ВВЕДЕНИЕ
Для мультипроцессорных систем используют модульный принцип построения, позволяющий наращивать их структуру, решать проблемы надежности, а также снижать стоимость производства.
Под модулем понимают любое функциональное устройство вычислительной системы с собственным управлением, способное функционировать самостоятельно под воздействием команд процессора. Наличие однотипных модулей в вычислительных системах дает возможность переключать потоки информации при обнаружении неисправностей в модулях. В результате этого система изменяет параметры, но сохраняет работоспособность. Так модульность аппаратных средств повышает • живучесть» вычислительной системы.
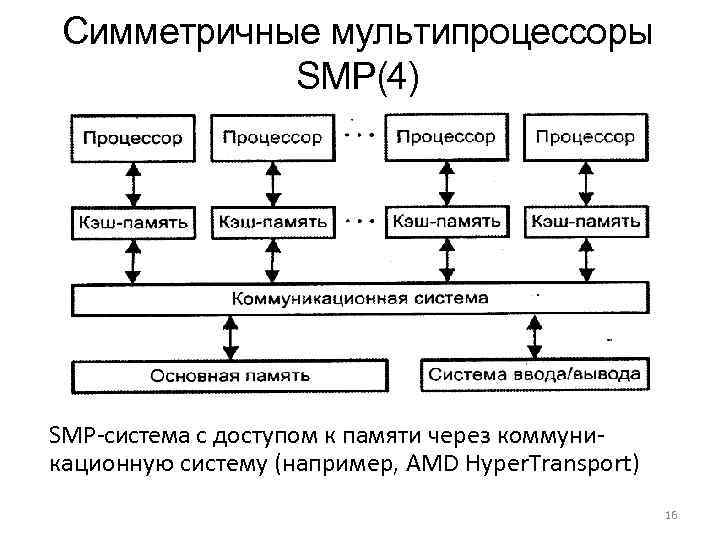
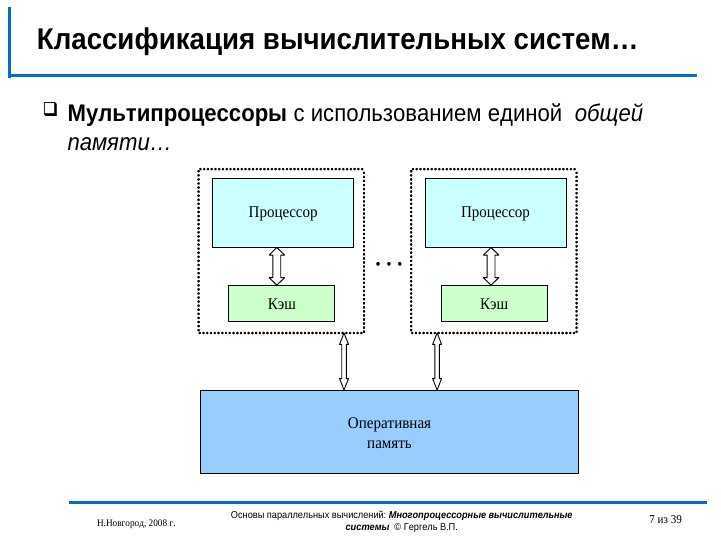
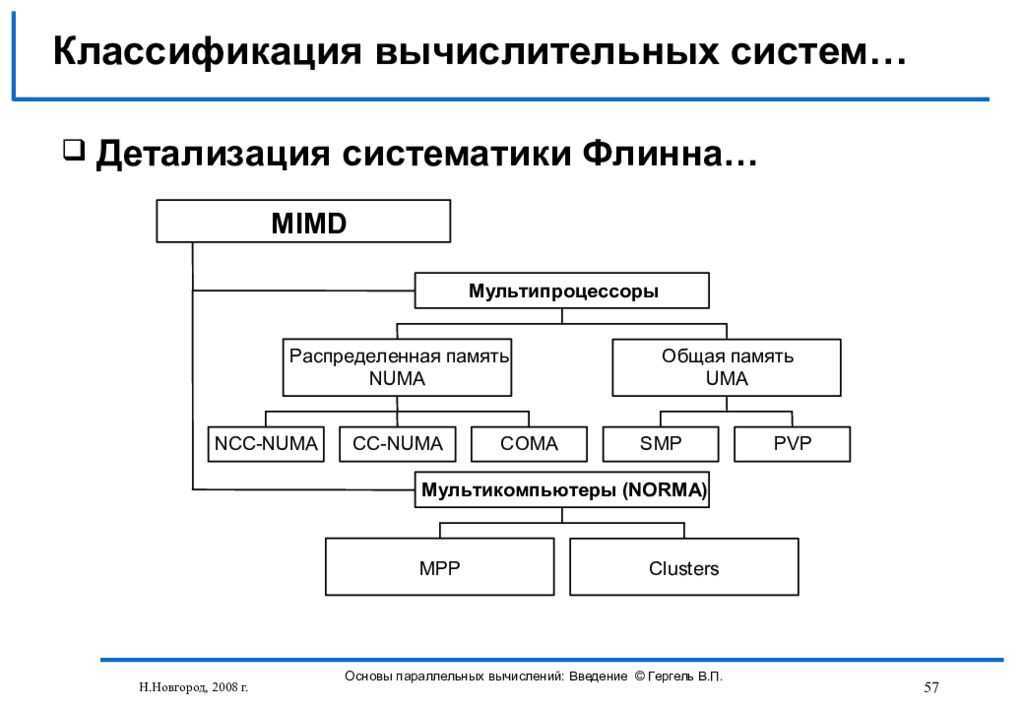
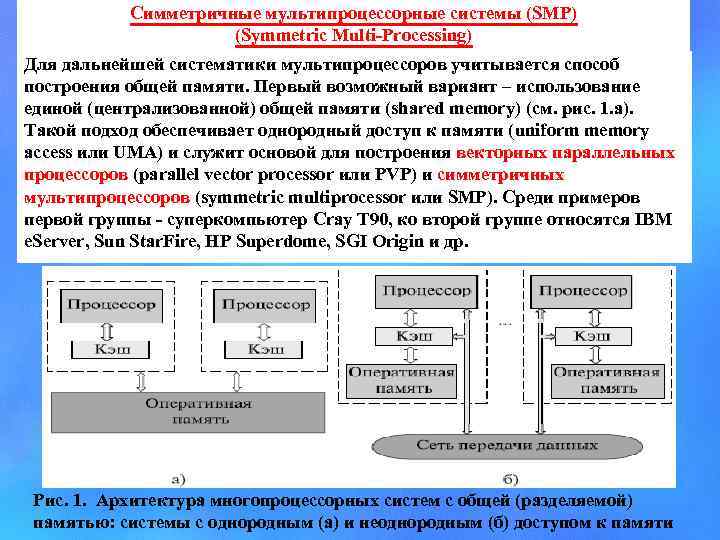
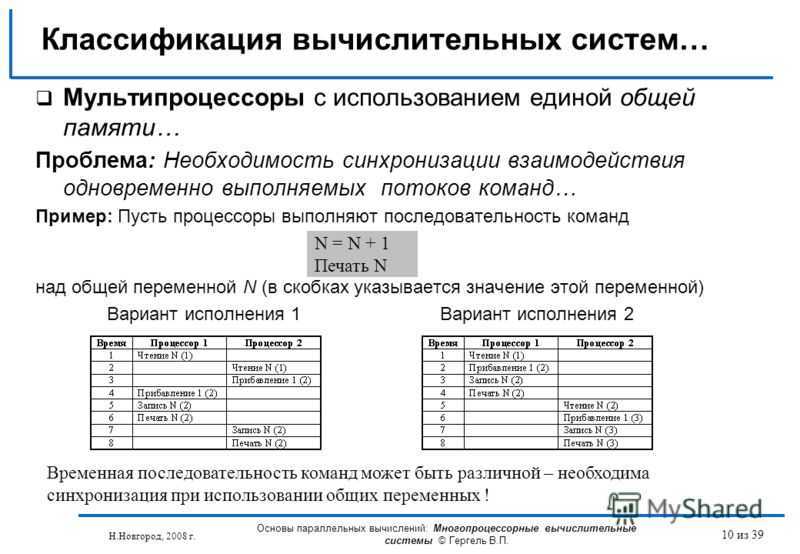
Мультипроцессор — это подкласс многопроцессорных компьютерных систем, где есть несколько процессоров и одно адресное пространство, видимое для всех процессоров. В таксономии Флинна мультипроцессоры относятся к классу SM-MIMD-машин. Мультипроцессор запускает одну копию ОС с одним набором таблиц, в том числе тех, которые следят какие страницы памяти свободны. По ролям, которые играют процессоры в мультипроцессорной системе, различают: симметричные мультипроцессоры (SMP) — все процессоры играют одинаковую роль и имеют одинаковый доступ к памяти и периферии, и асимметричные мультипроцессоры (AMP) — процессоры играют разные роли или по-разному обращаются к периферийным устройствам. Технология AMP была лишь переходной в 60-х годах до того момента, когда была отработана технология SMP.
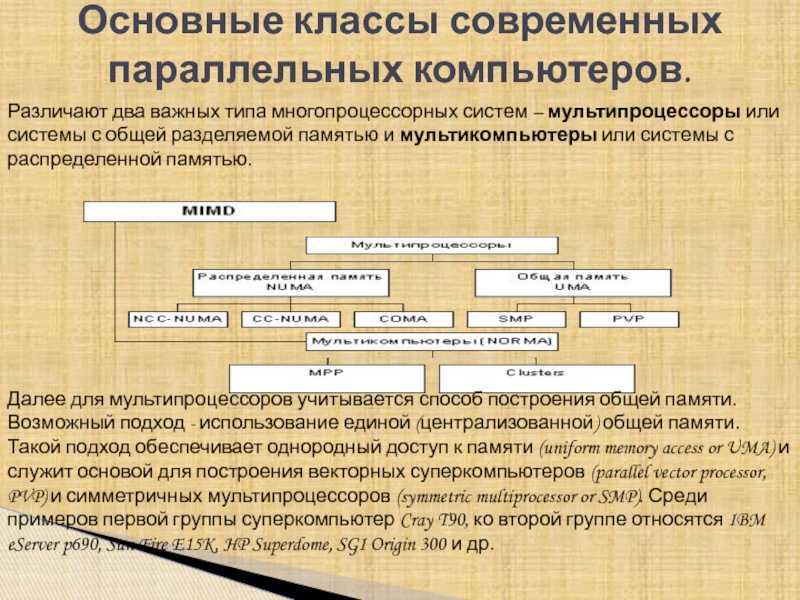
По способу адресации памяти различают несколько типов мультипроцессоров, среди которых: UMA (Uniform Memory Access), NUMA (Non Uniform Memory Access) и COMA (Cache Only Memory Access).
В связи с большой скоростью развития вычислительной техники и информационных систем в настоящее время, мультипроцессоры занимают одну из главных ролей в развитие сферы. Поэтому тема данной работы является актуальной в настоящее время.
Объект исследования – мультипроцессоры.
Предмет исследование – процесс использование мультипроцессоров в современном мире.
Цель данной работы – рассмотрение важности мультипроцессоров в современном мире. Для достижения поставленной цели будут решены следующие задачи:
Для достижения поставленной цели будут решены следующие задачи:
- будет рассмотрена теоретическая сущность мультипроцессоров.
- будут рассмотрены примеры использования мультипроцессоров в современном мире.
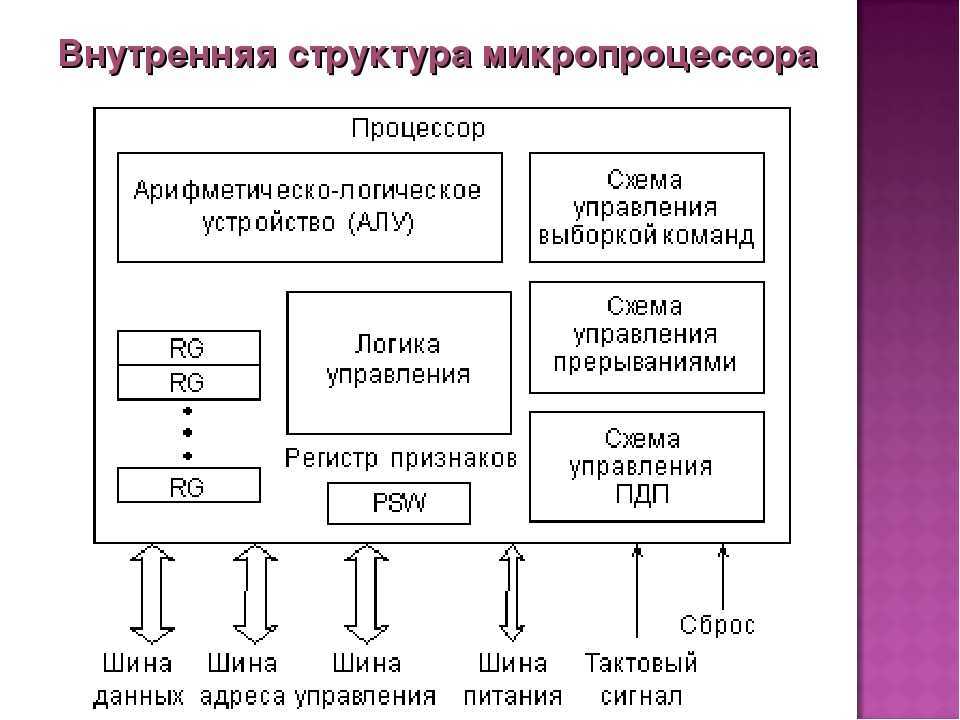
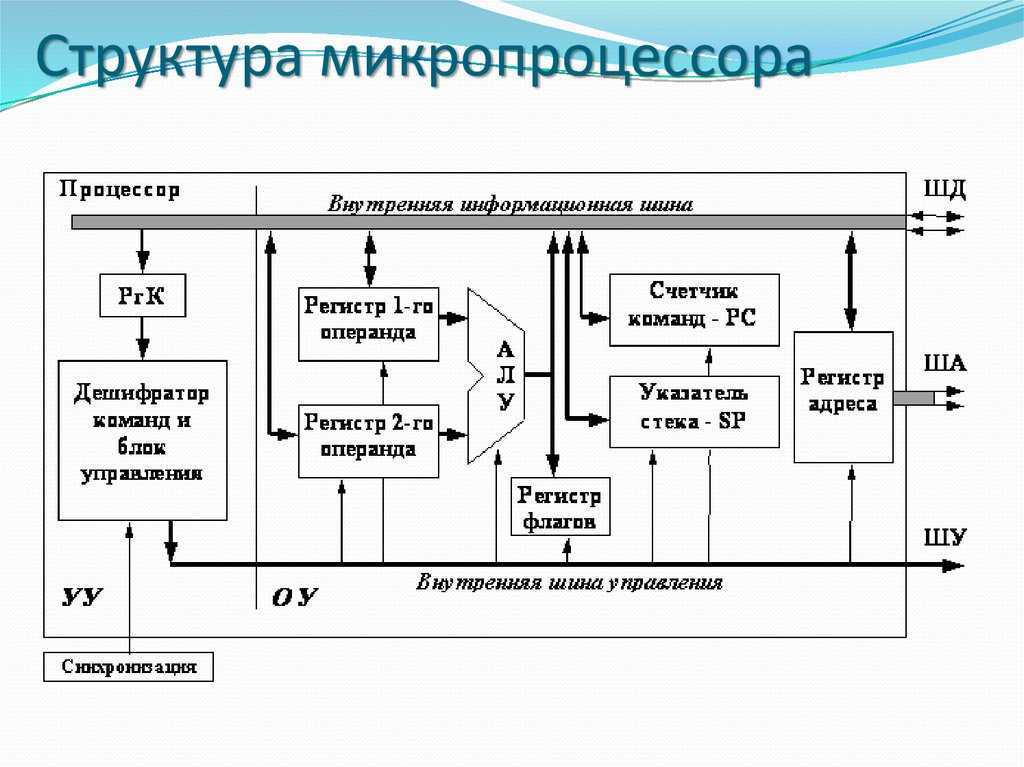
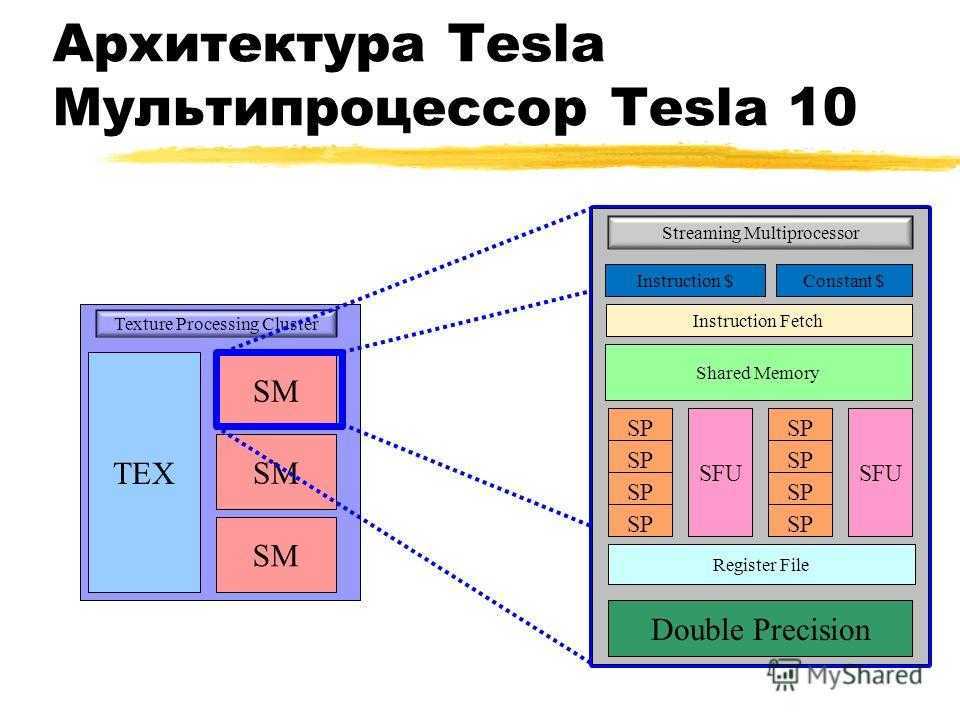
1.3 Основы мультитредовой архитектуры
При всем различии подходов к созданию мультитредовых микропроцессоров, общим для них является введение множества устройств выборки команд, каждое из которых организует окно исполнения для одного треда. В рамках одного треда выполняется предсказание переходов, переименование регистров, динамическая подготовка команд к исполнению. Тем самым, общее число команд, находящихся в обработке, значительно превышает размер окна исполнения однотредового процессора, с одной стороны, и тактовая частота не лимитируется размером окна исполнения, с другой стороны.
Выявление тредов может выполняться компилятором при анализе исходного кода на языке высокого уровня или исполняемого кода программы. Однако компиляторы не всегда могут разрешить проблемы зависимостей при использовании регистров и ячеек памяти между тредами, что требуется уже в ходе исполнения тредов. Для этого в микропроцессор вводится специальная аппаратура условного исполнения тредов, предусматривающая возврат с отбрасыванием наработанных результатов при обнаружении нарушения зависимостей между тредами. Нарушением зависимости, например, может служить запись по вычисляемому адресу в одном треде в ту же ячейку памяти, из которой выполняется чтение, которое должно следовать за этой записью, в другом треде. В случае, если адреса записи и чтения не совпадают, нарушение отсутствует. При совпадении адресов фиксируется нарушение, которое должно вернуть исполнение треда к команде чтения правильного значения.
Интерфейс между аппаратурой мультитредового процессора, поддерживающей протекание каждого отдельного треда и аппаратурой, общей для исполнения всех тредов, может быть установлен как сразу после устройств выборки команд тредов, так и на уровне доступа к разделяемой памяти. В первом случае все треды используют один регистровый файл и один набор функциональных устройств. Тесная связь по ресурсам позволяет эффективно исполнять последовательные программы с сильной зависимостью между тредами. В этом случае имеет место именно реализация мультискалярного мультитредового процессора.
СПИСОК ЛИТЕРАТУРЫ
- Бирюков А. Я., Голован Н. И., Медведев И. Л., Набатов А. С., Фищенко Е. А. Решающие поля многопроцессорных вычислительных систем. В кн.: Многопроцессорные вычислительные системы с общим потоком команд. М., ИПУ, 2016. — с. 22-32.
- Затуливетер Ю. С., Медведев И. Л. О групповом параллелизме и двойственной реализации параллельных вычислений. В кн.: вопросы кибернетики. Вып. 48. Вычислительные машины и системы с перестраиваемой структурой. М., Н. С. по комплексной проблеме «Кибернетика» АН СССР, 2016. — с. 44-63.
- Медведев И. Л. Принципы построения многопроцессорных вычислительных систем с общим потоком команд. В кн.: Многопроцессорные вычислительные системы с общим потоком команд. М., ИПУ, 2014. — с. 5-21.
- Медведев И. Л. Проектирование ядра структуры параллельных процессоров. М., Институт проблем управления, 2012. — 60 с.
- Медведев И. Л., Фищенко Е. А. Об одном способе описания программно-доступных средств параллельного процессора. В кн.: Вопросы кибернетики. Вып. 92. М., НС по комплексной проблеме «Кибернетика» АН СССР, 2012. — с. 43-67.
- Фищенко Е. А . Выбор системы команд для многопроцессорной вычислительной системы с общим потоком команд. В кн.: Многопроцессорные вычислительные системы с общим потоком команд. М., ИПУ, 2013. — с. 33-39.
- Экспедиционные геофизические комплексы на базе многопроцессорной ЭВМ ПС-2000. / В. А. Трапезников, И. В. Прангишвили, А. А. Новохатный, В. В. Резанов. — Приборы и системы управления, 2011. — с. 29-31.
- Прангишвили И. В., Виленкин С. Я., Медведев И. Л. Многопроцессорные вычислительные системы с общим управлением. — М., Энергоатомиздат, 2013. — 312 с.
- Фищенко Е. А. Принципы построения мнемокода многопроцессорных вычислительных систем с общим управлением. В сб.: Всесоюзное научно-техническое совещание «Проблемы создания и использования высокопроизводительных машин». М., ИПУ, 2012. — с.108-110.
-
Затуливетер Ю. С., Медведев И. Л. О групповом параллелизме и двойственной реализации параллельных вычислений. В кн.: вопросы кибернетики. Вып. 48. Вычислительные машины и системы с перестраиваемой структурой. М., Н. С. по комплексной проблеме «Кибернетика» АН СССР, 2016. — с. 44-63.
-
Медведев И. Л. Принципы построения многопроцессорных вычислительных систем с общим потоком команд. В кн.: Многопроцессорные вычислительные системы с общим потоком команд. М., ИПУ, 2014. — с. 5-21.
-
Фищенко Е. А. Принципы построения мнемокода многопроцессорных вычислительных систем с общим управлением. В сб.: Всесоюзное научно-техническое совещание «Проблемы создания и использования высокопроизводительных машин». М., ИПУ, 2012. — с.108-110.
-
Затуливетер Ю. С., Медведев И. Л. О групповом параллелизме и двойственной реализации параллельных вычислений. В кн.: вопросы кибернетики. Вып. 48. Вычислительные машины и системы с перестраиваемой структурой. М., Н. С. по комплексной проблеме «Кибернетика» АН СССР, 2016. — с. 44-63.
- Разработка регламента выполнения процесса (Контроль поставок товара)
- ЯЗЫКИ ПРОГРАММИРОВАНИЯ: СУЩНОСТЬ, КЛАССИФИКАЦИЯ, СРАВНИТЕЛЬНАЯ ХАРАКТЕРИСТИКА, ОСНОВНЫЕ ЭТАПЫ РАЗРАБОТКИ
- Оценка эффективности управления предприятием (Понятие эффективности деятельности предприятия)
- МЕНЕДЖМЕНТ КАК ОРГАНИЗАЦИОННО- ЦЕЛЕВОЕ УПРАВЛЕНИЕ (Менеджмент как вид управленческой деятельности)
- МЕНЕДЖМЕНТ КАК ОРГАНИЗАЦИОННО- ЦЕЛЕВОЕ УПРАВЛЕНИЕ
- Теории происхождения государства (Отличия первобытного общества от государства)
- ПОНЯТИЕ И КЛАССИФИКАЦИЯ ФУНКЦИЙ ГОСУДАРСТВА (Внутренние и внешние функции государства)
- Основные функции в системе менеджмента (Основные функции в теории менеджмента)
- Кадровая стратегия в системе стратегического управления организацией (Содержание кадровой стратегии)
- Роль мотивации в поведении организации (СУЩНОСТЬ И ВИДЫ МОТИВАЦИИ В СИСТЕМЕ УПРАВЛЕНИЯ)
- Организация управленческого учета в компании(Принципы постановки управленческого учета)
- Менеджмент человеческих ресурсов (Разработка и реализация программы по улучшению кадровой политики и мотивационной системы мебельной фабрики «Восток»)
Примечания
- МНОГОПРОЦЕССОРНАЯ АРХИТЕКТУРА ПС-2000 НА КРИСТАЛЛЕ СБИС. Дата обращения: 5 марта 2020. Архивировано 2 сентября 2013 года.
- Об опыте реализации программ построения регулярных сеток на ЭВМ архитектуры SIMD на примере ПС-2100
- НПО «Импульс» — колыбель отечественной промышленной системотехники. Дата обращения: 5 марта 2020. Архивировано 17 января 2020 года.
- НОУ ИНТУИТ | Лекция | Параллельные структуры вычислительных систем. Дата обращения: 5 марта 2020. Архивировано 4 февраля 2020 года.
- Вычислительный комплекс ПС-2000.Управляющие ЭВМ и искусственный интеллект. Дата обращения: 5 марта 2020. Архивировано 19 февраля 2020 года.
- Приборы и системы управления. Октябрь 1992.. Дата обращения: 5 марта 2020. Архивировано 18 января 2021 года.
- Многопроцессорный компьютер ПС-2000 | Открытые системы. СУБД | Издательство «Открытые системы». Дата обращения: 5 марта 2020. Архивировано 12 ноября 2019 года.
- Архивированная копия. Дата обращения: 5 марта 2020. Архивировано 20 января 2022 года.
- Научные школы компьютеростроения: история отечественной вычислительной техники — Ходаков В. Е. — Google книги
- Информационные технологии в СССР. Создатели советской компьютерной техники — Ревич Юрий Всеволодович — Google книги
- Информатика. Прошлое, настоящее, будущее — Василий Губарев — Google книги
2.2 Практическое применение многопроцессорных систем
С появлением доступных многопроцессорных систем возник у пользователей: как использовать мощность компьютерной техники. При использовании обыкновенного программного обеспечения количество процессоров системы в основном простаивает.
Практическим примером может служить, например преобразование музыкальных файлов flac → ogg. Можно, например использовать консольный запрос:
for i in *.flac ; do oggenc —quality=10 «$i» ; done
Но при большом количестве файлов простаивающие процессоры слегка вызывают раздражение. Для того, чтобы оценить мощность производительной техники нужно параллельное программное обеспечение.
Предлагается использовать хорошую программу на языке Lisp2D, которая запускает параллельно конвертацию файлов, заключённых в директориях. Количество одновременно запущенных задач будет всегда равно количеству процессоров.
((‘freemans defclass) defvar
n signal lock nwaitsignal)
(‘freemans defmethod freemans ()
(nil setq
n (nil nprocs)
signal (‘signal newobject)
lock (‘lock newobject)
nwaitsignal (0 copy)))
(‘freemans defmethod enter ()
(lock progn
(nil when (n = 0)
(nwaitsignal += 1)
(signal wait lock))
(n -= 1)))
(‘freemans defmethod exit ()
(lock progn
(n += 1)
(nil when (nwaitsignal > 0)
(nwaitsignal -= 1)
(signal send))))
(‘string defmethod flactoogg (q freemans)
(nil let (s (d (‘dir newobject this)))
(nil while (‘s set (d read))
(nil let ((fullname (this + «/» s)))
(nil cond
((s = «.»))
((s = «..»))

![Мультипроцессоры (основы мультитредовой архитектуры) [курсовая №11756]](https://robotrackkursk.ru/wp-content/uploads/1/e/e/1ee6621b3700cd95ba26160cd5343aec.jpeg)
![Пс-2000содержание а также история [ править ]](https://robotrackkursk.ru/wp-content/uploads/8/f/4/8f46d5c255d13500292578a5ca9a7a95.jpeg)
((fullname regp) ; is a file
(nil let ((ss (s size)))
(nil if (ss > 5)
(nil when (((s part (ss — 5)) lower) = «.flac»)
(freemans enter)
(nil fork
(nil if (0 = («oggenc» system («—quality=» + q) fullname))
(fullname unlink)
(cerr writeln «crash oggenc for » fullname))
(freemans exit))))))
((fullname dirp) ; is dir
(fullname flactoogg q freemans)))))
(d close)))
(«.» flactoogg (arg first) (‘freemans newobject))
Результатом использования параллельно запущенных процессов станет полноценная загрузка процессоров полезной работой. И огромная экономия личного времени.
История
Разработан на НПО «Импульс» (НИИ управляющих вычислительных машин) при участии Института проблем управления (автоматики и телемеханики) Минприбора СССР и АН СССР в 1979, выпуском занимался Северодонецкий приборостроительный завод с 1981 по 1988, выпустив за это время 242 машины.
Также была создана векторная вычислительная система ПС-2100 с повышенной производительностью. В ней предусмотрена возможность сегментации процессоров. Новизна состояла в проектировании набора интегральных схем для арифметико-логического устройства и памяти процессорных элементов. Опытная партия интегральных схем для ПС-2100 была изготовлена на Воронежском заводе полупроводников.
Применение
Основной сферой применения являлись геофизические расчёты, даже были сделаны специальные экспедиционные вычислительные комплексы ЭГВК ПС-2000, отлично приспособленные к работе в условиях геофизических экспедиций, которые не занимали большой площади, потребляли мало энергии и не требовали больших расходов на эксплуатацию. Особо данные машины подходили к обработке массивных данныхсейсмологических разведок.
В Центре управления полётами до конца XX века работал телеметрический вычислительный комплекс, в котором центральная система базировалась на «Эльбрусе-2», а предварительную обработку телеметрической информации осуществляла периферийная система на ПС-2000. Также данная машина применялась для орбитальной станции «Мир».
2.1 Мультипроцессорные системы общего назначения
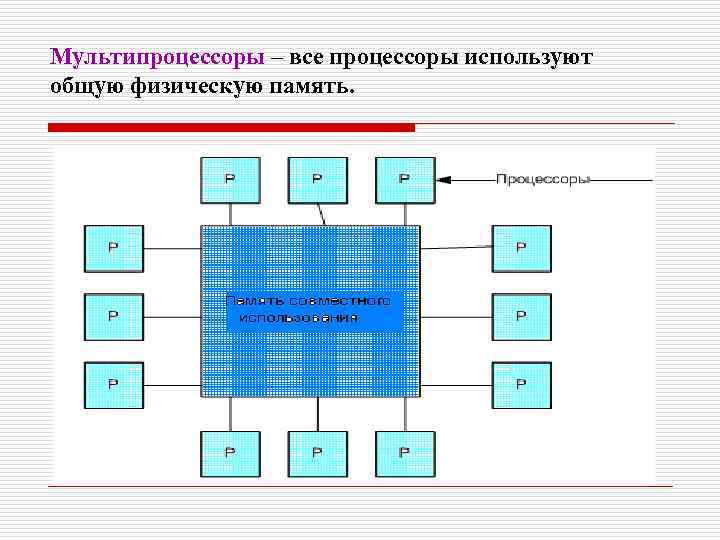
В мультипроцессорных системах (МПС) имеется несколько процессоров, каждый из которых может относительно независимо от остальных выполнять свою программу. В МПС существует общая для всех процессоров операционная система, которая оперативно распределяет вычислительную нагрузку между процессорами. Важным свойством МПС является отказоустойчивость, то есть способность к продолжению работы при отказах некоторых элементов, например процессоров или блоков памяти. При этом производительность, естественно, снижается, но не до нуля, как в обычных системах, в которых отсутствует избыточность.
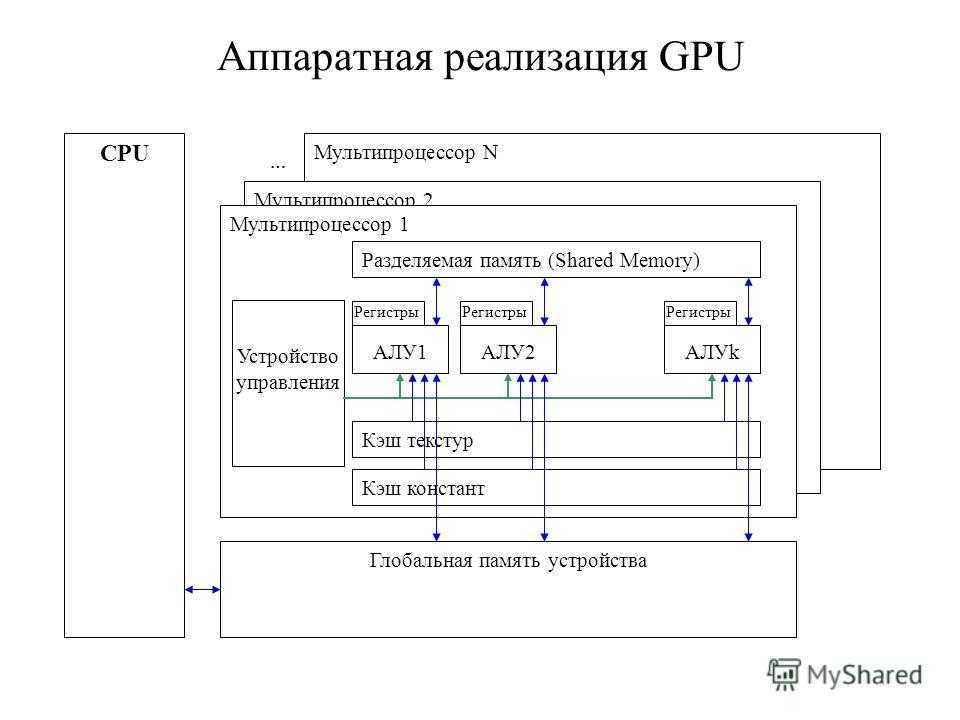
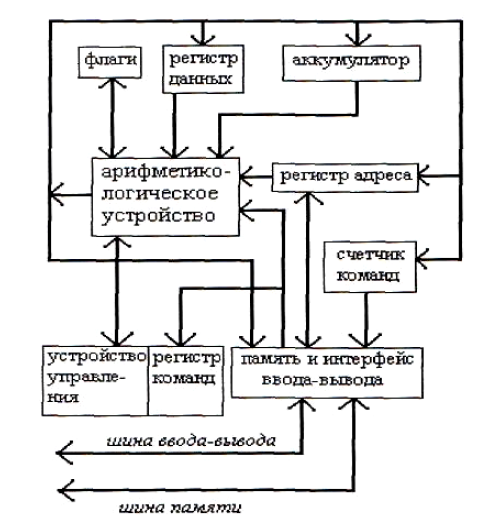
Любая вычислительная система достигает своей наивысшей производительности благодаря использованию высокоскоростных процессорных элементов (ПЭ) и параллельному выполнению большого числа операций.
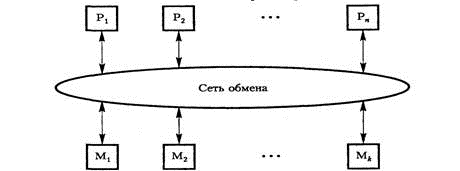
UMA состоит из n процессоров, k модулей памяти и коммуникационной сети, связывающей процессоры и память. Сеть может стать причиной значительной задержки при обращении процессора к памяти. Система, в которой такая задержка одинакова для всех операций доступа к памяти, называется мультипроцессорной системой с однородным доступом к общей памяти (Uniform Memory Access, UMA) или системой с общей памятью. Поскольку процессоры выполняют команды с огромной скоростью, слишком большие задержки на выборку из памяти команд и данных для них неприемлемы. Однако коммуникационные сети с малым временем задержки имеют очень сложную структуру и высокую стоимость.

Рис. 2. Мультипроцессорная система типа UMA
![Мультипроцессоры (основы мультитредовой архитектуры) [курсовая №11756]](https://robotrackkursk.ru/wp-content/uploads/1/3/3/13312c8f9d86a5ff4a4a67c17108b556.jpeg)

![Пс-2000содержание а также история [ править ]](https://robotrackkursk.ru/wp-content/uploads/3/7/8/3789b09e345ccf493abec1da877c95cc.png)

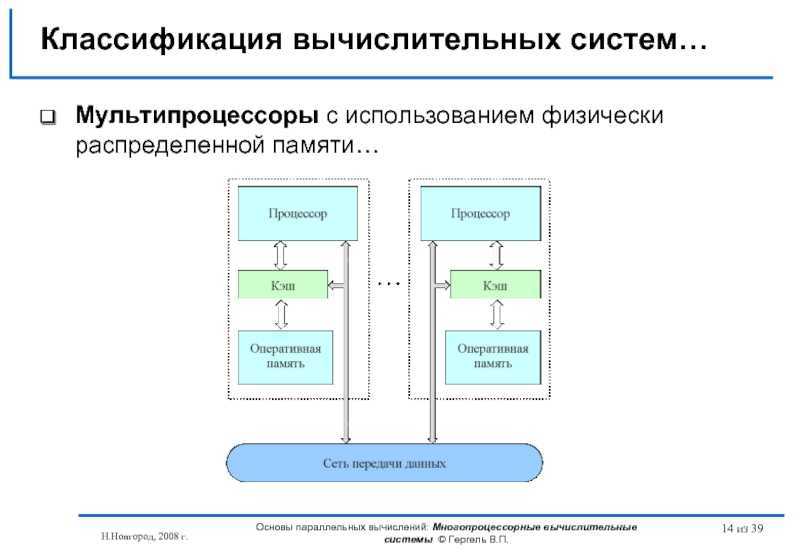
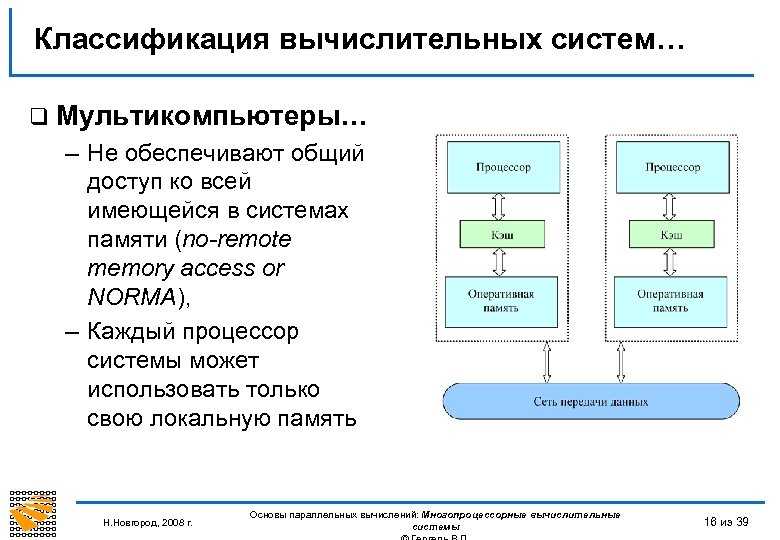
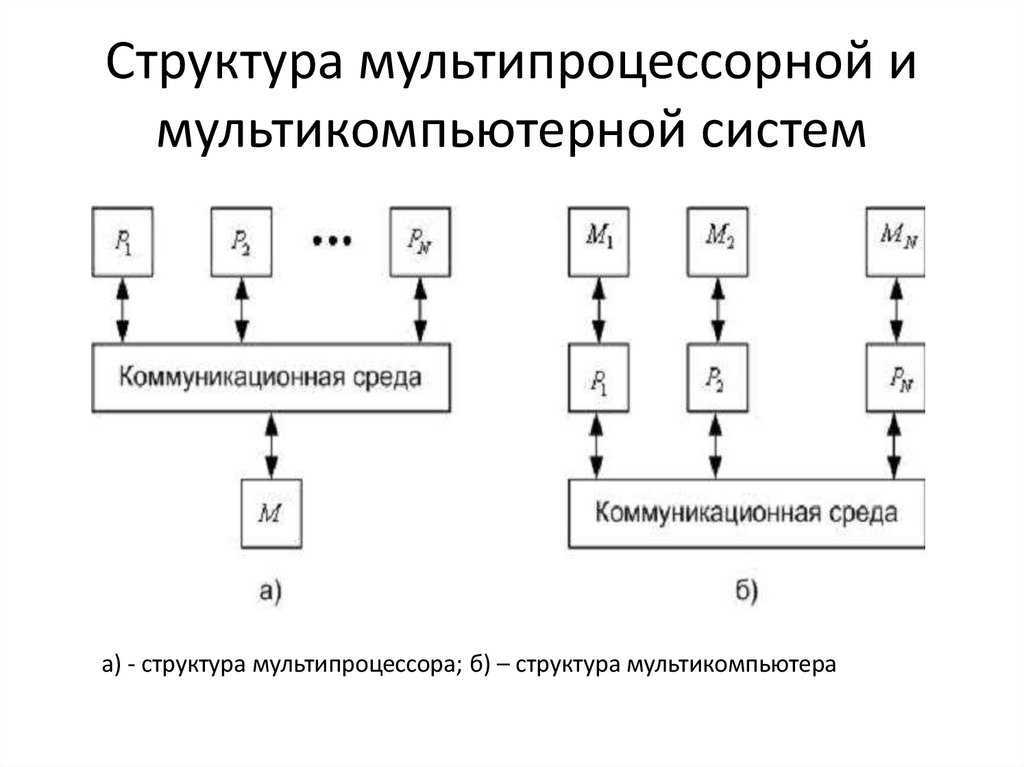
NUMA каждый процессор имеет доступ не только к собственной локальной памяти, но и к памяти других процессоров сети. Но поскольку при обращении к памяти других процессоров запросы проходят через сеть, они выполняются дольше, чем обращения к локальной памяти. Системы этого типа называются мультипроцессорными системами с неоднородным доступом к памяти (Non-Uniform Memory Access, NUMA).
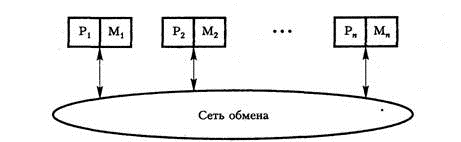
Рис. 3. Мультипроцессорная система типа NUMA
Ни один из процессоров не может обратиться к удаленной памяти без взаимодействия с удаленным процессором, которому она принадлежит
Взаимодействие между этими двумя процессорами осуществляется в форме обмена сообщениями. Системы такого типа называются системами с распределенной памятью и высокоскоростным протоколом передачи сообщений.
CC-NUMA (cache coherent NUMA) — система с кэш-когерентным доступом к неоднородной памяти. В отличие от классической архитектуры NUMA, при использовании кэш-когерентного доступа к неоднородной памяти все процессоры объединены в один узел, причем первый уровень иерархии памяти образует кэш-память процессоров. Архитектура ccNUMA поддерживает когерентность кэш памяти внутри узла аппаратно. Аппаратная когерентность кэш-памяти означает, что не требуется никакого программного обеспечения для поддержки актуальности множества копий данных.
В системе сс-NUMA физически распределенная память объединяется, как в любой другой SMP-архитектуре, в единый массив. Не происходит никакого копирования страниц или данных между ячейками памяти. Нет никакой программно-реализованной передачи сообщений. Существует просто одна карта памяти, с частями, физически связанными медным кабелем, и очень умные (в большей степени, чем объединительная плата) аппаратные средства. Аппаратно-реализованная кэш-когерентность означает, что не требуется какого-либо программного обеспечения для сохранения множества копий обновленных данных или для передачи их между множеством экземпляров операционной системы и приложений. Со всем этим справляется аппаратный уровень точно так же, как в любом SMP-узле, с одной копией операционной системы и несколькими процессорами.
При использовании большого числа кэшей возникает та же проблема что и в архитектуре UMA: необходимо поддерживать актуальность кэшированных данных. Практически это означает, что изменение любой ячейки памяти, копия которой находится в некотором кэше, должно быть повторено для всех её копий. Учитывая, что число копий может быть велико, это становится сложной технической задачей.
ЗАКЛЮЧЕНИЕ
Несмотря на то, что сегодня известно множество способов повышения производительности микропроцессоров с суперскалярной архитектурой, имеется также ряд препятствий и ограничений, исключающих возможность дальнейшего наращивания быстродействия. В данной главе показаны способы повышения производительности суперскалярных микропроцессоров на примере архитектур Alpha 21364 и Power4. Разбираются вопросы перехода к принципиально новой, так называемой мультитредовой архитектуре, позволяющей существенно изменить возможности нынешних микропроцессоров.
История развития микропроцессоров в полной мере подчиняется диалектике эволюционного усовершенствования архитектуры. Начиная от машины ENIAC, содержавшей 19 тыс. ламп, производительность компьютеров росла на порядок каждые пять лет. Большое число транзисторов на современном кристалле делает возможным применить в одном микропроцессоре все известные способы повышения производительности, сообразуясь только с их совместимостью. Однако для полного использования возможностей аппаратуры уже недостаточно ограничиться только аппаратно реализованными алгоритмами управления, достаточно единообразно функционирующими во всех ситуациях. Поэтому при реализации усложненной логики управления используется программное обеспечение, для поддержки которого вводятся дополнительные команды и регистры управления микропроцессора. В свою очередь, формирование программ для потактного управления микропроцессором под силу только компилятору. Таким образом, в современных микропроцессорах возник симбиоз программных и аппаратных средств. Этот симбиоз представляет собой нечто большее, нежели эволюционный ход развития, а смену самого направления развития микропроцессоров, выражающуюся в переходе к мультитредовым и многопроцессорным архитектурам.
С позиции реализации такого симбиоза открываются следующие способы повышения производительности:
- увеличение емкости памяти внутри кристалла;
- увеличение количества арифметико-логических устройств;
- введение блоков обработки мультимедийных данных, ранее использовавшихся, например, в сигнальных микропроцессорах;
- интеграция на кристалле функций управления памятью и периферийными устройствами, для исполнения которых в традиционных микропроцессорах используются наборы микросхем («чипсеты»);
- интеграция на кристалле интерфейсов сетевых и телекоммуникационных систем, что позволяет соединять эти микропроцессоры друг с другом и телекоммуникационными и вычислительными сетями без дополнительных адаптеров.
Принципы универсальных машинных вычислений (по фон Нейману) легли в основу компьютеров первых поколений. На их основе работает и большая часть нынешних компьютеров. Но эти аксиомы существенно ограничивают способы реализации машинного счета. Они диктуют последовательную (команда за командой) реализацию. Такое ограничение сильно сужает разнообразие архитектурных решений и лишает их перспектив к наращиванию производительности за счет увеличения числа одновременно работающих над одной задачей процессоров.
Искусство творения компьютеров имеет свои вершины мастерства. Многопроцессорные высокопараллельные архитектуры, выходя за пределы юрисдикции классической модели последовательного счета, требуют от создателей нестандартного, многомерного, но очень здравого мышления. (Здесь мысли могут взлетать очень высоко, чтобы затем разбиться о жесткие реалии.) В этой запредельной, рекордной области компьютеростроения архитектурных тайн и сегодня остается значительно больше, чем найдено решений. И тем ценнее достижения, прошедшие проверку практикой. Через положительный опыт открывается путь к новейшим многокомпонентным архитектурам, способным к полному погружению в микромир новых СБИС-технологий и обладающим за счет этого огромным вычислительным потенциалом.
![Мультипроцессоры (основы мультитредовой архитектуры) [курсовая №11756]](https://robotrackkursk.ru/wp-content/uploads/7/2/1/721eba36038869cab56cbe2b0a6fc733.jpeg)
![Пс-2000содержание а также история [ править ]](https://robotrackkursk.ru/wp-content/uploads/8/7/7/877cfcb10839956e7454cae9cf15fd0b.jpeg)