
Введение. Что мы называем контейнером
Наше с вами современное время во всех учебниках истории уже названо периодом очередной смены производственного уклада или четвертой промышленной революцией (Индустрией 4.0). Основную роль при этом отводят информации, в том числе ИТ-системам. В попытках удешевления ИТ-инфраструктуры, унификации и ускорения процессов разработки ИТ-решений человечество сначала придумало «облака» на замену традиционным ЦОДам, а затем и контейнеры на замену виртуальным машинам.
Вероятнее всего, сейчас словами «контейнер», «контейнеризованное приложение», «docker», «Kubernetes» и пр. уже никого не удивить. Однако что это такое, и чем, собственно, контейнер отличается от виртуальной машины, все же было бы нелишним кратко напомнить (Рис. 1).
Рис.1. Виртуализация и контейнеризация.
Как следует из этой иллюстрации, контейнером буквально можно считать процесс (дерево процессов), исполняемый на некотором физическом компьютере c определенной операционной системой с помощью специальной оболочки (контейнер runtime). В чем же состоит суть контейнеризации?
Если рассмотреть случай с виртуальными машинами, их изоляция друг от друга, а также их доступ к аппаратным ресурсам обеспечивается специальными аппаратными средствами (расширения виртуализации), и их поддержкой на уровне гипервизора. Возможности воздействия из виртуальной машины на гипервизор и физическое железо сведены к очень ограниченному набору интерфейсов, которые, опять же, в рамках, предусмотренных дизайном, могут влиять лишь на данную виртуальную машину. Иными словами, все вышеупомянутое служит для строгой изоляции виртуальных машин и всего, что в них может происходить, как друг от друга, так и от внешнего окружения, включая систему, на которой они функционируют.
Главной и практически единственной значимой целью контейнеризации является также достижение максимально возможной изоляции процессов как друг от друга, так и от возможного негативного воздействия на операционную систему, в которой они исполняются. Иногда в литературе для описания этой изоляции используются термины “sandbox” – «песочница» и “jail” – «тюрьма».
При этом, поскольку для изоляции процессов, исполняемых в едином пространстве ОС и на одном физическом компьютере, может быть использован гораздо более ограниченный набор инструментов и возможностей, то, очевидно, что с точки зрения безопасности контейнеры выглядят более уязвимыми. В чем, собственно, тогда преимущества контейнеризации перед виртуализацией? На самом деле, их довольно много:
-
возможность более гибкого использования имеющихся ресурсов (нет необходимости их резервирования как в случае с виртуальными машинами);
-
возможность экономии ресурсов (нет необходимости их тратить на множество копий ОС для каждой виртуальной машины);
-
нет задержек при старте (запуск процесса происходит практически мгновенно по сравнению с временем, затрачиваемым на загрузку виртуальной машины);
-
взаимодействие между процессами, пусть даже и изолированными, в случае необходимости гораздо проще реализовать, чем между виртуальными машинами. Так появилась, кстати, соответствующая концепция микросервисов, в последнее время ставшая очень популярной.
Все вышеперечисленное привело к весьма бурному развитию контейнерных технологий, несмотря на периодически возникающие проблемы с безопасностью уже развернутых контейнерных облачных систем, их взломами и утечками данных. Соответственно, работа по усилению безопасности контейнеров также не прекращается ни на секунду. Как раз об этом и пойдет речь далее в этой статье.
Пароль!
Все начинается с паролей. Они везде: в окне логина в Linux-дистрибутиве, в формах регистрации на интернет-сайтах, на FTP- и SSH-серверах и на экране блокировки смартфона. Стандарт для паролей сегодня — это 8–12 символов в разном регистре с включением цифр. Генерировать такие пароли своим собственным умом довольно утомительно, но есть простой способ сделать это автоматически:
Никаких внешних приложений, никаких расширений для веб-браузеров, OpenSSL есть на любой машине. Хотя, если кому-то будет удобней, он может установить и использовать для этих целей pwgen (поговаривают, пароль получится более стойким):
Где хранить пароли? Сегодня у каждого юзера их так много, что хранить все в голове просто невозможно. Довериться системе автосохранения браузера? Можно, но кто знает, как Google или Mozilla будет к ним относиться. Сноуден рассказывал, что не очень хорошо. Поэтому пароли надо хранить на самой машине в зашифрованном контейнере. Отцы-основатели рекомендуют использовать для этого KeePassX. Штука графическая, что не сильно нравится самим отцам-основателям, но зато работает везде, включая известный гугль-зонд Android (KeePassDroid). Останется лишь перекинуть базу с паролями куда надо.
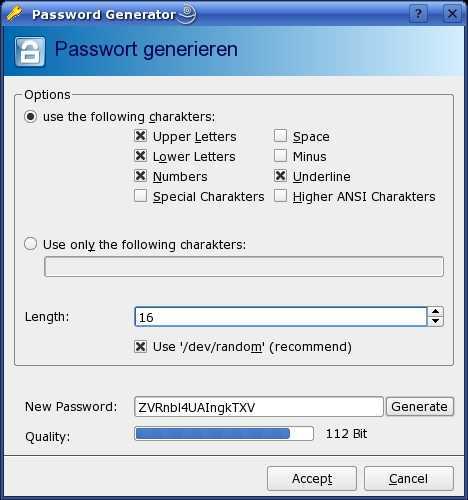 В KeePassX есть свой генератор паролей
В KeePassX есть свой генератор паролей
Другие статьи в выпуске:
↓ 03 — OpenMediaVault
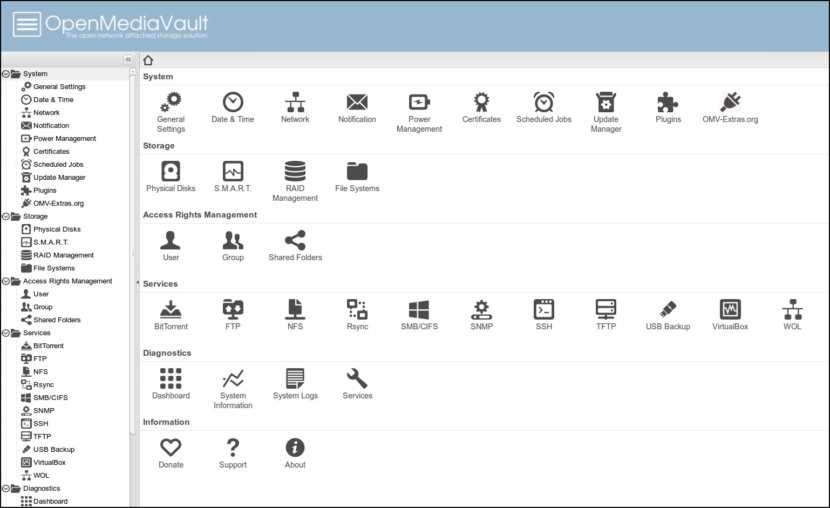
openmediavault — это сетевое хранилище (NAS) нового поколения, основанное на Debian Linux. Он содержит такие службы, как SSH, (S) FTP, SMB / CIFS, медиа-сервер DAAP, RSync, клиент BitTorrent и многие другие. Благодаря модульной конструкции фреймворка его можно расширять с помощью плагинов.
openmediavault в первую очередь предназначен для использования в небольших офисах или домашних офисах, но не ограничивается этими сценариями. Это простое и легкое в использовании готовое решение, которое позволит каждому устанавливать и администрировать сетевое хранилище без более глубоких знаний.
- ОС Debian Linux с веб-администрированием
- Управление томом и SMART
- Агрегация ссылок
- Wake On LAN
- Поддержка IPv6
- Уведомления по электронной почте
- Обмен файлами
hdparm
Команда hdparm получает информацию об устройствах sata, например, жестких дисков.
$ sudo hdparm -i /dev/sda
/dev/sda:
Model=ST3500418AS, FwRev=CC38, SerialNo=9VMJXV1N
Config={ HardSect NotMFM HdSw>15uSec Fixed DTR>10Mbs RotSpdTol>.5% }
RawCHS=16383/16/63, TrkSize=0, SectSize=0, ECCbytes=4
BuffType=unknown, BuffSize=16384kB, MaxMultSect=16, MultSect=16
CurCHS=16383/16/63, CurSects=16514064, LBA=yes, LBAsects=976773168
IORDY=on/off, tPIO={min:120,w/IORDY:120}, tDMA={min:120,rec:120}
PIO modes: pio0 pio1 pio2 pio3 pio4
DMA modes: mdma0 mdma1 mdma2
UDMA modes: udma0 udma1 udma2 udma3 udma4 udma5 *udma6
AdvancedPM=no WriteCache=enabled
Drive conforms to: unknown: ATA/ATAPI-4,5,6,7
* signifies the current active mode
Downloading NVIDIA OFED
-
Verify that the system has a NVIDIA network adapter installed by running lscpi command. The below table provides output examples per ConnectX-6 card configuration.
ConnectX-6 Card Configuration Single-port Socket Direct Card (2x PCIe x16) # lspci |grep mellanox -i a3:00.0 Infiniband controller: Mellanox Technologies MT28908 Family e3:00.0 Infiniband controller: Mellanox Technologies MT28908 Family
Dual-port Socket Direct Card (2x PCIe x16) # lspci |grep mellanox -i 05:00.0 Infiniband controller: Mellanox Technologies MT28908A0 Family 05:00.1 Infiniband controller: Mellanox Technologies MT28908A0 Family 82:00.0 Infiniband controller: Mellanox Technologies MT28908A0 Family 82:00.1 Infiniband controller: Mellanox Technologies MT28908A0 Family
Intheoutput exampleabove, thefirst tworowsindicate thatone cardis installed inaPCIslotwithPCIBusaddress05(hexadecimal),PCIDevicenumber00andPCIFunctionnumber0and1.TheothercardisinstalledinaPCIslotwithPCIBusaddress82(hexadecimal),PCIDevicenumber00andPCIFunctionnumber0and1.
Sincethe two PCIecards are installed intwo PCIe slots,eachcard getsa uniquePCIBusandDevicenumber.EachofthePCIex16bussesseestwonetworkports;ineffect,thetwophysicalportsoftheConnectX-6SocketDirectadapterareviewedasfournet devicesbythesystem.
Single-port PCIe x16 Card # lspci |grep mellanox -ia 3:00.0 Infiniband controller: Mellanox Technologies MT28908 Family
Dual-port PCIe x16 Card # lspci |grep mellanox -ia 86:00.0 Network controller: Mellanox Technologies MT28908A0 Family 86:00.1 Network controller: Mellanox Technologies MT28908A0 Family
-
- Scroll down to the Download wizard, and click the Download tab.
- Choose your relevant package depending on your host operating system.
- Click the desired ISO/tgz package.
- To obtain the download link, accept the End User License Agreement (EULA).
-
Use the md5sum utility to confirm the file integrity of your ISO image. Run the following command and compare the result to the value provided on the download page.
md5sum MLNX_OFED_LINUX-<ver>-<OS label>.iso
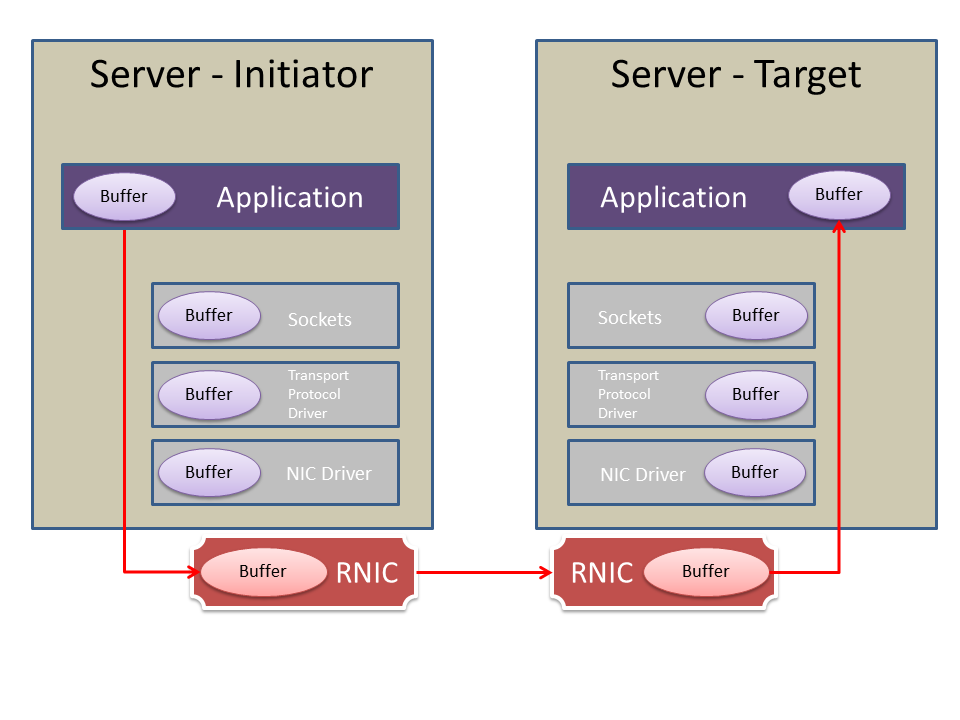
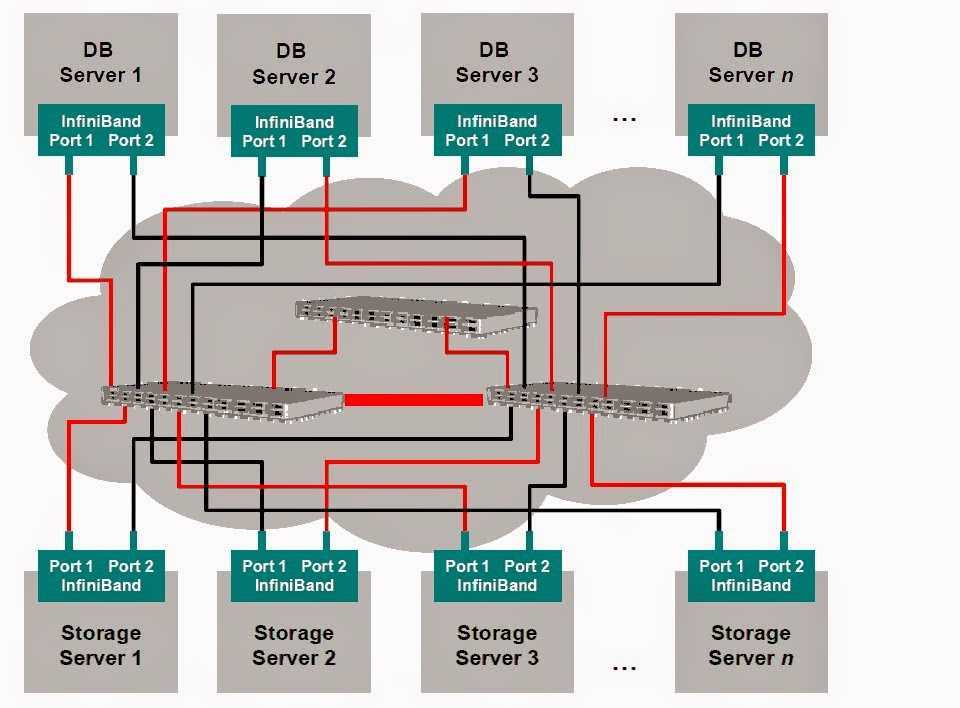
Remote data storage
You can share physical or virtual devices from a target (host/server) to an initiator (guest/client) system over an IB network, using iSCSI, iSCSI with iSER, or SRP. These methods differ from traditional file sharing (i.e. Samba or NFS) because the initiator system views the shared device as its own block level device, rather than a traditionally mounted network shared folder. i.e. ,
The disadvantage is only one system can use each shared device at a time; trying to mount a shared device on the target or another initiator system will fail (an initiator system can certainly run traditional file sharing on top).
The advantages are faster bandwidth, more control, and even having an initiator’s root filesystem being physically located remotely (remote booting).
targetcli
acts like a shell that presents its complex (and not worth creating by hand) as a pseudo-filesystem.
Installing and using
On the target system:
- Install AUR
- Start and enable
In :
- In any pseudo-directory, you can run to see the commands available in that pseudo-directory or (like ) for more detailed help
- Tab-completion is also available for many commands
- Run to see the entire pseudo-filesystem at and below the current pseudo-directory
Create backstores
Enter the configuration shell:
# targetcli
Within , setup a backstore for each device or virtual device to share:
- To share an actual block device, run: ; and
- To share a file as a virtual block device, run: ; and
- To share a physical SCSI device as a pass-through, run: ; and
- To share a RAM disk, run: ; and
- Where name is for the backstore’s name
- Where dev is the block device to share (i.e. , , , or a LVM logical volume )
- Where file is the file to share (i.e. )
- Where size is the size of the RAM disk to create (i.e. 512MB, 20GB)
iSCSI
iSCSI allows storage devices and virtual storage devices to be used over a network. For IB networks, the storage can either work over IPoIB or iSER.
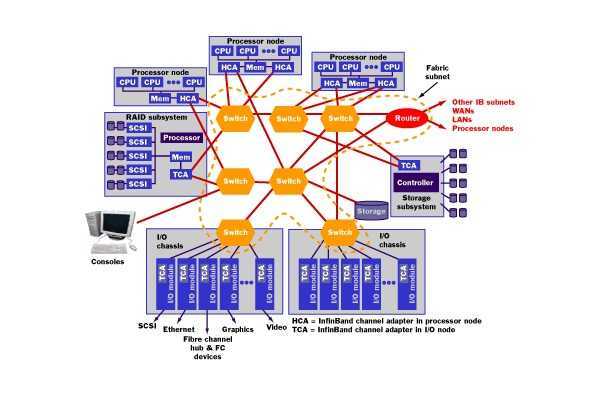
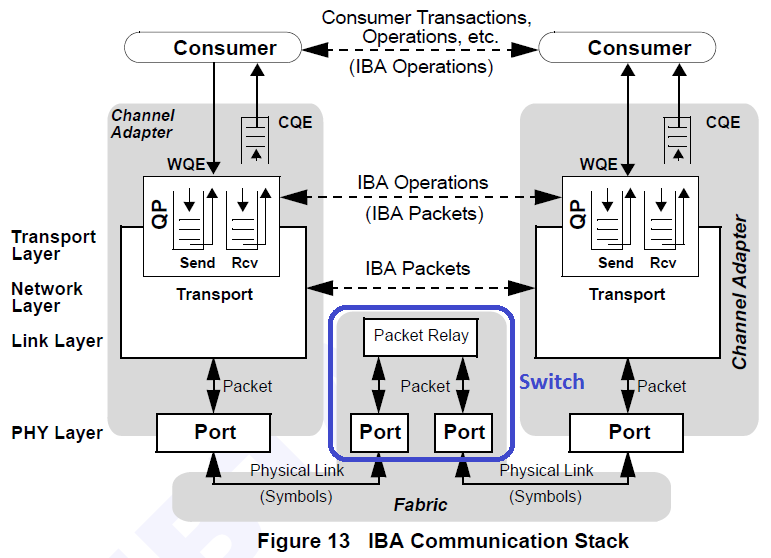
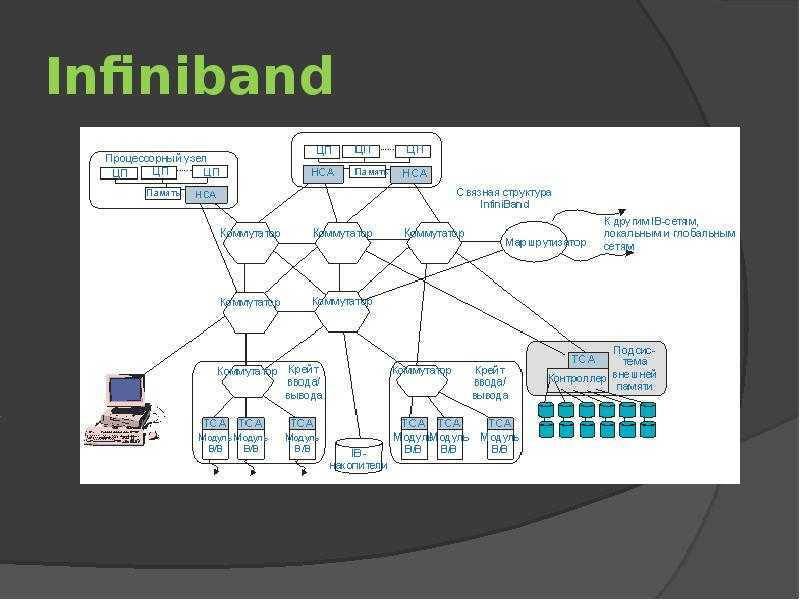
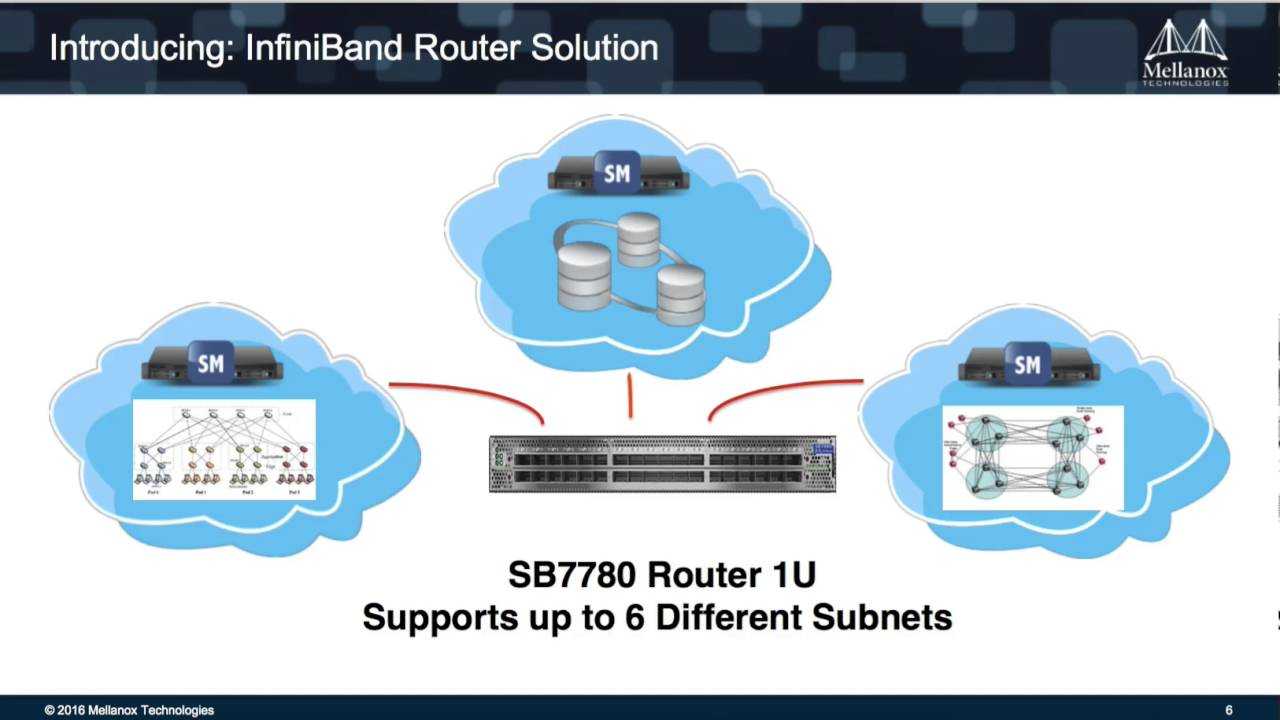
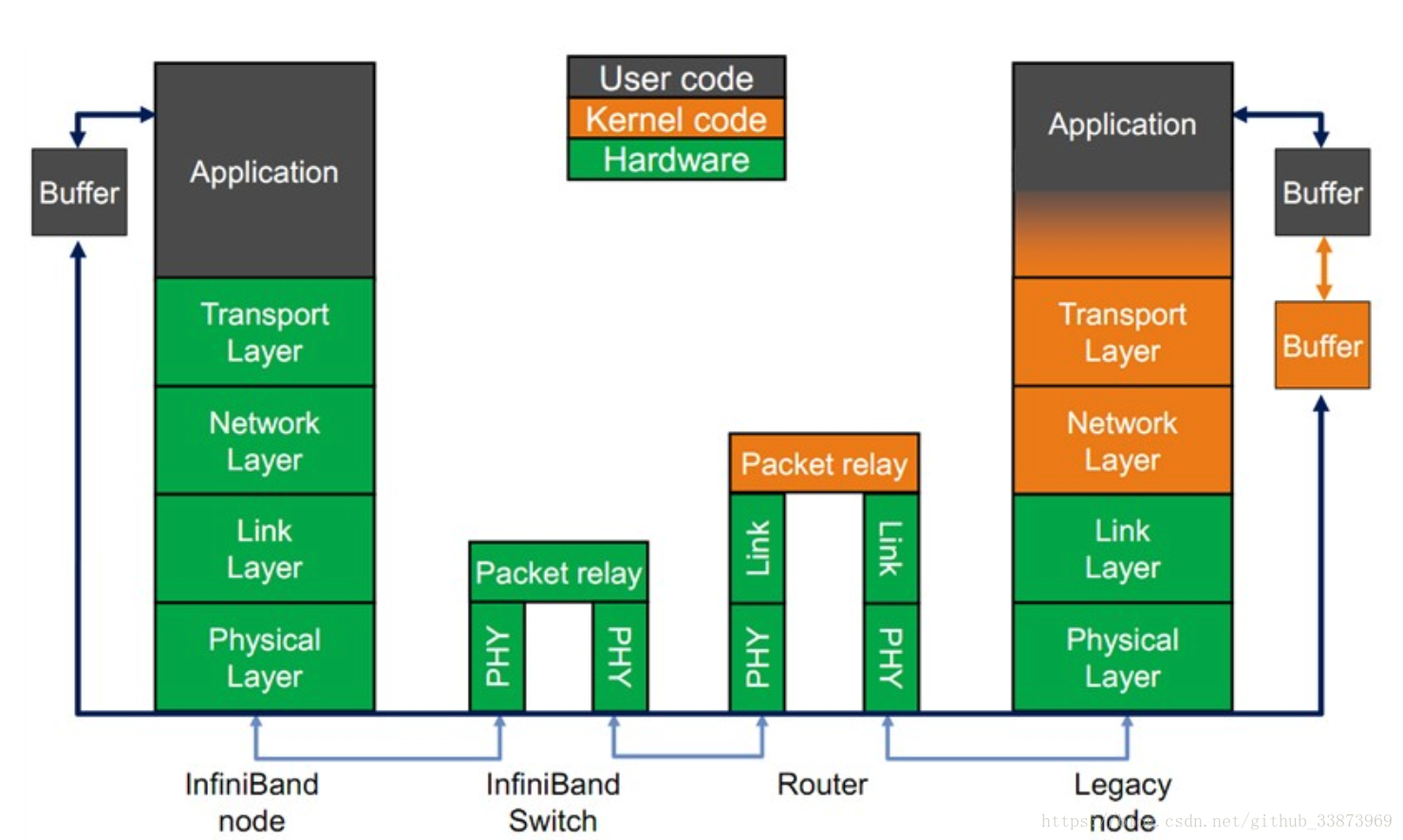
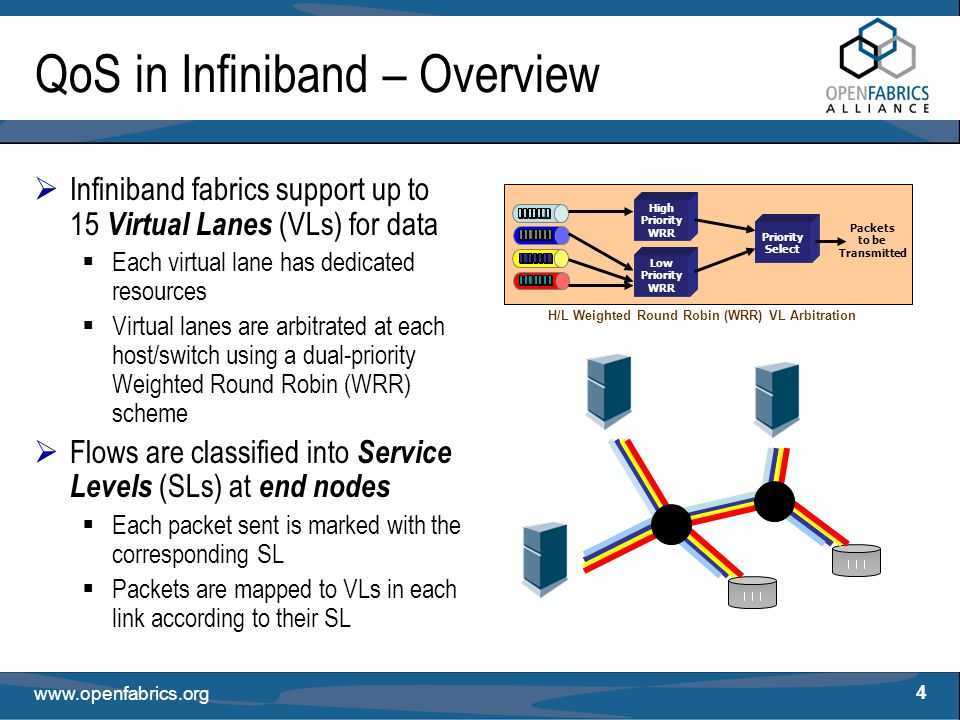
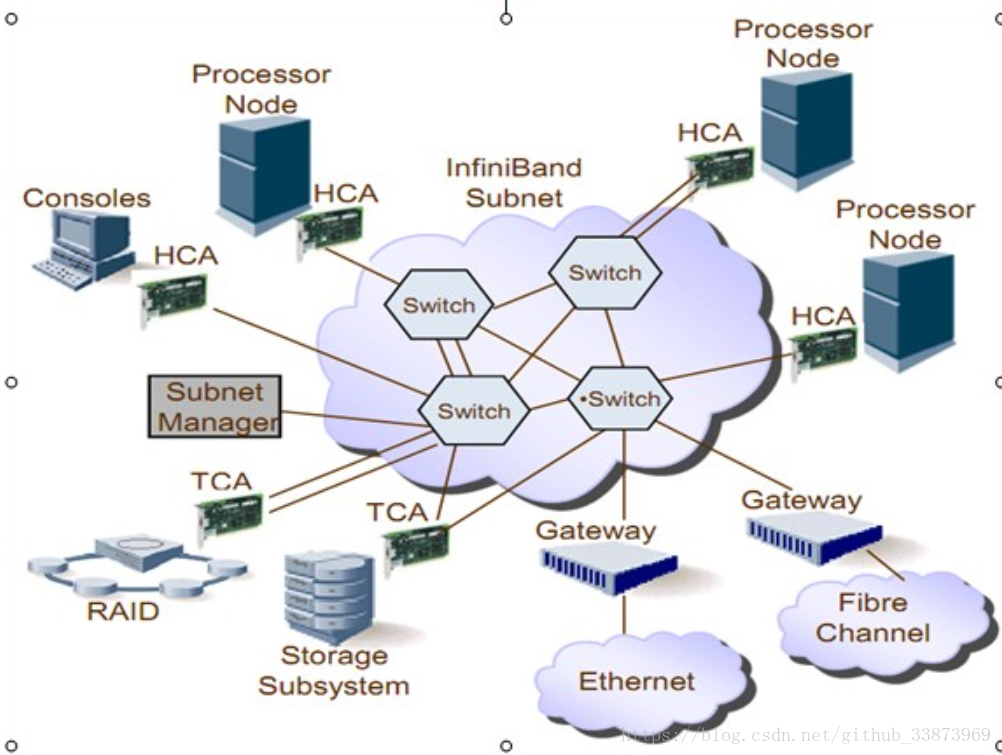
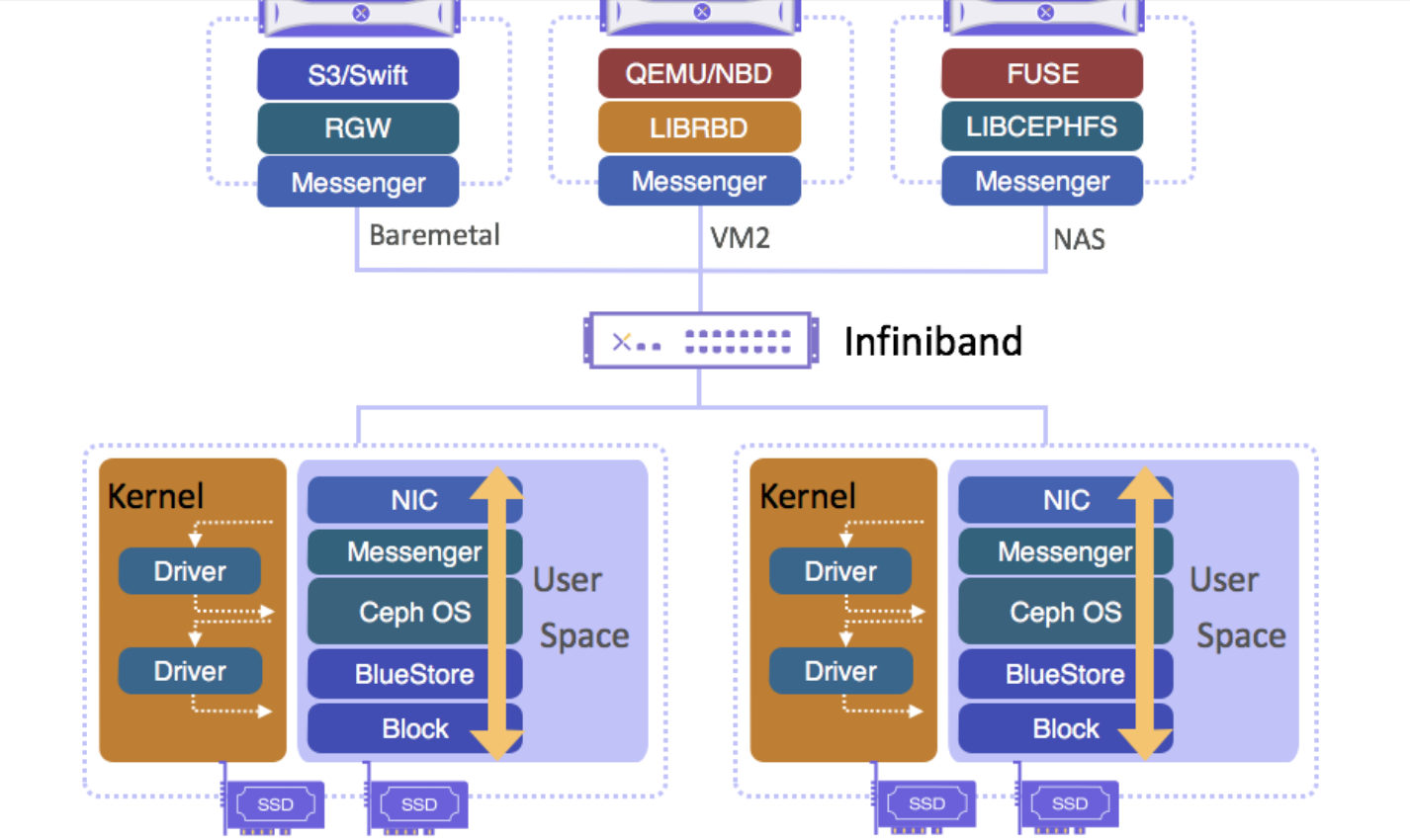
There is a lot of overlap with the iSCSI Target, iSCSI Initiator, and iSCSI Boot articles, but the necessities will be discussed since much needs to be customized for usage over IB.
Over IPoIB
Perform the target system instructions first, which will direct you when to temporarily switch over to the initiator system instructions.
On the target and initiator systems, install TCP/IP over IB
- On the target system, for each device or virtual device you want to share, in :
- For each backstore, create an IQN (iSCSI Qualified Name) (the name other systems’ configurations will see the storage as)
- Run: ; and . It will give you a randomly_generated_target_name, i.e.
- Set up the TPG (Target Portal Group), automatically created in the last step as tpg1
- Create a lun (Logical Unit Number)
- Create an acl (Access Control List)
- Run: ; and , where is the initiator system’s IQN (iSCSI Qualified Name), aka its (World Wide Name)
- Save and exit by running: ; ; and
- For each backstore, create an IQN (iSCSI Qualified Name) (the name other systems’ configurations will see the storage as)
- On the initiator system:
- Install
- At this point, you can obtain this initiator system’s IQN (iSCSI Qualified Name), aka its wwn (World Wide Name), for setting up the target system’s :
- should have displayed
- Otherwise, run: to see
- Start and enable
- To automatically login to discovered targets at boot, before discovering targets, edit to set
- Discover online targets. Run as root, where portal
If using a hostname, make sure it routes to the IB IP address rather than Ethernet — it may be beneficial to just use the IB IP address
is an IP (v4 or v6) address or hostname
- To automatically login to discovered targets at boot, Start and enable
- To manually login to discovered targets, run as root.
- View which block device ID was given to each target logged into. Run as root. The block device ID will be the last line in the tree for each target ( is the print command, its option is the verbosity level, and only level 3 lists the block device IDs)
Over iSER
iSER (iSCSI Extensions for RDMA) takes advantage of IB’s RDMA protocols, rather than using TCP/IP. It eliminates TCP/IP overhead, and provides higher bandwidth, zero copy time, lower latency, and lower CPU utilization.
Follow the instructions, with the following changes:
- If you wish, instead of , you can just
- On the target system, after everything else is setup, while still in , enable iSER on the target:
- Run for each iqn
Where iqn is the randomly generated target name, i.e. iqn.2003-01.org.linux-iscsi.hostname.x8664:sn.3d74b8d4020a
you want to have use iSER rather than IPoIB
- Run
- Save and exit by running: ; ; and
- Run for each iqn
- On the initiator system, when running to discover online targets, use the additional argument , and when you login to them, you should see:
Adding to /etc/fstab
The last time you discovered targets, automatic login must have been turned on.
Add your mount entry to as if it were a local block device, except add a option to avoid attempting to mount it before network initialization.
Installation
First install which contains all core libraries and daemons.
Upgrade firmware
Running the most recent firmware can give significant performance increases, and fix connectivity issues.
Warning: Be careful or the device may be bricked!
For Mellanox
- Install AUR
- Determine your adapter’s PCI device ID (in this example, «05:00.0» is the adapter’s PCI device ID)
$ lspci | grep Mellanox
05:00.0 InfiniBand: Mellanox Technologies MT25418 [ConnectX VPI PCIe 2.0 2.5GT/s - IB DDR / 10GigE] (rev a0)
Determine what firmware version your adapter has, and your adapter’s PSID (more specific than just a model number — specific to a compatible set of revisions)
# mstflint -d <adapter PCI device ID> query
... FW Version: 2.7.1000 ... PSID: MT_04A0110002
- Check latest firmware version
- Choose the category of device you have
- Locate your device’s PSID on their list, that mstflint gave you
- Examine the Firmware Image filename to see if it is more recent than your adapter’s FW Version, i.e. , is version
- If there is a more recent version, download new firmware and burn it to your adapter
$ unzip <firmware .bin.zip file name> # mstflint -d <adapter PCI device ID> -i <firmware .bin file name> burn
For Intel/QLogic
Subnet manager
Each IB network requires at least one subnet manager. Without one, devices may show having a link, but will never change state from to . A subnet manager often (typically every 5 or 30 seconds) checks the network for new adapters and adds them to the routing tables. If you have an IB switch with an embedded subnet manager, you can use that, or you can keep it disabled and use a software subnet manager instead. Dedicated IB subnet manager devices also exist.
Enable port
If the port is in the physical state (can be verified with ) then it first needs to be enabled by running for it to wake up. This may need to be automated at boot if the ports at both ends of the link are sleeping.
Software subnet manager
On one system:
- Install AUR
- Start and enable
All of your connected IB ports should now be in a (port) state of , and a physical state of . You can check this by running .
$ ibstat
... (look at the ports shown you expect to be connected) State: Active Physical state: LinkUp ...
Or by examining the filesystem:
$ cat /sys/class/infiniband/kernel_module/ports/port_number/phys_state
5: LinkUp
$ cat /sys/class/infiniband/kernel_module/ports/port_number/state
4: ACTIVE
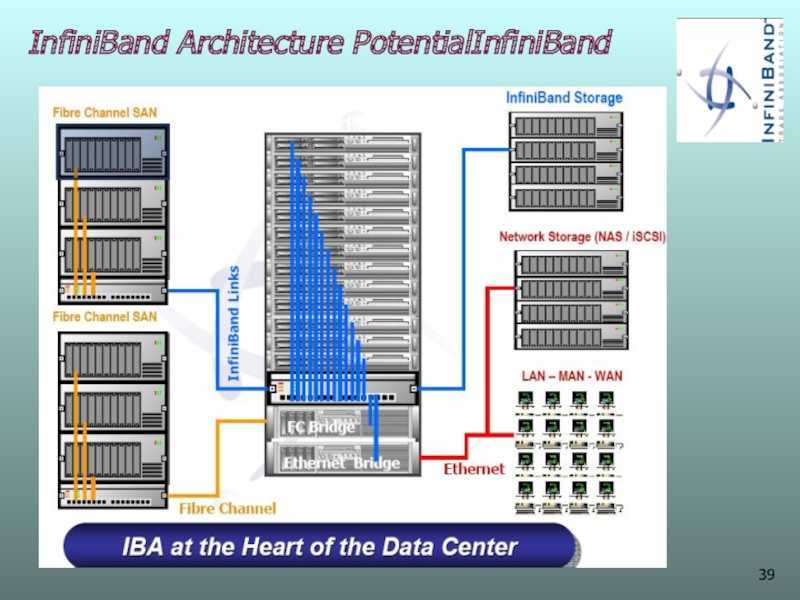
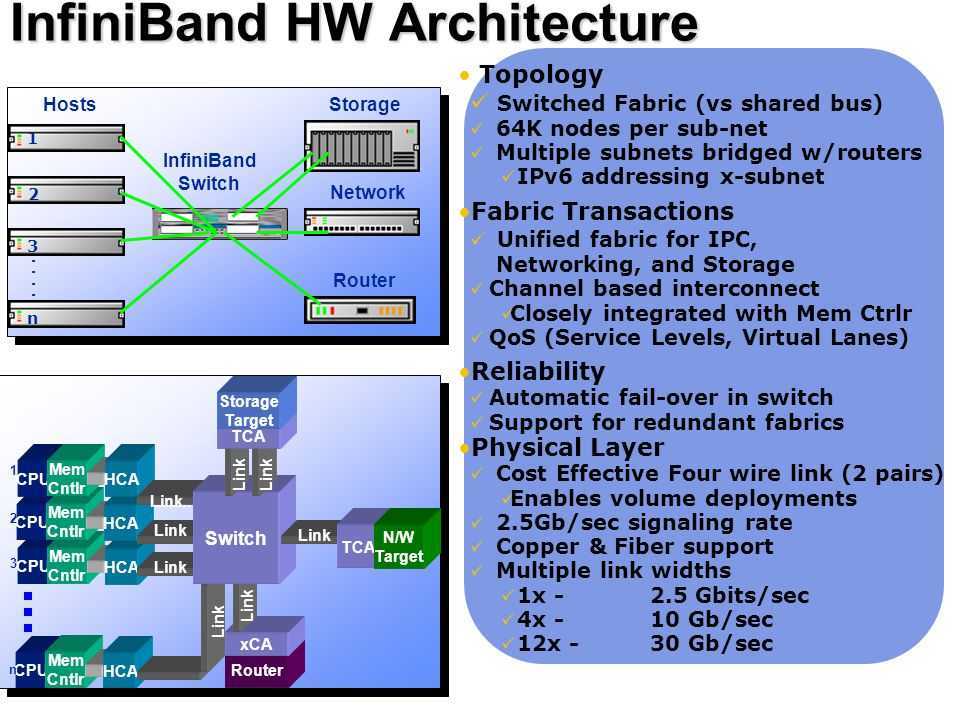
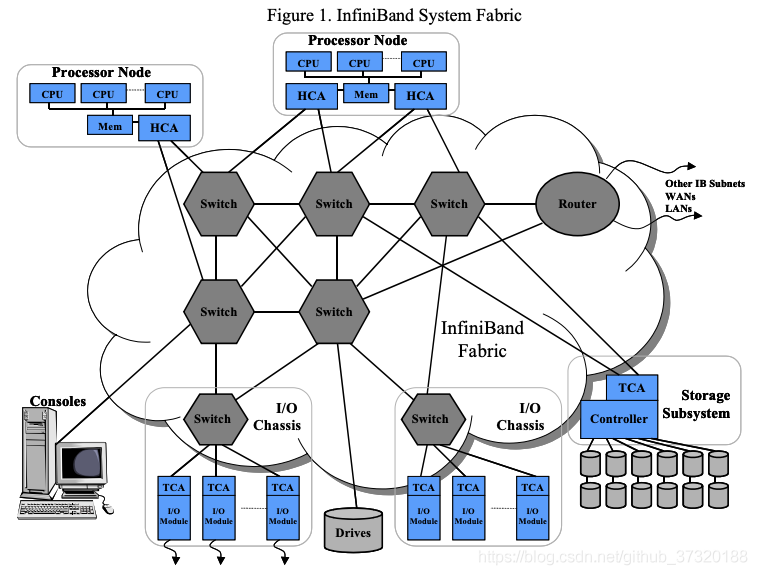
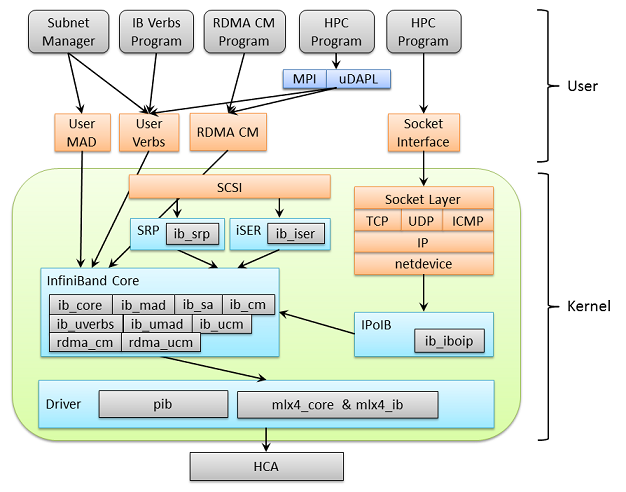
Introduction
Overview
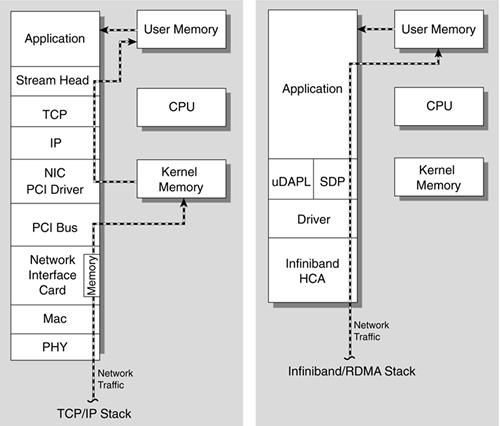
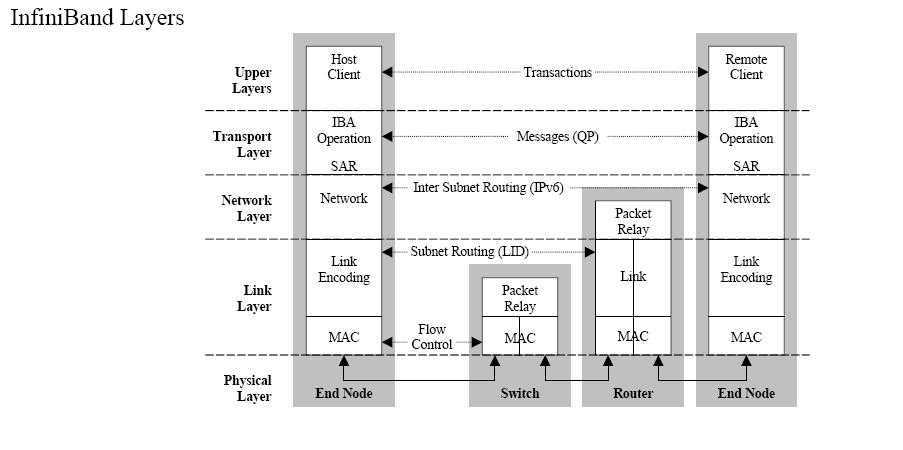
InfiniBand (abbreviated IB) is an alternative to Ethernet and Fibre Channel. IB provides high bandwidth and low latency. IB can transfer data directly to and from a storage device on one machine to userspace on another machine, bypassing and avoiding the overhead of a system call. IB adapters can handle the networking protocols, unlike Ethernet networking protocols which are ran on the CPU. This allows the OS’s and CPU’s to remain free while the high bandwidth transfers take place, which can be a real problem with 10Gb+ Ethernet.
IB hardware is made by Mellanox (which merged with Voltaire, and is heavily backed by Oracle) and Intel (which acquired QLogic’s IB division in 2012). IB is most often used by supercomputers, clusters, and data centers. IBM, HP, and Cray are also members of the InfiniBand Steering Committee. Facebook, Twitter, eBay, YouTube, and PayPal are examples of IB users.
Affordable used equipment
With large businesses benefiting so much from jumping to newer versions, the maximum length limitations of passive IB cabling, the high cost of active IB cabling, and the more technically complex setup than Ethernet, the used IB market is heavily saturated, allowing used IB devices to affordably be used at home or smaller businesses for their internal networks.
Bandwidth
Signal transfer rates
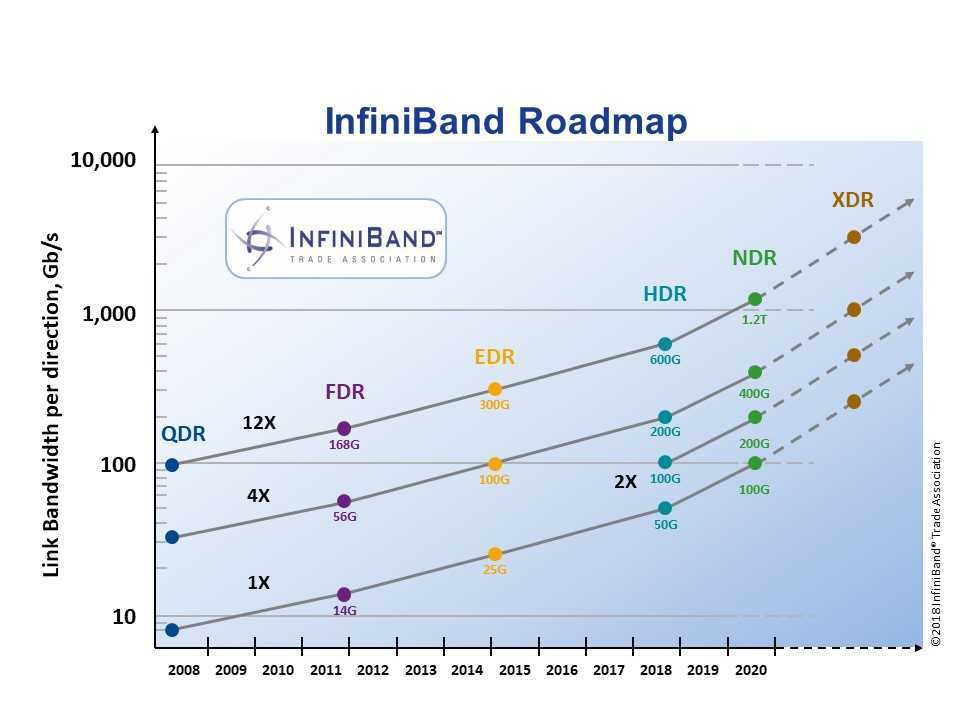
IB transfer rates corresponded in the beginning to the maximum supported by PCI Express (abbreviated PCIe), later on, as PCIe made less progress, the transfer rates corresponded to other I/O technologies and the number of PCIe lanes per port was increased instead. It launched using SDR (Single Data Rate) with a signaling rate of 2.5Gb/s per lane (corresponding with PCI Express v1.0), and has added: DDR (Double Data Rate) at 5Gb/s (PCI Express v2.0); QDR (Quad Data Rate) at 10Gb/s (matching the throughput of PCI Express 3.0 with improved coding of PCIe 3.0 instead of the signaling rate); and FDR (Fourteen Data Rate) at 14.0625Gbps (matching 16GFC Fibre Channel). IB is now delivering EDR (Enhanced Data Rate) at 25Gb/s (matching 25Gb Ethernet). Planned around 2017 will be HDR (High Data Rate) at 50Gb/s.
Effective throughput
Because SDR, DDR, and QDR versions use 8/10 encoding (8 bits of data takes 10 bits of signaling), effective throughput for these is lowered to 80%: SDR at 2Gb/s/link; DDR at 4Gb/s/link; and QDR at 8Gb/s/link. Starting with FDR, IB uses 64/66 encoding, allowing a higher effective throughput to signaling rate ratio of 96.97%: FDR at 13.64Gb/s/link; EDR at 24.24Gb/s/lane; and HDR at 48.48Gb/s/link.
IB devices are capable of sending data over multiple links, though commercial products standardized around 4 links per cable.
When using the common 4X link devices, this effectively allows total effective throughputs of: SDR of 8Gb/s; DDR of 16Gb/s; QDR of 32Gb/s; FDR of 54.54Gb/s; EDR of 96.97Gb/s; and HDR of 193.94Gb/s.
Latency
IB’s latency is incredibly small: SDR (5us); DDR (2.5us); QDR (1.3us); FDR (0.7us); EDR (0.5us); and HDR (< 0.5us). For comparison 10Gb Ethernet is more like 7.22us, ten times more than FDR’s latency.
Backwards compatibility
IB devices are almost always backwards compatible. Connections should be established at the lowest common denominator. A DDR adapter meant for a PCI Express 8x slot should work in a PCI Express 4x slot (with half the bandwidth).
Cables
IB passive copper cables can be up to 7 meters using up to QDR, and 3 meters using FDR.
IB active fiber (optical) cables can be up to 300 meters using up to FDR (only 100 meters on FDR10).
Mellanox MetroX devices exist which allow up to 80 kilometer connections. Latency increases by about 5us per kilometer.
An IB cable can be used to directly link two computers without a switch; IB cross-over cables do not exist.
lshw – список аппаратных устройств
Утилита общего назначения, которая сообщает подробную и краткую информацию о нескольких различных аппаратных устройствах, таких как процессор, память, диск, контроллеры usb, сетевые адаптеры и т.д. Команда lscpu извлекает информацию из различных файлов /proc.
$ sudo lshw -short
H/W path Device Class Description
===================================================
system ()
/0 bus DG35EC
/0/0 processor Intel(R) Core(TM)2 Quad CPU Q8400 @ 2.66GHz
/0/0/1 memory 2MiB L2 cache
/0/0/3 memory 32KiB L1 cache
/0/2 memory 32KiB L1 cache
/0/4 memory 64KiB BIOS
/0/14 memory 8GiB System Memory
/0/14/0 memory 2GiB DIMM DDR2 Synchronous 667 MHz (1.5 ns)
/0/14/1 memory 2GiB DIMM DDR2 Synchronous 667 MHz (1.5 ns)
/0/14/2 memory 2GiB DIMM DDR2 Synchronous 667 MHz (1.5 ns)
/0/14/3 memory 2GiB DIMM DDR2 Synchronous 667 MHz (1.5 ns)
/0/100 bridge 82G35 Express DRAM Controller
/0/100/2 display 82G35 Express Integrated Graphics Controller
/0/100/2.1 display 82G35 Express Integrated Graphics Controller
/0/100/19 eth0 network 82566DC Gigabit Network Connection
/0/100/1a bus 82801H (ICH8 Family) USB UHCI Controller #4
/0/100/1a.1 bus 82801H (ICH8 Family) USB UHCI Controller #5
/0/100/1a.7 bus 82801H (ICH8 Family) USB2 EHCI Controller #2
/0/100/1b multimedia 82801H (ICH8 Family) HD Audio Controller
/0/100/1c bridge 82801H (ICH8 Family) PCI Express Port 1
/0/100/1c.1 bridge 82801H (ICH8 Family) PCI Express Port 2
/0/100/1c.2 bridge 82801H (ICH8 Family) PCI Express Port 3
/0/100/1c.2/0 storage JMB368 IDE controller
/0/100/1d bus 82801H (ICH8 Family) USB UHCI Controller #1
/0/100/1d.1 bus 82801H (ICH8 Family) USB UHCI Controller #2
/0/100/1d.2 bus 82801H (ICH8 Family) USB UHCI Controller #3
/0/100/1d.7 bus 82801H (ICH8 Family) USB2 EHCI Controller #1
/0/100/1e bridge 82801 PCI Bridge
/0/100/1e/5 bus FW322/323 1394a Controller
/0/100/1f bridge 82801HB/HR (ICH8/R) LPC Interface Controller
/0/100/1f.2 storage 82801H (ICH8 Family) 4 port SATA Controller
/0/100/1f.3 bus 82801H (ICH8 Family) SMBus Controller
/0/100/1f.5 storage 82801HR/HO/HH (ICH8R/DO/DH) 2 port SATA Controller [IDE m
/0/1 scsi3 storage
/0/1/0.0.0 /dev/sda disk 500GB ST3500418AS
/0/1/0.0.0/1 /dev/sda1 volume 70GiB Windows NTFS volume
/0/1/0.0.0/2 /dev/sda2 volume 395GiB Extended partition
/0/1/0.0.0/2/5 /dev/sda5 volume 97GiB HPFS/NTFS partition
/0/1/0.0.0/2/6 /dev/sda6 volume 97GiB Linux filesystem partition
/0/1/0.0.0/2/7 /dev/sda7 volume 1952MiB Linux swap / Solaris partition
/0/1/0.0.0/2/8 /dev/sda8 volume 198GiB Linux filesystem partition
/0/3 scsi4 storage
/0/3/0.0.0 /dev/cdrom disk DVD RW DRU-190A
Если вы хотите больше узнать о команде lshw, то обратите внимание на пост
TCP/IP (IPoIB)
You can create a virtual Ethernet Adapter that runs on the HCA. This is intended so programs designed to work with TCP/IP but not IB, can (indirectly) use IB networks. Performance is negatively affected due to sending all traffic through the normal TCP stack; requiring system calls, memory copies, and network protocols to run on the CPU rather than on the HCA.
Configure the IB interface (e.g. ) like a traditional Ethernet adapter.
Connection mode
IPoIB can run in datagram (default) or connected mode. Connected mode , but does increase TCP latency for short messages by about 5% more than datagram mode.
To see the current mode used:
$ cat /sys/class/net/interface/mode
MTU
In datagram mode, UD (Unreliable Datagram) transport is used, which typically forces the MTU to be 2044 bytes. Technically to the IB L2 MTU — 4 bytes for the IPoIB encapsulation header, which is usually 2044 bytes.
In connected mode, RC (Reliable Connected) transport is used, which allows a MTU up to the maximum IP packet size, 65520 bytes.
To see your MTU:
$ ip link show interface
Finetuning connection mode and MTU
You only need if you want to change the default connection mode and/or MTU.
- Install AUR
- Configure through , which contains instructions on how to do so
- Start and enable
Different setups will see different results. Some people see a gigantic (double+) speed increase by using mode and MTU , and a few see about the same or even worse speeds. Use and to finetune your system.
Using the examples given in this article, here are example results from an SDR network (8 theoretical Gb/s) with various finetuning:
| Mode | MTU | MB/s | us latency |
|---|---|---|---|
| datagram | 2044 | 707 | 19.4 |
| connected | 2044 | 353 | 18.9 |
| connected | 65520 | 726 | 19.6 |
Tip: Use the same connection and MTU settings for the entire subnet. Mixing and matching does not work optimally.
Общий способ взаимодействия с аппаратным обеспечением
Как только все в лаборатории расселись, лаборант Прити начал с введения в аппаратные интерфейсы системы Linux. Если не вдаваться в теоретические детали, то на первом интересном слайде была представлена общая схема архитектурно-прозрачных аппаратных интерфейсов (смотрите рис.1).
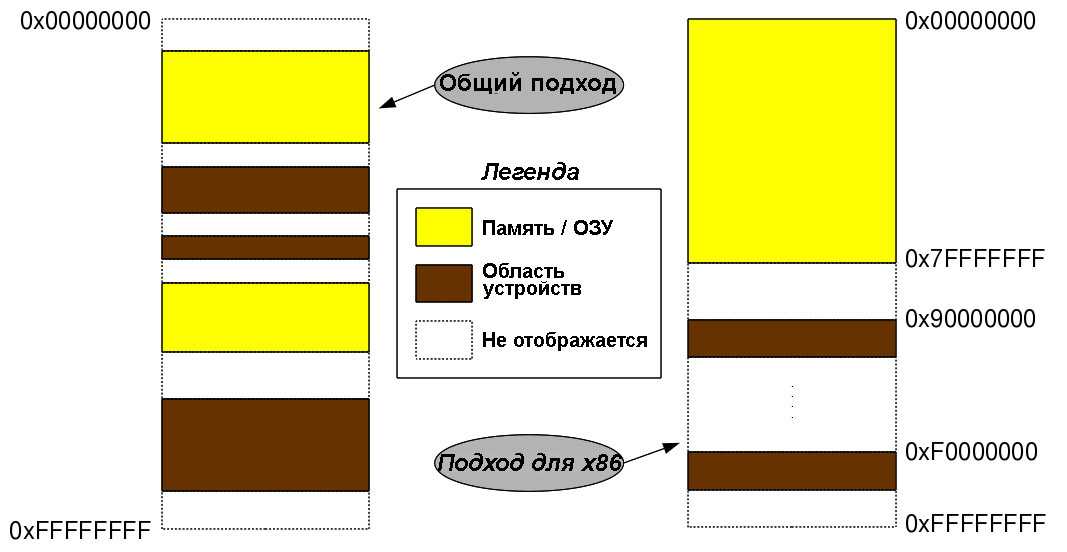
Рис.1: Отображение аппаратных средств
Основным допущением является то, что рассматривается 32-битная архитектура. Для других вариантов
архитектуры отображение в память будет соответствующим образом изменено. Для 32-разрядной адресной
шины диапазоны отображения адресов / памяти будут от 0 () и до «232 – 1» (). Архитектурно-независимая схема использования отображения будет такой, как она показана на рис.1 — области, используемые под память (RAM — оперативная память) и используемые для устройств (регистры и память устройств), чередуются. В действительности, эти адреса зависят от используемой архитектуры. Например, в архитектуре x86, первые 3 Гб (с до ) , как правило, используются под память, а последние 1 Гб (с до ) — для отображения устройств. Однако, если оперативной памяти меньше, скажем, 2 Гб, отображение устройств может начаться с 2 Гб ().
Запустите команду для того, чтобы получить
схему отображения памяти (карту памяти), используемую в вашей системе. Запустите команду для того, чтобы получить приблизительный размер оперативной памяти, имеющийся на вашем компьютере. На рис.2 приведены скриншоты результатов работы этих команд.
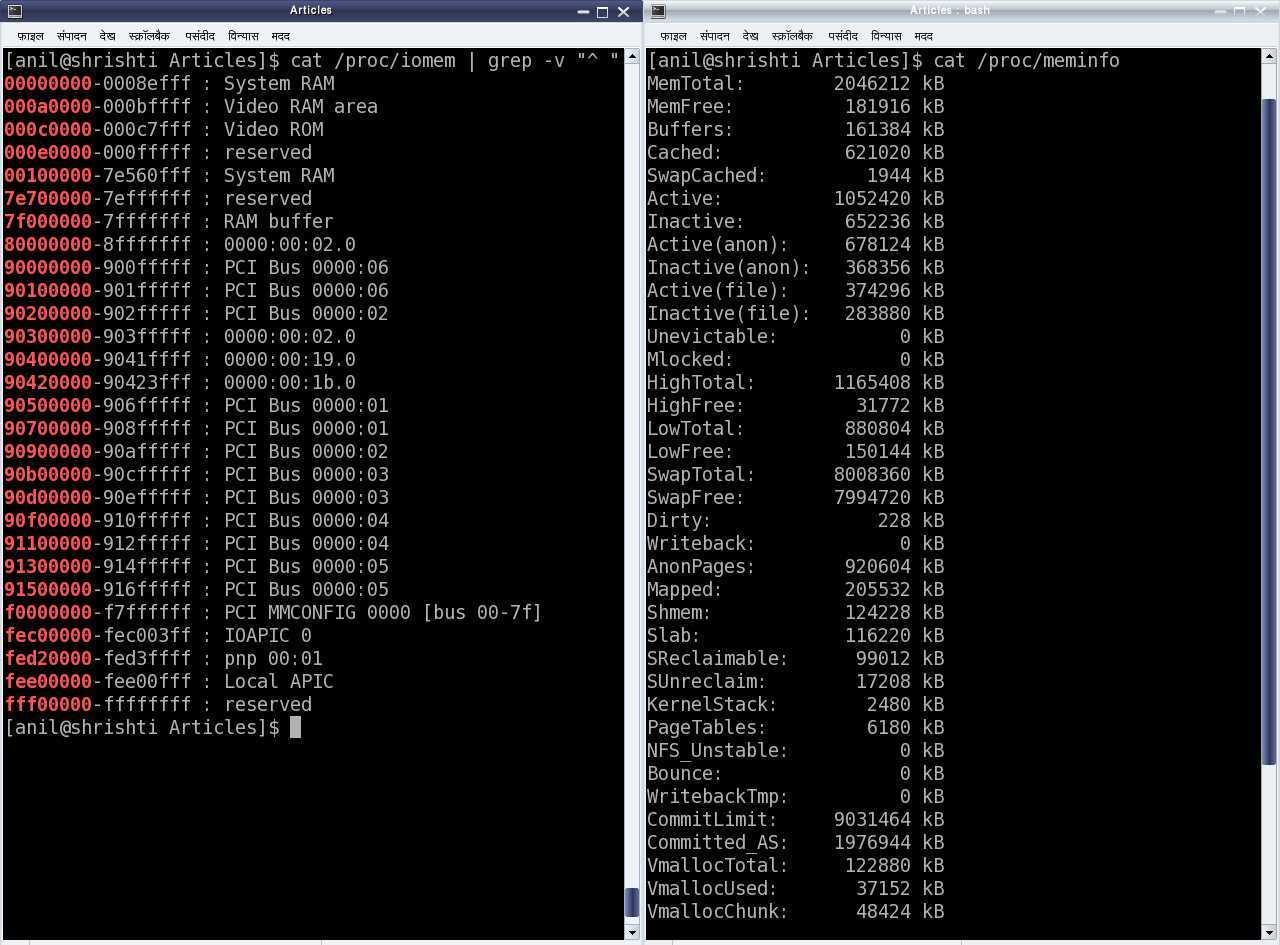
Рис.2: Физические адреса памяти и адреса шин в системе x86
Независимо от фактических значений, адреса, которые отображаются в оперативную память, называются физическими адресами, а те адреса, которые используются для карт устройств, называются адресами шин, т. к. как эти устройства всегда отображаются через некоторую шину, зависящую от архитектуры, например, шину PCI — в архитектуре x86 , шину AMBA — в архитектуре ARM, шину SuperHyway — в архитектуре SuperH и т.д.
Все зависящие от архитектуры значения этих физических и шинных адресов либо конфигурируются динамически, либо берутся из спецификационных данных (например, руководств по аппаратному обеспечению) процессоров/ контроллеров соответствующей архитектуры. Самое интересное, что в Linux ни к какому из этих устройств нет непосредственного доступа, для этого используется отображение в виртуальные адреса, а затем через эти адреса происходит доступ к устройствам; в результате этого доступ к оперативной памяти и к устройствам становится почти одинаковым. Для подключения или отключения отображения адресов шины устройства в виртуальные адреса есть соответствующие API (прототип в ):
void *ioremap(unsigned long device_bus_address, unsigned long device_region_size); void iounmap(void *virt_addr);
Поскольку отображение осуществляется в виртуальные адреса, оно
зависит от спецификаций устройства, таких как набор регистров и/или памяти устройства, используемой
в операциях чтения и записи; поэтому к
виртуальному адресу, возвращаемому функцией , добавляется
соответствующее смещение. Для этого есть следующие API (прототип также
в ):
unsigned int ioread8(void *virt_addr); unsigned int ioread16(void *virt_addr); unsigned int ioread32(void *virt_addr); unsigned int iowrite8(u8 value, void *virt_addr); unsigned int iowrite16(u16 value, void *virt_addr); unsigned int iowrite32(u32 value, void *virt_addr);
За пределами
Теперь поговорим о том, как сохранить свою анонимность в Сети и получить доступ к сайтам и страницам, заблокированным по требованию различных организаций-правообладателей и прочих Мизулиных. Самый простой способ сделать это — воспользоваться одним из тысяч прокси-серверов по всему миру. Многие из них бесплатны, но зачастую обрезают канал до скорости древнего аналогового модема.
Чтобы спокойно ходить по сайтам и только в случае необходимости включать прокси, можно воспользоваться одним из множества расширений для Chrome и Firefox, которые легко находятся в каталоге по запросу proxy switcher. Устанавливаем, вбиваем список нужных прокси и переключаемся на нужный, увидев вместо страницы табличку «Доступ к странице ограничен по требованию господина Скумбриевича».
В тех ситуациях, когда под фильтр попал весь сайт и его адрес внесли в черный список на стороне DNS-серверов провайдеров, можно воспользоваться свободными DNS-серверами, адреса которых опубликованы здесь. Просто берем два любых понравившихся адреса и добавляем в /etc/resolv.conf:
Чтобы разного рода DHCP-клиенты и NetworkManager’ы не перезаписали файл адресами, полученными от провайдера или роутера, делаем файл неперезаписываемым с помощью расширенных атрибутов:
После этого файл станет защищен от записи для всех, включая root.
Чтобы еще более анонимизировать свое пребывание в Сети, можно воспользоваться также демоном dnscrypt, который будет шифровать все запросы к DNS-серверу в дополнение к прокси-серверу, используемому для соединения с самим сайтом. Устанавливаем:
Указываем в loopback-адрес:
Запускаем демон:
Кстати, версии dnscrypt есть для Windows, iOS и Android.
Оптический век
С первых опытов уже прошло пять лет, и год стал 2018. Насколько я понимаю ситуацию, и почему так произошло — штатовские дата центры начали (и закончили) апгрейды своих сетей, и на eBay появилась куча новых интересных б/у железок за гуманную цены. А именно карточки ConnectX-3, свитчи, и оптические кабели. Это уже не предания старины глубокой, а относительно новое железо.
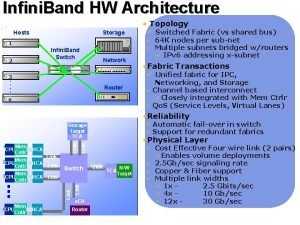
SIDENOTE: как я понимаю, это из-за перехода с 10/40GbE на 25/50/100+GbE. И у них есть вопросы совместимости, поэтому старое просто утилизировали.
Что тут можно рассказать, сначала были куплены карточки и кабели. Причем они уже были настолько распространены, что искать не обязательно Mellanox’ы, есть тоже самое под именами HP/Dell/IBM, и они дешевле. Драйвера встроенные есть и в Win, и в Linux, работает всё почти само. Это всё железо умеет QDR/FDR10/FDR14, то есть по сути 40/56Gbps. Реальную скорость при правильной настройке можно 4700+MB/sec увидеть. Хоть диски и стали NVMe (PCI 3 все-таки), но сеть всё равно оказалась быстрее.
А самое хорошее — есть свитчи за разумные деньги (
Например старенький IS5022, из недостатков — умеет только QDR, и кому-то может быть важно, что только 8 портов, из плюсов — можно держать дома и даже спать рядом, если доработать
Вообще не шумит, если вентилятор Noctua, дует холодным воздухом, но совершенно не продакшен решение, конечно. Зато по ГОСТ 26074-84 и ГОСТ 8486-86.
WARNING: если кто-то захочет повторить — надо перепаивать провода у вентилятора, там другая распиновка. При попытке просто воткнуть обычный вентилятор — он не вертится, а начинает дымиться!
Или SX6005 — эти уже умеют FDR10 на 12 портов, но главный чип у них снизу, и просто бросить кулер сверху я пока не решился. Но собираюсь этот свитч раскурочить и попробовать. DIY, всё-же.
Есть ещё много разных вариантов, но все их расписывать — я не настолько разбираюсь в ситуации (Brocade ICX серию можно посмотреть).
У всего этого благолепия есть один важный недостаток — те два примера железок, что я выше привёл — это InfiniBand свитчи. Они не умеют Ethernet, и получается только IPoIB. Что из этого следует — Win/Linux машины прекрасно видят друг друга, общаются и всё работает отлично. Главная проблема для меня была — если вам нужны виртуальные машины и чтобы они видели друг друга по быстрой сети — просто так не получится, IB не маршрутизируется на level 3 (поправьте, кто умнее, если я тут чушь написал). Точнее сделать это с виртуальными машинами можно, но не на домашнем железе (SR-IOV нужен и проброс VF внутрь виртуалки), с муторным процессом настройки, плюс с миграцией отдельные заморочки.
К сожалению, пока на eBay нет дешевых 40/56GbE Ethernet свитчей (можете поискать SX1012, если интересно), с которыми можно было-бы поэкспериментировать. Придётся ещё несколько лет подождать. А там, глядишь, и до 25/100GbE можно будет в домашней лабе подобраться.
PS: С IB есть ещё всякие нюансы типа необходимости OpenSM где-то, если switch non-managed, но это всё-же не про настройку IB статья.
Подведем итог
Затем Светлана повторила обычные действия:
- Собрала драйвер «видеопамяти» (файл ) с помощью запуска команды с измененным файлом .
- Загрузила драйвер с помощью команды .
- Выполнила запись в с помощью команды
- Выполнила чтение из с помощью команды . (Также можно воспользоваться обычной командой , но она выдаст все данные в двоичном формате. С помощью команды данные выдаются в шестнадцатеричном формате. Подробности узнайте, запустив команду .)
- Выгрузила драйвер с помощью команды .
До конца практических занятий осталось еще полчаса и Светлана решила пройтись по классу и, возможно, помочь кому-нибудь с экспериментами.
| К предыдущей статье | Оглавление | К следующей статье |



