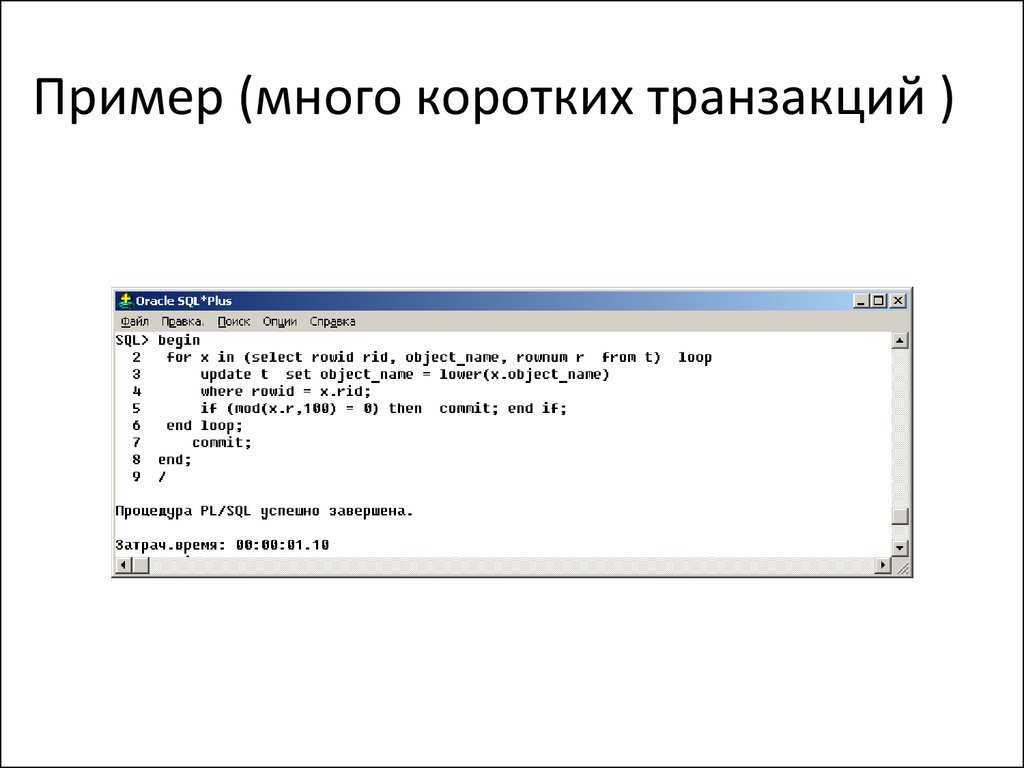
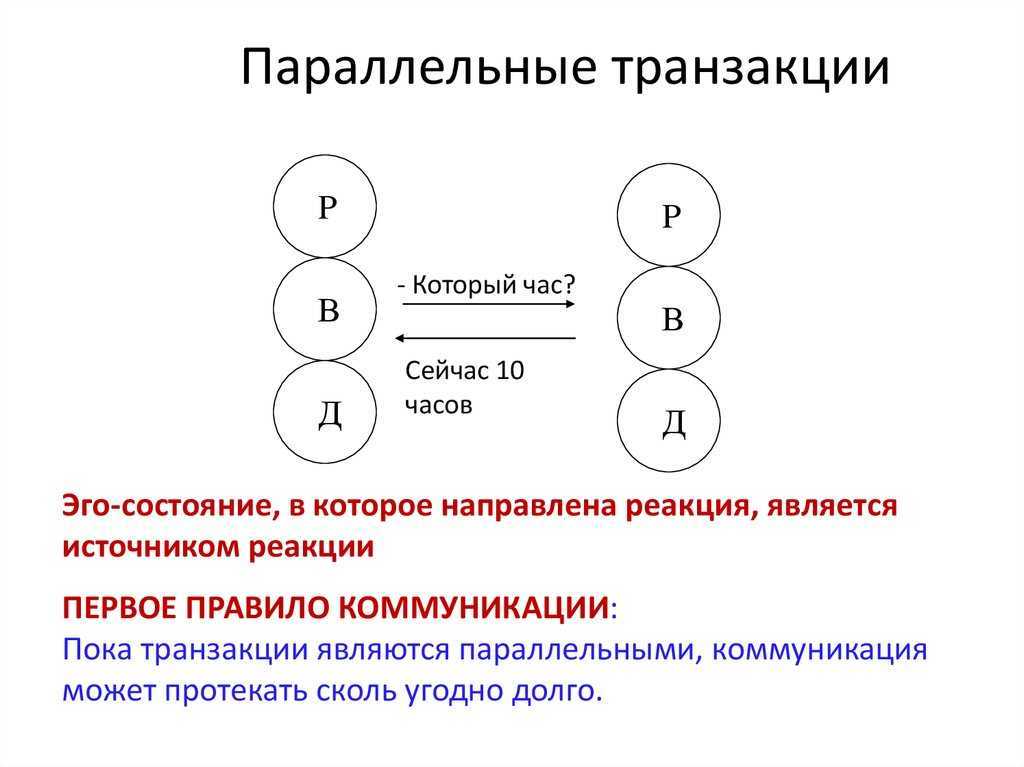
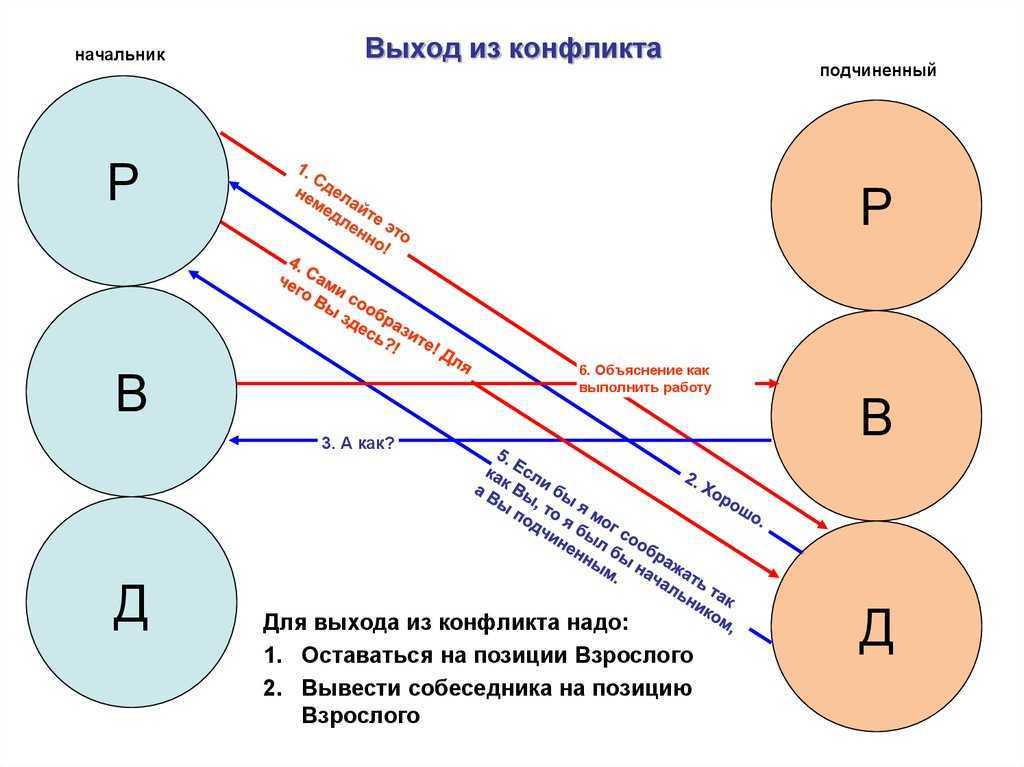
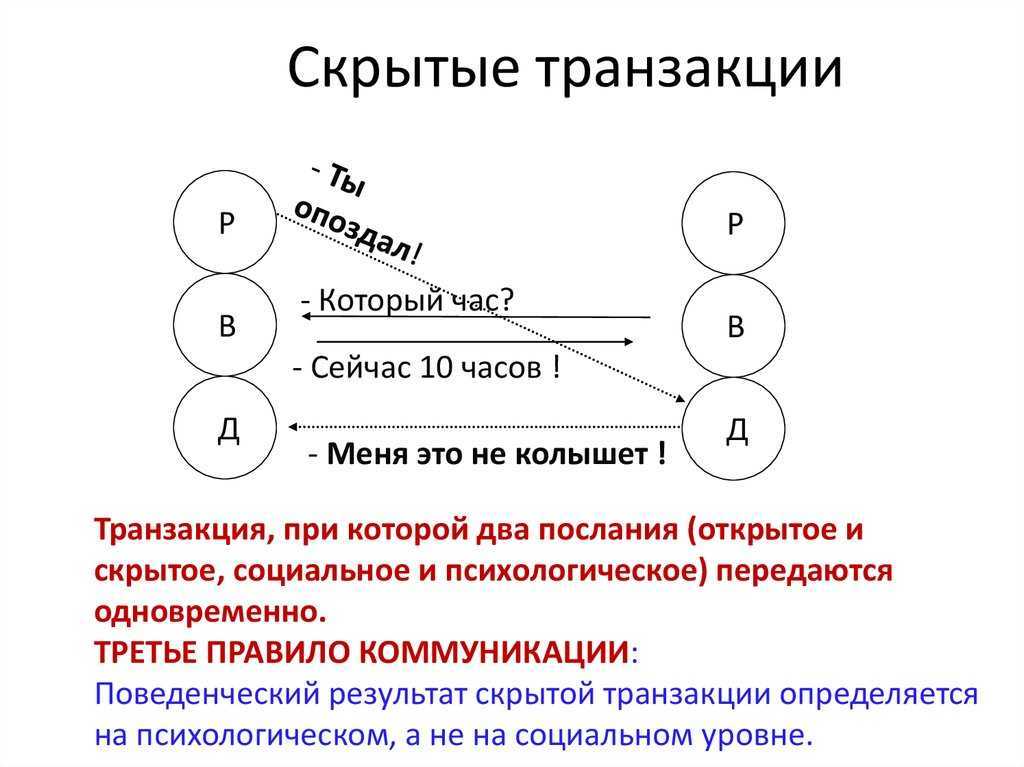
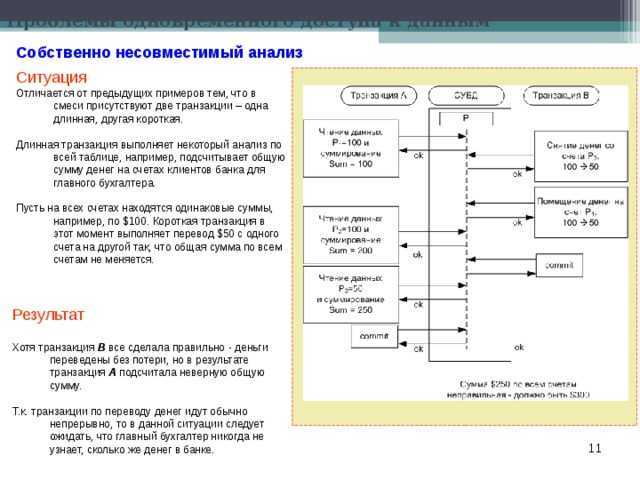
Выявление узких мест в производительности
Узкие места в производительности могут поставить под угрозу масштабируемость приложения, поэтому хорошо знать общие причины возникновения узких мест.
Монолитная база данных
Ваше приложение имеет высокую задержку. Само приложение хорошо спроектировано, и несколько узлов справляются с его рабочей нагрузкой. Ваше приложение может масштабироваться по горизонтали, и все выглядит нормально.
В чем может быть причина отставания? Вы можете иметь дело с монолитной базой данных, где одна база данных отвечает за обработку всех запросов данных для каждого узла сервера. Существует ограниченное количество запросов, на которые одна база данных может ответить одновременно.
Один из способов обеспечить масштабируемость базы данных — разумно использовать секционирование и сегментирование базы данных.
Разделение базы данных разбивает большие базы данных на более мелкие, известные как сегменты, чтобы ускорить поиск данных.
Например, предположим, что у вас есть база данных из 500 000 сотрудников по всему миру. Просматривать каждую из этих записей каждый раз, когда делается запрос, было бы огромной тратой времени.
Вы можете разделить эту базу данных на множество более мелких баз данных, организованных по континентам, странам, филиалам компании или другим образом.
Неправильный тип базы данных
Выбор подходящей базы данных для вашего приложения может существенно повлиять на задержку. Если вы собираетесь выполнять много транзакций и вам нужна строгая согласованность, то лучшим выбором будет использование реляционной базы данных.
В этом контексте сильная согласованность относится к данным, имеющим согласованные значения на всех узлах сервера в любой момент времени.
Если приоритетом для вашего приложения является не строгая согласованность, а горизонтальная масштабируемость, то база данных NoSQL будет хорошим выбором для вашей базы данных. Знание того, какой тип хранилища данных лучше всего подходит для нужд вашего бизнеса, и рассмотрение преимуществ одной технологии перед другой на раннем этапе — это простой способ избежать этого конкретного узкого места.
Архитектурные ошибки
Плохо спроектированная программная архитектура не всегда заметна поначалу, но со временем ее недостатки часто становятся очевидными. Выбор неправильной программной архитектуры может затруднить добавление новых функций и удорожить обслуживание, а также может значительно сократить срок службы программной системы.
Одним из примеров архитектурной ошибки является планирование последовательного выполнения процессов вместо асинхронного. Если вы имеете дело с несколькими одновременными запросами без каких-либо зависимостей, то асинхронные процессы и модули — это один из способов сократить время, затрачиваемое на выполнение этих запросов.
Начните рассматривать масштабируемость системы как можно раньше и создайте модели производительности, чтобы выявить потенциальные узкие места, прежде чем приступить к созданию.
Отсутствие кэширования
Неэффективное кэширование в приложении также может привести к проблемам с масштабируемостью
Кэширование жизненно важно для производительности любого приложения, обеспечивая низкую задержку и высокую пропускную способность. Кэши перехватывают все запросы к базе данных до того, как они попадут на исходные серверы
Перехват этих запросов позволяет базе данных высвободить ресурсы для работы с другими запросами.
Исходные серверы содержат исходную версию вашего веб-сайта, которая кэшируется серверами на периферии. CDN могут кэшировать и сжимать точные копии ваших веб-страниц, чтобы уменьшить время приема-передачи (RTT) и задержку.
Если вы работаете с системой со значительным объемом статических данных, кэширование любых часто используемых данных из базы данных и сохранение их в ОЗУ может ускорить время отклика и значительно снизить затраты на развертывание.
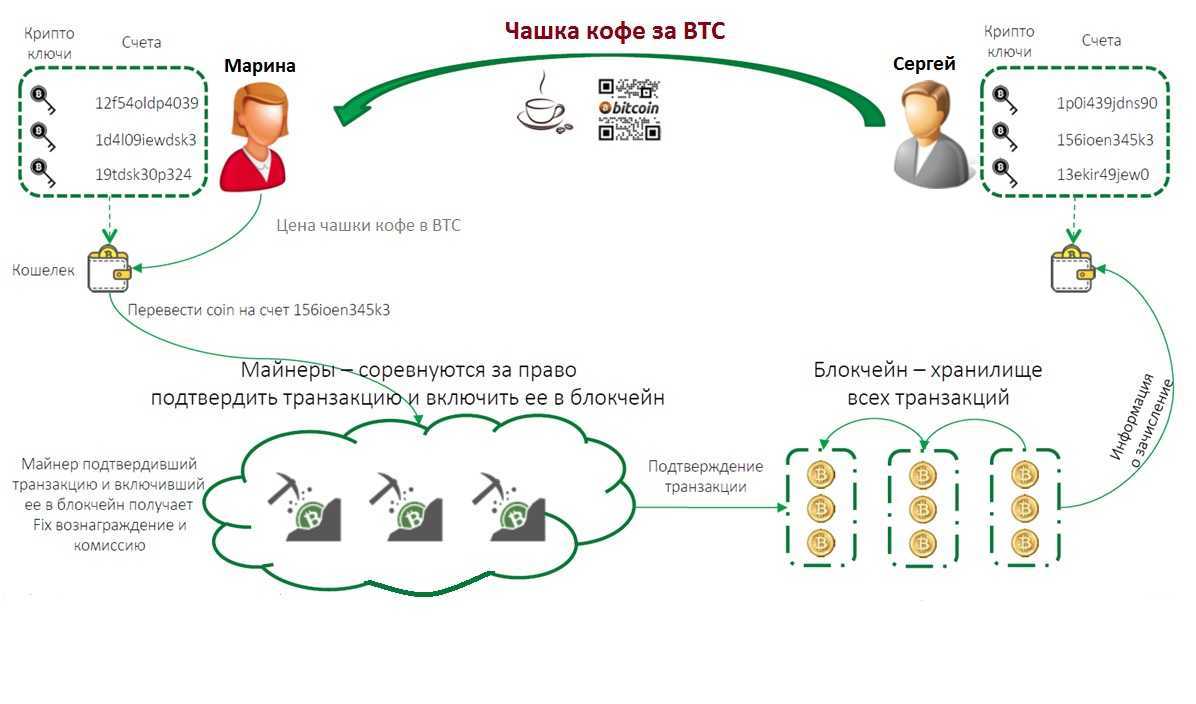
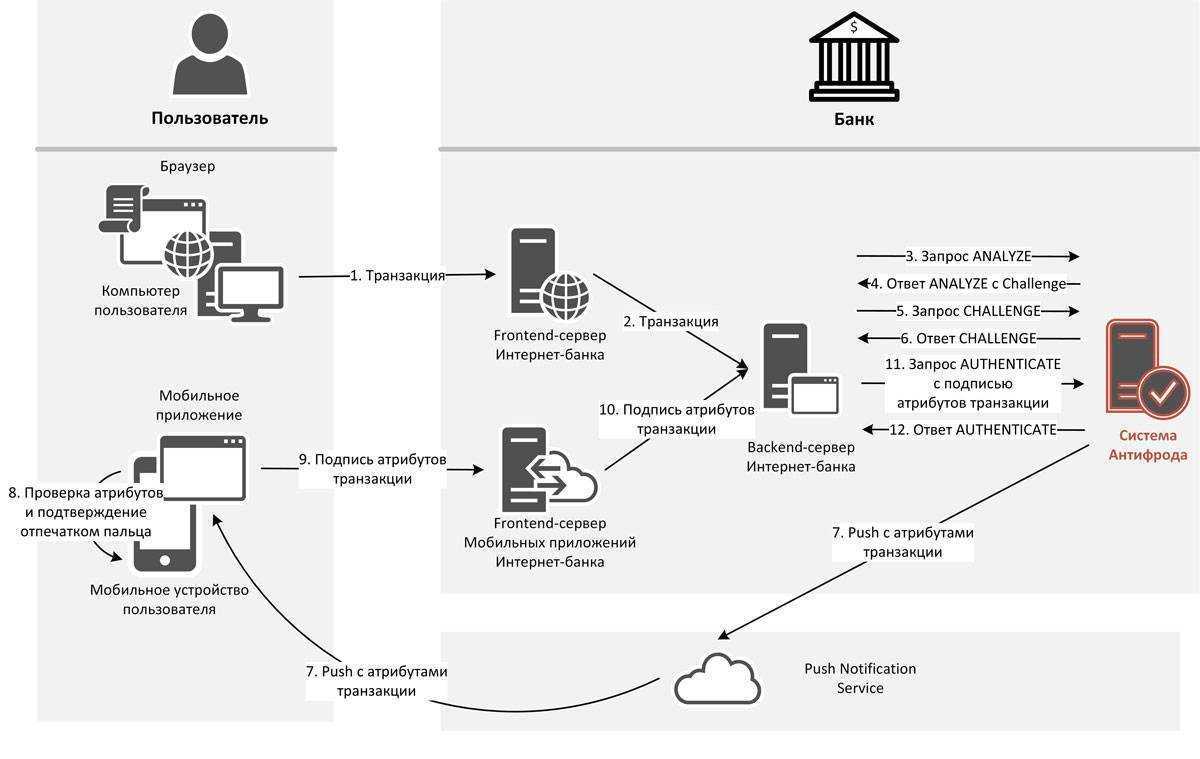
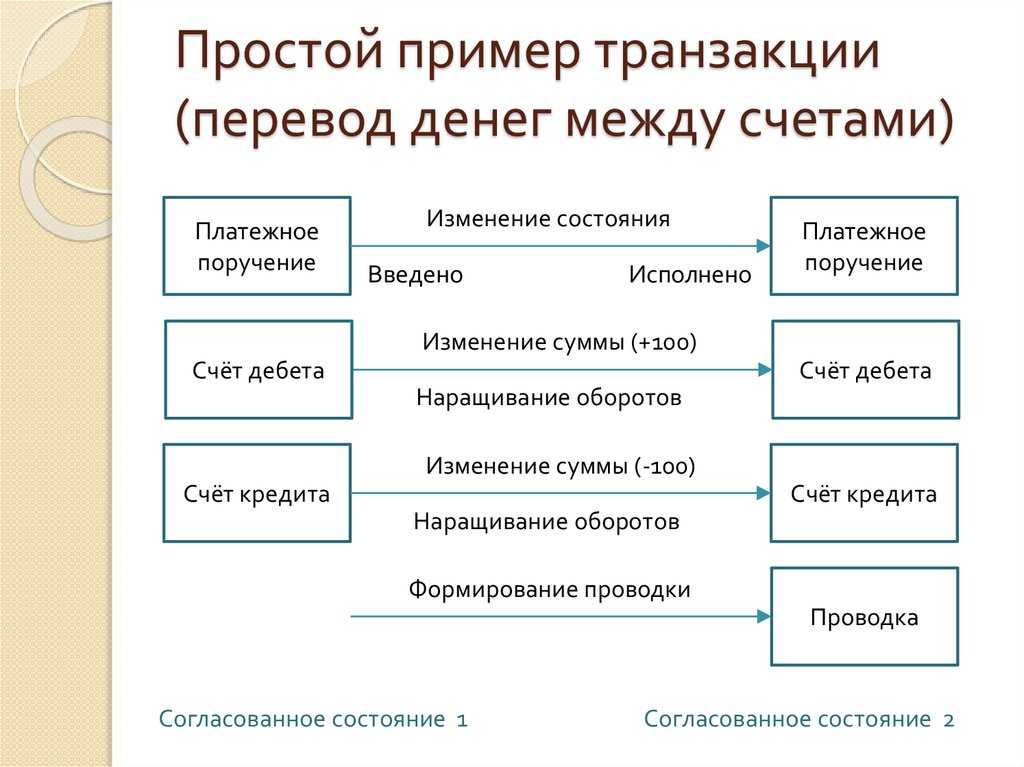
Как работают цифровые транзакции
Цифровая транзакция превращает традиционное общество операций с наличными деньгами в безналичное. Это может быть что угодно, от оплаты товаров в обычном магазине до перевода денег в Интернете и проведения инвестиционных сделок.
Вот пример повседневной транзакции, которая выглядит довольно простой, но на самом деле в нее встроены цифровые сложности на каждом этапе:
Джейн платит наличными каждый раз, когда идет в продуктовый магазин (Fresh Chain). Это означает, что каждый раз, когда у нее заканчиваются наличные, она должна совершать поездку в свой банк (Future Bank), чтобы пополнить свой кошелек. К сожалению, если ей понадобится немного наличных после закрытия или в выходные, ей придется подождать до следующего рабочего дня, когда Future Bank откроется. Чтобы включить Джейн в мир цифровых финансов, Future Bank предоставляет Джейн дебетовую карту, автоматически связанную с ее текущим счетом. В следующий раз, когда Джейн пойдет за продуктами в Fresh Chain, она проведет своей картой через портативное устройство обработки платежей, известное как Point of Sale (POS). Оплата производится в считанные секунды, и довольная Джейн идет домой.
Теперь давайте посмотрим на закулисную цифровую транзакцию. Дебетовая карта, выданная Джейн, является картой Visa. Visa создает карты, подобные Jane’s, с магнитной полосой, на которой информация хранится в цифровом виде. Когда Джейн проводит магнитной полосой по кассовому терминалу или платежному процессору, информация о транзакции передается в Visa. Платежный процессор действует как посредник между Visa и Fresh Chain. Visa принимает к сведению информацию, полученную от платежной системы, и направляет ее в Future Bank для утверждения. Future Bank подтверждает, что на текущем счете Джейн есть необходимые средства для завершения покупки, и санкционирует транзакцию. Затем Visa передает эту информацию через кассовый терминал в качестве авторизованной транзакции.
Точная сумма транзакции списывается с текущего счета Джейн, и процент от этой суммы, скажем, 98%, зачисляется на счет Fresh Chain. Оставшиеся 2% делятся между Future Bank и Visa в качестве их комиссии. Хотя процесс кажется долгим, на самом деле это происходит за секунды.
Три обобщенных схемы
Схема 1: современная бизнес-аналитика
Облачно-ориентированная бизнес-аналитика для компаний любого размера — простая в использовании, недорогая для начала работы и более масштабируемая, чем предыдущие модели хранилищ данных.
Эта схема постепенно становится вариантом по умолчанию для компаний с относительно небольшими командами и бюджетами. Предприятия также все чаще переходят с устаревших хранилищ данных на эту схему, пользуясь преимуществами гибкости и масштабируемости облака.
Основные варианты использования включают отчеты, дашборды и специальный анализ, в основном с использованием SQL (и некоторого количества Python) для анализа структурированных данных.
К сильным сторонам этой модели относятся низкие первоначальные инвестиции, скорость и простота начала работы, а также широкая доступность кадров. Этот план менее приемлем для команд, у которых есть более сложные потребности в данных, включая обширную data science, машинное обучение или приложения для потоковой передачи / с низкой задержкой.
Схема 2: мультимодальная обработка данных
Новейшие озера данных, поддерживающие как аналитические, так и оперативные варианты использования, также известные как современная инфраструктура для Hadoop-беженцев
Перейдите сюда, чтобы просмотреть версию в высоком разрешении.
Эта модель наиболее часто встречается на крупных предприятиях и технологических компаний с сложными, высокотехнологичными потребностями в обработке данных.
Сценарии использования включают в себя как бизнес-аналитику, так и более продвинутые функции, включая оперативный AI/ML, аналитику, чувствительную к потоковой передаче / задержке, крупномасштабные преобразования данных и обработку различных типов данных (включая текст, изображения и видео) с использованием целого набора языков (Java/Scala, Python, SQL).
Сильные стороны этого шаблона включают гибкость для поддержки разнообразных приложений, инструментальных средств, определяемых пользователем функций и контекстов развертывания, а также преимущество в стоимости на больших наборах данных. Этот план менее приемлем для компаний, которые только хотят начать работу или имеют небольшие команды обработки данных — его поддержание требует значительных временных, денежных затрат и опыта.

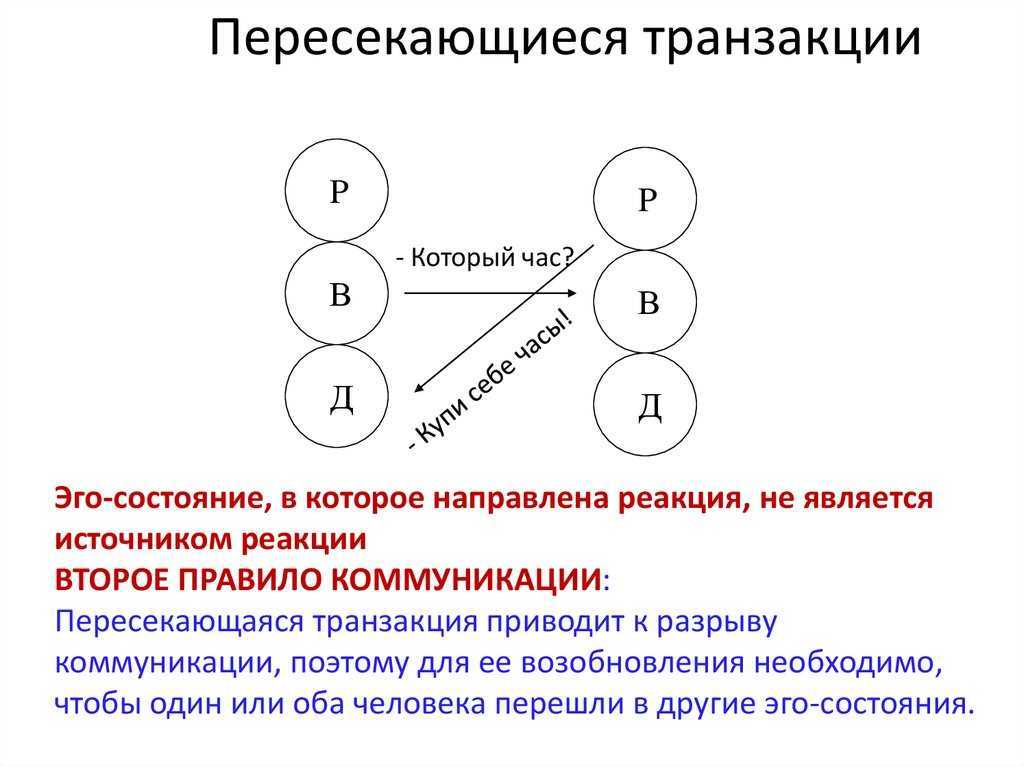
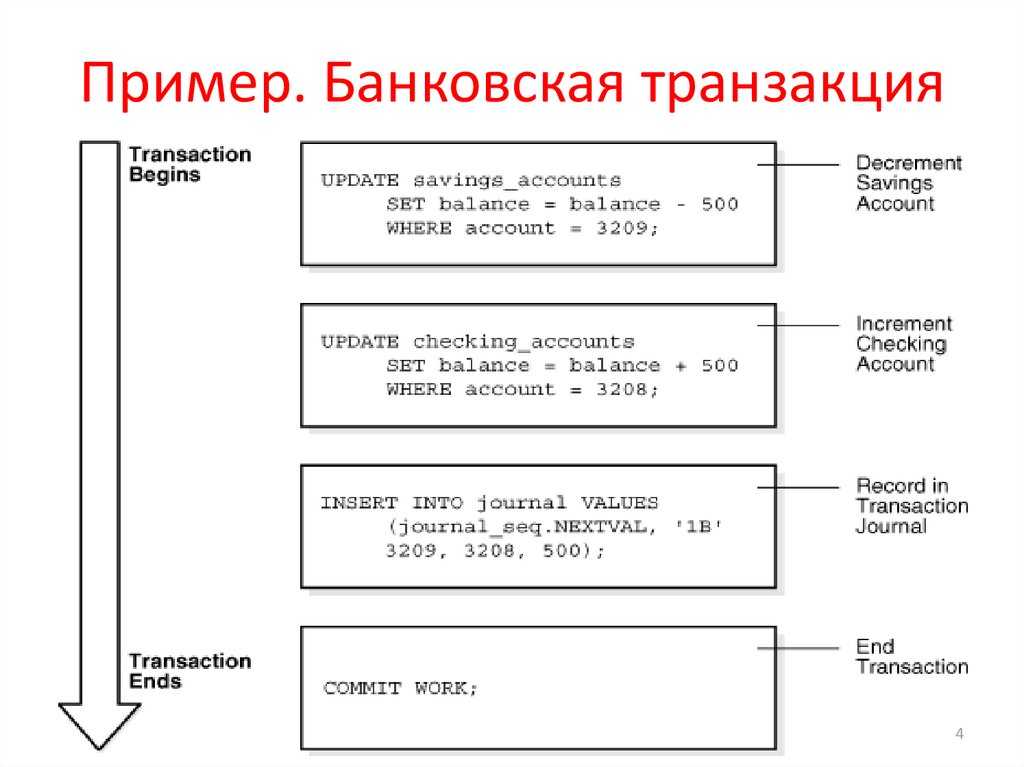






Схема 3: Искусственный интеллект и машинное обучение.
Совершенно новый, еще развивающийся стек для поддержки надежной разработки, тестирования и эксплуатации моделей машинного обучения.
Большинство компаний, занимающихся машинным обучением, уже используют некоторую часть технологий из этого шаблона. Серьезные специалисты по машинному обучению часто реализуют полную схему, полагаясь на собственные разработки в качестве недостающих инструментов.
Основные варианты использования сосредоточены на возможностях работы с данными как для внутренних, так и для клиентских приложений — запускаемых либо онлайн (т. е. в ответ на ввод данных пользователем), либо в пакетном режиме.
Сильной стороной этого подхода, в отличие от готовых решений машинного обучения, является полный контроль над процессом разработки, создание большей ценности для пользователей и формирование ИИ / машинного обучения как основного долгосрочного ресурса. Этот план менее приемлем для компаний, которые только тестируют машинное обучение, используют его для менее масштабных, внутренних вариантов использования или тех, кто предпочитает полагаться на вендоров — масштабное машинное обучение сегодня является одной из самых сложных задач обработки данных.
Смотря в будущее
Инфраструктура данных претерпевает быстрые фундаментальные изменения на архитектурном уровне. Создание современного стека данных включает в себя разнообразный и постоянно растущий набор вариантов. И сделать правильный выбор сейчас важнее, чем когда-либо, поскольку мы продолжаем переходить от программного обеспечения, основанного исключительно на коде, к системам, которые объединяют код и данные для обеспечения ценности. Эффективные возможности обработки данных теперь являются главной ставкой для компаний во всех секторах, и выигрыш в данных может обеспечить твердое конкурентное преимущество.
Мы надеемся, что эта статья послужит ориентиром, который поможет организациям, работающим с данными, понять текущее состояние дел, реализовать архитектуру, которая наилучшим образом соответствует потребностям их бизнеса, и спланировать будущее в условиях непрекращающейся эволюции в этой сфере.
Характеристики
Лидеры транзакций используют награды и наказания, чтобы добиться согласия со стороны своих последователей. В любом случае транзакционных лидеров не волнует благополучие рабочих по сравнению с трансформационным лидерством. Это внешние мотиваторы, которые приносят минимальное согласие со стороны последователей. Они принимают цели, структуру и культуру существующей организации. Лидеры транзакций склонны быть директивными и ориентированными на действия. Трансформационные лидеры хотят, чтобы последователи добивались внутренней мотивации и выполняли свою работу…
Лидеры транзакций готовы работать в рамках существующих систем и вести переговоры для достижения целей организации. При решении проблем они склонны мыслить нестандартно. С другой стороны, трансформационные лидеры прагматичны и при решении проблем мыслят нестандартно.
Транзакционное лидерство в первую очередь пассивно. С другой стороны, трансформационное лидерство интерактивно и вдохновляет. Поведение, наиболее связанное с этим типом лидерства, устанавливает критерии вознаграждения последователей и поддержания статус-кво.
Общая эффективность управления транзакциями заключается в том, что оно может быть очень практичным и директивным. Посредством управления транзакциями явную меру успеха можно обнаружить через постоянный мониторинг менеджеров. Модель также считается очень простой и понятной из-за простой системы вознаграждений и наказаний.
В рамках транзакционного лидерства есть два фактора: условное вознаграждение и индивидуальное управление. Условное вознаграждение предусматривает вознаграждение за усилия и признание хорошей работы. Управление в порядке исключения поддерживает статус-кво, вмешивается, когда подчиненные не соответствуют приемлемому уровню производительности, и инициирует корректирующие действия для повышения производительности.
Преимущества транзакционного лидерства во многом зависят от обстоятельств — его преимущества не будут реализованы во всех ситуациях. Там, где это может быть полезно, есть явные преимущества, но есть и некоторые недостатки. Некоторые из преимуществ включают в себя вознаграждение людей, которые мотивированы и следуют инструкциям, его преимущества, как правило, быстро реализуются при быстром достижении краткосрочных целей, у работников четко определены вознаграждения и штрафы, он способствует продуктивности, обеспечивает ясную и простую для понимания структуры он отлично подходит для рабочих сред, где необходимо воспроизвести структуру и системы (например, при крупносерийном производстве), и служит для согласования всех в крупных организациях.
С другой стороны, у транзакционного лидерства есть свои недостатки: оно плохо работает в гибкой рабочей среде, оно вознаграждает рабочих только льготами или деньгами, никаких других реальных мотиваторов не используется, оно не вознаграждает людей, проявляющих личную инициативу, его можно рассматривать как ограничивающий, а не личный, творческий потенциал сотрудников ограничен или отсутствует, структуры могут быть очень жесткими, и нет места для гибкости в целях и задачах.[нужна цитата ]
Оркестровка
В модульном монолите мы используем локальные транзакции и всегда знаем состояние системы. Распределенные транзакции, основанные на протоколе двухфазной фиксации, также гарантируют согласованное состояние. Единственным исключением может быть неисправимый сбой, связанный с координатором транзакции. Но что, если бы мы хотели упростить требования к согласованности, при этом зная состояние всей распределенной системы и координируя ее из одного места? В этом случае мы можем рассмотреть оркестровку — подход, при котором одна из служб действует как координатор и оркестратор общего изменения распределенного состояния. Служба оркестратора обязана вызывать другие службы, пока они не достигнут желаемого состояния, или предпринимать корректирующие действия в случае сбоя. Оркестратор использует свою локальную базу данных для отслеживания изменений состояния и отвечает за восстановление любых сбоев, связанных с изменениями состояния.
Реализация архитектуры оркестровки
Самыми популярными реализациями техники оркестрации являются реализации спецификации BPMN, такие как проекты jBPM и Camunda . Потребность в таких системах не исчезает из-за чрезмерно распределенных архитектур, таких как микросервисы или бессерверные архитектуры, а, наоборот, увеличивается. В качестве доказательства мы можем обратиться к более новым механизмам оркестровки с отслеживанием состояния, которые не соответствуют спецификации, но обеспечивают аналогичное поведение с отслеживанием состояния, например, Netflix Conductor, Uber Cadence и Apache Airflow. Бессерверные архитектуры с отслеживанием состояния, такие как Amazon StepFunctions, Azure Durable Functions и Azure Logic Apps, также относятся к этой категории. Кроме того, существуют библиотеки с открытым исходным кодом, которые позволяют реализовать поведение координации и отката с отслеживанием состояния, такие как реализация шаблона Apache Camel Saga и функциональность NServiceBus Saga . Многие встроенные реализации паттерна «Saga» также относятся к этой категории.
Рисунок 5: Организация распределенных транзакций между двумя сервисами
В нашем примере диаграммы, показанном на рисунке 5, у нас есть служба A, действующая как оркестратор с отслеживанием состояния, ответственный за вызов службы B и восстановление после сбоев с помощью операции компенсации, если это необходимо. Важнейшей характеристикой этого подхода является то, что служба A и служба B имеют локальные границы транзакций, но служба A обладает знаниями и обязанностью управлять общим потоком взаимодействия. Вот почему его граница транзакции касается конечных точек службы B. Что касается реализации, мы могли бы использовать синхронный подход, как показано на диаграмме, или асинхронный с помощью очереди сообщений между службами (в этом случае вы также можете использовать двухфазную фиксацию).
Преимущества и недостатки оркестровки
Оркестровка — это подход, обеспечивающий согласованность-в-конечном-счете, который может включать повторные попытки и откаты для приведения системы в согласованное состояние. Хотя это позволяет избежать необходимости в распределенных транзакциях, оркестровка требует, чтобы участвующие службы предлагали идемпотентные операции в случае, если координатор должен повторить операцию. Взаимодействующие службы также должны предлагать конечные точки восстановления на случай, если координатор решит откатиться и исправить глобальное состояние.
Большим преимуществом этого подхода является возможность приводить разнородные службы, которые могут не поддерживать распределенные транзакции, в согласованное состояние, используя только локальные транзакции. Координатору и участвующим службам нужны только локальные транзакции, и всегда можно узнать состояние системы, спросив координатора, даже если система находится в частично согласованном состоянии.
|
Преимущества |
Координирует состояние разнородных распределенных компонентов. Нет необходимости в транзакциях XA. Известное распределенное состояние на уровне координатора. |
|
Недостатки |
Сложная модель распределенного программирования. Может потребоваться идемпотентность и компенсационные операции от участвующих служб. Конечная последовательность. Возможны неисправимые отказы при компенсациях. |
|
Примеры |
jBPM Camunda MicroProfile Long Running Actions Netflix Conductor Uber Cadence Amazon StepFunctions Azure Durable Functions Реализация паттерна Apache Camel Saga Реализация паттерна NServiceBus Saga Спецификация CNCF Serverless Workflow Встроенные реализации паттерна Saga |
внешняя ссылка
Шульц и Шульц, Дуэйн (2010). Психология и работа сегодня. Нью-Йорк: Прентис-Холл. С. 164. ISBN 0-205-68358-4.




- Бисио, П., Хакетт, Р. Д., и Аллен, Дж. С. (1995). Дальнейшие оценки концептуализации трансакционного и трансформационного лидерства Басса (1985). Журнал прикладной психологии, 80 (4), 468-478.
- Хауэлл, Дж. М., и Аволио, Б. Дж. (1993). Трансформационное лидерство, транзакционное лидерство, локус контроля и поддержка инноваций: ключевые факторы, предсказывающие эффективность консолидированного бизнес-подразделения. Журнал прикладной психологии, 78 (6), 891-902.
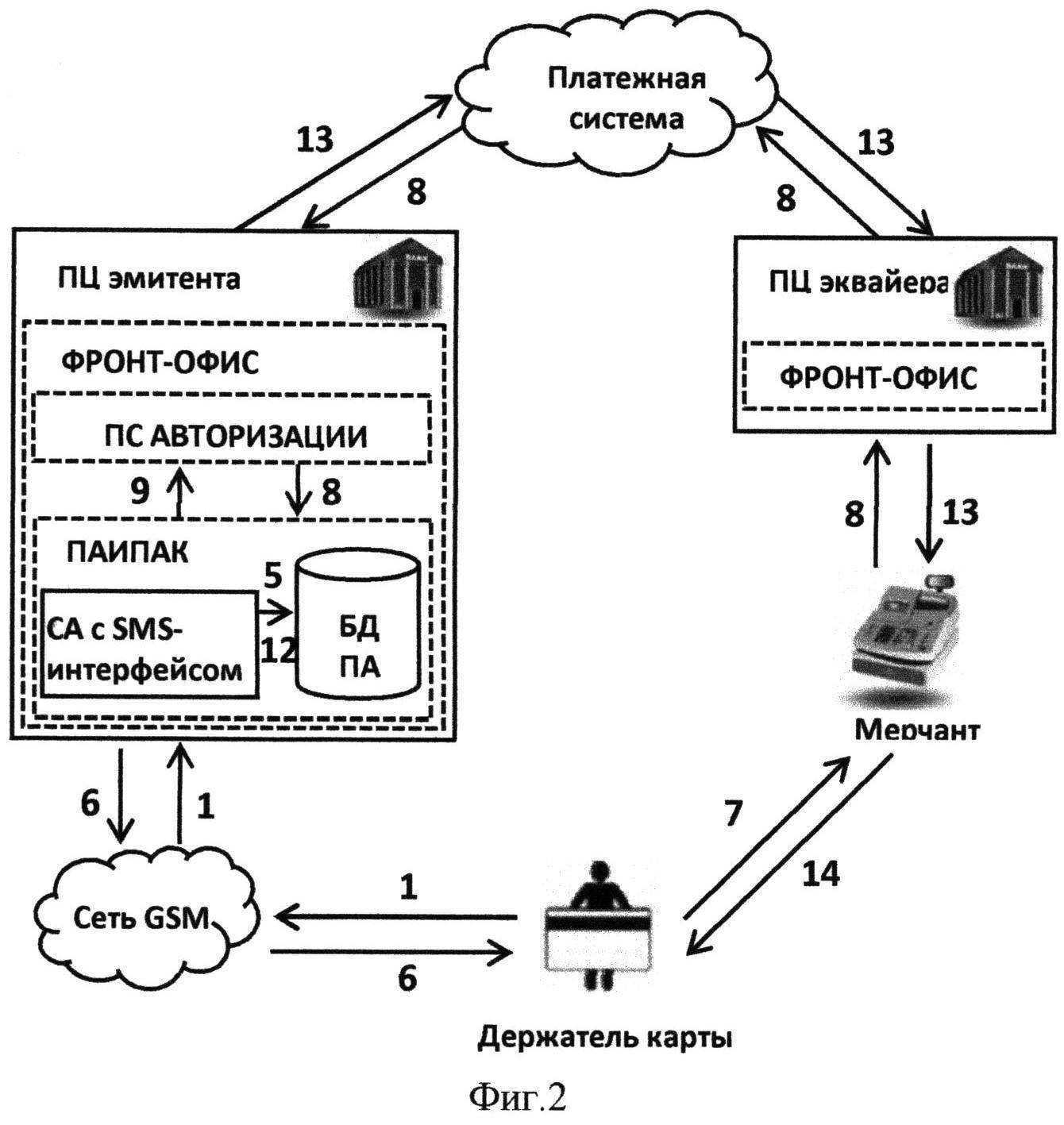
Развертывание failover-кластера
Процедуру установки кластера можно разделить на четыре этапа. На первом этапе необходимо сконфигурировать аппаратную часть, которая должна соответствовать The Microsoft Support Policy for Windows Server 2008 Failover Clusters. Все узлы кластера должны состоять из одинаковых или сходных компонентов. Все узлы кластера должны иметь доступ к хранилищу, созданному с использованием FibreChannel, iSCSI или Serial Attached SCSI. От хранилищ, работающих с Windows Server 2008, требуется поддержка persistent reservations.
На втором этапе на каждый узел требуется добавить компонент Failover Clustering — например, через Server Manager. Эту задачу можно выполнять с использованием учетной записи, обладающей административными правами на каждом узле. Серверы должны принадлежать к одному домену. Желательно, чтобы все узлы кластера были с одинаковой ролью, причем лучше использовать роль member server, так как роль domain controller чревата возможными проблемами с DNS и Exchange.
Третий не обязательный, но желательный этап заключается в проверке конфигурации. Проверка запускается через оснастку Failover Cluster Management. Если для проверки конфигурации указан только один узел, то часть проверок будет пропущена.
На четвертом этапе создается кластер. Для этого из Failover Cluster Management запускается мастер Create Cluster, в котором указываются серверы, включаемые в кластер, имя кластера и дополнительные настройки IP-адреса. Если серверы подключены к сетям, которые не будут использоваться для общения в рамках кластера (например, подключение только для обмена данными с хранилищем), то в свойствах этой сети в Failover Cluster Management необходимо установить параметр «Do not allow the cluster to use this network».
После этого можно приступить к настройке приложения, которое требуется сконфигурировать для обеспечения его высокой доступности.
Для этого необходимо запустить High Availability Wizard, который можно найти в Services and Applications оснастки Failover Cluster Management.
Виды кластеров
Кластер — это группа независимых компьютеров (так называемых узлов или нодов), к которой можно получить доступ как к единой системе. Кластеры могут быть предназначены для решения одной или нескольких задач. Традиционно выделяют три типа кластеров:
- Кластеры высокой готовности или отказоустойчивые кластеры (high-availability clusters или failover clusters) используют избыточные узлы для обеспечения работы в случае отказа одного из узлов.
- Кластеры балансировки нагрузки (load-balancing clusters) служат для распределения запросов от клиентов по нескольким серверам, образующим кластер.
- Вычислительные кластеры (compute clusters), как следует из названия, используются в вычислительных целях, когда задачу можно разделить на несколько подзадач, каждая из которых может выполняться на отдельном узле. Отдельно выделяют высокопроизводительные кластеры (HPC — high performance computing clusters), которые составляют около 82% систем в рейтинге суперкомпьютеров Top500.
Системы распределенных вычислений (gird) иногда относят к отдельному типу кластеров, который может состоять из территориально разнесенных серверов с отличающимися операционными системами и аппаратной конфигурацией. В случае грид-вычислений взаимодействия между узлами происходят значительно реже, чем в вычислительных кластерах. В грид-системах могут быть объединены HPC-кластеры, обычные рабочие станции и другие устройства.
Такую систему можно рассматривать как обобщение понятия «кластер». ластеры могут быть сконфигурированы в режиме работы active/active, в этом случае все узлы обрабатывают запросы пользователей и ни один из них не простаивает в режиме ожидания, как это происходит в варианте active/passive.
Oracle RAC и Network Load Balancing являются примерами active/ active кластера. Failover Cluster в Windows Server служит примером active/passive кластера. Для организации active/active кластера требуются более изощренные механизмы, которые позволяют нескольким узлам обращаться к одному ресурсу и синхронизовать изменения между всеми узлами. Для организации кластера требуется, чтобы узлы были объединены в сеть, для чего наиболее часто используется либо традиционный Ethernet, либо InfiniBand.
Программные решения могут быть довольно чувствительны к задержкам — так, например, для Oracle RAC задержки не должны превышать 15 мс. В качестве технологий хранения могут выступать Fibre Channel, iSCSI или NFS файловые сервера. Однако оставим аппаратные технологии за рамками статьи и перейдем к рассмотрению решений на уровне операционной системы (на примере Windows Server 2008 R2) и технологиям, которые позволяют организовать кластер для конкретной базы данных (OracleDatabase 11g), но на любой поддерживаемой ОС.
Типы систем обработки транзакций
Пришло время разобраться в типах систем обработки транзакций, которые делятся на два вида. Обработка в пакетном режиме, а также обработка в режиме реального времени. Давайте теперь посмотрим на них.
Пакетная обработка
Пакетная обработка — это метод, который может быть полезен для сбора и обработки больших объемов данных. Когда это будет проще или дешевле, транзакции будут собираться и обновляться партиями. В прошлом это был наиболее распространенный метод из-за отсутствия возможностей обработки в реальном времени в информационных технологиях.
Примером пакетной обработки является ежемесячное членское обслуживание. Поскольку транзакции происходят одновременно, система обрабатывает их как пакет в конце месяца, когда каждый клиент оплачивает услугу. Поскольку система сканирует пакеты только один раз в месяц, задержка в обработке транзакций в этом случае допустима.
Обработка в режиме реального времени
В других типах систем обработки транзакций это обработка данных в реальном времени. Это позволяет быстро подтверждать транзакции. Это может повлечь за собой одновременное выполнение транзакций по изменению данных большим количеством пользователей. Благодаря техническим разработкам теперь возможно обновление в режиме реального времени. Например, веб-сайт электронной коммерции может использовать TPS для обработки транзакций по кредитным картам в режиме реального времени для проверки платежа перед началом процесса выполнения.
Повышение грамотности населения
Обычных людей не сильно волнует вопрос о том, что такое транзакция, хоть все сталкиваются с этим процессом постоянно. А вот непонятные слова или предметы их пугают. Если человек получил зарплату наличными – это четко и понятно, а если пришел перевод на банковскую карту – это настораживает. Если произносится фраза, что человек снял деньги в банкомате, всем все понятно. А если сказать, что произошла транзакция денег, это напрягает окружающих. И дело здесь не в ограниченности людей. Людям старшего возраста трудно перестроиться вообще на все новое. Молодежь часто выхватывает из потока информации только то, что ей кажется нужным и полезным. Сейчас нужно еще со школьной скамьи готовить не только к требованиям современного мира, но и к готовности получать новую информацию на протяжении всей последующей жизни.
Oracle RAC
Oracle Real Application Clusters (RAC) — это дополнительная опция Oracle Database, которая впервые появилась в Oracle Database 9i под названием OPS (Oracle Parallel Server). Опция предоставляет возможность нескольким экземплярам совместно обращаться к одной базе данных. Базой данных в Oracle Database называет ся совокупность файлов данных, журнальных файлов, файлов параметров и некоторых других типов файлов. Для того, чтобы пользовательские процессы могли получить доступ к этим данным, должен быть запущен экземпляр. Экземпляр (instance) в свою очередь состоит из структур памяти (SGA) и фоновых процессов. В отсутствии RAC получить доступ к базе данных может строго один экземпляр.
Опция RAC не поставляется с Enterprise Edition и приобретается отдельно. Стоит отметить, что при этом RAC идет в составе Standard Edition, но данная редакция обладает большим количеством ограничений по сравнению с Enterprise Edition, что ставит под сомнение целесообразность ее использования.
Заключение
Что предлагает Serum?
Токен Serum (SRM)
SRM — это маркер полезности и управления экосистемы Serum
SRM будет полностью интегрирован в Serum и получит выгоду от покупки/сжигания сборов.
Книга заказов
Децентрализованный автоматизированный полный лимитный справочник ордеров дает трейдерам полный контроль над своими ордерами, в отличие от AMM
Книга заказов и сопоставление полностью автоматизированы по цепочке, а заказы поступают от конечных пользователей Serum
Скорость и стоимость Solana
Solana позволяет осуществлять торговлю и расчеты в течение секунды сверхнизких транзакционных издержек в размере 0,00001 долларов США за транзакцию
Кросс-чейн соединение
Wormhole — это кроссчейн мост, который позволяет пользователям превращать токены ERC20 в токены SPL. Этот мост позволяет пользователям воспользоваться скоростью и стоимостью Solana и вернуться к сети Ethereum.