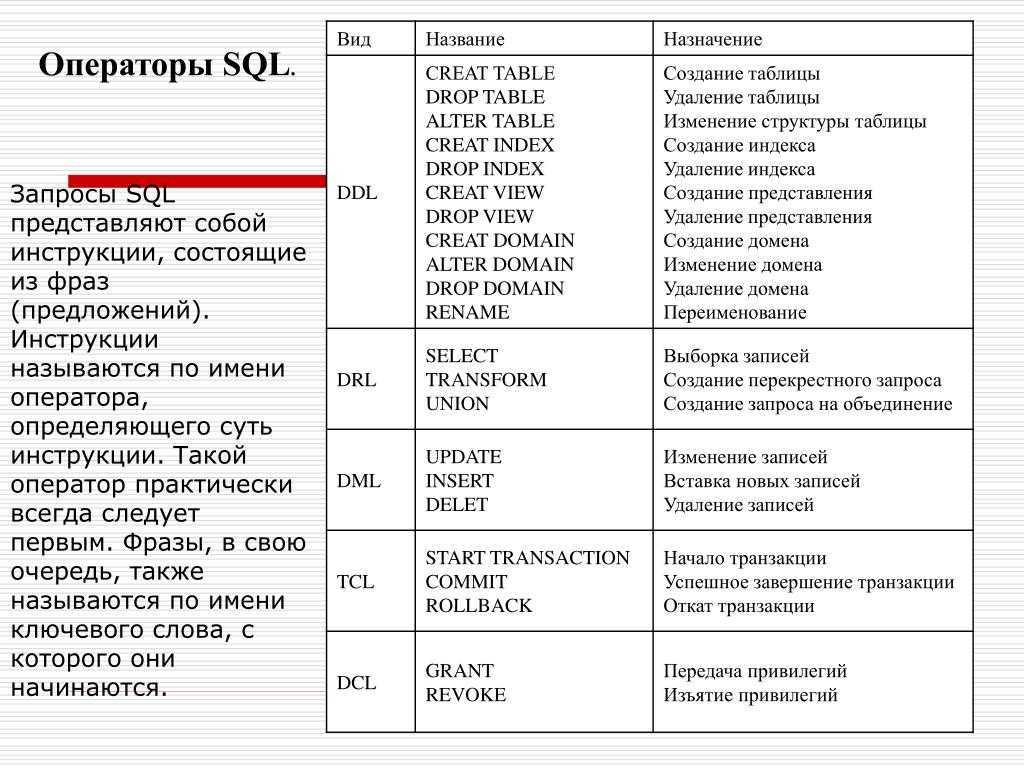
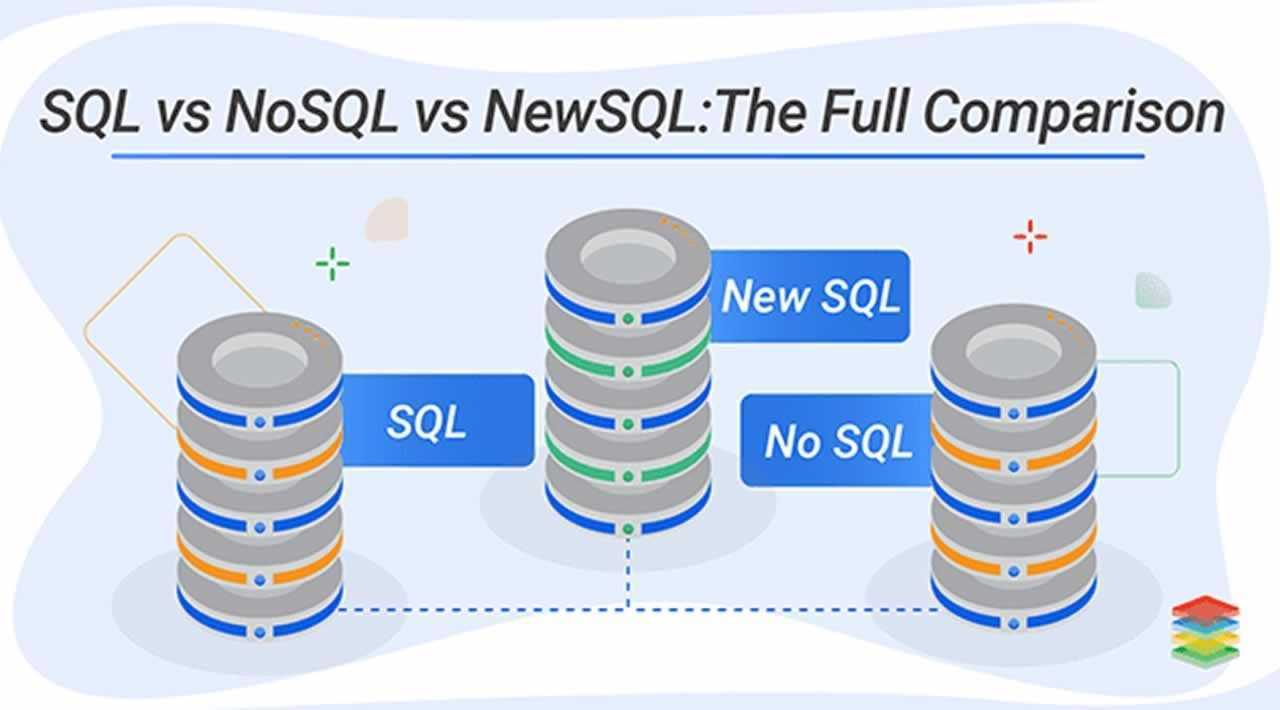
А что там внутри. Пример нормализации
Разберём устройство реляционной БД подробнее на примере. Позже это поможет нам понимать и сравнивать базы разных типов.
Допустим, у нас есть база данных, в которой всего одна таблица — Messages. В ней хранится информация о телефонных разговорах клиентов и операторов компании по ремонту техники.
Каждая строка этой таблицы содержит данные о звонке клиента по его проблеме и ответ оператора, а также дату обращения.
Телефон у компании многоканальный. Поэтому одному и тому же оператору могут звонить разные клиенты, а один и тот же клиент может попадать на разных операторов с разными вопросами.
Какие реляционные БД популярны в веб-разработке
MySQL
Это открытая СУБД, купленная Oracle в придачу к Sun Microsystems. С ней работают более половины (55,6%) всех разработчиков (по опроса, который в 2020 году провёл сайт StackOverflow.com среди 65 тысяч респондентов).
Главные её преимущества — бесплатность и высокая скорость работы с данными. MySQL создавалась для обработки огромных массивов информации в промышленных масштабах, но благодаря доступности и быстродействию оккупировала Всемирную паутину, заслужив звание «СУБД всея интернета». И сегодня MySQL всё ещё самая удобная СУБД для работы с интернет-страницами и веб-приложениями.
MySQL пользуется мощной поддержкой у создателей языков программирования: практически во всех популярных языках есть интерфейс для работы с ней.
SQLite
Эта СУБД использует большую часть стандартного языка SQL.
Главное преимущество SQlight — встраиваемость. Это объясняется тем, что SQlight не приложение типа «клиент-сервер» (в отличие от других реляционных СУБД), а библиотека, которую подключают непосредственно к программе.
И она тоже весьма популярна: достаточно сказать, что SQLite есть в каждом смартфоне. Например, в смартфонах на Android там хранятся контакты и медиа, а в iOS её используют многие приложения.
PostgreSQL
Её можно назвать самой продвинутой. Это не просто реляционная, а объектно-реляционная свободная СУБД.
PostgreSQL поддерживает не только типы данных, которые есть в других реляционных СУБД. Помимо числовых, текстовых, булевых и других стандартных типов, в ней можно хранить и обрабатывать геометрические и денежные данные, сетевые адреса, JSON, XML, массивы, а также создавать собственные типы данных.
Что дальше
Каждый виток спирали в IT-индустрии знаменуется очередным открытием модели или подходом в реализации. Так было с реляционными базами данных, затем на сцене появились объектно-ориентированные базы данных, после ворвались noSQL с лозунгом «Долой жесткие структуры отношений!». Я уверен, что эта история будет повторяться снова и снова в зависимости от вызовов, которые стоят уже сейчас и будут появляться перед IT-сообществом.
Но тем не менее сейчас следует обратить внимание на то, что в топ-5 баз данных 4 первых места занимают реляционные базы данных (по данным исследования Solid IT).
Почему это так? Как, учитывая полувековую историю, РСУБД может претендовать на такое высокое место в современном мире? Может быть, причина в legacy кода и созданных структурах моделей, которые нужно поддерживать в рамках реляционных баз данных? Или же причина в том, что переходить на более современные движки слишком дорого?
Можно вспомнить, что у реляционных баз данных есть принцип ACID и фундаментальный математический аппарат. А у нереляционных баз данных есть BASE-семантика с более «мягкими» условиями функционирования и моделирования, а также набор алгоритмов, поддерживающих работу с данными. Семантика против Принципа, иногда хочется жить по Принципам без аномалий в данных и в режиме SERIALIZABLE.
Но все-таки истина лежит где-то посередине, и это видно в разных архитектурах проектов, когда используется «зоопарк» (в хорошем смысле слова) гетерогенных баз данных и их интеграция между собой. А особенно это прослеживается при создании общих хранилищ данных (DWH + Data Lake) в корпорациях.
Как совместить OLAP и OLTP и получить полноценные «диагональные» базы данных? Почему бы не посмотреть в сторону дедуктивных баз данных? Наконец, почему бы полноценно не привлечь весь аппарат Data Science в движки оптимизаторов и обработки информации?
Новое отдельное направление — Data Engineering дает сильный толчок в исследованиях не только данных, но и в поиске архитектуры / интеграции / валидации данных для конкретного бизнес-домена. Появляются стандарты определения данных / информации / знаний / мудрости, что перерастает в обобщенное логическое восприятие информации через разные логические слои данных (тут я могу сослаться на книгу DAMA-DMBOK) при помощи новых инженерных ролей и разграничения ответственности в направлении Data Engineering:
-
Data Quality Engineer
-
Data Steward
-
Data Owner
-
Data Ops
-
Data Analytic
-
Data Science Engineer (все-таки они тоже работают с данными).
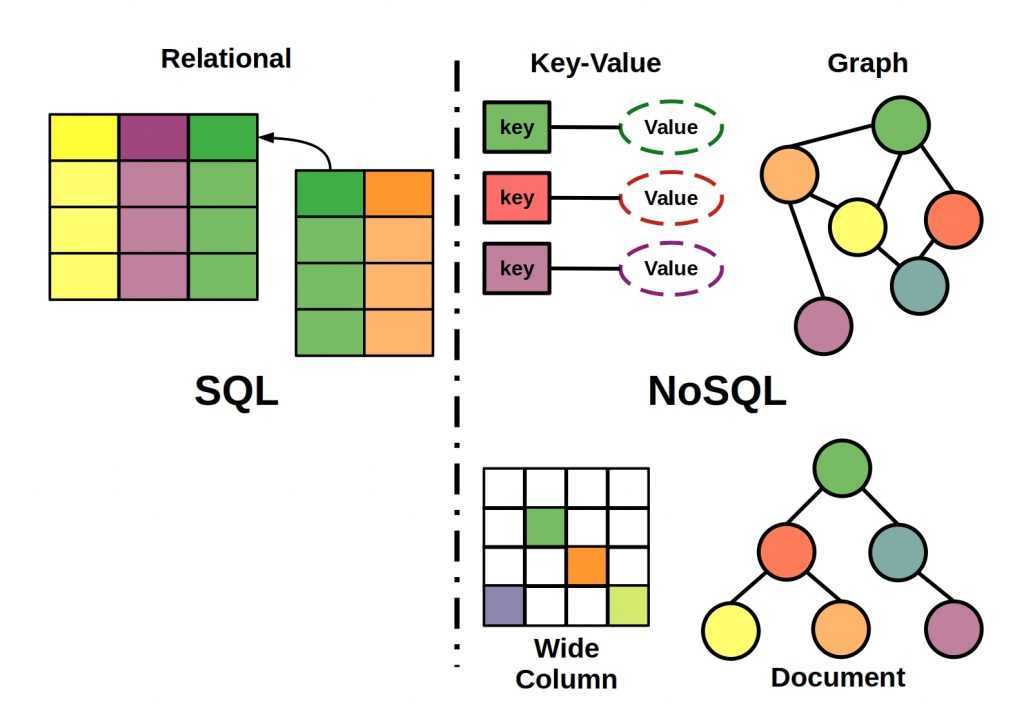
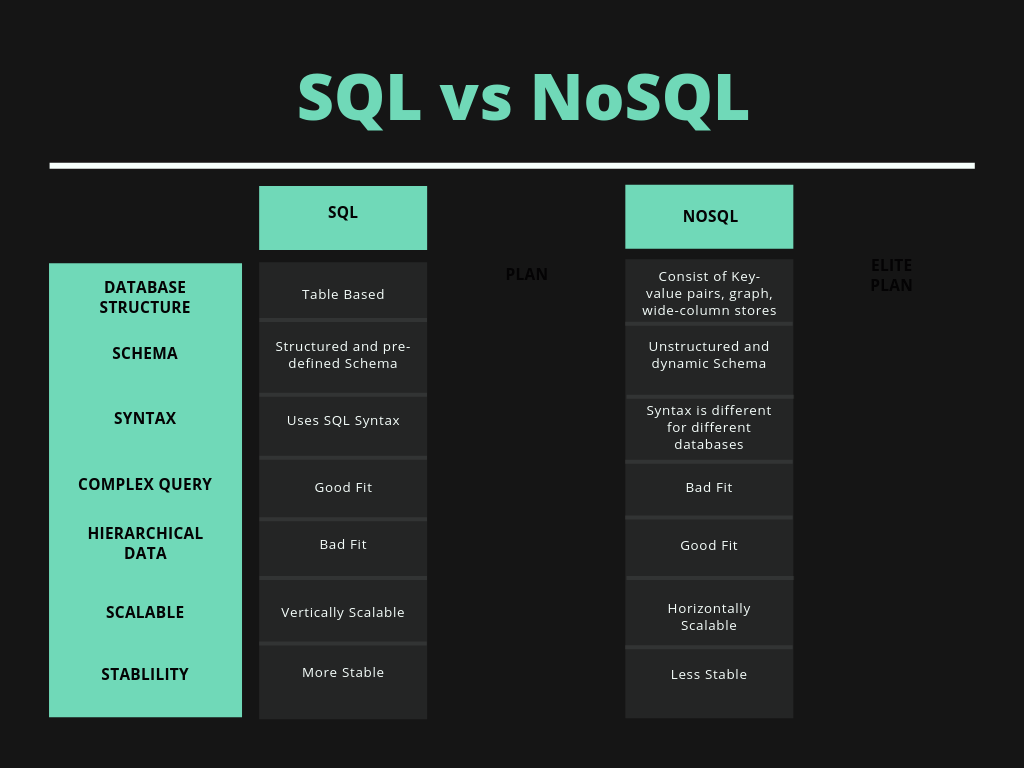
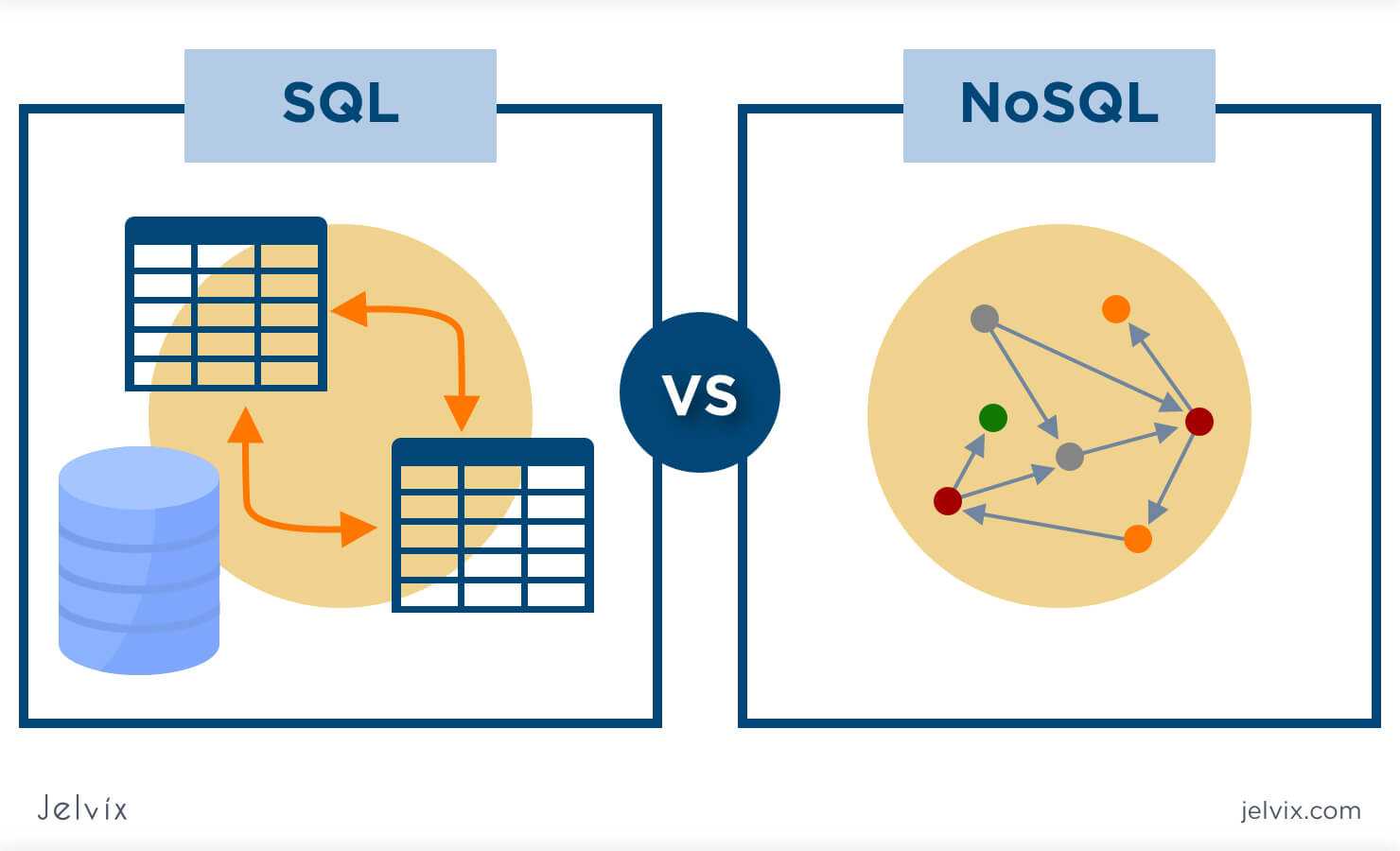
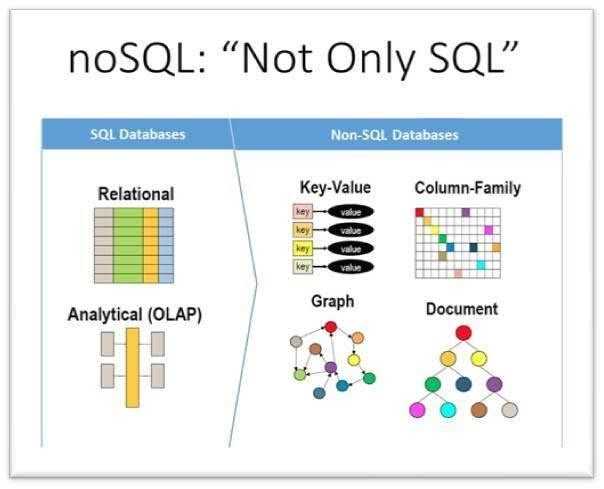
Что такое NoSQL
Как это часто бывает, первые успехи в создании нового типа БД получили крупные компании — Google и Amazon. Они одни из первых решили отойти от реляционности и обрести новую парадигму. В течение 2006-2007 годов появились статьи Big Table от Google и Dynamo от Amazon об их облачных базах данных. Озвученные в публикациях идеи не были соединены с реляционной теорией. Там не было табличек, связей, джойнов, а главное — разработчики этих систем достигли подлинного масштабирования.
Этот опыт вдохновил многих программистов развивать подобные идеи. Так, в 2009 году несколько разработчиков организовали митап на эту тему. К событию присоединились серьезные бренды, в том числе MongoDB, CouchDB и другие
Инициаторы мероприятия искали не столько лозунг к нему, а что-то вроде хэштега, чтобы привлечь внимание сообщества в Twitter. Так и возникло название NoSQL
Основных моделей несколько, и у каждой есть свои особенности, преимущества и недостатки. Поэтому немного расскажу о каждой из них.
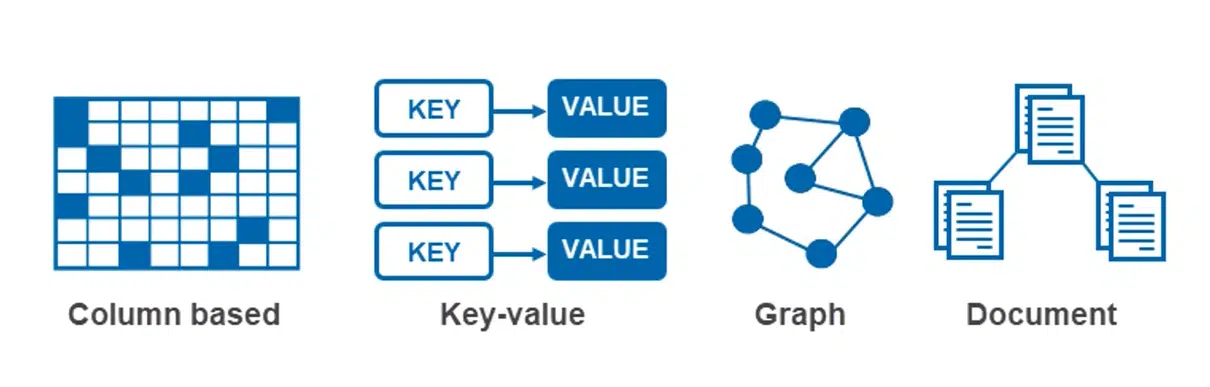
Key-Value Store
Это самая простая NoSQL-парадигма. В хранилище хранится ключ и value — и все. Нет никаких сложных филдов, связей между key-value, нет вообще ничего. Главное преимущество — такая структура масштабируется безгранично. Ее самый яркий пример — Redis, который многие используют как кэш.

Нажмите, чтобы рассмотреть
Column Family
Эта модель взяла key-value и подвинула ее дальше. Здесь также есть key, но value уже не простая строка, а набор из собственных пар key-value. То ест это уже система колонок со значением, где каждая строка может иметь свои наборы. Пример такой БД — Cassandra.
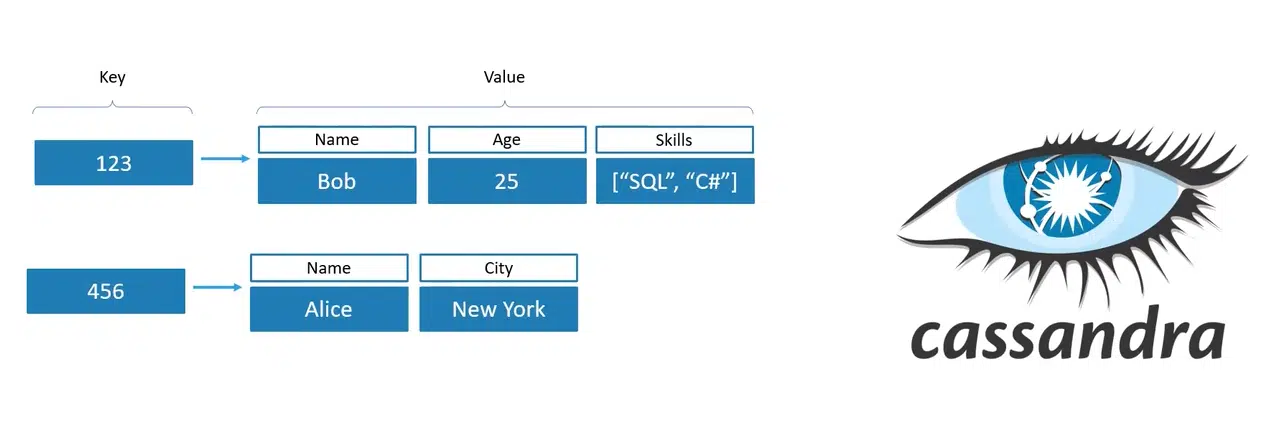
Нажмите, чтобы рассмотреть
Graph Databases
Этот вариант несколько экзотичен и основан на концепции графов. Согласно идее, связь между данными — это тоже определенные данные. Построение таких связей-данных и будет напоминать граф. Таким образом можно получить широкие возможности создания иерархии или запутанных связей. Так работают практически все соцсети.
Один пользователь связан с другим как друг, тот, в свою очередь, подписан на какую-то группу, а первый лайкает какие-то посты — и это все примеры связей, являющихся данными. На этой модели создан Neo4j. У него есть даже очень интересный синтаксис для написания запросов к столь необычной БД.
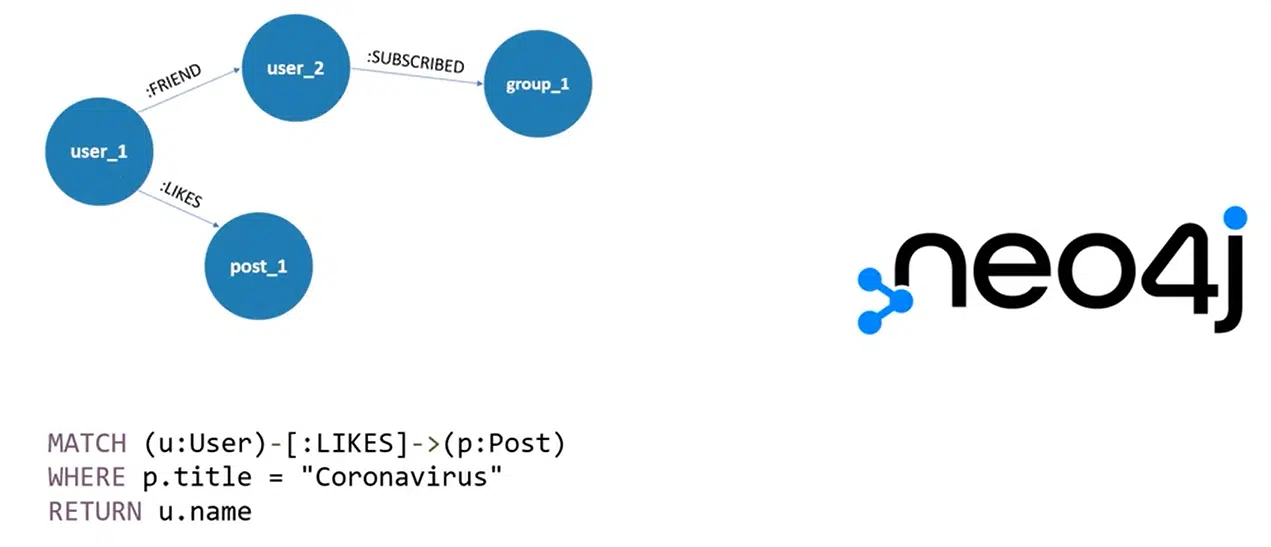
Нажмите, чтобы рассмотреть
Document Databases
У многих разработчиков NoSQL ассоциируется, прежде всего, с Document Databases — документными БД. Их принцип выглядит следующим образом: по какому-то ключу хранится целый документ в виде набора из key-value-значений бесконечной вложенности и неожиданной структуры, которая только может понадобиться. Один из популярных примеров реализации этой парадигмы — MongoDB.

Нажмите, чтобы рассмотреть
Виды нереляционных баз данных
Базы NoSQL делятся на четыре основные категории (в зависимости от решаемых с их помощью задач).
Ключ-значение
Такую базу можно представить как огромную таблицу. В каждой её ячейке хранятся данные произвольного типа, а каждому значению присвоен уникальный ключ, по которому это значение можно найти.
Такая СУБД не поддерживает связи между объектами, выполняет лишь операции поиска значений по ключу, добавления и удаления записи.
Например:
| key | value |
|---|---|
| user1 | {Кузнецов В., отдел маркетинга} |
| user2 | {name:Лена, position:секретарь} |
| user3 | {ООО «Вектор»} |
| user4 | {Трофимова Таня, отд.2, дизайнер} |
| user5 | {Галина Николаевна, гл. бух.} |
| user6 | {65,84,236} |
Базы «ключ-значение» часто используют для кэширования данных и организации очередей.
Их достоинства — быстрый поиск и простое масштабирование.
Их недостаток — нельзя производить операции со значениями. Например — сортировать их или анализировать.



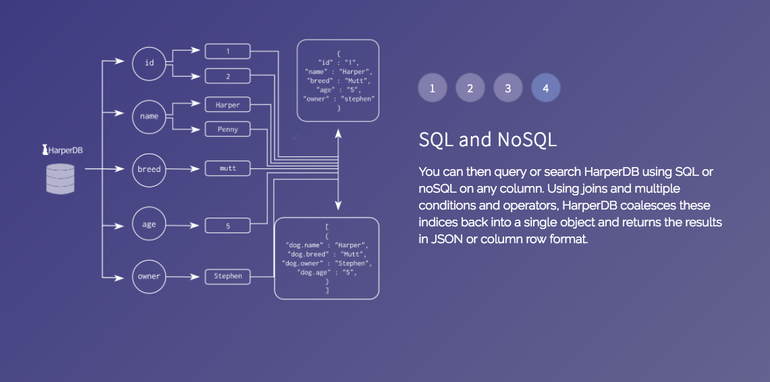
Одна из самых популярных — Redis. Её используют Uber, Slack, Stack Overflow, сайты гостиниц и туристические, социальная сеть Twitter.
Документоориентированные СУБД
В таких данные хранятся в виде иерархических структур (документов) с произвольным набором полей и их значений. Документы объединяются в коллекции.
Если провести аналогию с реляционными СУБД, то коллекциям соответствуют таблицы, а документам — строки в них.
Например, фрагмент документа с информацией о фильмах:
Документоориентированные базы используют в системах управления содержимым (CMS) — для хранения каталогов и пользовательских профилей.
Одна из самых популярных — MongoDB (там можно создавать процедуры на JavaScript).
Колоночные
Эти базы отличаются от реляционных лишь способом хранения данных на накопителе.
Если реляционная база создаёт для каждой таблицы по файлу, то в колоночной отдельный файл создаётся для каждого столбца таблицы.
Например, если реляционная таблица выглядит так:
| name | color | property |
|---|---|---|
| волк | серый | зубастый |
| коза | белая | рогатая |
| капуста | зелёная |
То те же записи колоночной базы будут выглядеть примерно так:
| name | волк | коза | капуста |
| color | серый | белая | зелёная |
| property | зубастый | рогатая |
Что это даёт? Представьте, что вам нужны только названия объектов, а их свойства вас не интересуют.
При выполнении запроса в реляционной таблице просматривается каждая запись и из неё выбираются нужные данные. В колоночной базе с диска будет считана только одна колонка с названиями. Это сокращает время выполнения запроса, причём намного.
Колоночные базы применяются в различных каталогах и архивах данных, работа с которыми основана на подобных выборках.
Одна из самых популярных СУБД такого типа — Apache Cassandra.
Графовые
В некоторых предметных областях данные удобно представлять в виде графов. Для их хранения лучше всего подходят графовые базы.
Вершины (или узлы графа) — это объекты (сущности), а рёбра графа — взаимосвязи между ними.
MongoDB на практике
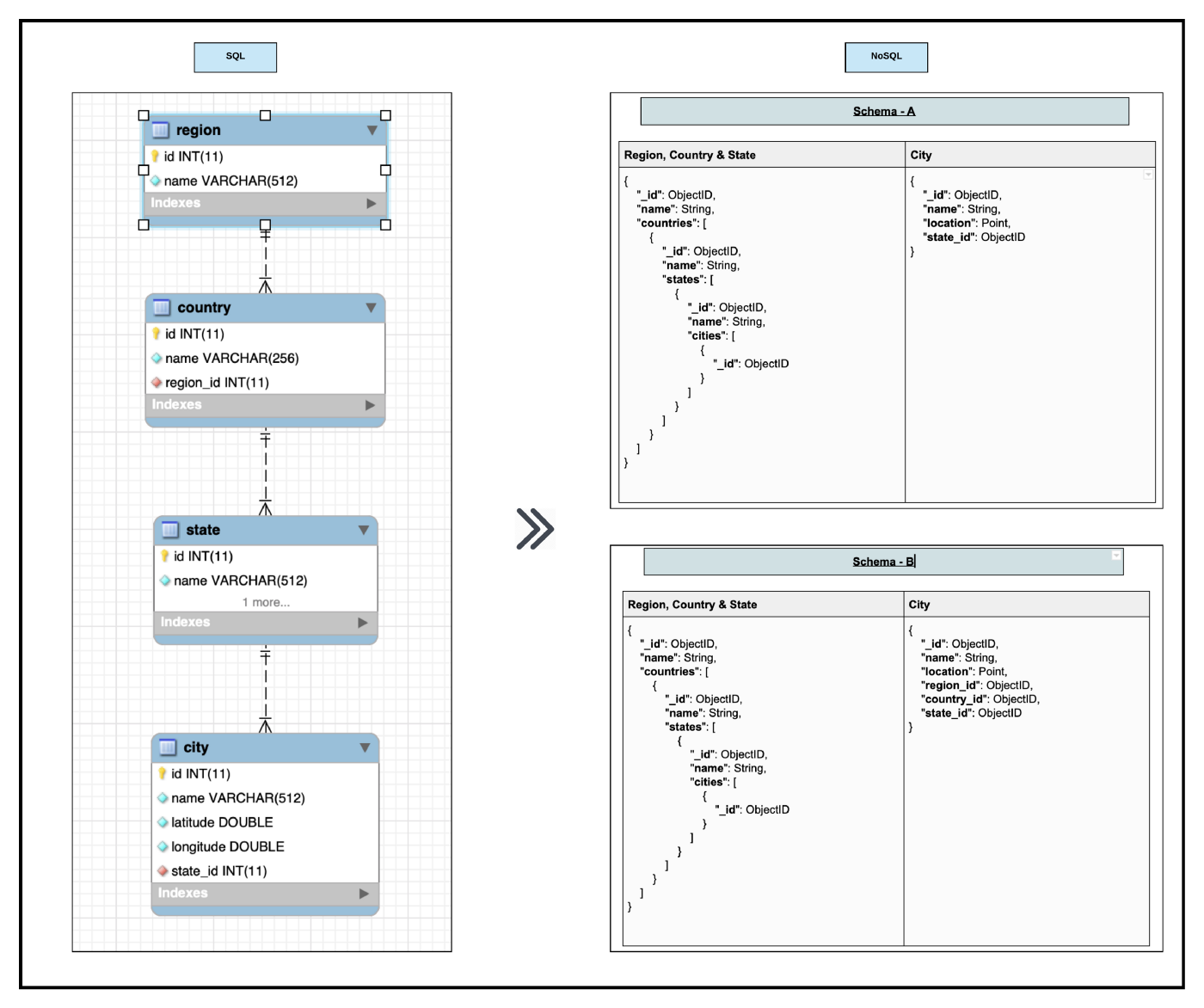
О MongoDB мне хотелось бы рассказать поподробнее. Представим проект, в котором нужно построить Google Forms с простой функциональностью: пользователь может создавать форму со свободным набором полей, любого количества.
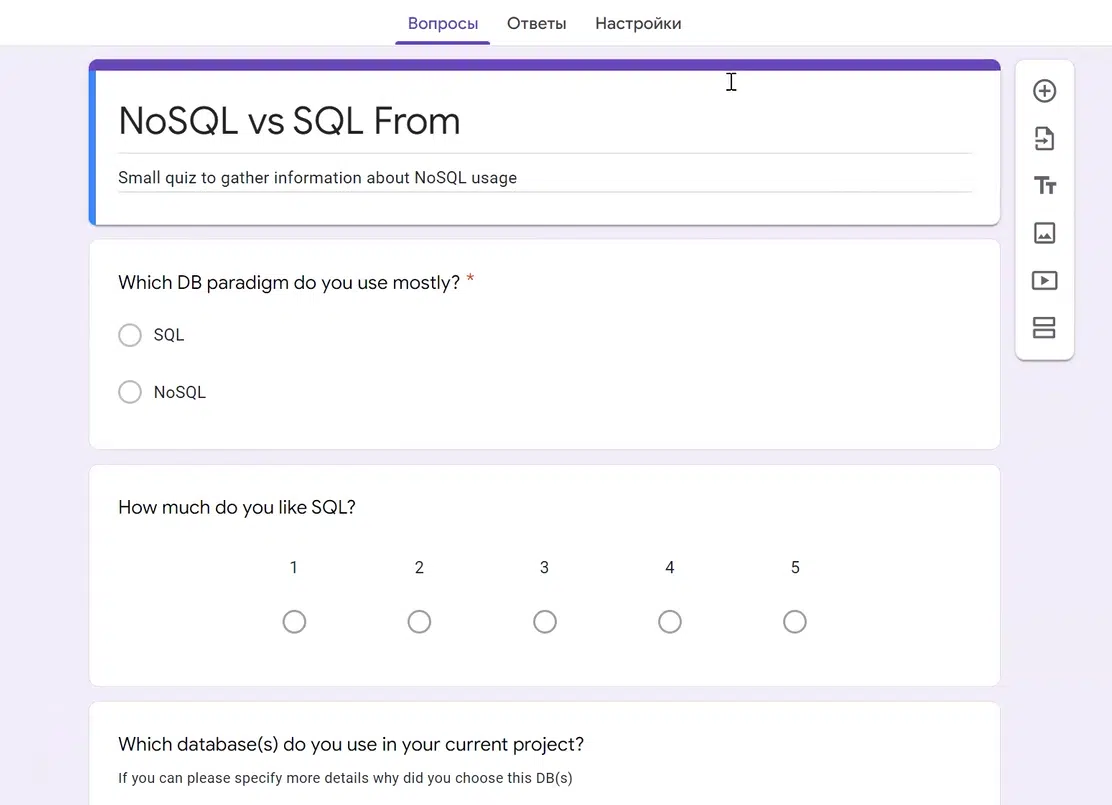
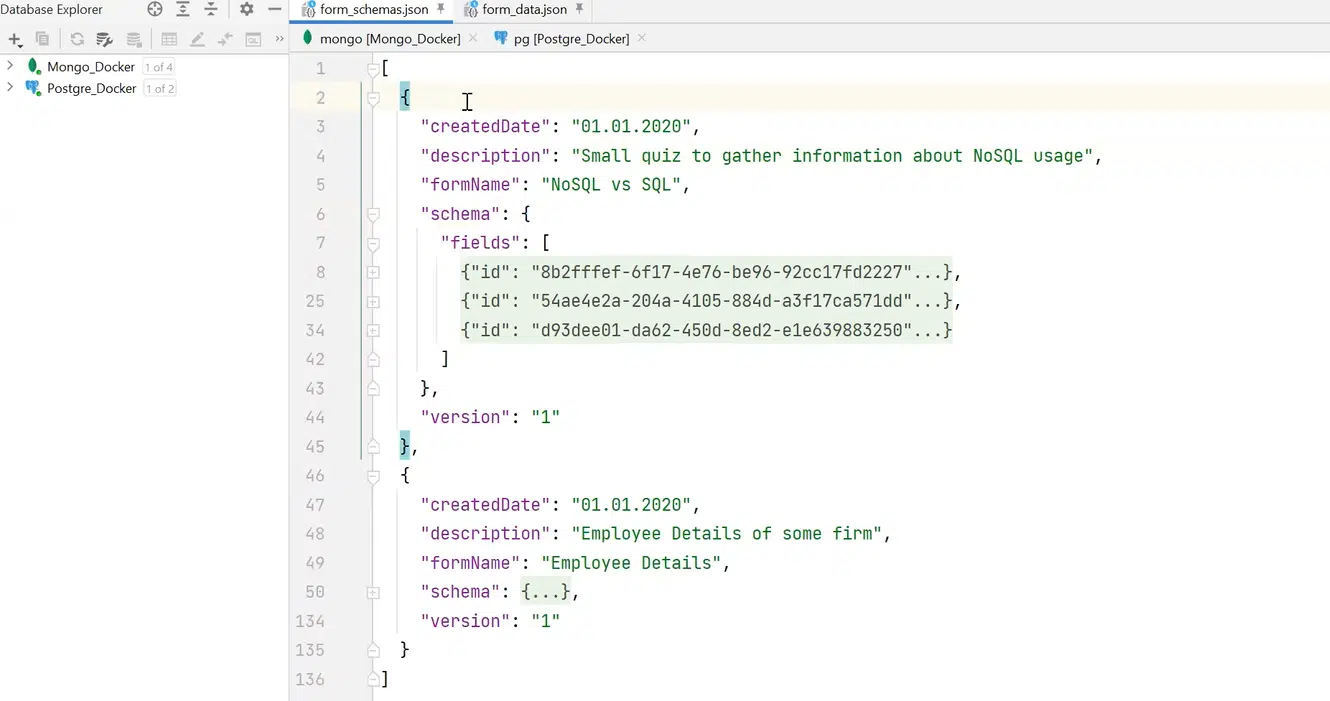
Моя форма «NoSQL vs SQL» проста: поля с радиобаттоном, со шкалой и free-text. Но пользователь может создать сложную форму. Например, из Personal Information или Employee Details, где есть табы: ФИО, дата рождения, опыт работы, технологии и т.д.
Если бы мы решали эту задачу в реляционной парадигме, было бы очень сложно создать схему БД. Вы ведь не знаете, сколько филдов будет, какие филды будут созданы в будущем, как будет расширяться их функционал и т.д. Именно здесь пригодится MongoDB.
Нажмите, чтобы рассмотреть
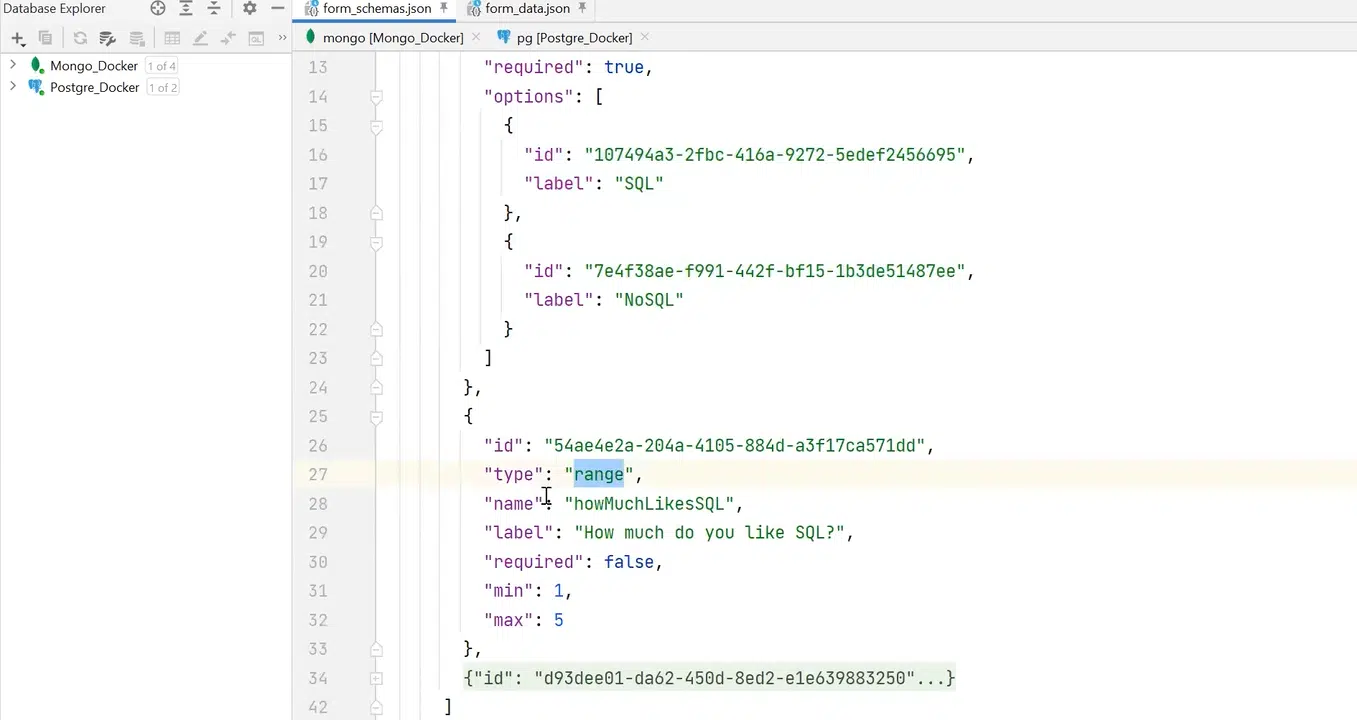
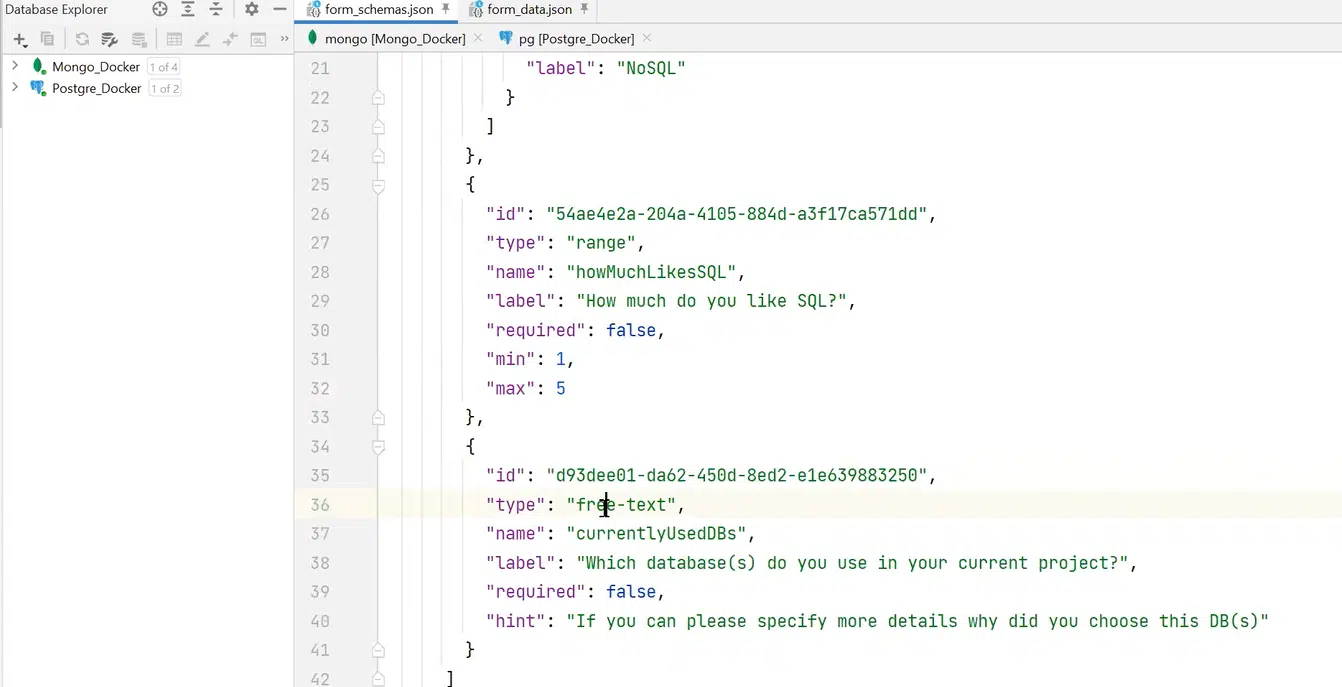
Для решения проблемы можно создать form schema, описывающую структуру и возможные данные. К примеру, в form schema есть служебные поля: createdDate, description, название формы. В поле schema будет набор филдов, которые описывает схема. К примеру, есть филд single-choice с полями name и options. При этом последний — это массив объектов. Также есть филд типа range с метками min и max, с простым числом, и филд free-text с каким-то hint.
Нажмите, чтобы рассмотреть
Нажмите, чтобы рассмотреть
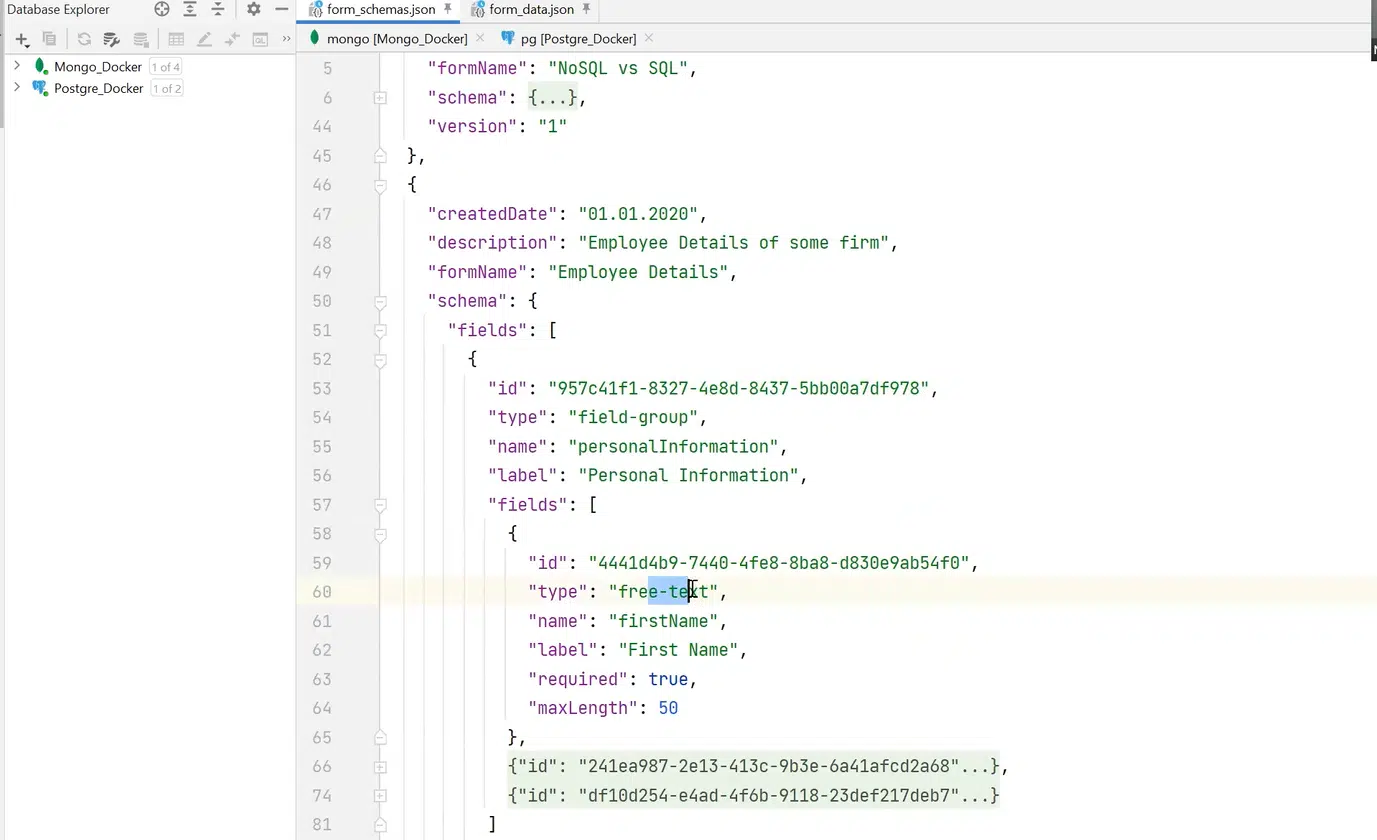
Предположим, что нам нужна не столь сложная форма Employee Details. Можно создать field type с названием field-group, у которого будут свои филды — это будет эдакая рекурсивная структура. Там может быть free-text, number, date — и так же со вторым табом.
Нажмите, чтобы рассмотреть
Идеально все это хранить в JSON, а ответы — в другом формате. К примеру, у нас есть fillDate, информация о том, что мы заполнили, и поле data, где все нужные данные заполняется в соответствии с описанной схемой.
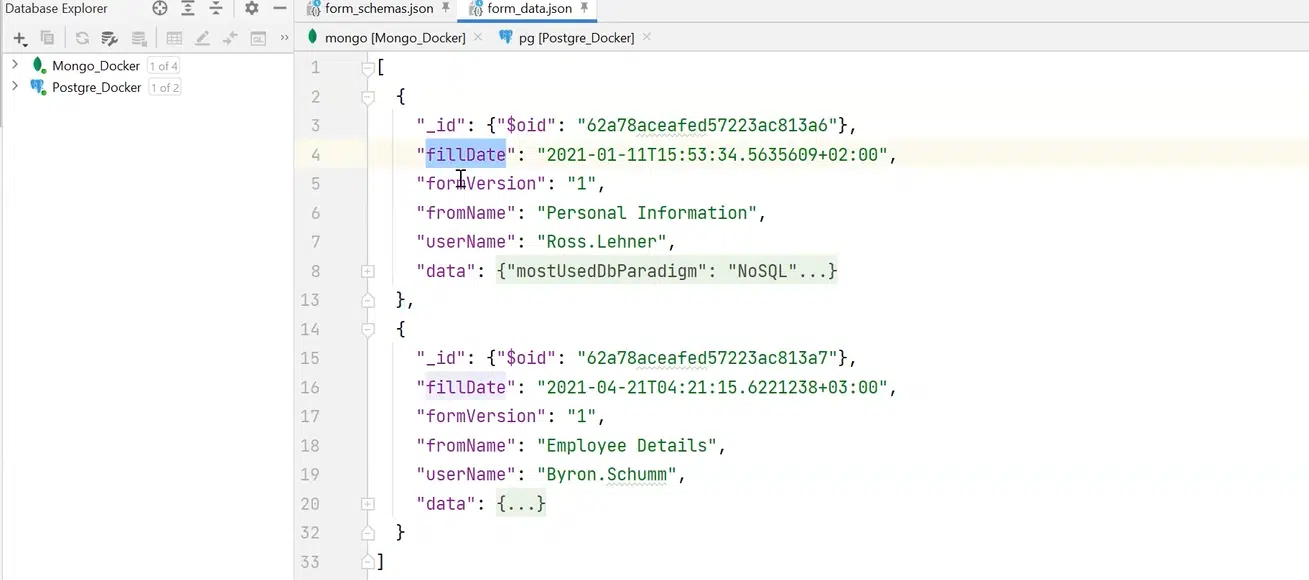
Нажмите, чтобы рассмотреть
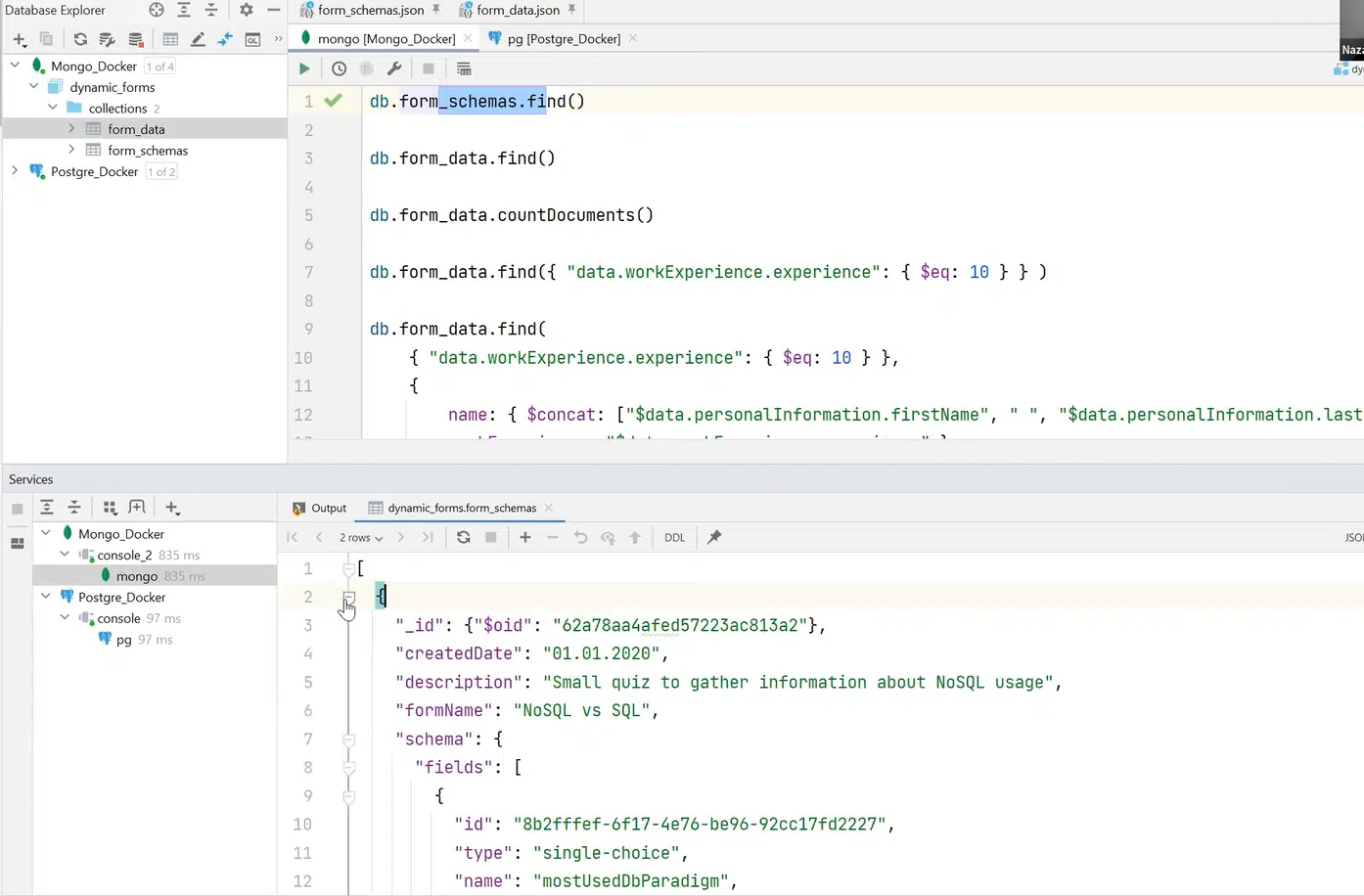
Как это реализовать в MongoDB? В этой БД есть такое понятие, как коллекции. Если сравнить это с реляционным миром, то это таблицы, но с одним очень важным отличием. В коллекции может лежать что угодно. Например, я создал коллекции form_schemas и form_data для одного и другого JSON-файлов соответственно.
Нажмите, чтобы рассмотреть
Также с помощью API и Query-синтаксиса в Mongo я могу задать поиск всех имеющихся form_schema и получить список документов. В нашем случае их два. Это те же определенные выше form_schema.
Нажмите, чтобы рассмотреть
Также я могу получить все form_data и документы, относящиеся к этой коллекции.
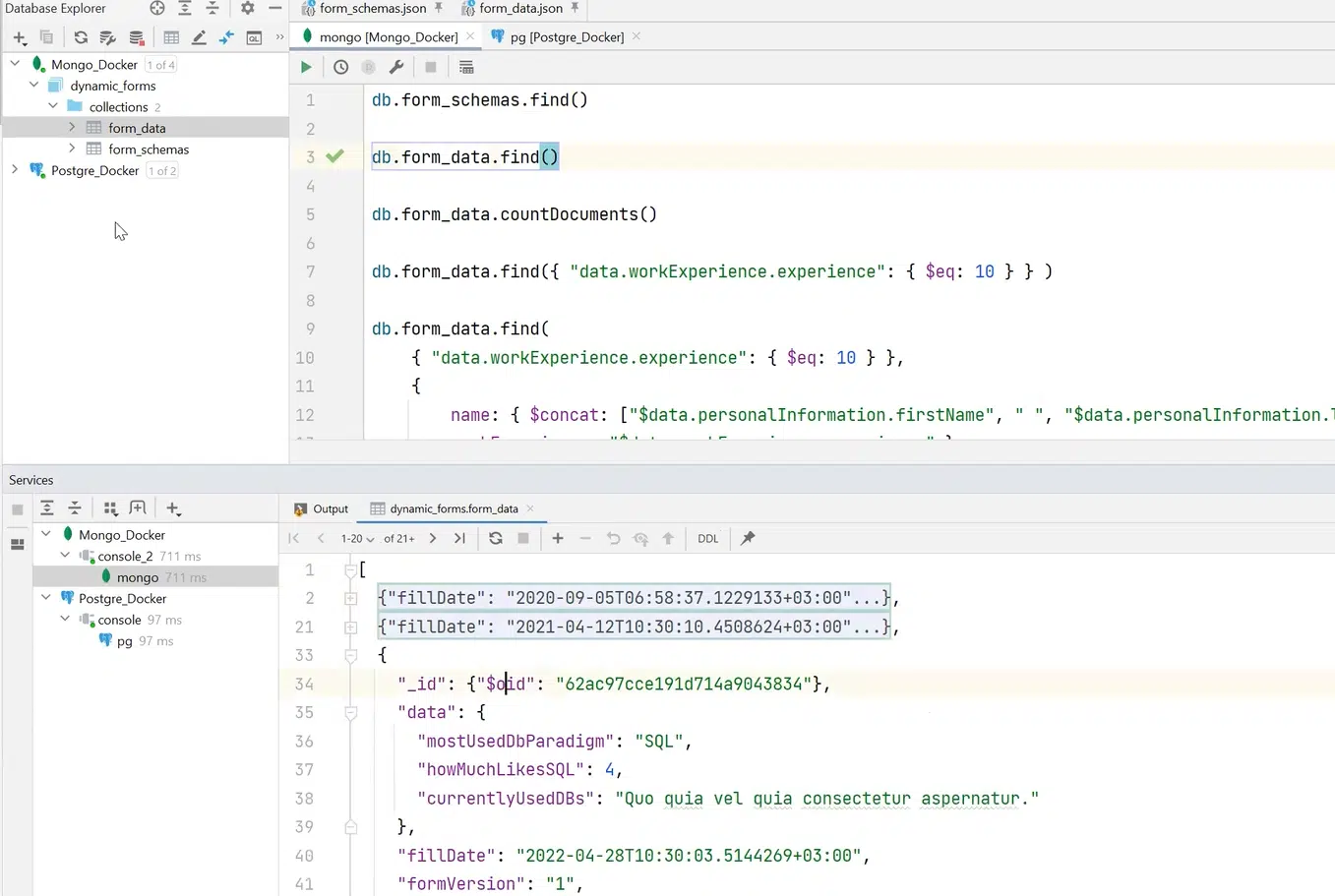
Нажмите, чтобы рассмотреть
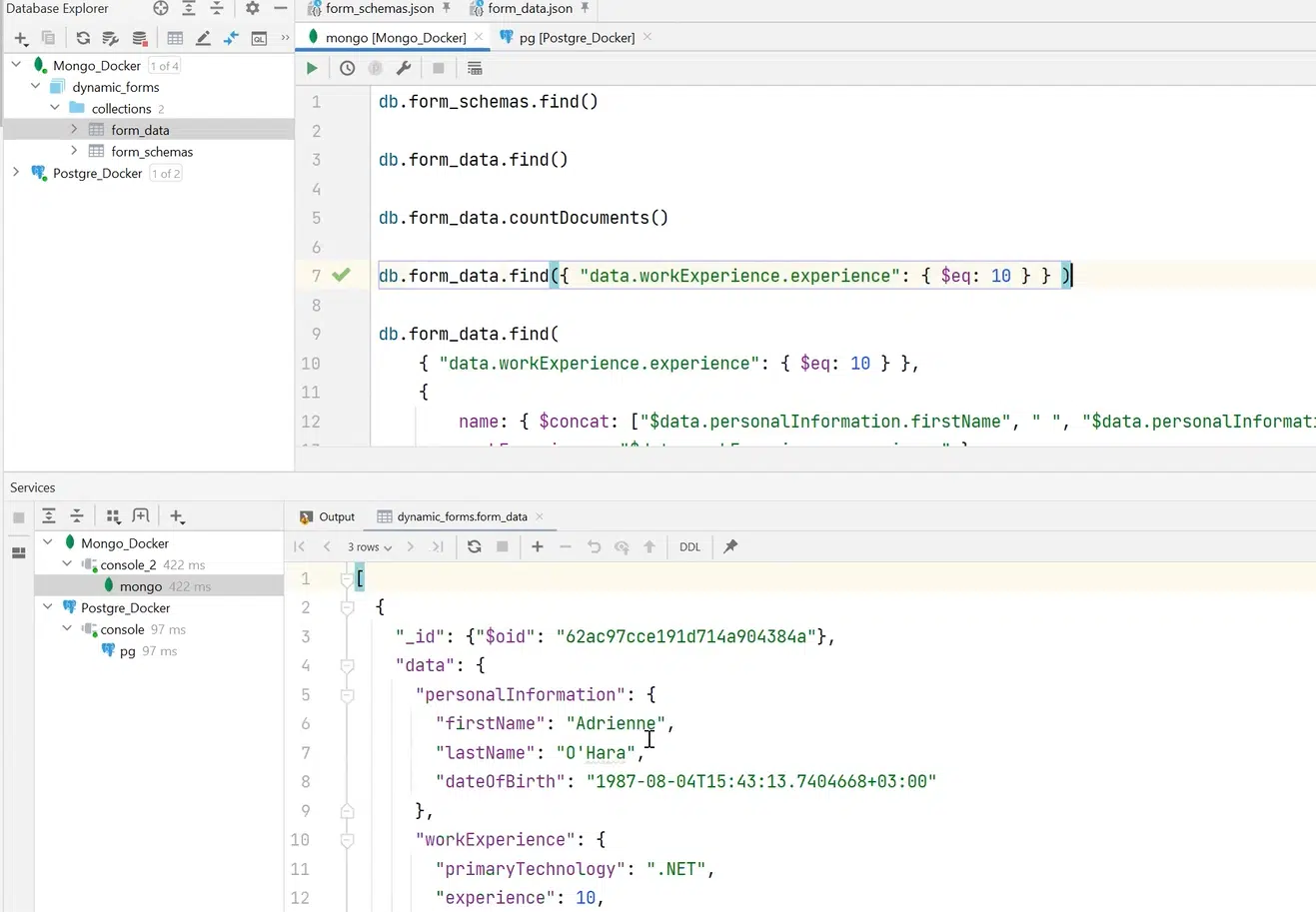
Кроме того, можно создавать и запросы. К примеру, нужно выбрать специфическую form_data — только те данные, где workExperience 10 лет. С помощью специального синтаксиса и инструментов MongoDB можно найти людей с опытом 10 лет.
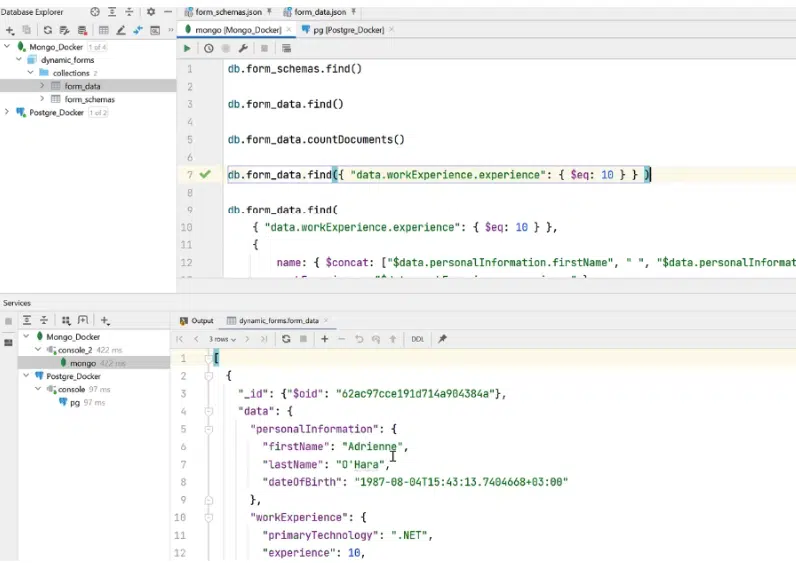
Нажмите, чтобы рассмотреть
Если эти филды не нужны, можно расширить запрос и сделать выборку нужных полей. К примеру, name и workExperience.
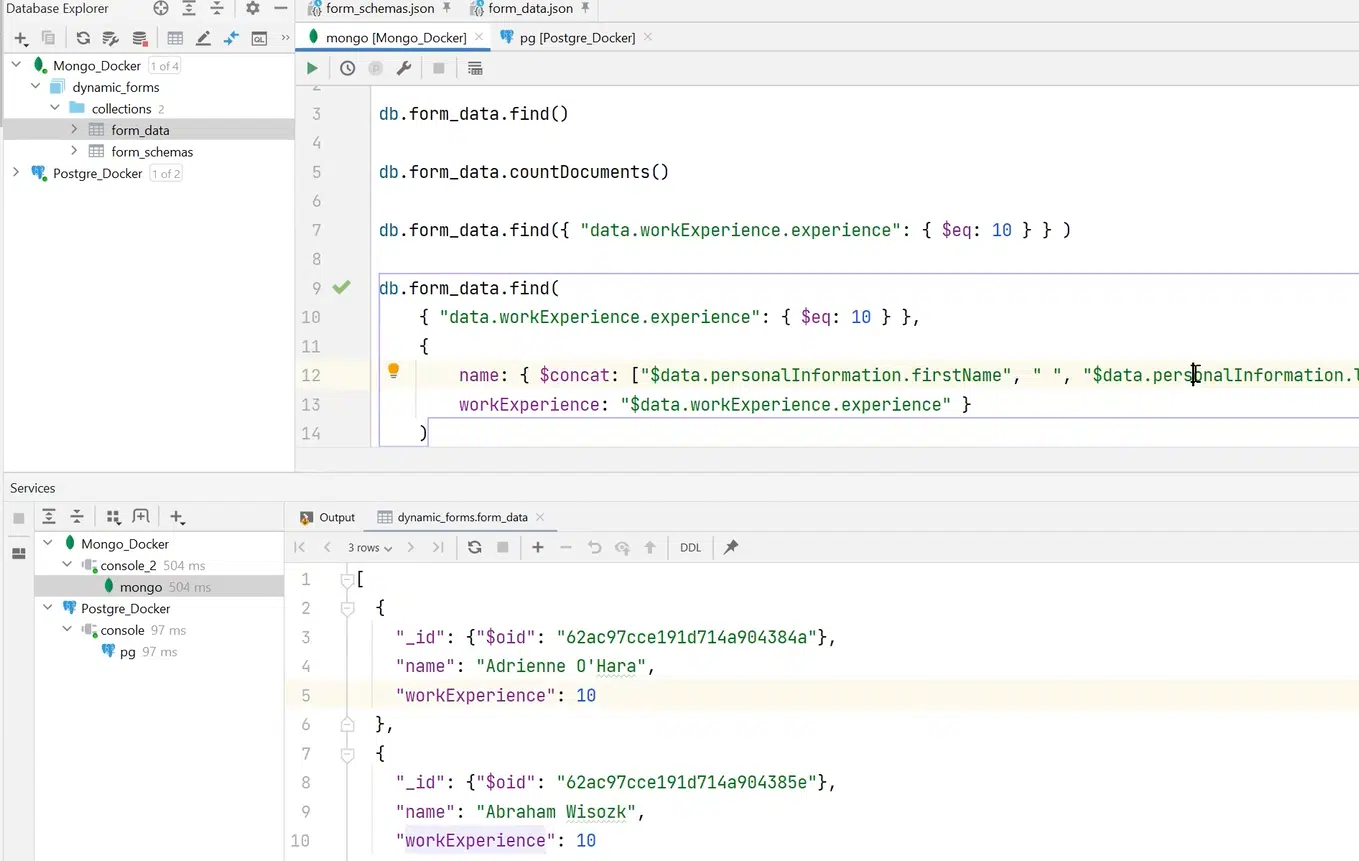
Нажмите, чтобы рассмотреть
Важно помнить, что коллекции — schemaless. Вам не нужно инсертить данные, подпадающие под схему
Это может быть рандом. К примеру, как объект на иллюстрации ниже. Такой запрос выполняется без проблем:


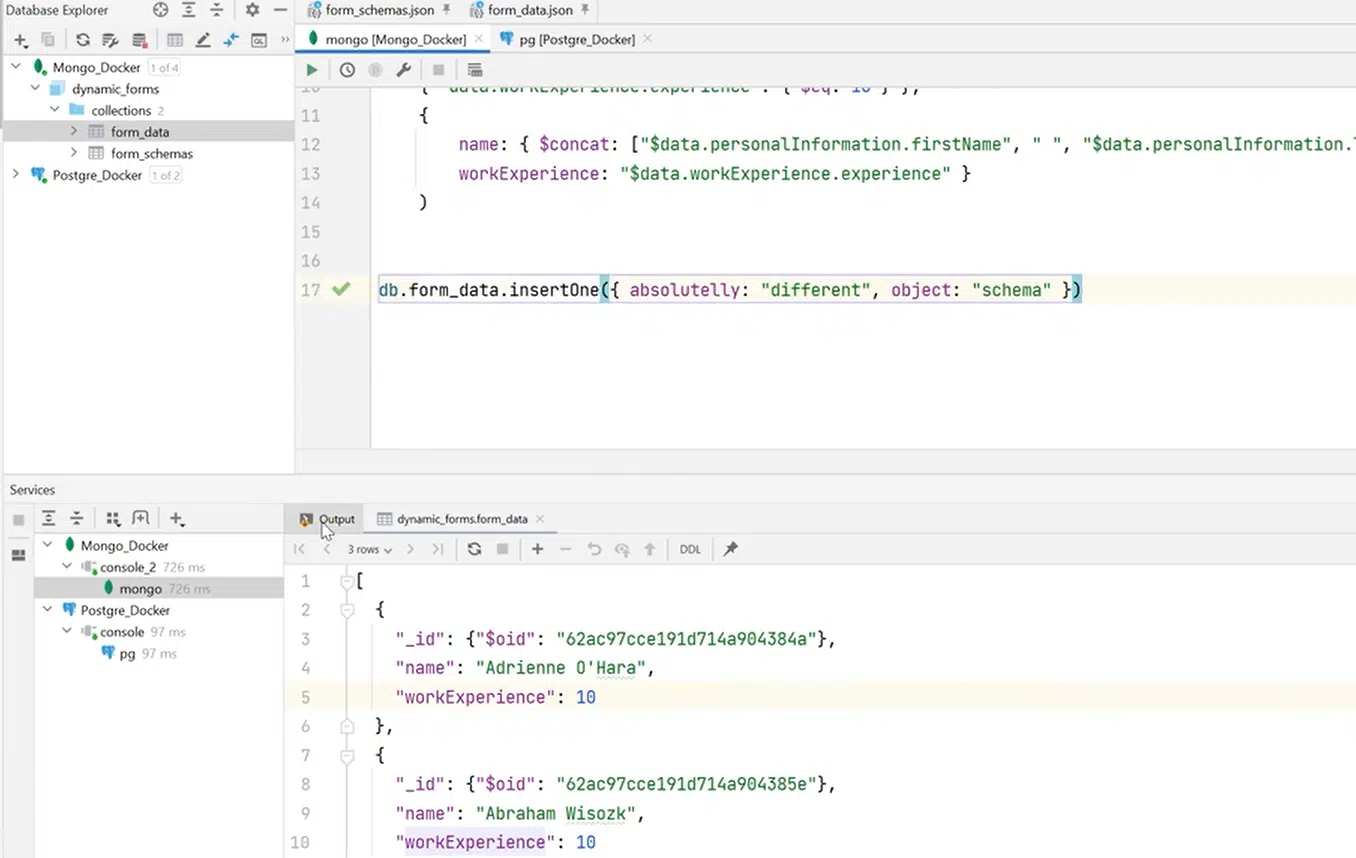
Нажмите, чтобы посмотреть
Что такое нормализация
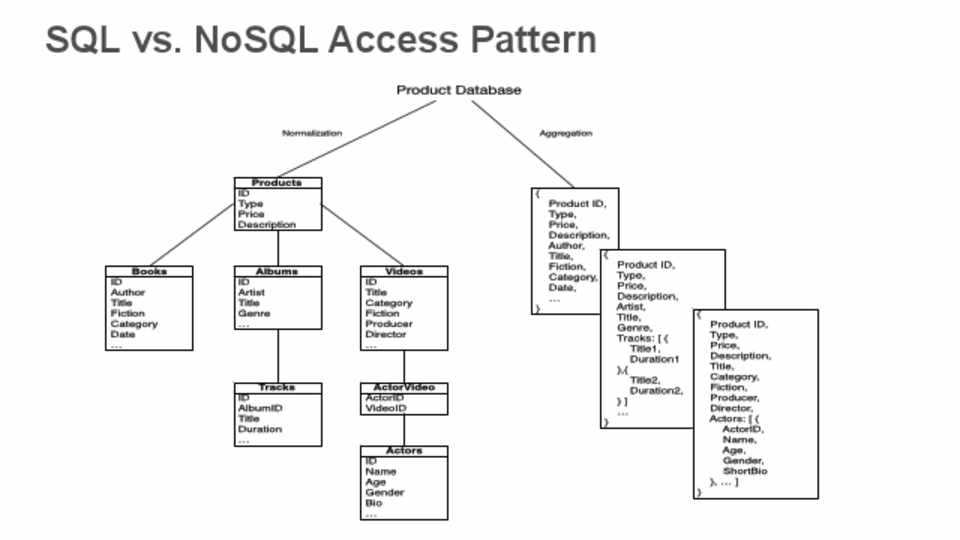
Чтобы уменьшить размер реляционной базы (не хранить избыточные данные) и избежать противоречивости (аномалий) при работе с ними, отношения в базе нормализуют. Проще говоря — разбивают их на взаимосвязанные таблицы. Это называется декомпозицией.
Избыточность данных — это когда одни и те же данные хранятся в базе сразу в нескольких местах.
Проверим наш пример на избыточность
Каждая строка таблицы Messages содержит имя клиента и никнейм оператора, а также их телефоны. Причём в 1-й и 3-й строках мы видим звонки от одного и того же клиента, а в 1-й и во 2-й — ответы одного и того же менеджера. То есть в 1-й и 3-й строках дублируются имя и телефон клиента — Васи, а в 1-й и 2-й — никнейм менеджера «Оператор1».
Чтобы избавиться от дублирования информации, выделим сущности Клиент и Оператор. И вынесем специфичные для каждой атрибуты в отдельные таблицы.
В первой (Clients) будут храниться имена и телефоны клиентов, а во второй (Operators) — операторов. Кроме того, каждой записи в этих таблицах мы присвоим атрибут id — так называемый первичный ключ (его значение уникально, то есть не может повторяться в пределах таблицы). С его помощью мы установим связь с записями таблицы Messages.
Для этого к каждой записи в Messages (напомним, она всё ещё представляет сущность «звонок») добавим два новых атрибута (внешних ключа): id_client и id_oper. Они будут ссылаться на первичные ключи из таблиц Clients и Operators соответственно. Столбцы с именами и телефонами из таблицы Messages уберём.
И вот что получим:
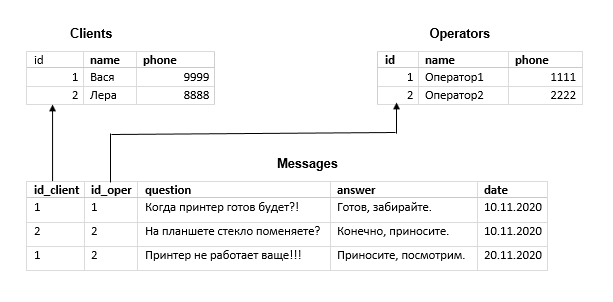
В такой базе, чтобы поменять телефон клиента сразу для всех записей, достаточно изменить всего одно поле в таблице Clients.
Всего существует шесть форм нормализации реляционных баз данных — в порядке уменьшения избыточности отношений. Все они описаны формальными правилами. Наше отношение мы привели ко второй нормальной форме.
Важные составляющие реляционной базы данных
SQL
Structured Query Language (язык программирования SQL) является основой интерфейса для реляционных баз данных. Он в 1986 г. стал стандартом ANSI (Национальный институт стандартов Соединенных Штатов). Сейчас этот стандарт поддерживают все самые распространенные ядра реляционных баз данных. Существуют также расширения стандарта ANSI SQL.
Они поддерживаются некоторыми ядрами реляционных баз данных. В реляционных базах данных SQL применяют для работы со строками данных (удаление, добавление, обновление), отбора блоков данных для приложений аналитики и обработки транзакций. Кроме того, этот язык программирования используется для управления всеми видами работы реляционных баз данных.
Целостность данных
Под целостностью данных понимают обеспечение их точности, полноты и единообразия. Для решения этой задачи в контексте реляционных баз данных применяется определенный комплекс инструментов, включающий первичные и внешние ключи, а также ограничители «Not NULL», «Unique», «Default» и «Check».
С помощью инструментов обеспечения целостности данных решаются вопросы применения практических правил к табличной информации, а также гарантируется точность данных и их надежность. Многие ядра реляционных БД поддерживают внедрение пользовательского кода, который выполняется при конкретных операция в базах данных.
Транзакции
Транзакций в базе данных называют комплекс последовательных операций, являющихся единой логической задачей и применением одного или ряда операторов SQL. Это неделимое действие. Транзакция должна выполняться как единая операция, поэтому она должна записываться в БД полностью, или ни один из ее элементов не должен записываться.
Транзакции в реляционных базах данных завершают действия COMMIT или ROLLBACK. Любой комплекс транзакционных операций следует рассматривать как надежный, имеющий внутренние связи элемент, не зависящий от остальных транзакций.
Соответствие требованиям ACID
Чтобы обеспечить требование по целостности реляционных баз данных, все транзакции в них должны удовлетворять требованиям ACID (они должны быть атомарными, единообразными, изолированными, надежными).
ТОП-30 IT-профессий 2022 года с доходом от 200 000 ₽
Команда GeekBrains совместно с международными специалистами по развитию карьеры
подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности
и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились
с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:

Александр Сагун
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2022
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Получить подборку бесплатно
pdf 3,7mb
doc 1,7mb
Уже скачали 16914
Первое условие – «атомарность». Оно указывает, что любая транзакция должна быть выполнена полностью. Если хоть один из ее элементов не выполняется, то должна отменяться вся транзакция. В соответствии с условием «единообразие», все элементы, записываемые в поля реляционной базы данных по транзакции, должны удовлетворять комплексу правил и ограничений, в том числе по целостности, каскадам и триггерам.
Условие «изолированность» важно для контроля согласованности данных. Кроме того, его выполнение необходимо для гарантии базовой независимости всех транзакций
В соответствии с условием «надежность», все изменения, которые внесены в реляционную базу данных до момента завершения транзакции, получают статус постоянных.
Перспективы реляционных баз данных
Существующие виды реляционных баз данных уже длительное время развиваются в плане повышения производительности, безопасности и надежности. Они стали более удобными в обслуживании, но при этом структура их сильно усложнилась. Сегодня администрирование реляционных баз данных связано с существенными затратами времени и ресурсов в плане администрирования.
В результате разработчики вынуждены направлять свои силы на управление СУБД и их оптимизацию вместо того, чтобы работать над созданием новых приложений, способных приносить высокую прибыль бизнесу.

Перспективы реляционных баз данных
Автономные технологии сейчас больше применяются для расширения функционала реляционной модели базы данных, разработки облачных хранилищ, машинного обучения и информационных баз нового типа. Автономные БД обладают всеми преимуществами реляционных систем, поддерживают те же функции, но плюс к этому способны использовать средства машинного обучения и искусственного интеллекта для контроля и повышения скорости ответа на запросы и эффективности управления.
К примеру, чтобы запросы выполнялись быстрее, самоуправляемые базы данных осуществляют прогнозирование и проверяют индексы. После этого более высокие результаты находят практическое применение. Примечательно, что все эти процессы происходят без вмешательства администратора. Другими словами, автономные БД на постоянной основе могут обеспечивать улучшения в своей работе без участия человека.
Автономные технологии освобождают разработчиков от рутинной работы по обслуживанию СУБД. В отличие от реляционных баз данных, примеры которых мы рассматривали в этом материале, самоуправляемые БД избавляют от необходимости предварительно выяснять все требования к инфраструктуре.
Автономные базы позволят расширять хранилища данных и увеличивать вычислительные мощности при появлении такой необходимости. Их создание может происходить намного быстрее, чем проектирование реляционных баз данных, что значительно сократит время, необходимое для разработки приложений.






Как всё начиналось
В 60-х годах прошлого столетия появилась необходимость в надежной модели хранения и обработки данных. В первую очередь эти данные генерировались банками и финансовыми организациями. В то время не существовало единых стандартов работы с данными и моделями, да и работа как таковая заключалась в ручном упорядочении и организации хранящейся информации.
У банков худо-бедно получалось записывать информацию о транзакциях в виде файлов в заранее подготовленную структуру. У каждой организации было собственное понимание того, как все это должно выглядеть и работать. Не было таких понятий, как консистентность (англ. data consistency), целостности данных (англ. data integrity). В файлах часто встречались дубликаты данных клиентов и их транзакций, которые необходимо было каким-то образом уточнять и приводить в порядок, делалось это в основном вручную. В целом все проблемы того времени в отношении работы с данными можно разделить на несколько основных видов:
-
Представление структуры в каждом файле было различным.
-
Необходимо было согласовывать данные в разных файлах, чтобы обеспечить непротиворечивость информации.
-
Сложность разработки и поддержки приложений, работающих с конкретными данными, и их обновления при изменении структуры файла.
По сути, здесь мы видим антипаттерн «чистой архитектуры», который был описан Робертом Мартином (Robert C. Martin).
Следует отметить, что были попытки создания моделей, позволяющих навести порядок в данных и их обработке. Одна из таких попыток — иерархическая модель, в которой данные были организованы в виде древовидной структуры. Иерархическая модель была востребованной, но не гибкой. В ней каждая запись могла иметь только одного «предка», даже если отдельные записи могли иметь несколько «потомков». Из-за этого базы данных представляли только отношения «один к одному» или «один ко многим». Невозможность реализации отношения «многие ко многим» могла привести к проблемам при работе с данными и усложняла модель. Более того, вопросы консистентности данных и отсутствия дублирования информации здесь вообще не стояли. Первая иерархическая СУБД называлась IMS от IBM.
На помощь иерархической пришла сетевая модель данных, и уже новая концепция реализовала отношение «многие ко многим». Данный подход был предложен как спецификация модели CODASYL в рамках рабочей группы DBTG (Data Base Task Group).
Но всё это модели, которые сложно было поддерживать. Упростить задачу сбора и обработки данных смог Франк Кодд (Edgar F. Codd). Его фундаментальная работа привела к появлению реляционных баз данных, которые нужны практически всем отраслям. Кодд предложил язык Alpha для управления реляционными данными. Коллеги Кодда из IBM — Дональд Чемберлен (Donald Chamberlin) и Рэймонд Бойс (Raymond Boyce) — создали один из языков под влиянием работы Кодда. Они назвали свой язык SEQUEL (Structured English Query Language), но изменили название на SQL из-за существующего товарного знака.
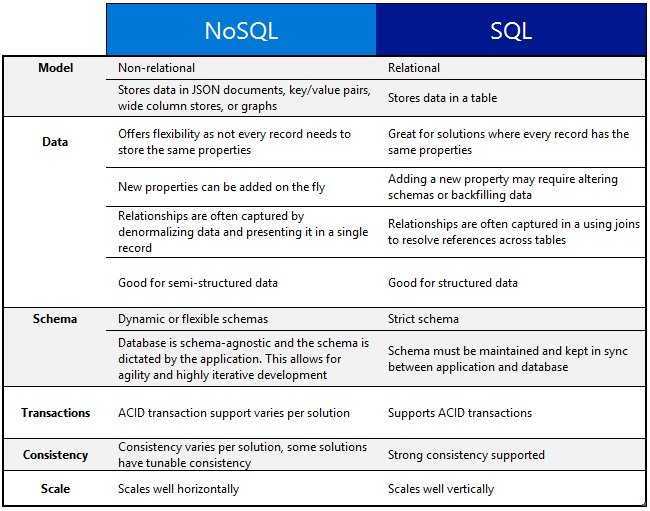
Преимущества и недостатки NoSQL
Как и любое другое решение, у нереляционных баз данных есть положительные и отрицательные черты. Если обобщить разные модели NoSQL, то среди их преимуществ можно выделить:
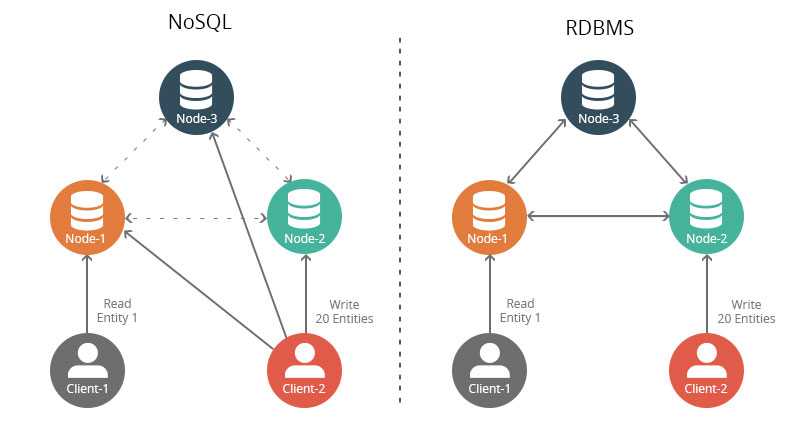
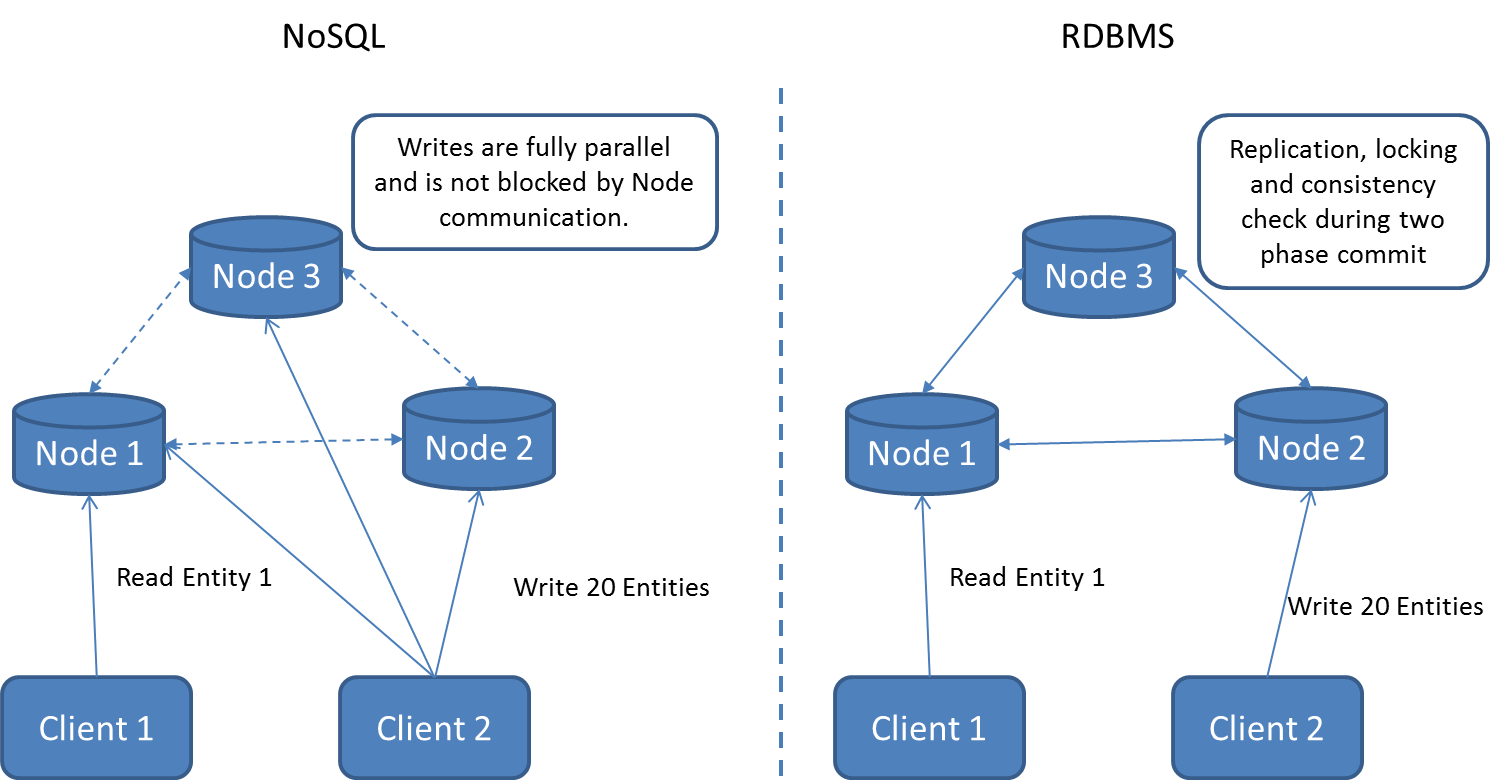
- Масштабирование. Обычно выполняется благодаря PartitionKey. Это фрагмент данных, о котором известно, что он находится в одном месте. В этом сущность горизонтального масштабирования. Если мы кладем данные заранее, потому что мы знаем PartitionKey, масштабирование будет почти безграничным.
- Лишение Object-relational impedance mismatch. На примерах MongoDB я показал, что у данных может быть нужная схема и структура. Для этого не нужно писать сложные джойны или моделировать данные не так, как вы их используете.
- Schemaless. В одну коллекцию можно инсертить объекты любой формы так, как вам удобно. Хотя, конечно, это может быть и недостатком NoSQL.
По-моему, главные недостатки нереляционных баз данных таковы:
Частичная поддержка транзакций. Различные парадигмы NoSQL и отдельные базы данных частично поддерживают концепты ACID, но в целом их нет. Ими пожертвовали ради масштабирования системы.
Отказ от реляционности. Если у вас нет джойнов, то у вас появляется… дублирование данных
Здесь важно понимать: это норма для подобной системы — не баг, а фича, как говорится. Поэтому нужно моделировать данные так, чтобы подобная система была настолько эффективна, насколько это реально.
Ограничены возможности поиска по сложным критериям
У NoSQL есть find, как я упоминал в примере. Но в глобальном концепте масштабирования есть проблемы. Если данные лежат на большом количестве нод, то для поиска по определенному критерию без Partition нужно обойти буквально все ноды. Это фактически нивелирует масштабирование как таковое.
Что касается концептов нереляционных баз данных, здесь следует учитывать, где вы будете использовать ту или иную базу. Ведь что хорошо для одного разработчика не всегда хорошо для другого. Это ярко показывает использование NoSQL-моделей теми или иными компаниями.
К примеру, на Key-Value Store базируется Redis, стандарт для fileload-систем. Column Based встречается в продуктах Facebook, Instagram и Netflix для предикшенов, улучшения Machine Learning и фильтрации контента. На Graph Databases построен каталог eBay. Document Databases — наиболее распространенный тип NoSQL-баз. С ним можно смоделировать любую структуру данных и CMS.
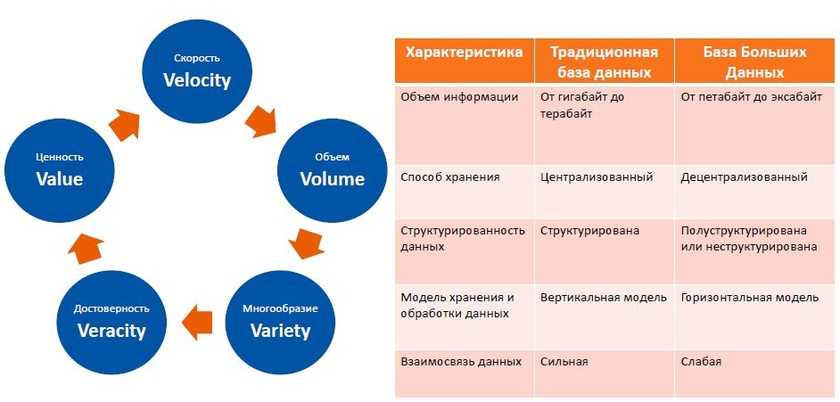
NoSQL как альтернатива традиционным БД
Мир меняется. В ходе цифровой трансформации перед бизнесом встают новые задачи. Компании решают их с помощью новых баз данных. Во-первых, чтобы не перегружать имеющиеся, во-вторых, не для всех современных задач подходят классические реляционные СУБД.
И вот, в начале 2000-х появились нереляционные базы. Помимо решения новых задач, их разработчики сделали упор на исправление главных недостатков реляционных баз — проблем с гибкостью, низкой производительностью и масштабируемостью.
В NoSQL нет таких понятий, как строки, столбцы, таблицы и их соединения. Данные в нереляционных базах хранятся как объекты с произвольными атрибутами: это могут быть пары «ключ-значение», документы в формате JSON, графы и так далее.
Иерархическая база данных — пример
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.
Выводы
Подводя итоги, скажу, что использование JSON в реляционной модели будет оправдано в нескольких случаях:
- Существующие проекты на SQL. Если в вашем приложении с реляционной БД появляется фича, нуждающаяся в динамических данных, NoSQL-методы точно пригодятся.
- Динамические конструкторы чего-либо с учетом масштабирования. Если вы не знаете, какими объектами будет оперировать пользователь и какие связи будут между ними, попробуйте следующие принципы. Как правило, это те же формы, рабочие флоу и прочее из того, что пользователь может создавать с помощью вашего инструмента.
- Оптимизация, когда реляционная модель является проблемой. Иногда разработчики могут так заиграться с нормализацией данных в SQL, что количество таблиц и связей станет слишком большим. Это может привести к остановке некоторых операций по записи или чтению. В таком случае из-за множества джойнов не спасут никакие индексы. Поэтому для денормализации данных нужно обратиться к NoSQL-подходу. Вместо миллионов связей вы будете иметь форму JSON в одной колонке. При этом, если у вас были фильтрации, они останутся благодаря новым функциям и синтаксисам БД.
Существует еще множество примеров задач, которые можно решать по следующему подходу:
- во-первых, это Metadata Forms — сложные динамические формы;
- во-вторых, BPMN Workflows, где все степи описаны в JSON;
- и в-третьих, это CMS.
Здесь вы обеспечите пользователю приложения возможность создания любого динамического контента. Во всяком случае всегда помните: то, что хорошо сработало для кого-то, не факт, что подойдет в вашем случае. Внимательно рассматривайте разные кейсы, экспериментируйте, и все у вас получится.