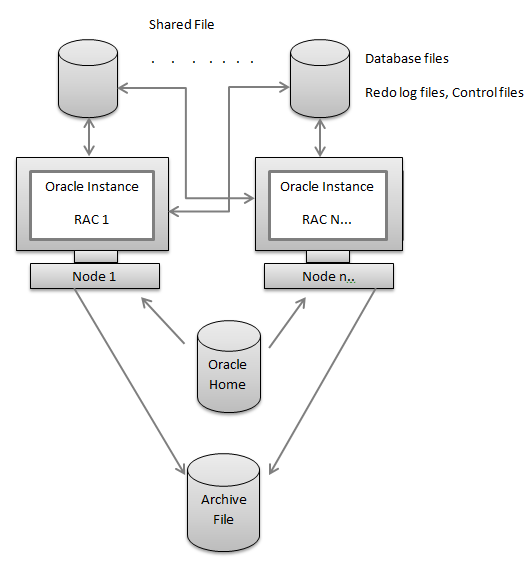
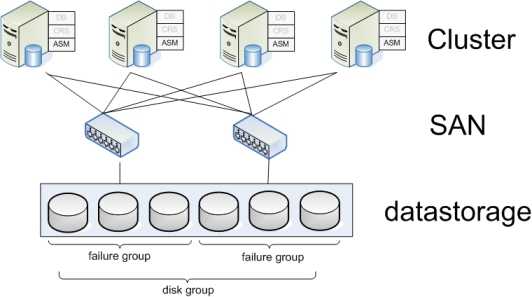
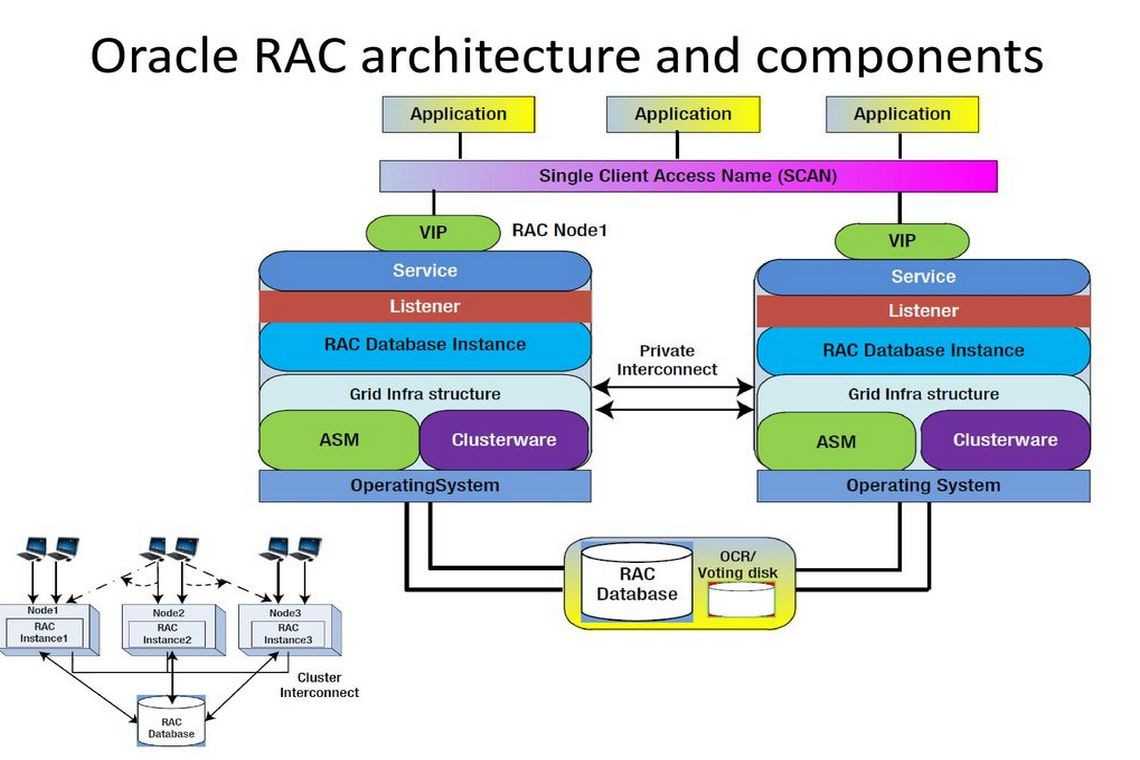
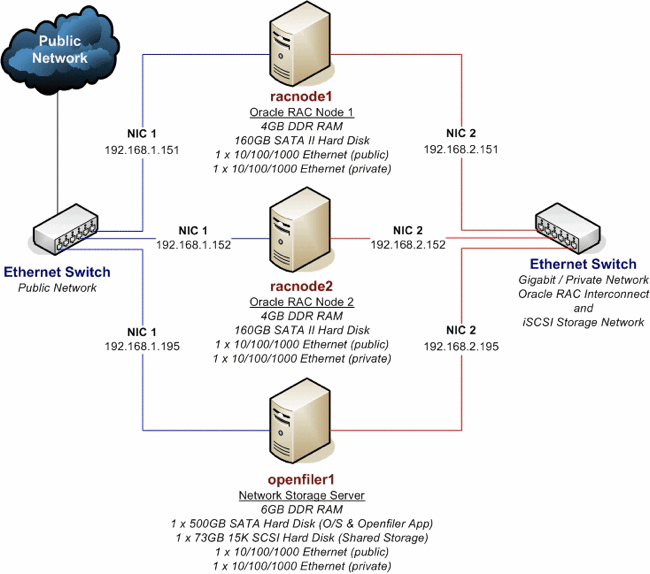
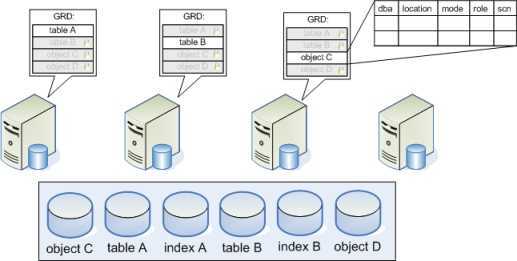
2.3. Реляционная модель, как платформа для разработки современных информационных систем на примере интерактивной системы патентного обеспечения технологического проектирования.
И так мы расссмотрели различные подходы к внутренней организации баз данных. И в результате пришли к выводу о необходимости использования реляционной модели, так как она решает одну из основных проблем — внесения изменений в базу данных в процессе ее использования. Ведь в реляционной безе данных проблемы синхронизации данных не возникает вовсе, так как данные хранятся в одном экземпляре. Для большей ясности этого вопроса приведем отличия традиционных и реляционных баз данных.
|
Выполняемая операция |
Традиционные базы данных |
Реляционные базы данных |
|
Разработка приложений |
Необходимо определить, какая информация требуется различным приложениям и создать ряд общих файлов. |
Необходимо определить виды хранимых данных и взаимосвязи между ними |
|
Реализация приложений |
Поступающие данные записываются в основные файлы; в каждую информационную ячейку каждого основного файла записывается один элемент данных. |
Различные виды данных записываются в таблицы данных, соответствующие этим видам. В результате каждый элемент информации хранится в одном единственном месте |
|
Модификация приложений |
Требуется пересмотр структуры базы данных с последующей перезаписью основных файлов, которые затронуты вносимыми изменениями, и с переработкой всех приложений, использующих эти файлы |
Достаточно найти и модифицировать таблицу, в которой должно содержаться определение нового вида данных Сами данные хранятся в других таблицах, не затрагиваемых при подобных изменениях. |
|
Внесение частичных изменений в данные |
Необходимо прочитать каждый основной файл с начала до конца, модифицируя изменяемые ячейки данных и оставляя все остальные прочитанные ячейки без изменений. |
В соответствующих таблицах достаточно выделить множество строк, в которые необходимо внести изменения, и произвести эти изменения с помощью одного SQL- оператора. |
Итак, основные черты реляционных баз данных:
- Структура реляционной базы данных определяется хранящимися в них данными и не фиксируется в момент завершения разработки (т.е. является гибкой и масштабируемой).
- Структурам данных можно давать весьма информативные названия.
- Данные хранятся в единственном экземпляре; все опции чтения и модификации данных производятся только с этим экземпляром данных, что качественно облегчает синхронизацию данных между многими приложениями и пользователями.
- Данные хранятся в соответствии с четко определенными и строго соблюдаемыми правилами.
Назад |
|
Вперед
Публикации, цитирующие эту работу
Главная
СУРБД Оракл :
Ошибки ORA- |
Реплицирование в Оракл |
Практический опыт DBA Oracle
На правах рекламы (см.
условия):
|
Алфавитный перечень страниц (Alt-Shift-): А | 0-9 | |
|
|
На русском языке: асинхронная репликация реляционных баз данных Оракл, распределенная БД Oracle в гетерогенных средах, На английском языке: advanced asynchronous replication, Multimaster, master-site, snapshot, Oracle database tuning, PL/SQL-optimization. |
«Сайт Игоря Гаршина», 2002, 2005.
Автор и владелец — Игорь Константинович Гаршин
(см. резюме).

Пишите письма
().
Страница обновлена 10.11.2020
Файлы книги об асинхронной репликации гетерогенной БД Oracle
Если есть желание проделать весь опыт с новой версией Oracle и проиллюстрировать
(у меня есть тьма иллюстраций, но не в Word в таком большом документе они не отображаются) — приглашаю быть соавтором.
Также буду благодарен, если найдется издатель.
Книга, хоть и зарегистрирована со всеми ISBN, УДК и ББК, но из-за отсутствия средств в то время издана не была.
Впрочем, одна фирма ее издала для своих сотрудников. ![]()
Контакты для заинтересованных издателей:
garchine@mail.ru
- Лицевая обложка (JPG, 800×600)
- Задняя обложка (Word, без иллюстраций)
- Текст (Zip, без иллюстраций) с лицевой и задней обложками
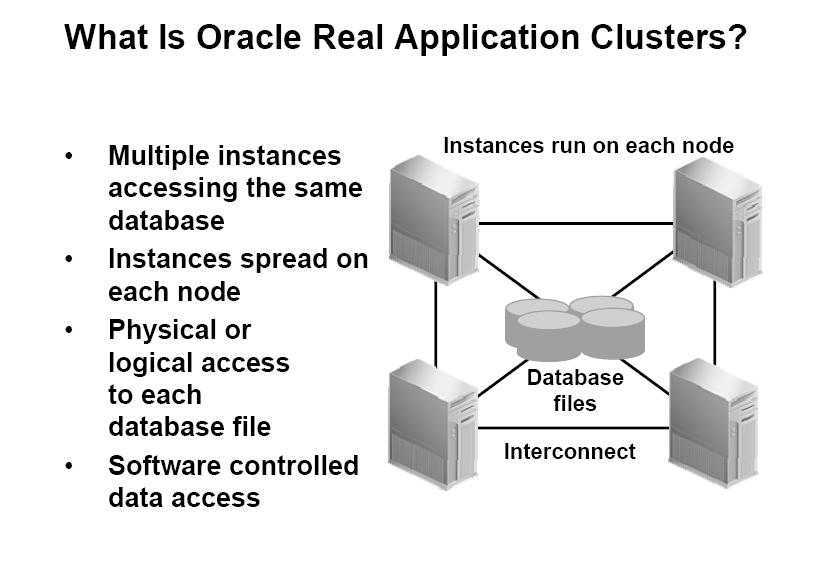
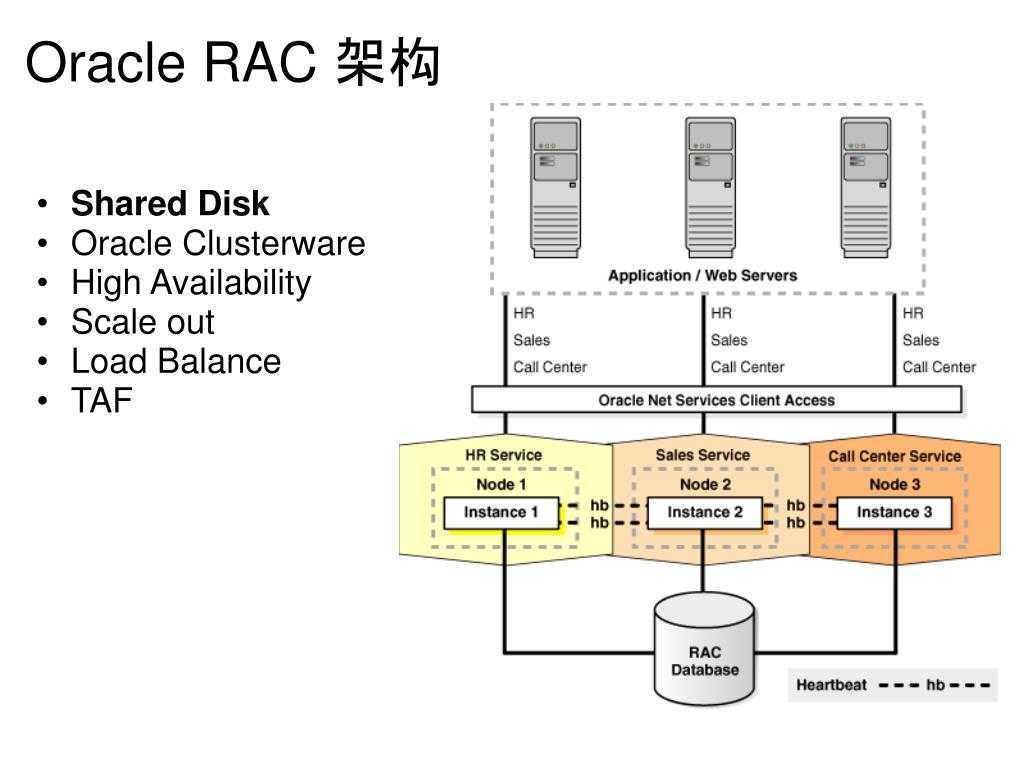
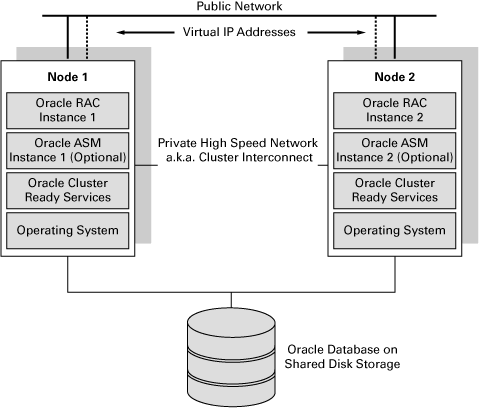
Clusterware. CRS.
CRSCluster-Ready Services
- CSSD – Cluster Synchronization Service Daemon
- CRSD – Cluster Ready Services Daemon
- EVMD – Event Monitor Daemon
| x | Назначение (вкратце) | С какими правами работает | При смерти процесса, перезагружается: |
| CSSD | Механизм синхронизации для взаимодействия узлов в кластерной среде. | user | процесс |
| CRSD | Основной «движок» для поддержки доступности ресурсов | root | хост |
| EVMD | Процесс оповещения о событиях, происходящих в кластере | user | процесс |
OCROracle Cluster RegistryCRSDCluster Ready Services DaemonCSSDCluster Synchronization Service Daemon
- Node Membership (NM).Каждую секунду проверяет heartbeat между узлами. NM также показывает остальным узлам, что он имеет доступ к так называемому voting disk (если их несколько, то хотя бы к большинству), делая регулярно туда записи. Если узел не отвечает на heartbeat или не оставляет запись на voting disk в течение нескольких секунд (10 для Linux, 12 для Solaris), то master узел исключает его из кластера.
- Group Membership (GM). Функция отвечает за своевременное оповещение при добавлении / удалении / выпадении узла из кластера, для последующей реконфигурации кластера.
EVMDEvent Manager DaemonВедущим (master) узлом становится первый запустившийся узелCluster InterconnectIPCInterprocess CommunicationInfiniBandПродолжение статьи
2.3.2.2 Типы обрабатываемых данных
Типы данных обрабатываемых СУБД Oracle представлены в таблице.
Таблица 2. Типы обрабатываемых данных.
| Тип данных | Описание |
| СНАR(size) | Символьная строка фиксированной длины, имеющая максимальную длину size символов. Длина по умолчанию 1, максимальная -255. |
| СНАRАСТЕR(size) | То же, что и CHAR. |
| DATE | Правильные даты в интервале от 1 января 4712 года до н.э. до 31 декабря 4712 года. |
| LONG | Символьные данные переменной длины до 2 Гигабайт. |
| LONG RAW | Двоичные данные переменной длины вплоть до 2 Гигабайт или 231-1. |
| MLSLABEL | Используется в Trusted ORACLE. |
| NUMBER(p,s) | Число, имеющее p значащих цифр и масштаб s. р может быть от 1 до 38. s может принимать значения от -84 до 127. |
| RAW(size) | Двоичные данные длиной size байт. Максимальное значение для size — 2000 байт. Параметр те для RAW обязателен. |
| RAW MLSLABEL | Используется в Trusted ORACLE. |
| ROWID | Значения псевдостолбца ROWID. |
| VARCHAR2(size) | Символьная строка переменной длины, имеющая максимальную длину size символов. Длина по умолчанию 1, максимальная — 2000. |
| VARCHAR(size) | То же что и VARCHAR2. |
Извлекать данные можно также и из псевдостолбцов (табл.3), которые похожи на столбцы таблиц, но их значения нельзя изменять при помощи операторов DML.
Таблица 3. Псевдостолбцы.
| Название столбца | Возвращаемое значение |
| sequence.CURRVAL | Текущее значение sequence в данном сеансе (sequence.NEXTVAL должен быть выбран). |
| sequence.NEXTVAL | Следующее значение sequence в текущем сеансе. |
| LEVEL | 1 — для корня дерева, 2 — для узлов второго уровня и так далее. Используется в операторе SELECT в иерархических запросах. |
| ROWID | Значение, которое идентифицируют строку в таблице table уникальным образом. Значения псевдостолбца ROWID имеют тип данных ROWID, а не NUMBER и не CHAR. |
| ROWNUM | Порядковый номер строки среди других строк, выбираемых запросом. ORACLE выбирает строки в произвольном порядке и приписывает значения ROWNUM, прежде чем строки будут отсортированы предложением ORDER BY. |
Требования к именам объектов базы данных
- должны иметь длину от 1 до 30 бант, за исключением имен баз данных, длина которых ограничена 8 байтами;
- не могут содержать кавычек;
- не могут совпадать с именами других объектов.
Имена, которые всегда заключены в двойные кавычки, могут нарушать, приведенные ниже правила. В противном случае, имена
- должны начинаться с букв A-Z;
- могут содержать только символы A-Z, 0-9, _, $ и #;
- не могут дублировать зарезервированные слова SQL.
Различие между прописными и строчными буквами учитывается только в именах, заключенных о двойные кавычки.
Операции и их приоритеты
|
Арифметические операции |
Символьные операции |
Логические операции |
Операции сравнения |
|
+ — (один операнд) |
| | |
NOT |
= |
|
* / |
AND |
!= ^= ~= <> |
|
|
+ — (два операнда) |
OR |
> >= < <= |
|
|
IN |
|||
|
NOT IN |
|||
|
ANY, SOME |
|||
|
ALL |
Назад |
|
Вперед
2.1.1.2 Сетевая модель.
Сети — естественный способ представления отношений между объектами. Они широко применяются в математике, исследованиях операций, химии, физике, социологии и других областях знаний. Сети обычно могут быть представлены математической структурой, которая называется направленным графом. Направленный граф имеет простую структуру. Он состоит из точек или узлов,соединенных стрелками или ребрами. В контексте моделей данных узлы можно представлять как типы записей данных, а ребра представляют отношения один-к -одному или один-ко-многим. Структура графа делает возможными простые представления иерархических отношений (таких, как генеалогические данные) .
Сетевая модель данных — это представление данных сетевыми структурами типов записей и связанных отношениями мощности один-к-одному или один-ко-многим. В конце 60-х конференция по языкам систем данных (Conference on Data Systems Languages, CODASYL) поручила подгруппе, названной Database Task Group (DTBG), разработать стандарты систем управления базами данных. На DTBG оказывала сильное влияние архитектура, использованная в одной из самых первых СУБД, Iategrated Data Store (IDS), созданной ранее компанией General Electric.Это привело к тому, что была рекомендована сетевая модель.
Документы Database Task Group (DTBG) (группа для разработки стандартов систем управления базами данных) от 1971 года остается основной формулировкой сетевой модели, на него ссылаются как на модель CODASYL DTBG. Она послужила основой для разработки сетевых систем управления базами данных нескольких производителей. IDS (Honeywell) и IDMS (Computer Associates) — две наиболее известных коммерческих реализации. В сетевой модели существует две основные структуры данных: типы записей и наборы:
- Тип записей. Совокупность логически связанных элементов данных.
- Набор. В модели DTBG отношение один-ко-многим между двумя типами записей.
- Простая сеть. Структура данных, в которой все бинарные отношения имеют мощность один-ко-многим.
- Сложная сеть. Структура данных, в которой одно или несколько бинарных отношений имеют мощность многие-ко-многим.
- Тип записи связи. Формальная запись, созданная для того, чтобы преобразовать сложную сеть в эквивалентную ей простую сеть.
В модели DBTG возможны только простые сети, в которых все отношения имеют мощность один-к-одному или один-ко-многим. Сложные сети, включающие одно или несколько отношений многие-ко-многим, не могут быть напрямую реализованы в модели DBTG. Следствием возможности создания искусственных формальных записей является необходимость дополнительного объема памяти и обработки, однако при этом модель данных имеет простую сетевую форму и удовлетворяет требованиям DBTG.
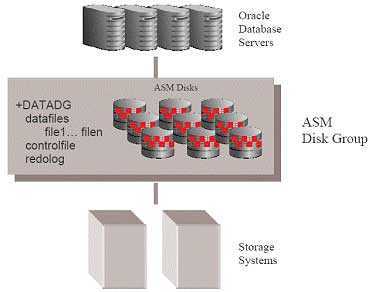
Уровень доступа к данным. ASM.
datastorageSANStorage Area NetworkASMAutomatic Storage Management
- отсутствие необходимости в отдельном ПО для управления разделами дисков
- нет необходимости в файловой системе
Disk group
- Зеркалирование данных:
как правило, 2-х или 3-х ступенчатое, т.е. данные одновременно записываются на 2 или 3 диска. Для зеркалирования диску указываются не более 8 дисков-партнеров, на которые будут распределяться копии данных. - Автоматическая балансировка нагрузки на диски (обеспечение высокой доступности):
если данные tablespace разместить на 10 дисках и, в некоторый момент времени, чтение данных из определенных дисков будет «зашкаливать», ASM сам обратится к таким же экстентам, но находящимся на зеркалированных дисках. - Автоматическая ребалансировка:
При удалении диска, ASM на лету продублирует экстенты, которые он содержал, на другие оставшиеся в группе диски. При добавлении в группу диска, переместит экстенты в группе так, что на каждом диске окажется приблизительно равное число экстентов.
Failure GroupsSPFSingle Point of Failure