
Введение
На сегодняшний день компьютерная архитектура получила большое развитие и уже не ограничивается стандартными средствами реализации. В качестве примера реализации нестандартной архитектуры можно привести мультипроцессорность. Мультипроцессорность является относительно новым явлением в индустрии информационных технологий, которое положило начало новому витку развития мощностей информационных систем.
Целью данной работы является сбор информации об применении мультипроцессорности для корректного понимания правильности условий использования данной технологии.
Объектом исследования является явление мультипроцессорности, предметом исследования – мультипроцессоры как аппаратное обеспечение.
Задачами данной работы являются:
- обзор понятия мультипроцессорности;
- разбор видов мультипроцессорности;
- рассмотрение программных реализаций мультипроцессорности;
- обзор понятия мультипроцессора;
- проведение классификации мультипроцессоров;
- изучение программирования мультипроцессоров;
- рассмотрение истории мультипроцессоров.
В основу данного исследования легли работы Таненбаума, Паттерсона и Хеннеси.
Таненбаум является заслуженным профессором Гарвардского университета, опубликовавшим много трудов в сфере информационных технологий, ставших фундаментальными. На его трудах основываются многие исследования, а его учеником был Линус Торвальдс, создатель операционной системы Линукс.
Паттерсон является заслуженным профессором Калифорнийского университета в Беркли, работающим в области микропроцессоров и информатики. Он известен своим вкладом в проектирование RISC-процессоров и создание принципа работы RAID-массивов.
Хеннесси является американским ученым, работающим в области микропроцессоров и информатики. Также он является основателем MIPS Computer Systems Inc. и ректором Стэнфордского университета.
Данные авторы публикуются довольно длительно время, имеют по несколько редакций каждой из своих работ и пользуются спросом у рядовых пользователей, так как описывают сложные технические термины легким для понимания языком.
Общая архитектура брокера объектных запросов (CORBA)
В 1980-х началось активное использование корпоративных сетей и клиент-серверной архитектуры. Возникла потребность в стандартном способе взаимодействия приложений, которые созданы с использованием разных технологий, исполняются на разных компьютерах и под разными ОС. Для этого была разработана CORBA. Это один из стандартов распределённых вычислений, зародившийся в 1980-х и расцветший к 1991 году.
Стандарт CORBA был реализован несколькими вендорами. Он обеспечивает:
- Не зависящие от платформы вызовы удалённых процедур (Remote Procedure Call).
- Транзакции (в том числе удалённые!).
- Безопасность.
- События.
- Независимость от выбора языка программирования.
- Независимость от выбора ОС.
- Независимость от выбора оборудования.
- Независимость от особенностей передачи данных/связи.
- Набор данных через язык описания интерфейсов (Interface Definition Language, IDL).
Сегодня CORBA всё ещё используется для разнородных вычислений. Например, он до сих пор является частью Java EE, хотя начиная с Java 9 будет поставляться в виде отдельного модуля.
Хочу отметить, что не считаю CORBA паттерном SOA (хотя отношу и CORBA, и SOA-паттерны к сфере распределённых вычислений). Я рассказываю о нём здесь, поскольку считаю недостатки CORBA одной из причин возникновения SOA.
Принцип работы
Сначала нам нужно получить брокер объектных запросов (Object Request Broker, ORB), который соответствует спецификации CORBA. Он предоставляется вендором и использует языковые преобразователи (language mappers) для генерирования «заглушек» (stub) и «скелетов» (skeleton) на языках клиентского кода. С помощью этого ORB и определений интерфейсов, использующих IDL (аналог WSDL), можно на основе реальных классов генерировать в клиенте удалённо вызываемые классы-заглушки (stub classes). А на сервере можно генерировать классы-скелеты (skeleton classes), обрабатывающие входящие запросы и вызывающие реальные целевые объекты.
Вызывающая программа (caller) вызывает локальную процедуру, реализованную заглушкой.
- Заглушка проверяет вызов, создаёт сообщение-запрос и передаёт его в ORB.
- Клиентский ORB шлёт сообщение по сети на сервер и блокирует текущий поток выполнения.
- Серверный ORB получает сообщение-запрос и создаёт экземпляр скелета.
- Скелет исполняет процедуру в вызываемом объекте.
- Вызываемый объект проводит вычисления и возвращает результат.
- Скелет пакует выходные аргументы в сообщение-ответ и передаёт его в ORB.
- ORB шлёт сообщение по сети клиенту.
- Клиентский ORB получает сообщение, распаковывает и передаёт информацию заглушке.
- Заглушка передаёт выходные аргументы вызывающему методу, разблокирует поток выполнения, и вызывающая программа продолжает свою работу.
Достоинства
- Независимость от выбранных технологий (не считая реализации ORB).
- Независимость от особенностей передачи данных/связи.
Недостатки
- Независимость от местоположения: клиентский код не имеет понятия, является ли вызов локальным или удалённым. Звучит неплохо, но длительность задержки и виды сбоев могут сильно варьироваться. Если мы не знаем, какой у нас вызов, то приложение не может выбрать подходящую стратегию обработки вызовов методов, а значит, и генерировать удалённые вызовы внутри цикла. В результате вся система работает медленнее.
- Сложная, раздутая и неоднозначная спецификация: её собрали из нескольких версий спецификаций разных вендоров, поэтому (на тот момент) она была раздутой, неоднозначной и трудной в реализации.
- Заблокированные каналы связи (communication pipes): используются специфические протоколы поверх TCP/IP, а также специфические порты (или даже случайные порты). Но правила корпоративной безопасности и файрволы зачастую допускают HTTP-соединения только через 80-й порт, блокируя обмены данными CORBA.
6 Continuous Delivery (CD)
6.1 Цели
- Короткий цикл (до 1 часа) от изменения в коде до поставки готового ПО пользователям;
- Готовность системы к поставке в любое время;
- Всесторонняя автоматическая проверка качества релиза (п. 7);
- Уменьшение стоимости, времени и рисков при поставке изменений;
- Повторяемый автоматический процесс поставки изменений.
6.2 Этапы CD
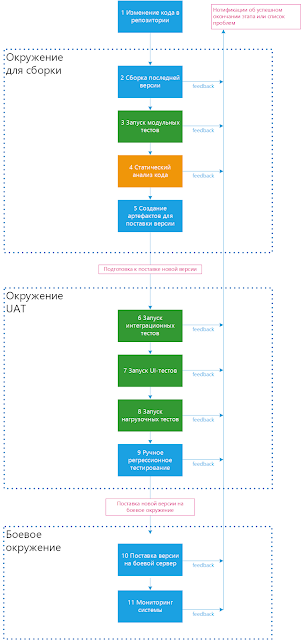
- Изменение кода в репозитории;
- Сборка последней версии – если сборка не прошла, процесс прерывается, команде возвращается лог с описанием проблемы.
- Запуск модульных тестов – если хотя бы один тест не прошел, процесс прерывается, команде возвращается лог с описанием проблемы.
- Статический анализ кода – если качество кода на недостаточном уровне, процесс прерывается, команде возвращается лог с описанием проблемы.
- Создание артефактов для заливки — создается Docker-контейнер(ы), который содержит последнюю версию приложения. Результатом шага является система готовая к заливке «в один клик».
Следующие шаги запускаются при поставке изменений пользователям:
- Запуск интеграционных тестов – автоматически поднимается окружение для тестирования, запускаются тесты. Если хотя бы один тест не прошел, процесс прерывается, команде возвращается лог с описанием проблемы;
- Запуск UI-тестов (если такие тесты есть) – автоматически поднимается окружение для тестирования, запускаются тесты. Если хотя бы один тест не прошел, процесс прерывается, команде возвращается лог с описанием проблемы;
- Запуск нагрузочных тестов (если такие тесты есть) – автоматически поднимается окружение для тестирования, запускаются тесты. Если хотя бы один тест не прошел, процесс прерывается, команде возвращается лог с описанием проблемы;
- Ручное тестирование по тест-плану (если требуется) – инженер по качеству тестирует подготовленную на 4-м шаге версию системы по тестовым сценариям.
- Поставка версии на боевой сервер — если все критерии качества соблюдены, значит систему можно заливать на боевой сервер.
- Мониторинг системы (п. 5.8)
Используем Feature Toggle вместо Feature Branching http://martinfowler.com/articles/feature-toggles.html
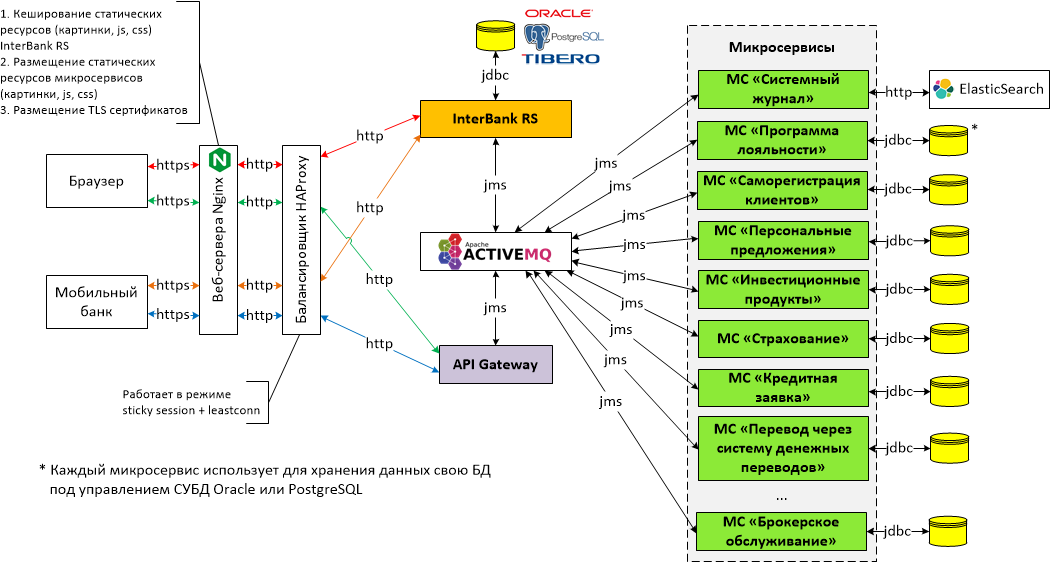
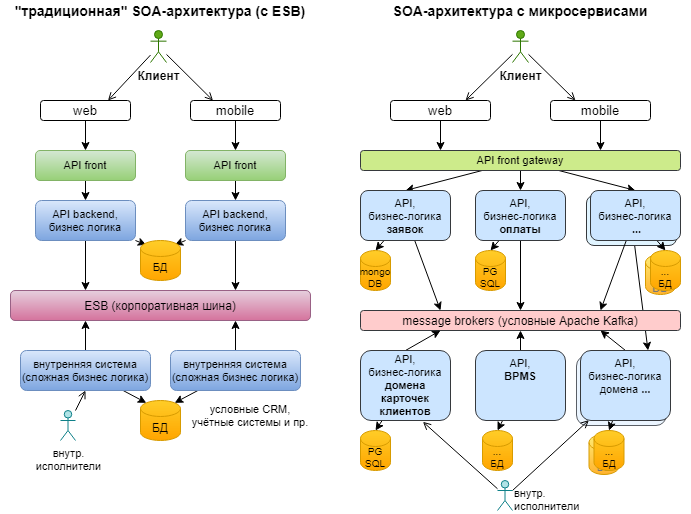
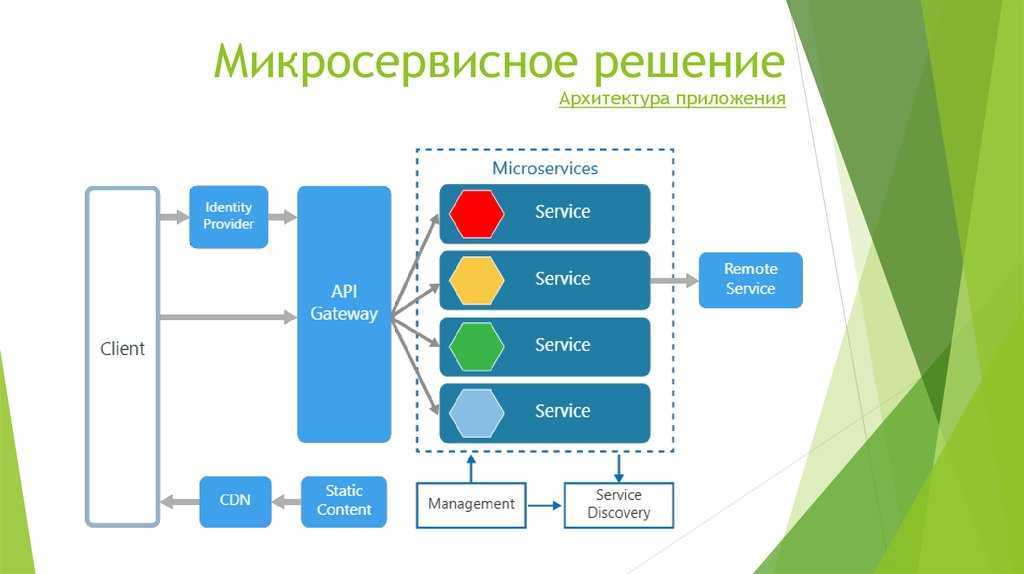
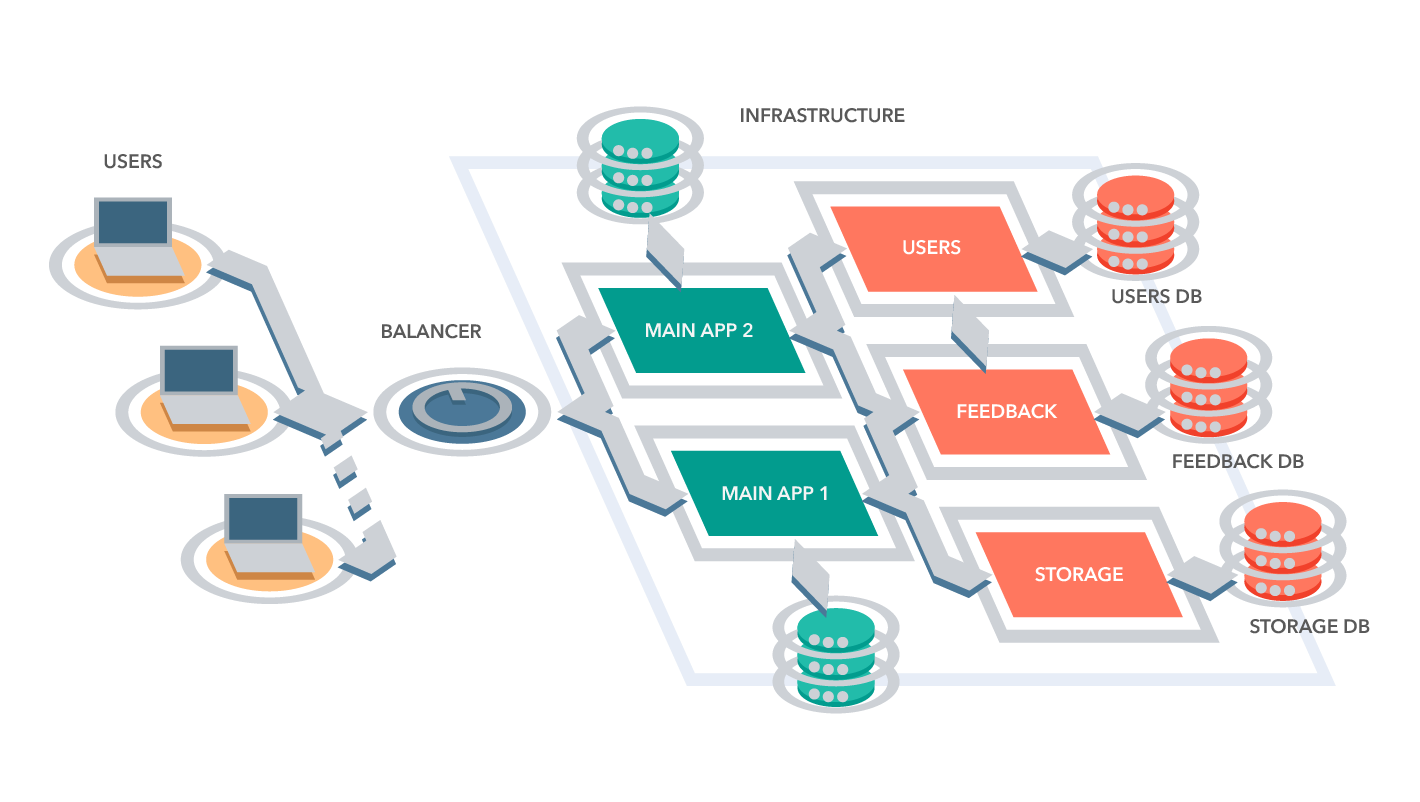
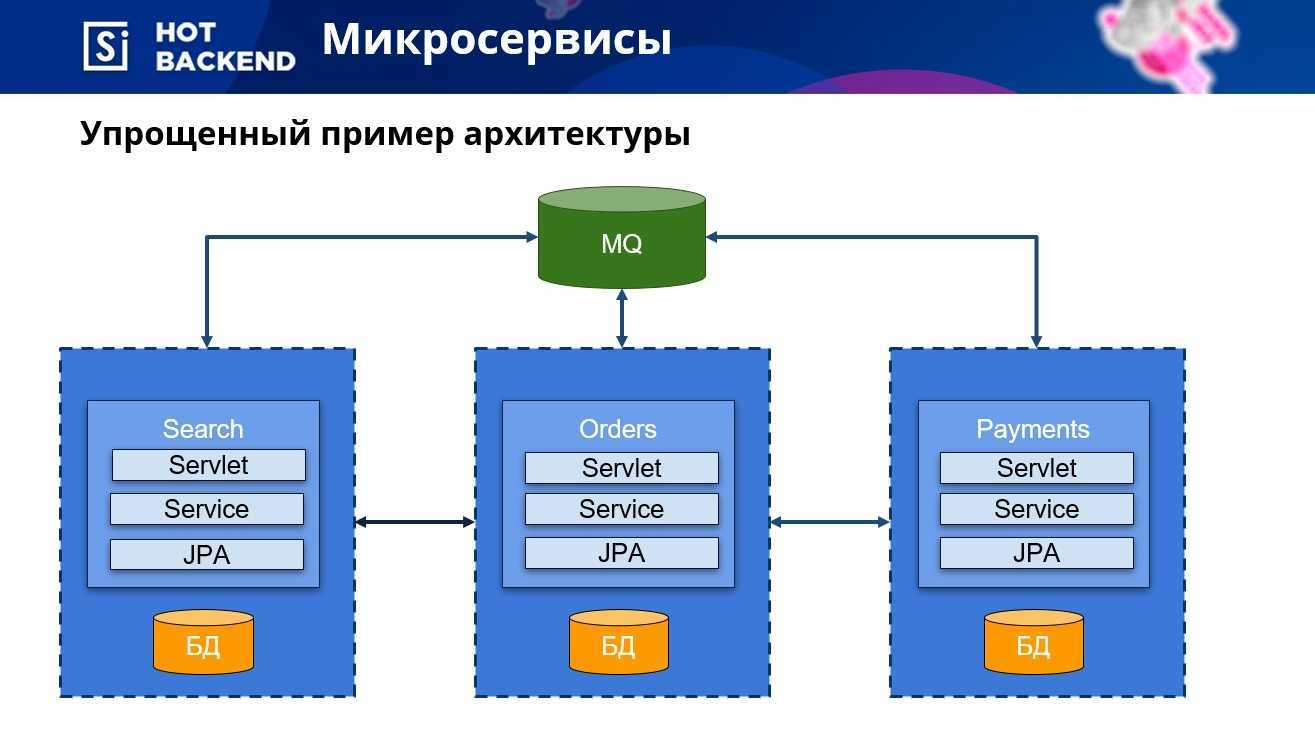
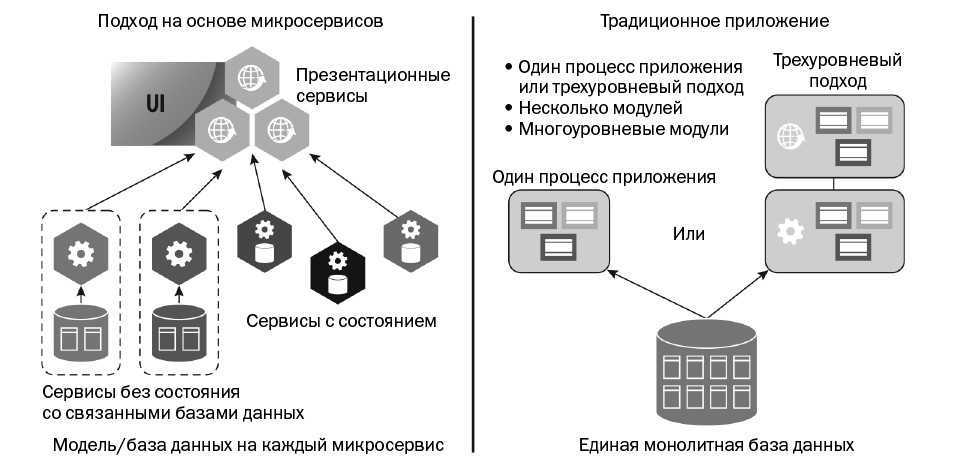
Основные принципы SOA
Многие отождествляют SOA c Web-сервисами или workflow-системами, но это не так. SOA — не набор технологий, а прежде всего процессно-ориентированная архитектура ИС. Можно определить SOA следующим образом: это архитектура приложений, построенная на основе формализованных бизнес-процессов, функции которых представлены в виде многократно используемых сервисов с прозрачными описанными интерфейсами.
В концепции SOA выделяются две стороны: бизнес-процессы и технические возможности — ИТ-сервисы. Понятие «сервис» трактуют по-разному — как некую функцию, программный компонент или типизированный процесс. Для каждой организации может быть свой уровень сервисов. Кроме того, интересы бизнеса отнюдь не идентичны интересам ИТ-служб: как правило, бизнес хочет, чтобы учитывались пожелания каждого ключевого пользователя, то есть множества разнообразных сервисов.
Но ИТ-подразделению для минимизации затрат на управление сервисами необходима типизация процессов и выполняемых с помощью ИТ функций, то есть в его интересах — иметь минимальное число агрегированных сервисов. В результате между разнообразными требованиями ключевых пользователей от бизнеса и типовыми решениями в области процессов и ИТ-сервисов следует найти «золотую середину». Методология SOA как раз и предоставляет возможность стандартизации в той сфере, где ее катастрофически не хватает.
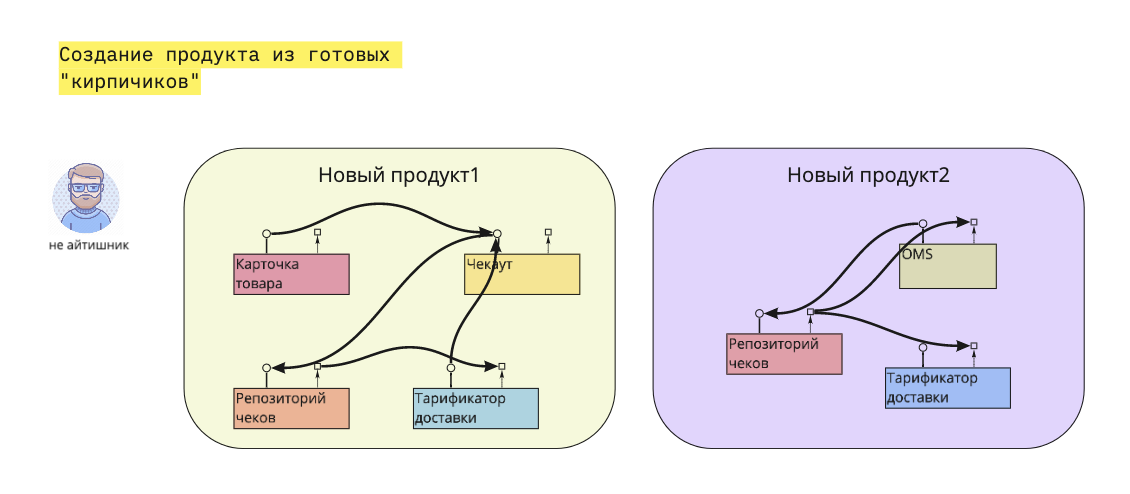
Одно из основных требований, возникающих при использовании SOA, — необходимость создания библиотеки типовых сервисов. Фактически при построении информационной системы на принципах SOA помимо описанного процесса нужно иметь перечень сервисов с подробным описанием входов и выходов. Тогда на этапе разработки к определенной функции будет подключаться определенный сервис из библиотеки, а в случае его отсутствия — определяться требования на его разработку. Здесь можно провести аналогию с библиотеками объектов, используемыми в программировании, только уровень абстракции в случае SOA выше.
Фактически сервис представляет собой результат выполнения части процесса (из области ИТ или бизнеса), поэтому в рамках проектирования архитектуры приложения на основе SOA необходимо определиться с уровнем типизируемого сервиса. Под сервисом верхнего уровня понимается ИТ-услуга, поставляемая бизнесу (например, корпоративная информационная система, автоматизирующая процесс сбыта), под сервисом нижнего уровня — автоматизированная операция, в рамках которой возникает определенный результат (скажем, получение данных о клиенте из CRM-системы).
Наиболее эффективно типизацию осуществлять на более высоких уровнях сервиса, однако чем выше уровень типизации, тем больше изменений придётся вносить в сервис и тем сложнее будет удержать его в «элементарном» виде. С одной стороны, размер сервиса не должен сдерживать изменение процесса, с другой — он должен быть таким, чтобы им можно было свободно оперировать на уровне изменяемых бизнес-процессов.
Поэтому начинать желательно с самого элементарного уровня — выделять сервисы, сформированные на уровне функций бизнес-процессов, причем принципом их выделения будет выполнение одним исполнителем. В дальнейшем можно пытаться переходить на более высокий уровень типизации и вместе с сервисами типизировать части бизнес-процессов.
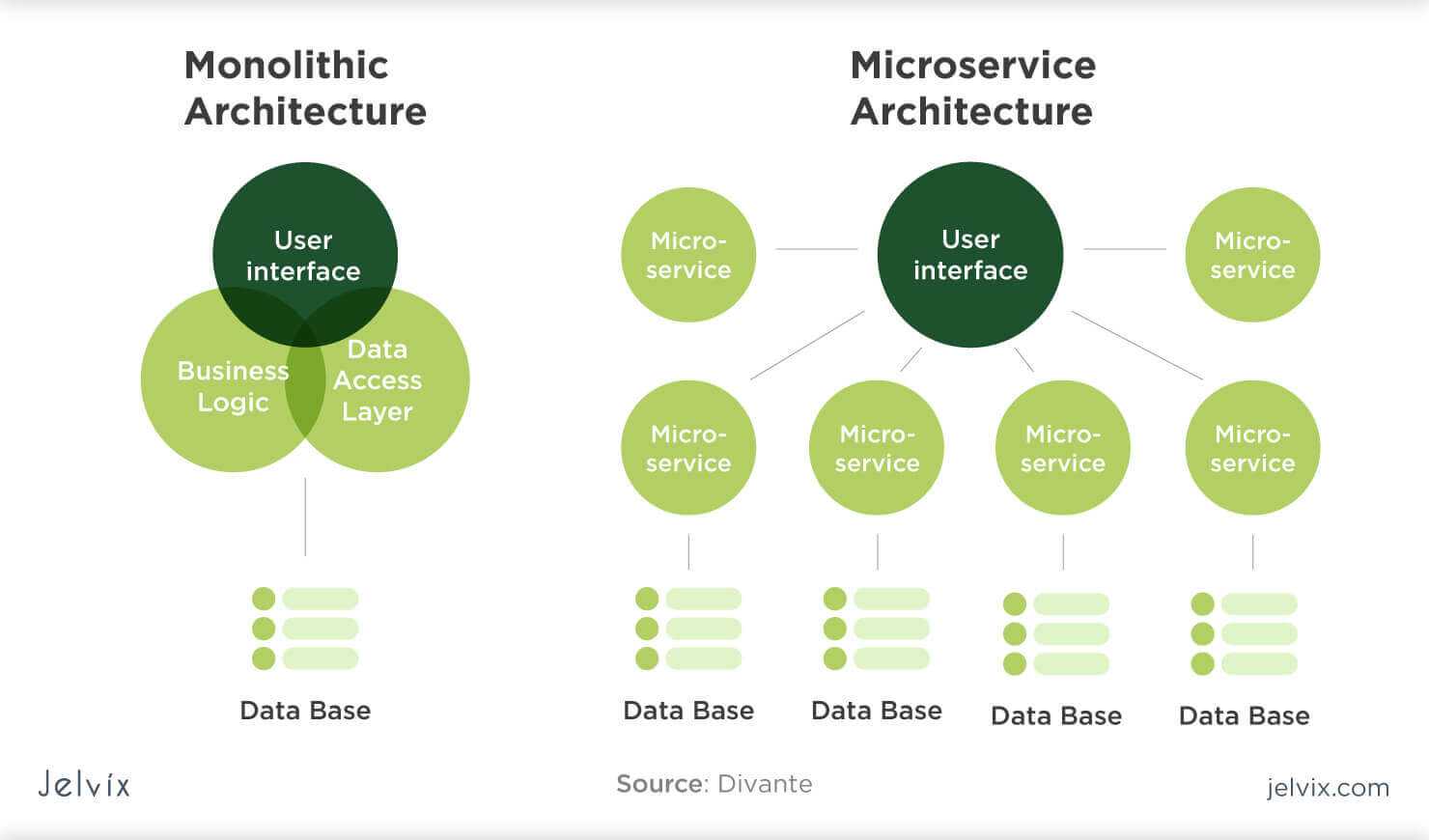
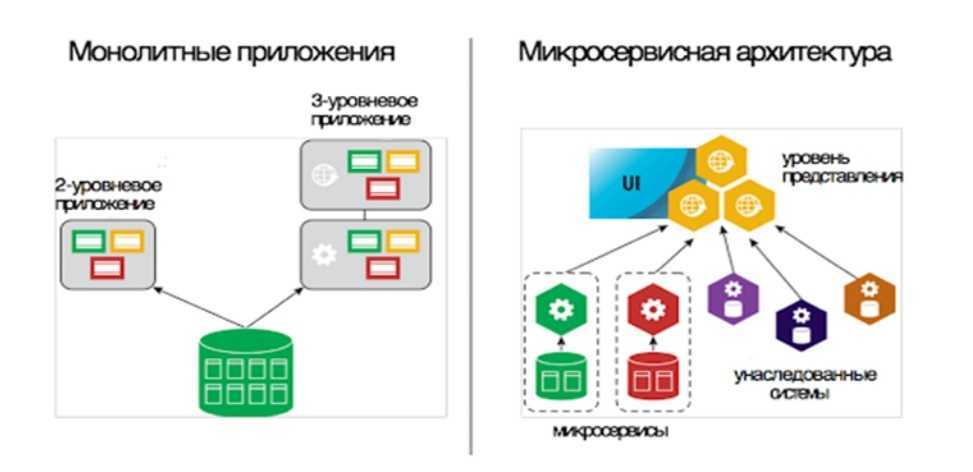
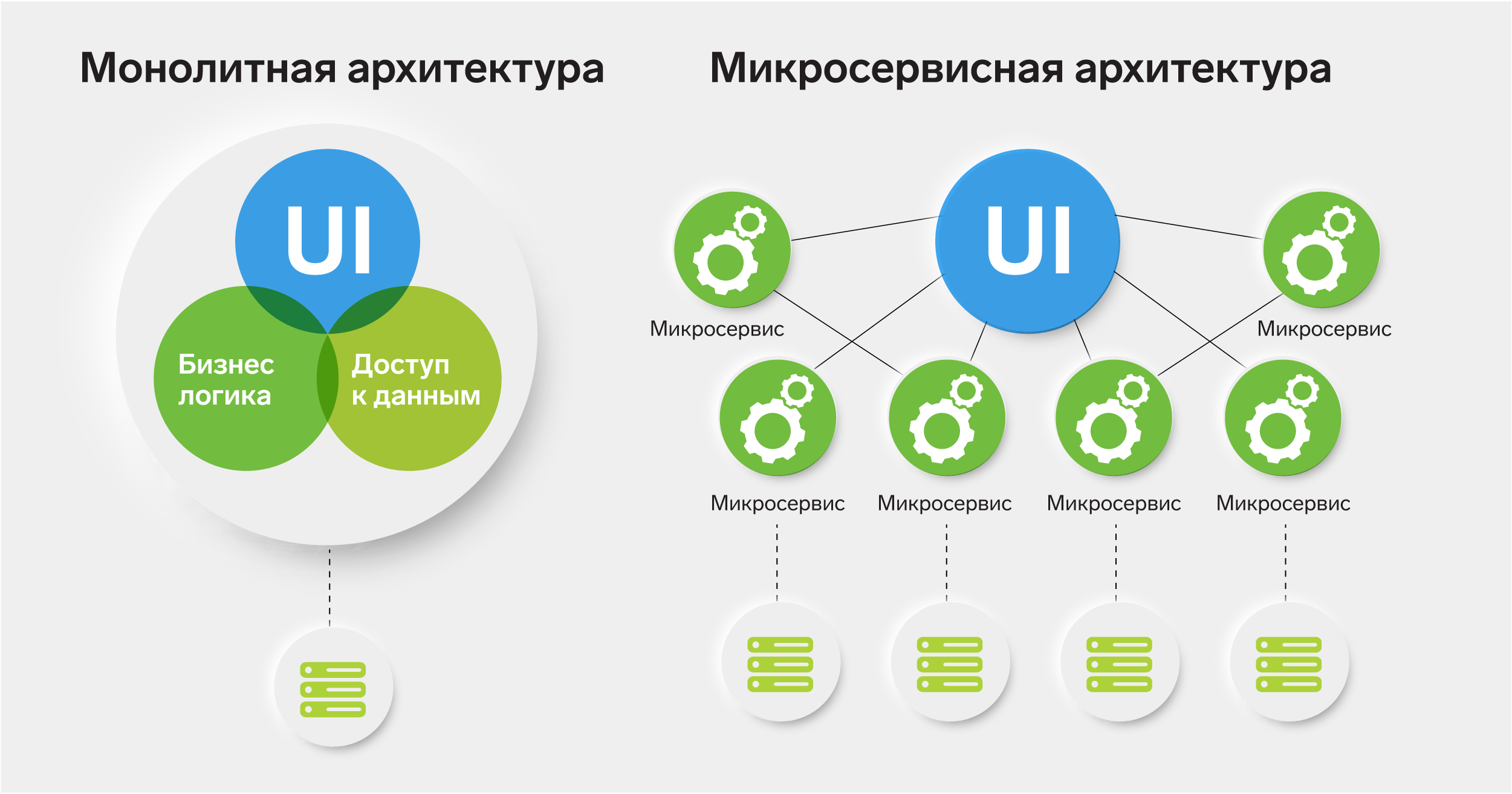
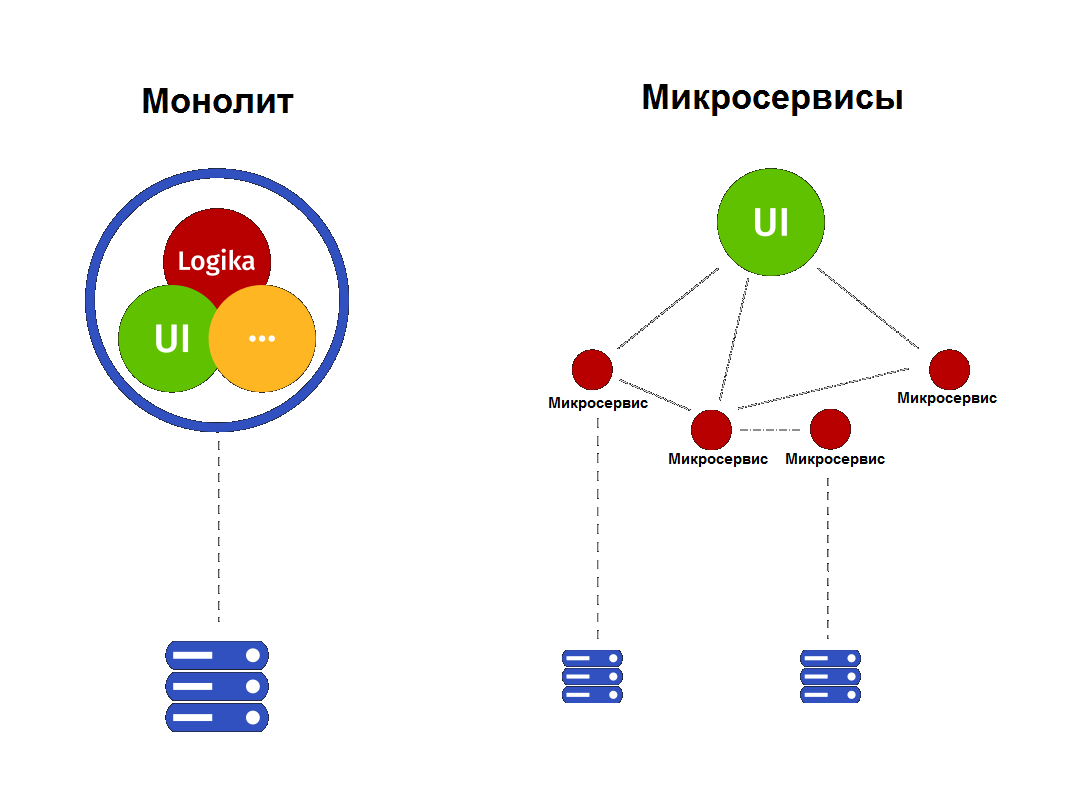
Этап №1. Монолит
1.1 Характеристики
Обычно монолитную архитектуру можно описать так:
- Единая точка разработки и деплоя
- Единая база данных
- Единый цикл релиза для всех изменений
- В одной системе реализовано несколько бизнес-задач
1.2 Проблемы
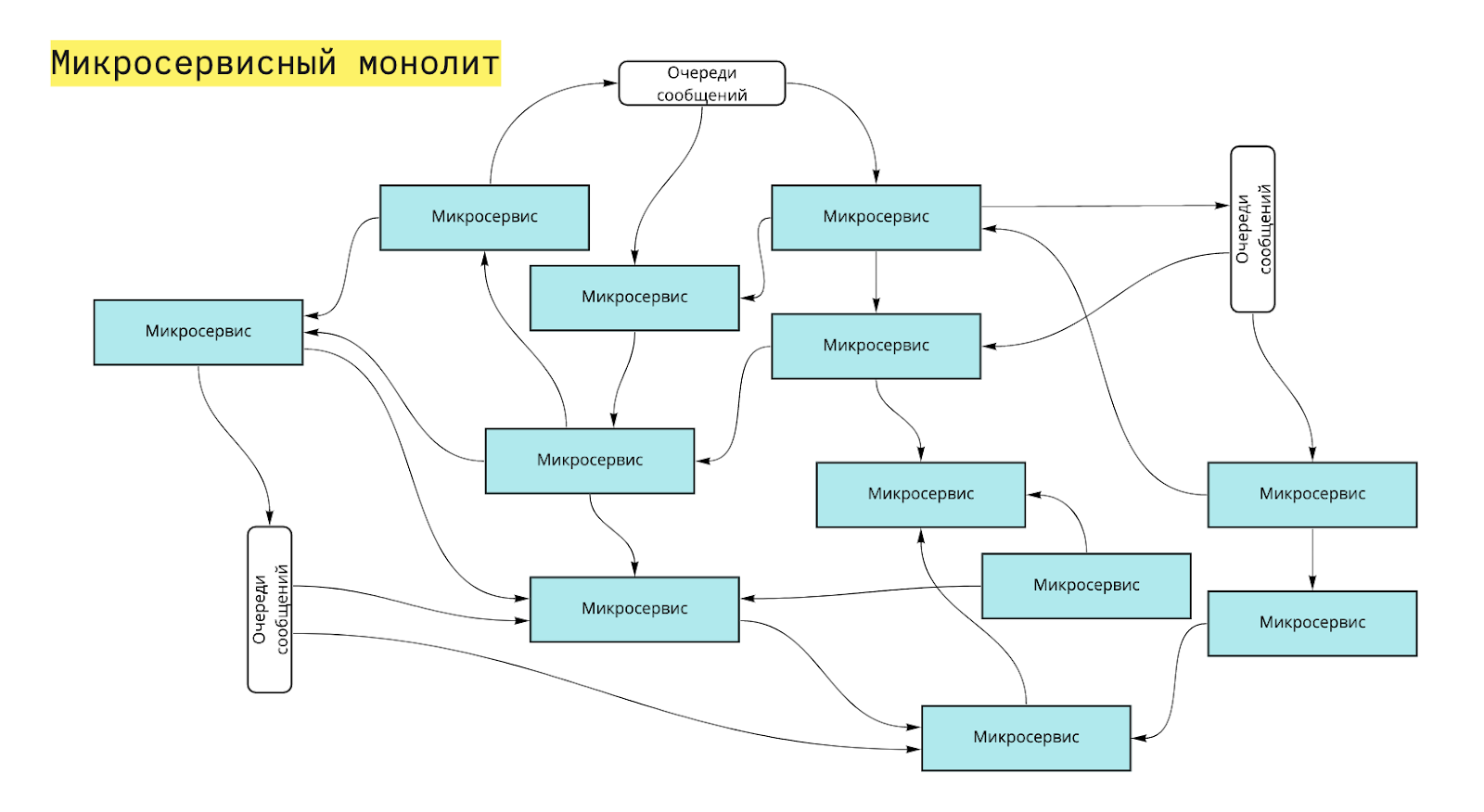
- Система единая, при этом решает много разных бизнес-задач. Разные бизнес-задачи развивают разные подразделения компании и двигаются с разной скоростью. Отсюда возникает проблема с взаимозависимыми релизами разных подразделений, когда все ждут самого медленного.
- Сложно масштабировать бизнес-приложения, которые объединяет монолит. Это приводит к тому, что не учитываются особенности каждого приложения, и масштабирование делается неэффективно.
- При выборе технологического стека для новой бизнес-задачи приходится подстраиваться под среду разработки монолита, хотя этот выбор не всегда является наилучшим.
- Система уходит в релиз целиком, поэтому должна быть протестирована целиком. Это приводит к сложному регрессионному тестированию, затягиванию процесса тестирования и репотинга багов всем поставщикам изменений, замедлению скорости релизов, и, соответственно, увеличению времени time-to-market.
- Последнее ведет к тому, что бизнесу тяжело быстро собрать обратную связь от рынка.
Недостатки
-
Инфраструктура требует больших затрат, поскольку различные технологии имеют различные методологии тестирования, среды для каждого сервиса и деплоя.
-
Дебаг может стать громоздким из-за различных логов каждого сервиса и выявления ошибок в реальном сервисе.
-
Полиглот микросервисов имеет и побочные эффекты, когда компании необходимо поддерживать ресурсы для каждой технологии, используемой для разработки сервисов.
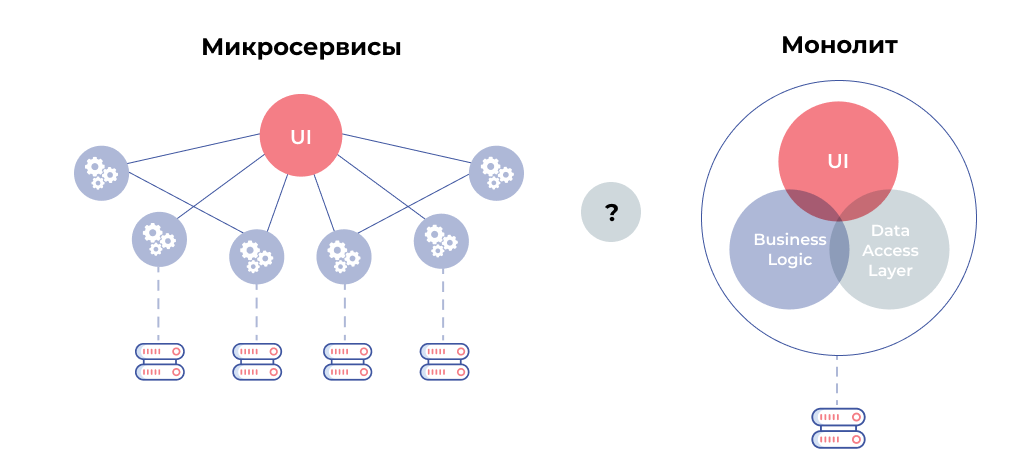
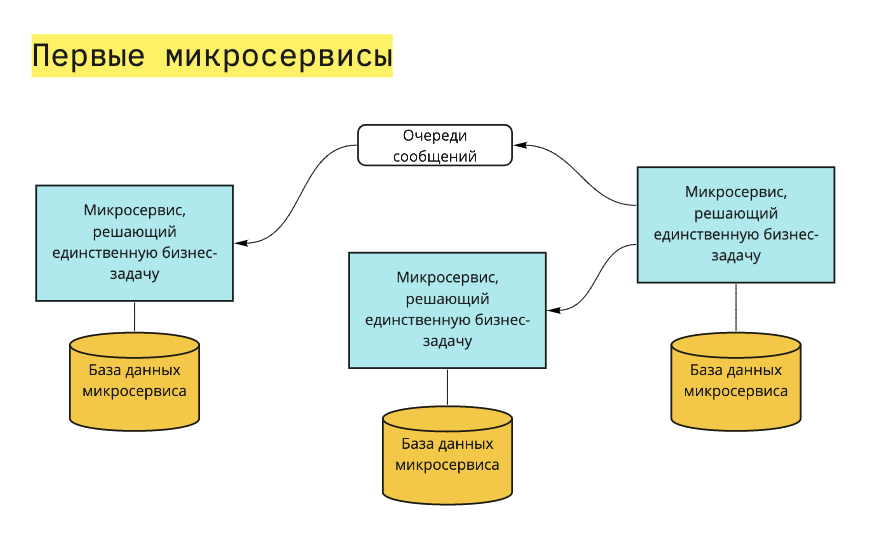
В статье рассказано про микросервисную архитектуру, а также приведено сравнение ее с монолитной архитектурой. Здесь кратко обозначены их характеристики для дальнейшего понимания. Были рассмотрены важные паттерны проектирования, а также преимущества и недостатки каждой архитектуры.
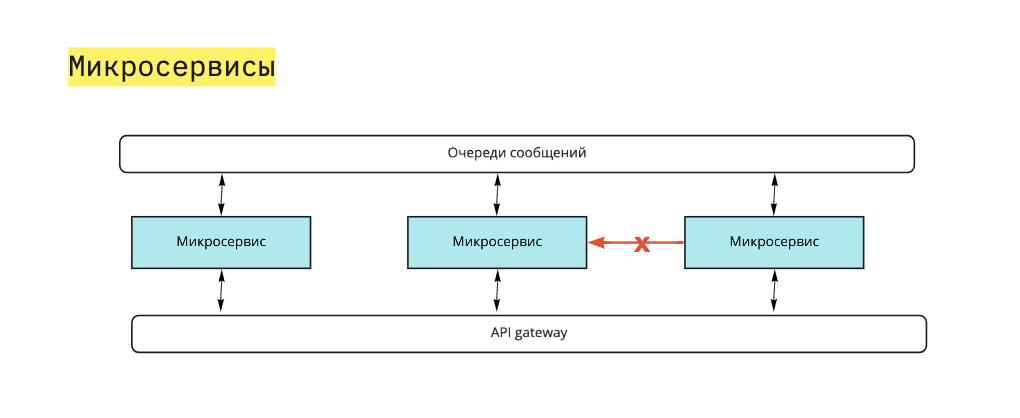
Контроль зависимостей
Трудно сопроводить и поддерживать 50 проектов с 50 репозиториями, если вдруг обнаружится баг безопасности, который нужно срочно пофиксить во всех них. Поэтому используйте контроль зависимостей, общие библиотеки для микросервисов и семантическое версионирование. Причём не делайте одну раздутую библиотеку, а разбивайте её на кучу маленьких, чтобы избежать страха выпуска мажорной версии.

Инвертируйте зависимости: прописывайте версию драйвера в пакет, куда добавляете нужные микросервисы, чтобы потом не пришлось сломя голову перепроверять версии во всех проектах. Для внешних зависимостей лучше зафиксировать версии.
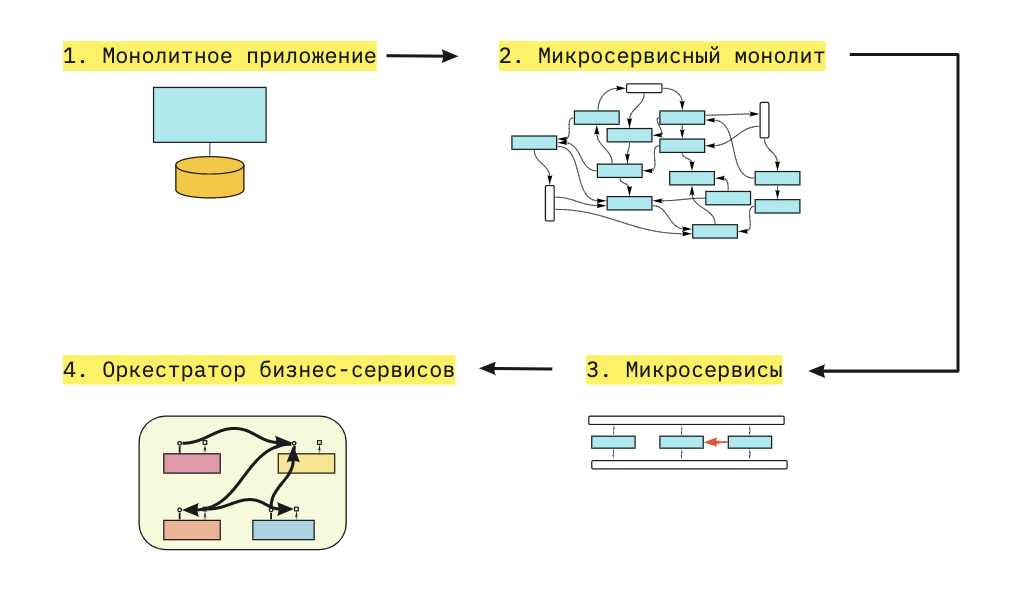
Паттерн Saga
Этот паттерн помогает в управлении транзакциями, где локальные транзакции в каждом сервисе (saga) выполняются, и выдают событие для следующего сервиса, чтобы начать транзакцию. Если какая-либо из транзакций терпит неудачу, серия транзакций, компенсирующих предыдущую транзакцию, будет выполнена saga, чтобы отменить все изменения, сделанные локальными транзакциями, предшествующими этой.
Ниже приведены два способа реализации паттерна Sagа.
Хореография
В хореографии точка управления не централизована, что означает, что каждый сервис будет публиковать сообщение или событие для других сервисов, запуская локальную транзакцию.
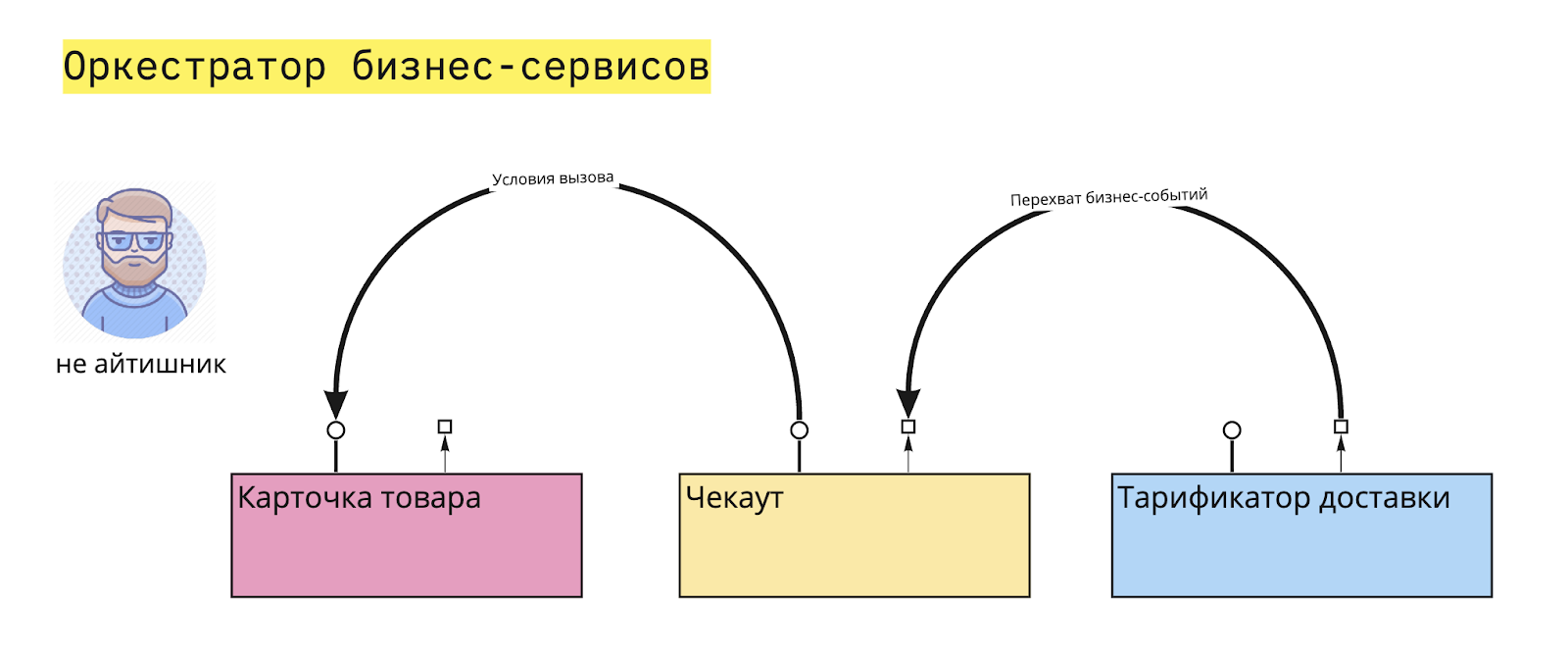
Оркестрирование
Оркестрирование обеспечивает способ управления участниками saga (сервисами), сообщая каждому сервису о локальной транзакции, которую ему необходимо выполнить. На событийной основе операции для saga и транзакций обрабатываются оркестратором saga. Состояние отдельной задачи управляется saga, и в случае сбоя он выполнит транзакцию, чтобы компенсировать предыдущие транзакции.
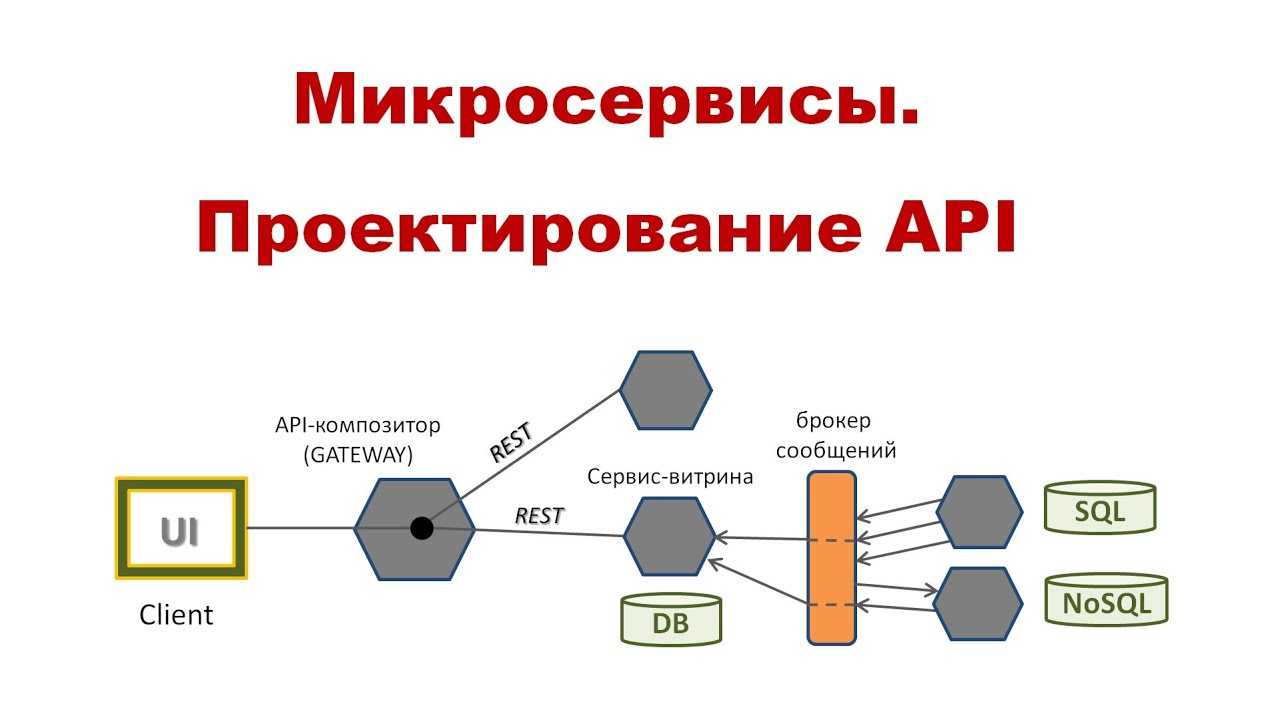
Сервисная шина предприятия (ESB)
Сервисная шина предприятия использовала веб-сервисы уже в 1990-х, когда они только развивались (быть может, некоторые реализации сначала использовали CORBA?).
ESB возникла во времена, когда в компаниях были отдельные приложения. Например, одно для работы с финансами, другое для учёта персонала, третье для управления складом, и т. д., и их нужно было как-то связывать друг с другом, как-то интегрировать. Но все эти приложения создавались без учёта интеграции, не было стандартного языка для взаимодействия приложений (как и сегодня). Поэтому разработчики приложений предусматривали конечные точки для отправки и приёма данных в определённом формате. Компании-клиенты потом интегрировали приложения, налаживая между ними каналы связи и преобразуя сообщения с одного языка приложения в другой.
Очередь сообщений может упростить взаимодействие приложений, но она не способна решить проблему разных форматов языков. Впрочем, была сделана попытка превратить очередь сообщений из простого канала связи в посредника, доставляющего сообщения и преобразующего их в нужные форматы/языки. ESB стал следующей ступенью в естественной эволюции простой очереди сообщений.
В этой архитектуре используется модульное приложение (composite application), обычно ориентированное на пользователей, которое общается с веб-сервисами для выполнения каких-то операций. В свою очередь, эти веб-сервисы тоже могут общаться с другими веб-сервисами, впоследствии возвращая приложению какие-то данные. Но ни приложение, ни бэкенд-сервисы ничего друг о друге не знают, включая расположение и протоколы связи. Они знают лишь, с каким сервисом хотят связаться и где находится сервисная шина.
Клиент (сервис или модульное приложение) отправляет запрос на сервисную шину, которая преобразует сообщение в формат, поддерживаемый в точке назначения, и перенаправляет туда запрос. Всё взаимодействие идёт через сервисную шину, так что если она падает, то с ней падают и все остальные системы. То есть ESB — ключевой посредник, очень сложный компонент системы.
Это очень упрощённое описание архитектуры ESB. Более того, хотя ESB является главным компонентом архитектуры, в системе могут использоваться и другие компоненты вроде доменных брокеров (Domain Broker), сервисов данных (Data Service), сервисов процессной оркестровки (Process Orchestration Service) и обработчиков правил (Rules Engine). Тот же паттерн может использовать интегрированная архитектура (federated design): система разделена на бизнес-домены со своими ESB, и все ESB соединены друг с другом. У такой схемы выше производительность и нет единой точки отказа: если какая-то ESB упадёт, то пострадает лишь её бизнес-домен.
Главные обязанности ESB:
- Отслеживать и маршрутизировать обмен сообщениями между сервисами.
- Преобразовывать сообщения между общающимися сервисными компонентами.
- Управлять развёртыванием и версионированием сервисов.
- Управлять использованием избыточных сервисов.
- Предоставлять стандартные сервисы обработки событий, преобразования и сопоставления данных, сервисы очередей сообщений и событий, сервисы обеспечения безопасности или обработки исключений, сервисы преобразования протоколов и обеспечения необходимого качества связи.
У этого архитектурного паттерна есть положительные стороны. Однако я считаю его особенно полезным в случаях, когда мы не «владеем» веб-сервисами и нам нужен посредник для трансляции сообщений между сервисами, для оркестрирования бизнес-процессами, использующими несколько веб-сервисов, и прочих задач.
Также рекомендую не забывать, что реализации ESB уже достаточно развиты и в большинстве случаев позволяют использовать для своего конфигурирования пользовательский интерфейс с поддержкой drag & drop.
Достоинства
- Независимость набора технологий, развёртывания и масштабируемости сервисов.
- Стандартный, простой и надёжный канал связи (передача текста по HTTP через порт 80).
- Оптимизированный обмен сообщениями.
- Стабильная спецификация обмена сообщениями.
- Изолированность контекстов домена (Domain contexts).
- Простота подключения и отключения сервисов.
- Асинхронность обмена сообщениями помогает управлять нагрузкой на систему.
- Единая точка для управления версионированием и преобразованием.
Недостатки
- Ниже скорость связи, особенно между уже совместимыми сервисами.
- Централизованная логика:
- Единая точка отказа, способная обрушить системы связи всей компании.
- Большая сложность конфигурирования и поддержки.
- Со временем можно прийти к хранению в ESB бизнес-правил.
- Шина так сложна, что для её управления вам потребуется целая команда.
- Высокая зависимость сервисов от ESB.
3 Архитектура
3.1 Цели перехода к новой архитектуре
- Дать возможность внедрять тысячи изменений в год;
- Разработка независимых частей делается независимо;
- Оптимизация трудозатрат пользователей за счет удобной работы и убирания ручной работы;
- Иметь возможность развивать инновационные приложения, которые дают серьёзные преимущества бизнесу;
- Создавать инновации с адекватными затратами.
3.2 Принципы
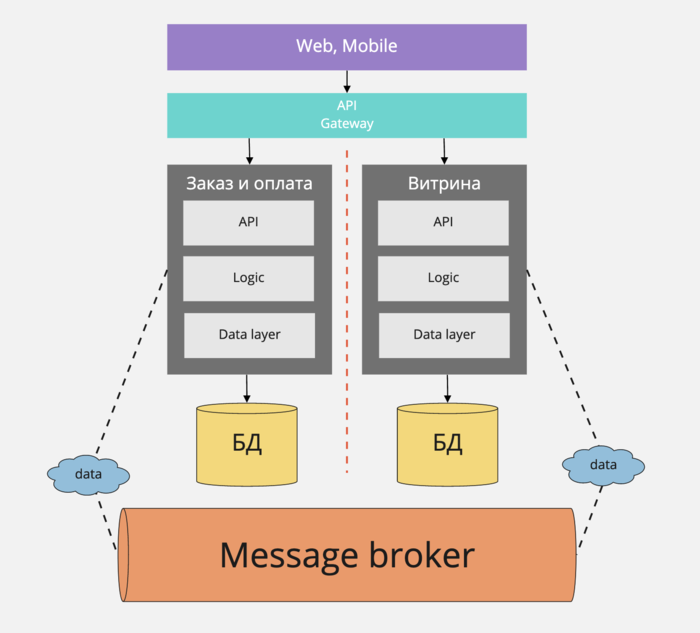
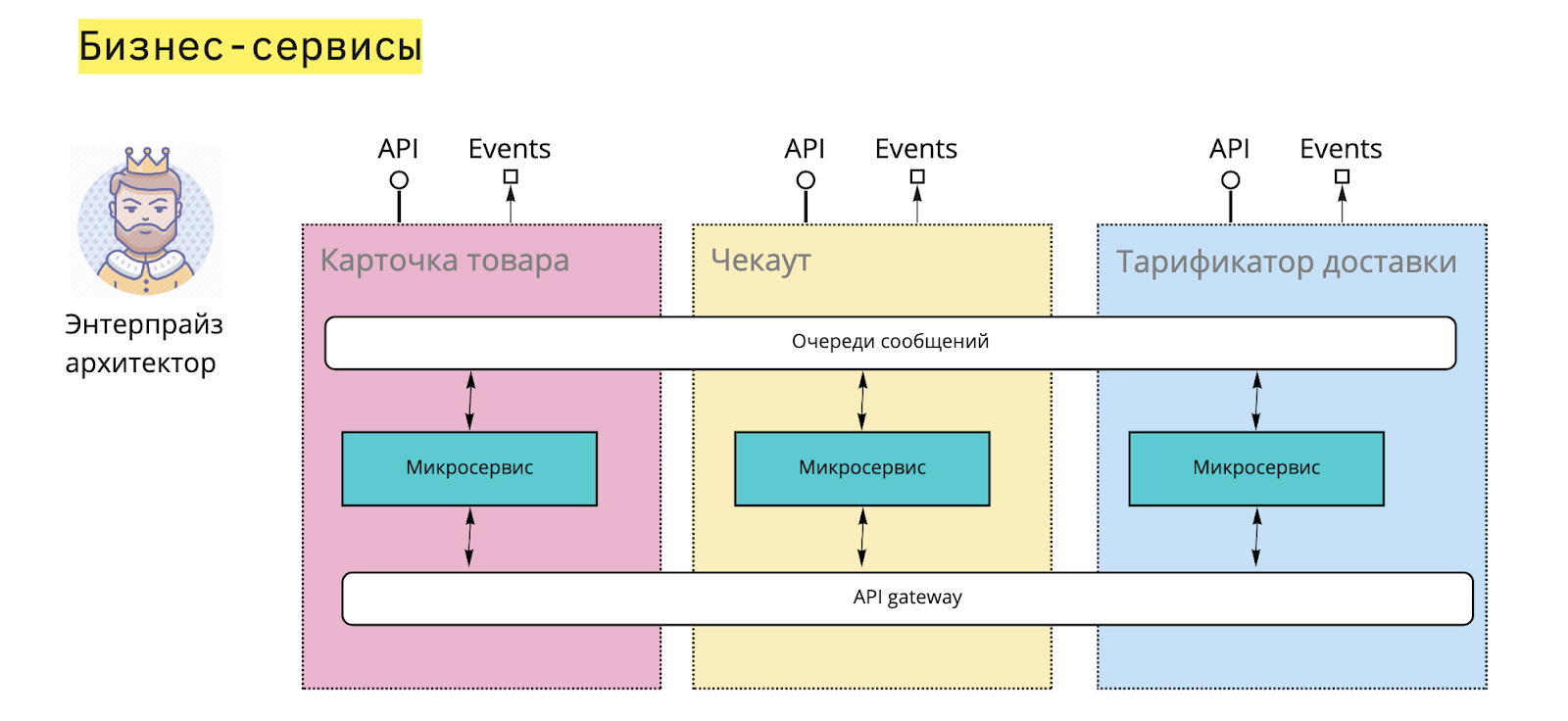
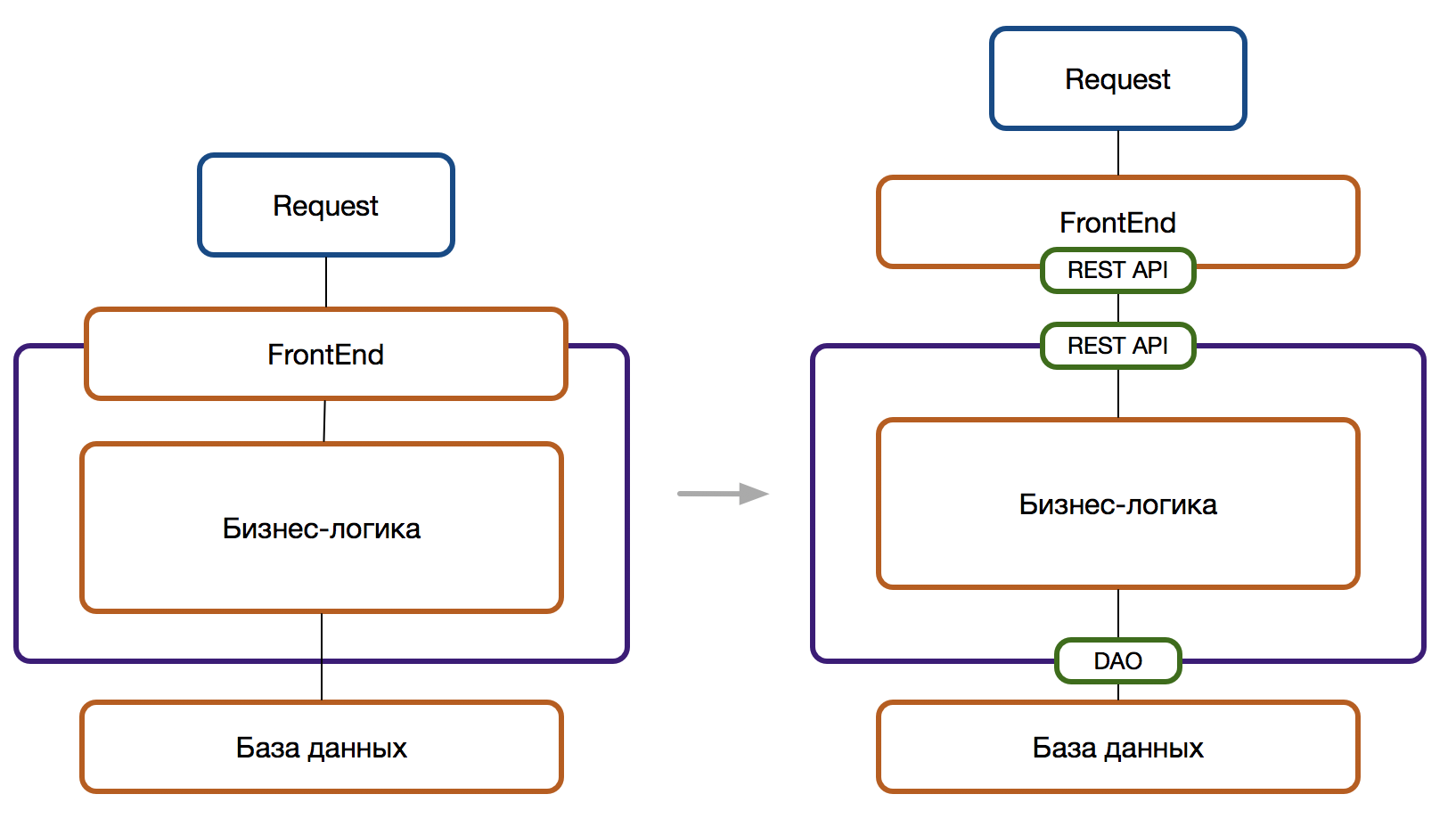
- Объединить идею с единым интерфейсом и микросервисной архитектурой.
- Единый веб-интерфейс использует не монолитную инфраструктуру, а разбит на микросервисы, каждый из которых дополняет UI данными и функциями.
- Пользователи работают в одном окне, без привязки к конкретному сервису. Веб-приложение Корпоративного портала распределяет запросы пользователей по микросервисам. Сбор страницы для отображения происходит тоже из ряда микросервисов.
- Обновление данных в Корпоративном портале происходит по сигналу из шины сообщений или через REST API напрямую от микросервисов.
- Каждый микросервис сам заботиться об интеграции, т.е. показывает, как с ним можно интегрироваться и интегрирует существующие микросервисы. Интеграция может быть сделана через шину сообщений или REST API.
- Пользователи не имеют возможности перемещать данные самостоятельно, например, по средствам выгрузки в Excel в одном месте и загрузки этого Excel в другом.
- Портал должен быть построен так, чтобы очередной микросервис подключался через стандартные процедуры. Для этого у портала должен быть фреймворк для UI и регламентированное API. Тогда можно без крупных вложений подключать и отключать микросервисы.
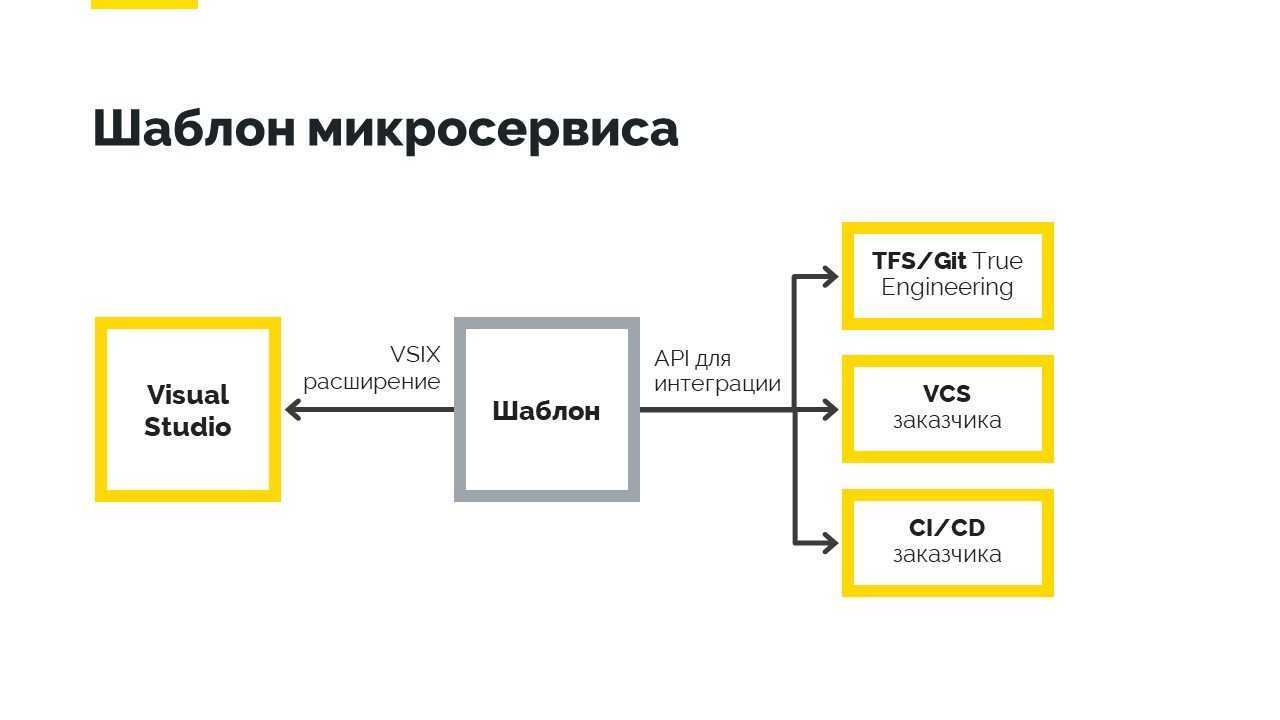
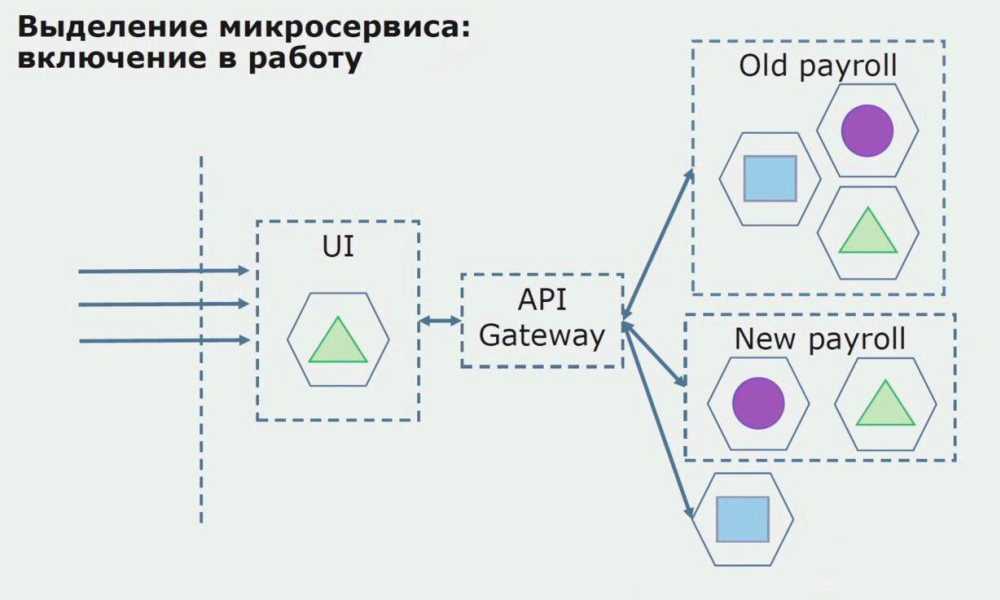
3.4 Подключение нового микросервиса
- Микросервис подключается к Continuous Delivery.
- Микросервис разворачивается в контейнере в облаке.
- Если сервис влияет на интерфейс пользователя, то использует стандартные стили и скрипты для создания/дополнения Корпоративного портала.
- Если у сервиса есть публичный API, то он должен быть описан в определенном формате в базе знаний компании.
- Если сервису нужно принимать события из Event bus и/или отдавать события в Event bus, то формат сообщений должен быть описан в базе знаний компании.
3.5 Физическая архитектура
Схему убрал из-за NDA
Ключевые части:
- Event bus — шина сообщений для интеграции. Горизонтально масштабируется под нагрузкой. Ожидается небольшая нагрузка, не больше 1К сообщений в секунду. Будет создана или на виртуальной машине, или использовано готовое облачное решение.
- Orchestration — стандартизованное управление контейнерами (обновление, версионность и т.п.)
- Continuous Delivery — набор инструментов для реализации постоянной поставки. Будет развернут или на виртуальной машине или использовано готовое облачное решение.
- Контейнеры — процессы, которые содержат работающие реализации микросервисов.
3.7 Способы интеграции
При интеграции рекомендовано использовать один из способов или сразу оба:
- REST API (Remote Procedure Invocation) — при синхронном характере интеграции. Например, если микросервис отвечает за хранение и обработку фотографий изделий, то он открывает описание API, чтобы любой другой микросервис или ПО могли обратиться к API и получить фотографию изделия.
- Event bus (Messaging) — при событийном и асинхронном характере интеграции. Например, если Сервис1 завершает процесс и должен асинхронно известить об этом всех заинтересованных в результатах его работы, то Сервис1 создает событие, запаковывает в него все необходимые данные с результатами и отправляет в Event bus.
Запрещено использовать следующие способы интеграции:
- Обмен файлами (File Transfer)
- Общая база данных (Shared Database)
Фронтенд/бэкенд
- Раскидать все части пользовательского интерфейса по микросервисам и сохранять взаимосвязи между соответствующими микросервисами. Это позволяет наладить внутрипроцессное взаимодействие между фронтендом и бэкендом. Но тогда будет очень сложно, если вообще возможно, поддерживать связность UI. В случае перекрёстных изменений границ в UI нам придётся одновременно обновлять несколько микросервисов, создавая взаимосвязи и нарушая изолированность и независимость микросервисов, обеспечиваемые самой архитектурой. Получается практически антипаттерн!
-
Раскидать кодовые базы фронтенда и бэкенда, оставив UI приложения одним целым, чтобы они потом взаимодействовали по HTTP. Микросервисы будут отделены друг от друга, что дополнительно разделит фронтенд и бэкенд. Зато UI можно поддерживать целиком, легко сохраняя его связность. Такую структуру рекомендует использовать Рейчел Майерс, и, насколько я понимаю, это единственный способ. В таком случае у нас есть два варианта взаимодействия между фронтендом и бэкендом:
- Много маленьких асинхронных HTTP-запросов вместо одного большого, что исключит возможность блокировки (этот подход предпочитает Чед Фаулер).
- Один большой запрос к специализированным сервисам (шлюзу/агрегатору/кешу), которые собирают данные со всей микросервисной экосистемы. Это уменьшает сложность UI.
Трехуровневая и n-уровневая системы
Так выглядит трехуровневая архитектура
Такие архитектуры обладают высокой масштабируемостью как по горизонтали, так и по вертикали. Реализация n-уровневой системы, как правило, обходится дороже, но обеспечивает высокую производительность. Поэтому она обычно применяется в крупных и комплексных программных решениях.
Этот подход можно сочетать с современной сервис-ориентированной архитектурой, чтобы создавать сложнейшие модели. Поскольку реализация может оказаться дорогостоящей с точки зрения времени и ресурсов, рекомендуется использовать его для сложных ПО, требующих производительности и масштабируемости.
Сервис-ориентированная архитектура (SOA)
Эта архитектурная модель состоит из компонентов и приложений, которые связываются друг с другом с помощью четко определенных сервисов.
Она состоит из 5 элементов:
- сервисы (Services);
- сервисная шина (Service Bus);
- сервисный репозиторий (Service Repository );
- безопасность SOA (SOA Security);
- управление SOA (SOA Governance).
Клиент отправляет запрос с использованием стандартного протокола и формата данных по сети. Этот запрос обрабатывается ESB (enterprise service bus — сервисная шина предприятия), которая считается сердцем сервис-ориентированной архитектуры и отвечает за оркестровку и маршрутизацию. С помощью сервисного репозитория ESB направляет запрос в специальный сервис, который может взаимодействовать с другими сервисами и базами данных, чтобы составить полезную нагрузку (данные) ответа.
![Мультипроцессоры [курсовая №92641]](https://robotrackkursk.ru/wp-content/uploads/b/a/c/bacf79a4b3be16327034e96608a970f4.png)
Полный вызов ответа на запрос согласуется с правилами управления и безопасности SOA для выполнения безопасной и корректной транзакции.
Как правило, сервисы делятся на два вида.
- Атомарные сервисы (Atomic services) предоставляют функциональности, которые не подлежат дальнейшей декомпозиции.
- Композиционные сервисы (Composite services) сочетают в себе несколько атомарных сервисов, чтобы предоставлять сложную составную функциональность.
1.3.1. Многопроцессорная обработка с SISD
В компьютере с одиночным потоком данных и одиночным потоком команд одним процессором последовательно обрабатываются машинные команды; каждая из которых обрабатывает один элемент данных. В качестве примера можно привести фон-неймановскую архитектуру.
SISD-компьютеры являются обычными, традиционными последовательными компьютерами, в которых в каждый момент времени выполняется лишь одна операция над одним элементом данных, которое является числовым или каким-либо другим значением. Например, большинство персональных компьютеров до последнего времени попадает именно в эту категорию. Также иногда сюда относят некоторые типы векторных компьютеров, но это зависит от того, что понимать под потоком данных .



