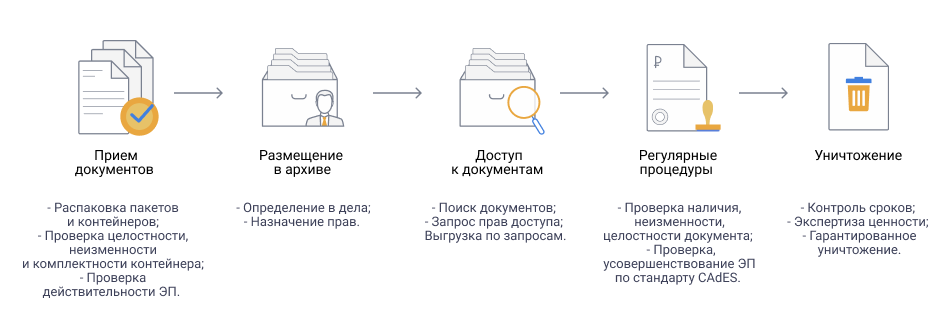
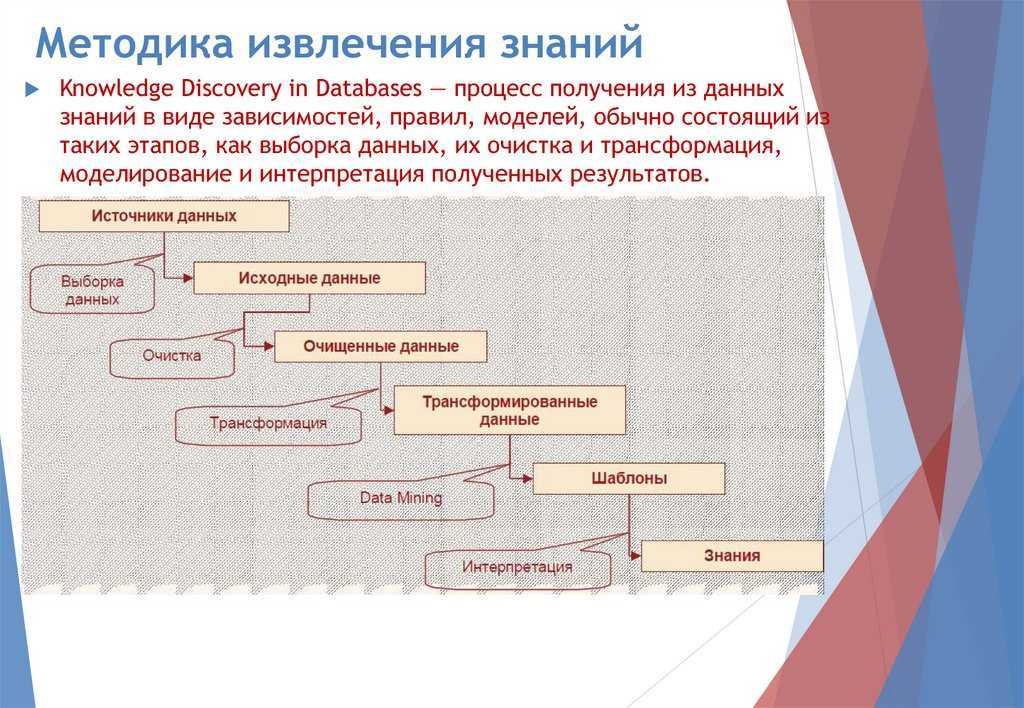
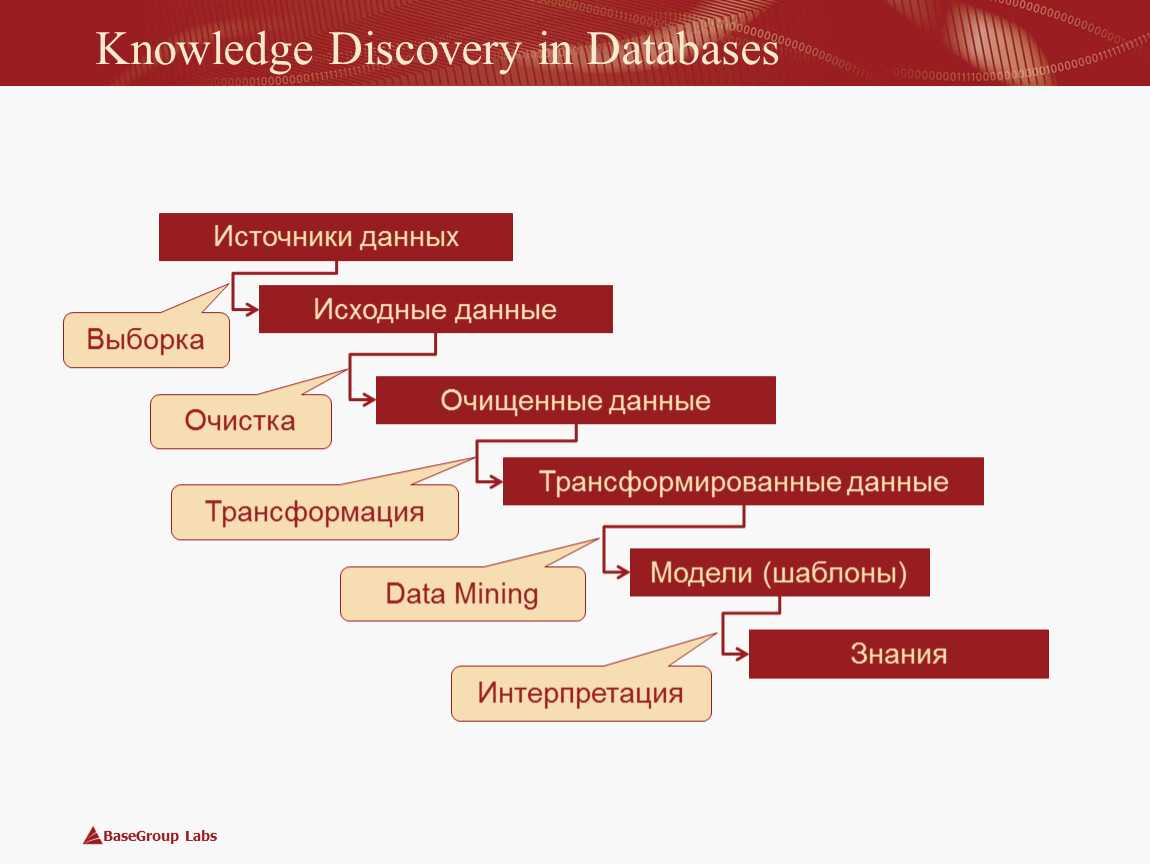
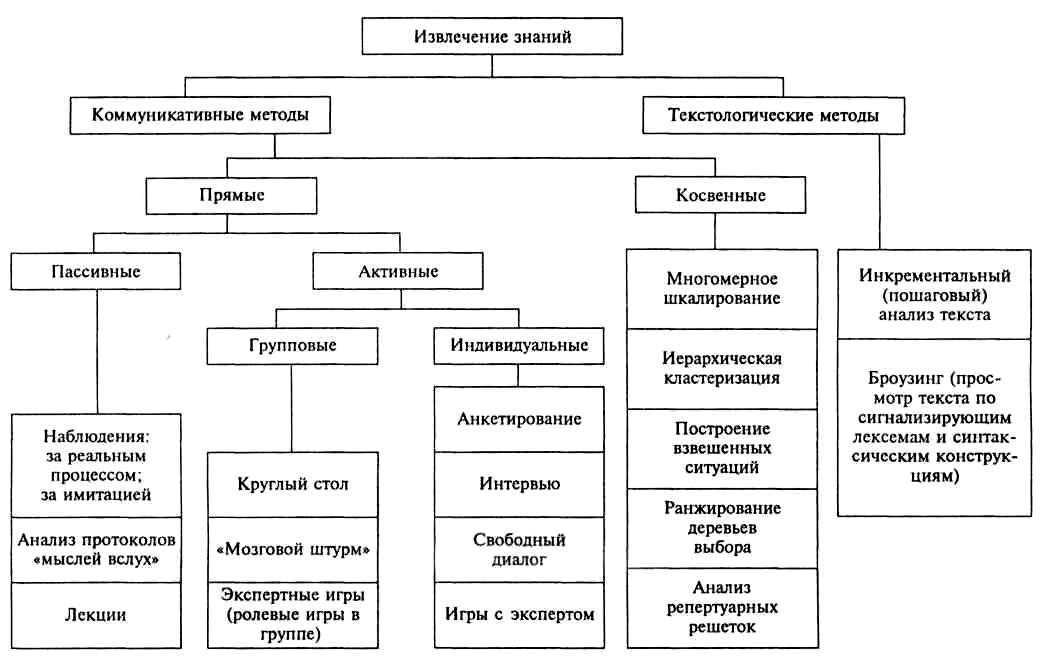
IV. RocksDB
Выше уже была ссылка на анонс Stardog 7 Beta, где говорилось, что Stardog собирается использовать в качестве нижележащей системы хранения RocksDB — хранилище «ключ-значение», фейсбуковский форк гугловской LevelDB. Почему уже стоит говорить о некоем тренде?
Во-первых, cудя по , на RocksDB пересаживаются не только RDF-хранилища. Есть проекты по использованию RocksDB как движка хранения в ArangoDB, MongoDB, MySQL и MariaDB, Cassandra.
Во-вторых, на RocksDB делаются проекты (т. е. не продукты) соответствующей тематики.
Например, eBay использует RocksDB в платформе для своего «графа знаний». Между прочим, забавно читать: the query language started as a home grown format, but more recently it has been transitioning to be much more like SPARQL. Как в анекдоте: сколько knowledge graph ни делаем, все равно получается RDF.
Другой пример — появившийся несколько месяцев назад Wikidata History Query Service. До его появления за историческими сведениями Викиданных приходилось обращаться через MWAPI к стандартному Mediawiki API. Теперь многое возможно на чистом SPARQL. «Под капотом» там тоже RocksDB. Кстати, сделал WDHQS, похоже, человек, занимавшийся импортом Freebase в Google Knowledge Graph.
RDF в виде графа
Есть два взаимодополняющих способа рассматривать информацию,
представленную в RDF. Первый способ — считать её набором
утверждений, как в примерах выше: каждое утверждение представляет
собой факт. Второй способ — считать её графом.
Граф — это, в общем, то же самое, что сеть. Граф состоит из
узлов, соединённых рёбрами. Например, в Интернете узлы — это
компьютеры, а рёбра — соединяющие их сетевые шнуры. В RDF узлы —
это имена (но не сами сущности), а рёбра — утверждения.
Например:
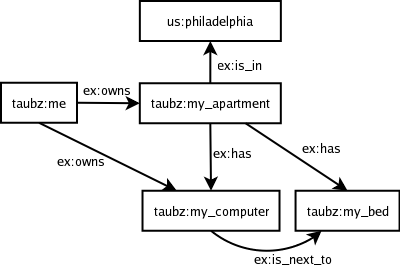
Здесь каждая стрелка (ребро) — это RDF-утверждение: имя у начала
стрелки — это подлежащее утверждения, имя у конца стрелки — его
дополнение, и имя у самой стрелки — сказуемое. Когда RDF
представлен в виде графа, он содержит всю ту же информацию, что и
выписанный в виде троек-утверждений; но графическое представление
позволяет человеку легче увидеть структуру описываемых данных.
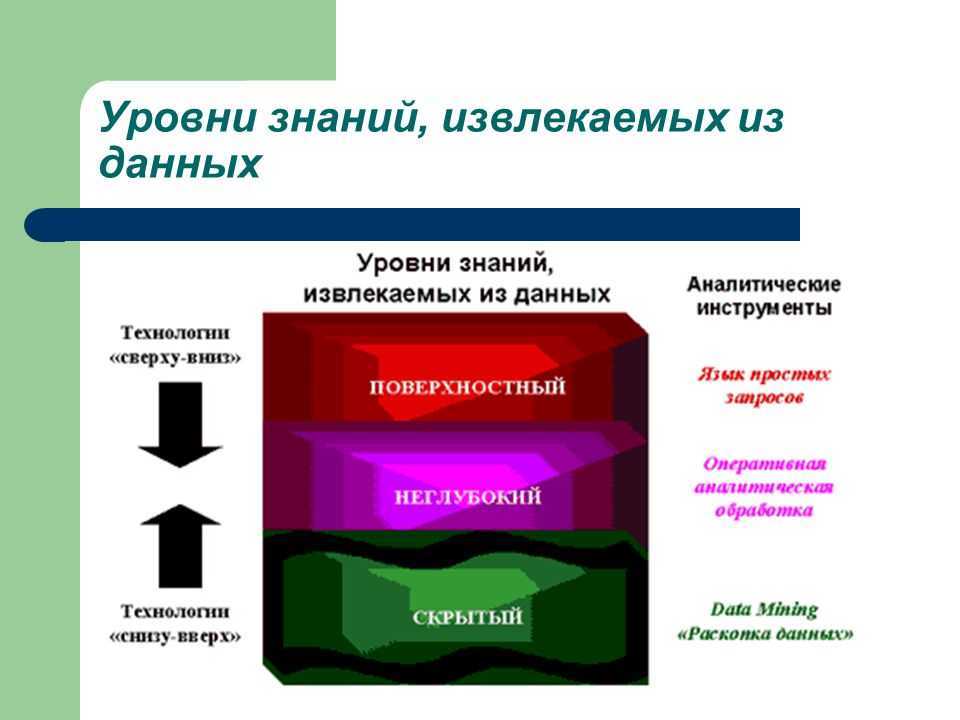
Обобщающий пример
В сведены воедино все продемонстрированные к настоящему моменту элементы, а также добавлены такие элементы, как breadcrumb.
Листинг 9. Использование всех пяти атрибутов RDFa Lite
…
Web development >
Technical library
An introduction to RDF
By Uche Ogbuji, Partner,
Zepheira.
Published: 01 Dec 2000
Summary: This article introduces Resource Description Framework (RDF),
developed by the W3C for Web-based metadata, using XML as an interchange syntax.
RDF»s essential aim is to make work easier for autonomous agents,
which would refine the Web by improving search engines and service directories.
Author Uche Ogbuji gives an overview of RDF aspects from schemas to usage scenarios.
The article assumes that you are already familiar with XML.
Tags for this article:
introduction,
rdf,
tutorial
.
This article»s texts is suitable for a wide audience, with a Fog index of
10.2.
…
С точки зрения структуры здесь нет ничего нового, однако в показано несколько других свойств Schema.org, которые вы сможете использовать для какой-либо статьи.
V. Поддержка LPG
Напомню основное отличие LPG-графов от RDF-графов.
В LPG на экземпляры ребер могут навешиваться скалярные свойства, в то время как в RDF они могут навешиваться лишь на «типы» ребер (зато не только скалярные свойства, но и обычные связи). Эта ограниченность RDF по сравнению с LPG преодолевается теми или иными техниками моделирования. Ограниченность же LPG по сравнению с RDF преодолевается сложнее, но LPG-графы больше, чем RDF-графы, похожи на картинки из учебника Харари, поэтому люди их хотят.
Очевидно, задача поддержки LPG распадается на две части:
- внесение в модель RDF изменений, дающих возможность имитировать в ней LPG-конструкции;
- внесение в язык запросов к RDF изменений, дающих возможность обращаться к данным в этой измененной модели, — либо же реализация возможности делать запросы к этой модели на популярных языках запросов к LPG.
V.1. Модели данных
Здесь имеется несколько возможных подходов.
V.1.1. Singleton Property
Самый буквальный подход к гармонизации RDF и LPG — это, наверное, singleton property:
- Вместо, например, употребляются предикаты , и т. д.
- Затем эти предикаты становятся субъектами новых триплетов: и пр.
- Связь этих экземпляров предикатов с общим предикатом устанавливается триплетами вида .
- Очевидно, что , но подумайте, почему не стоит писать просто .
Задача поддержки LPG решается здесь на уровне RDFS. Такое решение требует внесения в соответствующий стандарт. Какие-то изменения могут потребоваться от RDF-хранилищ, поддерживающих присоединение следствий, а пока Singleton Property можно воспринимать просто как еще одну технику моделирования.







V.1.2. Reification Done Right
Менее наивные подходы проистекают из осознания того, что экземпляры свойств вполне инстанциируются триплетами. Имея возможность говорить что-то о триплетах, мы получим возможность говорить и об экземплярах свойств.
Самый солидный из этих подходов — RDF*, он же RDR, родившийся в недрах Blazegraph. Его с самого начала избрал для себя и AnzoGraph. Солидность подхода определяется тем, что в его рамках предлагаются соответствующие изменения в RDF Semantics. Суть, однако, чрезвычайно проста. В Turtle-сериализации RDF можно теперь будет писать примерно так:
V.1.3. Прочие подходы
Можно не заморачиваться формальной семантикой, а просто считать, что у триплетов есть некие идентификаторы, являющиеся, естественно, URI, и составлять новые триплеты с этими URI. Останется лишь дать доступ к этим URI в SPARQL. Так Stardog.
В Allegrograph пошли промежуточным путем. Известно, что идентификаторы триплетов в Allegrograph есть, но при реализации triple attributes наружу они не торчат. Однако и до формальной семантики очень далеко. Примечательно, что атрибуты триплетов — не URI, и значения этих атрибутов тоже могут быть только литералами. Адепты LPG получают ровно то, что хотели. В специально изобретенном формате NQX пример, аналогичный приведенному выше для RDF*, выглядит так:
V.2. Языки запросов
Поддержав тем или иным способом LPG на уровне модели, нужно дать возможность делать запросы к данным в такой модели.
- Anzograph тоже поддерживает SPARQL* и собирается поддерживать Cypher, язык запросов в Neo4j.
- Stardog поддерживает собственное SPARQL и Gremlin. Получить в SPARQL URI триплета и «метаинформацию» можно с помощью примерно такой конструкции:
Кстати, GraphDB одно время поддерживала Tinkerpop/Gremlin, не поддерживая при этом LPG, но в версии 8.0 или 8.1 это прекратилось.
I. GraphQL для доступа к RDF
Говорят, что GraphQL претендует стать универсальным языком доступа к базам данных. Как обстоят дела с возможностью использовать GraphQL для доступа к RDF?
«Из коробки» такую возможность предоставляют:
- Stardog (блог, );
- продукты TopQuadrant (вебинар, документация).
Если же хранилище такой возможности не предоставляет, её реализуют самостоятельно, написав соответствующий «распознаватель» (resolver). Так поступили, например, во французском проекте DataTourisme. Или уже можно ничего не писать, а просто взять HyperGraphQL.
С точки зрения ортодоксального приверженца Semantic Web и Linked Data всё это, конечно, печально, поскольку кажется предназначенным для интеграций, выстраиваемых вокруг очередных data silos, а не подходящих для того платформ (разумеется, RDF-хранилищ).
Впечатления от сравнения GraphQL со SPARQL двоякие.
- С одной стороны, GraphQL выглядит дальним родственником SPARQL: в нем решены характерные для REST проблемы перевыборки и множественности запросов — без чего, наверное, и нельзя было бы считаться языком запросов, хотя бы и для веба, и иметь в названии «-QL»;
- С другой стороны, огорчает жесткая схемность GraphQL. Соответственно, его «интроспективность» кажется очень ограниченной в сравнении с полной рефлексивностью RDF. И нет никакого аналога property paths, так что даже не очень понятно, почему он «Graph-».
XML базы данных
- Технология XML.
- Создание и обработка XML-документов.
- XML-генераторы.
- Спецификация схем данных для XML-документов. Создание DTD – определения. Спецификация Namespaces. Объектная модель документа DOM.
- XML-база данных (Native XML Database, NXD) и база данных, поддерживающая XML как тип данных (XML Enabled Database, XED). Язык запросов XPath.
- Технология RDF (Resource Description Framework).
- RDF — способ представления распределенных данных.
- Использование форматов XML и N3 для записи RDF. Отличительные особенности RDF. Определение RDF как совокупности трёх правил. Области применимости RDF. Информация, представляемая в RDF, как набор утверждений и как граф. Пример сведения распределённой информации в общую систему на основе RDF представления.
Практические занятия
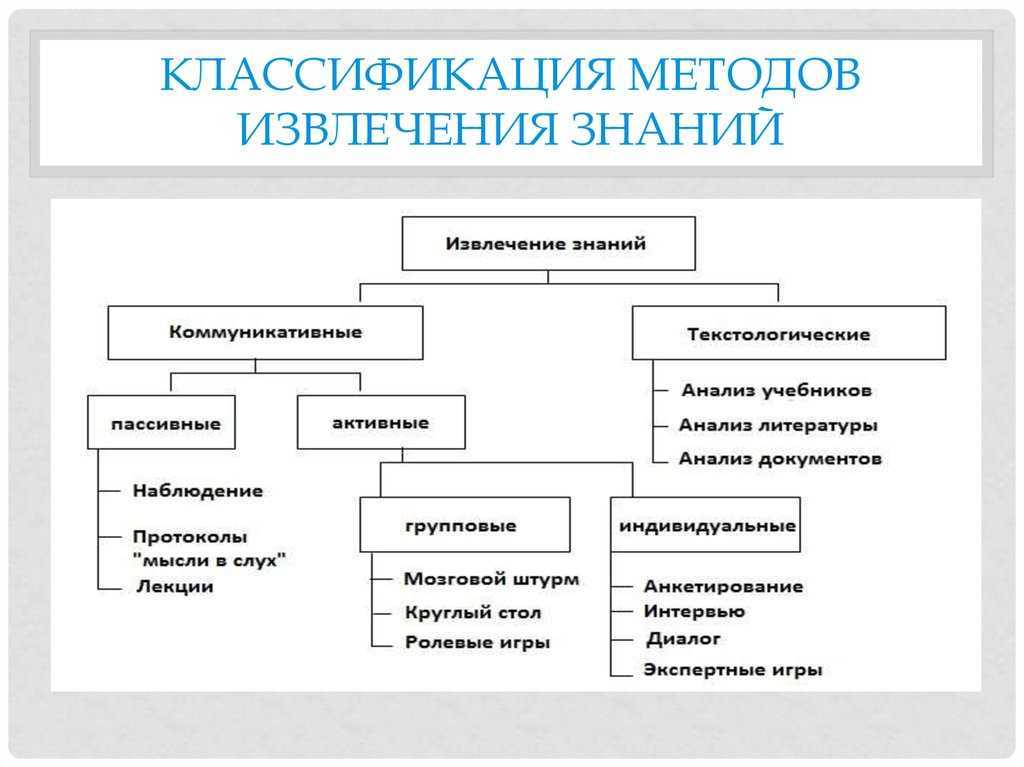
- Методы и приемы выбора источников информации и сбор вторичных данных. Оценка полученных данных и решение о необходимости первичных данных.
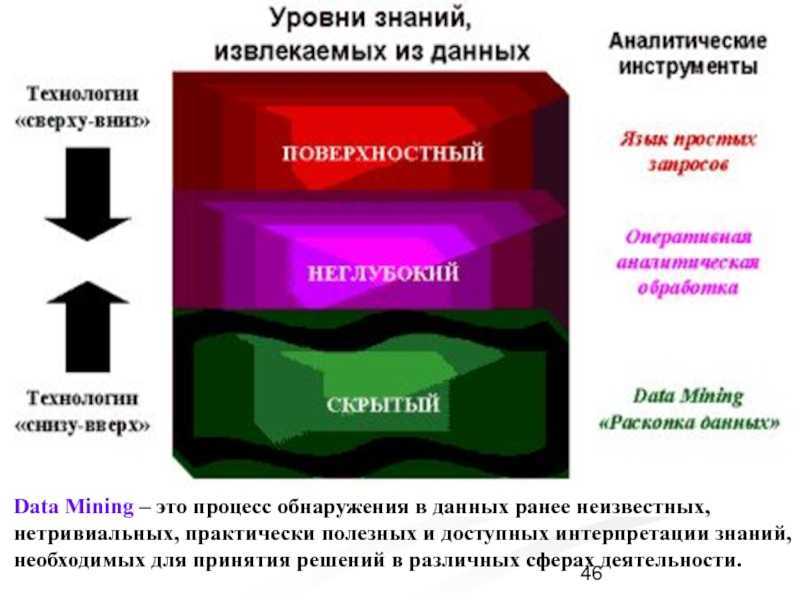
- Построение моделей методами Data Mining. Преобразование данных в полезную для принятия решений информацию.
- Способы устранение рассогласованности данных. Неопределенность данных, виды неопределенности.
- Представление документов в виде векторов взвешенных ключевых слов.
- Концептуальное, логическое и физическое представления данных на этапах проектирования баз данных и при сопровождении информационной модели.
- Организация данных на носителях в среде хранения, указатели, цепи и кольцевые структуры, физическое представление древовидных и сетевых структур.
- Растровое и векторное представление метрической информации. Топологическое и нетопологическое векторное представление.
- Визуализация базы геоданных. Основные топологические характеристики моделей баз геоданных. Способы представления трехмерных моделей.
- Значения отношений, переменные отношений, виды отношений. Алгебра отношений и исчисление отношений, реляционные операции: выборка, проекция и соединение.
- Предложения CREATE, ALTER, DROP, INSERT, UPDATE, DELETE, GRANT, REVOKE, SET ROLE.
- Использование реляционных и булевых операторов для создания сложных предикатов, элементы мат. логики.
- Использование подзапросов с командами обновления INSERT, DELETE, UPDATE.
- Корректное удаление и обновление информационных ресурсов.
- Системный каталог, использование представлений для таблиц каталога.
- Основные понятия ODL. Объектно-ориентированное проектирование.
- Базы данных SQL Server. Объекты базы данных.
- Настройка свойств среды SQL Server Management Studio.
- Интеграция серверов Web и SQL Server.
- Доступ к источникам данных ODBC. Модель объектов рабочего пространства ODBCDirect.
- Язык запросов XPath.
- Пример сведения распределённой информации в общую систему на основе RDF представления.
Обзор
Исторически веб-технологии концентрировались на «впечатлениях и ощущениях», порождаемых веб-страницами и веб-сайтами. Самыми важными были следующие соображения: визуально привлекательный дизайн, ссылки и JavaScript-приложения, работающие надлежащим образом и поддерживающие новейшие мультимедийные функции. Все более важным стало нахождение в верхней части результирующих списков, выдаваемых поисковыми машинами. К сожалению, поисковые машины не видят дизайна веб-сайта и не ощущают динамики его поведения; они видят лишь разметку, которая сводится для них к типу шрифта (полужирный, курсив и т. д.) или к выделению того или иного блока контента.
Часто используемые сокращения
- HTML: HyperText Markup Language
- RDF: Resource Description Framework
- SEO: Search Engine Optimization
Сетевые авторы начали осознавать, что они нуждались в чем-то большем, чем презентационные украшения. Они нуждались в средствах, позволяющих указать поисковой машине или любой другой подобной программе на реальную структуру данных. Например, на то, какая именно информация соответствует цене, дате проведения мероприятия, элементу контактной информации человека и т. д. Существовала потребность в т. н. «сети данных», удовлетворение которой на протяжении долгого времени являлось основной заботой разработчиков модели RDF (Resource Description Framework).
Концепция RDF весьма проста, однако, к сожалению, многие ее аспекты слишком сложны при описании, обсуждении и обработке. Применительно к веб-технологиям типичная рекомендация звучит следующим образом: «Убедитесь в том, что обычный сетевой автор сможет изучить предлагаемую технологию за один день». Для решения этой задачи потребовалось много лет, однако теперь, наконец, появилась разновидность RDF, которая успешно проходит этот тест, а именно RDFa 1.1 Lite.
RDFa Lite — это упрощенная версия RDFa (RDF annotations). RDFa представляет собой механизм для кодирования полной модели данных RDF в рамках HTML и подобных словарей. Сложность модели RDFa несколько превышает пороговое требование «возможность изучения за один день», поэтому группа WHAT WG (которая создала HTML5) создала HTML-спецификацию под названием Microdata. Спецификация Microdata стала ядром Schema.org (см. раздел ), — инициативы по кодификации способов разметки данных в сети. Со временем спецификация Microdata получила статус W3C Working Draft (действующий проект)(см. раздел ), однако защитники RDF и RDFa считали, они смогли бы продвигать RDFa, если бы у них имелось подмножество RDFa, столь же простое как и Microdata. И вот, наконец, мы получили преимущества отработанной модели данных, но с простым синтаксисом.
В прошлом году основатели Schema.org провели семинар для сообщества специалистов по структурированным веб-данным. Я посетил этот семинар, на котором Бен Адида (Ben Adida), редактор спецификации RDFa, продемонстрировал нам работу, которую группа RDF Web Applications Working Group выполнила при создании RDFa Lite. Весьма положительные отзывы о предварительной версии этой спецификации вдохновили организацию W3C на интенсификацию дальнейших усилий в этой области. RDFa 1.1 Lite — это весьма лаконичный действующий проект (working draft) от организации W3C (вполне возможно, что к тому моменту, когда вы будете читать этот текст, этот проект уже превратится в официальную рекомендацию W3C).
Прочитав эту статью, вы узнаете о RDFa 1.1 Lite и сможете быстро приступить к созданию HTML-страниц, включенных в сеть данных. Предполагается, что читатель уже имеет представление о HTML.




Атрибуты для уточнения контента
Совместимость
Формат RDFa совместим со спецификациями HTML 4, HTML 5 и XHTML.
RDFa предусматривает разметку структурированных данных в рамках веб-сайта. Вы не сосредотачиваетесь лишь на том, как контент должен выглядеть с точки зрения пользователя. Вы можете пометить дату как дату, имя человека как имя человека, событие как событие, организацию как организацию и т. д. RDFa Lite редуцирует высокий уровень амбиций до простейших вещей, которые вполне способны работать: к HTML или к XHTML добавляется всего пять атрибутов. Машина способна с легкостью интерпретировать эти атрибуты, чтобы извлечь из веб-страницы полезные данные. Если говорить коротко, то это все.
В показан пример «чистого» HTML-кода для онлайновой статьи.
Основы информационного моделирования
- Введение в системы, использующие информационные ресурсы.
- Краткая история развития компьютерных технологий и методов хранения информации.
- Методы сбора данных. Определение проблемы и формулирование целей исследования.
- Планирование сбора первичных данных. Оценка полученных данных.
- Методы обработки информационных ресурсов.
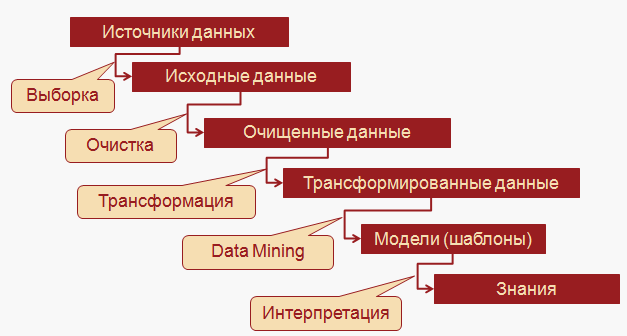
- Интеллектуальный анализ данных (Data Mining), история и предпосылки возникновения.
- Классификация и кластеризация данных. Функции сходства. Коэффициенты подобия.
- Специфика обработки неструктурированных данных. Системы сбора и хранения текстовых документов.
- Примеры информационных систем. Метод выделения ключевых слов. Метод латентных семантик LSI.
Интеллектуальный анализ НД
Бизнес-аналитика только на основе числовых рядов уходит в прошлое, сейчас программы, на основании которых принимаются управленческие решения, работают с неструктурированными данными и текстовой информацией.
Для достижения лучшего результата используются следующие виды анализа:
- интеллектуальный анализ данных (data mining);
- обработка естественного языка (Natural Language Processing);
- интеллектуальное изучение текста.
Эти типы исследований данных нацелены на поиск закономерностей, служащих предпосылками для выводов, имеющих значение для бизнеса.
Первым этапом работы программного обеспечения с данными является структурирование. Оно происходит путем поиска и нахождения общих смысловых единиц, характерных для речи или текста, например, частей речи или иных лингвистических или аудиальных структур.
Среди решений, обеспечивающих изучение неструктурированных данных с использованием метода естественного языка и интеллектуального анализа, называют:
- IBM Watson – программа на базе искусственного интеллекта получает вопросы на естественном языке и ищет на них ответы среди неструктурированных данных с использованием технологий ИИ;
- ABBYY FlexiCapture – программа для интеллектуальной работы с НД;
- SPSS Statistics, предлагающая статистические методы исследования НД для общественных наук.
Если ранее неструктурированные данные являлись проблемой, пугали своим количеством, неподконтрольностью и недоступностью для использования в качестве базы для принятия решений, то сегодняшний рынок предлагает достаточно продуктов, способных категоризировать и проанализировать НД.
12.12.2019
Обработка неструктурированных данных
Задача анализа неструктурированных данных с разной долей успеха решается уже несколько лет. Большинство информации, образующейся в компании или полученной из внешних источников, не структурируется и не проходит специальную подготовку. Около 60% информации, хранящейся на серверах корпораций, не только не является структурированной, она или бесполезна, или копирует уже существующие данные, или не пригодна для применения.
Бессистемное хранение важных сведений способно привести к тому, что персональные данные и другая конфиденциальная информация окажутся в открытом доступе. Поэтому необходимо проанализировать все корпоративные информационные ресурсы на предмет их содержания, условий хранения, соблюдения режима конфиденциальности. Агентство Gartner, один из лидеров мирового рынка в сфере информационных технологий и ERP (англ. Enterprise Resource Planning, планирование ресурсов предприятия), в 2014 году выпустило политику с правилами работы с неструктурированными корпоративными данными, где обозначила конечные цели работы с данными:
- оптимизация хранения данных. Понимание, какие именно массивы информации находятся в распоряжении компании, помогает систематизировать их, удалить лишнее, освободив место на дисках;
- выявление ненужных данных, их ликвидация и перенос корпоративного архива в облако. Агентство рекомендует эту модель работы с корпоративной информацией как оптимальную;
- классификация. Позволит присвоить данным метки конфиденциальности, структурировать по группам, что облегчит их использование в бизнес-процессах;
- выполнение предписаний регулятора по защите персональных данных и внутренних политик информационной безопасности по обеспечению режима конфиденциальности для коммерческой тайны;
- присвоение уровней доступа. Систематизация данных, информационных массивов и присвоение им меток позволят увеличить степень конфиденциальности, структурировав уровни доступа пользователей к данным разных типов;
- упрощение проведения аудита и расследований инцидентов информационной безопасности.
«СёрчИнформ FileAuditor» проводит автоматическую классификацию данных в файловой системе, которые содержат конфиденциальную информацию.
Практический пример
Так чем же полезен RDF? Тем, что это самая подходящая
технология, когда нужно свести распределённую информацию в общую
систему.
Вот пример ситуации, когда информация была бы распределённой:
база данных о продуктах различных поставщиков и оценках этих
продуктов различными экспертами. Ни один поставщик не согласится
взять на себя ответственность за поддержание общей центральной базы
данных, в том числе и потому, что она содержала бы информацию о его
конкурентах, и возможно, отрицательные оценки его собственной
продукции. У экспертов же может не хватать ресурсов для постоянного
поддержания в общей базе данных актуальной информации.
RDF бы подошёл в этом проекте особенно хорошо. Каждый поставщик
и каждый эксперт бы размещали на собственном веб-сервере RDF-файл.
Поставщики выбирают для своих продуктов URI, и эксперты используют
эти URI, когда публикуют свои оценки. Тогда поставщики не вынуждены
выбирать общую схему наименования для своих продуктов, и эксперты
не привязаны к форматам данных, выбранным поставщиками. RDF
позволяет и поставщикам, и экспертам использовать те инструменты,
которые им удобнее, и никто не заставляет никого пользоваться
каким-то определённым языком.
Такой вид имели бы RDF-файлы, которыми они обмениваются:
Поставщик 1:
vendor1:productX dc:title "Cool-O-Matic" .
vendor1:productX retail:price "$50.75" .
vendor1:productX vendor1:partno "TTK583" .
vendor1:productY dc:title "Fluffertron" .
vendor1:productY retail:price "$26.50" .
vendor1:productY vendor1:partno "AAL132" .
Поставщик 2:
vendor2:product1 dc:title "Can Closer" .
vendor2:product2 dc:title "Dust Unbuster" .
Эксперт 1:
vendor1:productX dc:description "This product is good buy!"
.
Эксперт 2:
vendor2:product2 dc:description "Who needs something to unbust dust?
A dust buster would be a better idea,
and I wish they posted the price." .
vendor2:product2 review:rating review:Excellent .
Отдельный вопрос — как именно они обменивались бы этими файлами;
его пока оставим в стороне. Как только приложение получает эти
файлы, у него появляется достаточно информации, чтобы соотнести
продукты, цены, оценки, и даже такую специфическую информацию, как
vendor1:partno (шифр изделия). То, что вы должны понять из этого
примера, — это насколько гибок RDF: он не накладывает практически
никаких ограничений и всё же позволяет приложениям моментально
соотносить распределённую информацию.
Поставщикам и экспертам не приходилось идти на компромиссы: они
договорились использовать RDF, и всё. Им не приходилось
договариваться о конкретном формате данных, или даже о конкретных
URI. Что важнее всего, им не пришлось перечислять заранее все
пункты, которые поставщик может включить в информацию о своём
продукте, и в этой системе ни одного из экспертов невозможно лишить
возможности публиковать свои оценки.
Кроме того, можно рассмотреть эту систему с точки зрения
взаимной совместимости. Формат, используемый Поставщиком 1,
полностью совместим с форматом, используемым всеми остальными, хотя
они не вырабатывали общий формат целенаправленно. Когда в системе
появится новое действующее лицо, которое захочет работать с
информацией Поставщика 1, ему не потребуется реализовывать новый
формат: всё что ему будет нужно — это выбрать те же подлежащие,
сказуемые и дополнения, которые выбрал Поставщик 1.
Заключение
Помимо Schema.org существуют и другие словари, в том числе Dublin Core (имеющий базовую поддержку в RDFa) и Facebook Social Open Graph. Тем не менее, стандарт Schema.org в последнее время получил мощную поддержку, особенно с учетом своих выдающихся апологетов. Это новейшее достижение в длинном перечне событий в такой сфере, как оптимизация поисковых механизмов (search-engine optimization, SEO).
Вполне возможно, что идея SEO имеет преимущественно маркетинговый характер, однако она полностью базируется на таких концепциях совершенствования веб-технологий, как достижимость, чистая разметка и аннотирование страниц — везде, где это возможно, и с привлечением большего количества информации о фактическом значении контента. Такие достижения, как RDFa Lite, призваны разместить мощные возможности SEO в пределах досягаемости практически любого сетевого автора. Я надеюсь, что эта статья поможет вам изучить RDFa за один день и призывают вас немедленно приступить к аннотированию своих страниц.