
Работа в сети Интернет
За время существования Интернета разработано много программ-браузеров, с помощью которых пользователь может получать доступ к самой разнообразной информации, расположенной на многочисленных Web-страницах. Они различаются своими возможностями и постоянно совершенствуются. К нашему времени подавляющее большинство клиентов Интернета использует браузеры Microsoft Edge, Google Chrome или Mozilla Firefox. Все программы-браузеры имеют примерно одинаковые возможности.
Программа Google Chrome является наиболее популярной и позволяет не только просматривать Web-страницы, но и работать со всеми сервисами Интернета и службами самого Google (электронной почтой, сетевыми новостями, облачным хранилищем, видеозаписями и др.).
Основная панель инструментов любого браузера имеет следующие кнопки:
- «Назад» — для перехода к предыдущей загруженной пользователем страницы;
- «Вперед» — для перехода к следующей странице (кнопка становится доступна после одного или нескольких щелчков мышью на кнопке «Назад»)
- «Остановить» — для прерывания связи с текущим узлом и остановки передачи данных;
- «Обновить» — позволяет восстановить информацию в текущем окне, снова загрузив страницу с сервера (применяется тогда, когда что-то на экране имеет нежелательный вид, или если информация на узле восстанавливается очень часто и необходимо пересмотреть самую свежую страницу)
- «Домой» — для перехода к «домашней» странице, с которой вы начинаете навигацию в Интернете;
- «Поиск» — для поиска ресурсов Интернета по введенным словам с помощью поисковых систем;
- «Избранное» — для накопления интересных страниц и удобного доступа к ним;
- «Журнал» — для поиска и выбора страниц, к которым обращались во время предыдущих сеансов работы с программой браузера;
- «Печать» — для распечатки содержимого текущего окна браузера.
Сейчас в сети Интернет по разным оценкам размещено более миллиарда сайтов (Web-страниц). Чтобы облегчить поиск необходимых данных, создаются специальные поисковые серверы , которые собирают и хранят характеристики документов в своих базах данных. При обращении к поисковому серверу открывается страница, содержащая каталоги новостей по различным темам (наука, спорт, погода, политика и т. д.) и элементы для контекстного поиска. Благодаря каталогам можно вести направленный поиск необходимых данных, просматривая их содержимое.
Кроме этого, поисковые системы выполняют контекстный поиск, то есть поиск по содержанию документов, используя собственные базы данных. На странице есть специальное поле, в котором задается запрос: ключевые слова для поиска или их комбинация с использованием логических операторов «И» ( «+»), «ИЛИ» ( «,»), «НЕТ» ( «-«) и др . В ответ на запрос предлагается список документов со ссылками на соответствующий адрес с объяснением и / или короткой аннотацией документа.
Качество поиска и количество найденных документов во многом зависят от корректности запроса и объема базы данных поисковой системы, например, они будут отличаться для запросов «МЕНЕДЖМЕНТ» и «МЕНЕДЖМЕНТ + ПРЕДПРИЯТИЕ». На странице поиска обычно доступна справка по составлению запроса, с которой целесообразно познакомиться перед поиском.
С целью проведения первичного поиска на конкретную тему целесообразно использовать поисковые каталоги . Для специалистов, хорошо знакомых с ресурсами сети Интернет в своей области, полезным является поиск по ключевым словам. Самыми популярными являются такие поисковые серверы:
- www.yandex.ru
- www.google.com
- www.rambler.ru
Поисковые серверы связаны между собой. Специальные программы-спайдеры (пауки) постоянно просматривают узлы, корректируя собственные базы данных. Оперативность их работы обеспечивается за счет быстродействующей аппаратуры. Так, поисковый сервер google сканирует миллионы cтраниц в сутки.
Для многих пользователей поисковые серверы являются отправной точкой для работы в сети. Это привело к превращению простых поисковых систем в порталы — универсальные сетевые ресурсы, имеющие широкий набор сервисов и облегчающие навигацию по сети. Они содержат поисковую машину, каталог ресурсов, почтовую систему, службу новостей и тому подобное.
История Всемирной паутины
Так выглядит самый первый веб-сервер, разработанный Тимом Бернерс-Ли
Изобретателями всемирной паутины считаются Тим Бернерс-Ли и в меньшей степени, Роберт Кайо. Тим Бернерс-Ли является автором технологий HTTP, URI/URL и HTML. В 1980 году он работал в Европейском совете по ядерным исследованиям (фр. Conseil Européen pour la Recherche Nucléaire, CERN) консультантом по программному обеспечению. Именно там, в Женеве (Швейцария), он для собственных нужд написал программу «Энквайр» (англ. Enquire, можно вольно перевести как «Дознаватель»), которая использовала случайные ассоциации для хранения данных и заложила концептуальную основу для Всемирной паутины.
В 1989 году, работая в CERN над внутренней сетью организации, Тим Бернерс-Ли предложил глобальный гипертекстовый проект, теперь известный как Всемирная паутина. Проект подразумевал публикацию гипертекстовых документов, связанных между собой гиперссылками, что облегчило бы поиск и консолидацию информации для учёных CERN. Для осуществления проекта Тимом Бернерсом-Ли (совместно с его помощниками) были изобретены идентификаторы URI, протокол HTTP и язык HTML. Это технологии, без которых уже нельзя себе представить современный Интернет. В период с 1991 по 1993 год Бернерс-Ли усовершенствовал технические спецификации этих стандартов и опубликовал их. Но, всё же, официально годом рождения Всемирной паутины нужно считать 1989 год.
В рамках проекта Бернерс-Ли написал первый в мире веб-сервер httpd и первый в мире гипертекстовый веб-браузер, называвшийся WorldWideWeb. Этот браузер был одновременно и WYSIWYG-редактором (сокр. от англ. What You See Is What You Get — что видишь, то и получишь), его разработка была начата в октябре 1990 года, а закончена в декабре того же года. Программа работала в среде NeXTStep и начала распространяться по Интернету летом 1991 года.
Первый в мире веб-сайт был размещён Бернерсом-Ли 6 августа 1991 года на первом веб-сервере доступном по адресу http://info.cern.ch/, (здесь архивная копия). Ресурс определял понятие Всемирной паутины, содержал инструкции по установке веб-сервера, использования браузера и т. п. Этот сайт также являлся первым в мире интернет-каталогом, потому что позже Тим Бернерс-Ли разместил и поддерживал там список ссылок на другие сайты.
Первая фотография во Всемирной паутине — группа Les Horribles Cernettes
На первой фотографии во Всемирной паутине была изображена пародийная филк-группа Les Horribles Cernettes. Тим Бернес-Ли попросил их отсканированные снимки у лидера группы после CERN Hardronic Festival.
И всё же теоретические основы веба были заложены гораздо раньше Бернерса-Ли. Ещё в 1945 году Ванна́вер Буш разработал концепцию Memex — вспомогательных механических средств «расширения человеческой памяти». Memex — это устройство, в котором человек хранит все свои книги и записи (а в идеале — и все свои знания, поддающиеся формальному описанию) и которое выдаёт нужную информацию с достаточной скоростью и гибкостью. Оно является расширением и дополнением памяти человека. Бушем было также предсказано всеобъемлющее индексирование текстов и мультимедийных ресурсов с возможностью быстрого поиска необходимой информации. Следующим значительным шагом на пути ко Всемирной паутине было создание гипертекста (термин введён Тедом Нельсоном в 1965 году).
С 1994 года основную работу по развитию Всемирной паутины взял на себя консорциум Всемирной паутины (англ. World Wide Web Consortium, W3C), основанный и до сих пор возглавляемый Тимом Бернерсом-Ли. Данный консорциум — организация, разрабатывающая и внедряющая технологические стандарты для Интернета и Всемирной паутины. Миссия W3C: «Полностью раскрыть потенциал Всемирной паутины путём создания протоколов и принципов, гарантирующих долгосрочное развитие Сети». Две другие важнейшие задачи консорциума — обеспечить полную «интернационализа́цию Сети́» и сделать Сеть доступной для людей с ограниченными возможностями.
W3C разрабатывает для Интернета единые принципы и стандарты (называемые «рекомендациями», англ. W3C Recommendations), которые затем внедряются производителями программ и оборудования. Таким образом достигается совместимость между программными продуктами и аппаратурой различных компаний, что делает Всемирную сеть более совершенной, универсальной и удобной. Все рекомендации консорциума Всемирной паутины открыты, то есть не защищены патентами и могут внедряться любым человеком без всяких финансовых отчислений консорциуму.
Две стороны
С одной стороны собрались инженеры, создающие браузеры в Apple, Google, Mozilla и Microsoft. Обычно эти компании — конкуренты, которые понимают конфиденциальность в интернете совершенно по-разному. Но все они слышали призыв государственных регуляторов и своих клиентов. И поэтому обращаются к W3C с просьбой разработать новые стандарты защиты данных, которые уберут методы отслеживания пользователей (причем, желательно, именно те, на которые полагаются другие компании).
Против них стоят компании, которые используют межсайтовый трекинг для повышения эффективности рекламы и оптимизации сайтов. Они борются за выживание своей индустрии. Сюда входят и небольшие фирмы, такие как 51Degrees, и гиганты индустрии, такие как Facebook.
Эти голоса — возможно, единственное, что мешает полностью адаптировать под себя интернет таким компаниям как Google, Apple и Microsoft. У которых, как говорят сторонники второго лагеря, уже и так вполне достаточно власти.
В то же время представители IT-гигантов утверждают, что W3C в своем текущем формате мешает браузерам разрабатывать новые важные средства для всех пользователей сети и мешает прогрессу. Пит Снайдер, директор по конфиденциальности в компании Brave, которая делает браузер с защитой от трекинга, об этом говорит:
Что пугает Снайдера еще больше — новые участники консорциума не просто пытаются убрать стандарты, которые могут нанести ущерб их бизнесу, они предлагают новые, которые могут принести им миллиарды от таргетинга, усложнив работу всех конкурентов. «К счастью, на таком форуме, как W3C, люди достаточно умны, чтобы понимать, что есть что», — говорит он. — «К сожалению, наши законодатели — другое дело. Повторяется ситуация, как когда FCC пыталась ограничить скорость интернета для определенных сайтов. Или позволить провайдерам блокировать ресурсы по своему усмотрению. Это можно сделать и изнутри, через консорциум. Если заставить его принять те правила, которые тебе нужны».
Сервисы on-line
Сервисы on-line интерактивные сервисы, где требуется моментальная реакция на полученную информацию.
Примеры сервисов on-line
World Wide Web (всемирная паутина, WWW) – Самый известный сервис Интернет. Основное назначения сервиса WWW интеграция разных ресурсов в единое информационное пространство, для удобной работы с самой разнообразной информацией.
FTP – Сервис системы файловых архивов. Этот сервис обеспечивают хранение, пересылку и доступ к файлам различного типа;
DNS (Domain Name System) Сервис – система доменных имен. Этот сервис обеспечивает «перевод» числовых адресов ресурсов в мнемонические имена и наоборот.
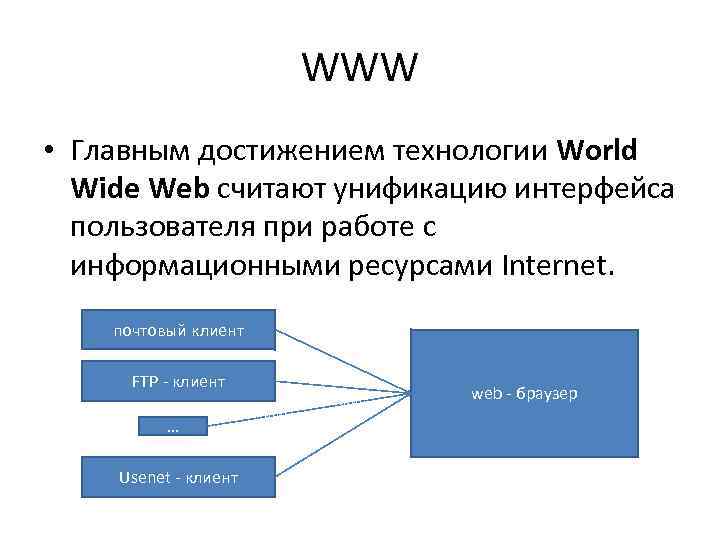









Telnet – сервис, созданный для управления удаленными компьютерами в режиме терминала;
Все выше перечисленные сервисы можно отнести к стандартным. То есть работа этих серверов основана на международные стандарты, а значит, работают во всей сети Интернет.
Кроме стандартных сервисов есть и сервисы нестандартные. По сути это уникальные разработки отдельных компаний.
Список источников
1. https://studentbank.ru/view.php?id=10907
2. https://www.bibliofond.ru/view.aspx?id=804195
3. https://psy.bobrodobro.ru/6624
4. https://erfa.ru/plyusy-i-minusy-world-wide-web-kratko-vsemirnaya-pautina-www-veliko-li.html
5. https://studbooks.net/1337828/psihologiya/takoe_vsemirnaya_pautina_nuzhna
6. https://topor.info/internet/internet-i-vsemirnaya-pautina
- Профессиональное ПО для редактирования и обработки звука.
- Особенности Скульптуры в эпоху Античной Греции (XII – VIII века до н. э. – эпоха зарождения греческой скульптуры)
- Лидерами рождаются или становятся. Лидер в организации
- Скульптура древней Греции
- Современный симфонический оркестр. Рассадка и звучание.
- История музыки (зарубежной, отечественной)
- Функциональная структура управления предприятий
- Правовое регулирование взыскания компенсации морального вреда в гражданском праве России (Гражданское право)
- Мотивация – от теории к практике (Психологический словарь)
- История ландшафтного дизайна от Древнего Египта до Западной Европы 20-х в.
- История ландшафтного дизайна
- Современные тенденции применения анимации в рекламе
Программное обеспечение сервиса www
Веб-серверы
Веб-сервер — это сетевое приложение, обслуживающее HTTP-запросы от клиентов, обычно веб-браузеров. Веб-сервер принимает запросы и возвращает ответы, обычно вместе с HTML-страницей, изображением, файлом, медиа-потоком или другими данными. Веб-серверы — основа Всемирной паутины. С расширением спектра сетевых сервисов веб-серверы все чаще используются в качестве шлюзов для серверов приложений или сами
представляют такие функции (например, Apache Tomcat).
Созданием программного обеспечения веб-серверов занимаются многие разработчики, но наибольшую популярность (по статистике http://netcraft.com) имеют такие программные продукты, как Apache (Apache Software Foundation), IIS (Microsoft), Google Web Server (GWS, Google Inc.) и nginx.
Apache — свободное программное обеспечение, распространяется под совместимой с GPL лицензией. Apache уже многие годы является лидером по распространенности во Всемирной паутине в силу своей надежности, гибкости, масштабируемости и безопасности.
IIS (Internet Information Services) — проприетарный набор серверов для нескольких служб Интернета, разработанный Майкрософт и распространяемый с серверными операционными системами семейства Windows. Основным компонентом IIS является веб-сервер, также поддерживаются протоколы FTP, POP3, SMTP, NNTP.
Google Web Server (GWS) — разработка компании Google на основе веб-сервера Apache. GWS оптимизирован для выполнения приложений сервиса Google Applications.
nginx [engine x] — это HTTP-сервер, совмещенный с кэширующим прокси-сервером. Разработан И. Сысоевым для компании Рамблер. Осенью 2004 года вышел первый публично доступный релиз, сейчас nginx используется на 9-12% веб-серверов.
Браузеры
Браузер, веб-обозреватель (web-browser) — клиентское приложение для доступа к веб-серверам по протоколу HTTP и просмотра веб-страниц. Как правило браузеры дополнительно поддерживают и ряд других протоколов (например ftp, file, mms, pop3).
Первые HTTP-клиенты были консольными и работали в текстовом режиме, позволяя читать гипертекст и перемещаться по ссылкам. Сейчас консольные браузеры (такие, как lynx, w3m или links) практически не используются рядовыми посетителями веб-сайтов. Тем не менее такие браузеры весьма полезны для веб-разработчиков, так как позволяют «увидеть» веб-страницу «глазами» поискового робота.
Исторически первым браузером в современном понимании (т.е. с графическим интерфейсом и т.д.) была программа NCSA Mosaic, разработанная Марком Андерисеном и Эриком Бина. Mosaic имел довольно ограниченные возможности, но его открытый исходный код стал основой для многих последующих разработок.
Существует множество различных программ-браузеров, но наибольшей популярностью на дату написания этой статьи пользуются следующие:
- Internet Explorer / (Edge с версии 11) (IE) — браузер, разработанный компанией Майкрософт и тесно интегрированный c ОС Windows.
- Firefox — свободный кроссплатформенный браузер, разрабатываемый Mozilla Foundation и распространяемый под тройной лицензией GPL/LGPL/MPL.
- Safari — проприетарный браузер, разработаный корпорацией Apple и входящий в состав операционной системы Mac OS X.
- Opera — кроссплатформенный многофункциональный веб-браузер, впервые представленный в 1994 году группой исследователей из норвежской компании Telenor. Дальнейшая разработка ведется Opera Software ASA.
Развернутая информация об этих и ряде альтернативных браузеров приводится в статье «Как выбрать лучший браузер?».
Роботы-«пауки»
Наряду с браузерами, ориентированными на пользователя, существуют и специализированные клиенты-роботы («пауки», «боты»), подключающиеся к веб-серверам и выполняющие различные задачи автоматической обработки гипертекстовой информации. Сюда относятся, в первую очередь, роботы поисковых систем, таких как google.com, yandex.ru, yahoo.com и т.п., выполняющие обход веб-сайтов для последующего построения поискового индекса.
Информационные службы Интернета
Информационные службы предоставляют пользователям возможность доступа к определенным информационным ресурсам, хранящимся в Интернете. Такими ресурсами являются либо файлы стандартных форматов, либо разного рода документы (в том числе мультимедийные), которые можно просмотреть, сохранить, распечатать.
Служба передачи файлов. Часто эту службу называют по имени используемого протокола: FTP (File Transfer Protocol — протокол передачи файлов). Со стороны Сети работу службы обеспечивают FTP-серверы, а со стороны пользователей — FTP-клиенты.
Назначение FTP-сервера — хранение набора файлов самого разнообразного назначения (обычно в архивированном виде). Чаще всего это программные файлы: средства системного и прикладного программного обеспечения. Но в наборах могут храниться файлы и любых других форматов: графические, звуковые, документы Microsoft Word, Microsoft Excel и др. Вся эта информация образует иерархическую структуру папок (каталогов и подкаталогов).
После соединения FTP-клиента с сервером на экране пользователя открывается файловый интерфейс хранилища папок и файлов на сервере (наподобие Проводника Windows). Далее работа происходит так же, как с файловой системой на собственном ПК: папки и файлы можно просматривать, сортировать, копировать на свои диски.
Клиент FTP входит в состав программы Internet Explorer и поэтому всегда имеется на ПК, работающем под управлением ОС Microsoft Windows.
World Wide Web (WWW, Всемирная паутина) — самая массовая сегодня информационная служба Интернета. Это огромная, распределенная по всему миру информационная система, содержащая миллионы документов на самые разнообразные темы.
Работает эта служба на базе протокола НТТР. Подробно о WWW будет рассказано в следующем параграфе. О популярности WWW говорят такие данные: с момента создания Интернета (1969 г.) до появления WWW (1993 г.) к услугам Сети подключились около 2 миллионов пользователей; с появлением WWW за 5-7 лет это число увеличилось приблизительно до 200 миллионов человек. В последнее время Интернет стал отождествляться с WWW. В настоящее время в мире насчитывается более 2 миллиардов пользователей Интернета и World Wide Wеb.
Сервисы on-line
Сервисы on-line интерактивные сервисы, где требуется моментальная реакция на полученную информацию.
Примеры сервисов on-line
World Wide Web (всемирная паутина, WWW) – Самый известный сервис Интернет. Основное назначения сервиса WWW интеграция разных ресурсов в единое информационное пространство, для удобной работы с самой разнообразной информацией.





![Www (world wide web) - глобальный механизм обмена информацией (по дисциплине «макетирование») [реферат №7140]](https://robotrackkursk.ru/wp-content/uploads/c/8/1/c81b71daf6133f60051f7a7ef22e7ee8.jpeg)




FTP – Сервис системы файловых архивов. Этот сервис обеспечивают хранение, пересылку и доступ к файлам различного типа;
DNS (Domain Name System) Сервис – система доменных имен. Этот сервис обеспечивает «перевод» числовых адресов ресурсов в мнемонические имена и наоборот.
Telnet – сервис, созданный для управления удаленными компьютерами в режиме терминала;
Все выше перечисленные сервисы можно отнести к стандартным. То есть работа этих серверов основана на международных стандартах, а значит, работают во всей сети Интернет.
Кроме стандартных сервисов есть и сервисы нестандартные. По сути это уникальные разработки отдельных компаний.
Браузеры
Для перемещения между сайтами в глобальной сети предназначены браузеры. Сегодня у пользователей есть возможность выбрать наиболее удобный для себя инструмент для доступа на просторы интернета.
World Wide Web
Борьба за звание лучшего проводника на просторах всемирной паутины началась в 90 годы минувшего столетия. Одна из первых подобных программ носила название World Wide Web. Ее аббревиатура – WWW – часто используется для обозначения интернета. В дальнейшем браузеру дали название Nexus, но сдал свои позиции, уступив лидерство наиболее продвинутым браузерам.
Mosaic
Небольшое количество людей, использующих интернет по России, знакомо с данным инструментом для «путешествий» во всемирной сети, однако это первый браузер с графическим интерфейсом. Существует версия, что такие популярные в 90-е годы браузеры, как Internet Explorer и Netscape Navigator, воспользовались кодом данного открытого проекта на начальном этапе его функционирования.
Nescape Navigator
Это первый браузер с поисковой строчкой, который существовал в период с 1994 по конец декабря 2007 года. Большая часть пользователей Российской Федерации познакомилась с интернетом, благодаря данному браузеру.
Google Chrome
В настоящее время трудно представить современный интернет без этого браузера, и, кажется, что он существовал с самого начала создания всемирной сети. Однако годом его появления является лишь 2008 год. Сегодня его исходным кодом и движком пользуются многие популярные браузеры, в том числе Яндекс и Opera.
Сервисы и услуги сети Интернет
На сегодняшний день в сети Интернет существует множество разнообразнейших сервисов, обеспечивающих работу со всеми типами ресурсов. Наиболее интересные и популярные среди них это:
- Электронная почта (e-mail), которая обеспечивает возможность не только обмениваться текстовыми сообщениями между неограниченным числом абонентов, но и пересылать прикреплённые файлы;
-
World Wide Web(WWW) – единое информационное пространство, включающее в себя различные сетевые ресурсы;
- Блоги
- Веб-форумы
- Вики-проекты
- Интернет-аукционы и магазины
- Социальные сети и сайты знакомств
- Телеконференции и группы новостей (Usenet) – дают возможность коллективно обмениваться различными сообщениями;
- FTP сервис – системы файловых архивов, которые обеспечивают хранение и распространение различных типов файлов;
- Telnet сервис – с его помощью можно управлять удалёнными компьютерами в режиме терминала;
- DNS сервис – система доменных имён, которая обеспечивает возможность использования мнемонических имён (типа https://moolkin.ru), вместо числового адреса https://81.177.6.144;
- IRC сервис – сервис поддержки чатов, мгновенный обмен текстовыми сообщениями в реальном времени.
Это стандартные сервисы сети Интернет, следовательно, все принципы работы программного обеспечения, протоколы взаимодействия клиент-серверного обеспечения сформулированы и прописаны в международных стандартах. А это значит, что все разработчики обязаны придерживаться этих технических требований.
День интернета в других странах
В странах Европы и Соединенных Штатах день интернета празднуется 4-го апреля. Существует две версии, почему выбрана именно эта дата.
- Во-первых, написание 4.04 очень похоже на обозначение ошибки 404, которое означает, что искомая страница отсутствует в web www.
- Другая версия имеет под собой религиозную основу. Принято считать, что покровитель Глобальной сети – это святой Исидор Севильский, которого канонизировала католическая церковь. Именно 4-е апреля является днем его вознесения. В 2000 году кандидатуру Исидора Севильского официально подтвердил и Ватикан. В качестве обоснования своего решения церковь сослалась на использование святым в своих трудах перекрестных ссылок, которые являлись прототипом используемых сегодня гиперссылок. Покровитель всемирной сети в результате открытого голосования, которое было инициировано Ватиканом на курируемом им сайте в интернете. Это означает, что выбор кандидатуры был одобрен пользователями глобальной паутины.
В некоторых государствах день создания интернета празднуют в тот день, когда появились их собственные национальные домены. К примеру, днем интернета на Украине считается 14-е декабря, а Узбекистан отмечает появление всемирной паутины 29-го апреля.
Технологии Всемирной паутины
Для улучшения визуального восприятия веба стала широко применяться технология CSS, которая позволяет задавать единые стили оформления для множества веб-страниц
Ещё одно нововведение, на которое стоит обратить внимание, — система обозначения ресурсов URN (англ. Uniform Resource Name).
Популярная концепция развития Всемирной паутины — создание семантической паутины. Семантическая паутина — это надстройка над существующей Всемирной паутиной, которая призвана сделать размещённую в сети информацию более понятной для компьютеров. Семантическая паутина — это концепция сети, в которой каждый ресурс на человеческом языке был бы снабжён описанием, понятным компьютеру. Семантическая паутина открывает доступ к чётко структурированной информации для любых приложений, независимо от платформы и независимо от языков программирования. Программы смогут сами находить нужные ресурсы, обрабатывать информацию, классифицировать данные, выявлять логические связи, делать выводы и даже принимать решения на основе этих выводов. При широком распространении и грамотном внедрении семантическая паутина может вызвать революцию в Интернете. Для создания понятного компьютеру описания ресурса, в семантической паутине используется формат RDF (англ. Resource Description Framework), который основан на синтаксисе XML и использует идентификаторы URI для обозначения ресурсов. Новинки в этой области — это RDFS (англ.)русск. (англ. RDF Schema) и SPARQL (англ. Protocol And RDF Query Language) (произносится как «спа́ркл»), новый язык запросов для быстрого доступа к данным RDF.
History
The Advanced Research Projects Agency (ARPA) created by the US in 1958 as a reply to the USSR’s launching of the Sputnik, led to creation of a department called the Information Processing Technology Office (IPTO) which started the Semi Automatic Ground Environment (SAGE) that linked all the radar systems of US together. With tremendous research happening across the world, the University of California in Los Angeles (UCLA) got the ARPANET, a smaller version of the Internet in 1969. Since then Internet has taken huge strides in terms of technology and connectivity to reach its current position. In 1978, the International Packet Switched Service (IPSS) was created in Europe by the British Post Office in collaboration with Tymnet & Western Union International and this network slowly spread its wings to the US and Australia. In 1983, the first Wide Area Network (WAN) was created by the National Science Foundation (NSF) of the US called the NSFnet. All these sub-networks merged together post 1985 with new definitions of the Transfer Control Protocols of the Internet Protocol (TCP/IP) for optimization of resources.
The Web was invented by Sir Tim Berners Lee. In March 1989, Tim Berners-Lee wrote a proposal that described the Web as an elaborate information management system. With help from Robert Cailliau, he published a more formal proposal for the World Wide Web on November 12, 1990. By Christmas 1990, Berners-Lee had built all the tools necessary for a working Web: the first web browser (which was a web editor as well), the first web server, and the first Web pages which described the project itself. On August 6, 1991, he posted a short summary of the World Wide Web project on the alt.hypertext newsgroup. This date also marked the debut of the Web as a publicly available service on the Internet.
Berners-Lee’s breakthrough was to marry hypertext to the Internet. In his book Weaving The Web, he explains that he had repeatedly suggested that a marriage between the two technologies was possible to members of both technical communities, but when no one took up his invitation, he finally tackled the project himself. In the process, he developed a system of globally unique identifiers for resources on the Web and elsewhere: the Uniform Resource Identifier.
The World Wide Web had a number of differences from other hypertext systems that were then available. The Web required only unidirectional links rather than bidirectional ones. This made it possible for someone to link to another resource without action by the owner of that resource. It also significantly reduced the difficulty of implementing web servers and browsers (in comparison to earlier systems), but in turn presented the chronic problem of link rot. Unlike predecessors such as HyperCard, the World Wide Web was non-proprietary, making it possible to develop servers and clients independently and to add extensions without licensing restrictions.
For more details see The History of the Internet and The History of the World Wide Web.
Как решается будущее
В W3C несколько сотен открытых групп, работающих над разными проблемами
Около десяти лет назад W3C создала рабочую группу, чтобы превратить идею конфиденциальности и безопасности пользовательских данных в формальный стандарт. Цель тогда была в том, чтобы создать функцию Do Not Track, которая позволила бы пользователям отказаться от межсайтового отслеживания с помощью простого переключателя в своих браузерах.
В рабочую группу входили в том числе представители технологических гигантов, включая Yahoo, IBM и Microsoft. Но поскольку стандарты W3C являются добровольными, никто не несет никаких реальных обязательств. Браузеры могут посылать сигнал, указывающий, что пользователь не хочет, чтобы его отслеживали, но веб-сайты и компании, размещающие рекламу, не обязаны ему подчиняться.
Поэтому идея не прижилась. Экосистема её не поддержала. В Firefox, Opera, Safari, Chrome, Internet Explorer и Microsoft Edge переключатель Do Not Track теперь есть, его можно включить, но большинство сайтов просто не поддерживают этот стандарт (а зачем, если их никто не обязывает, и им это не выгодно?).
Правда, теперь, в 2021-м, ситуация слегка другая. Появились браузеры, заботящиеся о конфиденциальности, такие как Brave и DuckDuckGo. В этом месяце был запущен новый, платный поисковик Neeva — от разработчиков Google. Пользователи могут, если что, уйти к ним. Многие ключевые игроки, включая The Washington Post, New York Times и WordPress, теперь принимают сигнал (показывающий, что пользователи не хотят, чтобы их отслеживали), и отключают трекинг.
Кто-то в W3C предлагает доработать этот стандарт. Кто-то — работает над его альтернативами. Например, онлайн-рекламодателям очень нравится SWAN. Microsoft работает над Parakeet, у них прошла презентация в феврале этого года.
Идея Google состоит в том, чтобы объединять пользователей в группы как минимум по 1000 человек в каждой, основываясь на их предпочтениях. И уже эти группы продавать рекламодателям. То есть, если компания запускает, например, растительное молоко, и хочет найти себе веганов, она может запустить рекламу только для этой когорты. Но она не увидит информацию об индивидуальных пользователях. Получается, личные данные не утекают: они остаются только в тех сервисах, которым вы их доверили.










В общем, FLoC лишит рекламодателей возможности отслеживать поведение отдельных людей в Сети с помощью файлов cookie, а вместо этого разделит пользователей Chrome на группы в зависимости от посещаемых ими веб-сайтов.
Предложение Google вызвало негативную реакцию со стороны защитников конфиденциальности и тысяч рекламных компаний, которые полагаются на межсайтовый трекинг. Первые говорят, что по собранию интересов можно будет легко реконструировать личность конкретных людей. И что разделение людей на группы в зависимости от их вкусов по-прежнему будет способствовать дискриминационной рекламе.
Рекламные сети, тем временем, обвинили Google в попытке убить их компании и заняться накоплением пользовательских данных только для себя. Производители «конфиденциальных» браузеров — Vivaldi, Brave, DuckDuckGo — в целом отвергли внедрение FLoC. Хотя Google, с ее огромной долей рынка, об этом мало переживает. Кстати, о своей позиции и огромной опасности FLoC Brave подробно написала в своем блоге на Хабре.
Одна из проблем для индустрии состоит в том, что наличие членских взносов в консорциум W3C и серьезное время, которое требуется для обсуждения каждой поправки в каждый стандарт, делают так, что гигантские компании с тысячами сотрудников имеют преимущество. Они могут упаковывать группы обсуждения своими членами и выдвигать бесконечные предложения, забирающие время у других участников. Более мелкие компании или частные лица, работающие над этими вопросами неполный рабочий день, просто тонут в запросах.
Один из защитников конфиденциальности данных, который дал интервью на условиях анонимности, рассказывает:
Например, 40 из 366 членов стратегической группы Improving Web Advertising, занимающейся разработкой стандартов для улучшения рекламы в сети, работают на Google. Еще по 8 представляют Facebook, Microsoft и Amazon.
Что такое Интернет?
Не вдаваясь в сложные технические подробности, можно сказать, что Интернет – это система, которая объединяет компьютерные сети по всему миру. Компьютеры подразделяются на две группы – клиенты и серверы.
Клиентами называют обычные пользовательские устройства, куда входят и персональные компьютеры, и ноутбуки, и планшеты, и, конечно же, смартфоны. Они отправляют запрос, получают и отображают информацию.

Всю информацию хранят сервера, которые могут классифицироваться по разным назначениям:
- веб-сервера,
- почтовые,
- чаты,
- системы трансляции радио и телевидения,
- обмен файлами.
Серверами являются мощные компьютеры, работающие непрерывно. Кроме хранения информации они получают запросы от клиентов и отправляют необходимый ответ. При этом обрабатывают они сотни таких запросов.
Ещё в нашем кратком ликбезе необходимо упомянуть стоит упомянуть интернет-провайдеров, которые обеспечивают связь клиента и сервера. Провайдер – это такая организация со своим интернет-сервером, к которому подключены все её клиенты. Провайдеры обеспечивают связь по телефонному кабелю, выделенному каналу или беспроводной сети.
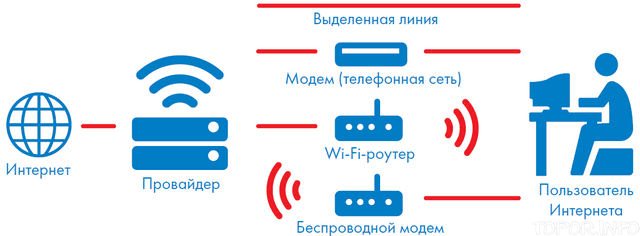
Вот таким образом вы попадаете в Интернет
Можно ли обойтись без провайдера и напрямую подключиться к сети Интернет? Теоретически можно! Вам придётся стать самому себе провайдером и потратить за огромную сумму денег, чтобы добраться к центральным серверам. Так что не ругайте сильно своего поставщика интернета за высокие тарифы – этим ребятам тоже нужно оплачивать многие вещи и тратиться на обслуживание оборудования.



