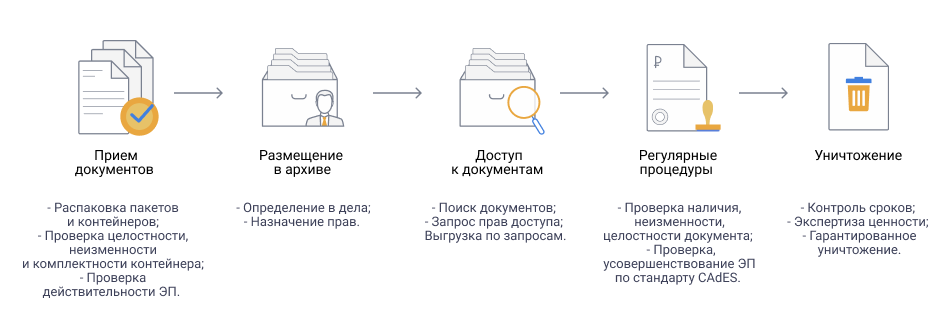
Возможно, вам также будет интересно
В статье рассматриваются наиболее востребованные речевые технологии и решаемые с их помощью задачи в различных отраслях и сферах нашей жизни.
В статье рассмотривается проект обновления системы водохозяйственных коммуникаций, реализованный в Канаде. Использование современного программного обеспечения (ПО) для промышленной беспроводной связи, диспетчерского управления и сбора данных (SCADA) позволило коммунальным службам лучше выполнять работы по водоснабжению и очистке сточных вод.
Специалисты компаний «ВИСТ Групп» (входит в ГК «Цифра») и «КонсОМ СКС» разработали специальный программный продукт для ГРК «Быстринское» и внедрили его. Это автоматизированная система управления открытыми горными работами (АСУ ОГР) — комплексная система диспетчеризации горных работ, которая оптимизирует процессы перевозки руды от мест ее добычи, хранения и переработки. Данное решение позволяет …
Что это такое?
Как можно определить, и в чём различие с другими AI.
Что же обычно подразумевается под Artificial General Intelligence? AGI можно определить как синтетический интеллект, работающий в широком диапазоне задач и обладающий хорошей способностью к обобщению в условиях разных контекстов при выполнения разнородных задач. Другими словами, ИИ, способный выполнять поставленные задачи так же успешно, как человек.
Иерархию AI в данный момент можно представить следующим образом (ранжируя от более простого, к более сложному):
- Artificial Narrow Intelligence (ANI, Narrow AI) – специализируется в одной области, решает одну проблему.
- Artificial General Intelligence (AGI, Strong AI) – способен выполнять большинство из задач, на которые способен человек.
- Artificial Super Intelligence (ASI) – превосходит возможности интеллекта любого из людей, способен решать сложные задачи моментально.
Определение AGI можно проиллюстрировать при сравнении Narrow AI (ANI) и Strong AI (AGI). Стоит заметить, что сейчас не существует ни одной системы, которую можно было бы с уверенностью назвать Strong AI – всё что мы сейчас видим, это AI системы, преуспевающие в выполнении узконаправленных задач: детектирование, распознавание, перевод с одного языка на другой, генерация изображений, генерация текстов, но пока сложно говорить о какой-то универсальности таких моделей и применимости одной модели для выполнения существенно различающихся друг от друга задач без необходимости дополнительной тренировки. Именно применимость одного AI для выполнения вышеперечисленных задач чаще всего называют сильным искусственным интеллектом.
Возвращаясь к разделению на категории, можно обнаружить ещё один термин, который вызывает не меньший интерес, что же это такое. Это Artificial Super Intelligence, возникновение которого предполагается почти следом за созданием AGI (при условии, что AGI умеет обучаться-эволюционировать за счёт модификации самого себя, или создания себе подобных). Если, говоря о AGI, мы говорим о интеллектуальных способностях, близких к человеческим, то суперинтеллект превосходит интеллект человека в разы. Именно вместе с созданием суперинтеллекта предположительно возникает технологическая сингулярность – гипотетический момент, когда наука начинает прогрессировать необозримыми темпами, что приведёт к непредсказуемым последствиям.
Зачем?
Прежде чем бросаться реализовывать подобную систему, искать критерии признания того или иного решения, удовлетворяющего требованиям, стоит прежде всего попытаться понять, что вообще может дать такая разработанная систем, и, в связи с этим, какие задачи она должна уметь выполнять.
В этом, пожалуй, и состоит одна из проблем исследований в этом направлении – они больше напоминают мечту футуриста, без явной привязки к действительной реальности. Какое применение может найти AGI в нашем мире, помимо “везде”? В том плане, какие задачи мы пока не пытаемся решить с помощью ANI? Какое применение в сфере бизнеса могут найти такие модели, если даже не будут достаточно умны?
Для меня прежде всего приходит мысль о способности обобщать, искать и запоминать информацию и делать из неё выводы, таким образом выполняя роль исследователя. Даже возможность искать информацию практически моментально в огромной базе знаний с последующим обобщением в виде набора тезисов-идей может значительно помочь исследователям (отчасти можно связать с термином exploratory search). Не говоря уже о том, что такая система в теории может сама решить сложные задачи, или предложить возможные пути и план, как же достичь решения.
Да, та же самая GPT-3 умеет создавать правдоподобные статьи на различные темы, но, по правде, это остаётся генерацией информации, но не знания. С равным успехом эта система может обосновать два противоположных тезиса, что можно связать с отсутствием критического мышления. В результате такого подхода, армия демагогов может образоваться огромное болото из однообразной информации, в которой будет практически нереально найти действительно новую, важную информацию.
Исходя из подобной проблемы, в качестве первичного этапа развития AGI систем, и целей, которых можно достигнуть, можно выбрать способность систем к обобщению информации с целью выделения из них основных тезисов, отсеивания лишнего и донесения до человека только самого важного
Иерархические конечные автоматы
Основные состояния:
| Состояние | Условие перехода | Новое состояние |
| Небоевые | враг видим и враг слишком силён | Поиск помощи |
| враг видим и здоровья много | Нападение | |
| враг видим и здоровья мало | Бегство | |
| Нападение | врага не видно | Небоевое |
| мало здоровья | Бегство | |
| Бегство | врага не видно | Небоевое |
| Поиск | искал в течение 10 секунд | Небоевое |
| враг видим и враг слишком силён | Поиск помощи | |
| враг видим и здоровья много | Нападение | |
| враг видим и здоровья мало | Бегство | |
| Поиск помощи | друг видим | Нападение |
| Начальное состояние: небоевое |
Небоевое состояние:
| Состояние | Условие перехода | Новое состояние |
| Ожидание | ожидал в течение 10 секунд | Патрулирование |
| Патрулирование | завершил маршрут патрулирования | Ожидание |
| Начальное состояние: ожидание |
Сферы использования технологий искусственного интеллекта
IBM Watson (суперкомпьютер на основе ИИ) стал популярен в 2011 году благодаря победе на «Jeopardy». Использующийся в IBM Watson алгоритм машинного обучения стал невероятно популярен, хотя сейчас он уже несколько видоизменен и используется в новом виде в качестве шаблона для разных коммерческих программ.
ИИ затрагивает практически все отрасли жизнедеятельности:
- ИИ в медицине и здравоохранении – речь идет об аппаратах УЗИ, о рентгене и о прочем медицинском оборудовании. Благодаря точной работе ИИ у пациента находят проблемы со здоровьем, а обнаружив таковые – могут подобрать оптимальное лечение. Сюда же можно отнести приложения, помогающие вести ЗОЖ: следить за пульсом, давлением, температурой, даже определять уровень кислорода в крови.
- ИИ в онлайн-магазинах – речь идет о той самой рекламе, которая постоянно возвращает нас к тем товарам, характеристики которых мы недавно изучали. На поисковиках предлагаются вещи, к которым проявили интерес пользователи. Машиной изучаются покупательские пристрастия человека, а потом предлагаются релевантные (по их мнению) товары.
- ИИ в политике – речь идет о работе в области сбора и анализа собранных данных. Вспомним, что Барак Обама стал второй раз президентом, поскольку его специалисты использовали ИИ при расчете наилучшего дня, штата и аудитории для публичного выступления Обамы. По оценкам, это обеспечило преимущество в 10-12 процентов.
- ИИ в промышленности – речь идет о возможностях ИИ собирать и анализировать данные с разных участков производства и, тем самым, грамотно распределять нагрузку на оборудование.
- ИИ в образовании и игровой индустрии – речь идет о создании игр, а также об активном продвижении ИИ в образовательных программах развитых стран.
Курсы от GeekBrains по изучению искусственного интеллекта для детей
Данные курсы понравятся тем, кто увлечен технологиями:
- Заинтересованы работой ИИ.
- Интересуются машинным обучением и нейронными сетями.
- Имеют начальный уровень программирования, хотят двигаться дальше, а также проявляют интерес к языку Python.
Всего за три месяца у детей получится освоить навык работы с математическими операциями, они научатся датасеты и создавать алгоритмы машинного обучения. Также, им будет предоставлена возможность запустить предобученную нейронную сеть, чтобы распознавать верные и ложные данные.
Курсы от GeekBrains по изучению искусственного интеллекта для детей
Есть три веские причины, по которым необходимо пройти курс по искусственному интеллекту:
- Открывающиеся карьерные перспективы – ребята попробуют познакомиться с профессией дата-сайентиста — специалиста по работе с данными, они хорошо подкованы в вопросах ИИ и машинном обучении, имеют хорошую финансовую перспективу.
- Это будет прекрасная подготовка к конкурсам или олимпиадам по программированию — ребята углубят знания по программированию, линейной алгебре и математическому анализу. Это поможет победить в соревнованиях и поступить на бюджетную основу в престижные технические вузы: МГУ, МГТУ им Н. Э. Баумана, МФТИ, ВШЭ.
- Вашему ребенку понравится это увлекательное обучение, ведь дети смогут почувствовать себя в роли исследователя, классифицируя привычки людей и прогнозируя поведение. В результате чего у них получится создать несколько нейронных сетей.
Как будет проходить учёба?
Будут проводиться вебинары (1 раз в неделю по 90 минут). Проводятся они во внеурочное время, после школы вечером или по выходным дням. Дети изучают новую тему, спрашивают, если что-то не понятно, а потом могут и пересмотреть урок, ведь видеозапись будет им всегда доступна.
После завершения вебинара будет открыт доступ к практическим заданиям, которые очень важно выполнять в срок, чтобы учитель смог проверить и прислать ответное письмо с обратной связью и полным разбором выполненного домашнего задания. Вам будет предоставлена постоянная поддержка от кураторов
Они будут на связи с родителями, чтобы оперативно отвечать на вопросы, и на связи с учениками, чтобы сориентировать по успеваемости, к примеру.
Вам будет предоставлена постоянная поддержка от кураторов. Они будут на связи с родителями, чтобы оперативно отвечать на вопросы, и на связи с учениками, чтобы сориентировать по успеваемости, к примеру.
Задачи
Теперь посмотрим, какие задачи решают авторы при помощи полученных векторных представлений.
-
Много-классовая классификация. В качестве меток используется отрасль (industry), которую указал пользователь.
-
Кластеризация. Здесь решаются три задачи: кластеризация пользователей по отрасли (industry), кластеризация навыков (skills) по домену (domain, размечено вручную), кластеризация профессии по специальности (specialty).
-
Восстановление связей. Три задачи: person-region, person-industry, person-skill. Задача рассматривается в режиме Closed World Assumption, поэтому используются метрики классификации (AUROC).
Помимо классических задач, проводится анализ векторов в пространстве. Например, можно добавить к вектору профессии вектор навыка и посмотреть на ближайшие векторы профессий. Таким образом, можно моделировать карьеру пользователя, обуславливаясь его текущими профессией и компанией, и предполагая, какую профессию он мог бы освоить, если бы изучил новый навык. Примеры из статьи показаны ниже.
В первом столбце представлены запросы, где второй элемент каждой пары — тип сущностей, наиближайшие векторы которых необходимо найти (приведены справа). Title — название профессии. Взято из https://arxiv.org/abs/1910.10763v1
Классификация проводилась как на маленьком, так и на большом датасетах, а остальные задачи проверялись только на большом. Очень странно, что на большом графе применяются только Skip-gram-подобные модели, тогда как на маленьком проверяются также Knowledge Graph Embeddings (TransE и подобные). Авторы говорят, что не удалось запустить TransE на большом графе, но с запуском node2vec у них никаких проблем не возникло. Это довольно странно, ведь, казалось бы, всё должно быть наоборот. Также, неясно, как авторы умудрились запустить методы для простых графов на графе знаний. Видимо, в LinkedIn’s Economic Graph между любыми двумя узлами может быть только одно ребро.
Жёстко заданные условные конструкции
в каждом кадре/обновлении, пока игра выполняется: если мяч слева от ракетки: двигать ракетку влево иначе если мяч справа от ракетки: двигать ракетку вправо
есть
- «Восприятие» — это два оператора «если». Игра знает, где находятся мяч и ракетка. Поэтому ИИ запрашивает у игры их позиции, таким образом «чувствуя», находится ли мяч слева или справа.
- «Мышление» тоже встроено в два оператора «если». В них находится два решения, которые в данном случае взаимно исключают друг друга, приводящие к выбору одного из трёх действий — двигать ракетку влево, двигать её вправо или ничего не делать, если ракетка уже расположена верно.
- «Действие» заключается в конструкциях «двигать ракетку влево» или «двигать ракетку вправо». В зависимости от способа реализации игры это может принимать вид мгновенного перемещения положения ракетки или задания скорости и направления ракетки, чтобы её можно было сдвинуть должным образом в другом коде игры.
Системы на основе полезности (Utility)
полезности
| Действие | Вычисление полезности |
| Поиск помощи | Если враг видим и враг силён, а здоровья мало, то возвращаем 100, в противном случае возвращаем 0 |
| Бегство | Если враг видим и здоровья мало, то возвращаем 90, иначе возвращаем 0 |
| Нападение | Если враг видим, возвращаем 80 |
| Ожидание | Если находимся в состоянии ожидания и уже ждём 10 секунд, возвращаем 0, в противном случае 50 |
| Патрулирование | Если находимся в конце маршрута патрулирования, возвращаем 0, в противном случае 50 |
БегствоПоиск помощиПоиск помощинепрерывногоБегствоНападениеБегствуНападениемлекцияхпрезентациях@IADaveMark
Повысить мотивацию к обучению

Учебный процесс многими воспринимается как обязательная повинность, а выполнение домашних заданий и подготовка к тестам и экзаменам вызывают массу негативных эмоций. Однако использование технологий в учебном процессе, таких как искусственный интеллект, виртуальная реальность, нейросети или роботы, могут это изменить.
Применение инноваций способно привнести в образование элемент игры, сделать учебный процесс более интерактивным и увлекательным. Если преподаватели научатся эффективно использовать современные технологии, это может значительно повысить уровень мотивации среди учеников, развить у них интерес к новым знаниям и навыкам.
Марковские модели
| Первая комната, в которой замечен игрок | Всего наблюдений | Следующая комната | Сколько раз замечен | Процент |
| Красная | 10 | Красная | 2 | 20% |
| Зелёная | 7 | 70% | ||
| Синяя | 1 | 10% | ||
| Зелёная | 10 | Красная | 3 | 30% |
| Зелёная | 5 | 50% | ||
| Синяя | 2 | 20% | ||
| Синяя | 8 | Красная | 6 | 75% |
| Зелёная | 2 | 25% | ||
| Синяя | 0% |
следующеймарковской моделью
| Наблюдение 1 | Гипотетическое наблюдение 2 | Вероятность в процентах | Гипотетическое наблюдение 3 | Вероятность в процентах | Накапливаемая вероятность |
| Зелёная | Красная | 30% | Красная | 20% | 6% |
| Зелёная | 70% | 21% | |||
| Синяя | 10% | 3% | |||
| Зелёная | 50% | Красная | 30% | 15% | |
| Зелёная | 50% | 25% | |||
| Синяя | 20% | 10% | |||
| Синяя | 20% | Красная | 75% | 15% | |
| Зелёная | 25% | 5% | |||
| Синяя | 0% | 0% | |||
| Всего: | 100% |
марковским свойством
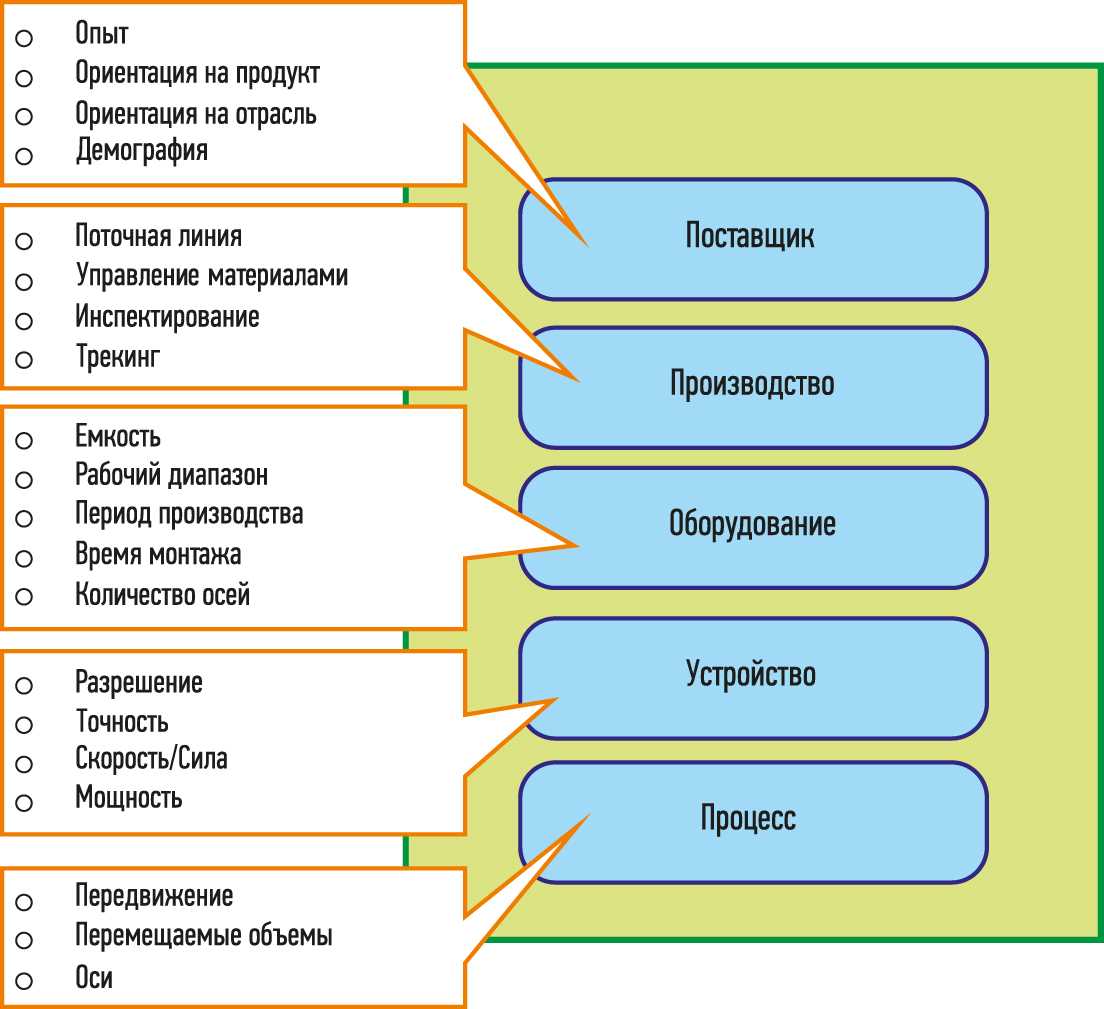
Применение машинного обучения для решения задач информационного поиска в «Индустрии 4.0»
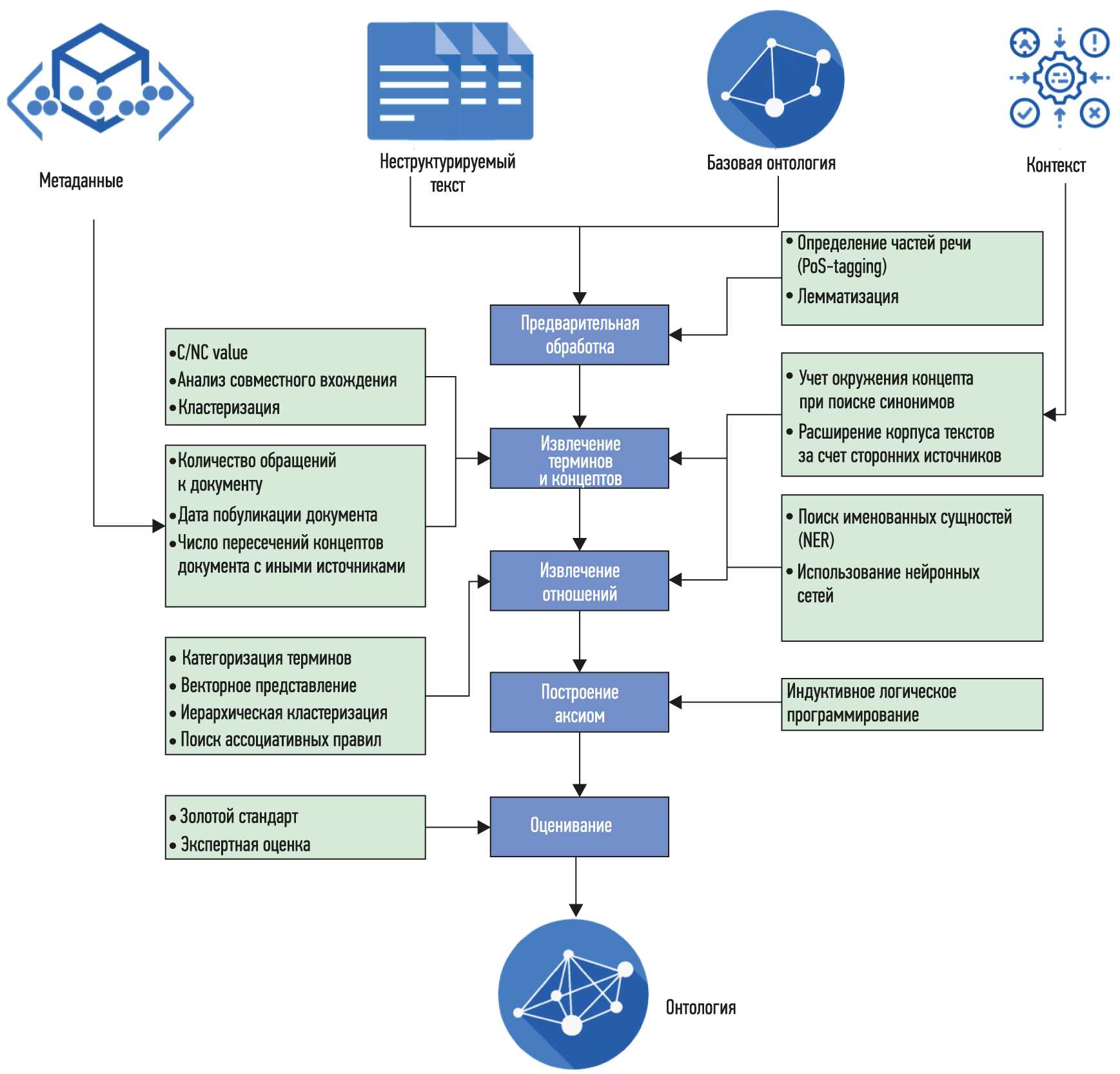
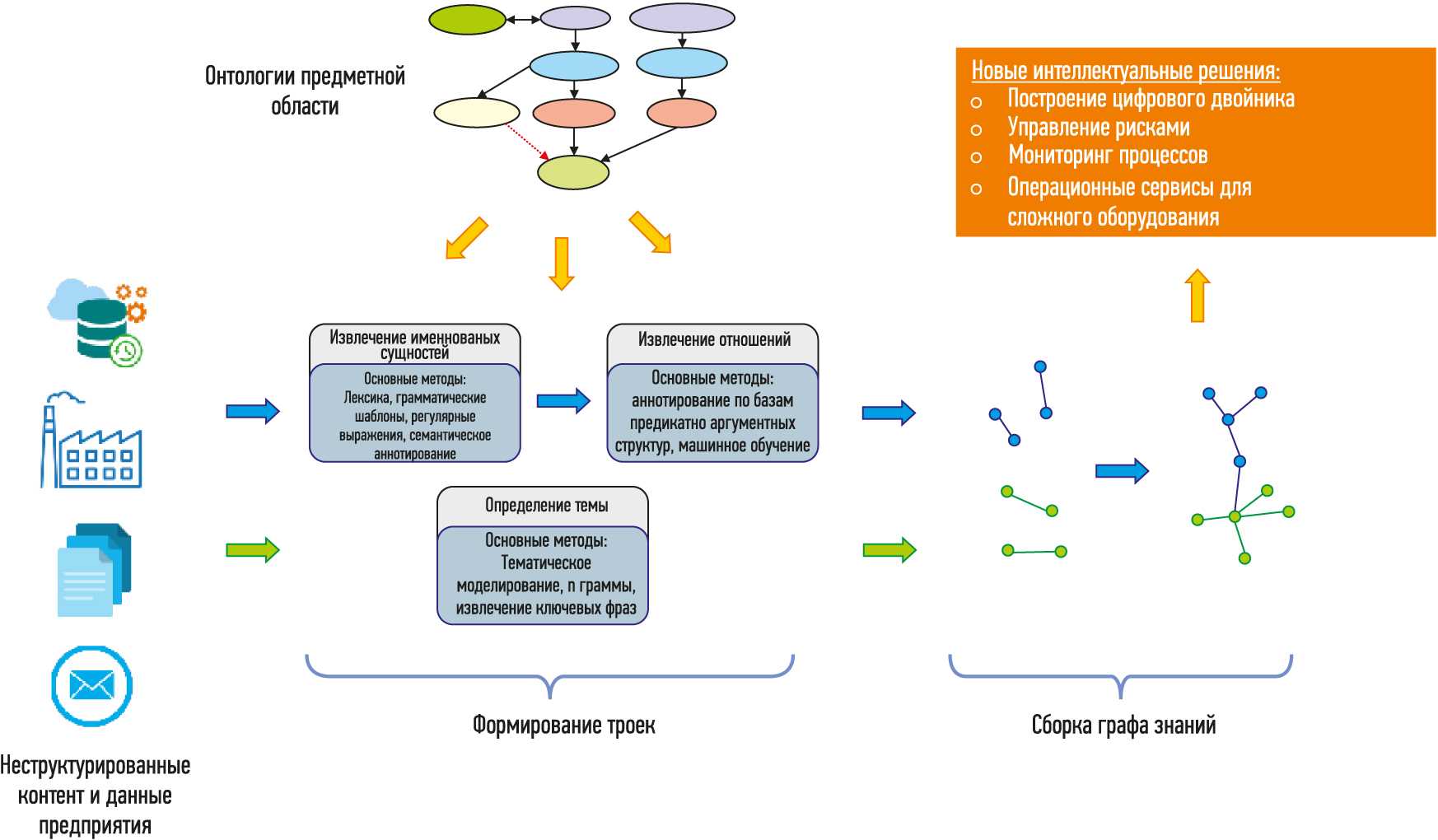
Как уже было сказано выше, имея онтологии в качестве семантической основы, графы знаний не только могут объединить различные источники данных в общее хранилище, но и решают проблему информационной совместимости и формализации производственных знаний. Но знания являются динамической структурой, имеющей свой жизненный цикл, что требует постоянной модификации и обновления данных в графах знаний. Подобная модификация использует комплекс методов машинного обучения и относится к задачам Information Extraction . Эти задачи включают:
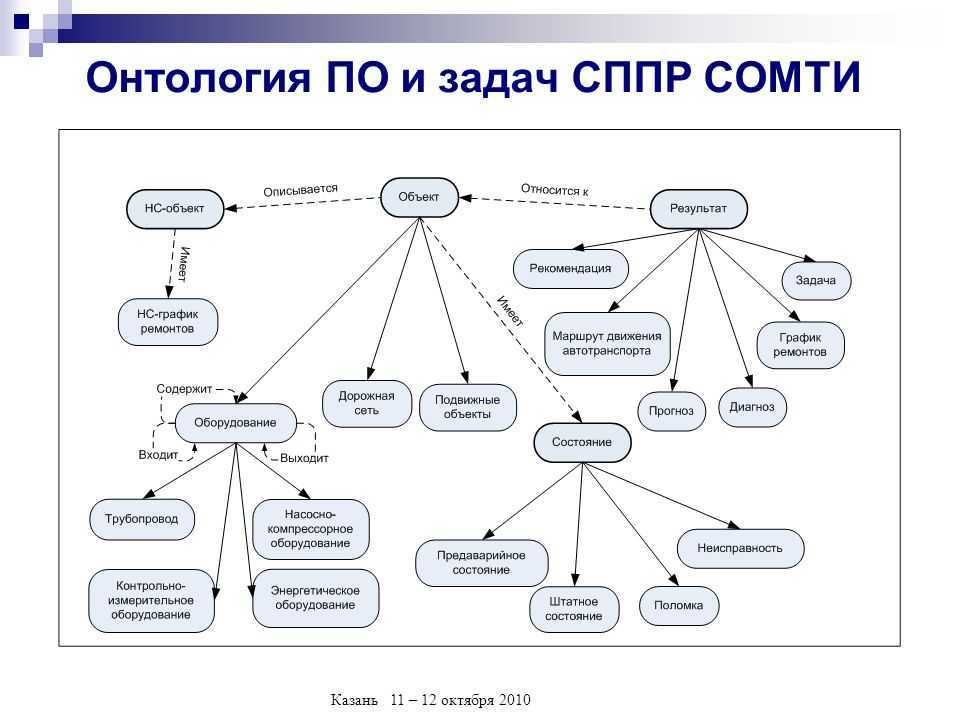
- Распознавание/извлечение именованных сущностей (Named Entity Recognition/Extraction) — разграничение позиций упоминаний сущностей во входном тексте. Например, в предложении «Пьер Кюри открыл пьезоэлектричество» подчеркнутый текст является упоминанием именованных сущностей.
- Связывание/снятие омонимии сущностей, или семантическое аннотирование (Entity Linking/Disambiguation, Semantic Annotation) — ассоциирование упоминаний сущностей с подходящим и однозначным идентификатором в базе знаний. Например, связывание «Пьер Кюри» с сущностью Q37463 в графе знаний Wikidata.
- Извлечение терминов (Term Extraction) — извлечение основных фраз, которые обозначают концепты, релевантные к выбранной предметной области и описанные в корпусе, иногда включая иерархические отношения между концептами. Например, выявление в тексте про машинное обучение, что «нейронная сеть» или «k-средних» являются важными концептами в предметной области. Дополнительно можно определить, что оба концепта являются уточнением понятия «искусственный интеллект», а также, что они могут быть связаны с определенным подразделом базы знаний.
- Извлечение ключевых слов/фраз (Keyword/Keyphrase Extraction) — извлечение основных фраз, которые позволяют категоризировать тематику текста (в отличие от извлечения терминов, задача извлечения ключевых фраз заключается в описании именно текста, а не предметной области). Ключевые фразы также могут быть связаны с базой знаний.
- Тематическое моделирование/классификация (Topic Modeling, Classification) — кластеризация слов/фраз, которые часто встречаются совместно в сходном контексте. Эти кластеры затем ассоциируются с более абстрактными темами, с которыми связан текст.
- Маркирование/идентификация темы (Topic Labeling/Identification) — для кластеров слов, идентифицированных как абстрактные темы, извлечение одиночного термина или фразы, наилучшим образом характеризующей эти темы. Например, определение, что тема, состоящая из {«машинное обучение», «выборка», «точность классификации», «градиентный спуск»}, наилучшим образом характеризуется термином «машинное обучение» (которое может быть связано, например, с концептом Q2539 в Wikidata).
- Извлечение отношений (Relation Extraction) — извлечение потенциальных n-арных отношений из неструктурированных или полуструктурированных (таких как HTML-таблицы) источников. Например, из предложения «Пьер Кюри открыл пьезоэлектричество» можно извлечь «открыл» (Пьер Кюри, пьезоэлектричество). Бинарные отношения могут быть интерпретированы как RDF-тройки после связывания предикатов-отношений с соответствующими свойствами в базе знаний (таким как discoverer or inventor (P61)).
Временное похолодание (1974–1980)
В 1969 году Марвин Мински и Сеймур Паперт опубликовали свою книгу «Перцептроны». В ней они показали принципиальные ограничения перцептронов и выдвинули на первый план неспособность перцептронов управлять элементарной схемой XOR. Это привело к смещению интереса исследователей искусственного интеллекта в противоположную от нейросетей область символьных вычислений.
Альтернативный подход символьного ИИ получил взрывной рост. Но этот подход не дал каких-либо существенных результатов. В 1970-х годах стало ясно, что исследователи ИИ чрезмерно оптимистичны в отношении ИИ. Цели, которые они обещали, ещё не были достигнуты и их достижение казалось делом весьма отдалённого будущего.
Исследователи поняли, что упираются в стену. ИИ применялся к простым задачам. Но реальные сценарии оказались слишком сложными для этих систем. Число возможностей, которые алгоритмы должны были исследовать, получалось астрономическим. Это привело к проблеме комбинаторного взрыва. А затем возник классический вопрос «как сделать компьютер умным». Это была проблема здравого смысла.
Всё этор привело к тому, что инвесторы разочаровались в технологии. Финансирование ИИ, таким образом, исчезло, а исследования прекратились. DARPA тоже больше не могла поддерживать хакерскую культуру исследований из-за изменений в законодательстве. Спонсоры заморозили финансирование исследований в области искусственного интеллекта. Поэтому период 1974–1980 гг. называют «зимой ИИ».
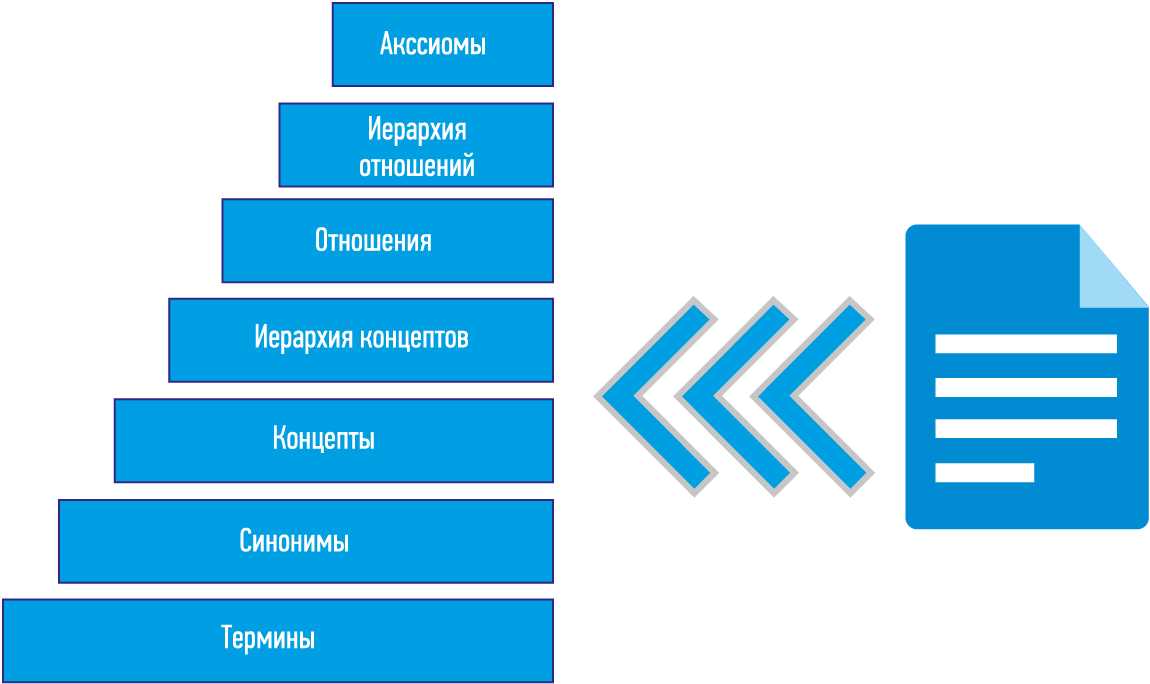
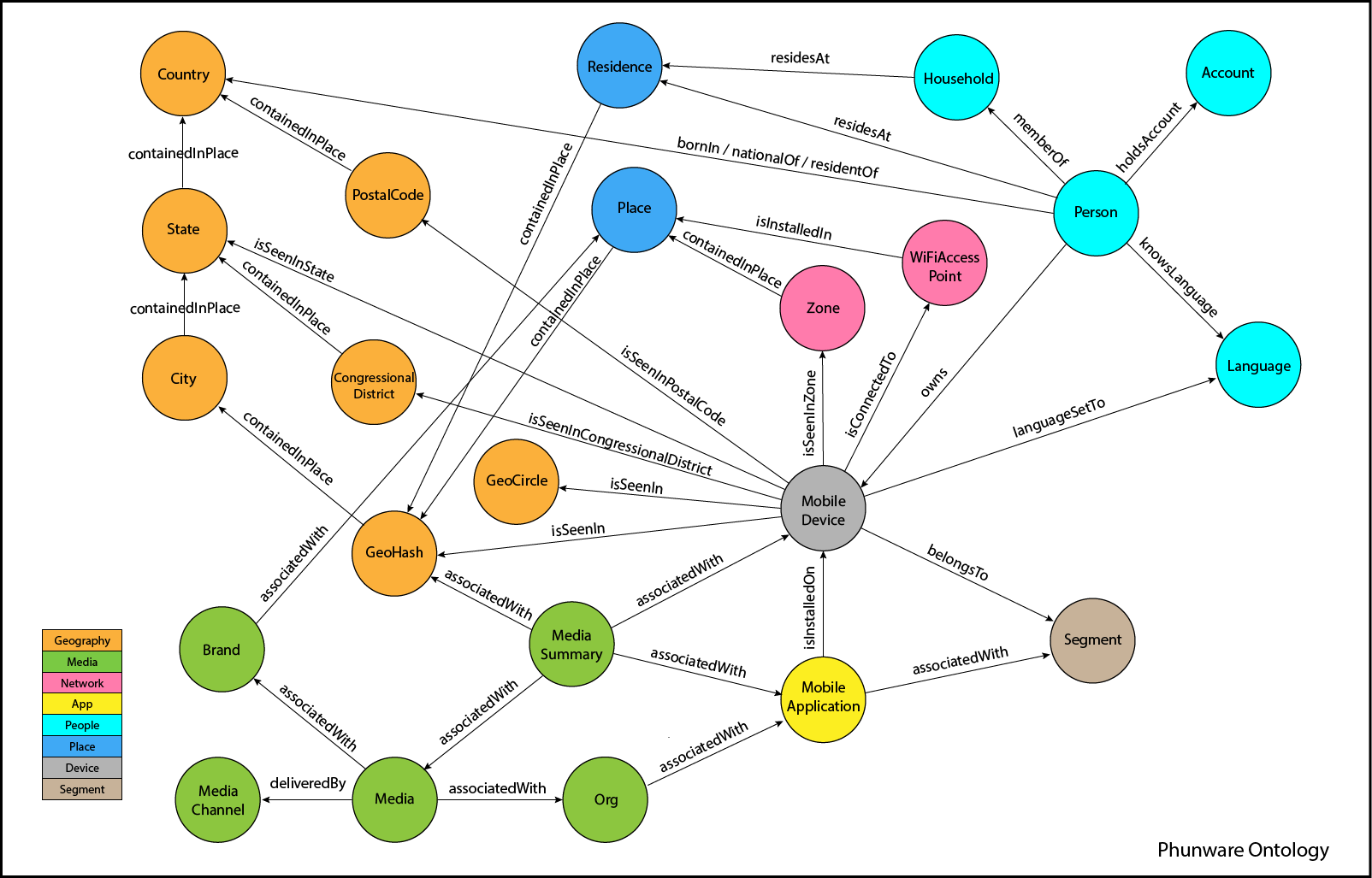
Графы и триплеты
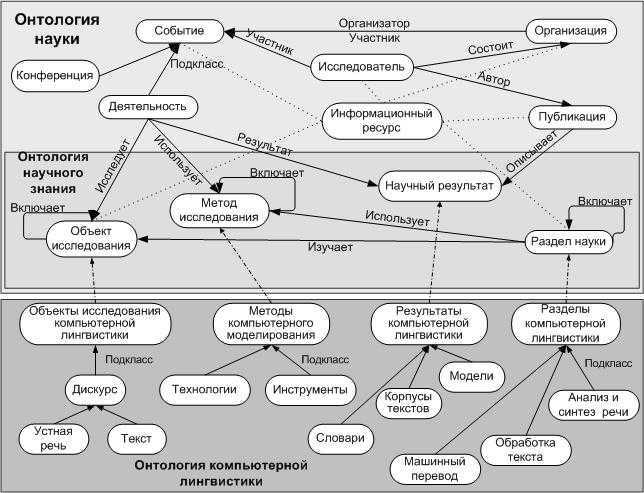
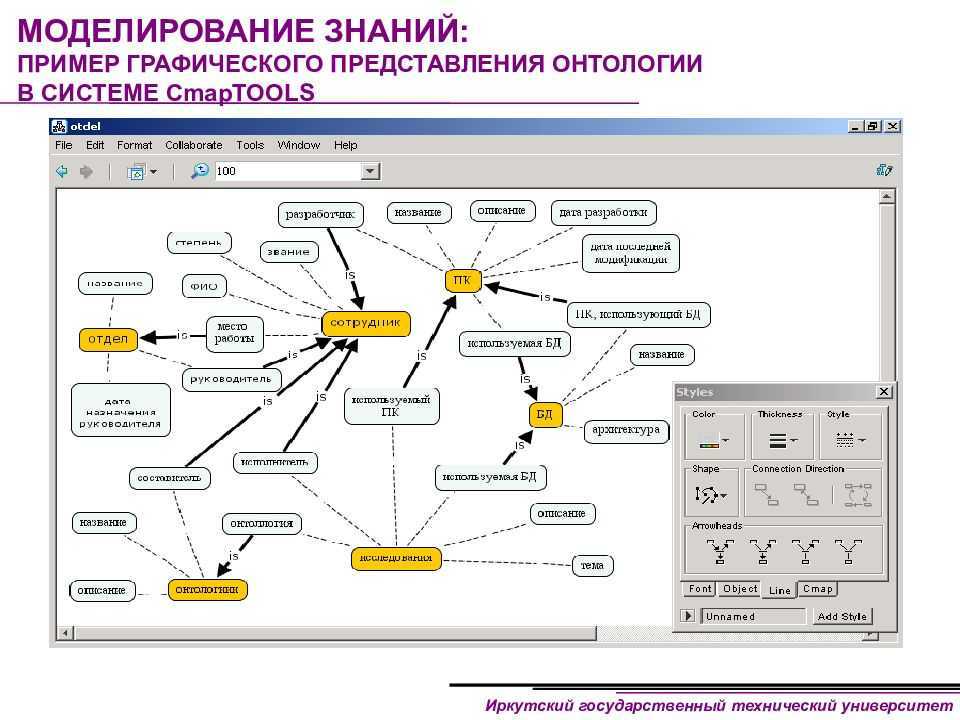
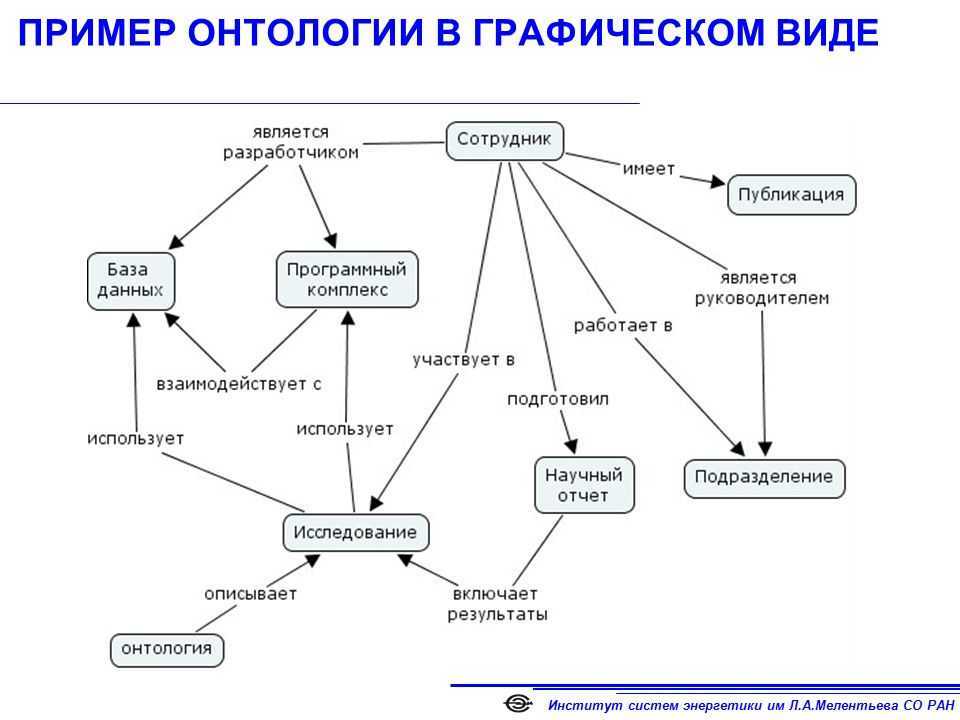
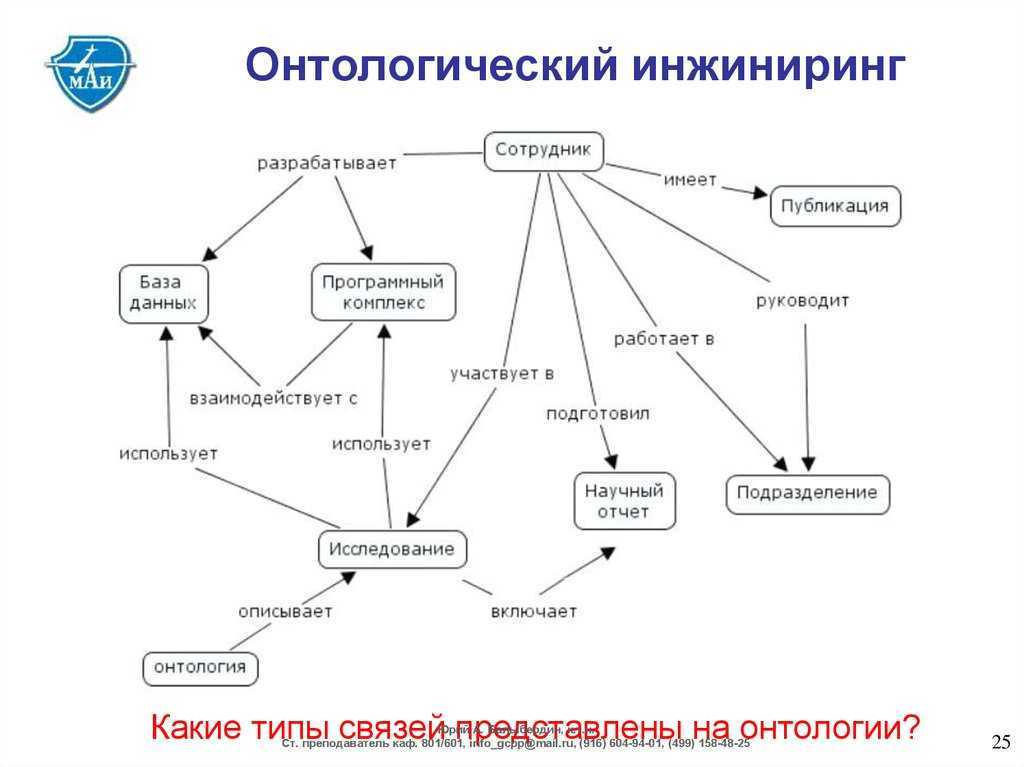
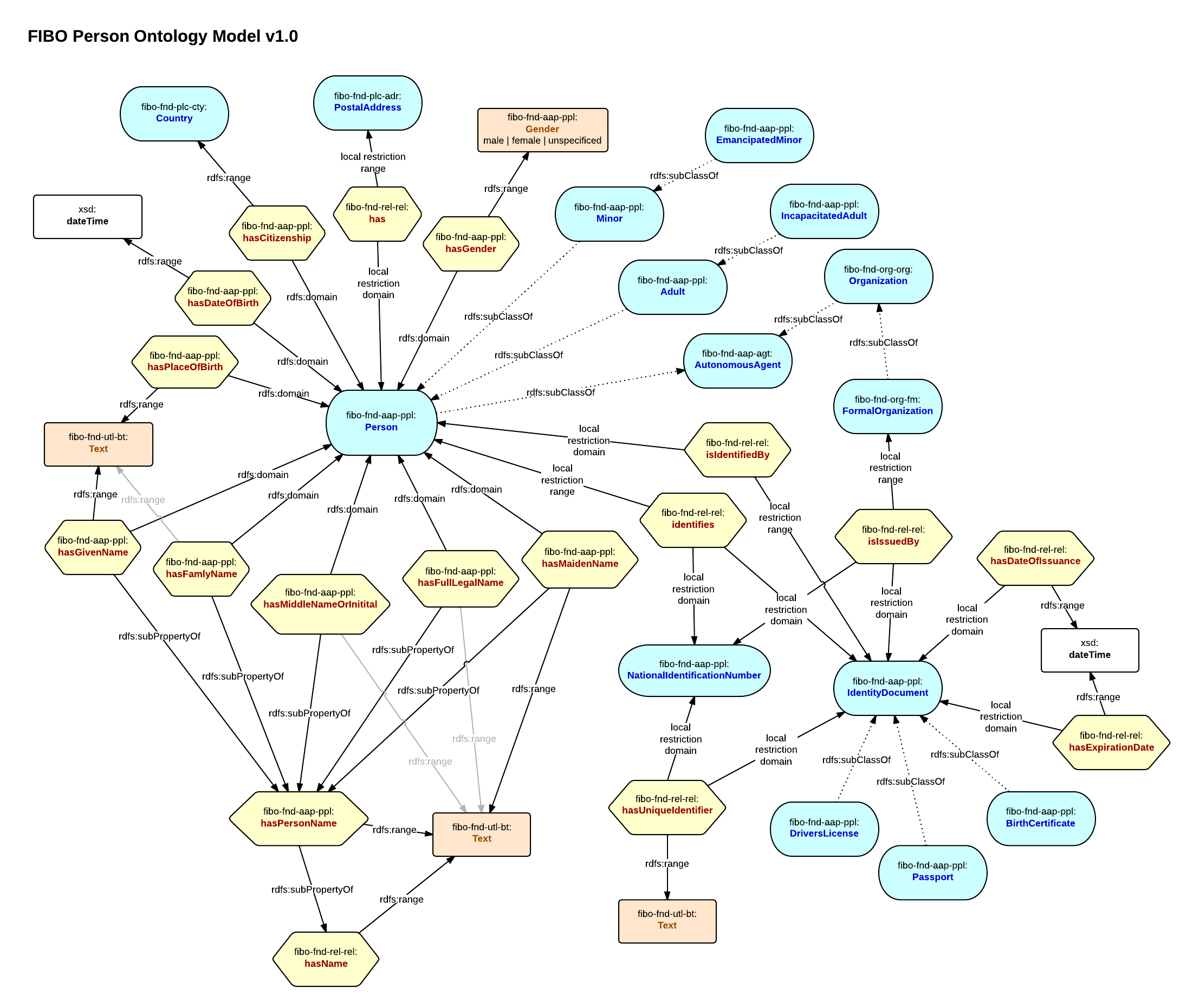
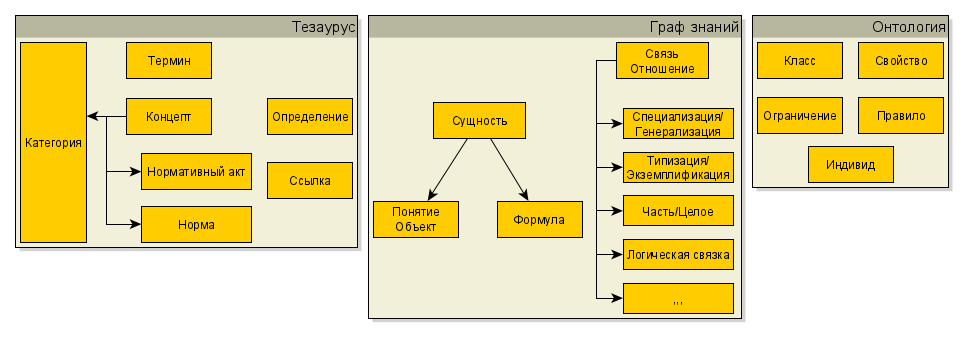
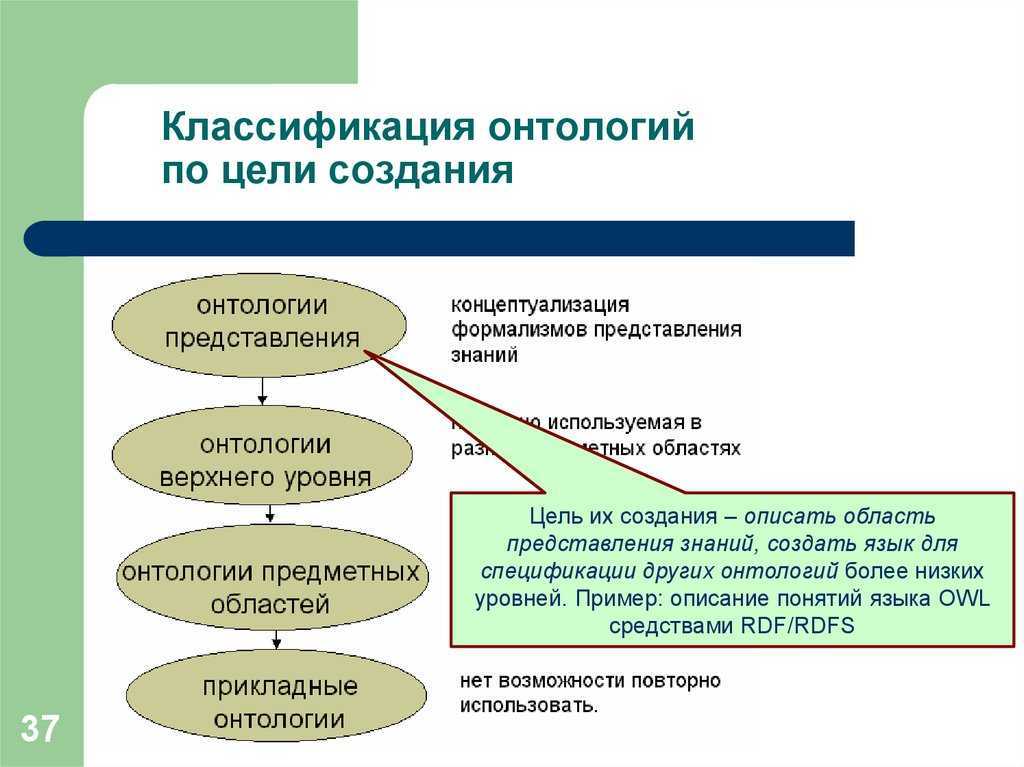
Графы знаний характеризуются детальным описанием содержащихся в них сущностей и машинопонимаемыми логическими связями между ними. Существует два способа представления графов знаний. Первый способ, онтологическое представление, основан на формальной логике и семантике. Второй способ векторных представлений использует статистические механизмы для минимизации расстояний между близкими сущностями в многомерных пространствах. В этой и нескольких следующих лекциях мы сосредоточимся на онтологическом представлении.
Итак, термин ”граф знаний” дает некоторое представление о его конструкции и содержимом. Графовая модель позволяет моделировать физические и абстрактные сущности и связи между ними. Граф определяется классически как набор вершин и ребер
\
В графах знаний мы, однако, дополнительно отметим, что вершины и ребра могут иметь типы: \. Следуя по цепочке концепций и связей можно исследовать близкие сущности и понятия, а также усиливать или уменьшать значимость конкретной связи между некоторыми сущностями или классами сущностей.
Термин “Классы сущностей”, в свою очередь, уже начинает намекать о содержимом графа, а именно знаниях. Как мы уже убедились в прошлой лекции, хранить знания в таблицах — несколько неестественный способ для человеческого мозга, который имеет сетевую природу, и здесь графы предлагают достойную альтернативу.
Для представления знаний в машиночитаемом виде используют формальные логики, а с понятием логики и знаний неразрывно связано и понятие семантики. С лингвистической трактовке семантика передает смысл символов некоторого формального или естественного языка. Здесь и далее мы будем иметь в виду формальную семантику, передающую смысл языков в математических терминах. Формальные логики предоставляют математический аппарат для представления смысла (интерпретации) языка.
Логик и семантик существует довольно много (пропозициональная логика, логика предикатов, модальная логика, логика первого порядка, и тд), и история их появления и развития достойна отдельной лекции. Рассматриваемые в курсе подходы основаны на логике первого порядка и дескрипционных логиках (как подмножество логики первого порядка) и теоретико-модельной семантике (семантике Тарского). Другими словами, они дают нам инструменты интерпретировать знания с ограничениями выразительности. Чем выразительнее логика, тем сложнее ее использовать для логического вывода.
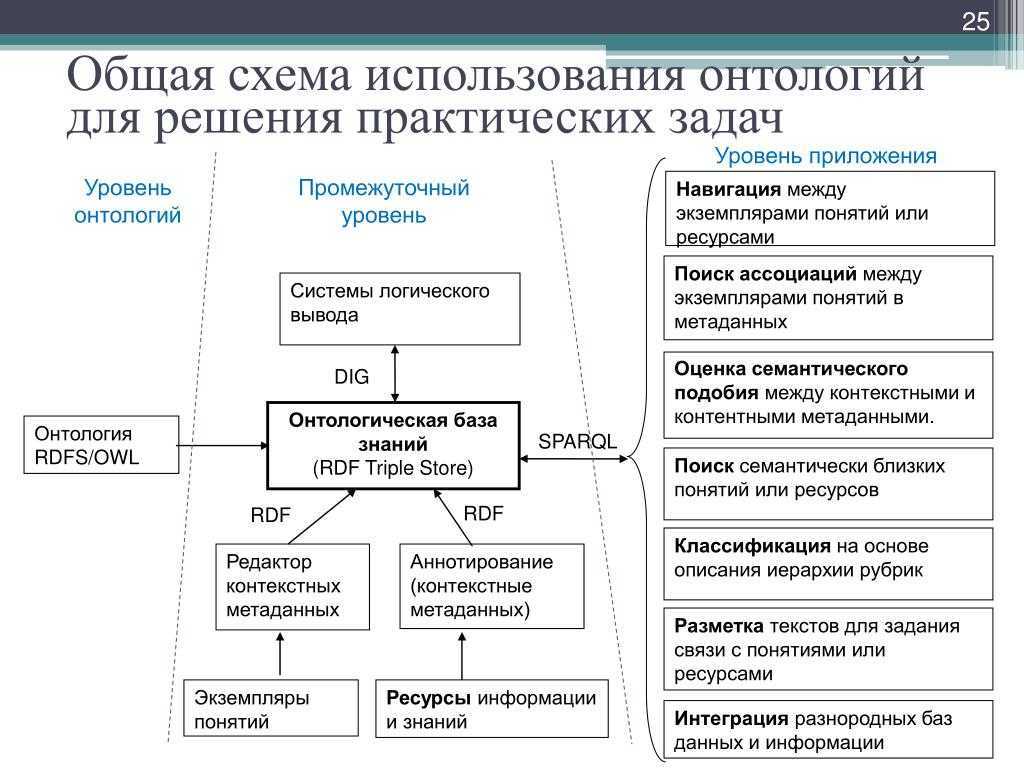
Формальная логика и семантика для онтологического представления графов знаний опирается на такие стандарты консорциума WWW как RDF [], RDFS [] и OWL []. В совокупности они образуют стэк технологий и стандартов, называемый Semantic Web Layer Cake:
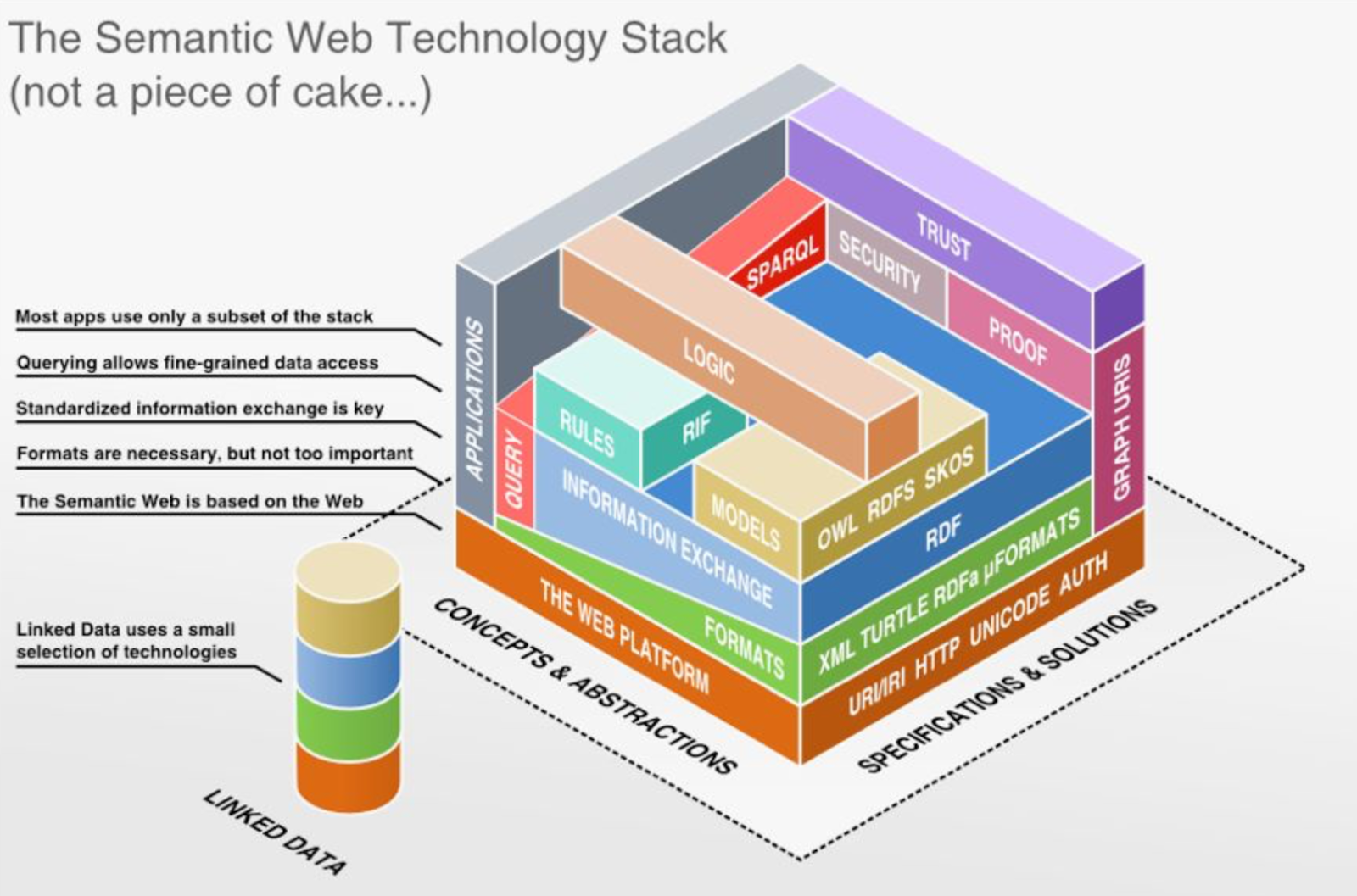
На нижнем уровне, обозначающем базовые средства передачи информации в сети, находятся уникальные идентификаторы ресурсов (URI), передающиеся по протоколу HTTP символами Юникода с возможностью аутентификации и авторизации.
На уровне выше находятся форматы — синтаксис представления данных. Среди них XML, Turtle, RDFa, JSON-LD и другие. Мы рассмотрим самые популярные и используемые дальше в этой лекции.
На следующем уровне представлен собственно метод представления данных — модель RDF, которая вводит начальную семантику описываемых ресурсов.
Поднимаясь уровнем абстракции выше, мы приходим к расширение логической модели и выразительности RDF с помощью стандартов RDFS, OWL, SKOS, также вводом формата описаний логических правил “если-то”. Правила могут описываться, например, с помощью стандарта RIF, SWRL или SPIN. Все логические расширения RDF так или иначе ведут к формальной логике, а именно дескрипционным логикам и логике первого порядка.
Для запросов к знаниям, представленным в RDF, используется язык запросов SPARQL, который связывает графы знаний с приложениями, опирающимися на графы знаний. У SPARQL может вводить и поддерживать собственные логические механизмы, а также служит для управления доступом к знаниям в зависимости от параметров пользователя, отправляющего запрос.
Стэк также предусматривает средства обеспечения достоверности и корректности представляемых знаний посредством указания и сохранения источников знаний — как на уровне отдельного утверждения, так и на уровне коллекции фактов (VoID, SHACL, ShEx).
Рассмотрим некоторые ключевые технологии подробнее.
Принятие сложных решений
Finite state machine
- Патрулирующий (Patrolling).
- Атакующий (Attacking).
- Убегающий (Fleeing).
- Если страж видит противника, он атакует.
- Если страж атакует, но больше не видит противника, он возвращается к патрулированию.
- Если страж атакует, но сильно ранен, он убегает.
- Бездействие (Idling) — между патрулями.
- Поиск (Searching) — когда замеченный враг скрылся.
- Просить о помощи (Finding Help) — когда враг замечен, но слишком силен, чтобы сражаться с ним в одиночку.
- Действия, которые мы периодически выполняем для текущего состояния.
- Действия, которые мы предпринимаем при переходе из одного состояния в другое.
Дерево поведений
- Теперь узлы возвращают одно из трех значений: Succeeded (если работа выполнена), Failed (если нельзя запустить) или Running (если она все еще запущена и нет конечного результата).
- Больше нет узлов решений для выбора между двумя альтернативами. Вместо них узлы Decorator, у которых есть один дочерний узел. Если они Succeed, то выполняют свой единственный дочерний узел.
- Узлы, выполняющие действия, возвращают значение Running для представления выполняемых действий.
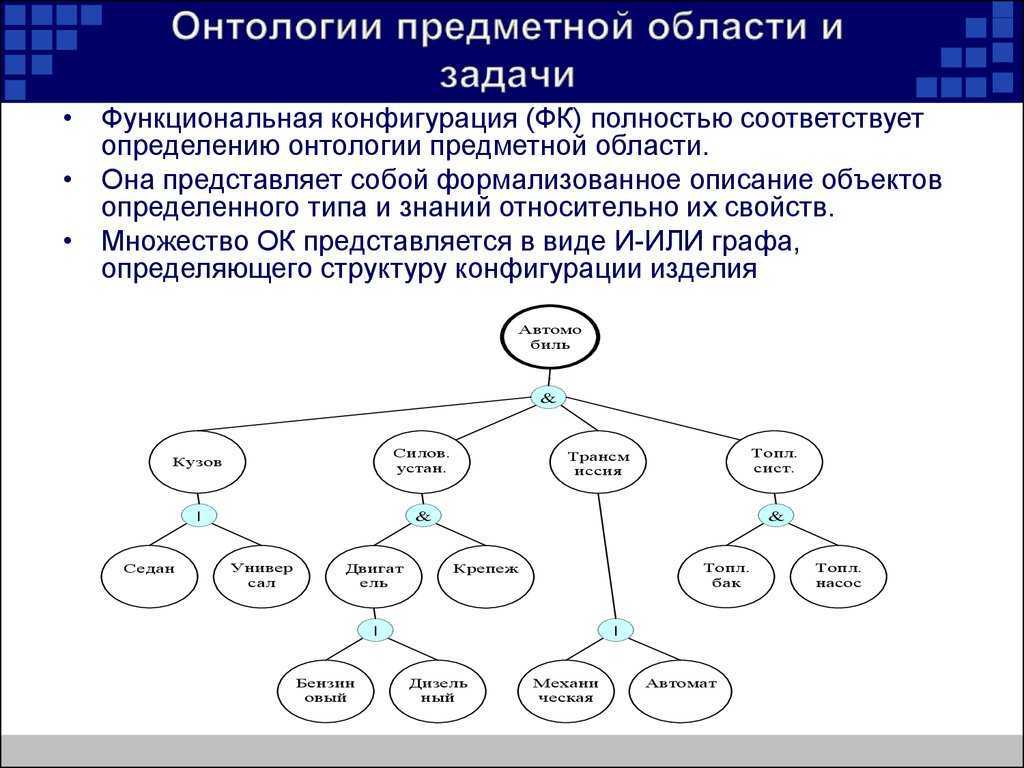
Что такое граф?
-
Граф- математический объект, который изображает отношения между сущностями. Граф состоит из вершин (объектов) и рёбер (связей). С помощью графов можно представить разныех ситуации: например, пользователей соцсети, которые находятся друг у друга в друзьях, клиентов банка, которые переводят друг другу денежные средства, географические объекты и пути между ними.
-
-
Графы могут быть направленными: в этом случае ребра обозначаются стрелками, идущими от одной вершины к другой, и называются дугами. Примеры направленных графов — звонки пользователей друг другу или банковские переводы.
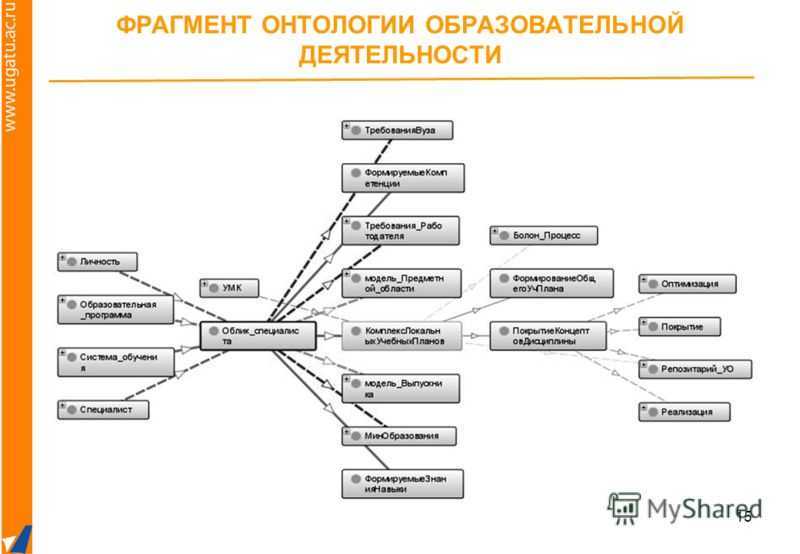
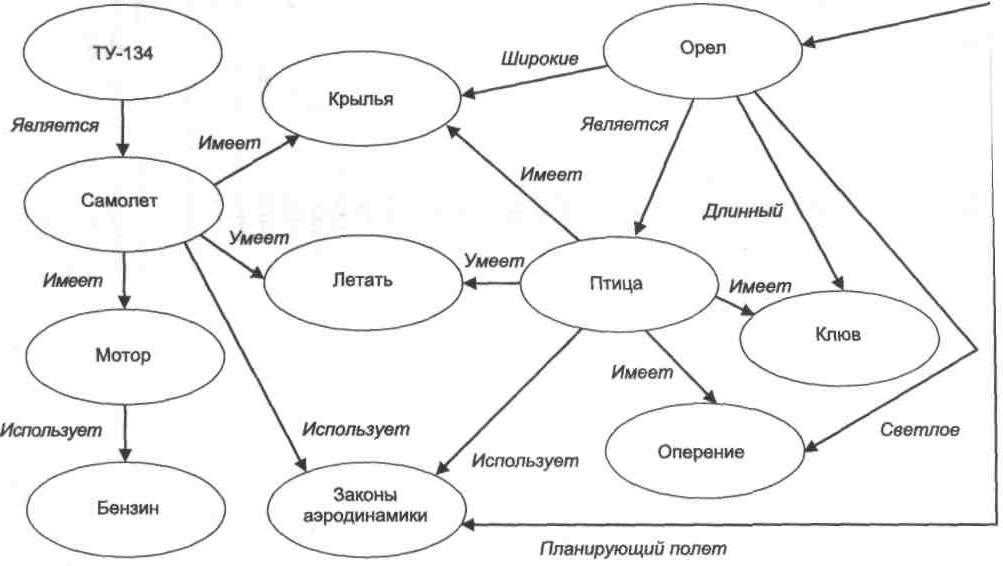
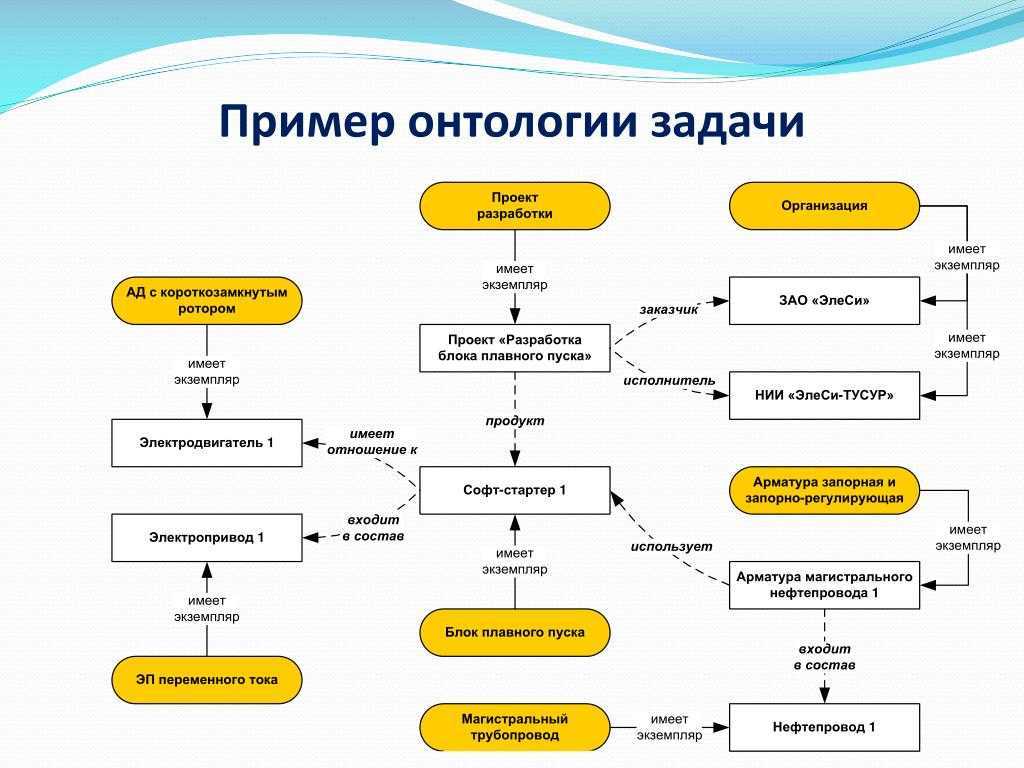
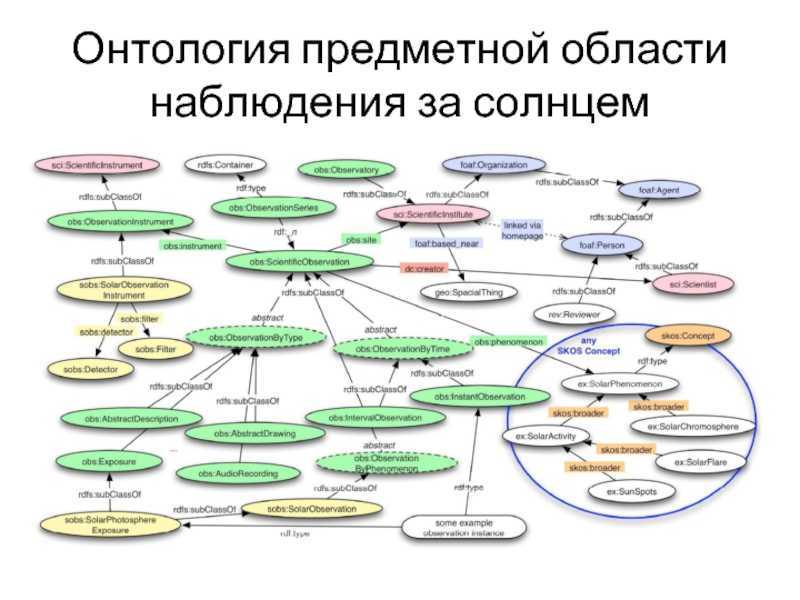
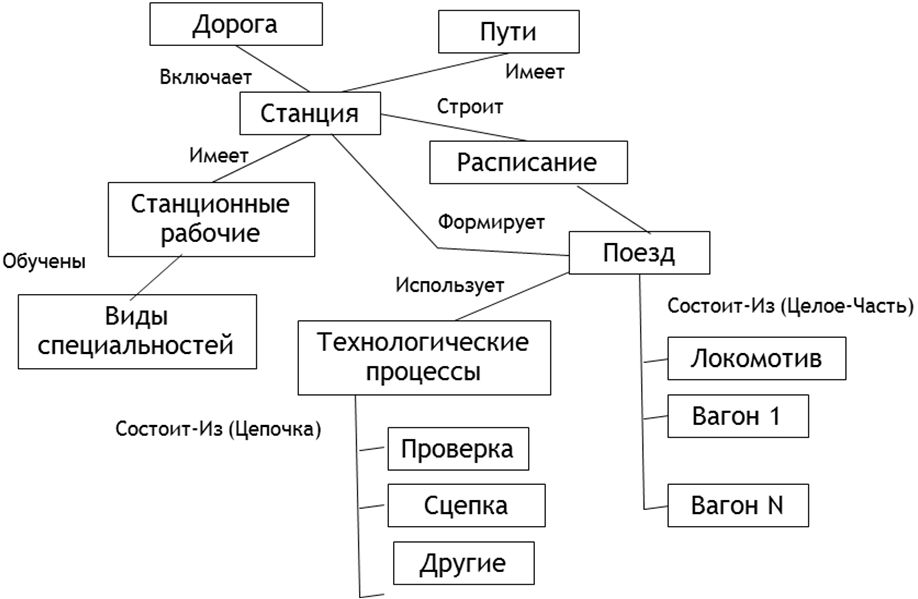
Рёбрам графа могут быть присвоены значения — веса. Веса характеризуют силу связей между вершинами. Как пример, это может быть количество звонков, сумма денежного перевода, расстояние между городами. Если у рёбер графа нет весов, то считается, что все веса равны между собой.
Граф называется циклическим, если в графе присутствует последовательность рёбер, которая начинается и заканчивается в одной вершине. Цикл необязательно должен включать в себя все вершины.
И наоборот, существуют ациклические графы, не содержащие замкнутых последовательностей рёбер. Их подвид, направленные ациклические графы, применяются для построения древовидных структур и используются во множестве сфер, включая биологию (эволюция), социологию. Другой распространенный пример — графы вычислений (Dask, Airflow), которые описывают набор зависящих друг от друга операций, выполняемых последовательно или параллельно.