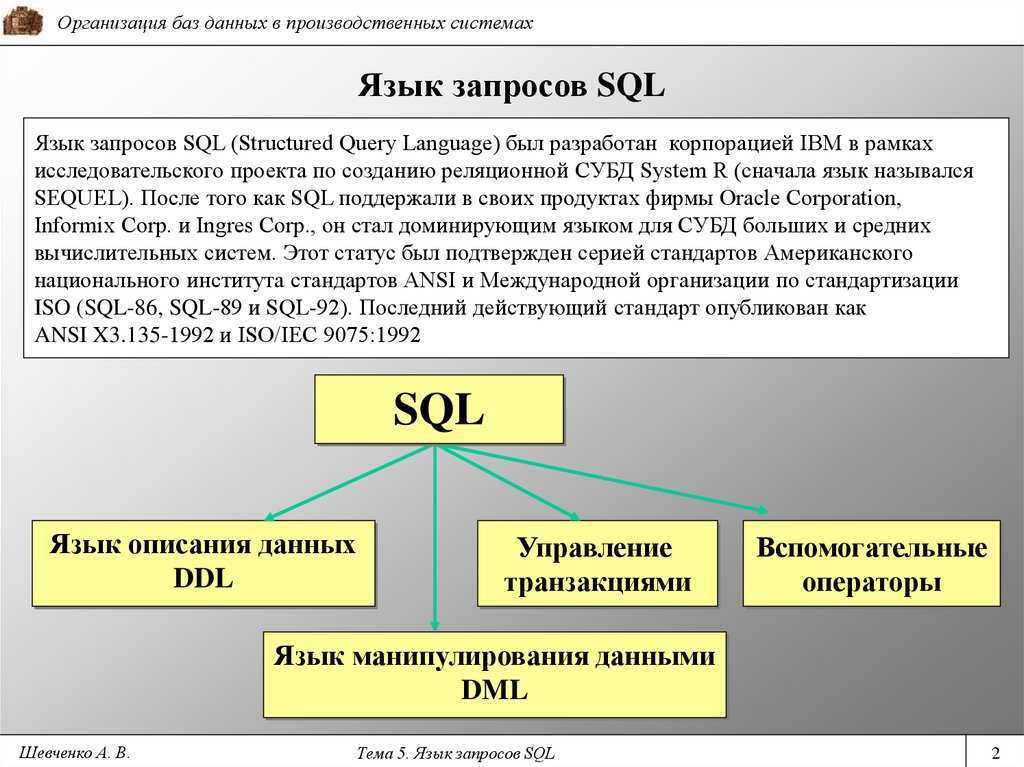
3. Вся суть SQL заключается в ссылках на таблицы
Из-за разницы между лексическим упорядочением и логическим упорядочением большинство новичков, вероятно, думают, что значения столбцов являются объектами первого класса в SQL. Но, нет. Наиболее важными являются ссылки на таблицы.
Стандарт SQL определяет предложение FROM следующим образом:
Вывод предложения FROM — это объединенная ссылка на таблицу объединенного значения всех ссылок. Попробуем это переварить.
Указанная выше запись производит комбинированную ссылку на таблицу значений a и b. Если a имеет 3 колонки и b 5 колонок, тогда выходная таблица “output table” будет состоять из 8 (3 + 5) столбцов.
Записи, содержащиеся в этой комбинированной табличной ссылке являются перекрестным / декартовым произведением a x b. Иными словами, каждая запись a образует пару с записью b. Если a имеет 3 записи, а b 5 записей, описанная выше ссылка на таблицу производит 15 записей (3 x 5).
Этот вывод переводится в предложение GROUP BY (после фильтрации в предложении WHERE), где преобразуется в новый вывод. Разберемся с этим позже.
Если мы посмотрим на эти примеры в свете реляционной алгебры / теории множества, то таблица SQL — это отношение или набор кортежей. Каждое предложение SQL преобразует одно или несколько отношений, чтобы создать новые отношения.
SQL-92
The next revision of the standard was SQL-92 – and it was a major revision. The language introduced by SQL-92 is sometimes referred to as SQL 2. The standard document grew from 120 to 579 pages. However, much of the growth was due to more precise specifications of existing features.
The most important new features were:
- An explicit syntax and the introduction of outer joins: , , .
- The introduction of and
- The introduction of set operations (set union, set intersection, and set difference).
- The introduction of the conditional expression .
- New scalar operations: string concatenation, substring extraction, and date and time mathematics.
- The operator, which allows the explicit casting of values into types.
SQL-92 also introduced new data definition statements: and for tables and views, and new data types (, , , , string, string, and strings). This version added an information schema (the standard way to get database metadata, such as table names, table columns, column types, and table constraints). It also introduced temporary tables, transaction isolation levels, and the dynamic execution of queries (dynamic SQL).
SQL standard was divided into three levels of conformance: entry (entry level SQL-92 was similar to SQL-89 with integrity constraints), intermediate, and full.
SQL-92 is the foundation of query language used in relational databases today. When they talk about “SQL”, most people mean SQL-92. Databases that had already existed in 1992 modified their implementation of SQL to be compliant with the standard. Newer databases used the standard as a reference for their implementation.
SQL-92 is still what people teach as “SQL” in schools. And rightfully so – SQL-92 is a very good starting point for learning SQL. For a lot of people, it’s enough to do their everyday work. You can learn advanced features later, when you need them. And most databases support SQL-92. No implementation is 100% compliant with the standard, but the incompatibilities are not that important, especially when you’re just getting started.
At LearnSQL.com, is the most important dialect we teach. We believe that if you learn the standard language, you can use it to work with most databases. It’s the foundation of our beginner-level courses; SQL Basics will teach you the statement with all the features available in SQL-92, including different kinds of , , set operations, and subqueries. The course How to INSERT, UPDATE, and DELETE Data in SQL will teach you , , and statements, while SQL JOINs will let you practice different types of .
For people interested in creating tables, we recommend our Creating Database Structure learning track. The track consists of five courses that will teach you how to create tables, define constraints, select appropriate data types, and create views using standard SQL syntax, which is easily portable between different database engines.
Типы данных SQL
Типы данных SQL разделяются на три группы: — строковые; — с плавающей точкой (дробные числа); — целые числа, дата и время.
1. Типы данных SQL строковые
| Типы данных SQL | Описание |
|---|---|
| Строки фиксированной длиной (могут содержать буквы, цифры и специальные символы). Фиксированный размер указан в скобках. Можно записать до 255 символов | |
| Может хранить не более 255 символов. | |
| Может хранить не более 255 символов. | |
| Может хранить не более 65 535 символов. | |
| Может хранить не более 65 535 символов. | |
| Может хранить не более 16 777 215 символов. | |
| Может хранить не более 16 777 215 символов. | |
| Может хранить не более 4 294 967 295 символов. | |
| Может хранить не более 4 294 967 295 символов. | |
| Позволяет вводить список допустимых значений. Можно ввести до 65535 значений в SQL Тип данных ENUM список. Если при вставке значения не будет присутствовать в списке ENUM, то мы получим пустое значение. Ввести возможные значения можно в таком формате: | |
| SQL Тип данных SET напоминает ENUM за исключением того, что SET может содержать до 64 значений. |
2. Типы данных SQL с плавающей точкой (дробные числа) и целые числа
| Типы данных SQL | Описание |
|---|---|
| Может хранить числа от -128 до 127 | |
| Диапазон от -32 768 до 32 767 | |
| Диапазон от -8 388 608 до 8 388 607 | |
| Диапазон от -2 147 483 648 до 2 147 483 647 | |
| Диапазон от -9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 | |
| Число с плавающей точкой небольшой точности. | |
| Число с плавающей точкой двойной точности. | |
| Дробное число, хранящееся в виде строки. |
3. Типы данных SQL — Дата и время
| Типы данных SQL | Описание |
|---|---|
| Дата в формате ГГГГ-ММ-ДД | |
| Дата и время в формате | |
| Дата и время в формате timestamp. Однако при получении значения поля оно отображается не в формате timestamp, а в виде ГГГГ-ММ-ДД ЧЧ:ММ:СС | |
| Время в формате | |
| Год в двух значной или в четырехзначном формате. |
Задание псевдонимов для столбцов запроса
| ФИО | Дата приема | Дата рождения | ZP |
|---|---|---|---|
| Иванов Иван Иванович | 2015-04-08 | 1955-02-19 | 5000 |
| Петров Петр Петрович | 2015-04-08 | 1983-12-03 | 1500 |
| NULL | 2015-04-08 | 1976-06-07 | 2500 |
| NULL | 2015-04-08 | 1982-04-17 | 2000 |
| FullName1 | FullName2 | FullName3 |
|---|---|---|
| Иванов Иван Иванович | Иванов Иван Иванович | Иванов Иван Иванович |
| Петров Петр Петрович | Петров Петр Петрович | Петров Петр Петрович |
| NULL | Сидоров Сидор | Сидоров Сидор |
| NULL | Андреев Андрей | Андреев Андрей |
Основные арифметические операторы SQL
| Оператор | Действие |
|---|---|
| + | Сложение (x+y) или унарный плюс (+x) |
| — | Вычитание (x-y) или унарный минус (-x) |
| * | Умножение (x*y) |
| Деление (x/y) | |
| % | Остаток от деления (x%y). Для примера 15%10 даст 5 |
| ID | Name | Result1 | Result2 | Result3 |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 2500 | 2500 | 2500 |
| 1001 | Петров П.П. | 225 | 225 | 225 |
| 1002 | Сидоров С.С. | NULL | ||
| 1003 | Андреев А.А. | 600 | 600 | 600 |
| 1004 | Николаев Н.Н. | NULL | ||
| 1005 | Александров А.А. | NULL |
| ID | Name |
|---|---|
| 1000 | Иванов И.И. |
| 1004 | Николаев Н.Н. |
| 1002 | Сидоров С.С. |
Самостоятельная работа для закрепления материала
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2a |
| 2 | L-2b |
| 3 | L-3 |
| 5 | L-5 |
| RCode | RDescr |
|---|---|
| 2 | B-2a |
| 2 | B-2b |
| 3 | B-3 |
| 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2a |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 3 | L-3 | 2 | B-2a |
| 5 | L-5 | 2 | B-2a |
| 1 | L-1 | 2 | B-2b |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 2 | B-2b |
| 5 | L-5 | 2 | B-2b |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2a | 3 | B-3 |
| 2 | L-2b | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2a | 4 | B-4 |
| 2 | L-2b | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Преимущества и недостатки языка SQL
Язык SQL является основой многих СУБД, т.к. отвечает за физическое структурирование и запись данных на диск, а также за чтение данных с диска, позволяет принимать SQL-запросы от других компонентов СУБД и пользовательских приложений. Таким образом, SQL – мощный инструмент, который обеспечивает пользователям, программам и вычислительным системам доступ к информации, содержащейся в реляционных базах данных.
Основные достоинства языка SQL заключаются в следующем:
− стандартность – как уже было сказано, использование языка SQL в программах стандартизировано международными организациями;
− независимость от конкретных СУБД – все распространенные СУБД используют SQL, т.к. реляционную базу данных можно перенести с одной СУБД на другую с минимальными доработками;
− возможность переноса с одной вычислительной системы на другую – СУБД может быть ориентирована на различные вычислительные системы, однако приложения, созданные с помощью SQL, допускают использование как для локальных БД, так и для крупных многопользовательских систем;
− реляционная основа языка – SQL является языком реляционных БД, поэтому он стал популярным тогда, когда получила широкое распространение реляционная модель представления данных. Табличная структура реляционной БД хорошо понятна, а потому язык SQL прост для изучения;
− возможность создания интерактивных запросов – SQL обеспечивает пользователям немедленный доступ к данным, при этом в интерактивном режиме можно получить результат запроса за очень короткое время без написания сложной программы;
− возможность программного доступа к БД – язык SQL легко использовать в приложениях, которым необходимо обращаться к базам данных. Одни и те же операторы SQL употребляются как для интерактивного, так и программного доступа, поэтому части программ, содержащие обращение к БД, можно вначале проверить в интерактивном режиме, а затем встраивать в программу;
− обеспечение различного представления данных – с помощью SQL можно представить такую структуру данных, что тот или иной пользователь будет видеть различные их представления. Кроме того, данные из разных частей БД могут быть скомбинированы и представлены в виде одной простой таблицы, а значит, представления пригодны для усиления защиты БД и ее настройки под конкретные требования отдельных пользователей;
− возможность динамического изменения и расширения структуры БД – язык SQL позволяет манипулировать структурой БД, тем самым обеспечивая гибкость с точки зрения приспособленности БД к изменяющимся требованиям предметной области;
− поддержка архитектуры клиент-сервер – SQL – одно из лучших средств для реализации приложений на платформе клиент-сервер. SQL служит связующим звеном между взаимодействующей с пользователем клиентской системой и серверной системой, управляющей БД, позволяя каждой из них сосредоточиться на выполнении своих функций.




Язык SQL может использоваться широким кругом специалистов, включая администраторов баз данных, прикладных программистов и множество других конечных пользователей.
Язык SQL – первый и пока единственный стандартный язык для работы с базами данных, который получил достаточно широкое распространение. Практически все крупнейшие разработчики СУБД в настоящее время создают свои продукты с использованием языка SQL либо с SQL-интерфейсом.
− Несоответствие реляционной модели данных. Создатели реляционной модели данных Эдгар Кодд, Кристофер Дейт и их сторонники указывают на то, что SQL не является истинно реляционным языком. В опубликованном Кристофером Дейтом и Хью Дарвеном Третьем Манифестеони излагают принципы СУБД следующего поколения и предлагают язык Tutorial D, который является подлинно реляционным.
− Сложность. Хотя SQL и задумывался как средство работы конечного пользователя, в конце концов он стал настолько сложным, что превратился в инструмент программиста.
− Отступления от стандартов. Несмотря на наличие международного стандарта ANSI SQL-92, многие компании, занимающиеся разработкой СУБД (например, Oracle, Sybase, Microsoft, MySQL AB), вносят изменения в язык SQL, применяемый в разрабатываемой СУБД, тем самым отступая от стандарта. Таким образом, появляются специфичные для каждой конкретной СУБД диалекты языка SQL.
Редакции Microsoft SQL Server
Кроме уровня версии, которая отражает стадию разработки Microsoft SQL Server в целом как продукта, есть еще и редакции SQL Server, которые отражают функциональность и возможности Microsoft SQL Server. Иными словами, каждая из редакций имеет какой-то определенный функционал и ограничения.
Дело в том, что у всех организаций разные потребности, и многим полный функционал Microsoft SQL Server просто не нужен, кроме этого должна же быть какая-то бесплатная версия, например, для обучения.
Существует 4 основные редакции Microsoft SQL Server:
- Enterprise – самый полный выпуск, включает все возможности SQL Server, предназначен для крупных баз данных, которые требуют максимальной производительности, надежности, масштабируемости и доступности, а также имеют очень строгие требования по бизнес-аналитике;
- Standard – самая распространенная редакция, включает ключевые возможности управления данными и бизнес-аналитики. В отличие от выпуска Enterprise у Standard имеются ограничения, как в функциональности, так и в объеме использования ресурсов, например, максимальное количество ядер, которое можно задействовать, это 24;
- Developer – редакция для разработчиков программного обеспечения, которая включает полный функционал SQL Server, она позволяет создавать и тестировать приложения на основе SQL Server без ограничений. Она бесплатна, но ее могут использовать только программисты для разработки и демонстрации приложений, иными словами, в качестве сервера баз данных на предприятии ее использовать нельзя;
- Express – бесплатная редакция SQL Server, она подходит для обучения и разработки приложений для обработки данных на настольных компьютерах и небольших серверах (размером до 10 ГБ). У этого выпуска также есть ограничения, например, задействовать можно только 4 ядра, а максимально возможный размер базы данных 10 ГБ. По функционалу данная редакция также значительно уступает платным вариантам.
Не использовать COALESCE
Пришло время неочевидных пунктов. Но сейчас мы поясним свои чаяния.
COALESCE — это оператор, который принимает N значений и возвращает первое, которое не NULL. Если все NULL, то вернется NULL.
Нужен этот оператор для того, чтобы в расчеты случайно не попадали пропуски. Такие пропуски всегда сложно заметить, потому что при расчете среднего на основании ста тысяч строк вы вряд ли заметите подвох, даже если 1000 просто будет отсутствовать. Обычно такие численные пропуски заполняют средними значениями/минимальными/максимальными/медианными/средними или с помощью какой-то интерполяции — зависит от задачи.
Мы же рассмотрим нечисловой пример, а вполне себе бизнесовый. Например, есть таблица клиентов Clients. В поле name заносится имя пользователя.
Очевидно, что если name is NULL, то это превратится в тыкву:
Вот в таких случаях и помогает COALESCE:
Совет: Лучше всегда перестраховываться. Особенно это касается вычислений и агрегирований — там вы не найдете ошибку примерно никогда, так что лучше подложить соломку.
6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
Что дает нам:
| avg |
|---|
| 3.000 |
И это можно использовать в качестве скалярной величины .
Теперь, наконец, можно написать весь запрос:
Это то же самое, что:
И результат:
| bookid | title | author | published | stock |
|---|---|---|---|---|
| 3 | Who Will Cry When You Die? | Robin Sharma | 2006-06-15 00:00:00 | 4 |
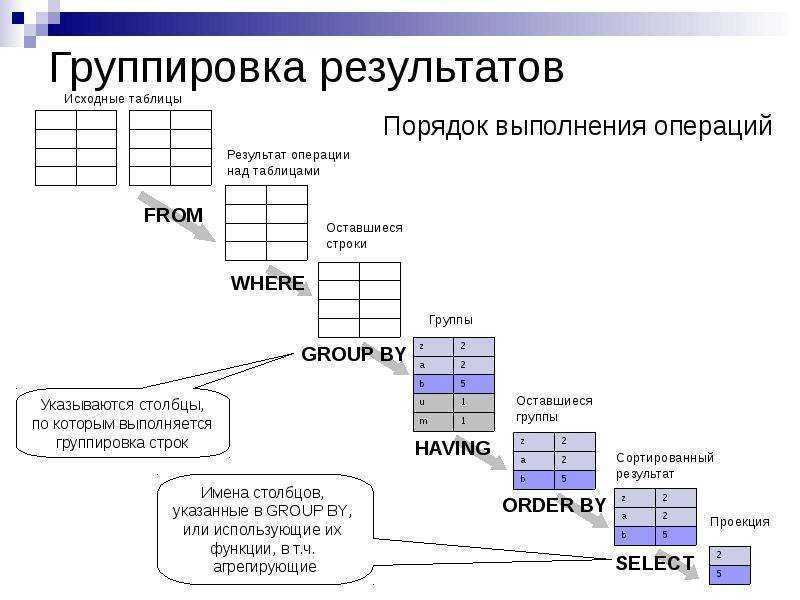
2. Код SQL не является упорядоченным
Обычно путаница происходит из-за того, что элементы кода SQL не расположены в том порядке, в каком они выполняются. Лексический порядок выглядит так:
- SELECT
- FROM
- WHERE
- GROUP BY
- HAVING
- UNION
- ORDER BY
Для простоты перечислены не все предложения SQL. Этот словесный порядок принципиально отличается от логического порядка (который в свою очередь может отличаться от порядка выполнения в зависимости от выбора оптимизатора):
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
- UNION
- ORDER BY
Три пункта, которые следует отметить:
Первое предложение здесь FROM, а не SELECT. Сначала происходит загрузка данных с диска в память, чтобы с ними можно было работать.
SELECT выполняется после большинства других предложений. Главное, после FROM и GROUP BY







Это важно понимать, если думаете, что можете ссылаться на элементы, которые объявляете в предложении SELECT из предложения WHERE. Следующее невозможно:
Есть два варианта повторно использовать z. Либо повторить выражение:
… либо прибегнуть к производным таблицам, общим табличным выражениям или представлениям данных, чтобы избежать повторения кода. Смотрите примеры ниже.
3. UNION ставится перед ORDER BY в лексическом и логическом порядках. Многие думают, что каждый подзапрос UNION можно упорядочить, но по стандарту SQL и в большинстве диалектов SQL это не так. Хотя в некоторых диалектах позволяется упорядочивание подзапросов или производных таблиц, нет никакой гарантии, что такой порядок будет сохранен после выполнения операции UNION.
Обратите внимание, что не все базы данных реализуют вещи одинаковым образом. Правило номер 2, например, не применяется в точности, как описано выше, для MySQL, PostgreSQL, и SQLite
Что мы из этого узнаем?
Чтобы избежать распространенных ошибок, всегда следует помнить о лексическом и логическом порядках предложений SQL. Если вы усвоили эти отличия, становится понятным, почему одни вещи работают, другие нет.
Конечно, неплохо, если бы язык был спроектирован таким образом, когда лексическая последовательность фактически отражает логический порядок, как это реализовано в Microsoft LINQ.
Булевы операторы и простые операторы сравнения
| AND | логическое И. Ставится между двумя условиями (условие1 AND условие2). Чтобы выражение вернуло True, нужно, чтобы истинными были оба условия |
|---|---|
| OR | логическое ИЛИ. Ставится между двумя условиями (условие1 OR условие2). Чтобы выражение вернуло True, достаточно, чтобы истинным было только одно условие |
| NOT | инвертирует условие/логическое_выражение. Накладывается на другое выражение (NOT логическое_выражение) и возвращает True, если логическое_выражение = False и возвращает False, если логическое_выражение = True |
| Условие | Значение |
|---|---|
| = | Равно |
| < | Меньше |
| > | Больше |
| <= | Меньше или равно |
| >= | Больше или равно |
| <> != |
Не равно |
| IS NULL | Проверка на равенство NULL |
|---|---|
| IS NOT NULL | Проверка на неравенство NULL |
Игнорирование CASE
Если вы используете CASE, то иногда вы можете сократить свои запросы в несколько раз.
Вот, например, была задача — вывести поле sum со знаком «-», если type=1 и со знаком «+», если type=0.
Пользователь предложил такое решение:
В целом, не так плохо. Но это всего лишь промежуточный запрос, задача была намного масштабней и таких конструкций в итоге было наворочено очень много.
А вот то же самое с CASE:
Согласитесь, получше?
Так более того, CASE можно использовать еще много для чего. Например, чтобы сделать из «длинной» таблицы «широкую».
А еще, кстати, COALESCE, который мы обсуждали выше — это просто «синтаксический сахар» и обертка вокруг CASE. Если интересно — мы подробно это описали в статье.
9. SQL SELECT в реляционной алгебре называется проекцией
Мне лично нравится термин «проекция», так как он используется в реляционной алгебре. После того как вы создали ссылку на таблицу, отфильтровали и преобразовали ее, можете переходить к проецированию в другую форму. Предложение SELECT подобно проектору. Табличная функция использующет выражение значения строки для преобразования каждой записи из ранее созданной ссылки на таблицу в конечный результат.
В предложении SELECT можно работать со столбцами, создавая сложные выражения столбцов как части записи/строки.
Есть много специальных правил в отношении характера доступных выражений, функций и т.д. Главное, нужно помнить следующее:
- Можно использовать только ссылки на столбцы, полученные из ссылки на таблицу в «output».
- Если у вас есть предложение GROUP BY, вы можете ссылаться только на столбцы из этого предложения или агрегатные функции.
- Если нет предложения GROUP BY вместо агрегатных можно использовать оконные функции.
- Если нет предложения GROUP BY, нельзя сочетать агрегатные и неагрегатные функции.
- Существуют некоторые правила, касающиеся переноса регулярных функций в агрегатные функции и наоборот.
- Есть…
Много сложных правил. Которыми можно заполнить еще один урок. Например, причина почему нельзя комбинировать агрегатные функции с неагрегатными функциями в проекции инструкции SELECT без предложения GROUP BY (правило № 4), такова:
- Это не имеет смысла. Интуитивно.
- Если не помогает интуиция (например, новичкам в SQL), выручают синтаксические правила. В SQL:1999 реализован оператор GROUPING SETS, а в SQL:2003 — пустой оператор grouping sets: GROUP BY (). Всякий раз, когда присутствует агрегатная функция и нет явного предложения GROUP BY, применяется неявный пустой GROUPING SET (правило №2). Следовательно, исходные правила о логическом упорядочении больше не являются верными, и проекция (SELECT) влияет на результат логически предшествующего, но лексически последовательного предложения (GROUP BY).
Запутались? Да. Я тоже. Давайте вернемся к более простым вещам.
Что мы из этого узнаем?
Предложение SELECT может быть одним из самых сложных предложений в SQL, даже если оно выглядит просто. Все другие предложения только переносят ссылки на таблицы от одного к другому. Предложение SELECT портит всю красоту этих ссылок, полностью их преобразовывая путем применения к ним правил.
Чтобы понять SQL, перед использованием оператора SELECT нужно усвоить все остальное. Даже если SELECT является первым предложением в лексической упорядоченности, он должен быть последним.
Выражение CASE – условный оператор языка SQL
| Первая форма: | Вторая форма: |
|---|---|
| CASE WHEN условие_1 THEN возвращаемое_значение_1 … WHEN условие_N THEN возвращаемое_значение_N END |
CASE проверяемое_значение WHEN сравниваемое_значение_1 THEN возвращаемое_значение_1 … WHEN сравниваемое_значение_N THEN возвращаемое_значение_N END |
Разберем на примере первую форму CASE:
| ID | Name | Salary | SalaryTypeWithELSE | SalaryTypeWithoutELSE |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | ЗП >= 3000 | ЗП >= 3000 |
| 1001 | Петров П.П. | 1500 | ЗП < 2000 | NULL |
| 1002 | Сидоров С.С. | 2500 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1003 | Андреев А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
| 1004 | Николаев Н.Н. | 1500 | ЗП < 2000 | NULL |
| 1005 | Александров А.А. | 2000 | 2000 <= ЗП < 3000 | 2000 <= ЗП < 3000 |
Разберем на примере вторую форму CASE:
- Сотрудникам ИТ-отдела выдать по 15% от ЗП;
- Сотрудникам Бухгалтерии по 10% от ЗП;
- Всем остальным по 5% от ЗП.
| ID | Name | Salary | DepartmentID | NewYearBonusPercent | BonusAmount |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | 1 | 5% | 250 |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 225 |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 250 |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 300 |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 225 |
| 1005 | Александров А.А. | 2000 | NULL | 5% | 100 |
- Первым делом ЗП должны получить сотрудники у кого оклад меньше 2500
- Те сотрудники у кого оклад больше или равен 2500, получают ЗП во вторую очередь
- Внутри этих двух групп нужно упорядочить строки по ФИО (поле Name)
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А.А. | 2000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П.П. | 1500 |
| 1000 | Иванов И.И. | 5000 |
| 1002 | Сидоров С.С. | 2500 |
| ID | Name | Salary | DepartmentID | NewYearBonusPercent1 | NewYearBonusPercent2 |
|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 5000 | 1 | 5% | 5% |
| 1001 | Петров П.П. | 1500 | 3 | 15% | 15% |
| 1002 | Сидоров С.С. | 2500 | 2 | 10% | 10% |
| 1003 | Андреев А.А. | 2000 | 3 | 15% | 15% |
| 1004 | Николаев Н.Н. | 1500 | 3 | 15% | 15% |
| 1005 | Александров А.А. | 2000 | NULL | — | 5% |
Новые возможности
Типы данных
Логические типы данных
Стандарт SQL: 1999 требует логического типа, но многие коммерческие SQL-серверы (База данных Oracle, IBM DB2 ) не поддерживают его как тип столбца, тип переменной и не допускают в наборе результатов. Microsoft SQL Server — одна из немногих систем баз данных, которая должным образом поддерживает значения BOOLEAN с использованием своего типа данных «BIT».[нужна цитата ]. Каждые 1–8-битные поля занимают на диске один полный байт. MySQL интерпретирует «BOOLEAN» как синоним TINYINT (8-битовое целое число со знаком).PostgreSQL предоставляет стандартный соответствующий логический тип








Определенные типы мощности, определяемые пользователем
Иногда называют просто отдельные типы, они были введены как дополнительная функция (S011), чтобы позволить существующим атомарным типам быть расширенными с отличительным значением для создания нового типа и, таким образом, позволяя механизму проверки типа обнаруживать некоторые логические ошибки, например случайно добавили возраст к зарплате. Например:
Создайте тип возраст в качестве целое число ФИНАЛЬНЫЙ;Создайте тип зарплата в качестве целое число ФИНАЛЬНЫЙ;
создает два разных и несовместимых типа. Различные типы SQL используют эквивалентность названий нет структурная эквивалентность подобно typedefs в C. По-прежнему возможно выполнять совместимые операции с (столбцами или данными) отдельных типов, используя явный тип .
Некоторые системы SQL поддерживают их. IBM DB2 один из тех, кто их поддерживает.База данных Oracle в настоящее время не поддерживает их, рекомендуя вместо этого подражать им в одном месте структурированный тип.
Структурированные пользовательские типы
Это основа объектно-реляционная база данных расширение в SQL: 1999. Они аналогичны классы в объектно-ориентированные языки программирования. SQL: 1999 позволяет только одинарное наследование.
Общие табличные выражения и рекурсивные запросы
В SQL: 1999 добавлена конструкция WITH , разрешающая рекурсивные запросы, например переходное закрытие, указывается в самом языке запросов; видеть общие табличные выражения.
В SQL: 1999 появилось ключевое слово UNNEST.
Подведем итоги
| Конструкция/Блок | Порядок выполнения | Выполняемая функция |
|---|---|---|
| SELECT возвращаемые выражения | 4 | Возврат данных полученных запросом |
| FROM источник | В нашем случае это пока все строки таблицы | |
| WHERE условие выборки из источника | 1 | Отбираются только строки, проходящие по условию |
| GROUP BY выражения группировки | 2 | Создание групп по указанному выражению группировки. Расчет агрегированных значений по этим группам, используемых в SELECT либо HAVING блоках |
| HAVING фильтр по сгруппированным данным | 3 | Фильтрация, накладываемая на сгруппированные данные |
| ORDER BY выражение сортировки результата | 5 | Сортировка данных по указанному выражению |
| SalaryAmount |
|---|
| 5000 |
| SalaryAmount |
|---|
| 2000 |
| 2500 |
| 5000 |