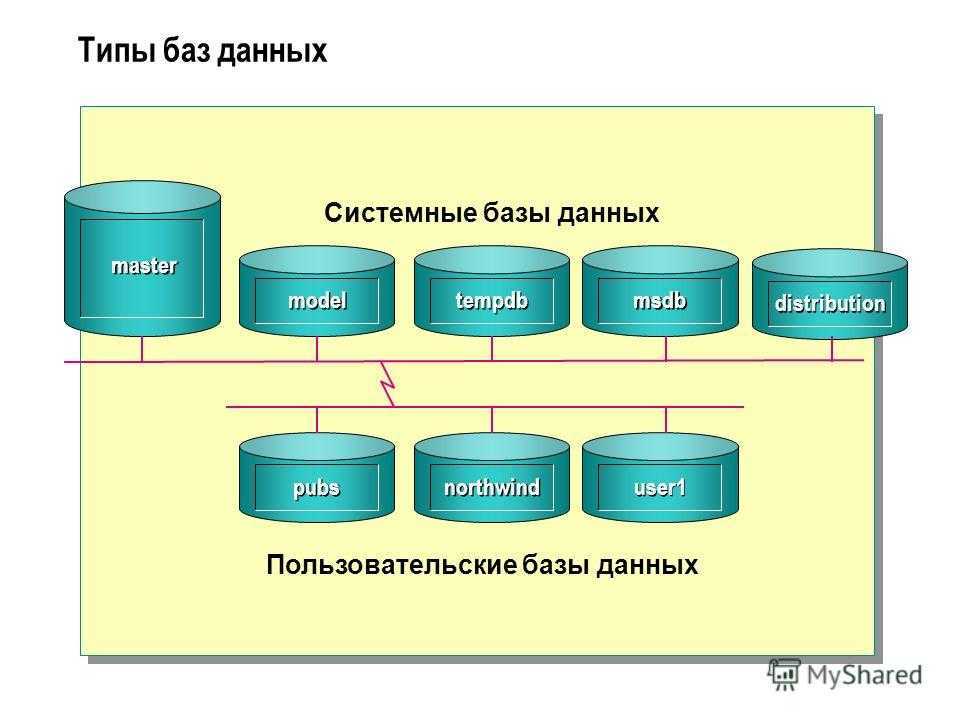
Базы данных с поддержкой XML
Базы данных с поддержкой XML обычно предлагают один или несколько из следующих подходов к хранению XML в традиционной реляционной структуре:
- XML хранится в CLOB (Большой объект персонажа )
- XML « разбивается » на серию таблиц на основе схемы
- XML хранится в собственном XML-типе, как определено стандартом ISO 9075-14.
РСУБД, поддерживающие тип ISO XML:
- IBM DB2 (pureXML)
- Microsoft SQL Server
- База данных Oracle
- PostgreSQL
Обычно база данных с поддержкой XML лучше всего подходит для случаев, когда большинство данных не являются XML. Для наборов данных, в которых большинство данных представляют собой XML, лучше подходит.
Пример запроса типа XML в IBM DB2 SQL
Выбрать я бы, объем, xmlquery('$ j / имя', прохождение журнал в качестве "j") в качестве имяиз журналыкуда xmlexists('$ j ', прохождение журнал в качестве "j")
Обоснование использования XML в базах данных [ править ]
Существует ряд причин для прямого указания данных в XML или других форматах документов, таких как JSON . В частности, для XML они включают:
- На предприятии может быть много XML в существующем стандартном формате.
- Возможно, данные должны быть представлены или загружены как XML, поэтому использование другого формата, такого как реляционные силы, двойное моделирование данных
- XML очень хорошо подходит для разреженных данных, глубоко вложенных данных и смешанного содержимого (например, текста со встроенными тегами разметки)
- XML удобочитаем, тогда как реляционные таблицы требуют опыта для доступа
- Метаданные часто доступны в формате XML.
- Семантические веб-данные доступны в формате RDF / XML.
- Предлагает решение для объектно-реляционного несоответствия импеданса
Стив О’Коннелл приводит одну причину использования XML в базах данных: все более широкое использование XML для передачи данных , что означает, что «данные извлекаются из баз данных и помещаются в документы XML и наоборот». Может оказаться более эффективным (с точки зрения затрат на преобразование) и проще хранить данные в формате XML. В приложениях, основанных на содержании, возможность собственной базы данных XML также сводит к минимуму необходимость извлечения или ввода метаданных для поддержки поиска и навигации.
Причины хранения XML-данных в SQL Server
Ниже приведены некоторые условия, при которых лучше использовать собственные XML-функции SQL Server , а не управлять XML-данными, хранящимися в файловой системе.
-
Требуется эффективно распространять, запрашивать и изменять свои XML-данные на основе транзакций. Большое значение имеет высокая детализация доступа к данным. Например, иногда нужно извлекать некоторые разделы XML-документа или вставлять в него новые разделы без замены всего документа.
-
Предстоит иметь дело с реляционными и XML-данными, и необходимо обеспечить их совместимость в приложении.
-
Необходима языковая поддержка запросов и модификации данных в приложениях, охватывающих несколько доменов.
-
Требуется, чтобы сервер гарантировал верность структуры данных и, возможно, проверял данные в соответствии с XML-схемами.
-
Требуется проиндексировать XML-данные для оптимизации обработки запросов и улучшения масштабируемости и использовать эффективный оптимизатор запросов.
-
Требуется обращаться к XML-данным, используя технологии SOAP, ADO.NET и OLE DB.
-
Требуется использовать для управления XML-данными средства администрирования, реализованные в сервере баз данных. Примерами таких задач управления могут служить резервное копирование данных, их восстановление и репликация.
Если же ни одно из этих условий не выполняется, то для хранения данных лучше использовать отличный от XML тип больших объектов (например, varchar(max) или varbinary(max) ).
Массовый импорт XML-данных в виде двоичного байтового потока
При массовом импорте XML-данных из файла, содержащего объявление кодировки, которое необходимо применить, нужно указать параметр SINGLE_BLOB в предложении OPENROWSET(BULK…). Параметр SINGLE_BLOB гарантирует, что средство синтаксического анализа XML в SQL Server произведет импорт данных в соответствии со схемой кодирования, указанной в XML-объявлении.
Образец файла данных
Перед запуском примера А необходимо создать файл в кодировке UTF-8 (), содержащий следующий образец, который определяет схему в кодировке .
Пример A
В этом примере используется параметр в инструкции для импорта данных из файла с именем и вставки экземпляра данных XML в таблицу с одним столбцом, образец таблицы .
Remarks
С помощью параметра SINGLE_BLOB можно избежать несоответствия между кодировкой XML-документа (указанной в объявлении кодировки XML) и кодовой страницей строки, используемой сервером.
Если при использовании типов данных NCLOB или CLOB возникает конфликт кодовой страницы или кодировки, необходимо выполнить одно из следующих действий.
-
Удалить XML-декларацию, чтобы успешно импортировать содержимое XML-файла данных.
-
Указать кодовую страницу в параметре CODEPAGE запроса, который соответствует схеме кодирования, используемой в XML-декларации.
-
Подобрать настройки параметров сортировки баз данных для схемы кодирования XML-данных, отличной от кодировки Юникод.
Как устроен XML
подсказок Дадаты по ФИО
Теги
Открывающий — текст внутри угловых скобок
Закрывающий — тот же текст (это важно!), но добавляется символ «/»
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!Москва* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!
count = 7count = 7документации метода
- Виктор Иван — строка
- 7 — число
без
Атрибуты элемента
party
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!
partyfieldfieldnamefieldfieldfieldattribute
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.
attribute
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?
XSD-схема
XSDXSD
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- …
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
doRegister
| Правильный запрос | Неправильный запрос |
|---|---|
|
Нет обязательного поля name |
|
|
Опечатка в названии тега (mail вместо email) |
|
| … | … |
WSDl сервиса
См также:XSD — умный XMLЯзык определения схем XSDЯзык описания схем XSD (XML-Schema)Пример XML схемы в учебнике
Изменяющаяся структура
Реляционные базы данных чрезвычайно хороши для хранения информации и не слишком хороши для управления полуструктурированными данными. Документоориентированный XML обычно имеет изменяющуюся структуру для учета гибкости, характерной для обычной прозы. Однако, не все полуструктурированные данные являются документоориентированными (например, списки материалов). Хотя полуструктурированную информацию можно преобразовать в реляционную модель, возможны накладные расходы на исполнение, особенно при выполнении запросов. NXD или XED с возможностью индексации XML-данных великолепно подходят для такого типа информации.








«Полуструктурированные данные — это данные, которые обладают некоторой структурой, но не являются жестко структурированными. Примером полуструктурированных данных может служить запись в медицинской карте. Так, для одного пациента она может содержать перечень прививок, для другого — показатели роста и веса, для третьего — операции, который ему сделали. Другой пример полуструктурированных данных — юридические документы, генеалогические записи…
Полуструктурированные данные сложно хранить в реляционной базе данных, поскольку в этом случае у вас либо много различных таблиц (что означает многочисленные соединения и продолжительное время поиска), либо единственная таблица с множеством пустых колонок. Полуструктурированные данные очень легко хранить как XML, и они великолепно подходят для XML-базы данных»(Рональд Бурре)
«Одно из главных достоинств (относящихся данных) модели данных XML заключается в возможности обрабатывать полуструктурированные данные. В то время как реляционные СУБД не могут достаточно хорошо обрабатывать полуструктурированные данные…»(Дэн Уэйнреб (Dan Weinreb))
Правильно построенные и действительные документы XML
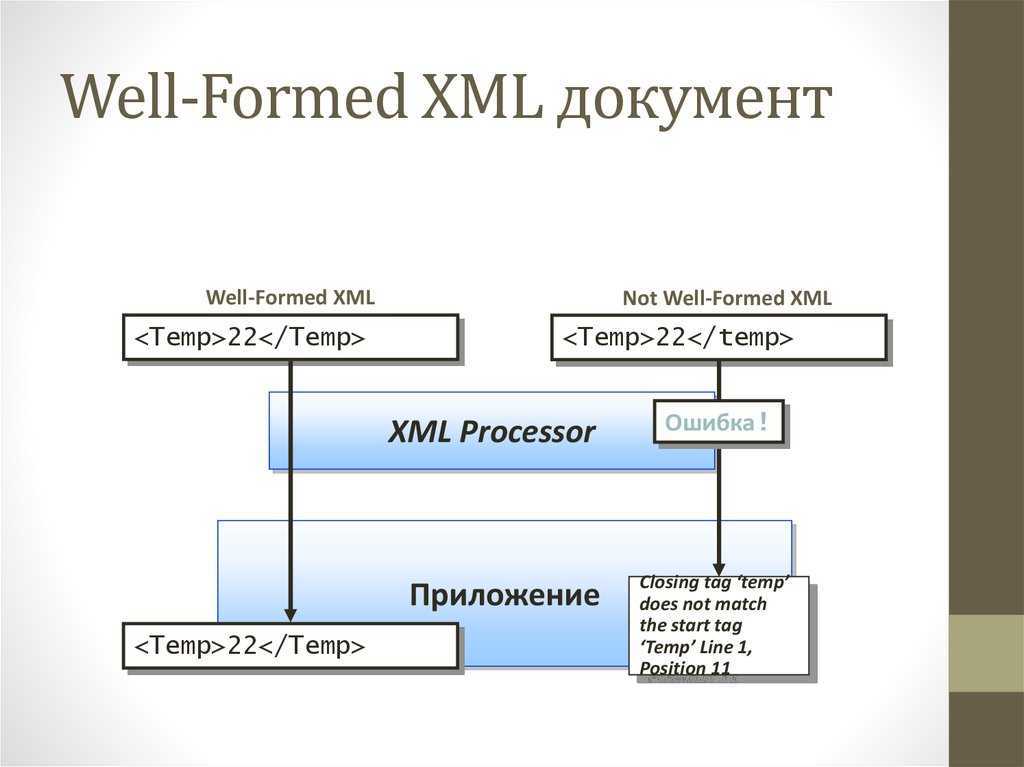
Стандартом определены два уровня правильности документа XML:
Правильно построенный (Well-formed). Правильно построенный документ соответствует всем общим правилам синтаксиса XML, применимым к любому XML-документу. И если, например, начальный тег не имеет соответствующего ему конечного тега, то это неправильно построенный документ XML. Документ, который неправильно построен, не может считаться документом XML; XML-процессор (парсер) не должен обрабатывать его обычным образом и обязан классифицировать ситуацию как фатальная ошибка.
Действительный (Valid). Действительный документ дополнительно соответствует некоторым семантическим правилам. Это более строгая дополнительная проверка корректности документа на соответствие заранее определённым, но уже внешним правилам, в целях минимизации количества ошибок, например, структуры и состава данного, конкретного документа или семейства документов. Эти правила могут быть разработаны как самим пользователем, так и сторонними разработчиками, например, разработчиками словарей или стандартов обмена данными. Обычно такие правила хранятся в специальных файлах — схемах, где самым подробным образом описана структура документа, все допустимые названия элементов, атрибутов и многое другое. И если документ, например, содержит не определённое заранее в схемах название элемента, то XML-документ считается недействительным; проверяющий XML-процессор (валидатор) при проверке на соответствие правилам и схемам обязан (по выбору пользователя) сообщить об ошибке.
Данные два понятия не имеют достаточно устоявшегося стандартизированного перевода на русский язык, особенно понятие valid, которое можно также перевести, как имеющий силу, правомерный, надёжный, годный, или даже проверенный на соответствие правилам, стандартам, законам. Некоторые программисты применяют в обиходе устоявшуюся кальку «Валидный».
Сложные вопросы
При рассмотрении технологии базы данных очень важно учесть, каким образом будет происходить доступ к данным. Если у вас , вероятно, РСУБД — лучший выбор, как и для XML-документов, которые имеют
Однако, как только вам потребуется выполнить поиск по всему тексту или манипулировать моделью рекурсивного контента, NXD или XED с подходящим языком XML-запросов кажутся более приемлемым решением.
«Если вам нужно выполнять запросы, которые будут обращаться к рекурсивной структуре ваших данных, XML-СУБД кажется более подходящей, чем «сырая» РСУБД. Например, если вам необходимо выяснить, какие изделия состоят из сборок или подсборок, или элементарных подсборок… которые включают определенную деталь, то XPath лучше обработает такие запросы по сравнению с SQL. (Хорошо известно, что запрос к «списку материалов» — это непростая задача для SQL, для XPath же это пара пустяков.) Полагаю, справедливости ради я должен сказать: «Если вам нужно делать запросы, которые подразумевают соединения по метаданным в различных совокупностях, использование РСУБД, похоже, более приемлемо, чем применение XML-СУБД, по крайней мере, пока разновидность XQuery не получит всеобщей поддержки». (Майкл Чэмпион)
«… SQL располагает гораздо более богатым набором операторов для манипулирования данными по сравнению с XPath (а XQuery лишь до некоторой степени) и (свободно) опирается на общую теорию данных, XML же гораздо более нерегламентирован… если у вы не располагаете относительно сложным XML-документом, то возможности *поиска* XML-СУБД вас не сильно прельстят по сравнению с СУБД, поддерживающей XML как тип. Однако, если у вас «интересная» XML-схема, например с рекурсивными элементами, простые запросы XQuery могут справиться с проблемами, которые трудноразрешимы с помощью SQL». (Майкл Чэмпион)
Хотя, наиболее популярным языком запросов — считается XPath (как правило, с расширениями для запросов ко многим документам), поддерживаются и многие другие языки запросов (все они фирменные). Это справедливо как в отношении реляционных баз данных, поддерживающих XML, так и XML-баз данных.
На это есть свои причины — XPath в достаточной мере развит, чтобы выполнить все запросы, которые необходимы пользователю, а XQuery пока еще не закончен. У меня есть подозрение, что, когда работы по над XQuery будут завершены, появится множество его реализаций». (Рональд Бурре)
Презентация на тему: » БАЗЫ ДАННЫХ ЛЕКЦИЯ 14. тема: XML-ТЕХНОЛОГИИ В БАЗАХ ДАННЫХ.» — Транскрипт:
1
БАЗЫ ДАННЫХ ЛЕКЦИЯ 14

2
тема: XML-ТЕХНОЛОГИИ В БАЗАХ ДАННЫХ

3
Язык разметки XML XML (Extensible Markup Language) расширяемый язык разметки Расширяемость в язык можно вводить собственные обозначения, с помощью которых выполняется разметка XML можно определить как язык для представления данных в виде деревьев Иерархия задается с помощью тегов

4
Структура XML-документа Основные компоненты: Инструкции по обработке Пространства имен Элементы Атрибуты Комментарии

5
Пример XML-документа

6
Пространство имен Пространство имен XML – это уникально именованное множество, которому могут принадлежать имена элементов и атрибутов XML- документа Глобальная уникальность пространства имен означает, что его идентификатор должен относиться к классу URI Пример: xmlns:bd=

7
Схема XML-документа Схема XML-документа – это модель, отделенная от самого документа, в которой заданы его структурные и параметрические ограничения Схема – это модель типов Три типа схем: 1. DTD (Data Type Definition) 2. XDR (XML Data Reduced) 3. XSD (XML Schema Definition)

8
Пример схемы XSD

9
XPath Концепция XPath – это концепция языка высокого уровня абстракции, предназначенного для адресации фрагментов XML-документа, подлежащих той или иной обработке в зависимости от среды применения XPath позволяет задавать выражения (XPath-выражения) в виде пути адресации с использованием имен элементов, атрибутов, их значений, XPath-функций и др. Пример:

10
Технология XSLT Технология XSLT – это технология, позволяющая преобразовывать (трансформировать) XML-документ – в другой XML-документ; – в HTML-документ для отображения Web-браузером; – в документы иных форматов (WML, RTF, PDF, TEX и т.п.). Таблица стилей – это XML-документ специального вида (обычно файл с расширением.xsl), содержащий набор правил преобразования исходного XML-документа, написанных на языке XSLT и предназначенных для XSLT- процессора.

11
Получение данных в формате XML Запросы SELECT…FOR XML Схемы сопоставления (Mapping Schema)

12
Запросы SELECT…FOR XML Режим Raw SELECT s_no, sname FROM s FOR XML RAW

13
Запросы SELECT…FOR XML Режим Auto SELECT s_no, sname FROM s FOR XML RAW

14
Запросы SELECT…FOR XML Режим Explicit SELECT s_no, sname FROM s FOR XML Explicit Smith Jones

15
Схемы сопоставления Схема сопоставления – это простое XML- представление реляционных данных Инструкции и ключевые слова, реализующие сопоставление элементов и атрибутов схемы объектам базы данных, а также выполняющие некоторые дополнительные преобразования выходных XML-данных, называются аннотациями. sql:relation – сопоставление таблице базы данных sql:field – сопоставление столбцу таблицы базы данных

16
Схемы сопоставления
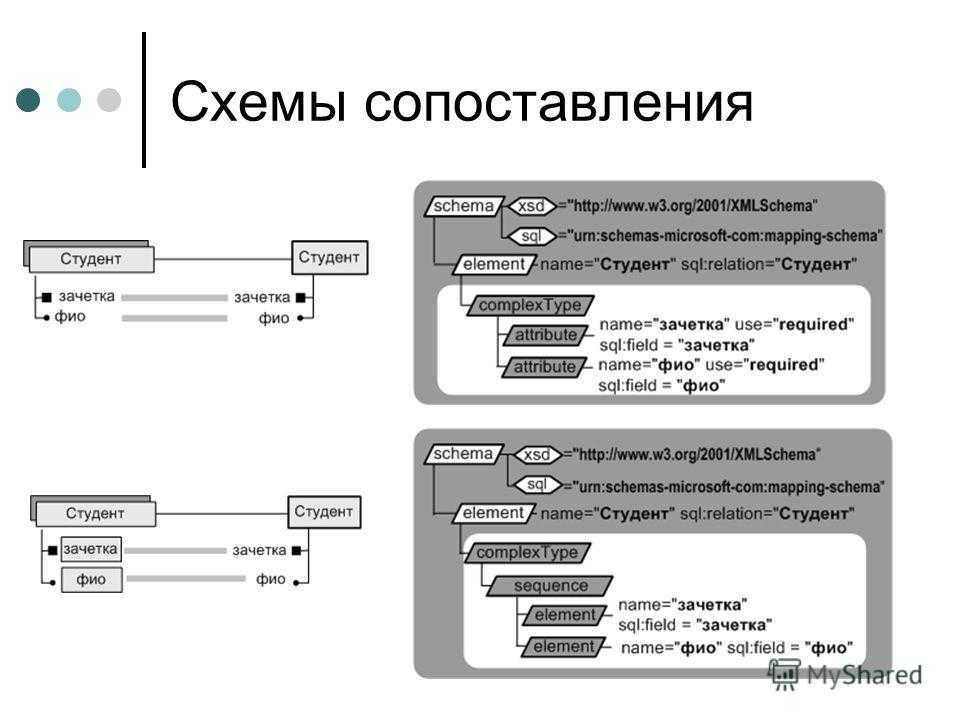

18
Апдейтграммы Апдейтграмма (файл обновления) XML-шаблон, выполняющий вставку, обновление и удаление записей из базы данных Аптейтграммы в качестве правил взаимодействия используют схемы сопоставления

Структура XML-файлов форматирования
XML-файлы форматирования, как и файл форматирования в формате, отличном от XML, определяют формат и структуру полей данных в файле данных и сопоставляют их со столбцами целевой таблицы.
XML-файл форматирования содержит два основных компонента: <RECORD> и <ROW>:
-
<RECORD> описывает данные в том виде, в котором они хранятся в файле данных.
Каждый <элемент RECORD> содержит набор из одного или нескольких <элементов FIELD> . Эти элементы соответствуют полям в файле данных. Базовый синтаксис:
<ЗАПИСИ>
<FIELD …/>
</ЗАПИСИ>
Каждый <элемент FIELD> описывает содержимое определенного поля данных. Поле может быть сопоставлено только с одним столбцом таблицы. Столбцам не обязательно сопоставлять все поля.
Поле в файле данных может иметь фиксированную или переменную длину или завершаться определенным символом. Значение поля может быть представлено в следующем виде: символ (однобайтовое представление), широкий символ (двухбайтовое представление Юникода), собственный формат базы данных или имя файла. Если значение поля представляется в виде имени файла, оно указывает на файл, который содержит значение столбца BLOB в целевой таблице.
-
-
<ROW> описывает, как создавать строки данных из файла данных при импорте данных в SQL Server таблицу.
Элемент <ROW> содержит набор <элементов COLUMN> . Эти элементы соответствуют столбцам таблицы. Базовый синтаксис:
<ROW>
<COLUMN …/>
</СТРОКИ>
Каждый <элемент COLUMN> можно сопоставить только с одним полем в файле данных. Порядок <элементов COLUMN> в элементе <ROW> определяет порядок, в котором они возвращаются массовой операцией. XML-файл форматирования присваивает каждому <элементу COLUMN> локальное имя, которое не имеет связи со столбцом в целевой таблице операции массового импорта.







Кодировка текста
SQL Server хранит XML-данные в кодировке Юникод (UTF-16). XML-данные, извлекаемые из баз данных сервера, предоставляются в кодировке UTF-16. Если требуются данные в другой кодировке, извлеченные данные нужно преобразовать. Иногда XML-данные могут быть представлены в другой кодировке. Если это так, во время загрузки данных нужно быть внимательным. Пример:
-
Если текстовый XML-код находится в Юникоде (UCS-2, UTF-16), его можно назначить XML-столбцу, переменной или параметру без каких-либо проблем.
-
Если кодировка не является Юникодом и неявна, из-за исходной кодовой страницы строка в базе данных должна совпадать с кодовыми точками, которые требуется загрузить. При необходимости используйте COLLATE. Если такой кодовой страницы на сервере не существует, необходимо добавить явную XML-декларацию с корректной кодировкой.
-
Чтобы явно задать кодировку, воспользуйтесь типом varbinary() , который не зависит от кодовых страниц, либо символьным типом для соответствующей кодовой страницы. После этого назначьте данные XML-столбцу, переменной или параметру.
Пример. Явное указание кодировки
Предположим, что у вас есть XML-документ vcdoc, хранящийся как varchar(max), который не имеет явного xml-объявления. Приведенная ниже инструкция добавляет объявление XML с кодировкой «iso8859-1», присоединяет к нему XML-документ, приводит результат к типу varbinary(max) (чтобы сохранить двоичное представление) и, наконец, приводит его к типу XML. Это позволяет процессору XML выполнять синтаксический анализ данных в соответствии с указанной кодировкой «iso8859-1» и создавать для строковых значений соответствующее представление UTF-16.
Несовместимости кодировки строк
При копировании и вставке XML в виде строкового литерала в окно Редактор запросов в SQL Server Management Studio может возникнуть несоответствие кодирования строк varchar. Это будет зависеть от кодировки копируемого экземпляра XML. Во многих случаях может возникнуть необходимость удаления XML-декларации. Пример:
Затем необходимо префиксировать строку, чтобы экземпляр XML был экземпляром Юникода. Пример:
Еcли Вы пришли с поискового сервера — посетите мою главную страничку
На главной странице Вы найдете программы комплекса Veles — программы для автолюбителей,
программу NumberPhoto, созданную для работы с фото, сделанными цифровым фотоаппаратом,
программу Локальный Web сайт — предназначенную для просмотра и прослушивания
файлов большинства графических и звуковых форматов в Web Browser,
программу Bricks — игрушку для детей и взрослых, программу записную книжку,
программу TellMe — говорящий Русско-Английский разговорник — программу для тех, кто собирается
погостить за бугром или повысить свои знания в английском, теоретический материал
по программированию в среде Borland C++ builder, C# (Windows приложения и ASP.Net Web сайты).
Ограничения типа данных xml
Обратите внимание, что на тип данных xml накладываются следующие ограничения:
-
Хранимые представления экземпляров типа данных xml не могут превышать 2 ГБ.
-
Его нельзя использовать в качестве подтипа экземпляра sql_variant .
-
Он не поддерживает приведение или преобразование в текст или ntext. Используйте вместо них varchar(max) или nvarchar(max) .
-
Его нельзя сравнить или отсортировать. Это означает, что тип данных xml нельзя использовать в инструкции GROUP BY.
-
Его нельзя использовать в качестве параметра для скалярных встроенных функций, отличных от ISNULL, COALESCE и DATALENGTH.
-
Его нельзя использовать в качестве ключевого столбца в индексе. Однако может включаться в виде данных в кластеризованный индекс или явно добавляться в некластеризованный индекс при его создании с помощью ключевого слова INCLUDE.
-
XML-элементы можно вкладывать до 128 уровней.
Внешние ссылки [ править ]
- Рейтинг собственных XML-СУБД по популярности, обновляемый ежемесячно, от DB-Engines
- Базы данных XML — экономическое обоснование, Чарльз Фостер, июнь 2008 г. — рассказывает о текущем состоянии баз данных и сохранении данных, о том, как текущая модель реляционной базы данных начинает трещать по швам, и дает представление о сильной альтернативе сегодняшним требованиям.
- База данных молекулярных путей на основе XML (2005-06-02) Сравнение скорости / производительности eXist, X-Hive, Sedna и Qizx / open
- Системы баз данных XML Native: Обзор Sedna, Ozone, NeoCoreXMS 2006
- Хранилища данных XML: новые практики
- Bhargava, P .; Rajamani, H .; Thaker, S .; Агарвал, А. (2005) Реляционные базы данных с поддержкой XML , Техас, Техасский университет в Остине.
- Инициатива для баз данных XML
- XML и базы данных, Рональд Бурре, сентябрь 2005 г.
- Состояние собственных баз данных XML, Эллиотт Расти Гарольд, 13 августа 2007 г.
Общие сведения о компонентах схемы
При использовании инструкции CREATE XML SCHEMA COLLECTION в базу данных импортируются различные компоненты схемы. К компонентам схемы относятся ее элементы, атрибуты и определения типов. При использовании инструкции DROP XML SCHEMA COLLECTION коллекция удаляется целиком.
Инструкция CREATE XML SCHEMA COLLECTION сохраняет компоненты схемы в различных системных таблицах.
Например, рассмотрим следующую схему:
В приведенной выше схеме показаны различные типы компонентов, которые могут храниться в базе данных. Это компоненты , , , , , , , , , и .
Категории компонентов
Компоненты схемы, хранящиеся в базе данных, делятся на следующие категории:
-
ELEMENT
-
ATTRIBUTE
-
TYPE (для простых и сложных типов);
-
ATTRIBUTEGROUP;
-
MODELGROUP.
Пример:
-
является компонентом ATTRIBUTE.
-
, и являются компонентами TYPE.
-
является компонентом ELEMENT.
При импорте схемы в базу данных SQL Server не сохраняет саму схему. Вместо этого SQL Server сохраняет различные отдельные компоненты. То есть <тег Schema> не сохраняется, сохраняются только определенные в нем компоненты. Все элементы схемы не сохраняются. <Если тег Schema> содержит атрибуты, определяющие поведение компонентов по умолчанию, эти атрибуты перемещаются в компоненты схемы в процессе импорта, как показано в следующей таблице.


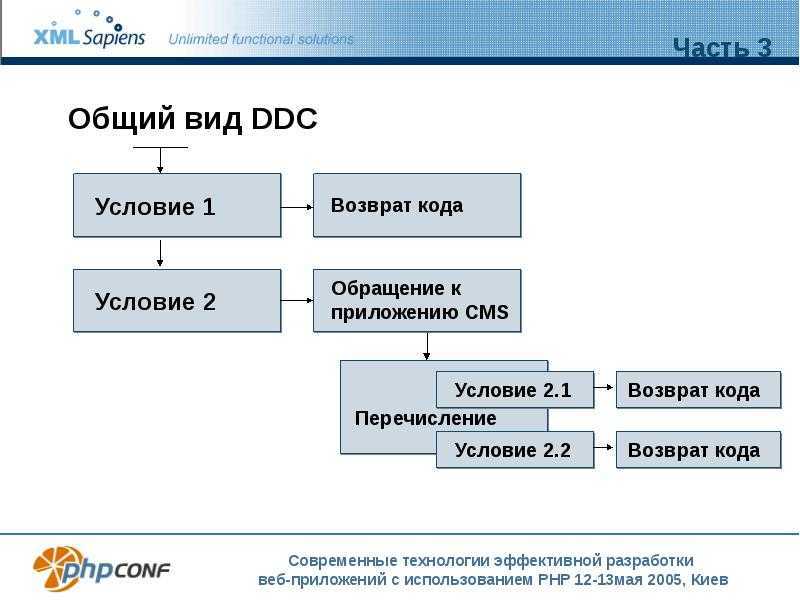


| Имя атрибута | Поведение |
|---|---|
| attributeFormDefault | Атрибут form применяется ко всем объявлениям атрибутов в схеме, где его еще нет. Ему присваивается значение, равное значению атрибута attributeFormDefault . |
| elementFormDefault | Атрибут form применяется ко всем объявлениям элементов в схеме, где его еще нет. Ему присваивается значение, равное значению атрибута elementFormDefault . |
| blockDefault | Атрибут block применяется ко всем объявлениям элементов и определениям типов в схеме, где его еще нет. Ему присваивается значение, равное значению атрибута blockDefault . |
| finalDefault | Атрибут final применяется ко всем объявлениям элементов и определениям типов в схеме, где его еще нет. Ему присваивается значение, равное значению атрибута finalDefault . |
| targetNamespace | Сведения о компонентах, принадлежащих целевому пространству имен, хранятся в метаданных. |
Сильные и слабые стороны
Достоинства
- XML — это самодокументируемый формат, который описывает структуру и имена полей также как и значения полей;
- XML имеет строго определённый синтаксис и требования к анализу, что позволяет ему оставаться простым, эффективным и непротиворечивым. Одновременно с этим, разные разработчики не ограничены в выборе экспрессивных методов (например, можно моделировать данные, помещая значения в параметры тегов или в тело тегов, можно использовать различные языки и нотации для именования тегов и т. д.);
- XML — формат, основанный на международных стандартах;
- Иерархическая структура XML подходит для описания практически любых типов документов, кроме аудио и видео мультимедийных потоков, растровых изображений, сетевых структур данных и двоичных данных;
- XML представляет собой простой текст, свободный от лицензирования и каких-либо ограничений;
- XML не зависит от платформы;
- XML не накладывает требований на расположение символов в строке;
- В отличие от бинарных форматов, XML содержит метаданные об именах, типах и классах описываемых объектов, по которым приложение может обработать документ неизвестной структуры (например, для динамического построения интерфейсов);
- XML имеет реализации парсеров для всех современных языков программирования;
- XML поддерживается на низком аппаратном, микропрограммном и программном уровнях в современных аппаратных решениях.
Недостатки
Синтаксис XML избыточен.
-
- Размер XML документа существенно больше бинарного представления тех же данных. В грубых оценках величину этого фактора принимают за 1 порядок (в 10 раз).
- Избыточность XML может повлиять на эффективность приложения. Возрастает стоимость хранения, обработки и передачи данных.
- XML содержит мета-данные (об именах полей, классов, вложенности структур), и одновременно XML позиционируется как язык взаимодействия открытых систем. При передаче между системами большого количества объектов одного типа (одной структуры), передавать метаданные повторно нет смысла, хотя они содержатся в каждом экземпляре XML описания.
- Для большого количества задач не нужна вся мощь синтаксиса XML и можно использовать значительно более простые и производительные решения.
Неоднозначность моделирования.
-
- Нет общепринятой методологии для моделирования данных в XML, в то время как для реляционной модели и объектно-ориентированной такие средства разработаны и базируются на реляционной алгебре, системном подходе и системном анализе.
- В природе есть множество объектов и явлений, для описания которых разные структуры данных (сетевая, реляционная, иерархическая) являются естественными, и отображение объекта в неестественную для него модель является болезненным для его сути. В случае с реляционной и иерархической моделями определены процедуры декомпозиции, обеспечивающие относительную однозначность, чего нельзя сказать о сетевой модели.
- В результате большой гибкости языка и отсутствия строгих ограничений, одна и та же структура может быть представлена множеством способов (различными разработчиками), например, значение может быть записано как атрибут тега или как тело тега и т. д. Например: <a b=»1″ c=»1″/> или <a b=»1″ c=»1″></a> или <a><b>1</b><c>1</c></a> или <a><b value=»1″/><c value=»1″/></a> или <a><fields b=»1″ c=»1″/></a> и т. д.
- Поддержка многих языков в именовании тегов дает возможность назвать, например вес русским словом, в таком случае компьютер никак не сможет установить соответствия этого поля с полем weight в англоязычной версии программы и с полями в версиях модели объекта на множестве других языков.
Решения, решения
Одна из наитруднейших задач, стоящих при выборе технологии — это формирование непредвзятой картины обо всех слабых и сильных сторонах выбираемого продукта. Это подтвердит любой, кто, пытаясь добраться до технической сути, оказывался увязшим в «глянцевом великолепии» «Белых бумаг».
Именно поэтому сообщества передовых пользователей, как, например, XML-DEV, обладают неоспоримым преимуществом в этом вопросе: они предоставляют место для объективного обсуждения и сопоставления достоинств различных технологий. Тогда, вооружившись фактами, и зная все «за и против», решительный разработчик сможет принять более обоснованное решение. Процесс принятия решения можно улучшить — если остальные члены сообщества пожелают поделиться своими выводами с другими пользователями.
Так, Брайен Мэджик (Brian Magick), столкнувшись с необходимостью выбрать подходящую технологию баз данных для XML-приложения, обратился к сообществу XML-DEV с вопросом: не пытался ли кто-нибудь собрать соответствующее «дерево решений» («decision tree»). Позднее он конкретизировал свою задачу.
«Я просто хотел в принципе понять, когда переходить к XML и создавать приложения с базами данных, а когда — не переходить и хранить данные в реляционных базах. Почему одни предпочитают держать данные в реляционном формате, а не преобразовывать их в XML и разработать XML-базу. Что касается новых приложений, что должен учитывать разработчик при принятии решения пойти традиционным путем, вместо того, чтобы воспользоваться новой «крутой» XML-технологией? К сожалению, выбрав XML-базу данных, многие разработчики захотят использовать это новое инструментальное средство, хотя оно, на самом деле, предназначено не для всех новых баз данных/приложений».
Хотя никто еще пока не создал этого «монстра», нескольким членам XML-DEV удалось поделиться своими мыслями по рассматриваемому вопросу. Это вылилось в продолжительный обмен мнениями, многие из которых сопровождались ценной информацией. Оценка технологии в условиях вакуума трудновыполнима — необходимо иметь некоторые представлениями о предъявляемых требованиях; принятие решения, как правило, подразумевает учет различных факторов. Вот почему достаточно сложно синтезировать в дерево решений обсуждения такого рода — для построения структуры дерева пришлось бы оценивать факторы относительно друг друга, помещая один над другим (в противном случае, все закончилось бы неким месивом, переплетенным сложными внутренними ссылками). Поэтому, чтобы подвести итог состоявшейся на этой неделе дискуссии, было решено использовать другой подход, а именно: «Признаки кода».
Если вы из числа «экстримальных» программистов или знакомы с реорганизацией кода (code refactoring) Кента Бека (Kent Beck) и Мартина Фаулера (Martin Fowler), концепция признаков кода (code smells) будет вам не в новинку. Вот несколько подсказок (code hints), которые помогут вам выяснить, что в коде что-то не так и требуются изменения; например, слишком большое количество параметров у метода. Признаки кода, подобно паттерному проектированию (design patterns), являются сосредоточием программистского опыта. Поэтому, мы могли бы прибегнуть к схожей методике — «необходимые признаки» («requirement smells») и поделиться с вами некоторыми соображениями, которые могли бы помочь вам принять правильное решение.
Однако, мы должны вас кое о чем предупредить. Во-первых, эти соображения принадлежат сообществу XML-DEV; вероятно, есть и другие, требующие рассмотрения, как, например, функциональные или бюджетные рамки, которые могут так или иначе повлиять на ваш выбор. Во-вторых, часть рекомендаций основывается на текущем состоянии рынка баз данных; по мере его развития, возможно, другие идеи станут более важными, а нынешние факторы будут менее актуальны. В-третьих, в поле зрения не попали специальные продукты. Не все системы управления базами данных одинаковы, так что, определенно, на каждое правило будет свое исключение. Как розы могут расти на навозе, так и продукты с хорошей репутацией могут скрывать что-нибудь, скажем, гадкое.
Если же вам есть что добавить, поделитесь своими соображениями, поместив их на XML.com (см. ниже) или отправьте их на XML-DEV, где они, вероятно, будет прочитаны большинством членов сообщества.