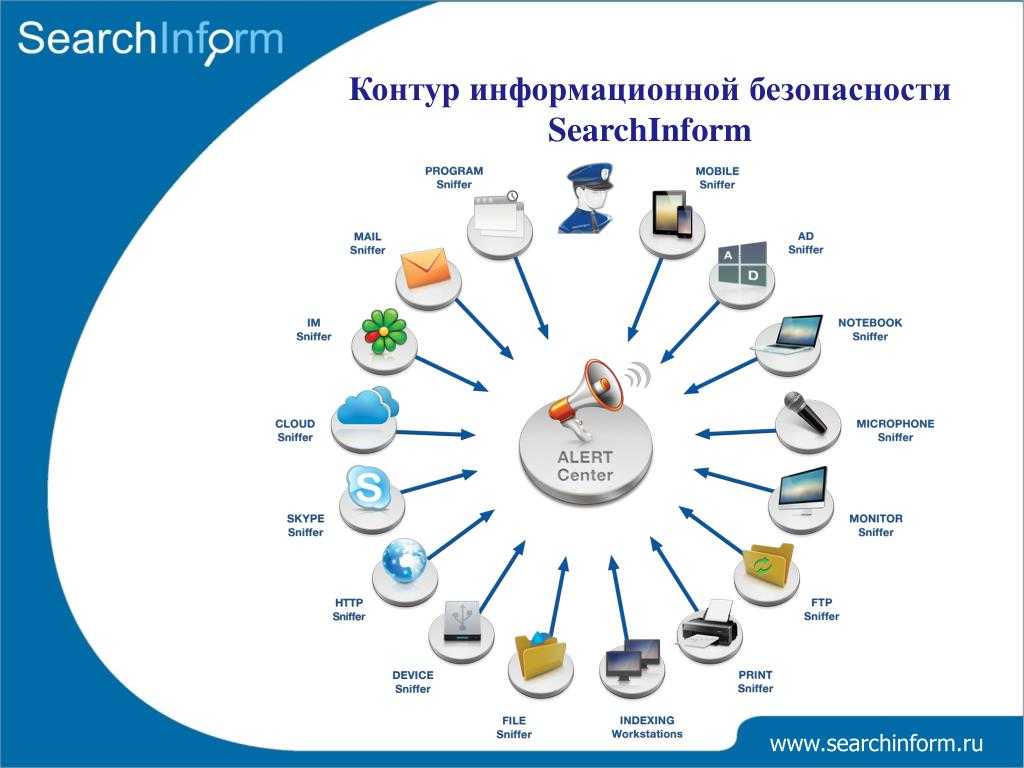
Сбор и хранение больших данных перед обработкой
Ресурсы, выдающие большие данные могут быть весьма разнообразны. Например:
- интернет — социальные сети, блоки и сайты СМИ, интернет вещей (IoT) и т.п.;
- корпоративные источники — транзакции, архивы, базы данных и т. п.;
- устройства, собирающие информацию — GPS-сигналы автомобилей, метеорологическое оборудование и т.п.
Совокупность методик по сбору данных и саму операцию называют Data Mining. В качестве примеров сервисов, осуществляющих процесс сбора информации, можно привести: Qlik, Vertica, Power BI, Tableau. Формат данных, как уже говорилось выше, может быть разнообразным — видео, текст, таблицы, SAS.
Если в сжатой форме описывать процесс сбора и обработки большого массива данных, то стоит выделить основные этапы:
- постановка задачи для аналитической программы;
- программа осуществляет сбор данных с их параллельной подготовкой (декодировка, отсев мусора, удаление нерелевантной информации);
- выбор алгоритма анализа данных;
- обучение программы выбранному алгоритму с дальнейшим анализом обнаруженных закономерностей.
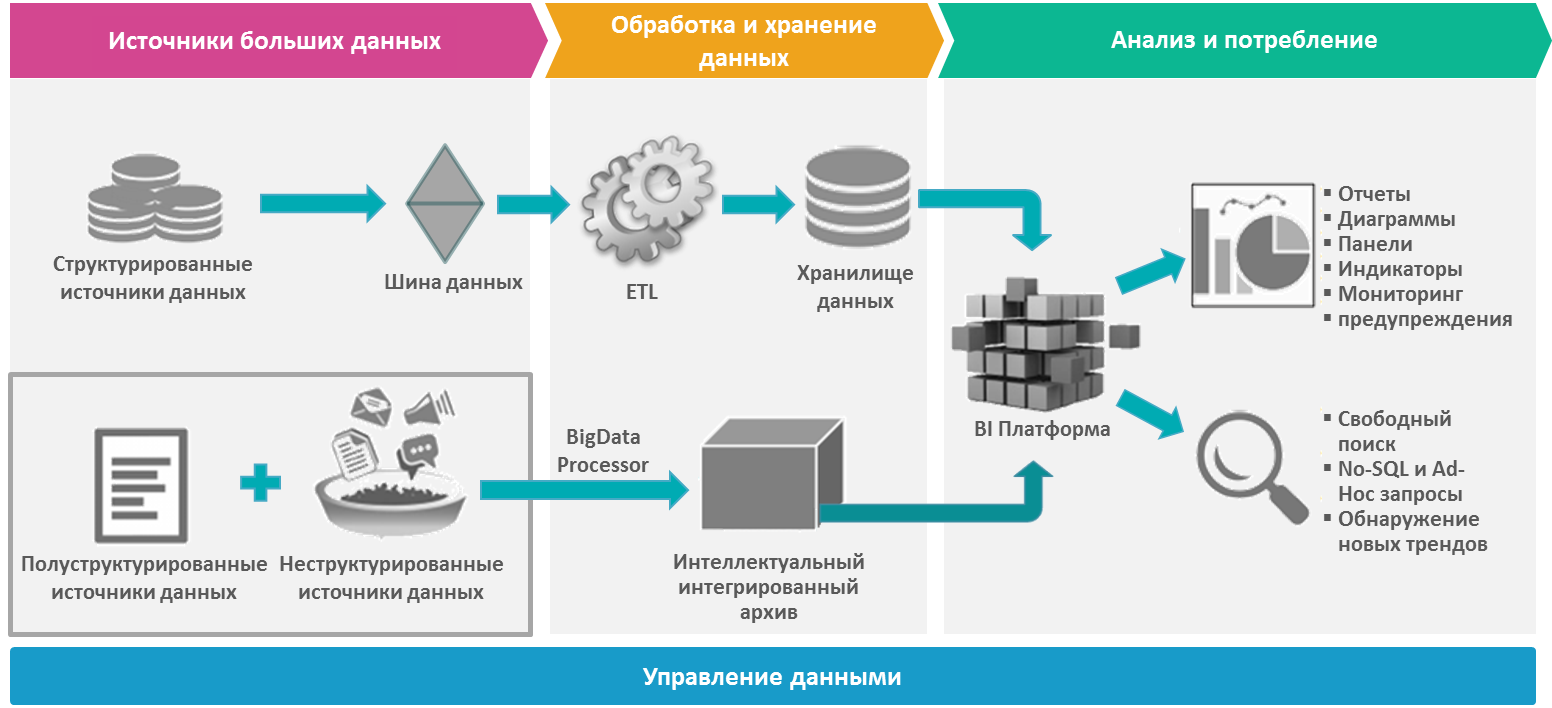
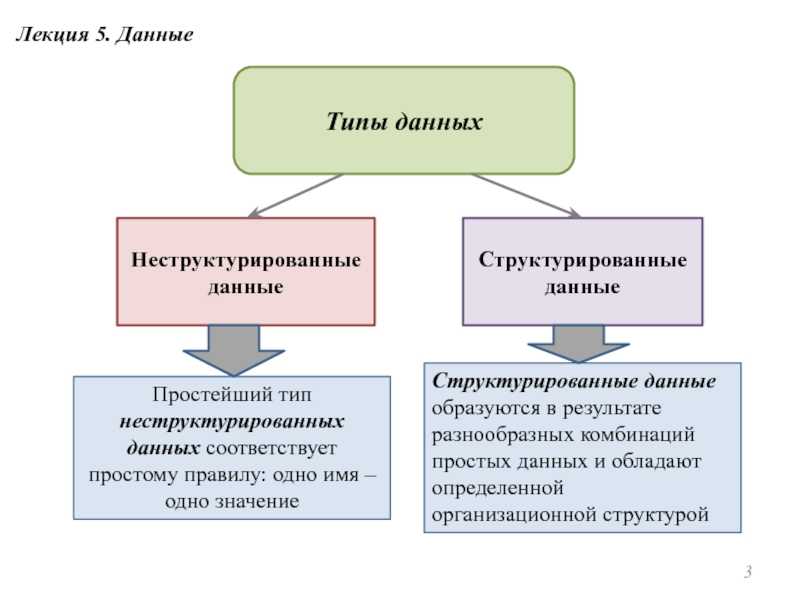
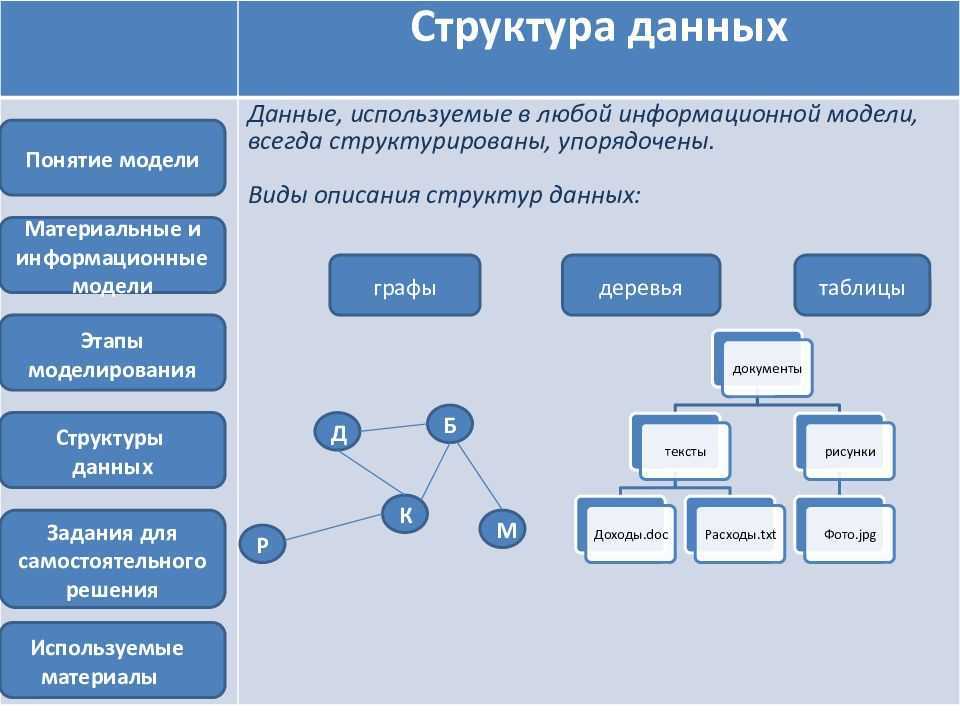
В большинстве случаев полученные необработанные данные хранятся в так называемом «озере данных» — Data Lake. Формат и уровень структуризации информации при этом может быть разнообразным:
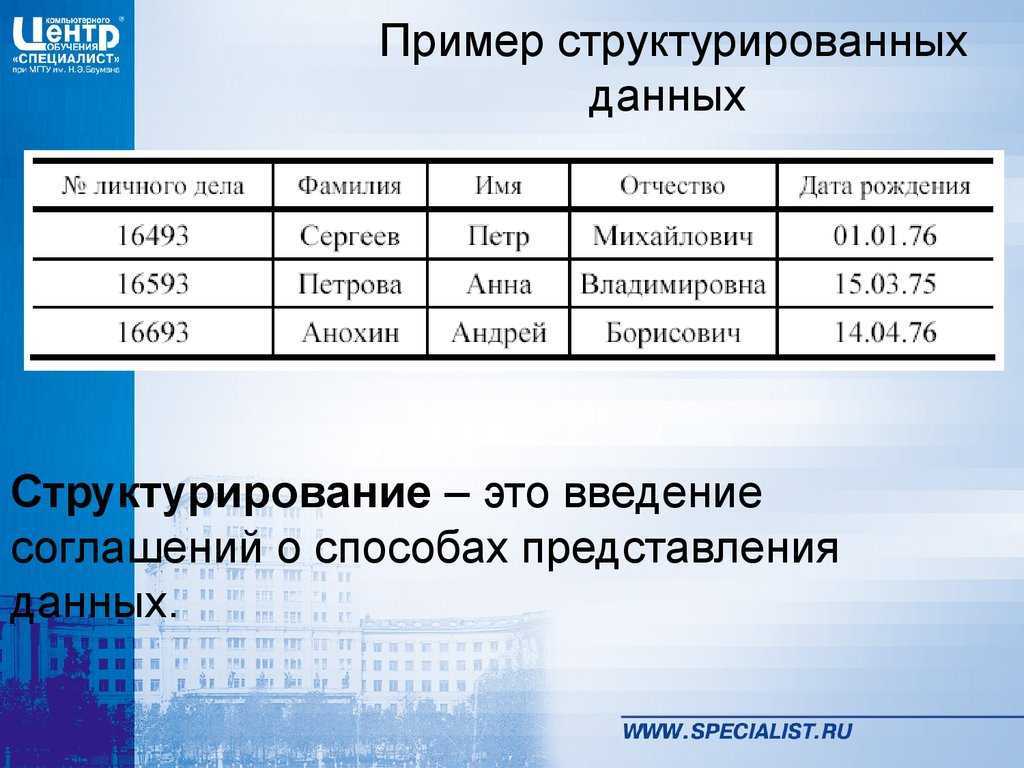
- структурные (данные в виде строк и колонок);
- частично структурированные (логи, CSV, XML, JSON-файлы);
- неструктурированные (pdf-формат, формат документов и т. п.);
- бинарные (формат видео, аудио и изображения).
Инструментарий, позволяющий хранить и обрабатывать данные в Data Lake:
- Hadoop — пакет утилит и библиотек, используемый для построения систем, обрабатывающих, хранящих и анализирующих большие массивы нереляционных данных: данные датчиков, интернет-трафика, объектов JSON, файлов журналов, изображений и сообщений в соцсетях.
- HPPC (DAS) – суперкомпьютер, способный обрабатывать данные в режиме реального времени или в «пакетном состоянии». Реализован LexisNexis Risk Solutions.
- Storm — фреймворк Big Data, созданный для работы с информацией в режиме реального времени. Разработан на языке программирования Clojure.
- DataLake – помимо функции хранения, включает в себя и программную платформу (например, такую как Hadoop), а также определяет источники и методы пополнения данных, кластеры узлов хранения и обработки информации, управления, инструментов обучения. DataLake при необходимости масштабируется до многих сотен узлов без прекращения работы кластера.
ТОП-30 IT-профессий 2022 года с доходом от 200 000 ₽
Команда GeekBrains совместно с международными специалистами по развитию карьеры
подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности
и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились
с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:
Александр Сагун
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2022
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Получить подборку бесплатно
pdf 3,7mb
doc 1,7mb
Уже скачали 16880
Месторасположение «озера», как правило, находится в облаке. Так, около 72 % компаний при работе с Big Data предпочитают собственным серверам облачные. Это связано с тем, что обработка больших баз данных требует серьезные вычислительные мощности, в то время как облако значительно снижает стоимость работ. Именно по этой причине компании выбирают облачные хранилища.
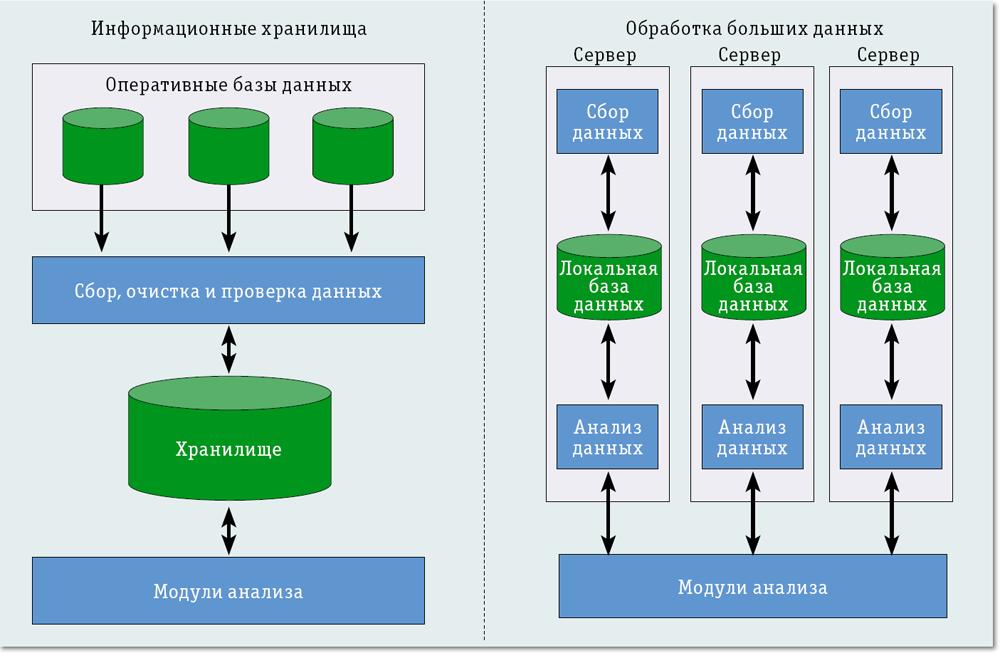

Облако имеет ряд преимуществ перед собственным дата-сервисом. Из-за того, что расчет предстоящей нагрузки на инфраструктуру затруднителен, то закупка оборудования не целесообразна. Аппаратура, купленная на случай востребованности в больших мощностях, может просто простаивать, принося убытки. Если же оборудование окажется недостаточным по мощности, то его ресурсов не хватит для полноценной работы.
Облако, напротив, не имеет ограничений по объему сохраняемых в нем данных. Следовательно, оно выгодно с точки зрения экономии средств для тех компаний, нагрузка которых быстро растет, а также бизнеса, связанного с тестами различных гипотез.
Как нормализовать данные
Нормализация данных позволяет масштабировать числовые значения в указанном диапазоне. Ниже представлены распространенные методы нормализации данных.
- Нормализация по методу минимакса: линейное преобразование данных в диапазоне, например, от 0 до 1, где минимальное и максимальное масштабируемые значения соответствуют 0 и 1 соответственно.
- Нормализация по Z-показателю: масштабирование данных на основе среднего значения и стандартного отклонения: деление разницы между данными и средним значением на стандартное отклонение.
- Десятичное масштабирование: масштабирование данных путем удаления десятичного разделителя значения атрибута.
Как обрабатывать пропущенные значения
При работе с пропущенными значениями лучше сначала определить причину их появления в данных, что поможет решить проблему. Вот какие бывает методы обработки пропущенных значений:
- Удаление: удаление записей с пропущенными значениями.
- Фиктивная подстановка — замена пропущенных значений фиктивными, например подстановка значения unknown (неизвестно) вместо категориальных или значения 0 вместо чисел.
- Подстановка среднего значения: пропущенные числовые данные можно заменить средним значением.
- Подстановка часто используемого элемента: пропущенные категориальные значения можно заменить наиболее часто используемым элементом.
- Подстановка по регрессии: использование регрессионного метода для замены пропущенных значений регрессионными.
Определение Big Data, или больших данных
К большим данным относят информацию, чей объем может быть свыше сотни терабайтов и петабайтов. Причем такая информация регулярно обновляется. В качестве примеров можно привести данные, поступающие из контакт-центров, медиа социальных сетей, данные о торгах фондовых бирж и т. п. Также в понятие «большие данные» иногда включают способы и методики их обработки.
Если же говорить о терминологии, то «Big Data» подразумевает не только данные как таковые, но и принципы обработки больших данных, возможность дальнейшего их использования, порядок обнаружения конкретного информационного блока в больших массивах. Вопросы, связанные с такими процессами, не теряют своей актуальности. Их решение носит важный характер для тех систем, которые многие годы генерировали и копили различную информацию.
Определение Big Data, или больших данных
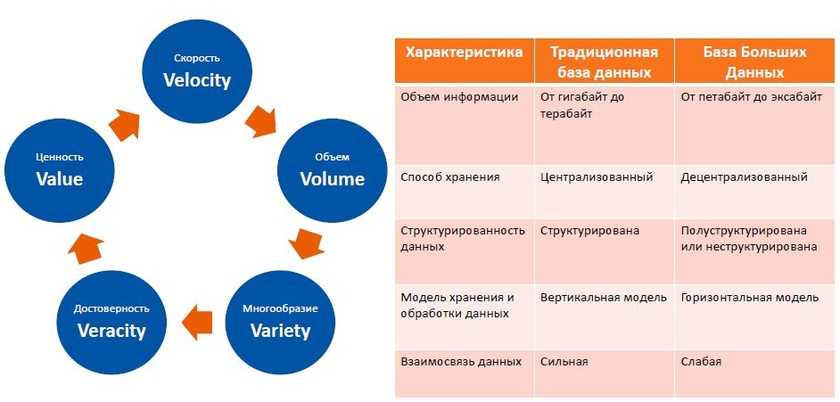
Существуют критерии информации, определенные в 2001 году Meta Group, которые позволяют оценить, соответствуют ли данные понятию Big Data или нет:
- Volume (объем) — примерно 1 Петабайт и выше.
- Velocity (скорость) — генерация, поступление и обработка данных с высокой скоростью.
- Variety (разнообразие)— разнородность данных, различные форматы и возможное отсутствие структурированности.
Только до25 декабря
Пройди опрос иполучи обновленный курс от Geekbrains
Дарим курс по digital-профессиям
и быстрому вхождения в IT-сферу
Чтобы получить подарок, заполните информацию в открывшемся окне
Перейти
Скачать файл
Зачастую к этим параметрам добавляют еще два фактора:
Следует отметить, что такие формулировки весьма условны, т. к. четкого и единого определения не существует. Есть даже мнение о необходимости отказа от термина «Big Data», т. к. происходит подмена понятий и Big Data часто путают с другими продуктами.
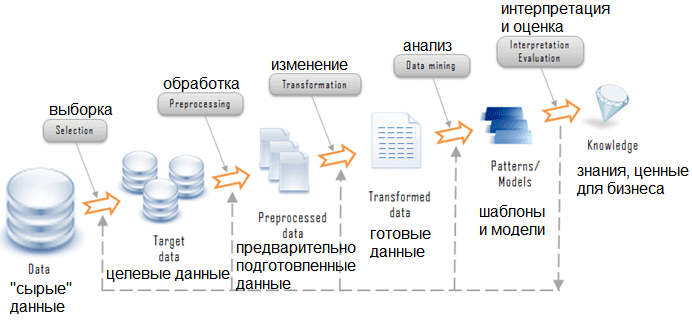
Зачем нужна предварительная обработка и очистка данных?
Реальные данные собираются для последующей обработки из разных источников и процессов. Они могут содержать ошибки и повреждения, негативно влияющие на качество набора данных. Вот какими могут быть типичные проблемы с качеством данных:
- Неполнота: данные не содержат атрибутов, или в них пропущены значения.
- Шум: данные содержат ошибочные записи или выбросы.
- Несогласованность: данные содержат конфликтующие между собой записи или расхождения.
Качественные данные — это необходимое условие для создания качественных моделей прогнозирования. Чтобы избежать появления ситуации «мусор на входе, мусор на выходе» и повысить качество данных и, как следствие, эффективность модели, необходимо провести мониторинг работоспособности данных, как можно раньше обнаружить проблемы и решить, какие действия по предварительной обработке и очистке данных необходимы.
Какие есть стандартные методы мониторинга работоспособности данных
Вот что нужно оценить, чтобы проверить качество данных:
- Количество записей.
- количество атрибутов (или компонентов);
- Типы данных атрибута (номинальные, порядковые или непрерывные).
- Количество пропущенных значений.
- Данные правильного формата.
- Если данные имеют формат TSV или CSV, проверьте правильность разделения столбцов и строк соответствующими разделителями.
- Если данные имеют формат HTML или XML, убедитесь, что формат данных соответствует надлежащим стандартам.
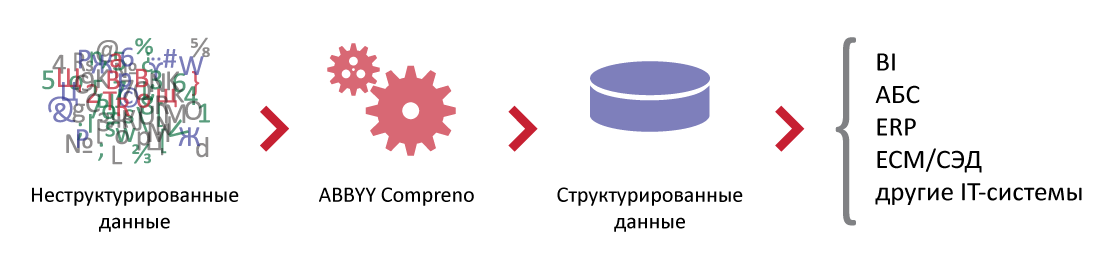
- Для извлечения структурированной информации из частично структурированных или неструктурированных данных также может потребоваться синтаксический анализ.
- Несогласованные записи данных. Проверьте допустимость диапазона значений. Например, если данные содержат средний балл ученика, проверьте, находится ли этот средний балл в обозначенном диапазоне (например, 0~4).
При обнаружении проблем с данными необходимо выполнить обработку, которая зачастую включает очистку пропущенных значений, нормализацию данных, дискретизацию, обработку текста для удаления и/или замены внедренных символов, которые могут влиять на выравнивание данных, смешанные типы данных в общих полях и пр.
В машинном обучении Azure используются табличные данные правильного формата. Если данные уже представлены в табличной форме, то вы можете провести их предварительную обработку прямо в Студии машинного обучения Azure (классическая версия) при машинном обучении. Если данные находятся не в табличной форме, а, например, в формате XML, для их преобразования в табличную форму может потребоваться синтаксический анализ.
3 главных принципа работы с большими данными
Ключевыми положениями для работы с большими данными являются:
Горизонтальная адаптивность
Количество данных неограниченyо, поэтому обрабатывающая их система должна иметь способность к расширению: при возрастании объемов данных должно пропорционально увеличиваться количество оборудования для поддержания работоспособности всей системы.
Стабильность в работе при отказах
Горизонтальная адаптивность предполагает наличие большого числа машин в компьютерном узле. К примеру, кластер Hadoop насчитывает более 40 000 машин. Само собой, что периодически оборудование, изнашиваясь, будет подвержено поломкам. Системы обработки больших данных должны функционировать таким образом, чтобы безболезненно переживать возможные сбои.






Только до 22.12
Как за 3 часа разбираться в IT лучше, чем 90% новичков и выйти надоход в 200 000 ₽?
Приглашаем вас на бесплатный онлайн-интенсив «Путь в IT»! За несколько часов эксперты
GeekBrains разберутся, как устроена сфера информационных технологий, как в нее попасть и
развиваться.
Интенсив «Путь в IT» поможет:
- За 3 часа разбираться в IT лучше, чем 90% новичков.
- Понять, что действительно ждет IT-индустрию в ближайшие 10 лет.
- Узнать как по шагам c нуля выйти на доход в 200 000 ₽ в IT.
При регистрации вы получите в подарок:
«Колесо компетенций»
Тест, в котором вы оцениваете свои качества и узнаете, какая профессия в IT подходит именно вам
«Критические ошибки, которые могут разрушить карьеру»
Собрали 7 типичных ошибок, четвертую должен знать каждый!
Тест «Есть ли у вас синдром самозванца?»
Мини-тест из 11 вопросов поможет вам увидеть своего внутреннего критика
Хотите сделать первый шаг и погрузиться в мир информационных технологий? Регистрируйтесь и
смотрите интенсив:
Только до 22 декабря
Получить подборку бесплатно
pdf 4,8mb
doc 688kb
Осталось 17 мест
Концентрация данных
В масштабных системах данные распределяются по большому количеству оборудования. Допустим, что местоположение данных — один сервер, а их обработка происходит на другом сервере. В этом случае затраты на передачу информации с одного сервера на другой могут превышать затраты на сам процесс обработки. Соответственно, чтобы этого избежать необходимо концентрировать данные на той же аппаратуре, на которой происходит обработка.
 Концентрация данных
Концентрация данных
В настоящее время все системы, работающие с Big Data, соблюдают эти три положения. А чтобы их соблюдать, нужно разрабатывать соответствующие методики и технологии.




Предпосылки
Самое раннее исследование бизнес-аналитики было сосредоточено на неструктурированных текстовых данных, а не на числовых данных. Еще в 1958 году исследователи информатики, такие как H.P. Лун был особенно озабочен извлечением и классификацией неструктурированного текста. Тем не менее, только на рубеже веков эта технология заинтересовала исследователей. В 2004 году институт SAS разработал программу SAS Text Miner, которая использует разложение по сингулярным значениям (SVD) для уменьшения гипермерного текстового пространства на меньшие размеры для значительно более эффективного машинного анализа. Математические и технологические достижения, вызванные машинным анализом текста, побудили ряд предприятий исследовать приложения, что привело к развитию таких областей, как анализ настроений, голос клиента майнинг и оптимизация call-центра. Появление больших данных в конце 2000-х годов привело к повышенному интересу к приложениям аналитики неструктурированных данных в современных областях, таких как прогнозная аналитика и анализ первопричин.