
Из чего состоят системы управления базами данных
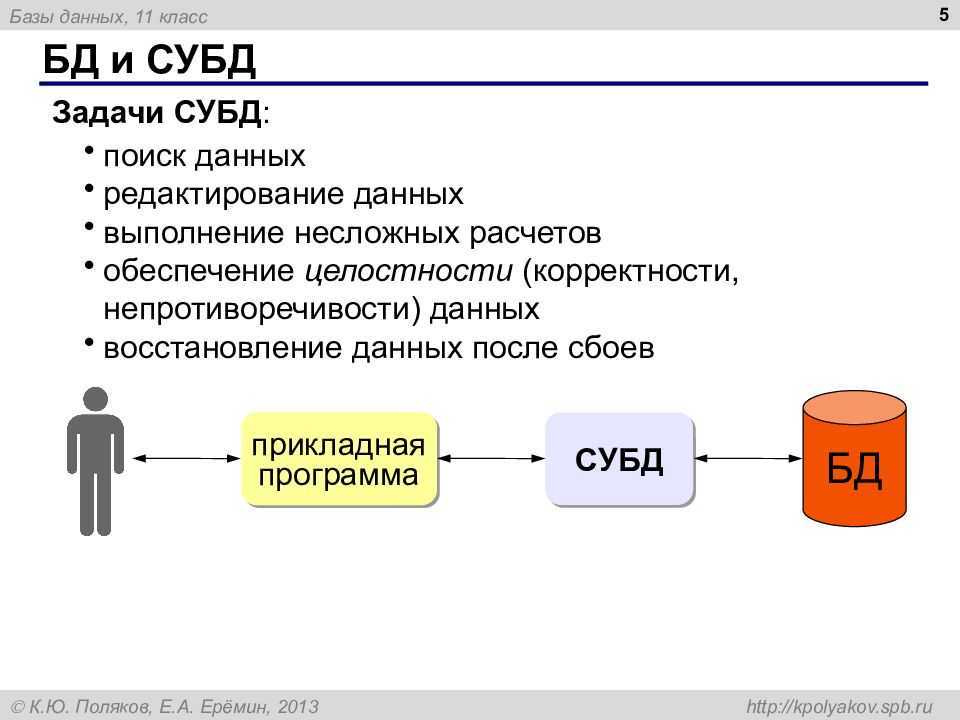
Если база — это хранилище, то СУБД — комплекс средств для обслуживания хранилища. СУБД имеет сложное устройство.
Ядро СУБД отвечает за главные операции: хранение базы, ее обслуживание, документирование изменений. Это основная часть системы.
Процессор языка или компилятор обрабатывает запросы. Обычно СУБД реляционного, объектно-ориентированного и объектно-реляционного типа поддерживают язык SQL и внутренние языки запросов.
Набор утилит предназначен для различных сервисных функций: их может быть очень много, а некоторые СУБД могут расширяться с помощью пользовательских модулей.
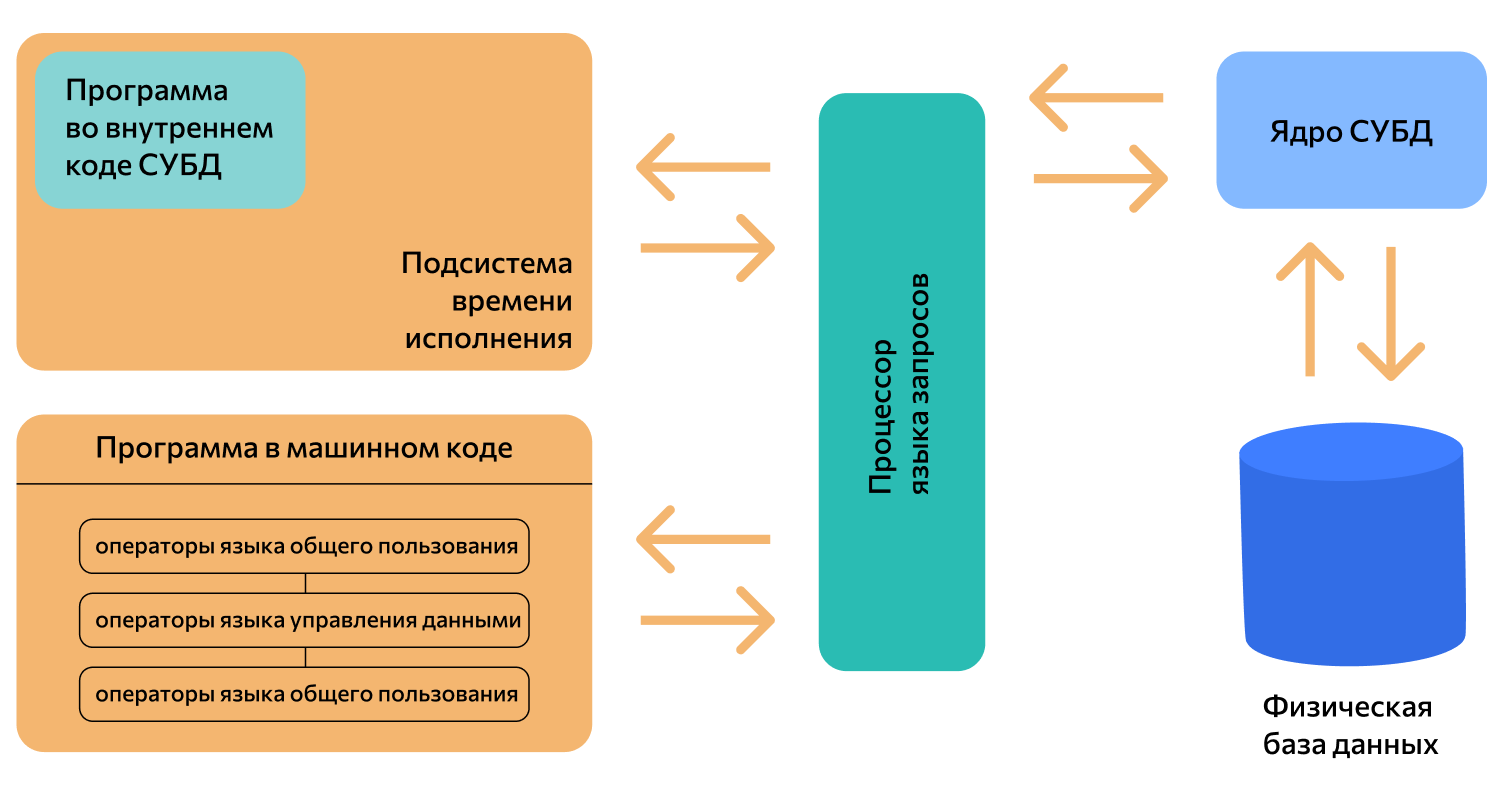
Устройство СУБД
Файлы данных / Datafiles
Третий тип необходимых файлов для работы это файлы данных. Как минимум требуется два файла, которые создаются в момент созданий БД. До версии 10g – можно было создать базу с одним файло – после создаются два файла, по одному для табличного пространства SYSTEM и SYSAUX. Как бы то ни было, в рабочей базе будет больше файлов.
Файлы данных – это хранилище для данных. Их размер и количество неограниченны. Маленькие БД размером в несколько гигабайт могут состоять из пол-дюжины файлов, каждый размером в несколько сот магабайт. Большие БД могут состоять из тысяч файлов, размер которых ограничен только возможностями ОС и аппаратным обеспечением.
Файлы данных с физической точки зрения – это системные файлы, которые видят системные администраторы. Логическая же структура файлов данных, это хранилище сегментов (segments) в которых хранятся пользовательские данных и логическая структура доступна программистам, а также сегментов словаря данных. Сегмент – это структура хранения для данных; типичные сегменты это таблицы и индексы. Файлы данных могут быть переиенованы, перемещены, удалены, добавлены в любое время жизни БД
Но важно помнить что некоторые операции требуют перезапуска экземпляра БД
С точки зрения ОС, файлы данных состоят из набора блоков операционной системы. Внутри файлов, они отформатированы на Oracle блоки (blocks). Эти блоки последовательно пронумерованы внутри каждого файла. Размер блока фиксирован и в большинстве случаев будет одинаковым для всей БД. Выбор размера блока задача для оптимизации. Допустимы значения от 2КБ до 64КБ. Нет взаимосвязи между размерами системных блоков и блоков Oracle.
Многие DBA используют одинаковый размер системного блока и Oracle блока. С точки зрения производительности системный блок не должен быть больше чем блок Oracle. Однако ничто не мешает системному блоку быть меньше чем блоку Oracle. К примеру системный блок в 1Кб и блок Oracle размеров в 8КБ вполне допустимая конфигурация.
Внутри блока находтся заголовок, область данных и возможно неиспользуемое место. Заголовок содержит информацию такую как: каталог строк, в котором перечислено расположение строк в области данных (если блок используется как часть таблицы), информация о блокировках строк, если данные используются в транзакциях. В области данных хранятся сами данные, такие как строки если блок является частью таблицы, или ключи индекса, если блок – часть индекса.
Когда пользовательскйо сессии необходимо работать с данными из блока, серверный процесс находит блок с нужными данными на диске и копирует этот блок в свободный буфер в database buffer cache. Если затем данные изменяются – в какой-то момент времени DBWn запишет этот блок обратно на диск.
Желательно регулярно делать копии файлов данных. В отличие от controlfile и redo log файлов, Oracle не поррерживает копии файлов данных (хотя вы можете построить RAID массив или использовать другие аппаратные возможности и возможности операционной системы). Если файлы данных повреждаются, они могут быть восстановлены из архивной копии и затем recovered (recovered — означает что к копии файлов данных будут применены изменения из redo log).
Файл контроля / Controlfile
Разберёмся с терминологией: кто-то говорит что у БД может быть несколько controlfile-ов, а другие утверждают что файл один, который может иметь несколько копий. Мы придержимся последнего определения, так как согласно Oracle “multiplexing control files” означает именно возможность иметь копии.
Controlfile – файл небольшого объёма, но он жизненно важный. Внутри содержатся указатели для всей БД: место online redo log-а, файлов данных, критически важную системную информацию для обеспечения целостности ( значение sequence и timestamp). Размер файла обычно не превышает несколько мегабайт но БД не существует без этого файла.
У каждой БД есь один controlfile, но хороший DBA всегда будет создавать копии файла, чтобы в случае проблем с какой либо копией всегда можно было быстро восстановить систему. Если все копии утеряны, то теоретичеески можно попробовать восстановить базу, но лучше никогда не попадать в такую ситуацию. Oracle сервер сам синхронизирует controlfile-ы – задача DBA решить сколько копий необходимо и где их хранить.
Если вы в момент создания базы данных не указали количество или путь – это можно изменить после, но потребует включения выключения БД, так что лучше планировать заранее. Нету определенного значения сколько копий делать, минимум – один файл, максимум – восемь. Проблемы с любой копией controlfile приводят к немедленной остановке экземпляра БД.
Возможности СУБД
В автоматизированных информационных системах скорость поиска и обработки информации настолько высока, что позволяет человеку осуществлять выбор без промедления и решать недоступные ранее задачи. Водитель, получая оперативные данные о «пробках» на дорогах, может за считанные секунды после их появления изменить свой маршрут. Человек, не умеющий готовить какое-то изысканное блюдо, может стать специалистом по его приготовлению, если ему дали время просмотреть соответствующий видеоурок в сети Интернет.
В первом примере данные от сотен тысяч источников поступают в единую информационную систему контроля ситуации на дорогах, но через несколько минут становятся никому не нужными, потому что теряют свою актуальность. Во втором примере, наоборот, видео, записанное одним человеком, хранилось несколько лет, прежде чем пригодилось кому-то. Для разных задач существуют разные способы хранения информации, определяемые типом базы данных.
База данных (БД) – это специальным образом организованная совокупность данных, хранящаяся в электронном виде в компьютерной системе.
Программное обеспечение, которое обеспечивает взаимодействие базы данных с пользователями и приложениями называется системой управления базами данных (СУБД).
Модуль доступа к РСУБД для приложений Java
Интерфейсы доступа к реляционным данным
- доступ напрямую к реляционным данным через интерфейс JDBC и язык SQL;
- доступ посредством объектной модели через объектно-реляционный адаптер JPA (Java Persistence API).
Конструктивная реализация модуля DAL для Java
JBoss TeiidРис. 8. Конструктивная реализация модуля DAL для Java
- предоставление интерфейса JPA для приложений Java;
- предоставление интерфейса JDBC для приложений Java;
- использование собственного унифицированного диалекта SQL (на основе стандарта SQL-99);
- трансляция собственного диалекта SQL в специфические диалекты поддерживаемых БД;
- наличие коннекторов к большинству используемых РСУБД и простая расширяемость;
- возможность работы как в режиме встроенного модуля, так и в режиме сетевого сервиса;
- открытые исходные коды (Open Source), возможность бесплатного использования в коммерческих целях, развитое сообщество и примеры внедрения в крупных предприятиях.
- объединение баз данных путем создания так называемой «виртуальной БД» (virtual DB, VDB) в настройках с помощью визуального дизайнера. Подобная «виртуальная БД» ассоциируется с реальными средствами хранения (не только реляционными);
- эффективное выполнение «кросс-запросов» — SQL-запросов к «виртуальной БД», которые автоматически транслируются в SQL-запросы к реальным БД;
- кеширование результатов запросов к «виртуальной БД».
Список используемых источников
- Лекция «Основные понятия баз данных и СУБД модели данных»: https://ppt-online.org/5753;
- Принципы построения баз данных: https://infopedia.su/3x23d8.html;
- Основные принципы построения баз данных, проблемы хранения больших объемов информации: https://www.sites.google.com/site/gosyvmkss12/bazy-dannyh/1-osnovnye-principy-postroenia-baz-dannyh-problemy-hranenia-bolsih-obemov-informacii;
- Классификация баз данных: https://cs.petrsu.ru/studies/filatova_information/CMD_1996566_M/my_files/Inform/DataBase/a-2.htm.
- Особенности восприятия времени у лиц с различным темпераментом
- Творческое мышление и способы его активизации
- Способы документирования и их развитие
- Развитие ECM-технологий
- Развитие ECM-технологий
- СПОСОБЫ РЕАЛИЗАЦИИ И ДЕЙСТВИЕ АДМИНИСТРАТИВНО-ПРАВОВЫХ НОРМ ВО ВРЕМЕНИ, ПРОСТРАНСТВЕ И ПО КРУГУ ЛИЦ
- Воинская преступность
- Системы автоматизации управления документооборотом
- Корыстная преступность
- Управление коммуникациями проекта
- Департамент правовых дисциплин
- Основы административного права
Создание LSM-дерева из SS-таблиц
Подсистемы хранения, основанные на принципе слияния и уплотнения отсортированных файлов, часто называются LSM-подсистемами хранения (Log-Structured Merge).
Основная идея LSM-деревьев — применение каскада SS-таблиц, объединяемых в фоновом режиме, — проста и эффективна. Она хорошо работает даже в случае, когда размер набора данных значительно превышает доступный объем оперативной памяти. То, что данные хранятся в отсортированном виде, дает возможность эффективно выполнять запросы по диапазонам (просмотр всех ключей между установленными минимальным и максимальным значениями), а поскольку записи на диск осуществляются последовательно, LSM-дерево способно поддерживать весьма высокую пропускную способность по записи.
Типы данных в СУБД Access
При формировании полей в таблицах используются различные типы данных, от правильного выбора которых зависит корректность и эффективность ее работы
Если, например, речь идет об электронных текстовых данных, то важно заранее определиться с допустимым размером строк. Выделив слишком мало позиций для символов, можно не уместить какую-то строку
Другая крайность – выделение слишком большого количества места – стремительно раздувает объем базы данных. Использование динамически изменяемых по размеру полей повышает вычислительную нагрузку, снижая быстродействие.
Выбор подходящего формата для хранения числовых данных тоже имеет свои тонкости: поле для целых чисел не может хранить дробную часть, округление «математическое» и «банковское» имеют разные правила.
Представление дат и времени, выбор точки или запятой в качестве разделителя, возможность использования кириллицы в ссылках зависят от языковых и культурных настроек системы.
Основные типы данных СУБД Access, их описание и примеры использования приведены в таблице.
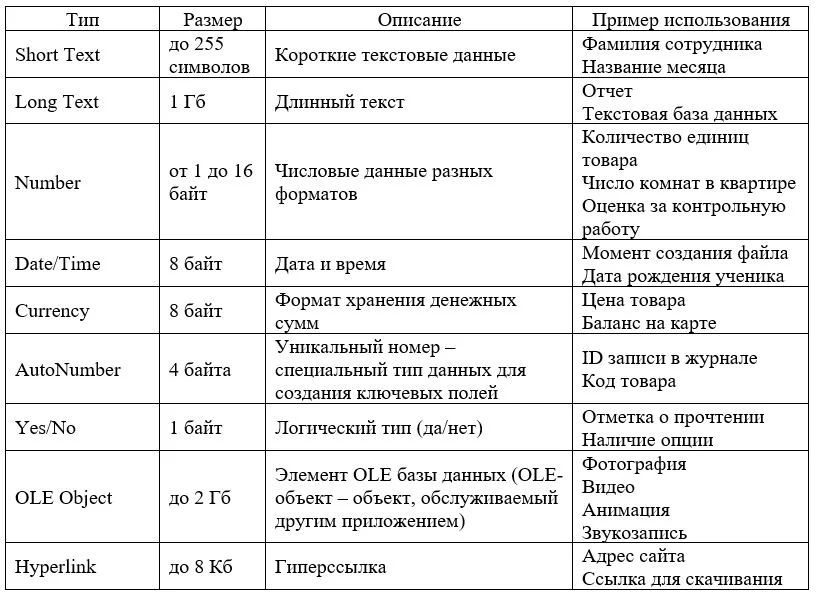
Для чего нужны СУБД
- Создание и хранение базы данных нужного типа — он зависит от того, к какому виду относится система.
- Управление базой — сюда относится создание новых записей, модификация существующих или удаление данных, которые уже не нужны.
- Получение нужных сведений из базы в удобной форме с помощью запросов, обычно на специальном языке SQL. Запросы фильтруют данные и выдают только нужную информациЮ, так как в базе могут быть миллионы записей. СУБД обязана поддерживать хотя бы один язык запросов.
- Администрирование и контроль доступа к базе данных, выдача разным пользователям различных прав и поддержка конфиденциальности сведений.
- Обеспечение безопасности и целостности данных, чтобы какая-либо проблема не привела к потере информации из базы.
- Защита от возможных атак и сбоев.
- Отслеживание изменений, резервное копирование и восстановление базы в случае падения.

Как работает СУБД
B-деревья
Наиболее широко используемая индексная структура — B-дерево. B-деревья очень хорошо выдержали испытание временем. Они остаются стандартной реализацией индексов практически во всех реляционных базах данных, да и многие нереляционные тоже их применяют.
Аналогично SS-таблицам B-деревья хранят пары «ключ — значение» в отсортированном по ключу виде, что позволяет эффективно выполнять поиск значения по ключу и запросы по диапазонам. Но на этом сходство заканчивается: конструктивные принципы B-деревьев совершенно другие.
Журналированные индексы, которые рассматривались ранее, разбивают базу данных на сегменты переменного размера и всегда записывают их на диск последовательно. В отличие от них, B-деревья разбивают БД на блоки или страницы фиксированного размера, обычно 4 Кбайт, и читают/записывают по одной странице за раз. Такая конструкция лучше подходит для нижележащего аппаратного обеспечения, поскольку диски тоже разбиваются на блоки фиксированного размера.
Все страницы имеют свой адрес/местоположение, благодаря чему одни страницы могут ссылаться на другие — аналогично указателям, но на диске, а не в памяти. Этими ссылками на страницы можно воспользоваться для создания дерева страниц, как показано на рис. 6.
Рис. 6 — Поиск ключа с помощью индекса на основе B-деревьев
Одна из страниц назначается корнем B-дерева, с него начинается любой поиск ключа в индексе. Данная страница содержит несколько ключей и ссылок на дочерние страницы. Каждая из них отвечает за непрерывный диапазон ключей, а ключи, располагающиеся между ссылками, указывают на расположение границ этих диапазонов.
В случае надобности добавить новый ключ следует найти страницу, в чей диапазон попадает новый ключ, и добавить его туда. Если на странице недостаточно места для него, то она разбивается на две полупустые страницы, а родительская страница обновляется, чтобы учесть это разбиение диапазона ключей на части.
Представленный алгоритм гарантирует, что дерево останется сбалансированным, то есть глубина B-дерева с n ключами будет равна O(log n). Большинству баз данных хватает деревьев глубиной три или четыре уровня, поэтому не придется проходить по множеству ссылок на страницы с целью найти нужную (четырехуровневое дерево страниц по 4 Кбайт с коэффициентом ветвления в 500 может хранить до 256 Тбайт информации).
При разбиении страницы из-за ее переполнения вследствие вставки необходимо записать две новые страницы, а также перезаписать их родительскую страницу для обновления ссылок на две дочерние страницы. Это опасная операция, ведь в случае фатального сбоя базы данных в тот момент, когда записана только часть страниц, индекс окажется поврежден.
Чтобы сделать БД отказоустойчивой, реализации B-деревьев обычно включают дополнительную структуру данных на диске: журнал упреждающей записи (writeahead log, WAL). Он представляет собой файл, предназначенный только для добавления, в который все модификации B-деревьев должны записываться еще до того, как применяться к самим страницам дерева. Когда база возвращается в норму после сбоя, этот журнал используется для восстановления B-дерева в согласованное состояние.
Пример использования базы данных в web-разработке
Использование базы данных в сфере веб-программирования необходимо только в некоторых случаях. Задайтесь вопросами:
- Какую информацию и зачем будете хранить?
- В каком виде и как планируете хранить эту информацию?
- Как и каким способом можно получить доступ к содержимому базы данных?
Только до25 декабря
Пройди опрос иполучи обновленный курс от Geekbrains
Дарим курс по digital-профессиям
и быстрому вхождения в IT-сферу
Чтобы получить подарок, заполните информацию в открывшемся окне
Перейти
Скачать файл
Рассмотрим сайт с ведением дневника. Здесь необходимо предусмотреть хотя бы один вид формы для заполнения с несколькими полями: дата, настроение, описание дня, главные мысли и так далее.
Пользователь будет каждый день записывать свои мысли в онлайн-дневник, значит должен иметь возможность вернуться к первым страницам через день или год. В этом случае разработчики должны предусмотреть, как и где будут сохраняться все эти данные, чтобы в любой момент можно было получить к ним доступ.
Это может быть краткий обзор по дням, либо что-то более сложное и изобретательное.
В отличие от своих бумажных аналогов, электронные варианты дневников могут иметь множество функций. Например, простого анализа: можно увидеть, какой день был самым веселым, самым грустным, в какой день было больше всего записей и так далее.
Для того чтобы не просто хранить данные и иметь доступ к ним, но и анализировать их, обрабатывать и делать определенные расчеты, были созданы базы данных.
Система хранения информации в базах данных
Структура база данных представлена тремя уровнями от большего к меньшему:
- база данных;
- таблица;
- запись.
База данных
База данных — это высокоуровневое понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Для большинства современных сайтов создаются отдельные базы данных, внутри которых будет храниться вся информация. Для нашего примера личного онлайн-дневника также понадобится определенная база данных.

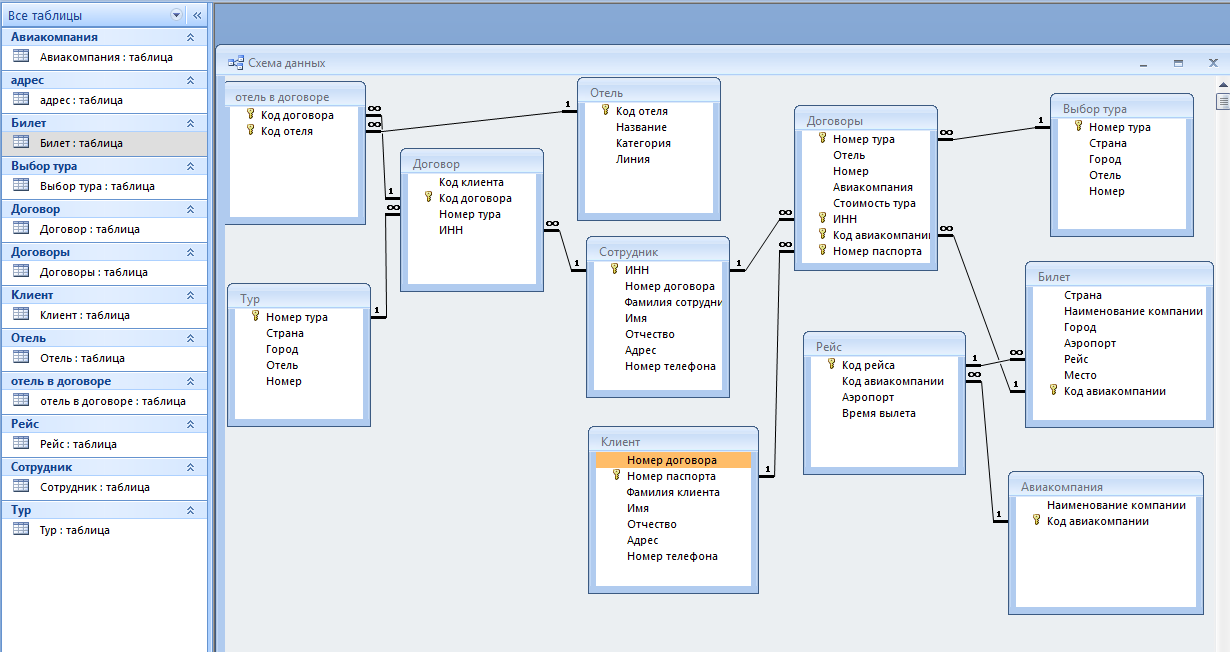

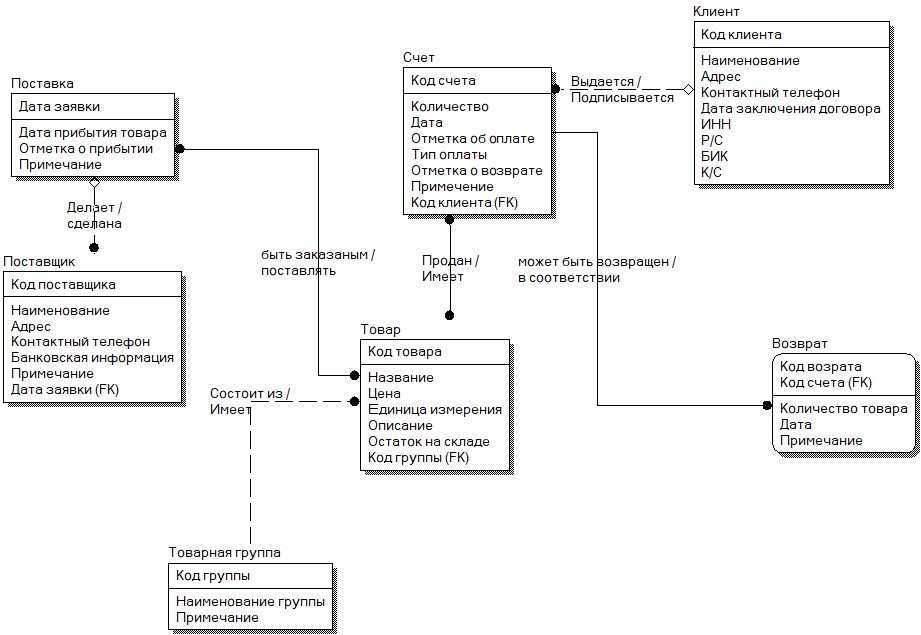

 Система хранения информации в базах данных
Система хранения информации в базах данных
Таблица
Таблица – часть базы данных. Это один из ее компонентов. В одной БД может храниться огромное количество таблиц.
Если представить, что большой шкаф – это база данных, то все, что лежит внутри, например, куча коробок – это таблицы.
Таблицы предназначены для укомплектовки одного типа информации, например, списка городов, пользователей сайта или библиотечного каталога.
Она может быть представлен в виде обычного Exсel-файла, или простого набора строк и столбцов.
ТОП-30 IT-профессий 2022 года с доходом от 200 000 ₽
Команда GeekBrains совместно с международными специалистами по развитию карьеры
подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности
и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились
с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:

Александр Сагун
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2022
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Получить подборку бесплатно
pdf 3,7mb
doc 1,7mb
Уже скачали 16914
Каждый из пользователей ПК уже умеет обращаться с такими файлами и представляет, как они выглядят. Вы самостоятельно можете определить количество строк и столбцов, заголовки и внести необходимую информацию для хранения.
Тот же процесс и в системе базы данных. При создании таблицы внутри системы, пользователь так же самостоятельно определяет ее вид и структуру.
Запись
Запись — меньший уровень из всей системы. Это часть таблицы, то есть ее содержимое. Запись нельзя разбить на части. Например, если пользователь заполняет электронную форму на сайте, то вся его информация уходит в базу данных как одна отдельная запись, которая занимает место в одной из таблиц. Запись может состоять из множества столбцов и их значений, который заранее определяются.
Попробуем рассмотреть, как бы выглядела база данных пользователей онлайн-дневника, приведенного в пример выше.
- Создадим для сайта новую базу данных и дадим ей название «private diary».
- Создадим в БД новую таблицу с именем «diary log» и определим там следующие столбцы:
- День недели (тип: текст);
- День (тип: дата);
- Номер записи (тип: число);
- Настроение (тип: число; от 0 (плохое) до 5 (отличное));
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу diary_log новую запись, и заполнять в ней все поля информацией из полей формы.
Благодаря этой базе данных все материалы, внесенные пользователями, сохраняться в неизменном виде и будут всегда в быстром доступе.
Суть базы данных
Все, что хранится в базе данных доступно для изменения и извлечения при необходимости.
Система базы данных представляет собой хранилище, куда приложение заносит полученную информацию. У небольших приложений она встроенная, но для сохранения объема памяти рекомендуется пользоваться отдельной.
 Суть базы данных
Суть базы данных
Все материалы в базе данных взаимодействуют определенным образом: за изменением одной строчки следуют изменения других данных. Это упрощает работу с большим объемом информации.
Но база данных требуется не для всего. Если у вас одностраничный сайт (лэндинг), который предназначен для рекламы и ознакомления с товаром или услугой, то создание базы данных вовсе не требуется.
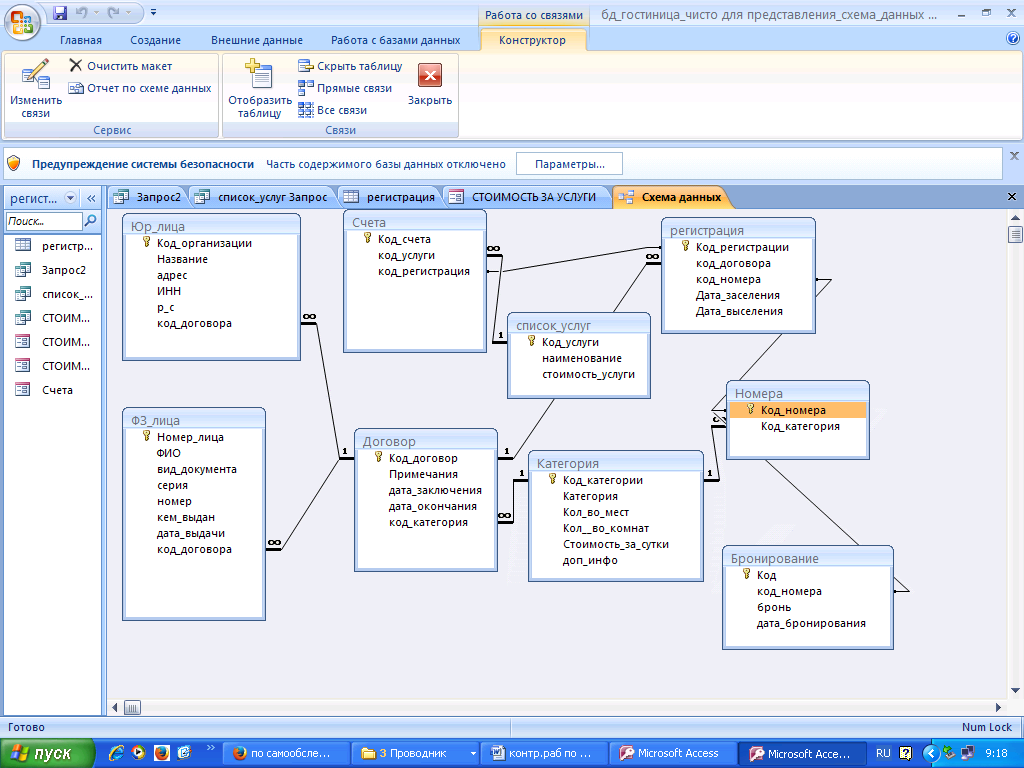
Пошаговая инструкция по созданию базы данных в Access
Существует два основных способа создания базы данных в Access: с использованием готового шаблона или вручную, «с нуля».
Примером создания базы данных с помощью шаблона может служить выбор одного из поставляемых вместе с программой Access шаблонов, доступных непосредственно из меню «создать».
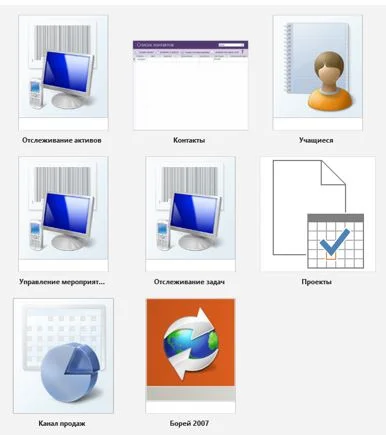
Рисунок 10 – Предустановленные шаблоны баз данных
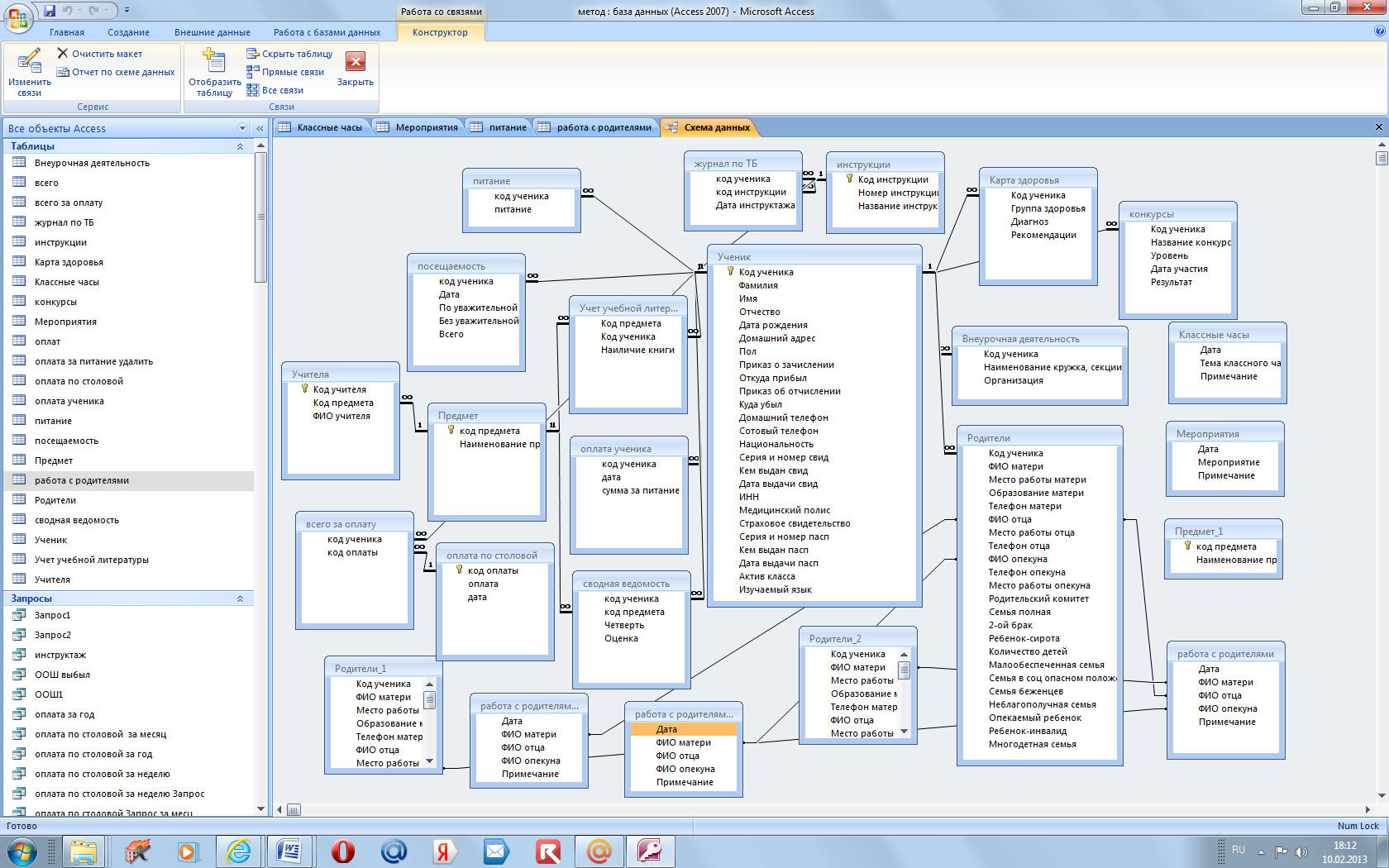
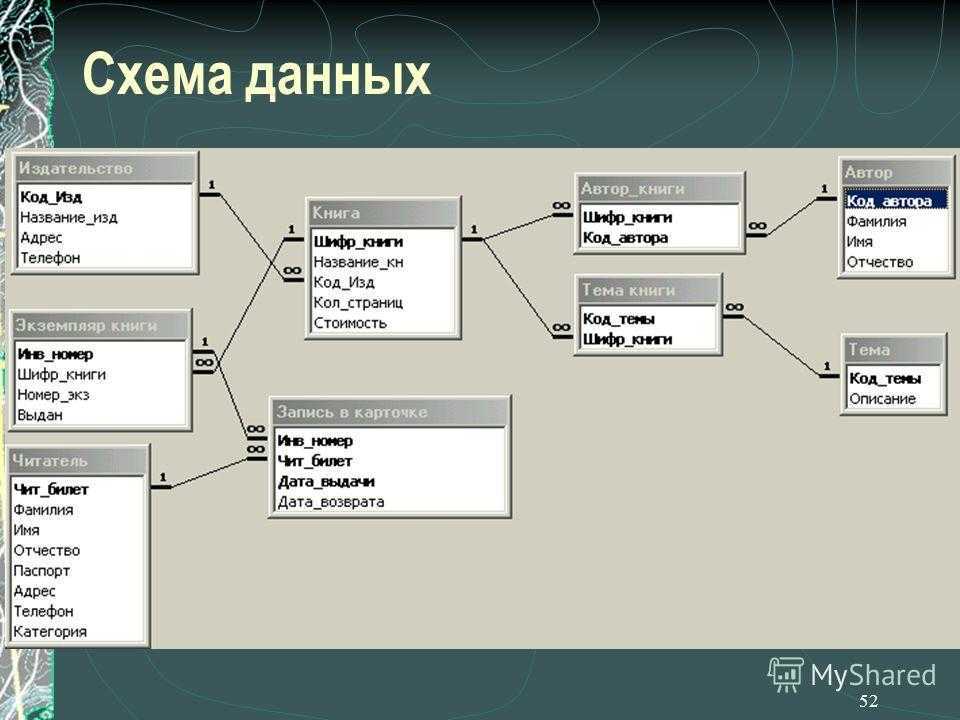
Выбрав один из предложенных шаблонов, мы получим простейшую базу, состоящую из одной-двух таблиц. Но это будут полноценные таблицы, с полями, ключами и связями. Например, схема данных для шаблона «учащиеся» выглядит так:
Рисунок 11 – Схема данных шаблонной базы «учащиеся»
Схема демонстрирует размещение в базе двух видов сущностей – «учащиеся» и «опекуны». Сущности эти связаны между собой по полю «учащийся» таблицы «опекуны», которое ссылается на ключ «ИД» таблицы «учащиеся». Тип связи «один ко многим».
Далее опишем порядок создания базы данных вручную, по шагам.
Обычно, первым шагом в разработке БД является создание сервера базы данных, но в нашем случае этого не требуется, так как Access, установленный в операционную систему, уже содержит в себе сервер файловых баз данных.
Шаг 1. Создание пустой базы
В меню «создать» выберите элемент «пустая база данных». Это инструментальное средство создания баз данных в виде заготовок с единственной пустой таблицей.
Рисунок 12 – Кнопка создания пустой базы
Укажите имя файла создаваемой базы и нажмите кнопку «создать»

Рисунок 13 – Окно ввода имени файла базы данных Access
Автоматически произойдет создание таблицы базы данных с названием «Таблица1», которую можно найти на вкладке «все объекты Access»
Рисунок 14 – Внешний вид вкладки «все объекты»
Шаг 2. Создание полей таблицы
В центральной части окна Access открыта активная таблица. Используя выпадающее меню «щелкните для добавления», добавьте поле с типом «Краткий текст».
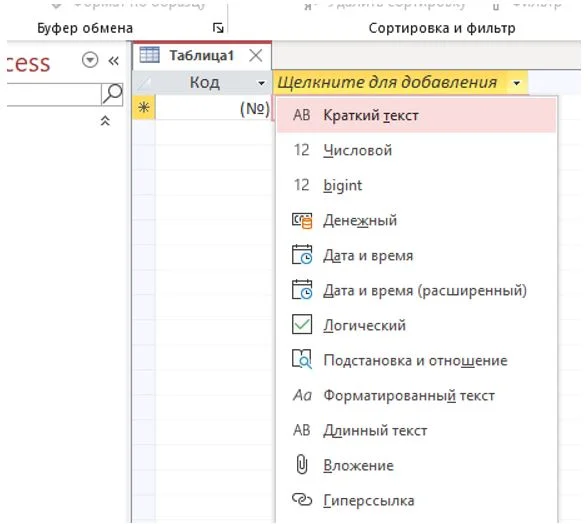
Рисунок 15 – Меню выбора типов данных
Вам будет предложено отредактировать название поля, введите «Фамилия» и нажмите «Enter».
Рисунок 16 – Редактирование имени поля
Аналогичным образом добавьте еще два поля: «Начало урока» с типом «дата и время» и «Оценка» с типом «числовой».
Шаг 3. Наполнение таблицы данными
Создание информационной базы данных не может считаться выполненным, пока эта база не содержит информации. Наполним данными нашу таблицу.
![Принципы построения и классификация баз данных [реферат №9366]](https://robotrackkursk.ru/wp-content/uploads/c/4/2/c42dbe661bfb9d85f237def2631a30bd.png)

Под созданными именами полей располагаются пустые строки – записи. Активная в данный момент запись отмечается цветным маркером.
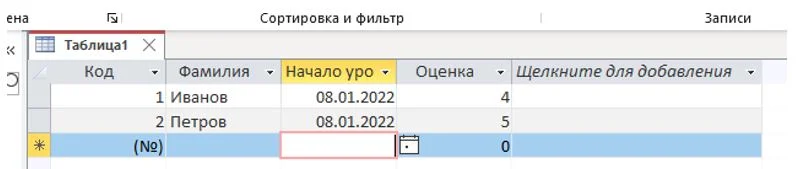
Рисунок 17 – Заполнение таблицы
Заполните их случайными данными о гипотетических учениках так, чтобы у некоторых была оценка «5»
Обратите внимание, что для указания даты можно использовать кнопку «календарь», а числовое поле не может оставаться пустым, в нем должен быть хотя бы ноль. После заполнения вернитесь на одну из первых записей и внесите изменения в любое поле
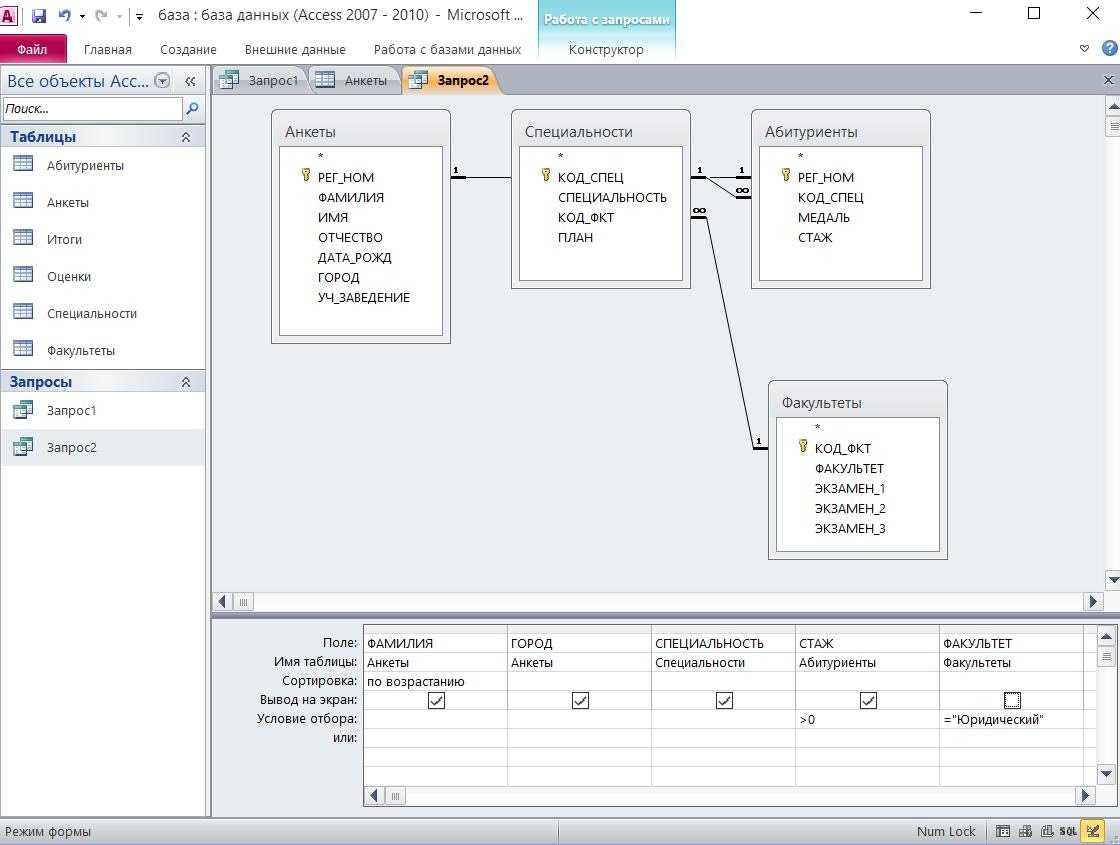
Шаг 4. Создание запроса пользователя к базе данных
Создайте запрос, результатом которого станет список учеников, получивших оценку «отлично». Для этого в меню «создание» выберите «конструктор запросов» и перетащите в появившуюся пустую область таблицу «Таблица 1»
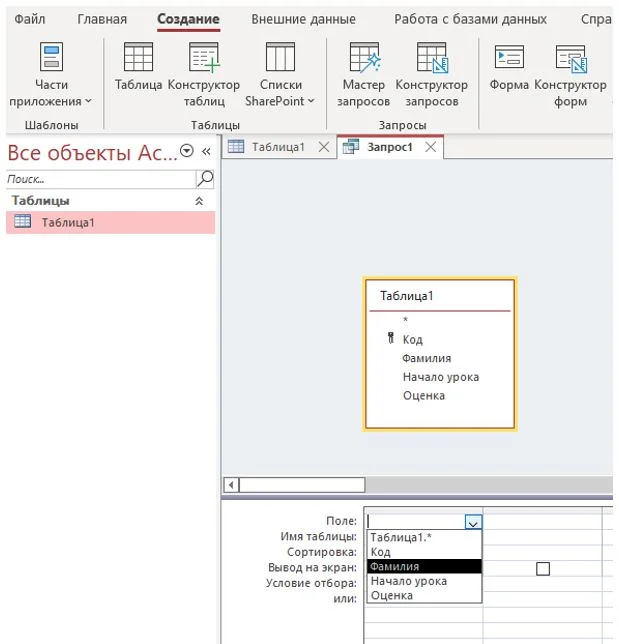
Рисунок 18 – Конструирование запроса
В нижней части окна в качестве первого поля укажите поле «Фамилия», в качестве второго – «Оценка». В столбце с оценкой укажите условие отбора «=5».
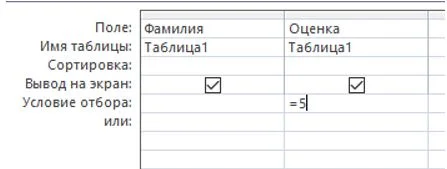
Рисунок 19 – Создание условия отбора
Запрос создан. Чтобы убедиться в корректности его работы, переключитесь в режим таблицы, нажав соответствующую кнопку в правом нижнем углу окна.
Рисунок 20 – Кнопки «режим таблицы», «режим SQL» и «конструктор»
Теперь вы видите не всю исходную таблицу, а только те поля, которые мы указали в запросе, причем записи взяты лишь содержащие оценку «отлично».
Рисунок 21 – Результат выполнения запроса
Если теперь вы выберете для запроса режим отображения «SQL», то увидите код запроса на том самом универсальном языке, который понятен всем базам данных.
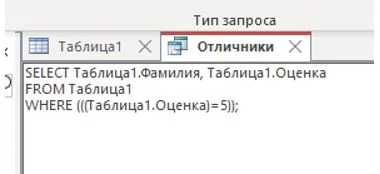
Рисунок 22 – SQL-код запроса
Сохраните запрос, нажав кнопку сохранения, расположенную в левом верхнем углу окна программы. При сохранении укажите название «Отличники».
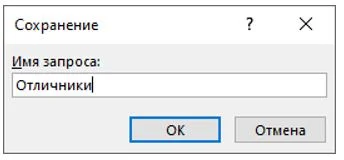
Рисунок 23 – Сохранение запроса
Шаг 5. Создание отчета
Теперь создадим отчет со списком отличников.
В меню «создание» выберите «мастер отчетов», на появившейся форме выберите запрос «Отличники», переместите оба поля в «выбранные поля» и нажмите кнопку «готово».
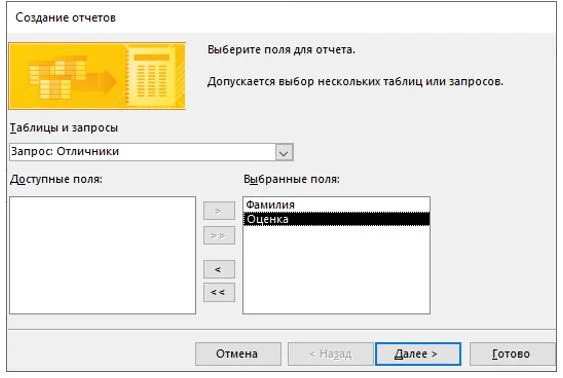
Рисунок 24 – Создание отчета
В результате должен появиться отчет, похожий на представленный на рисунке 25.
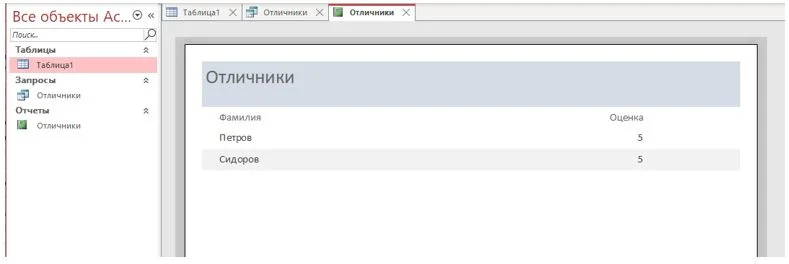
Рисунок 25 – Создание отчета
На этом процесс создания простейшей электронной базы данных завершен.
Обработка транзакций или аналитика?
«Транзакция» — это группа операций чтения и записи, составляющей логически единое целое. Транзакция не обязательно должна обладать свойствами ACID (Atomicity, Consistency, Isolation, Durability — атомарность, согласованность, изоляция и сохраняемость). Обработка транзакций означает просто возможность для клиентов выполнять операции чтения и записи с низким значением задержки — в противоположность заданиям пакетной обработки, запускаемым лишь периодически (например, один раз в день).
Приложение обычно ищет с помощью индекса небольшое количество записей по какому-либо ключу. На основе вводимых пользователем данных вставляются или обновляются записи. В силу интерактивности этих приложений такой паттерн доступа получил название «обработка транзакций в реальном времени» (online transaction processing, OLTP).
Однако БД все шире используются для аналитической обработки данных (data analytics), паттерны доступа которой совершенно другие. Обычно аналитический запрос должен просматривать огромное количество записей, вычисляя сводные статистические показатели (например, количество, сумму или среднее значение) вместо возврата пользователю необработанных данных.
Эти запросы чаще всего написаны бизнес-аналитиками и вставлены в отчеты, которые руководство компании использует для оптимизации коммерческих решений (бизнес-аналитика, business intelligence). Чтобы отличать этот паттерн применения БД от обработки транзакций, его назвали аналитической обработкой данных в реальном времени (online analytical processing, OLAP).
Рис. 7 — Сравнительные характеристики обработки транзакций и аналитических систем
Сначала как для обработки транзакций, так и для аналитических запросов использовались одни и те же базы данных. Язык SQL оказался в этом смысле весьма гибок: он работает при OLTP-запросах ничуть не хуже, чем при OLAP-запросах. Тем не менее в конце 1980-х — начале 1990-х годов возникла такая тенденция: компании прекращали задействовать OLTP-системы для целей аналитики и выполняли анализ на отдельных БД, которые назывались складами данных (data warehouse).
Возможности и виды СУБД
ТОП-30 IT-профессий 2022 года с доходом от 200 000 ₽
Команда GeekBrains совместно с международными специалистами по развитию карьеры
подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности
и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились
с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:
Александр Сагун
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2022
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Получить подборку бесплатно
pdf 3,7mb
doc 1,7mb
Уже скачали 16914
С помощью автоматизированной системы управления базами данных пользователь может проводить с БД различные действия: структурировать данные, вносить актуальную информацию или удалять лишнюю, настраивать фильтры, осуществлять поиск данных или выводить их на монитор и т.д.

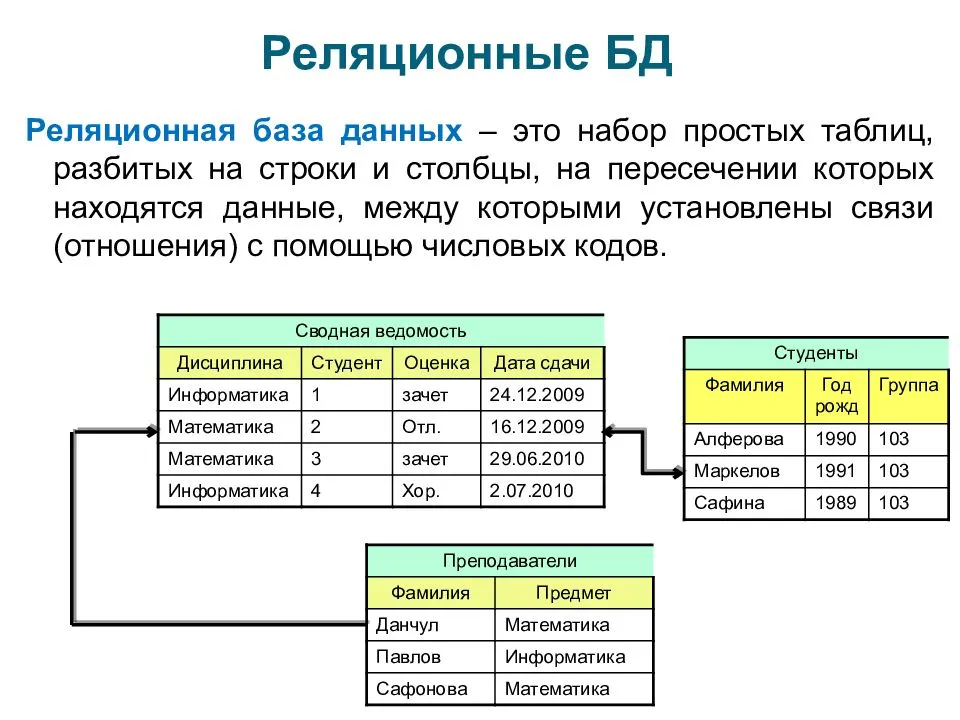
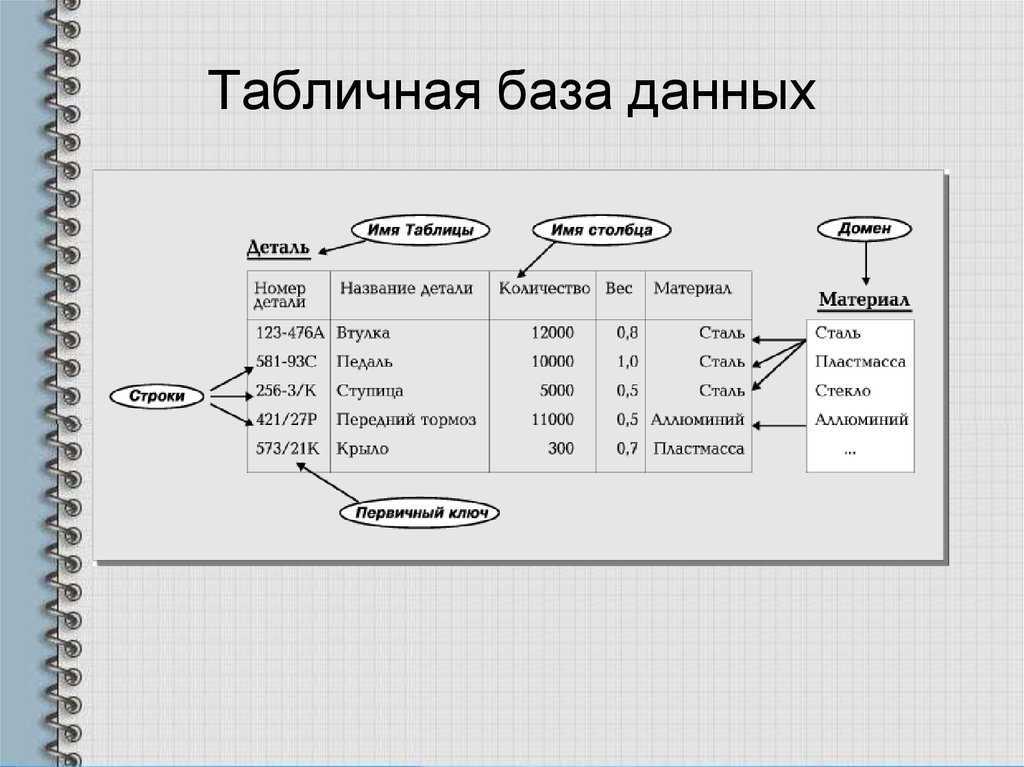
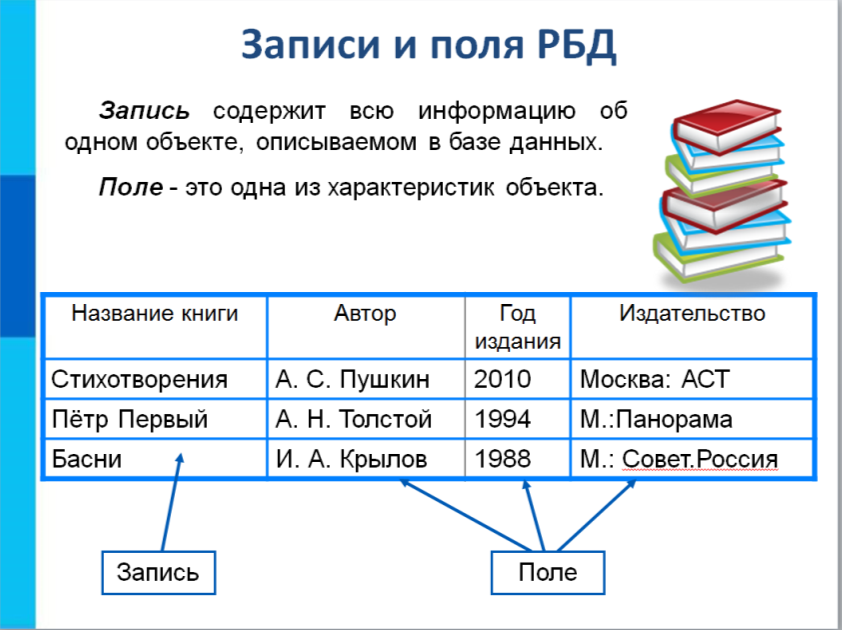
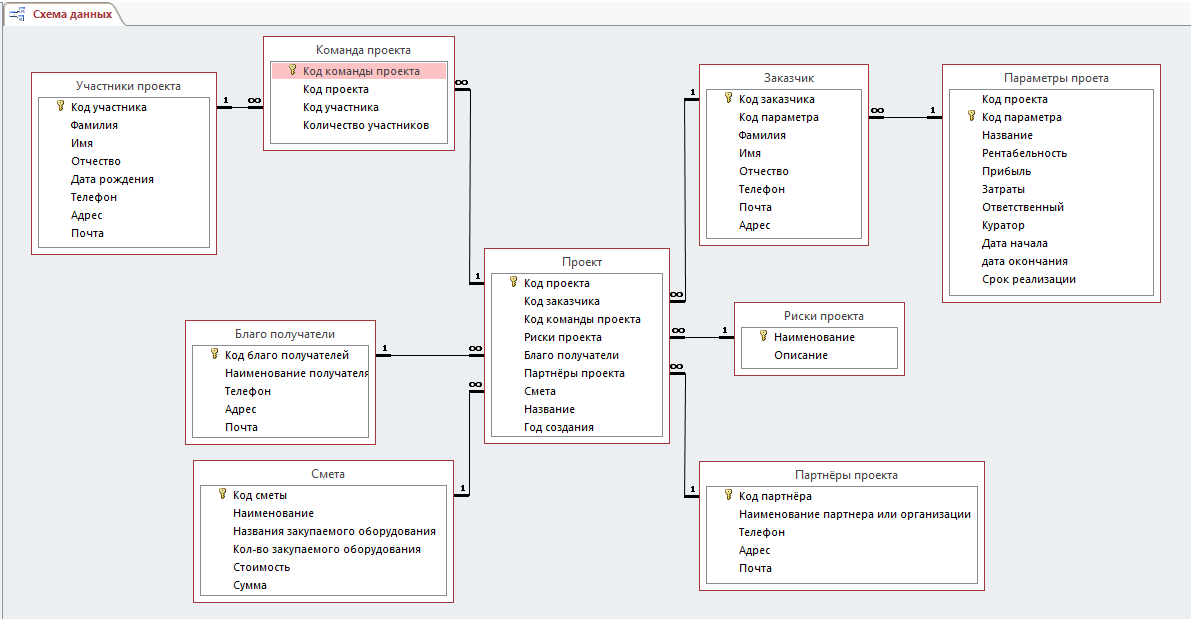
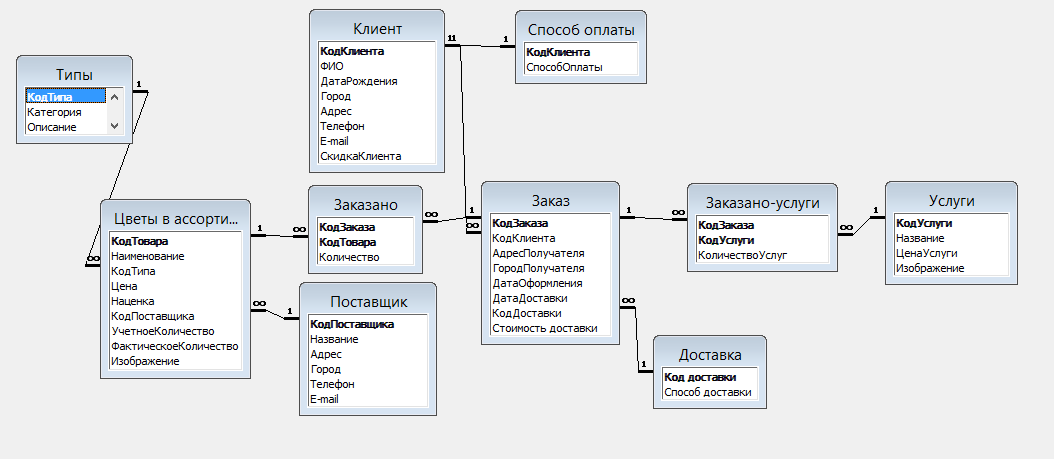
СУБД содержит в себе ряд элементов:
- ядро – позволяет управлять информацией во внешней и оперативной памяти, а также сохранять историю операций;
- процессор языка БД – генерирует исполняемый внутренний код и формирует запросы на извлечение и редактирование информации;
- подсистема поддержки времени исполнения – интерпретирует ПО для возможности действий с данными;
- вспомогательные программы – отвечают за дополнительные функции по работе с данными.
У СУБД имеется ряд назначений, которые способствуют комфортной работе пользователя, а также обеспечивают исправное функционирование БД.
 Возможности и виды СУБД
Возможности и виды СУБД
Основными назначениями СУБД являются:
- обеспечение корректной работы языков БД;
- регулирование рабочих процессов с данными во внешней памяти;
- регулирование рабочих процессов с данными в ОЗУ и сохранение дисковой памяти;
- сохранение редактирований, произведенных в БД;
- создание резервных копий и восстановление информации после сбоев.
Только до 26.12
Как за 3 часа разбираться в IT лучше, чем 90% новичков и выйти надоход в 200 000 ₽?
Приглашаем вас на бесплатный онлайн-интенсив «Путь в IT»! За несколько часов эксперты
GeekBrains разберутся, как устроена сфера информационных технологий, как в нее попасть и
развиваться.
Интенсив «Путь в IT» поможет:
- За 3 часа разбираться в IT лучше, чем 90% новичков.
- Понять, что действительно ждет IT-индустрию в ближайшие 10 лет.
- Узнать как по шагам c нуля выйти на доход в 200 000 ₽ в IT.
При регистрации вы получите в подарок:
«Колесо компетенций»
Тест, в котором вы оцениваете свои качества и узнаете, какая профессия в IT подходит именно вам
«Критические ошибки, которые могут разрушить карьеру»
Собрали 7 типичных ошибок, четвертую должен знать каждый!
Тест «Есть ли у вас синдром самозванца?»
Мини-тест из 11 вопросов поможет вам увидеть своего внутреннего критика
Хотите сделать первый шаг и погрузиться в мир информационных технологий? Регистрируйтесь и
смотрите интенсив:
Только до 26 декабря
Получить подборку бесплатно
pdf 4,8mb
doc 688kb
Осталось 17 мест
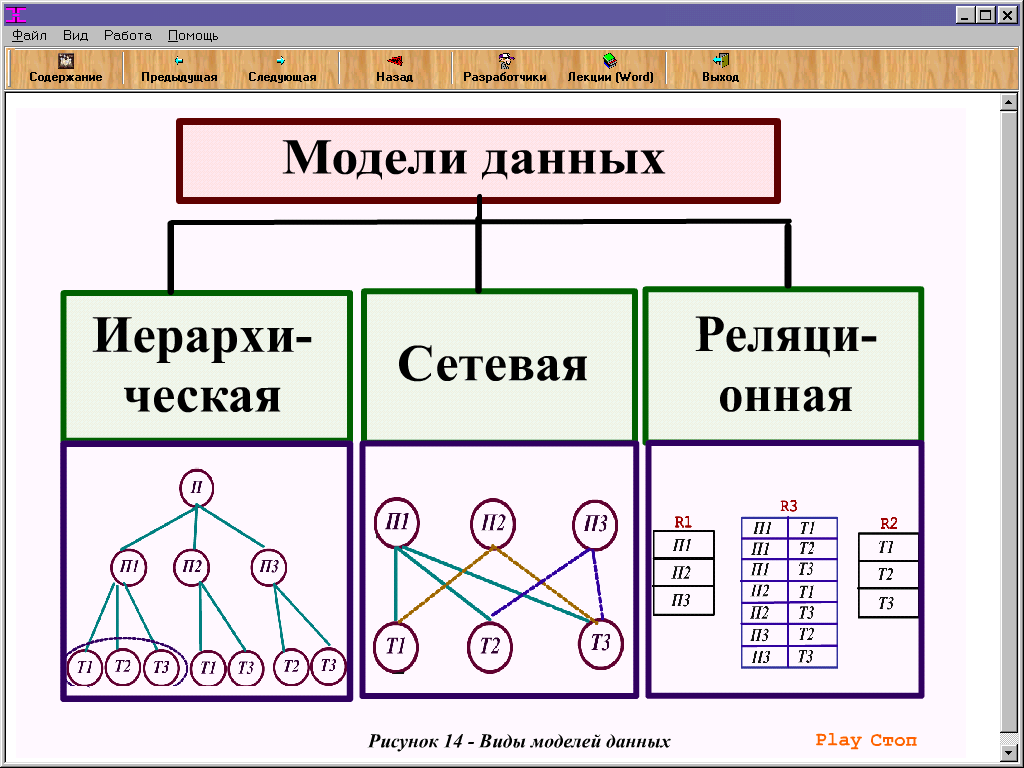
СУБД принято классифицировать по принципу совокупности структур данных, т.е. по модели данных, с которой работает СУБД:
- Иерархическая. Структура БД – древовидная, т.е. имеет иерархию из объектов разного уровня.
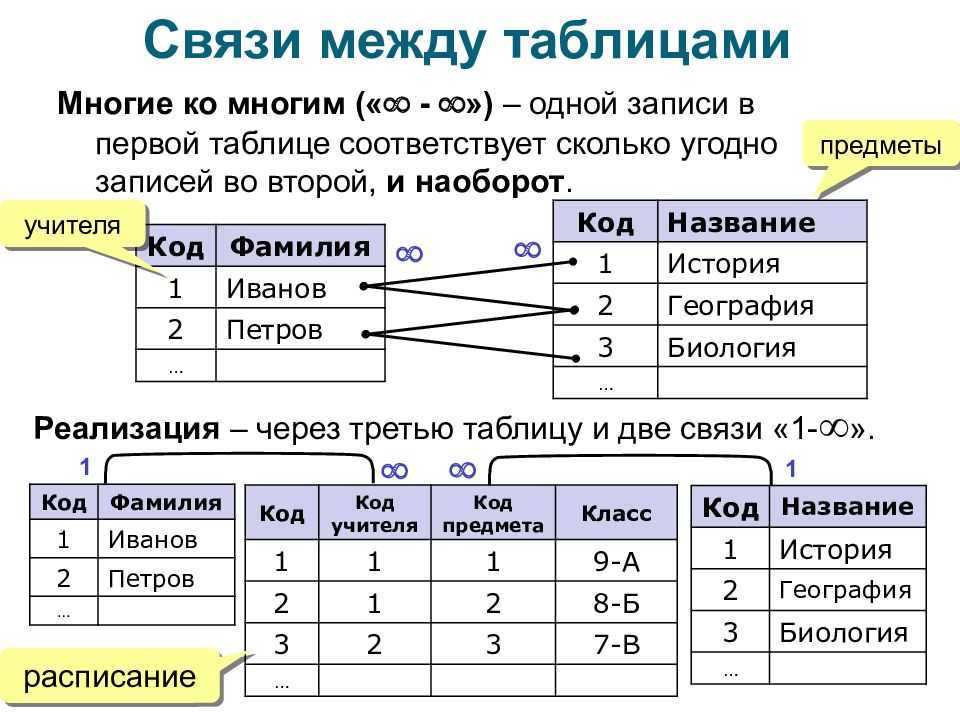
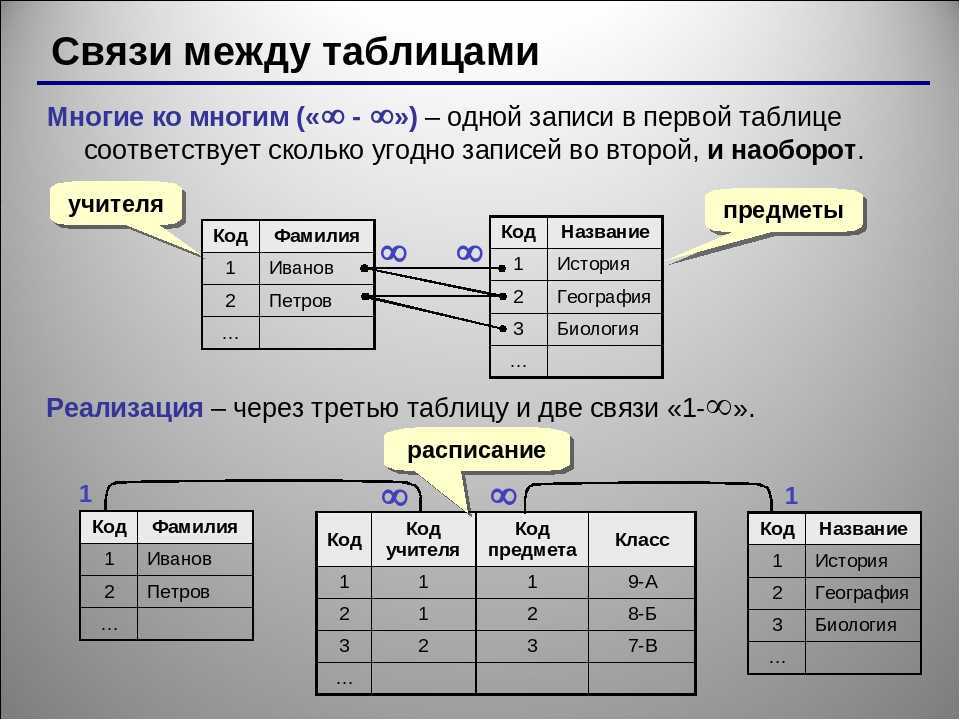
- Сетевая. По сути, это более расширенная иерархическая структура, но она придерживается принципа отношения данных «многие ко многим».
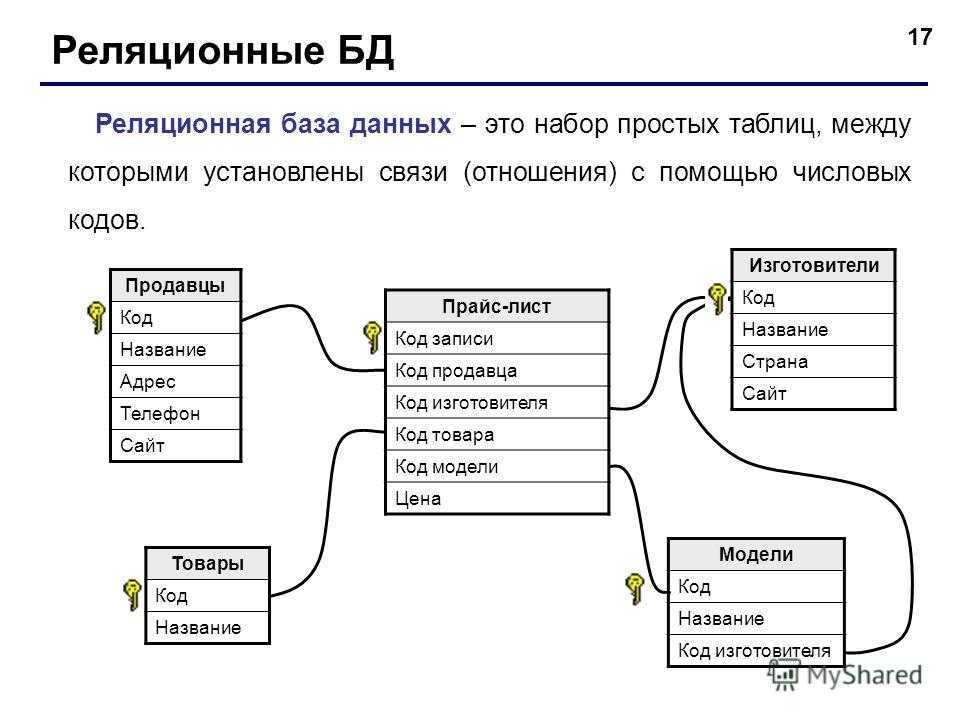
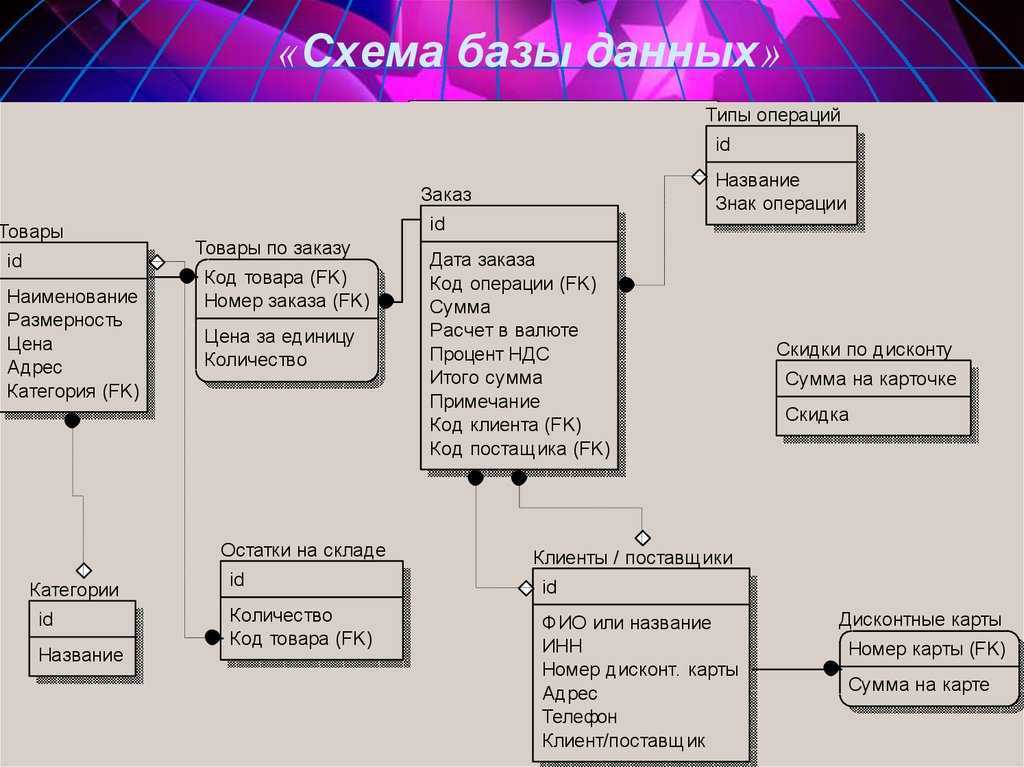
- Реляционная. Данные представлены в виде простых таблиц из столбцов и строк.
- Объектно-ориентированная. Такая СУБД управляет БД, в которых информация моделируется как объекты, методы и классы.
- Объектно-реляционная. Это реляционная СУБД, которая поддерживает некоторые технологии объектно-ориентированной СУБД.
Для того чтобы лучше понимать принцип работы той или иной автоматизированной системы управления базами данных, рассмотрим наиболее распространенные из них.
![[клякс@.net][информатика и икт в школе. компьютер на уроках.][[экзамен по информатике][билет №22]]](http://robotrackkursk.ru/wp-content/uploads/1/5/9/1594adaf3d8b758f87d9a5d258b06417.jpeg)


