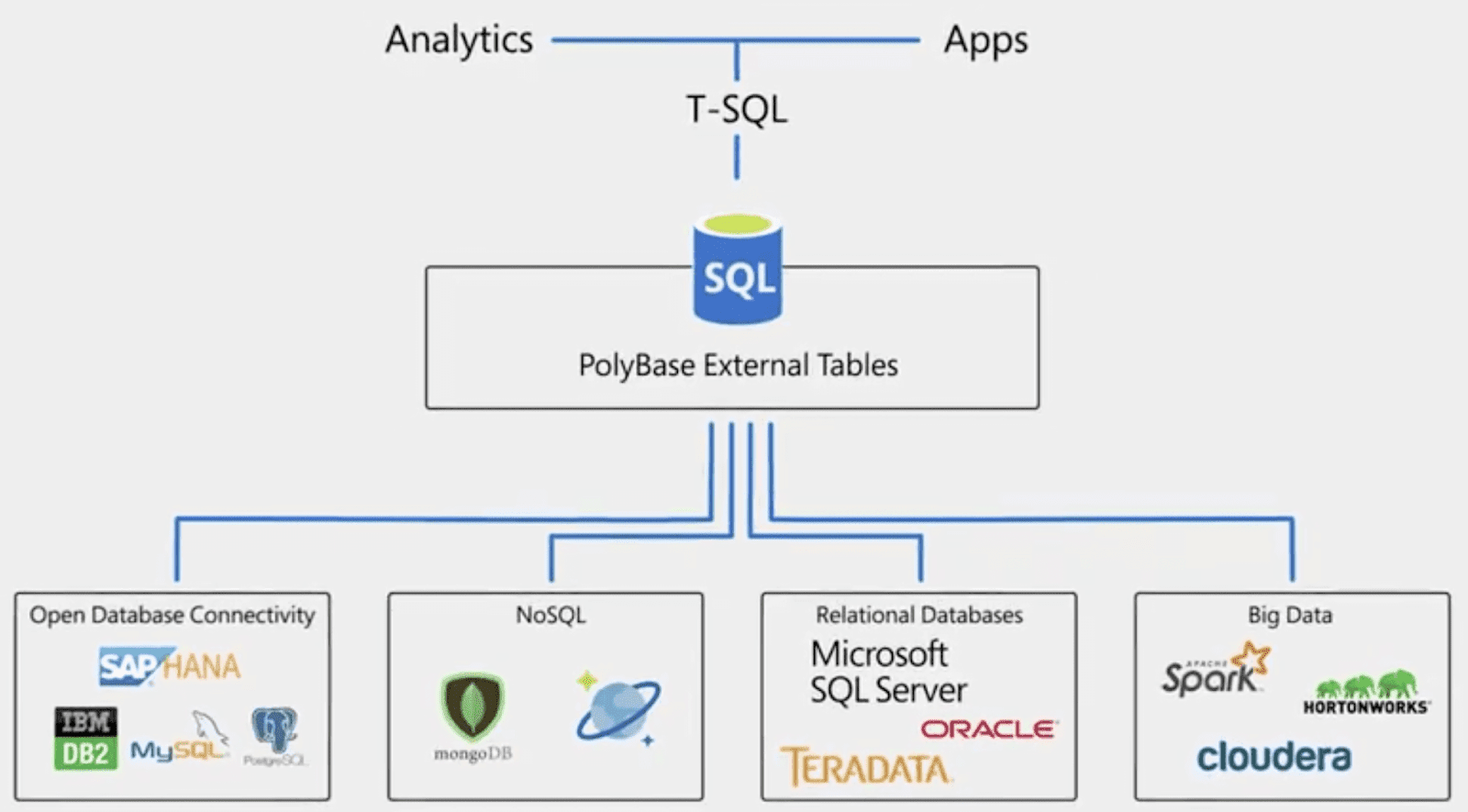
Зачем потребовалась интеграция Arenadata и Visiology?
Подходов к работе BI-систем на сегодняшний день несколько. Но когда речь идет о больших данных для самых разных задач, обычно используется ROLAP. Работает он достаточно просто: когда пользователь нажимает что-то на дашборде, например, выбирает какой-то фильтр, внутри платформы формируется SQL-запрос, который уходит на тот или иной бэкэнд. В принципе, под системой BI может лежать любая СУБД, которая поддерживает запросы — от Postgres до Teradata. Подробнее о схемах работы OLAP я рассказывал здесь.
Преимущество интеграции BI с СУБД заключается в том, что для работы системы, по сути, нет ограничения по объему данных. Но при этом падает скорость выполнения запросов — конечно, если не использовать специализированную колоночную СУБД, например, ClickHouse или Vertica. И, хотя у ClickHouse спектр возможностей пока еще уже, чем у той же Vertica, система развивается и выглядит очень многообещающей.
Но даже с колоночной СУБД есть свои минусы при работе с BI, и самый первый из них — это более низкая эффективность использования кэша на уровне платформы в целом, потому что СУБД, в отличие от самой BI-платформы, «не знает» многого о поведении пользователей и не может использовать эту информацию для оптимизации. Когда большое количество пользователей начинают работать, по-разному делать запросы и обращаться к дашбордам, требования к железу, на котором крутится СУБД — даже хорошая, аналитическая и колоночная — могут оказаться очень серьезными.
Второй момент — это ограничение аналитической функциональности: все, что не укладывается в SQL-запрос, поддерживаемый распределенной СУБД, отсекается автоматически (например, в случае ClickHouse — это оконные функции). И этопроблема, потому что в BI есть много вещей, которые с трудом транслируются в SQL-запросы или выполняются неоптимально.
Второй вариант — это In-memory OLAP. Он подразумевает перенос всех обрабатываемых данных в специальный движок, который молниеносно прорабатывает базу в 200-300 Гб — это порядок единицы миллиардов записей. Кстати, подробнее про ограничения In-Memory OLAP я уже рассказывал здесь. На практике встречаются инсталляции In-Memory OLAP, укомплектованные 1-2-3 терабайтами оперативной памяти, но это скорее экзотика, причем дорогостоящая.
Практика показывает, что далеко не всегда можно обойтись тем или иным подходом. Когда требуются одновременно гибкость, возможность работы с большим объемом данных и поддержка значительного количества пользователей, возникает потребность в гибридной системе, которая с одной стороны загружает данные в движок In-Memory OLAP, а с другой — постоянно подтягивает нужные записи из СУБД. В этом случае движок OLAP используется для доступа ко всему массиву данных, без всяких задержек. И в отличие от чистого In-Memory OLAP, который нужно периодически перезагружать, в гибридной модели мы всегда получаем актуальные данные.
Такое разделение данных на “горячие” и “холодные” объединяет плюсы обоих подходов — ROLAP и In-Memory, но усложняет проект внедрения BI. Например, разделение данных происходит вручную, на уровне ETL процедур. Поэтому для эффективной работы всего комплекса очень важна совместимость между бэкэндом и самой BI-системой. При том, что SQL-запросы остаются стандартными, в реальности всегда есть аспекты их выполнения, нюансы производительности.
Производительность QuickMarts
-
Типичные запросы быстрей чем за секунду
-
> 100 раз быстрей чем Hadoop и обычные СУБД
-
100 млн — 1 миллиард строк в секунду на одной ноде
-
До 2 терабайт в секунду для кластера на 400 нод
Но вернемся к Arenadata QuickMarts. Это сборка ClickHouse, которая немного отличается от сборки Яндекса. Наши коллеги из Arenadata даже позже выпускают релизы, потому что проводят больше тестов, чтобы серьезные задачи в продакшене работали только на стабильных версиях.
При этом установка и настройка ADQM происходит из Arenadata Cluster Manager. Кастомизированная СУБД обладает расширенными механизмами авторизации пользователей, a также средствами мониторинга на базе Graphite и Grafana. Но самое главное, что QuickMarts изначально располагает готовыми коннекторами и прозрачно взаимодействует с другими компонентами платформы, в т.ч. с ADB (Greenplum), что позволяет по мере необходимости подгружать данные из ADB в ADQM.
В нашем случае QuickMarts используется для работы с витринами, к которым через BI обращаются сотни или тысячи пользователей. Архитектура системы позволяет выдать им данные “здесь и сейчас”, а не ждать 20-30 секунд, когда обработается их запрос по витринам в более медленной СУБД.
Как работает интеграция Arenadata и Visiology
Когда Visiology используется вместе с Arenadata, схема работы системы выглядит следующим образом. Основное хранилище данных может быть реализовано на базе ADB (GreenPlum), из которой создаются витрины данных, хранящиеся уже в ADQM. За счет интеграции между компонентами решения система работает как единое целое, а необходимые для запросов данные поднимаются на нужный уровень автоматически.
Фактически в аналитической системе создается только один дашборд, а графику обрабатывает движок In-Memory ViQube — ядро платформы Visiology. Пользователь лишь выбирает те или иные фильтры, а задача по выгрузке самих транзакций выполняется уже на бэкенде ресурсами QuickMarts.
Раньше подобная интеграция была только с Vertica, но сейчас мы совместно с коллегами сделали интеграцию для Arenadata QuickMarts. Это радостная новость для сторонников ClickHouse, потому что BI работает с популярной СУБД по гибридной схеме. При этом Arenadata DB, выполняющая функцию корпоративного хранилища данных, обеспечивает необходимую трансформацию данных для дальнейшей работы QuickMarts и Visiology.
Все запросы BI обрабатываются движком ViQube. Если пользователь обращается к тем данным, которых нет в памяти, система автоматически генерирует SQL-запрос, который выполняется на Arenadata QuickMarts.
Чтобы все это заработало, мы реализовали поддержку диалекта ClickHouse для основных аналитических функций и добавили автоматическое переключение между режимами работы OLAP в зависимости от того, где находятся данные на самом деле. Однако для пользователя все остается предельно прозрачным: он даже не знает, как работает система — просто делает запросы в интерфейсе BI и получает результаты, причем достаточно быстро.
Конечно, у такой схемы есть и свои минусы. Например, учитывая ограничения SQL, не все аналитические функции будут доступны на полном объеме данных. Но зато появляется возможность отрабатывать огромное количество транзакций, для большого количества людей, которые в основном изучают тренды на готовых дашбордах, и лишь иногда ищут конкретные записи.
MapReduce
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи. Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.







3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce(). Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Чем понравилась Impala
- Высокая скорость выполнения аналитических запросов за счет альтернативного подхода по отношению к MapReduce. Промежуточные результаты вычислений не скидываются в HDFS, что существенно ускоряет обработку данных.
- Эффективная работа с поколоночным хранением данных в Parquet. Для аналитических задач часто используются так называемые широкие таблицы с множеством колонок. Все колонки используются редко — возможность поднимать из HDFS только нужные для работы позволяет экономить оперативную память и значительно ускорять запрос.
- Изящное решение с runtime-фильтрами, включающими bloom-фильтрацию. И Hive, и Impala существенно ограничены в использовании индексов, обычных для классических СУБД — из-за особенностей файловой системы хранения HDFS. Поэтому для оптимизации исполнения SQL-запроса движок СУБД должен эффективно воспользоваться доступным партиционированием даже когда оно не задано явно в условиях запроса. Кроме того, ему нужно попытаться предсказать, какое минимальное количество данных из HDFS нужно поднять для гарантированной обработки всех строк. В Impala это работает очень хорошо.
- Impala использует LLVM – компилятор на виртуальной машине с RISC-подобными инструкциями – для генерации оптимального кода выполнения SQL-запроса.
- Поддерживаются ODBC и JDBC интерфейсы. Это позволяет почти из коробки интегрировать данные Impala с аналитическими инструментами и приложениями.
- Есть возможность использования Kudu – чтобы обойти часть ограничений HDFS, и, в частности, писать конструкции UPDATE и DELETE в SQL-запросах.
Предпосылки
Самое раннее исследование бизнес-аналитики было сосредоточено на неструктурированных текстовых данных, а не на числовых данных. Еще в 1958 году исследователи информатики, такие как H.P. Лун был особенно озабочен извлечением и классификацией неструктурированного текста. Тем не менее, только на рубеже веков эта технология заинтересовала исследователей. В 2004 году институт SAS разработал программу SAS Text Miner, которая использует разложение по сингулярным значениям (SVD) для уменьшения гипермерного текстового пространства на меньшие размеры для значительно более эффективного машинного анализа. Математические и технологические достижения, вызванные машинным анализом текста, побудили ряд предприятий исследовать приложения, что привело к развитию таких областей, как анализ настроений, голос клиента майнинг и оптимизация call-центра. Появление больших данных в конце 2000-х годов привело к повышенному интересу к приложениям аналитики неструктурированных данных в современных областях, таких как прогнозная аналитика и анализ первопричин.
ORACLE CX Unity
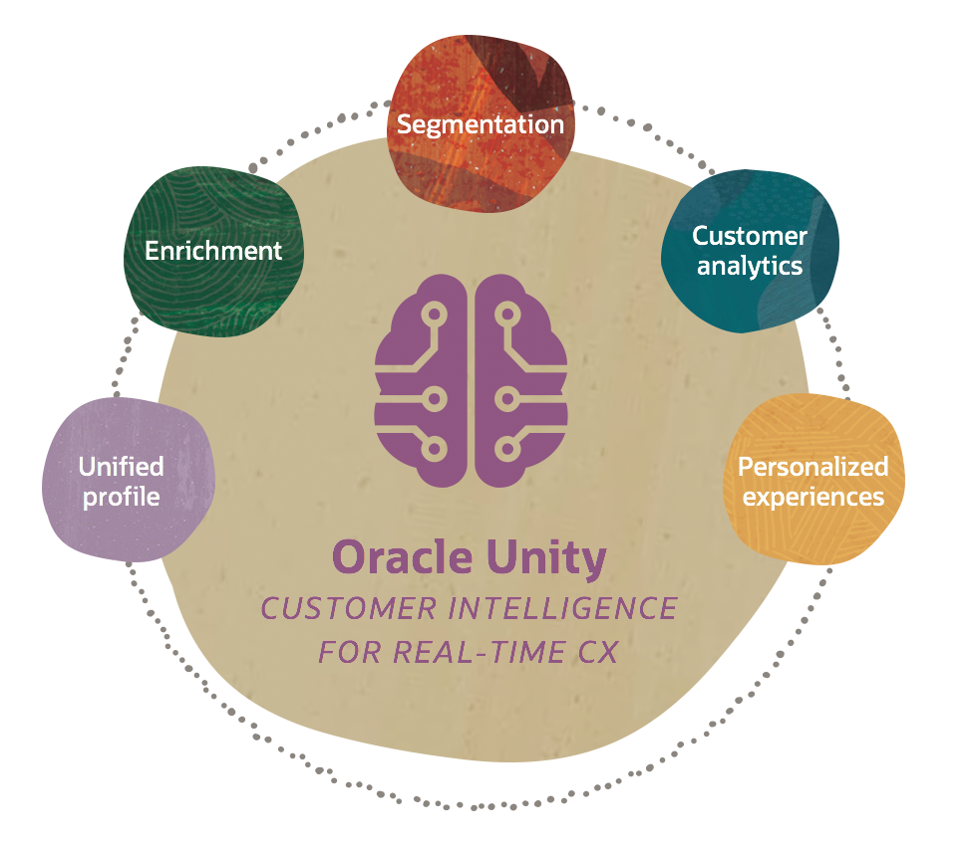
Платформа объединяет данные о клиентах из сетевых, офлайн- и сторонних источников, чтобы создать единое динамическое представление о каждом клиенте в режиме реального времени. А алгоритмы ИИ помогают определить оптимальные последующие действия с контактами в рамках любых существующих бизнес-процессов.
Возможности:
- Единый профиль клиента: объединение всех источников данных; модели структуры данных для разных отраслей бизнеса.
- Обогащение профиля: более 50 готовых встроенных атрибутов профилей клиентов; готовые коннекторы для сторонних поставщиков услуг передачи данных; доступ к крупнейшей в мире торговой площадке third-party-данных на базе Oracle Data Cloud (Oracle BlueKai Data Management Platform).
- Смарт-сегментация: сегментация в реальном времени для отправки сообщений определенным целевым группам; более 80 поведенческих оценок, таких как оценка вовлеченности по каналам, вероятность оттока, склонность к покупке и многое другое; более 100 готовых поведенческих сегментов, которые помогут вам найти самых ценных клиентов, охотников за скидками и другие ключевые для вашего бизнеса группы потребителей; персонализация в режиме реального времени.
- Аналитика на базе ИИ: предиктивный анализ поведения; отчеты по вовлеченности; RFM-анализ.
Цена: обсуждается индивидуально.
Бесплатный период: нет.
Представительства: Америка, Азия, Европа, Ближний Восток и Африка.
Last post
Платформы анализа больших данных: что это такое и зачем они нужны
Платформа для обработки больших данных — это решение, которое объединяет различные инструменты, необходимые специалистам по data science. Такие платформы существенно упрощают их работу, охватывая весь жизненный цикл data science проектов: от идеи и исследования данных до построения и развертывания аналитических моделей.
Они позволяют решить так называемую проблему «последней мили»: интегрировать результаты анализа данных в операционную деятельность, чтобы они влияли на принятие решений и трансформировали бизнес-процессы. Это может быть реализовано в виде API предиктивной модели, к которой обращаются другие системы, веб-приложения, которым могут пользоваться сотрудники, или просто ежедневного отчета, отправляемого на почту.
А для этого потребуется не только оборудование, но и регулярные поставки комплектующих, технологические карты, настроенные процессы контроля качества, обслуживания, модернизации продукта. Чтобы поставить производство на поток, нужны дополнительные ресурсы и компетенции.
Аналогичная ситуация возникает и в data science-проектах. Ключевой результат работы дата-сайентиста — аналитическая модель — это и есть тот самый опытный образец. Она работает, ее можно запустить, показать в действии. Но если сделать только модель, то на бизнес это не повлияет.
Чтобы разрабатывать модели и превращать их из пилотных проектов в работающие бизнес-приложения, чтобы модели работали с потоками данных и не «падали», чтобы выдавали результат за разумное время, нужна соответствующая технологическая оснастка — data science-платформы.
Такие решения делают работу data science-специалистов прозрачной и масштабируемой. Платформы могут использовать и системные интеграторы, и конечные заказчики, у которых есть специалисты по обработке данных и аналитике.
Isilon All-Flash Scale-Out NAS с ОС Isilon OneFS
Isilon All-Flash Scale-Out NASЭффективность высокопроизводительной и масштабируемой системы хранения корпоративного класса Dell EMC All Flash Isilon достигается за счет сочетания бездискового шасси высокой плотности с надежной и гибкой операционной системой Isilon OneFS.Dell EMC All Flash Isilon сделает переход к бездисковым ЦОД реальным.
- Производительность: для поддержки самых сложных неструктурированных рабочих нагрузок All Flash Isilon обеспечивает до 250 000 IOPS (операций ввода-вывода в секунду) и пропускную способность 15 Гбайт/с на шасси, а общая производительность кластера составляет до 25 М IOPS и 1,5 Тбайт/с.
- Масштабируемость: с All Flash Isilon можно увеличить емкость хранилища с 92 до 924 Тбайт в одном шасси 4U и до 92,4 Пбайт в одном кластере Isilon.
- Операционная гибкость: решение работает под управлением операционной системы Isilon OneFS с поддержкой нескольких протоколов (включая NFS, SMB, FTP, HDFS, REST, SWIFT и HTTP). Это дает возможность на одной платформе поддерживать широкий спектр приложений и типов нагрузок.
- Защита корпоративных данных: All Flash Isilon обеспечивает целостность неструктурированных данных и высокую доступность с резервированием до N + 4, а также резервное копирование и аварийное восстановление корпоративного уровня.
- Безопасность: Варианты обеспечения безопасности включают управление доступом на основе ролей (RBAC), зоны безопасного доступа, защиту данных WORM согласно SEC, аудит файловой системы и шифрование данных.
- Эффективность: Для All Flash Isilon характерна низкая совокупная стоимость хранения данных. Коэффициент использования хранилища может превышать 80%, а дедупликация SmartDedupe может увеличить эффективную емкость еще на 30%.
|
• 924 Tбайт флеш-памяти в шасси 4U; • масштабируемость до более чем 92 Пбайт (100 шасси) с единой файловой системой; • многопротокольная поддержка (NFS, SMB, HDFS, SWIFT, FTP, HTTP, NDMP); • SmartPools и CloudPools: автоматическая миграция данных по уровням хранения, включая облако; • управление данными: дедупликация, квотирование, SmartConnect, InsightIQ; • защита данных: от N+1 до N+4 ECC, зеркалирование, снапшоты, репликация; • безопасность: WORM, аудит, шифрование, зоны доступа, ролевая аутентификация. |
С помощью ПО InsightIQ видны все изменения в среде хранения.
В едином семействе
Семейство продуктов Dell EMC Isilon (гибридных и флеш-массивов) с разными показателями емкости и производительности позволяет подобрать решение для любой задачи.
- Флеш-массив с полной функциональностью OneFS: при обслуживании и защите контента первостепенное значение имеют возможности корпоративного уровня. В All Flash Isilon реализованы те же функции OneFS, которые есть в дисковых массивах Isilon — поддержка нескольких протоколов, шифрование и безопасность, автоматическая миграция между уровнями хранения и облаком, полный набор функций отказоустойчивости.
- Переход на флеш-память, когда это необходимо: All Flash Isilon с операционной системой Isilon OneFS можно объединять в пул хранения данных с существующими кластерами Isilon для создания гибридного решения. Гибкость развертывания позволяет переходить на флеш-накопители тогда, когда в этом есть потребность, но нет необходимости полностью заменять существующую инфраструктуру хранения. Это избавляет компанию от сложной и затратной миграции файлового хранилища большой емкости.
- Высокая плотность с гранулярной масштабируемостью: Для All Flash Isilon характерна высокая плотность — 924 Тбайт флеш-памяти в шасси 4U. Архитектура All Flash Isilon поддерживает масштабирование системы с меньшим шагом — до 24 Тбайт на каждый узел: так емкость наращивается постепенно, что сокращает единовременные инвестиции.
История вопроса и определение термина
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).








Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Зачем Data Science, если есть системы Business Intelligence
Иногда платформы Data Science воспринимают как аналоги систем Business Intelligence (BI), так как они тоже содержат инструменты для визуализации результатов анализа данных
Важно понимать отличия между ними, чтобы выбирать область применения
Традиционно BI-решения используются для статических отчетов о текущем или прошлом состоянии бизнеса. Они отвечают на такие вопросы, как:
- какая динамика объема продаж в прошедшем квартале?
- за счет чего произошел рост или падение продаж?
- какой тип продукции произвели больше всего за месяц?
Это так называемый дескриптивный или описательный анализ. Кроме того, BI системы работают со структурированными данными, извлеченными из хранилищ данных и представляют результат анализа в виде интерактивных информационных панелей — дашбордов или отчетов.
Платформы анализа больших данных — это уже инструмент для прогностического и динамического анализа. Они позволяют делать прогнозы по развитию любой сферы бизнеса и на их основе принимать более точные решения. Типовые вопросы: какой оптимальный сценарий развития бизнеса? Что будет, если продолжатся текущие тренды? Что случится, если принять новое управленческое решение?
Платформы могут использовать как структурированные, так и неструктурированные данные из множества источников, и умеют обрабатывать большие данные. Так как предиктивный анализ связан нацелен на прогнозирование какого-то параметра или события, то он фокусируется на конкретной задаче, в отличие от business intelligence. Дескриптивный же анализ должен позволять пользователям гибко создавать отчет в том разрезе, который им потребуется.
Современные BI-системы, например, Tableau или PowerBI, имеют большой набор средства визуализации: от линейных графиков и круговых диаграмм до тепловых карт и диаграмм санкей. Поэтому хотя BI-системы и data science-платформы предназначены для разных задач, но они могут дополнять друг друга. Например, существующая BI-система может в удобном виде представить результаты анализа данных, которые поступают из платформы.
Какие функции есть у платформ анализа больших данных
Каждый data science-проект проходит жизненный цикл, состоящий из трех этапов:
- Сбор данных и исследование.
- Экспериментирование и разработка модели.
- Развертывание и интеграция.
На каждом этапе специфические задачи, которые помогает выполнять платформа. И есть более общие задачи, включающие управление данными, управление процессами обработки и масштабирования.
Для решения всех этих задач платформы обработки данных предлагают такой технический функционал: прием, подготовка и исследование данных, генерация признаков, создание, обучение, тестирование и деплой моделей, мониторинг и обслуживание системы.
Также платформа должна обеспечивать безопасность данных и их хранение, каталогизацию источников, предоставлять инструменты для визуализации и формирования отчетов. Облачные платформы дополнительно дают большой объем хранилища и вычислительных мощностей.
Все перечисленные функции платформ нужны, чтобы:
- ускорять работу специалистов;
- публиковать модели и интегрировать их в бизнес-процессы;
- делиться понятными, читаемыми результатами анализа с сотрудниками всех подразделений;
- сохранять прошлые наработки, включая метаданные, код, датасеты и обсуждения, и использовать их в новых проектах;
- создать общую базу знаний и собирать лучшие практики, на которых будут учиться новые сотрудники;
- безопасно внедрять новые инструменты, не ломая текущие процессы и не вмешиваясь в работу коллег;
- масштабировать вычислительные мощности;
- контролировать доступы к каждому проекту, чтобы его видели только определенные сотрудники.
Интеллектуальный анализ НД
Бизнес-аналитика только на основе числовых рядов уходит в прошлое, сейчас программы, на основании которых принимаются управленческие решения, работают с неструктурированными данными и текстовой информацией.
Для достижения лучшего результата используются следующие виды анализа:
- интеллектуальный анализ данных (data mining);
- обработка естественного языка (Natural Language Processing);
- интеллектуальное изучение текста.
Эти типы исследований данных нацелены на поиск закономерностей, служащих предпосылками для выводов, имеющих значение для бизнеса.
Первым этапом работы программного обеспечения с данными является структурирование. Оно происходит путем поиска и нахождения общих смысловых единиц, характерных для речи или текста, например, частей речи или иных лингвистических или аудиальных структур.
Среди решений, обеспечивающих изучение неструктурированных данных с использованием метода естественного языка и интеллектуального анализа, называют:
- IBM Watson – программа на базе искусственного интеллекта получает вопросы на естественном языке и ищет на них ответы среди неструктурированных данных с использованием технологий ИИ;
- ABBYY FlexiCapture – программа для интеллектуальной работы с НД;
- SPSS Statistics, предлагающая статистические методы исследования НД для общественных наук.
Если ранее неструктурированные данные являлись проблемой, пугали своим количеством, неподконтрольностью и недоступностью для использования в качестве базы для принятия решений, то сегодняшний рынок предлагает достаточно продуктов, способных категоризировать и проанализировать НД.
12.12.2019






Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Решение:
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, ), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Задача: имеется csv-лог рекламной системы вида:
Решение:
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Segment

Возможности:
- Функции – универсальный способ подключения тысяч приложений к Segment с помощью нескольких строк JavaScript-кода без дополнительной инфраструктуры.
- Хранилища – все данные о клиентах стандартизируются и загружаются в выбранное вами хранилище данных в течение нескольких минут.
- Автоматизированная конфиденциальность данных с помощью Segment Privacy Portal (автоматическая блокировка сбора определенных типов данных, автоматическое управление правами субъектов данных и т. п.).
- Соответствие требованиям GDPR – возможность хранить и обрабатывать данные локально, оптимизировать запросы пользователей на удаление и ограничение использования данных.
Цена: бесплатный тариф Free, тариф Team – от $120 в месяц (есть бесплатный пробный период), тариф Business – по запросу. Тариф зависит от количества контактов и источников данных.
Представительства: США, Канада, Великобритания, Австралия.