
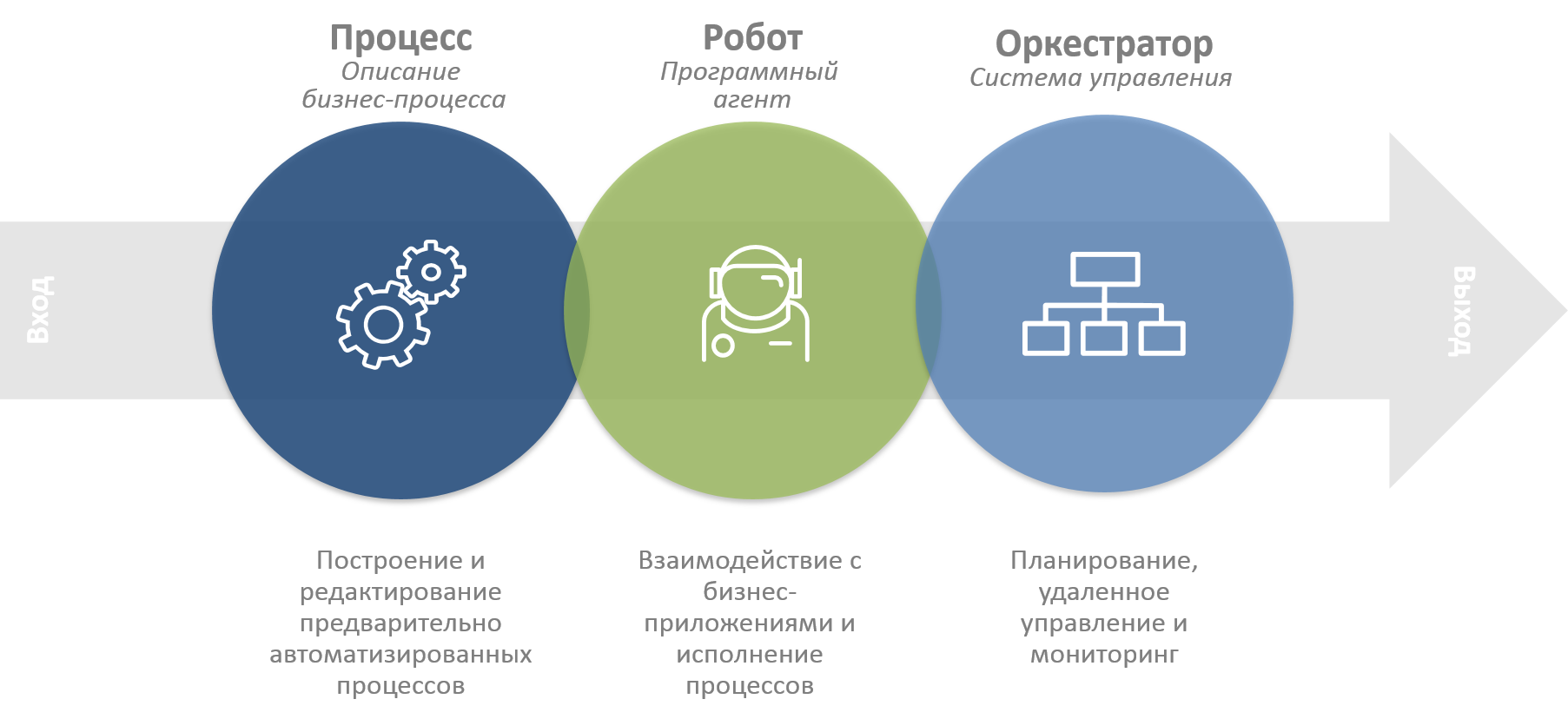
Программа Workspace Macro Pro
Скачать эту автоматизированную программу можно здесь https://workspace-macro-pro-automation-edition.en.softonic.com/.
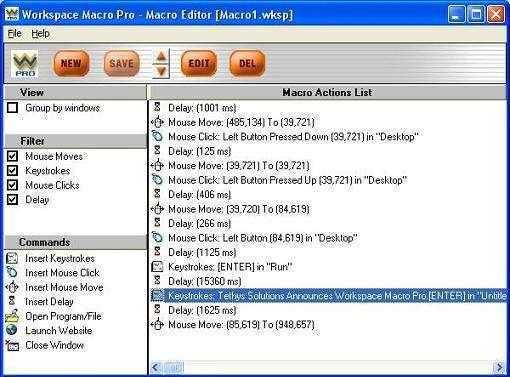 Программа Workspace Macro Pro
Программа Workspace Macro Pro
Тоже относится к категории условно бесплатных. Имеет множество возможностей – от стандартных встроенных шаблонов до построения задачи вручную с помощью визуального конструктора.
В приложении допускается и запись макросов путем записи последовательности действий пользователя на компьютере. Все как в предыдущих программах, плюс простой и дружественный интерфейс. Правда, русскоязычная версия программы отсутствует, но разве это существенный минус?
Создать макрос на базе существующих шаблонов достаточно просто, нужно лишь нажать на Templates и выбрать искомый вариант шаблона. Затем можно добавить созданный макрос в расписание Schedule.
Макросы также можно записать. Для этого следует нажать на кнопку Record в меню File. Чтобы остановить запись, нужно нажать на Stop.
Для создания макроса в визуальном конструкторе выполняют команду Create a macro using Macro Editor. Этот конструктор не имеет расширенных возможностей, но для стандартного варианта использования он вполне подходит.
AutoHotkey
Программа AutoHotkey (autohotkey.com) является форком AutoIt v2. Ее автор, Крис Маллетт, предложил добавить в AutoIt поддержку горячих клавиш, но идея не нашла отклика, и в результате в ноябре 2003 года вышел Initial release. В отличие от родительского продукта, AutoHotkey доступен по лицензии GNU GPL.
Синтаксис языка основан на AutoIt v2, некоторые идеи взяты из v3. С его помощью можно легко автоматизировать повторяющиеся задачи: запуск программы, отправку почты, редактирование реестра. Поддерживается работа с файлами, симуляция нажатий кнопок мыши, есть возможность создания GUI. Программа может отслеживать системные события и выполнять действия при их наступлении.
Но фишкой AutoHotkey является управление горячими клавишами. Например, чтобы запускать калькулятор комбинацией <Win+C>, пишем всего одну строку:
Значок решетки «#» соответствует клавише <Win>. Документация весьма подробна (перевод доступен по адресу www.script-coding.info/AutoHotkeyTranslation.html), в ней отражены все особенности языка. Кроме собственно интерпретатора, проект предлагает утилиту для создания GUI — SmartGUI Creator и редактор SciTE4AutoHotkey, имеющий подсветку и автодополнение кода.
Скрипты (расширение *.ahk) можно скомпилировать в exeфайл и выполнять на любом компьютере.
Модель Continuous Integration и Continuous Delivery
- TeamCity — основная система организации Continuous Integration;
- GitLab — система хранения исходного кода;
- Artifactory — система хранения собранных бинарных версий компонент и продуктов.
DevOps best practices: рекомендации по организации конфигураций в TeamCityРисунок 1. Базовые элементы типового проекта для релизной схемы сборок с продвижениями (по клику откроется в полном размере)
- обеспечить хранение кода в системе GitLab (выделить им проект);
- разработать сборочную конфигурацию на базе одного из типовых шаблонов и обеспечить хранение собранных артефактов в системе Artifactory;
- реализовать конфигурации для деплоя артефактов на серверах тестировщиков и помочь им с реализацией тестовых конфигураций;
- в случае успешного тестирования — «продвинуть сборку» — то есть, переместить ее в хранилище протестированных артефактов в Artifactory, для чего также создается специальная конфигурация;
- далее сборка может быть опубликована на Global Update сервере компании, откуда автоматически будет распространена на FUS-серверы у заказчиков;
- при помощи скриптов инсталляции, реализованных на базе SaltStack, сборка развернется на конкретном сервере.
Рисунок 2. Верхнеуровневая IDEF0-модель процессов Continuous Integration и Continuous Delivery в компании Positive TechnologiesЛичный опыт: как выглядит наша система Continuous Integration
Часть 4: Тестирование библиотек
- Тривиальные ошибки – к ним относятся, например, опечатки в сообщениях или мелкие корректировки. Часто больше времени тратится на донесение информации до разработчика, нежели на само исправление. Автоматизация проверок на наличие подобных ошибок возможна, но обычно не стоит того, чтобы ее реализовывать
- Ошибки отдельных частей кода – могут возникать, если разработчик не предусмотрел все возможные варианты использования его методов, в результате чего они оказываются неработоспособными или возвращают неожиданный результат. В отличие от остальных ситуаций подобные ошибки вполне могут быть выявлены в автоматическом режиме – при написании разработчик обычно понимает, как будет использоваться его код, а значит, может описать это в виде проверок
- Ошибки взаимодействия частей кода – если разработкой каждой конкретной части занимается обычно один человек, то когда частей много, то понимание принципов их совместной работы также является некоторым общим знанием. В данном случае несколько сложнее определить все варианты использования кода, однако, при должной проработке подобные ситуации также можно оформить в виде автоматических проверок, правда, уже лишь для некоторых сценариев его работы
- Ошибки логики – они же ошибки несоответствия работы программы предъявленным к ней требованиям. Достаточно сложно описать их в виде автоматизированных проверок, поскольку они и сами проверки формулируются в разной терминологии. Поэтому ошибки подобного рода лучше выявлять при ручном тестировании
Выгрузка/загрузка XML

Второй способ работы с 1С-разработками – это выгрузка и загрузка из XML.
- Это официальный механизм, который рекомендуется компанией 1С и используется во всех ее продуктах, например, в БСП и в СППР. Фирма 1С гарантирует, что этот инструмент будет корректно работать в обе стороны на тех платформах, для которых он запущен.
- Плюсом этого решения является то, что он выгружает конфигурацию в понятную структуру. У нас есть:
- Корневой уровень – уровень конфигурации в целом;
- Отдельные папки – для документов, справочников, отчетов, обработок.
- В каждой этой папке есть подпапка для каждого документа, для каждого справочника.
Работать с этой структурой намного проще, чем со структурой, выгруженной нестандартными средствами.
- В новых решениях также доступна частичная выгрузка данных.
- Также для этого инструмента есть очень много типовых примеров использования в той же БСП. Опираясь на эти примеры, очень удобно разбираться.
Ну и есть некоторые небольшие минусы в том, что:
- Конфигурация, разобранная на одной платформе, может не загрузиться в другой платформе – мы должны работать на одной и той же платформе из-за проблем с совместимостью.
- Кроме того, до версии 8.3.7 этот инструмент не умел работать с внешними отчетами и обработками. Сейчас такой проблемы нет, но если вы используете более старую платформу, то внешние отчеты и обработки вы им в текст не выгрузите.
- Он не умеет работать с байт-кодом – защищенные модули он выгружает в бинарном виде.
В целом, это один их наиболее удобных инструментов – простой и понятный.
Automate
Наверное, самой известной коммерческой программой для автоматизации задач является AutoMate, разрабатываемой компанией Network Automation, Inc (networkautomation.com). Главная ее особенность — создание задач при помощи удобного GUI, без необходимости в написании кода. Весь процесс упрощен за счет использования мастеров и специального редактора задач Task Builder. Программа содержит большое количество готовых шаблонов действий и реакции на них, что еще более упрощает процесс создания цепочки действий. Актуальная на момент написания статьи версия AutoMate 7 поддерживает более 230 предустановленных действий, позволяющих планировать задачи, работать с файлами и БД, передавать данные по FTP/SFTP, шифровать с помощью PGP, мониторить системы, получать доступ к WMI и многое другое.
AutoMate доступна в четырех редакциях, все они ориентированы на определенное использование: AutoMate Professional и Premium, AutoMateBPAServer 7 Standard и Enterprise. Самая простая — AutoMate Professional — обеспечивает удобный интерфейс для создания задач на локальной системе. Самая продвинутая — Enterprise — предоставляет возможности по простому управлению учетными записями и ролями, работе в AD, предусмотрено централизованное управление несколькими машинами, поддержка SNMP, эмулятор telnet и терминала.
Поддерживаются все ОС Win от XP SP2 до 2k8/7. Для установки понадобится платформа Microsoft .NET Framework версии 3.0.
Собственно управление осуществляется при помощи двух консолей — Task Builder и Task Administrator. В Task Builder создаются задания. Этот процесс довольно прост: в панели слева из 29 доступных групп выбираем нужное действие и переносим мышкой в среднее поле. Появляется мастер, который поможет уточнить настройки. Например, создадим действие, позволяющее получить данные по разделу жесткого диска. Переходим в меню System –> Get Volume Information, появляется одноименный мастер, состоящий из четырех вкладок.
Нам нужно последовательно пройти и выбрать параметры в каждой из них. В General указываем раздел диска и параметры, которые хотим получать: тип, метка, файловая система, место. Как вариант, можно сразу указать выбор всех разделов (All volumes) и затем, нажав значок рядом с полем, задать условие проверки. Программа предоставляет ряд встроенных переменных, функций и триггеров, которые можно использовать в этом поле. Также можно создать свое условие. В других вкладках задается описание задания и действие при ошибках.
После того, как создали задание, оно появляется в списке посередине, где его можно редактировать, перемещать, отключать и так далее. Далее аналогичным образом выбираем и заносим другие Actions. Для отладки в задание можно добавить точки останова (Breakpoint, <F8>).
Для управления всеми задачами, как на локальной, так и удаленной системе, предназначен Task Administrator. Выбрав в нем любую задачу, можем просмотреть ее свойства, активировать или создать новую задачу. В свойствах заданию предписываются триггеры, приоритет, защита, учетная запись, от имени которой оно будет выполнено. Настроек много, они очень разнообразны. Задачи сохраняются в файлах с расширением *.aml.
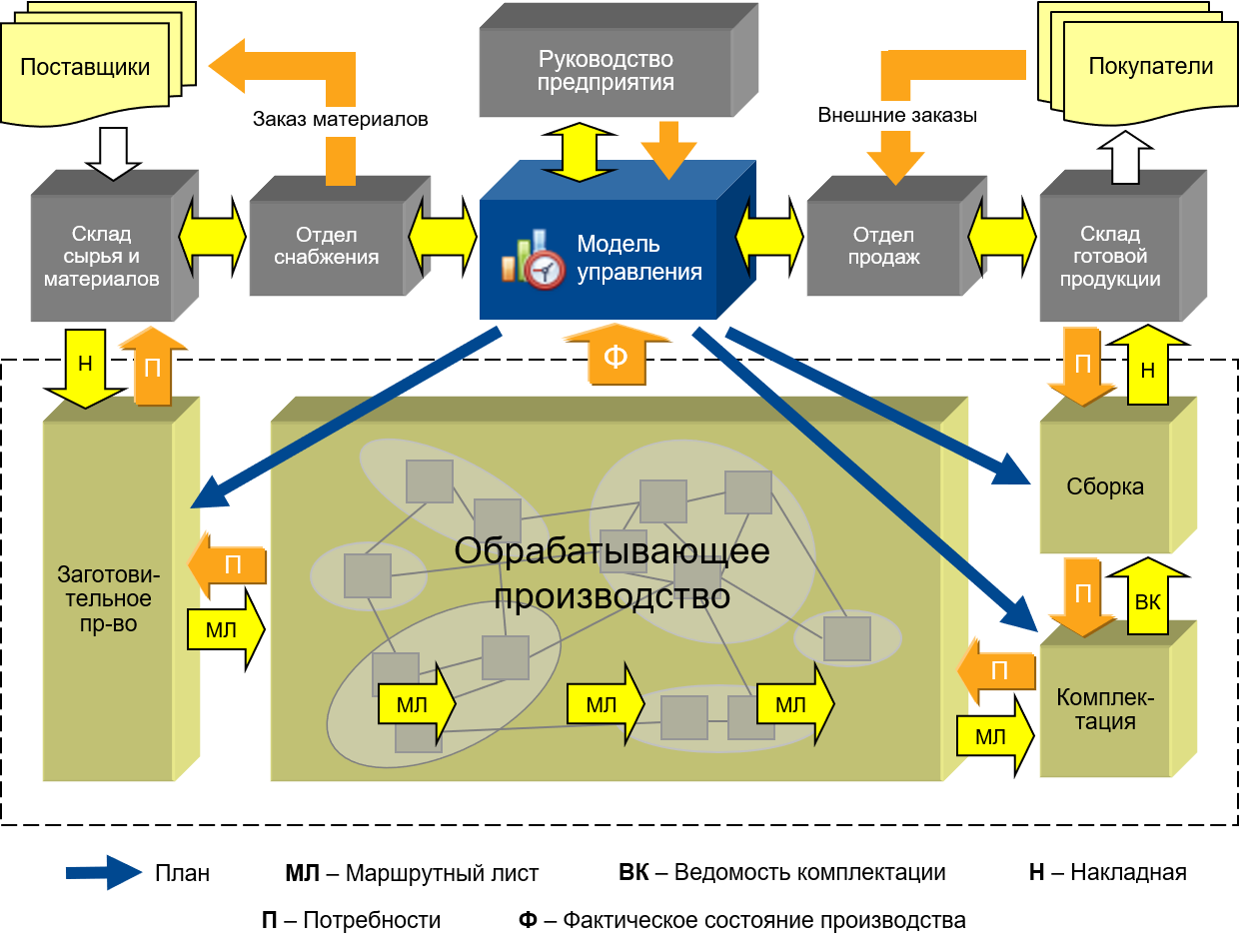
Исходный, объектный и загрузочный модули.
Рассмотрим структуру абстрактной многоязыковой, открытой, компилирующей системы программирования и процесс разработки приложений в данной среде.
- Ввод. Программа на исходном языке (исходный модуль) готовится с помощью текстовых редакторов и в виде текстового файла или раздела библиотеки поступает на вход транслятора.
- Трансляция. Трансляция исходной программы есть процедура преобразования исходного модуля в промежуточную, так называемую объектную форму. Трансляция в общем случае включает в себя препроцессинг (предобработку) и компиляцию.
- Препроцессинг — необязательная фаза, состоящая в анализе исходного текста, извлечения из него директив препроцессора и их выполнения. Директивы препроцессора представляют собой помеченные спецсимволами (обычно %, #, &) строки,содержащие аббревиатуры или другие символические обозначения конструкций, включаемых в состав исходной программы перед ее обработкой компилятором.
- Компиляция — в общем случае многоступенчатый процесс, включающий следующие фазы:
- Синтаксический анализ — проверка правильности конструкций, использованных программистом при подготовке текста;
- Семантический анализ — выявление несоответствий типов и структур переменных, функций и процедур;
-
Генерация объектного кода — завершающая фаза трансляции.
Выполнение трансляции (компиляции) может осуществляться в различных режимах, установка которых производится с помощью ключей, параметров или опций. Может быть,например, потребовано только выполнение фазы синтаксического анализа и т.п. Объектный модуль представляет собой текст программы на машинном языке, включающий машинные инструкции, словари, служебную информацию. Объектный модуль не работоспособен, поскольку содержит неразрешенные ссылки на вызываемые подпрограммы библиотеки транслятора (в общем случае — системы программирования), реализующие функции ввода-вывода, обработки числовых и строчных переменных, а также на другие программы пользователей или средства пакетов прикладных программ.
- Построение исполнительного модуля. Построение загрузочного модуля осуществляется специальными программными средствами — редактором связей, построителем задач, компоновщиком, основной функцией которых является объединение объектных и загрузочных модулей в единый загрузочный модуль с последующей записью в библиотеку или файл.
- Загрузка программы (Обычно это делает уже операционная система, но в целях отладки программа может быть запущена и в IDE). Загрузочный модуль после сборки помещается в качестве файла на диске. Выполнение модуля состоит в загрузке его в оперативную память, настройке по месту в памяти и передаче ему управления. Образ загрузочного модуля в памяти называется абсолютным модулем, поскольку все команды ЭВМ здесь приобретают окончательную форму и получают абсолютные адреса в памяти.
Современные системы программирования позволяют удобно переходить от одного этапа к другому. Это осуществляется в рамках так называемой интегрированной среды программирования, которая содержит в себе текстовый редактор, компилятор, компоновщик, встроенный отладчик и, в зависимости от системы или ее версии, предоставляет программисту дополнительные удобства для написания и отладки программ.
Ретроспектива и планы на будущее
- 2014 год — осознание того, что на имеющихся у нас тогда технологиях (svn, SharePoint, TFS) далеко не уедешь, после чего были начаты работы по исследованию и пилотированию новых CI/CD-систем.
- 2015 год — подготовлены и настроены типовые сценарии и процессы, построен каркас системы DevOps на базовой связке TeamCity + GitLab + Artifactory (подробнее на видео).
- 2016 год — активное наращивание объемов сборочных и тестовых конфигураций (до +200 в месяц!), перевод всех процессов на типовую релизную схему сборок с продвижениями, обеспечении стабильности и отказоустойчивости сборочной инфраструктуры.
- 2017 год — закрепление успехов и стабилизация роста проектов, качественный переход на удобство использования всех сервисов, предоставляемых DevOps-командой. Немного подробнее:
- по статистике, только за ноябрь 2017 для имеющихся сейчас ~4800 активных сборочных конфигураций на нашей инфраструктуре было запущено ~110000 сборок, общей длительностью ~38 мес., в среднем по 6.5 мин. на сборку;
- 2017 год мы впервые в нашем отделе начали с годовым планом, в который входили нестандартные задачи, выходящие за обычную рутину, с которой может справиться один инженер, и решение которых потребовало значительных трудозатрат, совместных усилий и экспертизы;
- завершили перевод сборочных окружений в docker и выделили два единых пула сборщиков под windows и linux, вплотную подошли к описанию сборок и инфраструктуры на DSL (для парадигм build as a code и infrastructure as code);
- стабилизировали систему доставки обновлений SupplyLab (немного статистики по ней: заказчики выкачали ~80Тб обновлений, опубликовано 20 релизов продуктов и ~2000 пакетов обновлений).
- в этом году мы стали рассматривать свои производственные процессы с точки зрения используемых технологических цепочек и получения так называемого конечного полезного результата (КПР).
- Обеспечение стабильности процессов разработки за счет:
- соблюдения SLA по сборкам и времени решения типовых задач
- профилирования и оптимизации «узких» мест по всем направлениям работ и процессам в командах;
- ускорения локализации проблем в сложных производственных цепочках за счет более точной диагностики и мониторинга).
- Регулярное проведение вебинаров о существующих наработках, чтобы переиспользовать решения в продуктах и обеспечить серийность производства.
- Перевод на серийное дублирование процессов и инструментов в командах. Например, ускорение подготовки типовых сборочных проектов, в первую очередь, за счет CrossBuilder.
- Ввод в эксплуатацию системы управления составом релиза и качеством собранных компонент и инсталляторов, за счёт использования возможностей CrossPM и DevOpsLab.
- Разработка DevOpsLab — системы автоматизации и делегирования типовых задач в проектные команды. Например, продвижение пакетов и инсталляторов, генерация типовых сборочных, деплойных и тестовых проектов, управление ресурсами проектов, выдача прав, простановка меток качества компонент и инсталляторов.
- Разработка типового и тиражируемого процесса поставки наших продуктов через систему обновлений SupplyLab.
- Перевод всей инфраструктуры на использование парадигмы infrastructure as code. Например, подготовить типовые сценарии развертывания виртуальных машин и окружения на них, разработать классификацию машин по потребляемым ресурсам, учет и оптимизация использования виртуальных ресурсов.
Часть 7: Интерфейсное тестирование
- Интерфейсное тестирование очень нестабильно: если логика работы небольшой части кода или нескольких взаимодействующих областей довольно редко меняется, то интерфейсное тестирование затрагивает на порядок больше – стоит поменяться отображению, как будет неясно куда щелкать, стоит изменить имя окна и станет неясно, появилось оно или нет
- Тесты выполняются гораздо дольше, чем обычные: нужно не только проверить, что программа работает, нужно удостовериться, что она устанавливается, обновляется, корректно удаляется, что все сценарии проходятся и возможно не единожды. Отображение информации на экране и взаимодействие с программой через интерфейс также сильно замедляет проверку
Часть 2: Тестирование кода
- Компоновка инсталляторов – пользователям системы обычно интересна именно она сама, а не то, как она была написана или собрана, а значит, они должны получить возможность ее у себя установить
- Формирование обновлений – если ваша система поддерживает технологию обновлений, то хорошим вариантом было бы не только получение полноценных инсталляторов, но и набора инкрементальных патчей для быстрого перехода с одной версии на другую
- Тестирование системы – пользователи должны получать только те версии, которые являются стабильными и реализующими требуемую функциональность, поэтому их необходимо проверять, при этом часть проверок можно переложить на автоматику
- Документирование – данное действие может оказаться полезным, как если вы отдаете внешнее API системы сторонним разработчикам, так и при внутренней разработке, поскольку, чем больше система и чем больше в ней кода, тем становится все меньше людей, знающих ее досконально
- Проверка совместимости версий – если сравнивать различные версии собираемых библиотек, то можно вовремя заметить, когда доступное в каждом модуле внешнее API претерпевает изменения: если что-то в нем перестает быть видимым извне – использующие его модули или программы могут оказаться несовместимы с новой версией; и наоборот – чрезмерное количество непрописанных в документации API функций говорит о том, что либо их необходимо в нее добавить, либо же скрыть от посторонних глаз
- Проверка принятых правил и стандартов – когда код оформлен одинаково, то любой из разработчиков системы сможет в нем свободно ориентироваться. Если же при поиске чего-либо оно не обнаруживается в ожидаемом месте или записано в нестандартной форме, то, даже если искомое и будет найдено или осмыслено, на это будет потрачено дополнительное время, которого можно было бы избежать
- Проверка самой сборки – бывает довольно неприятно, когда после длительного использования автоматической сборки обнаруживается, что она делала не совсем то, для чего предназначалась: например, тесты запускались не все из-за того, что они не были найдены, или же в ней не производилась сборка документации редко используемого модуля, которая внезапно срочно понадобилась
- Можно проверять наличие файлов или директорий, способы их именования, правила вложенности: вряд ли это пригодится большинству разработчиков, но порой встречаются и подобные ситуации
- Анализировать содержимое файлов исходного кода для проверки соблюдения принятых стандартов: например, какое-то время распространенным было правило в начале каждого файла размещать многострочный комментарий с описание функциональности и указанием автора
- Проверять соблюдение требований, предъявляемых к файлам внешними приложениями: например, если в дальнейшем в сборке предполагается запуск тестов, то нужно удостовериться, что файл, содержащий их описание, настроен корректно и тесты при своем запуске смогут обнаружить проверяемые библиотеки
- Статический анализ кода – когда разработчики совершают ошибки в программе по невнимательности, то бывают случаи, в которых подобные некорректности не выявляются даже тестами и только пристальное изучение исходного кода помогает их найти. Внешние же анализаторы позволяют выявить такие ситуации автоматически, что сильно упрощает разработку
- Сбор разнообразной статистики: количество строк в файлах кода, есть ли полностью совпадающие куски функций, самые редактируемые файлы – не самая важная информация, но иногда она дает возможность взглянуть на проект немного иначе
http://habrahabr.ru/post/75123/https://ru.wikipedia.org/wiki/Статический_анализ_кода
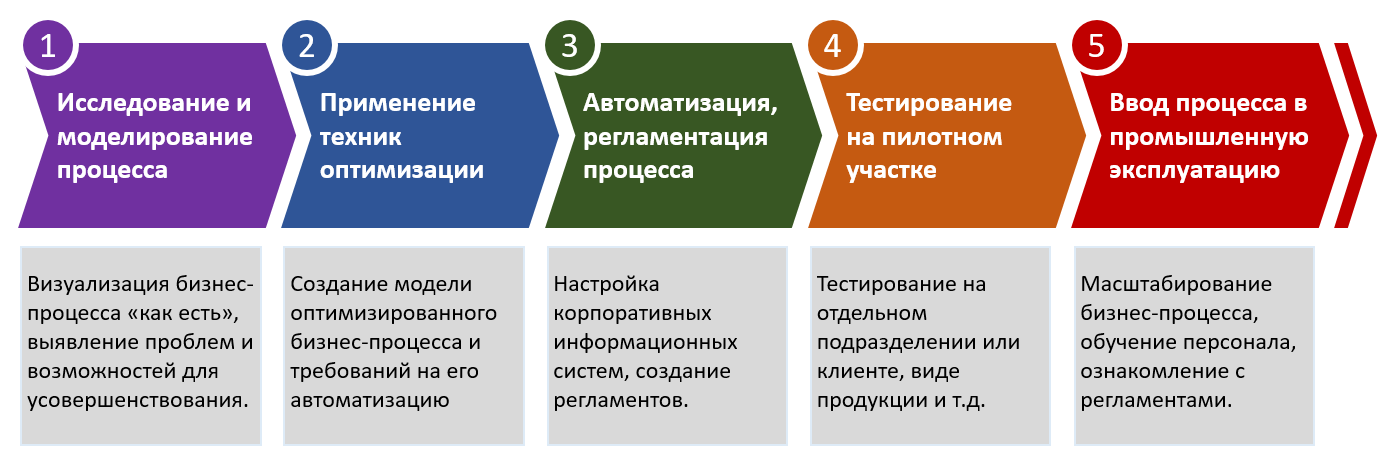
Направления автоматизации
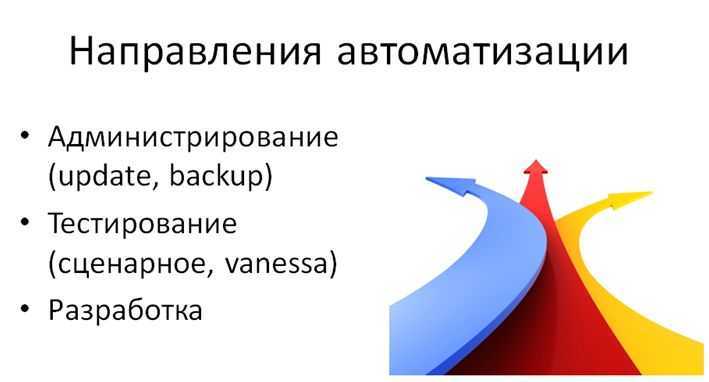
Какие наиболее популярные направления автоматизации?
- Говоря об автоматизации, мы чаще всего подразумеваем автоматизацию задач администрирования (создания архивных копий, обновления конфигурации). С этим направлением проще всего, потому что все актуальные типовые решения построены на базе Библиотеки Стандартных Подсистем (БСП), которая уже содержит в себе механизмы, помогающие в автоматическом режиме обновить конфигурацию и создать ее копию. Более того, если ваша база небольшая, и у вас есть активная подписка на ИТС, то БСП может сама положить копию вашей базы в облачное хранилище 1С, чтобы вы не потеряли данные, даже если с компьютером что-либо случится
- Второе направление автоматизации – это тестирование решений. В 1С-мире с этим немного сложнее, чем в классической разработке, но, тем не менее, последнее время очень много говорится о том, что при каждом изменении конфигурацию стоит тестировать, и лучше это делать автоматически. Сейчас на рынке есть достаточно много инструментов для создания автотестов. Наиболее интересные из них, на мой взгляд, это – «Сценарное тестирование» от компании 1С, а также опенсорс-разработка «Vanessa Behavior». У них немного разная логика работы, но, в принципе, оба эти решения справляются с задачей автоматизации тестирования. Что из них выбрать – решение пользователя.
- И третье направление автоматизации – это то, о чем я буду говорить остальную часть презентации – это автоматизация разработки. Для многих людей единственным способом создания решений на 1С является написание кода в конфигураторе. Но я хочу рассказать о том, что есть много вариантов работы с кодом программно.
Какие процессы подходят для автоматизации
Выбор и оценка процессов
- Операции, которые подвержены повторению;
- Стандартные процессы;
- Логические деревья решений (если «x», то «y»);
- Процессы, которые подвержены человеческому фактору.
Автоматизация процессов: первоначальная оценка потенциала автоматизации
- Структурированы ли входные данные;
- Количество или стоимость процессов;
- Можно ли отобразить процесс с помощью четких, логичных правил;
- Подвержен ли процесс повторению;
- Подвержен ли процесс ошибкам и переделкам;
- Как часто меняются процессы/системы.
Автоматизация процессов: факторы успеха
- Прозрачность и оценка проектов и их прогресса;
- Управление отдельными и всеми проектами в компании;
- Сотрудничество: успешное, эффективное сотрудничество между различными экспертами;
- Высокая масштабируемость внедренной технологии автоматизации технологических процессов.
Алгоритм пошагового автосоздания 1С-разработок
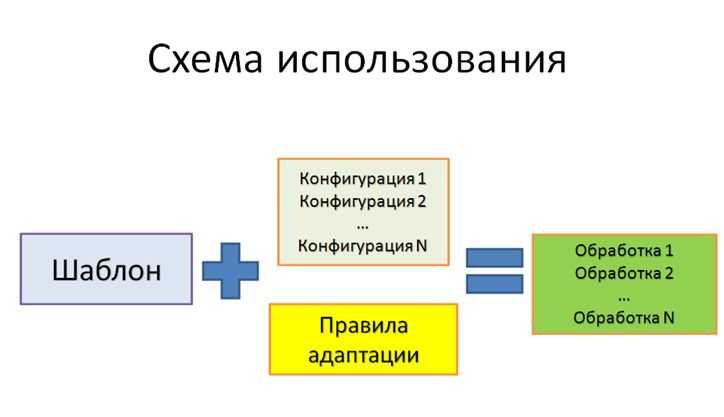
О том, как все это использовать для автоматической адаптации ваших решений к конфигурациям. На этом слайде показана очень сильно упрощенная схема, применимая для расширений, обработок и отчетов.
- Идея в том, что если ваше решение должно иметь разные файлы под разные конфигурации, то вы разрабатываете шаблон, который включает в себя все механизмы, наличие которых необходимо для работы этого решения во всех конфигурациях.
- И дополнительно к шаблону разрабатываются правила, которые адаптируют этот шаблон к конкретной конфигурации пользователя (желательно, к любой конфигурации). Например, если вы реализуете тот же самый механизм внешних печатных форм на базе расширения, то:
- В общем шаблоне будут механизмы:
- Печати;
- И загрузки печатных форм.
- А в правилах будет информация о том, как подключать это расширение к справочникам и документам.
- В общем шаблоне будут механизмы:
- Благодаря этому для каждой конфигурации мы сможем автоматически сформировать файлик с нашим расширением, учитывающим особенности данной конфигурации.
Способы создания универсальных решений

Какие вообще есть способы создания универсальных решений?
Я думаю, что у каждого программиста-консультанта, который работает с 1С, есть какая-то своя папочка личных обработок/отчетов, которые делались для решения конкретной задачи. Проблема в том, что в большинстве случаев такие разработки пишутся под очень узкую задачу и при появлении похожей задачи их приходится адаптировать. Более удобно потратить немного времени и сделать обработку изначально более универсальной.
-
Один из способов создания универсальных решений – это анализ метаданных. Фактически все типовые обработки используют этот способ:
- Обработка по универсальной выгрузке данных,
- Универсальный отчет,
- Обработка по установке реквизитов.
Эти инструменты работают на любых конфигурациях, потому что просто при запуске анализируют метаданные той конфигурации, в которой они запущены.
-
В некоторых случаях такой подход не срабатывает, потому что для разных конфигураций нужны разные правила работы. В этом случае можно использовать отдельные ветки кода под различные конфигурации:
- Если конфигурация такая-то, то выполняем один текст;
- Если конфигурация другая, то выполняем другой текст.
В большинстве случаев этот подход позволяет делать одну обработку, работающую на разных конфигурациях пользователя.
Но это, к сожалению, работает все-таки не всегда. Например, для тех же расширений иногда нужно иметь разные файлы для разных конфигураций, и в каждом расширении должны быть метаданные именно этой конфигурации. Это тоже достаточно просто автоматизируется путем создания шаблона с последующей программной адаптацией под конфигурацию пользователя.

Первые шаги со «Студия 1.0»
Мы решили делать low-code систему, которая потребует минимум разработчиков высокого уровня, и будет понятна технологам, ранее никогда не писавшим код. Обычно подобные проекты используют визуальные интерфейсы с простой логикой и функциями drag-and-drop для прописывания жизненного цикла. Код подставляется в автоматическом режиме.
Чтобы визуально представить low-code систему, можно вспомнить среду для быстрой разработки Delphi 7. С ней многие читатели могли познакомиться ещё в школе или вузе. Для создания элемента достаточно было перетащить его на поле рабочий области. Он тут же прописывался в теле программы и оставалось лишь закодировать логику.
Первые шаги автоматизации процесса разработки
В «Студии 1.0» принцип был схож с Delphi 7, но только описывать логику уже было не нужно. Из имеющейся базы подтягивался написанный метод, который ранее использовался на проектах
Важно отметить, что мы не собирались полностью отказываться от труда программистов. Если технолог не находил нужный код, то разработчик, обслуживающий проект, дописывал недостающие куски самостоятельно
С каждой итерацией инструмент становился мощнее.
Как только модуль саморазработки выдавал созданный на основе сконструированных элементов код, проходил процесс тестирования. После чего готовый продукт отдавался клиенту.
С этим low-code решением нам удалось сократить количество высокоуровневых разработчиков, которые работают над проектами, на 44%. А также уменьшить время разработки и тестирования готового продукта.
Эксплуатация интеллектуальных алгоритмов
Пока одни боятся, что ИИ скоро отберет у них работу (как минимум превратит в серую слизь), другие используют любые возможности компьютеров, чтобы облегчить себе жизнь.
За примерами далеко ходить не надо: Prisma, Artisto, Vinci и другие приложения «эпохи бума нейросетей» появились после того, как ученые выложили в открытый доступ результаты исследований по сверточным нейросетям.
Следующий прорыв, возможно, следует ждать в области генерации текста, но еще десять лет назад статьи, созданные компьютерами, люди использовали для собственного обогащения. Экономист Фил Паркер тщательно настроил процесс автоматизированного написания книг. Проблема возникла у него при подготовке собственного академического издания — книга требовала тщательности, времени и денег.
Неожиданное решение — доверить работу компьютерным алгоритмам — привело его в удивительный мир качественного копипаста. Он «создал» сотни тысяч книг — от руководства для врачей по синдрому Клайнфельтера до бесчисленных подборок кроссвордов.
Работа выстраивается просто: компьютеры компилируют информацию, собранную из открытых источников, в книги разных жанров объемом в 100–200 страниц. Весь процесс для одного экземпляра занимает 20 минут. Затем электронная книга выставляется на продажу, ее также можно заказать по принципу «печать по требованию».
У многих книг Паркера внушительные тиражи — десятки и даже сотни экземпляров. Медицинские библиотеки покупали почти все, что он производил.
Качество подобной литературы оставляет желать лучшего и любой человек с доступом к интернету быстрее найдет ответы на интересующий его вопрос, но революция в создании текстов уже случилась.
Сегодня роботы пишут результаты спортивных матчей, прогноз погоды, страховые отчеты, презентации новых продуктов, экономические новости — и делают это так, что вы не замечаете подвоха.
Система Wordsmith, созданная компанией Automated Insights, ежегодно пишет более миллиарда (!) заметок. Например, она ответственна за некоторые публикации в . Automated Insights берут данные из пресс-релизов компаний и официальных отчетов, сравнивают их с публикациями за прошлый период и затем на основе полученных сведений выдают новостную заметку. Конечно, Wordsmith не заменяет журналиста, но избавляет его от рутинной, скучной работы с одной и той же информацией.
Интересное мнение высказала Джинни Рометти, генеральный директор IBM. По ее словам, развитие средств автоматизации приведет к тому, что людям больше не придется программировать. В IBM все сводят к Watson, который однажды сможет смотреть на данные, понимать их и рассуждать над ними, но измышления про всемогущий ИИ, который отберет у всех работу, относятся к области гипотетических спекуляций. Да, в отдаленном будущем такое действительно возможно, но много ли людей готовы бросить программирование или забрать своего ребенка с образовательных IT-курсов?

С практической точки зрения нам интересно не то, что сильный ИИ однажды сможет сделать. Полезнее знать, какие инструменты автоматизации помогут прямо сейчас — пусть они будут не интеллектуальными, не основанными на нейронных сетях и не использующими все возможности бигдаты. Зачем ждать будущее, если каждый сможет стать собственным ИИ? Каким минимум одним качеством для этого мы обладаем — речь идет про человеческий интеллект, который однажды придумал, как выполнять работу, а теперь задумывается, как сократить ее количество до нуля.



