Возможно, вам также будет интересно
Объединение энергоэффективной сети дальнего радиуса действия и Bluetooth с низким энергопотреблением позволяет корпоративному «Интернету вещей» подключаться по беспроводной сети к самым удаленным объектам, что весьма актуально в сложных условиях индустриальной среды.
Надо уметь не только говорить, но и слушать — помня об этом, журналисты Control Engineering Россия задали несколько интересующих их вопросов специалистам, авторитетному мнению которых можно доверять. В результате за одним, неожиданно круглым, столом разместились две взаимосвязанные темы — электропривод и робототехника.
В компании ТОО ”Спецэнержи” введена в эксплуатацию интегрированная система диагностики, оценки состояния и управления ремонтами оборудования. Платформой для интеграции послужил программный комплекс TRIM.
ТОО ”Спецэнержи” (г. Жанаозен, Республика Казахстан) осуществляет сервисное обслуживание сети станций нефтеперекачки на магистральном нефтепроводе АО ”КазТрансОйл”. Являясь сервисной организацией, ”Спецэнержи” несет ответственность перед заказчиком за работоспособность насосного и другого оборудования. При этом вопросы вывода в ремонт, обоснования и оптимизации затрат на сервис находятся в …
Три обобщенных схемы
Схема 1: современная бизнес-аналитика
Облачно-ориентированная бизнес-аналитика для компаний любого размера — простая в использовании, недорогая для начала работы и более масштабируемая, чем предыдущие модели хранилищ данных.
Эта схема постепенно становится вариантом по умолчанию для компаний с относительно небольшими командами и бюджетами. Предприятия также все чаще переходят с устаревших хранилищ данных на эту схему, пользуясь преимуществами гибкости и масштабируемости облака.
Основные варианты использования включают отчеты, дашборды и специальный анализ, в основном с использованием SQL (и некоторого количества Python) для анализа структурированных данных.
К сильным сторонам этой модели относятся низкие первоначальные инвестиции, скорость и простота начала работы, а также широкая доступность кадров. Этот план менее приемлем для команд, у которых есть более сложные потребности в данных, включая обширную data science, машинное обучение или приложения для потоковой передачи / с низкой задержкой.
Схема 2: мультимодальная обработка данных
Новейшие озера данных, поддерживающие как аналитические, так и оперативные варианты использования, также известные как современная инфраструктура для Hadoop-беженцев
Перейдите сюда, чтобы просмотреть версию в высоком разрешении.
Эта модель наиболее часто встречается на крупных предприятиях и технологических компаний с сложными, высокотехнологичными потребностями в обработке данных.
Сценарии использования включают в себя как бизнес-аналитику, так и более продвинутые функции, включая оперативный AI/ML, аналитику, чувствительную к потоковой передаче / задержке, крупномасштабные преобразования данных и обработку различных типов данных (включая текст, изображения и видео) с использованием целого набора языков (Java/Scala, Python, SQL).
Сильные стороны этого шаблона включают гибкость для поддержки разнообразных приложений, инструментальных средств, определяемых пользователем функций и контекстов развертывания, а также преимущество в стоимости на больших наборах данных. Этот план менее приемлем для компаний, которые только хотят начать работу или имеют небольшие команды обработки данных — его поддержание требует значительных временных, денежных затрат и опыта.
Схема 3: Искусственный интеллект и машинное обучение.
Совершенно новый, еще развивающийся стек для поддержки надежной разработки, тестирования и эксплуатации моделей машинного обучения.
Большинство компаний, занимающихся машинным обучением, уже используют некоторую часть технологий из этого шаблона. Серьезные специалисты по машинному обучению часто реализуют полную схему, полагаясь на собственные разработки в качестве недостающих инструментов.
Основные варианты использования сосредоточены на возможностях работы с данными как для внутренних, так и для клиентских приложений — запускаемых либо онлайн (т. е. в ответ на ввод данных пользователем), либо в пакетном режиме.
Сильной стороной этого подхода, в отличие от готовых решений машинного обучения, является полный контроль над процессом разработки, создание большей ценности для пользователей и формирование ИИ / машинного обучения как основного долгосрочного ресурса. Этот план менее приемлем для компаний, которые только тестируют машинное обучение, используют его для менее масштабных, внутренних вариантов использования или тех, кто предпочитает полагаться на вендоров — масштабное машинное обучение сегодня является одной из самых сложных задач обработки данных.
Смотря в будущее
Инфраструктура данных претерпевает быстрые фундаментальные изменения на архитектурном уровне. Создание современного стека данных включает в себя разнообразный и постоянно растущий набор вариантов. И сделать правильный выбор сейчас важнее, чем когда-либо, поскольку мы продолжаем переходить от программного обеспечения, основанного исключительно на коде, к системам, которые объединяют код и данные для обеспечения ценности. Эффективные возможности обработки данных теперь являются главной ставкой для компаний во всех секторах, и выигрыш в данных может обеспечить твердое конкурентное преимущество.
Мы надеемся, что эта статья послужит ориентиром, который поможет организациям, работающим с данными, понять текущее состояние дел, реализовать архитектуру, которая наилучшим образом соответствует потребностям их бизнеса, и спланировать будущее в условиях непрекращающейся эволюции в этой сфере.
Основные принципы и логическая архитектура модели сети данных
Цель модели сети данных состоит в том, чтобы создать основу для получения ценности из аналитических и исторических данных в масштабе, применяемом к постоянному изменению ландшафта данных, распространению как источников данных, так и потребителей, разнообразию преобразований и обработки, которые требуются в случаях использования, скорости реагирования на изменения. Для достижения этой цели я предлагаю, чтобы было четыре основополагающих принципа, которые воплощает любая реализация сети данных для обеспечения потребностей масштабирования, обеспечивая при этом гарантии качества и целостности, необходимые для использования данных: 1) децентрализованное владение данными и архитектура, ориентированная на домен, 2) данные как продукт, 3) инфраструктура данных самообслуживания как платформа и 4) федеративное управление вычислениями.
Хотя я и ожидаю, что практика, технологии и реализация этих принципов будут меняться и совершенствоваться с течением времени, но эти принципы остаются неизменными.
Я намеренна чтобы эти четыре принципа были в совокупности необходимыми и достаточными; чтобы обеспечивали масштабирование и устойчивость при одновременном решении проблем, связанных с блокированием несовместимых данных или увеличением стоимости эксплуатации. Давайте углубимся в каждый принцип, а затем разработаем концептуальную архитектуру, которая его поддерживает.
Владение доменом (Domain Ownership)
Сеть данных, по сути, основана на децентрализации и распределении ответственности между людьми, которые находятся ближе всего к данным, чтобы поддерживать непрерывные изменения и масштабируемость. Вопрос в том, как нам разложить и децентрализовать компоненты экосистемы данных и их права собственности. Компоненты здесь состоят из аналитических данных, их метаданных и вычислений, необходимых для их обслуживания.
Сеть данных следует за границами организационных подразделений в качестве оси декомпозиции. Наши организации сегодня подразделяются на основе их бизнес-областей. Такая декомпозиция локализует влияние непрерывных изменений и эволюции, по большей части, в ограниченном контексте предметной области. Следовательно, создание ограниченного контекста бизнес-домена является хорошим кандидатом для распределения владения данными.
В этой статье я продолжу использовать тот же вариант использования, что и в оригинальной статье, «цифровая медиа-компания». Можно представить, что медиакомпания разделяет свою деятельность, следовательно, системы и команды, которые поддерживают эту деятельность, на основе таких доменов, как «подкасты», команды и системы, которые управляют публикацией подкастов и их размещением; «художники», команды и системы, которые управляют включением и оплатой артистов, и так далее. Модель сети данных утверждает, что владение и обслуживание аналитических данных должны соответствовать этим областям. Например, команды, которые управляют «подкастами», предоставляя API для выпуска подкастов, а также должны отвечать за предоставление исторических данных, которые представляют «выпущенные подкасты» с течением времени, связанными с другими фактами, такими как «аудитория» с течением времени. Для более глубокого понимания этого принципа см. раздел Декомпозиция и владение данными, ориентированными на домен (ссылка en).
Логическая архитектура: доменно-ориентированные данные и вычисления
Чтобы способствовать такой декомпозиции, нам необходимо смоделировать архитектуру, которая упорядочивает аналитические данные по доменам. В этой архитектуре интерфейс домена с остальной частью организации включает не только операционные возможности, но и доступ к аналитическим данным, которые обслуживает домен. Например, домен «подкасты» предоставляет операционные API для «создания нового эпизода подкаста», а также конечную точку аналитических данных для извлечения «всех данных эпизодов подкастов за последние <n> месяцев». Это означает, что архитектура должна устранять любые противоречия или стыковки, чтобы домены могли обслуживать свои аналитические данные и выпускать код для вычисления данных, независимо от других доменов. Для масштабирования архитектура должна поддерживать автономность групп домена в отношении выпуска и развертывания их операционных или аналитических систем данных.
Следующий пример демонстрирует принцип владения данными, ориентированными на домен. Диаграммы являются только логическими представлениями и являются иллюстрациями. Они не должны быть полными.
Каждый домен может предоставлять один или несколько операционных API, а также одну или несколько конечных точек доступа к аналитическим данным.
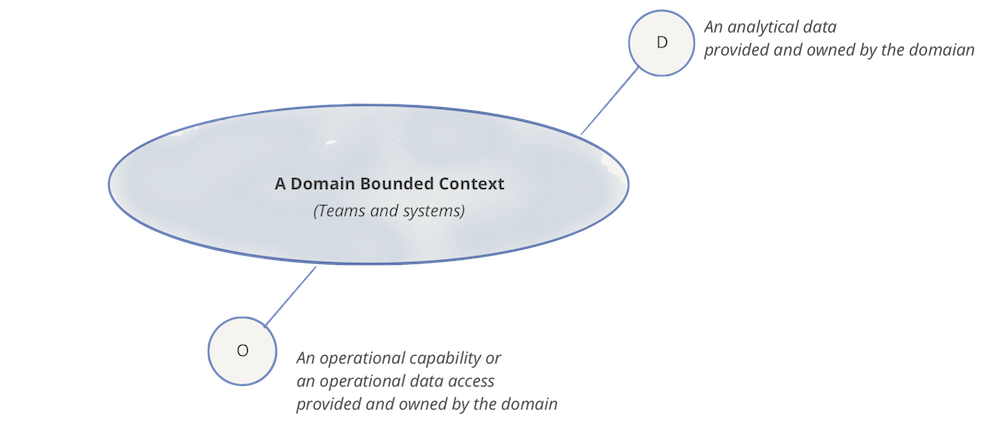
Естественно, каждый домен может иметь зависимости от точек доступа к операционных и аналитических данных других доменов. В следующем примере домен «подкасты» использует аналитические данные «обновлений пользователей» из домена «пользователи», чтобы он мог представить демографическую картину слушателей подкастов с помощью своего набора данных «Демография слушателей подкастов».
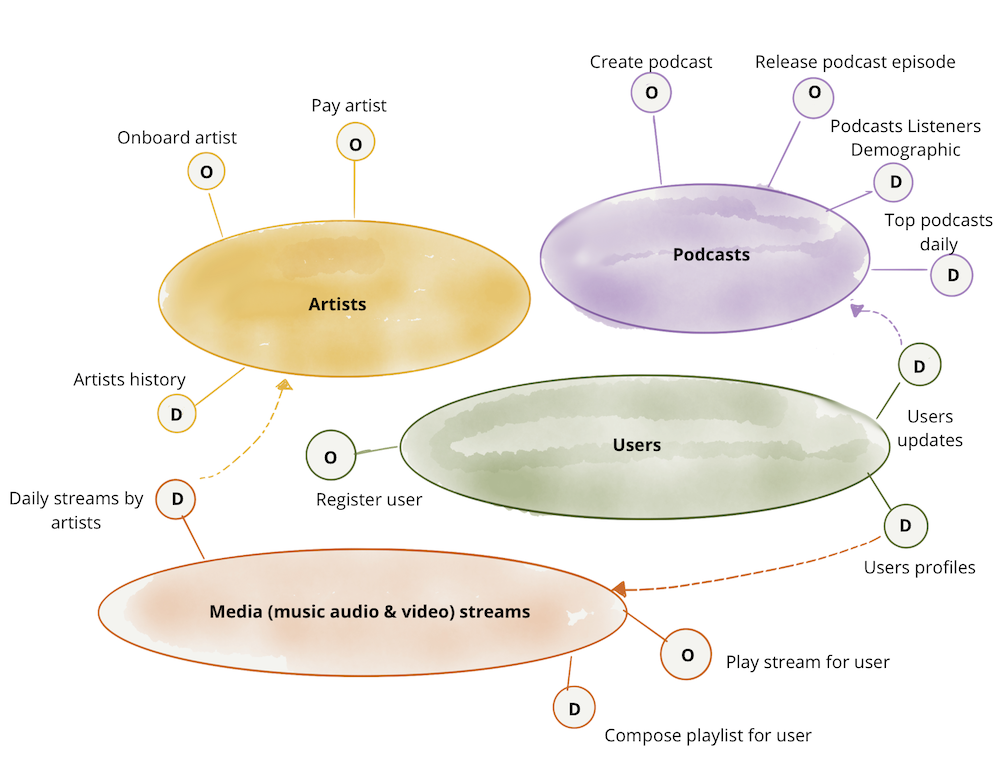
Примечание: В этом примере я использовала императивный язык для доступа к оперативным данным или возможностям, таким как «Платные исполнители». Это делается просто для того, чтобы подчеркнуть разницу между намерением получить доступ к оперативным данным и аналитическим данным. Я признаю, что на практике операционные API реализуются с помощью более декларативного интерфейса, такого как доступ к ресурсу RESTful или запросу GraphQL.
Проблемы анализа и обработки большого объема данных
Основная проблема обработки большого массива данных лежит на поверхности — это высокие затраты. Здесь учитываются расходы на закупку, содержание и ремонт оборудования, а также заработанная плата специалистов, которые компетентны в работе с Big Data.
Следующая проблема связана с большим объемом информации, нуждающейся в обработке. Например, если в процессе исследования мы получаем не два-три результата, а многочисленное число возможных итогов, то крайне сложно выбрать именно те, которые будут иметь реальное воздействие на показатели определенного события.
Еще одна проблема — это приватность больших данных. Конфиденциальность может быть нарушена, так как все большее количество сервисов, связанное с обслуживанием клиентов, используют данные онлайн. Соответственно, это увеличивает рост киберпреступлений. Даже обычное хранение персональных данных клиентов в облаке может быть подвержено утечке. Вопрос сохранности личных данных — одна из важнейших задач, которую необходимо решать при использовании методик Big Data.
Проблемы анализа и обработки большого объема данных
Угроза потери данных. Однократное резервирование не решает вопрос сохранения информации. Для хранилища необходимо создавать минимум две-три резервные копии. Но с ростом объемов данных увеличивается проблемность резервирования. Поэтому специалисты заняты поиском максимально результативного выхода из такой ситуации.
В заключение следует отметить, что развитие технологий обработки больших данных открывают широкие возможности для повышения эффективности различных сфер человеческой деятельности: медицины, транспортного обслуживания, государственного управления, финансов, производства. Именно это и определяет интенсивность развития данного направления в последние годы.
Традиционная архитектура хранилища данных
Трехуровневая архитектура
- Нижний уровень: этот уровень содержит сервер базы данных, используемый для извлечения данных из множества различных источников, например, из транзакционных баз данных, используемых для интерфейсных приложений.
- Средний уровень: средний уровень содержит сервер OLAP, который преобразует данные в структуру, лучше подходящую для анализа и сложных запросов. Сервер OLAP может работать двумя способами: либо в качестве расширенной системы управления реляционными базами данных, которая отображает операции над многомерными данными в стандартные реляционные операции (Relational OLAP), либо с использованием многомерной модели OLAP, которая непосредственно реализует многомерные данные и операции.
- Верхний уровень: верхний уровень — это уровень клиента. Этот уровень содержит инструменты, используемые для высокоуровневого анализа данных, создания отчетов и анализа данных.
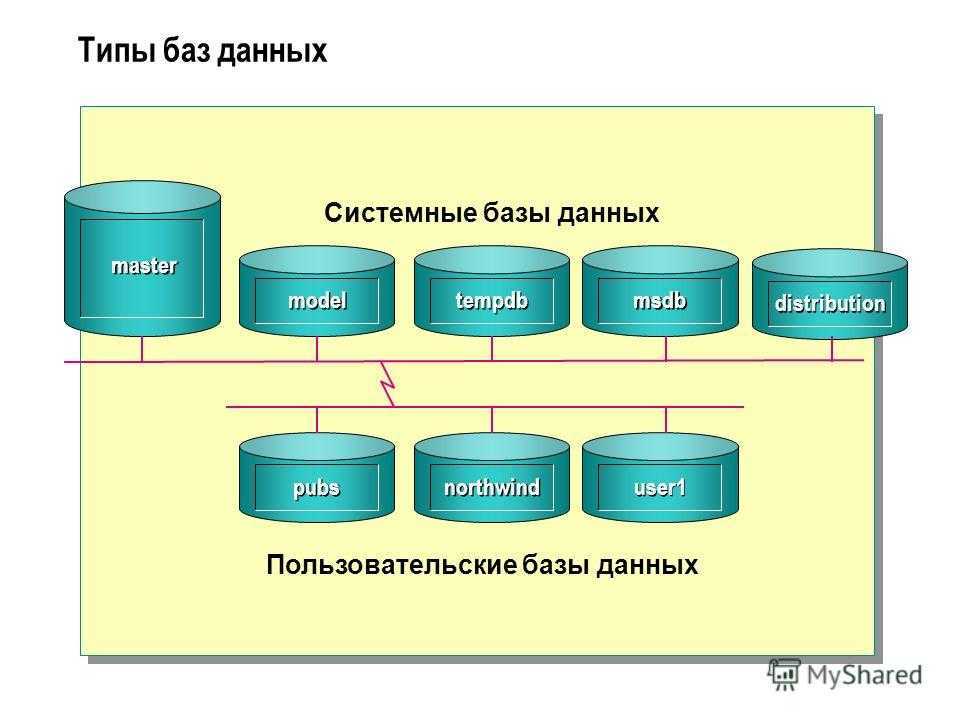
Модели хранилищ данных
- Виртуальное хранилище данных — это набор отдельных баз данных, которые можно использовать совместно, чтобы пользователь мог эффективно получать доступ ко всем данным, как если бы они хранились в одном хранилище данных;
- Модель витрины данных используется для отчетности и анализа конкретных бизнес-линий. В этой модели хранилища – агрегированные данные из ряда исходных систем, относящихся к конкретной бизнес-сфере, такой как продажи или финансы;
- Модель корпоративного хранилища данных предполагает хранение агрегированных данных, охватывающих всю организацию. Эта модель рассматривает хранилище данных как сердце информационной системы предприятия с интегрированными данными всех бизнес-единиц
3 главных принципа работы с большими данными
Ключевыми положениями для работы с большими данными являются:
Горизонтальная адаптивность
Количество данных неограниченyо, поэтому обрабатывающая их система должна иметь способность к расширению: при возрастании объемов данных должно пропорционально увеличиваться количество оборудования для поддержания работоспособности всей системы.
Стабильность в работе при отказах
Горизонтальная адаптивность предполагает наличие большого числа машин в компьютерном узле. К примеру, кластер Hadoop насчитывает более 40 000 машин. Само собой, что периодически оборудование, изнашиваясь, будет подвержено поломкам. Системы обработки больших данных должны функционировать таким образом, чтобы безболезненно переживать возможные сбои.
Только до 22.12
Как за 3 часа разбираться в IT лучше, чем 90% новичков и выйти надоход в 200 000 ₽?
Приглашаем вас на бесплатный онлайн-интенсив «Путь в IT»! За несколько часов эксперты
GeekBrains разберутся, как устроена сфера информационных технологий, как в нее попасть и
развиваться.
Интенсив «Путь в IT» поможет:
- За 3 часа разбираться в IT лучше, чем 90% новичков.
- Понять, что действительно ждет IT-индустрию в ближайшие 10 лет.
- Узнать как по шагам c нуля выйти на доход в 200 000 ₽ в IT.
При регистрации вы получите в подарок:
«Колесо компетенций»
Тест, в котором вы оцениваете свои качества и узнаете, какая профессия в IT подходит именно вам
«Критические ошибки, которые могут разрушить карьеру»
Собрали 7 типичных ошибок, четвертую должен знать каждый!
Тест «Есть ли у вас синдром самозванца?»
Мини-тест из 11 вопросов поможет вам увидеть своего внутреннего критика
Хотите сделать первый шаг и погрузиться в мир информационных технологий? Регистрируйтесь и
смотрите интенсив:
Только до 22 декабря
Получить подборку бесплатно
pdf 4,8mb
doc 688kb
Осталось 17 мест
Концентрация данных
В масштабных системах данные распределяются по большому количеству оборудования. Допустим, что местоположение данных — один сервер, а их обработка происходит на другом сервере. В этом случае затраты на передачу информации с одного сервера на другой могут превышать затраты на сам процесс обработки. Соответственно, чтобы этого избежать необходимо концентрировать данные на той же аппаратуре, на которой происходит обработка.
Концентрация данных
В настоящее время все системы, работающие с Big Data, соблюдают эти три положения. А чтобы их соблюдать, нужно разрабатывать соответствующие методики и технологии.
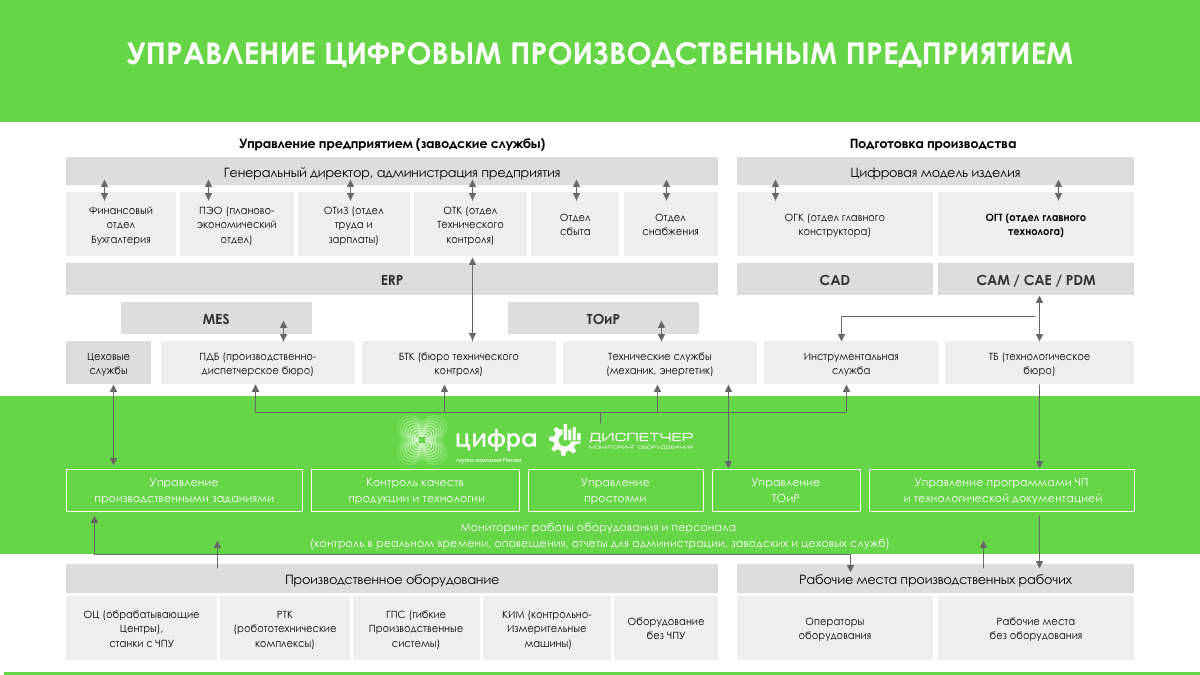
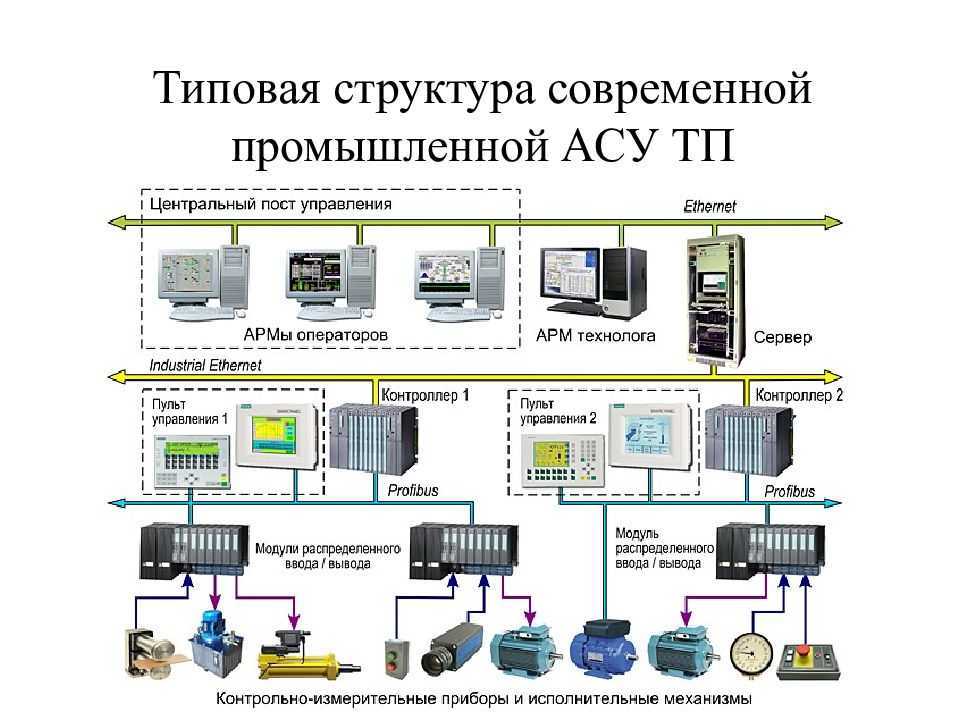
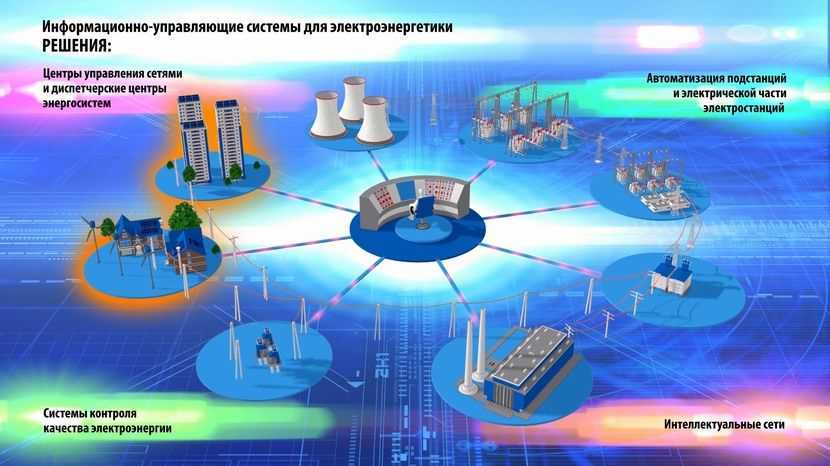
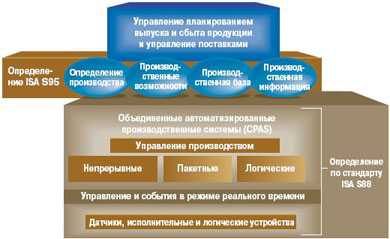
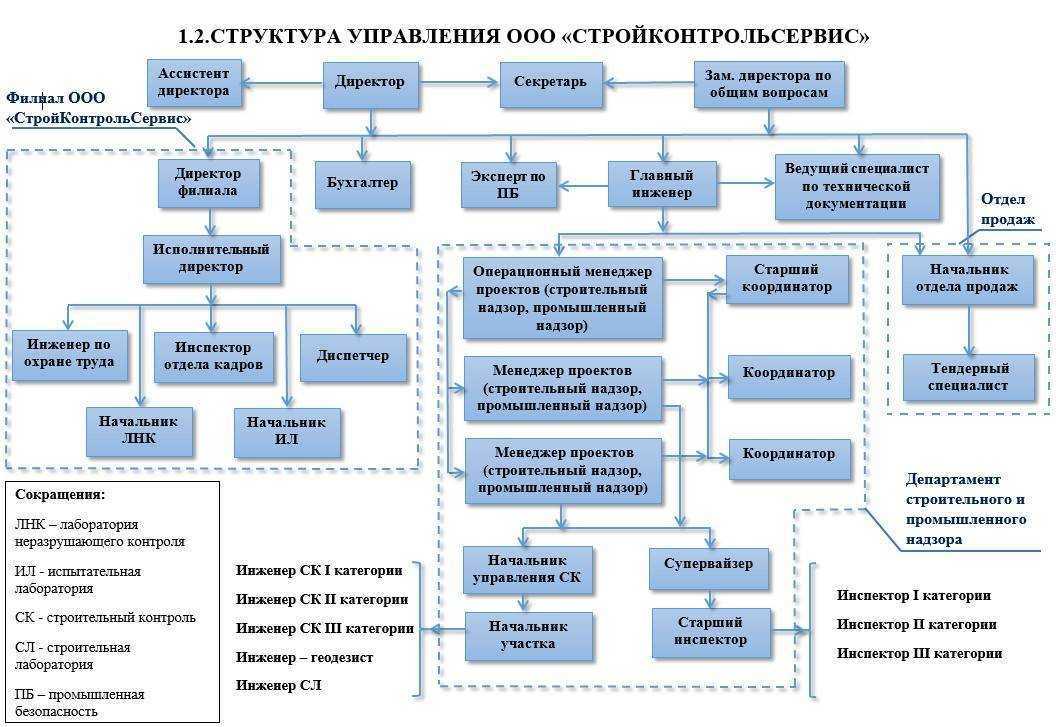
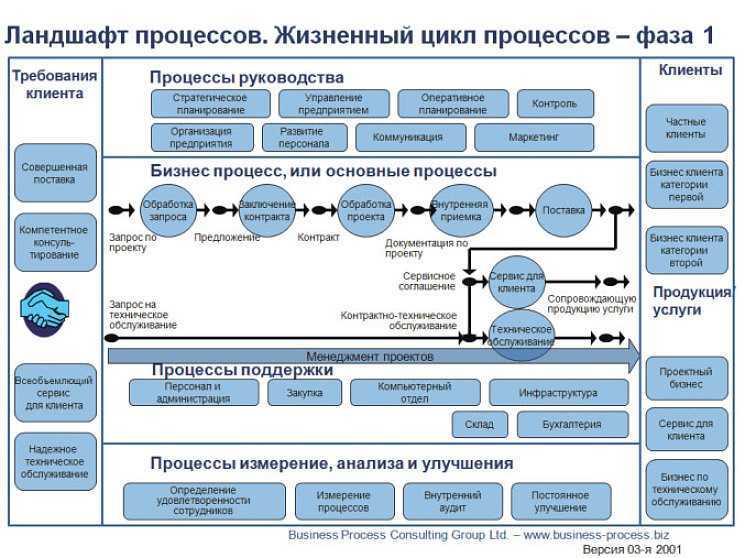
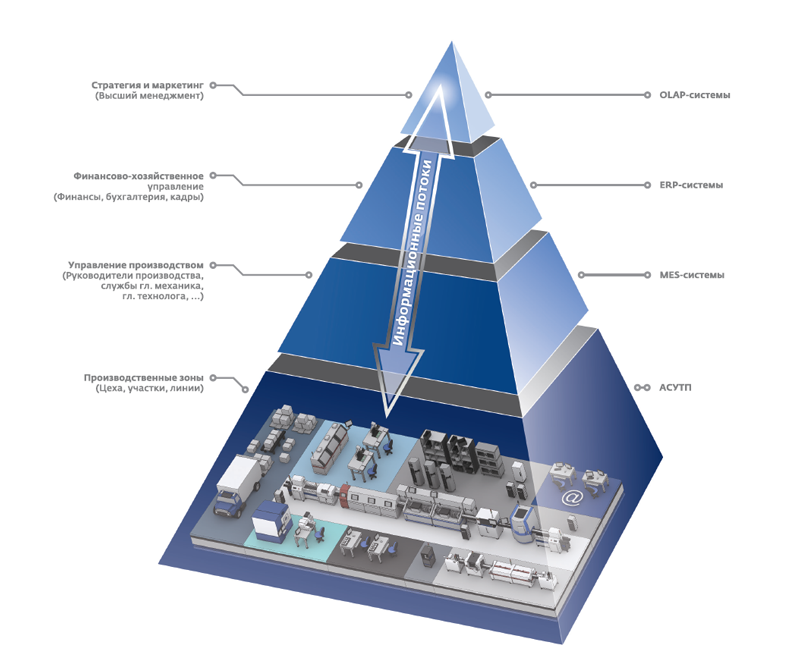
Платформы управления данными: для чего они нужны, и какую играют роль?
- Управлять файлами, объектами, данными приложений, базами данных, данными виртуальных и облачных сред, получать доступ к данным разных типов.
- С помощью инструментов оркестрации и автоматизации перемещать данные туда, где их хранение наиболее эффективно — в первичную, вторичную инфраструктуру хранения, в ЦОД провайдера или в облако.
- Использовать комплексные функции защиты данных.
- Обеспечить интеграцию данных.
- Получать из данных оперативную аналитику.
Практические области управления данными (источник; CMMI Institute).
| Компонент | Область применения |
|---|---|
| Стратегия управления данными | Цели и задачи управления, корпоративная культура управления данными, определение требований к жизненному циклу данных. |
| Управление данными | Управление данными и метаданными |
| Операции с данными | Стандарты и процедуры работы с источниками данных |
| Качество данных | Обеспечение качества, фреймворк качества данных |
| Платформа и архитектура | Архитектурный фреймворк, платформы и интеграция |
| Поддерживающие процессы | Оценка и анализ, управление процессами, обеспечение качества, управление рисками, управление конфигурацией |
- Изменение управления данными в существующих системах, внедрение ролевой модели с разделением обязанностей и полномочий. Контроль качества данных, перекрестная проверка данных между системами, исправление недостоверных данных.
- Настройка процессов извлечения и сбора данных, их трансформации и загрузки. Приведение данных к единой системе без усложнения контроля качества данных и изменения бизнес-процессов.
- Интеграция данных. Автоматизация процессов доставки нужных данных в нужное место и в нужное время.
- Введение полноценного контроля качества данных. Определение параметров контроля качества, разработка методологии использования автоматических систем.
- Внедрение инструментов управления процессами сбора данных, их верификации, дедупликации и очистки. Как следствие — увеличение качества, достоверности и унификации данных всех систем предприятия.
Шесть преимуществ больших данных
Поставщики и провайдеры систем управления (ICS), объединяющих разрозненные источники данных в единое целое и анализирующих их через распознавание шаблонов, что позволяет конечным пользователям принимать более эффективные решения, будут определять новую базу для конкуренции и роста бизнеса компаний, что, соответственно, создает и условия для дальнейшего роста всей мировой экономики. Однако практическая реализация решений с использованием больших данных может быть затруднена, поскольку собранная информация предоставляется с большого числа удаленных узлов сети, датчиков и систем, что может потребовать не только значительных финансовых вложений, но и затрат времени на их имплементацию, а также технических знаний и опыта.
Большие данные можно применить для следующих целей:
- Сделать информацию более транспарентной (прозрачной).
- Получить дополнительную детальную информацию об эффективности того или иного производственного и технологического оборудования, что стимулирует инновации и повышает качество конечной продукции.
- Использовать более эффективную, точную аналитику, чтобы минимизировать риски и заранее обнаруживать проблемы, незаметные до непосредственного их проявления и способные иногда приводить к катастрофическим последствиям.
- Внедрить те или иные идеи и проанализировать полученные результаты в контролируемых экспериментальных средах и таким образом определить целесообразность конкретных инвестиционных проектов.
- Обеспечить персонал центра управления (диспетчерской) операционными данными в режиме реального времени, содержащими информацию от систем автоматизации производственных и технологических процессов и аналитику. Это делает управление рисками более эффективным и минимизирует время простоя оборудования, что, в свою очередь, приводит к сокращению персонала управления на 15% и увеличению выпуска конечной продукции на 5%.
- Укоренить революционное управление цепочками поставок, прогнозирование спроса, комплексное бизнес-планирование, организацию сотрудничества с поставщиками и эффективный анализ рисков.
Краткое изложение принципов и логическая архитектура высокого уровня
Давайте сведем все это воедино, мы обсудили четыре принципа, лежащих в основе сетки данных:
| Децентрализованное владение данными и архитектура, ориентированные на домен | Чтобы экосистема, создающая и потребляющая данные, могла масштабироваться по мере увеличения числа источников данных, числа вариантов использования и разнообразия моделей доступа к данным просто увеличивая автономные узлы в сети. |
| Данные как продукт | Чтобы пользователи данных могли легко находить, понимать и безопасно использовать высококачественные данные с приятным опытом; данные, которые распределены по многим доменам. |
| Инфраструктура данных самообслуживания как платформа | Чтобы команды домена могли создавать и использовать продукты данных автономно, используя абстракции платформы, скрывая сложность создания, выполнения и поддержки безопасных и совместимых продуктов данных. |
| Федеративное управление вычислениями | Чтобы пользователи данных могли получать выгоду от агрегирования и корреляции независимых продуктов данных, сеть ведет себя как экосистема, следуя глобальным стандартам взаимодействия; стандартам, которые вычислительно интегрированы в платформу. |
Эти принципы управляют логической архитектурной моделью, которая, хотя и сближает аналитические данные и оперативные данные в одной и той же области, учитывает лежащие в их основе технические различия. Такие различия включают в себя, где могут размещаться аналитические данные, различные компьютерные технологии для обработки операционных и аналитических услуг, различные способы запроса и доступа к данным и т.д.
Логическая архитектура подхода к сети данных:
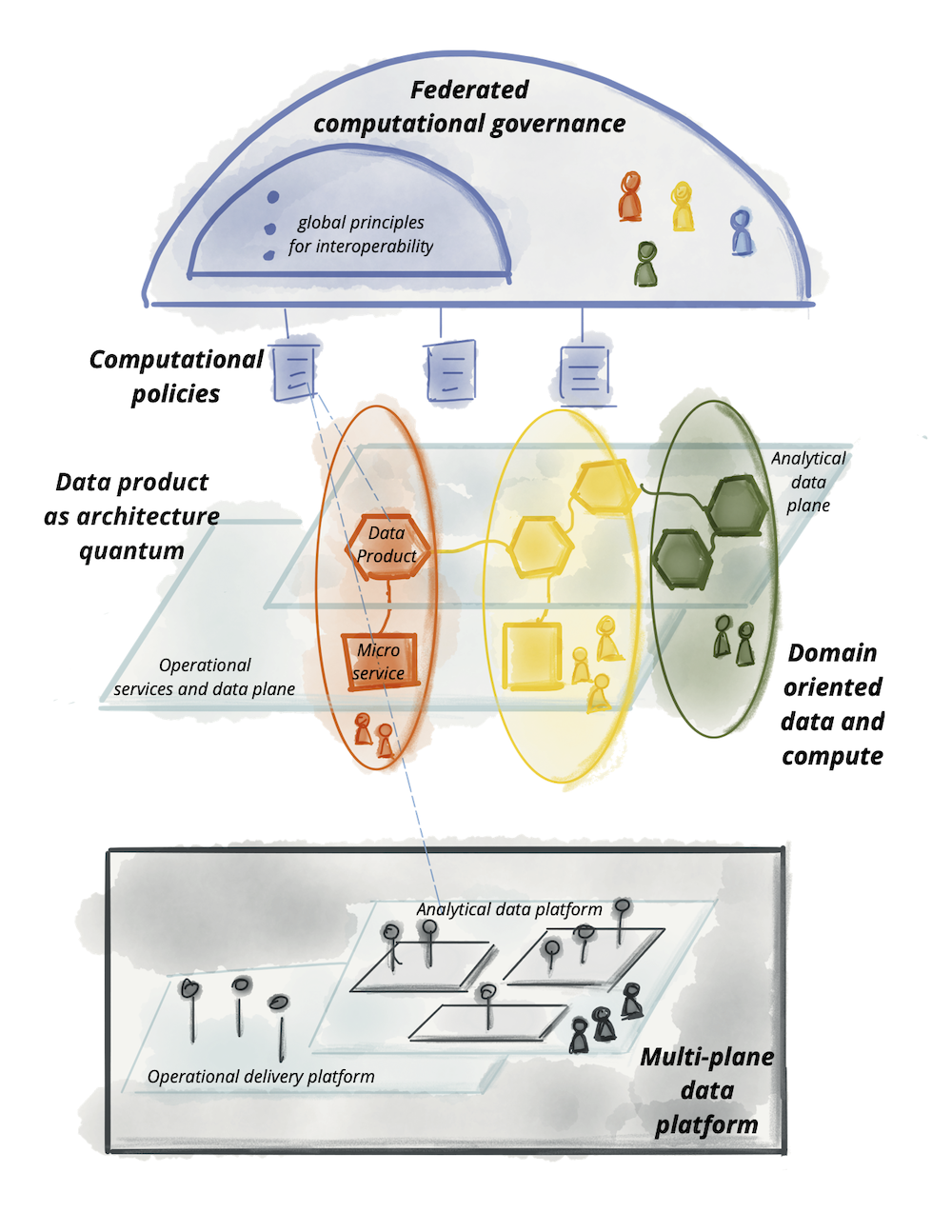
Я надеюсь, что к этому моменту мы уже выработали общий язык и логическую ментальную модель, которую мы сможем коллективно использовать для детализации схемы компонентов сетки, таких как продукт данных, платформа и необходимые стандартизации.