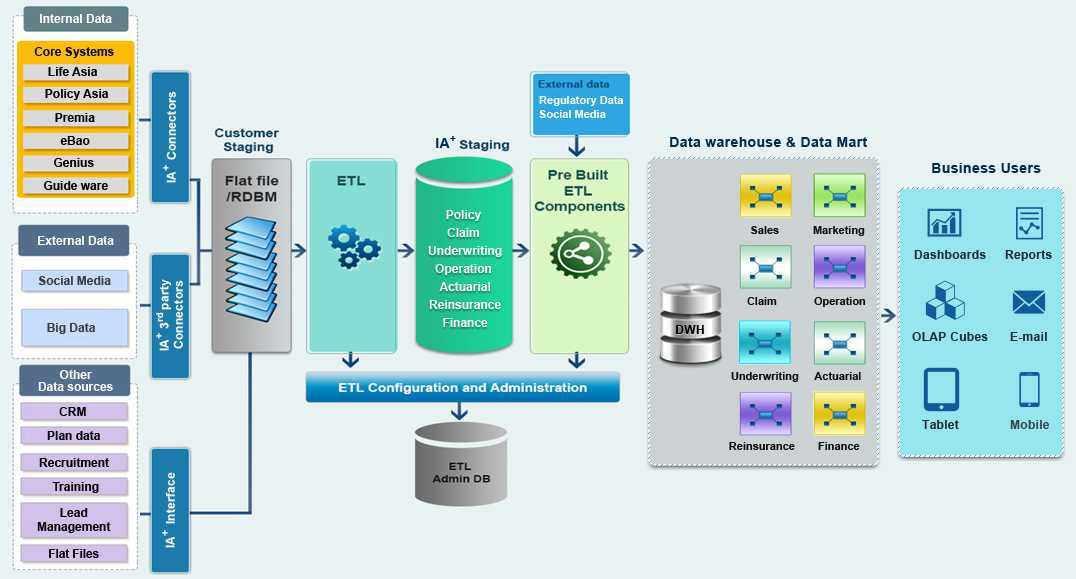
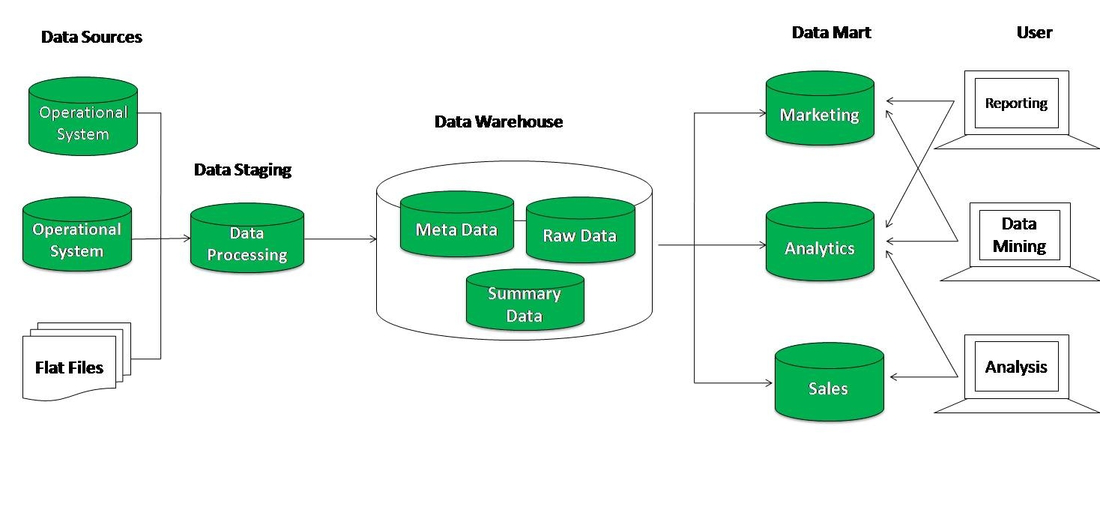
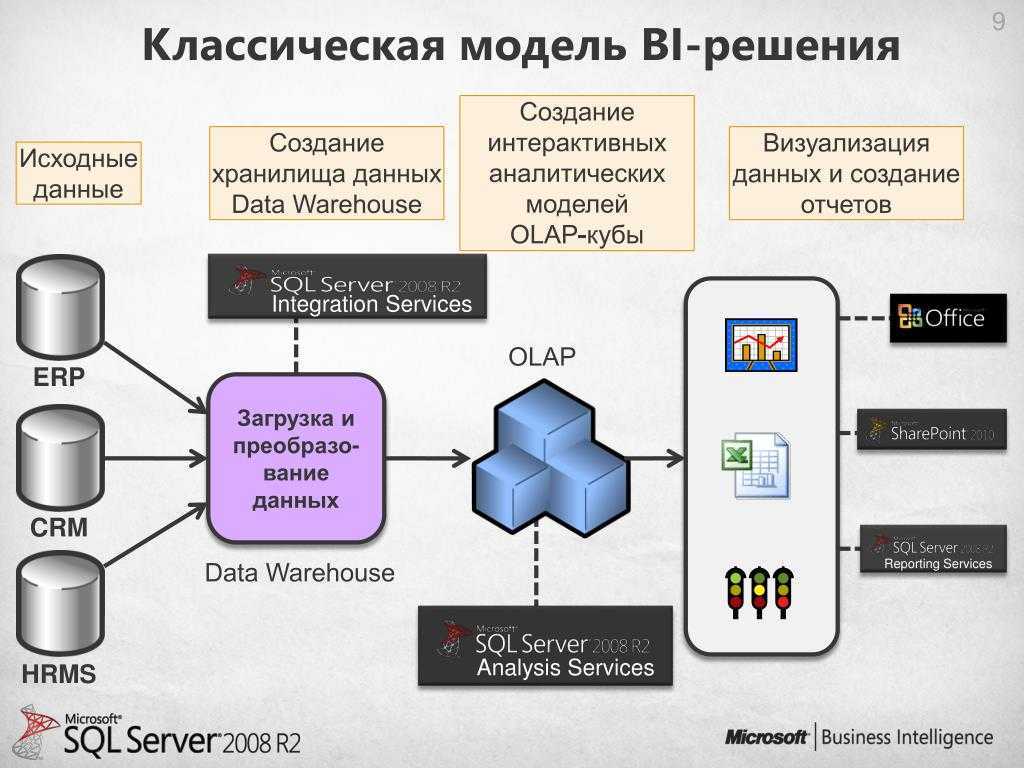
В чём ценность решений Data Warehouse
DWH используют для реализации BI — business intelligence. То есть внедрения процесса анализа данных и получения сведений, которые помогают ответственным лицам принимать стратегически правильные решения.
Приведём пример. Допустим, у промышленного предприятия упала выручка. Бизнес-аналитик по просьбе менеджеров собирает из DWH данные по продажам, выручке, количеству клиентов, расходам, спросу, и составляет отчёт, в котором в цифрах и деталях говорится, почему так произошло. Используя эту информацию менеджмент решает, что нужно изменить на производстве, в ассортименте, работе с клиентами или в цепочке поставок.
Без такого отчёта искать информацию пришлось бы долго и наугад. Нужно ли ради простого агрегатора данных городить чуть ли не культ? Нужно, потому что DWH — не просто агрегатор. Это удобное гибкое решение, которое экономит бюджет и время. Каким образом?
- Доступность только нужных данных. В большой компании можно долго собирать информацию с разных филиалов и отделов, а потом сводить всё это воедино. В Data Warehouse всё уже есть, причём структурированное и в удобной форме. Достаточно лишь проанализировать нужные метрики.
- Сохранность важных данных. Вся информация в DWH хранится столько, сколько это нужно компании. Есть исторические записи, агрегированные данные. Если обычные БД могут удалить из-за устаревания, то DWH ценят и берегут.
- Стабильность и устойчивость. Данные DWH могут понадобиться для работы аналитического отдела, который обрабатывает огромные объёмы информации. Запрашивать данные с рабочего сервера — это неоправданный риск, он может засбоить, игнорировать любые запросы до выполнения задачи от аналитиков и т.д. А скачивание с DWH никому не принесёт проблем. >
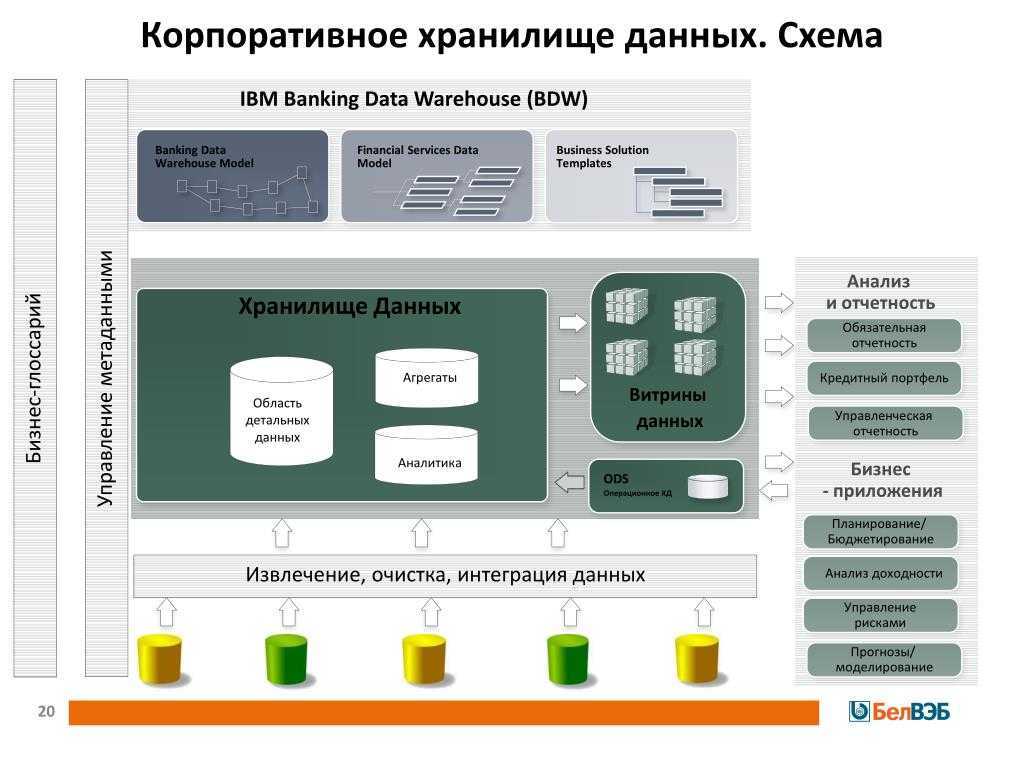
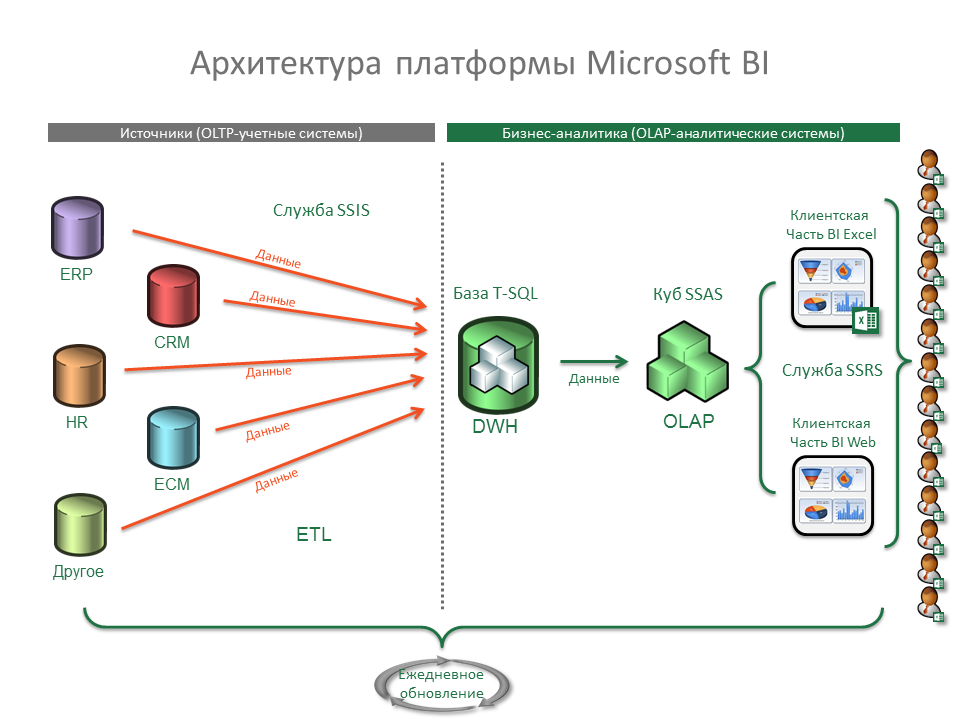
Функциональная архитектура
Руслан Султанов. Функциональная архитектура платформы включает две ключевые подсистемы — подсистему интеграции, выполняющую все классические задачи по сбору и загрузке данных, потоковой и пакетной обработке данных, и подсистему хранения и обработки данных, в которой выделяют различные слои хранения:
Функциональная архитектура
Платформа также включает традиционную BI-платформу, возможность создания аналитической отчетности и пользовательских отчетов, математических моделей и т. д. На базе платформы может быть организована так называемая область лаборатории данных, когда пользователям выделяются определенные ресурсы и полномочия, и они могут работать с данными внутри платформы, проверять гипотезы, в том числе, используя Python, и в целом выполнять все традиционные задачи.
Не стоит забывать про системы класса Data Governance (подсистемы управления данными), поскольку именно они обеспечивают прозрачность источников и процессов получения данных, преобразования данных перед использованием в витринах, что улучшает осведомленность пользователей и создает объективную картину данных. К решению класса Data Governance также относится каталог данных. Все эти модули в подсистеме управления данными, как правило, уместны и внедряются вместе с платформой.
К платформе можно подключать различные системы, например подсистему управления бизнес-процессами (BPM), которая обращается за данными, чтобы запустить некий бизнес-процесс.
Вывод
Если у вас нет DWH, то простой MVP можно накликать в облаке. Вы выбираете продукт, который поддерживается managed-сервисом, тот же Hadoop, и у вас уже есть какое-то хранилище. Попробуйте, и вы поймете, что это лучше, чем без хранилища.
Если вас не устраивает ваше DWH, попробуйте посмотреть на технологии вокруг. Для нас это был стресс. Я помню, каким для меня было вызовом, когда мне сказали: «Твой бесплатный Hadoop работает плохо, давайте посмотрим, какие есть платные хорошие решения». Я в ответ: «Что? Мой Hadoop? Да я сейчас напишу на Spark, всё будет работать очень быстро». Но я благодарен своим руководителям за то, что они предложили погонять PoC, и я понял, что коробочные решения могут делать гораздо быстрее и надежнее, чем Hadoop, который нужно настраивать несколько месяцев под одну задачу. Смотрите вокруг, ищите что-то хорошее, читайте Хабр и Medium. Иногда даже специфические продукты взлетают.