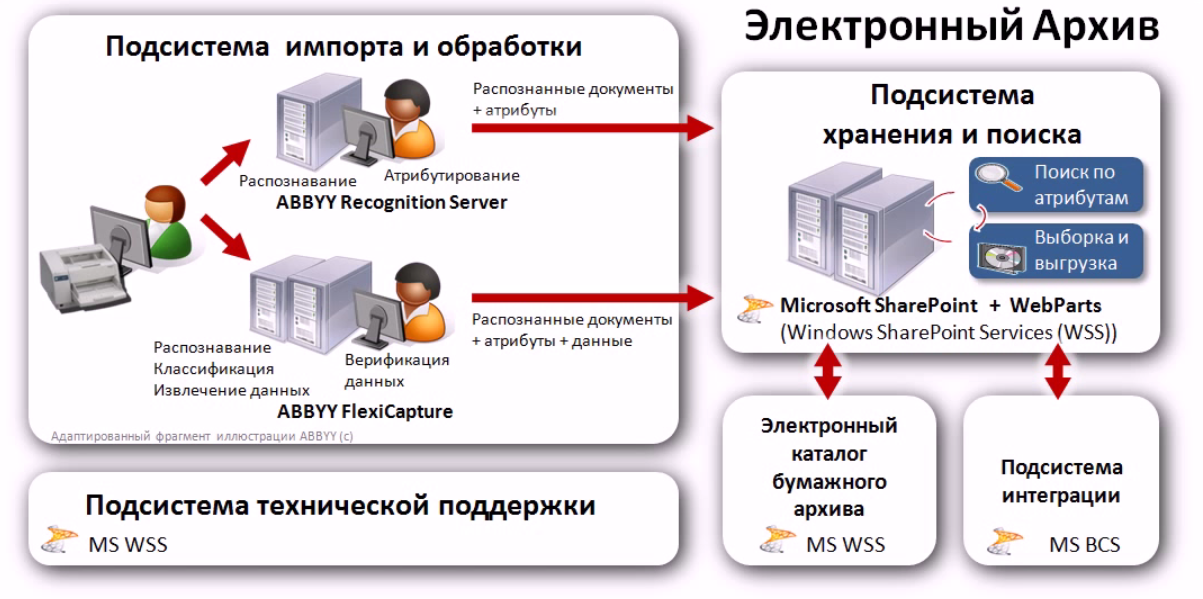
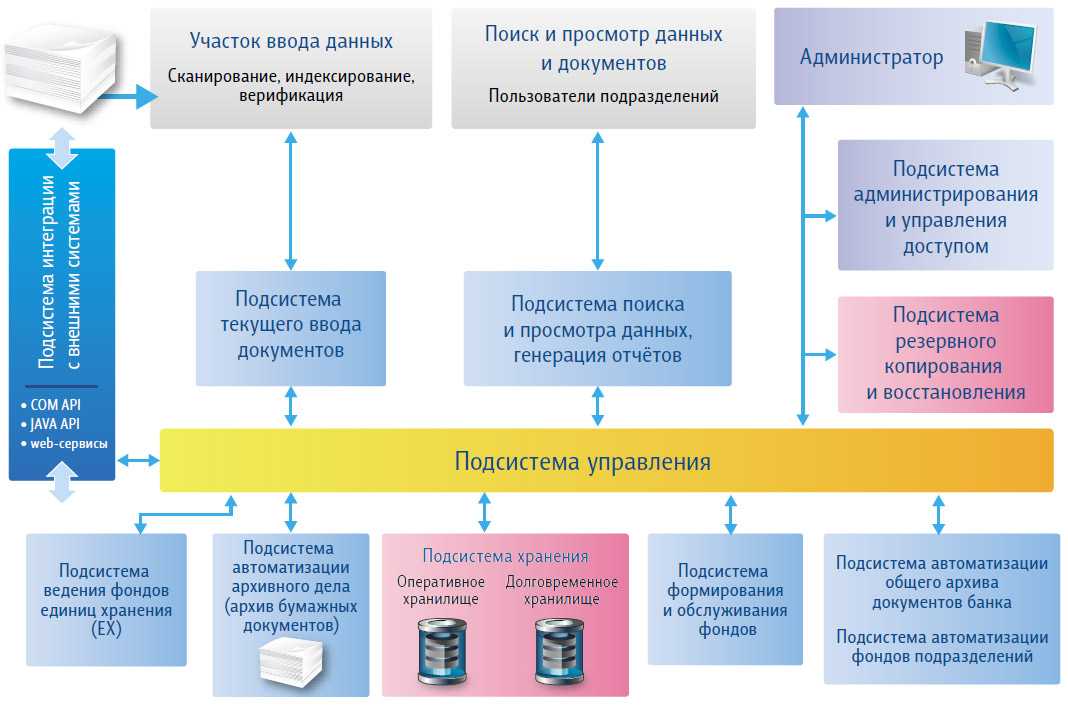
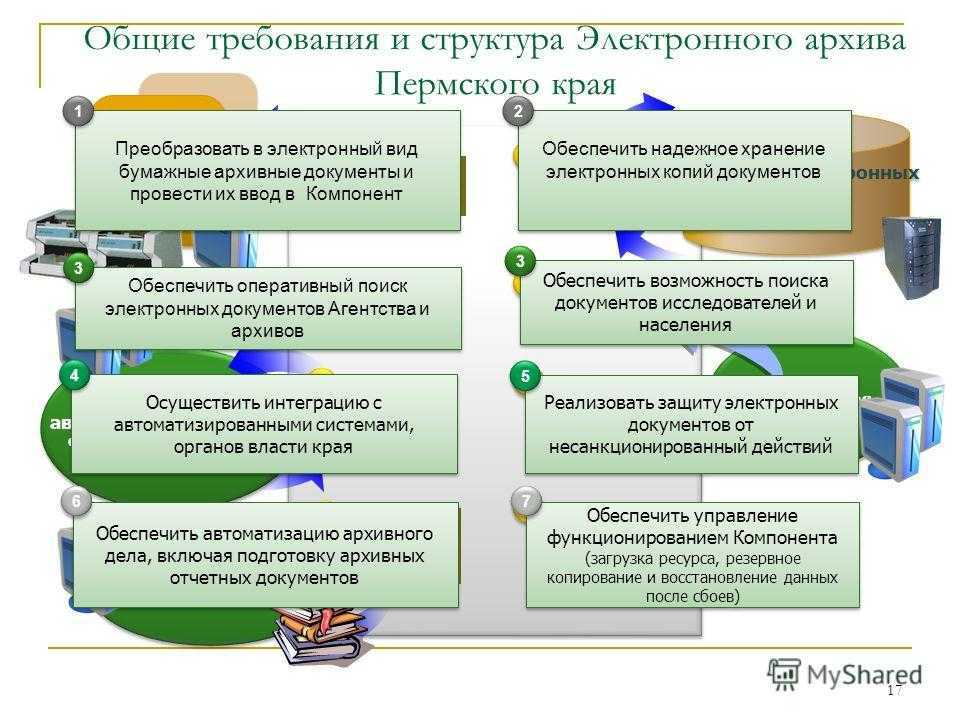
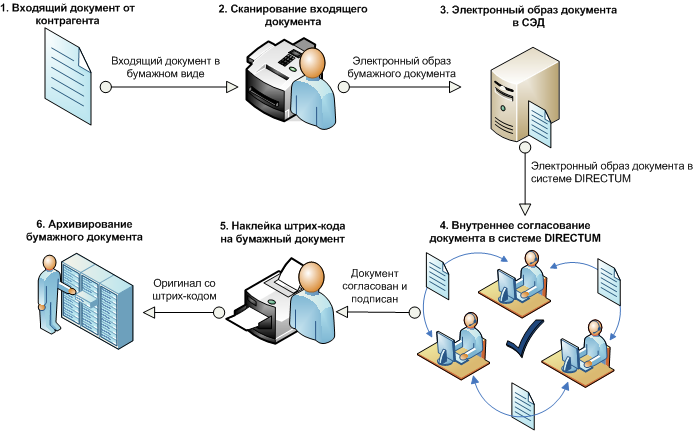
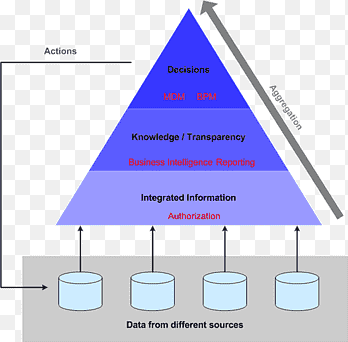
открытие знаний
открытие знаний описывает процесс автоматического поиска в больших объемах данных шаблонов, которые могут считаться знаниями о данных. Это часто описывается как получение знаний из входных данных. Поиск знаний развился из области интеллектуального анализа данных и тесно связан с ней как с точки зрения методологии, так и с точки зрения терминологии.
Наиболее известная ветвь интеллектуального анализа данных — это обнаружение знаний, также известное как обнаружение знаний в базах данных (KDD). Как и многие другие формы открытия знаний, он создает абстракции входных данных. Знания, полученные в процессе, могут стать дополнительными данными, которые можно использовать для дальнейшего использования и обнаружения. Часто результаты обнаружения знаний не требуют действий, обнаружение знаний с практическими действиями, также известное как анализ данных на основе предметной области, нацелено на обнаружение и предоставление практических знаний и идей.
Еще одно многообещающее применение обнаружения знаний — это область модернизации программного обеспечения, обнаружения слабых мест и соответствия требованиям, что предполагает понимание существующих программных артефактов. Этот процесс связан с концепцией обратного проектирования. Обычно знания, полученные с помощью существующего программного обеспечения, представлены в виде моделей, к которым при необходимости могут быть сделаны конкретные запросы. Отношение сущностей — это частый формат представления знаний, полученных из существующего программного обеспечения. Группа управления объектами (OMG) разработала спецификацию Метамодель обнаружения знаний (KDM), которая определяет онтологию для программных активов и их взаимосвязей с целью выполнения обнаружения знаний в существующем коде. Обнаружение знаний из существующих программных систем, также известное как интеллектуальный анализ программного обеспечения, тесно связано с интеллектуальным анализом данных, поскольку существующие программные артефакты имеют огромное значение для управления рисками и бизнес-ценности, ключ для оценки и развития программных систем. Вместо анализа отдельных наборов данных, программный анализ фокусируется на метаданных, таких как потоки процессов (например, потоки данных, потоки управления и карты вызовов), архитектура, схемы базы данных и бизнес-правила / условия / процесс.
Входные данные
-
Базы данных
- Реляционные данные
- База данных
- Хранилище документов
- Хранилище данных
-
Программное обеспечение
- Исходный код
- Файлы конфигурации
- Скрипты сборки
-
Текст
Концептуальный анализ
-
Графы
Молекулярный анализ
-
Последовательности
- Анализ потока данных
- Изучение изменяющихся во времени потоков данных в условиях дрейфа концепции
- Веб
Форматы вывода
- Модель данных
- Метаданные
- Метамодели
- Онтология
- Представление знаний
- Теги знаний
- Бизнес-правило
- Метамодель обнаружения знаний (KDM)
- Моделирование бизнес-процессов Обозначение (BPMN)
- Промежуточное представление
- Структура описания ресурсов (RDF)
- Метрики программного обеспечения
Технологии извлечения знаний
Data Mining является многодисциплинарной сферой, которая возникла и развивалась на основе:
- прикладной статистики,
- распознавания образов,
- искусственного интеллекта,
- теории баз данных и других.
Data Mining является процессом поддержки выработки и принятия решений, который основан на обнаружении в информационных данных неявных, то есть скрытых, закономерностей, выступающих как шаблоны информации.
Одним из достаточно точных определений технологии Data Mining может считаться следующее:
Определение 2
Data Mining является процессом поиска в сырых данных ранее неизвестных, нетривиальных, полезных, с точки зрения практики, и доступных интерпретации знаний, требуемых для принятия решений в разных областях деятельности людей.
Сущность и цели технологии Data Mining могут быть охарактеризованы как технология, предназначенная для поиска в больших объемах данных неочевидных, объективных и являющихся полезными в практической деятельности закономерностей.
Существует ряд дисциплин, на стыке которых и возникла технология Data Mining. Одной из них является статистика, то есть, наука о методиках сбора данных, их обработки и анализа для обнаружения закономерностей, которые присущи исследуемому явлению. Статистика выступает как совокупность методик планирования эксперимента, сбора данных, их отображения и обобщения, а также анализа и формирования итоговых выводов на базе этих данных. Статистика способна оперировать данными, которые были получены в результате наблюдений либо экспериментов.


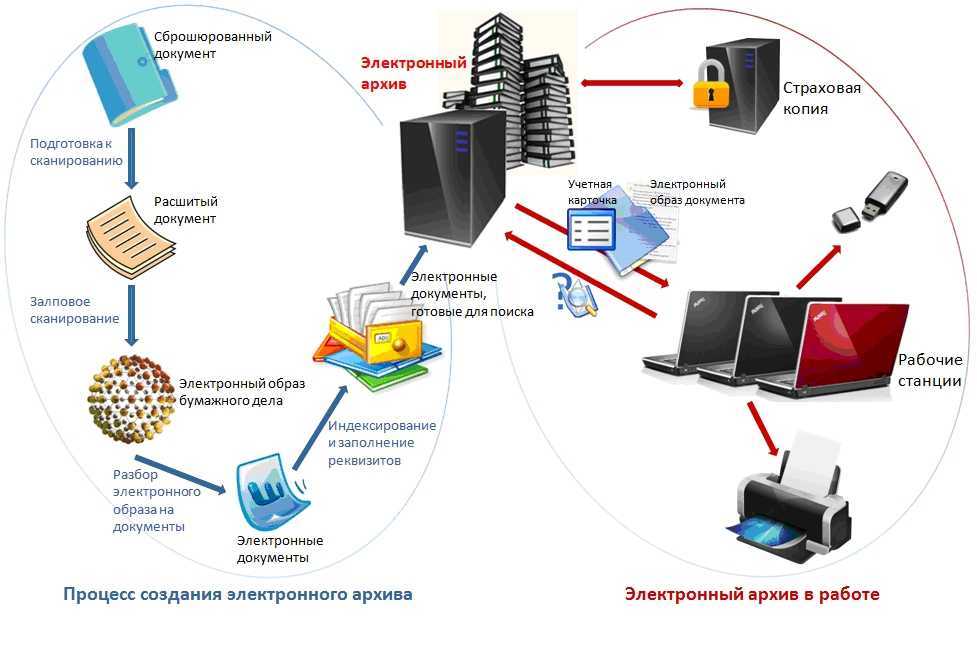
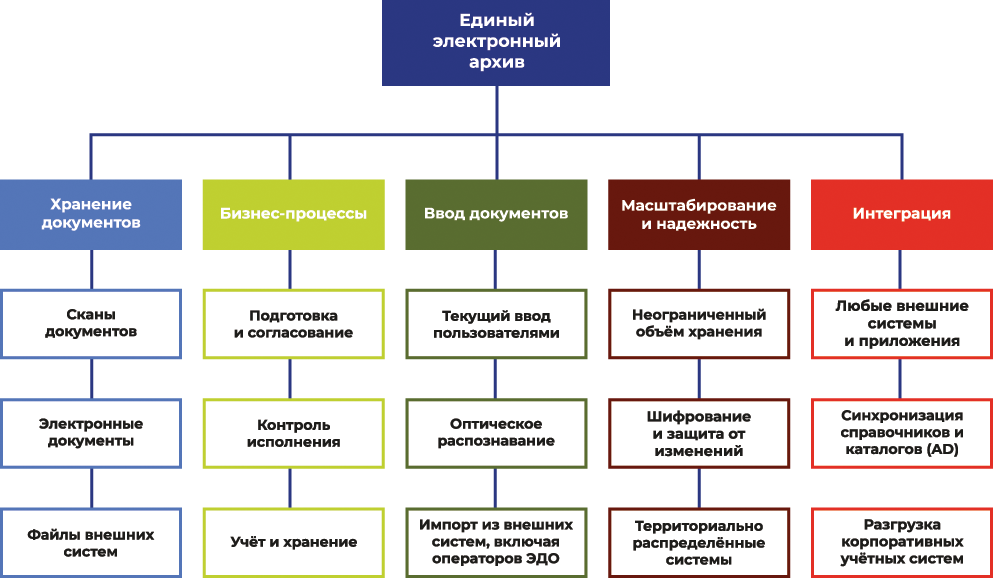
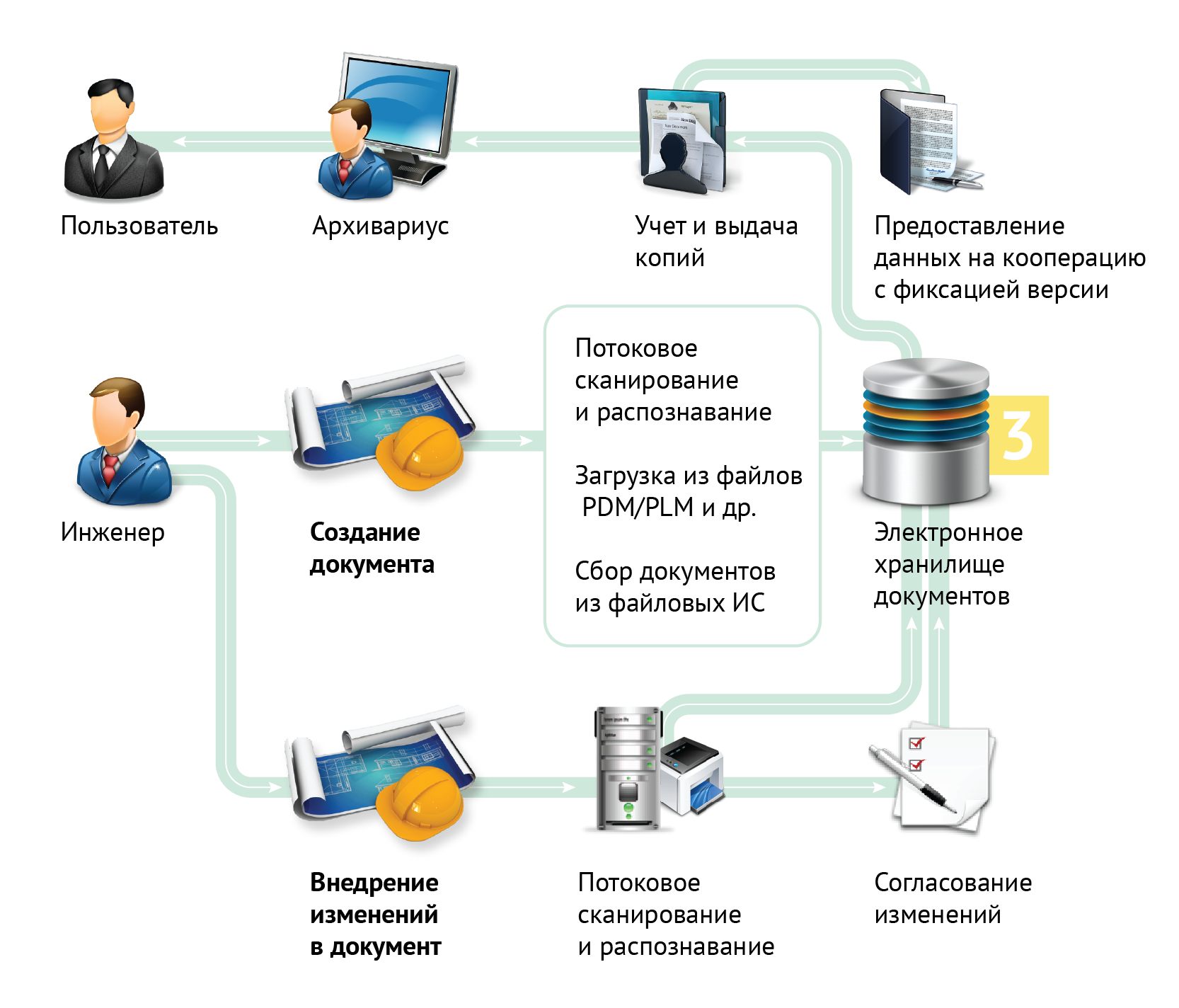
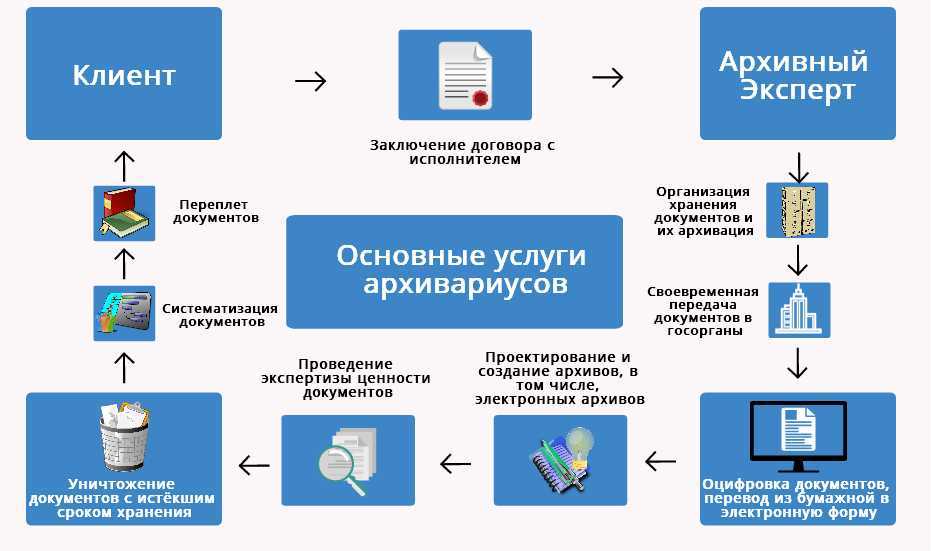
Машинное обучение может быть охарактеризовано как процесс формирования и получения программой новых знаний. Известно следующее определение машинного обучения, машинным обучением является наука, изучающая компьютерные алгоритмы, которые способны в автоматическом режиме улучшаться в процессе работы. Одним из самых известных примеров алгоритма машинного обучения могут считаться нейронные сети.
Искусственным интеллектом является научное направление, в границах которого могут быть поставлены и решены задачи аппаратного или программного моделирования типов человеческой деятельности, обычно считающиеся интеллектуальными. Искусственным интеллектом считается свойство интеллектуальных систем исполнять творческие функции, которые всегда оставались прерогативой только человека.
Появление и развитие Data Mining объясняется разными факторами, главными из которых являются следующие:
- Необходимость совершенствования аппаратного и программного обеспечения.
- Необходимость совершенствования технологий хранения и записи данных.
- Было накоплено значительное количество ретроспективных данных.
- Необходимость совершенствования алгоритмов информационной обработки.
Основой технологии Data Mining является концепция шаблонов (patterns), которые считаются закономерностями, присущими выборкам данных и способными отображаться в формате, понятном человеку. «Mining» переводится с английского как добыча полезных ископаемых, а поиск закономерностей в очень больших объемах данных и в самом деле может быть причислен к этому процессу. Целью поиска закономерностей является отображение данных в формате, который отражает искомые процессы. Формирование модели прогнозирования тоже может быть целью поиска закономерностей.
Knowledge Discovery in Databases (KDD) является процессом обнаружения полезных познаний в «сырых» данных. KDD состоит из следующих действий:
- Процесс подготовки данных.
- Осуществление выбора информативных признаков.
- Выполнение очистки данных.
- Реализация методов Data Mining.
- Последующая обработка данных и интерпретация полученных итоговых результатов.
Необходимо подчеркнуть, что основанием всех этих процессов однозначно выступают методики DM, которые как раз и позволяют обнаружить знания. Такими знаниями могут являться правила, которые описывают связи между свойствами данных, то есть, это могут быть деревья решений, часто встречающиеся шаблоны (ассоциативные правила), а также итоги классификации (нейронные сети) и кластеризации данных (карты Кохонена) и так далее. Основателями концепции KDD являются Григорий Пятецкий-Шапиро (Gregory Piatetsky-Shapiro) и Усама Файад (Usama Fayyad), которые и заложили ее базовый фундамент.
Программное обеспечение
Следующие приложения доступны под бесплатными лицензиями / лицензиями с открытым исходным кодом. Также доступен открытый доступ к исходному коду приложения.
- Carrot2 : структура кластеризации текста и результатов поиска.
- Chemicalize.org : программа для разработки химических структур и поисковая система в Интернете.
- ELKI : университетский исследовательский проект с расширенным кластерным анализом и методами обнаружения выбросов, написанный на языке Java .
- GATE : инструмент для обработки естественного языка и языковой инженерии.
- KNIME : Konstanz Information Miner, удобный и комплексный фреймворк для анализа данных.
- Massive Online Analysis (MOA) : интеллектуальный анализ потоков больших данных в реальном времени с помощью инструмента смещения концепций на языке программирования Java .
- MEPX : кроссплатформенный инструмент для задач регрессии и классификации на основе варианта генетического программирования.
- ML-Flex: программный пакет, который позволяет пользователям интегрироваться со сторонними пакетами машинного обучения, написанными на любом языке программирования, выполнять анализ классификации параллельно на нескольких вычислительных узлах и создавать отчеты о результатах классификации в формате HTML.
- mlpack : набор готовых алгоритмов машинного обучения, написанных на языке C ++ .
- NLTK ( Natural Language Toolkit ): набор библиотек и программ для символьной и статистической обработки естественного языка (NLP) для языка Python .
- OpenNN : открытая библиотека нейронных сетей .
- Orange : программный пакет для анализа данных и машинного обучения на основе компонентов, написанный на языке Python .
- PSPP : программное обеспечение для сбора данных и статистики в рамках проекта GNU, аналогичное SPSS.
- R : язык программирования и программная среда для статистических вычислений, интеллектуального анализа данных и графики. Это часть проекта GNU .
- Scikit-learn : библиотека машинного обучения с открытым исходным кодом для языка программирования Python
- Torch : библиотека глубокого обучения с открытым исходным кодом для языка программирования Lua и среды научных вычислений с широкой поддержкой алгоритмов машинного обучения .
- UIMA : UIMA (Архитектура управления неструктурированной информацией) — это компонентная структура для анализа неструктурированного контента, такого как текст, аудио и видео, первоначально разработанная IBM.
- Weka : набор программных приложений для машинного обучения, написанных на языке программирования Java .
Проприетарное программное обеспечение и приложения для интеллектуального анализа данных
Следующие приложения доступны по проприетарным лицензиям.
- Angoss KnowledgeSTUDIO: инструмент интеллектуального анализа данных
- LIONsolver : интегрированное программное приложение для интеллектуального анализа данных, бизнес-аналитики и моделирования, реализующее подход обучения и интеллектуальной оптимизации (LION).
- Megaputer Intelligence: программное обеспечение для интеллектуального анализа данных и текста называется PolyAnalyst .
- Microsoft Analysis Services : программное обеспечение для интеллектуального анализа данных, предоставляемое Microsoft .
- NetOwl : набор многоязычных продуктов для анализа текста и сущностей, которые позволяют интеллектуальный анализ данных.
- Oracle Data Mining : программное обеспечение для интеллектуального анализа данных от Oracle Corporation .
- PSeven : платформа для автоматизации инженерного моделирования и анализа, междисциплинарной оптимизации и интеллектуального анализа данных, предоставляемая DATADVANCE .
- Qlucore Omics Explorer: программное обеспечение для интеллектуального анализа данных.
- RapidMiner : среда для экспериментов по машинному обучению и интеллектуальному анализу данных.
- : программное обеспечение для интеллектуального анализа данных, предоставленное институтом SAS .
- SPSS Modeler : программное обеспечение для интеллектуального анализа данных, предоставленное IBM .
- STATISTICA Data Miner: программное обеспечение для интеллектуального анализа данных, предоставляемое StatSoft .
- Tanagra : Программное обеспечение для интеллектуального анализа данных, ориентированное на визуализацию, также предназначенное для обучения.
- Vertica : программное обеспечение для интеллектуального анализа данных, предоставленное Hewlett-Packard .
- Google Cloud Platform : автоматизированные пользовательские модели машинного обучения под управлением .
- Amazon SageMaker : управляемый сервис, предоставляемый Amazon для создания и производства пользовательских моделей машинного обучения .
Обзор
После стандартизации языков представления знаний, таких как RDF и OWL, в этой области было проведено много исследований, особенно в отношении преобразования реляционных баз данных в RDF, разрешение идентификации, знание открытие dge и изучение онтологий. В общем процессе используются традиционные методы из извлечения информации, и извлечения, преобразования и загрузки (ETL), которые преобразуют данные из источников в структурированные форматы.
Следующие критерии можно использовать для категоризации подходов в этой теме (некоторые из них учитывают только извлечение из реляционных баз данных):
| Источник | Какие источники данных охватываются: текст, реляционные Базы данных, XML, CSV |
|---|---|
| Описание | Как извлеченные знания становятся явными (файл онтологии, семантическая база данных)? Как вы можете запросить это? |
| Синхронизация | Выполняется ли процесс извлечения знаний один раз для создания дампа или результат синхронизируется с источником? Статический или динамический. Записываются ли изменения в результат обратно (двунаправленные) |
| Повторное использование словарей | Инструмент может повторно использовать существующие словари при извлечении. Например, столбец таблицы «firstName» можно сопоставить с foaf: firstName. Некоторые автоматические подходы не могут отображать словарь. |
| Автоматизация | Степень поддержки / автоматизации экстракции. Ручной, графический, полуавтоматический, автоматический. |
| Требуется онтология предметной области. | Для сопоставления с ней необходима уже существующая онтология. Таким образом, либо создается отображение, либо схема изучается из источника (изучение онтологии ). |
Перед Feature Extraction: 5 NLP-операций для обработки текста
Перед тем, как запускать извлечение признаков из текста, его нужно предварительно подготовить — сделать пригодным для обработки алгоритмами машинного обучения (Machine Learning). Для этого необходимо выполнить над текстом следующие операции :
- Токенизация – разбиение длинных участков текста на более мелкие (абзацы, предложения, слова). Токенизация – это самый первый этап обработки текста.
- Нормализация – приведение текста к «рафинированному» виду (единый регистр слов, отсутствие знаков пунктуации, расшифрованные сокращения, словесное написание чисел и т.д.). Это необходимо для применения унифицированных методов обработки текста. Отметим, что в случае текста термин «нормализация» означает приведение слов к единообразному виду, а не преобразование абсолютных величин к единому диапазону.
- Стеммизация – приведение слова к его корню путем устранения придатков (суффикса, приставки, окончания).
- Лемматизация – приведение слова к смысловой канонической форме слова (инфинитив для глагола, именительный падеж единственного числа — для существительных и прилагательных). Например, «зарезервированный» — «резервировать», «грибами» — «гриб», «лучший» — «хороший».
- Чистка – удаление стоп-слов, которые не несут смысловой нагрузки (артикли, междометья, союзы, предлоги и т.д.).
По завершении всех этих операций текст становится пригодным для его перевода в числовую форму, чтобы дальше продолжить извлечение признаков.
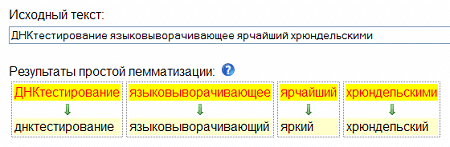
Принцип лемматизации в Text Mining
Векторизация: превращение слов в цифры
Итак, как только текст превратился в очищенную нормализованную последовательность слов, запускается процесс их векторизации – преобразования в числовые вектора . Для такой трансформации используются специальные модели, наиболее популярными из которых являются:
- cумка слов» (bag of words) – детальная репрезентативная модель для упрощения обработки текстового содержания. Она не учитывает грамматику или порядок слов и нужна, главным образом, для определения количества вхождений отдельных слов в анализируемый текст . На практике bag of words реализуется следующим образом: создается вектор длиной в словарь, для каждого слова считается количество вхождений в текст и это число подставляется на соответствующую позицию в векторе.Однако, при этом теряется порядок слов в тексте, а значит, после векторизации предложения, к примеру, «i have no cats» и «no, i have cats» будут идентичны, но противоположны по смыслу. Для решения этой проблемы при токенизации используются n-граммы .
- n-граммы — комбинации из n последовательных терминов для упрощения распознавания текстового содержание. Эта модель определяет и сохраняет смежные последовательности слов в тексте . При этом можно генерировать n-граммы из букв, например, чтобы учесть сходство родственных слов или опечаток .
- Word2Vec — набор моделей для анализа естественных языков на основе дистрибутивной семантике и векторном представлении слов. Этот метод разработан группой исследователей Google в 2013 году. Сначала создается словарь, «обучаясь» на входных текстовых данных, а затем вычисляется векторное представление слов, основанное на контекстной близости. При этом слова, встречающиеся в тексте рядом, в векторном представлении будут иметь близкие числовые координаты. Полученные векторы-слова используются для обработки естественного языка и машинного обучения .
На основе этих моделей существуют и другие, более сложные, методы векторизации текстов. Практически все эти способы Text Mining реализованы в специальных средах, например, GATE, KNIME, Orange, RapidMiner, LPU, а также специальных библиотеках на языках программирования Pythone и R .
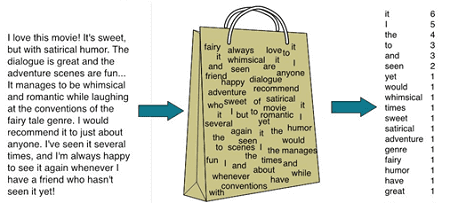
Принцип метода Text Mining «bag of words» (сумка слов)
Еще больше интересных подробностей и прикладных знаний про Feature Extraction и другие этапы Data Preparation в нашем новом обучающем курсе для аналитиков больших данных: подготовка данных для Data Mining. Следите за новостями!
Смотреть расписание
Записаться на курс
Источники
- https://ru.wikipedia.org/wiki/Обработка_естественного_языка
- https://singularika.com/ru/nlp/natural-language-processing-terms/
- https://habr.com/ru/company/ods/blog/325422/
- https://ru.wikipedia.org/wiki/Word2vec
- http://datareview.info/article/top-5-instrumentov-dlya-text-mining/