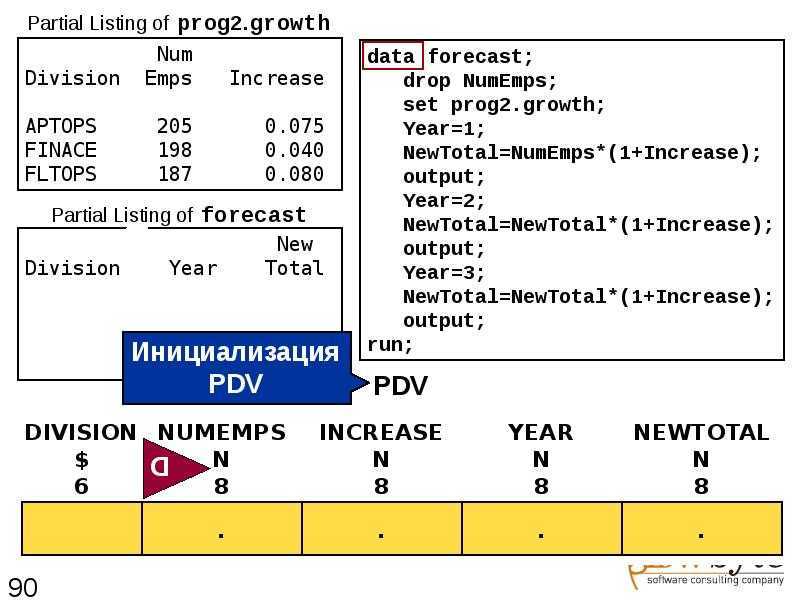
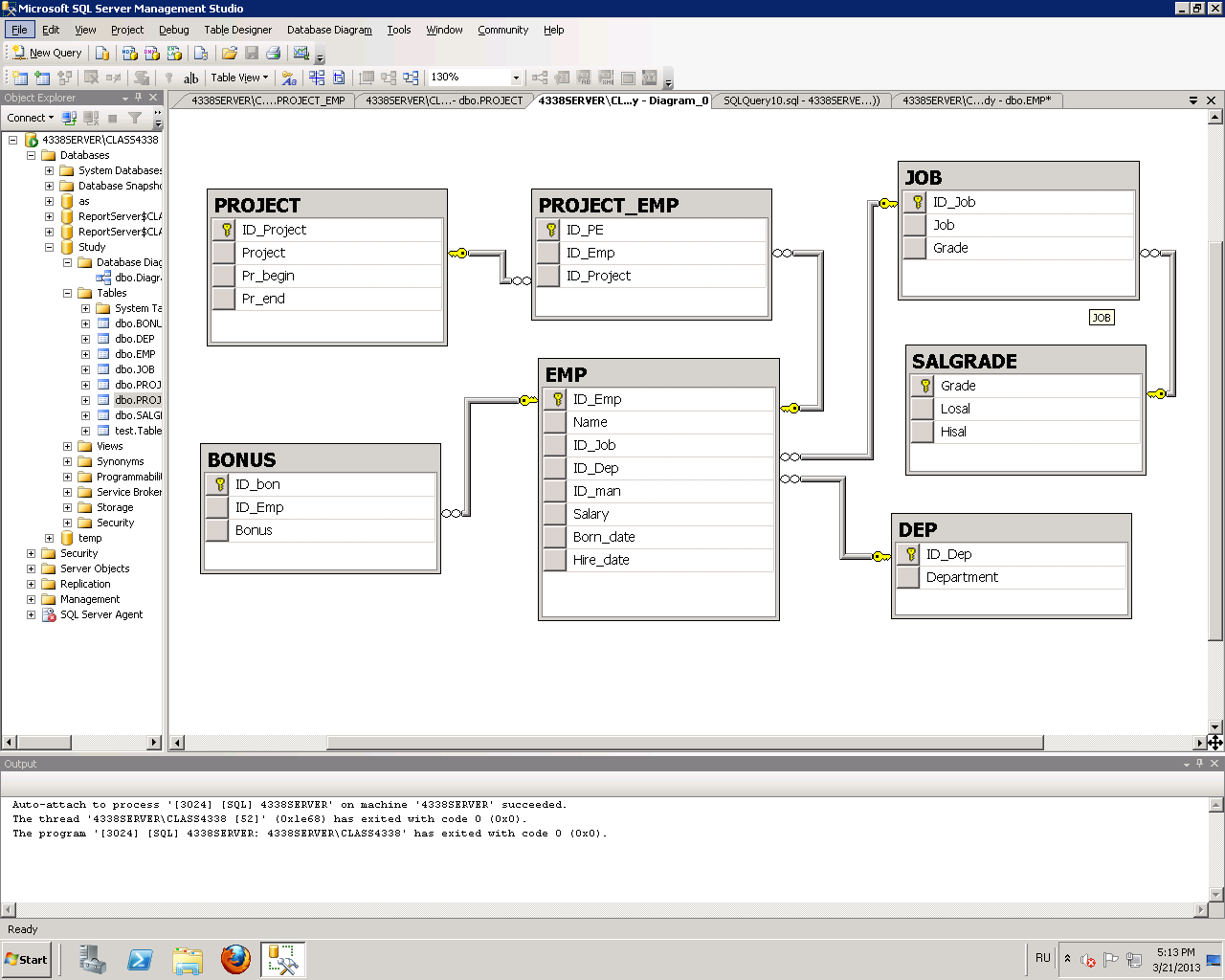
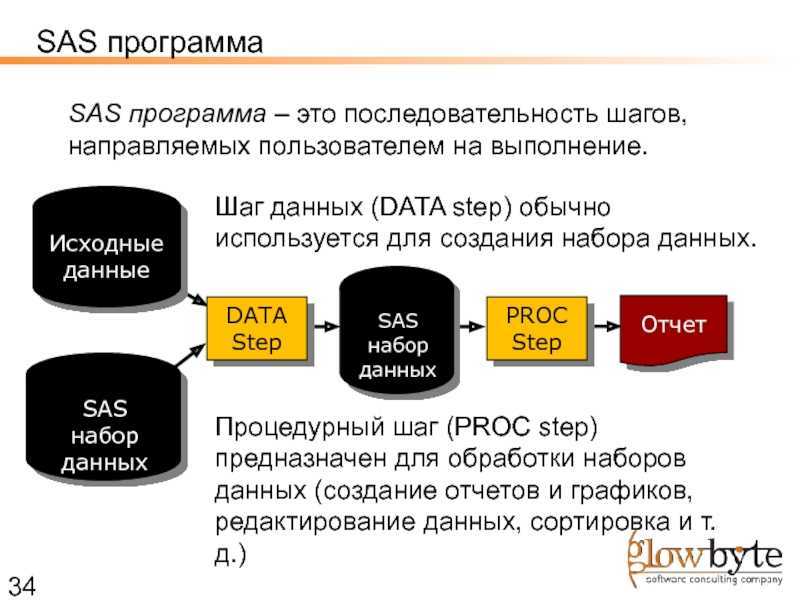
Модель ядра хранилища и корпоративная модель данных
Миф 1.На самом деле.Миф 2.На самом деле.Миф 3.На самом деле.Разработка модели данных – это не процесс изобретения и придумывания чего-то нового. Фактически, модель данных в компании уже существует. И процесс ее проектирования скорее похож на «раскопки». Модель аккуратно и тщательно извлекается на свет из «грунта» корпоративных данных и облекается в структурированную форму.Миф 4.На самом деле.Миф 5.На самом деле.Миф 6.На самом деле.
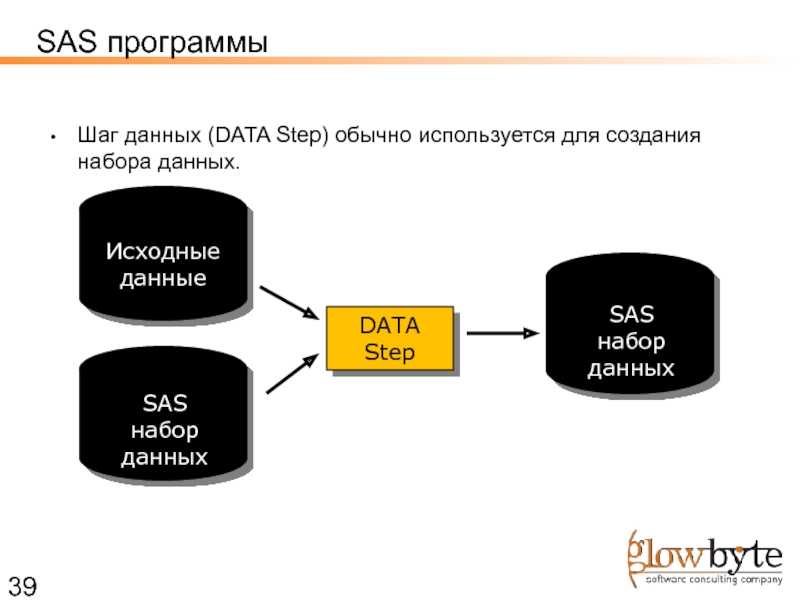
Слой первичных данных (или историзируемый staging или операционный слой)
очищаемый
- возможность ошибиться (в структурах, в алгоритмах трансформации, в гранулярности ведения истории) – имея полностью историзируемые первичные данные в зоне доступности для хранилища, мы всегда можем сделать перезагрузку наших таблиц;
- возможность подумать – мы можем не торопиться с проработкой большого фрагмента ядра именно в этой итерации развития хранилища, т.к. в нашем стейджинге в любом случае будут, причем с ровным временным горизонтом (точка «отсчета истории» будет одна);
- возможность анализа – мы сохраним даже те данные, которых уже нет в источнике – они могли там затереться, уехать в архив и т.д. – у нас же они остаются доступными для анализа;
- возможность информационного аудита – благодаря максимально подробной первичной информации мы сможем потом разбираться – как у нас работала загрузка, что мы в итоге получили такие цифры (для этого нужно еще иметь маркировку мета-атрибутами и соответствующие метаданные, по которым работает загрузка – это решается на сервисном слое).
- было бы удобно выставить требования к транзакционной целостности этого слоя, но практика показывает, что это трудно достижимо (это означает то, что в этой области мы не гарантируем ссылочную целостность родительских и дочерних таблиц) – выравнивание целостности происходит на последующих слоях;
- данный слой содержит очень большие объемы (самый объемный на хранилище — несмотря на всю избыточность аналитических структур) – и надо уметь обращаться с такими объемами – как с точки зрения загрузки, так и с точки зрения запросов (иначе можно серьезно деградировать производительность всего хранилища).
Сервисный слой
- область метаданных – используется для механизма управления загрузкой данных;
- область качества данных – для реализации офф-лайн проверок качества данных (т.е. тех, что не встроены непосредственно в ETL-процессы).
управляющий процесс
Проектирование и ведение моделей данных хранилища
проектировать«сущность-связь»многомерная модель
- задача построение концептуальной (логической) модели ядра — системный и бизнес анализ — исследование предметной области, углубление в детали и учет нюансов «живых данных» и их использования в бизнесе;
- задача построения модели анализа – и далее концептуальной (логической) модели витрин;
- задача построения физических моделей – управление избыточностью данных, оптимизация с учетом особенностей СУБД под запросы и загрузку данных.
- Модель данных – это не набор «красивых картинок», а процесс ее проектирования – это не процесс их рисования. Модель отражает наше понимание предметной области. А процесс ее составления – это процесс ее изучения и исследования. Вот на это тратится время. А вовсе не на то, чтобы «нарисовать и раскрасить».
- Модель данных – это проектный артефакт, способ обмена информацией в структурированном виде между участниками команды. Для этого она должна быть всем понятна (это обеспечивается нотацией и пояснением) и доступна (опубликована).
- Модель данных не создается единожды и замораживается, а создается и развивается в процессе развития системы. Мы сами задаем правила ее развития. И можем их менять, если видим – как сделать лучше, проще, эффективнее.
- Модель данных (физическая) позволяет консолидировать и использовать набор лучших практик, направленных на оптимизацию – т.е. использовать те приемы, которые уже сработали для данной СУБД.
.1 Средство разработки
В качестве средства разработки и развертывания проекта куба данных мною
была выбрана среда Business
Intelligence Development Studio.
SQL Server Business Intelligence Development Studio (BI Dev Studio) — инструмент, предназначенный для разработки
полноценных систем бизнес-анализа на основе Analysis Services, Reporting Services и Integration Services.
olap хранилище программный abitura
Рисунок 2.1- BI Dev Studio
BI Dev Studio интегрируется в оболочку Visual Studio, что позволяет создавать дополнительные типы проектов
для SSAS; При помощи среды BI Dev Studio можно создавать проекты служб SSAS, содержащие определения объектов
(кубов, измерений и т.д.) служб SSAS,
которые хранятся в XML-файлах,
содержащих элементы языка сценариев служб SSAS (ASSL).
Эти проекты содержатся в решениях, где также содержатся проекты из других
компонентов SQL Server, включая службы SQL Server Integration Services и SQL Server Reporting Services. В среде BI DevStudio можно разрабатывать проекты служб SSAS как часть решения, которое не
зависит от какого-либо конкретного экземпляра служб SSAS. Во время разработки объекты могут быть развернуты на
экземпляре на тестовом сервере с целью проверки, после чего этот же проект
служб SSAS может быть использован для развертывания
объектов в экземплярах на одном или нескольких промежуточных или рабочих
серверах. Средой BI DevStudio можно
также воспользоваться, чтобы напрямую подсоединиться к существующему экземпляру
служб SSAS для создания и изменения объектов
служб SSAS, без работы с проектом и без
хранения определений объекта в XML-файлах. В BI Dev Studio входит средство оповещения Best Practice Design
Alerts, автоматически информирующее о возможных недочетах в проекте на ранних
стадиях процесса разработки, и сокращающее потери времени, вызванные проектными
ошибками, что существенно ускоряет разработку.
Принцип слоеного пирога или архитектура КХД
Вышеприведенное определение DWH показывает, что это средство хранения данных является реляционным. Однако, не стоит считать КХД просто большой базой данных с множеством взаимосвязанных таблиц. В отличие от традиционной SQL-СУБД, Data Warehouse имеет сложную многоуровневую (слоеную) архитектуру, которая называется LSA – Layered Scalable Architecture. По сути, LSA реализует логическое деление структур с данными на несколько функциональных уровней. Данные копируются с уровня на уровень и трансформируются при этом, чтобы в итоге предстать в виде согласованной информации, пригодной для анализа .
Классически LSA реализуется в виде следующих уровней :
- операционный слой первичных данных(Primary Data Layer или стейджинг), на котором выполняется загрузка информации из систем-источников в исходном качестве и сохранением полной истории изменений. Здесь происходит абстрагирование следующих слоев хранилища от физического устройства источников данных, способов их сбора и методов выделения изменений.
- ядро хранилища (Core Data Layer) – центральный компонент, который выполняет консолидацию данныхиз разных источников, приводя их к единым структурам и ключам. Именно здесь происходит основная работа с качеством данных и общие трансформации, чтобы абстрагировать потребителей от особенностей логического устройства источников данных и необходимости их взаимного сопоставления. Так решается задача обеспечения целостности и качества данных.
- аналитические витрины (Data Mart Layer), где данные преобразуются к структурам, удобным для анализа и использования в BI-дэшбордах или других системах-потребителях. Когда витрины берут данные из ядра, они называются регулярными. Если же для быстрого решения локальных задач не нужна консолидация данных, витрина может брать первичные данные из операционного слоя и называется соответственно операционной. Также бывают вторичные витрины, которые используются для представления результатов сложных расчетов и нетипичных трансформаций. Таким образом, витрины обеспечивают разные представления единых данных под конкретную бизнес-специфику.
- Наконец, сервисный слой (Service Layer) обеспечивает управление всеми вышеописанными уровнями. Он не содержит бизнес-данных, но оперирует метаданными и другими структурами для работы с качеством данных, позволяя выполнять сквозной аудит данных (data lineage), использовать общие подходы к выделению дельты изменений и управления загрузкой. Также здесь доступны средства мониторинга и диагностики ошибок, что ускоряет решение проблем.
LSA — слоеная архитектура DWH: как устроено хранилище данных
Все слои, кроме сервисного, состоят из области постоянного хранения данных и модуля загрузки и трансформации. Области хранения содержат технические (буферные) таблицы для трансформации данных и целевые таблицы, к которым обращается потребитель. Для обеспечения процессов загрузки и аудита ETL-процессов данные в целевых таблицах стейджинга, ядра и витринах маркируются техническими полями (мета-атрибутами) . Еще выделяют слой виртуальных провайдеров данных и пользовательских отчетов для виртуального объединения (без хранения) данных из различных объектов. Каждый уровень может быть реализован с помощью разных технологий хранения и преобразования данных или универсальных продуктов, например, SAP NetWeaver Business Warehouse (SAP BW) .
Новые архитектуры хранилищ данных
Panoply
- Анализ запросов и данных — определение наилучшей конфигурации для каждого варианта использования, корректировка ее с течением времени и создание индексов, сортировочных ключей, дисковых ключей, типов данных, вакуумирование и разбиение.
- Идентификация запросов, которые не следуют передовым методам — например, те, которые включают вложенные циклы или неявное приведение — и переписывает их в эквивалентный запрос, требующий доли времени выполнения или ресурсов.
- Оптимизация конфигурации сервера с течением времени на основе шаблонов запросов и изучения того, какая настройка сервера работает лучше всего. Платформа плавно переключает типы серверов и измеряет итоговую производительность.
По ту сторону облачных хранилищ данных
Загрузка данных в облачные хранилища данных нетривиальна, а для крупномасштабных конвейеров данных требуется настройка, тестирование и поддержка процесса ETL
Эта часть процесса обычно выполняется сторонними инструментами;
Обновления, вставки и удаления могут быть сложными и должны выполняться осторожно, чтобы не допустить снижения производительности запросов;
С полуструктурированными данными трудно иметь дело — их необходимо нормализовать в формате реляционной базы данных, что требует автоматизации больших потоков данных;
Вложенные структуры обычно не поддерживаются в облачных хранилищах данных. Вам необходимо преобразовать вложенные таблицы в форматы, понятные хранилищу данных;
Оптимизация кластера
Существуют различные варианты настройки кластера Redshift для запуска ваших рабочих нагрузок. Различные рабочие нагрузки, наборы данных или даже различные типы запросов могут потребовать иной настройки. Для достижения оптимальной работы, необходимо постоянно пересматривать и при необходимости дополнительно настраивать конфигурацию;
Оптимизация запросов — пользовательские запросы могут не соответствовать передовым методам и, следовательно, будут выполняться намного дольше. Вы можете работать с пользователями или автоматизированными клиентскими приложениями для оптимизации запросов, чтобы хранилище данных могло работать так, как ожидалось
Резервное копирование и восстановление — несмотря на то, что поставщики хранилищ данных предоставляют множество возможностей для резервного копирования ваших данных, их нетривиально настроить и они требуют мониторинга и пристального внимания
Ссылка на оригинальный текст: panoply.io/data-warehouse-guide/data-warehouse-architecture-traditional-vs-cloud
SDS
Software-defined storage — программно определяемое хранилище данных, основанное на DAS, при котором дисковые подсистемы нескольких серверов логически объединяются между собой в кластер, который дает своим клиентам доступ к общему дисковому пространству.
Наиболее яркими представителями являются GlusterFS и Ceph, но также подобные вещи можно сделать и традиционными средствами (например на основе LVM2, программной реализации iSCSI и NFS).
Пример SDS на основе GlusterFS
Из преимуществ SDS — можно построить отказоустойчивую производительную реплицируемую систему хранения данных с использованием обычного, возможно даже устаревшего оборудования. Если убрать зависимость от основной сети, то есть добавить выделенные сетевые карты для работы SDS, то получается решение с преимуществами больших SAN\NAS, но без присущих им недостатков. Я считаю, что за подобными системами — будущее, особенно с учетом того, что быстрая сетевая инфраструктура более универсальная (ее можно использовать и для других целей), а также дешевеет гораздо быстрее, чем специализированное оборудование для построения SAN. Недостатком можно назвать увеличение сложности по сравнению с обычным NAS, а также излишней перегруженностью (нужно больше оборудования) в условиях малых систем хранения данных.
Где хранить корпоративные данные: краткий ликбез по Data Warehouse
Потребность в КХД сформировалась примерно в 90-х годах прошлого века, когда в секторе enterprise стали активно использоваться разные информационные системы для учета множества бизнес-показателей. Каждое такое приложение успешно решало задачу автоматизации локального производственного процесса, например, выполнение бухгалтерских расчетов, проведение транзакций, HR-аналитика и т.д.
При этом схемы представления (модели) справочных и транзакционных данных в одной системе могут кардинально отличаться от другой, что влечет расхождение информации. Частично этот вопрос Data Governance мы затрагивали в контексте управления НСИ. Кроме того, большое разнообразие моделей данных затрудняет получение консолидированной отчетности, когда нужна целостная картина из всех прикладных систем. Поэтому возникли корпоративные хранилища данных (Data Warehouse, DWH) – предметно-ориентированные базы данных для консолидированной подготовки отчётов, интегрированного бизнес-анализа и оптимального принятия управленческих решений на основе полной информационной картины .
Чем понравилась Impala
- Высокая скорость выполнения аналитических запросов за счет альтернативного подхода по отношению к MapReduce. Промежуточные результаты вычислений не скидываются в HDFS, что существенно ускоряет обработку данных.
- Эффективная работа с поколоночным хранением данных в Parquet. Для аналитических задач часто используются так называемые широкие таблицы с множеством колонок. Все колонки используются редко — возможность поднимать из HDFS только нужные для работы позволяет экономить оперативную память и значительно ускорять запрос.
- Изящное решение с runtime-фильтрами, включающими bloom-фильтрацию. И Hive, и Impala существенно ограничены в использовании индексов, обычных для классических СУБД — из-за особенностей файловой системы хранения HDFS. Поэтому для оптимизации исполнения SQL-запроса движок СУБД должен эффективно воспользоваться доступным партиционированием даже когда оно не задано явно в условиях запроса. Кроме того, ему нужно попытаться предсказать, какое минимальное количество данных из HDFS нужно поднять для гарантированной обработки всех строк. В Impala это работает очень хорошо.
- Impala использует LLVM – компилятор на виртуальной машине с RISC-подобными инструкциями – для генерации оптимального кода выполнения SQL-запроса.
- Поддерживаются ODBC и JDBC интерфейсы. Это позволяет почти из коробки интегрировать данные Impala с аналитическими инструментами и приложениями.
- Есть возможность использования Kudu – чтобы обойти часть ограничений HDFS, и, в частности, писать конструкции UPDATE и DELETE в SQL-запросах.
Архитектура корпоративного хранилища данных
конвейер данных
- Слой «сырых» данных (источников данных)
- Хранилище и её экосистему
- Интерфейс пользователя (инструменты аналитики)
ETL
Одноуровневая архитектура
одноуровневую архитектуру
Слой отчётности соединён напрямую со всей базой данных EDW
- Традиционно считается, что накопитель становится хранилищем, начиная со 100 ГБ данных. Если работать с ними напрямую, это может привести к неаккуратным результатам запросов, а также низкой скорости обработки.
- Для запросов данных непосредственно из хранилища могут потребоваться чёткие формулировки, чтобы система могла отфильтровывать их от нерелевантных данных. Это усложняет работу с инструментами представления.
- Имеются ограниченные возможности обеспечения гибкости и аналитики.
Двухуровневая архитектура (архитектура витрин данных)
двухуровневой архитектуревитрин данных
В двухуровневой архитектуре EDW дополняется витринами данных, предоставляющими данные, относящиеся к конкретной предметной области
Трёхуровневая архитектура (аналитическая онлайн-обработка)
аналитической онлайн-обработки (OLAP)
Слой OLAP-кубов может получать информацию из распределённых витрин или напрямую из EDW
OLAP-куб, демонстрирующий многомерные данные продажoreilly.comдокументацию Microsoft
Облака и эфемерные хранилища
Логическим продолжением перехода на виртуализацию является запуск сервисов в облаках. В предельном случае сервисы разбиваются на функции, запускаемые по требованию (бессерверные вычисления, serverless)
Важной особенностью тут является отсутствие состояния, то есть сервисы запускаются по требованию и потенциально могут быть запущены столько экземпляров приложения, сколько требуется для текущей нагрузки. Большинство поставщиков (GCP, Azure, Amazon и прочие) облачных решений предлагают также и доступ к хранилищам, включая файловые и блочные, а также объектные
Некоторые предлагают дополнительно облачные базы, так что приложение, рассчитанное на запуск в таком облаке, легко может работать с подобными системами хранения данных. Для того, чтобы все работало, достаточно оплатить вовремя эти услуги, для небольших приложений поставщики вообще предлагают бесплатное использование ресурсов в течение некоторого срока, либо вообще навсегда.








Из недостатков: могут заблокировать аккаунт, на котором все работает, что может привести к простоям в работе. Также могут быть проблемы со связностью и\или доступностью таких сервисов по сети, поскольку такие хранилища полностью зависят от корректной и правильной работы глобальной сети.
Элементы КХД
- средства ETL-извлечения, преобразования и загрузки данных в центральное хранилище данных (ЦХД);
- ЦХД, предназначенное и оптимизированное для надежного и защищенного хранения данных;
- витрины данных, обеспечивающие эффективный доступ пользователей к данным, которые хранятся в структурах, оптимальных для решения конкретных задач пользователей. ЦХД включает в себя прежде всего три репозитория:
- репозиторий нормативно-справочной информации (НСИ);
- репозиторий данных;
- репозиторий метаданных.
Необходимость в репозитории данных стала бесспорной после ряда неудачных попыток создать виртуальные ХД. В этой архитектуре клиентская программа напрямую получала данные из источников, преобразуя их на лету. Время ожидания исполнения запроса и преобразования данных компенсировалось простотой архитектуры. Поскольку результат выполнения запроса не сохранялся, повторный запрос с теми же или подобными параметрами требовал повторного преобразования данных, что и привело к отказу от виртуальных хранилищ и к созданию репозиториев данных.
В репозиторий метаданных автоматически включаются словари источников данных. Здесь же хранятся форматы данных для их последующего согласования, периодичность пополнения данных, согласованность во времени.
Хранилище данных
Хранилище данных – очень большая предметно-ориентированная информационная корпоративная БД, специально разработанная и предназначенная для подготовки отчетов, анализа бизнес-процессов с целью поддержки принятия решений в организации.
Корпоративное хранилище данных (КХД) преобразует данные, метаданные и НСИ из разнородных источников и предоставляет их пользователям аналитических систем как единую версию правды. КХД строится на базе клиент-серверной архитектуры, реляционной СУБД и утилит поддержки принятия решений.
СУБД – это программная система, поддерживающая и управляющая логической базой или базами данных. СУБД для ХД, помимо поддержки реляционной модели данных (расширенной для поддержки новых структур и типов данных, таких как XML), обеспечивают доступ к информации со стороны независимых приложений, а также включают механизмы выявления требований к нагрузке и контроля различных параметров доступа пользователей к отдельной сущности данных.
Data Lake и корпоративное хранилище данных: как работать с Big Data
В 2010-х годах, с наступлением эпохи Big Data, фокус внимания от традиционных DWH сместился озерам данных (Data Lake). Однако, считать озеро данных новым поколением КХД не совсем корректно по следующим причинам:
разное целевое назначение – DWH используется менеджерами, аналитиками и другими конечными бизнес-пользователями, тогда как озеро данных – в основном Data Scientist’ами. Напомним, в Data Lake хранится неструктурированная, т.н. сырая информация: видеозаписи с беспилотников и камер наружного наблюдения, транспортная телеметрия, графические изображения, логи пользовательского поведения, метрики сайтов и информационных систем, а также прочие данные с разными форматами хранения (схемами представления). Они пока непригодны для ежедневной аналитики в BI-системах, но могут использоваться Data Scientist’ами для быстрой отработки новых бизнес-гипотез с помощью алгоритмов машинного обучения ;
разные подходы к проектированию. Дизайн DWH основан на реляционной логике работы с данными – третья нормальная форма для нормализованных хранилищ, схемы звезды или снежинки для хранилищ с измерениями
При проектировании озера данных архитектор Big Data и Data Engineer большее внимание уделяют ETL-процессам с учетом многообразия источников и приемников разноформатной информации. А вопрос ее непосредственного хранения решается достаточно просто – требуется лишь масштабируемая, отказоустойчивая и относительно дешевая файловая система, например, HDFS или Amazon S3 ;
наконец, цена – обычно Data Lake строится на базе бюджетных серверов с Apache Hadoop, без дорогостоящих лицензий и мощного оборудования, в отличие от больших затрат на проектирование и покупку специализированных платформ класса Data Warehouse, таких как SAP, Oracle, Teradata и пр.
Таким образом, озеро данных существенно отличается от КХД. Тем не менее, архитектурный подход LSA может использоваться и при построении Data Lake. Например, именно такая слоенная структура была принята за основу озера данных в Тинькоф-банке :
- на уровне RAW хранятся сырые данные различных форматов (tsv, csv, xml, syslog, json и т.д.);
- на операционном уровне (ODD, Operational Data Definition) сырые данные преобразуются в приближенный к реляционному формат;
- на уровне детализации (DDS, Detail Data Store) собирается консолидированная модель детальных данных;
- наконец, уровень MART выполняет роль прикладных витрин данных для бизнес-пользователей и моделей машинного обучения.
В данном примере для структурированных запросов к большим данным используется Apache Hive – популярное средство класса SQL-on-Hadoop. Само файловое хранилище организовано в кластере Hadoop на основе коммерческого дистрибутива от Cloudera (CDH). Традиционное DWH банка реализовано на массивно-параллельной СУБД Greenplum . От себя добавим, что альтернативой Apache Hive могла выступить Cloudera Impala, которая также, как Greenplum, Arenadata DB и Teradata, основана на массивно-параллельной архитектуре. Впрочем, выбор Hive обоснован, если требовалась высокая отказоустойчивость и большая пропускная способность. Подробнее о сходствах и различиях Apache Hive и Cloudera Impala мы рассказывали здесь. Возвращаясь к кейсу Тинькофф-банка, отметим, что BI-инструменты считывают данные из озера и классического DWH, обогащая типичные OLAP-отчеты информацией из хранилища Big Data. Это используется для анализа интересов, прогнозирования поведения, а также выявления текущих и будущих потребностей, которые возникают у посетителей сайта банка .
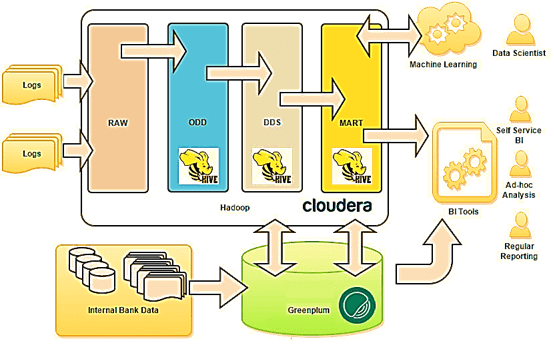
LSA-архитектура корпоративного Data Lake в Тинькоф-банке
В следующей статье мы продолжим разговор про архитектурные особенности современных DWH с учетом потребности работы с Big Data и рассмотрим еще несколько примеров таких гибридных подходов. А технические подробности реализации КХД и другие актуальные вопросы управления бизнес-данными вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Модели Данных
- Hadoop для инженеров данных
- Cloudera Impala Data Analytics
- Hadoop SQL администратор Hive
Смотреть расписание
Записаться на курс
Источники
- https://ru.wikipedia.org/wiki/Хранилище_данных
- https://habr.com/ru/post/269727/
- https://habr.com/ru/post/281553/
- https://habr.com/ru/post/495670/
- https://chernobrovov.ru/articles/kuda-slit-big-data-ili-zachem-vam-ozero-dannyh.html
- https://habr.com/ru/company/tinkoff/blog/259173/