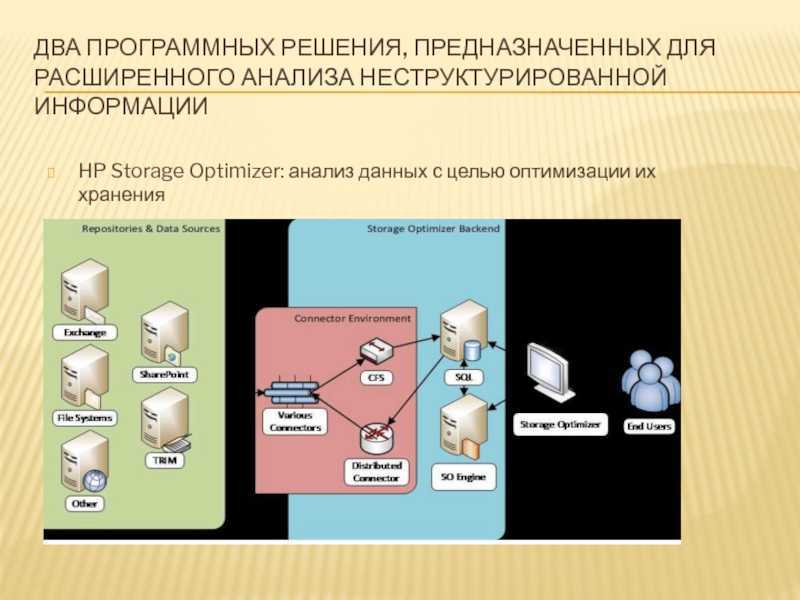
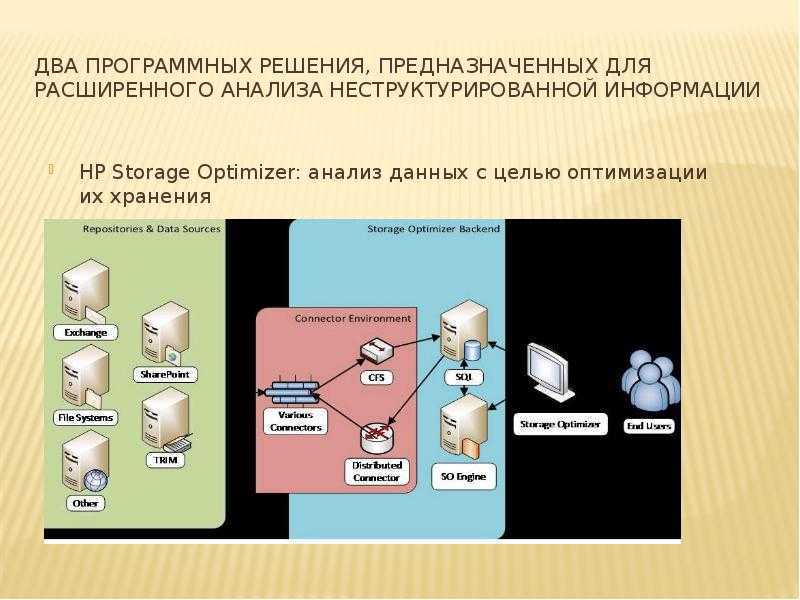
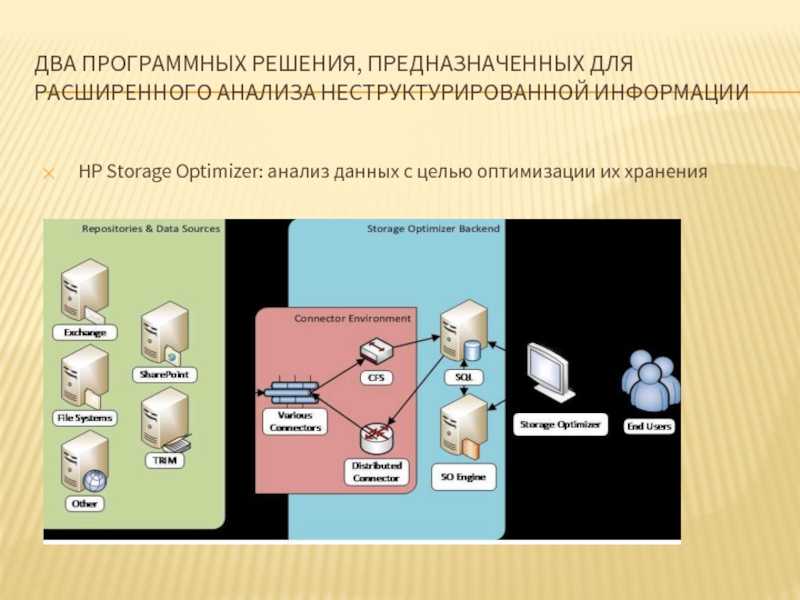
HP Storage Optimizer: анализ данных с целью оптимизации их хранения
HP Storage Optimizer объединяет в себе возможности по анализу метаданных объектов в репозиториях неструктурированной информации и назначению политик их иерархического хранения.
Архитектура HP Storage Optimizer
Источники анализируемой информации в терминологии HP Storage Optimizer называются репозиториями. В качестве репозиториев поддерживаются различные файловые системы, а также MS Exchange, MS SharePoint, Hadoop, Lotus Notes, Documentum и многие другие. Есть также возможность заказать разработку коннектора к репозиторию, который в настоящее время не поддерживается продуктом.
HP Storage Optimizer использует собственные соответствующие коннекторы для обращения к анализируемым репозиториям. Информация с коннекторов поступает в компонент под названием Connector Framework Server (обозначенный как «CFS» на картинке), который, в свою очередь, обогащает её дополнительными метаданными и направляет получившиеся данные на индексирование. Для повышения отказоустойчивости и балансировки нагрузки при взаимодействии приложения с коннекторами используется компонент Distributed Connector.
Метаданные индексируются «движком» HP Storage Optimizer Engine («SO Engine» на первой картинке) и помещаются в БД MS SQL. Для доступа к результатам анализа и назначения политик управления используется веб-приложение HP Storage Optimizer.
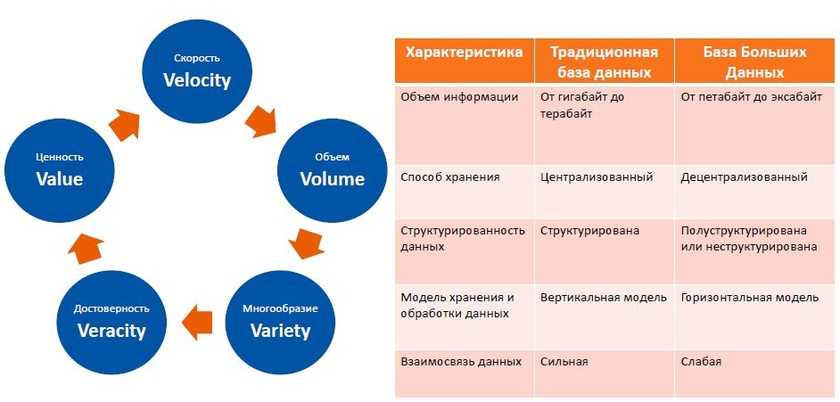
Для наглядного отображения информации, потенциально подлежащей оптимизации, в HP Storage Optimizer используются круговые диаграммы (ниже), показывающие дубликаты данных, редковостребованные и «ненужные» данные (ROT analysis: Redundant, Obsolete, Trivial). Критерии «редковостребованности» и «ненужности» можно гибко настроить, в том числе индивидуально для каждого репозитория. Кроме круговых диаграмм, доступны графики, иллюстрирующие разбивку данных по типам, времени и частоте добавления и др. Все элементы визуализации интерактивны, т.е. позволяют переходить в какую-либо категорию диаграммы (или столбец) и получать доступ к соответствующим данным.
Графический анализ данных в HP Storage Optimizer
Перечень метаданных, по которым может быть проведён анализ, необычайно широк и даёт возможность осуществлять высокоточные тематические выборки.
Пример работы с метаданными в HP Storage Optimizer
Хотелось бы заметить, что в состав продуктов HP Storage Optimizer и HP Control Point входит «движок» индексирования и визуализации, позволяющий просматривать более 400 различных форматов данных без установки на сервер соответствующих приложений для предпросмотра. Это значительно упрощает и ускоряет процесс анализа большого количества разноплановой информации.
После того как анализ данных проведён, администратору системы предоставляется возможность назначить политики удаления или перемещения данных. Политики на те или иные выборки данных возможно назначать как вручную, так и автоматически. Мощная ролевая модель управления, реализованная в HP Storage Optimizer и в HP Control Point, даёт возможность выдавать полномочия по работе с репозиториями, анализу данных в них, а также по назначению политик, максимально гибко.
Слайды и текст этой презентации

Анализ неструктурированных данных и оптимизация их хранения
Нигматуллина Юлия БИ-1

заключение
Спектр применения HP Storage Optimizer и HP Control Point для решения задач анализа и управления корпоративными данными весьма широк. Кроме того, возможности анализа документов на разных языках (включая русский), а также масштабируемая архитектура компонентов обоих продуктов позволяет эффективно решать задачи по анализу всего объёма неструктурированных данных в организациях любого масштаба и сложности.

Качественный анализ корпоративной информации является ключевым показателем зрелости информационной стратегии организации

Gartner выделяет следующие типовые сценарии использования аналитического ПО:
-Оптимизация хранения
— Выявление ненужных данных и избавление от них при миграции ИТ-инфраструктуры
-Классификация.
-Соблюдение нормативов и требований (compliance).
-Управление уровнями доступа
-Автоматизация проведения
Два программных решения, предназначенных для расширенного анализа неструктурированной информации
HP Storage Optimizer: анализ данных с целью оптимизации их хранения

HP Storage Optimizer
Основная этого решения – объединение в себе возможности по анализу метаданных объектов в репозиториях неструктурированной информации и назначению политик их иерархического хранения
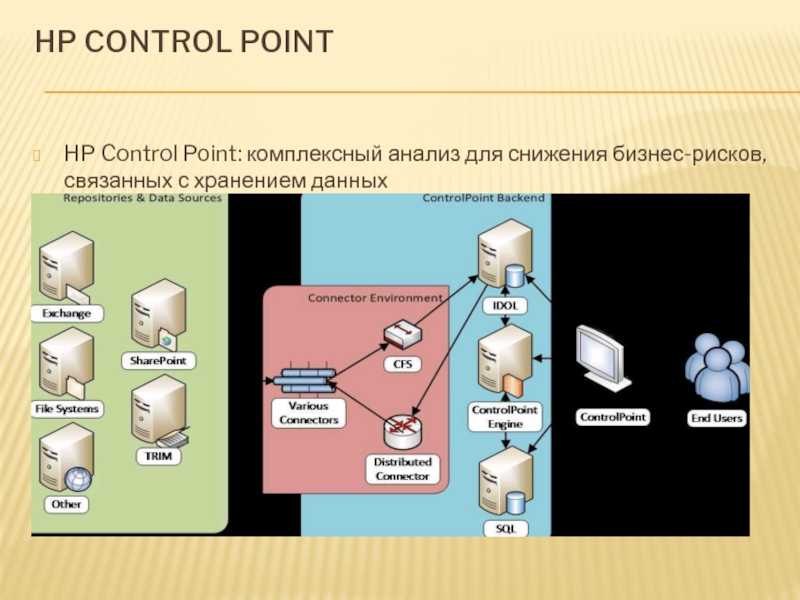
HP Control Point
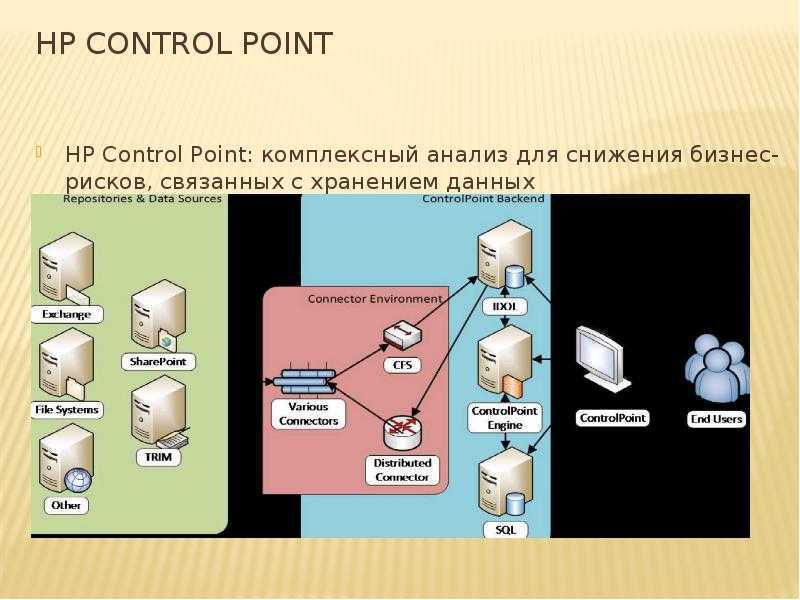
HP Control Point: комплексный анализ для снижения бизнес-рисков, связанных с хранением данных

HP Control Point
HP Control Point, по сути, представляет собой расширенную версию HP Storage Optimizer и предоставляет инструментарий не только для решения задач по оптимизации хранения, но и для внедрения политик хранения и управления жизненным циклом корпоративной информации.

ЗАКЛЮЧЕНИЕ
Спектр применения HP Storage Optimizer и HP Control Point для решения задач анализа и управления корпоративными данными весьма широк. Кроме того, возможности анализа документов на разных языках (включая русский), а также масштабируемая архитектура компонентов обоих продуктов позволяет эффективно решать задачи по анализу всего объёма неструктурированных данных в организациях любого масштаба и сложности.




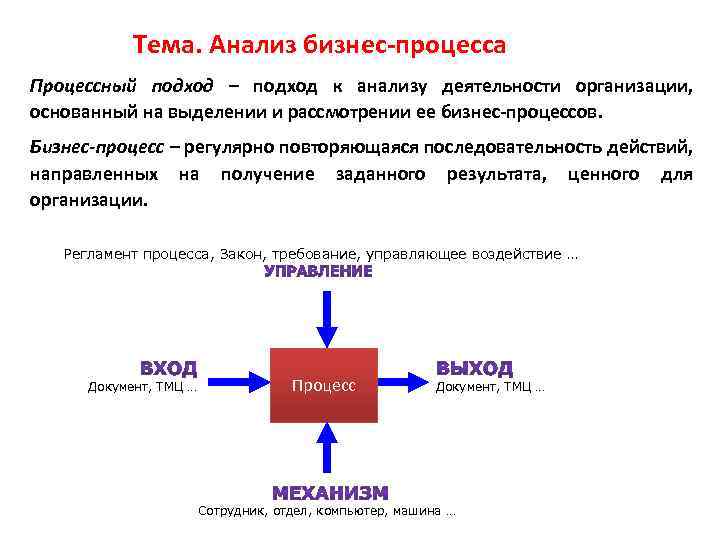
Что такое анализ данных?
Анализ – это заключение, или вывод из полученных данных. Данные могут анализироваться с помощью следующих методов и действий:
- математические методы;
- вычислительные алгоритмы (могут быть основаны на математических);
- исследование (сопоставление информации);
- фильтрация (отсеивание ненужной информации);
- экспериментальные методы (наблюдение);
- наглядные (моделирование ситуаций).
Любой из способов должен дать какой-либо результат, который поможет принять решение или выстроить правильный алгоритм действий. Например, бухгалтер хочет проанализировать прибыль компании. Он сделает это с помощью математического метода. Вывод покажет, упала прибыль или нет, что поможет выстроить стратегический план на следующий период.
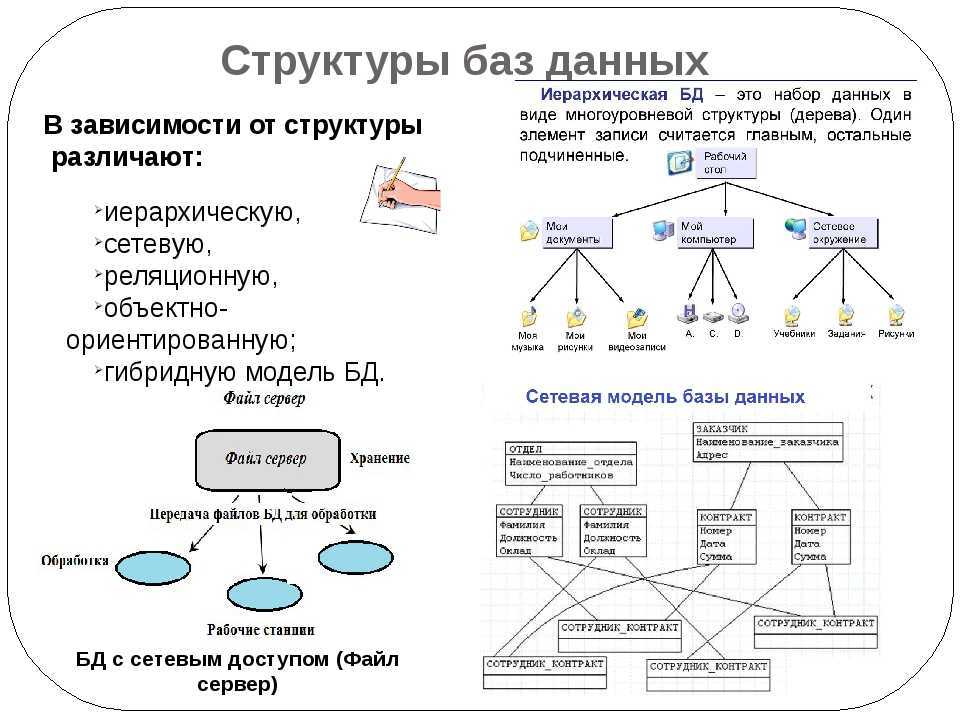
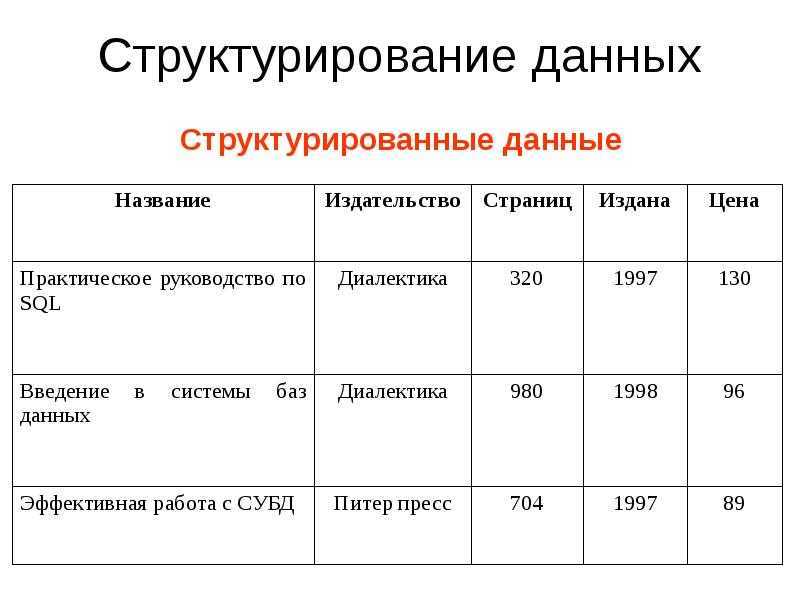
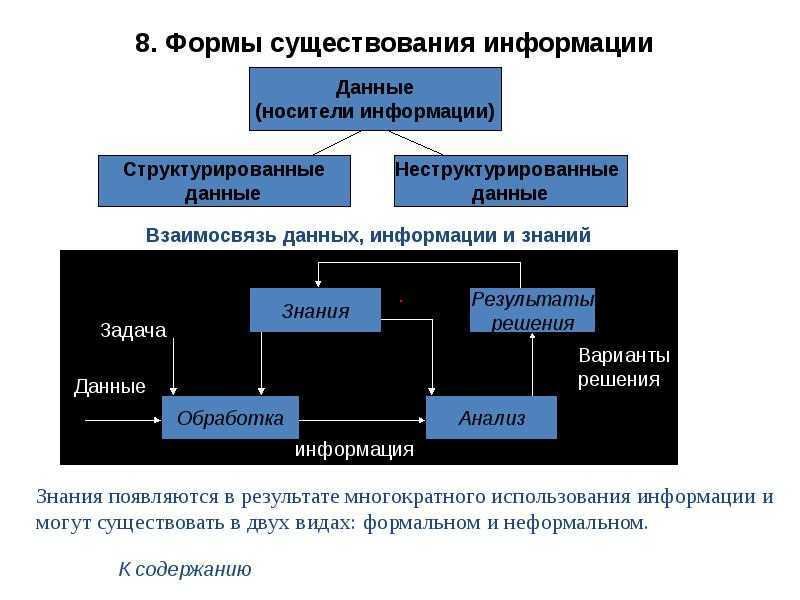
Понятие и использование неструктурированных данных
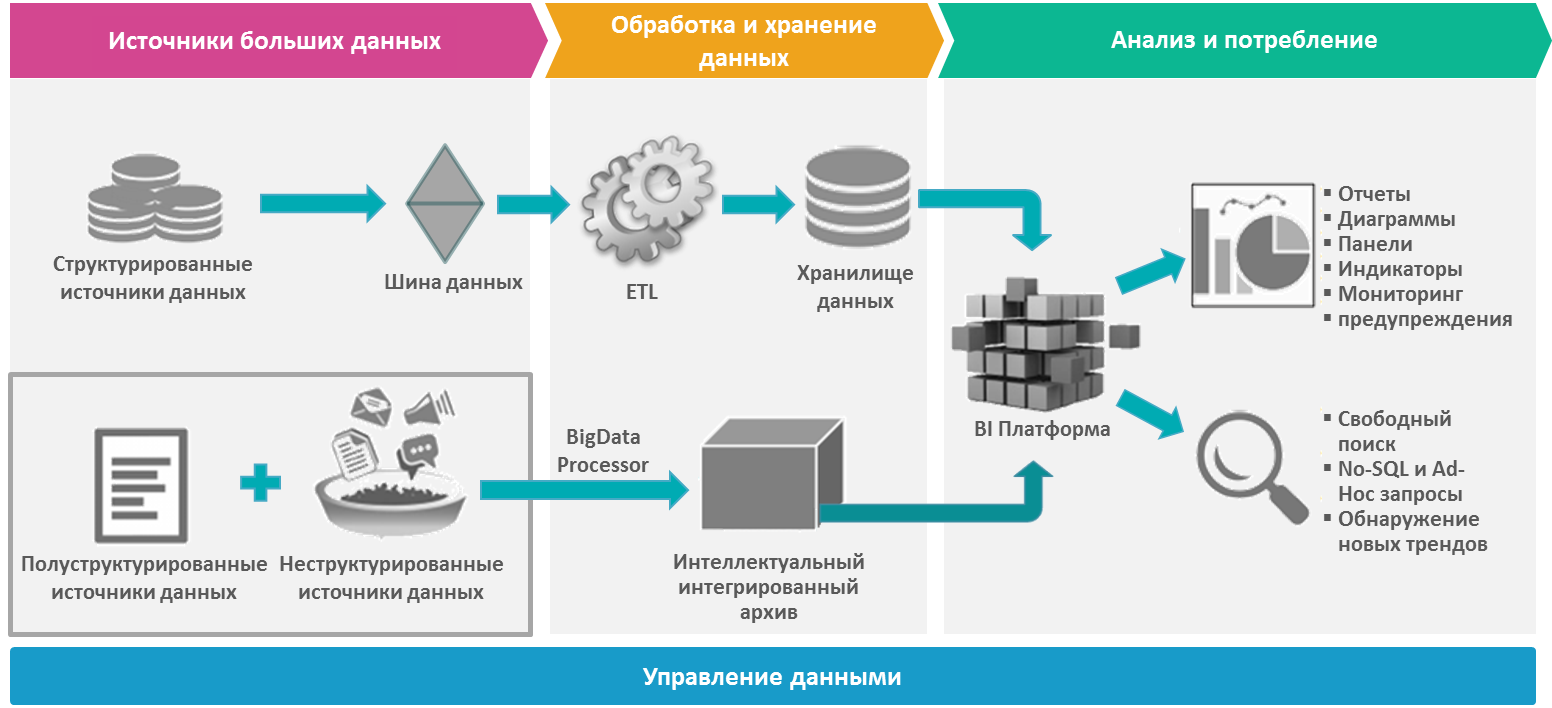
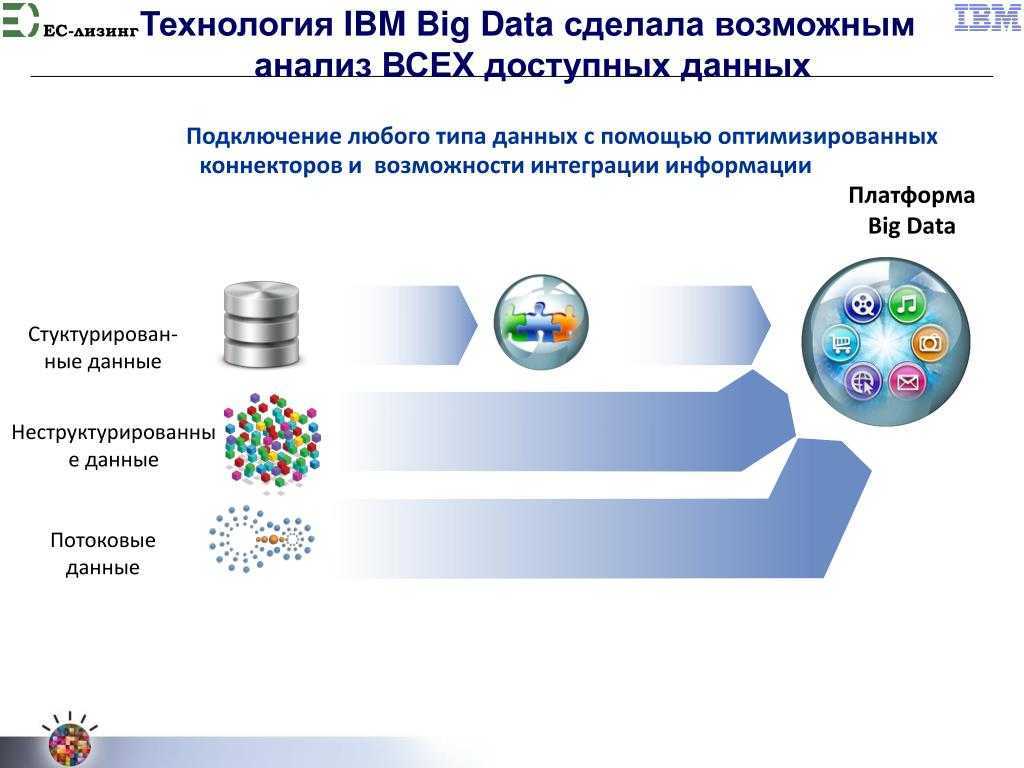
Возникающие в деятельности компании или получаемые из внешних источников неструктурированные данные (НД) могут храниться в разных форматах – текстовые документы, аудио- и видеофайлы, фотографии. Их анализ затруднен, так как они не конвертированы в общий формат. Вне зависимости от того, в какой форме существуют данные, программы по интеллектуальному анализу – data miming – способны с успехом обработать информацию и предложить руководству компании ожидаемые результаты. В этом случае анализ упрощается за счет использования только релевантной и достоверной информации.
Системному администратору приходится решать одновременно три задачи:
- хранения НД. По информации компании IDS, до 60 % корпоративной информации не имеет ценности, представляет собой дубликаты или информационный шум, при этом она занимает большие объемы памяти и ее перенос в облако не решает задачи проблему оптимизации хранения;
- обработки НД;
- организации контроля доступа к НД, способной обеспечить сохранение целостности и конфиденциальности корпоративной информации, персональных данных, коммерческой тайны.
Отказ от структурирования информации не только затрудняет ее анализ, но и снижает степень защиты. Политики безопасности не способны обеспечить безопасное хранение непроанализированной и неизученной информации, отказ от маркировки файлов и учетных записей в зависимости от их роли в корпоративной структуре приводит к серьезным утечкам. Контроль доступа к неструктурированным данным частично снимает эти риски.
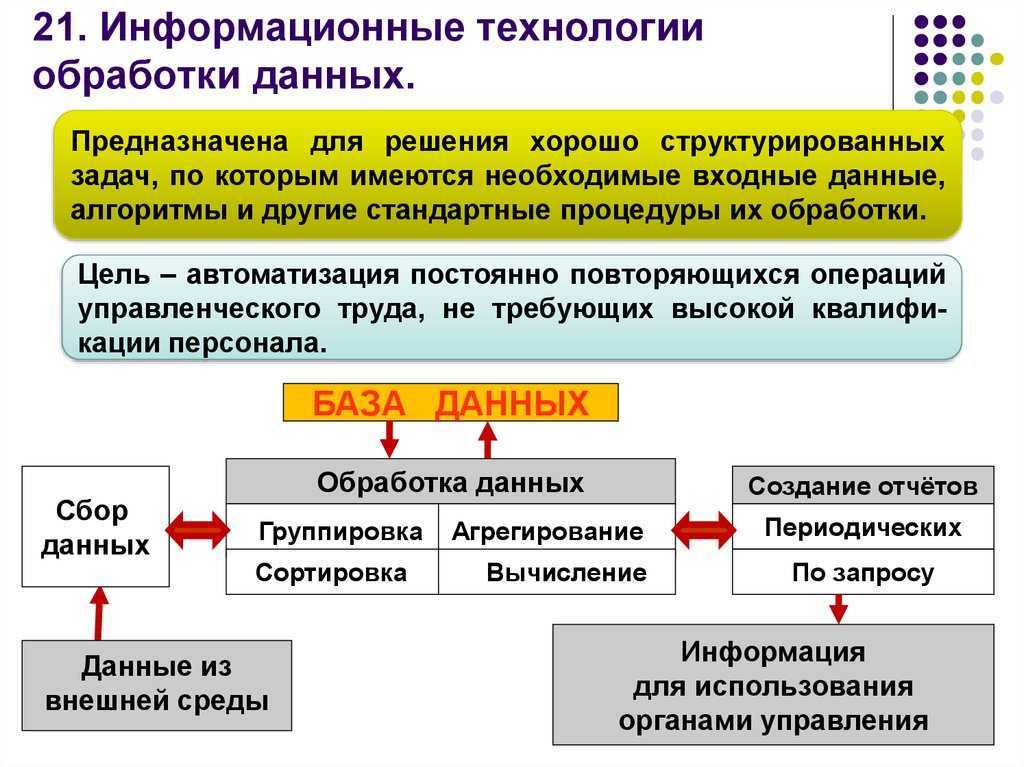
Использование аналитического ПО при работе с этим типом информации поможет решить следующие задачи:
- оптимизация хранения информации на файловых серверах. Определение типа неструктурированных данных позволяет обеспечить их классификацию и маркировку, назначив каждому файлу свою степень конфиденциальности и определив лиц, имеющих к нему доступ;
- выявление и уничтожение устаревшей или ненужной информации;
- классификация;
- выполнение требований регуляторов по особому режиму хранения информации с ограниченным доступом;
- назначение различных уровней доступа пользователей;
- создание системы аудита доступа и автоматизация расследований инцидентов информационной безопасности.
Контроль доступа реализуется на организационном и техническом уровне. На первом разрабатываются методики и правила безопасности, разграничиваются права доступа пользователей, на втором принятые решения внедряются при помощи программных и аппаратных средств, облегчающих работу с неструктурированными данными.
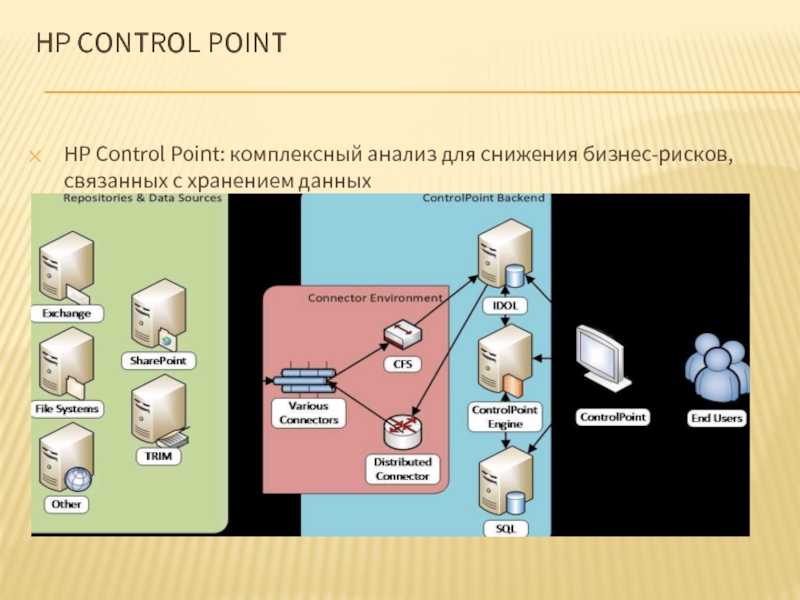
HP Control Point: комплексный анализ для снижения бизнес-рисков, связанных с хранением данных
HP Control Point, по сути, представляет собой расширенную версию HP Storage Optimizer и предоставляет инструментарий не только для решения задач по оптимизации хранения, но и для внедрения политик хранения и управления жизненным циклом корпоративной информации.Продукт позволяет проводить анализ информации не только по метаданным, но и по её содержимому. Кроме того, в нём реализованы дополнительные механизмы анализа данных и назначения политик по работе с ними.
Архитектура HP Control Point
В отличие от HP Storage Optimizer, в HP Control Point широко используются возможности индексирования и смысловой категоризации информации «движка» HP IDOL (Intelligent Data Operating Layer): визуализация, категоризация, тэгирование и др. В его основе лежит возможность определять «смысл» набора анализируемой информации независимо от её формата, языка и т.д.
В частности, в HP Control Point дополнительно доступны два типа визуализации информации: кластерная карта и спектрограф. Кластерная карта представляет собой двухмерное изображение информационных «кластеров». Один кластер объединяет в себе информацию, имеющую схожий смысл. Таким образом, глядя на кластерную карту, можно быстро получить понимание основных смысловых групп этой информации. Кластерные карты интерактивны, т.е. позволяют с помощью кликов на те или иные кластеры получать доступ к информации, содержащейся в них.
Внешний вид кластерной карты в HP Control Point
Спектрограф представляет собой набор информационных кластеров, снятых в различные моменты времени и даёт возможность графически отследить, как менялся смысл информации в анализируемых репозиториях с течением времени.
Внешний вид спектрограммы в HP Control Point
Помимо расширенных возможностей визуализации информации, в HP Control Point доступна возможность категоризации анализируемой информации. Изначально информация категоризируется автоматически — средствами HP IDOL, выдавая пользователю системы массив данных, разбитый на смысловые части. Получив первичное разбиение, аналитик далее может сделать более выверенную категоризацию. Например, использовать какой-либо набор файлов, заведомо для аналитика релевантных той или иной категории, для «тренировки» категории на этот набор файлов, чтобы впоследствии получать более точные результаты категоризации. Для ещё более тонкой настройки можно использовать индивидуальные весовые коэффициенты файлов и даже фраз и отдельных слов внутри файлов, отражающие степень соответствия тех или иных единиц информации «тренируемой» категории. Такая детализация может использоваться, например, для создания подробных правил отнесения анализируемой информации к разряду конфиденциальной.
Что касается политик работы с анализируемой информацией, то в HP Control Point кроме копирования, переноса и удаления доступны также следующие опции:
— «Заморозка» объектов. Позволяет заблокировать доступ к отдельным объектам, не допуская их несанкционированное изменение или удаление.
— Создание рабочего процесса (workflow). Например, информирование или запрос утверждения уполномоченного сотрудника или владельца анализируемых объектов перед их переносом или удалением.
— Безопасный перенос в систему управления корпоративными записями HP Records Manager (например, в случае выявления несанкционированного присутствия конфиденциальных документов на общедоступном файловом сервере). При этом переносимые данные сопровождаются метаданными, которые будут использованы для дальнейшего управления документами в системе HP Records Manager с необходимыми настройками доступа, уровнями секретности и т.п.
Анализ неструктурированных данных и оптимизация их хранения +26
- 31.08.15 10:30
•
Rovena
•
#265499
•
Хабрахабр
•
•
11799
ИТ-инфраструктура, Хранение данных, Big Data, Блог компании HP
Рекомендация: подборка платных и бесплатных курсов бизнес аналитики — https://katalog-kursov.ru/
Тема анализа неструктурированных данных сама по себе не нова. Однако в последнее время в эпоху «больших данных» этот вопрос встаёт перед организациями гораздо острее. Многократный рост объёмов хранимых данных в последние годы, его постоянно увеличивающиеся темпы и нарастающее разнообразие хранимой и обрабатываемой информации существенно усложняют задачу управления корпоративными данными. С одной стороны, проблема имеет инфраструктурный характер. Так, по данным IDC, до 60% корпоративных хранилищ занимает информация, не приносящая организации никакой пользы (многочисленные копии одного и того же, разбросанные по разным участкам инфраструктуры хранения данных; информация, к которой никто не обращался несколько нет и уже вряд ли когда-нибудь обратится; прочий «корпоративный мусор»)
С другой стороны, неэффективное управление информацией ведёт к увеличению рисков для бизнеса: хранение персональных данных и прочей конфиденциальной информации на общедоступных информационных ресурсах, появление подозрительных пользовательских зашифрованных архивов, нарушения политик доступа к важной информации и т.д. В этих обстоятельствах умение качественно анализировать корпоративную информацию и оперативно реагировать на любые несоответствия её хранения политикам и требованиям бизнеса является ключевым показателем зрелости информационной стратегии организации
Теме аналитики файловых данных посвящён отдельный документ Gartner, вышедший в сентябре 2014 г. под названием «Market Guide for File Analysis Software». В данном документе приводятся следующие типовые сценарии использования аналитического ПО:
Оптимизация хранения. Наиболее типичный сценарий. Целью внедрения файловой аналитики является снижение объёма хранимых данных, и, тем самым, повышение эффективности их хранения.
Выявление ненужных данных и избавление от них при миграции ИТ-инфраструктуры. Часто инициируются проектами по миграции данных в «облако»
Проводится сканирование контента и по его результатам имеющие важность и ценность для бизнеса данные «переезжают» в «облако», а остальные удаляются. Классификация
Целью таких проектов по анализу является группировка объектов по различным критериям для назначения на них общих политик, понимания ценности и потенциального риска, которые несёт хранимая информация.
Соблюдение нормативов и требований (compliance). Специалисты соответствующих подразделений могут разработать и внедрить политики доступа к важным данным и за счёт встроенной в аналитическое ПО классификации эффективно контролировать их соблюдение.
Управление уровнями доступа. За счёт получения информации об уровне и типе доступа пользователей к файлам и директориям возможно осуществлять информационный менеджмент с целью защиты персональных данных и иной конфиденциальной информации от несанкционированного доступа.
Автоматизация проведения расследований. Аналитическое ПО позволяет быстро находить объекты, имеющие отношение к проводимым в компании расследованиям, и автоматизированно и безопасно копировать или перемещать их в специальные хранилища.
Слайды и текст этой презентации

АНАЛИЗ НЕСТРУКТУРИРОВАННЫХ ДАННЫХ И ОПТИМИЗАЦИЯ ИХ ХРАНЕНИЯ
Нигматуллина Юлия БИ-1

ЗАКЛЮЧЕНИЕ
Спектр применения HP Storage Optimizer и HP Control Point для решения задач анализа и управления корпоративными данными весьма широк. Кроме того, возможности анализа документов на разных языках (включая русский), а также масштабируемая архитектура компонентов обоих продуктов позволяет эффективно решать задачи по анализу всего объёма неструктурированных данных в организациях любого масштаба и сложности.







КАЧЕСТВЕННЫЙ АНАЛИЗ КОРПОРАТИВНОЙ ИНФОРМАЦИИ ЯВЛЯЕТСЯ КЛЮЧЕВЫМ ПОКАЗАТЕЛЕМ ЗРЕЛОСТИ ИНФОРМАЦИОННОЙ СТРАТЕГИИ ОРГАНИЗАЦИИ

GARTNER ВЫДЕЛЯЕТ СЛЕДУЮЩИЕ ТИПОВЫЕ СЦЕНАРИИ ИСПОЛЬЗОВАНИЯ АНАЛИТИЧЕСКОГО ПО:
-ОПТИМИЗАЦИЯ ХРАНЕНИЯ
— ВЫЯВЛЕНИЕ НЕНУЖНЫХ ДАННЫХ И ИЗБАВЛЕНИЕ ОТ НИХ ПРИ МИГРАЦИИ ИТ-ИНФРАСТРУКТУРЫ
-КЛАССИФИКАЦИЯ.
-СОБЛЮДЕНИЕ НОРМАТИВОВ И ТРЕБОВАНИЙ (COMPLIANCE).
-УПРАВЛЕНИЕ УРОВНЯМИ ДОСТУПА
-АВТОМАТИЗАЦИЯ ПРОВЕДЕНИЯ
ДВА ПРОГРАММНЫХ РЕШЕНИЯ, ПРЕДНАЗНАЧЕННЫХ ДЛЯ РАСШИРЕННОГО АНАЛИЗА НЕСТРУКТУРИРОВАННОЙ ИНФОРМАЦИИ
HP Storage Optimizer: анализ данных с целью оптимизации их хранения

HP STORAGE OPTIMIZER
Основная этого решения – объединение в себе возможности по анализу метаданных объектов в репозиториях неструктурированной информации и назначению политик их иерархического хранения
HP CONTROL POINT
HP Control Point: комплексный анализ для снижения бизнес-рисков, связанных с хранением данных

HP CONTROL POINT
HP Control Point, по сути, представляет собой расширенную версию HP Storage Optimizer и предоставляет инструментарий не только для решения задач по оптимизации хранения, но и для внедрения политик хранения и управления жизненным циклом корпоративной информации.

ЗАКЛЮЧЕНИЕ
Спектр применения HP Storage Optimizer и HP Control Point для решения задач анализа и управления корпоративными данными весьма широк. Кроме того, возможности анализа документов на разных языках (включая русский), а также масштабируемая архитектура компонентов обоих продуктов позволяет эффективно решать задачи по анализу всего объёма неструктурированных данных в организациях любого масштаба и сложности.
Нейронные сети
С развитием искусственного интеллекта широкое применение приобрел метод анализа использования данных с помощью нейронных сетей. Он применяется в различных областях науки, производства, коммерции.
Задачи, которые ставятся перед нейронными сетями:
- Классификация образов. Разработаны программные продукты, распознающие буквы, речь в аудиофайлах, графические ритмы, применяемые при изучении электрокардиограмм, биометрической информации.
- Кластеризация и классификация. Данные сжимаются, исследуются, из них извлекаются знания новой природы.
- Аппроксимация функций. Метод позволяет обеспечить шумоподавление при приеме звуковых сигналов безотносительно к типу звуковой информации.
- Предсказания и прогнозы. Нейронные сети способны предсказать направления движения биржевых котировок и изменения погоды.
- Ассоциативная память. Используется при создании мультимедийных баз данных.
- Управление. Нейронные сети применяются в программах беспилотного управления кораблям или самолетами.
Схема изучения данных при помощи технологии нейронных сетей состоит из следующих этапов:
- выбор топологии сети из девяти возможных типов;
- подбор характеристик сети. Производится экспериментальным путем, определяется количество нейронов, направление их движения и другие параметры;
- подбор характеристик обучения – времени, количества данных, максимально допустимых отклонений и ошибок;
- обучение сети;
- проверка качества обучения.
Нейронные сети с успехом были применены для изучения электоральных предпочтений и предсказания результатов выборов в США. Сетям нужно было найти ответ на пять вопросов:
- Была ли серьезная конкуренция при выдвижении конкурентов от правящей партии?
- Были ли серьезные социальные взрывы в течение текущего срока?
- В год выборов наблюдался экономический рост или спад?
- Происходили ли существенные изменения в политической жизни?
- Была ли активна третья партия?
Ответы на эти вопросы помогли точно предсказать результаты выборов.
Современные методы исследования
Изучение различных вопросов с использованием данных, как числовых, так и семантических, позволяет улучшить качество бизнес-процессов. Для целей бизнеса информация собирается методом анкетирования, опросов, из первичных учетных документов и CRM-систем, наборы данных могут быть заказаны у специализированных консалтинговых организаций. Выбор метода исследования зависит от категории вопросов, на которые необходимо получить ответ.
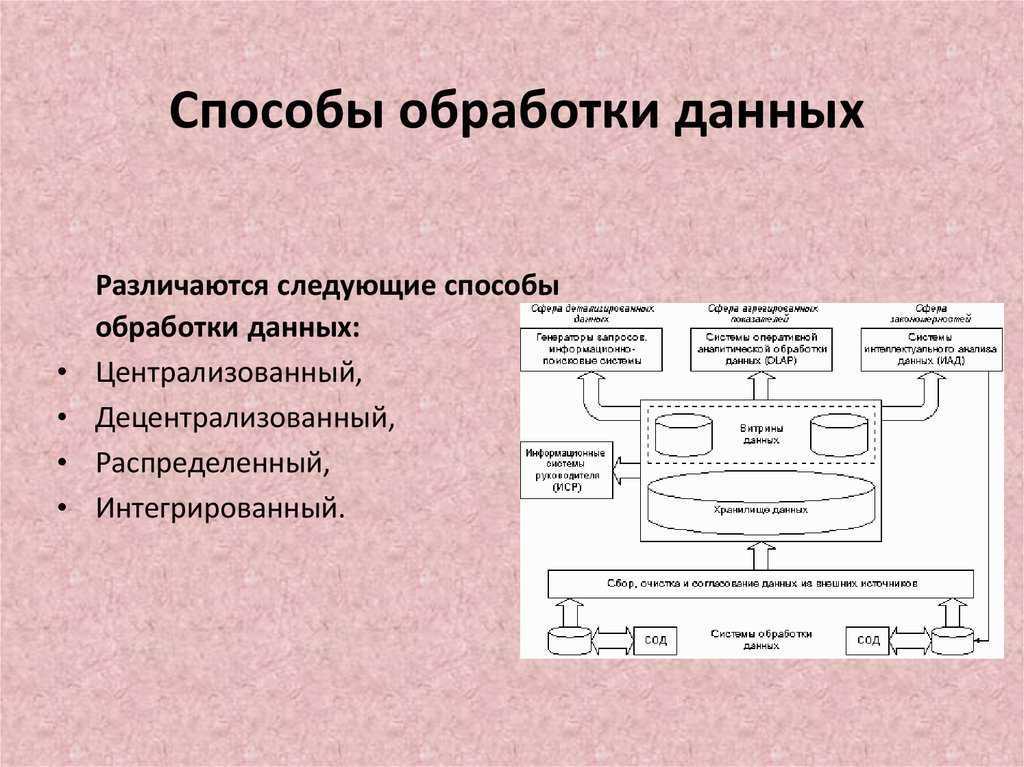
Алгоритмы исследования делятся одномерные и многомерные. В одномерном сравнение характеристик проводится только по одному параметру. Многомерный анализ данных позволяет одновременно исследовать взаимоотношения двух и более переменных и устанавливать корреляцию и причинно-следственные связи между ними.
Наиболее часто используются факторный и кластерный методы. Факторный позволяет выявить параметры, определяющие наиболее значимые различия между переменными, классифицировать данные и сократить количество используемых переменных. На практике применение метода эффективно для оценки имиджа компании, составления социально-психологического портрета потребителя, изучения уровня доверия партнеров к банку или финансовой компании.
При применении кластерного метода данные со схожими параметрами распределяются по группам, кластерам, которые уже сами подлежат изучению. Подход позволяет сократить объем логических операций.




В ходе кластерного анализа формируется портрет целевой аудитории бренда:
1. Проводится выборка данных из клиентской базы.
2. Организуется анкетирование.
3. Определяются параметры, на основании которых проводится исследование.
4. Изучаются ответы респондентов, выявляются сходства и различия между ними, исключаются нерелевантные значения, шумы, искажения.
5. Создаются правила кластеризации, на основании которых респонденты объединяются в группы.
6. Определяется оптимальное число кластеров.
7. Результатом исследования становится таблица, в которой клиенты сгруппированы по их предпочтениям.
Факторный метод исследования на основе данных различного происхождения широко применяется:
- в социологии. Позволяет разделить респондентов на разные социальные и демографические группы;
- в маркетинге. Потребители и товары сегментируются по предпочтениям, уровню продаж, региональным особенностям;
- в менеджменте. Для изучения активности конкурентов или отраслей.
Многомерные методы изучения данных доступны в Excel и специализированных программах.
«СёрчИнформ FileAuditor» позволяет провести классификацию данных в автоматизированном режиме и узнать, сколько в компании данных, содержащих конфиденциальные сведения.