Введение
Напомню, что понятие виртуальная частная база данных (virtual private database,
VPD), появилось в версии Oracle 8.1 для обозначения возможности ограничить
конкретным сеансам доступное множество строк в таблице (в том числе выводимой,
view), чтобы каждый сеанс, обращаясь формально к одной и той же таблице, имел
доступ в ней («видел») только положенные строки. Сам термин VPD рекламный,
его технический эквивалент, фигурирующий наравне в документации – детальный
контроль доступа (fine grained access control, FGAC)1. Пользоваться
VPD можно напрямую, через пакет SYS.DBMS_RLS, а так же неявно и не догадываясь
об этом, поскольку это средство положено в основу другого, label security,
реализующего известную модель мандатного доступа применительно к строкам таблицы
из приложения. Пример работы непосредственно с VPD приводился в статье Каждому
(пользователю) свое (данное в таблице). Часть
2 , а пример работы с label security приводился в статье К
каждой строке охранника приставишь!.
Фирма Oracle не считает для себя направление VPD случайным, о чем свидетельствует
непрерывное развитие этого средства от одной версии СУБД к другой. Так, в числе
новшеств VPD в версии 9 – собственная GUI-программа администрирования Policy
Manager и поддержка синонимов, а в версии 10.1 – отбор строк (и даже значений
в строках) с учетом указанных столбцов и возможность выбора между статическим
и динамическим вычислением заданного предикатом отбора критерия видимости.
Именно первая из указанных двух новых возможностей VPD версии 10.1 и будет
продемонстрирована в этой статье.
MS SQL-сервер
Являясь полностью коммерческим инструментом, Microsoft SQL Server является одной из самых популярных реляционных СУБД. Он хорошо справляется с эффективным хранением, изменением и управлением реляционными данными. Для взаимодействия с базами данных SQL Server инженеры баз данных обычно используют язык Transact-SQL (T-SQL), который является расширением стандарта SQL.Плюсы MSSQL1) Разнообразие версий. Microsoft SQL Server предоставляет широкий выбор различных опций с различными функциональными возможностями. Например, Express edition с бесплатной базой данных предлагает инструменты начального уровня, идеально подходящие для обучения и создания настольных или небольших серверных приложений, управляемых данными. Опция разработчиков позволяет создавать и тестировать приложения, включая некоторые корпоративные функции, но без лицензии на производственный сервер. Для более крупных проектов существуют также веб-версии, стандартные и корпоративные версии с различными административными возможностями и уровнями обслуживания.2) Комплексное решение для обработки бизнес-данных. Ориентируясь в основном на коммерческие решения, MSSQL предоставляет множество дополнительных функций для бизнеса. Дополнительный выбор компонентов позволяет создавать ETL-решения, формировать базу знаний и осуществлять очистку данных. Кроме того, он предоставляет инструменты для общего администрирования данных, онлайн-аналитической обработки и интеллектуального анализа данных, дополнительно предоставляя возможности для создания отчетов и визуализации.3) Внушительная документация.4) Поддержка облачных решений. Являясь частью согласованной экосистемы Microsoft, MSSQL может быть интегрирован с Microsoft cloud, базой данных SQL Azure или SQL Server на виртуальных машинах Azure. Эти решения позволяют перенести администрирование баз данных в облако, если ваша база данных бизнес-программного обеспечения становится действительно огромной и сложной в администрировании.Минусы MSSQL1) Привязка к платформе Microsoft Windows. Выбирая MSSQL, на практике приходится автоматически выбирать ОС Windows. Несмотря на недавнее появление версий под Linux, такая связка остаётся экзотикой. 2) Высокая стоимость. Будучи в основном используемым в масштабах предприятия, MSSQL-сервер остается одним из самых дорогих решений. Говоря о цифрах, издание Enterprise в настоящее время стоит более 14 000 долларов за ядро, продаваемое в виде 2 основных пакетов.3) Высокая требовательность к аппаратным ресурсам.4) Неясные и плавающие условия лицензии. Еще одна проблема – постоянно меняющийся процесс лицензирования. Ценовую стратегия трудна для понимания.5) Сложный процесс настройки. Для тех новичков, которым приходится работать с массивными наборами данных, работа с оптимизацией запросов и настройкой производительности может оказаться проблематичной. Поскольку этот процесс не столь очевиден, он может создать существенные узкие места на ранней стадии.6) Восстановление данных после аварийного отключения питания обязательно требует участия специалиста.Сервер MSSQL является разумным вариантом для компаний с уже имеющимися подписками на продукты Microsoft. Поскольку Microsoft создает устойчивую экосистему с хорошо интегрированными сервисами, MSSQL здесь с его доступом к облаку и мощными инструментами поиска данных пригодится.
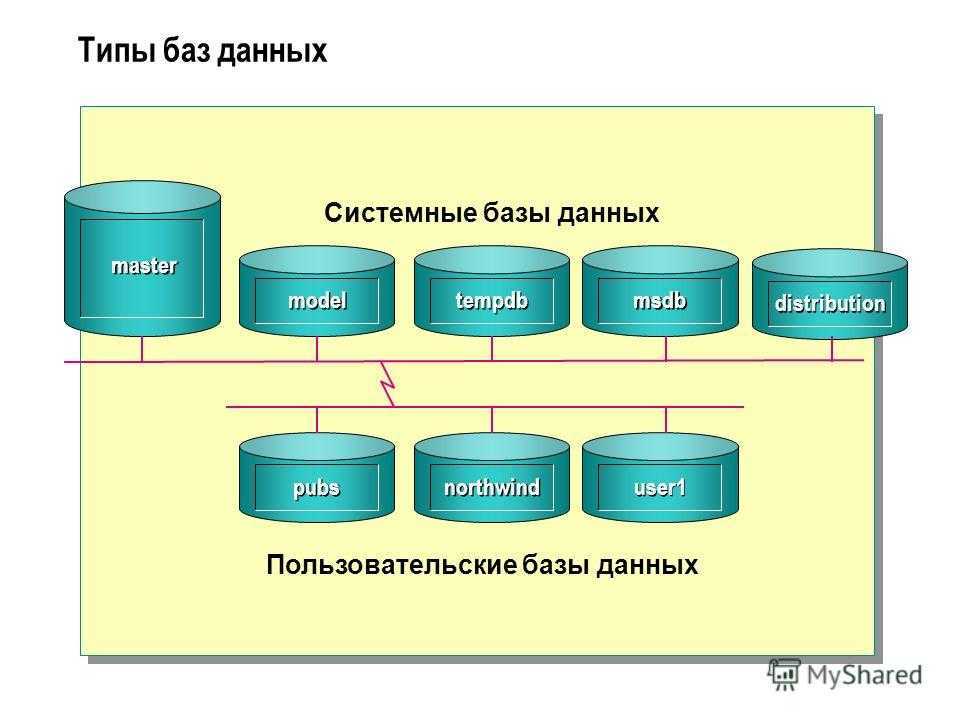
Запуск и останов БД
Запуск БД
Процесс запуска БД проходит 3
стадии:
·NOMOUNT, когда открывается файл INIT<SID>.ORA и в ОЗУ компьютра создается экземпляр БД
·MOUNT, когда открываются управляющие файлы (CTL1<SID>.ORAи
т.д.)
·OPEN, когда открываются файлы табличных пространств
Если запустить утилиту SVRMGR30 и ввести команду
startup
pfile=%ORACLE_HOME%\DATABASE\INIT<SID>.ORA
то
произойдет запуск БД до состояния OPEN (по
умолчанию). Можно ввести команду ORASTART.NCF, что
приведет к аналогичному эффекту. Можно ввести эту же команду, но добавить
параметр NOMOUNT. При этим произойдет запуск БД до первого состояния.
Чтобы затем ее открыть, нужно последовательно задать команды:
alterdatabasemount;
alterdatabaseopen;
СУБД Oracle имеет собственный язык PL/SQL
PL/SQL — это принадлежащее фирме Oracle процедурное языковое расширение языка SQL. PL/SQL сочетает легкость и гибкость SQL с процедурными возможностями языка структурного программирования, такими как IF…THEN, WHILE и LOOP.
При написании приложения базы данных разработчик должен рассмотреть преимущества использования хранимых подпрограмм PL/SQL:
— Поскольку код PL/SQL может сохраняться централизованно в базе данных, сетевой трафик между приложениями и базой данных сокращается, что увеличивает производительность как приложений, так и системы.
— Благодаря хранимому коду PL/SQL можно контролировать доступ к данным. При этом методе пользователи PL/SQL могут обращаться к данным лишь так, как это предусмотрено разработчиком приложения (если не предоставлен иной маршрут доступа). — Блоки PL/SQL могут пересылаться приложениями к базе данных, что позволяет выполнять комплексные операции без избыточной нагрузки на сеть.
Даже если PL/SQL не хранится в базе данных, приложения могут пересылать к базе данных не отдельные предложения SQL, а целые блоки, опять-таки сокращая сетевой трафик. Следующие секции описывают различные программные единицы, которые могут быть определены и централизованно сохранены в базе данных.
Процедуры и функции представляют собой совокупности предложений SQL и PL/SQL, сгруппированных в единицу для решения специфической проблемы или выполнения множества взаимосвязанных задач. Процедура создается и сохраняется в базе данных в откомпилированной форме, и может выполняться (вызываться) любым пользователем или приложением. Процедуры и функции похожи друг на друга, с той разницей, что функция всегда возвращает вызывающей программе единственное значение, тогда как процедура не возвращает значения.
Пакеты дают метод инкапсулирования и хранения взаимосвязанных процедур, функций, переменных и других конструктов пакета как единицы в базе данных. Предоставляя администратору базы данных или разработчику приложений организационные преимущества, пакеты в то же время расширяют функциональные возможности (например, глобальные переменные пакета могут объявляться и использоваться любой процедурой в пакете) и увеличивают производительность базы данных (так, все объекты пакета синтаксически разбираются, компилируются и загружаются в память один раз).
Триггеры базы данных ORACLE позволяет вам писать процедуры, которые выполняются автоматически в результате обновления, вставки или удаления из таблицы. Такие процедуры называются триггерами базы данных. Триггеры базы данных могут использоваться самыми разнообразными способами для информационного управления вашей базой данных. Например, их можно использовать для автоматизации генерации данных, аудита модификаций данных, введения в действие комплексных ограничений целостности или организации сложных процедур обеспечения защиты.
Многопользовательские системы баз данных, такие как ORACLE, включают средства защиты, которые контролируют обращения к базе данных и использование данных. Например, механизмы защиты выполняют следующее:
— предотвращают несанкционированный доступ к базе данных
— предотвращают несанкционированный доступ к объектам схем
— контролируют использование дисков
— контролируют использование системных ресурсов (таких как время процессора)
— осуществляют аудит действий пользователя
Защита базы данных может быть классифицирована по двум различным категориям: защита системы и защита данных. ЗАЩИТА СИСТЕМЫ включает механизмы, контролирующие доступ к базе данных и ее использование на уровне системы.
Например, защита системы включает:
— действительные комбинации имен пользователей и паролей;
— уполномочен ли пользователь присоединяться к базе данных ;
— объем дисковой памяти, доступный объектам пользователя ;
— лимиты ресурсов для пользователя ;
— активность или неактивность аудита базы данных ;
-какие системные операции разрешено выполнять пользователю .
Защита данных включает механизмы, контролирующие доступ к базе данных и ее использование на уровне объектов.
Например, защита данных включает:
— какие пользователи имеют доступ к конкретному объекту схемы и какие типы действий разрешены каждому пользователю на этом объекте (например, пользователь SCOTT может выдавать для таблицы EMP предложения SELECT и INSERT, но не предложения DELETE) ;
— какие действия подлежат аудиторскому отслеживанию для каждого объекта схемы.
ORACLE управляет защитой базы данных, используя несколько различных средств, среди которых:
— пользователи базы данных и схемы;
— привилегии;
— роли;
— назначения пространства и квоты;
— лимиты на ресурсы;
— аудитинг.
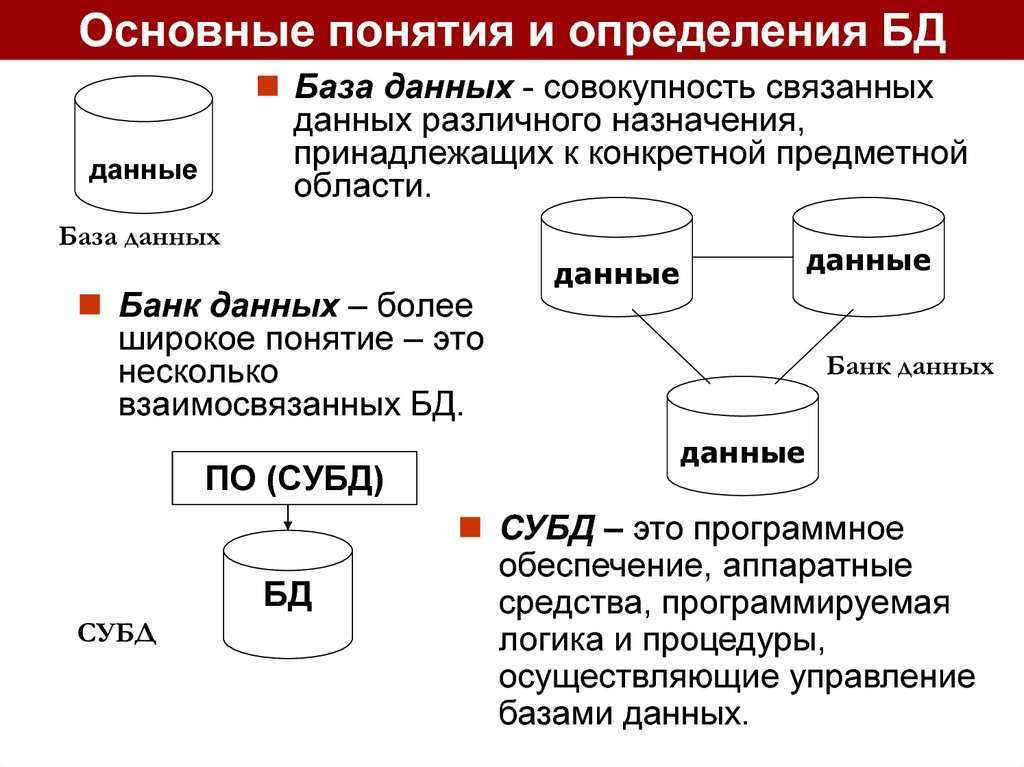
Базы данных SQL
Как уже было сказано, SQL-базы данных используют структурированный язык запросов (SQL) для управления данными, для их обработки, хранения, обновления, удаления. В реляционных хранилищах данных используются реляционные системы управления базами данных (РСУБД, Relational Database Management Systems, RDBMS). В РСУБД данные хранятся в табличном формате. Таблица — это базовая единица базы данных, она состоит из строк и столбцов, в которых хранятся данные. Таблицы — это самый часто используемый тип объектов баз данных, или структур, которые в реляционной БД хранят данные или ссылки на них. Среди других типов объектов баз данных можно отметить следующие:
-
Представления (views) — виртуальные представления данных, собранных из одной или нескольких таблиц базы данных.
-
Индексы (indexes) — таблицы, используемые для поиска данных, помогающие ускорить соответствующие возможности БД.
-
Отчёты (reports) — они состоят из данных, полученных из одной или большего количества таблиц. Обычно они представляют некое подмножество данных, выбранных из БД на основе каких-то критериев поиска.
Исследуем то, что называется реляционной моделью данных. Если попытаться сохранить данные об учителях и о классах, в которых они ведут занятия, то у нас получится (учитывая то, что это — простой пример) две таблицы. Одна — для учителей, вторая — для классов.
Учитель может вести занятия в нескольких классах, а в одном классе занятия могут вести несколько учителей
Итак, в этом примере имеется две таблицы. Одна содержит данные об учителе (), а вторая — о классе ().
В таблице имеются следующие атрибуты/столбцы:
-
— идентификатор конкретного учителя.
-
— имя учителя.
-
— фамилия учителя.
-
— внешний ключ (foreign key), который связывает ID конкретного класса с учителем.
А в таблице имеются такие столбцы:
-
— идентификатор класса.
-
— название класса.
-
— предмет класса.
-
— категория класса.
-
— внешний ключ, связывающий ID учителя с классом.
Это — простой пример отношений таблиц, где имеется две таблицы, в каждой из которых имеются атрибуты, содержащие сведения об объекте. Эти два объекта связаны друг с другом с помощью связи многие-ко-многим (many-to-many). В РСУБД существуют и другие типы связей.
-
Многие-ко-многим (many-to-many) — это связь между таблицами — , которую мы только что рассмотрели.
-
Многие-к-одному (many-to-one) — это, например, отношения таблицы (представляющей ученика) и таблицы (представляющей класс). Ученик может входить в состав лишь одного класса.
-
Один-ко-многим (one-to-many) — такая связь описывает ситуацию, обратную предыдущей, когда в состав одного класса может входить несколько учеников.
-
Один-к-одному (one-to-one) — например, такая связь описывает взаимоотношения объекта (ученик) и (парта). У каждого ученика имеется в точности одна парта, а одна парта принадлежит лишь одному ученику.
Инструкции SQL
SQL — это язык, который позволяет удобно работать с РСУБД. SQL — это механизм взаимодействия с объектами базы данных, который позволяет воспользоваться тем, что заложено в неё на этапе её проектирования. Существуют различные подмножества команд SQL, в их состав, кроме прочих, входят следующие:
-
Язык описания данных (Data Definition Language, DDL) — это команды, которые ещё называют командами описания данных, так как они используются при описании структуры таблиц баз данных.
-
Язык управления данными (Data Manipulation Language, DML) — это команды, которые используются для управления данными в существующих таблицах путём добавления, изменения или удаления данных. В отличие от команд группы DDL, которые описывают то, как хранятся данные, DML-команды работают в уже существующих таблицах, описанных с помощью DDL-команд.
-
Язык запросов данных (Data Query Language, DQL) — эта группа состоит всего из одной команды — , которая используется для получения необходимых данных из таблиц. Эту команду иногда включают в состав команд группы DML.
-
Язык для осуществления административных функций (Data Control Language, DCL) — команды из этой группы применяются для управления пользователями, для предоставления или отмены доступа к базе данных.
-
Язык для управления транзакциями (Transaction Control Language, TCL) — это команды, используемые для изменения состояния неких данных. Например — это команда , заканчивающая текущую транзакцию с сохранением изменений в базе данных, или команда , заканчивающая текущую транзакцию с отменой изменений в базе данных.
Рассмотрим некоторые инструкции SQL, которые используются чаще всего.
UPDATE
Команда позволяет обновлять данные строк в таблицах. Здесь мы обновляем данные в строках таблицы , поле которых содержит :
Что применять для ввода команд: SVRMGR30, SQL Plus или SQL Worksheet ?
Указанные
в заголовке утилиты предназначены для ввода команд SQL (DMLи DDL),
запуска скриптов, просмотра ошибок выполнения команд и ввода других команд,
необходимых для управления БД. Следует отметить, что большинство «ручных»
действий (т.е. выполняемых фактически в режиме командной строки), можно проще,
нагляднее и быстрее осуществить в диалоговом режиме с помощью утилит пакета OracleEnterpriseManagerи других. В то же время,
наиболее «тонкое» управление БД, также как и самую исчерпывающую информацию
(находящуюся в Словаре БД, состоящим из многих групп таблиц и представлений),
можно получить только в режиме командной строки.
Ниже вкратце перечислены лишь некоторые достоинства и
недостатки описываемых утилит, что позволит гибко подойти к их выбору в
конкретной ситуации.
·SVRMGR30. Главное удобство – можно пользоваться на сервере NovellNetware. Имеется также удобная команда showparametersдля
просмотра конфигурационных параметров. Удобна для запуска больших скриптов
(например, генерации БД или запроса к большой таблице), т.к. не имеет буфера
для хранения исполненных команд. Недостатки – обычные недостатки утилит
командной строки, где все действия нужно определять вводом команд. Но это также
является мощным достоинством – эту утилиту можно использовать в командных
файлах (BATи NCF), что позволяет набор однотипных действий выполнить
одним нажатием клавиши. Впрочем, был обнаружен более существенный недостаток – выполняемый
в этой утилите скрипт ломался на комментариях более 1000 символов (в OracleSQL*Plusвсе
прошло нормально). Следовательно, и слишком длинные SQL-выражения (часто
встречающиеся в insertи update) также
не пройдут.
·OracleSQL*Plus. Главные удобства: имеется везде; можно использовать для запуска
больших скриптов (т.к. буфер ограничен); выводит после соединения версию БД. Неудобства:
никаких удобств (нельзя «ползать» по вводимой строке для ее правки; нельзя повторить
предыдущий ввод и т.д.). Еще один недостаток – при соединении нельзя указывать asdba (как в OracleSQLWorksheet) – для этого нужно явно вводить команду (как и вообще
последующие команды connect). И еще неудобство
– по умолчанию длинные строки переносятся (в отличие от OracleSQLWorksheet).
Впрочем, при определенном навыке, работа с OracleSQL*Plus перестает казаться неудобной.
·OracleSQLWorksheet.
Это наиболее удобный «командный» пульт. Имеет неограниченный буфер выполненных
команд и их результатов, имеет историю команд (Ctrl-P – ввод предыдущей комнды, Ctrl-N – ввод следующей команды), позволяет редактировать
вводимую строку. Запуск команды осуществляется кнопкой с молнией или клавишей Ctrl-Enter (в SVRMGR30 и OracleSQL*Plusнадо
было вводить «;», затем нажимать Enter).
Имеется также кнопка для соединения с БД. Утилитой можно пользоваться только на
клиенте, где установлен пакет OEM. Главный недостаток (запомните!) – нельзя
использовать для запуска больших скриптов (например, генерации Словаря БД),
т.к. при заполнении буфера происходит пропорциональное замедление обработки
следующих команд. Если Вам не повезет и в голову придет идея запустить скрипт
генерации БД (да еще без спулинга), то через несколько часов Вы все равно
снимите эту задачу, а потом потратите не известно сколько времени, чтобы
понять, что было создано, а что еще нет (и что надо удалять и заново
пересоздавать). Еще один недостаток – если скрипт большой или запрос
выполняется долго, а Вы переключились в другое окно, то, вернувшись, кроме
песочных часов можете обнаружить белый экран. В OracleSQL*Plusтакая
проблема возникает реже — Вы почти всегда видите весело бегущие строчки. Так
что — да здравствует неудобный OracleSQL*Plus. А если и он немеет – посмотрите, не «отвалилась» ли
сетка. Такое, к сожалению,
часто бывает.
Сравнение SQL и NoSQL
Сейчас мы уже можем исследовать множество различных аспектов реляционных и нереляционных подходов к хранению данных. Пришло время сравнить их по разным показателям.
Масштабирование
SQL: масштабируется вертикально. То есть — путём увеличения производительности за счёт использования более мощных серверов. SQL-БД сложнее масштабировать, чем NoSQL-БД.
NoSQL: масштабируется горизонтально. То есть — путём добавления дополнительных узлов к уже существующим, использующимся узлам. Это упрощает масштабирование — при необходимости можно быстро как повысить, так и понизить мощность системы. Это, кроме того, означает, что владелец NoSQL-БД может увеличивать её мощность практически неограниченно.
Гибкость
SQL: эти БД не дают пользователю особой гибкости. Для работы с ними сначала надо спроектировать схему базы данных. А если в систему нужно внести какие-то изменения, например — добавить к записям новое свойство/столбец, придётся добавлять этот столбец к каждой строке. Это — ресурсозатратная и длительная операция.
NoSQL: эта технология даёт гораздо больше гибкости, чем её «старший брат». Здесь нет фиксированного количества столбцов, NoSQL-БД очень легко адаптируются к новым схемам данных. Программисту, кроме того, не нужно заранее создавать схему БД. Это ускоряет подготовку к работе систем, основанных на NoSQL. Правда, использование этой технологии может вылиться в дополнительные затраты времени в том случае, если для некоего проекта понадобятся достаточно жёсткие схемы данных.
Структура данных
SQL: данные хранятся в таблицах. Каждая сущность имеет собственную таблицу, они связаны друг с другом с использованием реляционных механизмов. Отсюда и термин — «реляционная система управления базами данных».
NoSQL: данные хранятся с использованием большего количества подходов, чем при использовании SQL-БД. В частности, доступны такие способы хранения данных, как база данных типа «ключ-значение», документоориентированная база данных, колоночная база данных, графовая база данных.
Набор требований, обеспечивающий сохранность данных
SQL: эти БД следуют требованиям ACID. ACID — это сокращение от Atomicity (атомарность), Consistency (согласованность), Isolation (изолированность) и Durability (надёжность).
NoSQL: эти БД следуют требованиям теоремы CAP. CAP расшифровывается как Consistency (согласованность), Availability (доступность) и Partition Tolerance (устойчивость к разделению).
Поддержка и сообщество
SQL: так как история SQL начинается в 1970-х, вокруг этой идеологии работы с данными сложилось обширное сообщество, готовое помочь тем, у кого возникают сложности. Наработан большой опыт применения SQL в самых разных проектах. Но при этом многие диалекты SQL являются либо собственностью неких компаний, либо связаны с отдельными большими компаниями, что означает некоторую их изоляцию.
NoSQL: так как БД NoSQL гораздо моложе БД SQL, они отличаются меньшим сообществом, для которого характерна большая разобщённость из-за разных подходов, использующихся в разных NoSQL-базах данных. При этом такие БД пользуются поддержкой опенсорс-сообщества, у каждой из них есть детальное руководство, описывающее особенности её использования.




Сценарии использования
SQL: SQL-базы данных обычно предназначены для решения широкого круга задач. Они используются в достаточно старых системах, в приложениях, нуждающихся в строгом контроле данных, там, где нужно выполнять большие и сложные запросы. Такие базы данных, кроме того, часто используются в финансовом секторе, так как транзакции, проводимые в таких БД, строго соответствуют требованиям ACID.
NoSQL: NoSQL-базы данных тоже можно назвать универсальными, но они по-настоящему раскрываются в приложениях, которые работают с разными источниками данных, имеющих различную структуру. Это могут быть IoT-приложения, игры и прочее подобное. Если рассмотреть варианты использования разных типов NoSQL-БД, о которых мы говорили выше, то получится следующее:
-
Документоориентированные базы данных: широкий круг задач.
-
Базы данных типа «ключ-значение»: обработка больших объёмов данных, где применяются простые запросы на поиск данных (например — управление сессиями в крупномасштабных системах).
-
Колоночные базы данных: обработка больших объёмов данных с предсказуемыми шаблонами запросов (работа с журналами, IoT).
-
Графовые базы данных: анализ и просмотр отношений между связанными данными (обнаружение мошенничеств, рекомендательные системы).
Определение оптимальности некоторых конфигурационных параметров
·Для определения, нужно ли изменять
размер буферного кэша, введите запрос:
select NAME,
VALUE from V$SYSSTAT where NAME in
(‘CONSISTENT_GETS’,
‘DB_BLOCK GETS’, ‘PHYSICAL_READS’);
Затем вычислите коэффициентт попадания в SGAпо следующей
формуле:
HIT_RATIO =
1-(PHYSICAL READS / (DB BLOCK_GETS + CONSISTENT_GETS)
Если HIT_RATIO меньше 0.7 — увеличьте
параметр DB_BLOCK_BUFFERS
·Для определения, нужно ли изменять
размер разделяемого пула, введите запросы:
select sum(PINS)
PINS, sum(RELOADS) RELOADS from V$LIBRARYCACHE;
ЕслиPINS / RELOADSбольше 1 – увеличтепараметрSHARED_POOL_SIZE
select sum(GETS)
GETS, sum(GETMISSES) GETMISSES from V$ROWCACHE;
ЕслиGETS / GETMISSESбольше 0.1 — увеличтепараметрSHARED_POOL_SIZE
·Для определения, нужно ли изменять
размер области сортировки, введите запрос:
select NAME, VALUE from
V$SYSSTAT where NAME like ‘sort%’
Возможен
такой результат запроса:
NAMEVALUE
——————————————————
———-
sorts
(memory) 231
sorts
(disk) 0
sorts
(rows) 340
Если
sorts (disk) больше 0, значит для параметра SORT_AREA_SIZEтребуется
больше памяти
Для
параметра SORT_AREA_SIZE_RETAINEDможно
установить минимальный размер
·Для определения, имеется ли
конкуренция за журнальные файлы, введите запрос:
select
NAME,GETS,MISSES,SLEEPS,IMMEDIATE_GETS,IMMEDIATE_MISSES
from V$LATCH where NAME
in (‘REDO ALLOCATION’, ‘REDO COPY’)
Вычислитедвазначения
IMM_CONTENT=(IMMEDIATE_MISSES/(IMMEDIATE_GETS+IMMEDIATE_MISSES))
WAIT_CONTENTION=(MISSES/(GETS+MISSES))
Если
любое значение больше 1, то имеетсяся конкуренцияция за защелку.
·чтобы снизить конкуренцию за
защелку выделения журнального буфера – уменьшите параметр LOG_SMALL_ENTRY_MAX_SIZE
·чтобы снизить конкуренцию за
защелку копирования журнала – увеличьте параметр LOG_SIMULTANEOUS_COPIES
Polyglot persistence
Сказанное выше приводит к тому, что порою в рамках даже одной системы приходится для хранения данных и решения различных задач по их обработке использовать несколько различных СУБД, каждая из которых поддерживает свою модель данных. С легкой руки М. Фаулера, автора ряда известных книг и одного из соавторов Agile Manifesto, такая ситуация получила название многовариантного хранения («polyglot persistence»).
Фаулеру принадлежит и следующий пример организации хранения данных в полнофункциональном и высоконагруженном приложении в сфере электронной коммерции.
Пример этот, конечно, несколько утрированный, но некоторые соображения в пользу выбора той или иной СУБД для соответствующей цели можно найти, например, здесь.
Понятно, что быть служителем в таком зоопарке нелегко.
- Объем кода, выполняющего сохранение данных, растет пропорционально числу используемых СУБД; объем кода, синхронизирующего данные, — хорошо если не пропорционально квадрату этого числа.
- Кратно числу используемых СУБД возрастают затраты на обеспечение enterprise-характеристик (масштабируемости, отказоустойчивости, высокой доступности) каждой из используемых СУБД.
- Невозможно обеспечить enterprise-характеристики подсистемы хранения в целом — особенно транзакционность.
С точки зрения директора зоопарка все выглядит так:
- Кратное увеличение стоимости лицензий и техподдержки от производителя СУБД.
- Раздутие штата и увеличение сроков.
- Прямые финансовые потери или штрафные санкции из-за несогласованности данных.
Имеет место значительный рост совокупной стоимости владения системой (TCO). Есть ли из ситуации «многовариантного хранения» какой-то выход?
Миграция в облако
Часто возникает вопрос, как перенести БД в облако. Мы разработали сценарии миграции данных на облачную инфраструктуру с использованием технологий Microsoft Mirroring и Always On Availability Groups, Oracle Data Guard, Oracle Golden Gate, Oracle Dbvision. Миграция включает в себя:
• Анализ с выбором методов решения задачи.
• Исследование на готовность системы.
• Рекомендации по подготовки системы.
• Составление детального плана.
• Тестирование процедуры миграции.
• Актуализацию результатов.
• Тестирование перед запуском в эксплуатацию.
• Финальную миграцию.
• Сопровождение постмиграционного периода.
• Решение проблемных вопросов.
• Контроль качества на всех этапах работ.
• Учет всех требований по простою системы, методик и оформления миграционных процедур.
Сколько это стоит?
Закономерный вопрос. Давайте посчитаем. Ежемесячная стоимость сервиса формируется, исходя из конфигурации сервера и размера размещенных на нем баз данных. Активно развивая пул облачных услуг, сегодня мы предлагаем сервисы дешевле, чем зарубежные игроки, а стабильные рублевые цены гарантируют независимость от колебания курса валют. Вот примеры конфигураций сервиса.


Вариант 1. Функциональное тестирование на СУБД PostgreSQL для разработчиков конфигурации «1С: Зарплата и кадры», эксплуатируемой в сети автосервисов.
Вариант 2. Пример расчета стоимости сервиса БД MS SQL для ERP MS Axapta эксплуатируемой в сети магазинов детских игрушек.
Вариант 3. Пример расчета стоимости сервиса БД Oracle для системы поддержки туристического бизнеса используемой туристическим оператором и его агентствами.
У нас на сайте можно рассчитать стоимость услуги с помощью .
Поскольку услуга новая, то будет много акций и прочих промо. А пока для первых 10 заказчиков, заявивших, что они пришли с Хабра, мы проводим миграцию данных бесплатно.
Оптимизация запросов Oracle
Даже не пользуясь индексами или кластерами,Oracle
способен производить достаточно быстрый поиск в одной небольшой таблице. Однако,
если во фразе whereв операторе SELECTиспользуется
столбец, для которого установлен индекс или кластер, то выборка данных
производится гораздо быстрее.
1. Если во
фразах whereвстречается
много столбцов, то определение того, какой столбец или столбцы будут
“руководить” поиском в базе данных или служить отправной точкой для такого
поиска, ведется по определенной схеме. Каждое из выражений (предикатов) во
фразе where, связанных между через and, получает отдельную оценку в следующей
последовательности:
Обнаруженные некорректности
·Неточности и подводные камни в
технической документации:
·Никогда не делайте просто shutdown (как сплошь и рядом написано в документации) –
компьютер виснет надолго, а, может, и навсегда (до перезагрузки, что чревато).
Всегда указывайте конкретно, например, shutdown normalили shutdown
immediate.
·Для останова БД рекомендовано запускать
ORASTOP.NCF, а для запуска – ORASTART.NCF. Посмотрите вызываемые в них файлы STOPDB.SQLи STARTDB.SQL – и Вы не всегда будете пользоваться этими командными
файлами, либо их откорректируете:
·в останове БД выполняется immediate (хотя при отсутствии сервисов лучше делать normal);
·БД запускается как nomount (потом надо делать alterdatabaseopenлибо
«переключить светофор» в OracleInstanceManagerиз OEM).
·Хотя и декларируется, что NovellNetware 5 допускает
длинные имена файлов (и это на самом деле так), но при генерации БД имена
файлов для табличных пространств следует задавать все-таки 8-значными
(например, не INDX1ORCL.ORA, а IND1ORCL.ORA), иначе файл не будет создан.
·Неприятности с версиями Oracle:
·Если БД создана в OracleEnterpriseEdition
8.0.3. forNovellNetware 5, а на
рабочем месте установлен OracleClient
8.0.3. forNovellNetware, то Вы сможете лицезреть некорректную работу OracleODBCDriver: если
в MSAccess 97 в присоединяемой к Oracleтаблице имеются пустые поля типа даты, то
соответствующие записи могут отображаться как ошибочные (метка «Ошибка» в
каждом поле такой записи), запросы к таким таблицам выполняться не будут, а
формы, источниками строк в которых являются эти запросы, будут падать.
·Если БД создана в OracleEnterprise 8.0.3. forNovellNetware 5, а на рабочем месте установлен OracleClient 8.0.4. forNovellNetware, то
работа OracleODBCDriver исправляется, но утилиты EXP80.EXEи IMP80.EXE, а также OracleDataManagerиз
пакета OEMвыдают
при работе ошибку: Не могу выполнить экспорт/импорт с БД устаревшей версии.
·Единственная корректная версия Oracleдля NovellNetware 5 – 8.0.4. Установите
сервер и клиент именно этой версии и затем генерите БД. Не стоит создавать БД
на сервере 8.0.3, а затем делать ее upgrade, т.к.
этот процесс более трудоемкий, чем об этом написано в сопроводительной
документации (в частности, там ничего не говорится о необходимости
перекомпиляции хранимых процедур, модулей и других объектов).
·Существуют свои засады и с
версиями Oracle, серверная часть которого установлена на сервере MSWindowsNT 4.0, а клиентская – на MSWindowsNT 4.0, MSWindows
95 и MSWindows 98.
Колоночные СУБД
Колоночные СУБД очень похожи на реляционные. Они так же состоят из строк, которые имеют атрибуты, а строки группируются в таблицах. Различия в логических моделях несущественные, а вот на уровне физического хранения данных различия значительные.
В реляционных СУБД данные хранятся «построчно», это означает что для считывания значения определенной колонки, придется прочитать практически всю строку, как минимум от первой до нужной колонки. В колоночной СУБД данные хранятся «поколоночно», т.е. колонка — это как отдельная таблица. Соответственно чтение будет происходить из конкретного столбца сразу. На практике это реально работает очень быстро (проверено мной на нескольких реализованных хранилищах данных).
Основные преимущества колоночных СУБД – эффективное выполнения сложных аналитических запросов на больших объемах, и легкое, практически мгновенное, изменение структуры таблиц с данными, плюс существенная компрессия и сжатие, которое позволяет значительно экономить место.
Яркие представители колоночных СУБД — Sybase IQ (ныне SAP IQ), Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra.
Когда выбирать колоночные СУБД
Один из весомых аргументов за использование именно колоночной СУБД — это если вы хотите построить хранилище данных, и планируете делать выборки со сложными аналитическими вычислениями. Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД — это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Когда не выбирать колоночные СУБД
Учитывая специфику колоночных СУБД, будет не эффективно ее использовать, если выборки достаточно простые, параметры выборки статичны, и если преобладают выборки по ключевым значениям. Так же, если количество строк в таблице, из которой делается выборка, меньше сотен миллионов строк, то скорее всего не будет большого преимущества, по сравнению с реляционной СУБД.
Нужно так же иметь ввиду, что в колоночных СУБД могут быть и другие ограничения. Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.