ВВЕДЕНИЕ
Машинное обучение – это обширный раздел связанный с искусственным интеллектом. Машинное обучение изучает методы построения алгоритмов, которые способны самостоятельно изучаться или воспринимать опыт и знания у экспертов в виде базы знаний.
Сама идея создания искусственного интеллекта или правильнее сказать подобия человека, который будет моделировать человеческий разум для решения сложных задач зародилась ещё в древние времена. Но первым экспериментатором и по совместительству родоначальником искусственного интеллекта необходимо считать ученого и философа родившийся в Майорке (нынешней Испании) Раймонд Луллий, который в 14 веке попытался создать механическую машину для решения различных задач, на основе разработанной им классификации понятий, связанные с комбинаторикой. И после него было много попыток продолжения этой идеи создания нечто похожего на разум.
Окончательное рождение искусственного интеллекта как научного направления произошло только после создания ЭВМ в 40-х годах ХХ века, людям уже тогда было любопытно, могут ли компьютеры обучаться. Если мы осознаем, как запрограммировать их для самообучения, чтобы они улучшались автоматически от каждого байта информации в нем, то исходом может быть… Представьте человека который выучился в мед. Вузе, данный врач способен определить болезнь и какие виды лечения более эффективны, а теперь представьте, что те же знания и опыт множества врачей передать компьютеру, но накапливая опыт он способен это делать быстрее и точнее, а также при обнаружение новых болезней сможет определить угрозу новой болезни и выявить максимально эффективные способы лечения. Но в отличие от человека это можно будет делать без посещения врача или просто анализировать результаты исследований и выдавать высокоточные «врачебные рекомендации». Или дома, обучающиеся на опыте, оптимизировать энергетические издержки, основываясь на обычных данных употребления энергии его жителями; или персональная компьютерная программа, которая изучает изменения интересов своих пользователей, чтобы поместить на передний план, главным образом, ту новость из сегодняшних утренних газет, которая была бы уместна конкретному пользователю.
Умение научить компьютер самообучению могло бы открыть новые уровни знания, компетентности, производительности. И подробное понимание информационной обработки алгоритмов для машинного обучения могло бы привести также к лучшему пониманию человеческой обучающей способности.
Целью данной курсовой работы является разбор понятий и определений, которые связанны с машинным обучением, как работает машинное обучение, где уже работает машинное обучение, как может помочь в экономике машинное обучение и какие проблемы для экономики ещё не решены.
Жизненный цикл содержимого
Хранилище знаний обновляется при каждом запуске индексатора и набора навыков, если есть изменения в наборе навыков или базовом источнике данных. Любые обнаруженные индексатором изменения передаются через процесс обогащения в проекции в хранилище знаний. Это гарантирует, что проецируемые данные являются актуальным представлением содержимого в источнике данных.
Примечание
Вы можете изменять данные в проекциях, но такие изменения будут перезаписаны при следующем вызове конвейера, если изменится документ в исходных данных.
Изменения в исходных данных
Для источников данных, которые поддерживают отслеживание изменений, индексатор будет обрабатывать новые и измененные документы, пропуская существующие документы, которые уже были обработаны. Сведения о метке времени зависят от конкретного источника данных, например в контейнере больших двоичных объектов индексатор проверяет дату , чтобы определить, какие большие двоичные объекты нужно принимать.
Изменения в наборе навыков
При внесении изменений в набор навыков следует включить кэширование обогащенных документов, чтобы повторно использовать все существующие обогащения, насколько это возможно.
Без добавочного кэширования индексатор всегда будет обрабатывать документы в порядке увеличения значений метки, не возвращаясь в обратную сторону. Например, индексатор будет обрабатывать большие двоичные объекты в порядке сортировки по , независимо от изменений параметров индексатора или набора навыков. Если вы измените набор навыков, ранее обработанные документы не будут обновляться с учетом нового набора навыков. Для документов, которые обрабатываются после изменения набора навыков, будет применяться новый набор навыков, а значит в документах индекса будут перемешаны результаты, полученные старым и новым наборами навыков.
При добавочном кэшировании в случае обновления набора навыков индексатор будет использовать любые сохраненные обогащения, которых не коснулось изменение набора навыков. Обогащения, которые выполняются до измененного навыка или вовсе с ним не связаны, извлекаются из кэша.
Удаления
Индексатор только создает и обновляет структуры и содержимое в служба хранилища Azure, но не удаляет их. Проекции продолжат существовать даже в случае удаления индексатора или набора навыков. Удаление ненужных проекций оставляется на усмотрение владельца учетной записи хранения.
Программное обеспечение
Следующие приложения доступны под бесплатными лицензиями / лицензиями с открытым исходным кодом. Также доступен открытый доступ к исходному коду приложения.
- Carrot2 : структура кластеризации текста и результатов поиска.
- Chemicalize.org : программа для разработки химических структур и поисковая система в Интернете.
- ELKI : университетский исследовательский проект с расширенным кластерным анализом и методами обнаружения выбросов, написанный на языке Java .
- GATE : инструмент для обработки естественного языка и языковой инженерии.
- KNIME : Konstanz Information Miner, удобный и комплексный фреймворк для анализа данных.
- Massive Online Analysis (MOA) : интеллектуальный анализ потоков больших данных в реальном времени с помощью инструмента смещения концепций на языке программирования Java .
- MEPX : кроссплатформенный инструмент для задач регрессии и классификации на основе варианта генетического программирования.
- ML-Flex: программный пакет, который позволяет пользователям интегрироваться со сторонними пакетами машинного обучения, написанными на любом языке программирования, выполнять анализ классификации параллельно на нескольких вычислительных узлах и создавать отчеты о результатах классификации в формате HTML.
- mlpack : набор готовых алгоритмов машинного обучения, написанных на языке C ++ .
- NLTK ( Natural Language Toolkit ): набор библиотек и программ для символьной и статистической обработки естественного языка (NLP) для языка Python .
- OpenNN : открытая библиотека нейронных сетей .
- Orange : программный пакет для анализа данных и машинного обучения на основе компонентов, написанный на языке Python .
- PSPP : программное обеспечение для сбора данных и статистики в рамках проекта GNU, аналогичное SPSS.
- R : язык программирования и программная среда для статистических вычислений, интеллектуального анализа данных и графики. Это часть проекта GNU .
- Scikit-learn : библиотека машинного обучения с открытым исходным кодом для языка программирования Python
- Torch : библиотека глубокого обучения с открытым исходным кодом для языка программирования Lua и среды научных вычислений с широкой поддержкой алгоритмов машинного обучения .
- UIMA : UIMA (Архитектура управления неструктурированной информацией) — это компонентная структура для анализа неструктурированного контента, такого как текст, аудио и видео, первоначально разработанная IBM.
- Weka : набор программных приложений для машинного обучения, написанных на языке программирования Java .
Проприетарное программное обеспечение и приложения для интеллектуального анализа данных
Следующие приложения доступны по проприетарным лицензиям.
- Angoss KnowledgeSTUDIO: инструмент интеллектуального анализа данных
- LIONsolver : интегрированное программное приложение для интеллектуального анализа данных, бизнес-аналитики и моделирования, реализующее подход обучения и интеллектуальной оптимизации (LION).
- Megaputer Intelligence: программное обеспечение для интеллектуального анализа данных и текста называется PolyAnalyst .
- Microsoft Analysis Services : программное обеспечение для интеллектуального анализа данных, предоставляемое Microsoft .
- NetOwl : набор многоязычных продуктов для анализа текста и сущностей, которые позволяют интеллектуальный анализ данных.
- Oracle Data Mining : программное обеспечение для интеллектуального анализа данных от Oracle Corporation .
- PSeven : платформа для автоматизации инженерного моделирования и анализа, междисциплинарной оптимизации и интеллектуального анализа данных, предоставляемая DATADVANCE .
- Qlucore Omics Explorer: программное обеспечение для интеллектуального анализа данных.
- RapidMiner : среда для экспериментов по машинному обучению и интеллектуальному анализу данных.
- : программное обеспечение для интеллектуального анализа данных, предоставленное институтом SAS .
- SPSS Modeler : программное обеспечение для интеллектуального анализа данных, предоставленное IBM .
- STATISTICA Data Miner: программное обеспечение для интеллектуального анализа данных, предоставляемое StatSoft .
- Tanagra : Программное обеспечение для интеллектуального анализа данных, ориентированное на визуализацию, также предназначенное для обучения.
- Vertica : программное обеспечение для интеллектуального анализа данных, предоставленное Hewlett-Packard .
- Google Cloud Platform : автоматизированные пользовательские модели машинного обучения под управлением .
- Amazon SageMaker : управляемый сервис, предоставляемый Amazon для создания и производства пользовательских моделей машинного обучения .
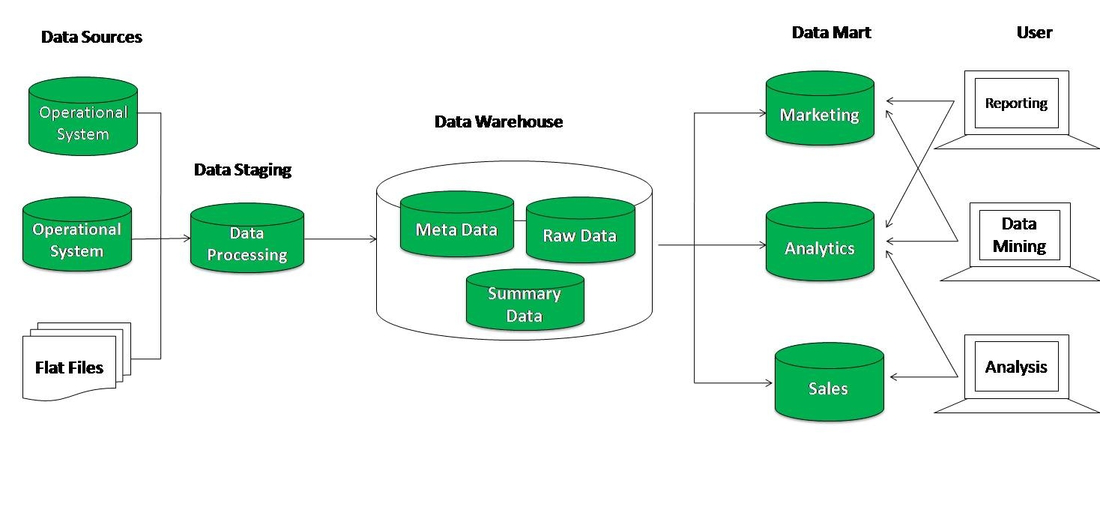
2.Хранилища данных
Для того чтобы обеспечить возможность анализа накопленных данных, организации стали создавать хранилища данных, которые представляют собой интегрированные коллекции данных, которые собраны из различных систем оперативного доступа к данным. Хранилища данных становятся основой для построения систем принятия решений. Несмотря на различия в подходах и реализациях, всем хранилищам данных свойственны следующие общие черты:
- Предметная ориентированность. Информация в хранилище данных организована в соответствии с основными аспектами деятельности предприятия (заказчики, продажи, склад и т.п.); это отличает хранилище данных от оперативной БД, где данные организованы в соответствии с процессами (выписка счетов, отгрузка товара и т.п.). Предметная организация данных в хранилище способствует как значительному упрощению анализа, так и повышению скорости выполнения аналитических запросов. Выражается она, в частности, в использовании иных, чем в оперативных системах, схемах организации данных. В случае хранения данных в реляционной СУБД применяется схема «звезды» (star) или «снежинки» (snowflake). Кроме того, данные могут храниться в специальной многомерной СУБД в n-мерных кубах.
- Интегрированность. Исходные данные извлекаются из оперативных БД, проверяются, очищаются, приводятся к единому виду, в нужной степени агрегируются (то есть вычисляются суммарные показатели) и загружаются в хранилище. Такие интегрированные данные намного проще анализировать.
- Привязка ко времени. Данные в хранилище всегда напрямую связаны с определенным периодом времени. Данные, выбранные их оперативных БД, накапливаются в хранилище в виде «исторических слоев», каждый из которых относится к конкретному периоду времени. Это позволяет анализировать тенденции в развитии бизнеса.
- Неизменяемость. Попав в определенный «исторический слой» хранилища, данные уже никогда не будут изменены. Это также отличает хранилище от оперативной БД, в которой данные все время меняются, «дышат», и один и тот же запрос, выполненный дважды с интервалом в 10 минут, может дать разные результаты. Стабильность данных также облегчает их анализ.
Вышеприведенные особенности были впервые сформулированы в 1992 году «отцом-основателем» хранилищ данных Биллом Инмоном (Bill Inmon) в его книге «Building the Data Warehouse».
Определение хранилища знаний
Хранилище знаний определяется в определении набора навыков и состоит из двух компонентов:
-
Строка подключения к службе хранилища Azure
-
Проекции , определяющие, состоит ли хранилище знаний из таблиц, объектов или файлов.
Элемент projections является массивом. В одном хранилище знаний можно создать несколько наборов сочетаний таблиц, объектов и файлов.
Тип проекции, заданный в этой структуре, определяет тип хранилища, используемого хранилищем знаний.
-
проецирует обогащенное содержимое в Хранилище таблиц. Определите проекцию таблицы, если вам нужны табличные структуры отчетов для входных данных средств аналитики или экспорта в виде кадров данных в другие хранилища данных. Можно указать несколько элементов в одной группе проекции, чтобы получить некоторое подмножество или пересечение обогащенных документов. В одной группе проекции связи между таблицами сохраняются, чтобы можно было работать со всеми таблицами.
Проецированное содержимое не агрегируется и не нормализуется. На следующем снимке экрана показана таблица, отсортированная по ключевой фразе, с родительским документом, указанным в соседнем столбце. В отличие от приема данных во время индексирования, лингвистического анализа или агрегирования содержимого не выполняется. Формы множественного числа и различия в регистре считаются уникальными экземплярами.
-
-
проецирует документ JSON в Хранилище BLOB-объектов. Физическое представление — это иерархическая структура JSON, которая представляет обогащенный документ.
-
проецирует файлы изображений в Хранилище BLOB-объектов. — это изображение, извлеченное из документа, которое переносится в хранилище BLOB-объектов без изменений. Хотя он называется «файлы», он отображается в хранилище BLOB-объектов, а не в хранилище файлов.


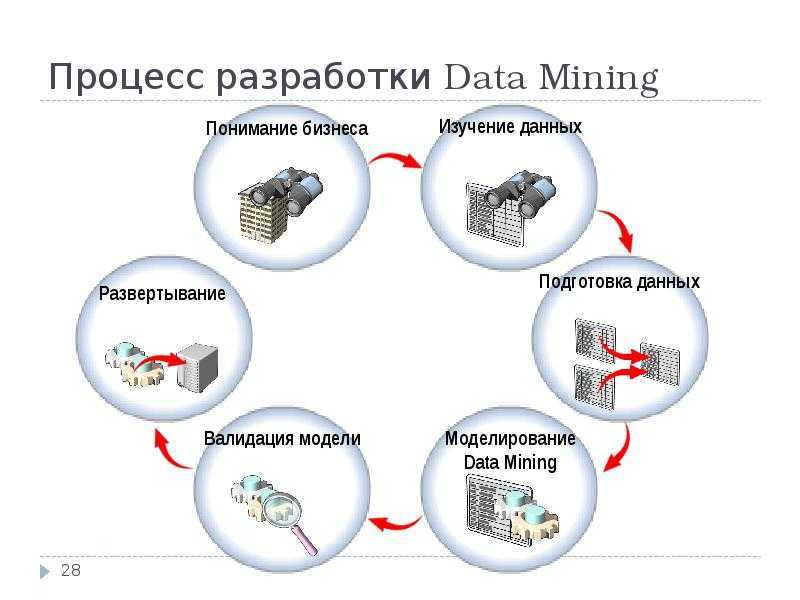


![Технологии хранилищ данных [реферат №8969]](https://robotrackkursk.ru/wp-content/uploads/9/4/c/94c02a370a3bf65b3a6ed478db6e558f.webp)
Смысл правильного, ошибочного и недопустимого значений
Каждому значению в таблице Значение на странице Значения домена назначается параметр Тип — Правильно, Ошибкаили Недопустимо. Тип значения первоначально назначается операцией обнаружения знаний, и его вы можете изменить по своему усмотрению. Последний тип, основанный на обнаружении и интерактивных изменениях, формируется операцией очистки. Эти значения имеют следующий смысл.
-
Правильно. Это значение принадлежит к домену и не имеет каких-либо синтаксических ошибок. Например, значение «Чикаго» в домене «Город» — правильное.
-
Ошибка. Это значение принадлежит домену, но является неверным. Например, «Шикаго» вместо «Чикаго» в домене «Город» — ошибка. Службы DQS определяют значение как ошибочное, если выявлена синтаксическая ошибка, и назначают связанное исправление в процессе обнаружения. Орфографические ошибки относятся к числу синтаксических ошибок.
-
Недопустимый. Это значение не принадлежит к домену и не имеет исправления. Например, значение «12345» в домене «Город» является недопустимым. Службы DQS определяют значение как недопустимое, если оно не соответствует правилу домена.
Тип значения вы можете изменить вручную на любое из двух других значений. Службы DQS не обеспечивают правильность и семантику ошибок при ручных операциях. Исправление для недопустимого значения вы можете ввести без изменения его статуса. Вы можете объявить значение недопустимым, даже если оно не нарушает правила домена. Службы DQS могут определить значение как ошибочное, даже если в процессе обнаружения не выявлены синтаксические ошибки. Вы можете также удалить исправление ошибочного значения, которое отмечено как правильное, без изменения его статуса.
При интерактивной очистке данных на странице Управление результатами и их просмотр операции Очистка как недопустимые, так и ошибочные значения представлены на вкладке Недопустимые на странице Управление результатами и их просмотр .
Этап обнаружения
-
Нажмите кнопку Запустить для анализа источника данных.
Примечание
Обнаружение выполняется для столбцов, заданных в таблице Сопоставления на странице Карта . Домены, сопоставленные с каждым из столбцов, будут заполняться полученными при обнаружении набора знаний. Если домен является составным, то набор знаний будут добавлены в отдельные домены, входящие в составной домен.
-
По мере выполнения процесса обнаружения проверяйте состояние завершения каждого из шагов обнаружения: Предварительная обработка записей, Выполнение правил доменаи Выполнение обнаружения. Для каждого из этих этапов отображаются процент завершения и состояние завершения.
-
После завершения анализа убедитесь, что строка состояния под статистическими показателями выполнения содержит сообщение об успешном завершении.
Примечание
Если покинуть экран до загрузки файла, процесс загрузки файла будет прерван.
-
После завершения анализа проверьте статистические показатели на вкладке «Профилировщик» , чтобы определить состояние данных. Дополнительные сведения см. в разделе Профилирование данных и уведомления в DQS.
-
После завершения анализа данных кнопка Пуск преобразуется в кнопку Перезапустить . Нажмите кнопку Перезапуск для повторного запуска процесса анализа. Однако если результаты предыдущего анализа еще не были сохранены, то после нажатия кнопки Перезапустить ранее полученные данные теряются. Чтобы продолжить нажмите кнопку Да во всплывающем меню. Во время выполнения анализа не уходите с этой страницы, поскольку процесс анализа будет прекращен.
-
Нажмите кнопку Далее , чтобы перейти на страницу Управление значениями домена мастера обнаружения набора знаний. На этой странице вы можете изменить знания, добавленные в домены базы знаний. Также вы можете выбрать следующие действия.
-
Нажмите кнопку Отмена , чтобы прекратить действие обнаружения набора знаний с потерей полученных результатов и вернуться на домашнюю страницу DQS.
-
Нажмите кнопку Закрыть , чтобы вернуться на домашнюю страницу DQS с сохранением результатов работы. База знаний будет заблокирована вами, а в таблице баз знаний на экране Открытие базы знаний эта база знаний перейдет в состояние Обнаружение — обнаружение. После нажатия кнопки Закрытьдля выполнения действий управления доменами потребуется нажать кнопку Обнаружение знаний на экране Открыть базу знаний , перейти на экран Управление базами знаний: управление терминами доменов , нажать кнопку Готово, а затем кнопку Да , чтобы опубликовать базу знаний, или Нет , чтобы сохранить работу в базе знаний и выйти.
-
Щелкните, чтобы вернуться на страницу Обнаружение .
-
открытие знаний
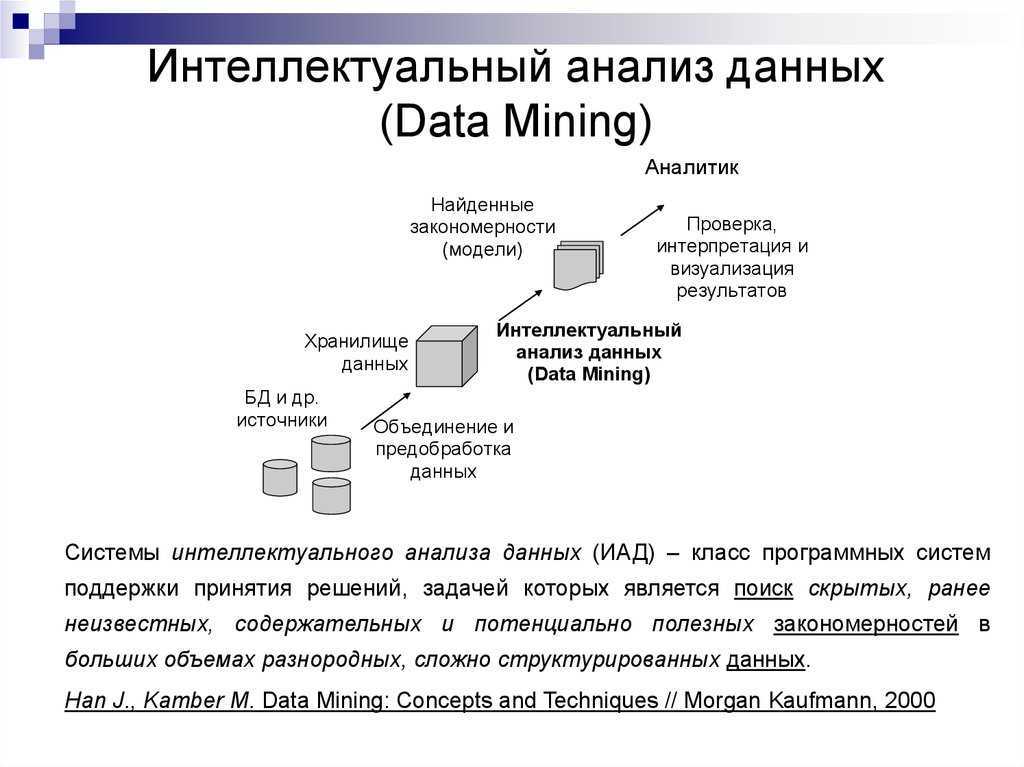
открытие знаний описывает процесс автоматического поиска в больших объемах данных шаблонов, которые могут считаться знаниями о данных. Это часто описывается как получение знаний из входных данных. Поиск знаний развился из области интеллектуального анализа данных и тесно связан с ней как с точки зрения методологии, так и с точки зрения терминологии.
Наиболее известная ветвь интеллектуального анализа данных — это обнаружение знаний, также известное как обнаружение знаний в базах данных (KDD). Как и многие другие формы открытия знаний, он создает абстракции входных данных. Знания, полученные в процессе, могут стать дополнительными данными, которые можно использовать для дальнейшего использования и обнаружения. Часто результаты обнаружения знаний не требуют действий, обнаружение знаний с практическими действиями, также известное как анализ данных на основе предметной области, нацелено на обнаружение и предоставление практических знаний и идей.
Еще одно многообещающее применение обнаружения знаний — это область модернизации программного обеспечения, обнаружения слабых мест и соответствия требованиям, что предполагает понимание существующих программных артефактов. Этот процесс связан с концепцией обратного проектирования. Обычно знания, полученные с помощью существующего программного обеспечения, представлены в виде моделей, к которым при необходимости могут быть сделаны конкретные запросы. Отношение сущностей — это частый формат представления знаний, полученных из существующего программного обеспечения. Группа управления объектами (OMG) разработала спецификацию Метамодель обнаружения знаний (KDM), которая определяет онтологию для программных активов и их взаимосвязей с целью выполнения обнаружения знаний в существующем коде. Обнаружение знаний из существующих программных систем, также известное как интеллектуальный анализ программного обеспечения, тесно связано с интеллектуальным анализом данных, поскольку существующие программные артефакты имеют огромное значение для управления рисками и бизнес-ценности, ключ для оценки и развития программных систем. Вместо анализа отдельных наборов данных, программный анализ фокусируется на метаданных, таких как потоки процессов (например, потоки данных, потоки управления и карты вызовов), архитектура, схемы базы данных и бизнес-правила / условия / процесс.
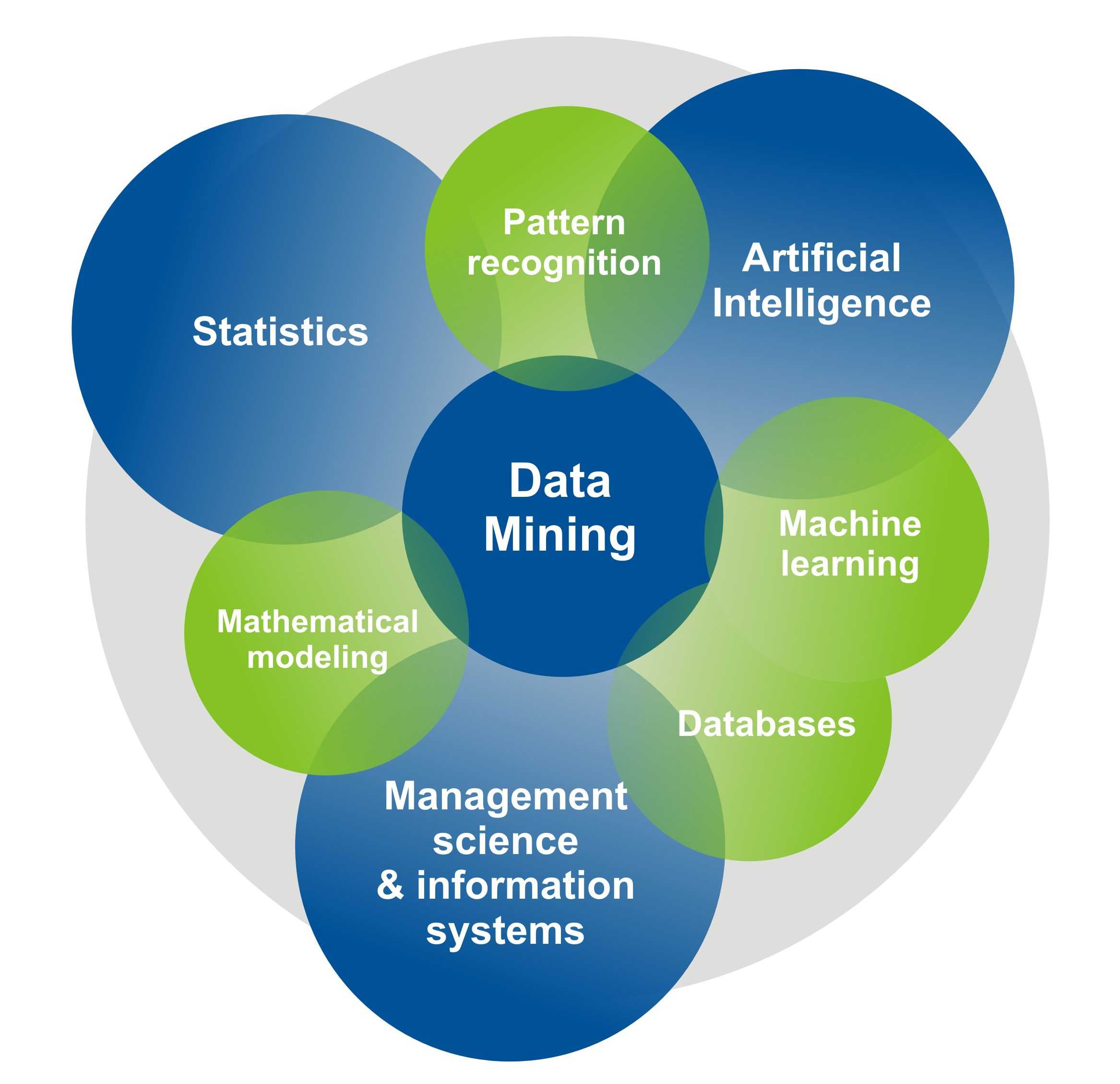


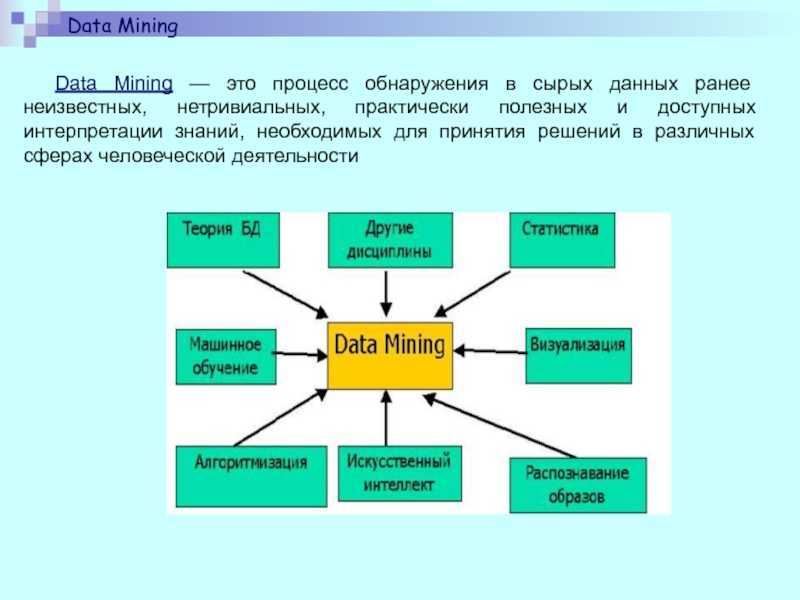

![Цифровая экономика. машинное обучение [курсовая №36991]](https://robotrackkursk.ru/wp-content/uploads/d/f/4/df4d9615b32d803a3f7027deed498dbe.jpeg)

Входные данные
-
Базы данных
- Реляционные данные
- База данных
- Хранилище документов
- Хранилище данных
-
Программное обеспечение
- Исходный код
- Файлы конфигурации
- Скрипты сборки
-
Текст
Концептуальный анализ
-
Графы
Молекулярный анализ
-
Последовательности
- Анализ потока данных
- Изучение изменяющихся во времени потоков данных в условиях дрейфа концепции
- Веб
Форматы вывода
- Модель данных
- Метаданные
- Метамодели
- Онтология
- Представление знаний
- Теги знаний
- Бизнес-правило
- Метамодель обнаружения знаний (KDM)
- Моделирование бизнес-процессов Обозначение (BPMN)
- Промежуточное представление
- Структура описания ресурсов (RDF)
- Метрики программного обеспечения
Стандарты
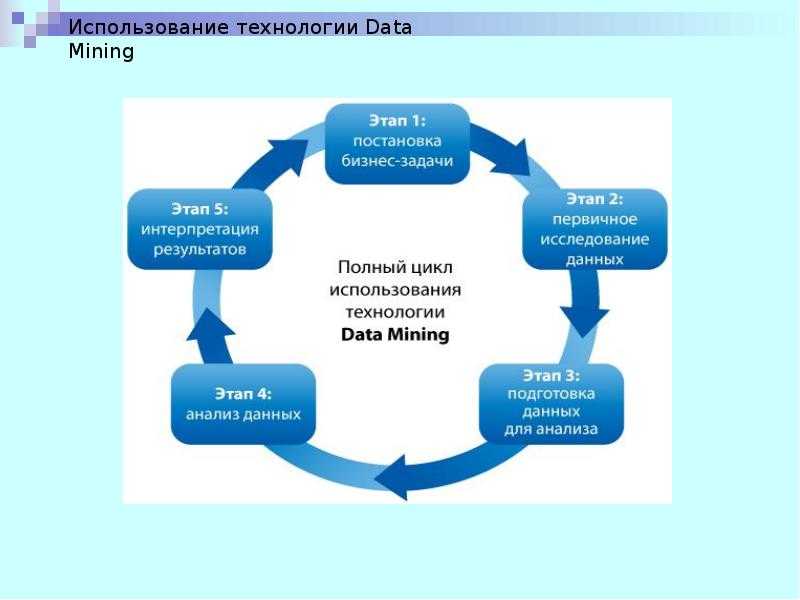
Были предприняты некоторые попытки определить стандарты для процесса интеллектуального анализа данных, например, Европейский межотраслевой стандартный процесс интеллектуального анализа данных 1999 г. (CRISP-DM 1.0) и стандарт интеллектуального анализа данных Java 2004 г. (JDM 1.0). Разработка преемников этих процессов (CRISP-DM 2.0 и JDM 2.0) была активна в 2006 году, но с тех пор остановилась. JDM 2.0 был отозван, не дойдя до окончательной версии.
Для обмена извлеченными моделями — в частности, для использования в прогнозной аналитике — ключевым стандартом является язык разметки прогнозных моделей (PMML), который представляет собой язык на основе XML, разработанный Группой интеллектуального анализа данных (DMG) и поддерживаемый многими в качестве формата обмена. приложения для интеллектуального анализа данных. Как следует из названия, он охватывает только модели прогнозирования — особую задачу интеллектуального анализа данных, имеющую большое значение для бизнес-приложений. Однако расширения для охвата (например) кластеризации подпространств были предложены независимо от DMG.
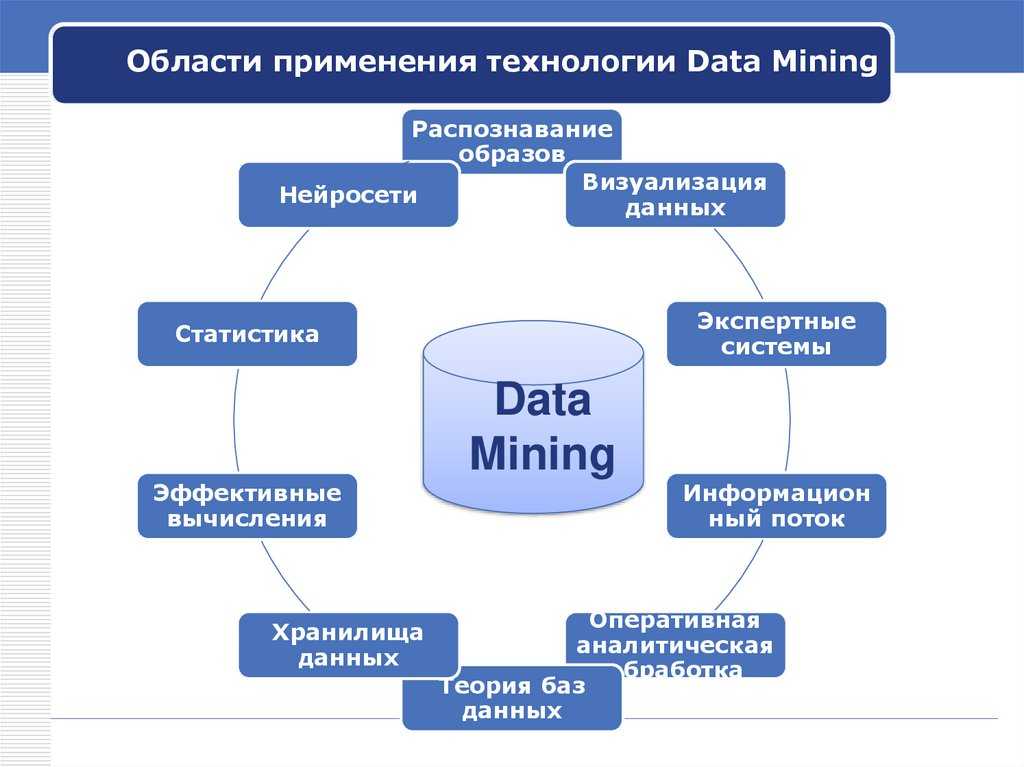
Технологии извлечения знаний
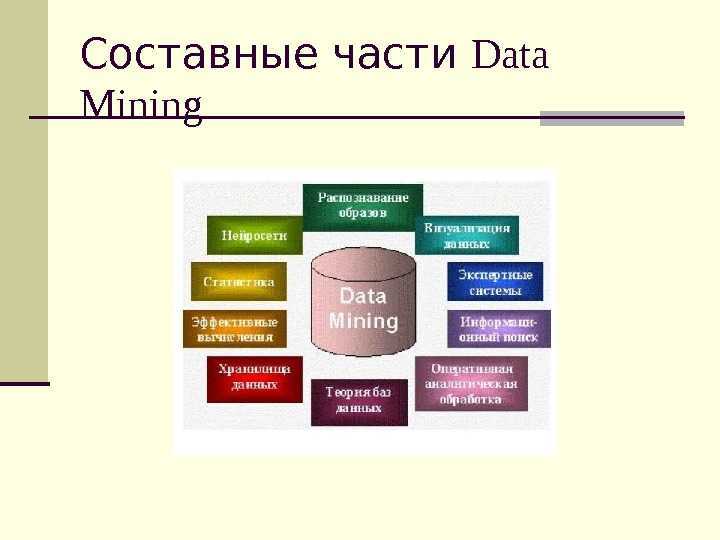
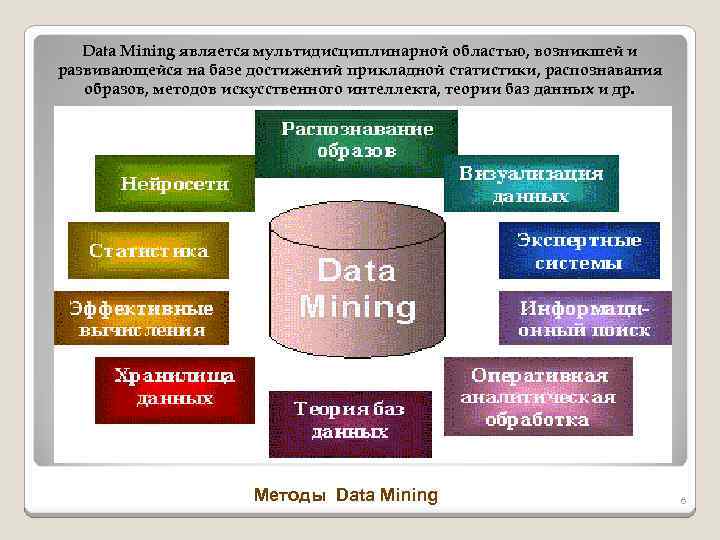
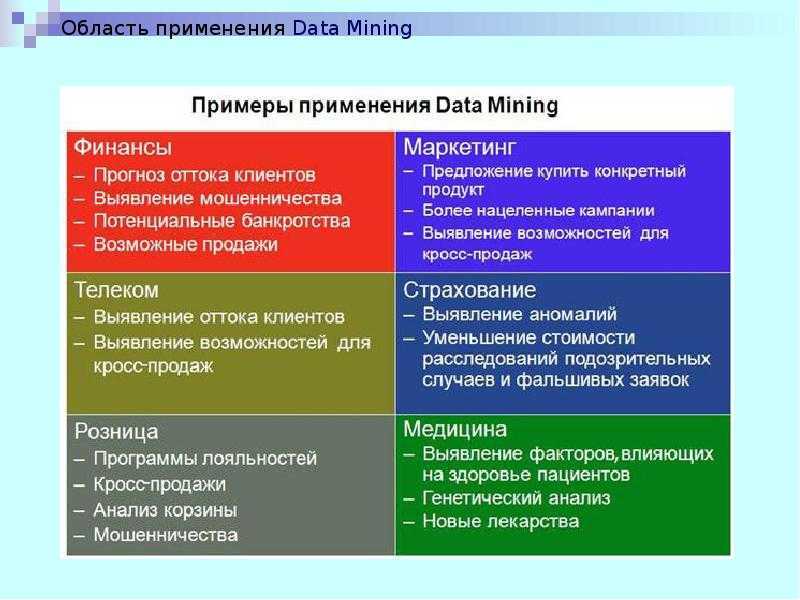
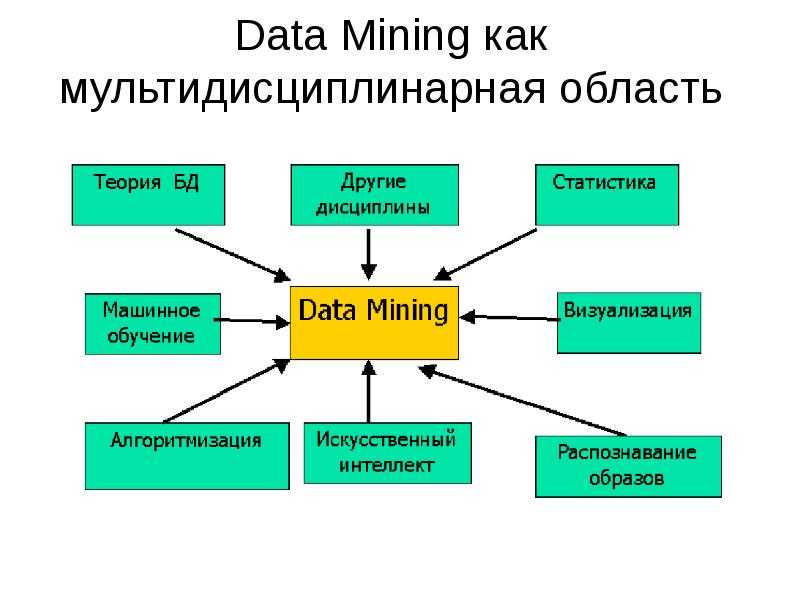
Data Mining является многодисциплинарной сферой, которая возникла и развивалась на основе:
- прикладной статистики,
- распознавания образов,
- искусственного интеллекта,
- теории баз данных и других.
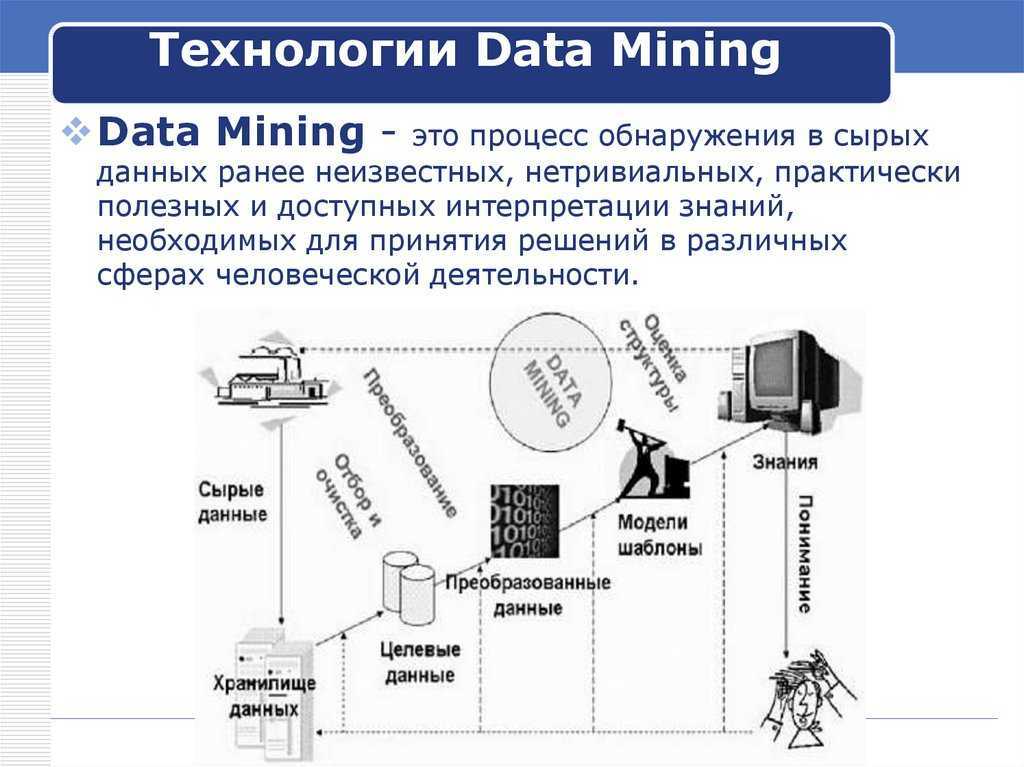
Data Mining является процессом поддержки выработки и принятия решений, который основан на обнаружении в информационных данных неявных, то есть скрытых, закономерностей, выступающих как шаблоны информации.
Одним из достаточно точных определений технологии Data Mining может считаться следующее:
Определение 2
Data Mining является процессом поиска в сырых данных ранее неизвестных, нетривиальных, полезных, с точки зрения практики, и доступных интерпретации знаний, требуемых для принятия решений в разных областях деятельности людей.
Сущность и цели технологии Data Mining могут быть охарактеризованы как технология, предназначенная для поиска в больших объемах данных неочевидных, объективных и являющихся полезными в практической деятельности закономерностей.
Существует ряд дисциплин, на стыке которых и возникла технология Data Mining. Одной из них является статистика, то есть, наука о методиках сбора данных, их обработки и анализа для обнаружения закономерностей, которые присущи исследуемому явлению. Статистика выступает как совокупность методик планирования эксперимента, сбора данных, их отображения и обобщения, а также анализа и формирования итоговых выводов на базе этих данных. Статистика способна оперировать данными, которые были получены в результате наблюдений либо экспериментов.
Машинное обучение может быть охарактеризовано как процесс формирования и получения программой новых знаний. Известно следующее определение машинного обучения, машинным обучением является наука, изучающая компьютерные алгоритмы, которые способны в автоматическом режиме улучшаться в процессе работы. Одним из самых известных примеров алгоритма машинного обучения могут считаться нейронные сети.
Искусственным интеллектом является научное направление, в границах которого могут быть поставлены и решены задачи аппаратного или программного моделирования типов человеческой деятельности, обычно считающиеся интеллектуальными. Искусственным интеллектом считается свойство интеллектуальных систем исполнять творческие функции, которые всегда оставались прерогативой только человека.
Появление и развитие Data Mining объясняется разными факторами, главными из которых являются следующие:
- Необходимость совершенствования аппаратного и программного обеспечения.
- Необходимость совершенствования технологий хранения и записи данных.
- Было накоплено значительное количество ретроспективных данных.
- Необходимость совершенствования алгоритмов информационной обработки.
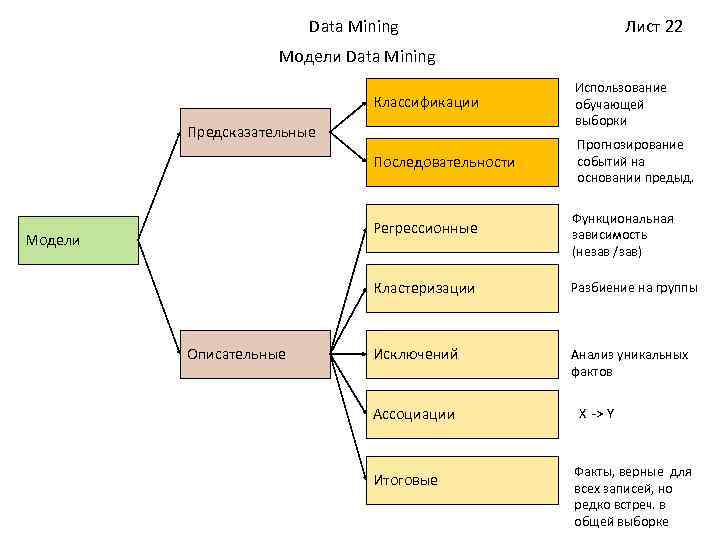
Основой технологии Data Mining является концепция шаблонов (patterns), которые считаются закономерностями, присущими выборкам данных и способными отображаться в формате, понятном человеку. «Mining» переводится с английского как добыча полезных ископаемых, а поиск закономерностей в очень больших объемах данных и в самом деле может быть причислен к этому процессу. Целью поиска закономерностей является отображение данных в формате, который отражает искомые процессы. Формирование модели прогнозирования тоже может быть целью поиска закономерностей.
Knowledge Discovery in Databases (KDD) является процессом обнаружения полезных познаний в «сырых» данных. KDD состоит из следующих действий:
- Процесс подготовки данных.
- Осуществление выбора информативных признаков.
- Выполнение очистки данных.
- Реализация методов Data Mining.
- Последующая обработка данных и интерпретация полученных итоговых результатов.
Необходимо подчеркнуть, что основанием всех этих процессов однозначно выступают методики DM, которые как раз и позволяют обнаружить знания. Такими знаниями могут являться правила, которые описывают связи между свойствами данных, то есть, это могут быть деревья решений, часто встречающиеся шаблоны (ассоциативные правила), а также итоги классификации (нейронные сети) и кластеризации данных (карты Кохонена) и так далее. Основателями концепции KDD являются Григорий Пятецкий-Шапиро (Gregory Piatetsky-Shapiro) и Усама Файад (Usama Fayyad), которые и заложили ее базовый фундамент.
Стадия сопоставления
-
В поле Источник данных выберите SQL Server (по умолчанию) или Файл Excel.
Примечание
На этой странице устанавливается соединение с сервером SQL Server или источником данных Excel, а затем сопоставляются столбцы источника данных с доменом в базе знаний. В таблице «Сопоставления» отображаются все столбцы в базе данных-источнике, которые будут проанализированы для добавления набора знаний в соответствующие домены. Сопоставление производится между столбцами источника данных и доменом в базе знаний.
-
Если используется источник данных SQL Server, выполните следующие действия.
-
В поле База данных выберите базу данных-источник, которую необходимо проанализировать для создания базы знаний. В текстовом поле с раскрывающимся списком содержится список доступных баз данных. База данных-источник должна присутствовать в том же экземпляре SQL Server, что и сервер Data Quality Server. В противном случае она не появится в раскрывающемся списке.
-
В поле Таблица или представление выберите таблицу или представление, которые необходимо проанализировать для создания базы знаний. Таблица или представление должны быть образцом данных, а не всей базой данных-источником, в которой выполняется очистка или сопоставление. В текстовом поле с раскрывающимся списком отображается список таблиц и представлений, доступных в выбранной базе данных.
-
-
Если используется источник данных Excel, выполните следующие действия.
-
Нажмите кнопку Обзор и выберите файл Excel, который необходимо проанализировать для создания базы знаний. Чтобы выбрать файл Excel, необходимо установить на Data Quality Client компьютере. Если excel не установлен на компьютере Data Quality Client, кнопка «Обзор» будет недоступна, и вы получите уведомление под этим текстовым полем, что Excel не установлен.
-
-
Установите флажок Использовать первую строку в качестве заголовка , если первая строка файла Excel содержит данные заголовков.
-
-
В таблице Сопоставления сопоставьте каждый из исходных столбцов, в которых необходимо провести обнаружение наборов знаний, с доменами в базе знаний, как описано ниже.
-
Создайте сопоставление, выбрав исходный столбец из раскрывающегося списка для столбца Исходный столбец пустой строки, а затем выбрав домен из раскрывающегося списка в столбце Домен той же строки, если домен существует. Если домен не существует, нажмите кнопку Создать домен или Создать составной домен , чтобы создать домен. Дополнительные сведения см. в разделе Create a Domain Rule или Create a Composite Domain.
-
Повторите предыдущий шаг для каждого сопоставления. Чтобы изменить число строк в таблице, нажмите кнопку Добавить сопоставление столбцовили выберите строку и нажмите кнопку Удалить выбранное сопоставление столбцов. Если нажать кнопку Удалить выбранное сопоставление столбцов при выбранной заполненной строке, эта заполненная строка будет удалена даже при наличии другой незаполненной строки.
Примечание
Вы можете сопоставить исходные данные с доменом служб DQS для проведения обнаружения набора знаний, только если исходный тип данных поддерживается службами DQS и совпадает с типом данных домена служб DQS. Дополнительные сведения о поддерживаемых типах данных см. в разделе Типы данных SQL Server и службы SSIS, поддерживаемые для доменов DQS.
-
Нажмите кнопку Просмотр/выбор составных доменов для отображения определенных составных доменов. Если составные домены не определены, элемент управления будет недоступен.
-
Нажмите кнопку Предварительный просмотр источника данных , чтобы просмотреть во всплывающем окне все данные из источника данных, выбранного в текстовом поле Таблица или представление или Файл Excel .
-
-
Нажмите кнопку Далее , чтобы перейти на страницу Обнаружение мастера обнаружения набора знаний. Также вы можете выбрать следующие действия.
-
Нажмите кнопку Отмена , чтобы прекратить действие обнаружения набора знаний с потерей полученных результатов и вернуться на домашнюю страницу DQS.
-
Нажмите кнопку Закрыть , чтобы вернуться на домашнюю страницу DQS с сохранением результатов работы. База знаний будет заблокирована вами, а в таблице баз знаний на экране Открытие базы знаний для этой базы знаний будет отображаться состояние Обнаружение — сопоставление. После нажатия кнопки Закрытьдля выполнения действий управления доменами потребуется нажать кнопку Обнаружение знаний на экране Открыть базу знаний , перейти на экран Управление базами знаний: управление терминами доменов , нажать кнопку Готово, а затем кнопку Да , чтобы опубликовать базу знаний, или Нет , чтобы сохранить работу в базе знаний и выйти.
-