
Изоляция снимков состояния и воспроизводимое чтение
На первый взгляд уровня изоляции чтения зафиксированных данных вполне достаточно для транзакций.
Однако на этом уровне изоляции все еще существует множество возможных ошибок конкурентного доступа. Например, на рис. 4 показана одна из вероятных проблем при чтении зафиксированных данных.
Рис. 4 — Асимметрия чтения: Алиса видит базу данных в несогласованном состоянии
Подобная аномалия носит название невоспроизводимого чтения (nonrepeatable read) или асимметрии чтения (read skew): если Алиса прочитала бы баланс счета 1 опять в конце транзакции, то увидела бы значение ($600), отличное от прочитанного предыдущим запросом. Асимметрия считается допустимой при изоляции уровня чтения зафиксированных данных: видимые Алисе балансы счетов были, безусловно, зафиксированы на момент их чтения.
В случае Алисы — это лишь временная проблема. Однако в некоторых ситуациях подобные временные несоответствия недопустимы.
-
Резервное копирование. Резервная копия представляет собой копию всей базы данных, и ее создание на большой БД может занять несколько часов. Операции записи в базу продолжают выполняться во время создания резервной копии. Следовательно, может оказаться, что одни части копии содержат старые версии данных, а другие — новые. В случае восстановления БД из подобной резервной копии упомянутые расхождения (например, пропавшие деньги) станут из временных постоянными.
-
Аналитические запросы и проверки целостности. Иногда приходится выполнять запросы, просматривающие значительные части базы данных. Они также могут быть частью периодической проверки целостности (мониторинга на предмет порчи данных). Если подобные запросы будут видеть разные части БД по состоянию на различные моменты времени, то их результаты будут совершенно бессмысленными.
Изоляция снимков состояния — чаще всего используемое решение этой проблемы. Ее идея состоит в том, что каждая из транзакций читает данные из согласованного снимка состояния БД, то есть видит данные, которые были зафиксированы в базе на момент ее (транзакции) начала.
Операции чтения не требуют никаких блокировок. С точки зрения производительности основной принцип изоляции снимков состояния звучит как «чтение никогда не блокирует запись, а запись — чтение».
Базы данных применяют для реализации изоляции снимков состояния похожий механизм, действие которого по части предотвращения «грязных» операций чтения мы наблюдали на рис. 2. БД должна хранить для этого несколько различных зафиксированных версий объекта, поскольку разным выполняемым транзакциям может понадобиться состояние базы на различные моменты времени. Вследствие хранения одновременно нескольких версий объектов этот метод получил название многоверсионного управления конкурентным доступом (multiversion concurrency control, MVCC).
Если базе необходима только изоляция уровня чтения зафиксированных данных, но не уровня изоляции снимков состояния, достаточно было бы хранить только две версии объекта: зафиксированную версию и перезаписанную, но еще не зафиксированную версию. Однако поддерживающие изоляцию снимков состояния подсистемы хранения обычно используют MVCC и для изоляции уровня чтения зафиксированных данных. При этом обычно при чтении таких данных применяется отдельный снимок состояния для каждого запроса, а при изоляции снимков состояния — один и тот же снимок состояния для всей транзакции.
Рис. 5 — Реализация изоляции снимков состояния
с помощью многоверсионных объектов
В каждой строке таблицы есть поле created_by, содержащее идентификатор транзакции, вставившей эту строку в таблицу. Более того, в каждой строке таблицы есть поле deleted_by, изначально пустое. Если транзакция удаляет строку, то строка на самом деле не удаляется из базы данных, а помечается для удаления путем установки значения этого поля в соответствии с идентификатором запросившей удаление транзакции. В дальнейшем, когда уже никакая транзакция точно не обратится к удаленным данным, процесс сборки мусора БД удалит все помеченные для удаления строки и освободит занимаемое ими место.
На этом первая часть конспекта, посвященного транзакциям, закончена. В следующей части рассмотрим асимметричные записи и фантомы, изоляцию уровня сериализуемости, в том числе различные методы, которые обеспечивают сериализуемость.
Очень долго запускается 1С предприятие 7.7 (конфигуратор, монитор, отладчик) Промо
Если у Вас всегда очень долго открывается 1С, заставка висит в течение нескольких минут, зависает при старте предприятия 7.7 и конфигуратор, и монитор, и отладчик, скорее всего, дело в файле 1cv7evt.txt, файл 1cv7evt.txt в подкаталоге Syslog в каталоге базы находится по адресу \\ИмяСервера\ИмяКаталогаБаз\ИмяБазы\SYSLOG\1cv7evt.txt, вернее в размере этого файла. Проблема проявляется в том, что во время запуска 1С предприятия 7.7 и конфигуратора, и монитора, и отладчика заставка висит несколько минут. Отключите пользователей, перенесите файл 1cv7evt.txt в другую папку, и 1С 7.7 будет стартовать очень быстро.
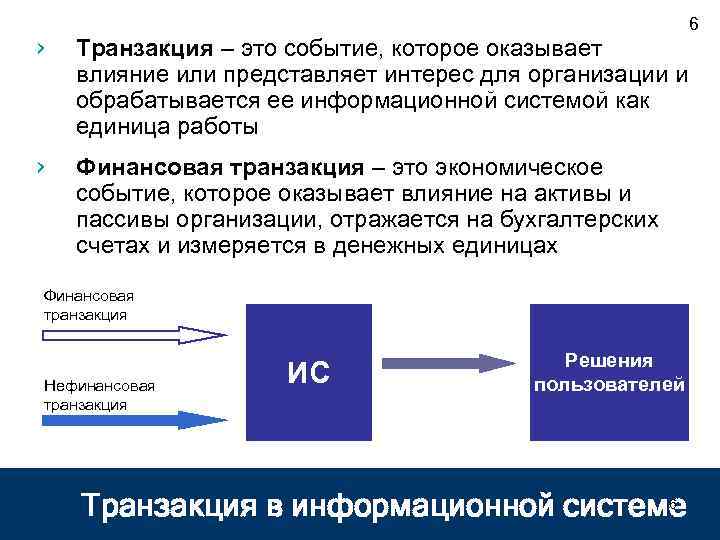
Стандартные характеристики данных о транзакциях
Как правило, данные о транзакциях имеют следующие характеристики:
| Требование | Описание |
|---|---|
| Нормализация | Высокая степень нормализации |
| схема | Схема при записи (строгое соблюдение) |
| Согласованность | Строгая согласованность (гарантии ACID) |
| Целостность | Высокая степень целостности данных |
| Использование транзакций | Да |
| Стратегия блокировки | Пессимистическая или оптимистическая |
| Возможность обновления | Да |
| Возможность добавления | Да |
| Рабочая нагрузка | Большое число операций записи, среднее число операций чтения |
| Индексация | Первичный и вторичные индексы |
| Размер данных | Небольшой и средний размер |
| Моделирование | Реляционный |
| Форма представления данных | Таблица |
| Гибкость запросов | Высокая гибкость |
| Масштабирование | Небольшой (МБ) и большой (несколько ТБ) |
Как работает обычное Управление транзакциями СБДЯ (JDBC)
Если вы думаете пропустить этот раздел, не зная транзакций СБДЯ изнутри: не стоит.
Как запускать, фиксировать или откатывать транзакции СБДЯ
Первый важный вывод заключается в следующем: Не имеет значения, используете ли вы аннотацию от Спринга, обычный Гибернэйт (Hibernate), «Жук» (jOOQ) или любую другую библиотеку баз данных.
В конечном счёте, все они делают одно и то же — открывают и закрывают (назовём это «управлением») транзакции базы данных. Обычный код управления транзакциями СБДЯ выглядит следующим образом:
Для запуска транзакций необходимо подключение к базе данных. DriverManager.getConnection(url, user, password) тоже подойдёт, хотя в большинстве корпоративных приложений вы будете иметь настроенный источник данных и получать соединения из него.
Это единственный способ «начать» транзакцию базы данных в Яве (Java), даже несмотря на то, что название может звучать немного странно. гарантирует, что каждый SQL-оператор будет автоматически завёрнут в собственную транзакцию, а — наоборот: Вы являетесь хозяином транзакции (транзакций), и Вам придётся начать вызывать и друзей
Обратите внимание, что флаг действует в течение всего времени, пока ваше соединение открыто, что означает, что вам нужно вызвать метод только один раз, а не несколько.
Давайте зафиксируем нашу транзакцию…
Или откатим наши изменения, если произошло исключение.
Да, эти 4 строки — это (в упрощенном виде) всё, что Спринг делает всякий раз, когда вы используете аннотацию . В следующей главе вы узнаете, как это работает. Но прежде чем мы перейдём к этому, вам нужно узнать ещё кое-что.
(Небольшое замечание для умников: Библиотеки пулов соединений, такие как HikariCP, могут переключать режим автокоммита автоматически, в зависимости от конфигурации. Но это уже продвинутая тема).
Как использовать уровни изоляции СБДЯ и точки сохранения
Если вы уже играли с аннотацией от Спринга, вы могли столкнуться с чем-то подобным:
Мы рассмотрим вложенные транзакции Спринга и уровни изоляции позже более подробно, но опять же полезно знать, что все эти параметры сводятся к следующему, основному коду СБДЯ:
Вот как Спринг устанавливает уровни изоляции для соединения с базой данных. Не такое уж хитросплетённый, не так ли?
Вложенные транзакции в Спринге — это просто точки сохранения СБДЯ / базы данных. Если вы не знаете, что такое точка сохранения, посмотрите, например, это руководство
Обратите внимание, что поддержка точек сохранения зависит от вашего драйвера СБДЯ/базы данных.
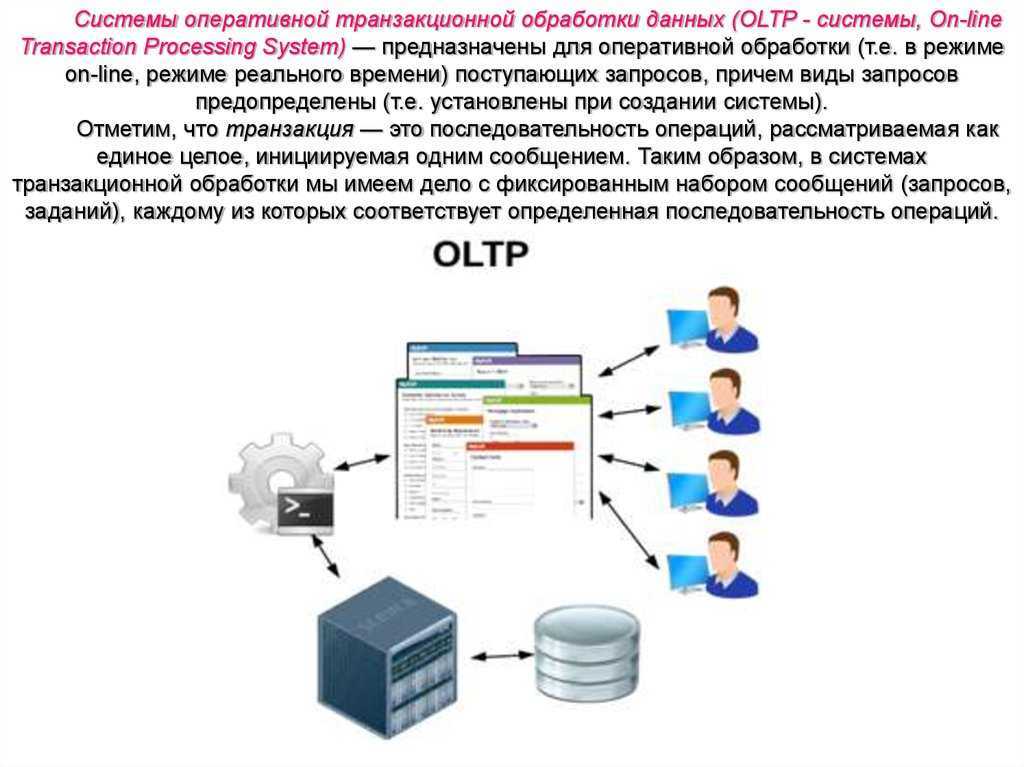
OLTP в Azure
Как правило, такие приложения, как веб-сайты, размещенные в веб-приложениях службы приложений, REST API, запущенные в службе приложений, а также мобильные и классические приложения, взаимодействуют с системой OLTP через промежуточный интерфейс REST API.
На практике большинство рабочих нагрузок выполняются не только в системе OLTP. Для них также требуется аналитический компонент. Кроме того, растет потребность в создании отчетов в режиме реального времени, например создание отчетов в операционной системе. Также это называют HTAP (гибридная транзакционно-аналитическая обработка). Дополнительные сведения см. в статье об оперативной аналитической обработке (OLAP).
Все следующие хранилища данных в Azure соответствуют основным требованиям к OLTP и управлению данными о транзакциях:
- База данных SQL Azure
- SQL Server на виртуальной машине Azure
- База данных Azure для MySQL
- База данных Azure для PostgreSQL
Распределенные транзакции
Таблица в YDB может быть шардирована по диапазонам значений первичного ключа. Различные шарды таблицы могут обслуживаться разными серверами распределенной БД (в том числе расположенными в разных локациях), а также могут независимо друг от друга перемещаться между серверами для перебалансировки или поддержания работоспособности шарда при отказах серверов или сетевого оборудования.
В YDB поддерживаются распределенные транзакции. Распределенные транзакции — это транзакции, которые затрагивают более одного шарда одной или нескольких таблиц. Они требуют больше ресурсов и выполняются дольше. В то время как точечные чтения и записи могут выполняться за время до 10 мс в 99 перцентиле, распределенные транзакции, как правило, занимают от 20 до 500 мс.
Isolation или изоляция (I)
Переходим к самому интересному свойству — изоляции. Представим ситуацию, когда в определенный момент времени с системой работают несколько пользователей. Естественно, операции транзакции в БД выполняются параллельно, чтобы ускорить работу системы. Но у параллельной работы транзакций есть свои подводные камни:
-
Если операции транзакции взаимодействуют с разным набором непересекающихся данных, все работает корректно.
-
Но что будет, если две и более операций транзакции в один момент времени начнут работать с одним и тем же набором данных? Возникнет явление, называемое race condition (состояние гонки).
Выделяют несколько эффектов, связанных с этим явлением.
Эффект потерянного обновления возникает, когда несколько транзакций обновляют одни и те же данные, не учитывая изменений, сделанных другими транзакциями.
Эффект чтения фантомов возникает, когда набор данных соответствует условиям поиска, но изначально не отображается.
Решение
Для устранения данных эффектов на уровне баз данных предусмотрены уровни изоляции, или transaction isolation levels, которые так или иначе реализованы во многих СУБД. Для примера рассмотрим движок InnoDB в СУБД MySQL:
Read uncommitted – это уровень изоляции, при котором каждая транзакция видит незафиксированные изменения другой транзакции. Справляется с эффектом потерянного обновления, но остаются остальные проблемы: эффекты грязного чтения, неповторяемого чтения, чтения фантомов.
![[перевод] обработка ошибок и транзакций в sql server. часть 1. обработка ошибок – быстрый старт](https://robotrackkursk.ru/wp-content/uploads/5/7/c/57cb994ec38bba0b11813926ac7857b7.jpeg)

Все запросы SELECT считывают данные в неблокирующей манере.
Блокирующее чтение (SELECT … FOR UPDATE, LOCK IN SHARE MODE), UPDATE и DELETE блокирует искомые индексные строки. Таким образом, возможна вставка данных в промежутки между индексами. Промежутки блокируются только при проверках на дублирующиеся и внешние ключи.
Read committed — это уровень изоляции, при котором параллельно исполняющиеся транзакции видят только зафиксированные изменения других транзакций. Справляется с эффектами потерянного обновления и грязного чтения, остаются эффекты неповторяемого чтения и чтения фантомов.
Согласованное чтение не накладывает блокировок, однако считывает данные из свежего снэпшота. В остальном ведёт себя так же, как и read uncommitted.
Repeatable read или snapshot isolation — это уровень изоляции, при котором транзакция не видит изменения данных, прочитанные ей ранее, однако способна прочитать новые данные, соответствующие условию поиска. Справляется с эффектами потерянного обновления, грязного чтения, неповторяемого чтения, остается эффект чтения фантомов.
Согласованное чтение не накладывает блокировок и считывает данные из снэпшота, который создается при первом чтении в транзакции. Таким образом, одинаковые запросы вернут одинаковый результат.
Блокировка для блокирующего чтения будет зависеть от типа условия:
-
если условие с диапазоном, например, WHERE (id > 7), то блокируется весь диапазон;
-
если уникальное, например, WHERE (id = 7), то блокируется одна индексная запись.
Кстати, в InnoDB именно уровень repeatable read используется по умолчанию.
Serializable — это уровень изоляции, при котором каждая транзакция выполняется так, как будто параллельных транзакций не существует. Справляется со всеми перечисленными выше эффектами.
Аналогично repeatable read, но есть интересный момент. Если выключен autocommit (а при явном старте транзакции START TRANSACTION он выключен по умолчанию), то все запросы SELECT превращаются в запросы SELECT … LOCK IN SHARE MODE.
SELECT … LOCK IN SHARE MODE – блокирует считываемые строки на запись.
SELECT … FOR UPDATE – блокирует считываемые строки на чтение.
Финальные замечания
Вы изучили основной образец для обработки ошибок и транзакций в хранимых процедурах. Он не идеален, но он должен работать в 90-95% вашего кода
Есть несколько ограничений, на которые стоит обратить внимание:
- Как мы видели, ошибки компиляции не могут быть перехвачены в той же процедуре, в которой они возникли, а только во внешней процедуре.
- Пример не работает с пользовательскими функциями, так как ни TRY-CATCH, ни RAISERROR нельзя в них использовать.
- Когда хранимая процедура на Linked Server вызывает ошибку, эта ошибка может миновать обработчик в хранимой процедуре на локальном сервере и отправиться напрямую клиенту.
- Когда процедура вызвана как INSERT-EXEC, вы получите неприятную ошибку, потому что ROLLBACK TRANSACTION не допускается в данном случае.
- Как упомянуто выше, если вы используете error_handler_sp или SqlEventLog, мы потеряете одно сообщение, когда SQL Server выдаст два сообщения для одной ошибки. При использовании ;THROW такой проблемы нет.
Я рассказываю об этих ситуациях более подробно в других статьях этой серии.
Перед тем как закончить, я хочу кратко коснуться триггеров и клиентского кода.
Триггеры
Пример для обработки ошибок в триггерах не сильно отличается от того, что используется в хранимых процедурах, за исключением одной маленькой детали: вы не должны использовать выражение RETURN (потому что RETURN не допускается использовать в триггерах).
С триггерами важно понимать, что они являются частью команды, которая запустила триггер, и в триггере вы находитесь внутри транзакции, даже если не используете BEGIN TRANSACTION. Иногда я вижу на форумах людей, которые спрашивают, могут ли они написать триггер, который не откатывает в случае падения запустившую его команду
Ответ таков: нет способа сделать это надежно, поэтому не стоит даже пытаться. Если в этом есть необходимость, по возможности не следует использовать триггер вообще, а найти другое решение. Во второй и третьей частях я рассматриваю обработку ошибок в триггерах более подробно.
Клиентский код
У вас должна быть обработка ошибок в коде клиента, если он имеет доступ к базе. То есть вы должны всегда предполагать, что при любом вызове что-то может пойти не так. Как именно внедрить обработку ошибок, зависит от конкретной среды.
Здесь я только обращу внимание на важную вещь: реакцией на ошибку, возвращенную SQL Server, должно быть завершение запроса во избежание открытых бесхозных транзакций:
Это также применимо к знаменитому сообщению Timeout expired (которое является не сообщением от SQL Server, а от API).
Почему надо бить тревогу
Для начала, давайте разберемся, что же такое представляет собой ошибка «В данной транзакции уже происходили ошибки». Это, на самом деле, предельно простая штука: вы пытаетесь работать с базой данных внутри уже откаченной (отмененной) транзакции. Например, где-то был вызван метод ОтменитьТранзакцию, а вы пытаетесь ее зафиксировать.
Почему это плохо? Потому что данная ошибка ничего не говорит вам о том, где на самом деле случилась проблема. Когда в саппорт от пользователя приходит скриншот с таким текстом, а в особенности для серверного кода, с которым интерактивно не работает человек — это… Хотел написать «критичная ошибка», но подумал, что это buzzword, на который уже никто не обращает внимания…. Это задница. Это ошибка программирования. Это не случайный сбой. Это косяк, который надо немедленно переделывать. Потому что, когда у вас фоновые процессы сервера встанут ночью и компания начнет стремительно терять деньги, то «В данной транзакции уже происходили ошибки» это последнее, что вы захотите увидеть в диагностических логах.
Есть, конечно, вероятность, что технологический журнал сервера (он ведь у вас включен в продакшене, да?) как-то поможет диагностировать проблему, но я сейчас навскидку не могу придумать вариант — как именно в нем найти реальную причину указанной ошибки. А реальная причина одна — программист Вася получил исключение внутри транзакции и решил, что один раз — не карабас «подумаешь, ошибка, пойдем дальше».
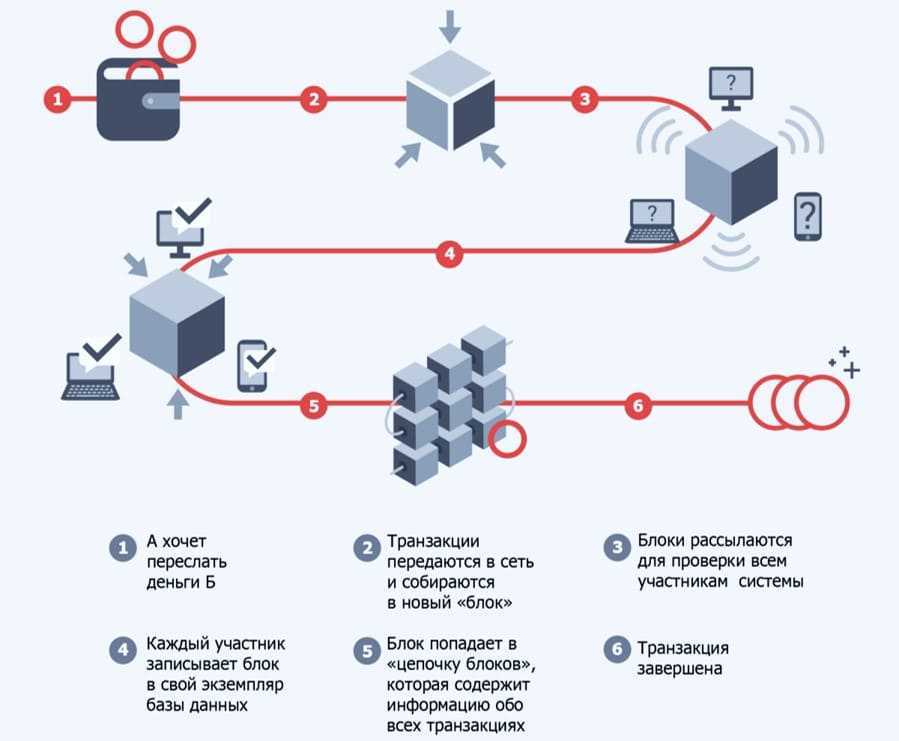
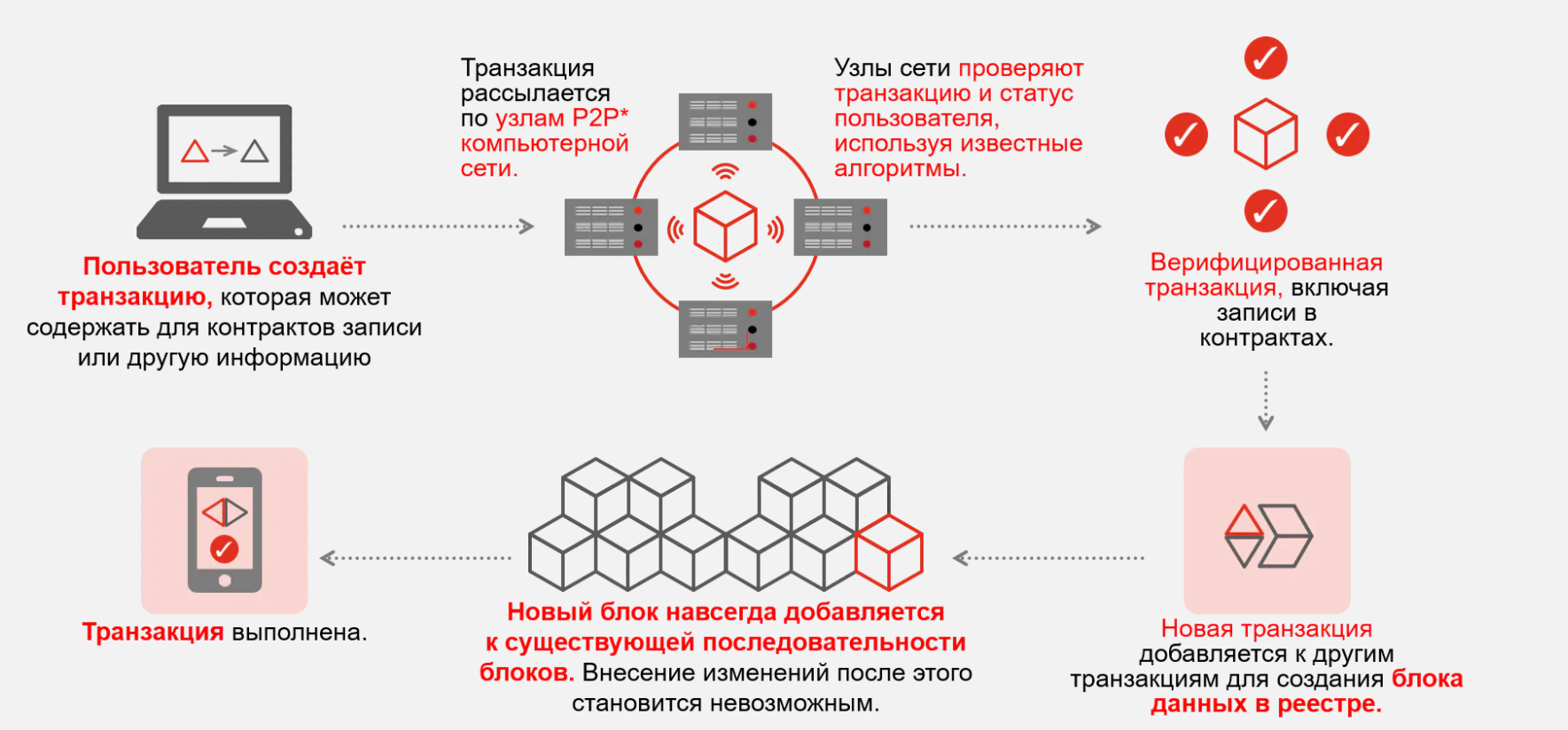
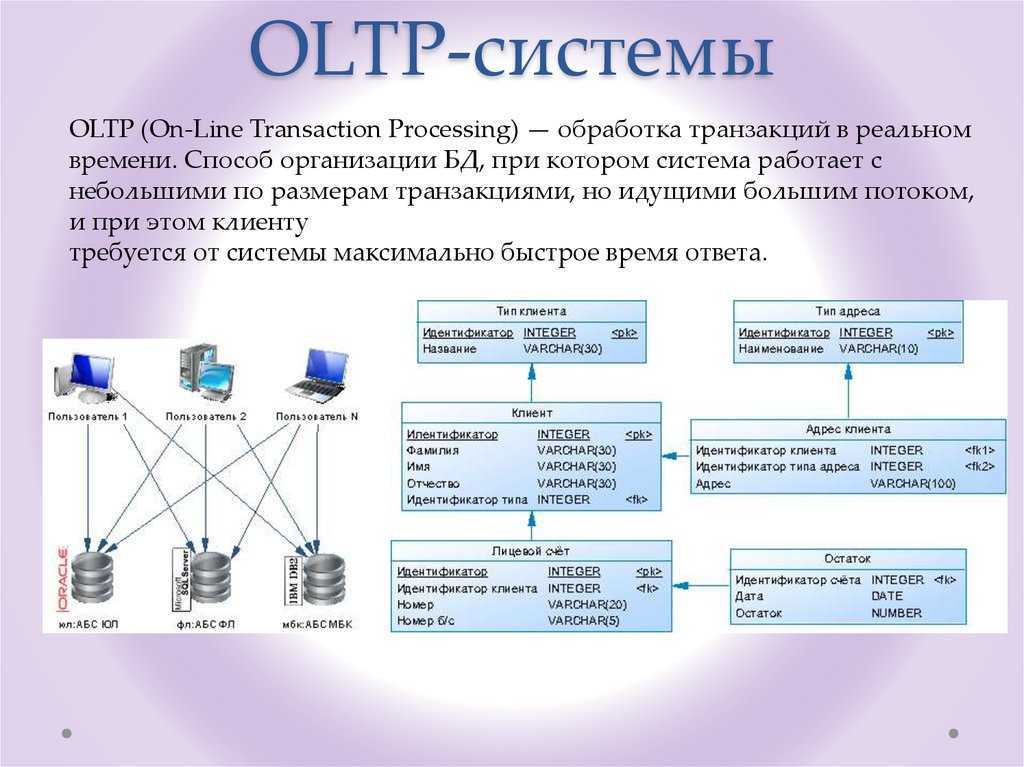
Данные о транзакциях
Данные о транзакциях — это сведения, полученные в результате отслеживания взаимодействий, связанных с деятельностью организации. Как правило, это бизнес-транзакции, например полученные от клиентов платежи, отправленные поставщикам платежи, поступление продуктов на склад или их перемещение со склада, оформленные заказы или предоставленные услуги. События транзакций, которые сами по себе являются транзакциями, обычно содержат измерение времени, некоторые числовые значения и ссылки на другие данные.
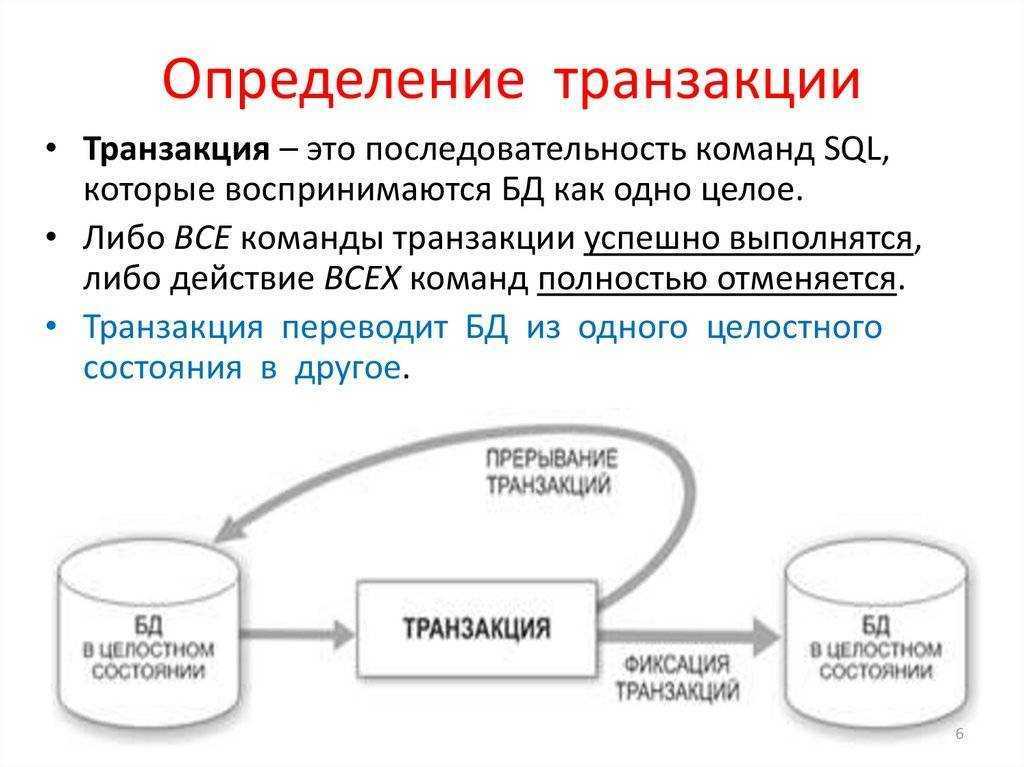
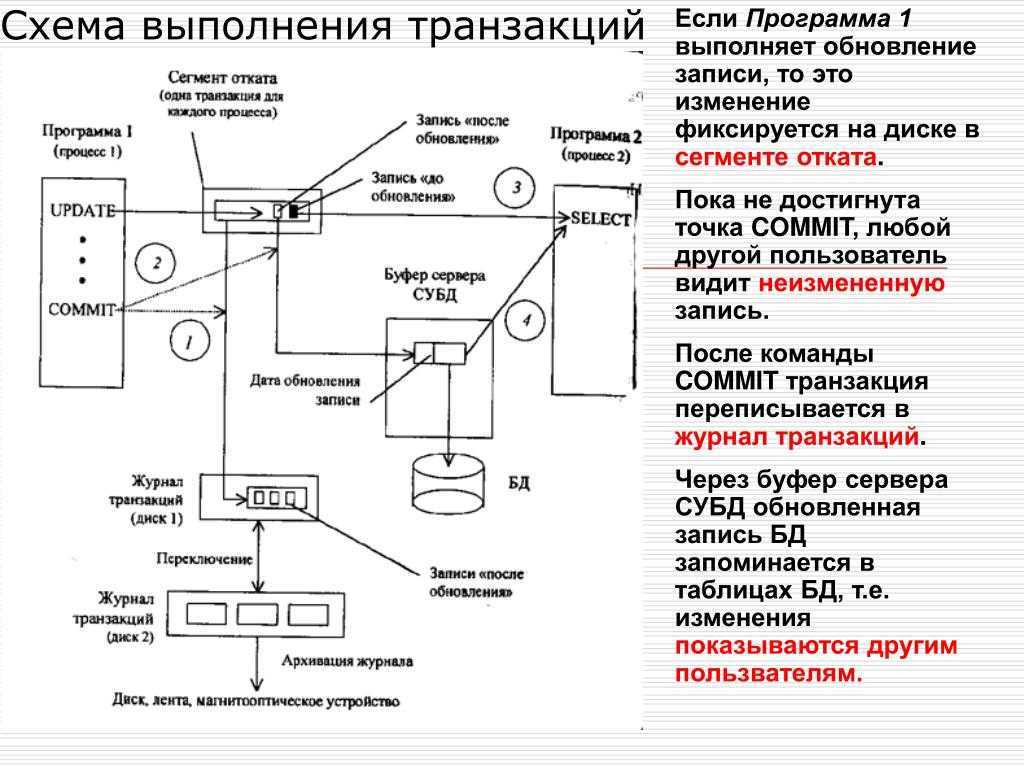
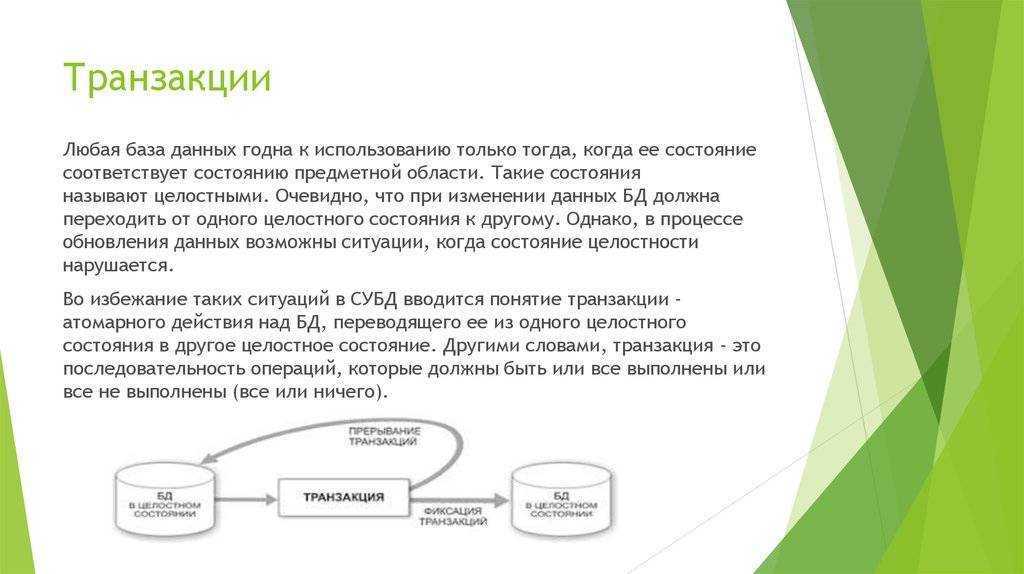
Транзакции обычно должны быть атомарными и согласованными. Атомарность означает, что транзакция всегда полностью завершается успешно либо неудачно как одна элементарная операция и никогда не остается в состоянии частичной завершенности. Если не удается выполнить транзакцию, система базы данных должна откатить все шаги, которые уже выполнены в рамках этой транзакции. В традиционной реляционной СУБД, если не удалось завершить транзакцию, откат происходит автоматически. Согласованность означает, что после выполнения транзакции данные всегда остаются в допустимом состоянии. (Это очень неформальные описания атомарности и последовательности. Существуют более формальные определения этих свойств, например ACID.)


![[перевод] обработка ошибок и транзакций в sql server. часть 1. обработка ошибок – быстрый старт / хабр](https://robotrackkursk.ru/wp-content/uploads/2/f/9/2f91f3f19baa5645f5e28c0325f33a89.jpeg)
В транзакционных базах данных строгая согласованность транзакций может поддерживаться с помощью различных стратегий блокировки, например пессимистической блокировки. Это обеспечивает строгую согласованность всех данных в контексте предприятия для всех пользователей и процессов.
Уровень хранилища данных в трехуровневой архитектуре чаще всего используется для развертываний с использованием данных о транзакциях. Как правило, трехуровневая архитектура состоит из уровня представления, уровня бизнес-логики и уровня хранилища данных. Соответствующая архитектура развертывания — n-уровневая архитектура, в которой может быть несколько средних уровней для бизнес-логики.
Сложности
При реализации и использовании системы OLTP могут возникнуть некоторые сложности:
- Системы OLTP не всегда подходят для обработки статистических выражений при больших объемах данных. Хотя существуют исключения, например хорошо продуманное решение на основе SQL Server. Анализ данных, которые основаны на статистических вычислениях более миллиона отдельных транзакций, является очень ресурсоемким для системы OLTP. Он может медленно выполняться и привести к снижению производительности из-за блокировки других транзакций в базе данных.
- При проведении анализа и создании отчетов по данным с высокой степенью нормализации запросы, как правило, будут сложными, так как для большинства запросов требуется денормализовать данные с помощью соединений. Кроме того, соглашения об именовании для объектов базы данных в системах OLTP, как правило, являются неполными и сжатыми. Из-за высокой нормализации и неполного соглашения об именовании бизнес-пользователям трудно выполнять запросы в системах OLTP без помощи разработчика архитектуры данных или администратора базы данных.
- Бессрочное хранение журналов транзакций и хранение большого количества данных в одной таблице могут снизить производительность запросов в зависимости от числа хранящихся транзакций. Распространенным решением является поддержание соответствующего периода времени (например, текущий финансовый год) в системе OLTP и перезапись данных журнала в другие системы, такие как киоск данных или хранилище данных.
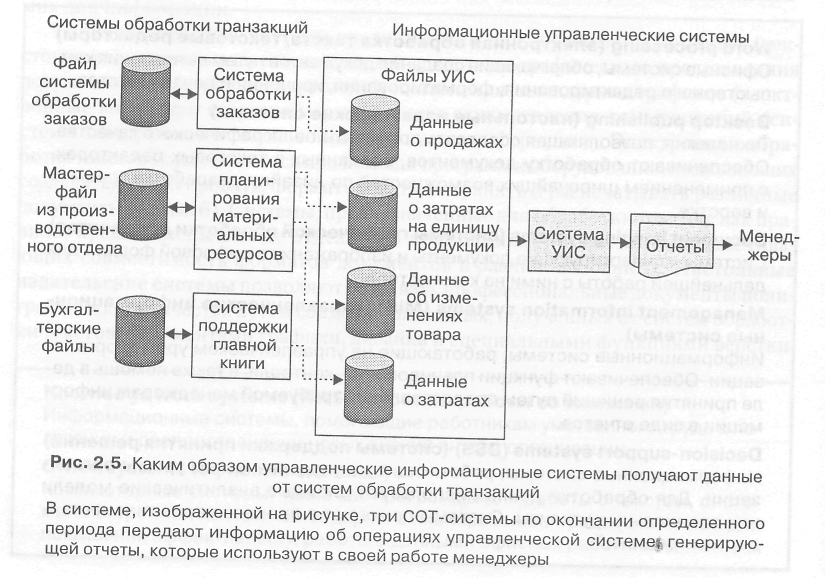
Система обработки транзакций
Система обработки транзакций (TPS) — это система обработки информации для бизнес-транзакций, которая собирает, изменяет и извлекает все данные транзакций. Система обработки транзакций обладает следующими характеристиками: производительность, надежность и согласованность. TPS также связан с обработкой транзакций или обработкой в реальном времени.
Другими словами, изолируя прикладные программы от сложностей управления транзакциями, TPS позволяет программистам приложений сосредоточить свои усилия на написании кода, который приносит пользу бизнесу: он управляет параллельной обработкой многих транзакций. Он также позволяет обмениваться данными. Таким образом, он защищает данные от манипуляций.
Компоненты системы обработки транзакций
Однако каждая система обработки транзакций имеет четыре основных компонента, которые обеспечивают ее правильное функционирование:
№1. Вход
Ввод — это запрос продукта или платеж, который должен быть оплачен TPS компании третьей стороной. Следовательно, если ваша организация использует пакетную обработку, ваш TPS будет сохранять и обрабатывать группы входных данных. Для сравнения, если ваш бизнес использует систему реального времени, каждый ввод обрабатывается в режиме реального времени. Типичные входные данные включают следующее:
- Счета
- Банкноты
- Купоны
- Индивидуальные заказы
#2. Вывод
Выходные данные TPS — это документы, которые система генерирует после обработки всех входных данных. Это может включать квитанции, хранящиеся в записях компании. Эти документы могут быть полезны при проверке продажи или транзакции. Кроме того, они могут быть важным источником информации для налоговых и других государственных целей. Например, если поставщик отправляет счет вашей компании, вы можете оплатить счет и предоставить поставщику подтверждение оплаты. После пересмотра исходный счет может быть указан как «оплаченный» в TPS компании.
№3. Место хранения
Компонент хранения TPS относится к местонахождению входных и выходных документов бизнеса или цифровой информации. Однако некоторые предприятия хранят эти записи в электронной базе данных. Таким образом, компонент хранения гарантирует, что каждый документ находится в надлежащем порядке, безопасен и может быть извлечен для будущего использования. Например, если поставщик хочет подтвердить, что ваша компания оплатила счет, вы можете найти счет в хранилище вашей системы и определить, произвели ли вы платеж.
№ 4. Обработка
Обрабатывающий компонент системы отвечает за считывание каждого ввода и создание полезного вывода, например квитанции. Этот элемент также может быть полезен для определения входных и выходных данных. Таким образом, сроки обработки зависят от типа TPS, используемого вашим бизнесом.
Подсистема «Инструменты разработчика» v6.54.1 Промо
Интегрированный набор инструментов разработчика:
— консоль кода
— консоль запросов
— консоль построителя отчетов
— консоль компоновки данных
— консоль заданий
— конструктор запроса
— справочник алгоритмов
— исследователь объектов
— интерфейсная панель
— настройка журнала регистрации
— анализ журнала регистрации
— настройка техножурнала
— анализ техножурнала
— подбор и обработка объектов
— редактор объекта БД
— редактор констант
— редактор параметров сеанса
— редактор изменений по плану обмена
— редактор пользователей
— редактор предопределенных
— редактор хранилищ настроек
— динамический список
— поиск дублей и замена ссылок
— контекстная подсказка
— синтакс-помощник
— поиск битых ссылок
— поиск ссылок на объект
— структура хранения БД
— удаление объектов с контролем ссылок
— и прочее
Язык YQL
Реализованные конструкции YQL можно разделить на два класса: data definition language (DDL) и data manipulation language (DML).
Подробнее о поддерживаемых конструкциях YQL можно почитать в документации YQL.
Ниже перечислены возможности и ограничения поддержки YQL в YDB, которые могут быть неочевидны на первый взгляд и на которые стоит обратить внимание:
Допускаются multistatement transactions, то есть транзакции, состоящие из последовательности выражений YQL. При выполнении транзакции допускается взаимодействие с клиентской программой, иначе говоря, взаимодействие клиента с базой может выглядеть следующим образом: . Стоит отметить, что если тело транзакции полностью сформировано до обращения к базе данных, то транзакция может обрабатываться эффективнее.
В YDB не поддерживается возможность смешивать DDL и DML запросы в одной транзакции. Традиционное понятие ACID транзакции применимо именно к DML запросам, то есть к запросам, которые меняют данные. DDL запросы должны быть идемпотентными, то есть повторяемы в случае ошибки. Если необходимо выполнить действие со схемой, то каждое из действий будет транзакционно, а набор действий — нет.
Реализация YQL в YDB использует механизм Optimistic Concurrency Control. На затронутые в ходе транзакции сущности ставятся оптимистичные блокировки, при завершении транзакции проверяется, что блокировки не были инвалидированы
Оптимистичность блокировок выливается в важное для пользователя свойство — в случае конфликта выигрывает транзакция, которая завершается первой. Конкурирующие транзакции завершатся с ошибкой .
Все изменения, производимые в рамках транзакции, накапливаются в памяти сервера базы данных и применяются в момент завершения транзакции
Если взятые блокировки не были инвалидированы, то все накопленные изменения применяются атомарно, если хотя бы одна блокировка была инвалидирована, то ни одно из изменений не будет применено. Описанная схема накладывает некоторые ограничения: объем изменений осуществляемых в рамках одной транзакции должен умещаться в память и транзакция «не видит» своих изменений.
Следует формировать транзакцию таким образом, чтобы в первой части транзакции выполнялись только чтения, а во второй части транзакции только модификации. Структура запроса тогда выглядит следующим образом:
Подробнее о поддержке YQL в YDB можно прочитать в документации YQL.
Примеры транзакций в T-SQL
Давайте рассмотрим примеры транзакций, реализованные на языке T-SQL.
Исходные данные для примеров
Но сначала нам необходимо создать тестовые данные для нашего примера.
Для этого выполните следующую инструкцию.
--Создание таблицы
CREATE TABLE Goods (
ProductId INT IDENTITY(1,1) NOT NULL,
ProductName VARCHAR(100) NOT NULL,
Price MONEY NULL,
);
--Добавление данных в таблицу
INSERT INTO Goods(ProductName, Price)
VALUES ('Системный блок', 50),
('Клавиатура', 30),
('Монитор', 100);
SELECT ProductId, ProductName, Price
FROM Goods;
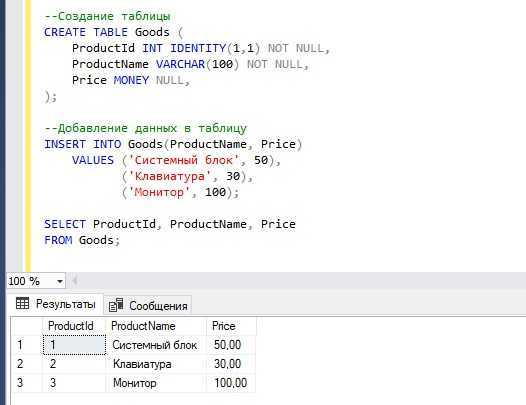
Простой пример транзакции в T-SQL
В данном примере у нас всего две инструкции, которые изменяют данные, но допустим, что они взаимосвязаны, т.е. они обе обязательно должны выполниться вместе или не выполниться также вместе.
Поэтому мы решили эти инструкции объединить в одну транзакцию.
Сначала мы открываем транзакцию командой BEGIN TRANSACTION, далее пишем все необходимые инструкции, которые мы хотим объединить в транзакцию.
После этого командой COMMIT TRANSACTION мы сохраняем все внесенные изменения.
В данном случае у нас нет никаких ошибок, все инструкции выполнились успешно. Как результат, транзакция завершена также успешно и все изменения сохранены на постоянной основе командой COMMIT TRANSACTION.
BEGIN TRANSACTION --Инструкция 1 UPDATE Goods SET Price = 70 WHERE ProductId = 1; --Инструкция 2 UPDATE Goods SET Price = 40 WHERE ProductId = 2; COMMIT TRANSACTION SELECT ProductId, ProductName, Price FROM Goods;
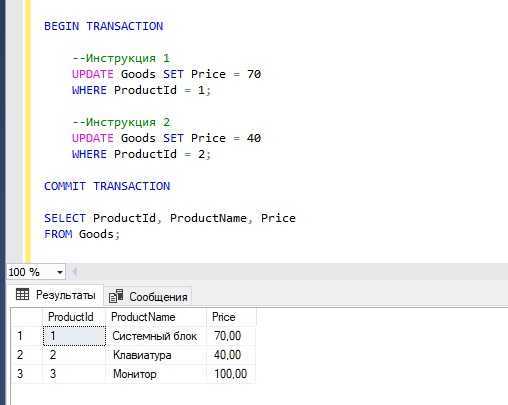
Однако, если в любой из инструкций возникнет ошибка, транзакция не завершится, и все изменения не сохранятся.
Например, если во второй инструкции мы попытаемся записать в столбец Price какое-нибудь текстовое значение, то у нас возникнет ошибка, и изменения, внесённые первой инструкцией, не зафиксируются на постоянной основе.
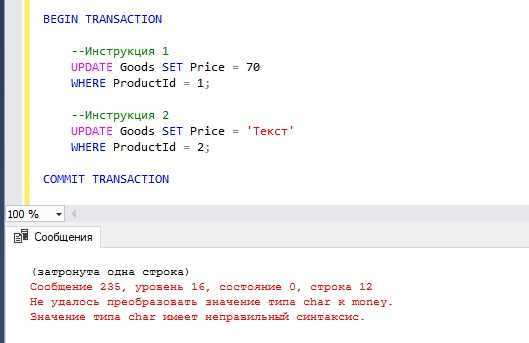
Пример транзакции в T-SQL с обработкой ошибок
В языке T-SQL существует механизм перехвата и обработки ошибок – конструкция TRY… CATCH.
Эту конструкцию можно использовать для отслеживания появления возможных ошибок внутри транзакции и в случае появления таких ошибок предпринять определенные действия.
Сначала мы открываем блок для обработки ошибок, затем открываем транзакцию командой BEGIN TRANSACTION, далее пишем наши инструкции, например, те же самые две инструкции UPDATE.
После этого закрываем блок TRY, открываем блок CATCH, в котором в случае возникновения ошибки мы откатываем все изменения командой ROLLBACK TRANSACTION. Также мы принудительно завершаем нашу инструкцию командой RETURN.
Если ошибок нет, то в блок CATCH мы, соответственно, не попадаем и у нас выполнится команда COMMIT TRANSACTION, которая сохранит все изменения.
В этом примере нет ошибок, поэтому транзакция завершена успешно.
BEGIN TRY
--Начало транзакции
BEGIN TRANSACTION
--Инструкция 1
UPDATE Goods SET Price = 70
WHERE ProductId = 1;
--Инструкция 2
UPDATE Goods SET Price = 40
WHERE ProductId = 2;
END TRY
BEGIN CATCH
--В случае непредвиденной ошибки
--Откат транзакции
ROLLBACK TRANSACTION
--Выводим сообщение об ошибке
SELECT ERROR_NUMBER() AS ,
ERROR_MESSAGE() AS
--Прекращаем выполнение инструкции
RETURN
END CATCH
--Если все хорошо. Сохраняем все изменения
COMMIT TRANSACTION
GO
SELECT ProductId, ProductName, Price
FROM Goods;
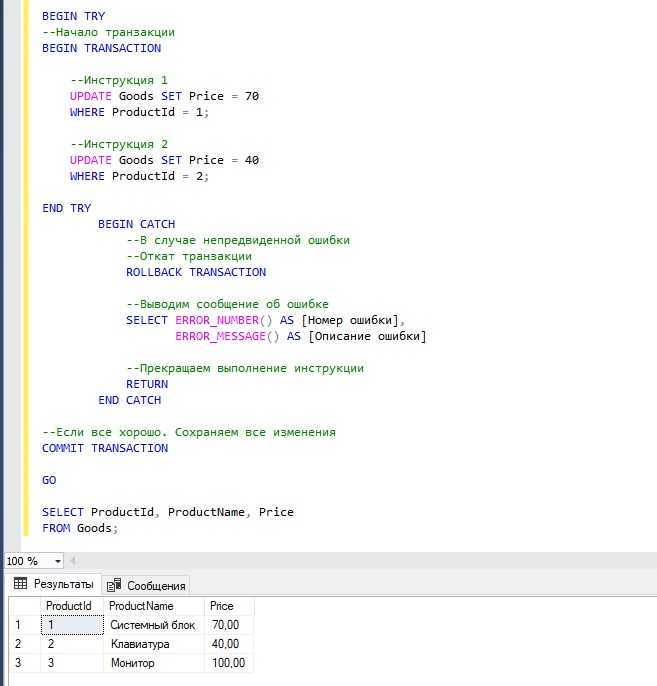
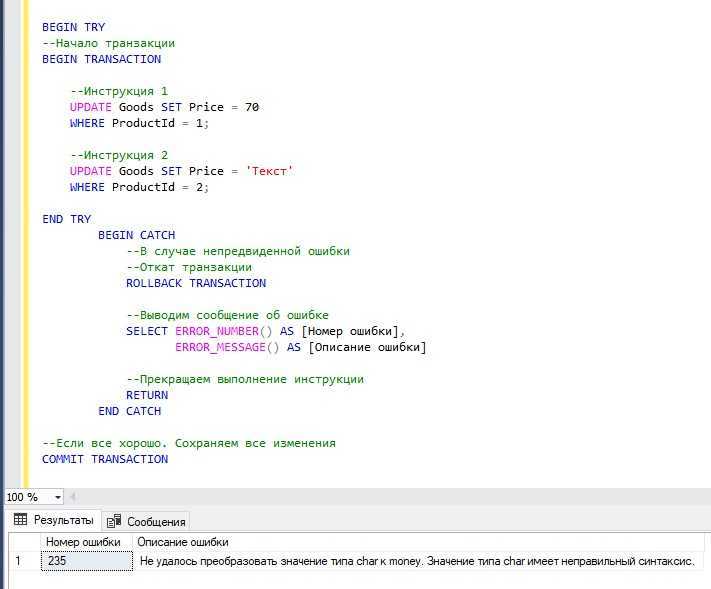
А в этом примере мы намерено допускаем ошибку во второй инструкции. Поэтому управление передается в блок CATCH, где мы откатываем все изменения, возвращаем номер и описание ошибки и принудительно завершаем всю инструкцию командой RETURN.
Первая инструкция отработала нормально, но ее изменения не были сохранены, так как вторая инструкция выполнена с ошибкой.
Обработка ошибок и прерывание транзакций
Отличительная особенность транзакций — возможность их прерывания и безопасного повторного выполнения в случае возникновения ошибки. На этом принципе построены базы данных ACID: при возникновении риска нарушения гарантий атомарности, изоляции или сохраняемости БД скорее полностью отменит транзакцию, чем оставит ее незавершенной.
Но не все системы следуют этой стратегии. В частности, хранилища данных, использующие репликацию без ведущего узла, работают более или менее на основе принципа «лучшее из возможного». Он формулируется следующим образом: «База данных делает все, что может, и при столкновении с ошибкой не станет откатывать уже выполненные действия», поэтому восстановление после ошибок является обязанностью приложения.
Хотя повторение прерванных транзакций — простой и эффективный механизм обработки ошибок, он имеет недостатки:
-
Если причина ошибки — в перегруженности, то повтор транзакции только усугубит проблему.
-
Имеет смысл повторять выполнение транзакций только для временных ошибок (происходящих, например, из-за взаимной блокировки, нарушения изоляции, временных проблем с сетью или восстановления после сбоя). Попытка повтора выполнения при постоянной ошибке (допустим, при нарушении ограничения) бессмысленна.
-
Если у транзакции есть побочные действия вне базы данных, то они могут выполняться даже в случае ее прерывания. Например, вряд ли вы захотите повторять отправку сообщения электронной почты при каждой попытке повтора транзакции.
-
В случае, когда транзакция была выполнена успешно, но произошел сбой сети при подтверждении клиенту ее успешной фиксации (вследствие чего клиент думает, что она завершилась неудачей), повтор приведет к выполнению этой транзакции дважды.
Описание формата внутреннего представления данных 1С в контексте обмена данными
Фирма 1С не рекомендует использовать внутреннее представление данных для любых целей, которые отличны от обмена с 1С:Предприятием 7.7. Но сама возможность заглянуть на «внутреннюю кухню» платформы с помощью функций ЗначениеВСтрокуВнутр(), ЗначениеВФайл(), ЗначениеИзСтрокиВнутр() и ЗначениеИзФайла(), дала возможность сообществу программистов 1С разработать новые приемы разработки и анализа.
Так, именно на использовании внутреннего представления был построен алгоритм «быстрого массива», который позволяет практически мгновенно создать массив в памяти на основании строки с разделителями. С помощью разбора внутреннего представления можно «на лету» программным кодом выполнить анализ обычной формы и даже сделать редактор графической схемы. Во внутреннем формате сохраняют свои данные между сеансами различные популярные внешние обработки. А еще это возможность сделать быстрый обмен с внешними системами.
1 стартмани
Обработка распределенных транзакций в микросервисной архитектуре +13
- 07.10.20 07:15
•
ph_piter
•
#522366
•
Хабрахабр
•
Перевод
•
•
5600
Программирование, Распределённые системы, Блог компании Издательский дом «Питер», Исследования и прогнозы в IT, Микросервисы
Рекомендация: подборка платных и бесплатных курсов 3D max — https://katalog-kursov.ru/
Привет, Хабр!
Сегодня мы предлагаем вашему вниманию небольшой материал о микросервисах и распределенной архитектуре. Он, в частности, затрагивает идею Мартина Фаулера о том, что новая система должна начинаться с монолита, а даже в развитой микросервисной архитектуре целесообразно оставлять большое монолитное ядро.
Приятного чтения!
Сегодня все только и размышляют о микросервисах, а также пишут их – и я не исключение. Если исходить из базовых принципов микросервисов и их истинного контекста, то понятно, что микросервисы – это распределенная система.



