Виртуоз
Virtuoso Universal Server — это безопасный, кроссплатформенный и высокопроизводительный сервер данных, который уникальным образом обеспечивает доступ к данным, интеграцию данных, мультимодальное управление данными и услуги развертывания приложений HTTP. Virtuoso является мультимодельной СУБД и поддерживает графические СУБД, СУБД Native XML, реляционные СУБД и модели хранения RDF.
Virtuoso, первоначально запущенная в 1998 году OpenLink Software, написана на языке C и представляет собой базу данных с открытым исходным кодом и поддерживает .NET, C, C #, C ++, Java, JavaScript, Perl, PHP, Python, Ruby и Visual Basic.
Ключевые особенности Virtuoso:
- Безопасность на основе политик обеспечивается компилятором Virtuoso SQL путем вставки дополнительных условий в операторы, в зависимости от того, какой пользователь готовит оператор. Таблицы или представления сами по себе могут быть доступны для чтения большой группе пользователей, но разделение на части достигается за счет автоматического добавления дополнительных условий в базу данных.
- Протокол двухфазной фиксации (2PC) может использоваться для гарантии свойств ACID распределенных транзакций, которые изменяют данные в нескольких базах данных.
- Способность выводить отношения (типы отношений сущности) в различных формах.
- HTTP-совместимый сервер приложений
- Поддержка отраслевого стандарта языка запросов SPARQL
- Virtuoso предоставляет ресурсы дескрипторов для каждого объекта (объекта данных) в собственном или виртуальном четырехъядерном хранилище и поддерживает широкий спектр форматов вывода, включая HTML + RDFa, RDF / XML, N3 / Turtle, N-Triples, RDF-JSON, OData + Атом и OData + JSON.
- Язык мета-схемы Virtuoso позволяет создавать связанные представления данных (или семантические покрытия) на основе RDF для источников данных SQL, XML, SOA и REST.
- Наборы данных RDF управляются выделенным модулем в ядре ORDBMS Virtuoso. Эта функциональность предоставляется клиентским приложениям посредством реализации языка запросов SPARQL и протокола, а также набора API-интерфейсов на основе веб-служб и Virtuoso / PL для создания, обновления и удаления наборов данных RDF.
- Virtuoso Sponger является компонентом связующего программного обеспечения Virtuoso. Он генерирует связанные данные (в форме RDF) из различных источников данных и поддерживает широкий спектр форматов представления и сериализации данных.
- Связанные представления данных через внешние источники данных и собственные источники данных SQL
- Virtuoso — это средство хостинга во время выполнения для логики приложений веб-служб, написанное на PHP, Java, .NET, Python, Perl, Ruby и многих других популярных средах веб-сценариев.
- Поддержка языка запросов SPARQL соответствует стандарту W3C SPARQL 1.1, обеспечивая совместимость с другими SPARQL-совместимыми инструментами, будь то домашние или сторонние.
- Поддерживаемые стандарты доступа к данным включают ODBC, JDBC, ADO.NET, OLE DB и XMLA.
- WebDAV-совместимый контент-менеджер
- Virtuoso — это средство хостинга во время выполнения для логики приложений веб-служб, написанное на PHP, Java, .NET, Python, Perl, Ruby и многих других популярных средах веб-сценариев.
- Virtuoso может преобразовывать веб-сервисы в связанные данные RDF на fly.ax
АллегроГраф
AllegroGraph, разработанный компанией Franz Inc в 2004 году, является высокопроизводительным, устойчивым хранилищем RDF с дополнительной поддержкой СУБД Graph. Он реализует модели данных документов, графиков и хранилищ RDF. AllegroGraph поддерживает языки C #, Clojure, Java, Lisp, Perl, Python, Ruby и Scala.
Возможности AllegroGraph включают в себя:
- AllegroGraph на 100% ACID, поддерживает транзакции: фиксация, откат и контрольные точки.
- Полное и быстрое восстановление
- 100% -ный параллелизм чтения, почти полный параллелизм записи
- Оперативное резервное копирование, восстановление на определенный момент времени, репликация, теплый резерв
- Динамическая и автоматическая индексация — все зафиксированные тройки всегда индексируются (7 индексов)
- Расширенная текстовая индексация — текстовая индексация по предикату
- СОЛР и интеграция с MongoDB
- Поддержка SPIN (Нотация SPARQL). API SPIN позволяет вам определять функцию в терминах запроса SPARQL, а затем вызывать эту функцию в других запросах SPARQL. Эти функции SPIN могут появляться в FILTER, а также могут использоваться для вычисления значений в присваивании и выбора выражений.
- Все клиенты на основе протокола REST — клиенты Java Sesame, Java Jena, Python, Clojure, Perl, Ruby, Scala и Lisp
- Полностью мультипроцессорная (SMP) — автоматическое управление ресурсами для всех процессоров и дисков и оптимизированное использование памяти. Смотрите руководство по настройке производительности здесь и руководство по настройке сервера здесь
- Сжатие индексов на основе столбцов — сокращение подкачки, лучшая производительность
- Трехуровневая безопасность с фильтрами безопасности
- AllegroGraph, размещенный в облаке — Amazon EC2
- Сервер AllegroGraph RDF может быть написан с помощью JavaScript API
- Основанный на JavaScript интерфейс (JIG) для общего обхода графа
- Поддержка Soundex — позволяет свободно индексировать текст на основе фонетического произношения
- Пользовательские индексы — полностью контролируются системным администратором
- Клиент-сервер GRUFF с графическим построителем запросов
- Плагин интерфейса для текстовых индексаторов (используйте SOLR / Lucene, полнотекстовый индексатор Native AG, японский токенизатор)
- Выделенные и открытые сеансы. В выделенных сеансах пользователи могут работать со своими собственными наборами правил для одной и той же базы данных.
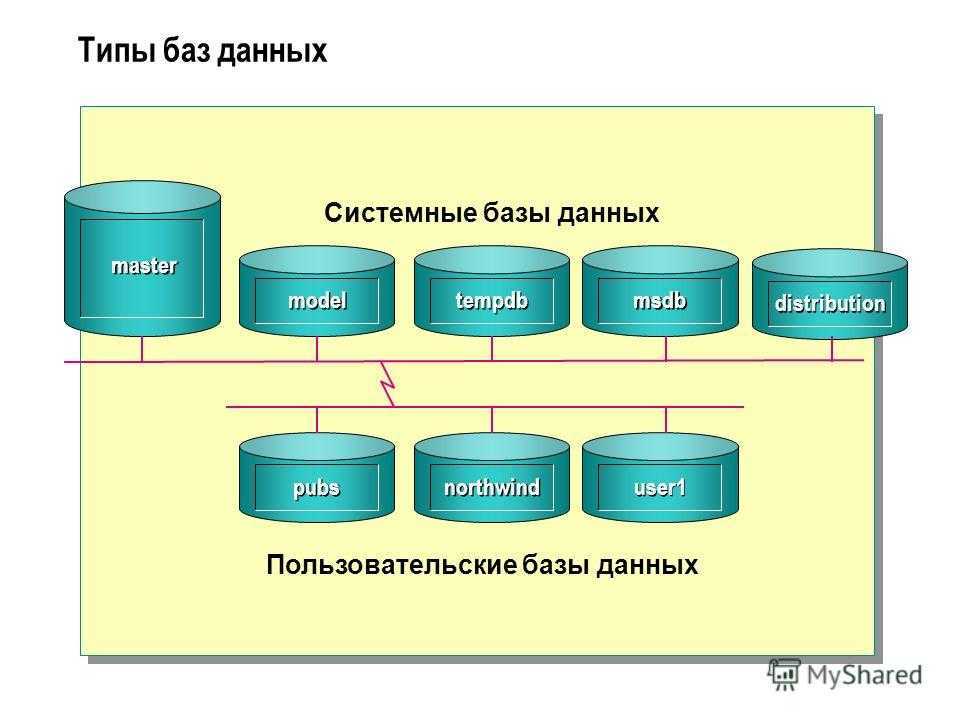
СУБД
Для управления базами данных используется специальные программные утилиты, получившие название систем управления базами данных (СУБД). Базы данных и СУБД часто путают, называя «базами данных» и то, и другое. Поэтому нелишне еще раз отметить:
База данных (БД) – это собственно данные в удобном для их хранения и обработки формате;
Система управления базами данных (СУБД) – это программа, которая умеет, с одной стороны, получать от пользователя или пользовательского приложения запросы на добавление, поиск и модификацию данных, с другой стороны, по запросам пользователя эти данные в базах искать, добавлять, извлекать, удалять, модифицировать.
Одна СУБД может управлять несколькими базами данных, и можно сказать, что у каждой СУБД свой формат баз данных.
Функциями СУБД являются также создание индексов, поддержка транзакций, обеспечение целостности данных, резервное копирование и восстановление, защита от сбоев и пр.
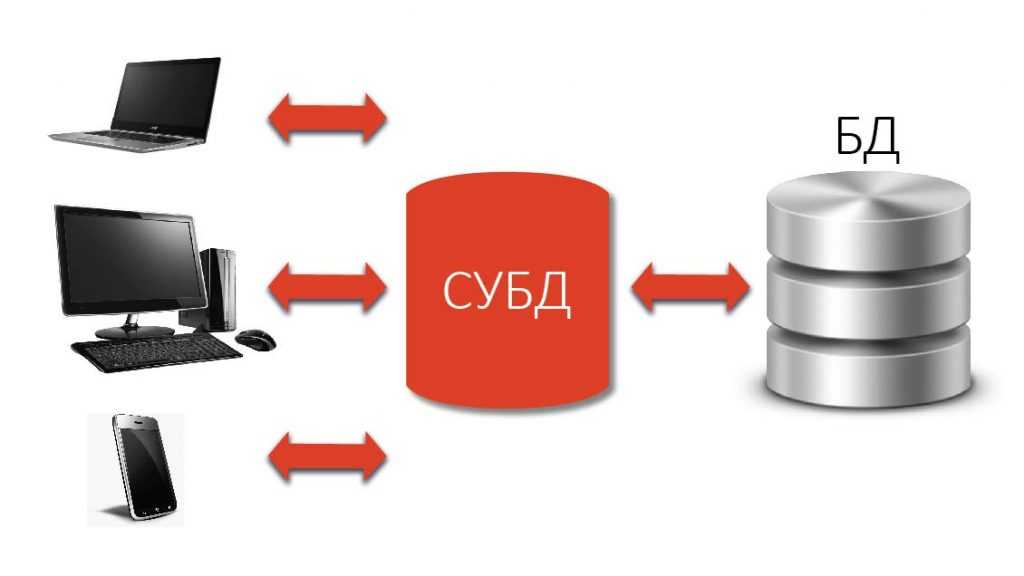
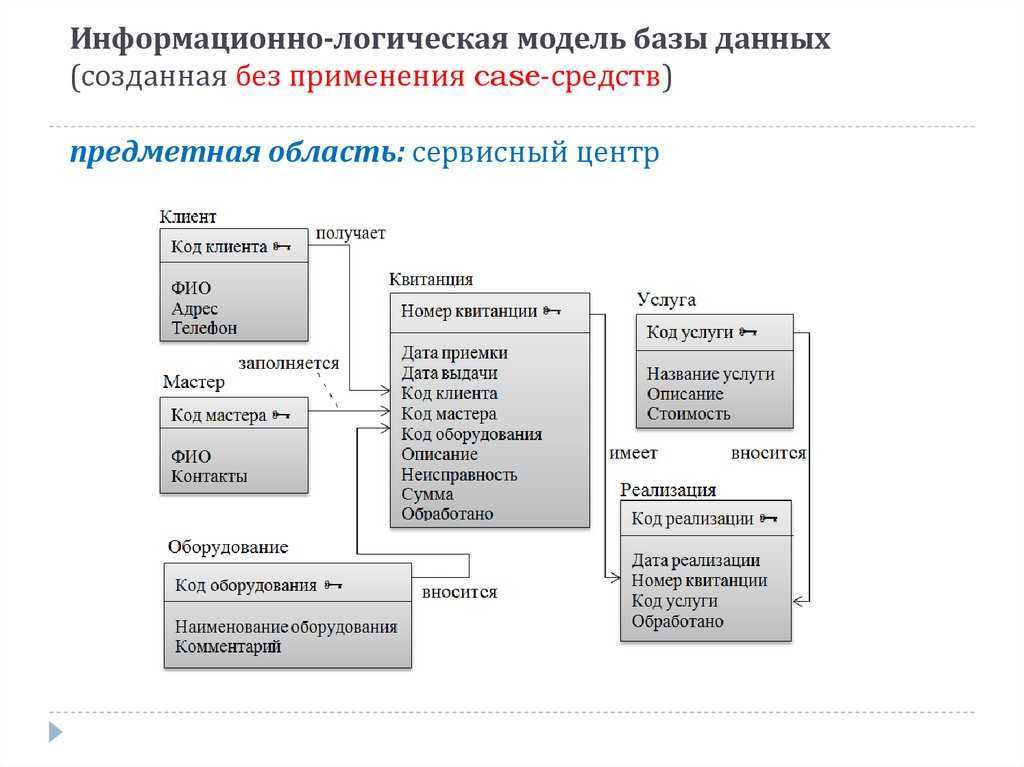
Как видно из рисунка, любая база данных управляется СУБД, доступна через СУБД, и только через СУБД. То есть, база данных и СУБД – это единый организм, одно без другого не существует.
Какие инструменты используются для графовой аналитики?
Если говорить о языках программирования, то для многих популярных из них уже созданы необходимые библиотеки для работы с графами. Например, для Java — это JGraph и JGraphT, Python — NetworkX и Plolty, С++ — Boost Graph Library.
В распространённом фреймворке Apache Spark для распределённой обработки неструктурированных и слабоструктурированных данных также имеется собственный компонент для работы с графами — GraphX.
Самой распространённой графовой СУБД считается Neo4j. Также используются для работы базы данных MongoDB, Amazon Neptune, ArangoDB, JanusGraph и другие проекты.
Поуровневое расположение вершин графа.
Поуровневое расположение вершин необходимо для исключения ошибок расположения вершин по вертикали, например, чтобы вершина-приемник не была выше вершины-источника.
Пример расположения:
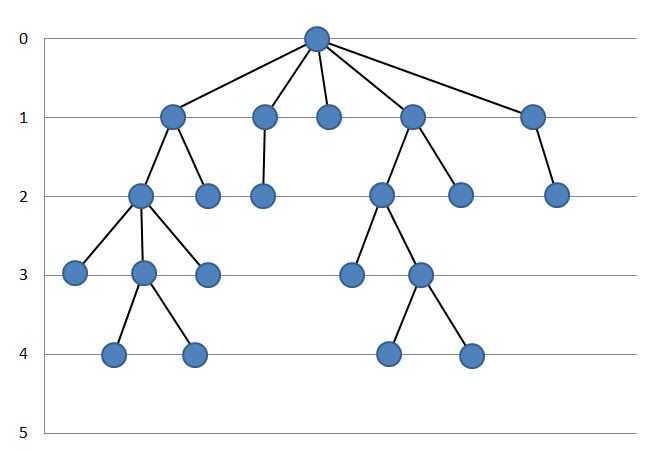
Граф надо расположить по уровням таким образом, чтобы:
1. Вершины-источники были выше чем вершины-приемники.
2. Ребро должно быть не длиннее одного уровня. Достигается это с помощью добавления фиктивных вершин.
3. Опционально: могут быть условия на предельную ширину/высоту и т.д. В данном материале дополнительные условия не рассматриваем. Ниже будут ссылки с более подробной информацией.
Если изобразить визуально.
Исходный граф:
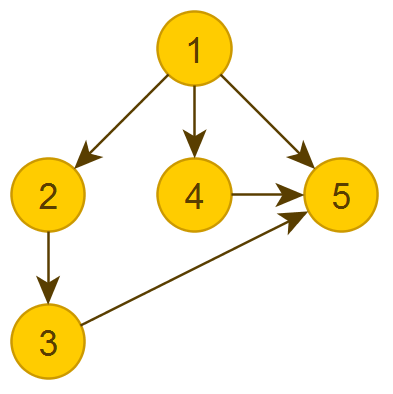
Граф, разбитый по уровням. Слева с фиктивными вершинами, справа — результат:
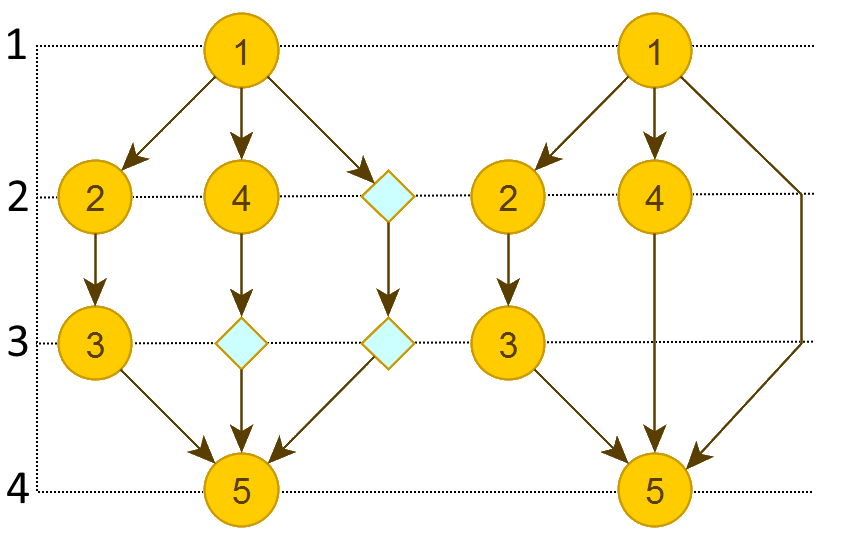
Алгоритм состоит из двух частей: проход от стоков (вершин без исходящих ребер) и проход от вершин-источников. Зачем проходить два раза? Потому что ширина при разных проходах может различаться. Оптимальнее выбирать наименьшую ширину.
Начнем с прохода от стоков.
2.1. Берем вершины, которые не имеют исходящих ребер (конечные точки). Располагаем на исходном уровне.
2.2. Берем вершины, которые входят в эту вершину с одним ребром (без альтернативных путей).
2.3. Повторяем п.2 n-раз пока не обойдем все вершины.
2.4. Достраиваем ребра длиннее одного уровня, через фиктивные вершины.
Исходный граф:
Гифка прохода от стоков:

Проход в обратную сторону по тому же алгоритму, только начинается от вершин-источников.

Дальше выбирается минимальная ширина графа: минимальное количество вершин на одном уровне. В нашем случае ширина одинаковая, поэтому берем любой из вариантов.




Я взял вариант с пересечениями, чтобы продемонстрировать следующий шаг.
Бум онлайн-образования и потребность в гибридной экспертизе
Это связано как с мировой экономической рецессией, так и с волатильностью рынков и торговыми войнами. Специалисты должны уметь быстро адаптироваться к новым условиям рынка, особенно в отраслях, где стремительно внедряются новые технологии.
Быстрое развитие рынка EdTech и обилие образовательного контента требует от профессионалов иного подхода к системе работы с информацией — нужны новые инструменты для быстрой навигации по базе знаний, поиска и обмена данными. Для компаний же задача состоит в том, чтобы сохранить накопленный опыт и эффективно передать его новым сотрудникам.
Кредитный риск
Сложная инфекцияэто явление, при котором для воздействия на поведение человека требуется несколько источников воздействия. Инвестирование — это выявление отношений, а выявление рисков — это всесложное заражение,
Существует экспоненциально растущее количество возможных связей (как прямых, так и косвенных), влияющих на данную компанию, отрасль, рынок или экономику. Графики знаний, являющиеся фактическими графами, в собственном математическом смысле позволяют применять методы, основанные на логических выводах. В этом смысле некоторые из наиболее важных случаев использования графов знаний относятся к рассуждению и «выводу отношений» — по сути, для установления связей между иногда разрозненными событиями или информацией, которые иначе не были бы связаны. Это позволяет количественно оценить подверженность риску в пределахсложное заражениефреймворк.
Одним из примеров применения является Yewno | Edge, новая финансовая платформа AI Yewno, которая количественно определяет подверженность портфеля сложным концепциям, будь то упущенная прибыль Apple, опасения по поводу торговой войны, замедление экономического роста в Китае, вы можете увидеть, как практически любой фактор влияет на ваш портфель. Используя Yewno | Edge, вы можете легко определить, какие компании, темы и события влияют на ваш портфель, отслеживая отношения компаний и воздействие идей, а не только ключевые слова.
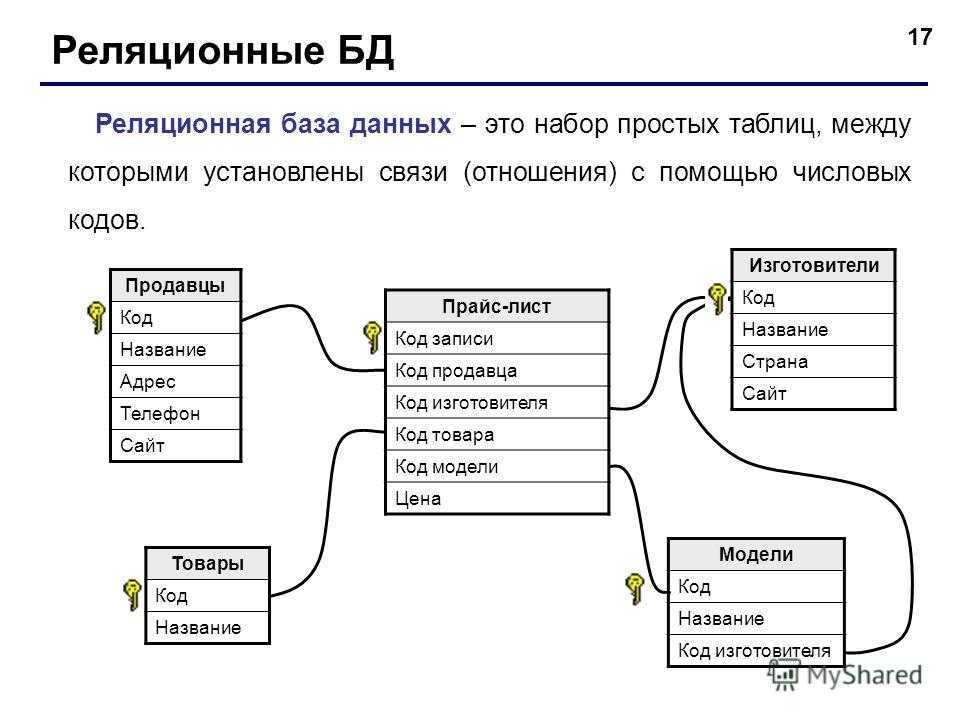
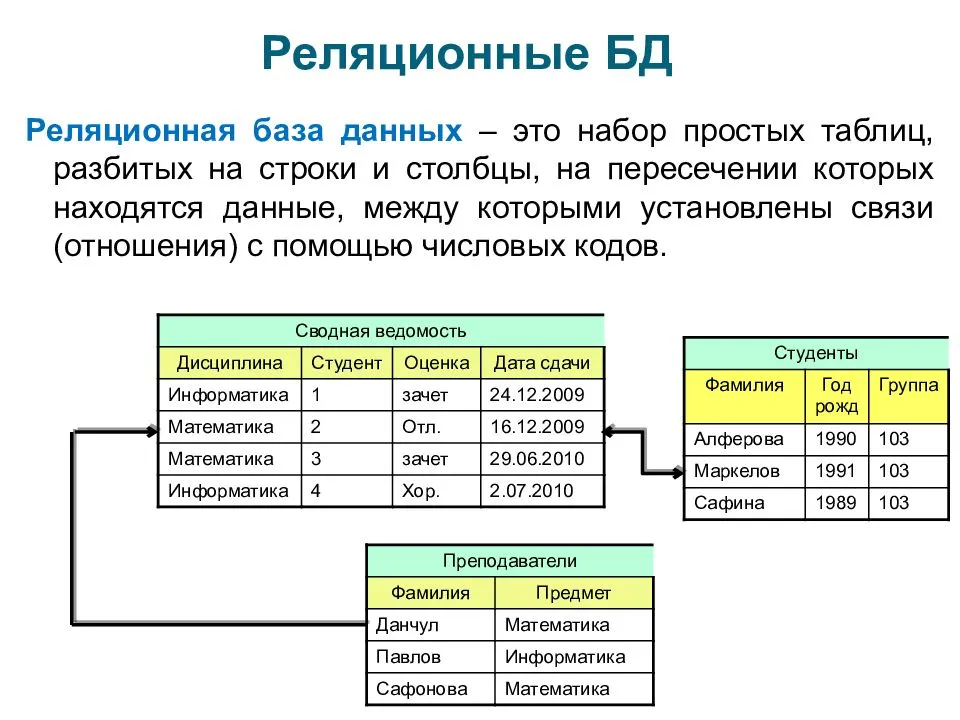
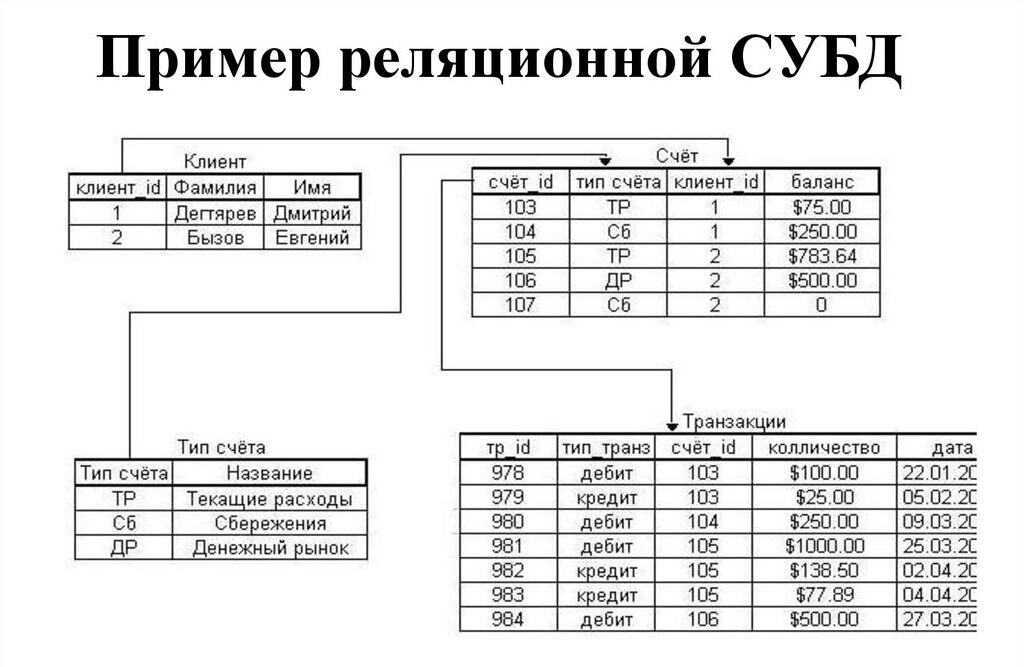
Реляционная модель
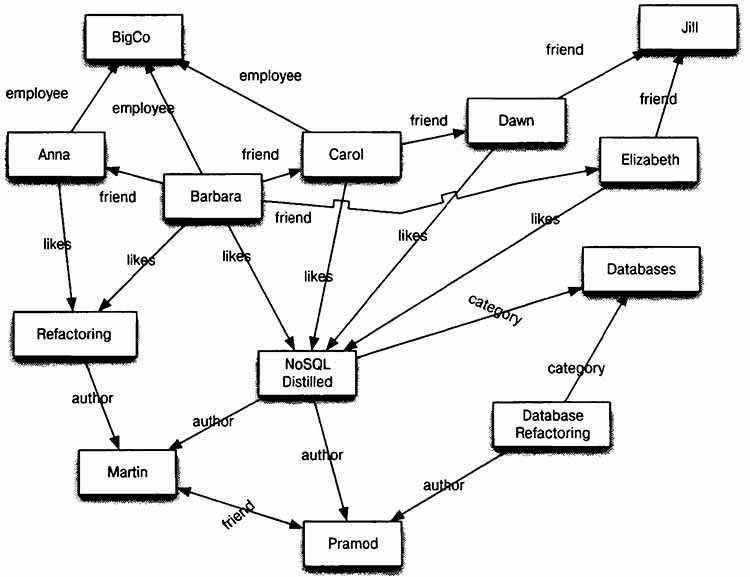
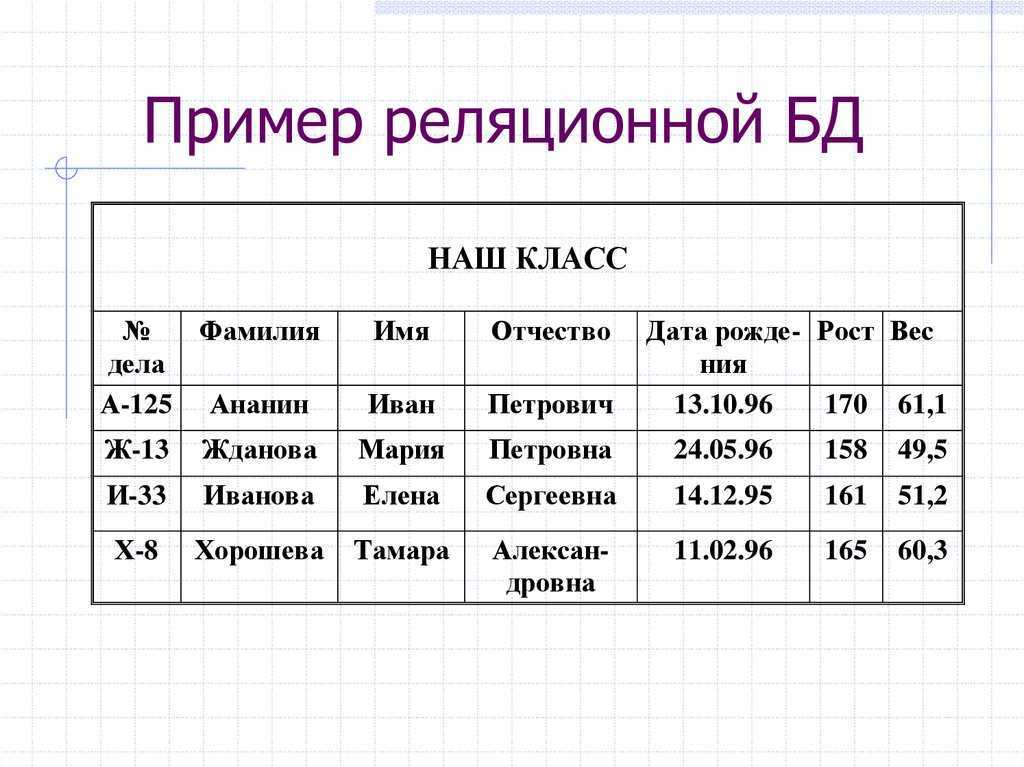
В числе первых моделей данных, описанных выше, отсутствует самая, возможно, простая и базовая модель, возникшая даже раньше других, но долго не имевшая общепринятого названия. Иногда ее называли линейной, иногда табличной. Суть ее заключается в простом последовательном расположении сведений об объектах. Например, на рисунке ниже каждая строка представляет собой запись сведений об одном объекте, и эти записи расположены последовательно (линейно).
Такую модель можно рассматривать как вырожденную иерархическую или сетевую. Однако именно она впоследствии развилась в ставшую широко известной реляционную модель Кодда. В начале 70-х Эдгар Кодд строго описал реляционную модель на основе разработанных им реляционной алгебры и реляционного исчисления.
Реляционная модель быстро завоевала популярность и стала использоваться повсеместно, отчасти в связи с тем, что в то время большая часть данных была слабо связанной и для большинства приложений было достаточно отдельных таблиц.
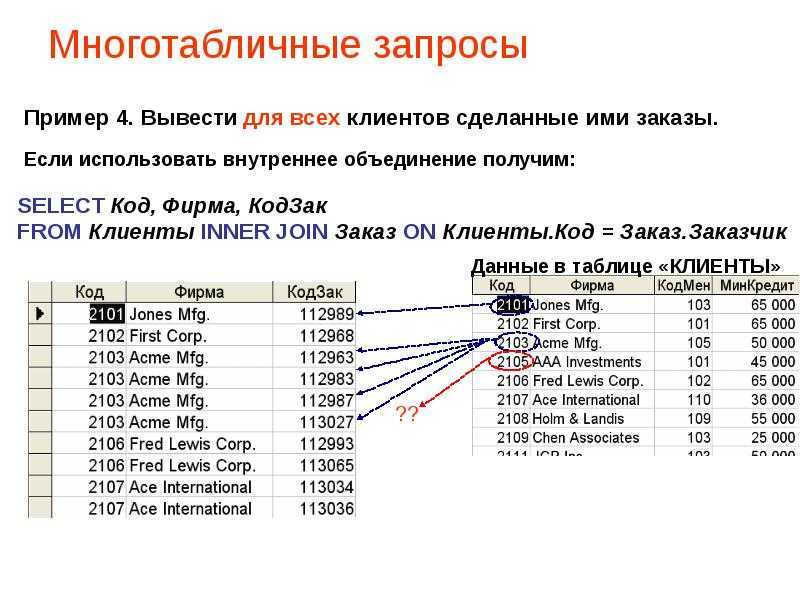
Однако иногда необходимо было связывать данные. В рамках реляционной модели это делалось довольно неудобным способом, и, что хуже, поиск по таким связям (операции соединения таблиц, JOIN), был очень медленным.
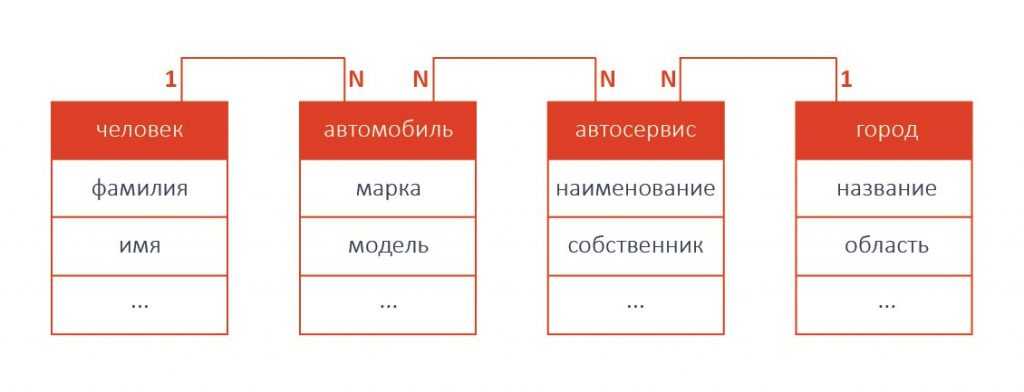
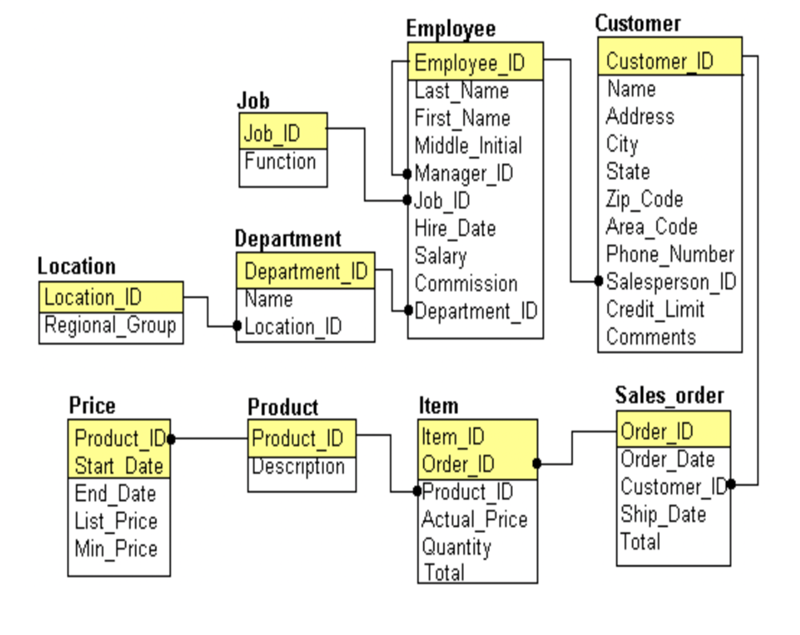
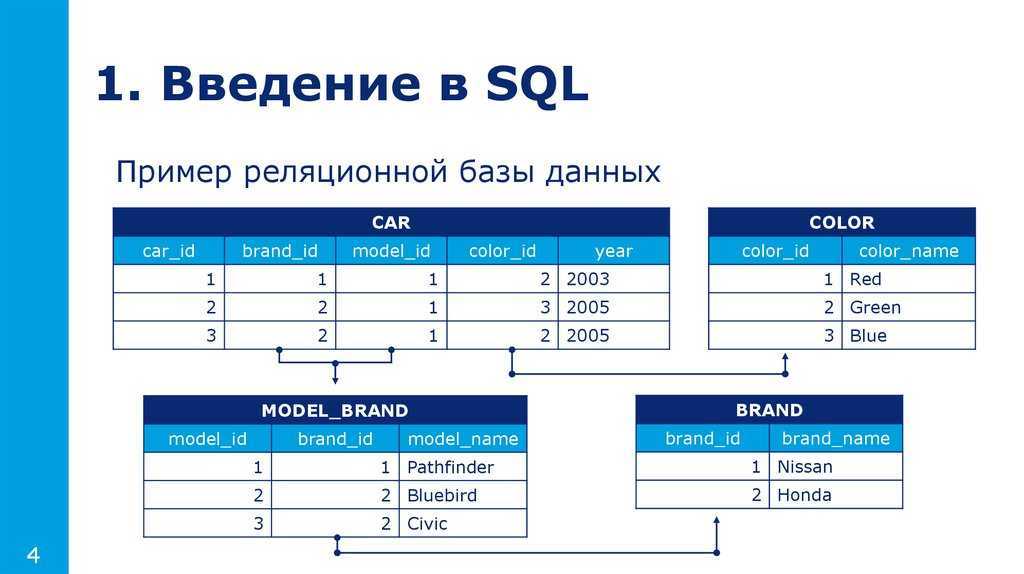
Производительность деградировала тем быстрее, чем больше соединяемых таблиц было задействовано в одном запросе. Например, если из базы данных, схема которой представлена на рисунке выше, требуется получить информацию о всех людях, имеющих автомобиль марки Toyota (одна операция JOIN), поиск будет достаточно быстрым. Однако если требуется получить информацию о всех людях, имеющих автомобили марки Toyota, ремонтировавшиеся в фирменных автосервисах, находящихся в определенном городе (четыре операции JOIN), скорость поиска будет намного ниже.
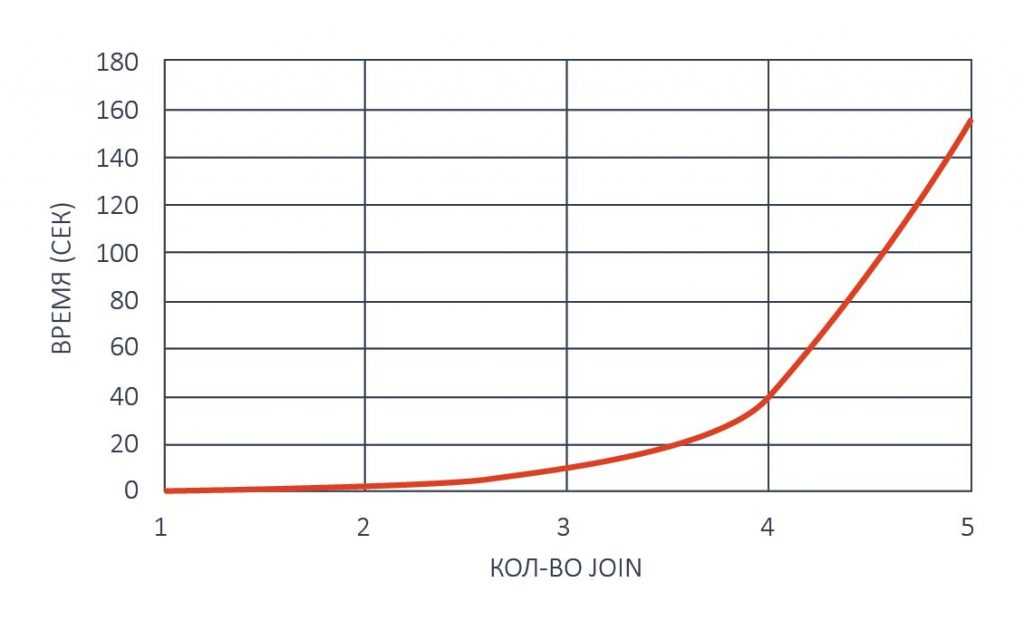
На рисунке выше видно, что рост времени поиска данных в реляционных базах данных в зависимости от количества операций JOIN может быть экспоненциальным.
Поскольку в эпоху становления реляционных баз данных «связей» было по сравнению с нынешним временем, немного, соответственно, выполнять запросы, требующие соединения таблиц, приходилось относительно нечасто, постольку неудобства работы с сильно связанными данными в рамках реляционной модели были проигнорированы.
Стандартизация реляционной модели, SQL
Большим достижением создателей реляционной модели явилась её стандартизация.
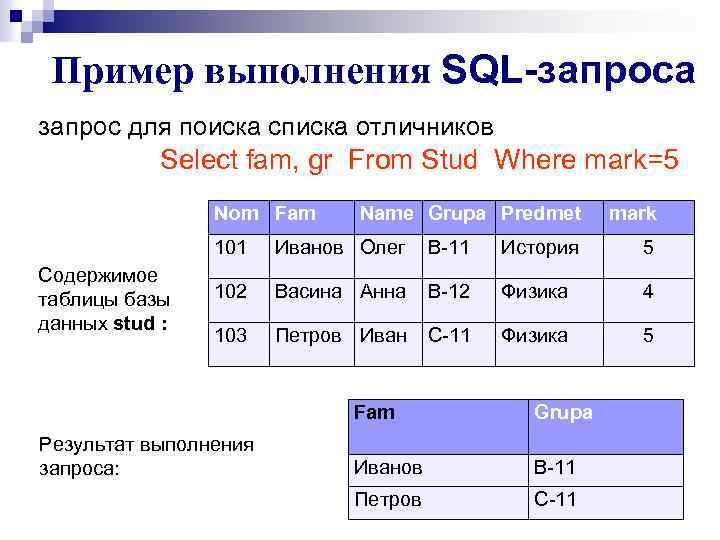
Были стандартизованы основные понятия и терминология, был разработан мощный язык запросов – Structured Query Language (SQL), на котором можно было выразить практически любое действие над базой данных. Поэтому реляционные СУБД часто называют SQL СУБД.
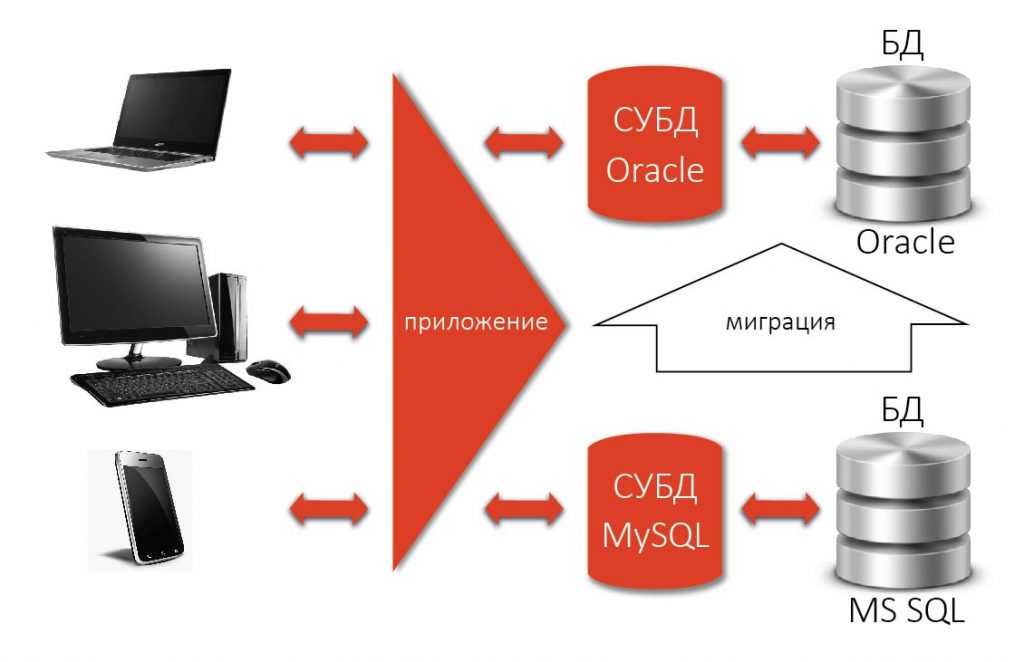
Стандартизация позволила в идеале безболезненно переходить (мигрировать) с одной реляционной СУБД на другую, не меняя разработанного приложения. На практике, конечно, такая миграция никогда не проходит гладко, но в целом это было большим шагом вперед по сравнению с практически полной несовместимостью существовавших тогда нереляционных СУБД.
По-видимому, именно эта стандартизованность явилась основным конкурентным преимущество реляционных СУБД. Для сравнения, объектным СУБД, развивавшимся в то же время, и обладавшим рядом архитектурных преимуществ, но так и оставшимся проприетарными в части, например, языков запросов, так и не удалось занять сколь-нибудь значительную долю рынка.
Knowledge management: как управлять своими знаниями
Google больше не помогает
Чем больше источников информации в интернете, тем больше растет спрос на агрегаторы контента. Раньше в этом помогал Google, но сейчас поиск профессиональных знаний с помощью сервиса стал малоэффективен.
Причины — существенный рост объема информации и SEO-оптимизации, а также SEO-атаки с генерацией фейковых страниц, которые ощутимо влияют на ранжирование источников.
Google создавался как инструмент для индексации веб-страниц, и до сих пор отлично справляется с этой миссией. Но эффективная навигация в потоке контента требует другого подхода.
Может быть, сервисы закладок?
Проблему навигации частично могут решить сервисы, позволяющие оставлять закладки на веб-страницах, к которым человек планирует вернуться. Этот перспективный рынок только формируется, однако, тут уже появилось несколько заметных игроков.
Heyday
Спустя два месяца после запуска Hints привлек инвестиции в размере $835 тыс.
Метод Zettelkasten и Mind Maps
Heptabase
Но каждый из этих проектов сосредоточен только на личных заметках. Современный инструмент управления знаниями должен иметь семантический слой, автоматически извлекающий сущности и контекст, создающий связи между заметками и обогащающий их информацией из открытых источников.
Это сделает исследование новой информации, навигацию и систему хранения существующих знаний более эффективными.
Граф знаний как инструмент организации информации
Граф знаний — это база знаний, где хранится информация о сущностях и взаимосвязях между ними. Сущностью или «узлом» могут быть люди, реальные объекты или концепции — все что угодно.
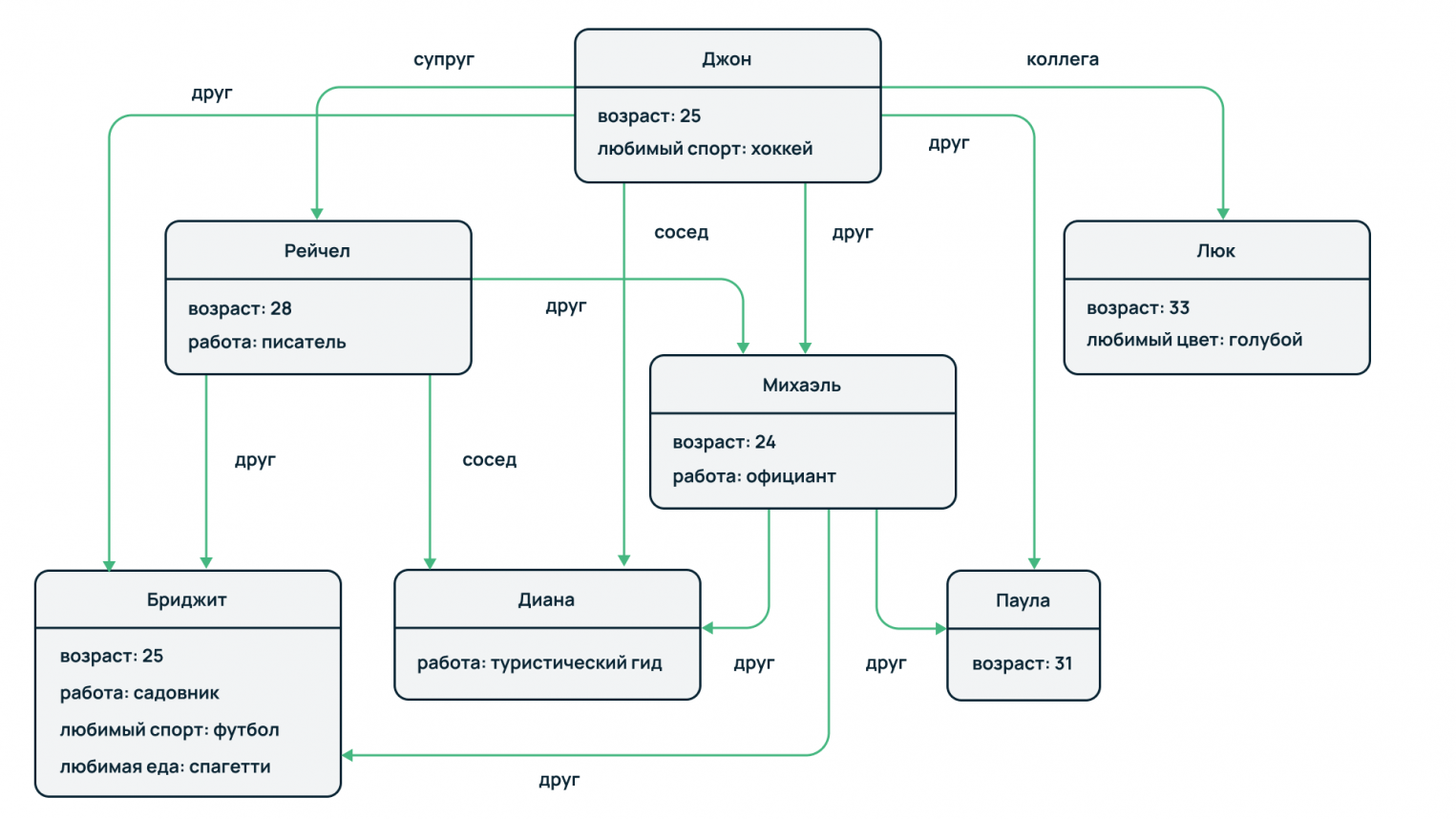
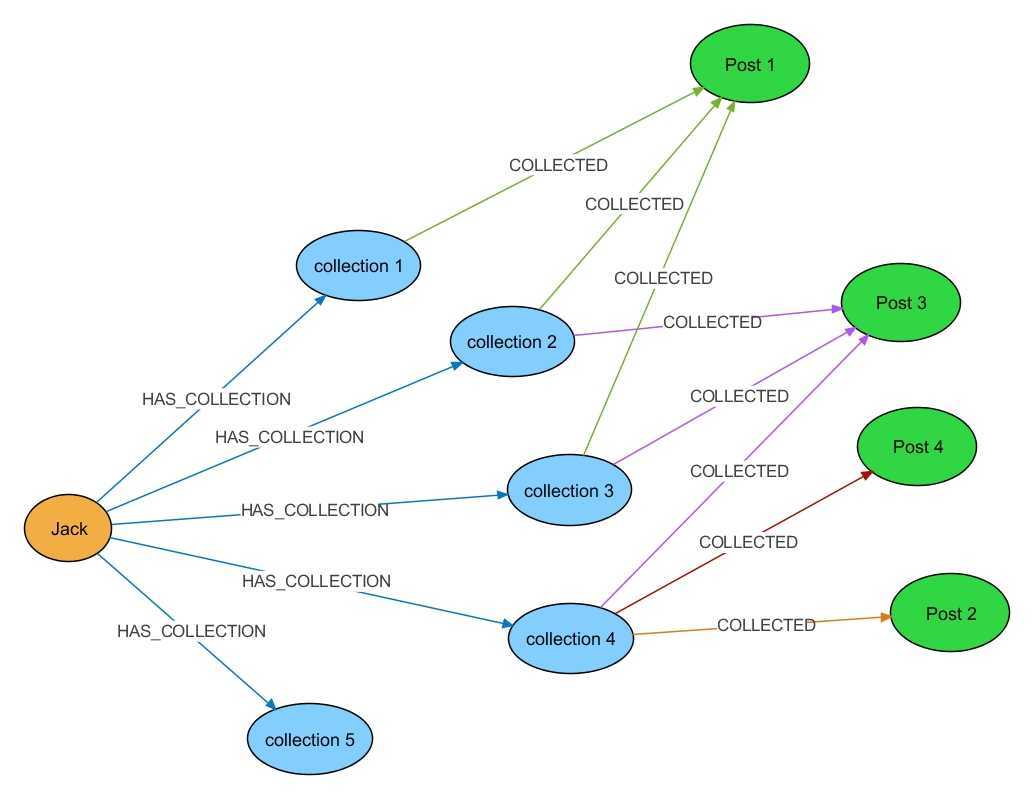

Например, когда вы набираете в Google «Квентин Тарантино»:
- вам говорят, что это кинорежиссер;
- дадут информацию о его карьере и наградах, а ниже будут фильмы, которые он режиссировал.
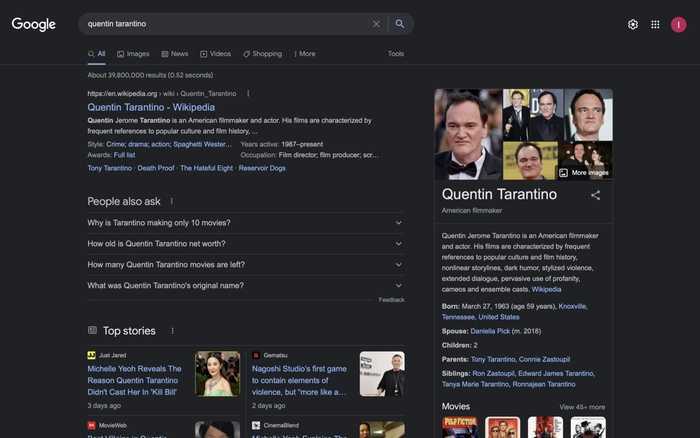
Это пример извлечения некоторой структурированной информации о сущности Квентина Тарантино из графа знаний.
Golden
предварительная работа
Схема, которая определяет граф знания музыки, выглядит следующим образом:
Мы использовали скрипт Python для генерации 1000 троек карт музыкальных знаний:
импорт данных:
- Импорт с использованием TDB Команда для использования инструмента tdbloader:
- Импорт с помощью Fuseki
Запустите сервис Fuseki: После импорта данных мы можем использовать интерфейс для запроса наших данных, поэтому мы используем Fuseki Server для запроса, команда запуска выглядит следующим образом, обратите внимание, что вам нужно указать путь к файлу и имя базы данных, сгенерированное TDB :
Метод запроса к базе данных:
- Запрос интерфейса Fuseki
- Используйте интерфейс конечной точки для запроса, адрес конечной точки: SPARQL Query: http://localhost:3030/music/query SPARQL Update: http://localhost:3030/music/update
- Используйте пакет SPARQLWrapper для запроса и обновления (подробности см.https://rdflib.github.io/sparqlwrapper/)
Автоматическое построение онтологий для ГЗ
Традиционным подходом к разработке онтологий, который развивался в конце 1990-х — начале 2000-х, является предположение, что основным источником знаний выступает эксперт — специалист в предметной области. Очевидно, что при таком подходе становятся актуальными и проблематичными множество аспектов, в том числе этические, психологические, лингвистические и гносеологические. В реалиях цифровой экономики технологические процессы порождают гигантские объемы информации, что делает привлечение человека как непосредственного источника знаний неэффективным. Гораздо разумнее и быстрее извлекать знания непосредственно из существующих структурированных и неструктурированных (текстовых) источников производственных данных с помощью различных интеллектуальных алгоритмов, включая методы машинного обучения и нейронные сети. А роль человека-эксперта в данной ситуации заключается в проектировании концептуальных верхнеуровневых абстракций, таких как описанные выше примеры онтологий, обеспечение надежных способов доступа к данным (некоторые данные могут потребовать специальных процедур обработки, например анонимизации), разметка данных (для использования методов искусственного интеллекта) и валидация полученных результатов. Данный автоматизированный подход получил название «обучение онтологий» (ontology learning).
В работе предлагается рассматривать обучение онтологий на основе слабоструктурированных данных как некоторую последовательность согласованных действий по извлечению из данных и сборке отдельных элементов онтологий. На рис. 4 изображено визуальное представление данного подхода, получившего название «слоеный пирог обучения онтологий» .
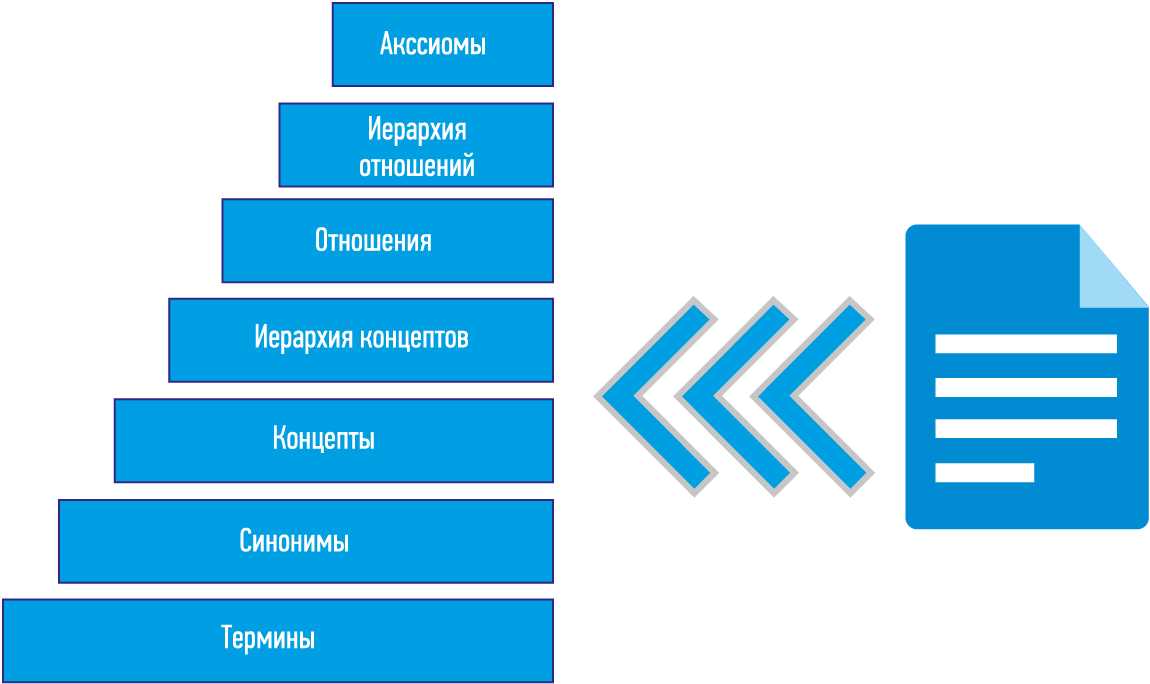
Рис. 4. Слоеный пирог обучения онтологий
Первым шагом является извлечение из текста основных терминов. Далее, при помощи определения синонимов множество терминов преобразовывается во множество концептов. Затем концепты структурируются для формирования иерархии концептов. Потом выявляются взаимосвязи между концептами, и определяется иерархия связей. А на заключительном этапе формируется схема аксиом и общие аксиомы онтологии.
Описанный подход позволяет создавать онтологии фактически с нуля, однако такая возможность появилась совсем недавно благодаря развитию методов анализа текста и новых методов машинного обучения, обеспечивающих выполнение качественного извлечения концептов и взаимосвязей между ними. Более ранние исследования предполагали, что сначала эксперты разрабатывают некоторую базовую версию онтологии, опираясь на которую можно производить извлечение знаний из слабоструктурированных данных и текстов на естественном языке.
Наиболее современные методы обучения онтологий и сопутствующие вспомогательные методы искусственного интеллекта могут быть сведены в единый стек, представленный на рис. 5.
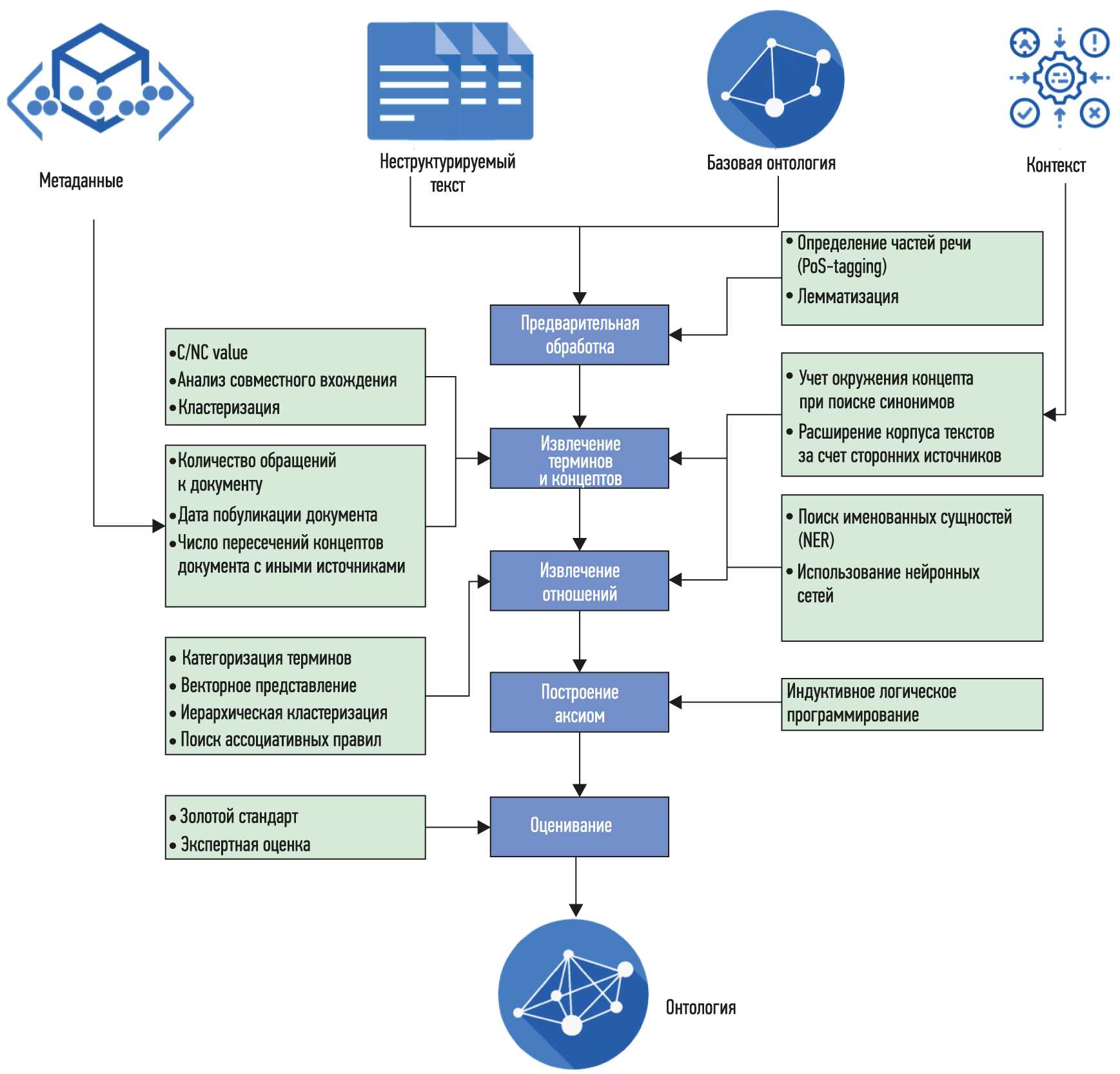
Рис. 5. Стек методов обучения онтологий
Графовый анализ
Графовый (также сетевой) анализ — это набор методов, направленных на изучение связей между сущностями. При помощи этих методов исследуется структура графа и выявляются неочевидные зависимости.
Извлекать из графов полезную информацию позволяют графовые алгоритмы, которые можно условно поделить на несколько семейств. Рассмотрим эти семейства на примере социальной сети:
Обнаружение сообществ (community detection) — это выделение тесно связанных между собой групп людей (к примеру, через большое количество общих связей). При этом совсем не обязательно, чтобы все участники взаимодействовали друг с другом напрямую. Это семейство алгоритмов является своего рода аналогом кластеризации.
Алгоритмы центральности (centrality algorithms) поможет выявить лидеров мнений и влиятельных людей в сообществах. Под центральностью мы подразумеваем некоторую меру значимости вершины или ребра.Алгоритмы центральности и сообществ можно применять для создания новых предикторов в ML-pipeline.
Предсказание связей (link prediction) оценивает вероятность наличия связи между двумя отдельными людьми в том случае, если её не существует на графе. Связи, подобранные таким образом, могут помочь в рекомендации друзей.
-
Алгоритмы сходства (similarity algorithms) пригодятся, чтобы найти похожие группы людей. Это может быть полезно, чтобы собрать аудиторию для рекламы по принципу lookalike или выявить поддельные учетные записи, основываясь на свойствах их окружения.
-
Поиск путей (path detection) окажется полезен для того, чтобы найти кратчайшую цепочку знакомств между людьми. В качестве меры расстояния (весов ребер) можно использовать характеристики взаимодействия пользователей — например, частоту их общения.
Takeaway: Графовый анализ эффективен, когда мы рассматриваем объекты в контексте связей с другими объектами.
Работа с графами
Взаимодействие с графами отличается от взаимодействия с привычными таблицами. Для этого существуют специальные программные решения, которые перечислим ниже.
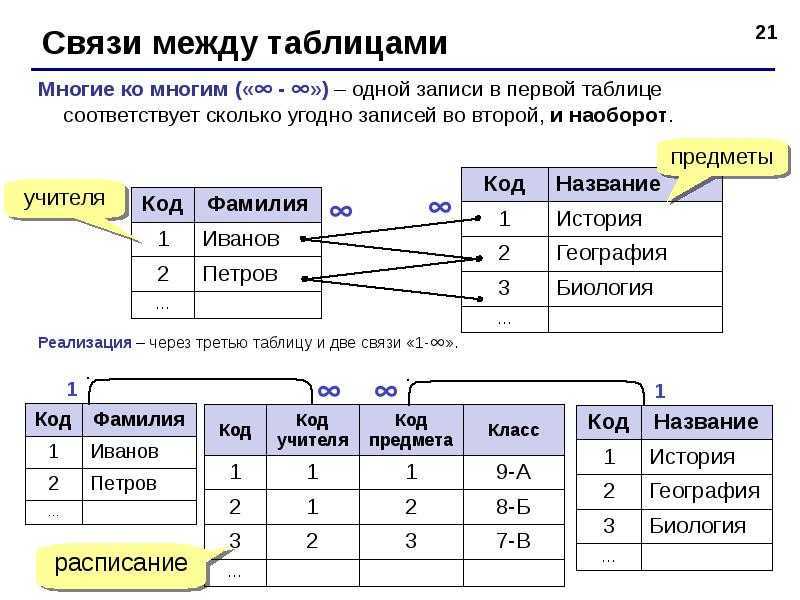
Графовые базы данных
Графовые базы данных традиционно относят к NoSQL-категории. Рассмотрим их особенности:
-
По сравнению с реляционными и документарными БД, графовые базы позволяют создавать гибкую структуру, в которую можно вносить любые изменения, не ломая её общую архитектуру.
-
Для общения с графовыми СУБД существуют отдельные языки запросов, например, Cypher (Neo4j) и SPARQL.
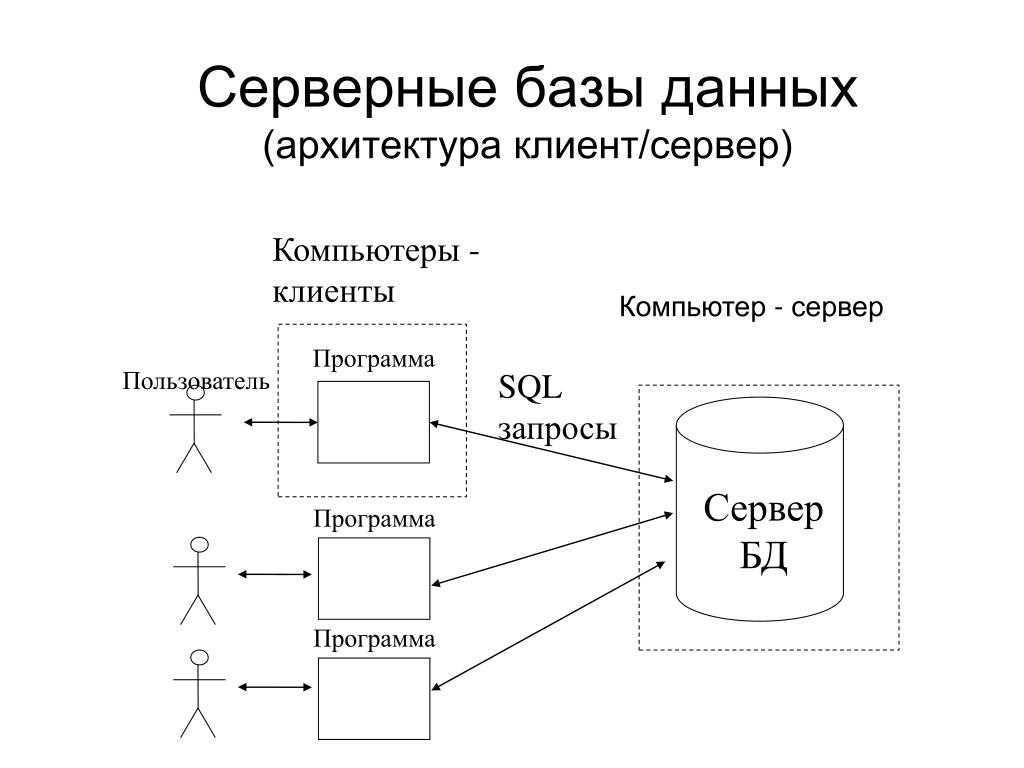
Графовые СУБД выигрывают у реляционных в скорости в тех случаях, когда мы работаем со связями и перемещаемся по графу. Это обусловлено тем, что каждая вершина графа вместе со своими связями хранится в оперативной памяти, и не используется JOIN.

Другие инструменты работы с графами
Помимо графовых СУБД, для работы с графами существуют специальные программные библиотеки (например, для Python написаны популярные библиотеки NetworkX и igraph). Также при необходимости логику графовых вычислений можно частично реализовать и в реляционных базах данных.
Заключение
Подведем итог:
-
Графовый анализ предлагает нам новые способы взаимодействия с привычными данными, такие как:
-
Визуализация связей между объектами;
-
Генерация новых признаков для машинного обучения;
-
Анализ объектов в контексте их окружения.
-
-
Для работы с графами уже существует достаточно большое число различных инструментов:
-
Графовые СУБД;
-
Средства визуализации;
-
Программные библиотеки для Python и других языков.
-
-
Использование графов не ограничивается узким набором бизнес-областей. Если проявить фантазию, можно найти для графов самые неожиданные применения.
-
Графы вряд ли могут полностью заменить традиционные подходы к решению задач, но окажутся отличным подспорьем и при грамотном использовании помогут усовершенствовать существующие подходы к решению многих задач в аналитике данных и машинном обучении.
Больше про графы в реальных бизнес-задачах мы общаемся в нашем сообществе NoML:
Присоединяйтесь!