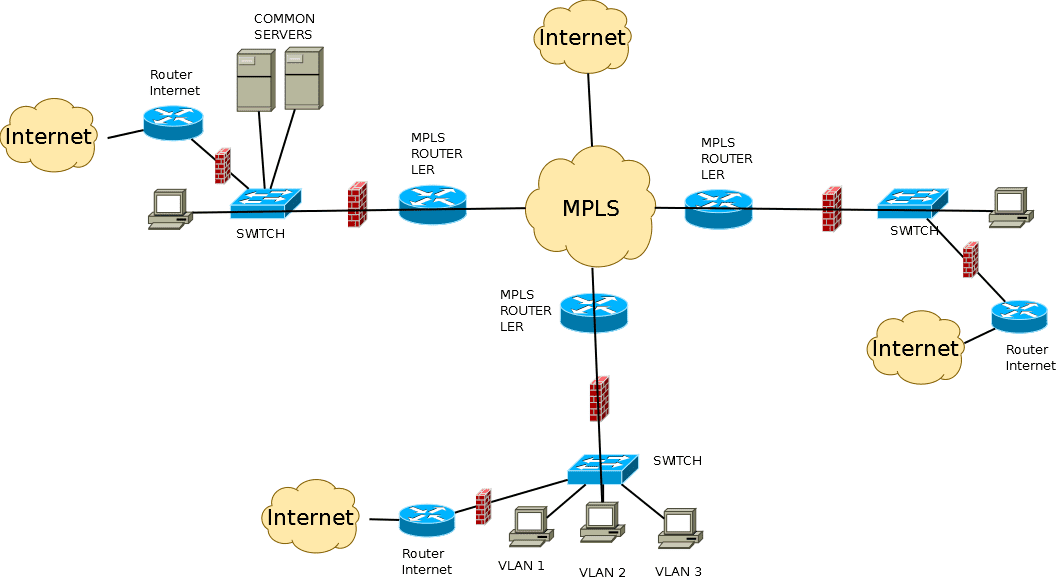
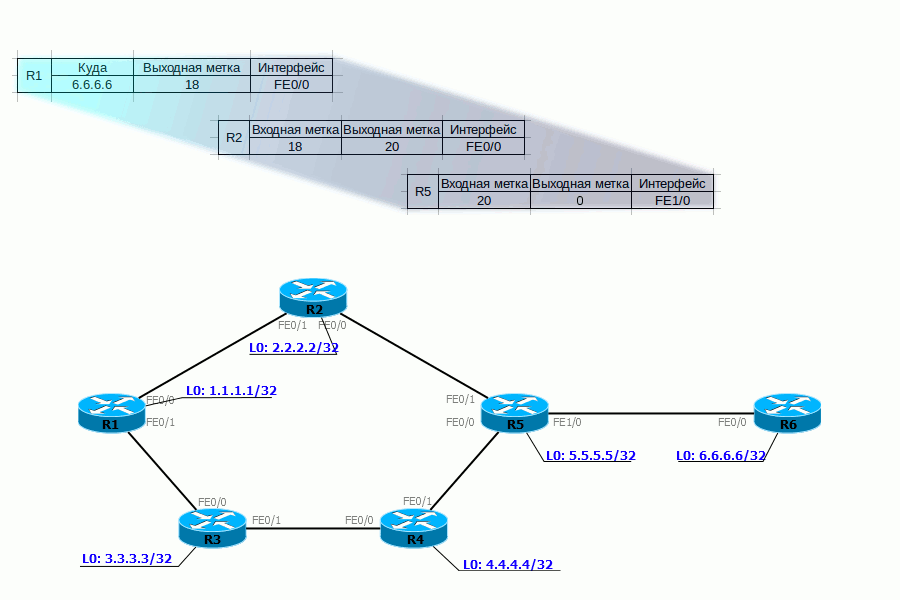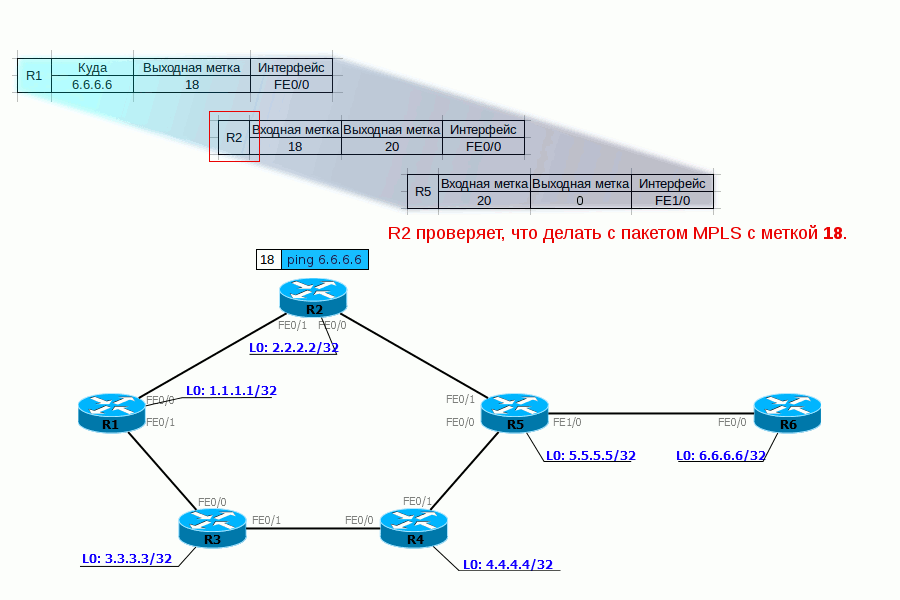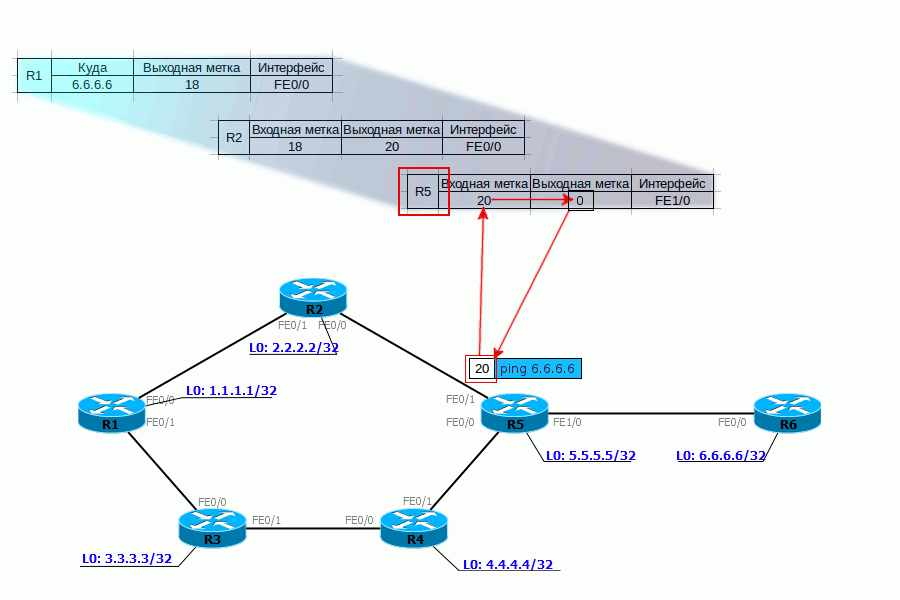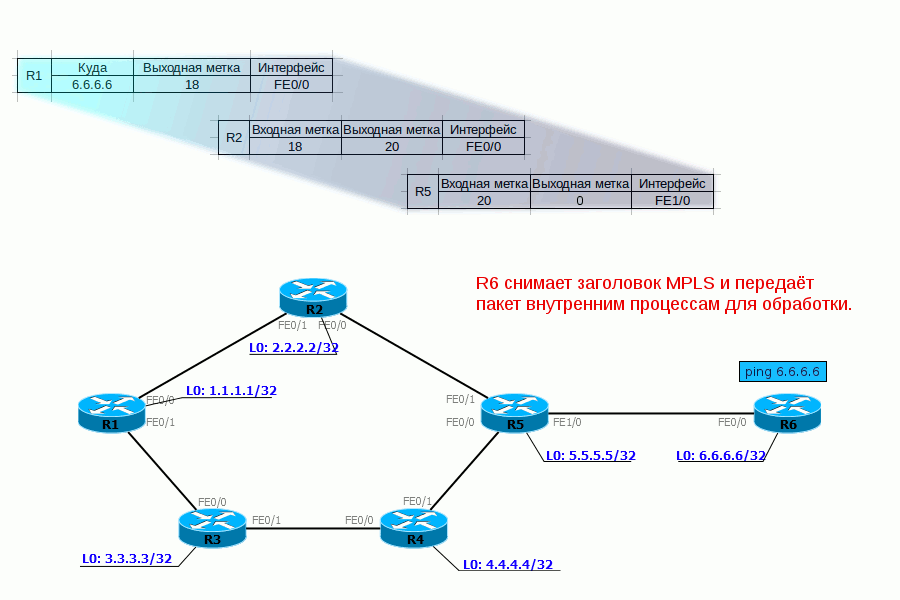
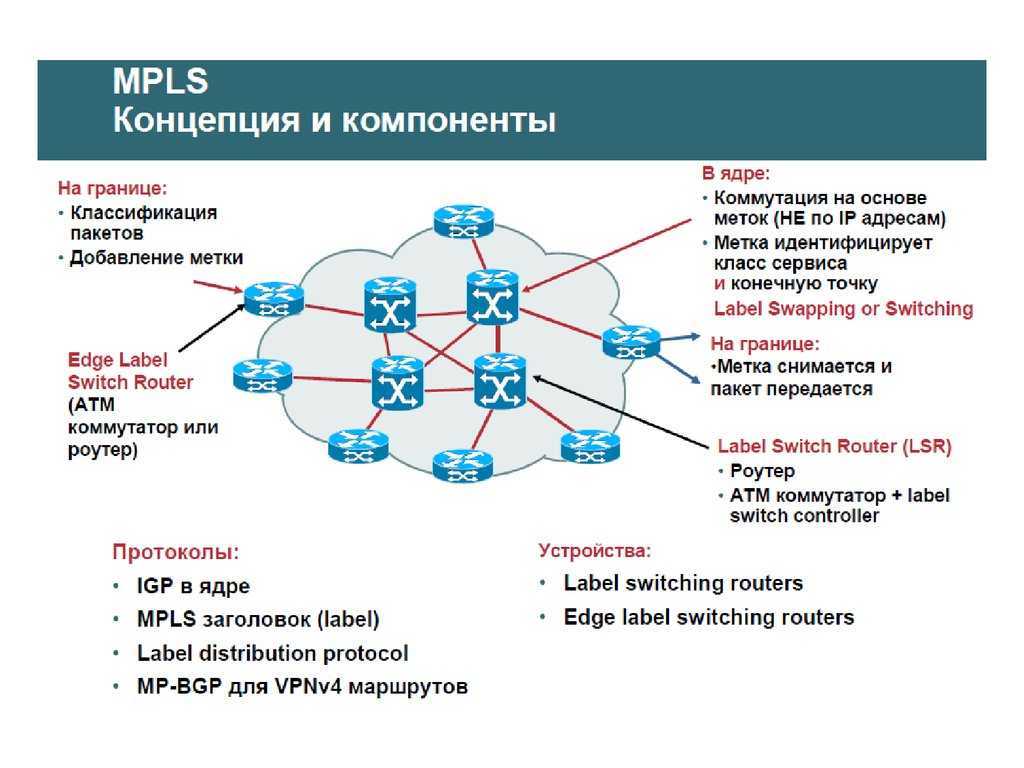
Administrative Groups или Affinity
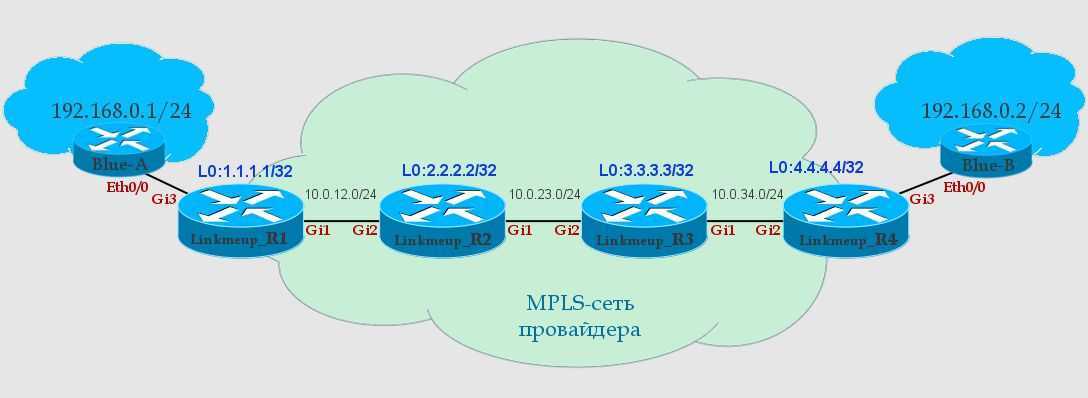
Вот сейчас должно стать страшно. Мне страшно.
- Метрика MPLS TE.
- Требования к полосе пропускания канала и приоритет замещения.
- Explicit-path.
- SRLG.
RFC3630Идея в том, что каждый интерфейс мы помечаем определёнными цветами.
А потом говорим, что вот этот туннель может идти по красным и фиолетовым линиям, но не может по зелёным, жёлтым и коричневым.Раз уж примеры у нас в консоли Cisco, то далее буду использовать термин Attribute-Flag наравне с Administrative group, что не совсем правильно.Affinity и маска
- РРЛ это или нет
- Магистральная линия или в сторону сегмента доступа
- Канал через интернет или нет
Взяли только первые 8 бит для простоты.
- Чтобы это не был РРЛ ()
- Чтобы это был магистральный линк (1)
- Канал не через интернет ()
Attribute-Flag 0000 0100 — Не РРЛ, магистральный и не через Интернет. Attribute-Flag && Mask = 0000 0100 = Affinity && Mask — сюда можно пускать трафик.
Attribute-Flag 0100 0000 — Не РРЛ, но в сторону сегмента доступа, да ещё и через интернет. Attribute-Flag && Mask = 0100 0000 ≠ Affinity && Mask — сюда нельзя пускать трафик.
Attribute-Flag 0000 0101 — Оптика, не РРЛ, магистральный и не через Интернет. Attribute-Flag && Mask = 0000 0100 = Affinity && Mask — сюда можно пускать трафик
Не важно, оптика или нет — результат тот же.
0x0 RFC 7308 разжёвывает Affinity
Практика
Файл конфигурации.
Надёжность и сходимость
- Защита на физическом уровне. Например, APS в SONET или LAG в Ethernet.
- IP — решение всех проблем. IGP, BGP, VRRP итд.
- Набор технологий в MPLS.
- Path Protection
- Local Protection
Резервное копирование 3-2-1
Только хорошо спланированная стратегия резервного копирования позволяет восстановить данные тогда, когда они вам понадобятся. Если вы находитесь только в самом начале или уже в процессе переосмысления существующей системы, следуйте правилу резервного копирования 3-2-1:
Первым шагом к защите данных является локальное резервное копирование. Вы защищаете ваши данные копией на разных носителях, что защитит от единой точки отказа. Например можно делать резервную копию с ПК на Synology NAS. В тоже время локальная резервная копия не защищает от пожара, кражи или любого другого стихийного бедствия. Поэтому копия данных за пределами площадки будет самым надежным, но и самым сложной и дорогостоящей задачей.
Резервная копия папок и файлов
Резервное копирование и синхронизация папок позволит легко восстановить данные после случайного или намеренного изменения. Подробнее
Автоматическая защита всего компьютера
Защитите свои компьютеры под управлением Windows и Linux с помощью полного резервного копирования всех файлов, программ и настроек на любом диске. Гибкое восстановление позволяет восстанавливать только файлы и папки или реплицировать все устройство на новое. Подробнее о .
Настраиваете резервное копирование важных данных в реальном времени или по расписанию.
Резервное копирование внешних дисков и карт памяти
Создание автоматического или ручного резервного копирования USB накопителей и карт памяти при подключении , а так же освобождение пространства после окончания операции. Подробнее о USB Copy.
Резервное копирование фотографий и видеозаписей
C Synology Photos на телефоне делайте резервные копии фотографий и видео файлов, а так же освобождайте место на мобильном устройстве. Просмотр ваших снимков никогда не был таким удобным.
Cloud Sync – только для файлов
Синхронизируйте ваши файлы с общедоступными облачными хранилищами такими как Google Drive, Microsoft OneDrive или Dropbox. Подробнее о Cloud Sync.
Hyper Backup – полное резервное копирование для больших объемов
С помощью Hyper Backup можно создавать резервные копии данных даже очень больших размеров например в облако mail.ru или в BackBlaze. Так же у SYnology есть своя собственная облачная служба для резервного копирования Synology C2
На внешнее устройство
Hyper Backup предоставляет огромный выбор вариантов резервного копирования, позволяет управлять версиями, сжатие для экономии места. Подробнее.
USB Copy менее функциональная, но не менее надежное решение. Подробнее
Резервное копирование всего NAS
Huper Backup простое и эффективное резервное копирование данных с NAS на NAS.
Хотите, чтобы все было просто и эффективно? Настройте автоматическую защиту данных, приложений и системных параметров. Сжатие и дедупликация значительно сокращают размер необходимой емкости хранения. Подробнее о Hyper Backup.
Защита данных с высокой частотой
Моментальные снимки файловой системы и репликация могут выполнятся каждые 5 минут. Подробнее о Snapshot Replication.
Больше информации в моем блоге
Path Protection
- Primary — это основной LSP, который и будет использоваться для передачи трафика.
-
Secondary — запасной LSP. Если Ingress PE узнаёт от падении основного — он переводит трафик на запасной.
Последний в свою очередь тоже может быть:- Standby — всегда наготове: путь заранее вычислен и LSP сигнализиован. То есть он сразу готов подхватить трафик. Может также называться Hot-standby.
- Non-standby — путь заранее вычислен, но LSP не сигнализирован. При падении основного LSP Ingress LSP сначала с помощью RSVP-TE строит запасной, потом пускает в него трафик. Зато полоса не простаивает зарезервированная. Может называться Ordinary.
- Best Effort — если основной и запасной пути сломались или не могут быть удовлетворены условия, то RSVP-TE построит хоть как-нибудь без резервирования ресурсов.
шаблона
Режимы QoS
- Uniform Mode
- Pipe Mode
- Short-Pipe Mode
cisco
Упрощение настройки туннелей
- LDP over TE
- RSVP Auto-Mesh
RSVP Auto-Mesh/Auto-Tunnel
- Знакомой командой включаем возможность Auto-tunnel в режиме Mesh:
- Определяем потенциальные PE в ACL:
- Заводим шаблон конфигурации:
Заключение
- OSPF с его Opaque LSA
- IS-IS с
Управлять тем, как построится RSVP LSP
- Метрика (IGP или TE)
- Требования к ресурсам
- Explicit-path
- SRLG
- Administrative Groups/Affinity
IGP распространяет и заносит в TEDB
- Состоянии линий
- Метриках
- Свободных ресурсах с учётом приоритетов удержания (Hold Priority)
- SRLG
- Attribute-Flag/Administrative Group
Требования туннеля:
- Требуемая полоса и приоритет установки
- Affinity/Administrative Group
- Explicit-Path
RSVP-TE в своих сообщениях передаёт:
- Требуемую полосу для резервирования с приоритетом установки и удержания
- Режим резервирования — SE или FF
- ERO — список узлов для прокладывания LSP
- RRO — реальный список узлов и меток на каждом участке
- Информацию о необходимости FRR
Направить трафик в туннель
- Статический маршрут или PBR
- IGP Shortcut (или Forwarding Adjacencies)
- Вендорозависимые механизмы: автоматически на Juniper или Tunnel-policy на Huawei/HP
Make-Before-Break:
- Переоптимизации туннелей
- FRR
- Важный туннель пытается вытеснить менее важный.
Shared Explicit или Fixed Filter:Защита туннелей:
- Когда ломается линия/узел, в первые 50 мс отрабатывает FastReRoute, спасая те пакеты, что уже идут в LSP.
- Потом Ingress LSR узнаёт о проблемах с основным LSP и перенаправляет трафик в резервный LSP — так уже спасаются все последующие пакеты.
- Далее Ingress LSR пытается восстановить основной LSP в обход проблемного участка, если это возможно.
Приоритет туннелей:
- Setup Priority
- Hold Priority.
Механизмы упрощения настройки:
- LDP over TE
- RSVP Auto-Mesh/Auto-tunnel
Правила обработки полей CoS в MPLS DS-TE:
- Uniform. На всём пути оператор обрабатывает трафик на основе значения поля CoS изначального PDU и полем может быть переписано им.
- Pipe. Значение поля CoS изначального PDU не меняется. Egress PE обрабатывает пакет на основе заголовка MPLS.
- Short-pipe. Значение поля CoS изначального PDU не меняется. Egress PE обрабатывает пакет на основе изначального поля CoS PDU.
Полезные ссылки
- Три документа от cisco на тему MPLS TE. Длинно и по делу:
- MPLS Traffic Engineering
- Advanced Topics in MPLS-TE Deployment
- Deploying MPLS Traffic Engineering
- Cisco же об FRR: MPLS Traffic Engineering. Traffic Protection using Fast Re-route (FRR)
- На практике об Autobandwidth: Deploying MPLS Traffic Engineering
- MPLS TE Affinity
- DiffServ Tunneling Modes for MPLS Networks
- Отличный подбор видео об MPLS: labminutes.com
тут глоссарии linkmeupБлагодарности Андрею Глазкову Александру Клипперу Александру Фатину Артёму Чернобаю
Рекомендации по аппаратным средствам файловых серверов, предназначенных для хранения копий
Дисковые устройства
К дискам, используемым для хранения и проверки восстанавливаемости файлов резервных копий, не применяются такие же высокие требования, как к дискам промышленных серверов. Так происходит потому, что у них почти все операции ввода-вывода выполняются последовательно и не носят случайный характер. Поэтому SATA диски в большинстве случаев очень хорошо подходят для этих целей.
Настройка RAID-контроллера
Для создания массивов логических дисков, на которых решено хранить файлы резервных копий, стоит выбрать большой размер сегмента (64 Кб, 128 Кб, 256 Кб и выше). Также, стоит установить полное кэширование записи, а кэширование чтения можно полностью отключить. Можно ещё активизировать кэш записи отдельных шпинделей, так как если во время резервного копирования произойдёт сбой по питанию, резервная копия так и так станет непригодной, и в таком случае не имеет значения, были ли потеряны какие-либо байты в кэше записи или нет.
Для тех логических дисков, которые будут задействованы в пробном восстановлении базы из копии, размер сегмента устанавливается в 64 Кб, применяется политика 100-процентного кэширования записи, а кэширование чтения выставляется на 0 процентов.
Выбор уровня RAID (1, 10, 5, 6 …) зависит от возможностей используемого RAID-контроллера или используемой системы хранилища. Поскольку нагрузка на файловом сервере при резервном копировании/восстановлении является последовательной записью и чтением данных, контроллер будет кэшировать данные, пока он не закончит запись всего страйпа целиком, в этом случае можно использовать любой уровень RAID. Если контроллер ведёт себя по-другому, и производительность является критическим параметром, массивы RAID1 или RAID10 будут единственным возможным вариантом.
Настройка HBA
Если в качестве дисков для файлов резервных копий используется дисковая подсистема типа SAN, максимальную глубину очереди для адаптеров, которые используются в подключении SAN, нужно увеличить настолько, насколько это возможно. Значение по умолчанию составляет 32, но резервное копирование и восстановление будут работать намного лучше при значениях близких к 256. Более подробную информацию можно найти в статье Настройка Windows Server 2008/2003 x64 для обслуживания SQL Server 2008 , в разделе “NumberOfRequests и MaximumSGList”.
Сетевые платы
Следует очень разборчиво подходить к выбору сетевых плат, которые будут использоваться на серверах. Число портов ещё не гарантирует адекватную производительность ввода-вывода для всех этих портов в одно и то же время. Бывает так, что два четырехпортовых адаптера могут оказаться более производительными, чем один адаптер с четырьмя портами
Количество процессорного времени, используемого драйвером сетевого интерфейса, также очень важно. Бывают такие сетевые платы, которые используют до 50 процентов ресурсов одного процессора, и в то же время есть другие, которые используют всего 3 – 5 процентов.
Если для резервного копирования используется несколько сетевых плат, очень важно, чтобы они использовали разные процессоры, т.е
чтобы их прерывания были привязаны к разным процессорным ядрам.
Системы на основе NUMA
Если сервер использует архитектуру с неоднородным доступом к памяти (NUMA), необходимо убедится в том, что все адаптеры ввода-вывода (например, NIC, RAID и HBA) распределены между всеми NUMA – узлами системы.
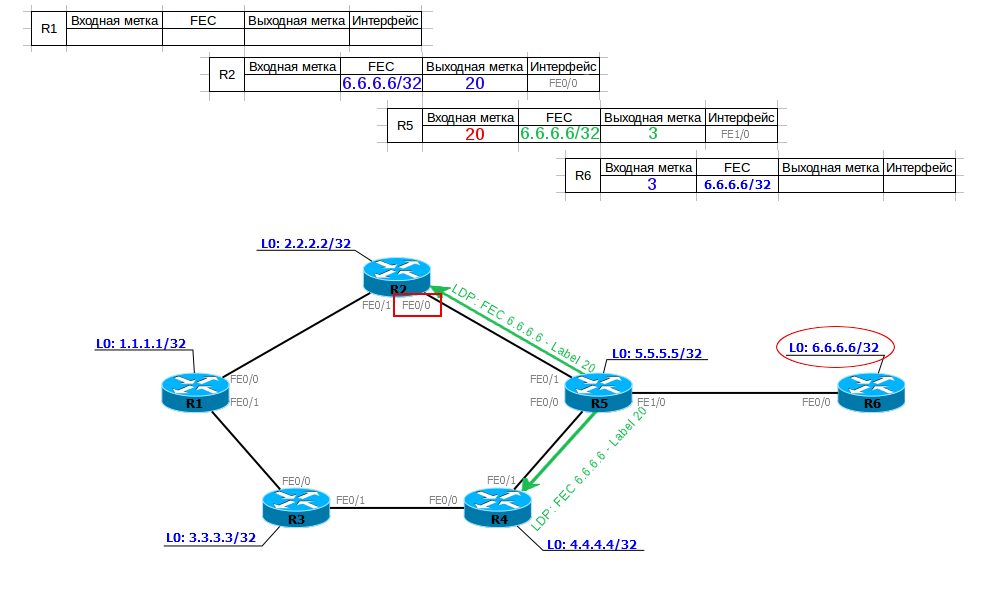
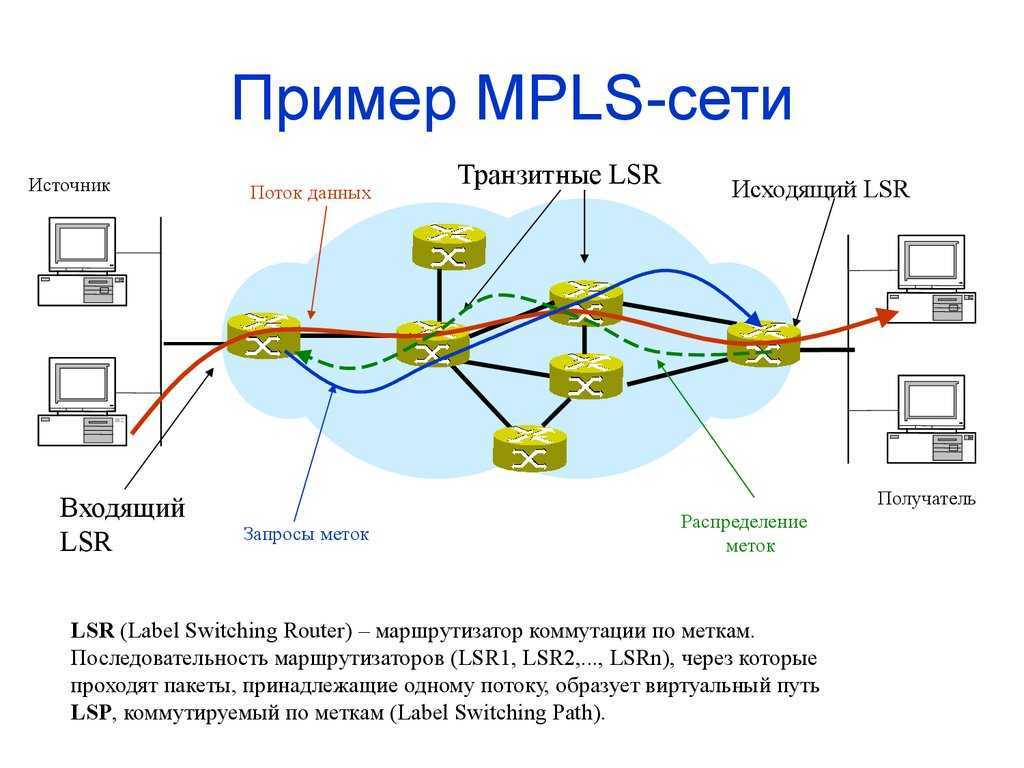
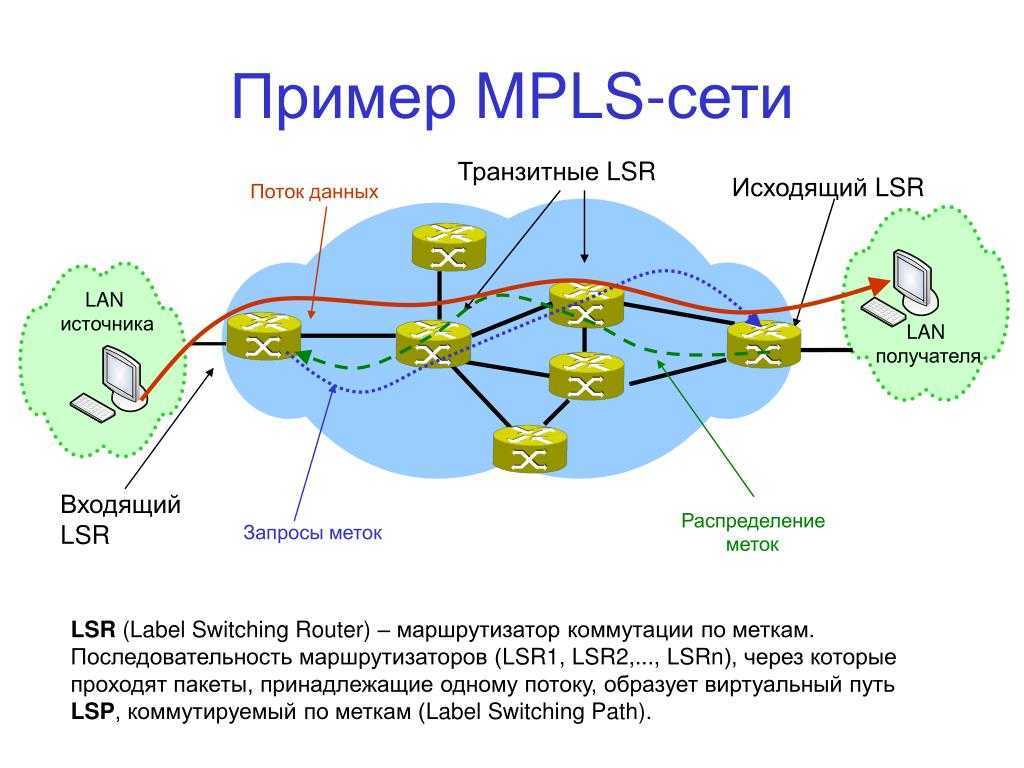
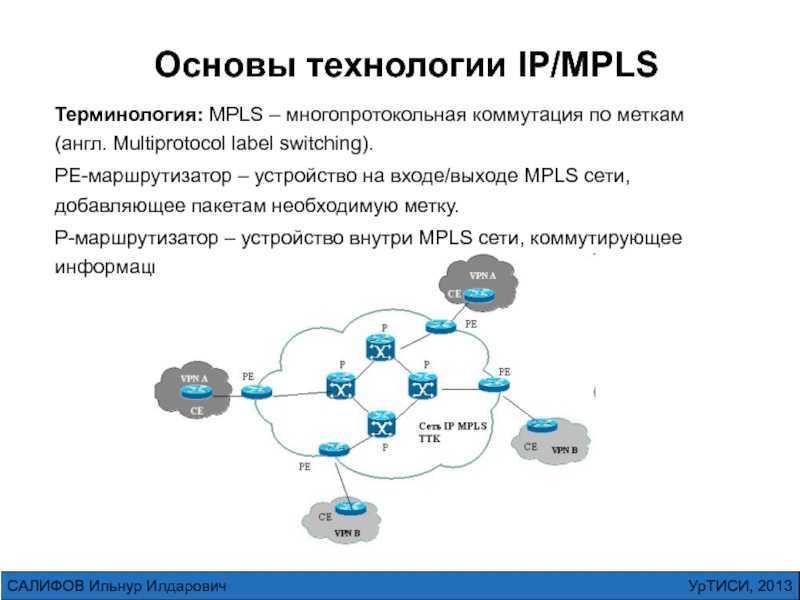
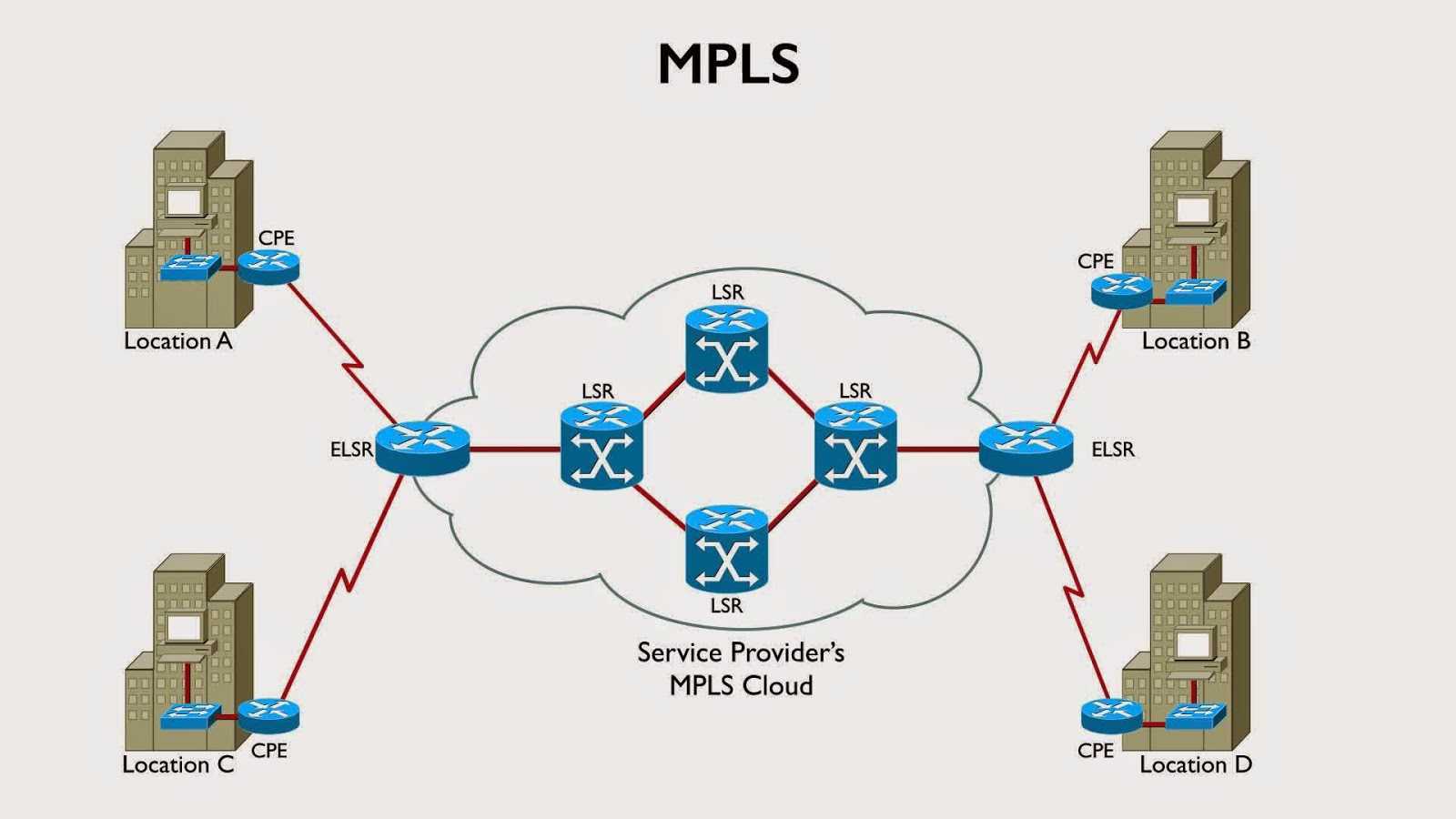
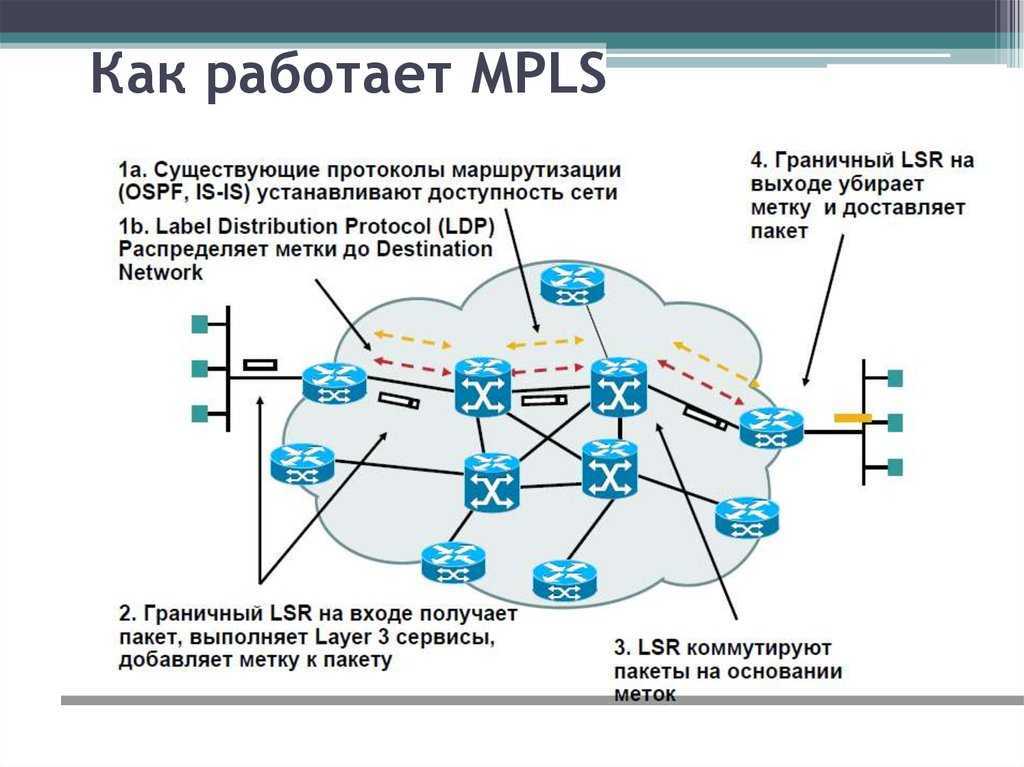
Принцип работы протокола
LDP — автоматом строит full mesh туннели до соседей.
RSVP — не просто строит туннели, а использует для построения TE + используются механизмы защиты трафика: FastRerote, LinkProtection…
RSVP — протокол signaling.
RSVP инкапсулируется сразу в ip.
RSVP пакет стоит из объектов. Объект имеет тип, и поле данных.
Типы сообщений:
- Path: запрос, чтобы LSP была построена: от ingress
- Resv: Резервирует ресурсы для LSP: от egress
- PathTear: удаляет path state и сообщает об этом: от LSR, где упала LSP к downstream
- ResvTear: удаляет reservation state: от LSR, где упала LSP к upstream
- PathErr: сообщение с ошибкой: к upstream
- ResvErr: сообщение с ошибкой: к downstream
Объекты path message:
- SESSION_ID
- LABEL_REQUEST
- EXPLICIT_ROUTE: strict/loose list of routers
- RECORD_ROUTE: list of addresses of all routers in path
- SESSION_ATTRIBUTE
- RSVP_HOP: interface ip of router which send path message
Для работы RSVP нужно:
- Включить протокол RSVP
- Конфигурируем туннель только на ingress.
Ingress -> Egress:
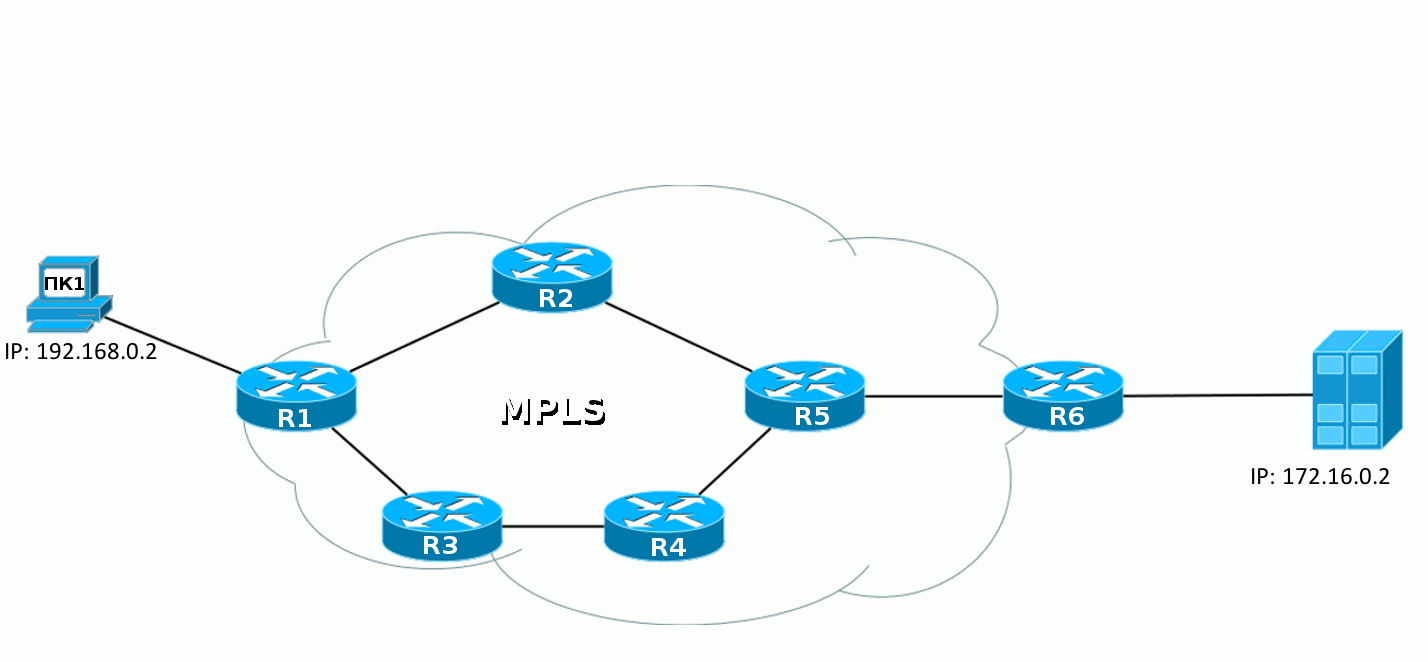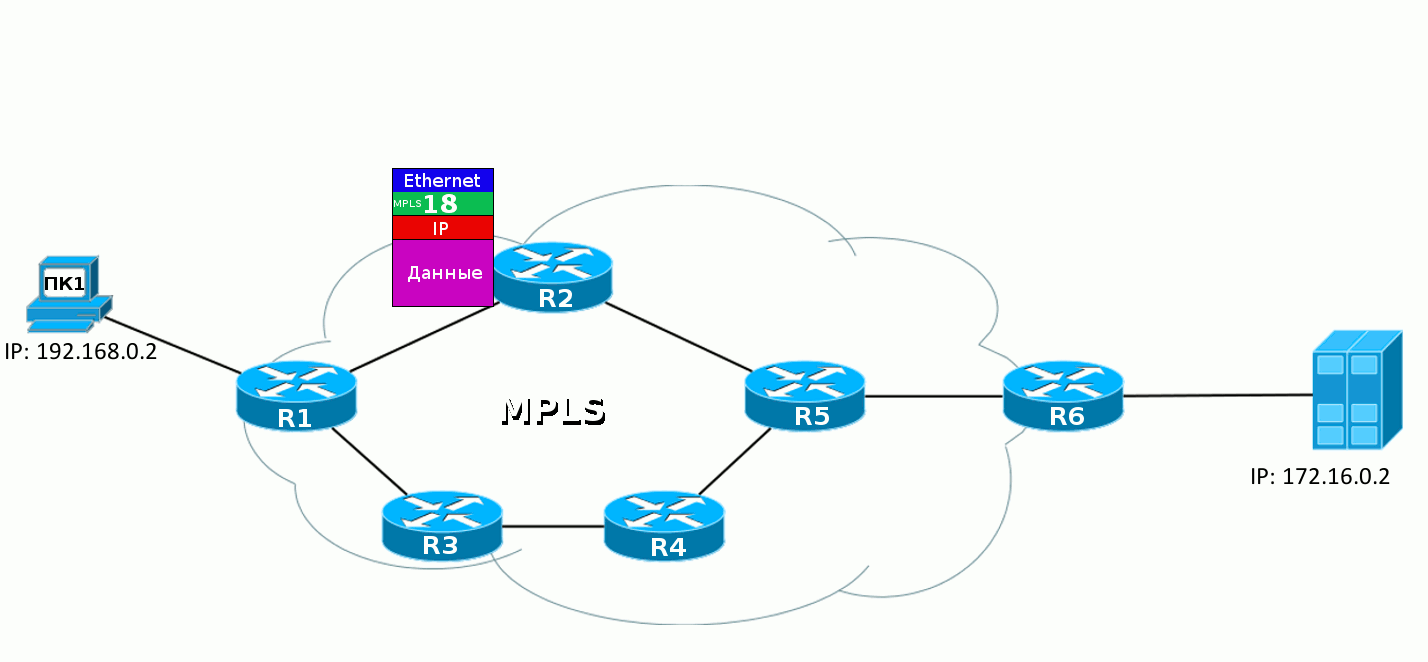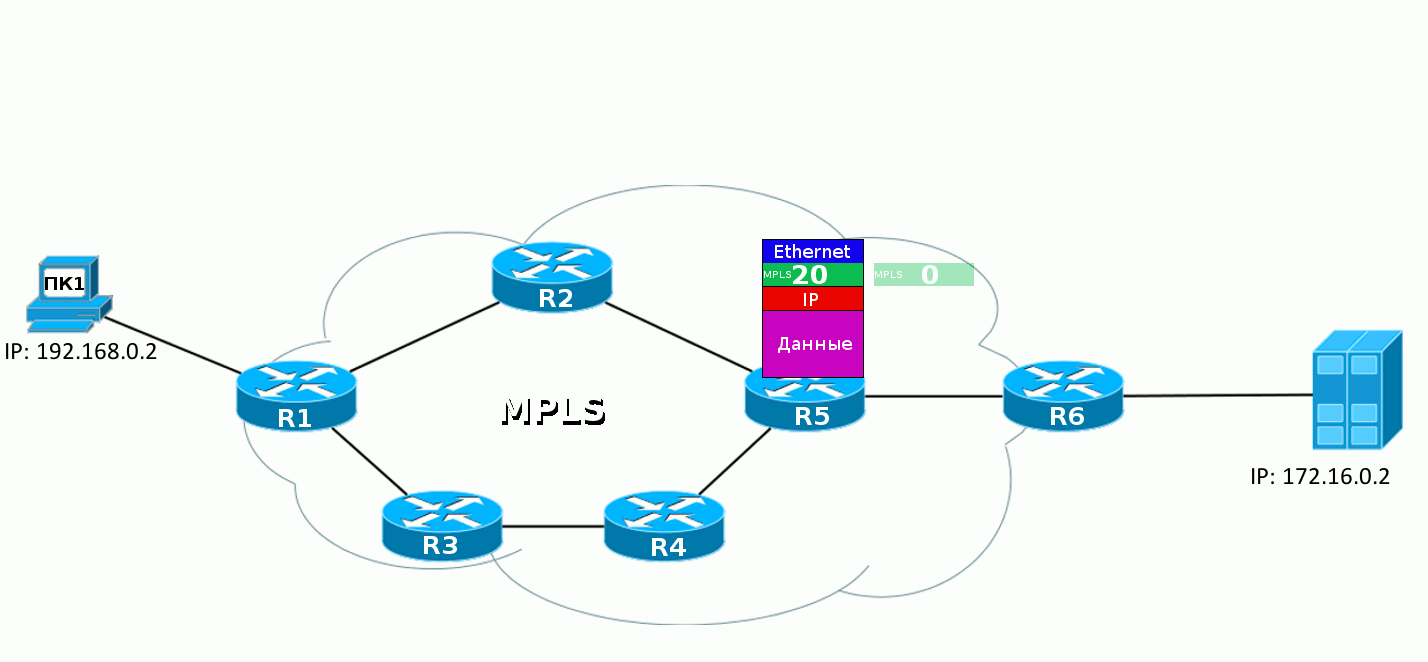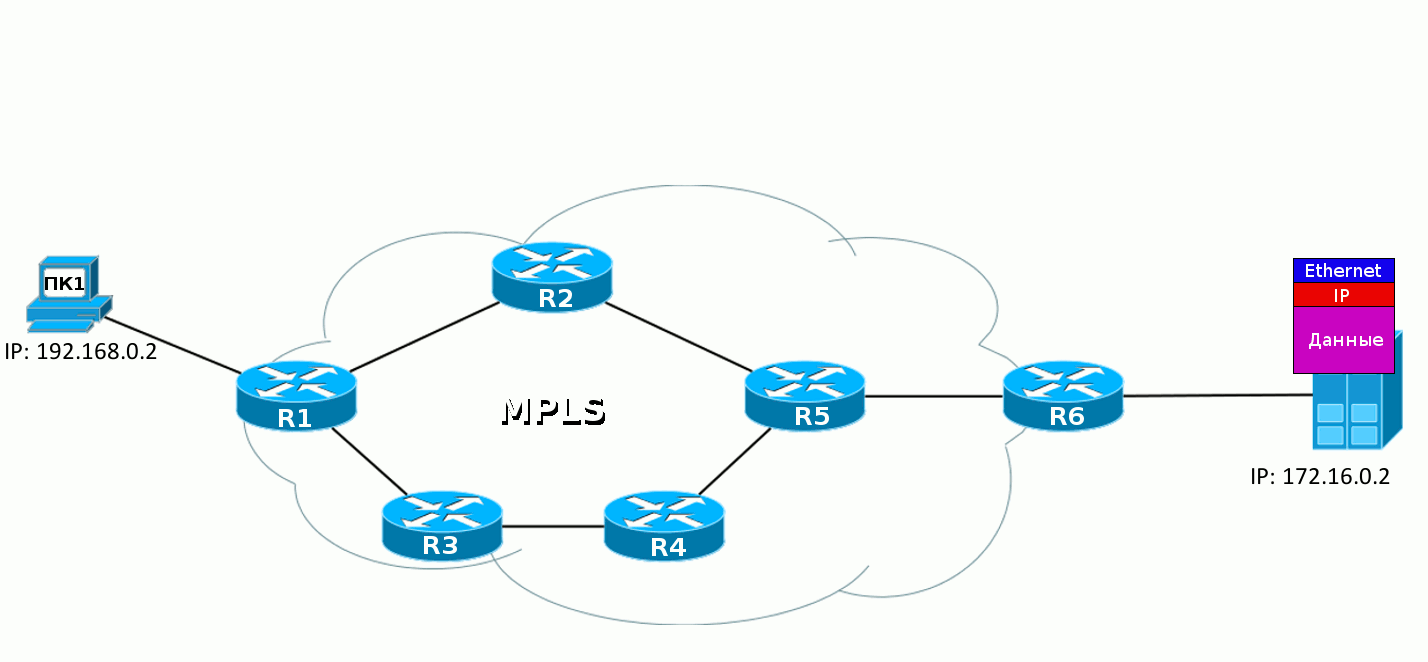
При построении туннеля на Ingress (A) создается ip-пакет pathMessage, который состоит из:
- dst: ip dst (192.168.0.4), по метриками внутреннего протокола узнает где конечный роутер.
- session ID — идентификатор rsvp сессии на control plane. Все rsvp роутеры, через которые строится туннель — ассоциируют все сообщения для туннеля по session ID. Генерируется ingress роутером, состоит из router ID + какое-то число.
- label request: определяет поведение транзитных маршрутизаторов, заставляет резервировать метки для туннеля.
Transit router 1 (B):
1.Видит label request, выделяет (запоминает, но никуда не записывает) для туннеля метку из свободных, ассоциирует ее с session ID.
Transit router 2 (C):
- Видит label request, выделяет (запоминает, но никуда не записывает) для туннеля метку из свободных, ассоциирует ее с session ID.
Egress router (D):
- dst addres = его loopback => он последний. Резервирует метку 3 (по дефлоту).
Формирует ResvPath — основная его суть — проанонсировать зарезервированную метку предыдущему роутеру.
Egress -> Ingress:
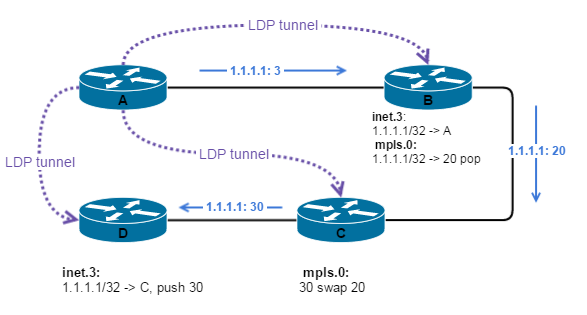
resvPath: session ID из PathMessage, label: (то, что он зарезервировал) 3.
Transit 2 (C):
- По session ID определяет какую метку он зарезервировал (30).
- Смотрит в label, видит 3. Понимает, что он должен передавать к egress пакет с меткой 3.
- mpls.0: 30 swap 3 = 30 pop
Transit 1 (B):
- По session ID определяет какую метку он зарезервировал (20).
- Смотрит в label, видит 30. Понимает, что он должен передавать к egress пакет с меткой 30.
- mpls.0: 20 swap 30
Ingress (A):
- inet.0: 192.168.0.4: -> BGP, push 30
Туннель — это просто метки.
При падении линка между роутерами:
Генерируются pathTear (в сторону ingress) и resvTear (в сторону egress), чтобы все транзитные роутеры освободили метки, а ingress понял, что этого туннеля больше нет.
В это время IGP пересчитал топологию, ingress router увидел next-hop для egress роутера и rsvp заново начал строить туннель.
Keepalive: Ingress роутер раз в 30 сек (по дефолту) обновляет состояние с помощью посылки pathMessage.
resvMessage должен пройти по тому же пути, что и pathMessage.
Но маршрутизация может быть не симметричной.
отличие resv и path: dst add — не loopback конечных роутеров, а адрес предыдущего роутера из ERO (также предотвращает зацикливание).
Туннель может устанавливаться с требованиями к полосе.
Задается в bandwith — передается в объекте TSpec.
Если RSVP не может установить туннель, то на проблемном участке генерируется pathErr — сообщение с кодом ошибки.
Bandwith — только для сигнализации, реально полосу не ограничивает.
Если нужно провести траблшутинг, лучше делать тут:
set protocol rsvp traceoptions file RSVP-trouble flag all detail
RSVP поддерживает mtu discovery и fragmentstion на ingress роутере.
RSVP поддерживает аутентификацию (MD5)
RSPV может использовать Gracefull restart.
RSVP может работать как point-to-multipoint => можно исключить из ядра всякие multicast протоколы.
Пример скрипта
Скрипт будет сравнивать файлы в рабочем каталоге и папке резервного копирования с помощью rsync. Это позволит нам сэкономить на времени выполнения задания. Долго будет выполняться только задание создания архива с помощью tar.

Создаем каталог для скриптов и сам скрипт:
mkdir /scripts
vi /scripts/samba_backup.sh
- #!/bin/bash
- PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
- source=»/data»
- destination_root=»/backup»
- fdate=$(date +%Y-%m-%d)
- # Clean old archives
- find ${destination_root}/archive -type f -name «*.tar.gz» -ctime +370 -exec rm -R {} \; 2>&1
- # Daily
- rsync -a —delete-after ${source}/ ${destination_root}/daily/
- # Weekly
- if ]
- then
- rsync -a —delete-after ${source}/ ${destination_root}/weekly/
- fi
- # Archive
- count_last_archives=$(find ${destination_root}/archive/ -name «*.tar.gz» -mtime -30 | wc -l)
- if ]
- then
- cd ${source}
- tar zcf ${destination_root}/archive/samba_${fdate}.tar.gz ./*
- fi
Задаем права скрипту на выполнение:
chmod +x /scripts/samba_backup.sh
Скрипт готов к работе.
Вычисление времени, необходимого для резервного копирования и восстановления базы данных
Одним из ключевых элементов SLA является тот интервал времени, который закладывается на задачи резервного копирования, т.е. нужно будет рассчитать и запланировать время, которое займёт весь этот процесс. Это поможет выполнить требования спецификации ко времени восстановления работоспособности, а также, это помогает сформировать другие важные моменты аварийного плана, такие как частота выполнения резервных копий и параметры сжатия. Определение времени, занимаемого процессами резервного копирования и восстановления, выполняется в несколько шагов. Вначале необходимо вычислить объём копируемых данных.
Далее, нужно определить максимальную продолжительность параллельного, последовательного чтения и записи используемых дисковых подсистем. Для того чтобы измерить эти значения при тестировании резервного копирования и восстановления, можно использовать системную утилиту Performance Monitor (известную ещё в некоторых версиях операционной системы Windows как System Monitor).
В результате, должно получиться 5 значений. Если имеется несколько логических дисков и сетевых плат, эти значения могут отличаться, и всегда нужно использовать самые худшие результаты вычислений.
-
- Производительность сетевого адаптера (МБ/сек);
- Производительность логического диска хранилища копий при последовательном чтении (МБ/сек);
- Производительность логического диска хранилища копий при последовательной записи (МБ/сек);
- Производительность логического диска файла базы данных при последовательном чтении (МБ/сек);
- Производительность логического диска файла базы данных при последовательной записи (МБ/сек).
После этого, опираясь на данные о числе логических дисков для параллельной работы с файлами базы данных, на число логических дисков, используемых для параллельной работы с файлами резервных копий и число используемых сетевых плат. Если сжатие не используется, это приведет к тому, что коэффициент сжатия станет таким: CompressionFactor = 1.
В большинстве случаев, без сжатия резервной копии производительность сети будет наименьшей по сравнению с производительностью дискового чтения и записи, но когда сжатие включено, основным ограничением может стать чтение из базы: DatabaseReadPerformance, или другие, не учтенные пока компоненты, такие как загруженные сжатием процессорные ядра.
Вычисления для расчета времени восстановления будут сложнее. Сначала нужно узнать, поддерживает ли используемая система мгновенную инициализацию файлов. Эта возможность позволяет SQL Server создавать файлы данных на томах NTFS без обнуления занимаемого файлами места во время создания или расширения файла. Поскольку у этого механизма существуют связанные с безопасностью риски, такой возможностью можно воспользоваться, только если учетной записи, под которой запущена служба SQL Server предоставить в локальных политиках право “Perform Volume Maintenance”. Если учетная запись пользователя входит в группу локальных администраторов, это право ей будет предоставлено по умолчанию (Примечание: время инициализации файла журнала транзакций может ограничивать производительность, так как занимаемое этим файлом место не может не заполняться нулями).
В случае если RestoreTime или BackupTime выше заданных SLA значений, можно воспользоваться изложенными ранее рекомендациями по уменьшению этих значений. Распараллеливание операций обычно ускоряет процесс больше чем попытка ускорить работу одного из компонент во всей цепочке. В сценариях с очень высокой производительностью стоит задуматься о применении обоих подходов.
Обратите внимание: на исполнение команды CHECKBD может потребоваться больше времени, чем время, которое необходимо для чтения с диска. Оно зависит от сложности схемы базы данных, и оно точно не будет меньше времени чтения
Общие положения
Настоящий Регламент проведения резервного копирования (восстановления) программ и данных, хранящихся на серверах ИТ-инфраструктуры Заказчика разработан с целью:
- определения порядка резервирования данных для последующего восстановления работоспособности автоматизированных систем Заказчика при полной или частичной потере информации, вызванной сбоями или отказами аппаратного или программного обеспечения, ошибками пользователей, чрезвычайными обстоятельствами (пожаром, стихийными бедствиями и т.д.);
- определения порядка восстановления информации в случае возникновения такой необходимости;
- упорядочения работы должностных лиц Исполнителя и Заказчика, связанной с резервным копированием и восстановлением информации.
В настоящем документе регламентируются действия при выполнении следующих мероприятий:
- резервное копирование;
- контроль резервного копирования;
- хранение резервных копий;
- полное или частичное восстановление данных и приложений.
Резервному копированию подлежит информация следующих основных категорий:
- персональная информация пользователей (личные каталоги на файловых серверах);
- групповая информация пользователей (общие каталоги отделов);
- информация, необходимая для восстановления серверов и систем управления базами данных (далее – СУБД);
- персональные профили пользователей сети;
- информация автоматизированных систем, в т.ч. баз данных;
- справочно-информационная информация систем общего использования («Гарант», «Консультант+» и т.п.);
- рабочие копии установочных компонент программного обеспечения рабочих станций;
- регистрационная информация системы информационной безопасности автоматизированных систем.
Машинным носителям информации, содержащим резервную копию, присваивается гриф конфиденциальности по наивысшему грифу содержащихся на них сведений в соответствии с «Перечнем сведений составляющих коммерческую тайну» Заказчика.
Члены
Объект QOS QOS_OBJECT_HDR.
Задает стиль резервирования RSVP для заданного потока и может использоваться для замены стилей резервирования по умолчанию, размещенных в определенном типе потока. Дополнительные сведения о стилях резервирования RSVP и параметрах по умолчанию для определенных сеансов сокетов с поддержкой QOS можно найти в разделе «Компоненты QOS на основе сети». Этот элемент может быть одним из следующих значений.
| Значение | Значение |
|---|---|
|
Реализует стиль резервирования WF RSVP. RSVP_WILDCARD_STYLE — это значение по умолчанию для приемников многоадресной рассылки и одноадресных приемников UDP. Указание RSVP_WILDCARD_STYLE через RSVP_RESERVE_INFO полезно для переопределения значения по умолчанию (RSVP_FIXED_FILTER_STYLE), применяемого к подключенным приемникам одноадресной рассылки. |
|
Реализует стиль резервирования RSVP с фиксированным фильтром (FF). RSVP_FIXED_FILTER_STYLE полезно переопределить стиль по умолчанию для приемников многоадресной рассылки или несоединенных одноадресных приемников UDP (RSVP_WILDCARD_STYLE). Он также может использоваться для создания нескольких резервирований RSVP_FIXED_FILTER_STLYE в тех случаях, когда по умолчанию создается только одно RSVP_FIXED_FILTER_STYLE резервирование, например с подключенными приемниками одноадресной рассылки. |
|
Реализует стиль резервирования RSVP общего явного (SE). |
|
Реализует стиль резервирования по умолчанию для компьютера. |
Примечание Важно отметить, что количество отправителей, включенных в любое отдельное RSVP_SHARED_EXPLICIT_STYLE резервирование, должно быть меньше 100 отправителей. Если более ста отправителей пытаются подключиться к резервированию RSVP_SHARED_EXPLICIT_STYLE, попытка одной сотни (и выше) завершается сбоем без уведомления.
Может использоваться принимающим приложением для запроса уведомления о запросе на резервирование, задав ConfirmRequest значение, отличное от нуля. Такое уведомление достигается, когда устройства с поддержкой RSVP в пути к данным между отправителем и получателем (или наоборот) передают сообщение RESV CONFIRMATION в запрашивающий узел
Обратите внимание, что узел RSVP не требуется для автоматического создания сообщений RESV CONFIRMATION
Указатель на набор элементов политики. Необязательные сведения о политике, как указано в структуре RSVP_POLICY_INFO .
Указывает число FLOWDESCRIPTOR.
Указатель на список объектов FLOWDESCRIPTOR.