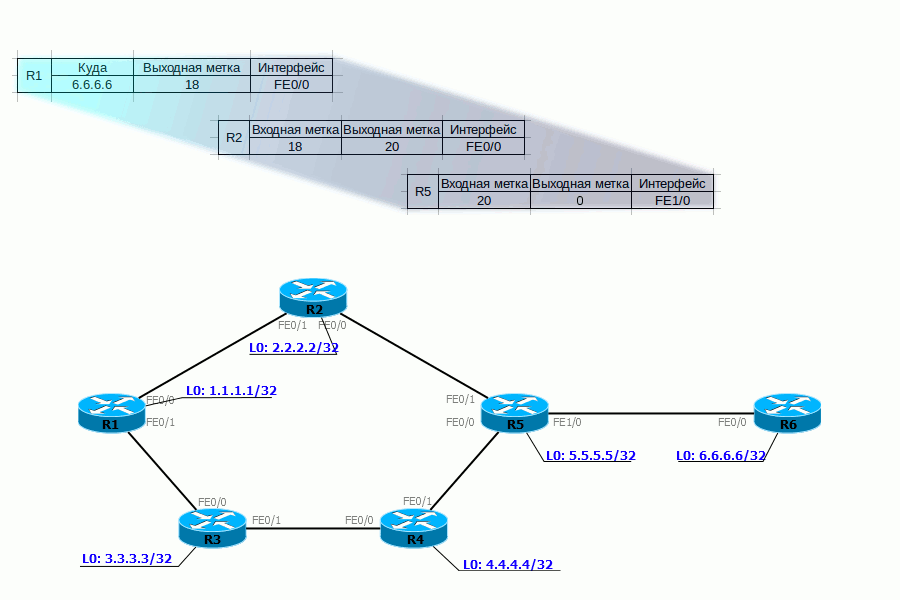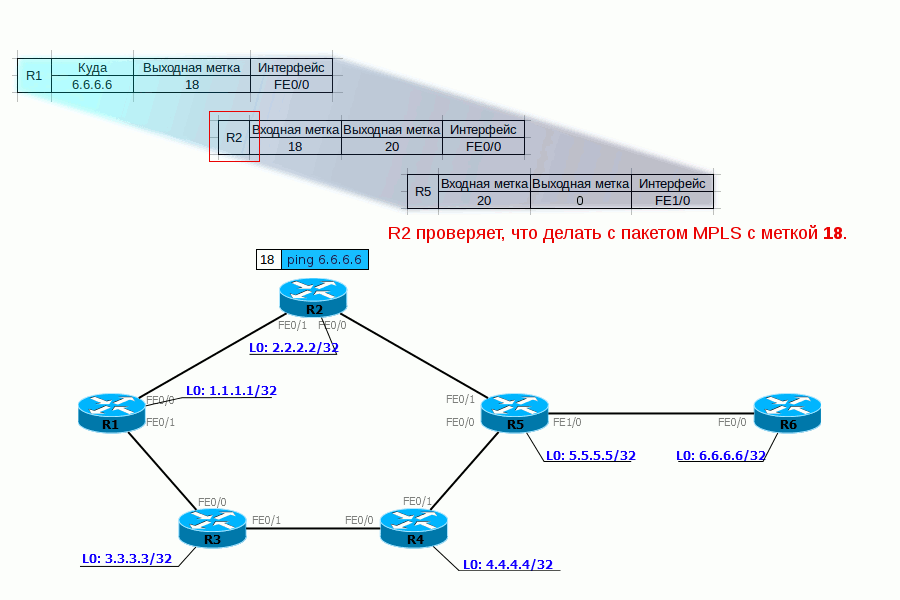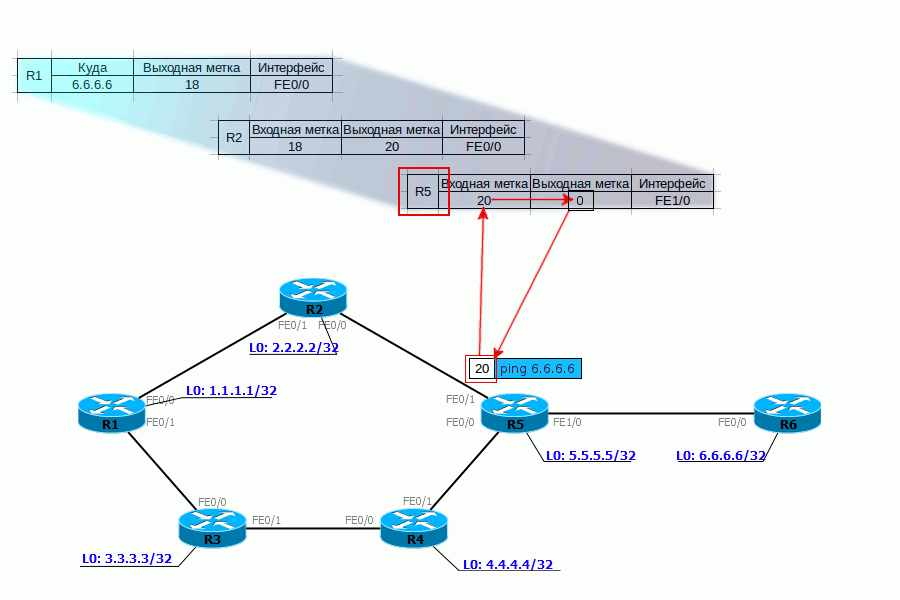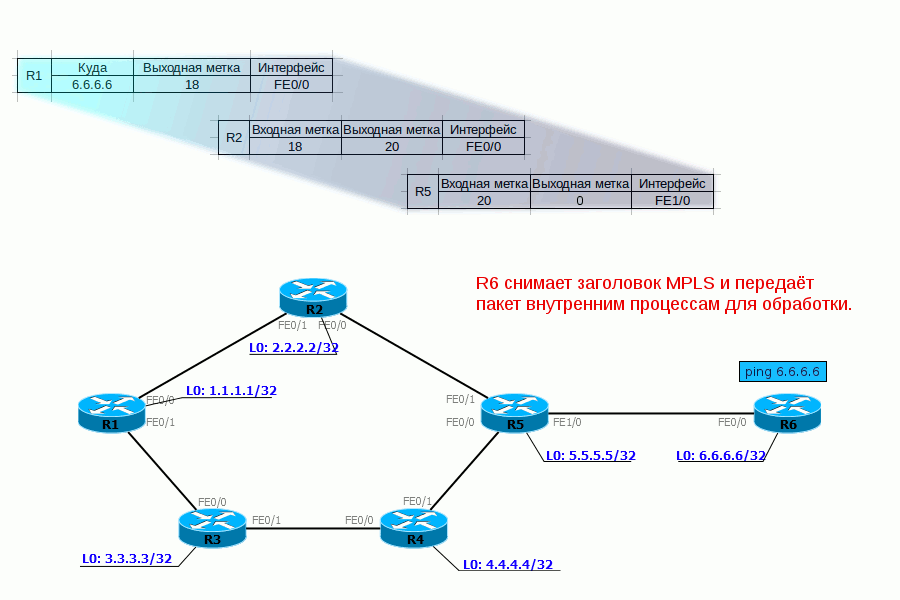
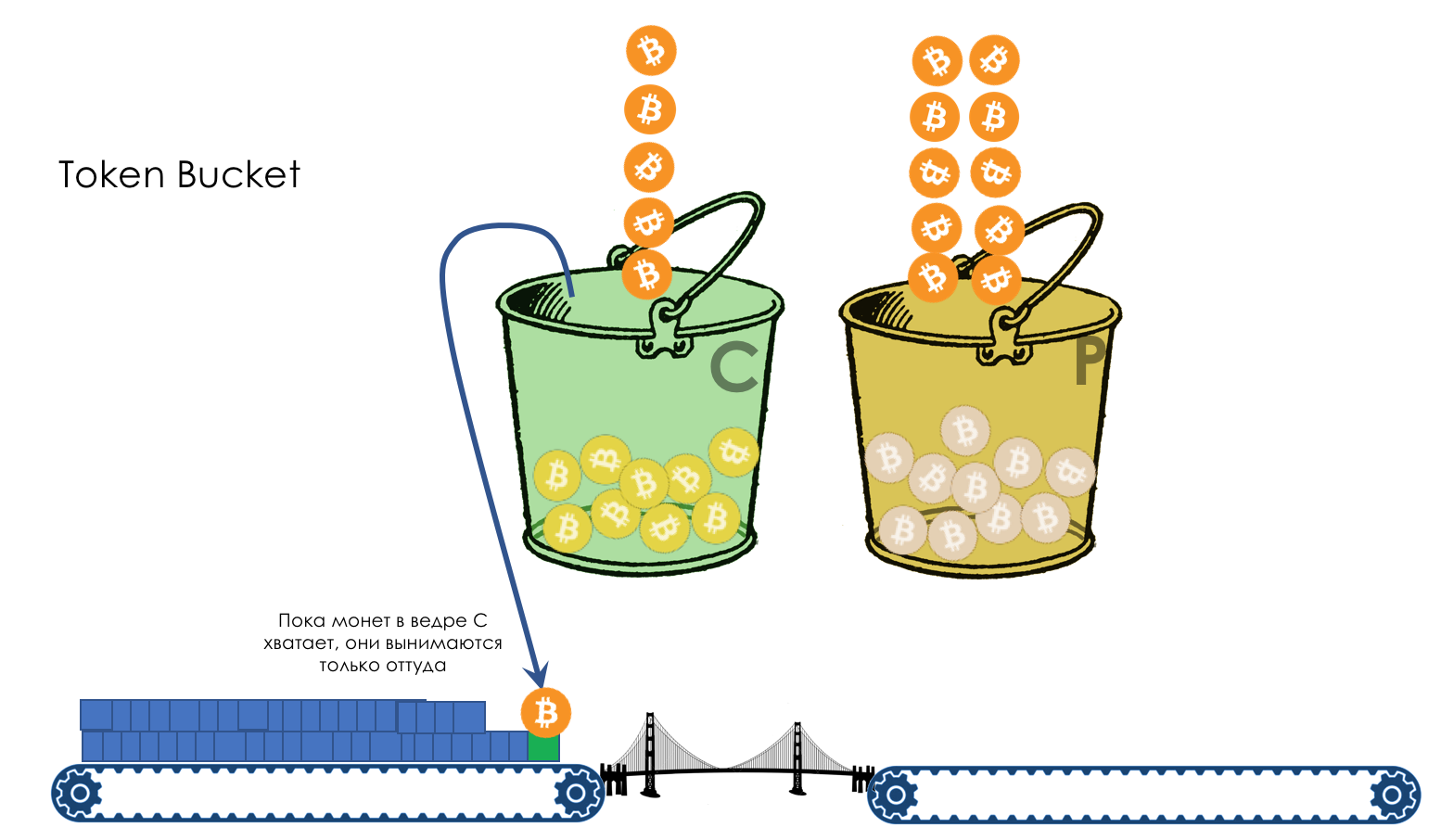
Tail Drop и Head Drop
Tail DropHead Dropпоглубжеэкстремально глубокоrwnd — Reciever’s Advertised WindowCWND — Congestion WindowSlow StartЭкспоненциальныйssthresholdлинейныйTCP BackoffFast Recovery
- отправляются потерянные сегменты (Fast Retransmission),
- окно скукоживается в два раза,
- значение ssthreshold тоже становится равным половине достигнутого окна,
- снова начинается линейный рост до первой потери,
- Повторить.
- Допустим через маршрутизатор лежит путь тысячи TCP-сессий. В какой-то момент трафик сессий достиг 1,1 Гб/с, скорость выходного интерфейса — 1Гб/с.
- Трафик приходит быстрее, чем отправляется, буферы заполняются всклянь.
- Включается Tail Drop, пока диспетчер не выгребет из очереди немного пакетов.
- Одновременно десятки или сотни сессий фиксируют потери и уходят в Fast Recovery (а то и в Slow Start).
- Объём трафика резко падает, буферы прочищаются, Tail Drop выключается.
- Окна затронутых TCP-сессий начинают расти, и вместе с ними скорость поступления трафика на узкое место.
- Буферы переполняются.
- Fast Recovery/Slow Start.
- Повторить.
RFC 2001TCP Slow Start, Congestion Avoidance, Fast Retransmit, and Fast Recovery AlgorithmsGlobal TCP SynchronizationГлобальнаяСинхронизацияTCPTCP Starvation
Производительность UDP и TLS
создавать и отправлять пакетыуже говорилиРис. 9: Различия в реализации между TCP и QUIC (исходное изображение) передать эти данные в ядро ОСбольшинство ОС добавиливарианты оптимизации и для UDPшифрует каждый пакет отдельнопакеты шифруются группамик блокировке HoLоптимизированные библиотеки шифрованияв два раза медленнее, чем TCP + TLSтщательно оптимизированного стека QUICна 20% медленнее, чем TCP + TLSРанние тесты, проведённые Fastlyв два раза больше серверов для QUICMsQuicQuantоборудования под QUIC.серьёзно вложились в специфичные решения на базе FreeBSDмежду конечными пользователями и границей CDN
Во-первых, механизм повторной передачи
Когда TCP теряются за потери пакетов, механизм повторной передачи будет решен.
Следующие четыре общие механизмы повторной передачи.
1, тайм-аута повторной передачи
После отправки данных, установите одинтаймерПо истечении указанного времени превышен, то другая сторона не получила.ACK Эти данные будут переданы повторно после подтверждения ответного сообщения.
Причина для воспроизведения тайм-аута:
- потеря пакетов
- Убедитесь, что ответ теряется
Примечание: Это может быть thoughable, тайм — аут retransmity, то оно должно быть не получено некоторое время, в это время, отбрасываются мешок , как правило , много, если просто Ack теряется, есть задний D-Sack решить.
Чуть больше, чем RTT (Round-Trip Time задержки туда-обратно)
- Слишком большой, повторная передача происходит очень медленно, а старый полдень будет переиздана, не эффективность, низкая производительность
- Слишком мала, что приводит к отсутствию потерь, увеличивают нагрузку на сеть (бремя), в результате чего больше тайм-аута, в результате чего более переиздание.
2, быстрая повторная передача (быстрая повторная передача)
Не во время приводится в действие, данные отброшен.
Что ты имеешь в виду?
Когда отправитель получает три идентичных ACK, предыдущий SEQ не был получен, и потерял SEQ будет передан повторно до истечения таймера.
Примечание: Быстрая повторная передача произошло, как правило, часть пакета теряется, в результате трех последовательных трех ACKs.
3、 SACK
Мешок (Селективный Acknowledge избирательного подтверждения).
Этот метод требует, чтобы добавить один в заголовке TCP полеSACK S вещи. Он может послать карту кэша отправителю.
После того, как отправитель получает, вы можете узнать, какие данные будут потеряны, что необходимо для повторной передачи.
Примечание: Если вы хотите поддержать SCAK, вы должны поддерживать обе стороны.
Под Linux, вы можете передатьnet.ipv4.tcp_sack Параметр открывает эту функцию.
4、 D-SACK
DUPLICATE МЕШОК, МЕШОК повторно, в дополнение к тому, что используется в SACK, который уже получен, который неоднократно принимал. Как различить?
Вот индивидуальное понимание:
Когда ACK
В это время, Сак выступает в качестве подтверждения ACK разделе сообщения, которое было получено, что указывает на SEQ в интервале было получено.
АСК в это время указывают на SEQ серийным номером, который ранее был получен.
Когда ACK> Sack.right:
В это время, ACK явно превысил МЕШОК. В это время, SACK называется Дубликат Sack, называется D-Сак.
В это время, D-Sack используется, чтобы сообщить отправителю: (я уже получил его раньше, но ACK я потерял в сети передачи, вы не должны посылать эту SEQ мне позже ~)
С точки зрения процесса:
Мешок используется для информирования отправителя, получатель не получил SEQ;
Д-Сак используется для информирования отправителя, и соответствующий ACK получен (потери пакетов) после приема SEQ но соответствующий ACK посылается (потеря пакетов).
Под Linux, вы можете передатьnet.ipv4.tcp_dsack Параметр открывает эту функцию.

Проблемы сигнала «потеря сегмента»
Если использовать потерю сегментов в качестве сигнала и перегрузки, то TCP фактически будет работать в режиме, который ведёт к перегрузке. TCP постоянно увеличивает размер окна пока перегрузка не произойдет, причем о перегрузке TCP узнает только после того, как она произошла, поэтому предотвратить ее при такой схеме нельзя.
Другая проблема называется глобальной синхронизацией TCP и TCP global synchronization, она заключается в том, что когда на маршрутизаторе на котором произошла перегрузка заканчивается место в буфере, он отбрасывает сегменты всех отправителей.
Отправитель обнаруживает потерю сегмента, понимает что произошла перегрузка уменьшает размер окна. В TCP в отличии от Ethernet или wi-fi, не встроена схема рандомизированное задержки, поэтому все отправители после уменьшения размера окна начинают передавать данные примерно в одно и то же время. В результате на маршрутизатор опять приходит большое количество пакетов, что в свою очередь ведет к перегрузке. Для того чтобы решить эти проблемы используются другие сигналы о перегрузке, которые мы сейчас рассмотрим.
Похожие:
| Документы1. /Худоярова Д.Р.Оптимизация .pdf | Конкурсная документация по выбору инвестора для реализации проекта по Механизму чистого развития Киотского протокола… | ||
| Методика организации двухэтапного вывоза твердых бытовых отходов. Утверждена приказом агентства «Узкоммунхизмат» №1 от 05. 01. 04гIi. Оптимизация размещения мусороперегрузочных станций при двухэтапном вывозе твердых бытовых отходов | Организация работы по устранению пробеловРабота по выявлению и устранению пробелов в знаниях учащихся — неотъемлемая часть деятельности каждого учителя. Своевременность и… | ||
| Xdsl – технология. Нормативное обеспечение для применения на сетях телекоммуникации Республики Узбекистан Е. В. Петрова гуп «unicon. Uz»Естественно, для операторов и провайдеров услуг Интернет возник вопрос как обеспечить быстрорастущий спрос на подключение к глобальной… | Телекоммуникация Концептуальная модель процесса установления соединения в подсистеме ims Кутбитдинов С. Ш. (Гуп «unicon. Uz»)В статье рассматриваются функциональные узлы подсистемы ims, применяемые как в мобильных, так и в фиксированных сетях, и поэтому… | ||
| 5. Анализ методической работы государственной специализированной общеобразовательной школы №60 Цель анализаЦель анализа: определение уровня продуктивности методической работы в педагогическом сопровождении учителя в процессе его профессиональной… | Постановление Президента республики узбекистан 21. 11. 2006 г. N пп-513 о мерах по повышению эффективности организации оперативно-розыскных мероприятий на сетях телекоммуникаций республики узбекистанСорм, эксплуатируемые операторами телекоммуникаций, являются неотъемлемым элементом их технологического оборудования и подлежат обязательной… | ||
| Телекоммуникация Особенности трафика в сетях с коммутацией пакетов Тарасенко Е. В. (Гуп «unicon. Uz»)В статье рассмотрены особенности трафика сетей с пакетной коммутацией. Приведены определения самоподобного процесса в широком и узком… | Узбекское агентство связи и информатизации ташкентский университет информационных технологий требования к содержанию и оформлению выпускной квалификационной работы бакалавра оглавлениеРуководство предназначено для студентов выпускников. В нём изложены основные требования к содержанию и оформлению выпускной квалификационной… | ||
| График работы сотрудников |
Документы
Предотвращение перегрузки
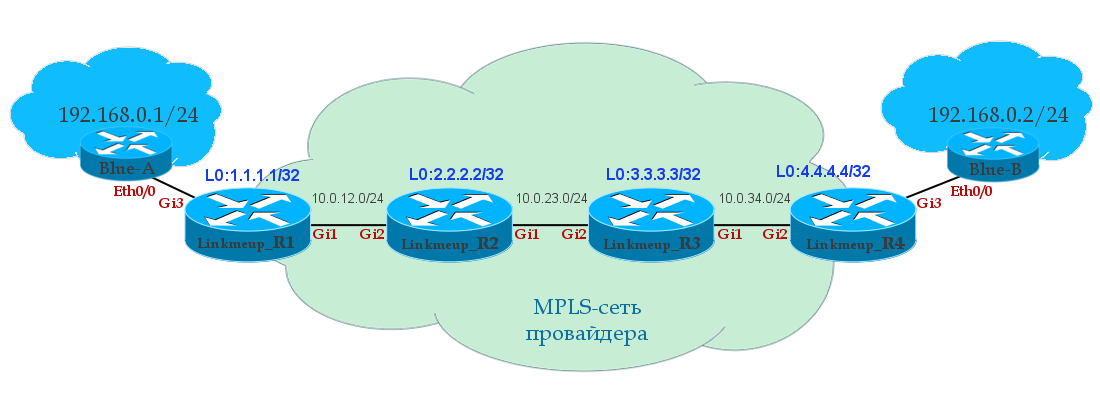
Предотвращение перегрузки построено на предположении, что потеря пакета является индикатором перегрузки в сети. Где-то на пути движения пакетов на линке или на роутере скопились пакеты, и это означает, что нужно уменьшить окно перегрузки, чтобы предотвратить дальнейшее «забитие» сети трафиком.
После того как окно перегрузки уменьшено, применяется отдельный алгоритм для определения того, как должно далее увеличиваться окно. Рано или поздно случится очередная потеря пакета, и процесс повторится. Если вы когда-либо видели похожий на пилу график проходящего через TCP-соединение трафика — это как раз потому, что алгоритмы контроля и предотвращения перегрузки подстраивают окно перегрузки в соответствии с потерями пакетов в сети.
Стоит заметить, что улучшение этих алгоритмов является активной областью как научных изысканий, так и разработки коммерческих продуктов. Существуют варианты, которые лучше работают в сетях определенного типа или для передачи определенного типа файлов и так далее. В зависимости от того, на какой платформе вы работаете, вы используете один из многих вариантов: TCP Tahoe and Reno (исходная реализация), TCP Vegas, TCP New Reno, TCP BIC, TCP CUBIC (по умолчанию на Linux) или Compound TCP (по умолчанию на Windows) и многие другие. Независимо от конкретной реализации, влияния этих алгоритмов на производительность веб-приложений похожи.
TCP vs self-made UDP
- С перегрузками, когда пакетов очень много и некоторые из них дропаются из-за перегрузки каналов или оборудования.
- Высокоскоростные с большими round-trip (например когда сервер располагается относительно далеко).
- Странные — когда в сети вроде бы ничего не происходит, но пакеты все равно пропадают просто потому-что Wi-Fi точка доступа находится за стенкой.
- Профиль Видео, когда вы подключаетесь и стримите тот или иной контент. Скорость соединения увеличивается, как на верхнем графике. Требования к этому протоколу: низкие задержки и адаптация битрейта.
- Вариант просмотра Ленты: импульсная загрузка данных, фоновые запросы, промежутки простоя. Требования к этому протоколу: получаемые данные мультиплексируются и приоритизируются, приоритет пользовательского контента выше фоновых процессов, есть отмена загрузки.
Отличия HTTP 2.0
- бинарный, сжатие заголовков;
- мультиплексирование данных;
- приоритизация;
- возможна отмена загрузки;
- server push
Высокоприоритетный контент загружается раньше.Server pushReset stream
- Профилях сети: Wi-Fi, 3G, LTE.
- Профилях потребления: cтриминг (видео), мультиплексирование и приоритизация с отменой загрузки (HTTP/2) для получения контента ленты.
Размер буфера
- пакеты 1 и 2 уже отправлены, для них получено подтверждение;
- пакеты 3, 4, 5, 6 отправлены, но результат доставки неизвестен (on-the-fly packets);
- остальные пакеты находятся в очереди.
Вывод:
Congestion control
- Flow control — это некий механизм защиты от перегрузки. Получатель говорит, на какое количество данных у него реально есть место в буфере, чтобы он был готов их принять. Если передать сверх flow control или recv window, то эти пакеты просто будут выкинуты. Задача flow control — это back pressure от нагрузки, то есть просто кто-то не успевает вычитывать данные.
- У congestion control совершенно другая задача. Механизмы схожие, но задача — спасти сеть от перегрузки.
- Если TCP window = 1, то данные передаются как на схеме слева: дожидаемся acknowledgement, отправляем следующий пакет и т.д.
- Если TCP window = 4, то отправляем сразу пачку из четырех пакетов, дожидаемся acknowledgement и дальше работаем.
- На верхней схеме сеть, в которой все хорошо. Пакеты отправляются с заданной частотой, с такой же частотой возвращаются подтверждения.
- Во второй строке начинается перегруз сети: пакеты идут чаще, acknowledgements приходят с задержкой.
- Данные копятся в буферах на маршрутизаторах и других устройствах и в какой-то момент начинают пропускать пакеты, acknowledgements на эти пакеты не приходят (нижняя схема).
- Cubic — дефолтный Congestion Control с Linux 2.6. Именно он используется чаще всего и работает примитивно: потерял пакет — схлопнул окно.
- BBR — более сложный Congestion Control, который придумали в Google в 2016 году. Учитывает размер буфера.
BBR Congestion Control
- BBR понимает, что идет переполнение буфера, и пытается схлопнуть окно, уменьшить нагрузку на маршрутизатор.
- Cubic дожидается потери пакета и после этого схлопывает окно.
jitterHighLoad++
Какой Congestion control выбрать
Выводы про congestion control:
- Для видео всегда хорош BBR.
- В остальных случаях, если мы используем свой UDP-протокол, можно взять congestion control с собой.
- С точки зрения TCP можно использовать только congestion control, который есть в ядре. Если хотите реализовать свой congestion control в ядро, нужно обязательно соответствовать спецификации TCP. Невозможно раздуть acknowledgement, сделать изменения, потому что просто их нет на клиенте.
Произведение ширины канала на задержку (Bandwidth-Delay Product – BDP)
Встроенные механизмы борьбы с перегрузкой в TCP имеют важное следствие: оптимальные значения окон для получателя и отправителя должны изменяться согласно круговой задержке и целевой скорости передачи данных. Вспомним, что максимально количество неподтвержденных пакетов «в пути» определено как наименьшее значение из окон приема и перегрузки (rwnd и cwnd)
Если у отправителя превышено максимальное количество неподтвержденных пакетов, то он должен прекратить передачу и ожидать, пока получатель не подтвердит какое-то количество пакетов, чтобы отправитель мог снова начать передачу. Сколько он должен ждать? Это определяется круговой задержкой.
Алгоритм работы TCP
Алгоритм работы TCP следующий:
- Используя трехкратное рукопожатие, между двумя узлами создаётся сеанс связи.
- При отправке пакетов узлы последовательно нумеруют их и рассчитывают контрольную сумму.
- Поскольку все пакеты имеют последовательные номера, то становится видно если какие-то из них отсутствуют. В этом случае отправляется запрос на повторную отправку пакета.
- Если для какого-то пакета не совпала контрольная сумма, то отправляется запрос на повторную отправку пакета.
При открытии даже одной веб странички создаются несколько TCP соединений для:
- html страницы;
- каждого CSS и JavaScript файлов;
- каждого изображения.
И для каждого такого соединения вначале устанавливается сеанс, что замедляет передачу данных.
Окно перегрузки в TCP
Таким образом в TCP у нас есть два типа окна. Окно управления потоком, которое мы рассматривали в статье «Протокол TCP — Управление Потоком». Размер этого окна задаются получателем, в зависимости от того сколько места в буфере, и передается отправителю в сегментах с подтверждением.
Окно перегрузки, существует на стороне отправителя, его размер рассчитывается отправителем в зависимости от того, какая нагрузка на сеть, а не от того сколько данных может принять приложение. Приложение может быть готово принять много данных, но сеть загружена, в этом случае отправлять так много данных не имеет смысла.
BDP определяет, какой максимальный объем данных может быть «в пути»
Если отправитель часто должен останавливаться и ждать АСК-подтверждения ранее отправленных пакетов, это создаст разрыв в потоке данных, который будет ограничивать максимальную скорость соединения. Чтобы избежать этой проблемы, размеры окон должны быть установлены достаточно большими, чтобы можно было отсылать данные, ожидая поступления АСК-подтверждений по ранее отправленным пакетам. Тогда будет возможна максимальная скорость передачи, никаких разрывов. Соответственно, оптимальный размер окна зависит от скорости круговой задержки.
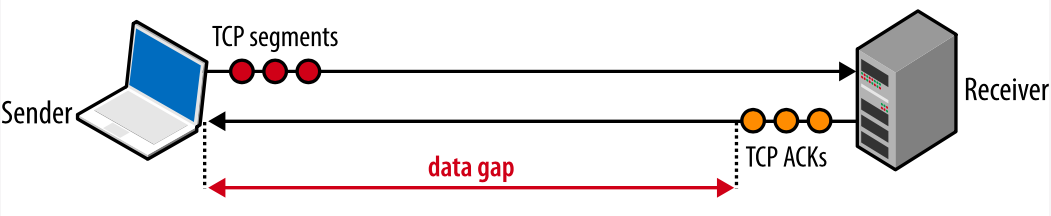 Рис. 5. Разрыв в передаче из-за маленьких значений окон.
Рис. 5. Разрыв в передаче из-за маленьких значений окон.
Насколько же большими должны быть значения окон приема и перегрузки? Разберем на примере: пусть cwnd и rwnd равны 16 КБ, а круговая задержка равна 100 мс. Тогда:
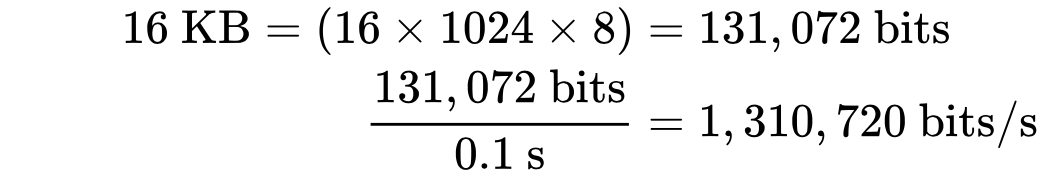
Получается, что какая бы ни была ширина канала между отправителем и получателем, такое соединение никогда не даст скорость больше, чем 1,31 Мбит/с. Чтобы добиться большей скорости, надо или увеличить значение окон, или уменьшить круговую задержку.
![[перевод] внутренние механизмы тср, влияющие на скорость загрузки: часть 2 - pcnews.ru](https://robotrackkursk.ru/wp-content/uploads/1/9/4/1940587047f295267d3af74a8513f2e5.jpeg)
Похожим образом мы можем вычислить оптимальное значение окон, зная круговую задержку и требуемую ширину канала. Примем, что время останется тем же (100 мс), а ширина канала отправителя 10 Мбит/с, а получатель находится на высокоскоростном канале в 100 Мбит/с. Предполагая, что у сети между ними нет проблем на промежуточных участках, мы получаем для отправителя:
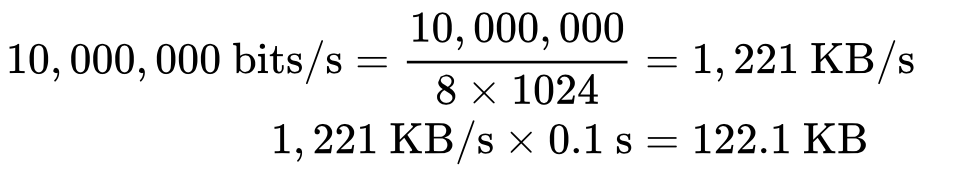
Размер окна должен быть как минимум 122,1 КБ, чтобы полностью занять канал на 10 Мбит/с. Вспомните, что максимальный размер окна приема в TCP равен 64 КБ, если только не включено масштабирование окна (RFC 1323). Еще один повод перепроверить настройки!
Хорошая новость в том, что согласование размеров окон автоматически делается в сетевом стэке. Плохая новость в том, что иногда это может быть ограничивающим фактором. Если вы когда-либо задумывались, почему ваше соединение передает со скоростью, которая составляет лишь небольшую долю от имеющейся ширины канала, это происходит, скорее всего, из-за малого размера окон.
Настройка приложения
То, как приложение использует соединения может иметь огромное влияние на производительность:
- Любая передача данных занимает время >0. Ищите способы уменьшить объем отправляемых данных.
- Приблизьте ваши данные к клиентам географически
- Повторное использование TCP-соединений может быть важнейшим моментом в улучшении производительности.
Исключение ненужной передачи данных, это, конечно, самый важный вид оптимизации
Если же определенные данные все же нужно передавать, важно убедиться, что для них используется подходящий алгоритм сжатия
Перенос данных поближе к клиентам посредством размещения серверов по всему миру либо с использованием CDN, поможет уменьшить круговую задержку и значительно повысит производительность TCP.
И наконец, во всех случаях, где это возможно, существующие соединения TCP должны использоваться повторно, чтобы избежать задержек, вызванных алгоритмом медленного старта и контроля перегрузки.
В заключение, вот контрольный список того, что нужно сделать для оптимизации TCP:
- Обновите ОС сервера
- Убедитесь, что параметр cwnd установлен равным 10
- Убедитесь, что масштабирование окон включено
- Отключите медленный старт после простоя соединения
- Включите TCP Fast Open, если это возможно
- Исключите передачу ненужных данных
- Сжимайте передаваемые данные
- Расположите серверы ближе к клиентам географически, чтобы снизить круговую задержку
- Используйте повторно TCP-соединения, где это возможно
- Изучите рекомендации Рабочей группы по HTTP
ссылка на оригинал статьи https://habrahabr.ru/post/327050/
Коллапс перезагрузки
Первый раз такая ситуация произошла в интернет в 1986 году, она называлась коллапс перегрузки, хотя теоретически она была предсказана раньше. Чтобы решить эту проблему, стали учитывать загрузку сети при формировании размера окна, то есть при определении количества сегментов, которые можно отправить в сеть, не дожидаясь получения подтверждения.
Если раньше, до коллапса перегрузки, такое количество сегментов всегда было одинаково 8 штук, то после коллапса перегрузки решили, что это количество нужно определять динамически в зависимости от того загружена сеть или нет. И для того чтобы определить количество сегментов, которое можно отправить в сеть, используется окно перегрузки.
Удаление блокировки HoL
большими потерями пакетов
Приоритизация потоков
первой частизадержке данных для нескольких ресурсовмультиплексируютсяCloudflareздесьздесьрассказывалWebpagetestтрехчасовое руководствоКак различия в мультиплексировании влияют на загрузку сайтов в разных браузерах (исходник)блокируют рендерингзагрузить полностьюРис. 6: Подход к мультиплексированию потока влияет на время загрузки ресурсов, блокирующих рендеринг (исходное изображение)принцип round-robinобрабатывать и использовать постепеннобольшинствапоследовательное мультиплексирование работает лучше
Устойчивость к потере пакетов
первой частиактивные12 пакетовблокировку HoLРис. 7: Последствия потери пакетов зависят от мультиплексора. Мы предполагаем, что у каждого потока больше для данных для отправки, чем на предыдущих изображениях (исходное изображение)один метод оптимизации нивелирует другойпачкамипо несколько штук одновременноперегружает сетьРис. 8: В зависимости от мультиплексора и количества потерянных пакетов будет затронут один или несколько потоков(исходное изображение)большинство результатовне так уж заметностатью с подробным описанием блокировки HoL в HTTP
Чего нужно ждать в будущем
новые расширения
-
Forward error correctionЦель этой техники — повысить устойчивость QUIC к потере пакетов. Суть заключается в отправке избыточных копий данных (они по-умному закодированы и сжаты, так что занимают не очень много места). Если пакет потерялся, но у нас есть его копия, снова передавать его не нужно.
Изначально такая возможность была в Google QUIC (откуда и пошли разговоры об устойчивости к потере пакетов), но в стандартизированный QUIC version 1 она не входит, потому что её влияние на производительность пока не проверено. Эксперименты уже ведутся, и вы можете поучаствовать в них через приложение PQUIC-FEC Download Experiments. -
Multipath QUICВы уже знаете о миграции соединения и о том, что она даёт, скажем, при переходе с Wi-Fi на сотовую сеть. А почему бы тогда не использовать Wi-Fi и сотовую сеть одновременно, чтобы увеличить полосу пропускания и повысить надёжность. Это главная концепция, на которой основан подход multipath.
В Google экспериментировали с этим, но в QUIC version 1 эта возможность не входит из-за своей сложности. Исследователи видят здесь большой потенциал, так что ждём QUIC version 2. Кстати, TCP multipath тоже существует, но ему понадобилось почти десять лет, чтобы стать применимым на практике. - Передача ненадёжных данных по QUIC и HTTP/3QUIC очень надёжный протокол, но работает поверх ненадёжного UDP, так что QUIC можно приспособить и для передачи ненадёжных данных. Механизм описан в предложенном расширении для датаграмм. Он, конечно, не подходит для отправки ресурсов веб-страницы, но может пригодиться для игр или видеостриминга. Так пользователи получат все преимущества UDP, но с шифрованием и, по желанию, контролем перегрузок от QUIC.
-
WebTransportБраузеры не открывают TCP или UDP для JavaScript напрямую, в основном, из соображений безопасности. Приходится использовать API на уровне HTTP, например Fetch, и более гибкие протоколы WebSocket и WebRTC. Самый новый вариант — WebTransport, с которым можно использовать HTTP/3 (а значит и QUIC) на более низком уровне (хотя его можно приспособить и для TCP и HTTP/2, если нужно).
Самое главное, он позволит использовать ненадёжные данные по HTTP/3 (см. выше), чтобы упростить реализацию в браузере, например, для игр. Для обычных (JSON) вызовов API мы всё равно будем использовать Fetch, который автоматически будет применять HTTP/3 по возможности. Вокруг WebTransport пока много дискуссий, так что неясно, как он в итоге будет выглядеть. Из браузеров только Chromium пока работает над открытой proof-on-concept реализацией. -
DASH и HLS для стриминга
Для видео по запросу (например, YouTube или Netflix) браузеры обычно используют протоколы Dynamic Adaptive Streaming over HTTP (DASH) и HTTP Live Streaming (HLS). Оба подразумевают кодирование видео маленькими фрагментами (2–10 секунд) и разные уровни качества (720p, 1080p, 4K).
При запуске браузер оценивает максимальное качество, которое потянет сеть (или оптимальный уровень для конкретного сценария), и запрашивает соответствующие файлы у сервера по HTTP. У браузера нет прямого доступа к стеку TCP (потому что он обычно реализуется в ядре), так что иногда он ошибается в своих оценках или медленно реагирует на изменение условий (и видео зависает).
QUIC реализуется как часть браузера, поэтому его можно заметно улучшить, если дать механизмам оценки доступ к информации на нижнем уровне протоколов (процент потерь, полоса пропускания и т. д.). Другие исследователи тоже экспериментировали со смешиванием надёжных и ненадёжных данных для видеостриминга и получили неплохие результаты. -
Другие протоколы (кроме HTTP/3)
QUIC — это транспортный протокол общего назначения, и, скорее всего, многие протоколы на прикладном уровне, которые сейчас используют TCP, будут работать и на QUIC. Сейчас уже разрабатывают DNS-over-QUIC, SMB-over-QUIC и даже SSH-over-QUIC. У этих протоколов другие требования, не связанные с HTTP и загрузкой веб-страниц, так что в них улучшения производительности QUIC могут проявляться заметнее.
5.7 Управление потоком TCP
5.7.1 Использование скользящего окна для управления потоком
Управление потоком: не позволяйте отправителю отправлять слишком быстро, пусть получатель успевает получить。
С помощью механизма скользящего окна можно легко реализовать управление потоком на отправителе по TCP-соединению.
Тупик:
Для решения вышеуказанных проблем в TCP естьНепрерывный таймер(Таймер сохраняемости), пока одна сторона TCP-соединения получает уведомление о нулевом окне от другой стороны, она запускает таймер сохраняемости. Если время, установленное непрерывным таймером, истекает, отправляется сегмент сообщения об обнаружении нулевого окна.
TCP предусматривает, что даже если для него установлено нулевое окно, должны приниматься следующие типы сегментов сообщения: сегменты сообщения обнаружения нулевого окна, сегменты подтверждающего сообщения и сегменты сообщения, несущие срочные данные.
5.7.2 Эффективность передачи TCP
Хотя отправитель не отправляет небольшой сегмент сообщения, получатель не должен спешить, чтобы уведомить отправителя с информацией о небольшом размере окна, как только в буфере появится небольшое пространство.
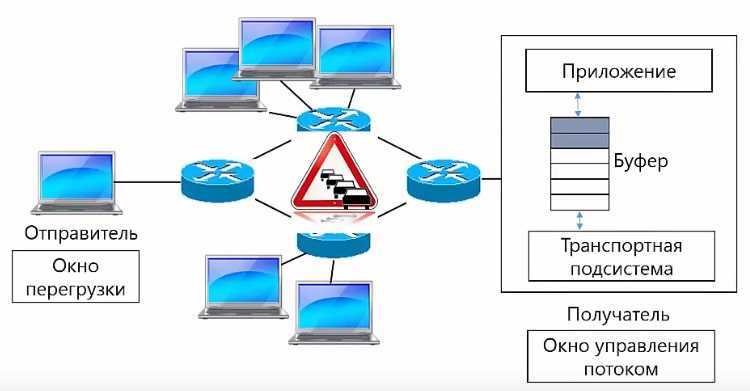
Блокировка начала очереди (Head-of-line blocking — HOL blocking)
Каждый TCP-пакет содержит уникальный номер последовательности, и данные должны поступать по порядку. Если один из пакетов был потерян, то все последующие пакеты хранятся в TCP-буфере получателя, пока потерянный пакет не будет повторно отправлен и не достигнет получателя. Поскольку это происходит в TCP-слое, приложение «не видит» эти повторные отправки или очередь пакетов в буфере, и просто ждет, пока данные не будут доступны. Все, что «видит» приложение — это задержка, возникающая при чтении данных из сокета. Этот эффект известен как блокировка начала очереди.
Блокировка начала очереди освобождает приложения от необходимости заниматься упорядочиванием пакетов, что упрощает код. Но с другой стороны, появляется непредсказуемая задержка поступления пакетов, что негативно влияет на производительность приложений.
Рис. 6. Блокировка начала очереди.
Некоторым приложениям может не требоваться гарантированная доставка или доставка по порядку. Если каждый пакет — это отдельное сообщение, то доставка по порядку не нужна. А если каждое новое сообщение перезаписывает предыдущие, то и гарантированная доставка также не нужна. Но в TCP нет конфигурации для таких случаев. Все пакеты доставляются по очереди, а если какой-то не доставлен, он отправляется повторно. Приложения, для которых задержка критична, могут использовать альтернативный транспорт, например, UDP.
Настройка приложения
То, как приложение использует соединения может иметь огромное влияние на производительность:
- Любая передача данных занимает время >0. Ищите способы уменьшить объем отправляемых данных.
- Приблизьте ваши данные к клиентам географически
- Повторное использование TCP-соединений может быть важнейшим моментом в улучшении производительности.
Исключение ненужной передачи данных, это, конечно, самый важный вид оптимизации
Если же определенные данные все же нужно передавать, важно убедиться, что для них используется подходящий алгоритм сжатия
Перенос данных поближе к клиентам посредством размещения серверов по всему миру либо с использованием CDN, поможет уменьшить круговую задержку и значительно повысит производительность TCP.
И наконец, во всех случаях, где это возможно, существующие соединения TCP должны использоваться повторно, чтобы избежать задержек, вызванных алгоритмом медленного старта и контроля перегрузки.
В заключение, вот контрольный список того, что нужно сделать для оптимизации TCP:
- Обновите ОС сервера
- Убедитесь, что параметр cwnd установлен равным 10
- Убедитесь, что масштабирование окон включено
- Отключите медленный старт после простоя соединения
- Включите TCP Fast Open, если это возможно
- Исключите передачу ненужных данных
- Сжимайте передаваемые данные
- Расположите серверы ближе к клиентам географически, чтобы снизить круговую задержку
- Используйте повторно TCP-соединения, где это возможно
Предотвращение перегрузки
Важно понимать, что TCP использует потерю пакетов как механизм обратной связи, который помогает регулировать производительность. Медленный старт создает соединение с консервативным значением окна перегрузки и пошагово удваивает количество передаваемых за раз данных, пока оно не достигнет окна приема получателя, системного порога sshtresh или пока пакеты не начнут теряться, после чего и включается алгоритм предотвращения перегрузки
Предотвращение перегрузки построено на предположении, что потеря пакета является индикатором перегрузки в сети. Где-то на пути движения пакетов на линке или на роутере скопились пакеты, и это означает, что нужно уменьшить окно перегрузки, чтобы предотвратить дальнейшее «забитие» сети трафиком.

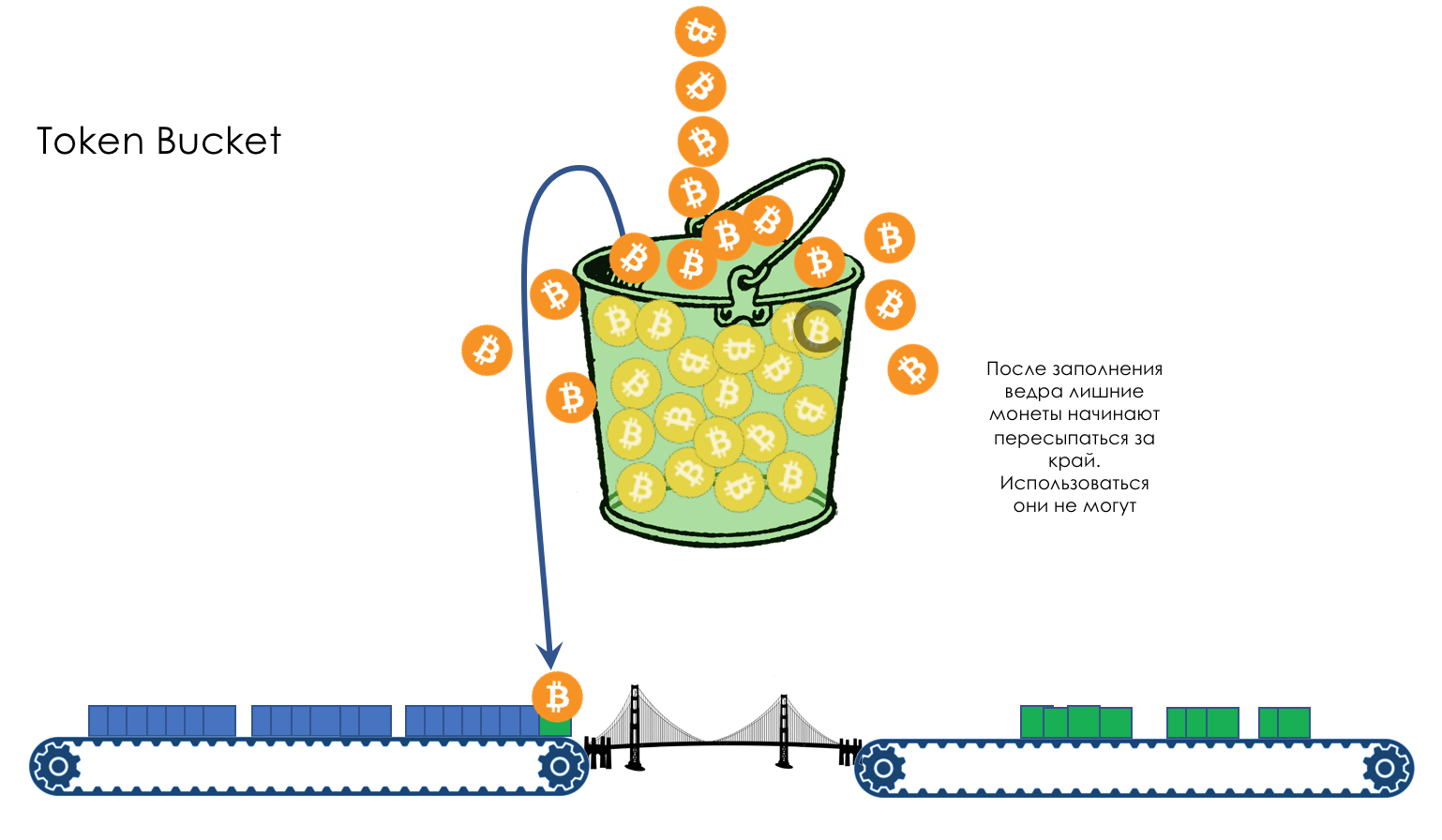
После того как окно перегрузки уменьшено, применяется отдельный алгоритм для определения того, как должно далее увеличиваться окно. Рано или поздно случится очередная потеря пакета, и процесс повторится. Если вы когда-либо видели похожий на пилу график проходящего через TCP-соединение трафика – это как раз потому, что алгоритмы контроля и предотвращения перегрузки подстраивают окно перегрузки в соответствии с потерями пакетов в сети.
Стоит заметить, что улучшение этих алгоритмов является активной областью как научных изысканий, так и разработки коммерческих продуктов. Существуют варианты, которые лучше работают в сетях определенного типа или для передачи определенного типа файлов и так далее. В зависимости от того, на какой платформе вы работаете, вы используете один из многих вариантов: TCP Tahoe and Reno (исходная реализация), TCP Vegas, TCP New Reno, TCP BIC, TCP CUBIC (по умолчанию на Linux) или Compound TCP (по умолчанию на Windows) и многие другие. Независимо от конкретной реализации, влияния этих алгоритмов на производительность веб-приложений похожи.
Сигнал о перегрузке
Следующий вариант, как отправитель может узнать о перегрузке это явный сигнал от маршрутизатора. Однако для этого маршрутизаторы должны поддерживать отправку сигналов. Одним из возможных вариантов является технология Random Early Detection, при этом маршрутизатор с некоторой вероятностью начинает отбрасывать пакеты еще до того как буфер полностью заполнен и началась перегрузка.
В результате отправители узнают о возможной перегрузке по потере сегмента ещё до того, как она произошла, и получают возможность заранее уменьшить окно перегрузки. Но это не явный тип сигнала, технологиях Explicit Congestion Notification, обеспечивает явную отправку сигнала от маршрутизатора к отправителю, о том что в сети происходит перегрузка.
Explicit Congestion Notification (ECN)
Рассмотрим на схеме, как она работает. Отправитель передает сегмент в сеть, который доходит до маршрутизатора. Маршрутизатор находится в состоянии близкому к перегрузке, буфер заполнен, но не полностью. Для того чтобы предупредить отправителя о перегрузке в сети, маршрутизатор устанавливать специальные флаги в заголовке IP, которые говорят о том, что в сети произошла перегрузка.
Сегмент передается по сети дальше и достигает получателя. Получатель в заголовке IP видит что установлен флаг, свидетельствующий о перегрузке, для того чтобы о перегрузке узнал не только получатель, но и отправитель, получатель устанавливает соответствующие флаги уже в заголовке TCP, когда передает подтверждение.
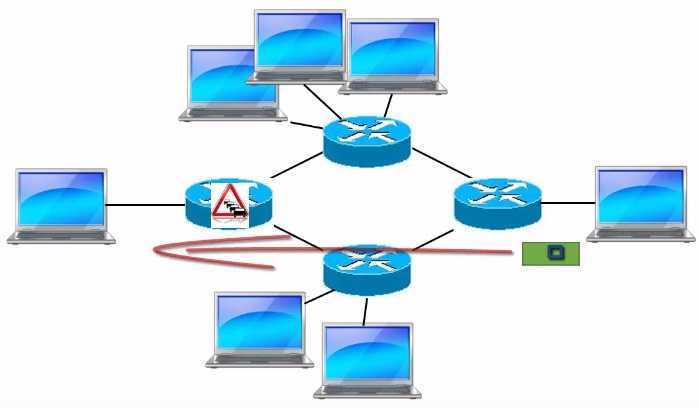
Отправитель получает подтверждение доставки сообщения, и в этом подтверждении он видит, что флаг сигнализирующий о перегрузке установлен, это будет сигналом о том что нужно уменьшить размер окна перегрузки.
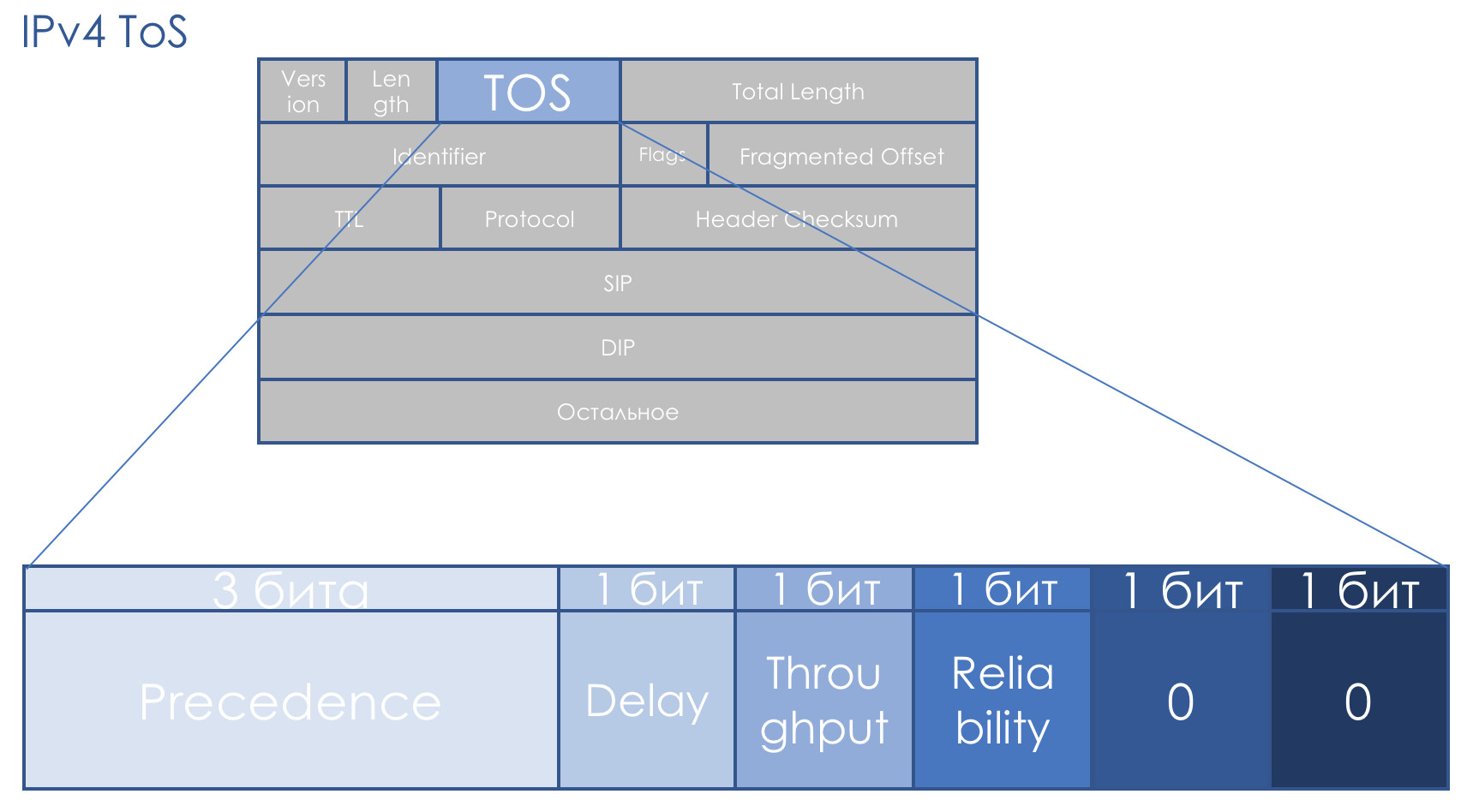
ECN в заголовке IP
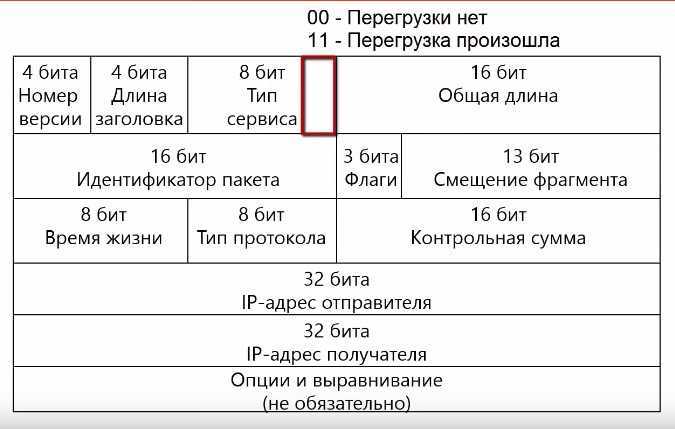
Рассмотрим, какие поля в заголовке IP и TCP используются в технологии Explicit Congestion Notification. В заголовке IP используются 2 бита в поле тип сервиса, значение 00 говорит о том, что перегрузки нет, а 11 означают что перегрузка произошла.
ECN в заголовке TCP
В заголовке TCP для этих целей используются три флага, NS, CWR, ECE.
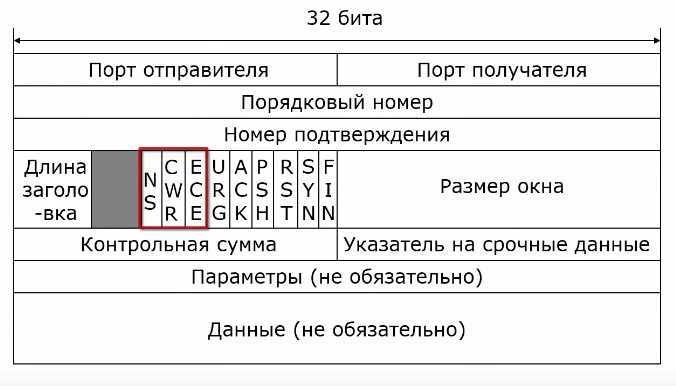
- Получатель, который принял от маршрутизаторов заголовки IP сигнал о перегрузке, использует флаг ECE (ECN-Echo). Получатель устанавливает этот флаг в подтверждение получения сегмента, который он передает отправителю.
- Отправитель в качестве подтверждения того, что он получил сообщение о перегрузки при передаче следующего сегмента устанавливает флаг CWR (Congestion Window Reduced), который говорит о том, что размер окна управление перегрузкой уменьшен.
- Еще один флаг NS (ECN-none concealment protection) используется для защиты от случайного или злонамеренного изменения полей, который относится к технологии Explicit Congestion Notification.