Основные принципы и логическая архитектура модели сети данных
Цель модели сети данных состоит в том, чтобы создать основу для получения ценности из аналитических и исторических данных в масштабе, применяемом к постоянному изменению ландшафта данных, распространению как источников данных, так и потребителей, разнообразию преобразований и обработки, которые требуются в случаях использования, скорости реагирования на изменения. Для достижения этой цели я предлагаю, чтобы было четыре основополагающих принципа, которые воплощает любая реализация сети данных для обеспечения потребностей масштабирования, обеспечивая при этом гарантии качества и целостности, необходимые для использования данных: 1) децентрализованное владение данными и архитектура, ориентированная на домен, 2) данные как продукт, 3) инфраструктура данных самообслуживания как платформа и 4) федеративное управление вычислениями.
Хотя я и ожидаю, что практика, технологии и реализация этих принципов будут меняться и совершенствоваться с течением времени, но эти принципы остаются неизменными.
Я намеренна чтобы эти четыре принципа были в совокупности необходимыми и достаточными; чтобы обеспечивали масштабирование и устойчивость при одновременном решении проблем, связанных с блокированием несовместимых данных или увеличением стоимости эксплуатации. Давайте углубимся в каждый принцип, а затем разработаем концептуальную архитектуру, которая его поддерживает.
Статические и динамические ссылки
Для выполнения задачи связывания используется компоновщик. Компоновщик — это программа, которая берет один или несколько объектных файлов, созданных компилятором, и объединяет их в один исполняемый файл.
- Статическая компоновка: пристатической компоновке компоновщик объединяет все необходимые программные модули в единую исполняемую программу. Таким образом, нет никакой зависимости от времени выполнения. Некоторые операционные системы поддерживают только статическое связывание, в котором библиотеки системного языка обрабатываются как любой другой объектный модуль.
- Динамическое связывание: основная концепция динамического связывания аналогична динамической загрузке. При динамической компоновке «заглушка» включается для каждой соответствующей ссылки на библиотечную подпрограмму. Заглушка — это небольшой фрагмент кода. Когда заглушка выполняется, она проверяет, находится ли нужная процедура уже в памяти или нет. Если он недоступен, программа загружает подпрограмму в память.
Как реализовать фабрику данных

Это будет полностью зависеть от типа вашей организации и ваших потребностей. Из-за различных требований бизнеса не существует универсального решения для реализации ячеистой сети передачи данных. Но есть некоторые общие черты или уровни архитектуры фабрики данных.
Управление данными: этот уровень обеспечивает безопасность и управление данными.
Прием данных: этот уровень начинает объединять все облачные данные, определяя, как связаны структурированные и неструктурированные данные.
Обработка данных: обеспечивает доступность соответствующих данных во время извлечения данных.
Организация данных: этот уровень включает в себя выполнение задач, включая разрозненный сбор данных, структурирование данных, очистку данных, интеграцию и преобразование для создания пригодных для использования данных.
Обнаружение данных: позволяет собирать данные путем интеграции различных источников. Это имеет решающее значение для удовлетворения клиента.
Доступ к данным: этот уровень предназначен для потребления данных. Одновременно этот уровень помогает получить доступ к соответствующим данным с помощью инструментов визуализации данных или информационных панелей приложений.
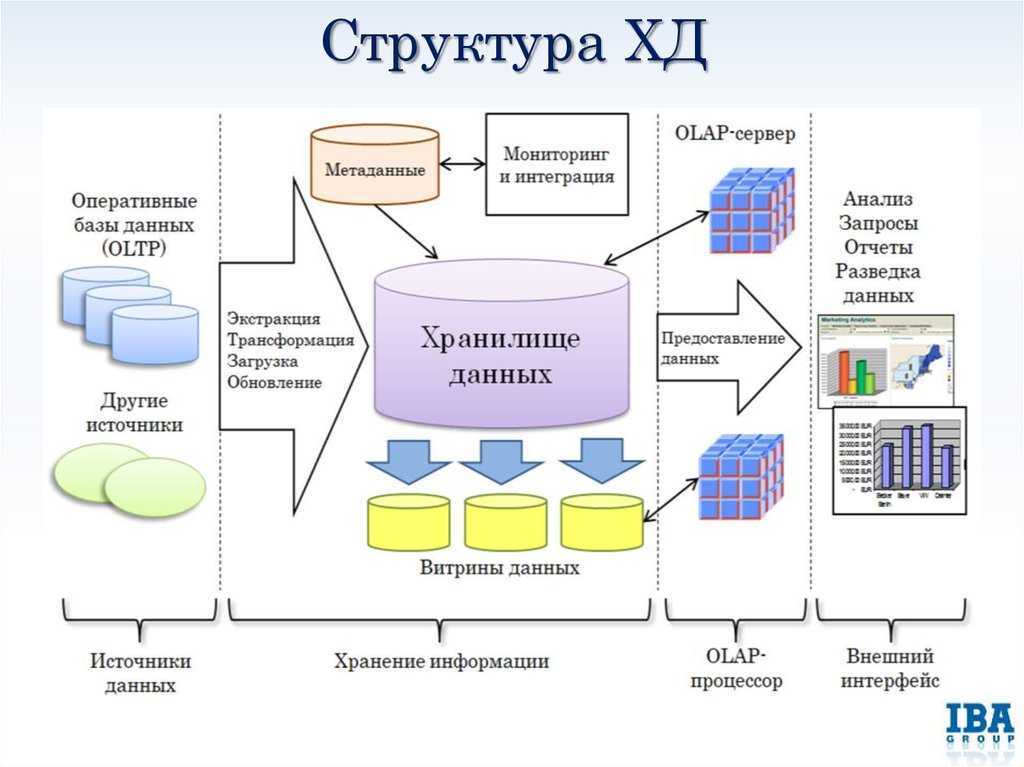
Метаданные (Metadata)
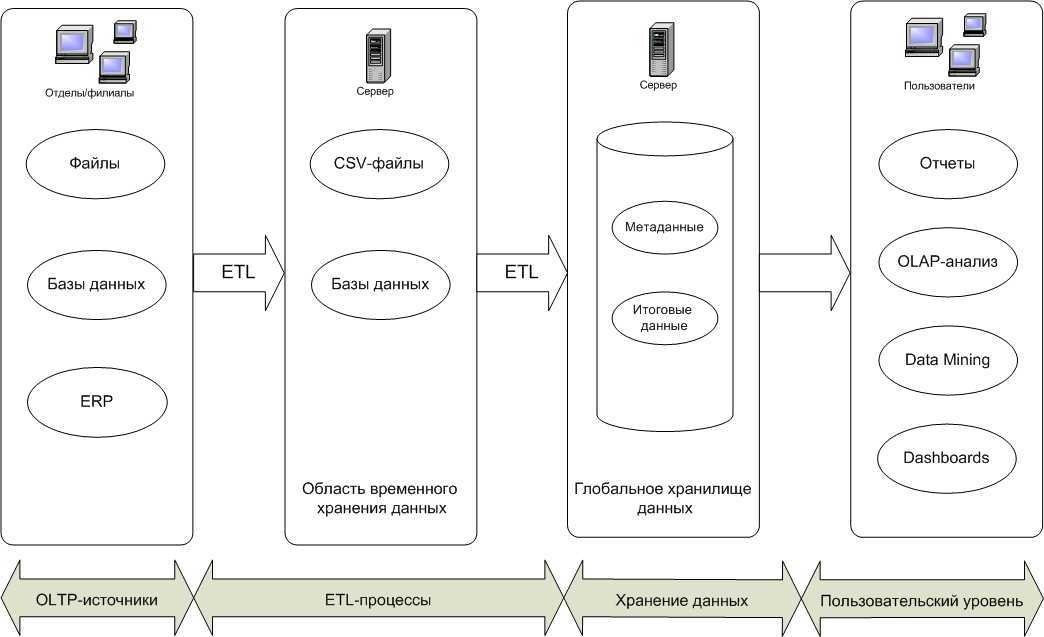
Разработка и сопровождение системы с хорошо спроектированными и описанными метаданными является более простой задачей, нежели при отсутствии таковых. Метаданные хранилища включают:
- информацию о данных, их бизнес-описание и структуру хранения;
- описание структур источников данных, их доступности;
- информацию о структуре процессов ETL, периодичности их выполнения, применяемых правил очистки и преобразования данных;
- описание бизнес-представления данных, помогающее пользователю работать с BI-приложением;
- информацию о настройках безопасности, правил аутентификации и назначенных прав доступа;
- статистику утилизации ресурсов, обращений к данным и др., которая помогает администратору оптимизировать работу базы данных хранилища.
Обычно управление метаданными осуществляется отдельными инструментами для каждого из компонентов хранилища. Например, для базы данных Oracle, метаданные которой хранятся в системных таблицах и настроечных файлах, это будет Oracle Enterprise Manager.
Сжатие
За счет того, что данные в одном атрибуте имеют общий тип и часто повторяются, их можно дополнительно сжимать, при этом экономится память, и мы можем обработать больший объем данных. Также в процессе сжатия все значения можно представить целыми числами, с которыми процессор умеет работать быстрее всего.
Для сжатия используются разные схемы, иногда пользователь сам может контролировать этот процесс, в зависимости от типов данных атрибутов, количества уникальных значений, порядка сортировки.
Один из вариантов – упорядочить наши данных по атрибуту «Дата». Представить даты в виде целых чисел и закодировать, указывая разницу между текущим и предыдущим значением (схема ниже). При этом для кодирования маленьких целочисленных смещений можно использовать всего 1 байт на смещение. Когда его станет недостаточно, можно начать кодирование следующей порции заново.

Сжатие не только позволяет экономить память, но и повышает производительность за счет того, что объем данных, который нужно переместить из памяти в кэш процессора при выполнении запроса, сокращается, при этом процессор может выполнять распаковку данных параллельно с пересылкой из памяти очередной порции. Также все современные процессоры могут выполнять операции не над одним значением, а сразу над множеством значений (векторизация), и эта возможность активно используется в In-Memory.
Как выбрать СХД?
В первую очередь нужно понимать, какие задачи она будет решать
Важно определиться с несколькими базовыми параметрами
Тип данных
Разные типы данных требуют разной скорости доступа, технологий обработки, компрессии и так далее. К примеру, виртуальный СХД для работы с большими медиа-файлами отличается от той системы, которая будет работать с неструктурированными данными для нейросети.
Объём данных
От этого зависит выбор дисковых накопителей. Иногда можно обойтись SSD потребительского класса — если известно, что ёмкость СХД даже в худшем случае не будет превышать 300 ГБ, а скорость доступа не критична.

Отказоустойчивость
Необходимо представлять, какова стоимость потери данных за определённое время. Это поможет рассчитать RPO (Recovery-Point Objective) и RTO (Recovery Time Objective), а также избежать лишних затрат на резервное копирование. Бэкапы, бэкапы и ещё раз бэкапы.
Производительность
Если СХД закупается под новый проект (нагрузку которого сложно предугадать), то лучше пообщаться с коллегами, которые уже решали эту задачу или протестировать СХД.
Вендор
Иногда даже для ресурсоемкого сервиса подойдет бюджетное или среднеуровневое решение (StarWind, Huawei, Fujitsu). Однако у топовых производителей — NetApp, HPE, Dell EMC — линейка продуктов достаточно широкая, и сравнительно недорогие СХД здесь также можно найти. В любом случае, желательно сильно не расширять количество вендоров на одной инфраструктуре.
⌘⌘⌘
Если сейчас вы находитесь в поисках решения для работы с данными, арендовать выделенный web-сервер и СХД (системы хранения данных) можно в одном из наших ЦОД. Мы, со своей стороны, обеспечим сервер быстрым соединением с интернетом на скорости до 10 Гбит/сек, постоянным подключением к электричеству и поддержкой 27/7 ;).
Арендовать выделенный сервер
Диски или лента?
Скорость доступа к данным и плотность записи у ленточных библиотек продолжают расти. По скорости записи новейшие ленточные картриджи LTO обогнали жесткие диски. Гарантированный срок хранения для картриджей Fujifilm — 30 лет. Долгосрочное хранение данных на ленте обходится намного дешевле дисков. Кроме того, ленточные картриджи не потребляют электроэнергию, занимают меньше места, а так называемый «воздушный зазор» защищает хранимые данные от хакерских атак.
«Корпоративные решения на ленте по стоимости владения на несколько порядков дешевле дисковых систем, построенных на гибридном принципе (HDD + SSD) или флэш-массивов. Самое существенное вложение — это ПО», — подчеркивают разработчики сервиса.
Осуществляется миграция данных на картриджи новых поколений. Как правило, устройства LTO новых поколений читают данные с носителей на два поколения младше, пишут и читают — на одно поколение младше (то есть система с LTO-7 читает LTO-5 и может читать и писать на картриджи LTO-6).
«При наличии софта и грамотной стратегии хранения данных существенных проблем при смене поколений быть не должно. С дисковыми накопителями может возникнуть больше проблем: с переходом на новый протокол дисковой подсистемы и придется покупать новый контроллер с дисковыми полками и новые носители», — считают в RCloud by 3data.
Максимальное время загрузки и перемотки картриджа не превышает минуты. Часто запрашиваемые (активные) данные ArcTape хранит на отдельном устройстве, которое играет роль кэша чтения/записи. Данные в нем хранятся на накопителях SSD, что обеспечивает оперативный доступ к ним.

Ленточные хранилища обычно используются для хранения архивов данных, видеоматериалов и резервных копий.
В общем случае скорость копирования данных в ArcTape зависит от нескольких факторов. В их числе — метод организации канала связи между системой хранения и площадкой заказчика, очередь на запись на СХД и структура файлов. Если ориентироваться на средний показатель при организации оптического канала между ЦОД с системой ArcTape и площадкой заказчика, то скорость копирования данных на флэш-массив составит около 2 ГБ\с.
В результате заказчики ArcTape получают высокую производительность, масштабируемость и безопасность хранения данных при значительно более низких затратах по сравнению с использованием дисковых накопителей. При этом им не нужно самим осваивать новую технологию, тратить деньги на новое оборудование, размещать его в ЦОД и нанимать квалифицированный ИТ-персонал. Гораздо выгоднее использовать готовую коммерческую услугу. Сервис ArcTape можно задействовать для хранения больших объемов данных, не требующих оперативного доступа для скачивания.
Выделение памяти
Чтобы добиться правильного использования памяти, необходимо эффективно распределять память. Один из простейших методов распределения памяти — разделить память на несколько разделов фиксированного размера, и каждый раздел содержит ровно один процесс. Таким образом, степень мультипрограммирования определяется количеством разделов.
Распределение нескольких разделов : в этом методе процесс выбирается из входной очереди и загружается в свободный раздел. Когда процесс завершается, раздел становится доступным для других процессов.
Фиксированное распределение разделов: в этом методе операционная система поддерживает таблицу, в которой указывается, какие части памяти доступны, а какие заняты процессами. Изначально вся память доступна для пользовательских процессов и считается одним большим блоком доступной памяти. Эта доступная память известна как «отверстие». Когда процесс прибывает и ему требуется память, мы ищем достаточно большую дыру, чтобы сохранить этот процесс. Если требование выполняется, мы выделяем память для процесса, в противном случае оставляя остальную доступной для удовлетворения будущих запросов. При распределении памяти иногда возникают проблемы с динамическим распределением памяти, которые касаются того, как удовлетворить запрос размера n из списка свободных отверстий. Есть несколько решений этой проблемы:
First fit:-
При первой подгонке первое доступное свободное отверстие удовлетворяет требованиям назначенного процесса.
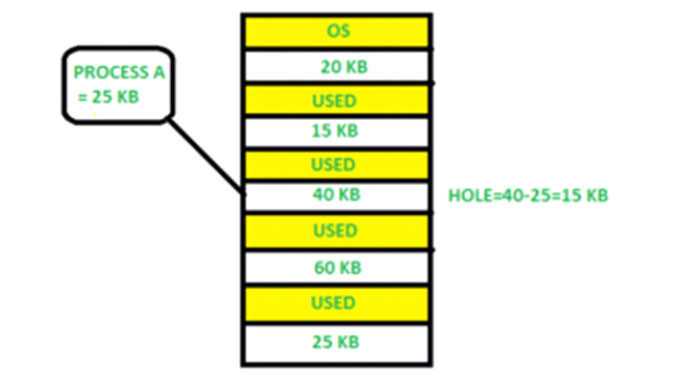
Здесь, на этой диаграмме, блок памяти размером 40 КБ является первым доступным свободным местом, в котором может храниться процесс A (размер 25 КБ), поскольку первые два блока не имели достаточного пространства памяти.
Best fit:-
В наиболее подходящем случае выделите наименьшее отверстие, которое достаточно велико для обработки требований. Для этого мы ищем весь список, если список не упорядочен по размеру.

Здесь, в этом примере, сначала мы просматриваем полный список и обнаруживаем, что последнее отверстие 25 КБ является наиболее подходящим отверстием для процесса A (размер 25 КБ).
В этом методе использование памяти максимально по сравнению с другими методами распределения памяти.
Worst fit:- В худшем случае выделите для обработки наибольшее доступное отверстие. Этот метод дает самое большое оставшееся отверстие.
Здесь, в этом примере, процесс A (размер 25 КБ) выделяется самому большому доступному блоку памяти, который составляет 60 КБ. Неэффективное использование памяти является серьезной проблемой в худшем случае.
Статическая и динамическая нагрузка
Загрузка процесса в основную память выполняется загрузчиком. Есть два разных типа загрузки:
- Статическая загрузка: — При статической загрузке загружает всю программу по фиксированному адресу. Это требует больше места в памяти.
- Динамическая загрузка: — Для выполнения процесса вся программа и все данные процесса должны находиться в физической памяти. Итак, размер процесса ограничен размером физической памяти. Для правильного использования памяти используется динамическая загрузка. При динамической загрузке подпрограмма не загружается, пока не будет вызвана. Все процедуры хранятся на диске в перемещаемом формате загрузки. Одним из преимуществ динамической загрузки является то, что неиспользуемая процедура никогда не загружается. Эта загрузка полезна, когда для ее эффективной обработки требуется большой объем кода.
Логическое и физическое адресное пространство
Логическое адресное пространство: адрес, генерируемый ЦП, известен как «логический адрес». Он также известен как виртуальный адрес. Логическое адресное пространство можно определить как размер процесса. Логический адрес можно изменить.
Физическое адресное пространство: адрес, видимый блоком памяти (т. Е. Тот, который загружен в регистр адреса памяти), обычно известен как «Физический адрес». Физический адрес также известен как реальный адрес. Набор всех физических адресов, соответствующих этим логическим адресам, известен как физическое адресное пространство. Физический адрес вычисляется MMU. Отображение виртуальных адресов в физические во время выполнения выполняется с помощью модуля управления памятью (MMU) аппаратного устройства. Физический адрес всегда остается постоянным.
Краткое изложение принципов и логическая архитектура высокого уровня
Давайте сведем все это воедино, мы обсудили четыре принципа, лежащих в основе сетки данных:
| Децентрализованное владение данными и архитектура, ориентированные на домен | Чтобы экосистема, создающая и потребляющая данные, могла масштабироваться по мере увеличения числа источников данных, числа вариантов использования и разнообразия моделей доступа к данным просто увеличивая автономные узлы в сети. |
| Данные как продукт | Чтобы пользователи данных могли легко находить, понимать и безопасно использовать высококачественные данные с приятным опытом; данные, которые распределены по многим доменам. |
| Инфраструктура данных самообслуживания как платформа | Чтобы команды домена могли создавать и использовать продукты данных автономно, используя абстракции платформы, скрывая сложность создания, выполнения и поддержки безопасных и совместимых продуктов данных. |
| Федеративное управление вычислениями | Чтобы пользователи данных могли получать выгоду от агрегирования и корреляции независимых продуктов данных, сеть ведет себя как экосистема, следуя глобальным стандартам взаимодействия; стандартам, которые вычислительно интегрированы в платформу. |
Эти принципы управляют логической архитектурной моделью, которая, хотя и сближает аналитические данные и оперативные данные в одной и той же области, учитывает лежащие в их основе технические различия. Такие различия включают в себя, где могут размещаться аналитические данные, различные компьютерные технологии для обработки операционных и аналитических услуг, различные способы запроса и доступа к данным и т.д.
Логическая архитектура подхода к сети данных:
Я надеюсь, что к этому моменту мы уже выработали общий язык и логическую ментальную модель, которую мы сможем коллективно использовать для детализации схемы компонентов сетки, таких как продукт данных, платформа и необходимые стандартизации.
Что такое основная память
Основная память играет центральную роль в работе современного компьютера. Основная память — это большой массив слов или байтов размером от сотен тысяч до миллиардов. Основная память — это хранилище быстро доступной информации, совместно используемой ЦП и устройствами ввода-вывода. Основная память — это место, где хранятся программы и информация, когда процессор эффективно их использует. Также основная память связана с процессором, поэтому перемещение инструкций и информации в процессор и из процессора происходит очень быстро. Основная память также известна как RAM (оперативная память). Эта память является энергозависимой. ОЗУ теряет свои данные при отключении питания.
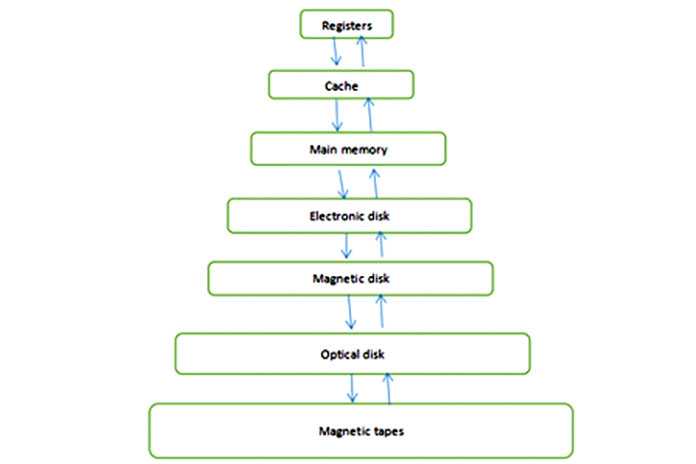
Рисунок 1: Иерархия памяти
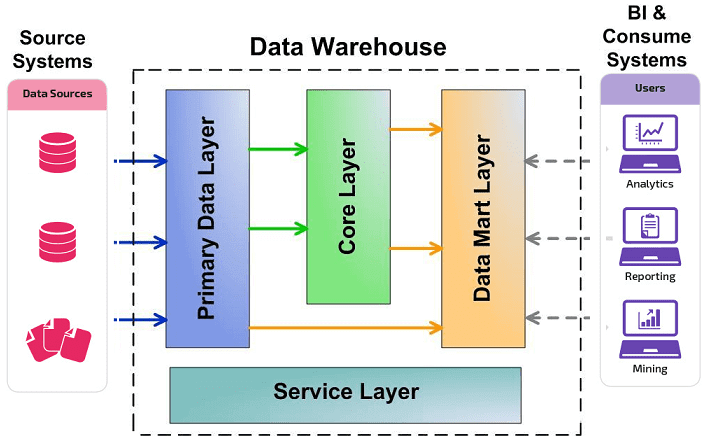
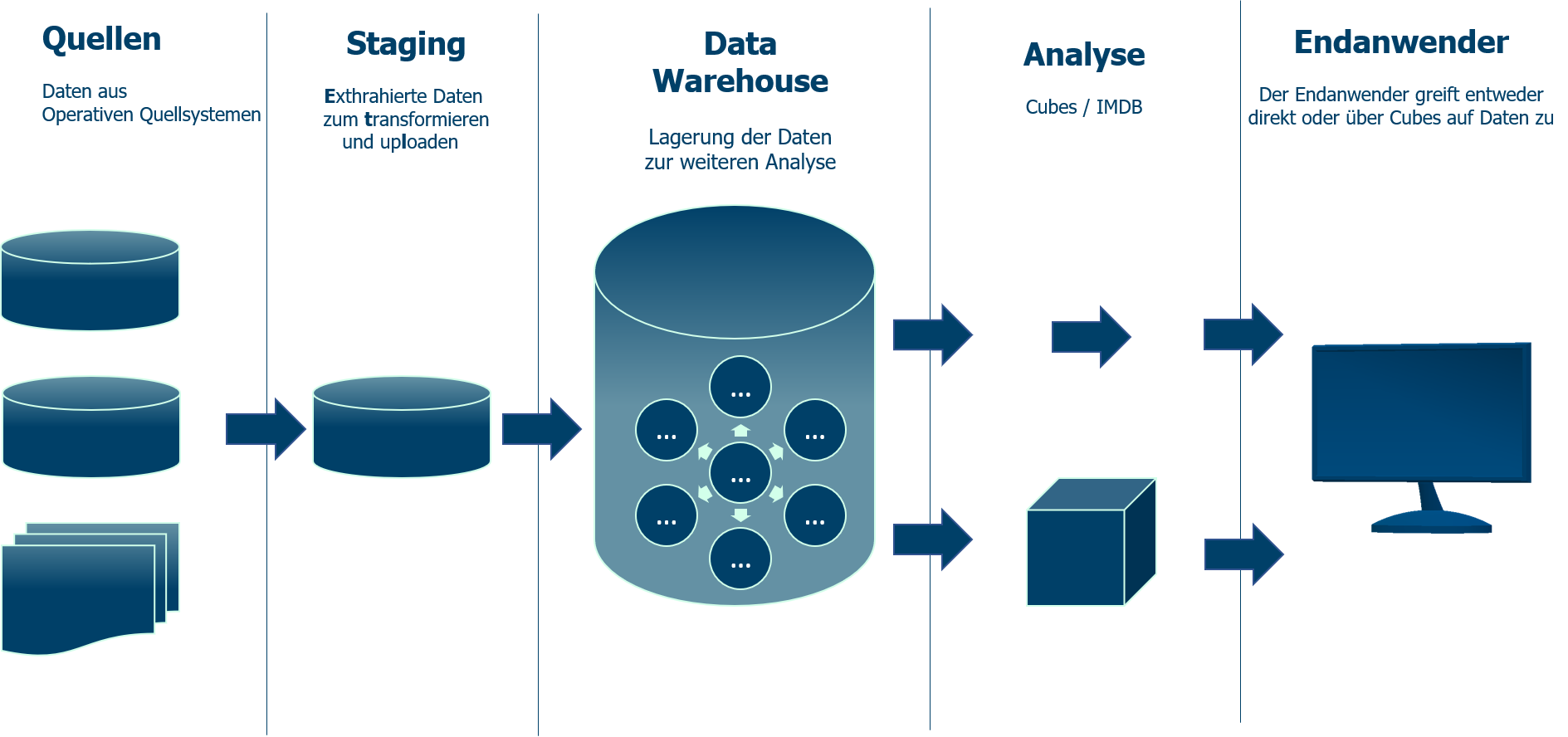
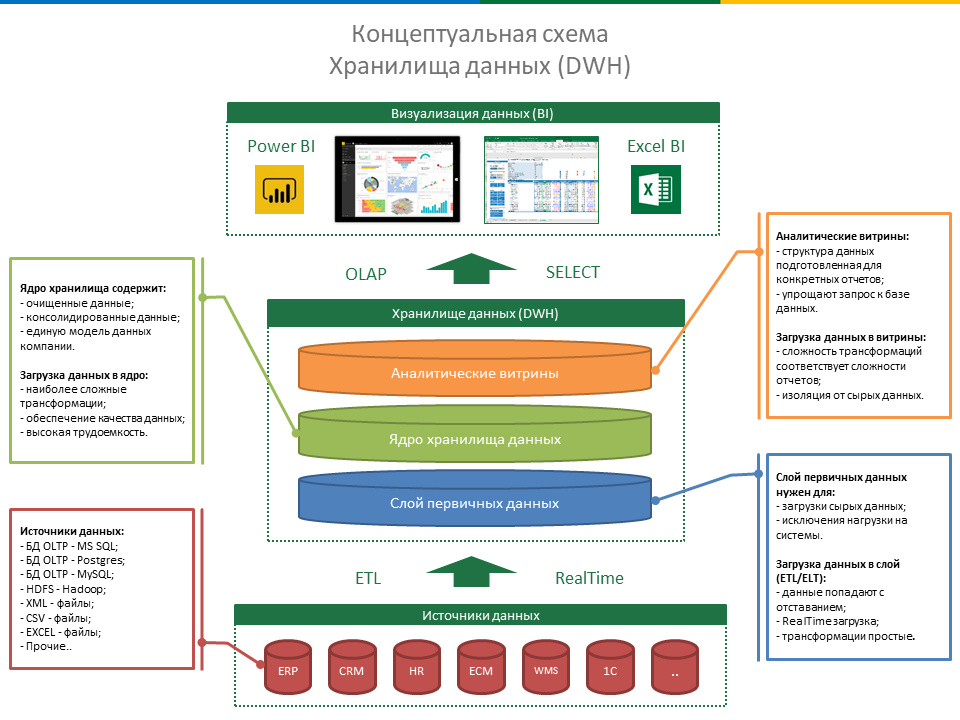
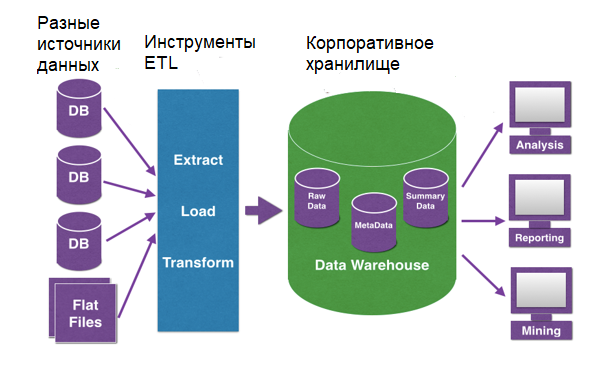
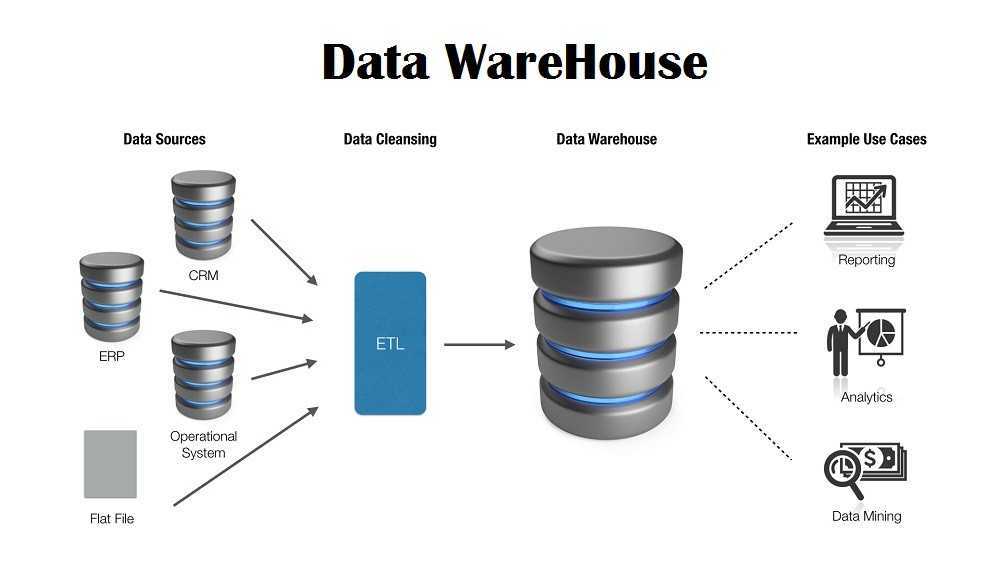
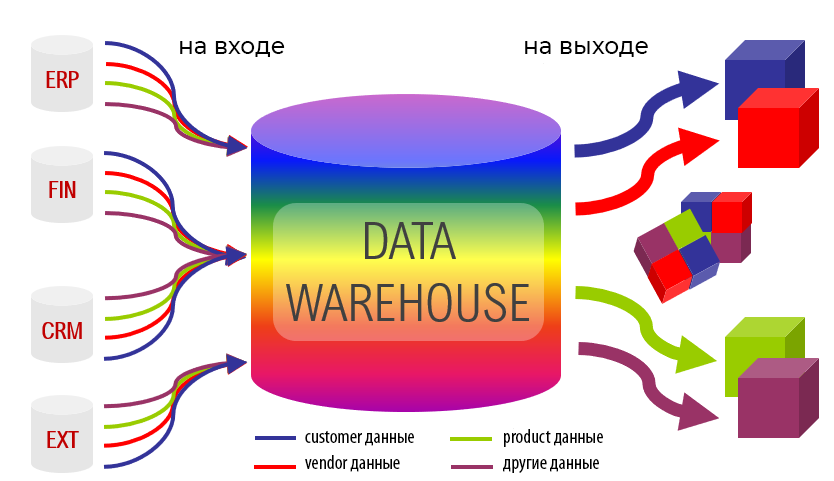
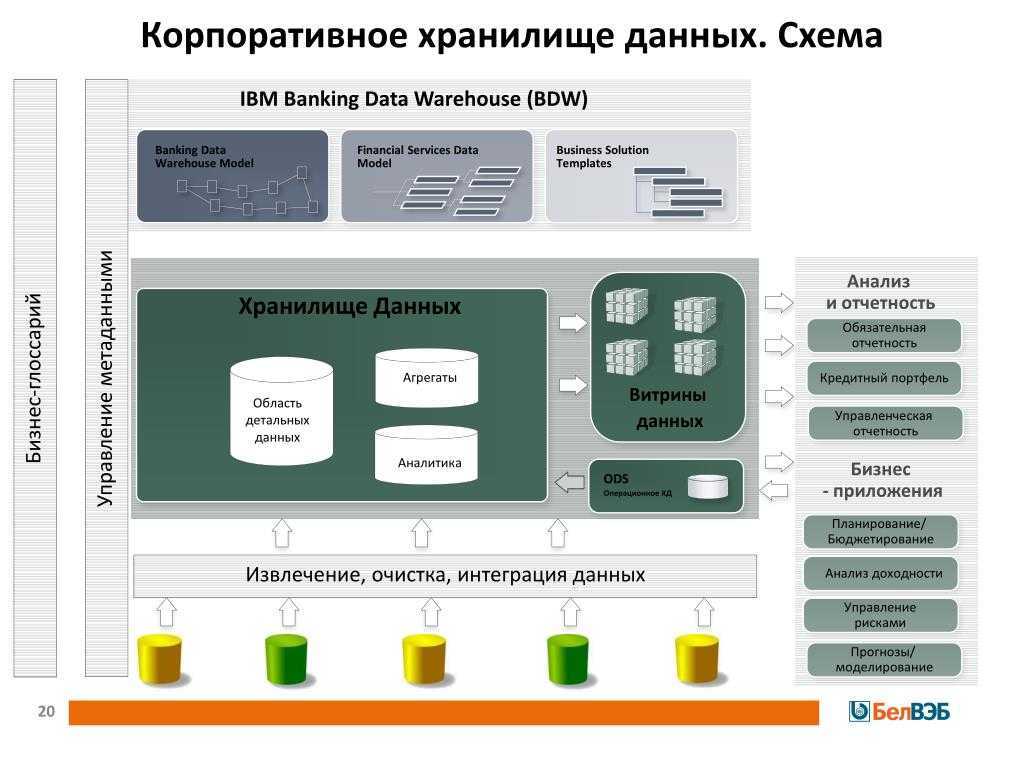
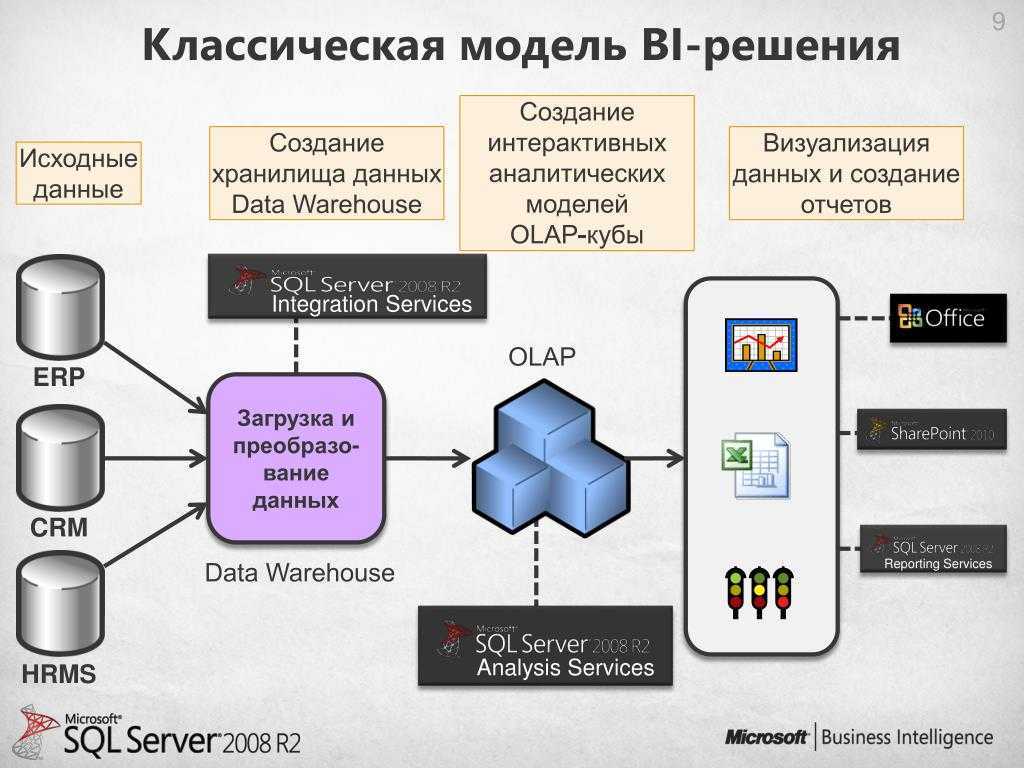
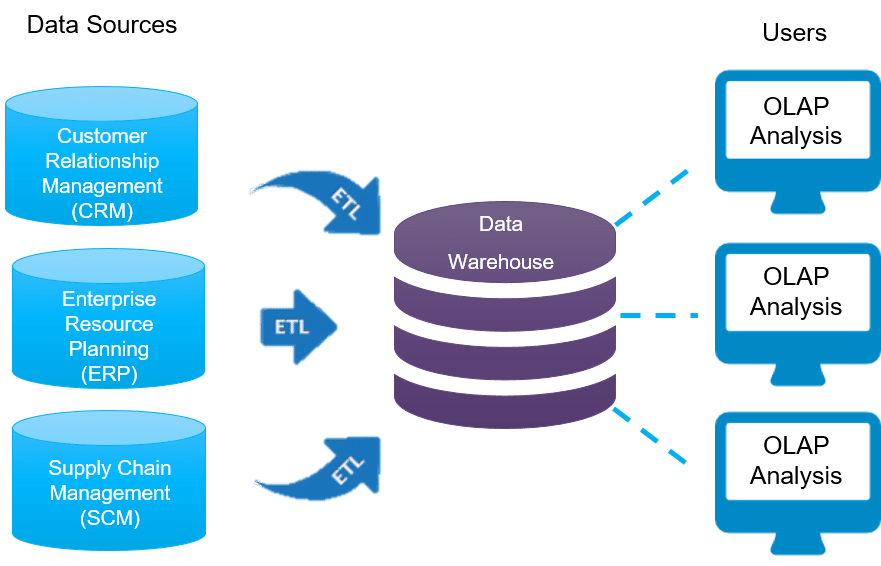
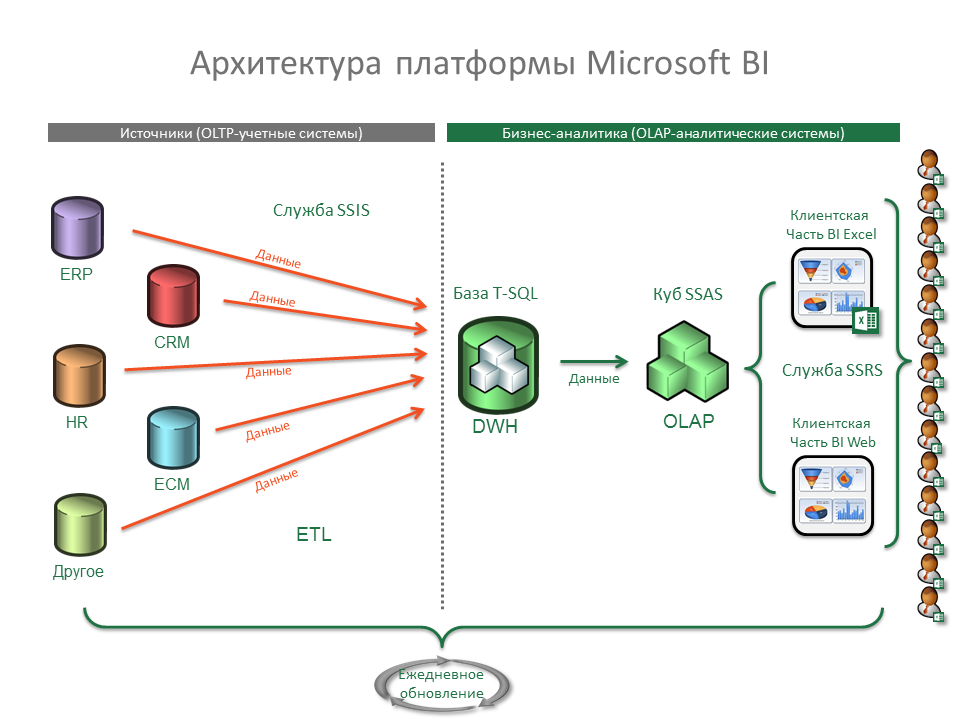
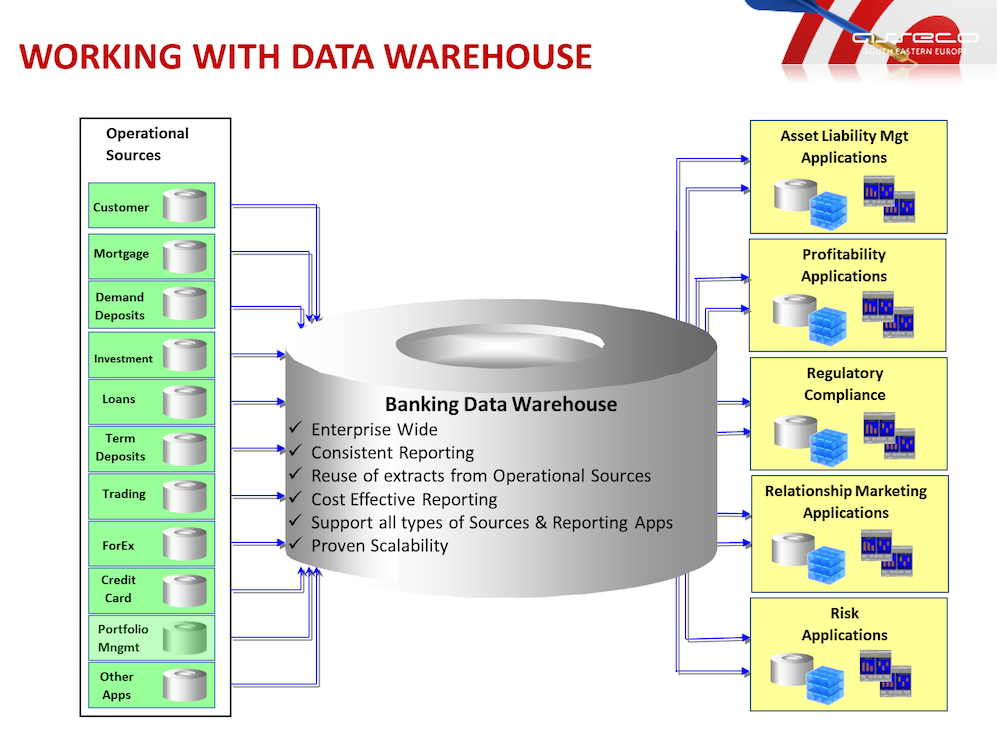
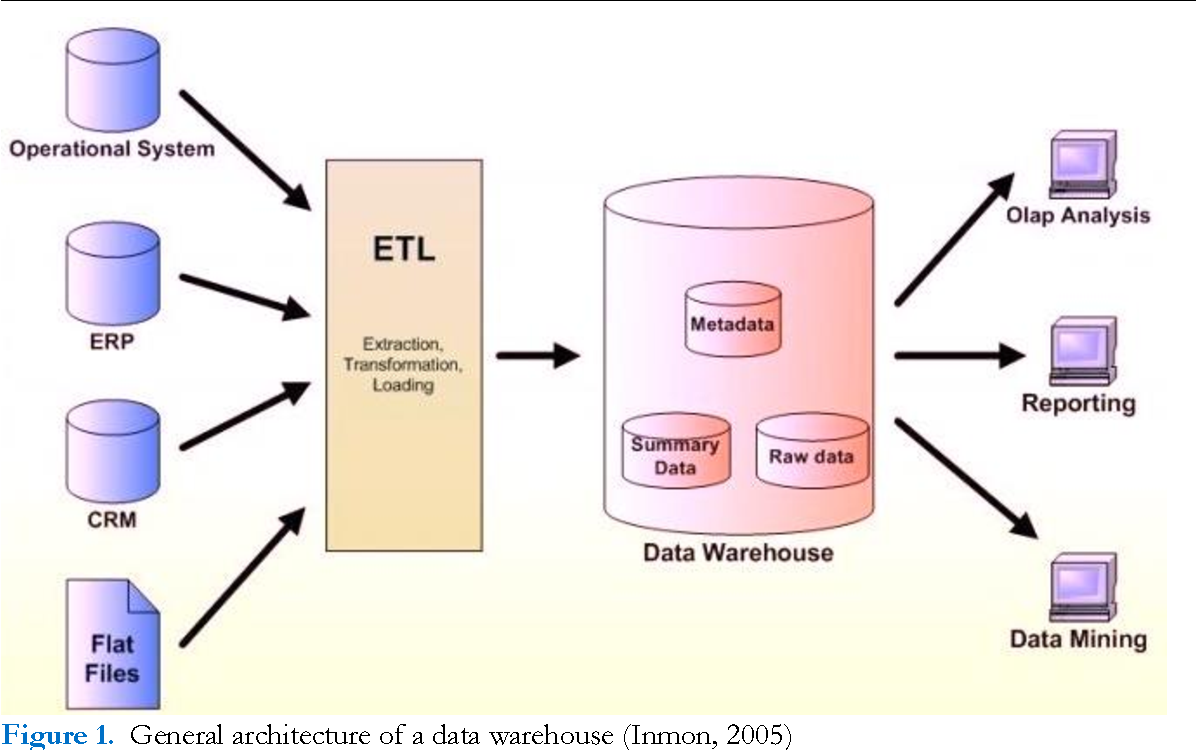
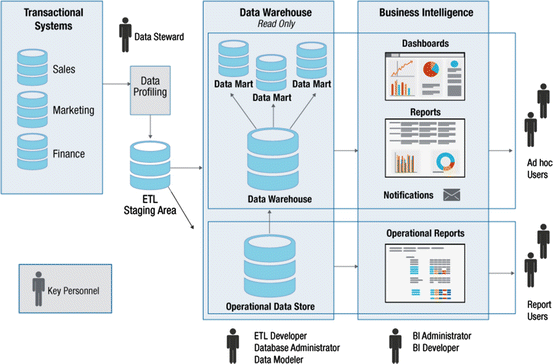
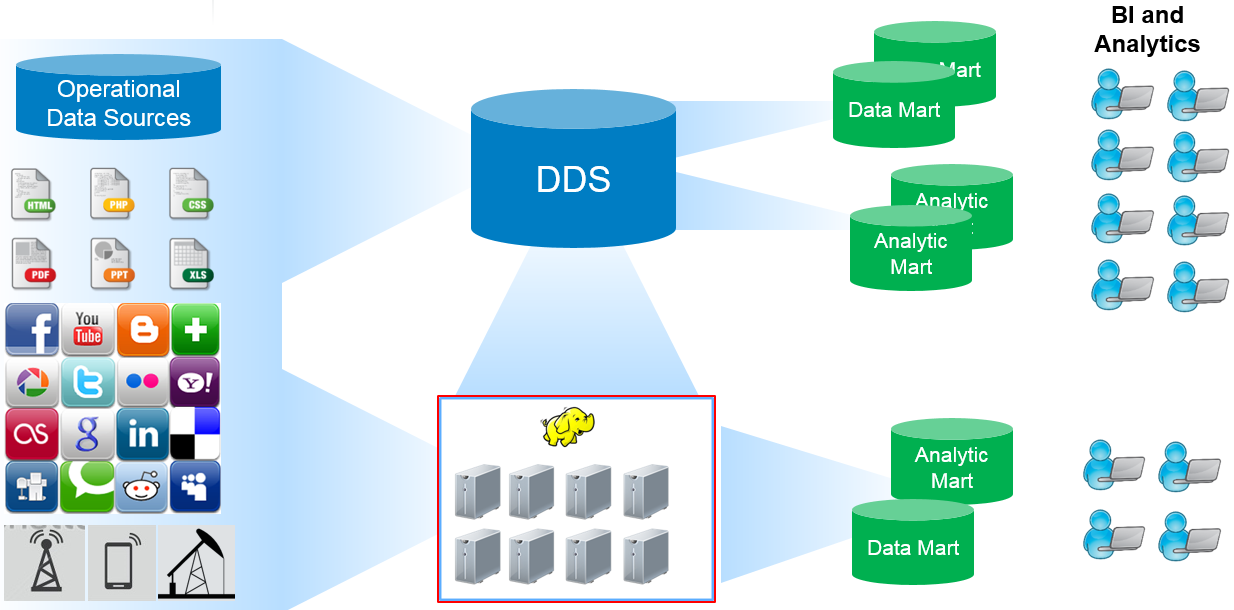
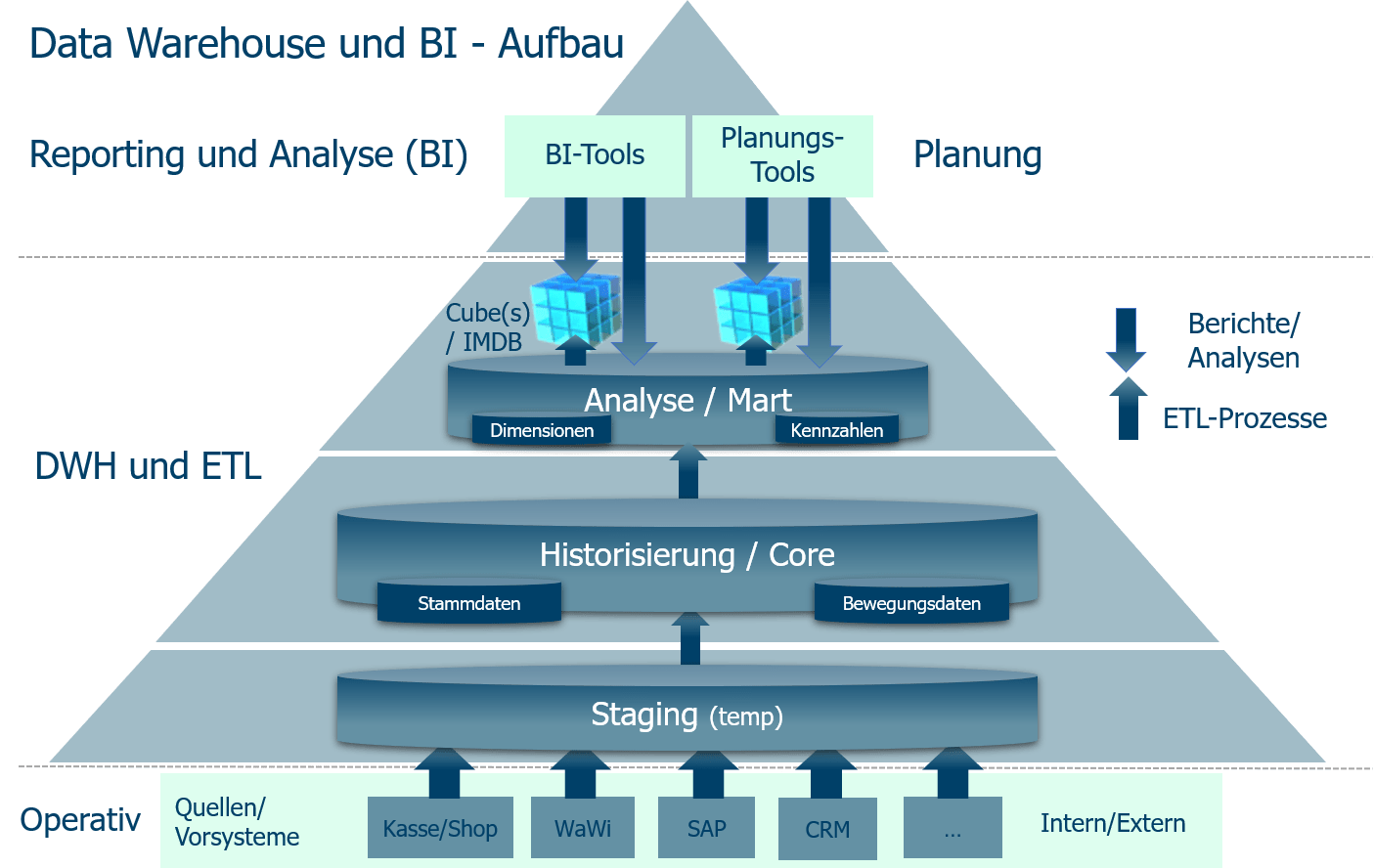
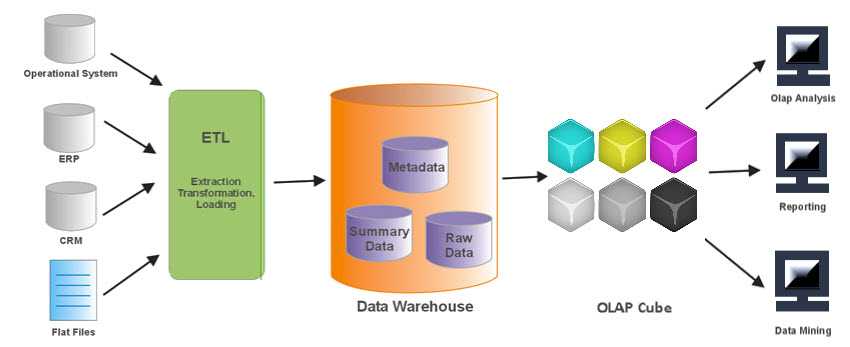
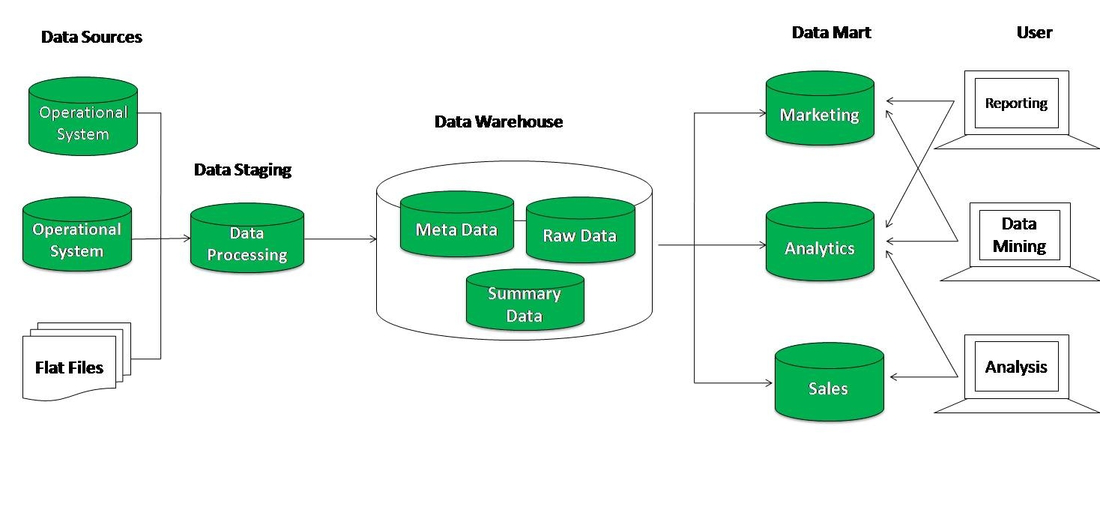
Витрины данных (Data Marts)
Витрины данных являются объектами хранения аналитической информации, нацеленными на поддержку конкретных бизнес-функций, конкретных подразделений компании. На уровне базы данных витрины обычно реализуются по схеме «звезда» или «снежинка» и содержат данные из области детальных данных (System of records). Также могут быть реализованы в виде многомерного OLAP-куба. Витрины данных являются основой, обеспечивающей возможность проведения многомерного анализа (OLAP) данных.
Ниже представлены основные принципы проектирования витрин данных.
- Витрины данных ориентированы на бизнес и при их проектировании необходимо учесть все измерения, показатели и иерархии, необходимые пользователям.
- При проектировании витрин данных необходимо учитывать особенности BI-приложения, используемого на проекте. Например, в Oracle Discoverer нет возможности создавать несбалансированные иерархии и это нужно учитывать.
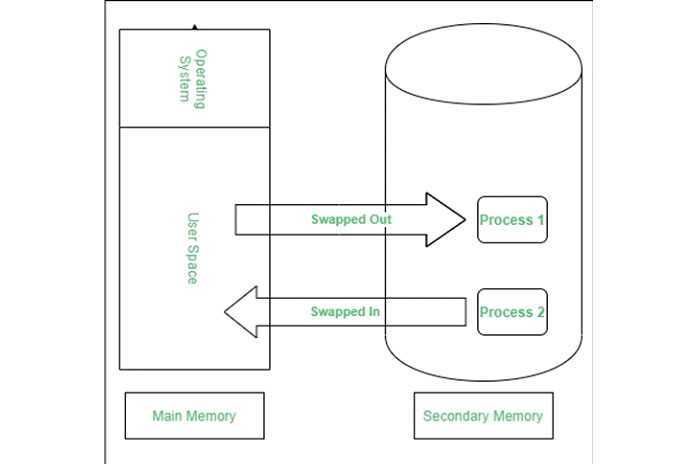
Обмен
Когда процесс выполняется, он должен находиться в памяти. Перекачка представляет собой процесс обмена процесс временно во вторичную память из в основной памяти, которая является быстрым, по сравнению с вторичной памятью. Подкачка позволяет запускать больше процессов и может быть помещена в память одновременно. Основная часть подкачки — это время передачи, а общее время прямо пропорционально объему подкачки памяти. Обмен также известен как развертывание, развертывание, потому что, если приходит процесс с более высоким приоритетом и ему требуется обслуживание, диспетчер памяти может заменить процесс с более низким приоритетом, а затем загрузить и выполнить процесс с более высоким приоритетом. После завершения высокоприоритетной работы,процесс с более низким приоритетом поменялись обратно в памяти и продолжал в процессе исполнения.
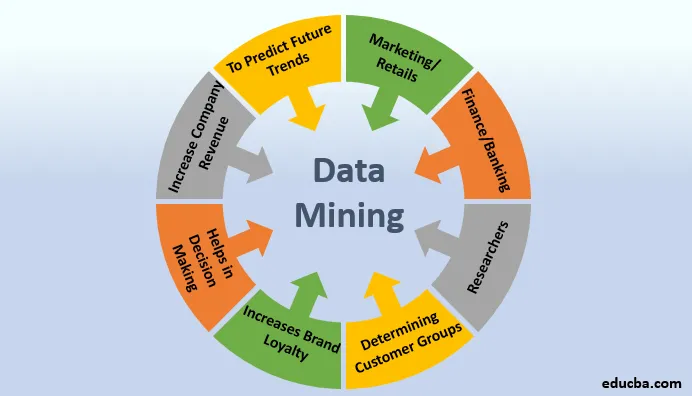
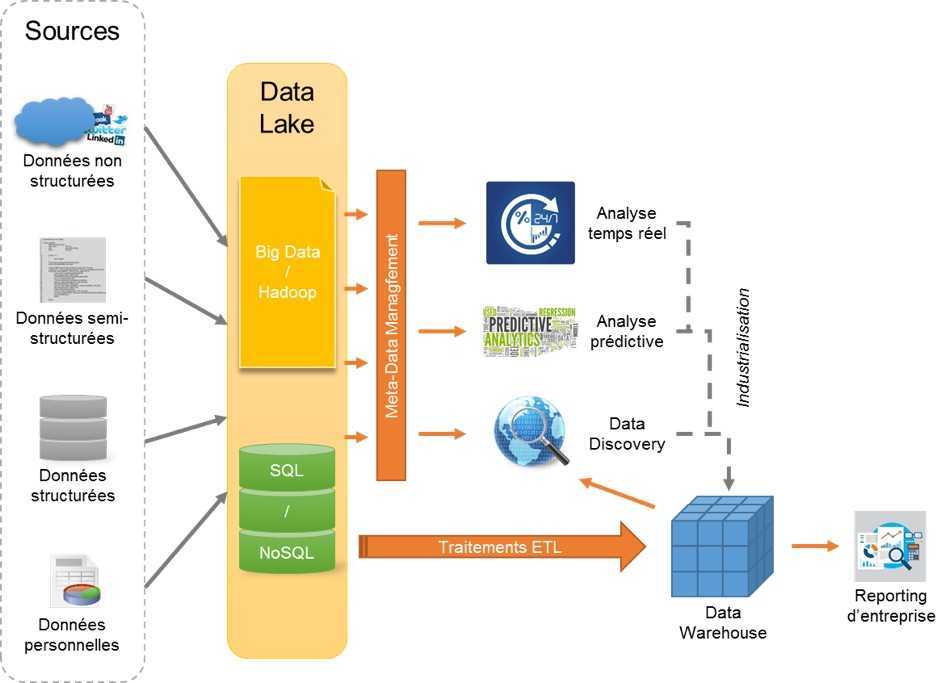
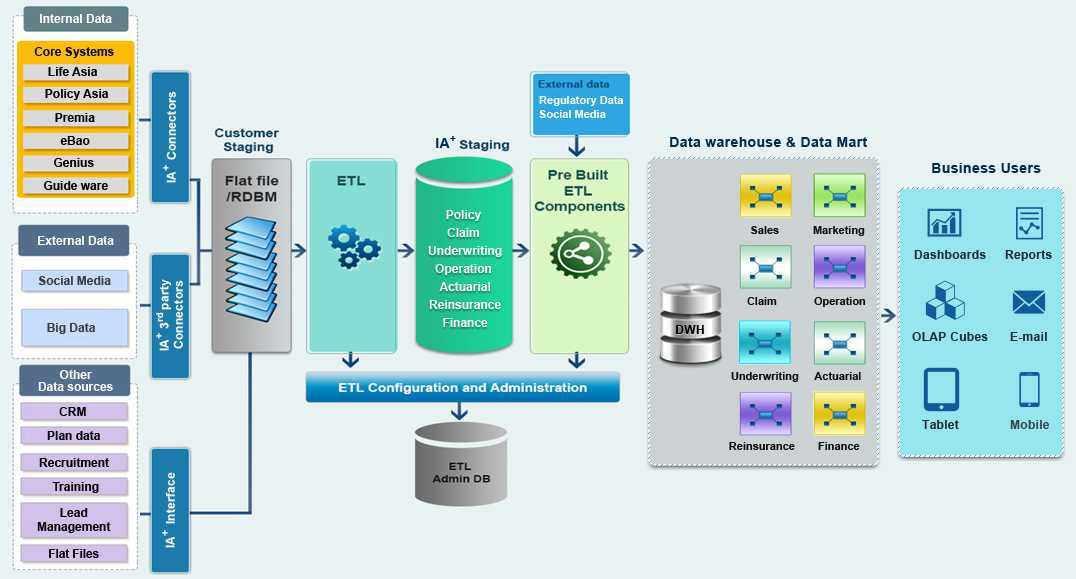
Цель Data Fabric
Препятствия, связанные с различными бизнес-приложениями, временем, пространством, хранением данных, методами извлечения данных, протоколами безопасности данных и т. д., являются макроузкими местами, которые тянут компанию сзади. Эти сдержки и противовесы также помогают вашему бизнесу защищать конфиденциальные данные. Следовательно, вы не можете ни избавиться от них, ни оставить их как есть.
Здесь вам нужна ячеистая сеть передачи данных. Автострада, которая освобождает путь для данных из различных объектов, бизнес-приложений, полевых офисов, витрин, серверов и многого другого. Кроме того, эти данные могут быть структурированными, полуструктурированными и необработанными. Не говоря уже о том, что разные данные поставляются с разными уровнями политик безопасности.
Но конечный пользователь, такой как клиент, торговые представители, руководители службы поддержки и менеджеры, не должен понимать все это. Им просто нужен безопасный доступ к данным для выполнения своих задач. Ткань данных выполнит это за счет автоматизации, искусственного интеллекта и машинного обучения (ML).
Другие известные цели:
- Подключается ко всем источникам бизнес-данных через контейнеры и соединители.
- Предлагает возможности интеграции и приема данных в хранилище, приложениях и т. д.
- Работает как высокоскоростная инфраструктура данных для анализа больших данных
- Объединяет потребителей и источники данных в одну ячеистую сеть.
- Предлагает гибридные операции с данными между частным облаком, общедоступным облаком, мультиоблачными, локальными и физическими рабочими станциями.

Предприятия тратят больше времени на принятие и утверждение данных, чем на их обработку. Сотрудники просматривают сотни сообщений электронной почты, прежде чем получить разрешение на обработку данных.
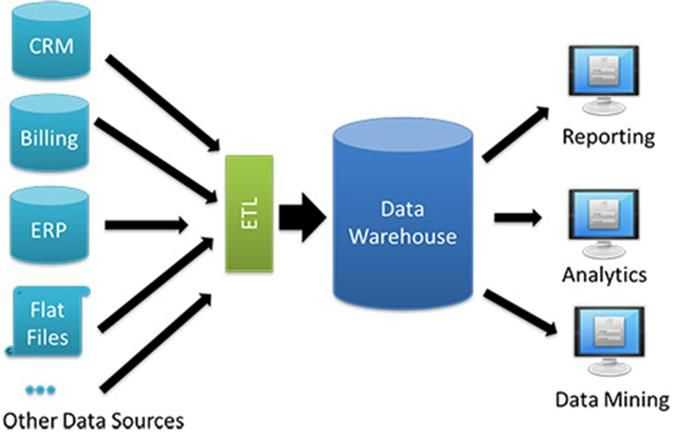
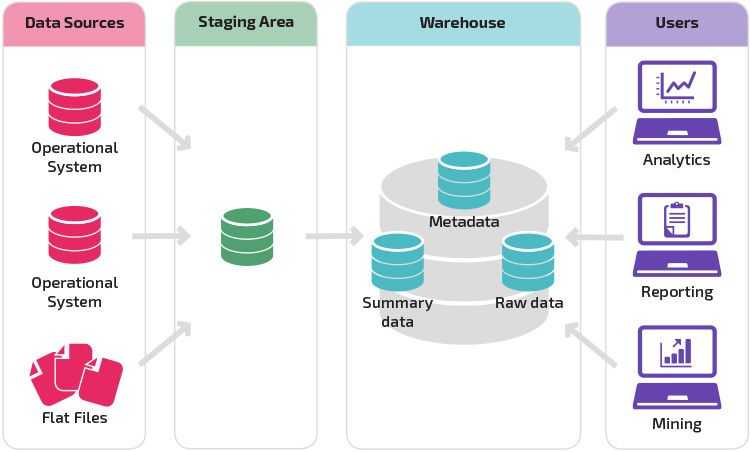
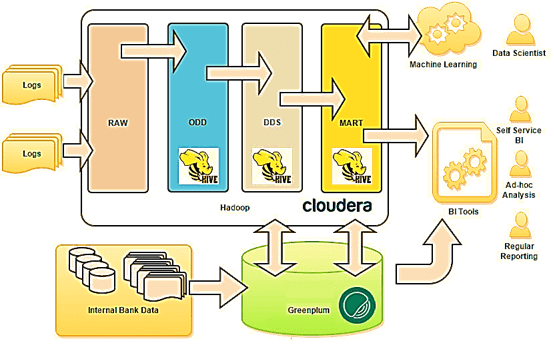
Это серьезная угроза производительности предприятий, готовых к будущему. Но фабрика данных может спасти организации следующими способами:
- Платформа «единого окна» для доступа, отправки, хранения и анализа данных любого типа.
- Хотя каждый в бизнесе может получить доступ к данным до определенного уровня, все политики управления данными и регулирования будут соблюдаться.
- Сделайте данные более надежными и удобными для восприятия, позволив ИИ обрабатывать данные до того, как люди получат к ним доступ.
- Обеспечьте связь между машинами или Интернетом вещей (IoT), чтобы уменьшить вмешательство человека в конфиденциальные данные.
- Легко адаптируйтесь к увеличению и уменьшению количества заявок, запросов клиентов, заявок на доступ к внутренним данным, внезапному притоку огромных маркетинговых данных и т. д.
- Сокращение потребностей бизнеса и зависимости от размещения устаревшей инфраструктуры и, следовательно, снижение затрат.
- Максимально используйте облачные технологии, подключив все виды источников цифровых данных в одном месте, защищенном строгими алгоритмами искусственного интеллекта.
В конечном счете, фронтовой агент будет быстрее получать данные в свои CRM и быстрее обрабатывать запросы клиентов. Это, в свою очередь, повышает доверие клиентов и их удовлетворенность вашим бизнесом.
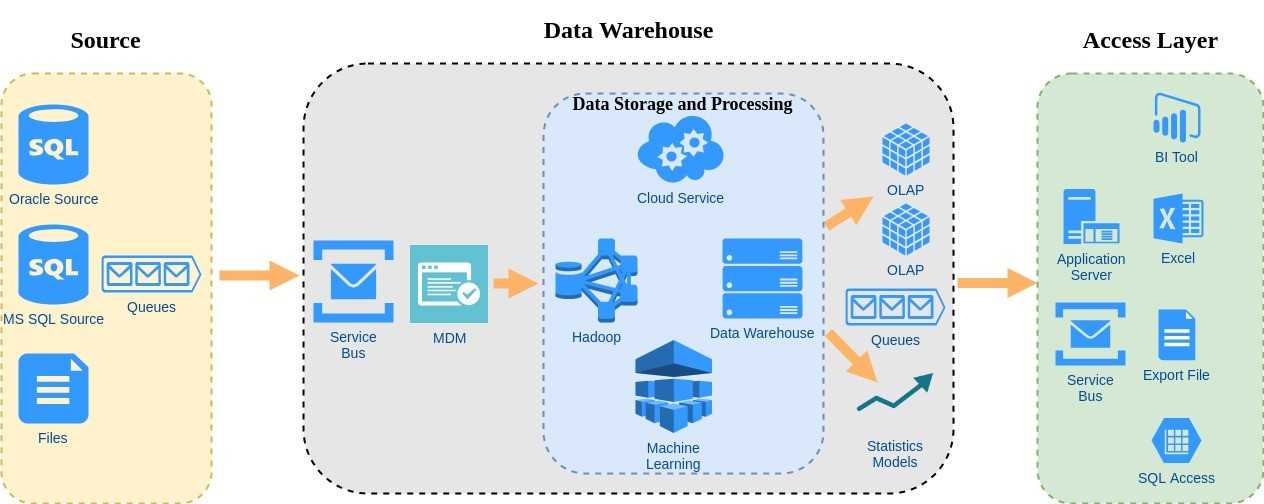
Что такое master-данные?
Мастер-данные («основные данные» или «нормативно-справочная информация») — это данные, записывающие справочную информацию, то есть значения, которые могут использоваться для указания, к чему какие данные относятся. Самый простой пример применения мастер-данных – разного рода справочники или классификаторы.
MDM-системы — это решения для управления справочной информацией. Их главная цель — обеспечить единство представления массивов данных во всех информационных системах. Кроме того, такой тип решений позволяет решить проблемы несоответствия, дублирования и несопоставимости данных.
Для того, чтобы разобраться в том, как MDM-система должна функционировать, важно понять, как устроены процессы по работе с данными. Процессы можно поделить на несколько видов
Процессы можно поделить на несколько видов.
- Reference Data Management — это простые линейные справочники, в которых не требуется какая-либо сложная логика, например, справочники стран или валют. Cамый многочисленный набор справочных данных, с которыми приходится работать.
- MDM— это данные линейных или иерархических справочников с идентичной структурой хранения, где одна запись по своему составу и атрибутам похожа на другую. Пример таких справочников —клиенты, контрагенты, абоненты, организационная структура (например, сотрудники и все, что с ними связано).
Такие данные чаще всего подвергаются обязательной функции дедубликации (выявление и слияние дубликатов данных), поскольку работа с дублированными справочными данными может приводить к несоответствию отчетности, неверным решениям в части работы с клиентами и т.д.. Так, если для многих справочников (продуктовых/материальных ценностей) характерно централизованное ведение, то для клиентских справочников, где присутствуют физические лица, используют другую схему работы, которая называется консолидацией данных или гармонизацией мастер-данных.
Процесс консолидации начинается с появления данных во фронтальных системах, например, на интернет-порталах, после чего происходит их расшифровка и перемещение в систему управления нормативно-справочной информацией для поиска дубликатов, далее начинается разработка единой записи на основе всех, которые были найдены ранее. Затем данные направляются в хранилища, озера данных и другие системы как единая версия правды.
- Сложные иерархические справочники, часто зависящие от других справочников. Самый частый пример — продукты, товары, услуги, работы.
Исходя из потребностей работы с мастер-данными, промышленные системы MDM в своем составе имеют возможность:
- моделирования справочников;
- выполнения интеграционных процессов по наполнению и последующему предоставлению мастер-данных;
- слияния записей, которые были найдены как потенциальные дубликаты, или их разделения. Поскольку система может принять неверное решение, специалист должен иметь возможность вручную разделить записи и указать, что они уникальны. Для оптимизации этого процесса можно настроить систему так, чтобы она позволяла найти способ создать золотую запись или мастер-запись, которая соберет несколько дубликатов с различными полями и значениями;
- установки вертикальных и горизонтальных связей между используемыми значениями. Так, если справочники иерархические, — например, справочник холдингов, — специалистам необходимо управлять составными частями холдингов и их частями, например, дочерними организациями, и «привязывать» туда людей. При этом между справочниками должны быть и горизонтальные связи. Например, есть клиент, у которого есть продукт, который он приобрел в конкретной торговой точке. Горизонтальная связь здесь формируется между этими тремя объектами.