
Введение в проблематику
Автоматическое реферирование текста – одно из классических направлений компьютерной лингвистики. Сейчас в связи с постоянным ростом объёмов информации проблема автоматического создания кратких и содержательных рефератов становится ещё более актуальной. Для решения задач автоматического реферирования проводятся ежегодные открытые тестирования, на которые международные коллективы могут присылать свои системы – о них расскажем чуть позже.
Автоматическое реферирование научных статей – одно из активно развивающихся направлений автоматического реферирования текстов. Для исследователей проблема особо актуальна, так как в последнее время появляется всё больше научных статей, и прочитать их все от начала до конца невозможно.
Реферат помогает сэкономить время и силы, предоставляет исследователю самую важную, ключевую, информацию, содержащуюся в статье, позволяет определить, релевантна ли эта статья для исследуемого поля деятельности и научных интересов, стоит ли читать её в оригинале. Кроме того, рефераты отдельных статей и сводные рефераты по какой-либо тематике (охватывающие сразу несколько статей — например, все классические работы, или работы, ознаменовавшие определённые вехи в развитии данного направления, или авторитетные работы в хронологическом порядке) становятся незаменимыми помощниками для тех исследователей, которые планируют перейти из одной научной области в другую.
Для получения автоматических рефератов научных статей до недавнего времени использовались те же методы, что и для простого автоматического реферирования текста. Однако стоит заметить, что научные статьи – это отдельный жанр со своей спецификой, следовательно, целесообразно развивать методы автоматического реферирования, подходящие именно для научных статей. Так, любой научный труд не находится в вакууме (в принципе, это относится и ко многим другим типам и жанрам текстов: например, твиты всегда сопровождаются большим количеством комментариев и ответных твитов; разные новостные статьи могут описывать одно и то же событие), а связан с другими статьями, в частности с помощью цитат и ссылок. Как правило, цитируются самые важные идеи, методы, результаты. Отсюда возникает идея использовать ссылки для извлечения наиболее релевантных предложений, текстовых отрезков из статьи, подвергающейся цитированию, чтобы в дальнейшем использовать извлечённый материал при создании автоматического реферата.
Предварительная текстовая обработка
Сложные естественные языки, к примеру, русский язык, имеют много различных форм одного и того же слова (в разных падежах), и в словарь частотного анализа попадают все словесные формы, которые отличаются разными предлогами и/или окончаниями. Это обстоятельство способно значительно увеличить объём словаря, и вместе с этим объём набора данных, предназначенных для обучения. Это вызовет снижение производительности системы и ухудшение обобщающих способностей классификаторов. Возможны разные варианты решения этой проблемы. Первым вариантом является лематизация, то есть приведение всех слов в тексте к нормальному формату (слово в единственном числе и именительном падеже). Лематизация предполагает наличие языковых словарей, на которых выполнен текстовый документ. Она осуществляет нахождение для всех слов, встречающихся в тексте, их нормализованного формата при помощи словарей, но это способно также уменьшать производительность.
Вторым методом является стеминг, то есть определение основания слов методом удаления приставок и окончаний. Данный метод, нормализующий текст, действует существенно более быстро, чем лематизация. Правда качество у него ниже, но для выполнения частотного анализа его хватает.
Программы для работы с неструктурированными данными
На рынке широко представлены программы для изучения неструктурированных данных. Среди популярных продуктов разработки компании Hewlett-Packard, но можно найти решения от других вендоров.
HP Storage Optimizer
Программа призвана решить задачи, связанные с оптимизацией хранения, она подойдет системным администраторам и лицам, отвечающим за сохранность данных.
В ней реализованы две функции:
- Изучение метаданных объектов в библиотеках и репозиториях НД.
- Присвоение меток и определение политик иерархического хранения.
Под репозиторием разработчики программы подразумевают место хранения анализируемой информации, это могут быть базы данных, файлы, MS Exchange, MS SharePoint, Hadoop (утилита для создания библиотек с открытым кодом), Lotus Notes, системы электронного документооборота. Разработчики предусмотрели возможность доработки ПО, если данные находятся в приложении, взаимодействие с которым в программе пока не предусмотрено, это делается по отдельному заказу.
Компоненты программы:
- коннекторы. Они от имени приложения взаимодействуют с репозиториями данных;
- Connector Framework Server, который получает информацию от коннекторов, снабжает метаданными (метками, содержащими информацию о характере данных) и направляет на индексирование, облегчающее дальнейший поиск.
После индексации информация хранится в базе данных MS SQL. Отчет о результатах работы генерируется в виде круговой диаграммы, в секторах которой указывается процент ненужных и редко востребованных данных, дубликатов. Критерии востребованности и ненужности настраиваются вручную на основании политик по работе с данными каждой организации. Также есть отчеты в виде графиков, анализирующих данные по времени добавления, типам, частоте обновления.
По результатам работы системному администратору предлагается настроить политики удаления или перемещения неструктурированных данных в автоматическом или ручном режиме.
HP Control Point
Продукт по работе с неструктурированными данными станет удачным решением для служб информационной безопасности. Он обеспечит комплексное изучение сведений и файлов, содержащихся в корпоративных информационных системах, и снизит бизнес-риски, связанные с хранением неизученных или избыточных НД.
В программе есть следующие функции:
- оптимизация хранения;
- разработка и внедрение политик хранения данных;
- управление жизненным циклом информации компании.
ПО способно анализировать информацию не только по метаданным, но и по содержимому. Информация индексируется и относится к определенной категории не только по меткам, но и по смыслу.
В качестве средств визуализации предлагаются кластерная карта и спектрограф. Один кластер содержит информацию, относящуюся к определенной группе. Просмотреть данные, отнесенные к определенному кластеру, можно в диаграмме.
Спектрограф покажет эволюцию кластеров во времени, графически отображая изменения объема и содержания входящей в него информации. Опция категоризации мобильна, на первом этапе это происходит автоматически, средствами HP IDOL, далее администратор может сам назначать политики разбиения данных на разные группы. По результатам работы программа предлагает принять решение по судьбе файлов, содержащих неструктурированные данные.
Помимо удаления или перемещения, можно:
- «заморозить» объект. Он находится в прежнем месте хранения, но никто из пользователей не вправе изменить или удалить его;
- создать рабочий процесс (workflow). Это значит, что перед тем, как файл будет перемещен или удален, об этом будет оповещен пользователь, указанный в качестве его владельца, и он сможет повлиять на судьбу интересующих его данных.
Перенос данных может производиться в безопасном режиме: они временно перемещаются в систему управления корпоративными записями HP Records Manage и маркируются метаданными, определяющими настройки конфиденциальности.
Основные методы систематизации информации
Систематизация информации подразумевает её переработку для формирования определённого её вида, а также выполнение интерпретации информации, что даёт возможность каждому пользователю правильно воспринимать полученную информацию. Обработанная информация располагается по определённым правилам, имеет вполне завершённый формат, что придаёт ей логический смысл и значение. При обработке информации формируются законченные образы, которые люди способны распознавать и понимать правильно. Всё это сопровождается процессом приведения набора сигналов информации до неких простых образных категорий.
Можно выделить три правила как надо обрабатывать информацию, чтобы получить образы:
- Необходимо установить правильное соотношение фигур и фоновой информации.
- Образы необходимо завершать.
- Надо установить приблизительность и сходство.
При формировании баланса фигуры и фона в информационной картине надо выделить, собственно, фигуру, то есть основной смысл картины (образ). И конечно, то что не есть фигура, становится фоном. Чаше всего фигуру можно выделить очень просто, но есть случаи, когда нет чётких границ между фигурой и фоном. Тогда есть вероятность, что после обработки информации, она может кардинально поменять свой образ, и соответственно будет иметь иное смысловое значение. Иногда процедура обработки информации способна привести к формированию неправильных (ложных) образов и неправильной интерпретации действий других людей и, кроме того, вызывать неправильное понимание человеком действий, идущих в его адрес из внешнего окружения.

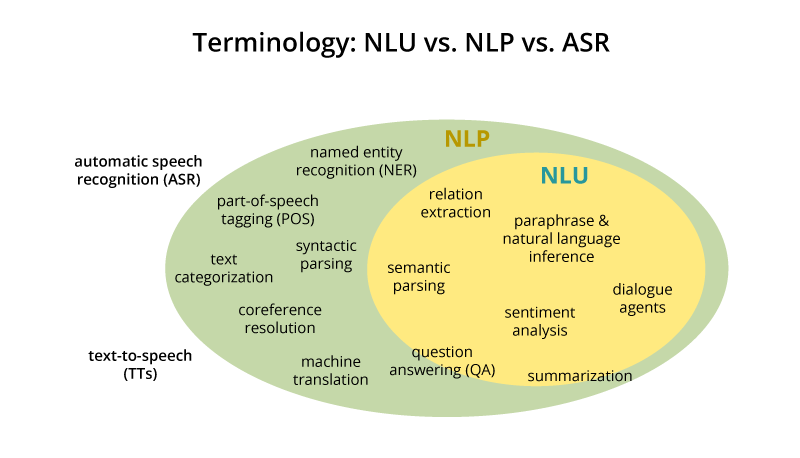
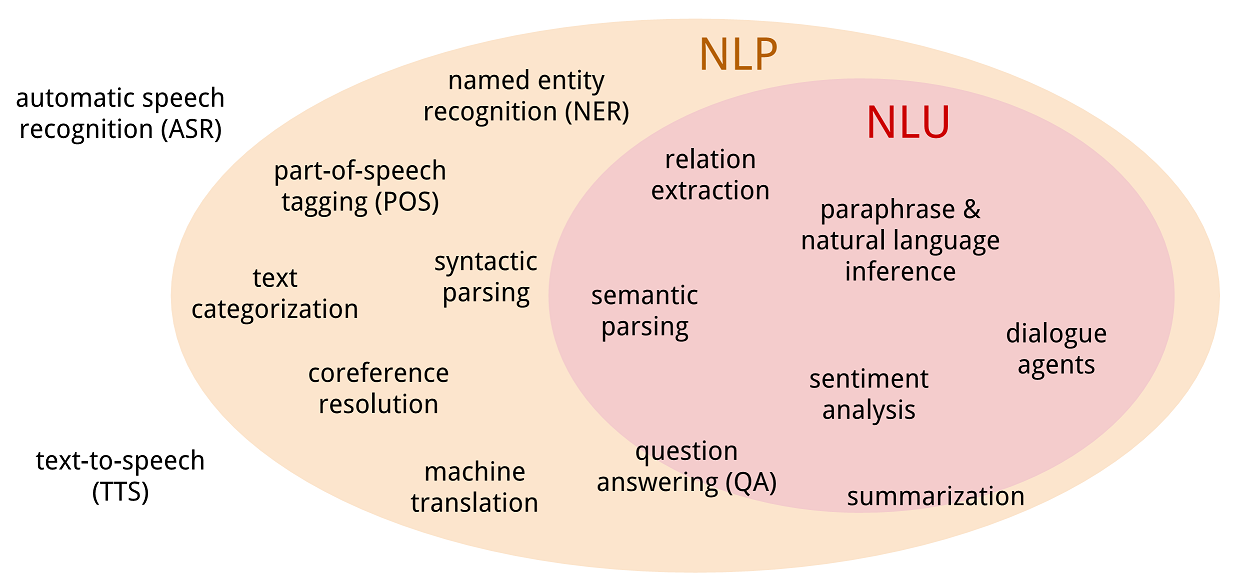

Люди обычно систематизируют информацию двумя методами:
- Метод обработки информации на основе логики. Он основан на систематическом и последовательном преобразовании информации на базе операций логики. Этот метод так же называют научной обработкой информации. Но люди способны не только к логической обработке информации, что позволяет выполнять адекватные ответные действия при получении внешних воздействий.
- Метод обработки информации на уровне чувств. Эмоциональные реакции человека предопределяют обработку информации на основе понятий, люблю — не люблю, плохо — хорошо и так далее.
Восприятие окружающего мира человеком во многом неоднозначный, достаточно непростой и быстро текущий процесс. Неправильно представлять себе, что этапы сбора, переработки и идентификации информации чётко разделены и идут друг за другом в строго заданном формате и по единой структуре. Выработка решения основывается на разнотипной информации.
Векторное представление (text embeddings)
В традиционном NLP слова рассматриваются как дискретные символы, которые далее представляются в виде one-hot векторов. Проблема со словами — дискретными символами — отсутствие определения cхожести для one-hot векторов. Поэтому альтернатива — обучиться кодировать схожесть в сами векторы.
Векторное представление — метод представления строк, как векторов со значениями. Строится плотный вектор (dense vector) для каждого слова так, чтобы встречающиеся в схожих контекстах слова имели схожие вектора. Векторное представление считается стартовой точкой для большинства NLP задач и делает глубокое обучение эффективным на маленьких датасетах. Техники векторных представлений Word2vec и GloVe, созданных Google (Mikolov) Stanford (Pennington, Socher, Manning) соответственно, пользуются популярностью и часто используются для задач NLP. Давайте рассмотрим эти техники.
Word2Vec
Word2vec принимает большой корпус (corpus) текста, в котором каждое слово в фиксированном словаре представлено в виде вектора. Далее алгоритм пробегает по каждой позиции t в тексте, которая представляет собой центральное слово c и контекстное слово o. Далее используется схожесть векторов слов для c и o, чтобы рассчитать вероятность o при заданном с (или наоборот), и продолжается регулировка вектор слов для максимизации этой вероятности.
Для достижения лучшего результата Word2vec из датасета удаляются бесполезные слова (или слова с большой частотой появления, в английском языке — a,the,of,then). Это поможет улучшить точность модели и сократить время на тренировку. Кроме того, используется отрицательная выборка (negative sampling) для каждого входа, обновляя веса для всех правильных меток, но только на небольшом числе некорректных меток.
Word2vec представлен в 2 вариациях моделей:
- Skip-Gram: рассматривается контекстное окно, содержащее k последовательных слов. Далее пропускается одно слово и обучается нейронная сеть, содержащая все слова, кроме пропущенного, которое алгоритм пытается предсказать. Следовательно, если 2 слова периодически делят cхожий контекст в корпусе, эти слова будут иметь близкие векторы.
- Continuous Bag of Words: берется много предложений в корпусе. Каждый раз, когда алгоритм видим слово, берется соседнее слово. Далее на вход нейросети подается контекстные слова и предсказываем слово в центре этого контекста. В случае тысяч таких контекстных слов и центрального слова, получаем один экземпляр датасета для нашей нейросети. Нейросеть тренируется и ,наконец, выход закодированного скрытого слоя представляет вложение (embedding) для определенного слова. То же происходит, если нейросеть тренируется на большом числе предложений и словам в схожем контексте приписываются схожие вектора.
Единственная жалоба на Skip-Gram и CBOW — принадлежность к классу window-based моделей, для которых характерна низкая эффективность использования статистики совпадений в корпусе, что приводит к неоптимальным результатам.
GloVe
GloVe стремится решить эту проблему захватом значения одного word embedding со структурой всего обозримого корпуса. Чтобы сделать это, модель ищет глобальные совпадения числа слов и использует достаточно статистики, минимизирует среднеквадратичное отклонение, выдает пространство вектора слова с разумной субструктурой. Такая схема в достаточной степени позволяет отождествлять схожесть слова с векторным расстоянием.
Помимо этих двух моделей, нашли применение много недавно разработанных технологий: FastText, Poincare Embeddings, sense2vec, Skip-Thought, Adaptive Skip-Gram.
Интеллектуальный анализ НД
Бизнес-аналитика только на основе числовых рядов уходит в прошлое, сейчас программы, на основании которых принимаются управленческие решения, работают с неструктурированными данными и текстовой информацией.
Для достижения лучшего результата используются следующие виды анализа:
- интеллектуальный анализ данных (data mining);
- обработка естественного языка (Natural Language Processing);
- интеллектуальное изучение текста.
Эти типы исследований данных нацелены на поиск закономерностей, служащих предпосылками для выводов, имеющих значение для бизнеса.
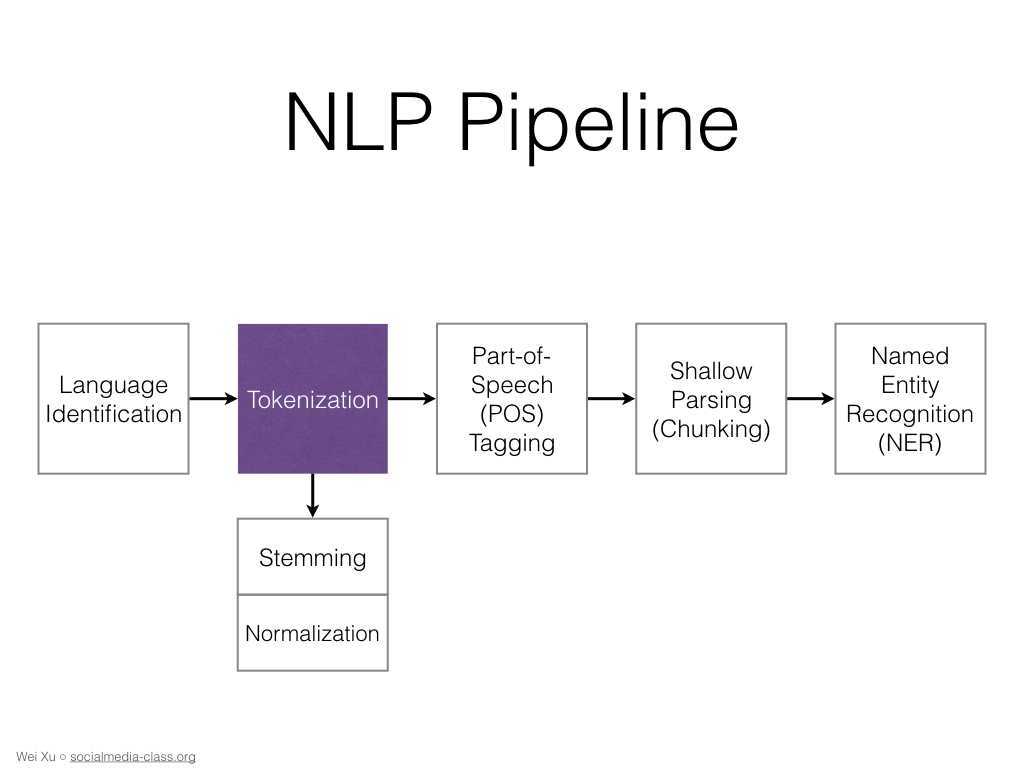
Первым этапом работы программного обеспечения с данными является структурирование. Оно происходит путем поиска и нахождения общих смысловых единиц, характерных для речи или текста, например, частей речи или иных лингвистических или аудиальных структур.
Среди решений, обеспечивающих изучение неструктурированных данных с использованием метода естественного языка и интеллектуального анализа, называют:
- IBM Watson – программа на базе искусственного интеллекта получает вопросы на естественном языке и ищет на них ответы среди неструктурированных данных с использованием технологий ИИ;
- ABBYY FlexiCapture – программа для интеллектуальной работы с НД;
- SPSS Statistics, предлагающая статистические методы исследования НД для общественных наук.
Если ранее неструктурированные данные являлись проблемой, пугали своим количеством, неподконтрольностью и недоступностью для использования в качестве базы для принятия решений, то сегодняшний рынок предлагает достаточно продуктов, способных категоризировать и проанализировать НД.
12.12.2019
Формальное представление задачи
Чтобы решить изложенные выше проблемы, можно использовать методики машинного обучения. Для их применения нужен размеченный текстовый набор Т, предназначенный для системного обучения. То есть каждый учебный текст получает метку фактического класса. Кроме того, следует сделать выбор метода, позволяющего формализовать эти данные, то есть определённым методом сформировать отображение f из текстового набора Т в область признаков Х:
f:T→X
Функция f называется операцией выборки признаков или feature extraction. После определения отображения f и формирования области признаков Х, все тексты из набора Т получат в соответствие точку из области Х. После этого можно использовать все методы математики для подразделения набора точек Х на ряд подмножеств. Таким образом, проблема обнаружения одинаковых текстов становится задачей кластеризации набора точек из области Х, а проблема, состоящая в текстовой сортировке по разным темам, может быть сведена к задаче классификации точек из Х. Говоря формальным языком, требуется сформировать отображение g из набора векторов признаков Х на множестве меток L:
g:X→L
Подводя некоторый итог, можем отметить, что проблема обработки текста может быть поделена на следующие этапы:
- Формирование пространства признаков (выборка признаков).
- Подразделение области признаков на зоны.
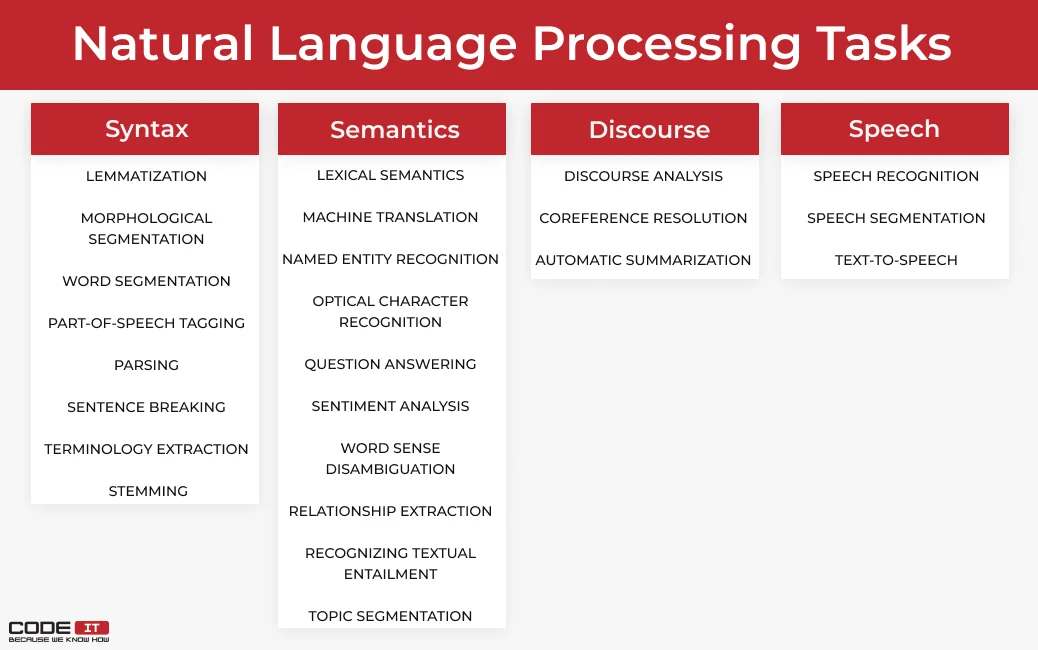
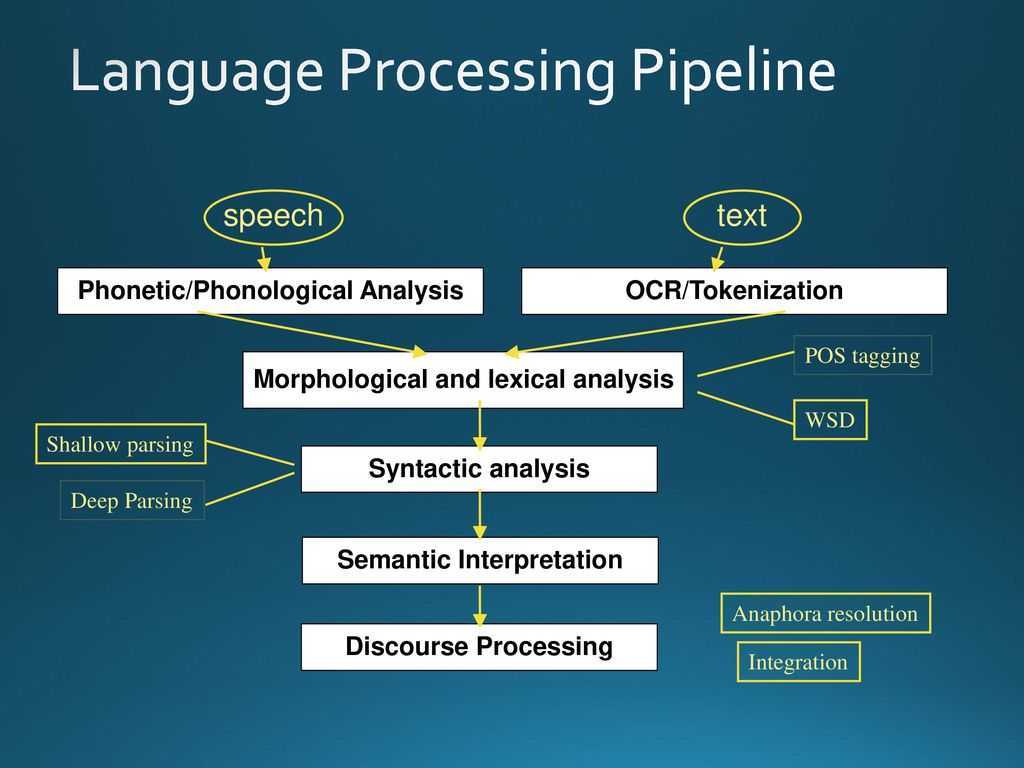
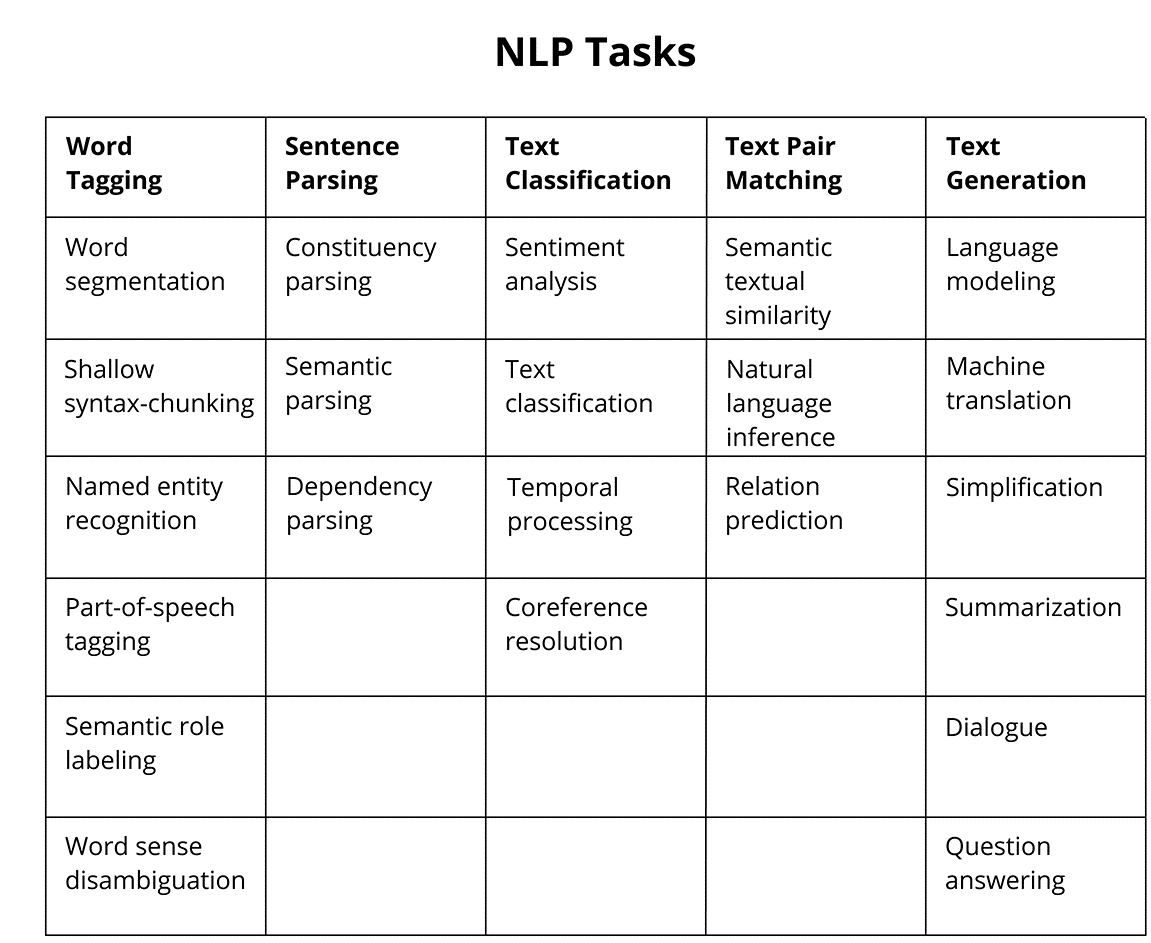
Задачи NLP
Распознавание речи. Этим занимаются голосовые помощники приложений и операционных систем, «умные» колонки и другие подобные устройства. Также распознавание речи используется в чат-ботах, сервисах автоматического заказа, при автоматической генерации субтитров для видеороликов, голосовом вводе, управлении «умным» домом. Компьютер распознает, что сказал ему человек, и выполняет в соответствии с этим нужные действия.
Обработка текста. Человек может также общаться с компьютером посредством письменного текста. Например, через тех же чат-ботов и помощников. Некоторые программы работают одновременно и как голосовые, и как текстовые ассистенты. Пример — помощники в банковских приложениях. В этом случае программа обрабатывает полученный текст, распознает его или классифицирует. Затем она выполняет действия на основе данных, которые получила.
Извлечение информации. Из текста или речи можно извлечь конкретную информацию. Пример задачи — ответы на вопросы в поисковых системах. Алгоритм должен обработать массив входных данных и выделить из него ключевые элементы (слова), в соответствии с которыми будет найден актуальный ответ на поставленный вопрос. Для этого требуются алгоритмы, способные различать контекст и понятия в тексте.
Анализ информации. Это схожая с предыдущей задача, но цель — не получить конкретный ответ, а проанализировать имеющиеся данные по определенным критериям. Машины обрабатывают текст и определяют его эмоциональную окраску, тему, стиль, жанр и др. То же самое можно сказать про запись голоса.
Анализ информации часто используется в разных видах аналитики и в маркетинге. Например, можно отследить среднюю тональность отзывов и высказываний по заданному вопросу. Соцсети используют такие алгоритмы для поиска и блокировки вредоносного контента. В перспективе компьютер сможет отличать фейковые новости от реальных, устанавливать авторство текста. Также NLP применяется при сборе информации о пользователе для показа персонализированной рекламы или использования сведений для анализа рынка.
Генерация текста и речи. Противоположная распознаванию задача — генерация, или синтез. Алгоритм должен отреагировать на текст или речь пользователя. Это может быть ответ на вопрос, полезная информация или забавная фраза, но реплика должна быть по заданной теме. В системах распознавания речи предложения разбиваются на части. Далее, чтобы произнести определенную фразу, компьютер сохраняет их, преобразовывает и воспроизводит. Конечно, на границах «сшивки» могут возникать искажения, из-за чего голос часто звучит неестественно.
Генерация текста не ограничивается шаблонными ответами, заложенными в алгоритм. Для нее используют алгоритмы машинного обучения. «Говорящие» программы могут учиться на основе реальных данных. Можно добиться того, чтобы алгоритм писал стихи или рассказы с логичной структурой, но они обычно не очень осмысленные.
Автоматический пересказ. Это направление также подразумевает анализ информации, но здесь используется и распознавание, и синтез.Задача — обработать большой объем информации и сделать его краткий пересказ. Это бывает нужно в бизнесе или в науке, когда необходимо получить ключевые пункты большого набора данных.
Машинный перевод. Программы-переводчики тоже используют алгоритмы машинного обучения и NLP. С их использованием качество машинного перевода резко выросло, хотя до сих пор зависит от сложности языка и связано с его структурными особенностями. Разработчики стремятся к тому, чтобы машинный перевод стал более точным и мог дать адекватное представление о смысле оригинала во всех случаях.
Машинный перевод частично автоматизирует задачу профессиональных переводчиков: его используют для перевода шаблонных участков текста, например в технической документации.
Морфологический анализ
| Название | Метод | Языки | Лицензия | Платформа |
|---|---|---|---|---|
| словарный | русский, английский, немецкий | LGPL | Linux, Windows | |
| Snowball | алгоритм Портера | русский, английский | BSD | Linux, Windows |
| Stemka | словарный | русский | Собственная | Linux, Windows |
| pymorphy | словарный | русский, английский, немецкий | MIT | Python |
| Myaso | алгоритм Витерби | русский, английский | MIT | Ruby |
| Eureka Engine | машинное обучение | русский | Коммерческая | Веб-сервис |
| машинное обучение | русский, английский | Бесплатная для исследовательских целей + коммерческая | Веб-сервис, Java, Python | |
| русский, английский | LGPLv3 + некоммерческая | Python, C++ | ||
| словарный | русский, английский, немецкий | LGPL | PHP | |
| словарный | русский, английский, украинский | Non-Commercial Freeware | .NET, .NET Core, Java и Python | |
| FreeLing | словарный | русский, англиский, итальянский, испанский, португальский, астурийский, валийский, галисийский, каталанский | GPL + Коммерческая | Linux |
| машинное обучение | английский | Apache License | Python | |
| машинное обучение | английский | MIT | Python | |
| машинное обучение | английский | GPL | Python | |
| правила, регулярные выражения | английский, испанский, немецкий, французский, итальянский, нидерландский | BSD | Python | |
| правила | английский, французский, японский | MIT | Node.js | |
| словарный | русский, английский | MIT | Linux | |
| алгоритм Витерби | английский, корейский | BSD | Linux, Windows | |
| метод опорных векторов | русский, английский | LGPL | Perl | |
| машинное обучение | английский | GPL | Java | |
| машинное обучение | английский, немецкий, арабский, китайский | GPL | Java | |
| словарный | русский | Apache License | Java | |
| словарный | русский | GPL | Java | |
| mystem | словарный | русский | Некоммерческая | Linux, Windows |
| TreeTagger | деревья принятия решений | русский, английский, немецкий, французский, итальянский, нидерландский, испанский, болгарский, греческий, португальский, китайский, суахили, латинский, эстонский | Некоммерческая | Linux, Windows |
| алгоритм Витерби | русский, английский | Некоммерческая | Linux | |
| словарный | русский, украинский | Коммерческая | Windows, Веб-сервис | |
| словарный | русский | Коммерческая | Windows | |
| словарный, правила | русский, английский | Коммерческая | Windows | |
| словарный | русский, английский | Коммерческая | Linux, Windows | |
| словарный | русский, украинский, английский, французский, немецкий, испанский, итальянский, португальский | Коммерческая | Windows | |
| словарный | русский | н/д | Windows | |
| словарный | русский | MIT + некоммерческая | Java on Linux, Windows | |
| машинное обучение, словарный | русский | некоммерческая | .NET on Linux, Windows | |
| машинное обучение, словарный | английский | некоммерческая | .NET on Linux, Windows |
Обработка неструктурированных данных
Задача анализа неструктурированных данных с разной долей успеха решается уже несколько лет. Большинство информации, образующейся в компании или полученной из внешних источников, не структурируется и не проходит специальную подготовку. Около 60% информации, хранящейся на серверах корпораций, не только не является структурированной, она или бесполезна, или копирует уже существующие данные, или не пригодна для применения.
Бессистемное хранение важных сведений способно привести к тому, что персональные данные и другая конфиденциальная информация окажутся в открытом доступе. Поэтому необходимо проанализировать все корпоративные информационные ресурсы на предмет их содержания, условий хранения, соблюдения режима конфиденциальности. Агентство Gartner, один из лидеров мирового рынка в сфере информационных технологий и ERP (англ. Enterprise Resource Planning, планирование ресурсов предприятия), в 2014 году выпустило политику с правилами работы с неструктурированными корпоративными данными, где обозначила конечные цели работы с данными:
- оптимизация хранения данных. Понимание, какие именно массивы информации находятся в распоряжении компании, помогает систематизировать их, удалить лишнее, освободив место на дисках;
- выявление ненужных данных, их ликвидация и перенос корпоративного архива в облако. Агентство рекомендует эту модель работы с корпоративной информацией как оптимальную;
- классификация. Позволит присвоить данным метки конфиденциальности, структурировать по группам, что облегчит их использование в бизнес-процессах;
- выполнение предписаний регулятора по защите персональных данных и внутренних политик информационной безопасности по обеспечению режима конфиденциальности для коммерческой тайны;
- присвоение уровней доступа. Систематизация данных, информационных массивов и присвоение им меток позволят увеличить степень конфиденциальности, структурировав уровни доступа пользователей к данным разных типов;
- упрощение проведения аудита и расследований инцидентов информационной безопасности.
«СёрчИнформ FileAuditor» проводит автоматическую классификацию данных в файловой системе, которые содержат конфиденциальную информацию.
Выборка текстовых признаков
Чтобы сформировать векторы признаков текста, можно использовать методику частотного анализа, а именно считать число повторений всех слов в тексте. Более подробный алгоритм частотного анализа состоит из следующих шагов:
- Сформировать словарь V, который включает все слова, применяемые в обрабатываемых текстах Т.
- Для всех текстов ti ∈T и для всех слов, входящих в словарь, vj ∈V, нужно определить количество вложений xij слова vj в текст ti.
В итоге, можно получить для всех текстов ti ∈T вектор целочисленных неотрицательных значений xi, размер которого равен числу слов в словаре V. Это основной вид методики частотного текстового анализа.
Для различного текстового объёма значение частоты х может иметь большие отличия, то есть чем объёмнее текстовый документ, тем количество повторений конкретного слова может быть больше. Чтобы уменьшить влияние такого эффекта, можно использовать методику нормализованного частотного анализа или TF (term frequency). Согласно этой методике величину частоты х нужно поделить на количество слов в тексте t.
Что такое обработка естественного языка
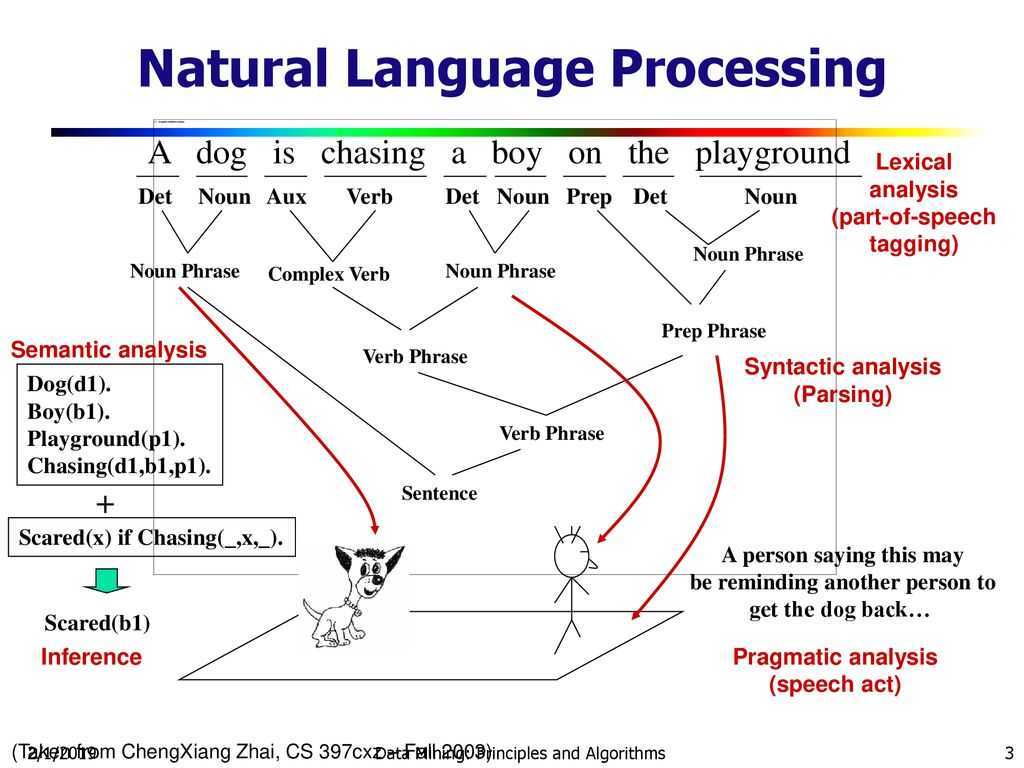
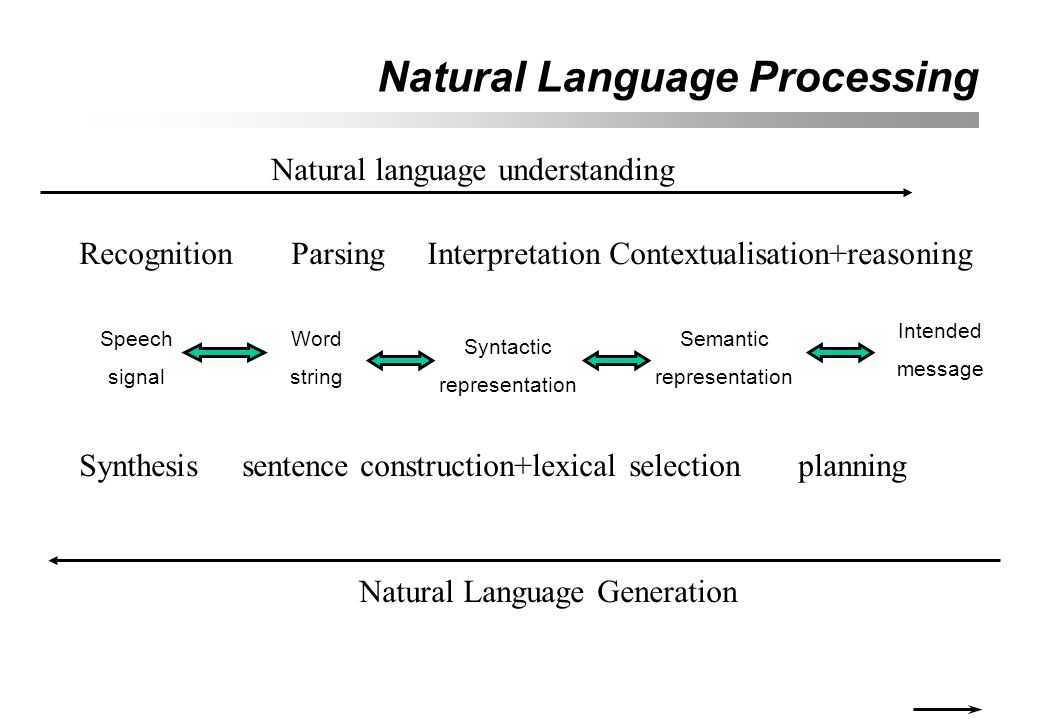
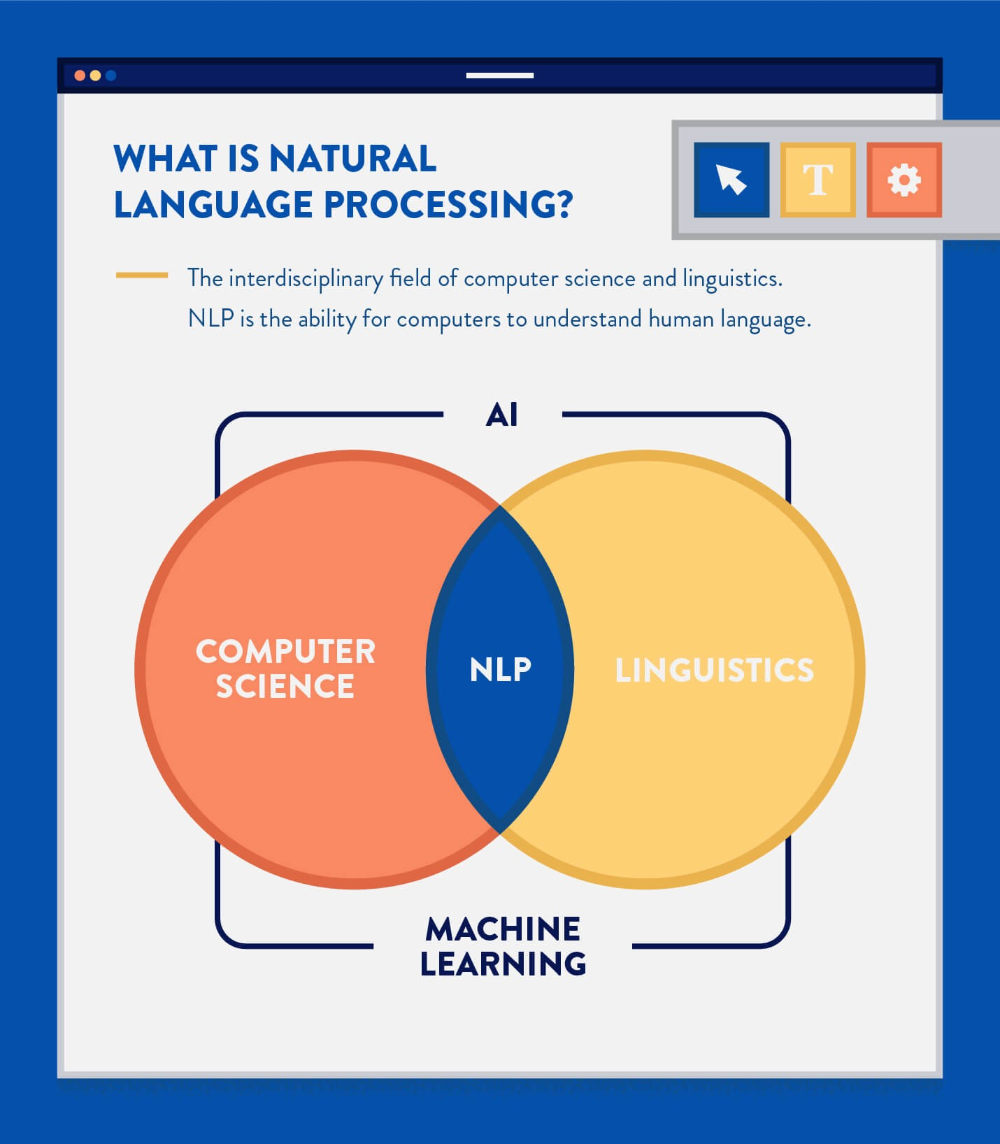
Обработка естественного языка (далее NLP — Natural language processing) — область, находящаяся на пересечении computer science, искусственного интеллекта и лингвистики. Цель заключается в обработке и “понимании” естественного языка для перевода текста и ответа на вопросы.
С развитием голосовых интерфейсов и чат-ботов, NLP стала одной из самых важных технологий искусственного интеллекта. Но полное понимание и воспроизведение смысла языка — чрезвычайно сложная задача, так как человеческий язык имеет особенности:
- Человеческий язык — специально сконструированная система передачи смысла сказанного или написанного. Это не просто экзогенный сигнал, а осознанная передача информации. Кроме того, язык кодируется так, что даже маленькие дети могут быстро выучить его.
- Человеческий язык — дискретная, символьная или категориальная сигнальная система, обладающая надежностью.
- Категориальные символы языка кодируются как сигналы для общения по нескольким каналам: звук, жесты, письмо, изображения и так далее. При этом язык способен выражаться любым способом.
Где применяется NLP
Сегодня быстро растет количество полезных приложений в этой области:
- поиск (письменный или устный);
- показ подходящей онлайн рекламы;
- автоматический (или при содействии) перевод;
- анализ настроений для задач маркетинга;
- распознавание речи и чат-боты,
- голосовые помощники (автоматизированная помощь покупателю, заказ товаров и услуг).
Глубокое обучение в NLP
Существенная часть технологий NLP работает благодаря глубокому обучению (deep learning) — области машинного обучения, которая начала набирать обороты только в начале этого десятилетия по следующим причинам:
- Накоплены большие объемы тренировочных данных;
- Разработаны вычислительные мощности: многоядерные CPU и GPU;
- Созданы новые модели и алгоритмы с расширенными возможностями и улучшенной производительностью, c гибким обучением на промежуточных представлениях;
- Появились обучающие методы c использованием контекста, новые методы регуляризации и оптимизации.
Большинство методов машинного обучения хорошо работают из-за разработанных человеком представлений (representations) данных и входных признаков, а также оптимизации весов, чтобы сделать финальное предсказание лучше.
В глубокомобучении алгоритм пытается автоматически извлечь лучшие признаки или представления из сырых входных данных.
Созданные вручную признаки часто слишком специализированные, неполные и требуют время на создание и валидацию. В противоположность этому, выявленные глубоким обучением признаки легко приспосабливаются.



Глубокое обучение предлагает гибкий, универсальный и обучаемый фреймворк для представления мира как в виде визуальной, так и лингвистической информации. Вначале это привело к прорывам в областях распознавания речи и компьютерном зрении. Эти модели часто обучаются с помощью одного распространенного алгоритма и не требуют традиционного построения признаков под конкретную задачу.
Недавно я закончил исчерпывающий курс по NLP с глубоким обучением из Стэнфорда.
Этот курс — подробное введение в передовые исследование по глубокому обучению, примененному к NLP. Курс охватывает представление через вектор слов, window-based нейросети, рекуррентные нейросети, модели долгосрочной-краткосрочной памяти, сверточные нейросети и некоторые недавние модели с использованием компонента памяти. Со стороны программирования, я научился применять, тренировать, отлаживать, визуализировать и создавать собственные нейросетевые модели.
Замечание: доступ к лекциям из курса и домашним заданиям по программированию находится в этом репозитории.
Словарь частотного анализа
Очень важной частью функционирования системы автоматизированной текстовой обработки является реализация словаря. Его словарный набор напрямую влияет на информативность векторов признаков и, естественно, эффективность системной работы
В словарь входят слова из всего текстового набора исходной задачи. Но, к примеру, предлоги можно встретить практически в каждом тексте. Чтобы решить задачу текстовой сортировки по разной тематике, эти слова следует исключить из словаря, поскольку они не являются информативными. Но с другой стороны, для решения проблемы нахождения автора текста, частота использования предлогов способна стать достаточно полезным признаком. Для решения этой проблемы есть версия задания вектора признаков на компромиссной основе TF-IDF. Согласно этой методике слова, которые очень часто употребляются, не отбрасываются, но их весовой параметр в векторе признаков уменьшается. С этой целью для каждого словарного слова определяется коэффициент обратной частоты IDF (inverse document frequency). Результирующая частотная характеристика будет являться произведением частотной характеристики TF на коэффициент обратной частоты IDF.
TFIDF(t,T,v) = TF(t,v) ⋅ IDF(t,T,v)
Существует ещё один метод формирования словаря, а именно применение N-грамм (N-grams). В словарь частотного анализа могут быть включены помимо отдельных слов ещё и словесные сочетания (упорядоченная словесная последовательность), размером не больше N слов. Эта методика увеличивает словарный объём, что снижает производительность, но часто повышает качественные показатели действия системы.



