
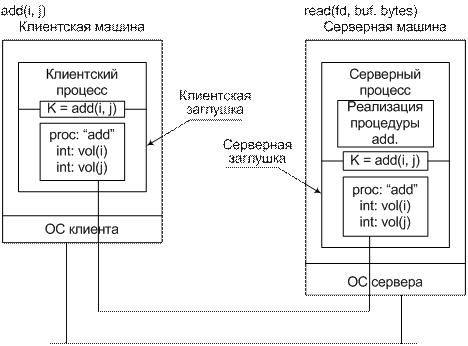
Удаленные процедуры (вызов удаленных процедур): характерные черты и реализации
Таким образом, можно выделить две главные особенности названных технологий:
- асимметричность (инициация выполнения удаленной процедуры только одной из сторон);
- синхронность (приостановка вызывающей процедуры с момента инициации запроса и возобновление после отправки ответа).
Что же касается реализаций, удаленные процедуры (вызов удаленных процедур) сегодня используют несколько базовых технологий, среди которых наиболее широко применяются следующие:
- DCE/RPC – бинарный протокол на основе TCP/IP, SMB/SIFC и т. д.;
- DCOM – объектно-ориентированное дополнение с возможностью передачи ссылок на объекты и вызовом методов их обработки;
- JSON-RPC – текстовый протокол, основанный на HTTP;
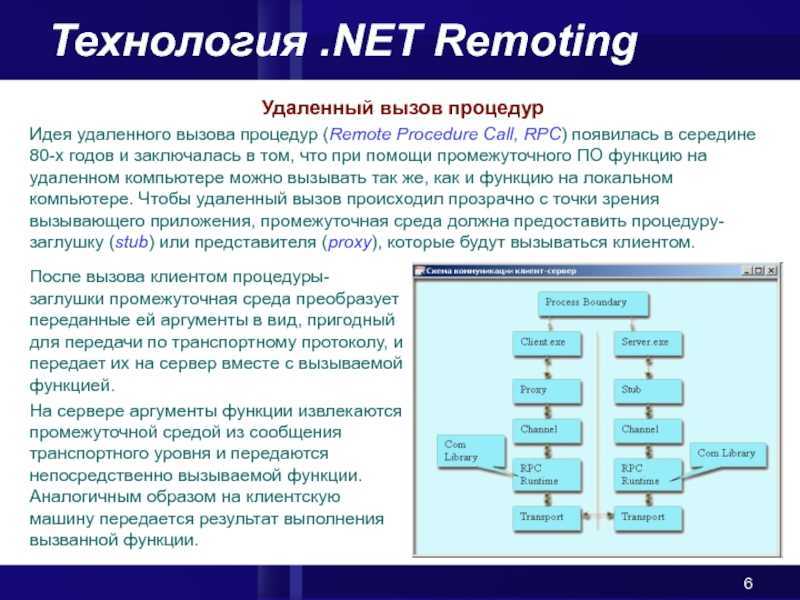
- .NET Remoting – бинарный протокол на основе UDP, TCP и HTTP;
- JAVA RMI;
- SOAP;
- XML RPC;
- SUN RPC;
- ZeroC ICE;
- Routix.RPC и др.
Устранение сбоев и ошибок
Наконец, посмотрим, что можно сделать, если выдается ошибка при удаленном вызове процедуры. В самом простом случае можно попытаться включить службу заново (если, конечно, получится).
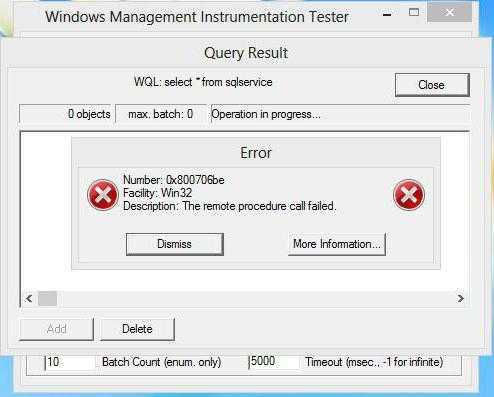
Для этого в соответствующем разделе, где находится искомая служба, двойным кликом вызывается меню редактирования параметров, нажимается кнопка включения, а сам тип включения устанавливается на автоматический. Если проделать такую процедуру при стандартной загрузке системы не представляется возможным, можно попытаться произвести аналогичные действия в безопасном режиме. Некоторые специалисты советуют заодно на время проведения действий на всякий случай отключить антивирусное ПО.
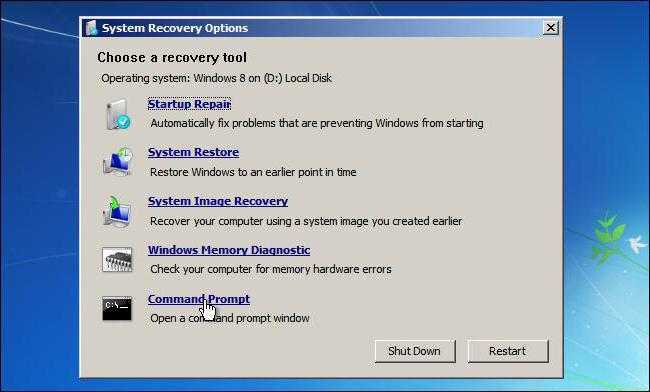
Если это не поможет, но под рукой имеется установочный или восстановительный диск системы, можно запустить командную консоль с правами администратора (загружаться с диска не нужно) и прописать в ней такие команды:
- cd z:\i386 (Z – литера оптического привода);
- expand explorer.ex_ %TEMP%\explorer.exe;
- expand svchost.ex_ %TEMP%\svchost.exe.
После этого запускаем «Диспетчер задач» (Ctrl + Del + Alt или taskmgr в меню «Выполнить») и завершаем процесс Explorer.exe.
Далее в командной консоли прописываем следующее: copy %TEMP%\explorer.exe %SYSTEMROOT% /y.
В «Диспетчере» останавливаем все процессы svhost.exe, после чего в течение 60 секунд нужно успеть в командой строке ввести строку copy %TEMP%\svchost.exe %systemroot%\system32 /y.
Наконец, если есть доступ к редактору системного реестра (regedit) восстановлен, нужно пройти по ветке HKCC через разделы SYSTEM и CurrentControlSet и добраться до параметра CSConfigFlags, изменив его значение на ноль.
Это далеко не все методы исправления ошибок, связанных с RPC. Дело в том, что, если эта служба повлекла за собой нарущения в работе других сервисов, возможно, сначала придется устранять проблемы с их работоспособностью, а только потом предпринимать какие-то действия в отношении RPC. И не всегда к вышеописанным параметрам и настройкам можно получить полный доступ. Если уж совсем ничего не получится, как это ни плачевно звучит, придется полностью переустанавливать операционную систему, хотя хочется надеяться, что до этого дело не дойдет.
Цепочки RPC
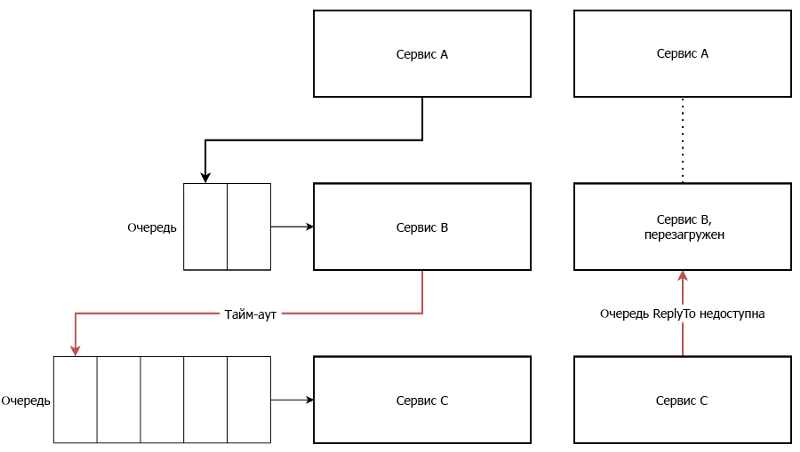
Если у вас есть несколько сервисов, которые взаимодействуют друг с другом с помощью RPC, вы можете столкнуться с ситуацией, когда один из сервисов перезагрузился или запрос не обработался вовремя из-за большой очереди.
Примеры проблем, которые могут возникнуть
Эти проблемы не относятся исключительно к цепочкам RPC, однако объединение нескольких служб в цепочку увеличивает вероятность возникновения указанных проблем, особенно если эти службы не отвечают в течение нескольких миллисекунд. Убедитесь, что при выполнении RPC через несколько служб такие случаи покрыты автоматическими повторными попытками.
Привязка ко многим удаленным вызовам процедур также может затруднить установку правильного таймаута, поскольку нет возможности определить, насколько далеко продолжается цепочка RPC.
Важно отметить: все было бы хорошо, если бы был выбран другой подход. Подход на основе команд или событий, подобный описанному выше, мог бы предотвратить отказ для этих запросов
Тем не менее, если все случаи сбоев обрабатываются правильно, то, безусловно, можно связать несколько сервисов в цепочку с RPC.
Общая архитектура брокера объектных запросов (CORBA)
В 1980-х началось активное использование корпоративных сетей и клиент-серверной архитектуры. Возникла потребность в стандартном способе взаимодействия приложений, которые созданы с использованием разных технологий, исполняются на разных компьютерах и под разными ОС. Для этого была разработана CORBA. Это один из стандартов распределённых вычислений, зародившийся в 1980-х и расцветший к 1991 году.
Стандарт CORBA был реализован несколькими вендорами. Он обеспечивает:
- Не зависящие от платформы вызовы удалённых процедур (Remote Procedure Call).
- Транзакции (в том числе удалённые!).
- Безопасность.
- События.
- Независимость от выбора языка программирования.
- Независимость от выбора ОС.
- Независимость от выбора оборудования.
- Независимость от особенностей передачи данных/связи.
- Набор данных через язык описания интерфейсов (Interface Definition Language, IDL).
Сегодня CORBA всё ещё используется для разнородных вычислений. Например, он до сих пор является частью Java EE, хотя начиная с Java 9 будет поставляться в виде отдельного модуля.
Хочу отметить, что не считаю CORBA паттерном SOA (хотя отношу и CORBA, и SOA-паттерны к сфере распределённых вычислений). Я рассказываю о нём здесь, поскольку считаю недостатки CORBA одной из причин возникновения SOA.
Принцип работы
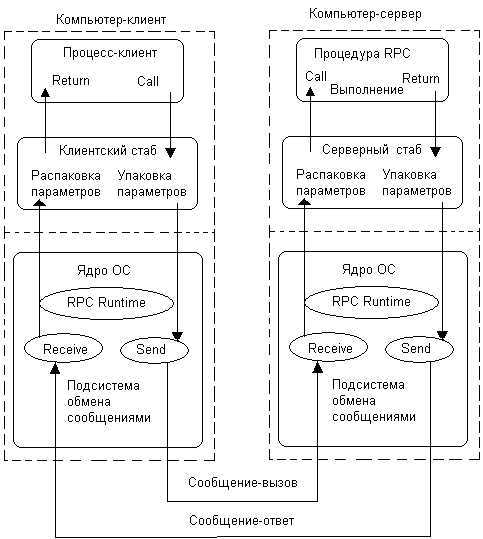
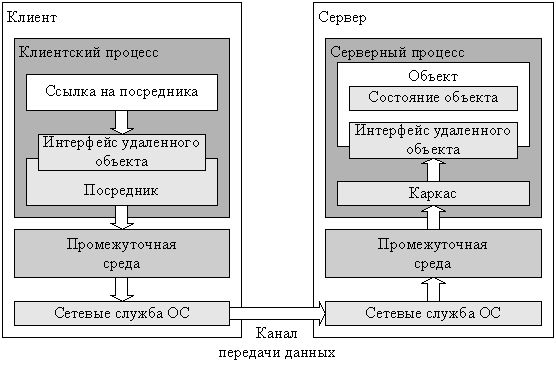
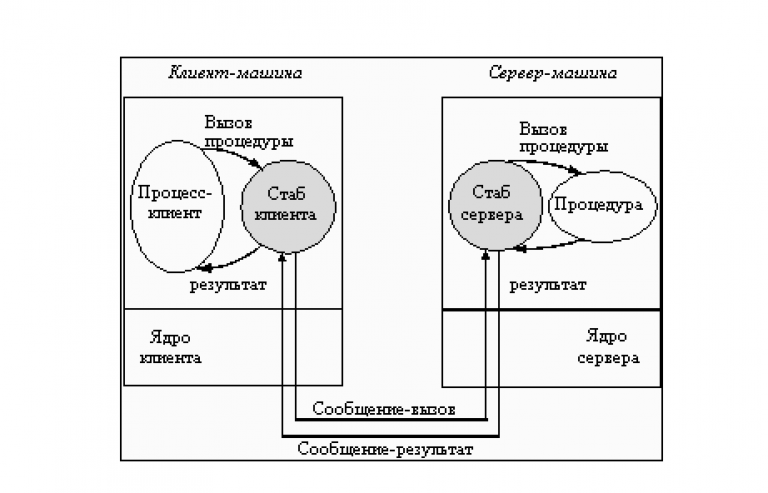
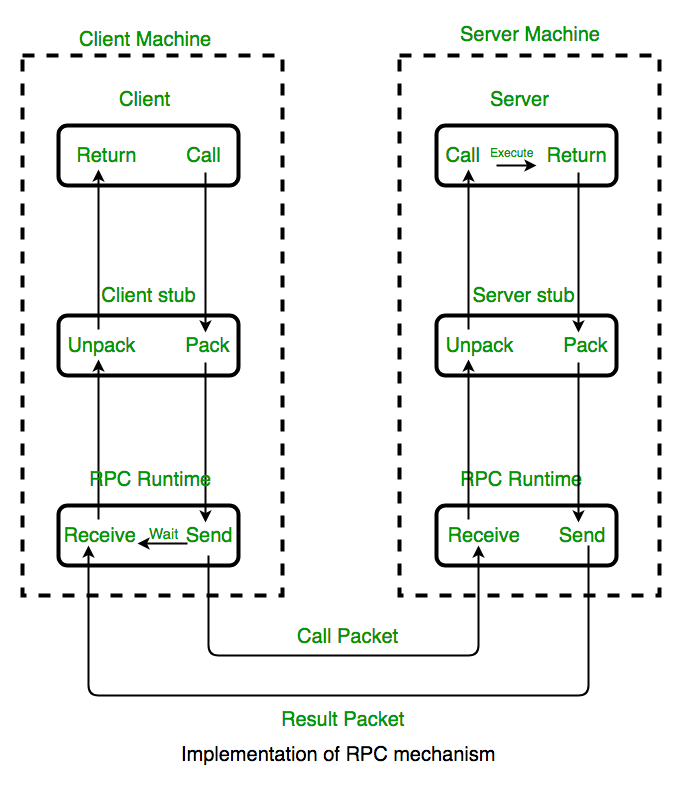
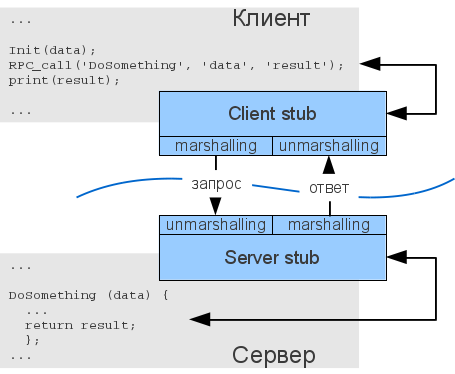
Сначала нам нужно получить брокер объектных запросов (Object Request Broker, ORB), который соответствует спецификации CORBA. Он предоставляется вендором и использует языковые преобразователи (language mappers) для генерирования «заглушек» (stub) и «скелетов» (skeleton) на языках клиентского кода. С помощью этого ORB и определений интерфейсов, использующих IDL (аналог WSDL), можно на основе реальных классов генерировать в клиенте удалённо вызываемые классы-заглушки (stub classes). А на сервере можно генерировать классы-скелеты (skeleton classes), обрабатывающие входящие запросы и вызывающие реальные целевые объекты.
Вызывающая программа (caller) вызывает локальную процедуру, реализованную заглушкой.
- Заглушка проверяет вызов, создаёт сообщение-запрос и передаёт его в ORB.
- Клиентский ORB шлёт сообщение по сети на сервер и блокирует текущий поток выполнения.
- Серверный ORB получает сообщение-запрос и создаёт экземпляр скелета.
- Скелет исполняет процедуру в вызываемом объекте.
- Вызываемый объект проводит вычисления и возвращает результат.
- Скелет пакует выходные аргументы в сообщение-ответ и передаёт его в ORB.
- ORB шлёт сообщение по сети клиенту.
- Клиентский ORB получает сообщение, распаковывает и передаёт информацию заглушке.
- Заглушка передаёт выходные аргументы вызывающему методу, разблокирует поток выполнения, и вызывающая программа продолжает свою работу.
Достоинства
- Независимость от выбранных технологий (не считая реализации ORB).
- Независимость от особенностей передачи данных/связи.
Недостатки
- Независимость от местоположения: клиентский код не имеет понятия, является ли вызов локальным или удалённым. Звучит неплохо, но длительность задержки и виды сбоев могут сильно варьироваться. Если мы не знаем, какой у нас вызов, то приложение не может выбрать подходящую стратегию обработки вызовов методов, а значит, и генерировать удалённые вызовы внутри цикла. В результате вся система работает медленнее.
- Сложная, раздутая и неоднозначная спецификация: её собрали из нескольких версий спецификаций разных вендоров, поэтому (на тот момент) она была раздутой, неоднозначной и трудной в реализации.
- Заблокированные каналы связи (communication pipes): используются специфические протоколы поверх TCP/IP, а также специфические порты (или даже случайные порты). Но правила корпоративной безопасности и файрволы зачастую допускают HTTP-соединения только через 80-й порт, блокируя обмены данными CORBA.
Долго выполняющиеся задачи
При выполнении удаленного вызова процедуры экземпляру придется ждать, пока он не получит ответ обратно. Запрос хранится в памяти, а это значит, что запрос окажется потерян, если экземпляр остановится.
Это может произойти при развертывании новой версии в рабочей среде. Когда мы развернем новую версию, старый экземпляр получит сигнал о том, что он должен корректно завершить работу. Он попытается перед этим завершить свой текущий запрос. Если сервисы не смогли этого сделать в течение нескольких секунд, то сервис будет вынужден прекратить работу.
Вот почему лучше добавить RPC тайм-аут через пару секунд. Это позволит убедиться, что экземпляр может корректно завершить работу при развертывании новой версии.
То же самое касается и взаимодействия с третьей стороной. Ненужно, чтобы вызовы достигали тайм-аута, если третья сторона обрабатывает запросы медленнее, чем ожидалось.
Лучший способ справиться с этой задачей — отправить команду или событие и сохранить состояние запроса в хранилище данных. Когда задача будет выполнена, она отправит событие, которое мы можем прослушивать. Когда событие прибудет, мы получим запрос из хранилища данных и продолжим его обработку. При таком подходе не требуется, чтобы сообщение обрабатывалось одним и тем же экземпляром.
Паттерны асинхронных обменов сообщениями
При работе сервисов возникает несколько типовых ситуаций, для которых мы выработали шаблоны решений — паттерны. Выбрать подходящий можно по числу отправителей и получателей сообщений.
Отправлять асинхронные сообщения можно:
-
между двумя сервисами;
-
от многих отправителей;
-
для многих получателей;
-
для нескольких получателей в одном сервисе;
-
для двустороннего обмена через очереди.
Сервис А отправляет запрос на шину данных, сервис В его читает
Обмен сообщениями между двумя сервисами. Это самый простой вариант взаимодействия: сервис А хочет отправить запрос сервису В. Для этого A публикует его в шину данных. B получает сообщение и может его обработать.


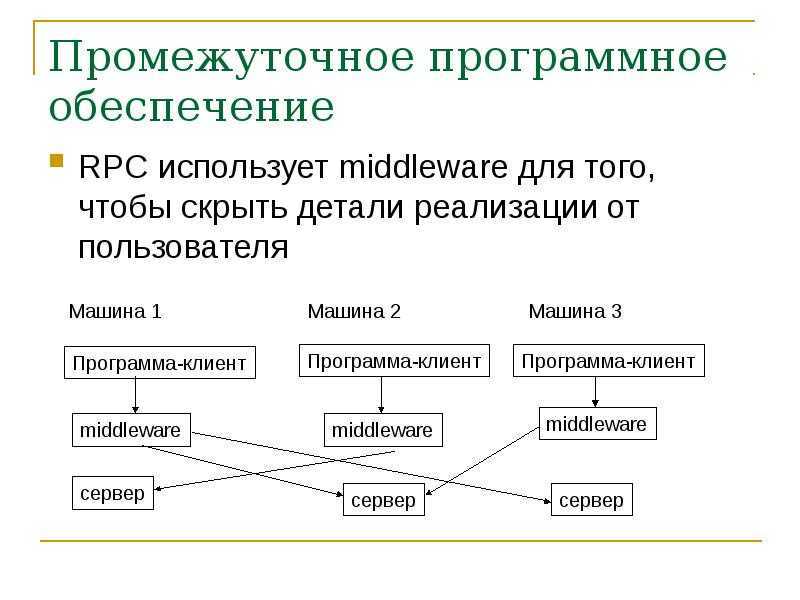


Здесь возможны два варианта реализации:
-
Сообщение предназначено только для сервиса В. Если два сервиса взаимодействуют только друг с другом, то лучше использовать не асинхронный обмен, а RPC.
-
Сообщение получает любой сервис на платформе. Если сообщение можно переиспользовать в дальнейшем, его нужно отправлять через шину данных. Например, в будущем появится новый сервис, которому нужны те же данные, которые уже записаны на шине. Не нужно будет писать новое сообщение — достаточно взять то, которое уже есть.
Несколько отправителей. Data Bus не ограничивает количество различных отправителей для конкретного сообщения. Любой сервис может отправлять запрос, если делает это в корректном формате.
Правильный формат сообщения важен, чтобы запрос могли отправлять и получать любые сервисы. В сообщении нужно передавать идентификаторы сущностей и минимально необходимые поля.
Все детали лучше передавать через RPC уже после обработки асинхронного сообщения. Например, сервис может получить запрос, который опубликован на шине данных несколько месяцев назад. После обработки сообщения сервис отправит RPC и в ответ получит актуальные данные, а не те, что были месяц назад.
Если множество отправителей публикуют одинаковое сообщение на регулярной основе, лучше разделить события названиями. Если в системе есть разные копии платёжных систем, то лучше присвоить их сообщениям OrderPaid разные названия: например, OrderPaymentOnePaid или OrderPaymentTwoPaid.
Сервис А отправляет запрос на шину данных.
Сервисы В и С получают от шины одинаковые сообщения
Несколько получателей. Нормальная ситуация, для которой и придумана шина данных. В Data Bus каждый получатель работает независимо от других сервисов. Допустим, A опубликовал сообщение на шине. Сервисы В и С получат полностью идентичные комплекты сообщений.
Сервис А отправляет запрос двум получателям на одном сервере через шину данных
Несколько получателей в одном сервисе. У каждого сервиса есть уникальный Client ID — идентификатор получателя сообщений. Если внутри сервиса есть несколько получателей, то сообщения от шины данных будут распределены между ними.
Можно получать несколько копий сообщений от шины, если это необходимо. Для этого нужно вручную присвоить каждому обработчику отдельный Client ID. Тогда для каждого получателя внутри сервиса будет сделана отдельная копия всех сообщений от Data Bus.
Сервис А отправляет информацию на шину данных.
Сервис B может ответить ему запросом RPC или сообщением
Двусторонний обмен через очереди. Иногда нужно, чтобы сервис всё-таки получил ответ на сообщение. Для этого паттерна возможны два решения:
-
Добавить в сервис B вызов RPC. То есть, получив сообщение от шины данных, B отправит к A идентификатор или статус обработанного сообщения. Для этого нужно, чтобы B всегда знал, кто именно отправляет ему сообщения.
-
Сервис B отправит сообщение для A через шину данных. В нём так же, как и в вызове RPC, будет статус или идентификатор, который сервис получит после обработки исходного сообщения.
Во втором случае нужно дополнительно продумать поле-идентификатор. По нему получатели сообщений будут понимать, что конкретно это сообщение — ответ на запрос, который был отправлен ранее. Но при этом сервису B не нужно знать, кто ему отправил сообщение: можно просто передать свой ответ в шину данных.
Какие типы программ требуют выполнения RPC?
Если же говорить о том, какие программные модули операционных систем требуют держать службу RPC включенной, все их перечислить просто невозможно.
Но среди всем известных компонентов Windows-систем можно отметить службу факсов, службы криптографии, регистрацию ошибок, справку и поддержку, доступ к устройствам HID, службу сообщений (Messenger), администрирование дисков и логических разделов, управление съемными накопителями, аудиосистему, установщик Windows и еще бог весть что.
Думается, этого списка достаточно, чтобы понять, насколько многие компоненты системы, да и сам пользователь, зависимы от этой службы.
Сервисная шина предприятия (ESB)
Сервисная шина предприятия использовала веб-сервисы уже в 1990-х, когда они только развивались (быть может, некоторые реализации сначала использовали CORBA?).
ESB возникла во времена, когда в компаниях были отдельные приложения. Например, одно для работы с финансами, другое для учёта персонала, третье для управления складом, и т. д., и их нужно было как-то связывать друг с другом, как-то интегрировать. Но все эти приложения создавались без учёта интеграции, не было стандартного языка для взаимодействия приложений (как и сегодня). Поэтому разработчики приложений предусматривали конечные точки для отправки и приёма данных в определённом формате. Компании-клиенты потом интегрировали приложения, налаживая между ними каналы связи и преобразуя сообщения с одного языка приложения в другой.
Очередь сообщений может упростить взаимодействие приложений, но она не способна решить проблему разных форматов языков. Впрочем, была сделана попытка превратить очередь сообщений из простого канала связи в посредника, доставляющего сообщения и преобразующего их в нужные форматы/языки. ESB стал следующей ступенью в естественной эволюции простой очереди сообщений.
В этой архитектуре используется модульное приложение (composite application), обычно ориентированное на пользователей, которое общается с веб-сервисами для выполнения каких-то операций. В свою очередь, эти веб-сервисы тоже могут общаться с другими веб-сервисами, впоследствии возвращая приложению какие-то данные. Но ни приложение, ни бэкенд-сервисы ничего друг о друге не знают, включая расположение и протоколы связи. Они знают лишь, с каким сервисом хотят связаться и где находится сервисная шина.
Клиент (сервис или модульное приложение) отправляет запрос на сервисную шину, которая преобразует сообщение в формат, поддерживаемый в точке назначения, и перенаправляет туда запрос. Всё взаимодействие идёт через сервисную шину, так что если она падает, то с ней падают и все остальные системы. То есть ESB — ключевой посредник, очень сложный компонент системы.
Это очень упрощённое описание архитектуры ESB. Более того, хотя ESB является главным компонентом архитектуры, в системе могут использоваться и другие компоненты вроде доменных брокеров (Domain Broker), сервисов данных (Data Service), сервисов процессной оркестровки (Process Orchestration Service) и обработчиков правил (Rules Engine). Тот же паттерн может использовать интегрированная архитектура (federated design): система разделена на бизнес-домены со своими ESB, и все ESB соединены друг с другом. У такой схемы выше производительность и нет единой точки отказа: если какая-то ESB упадёт, то пострадает лишь её бизнес-домен.
Главные обязанности ESB:
- Отслеживать и маршрутизировать обмен сообщениями между сервисами.
- Преобразовывать сообщения между общающимися сервисными компонентами.
- Управлять развёртыванием и версионированием сервисов.
- Управлять использованием избыточных сервисов.
- Предоставлять стандартные сервисы обработки событий, преобразования и сопоставления данных, сервисы очередей сообщений и событий, сервисы обеспечения безопасности или обработки исключений, сервисы преобразования протоколов и обеспечения необходимого качества связи.
У этого архитектурного паттерна есть положительные стороны. Однако я считаю его особенно полезным в случаях, когда мы не «владеем» веб-сервисами и нам нужен посредник для трансляции сообщений между сервисами, для оркестрирования бизнес-процессами, использующими несколько веб-сервисов, и прочих задач.
Также рекомендую не забывать, что реализации ESB уже достаточно развиты и в большинстве случаев позволяют использовать для своего конфигурирования пользовательский интерфейс с поддержкой drag & drop.
Достоинства
- Независимость набора технологий, развёртывания и масштабируемости сервисов.
- Стандартный, простой и надёжный канал связи (передача текста по HTTP через порт 80).
- Оптимизированный обмен сообщениями.
- Стабильная спецификация обмена сообщениями.
- Изолированность контекстов домена (Domain contexts).
- Простота подключения и отключения сервисов.
- Асинхронность обмена сообщениями помогает управлять нагрузкой на систему.
- Единая точка для управления версионированием и преобразованием.
Недостатки
- Ниже скорость связи, особенно между уже совместимыми сервисами.
- Централизованная логика:
- Единая точка отказа, способная обрушить системы связи всей компании.
- Большая сложность конфигурирования и поддержки.
- Со временем можно прийти к хранению в ESB бизнес-правил.
- Шина так сложна, что для её управления вам потребуется целая команда.
- Высокая зависимость сервисов от ESB.
Обработка сообщений при асинхронном обмене
Асинхронный обмен подразумевает, что сервис-отправитель сообщения не ждёт ответ на него, а продолжает работу в обычном режиме. Но когда сообщение доходит до сервиса-получателя, он сообщает об этом шине данных.
Если сервис получает от шины данных Data Bus одно сообщение, то возвращает для него один из двух ответов:
-
ACK (acknowledgement);
-
NACK (negative acknowledgement).
Результат ACK означает, что сообщение обработано и отправлять его повторно не нужно. То есть сервис-получатель должен отправлять ACK только тогда, когда выполнит все действия с сообщением и зафиксирует их. Например, этот ответ нужно отправлять после того, как закоммитили транзакцию в базу данных.
Результат NACK означает, что сообщение не может быть обработано. В этом случае шина данных отправит его повторно тому же получателю. То есть через заданный шиной промежуток времени то же самое сообщение придёт снова.
Если после отправки NACK получатель отключится. Затем шина данных отправит сообщение следующему получателю.



Сервис может получить несколько сообщений, то есть батч. В этом случае он отправляет шине данных значение счётчика processed. Это количество успешно обработанных сообщений, если считать от начала батча. Все остальные сообщения из этого батча будут считаться необработанными, как если бы сервис отправил для них значение NACK.
Батч сообщений, в котором три успешно обработаны, а последние два нет
Например, вы получили в батче пять сообщений, успешно обработали три из них. Затем произошёл какой-то сбой, и последние два сообщения сервис не обработал. На шину данных нужно отправить processed, который равен трём: сообщения m1, m2, m3 закоммичены как успешно обработанные. Сообщения m4 и m5 не обработаны, поэтому шина данных отправит их повторно.
Для асинхронных очередей внутри одного сервиса (Queues) есть ещё один вариант ответа на сообщение.
DEFER означает, что сообщение нужно не просто повторно отправить, а переложить в конец очереди. DEFER не блокирует получение всех последующих сообщений.
Перекладывать сообщения можно в отложенную очередь (DLQ). То есть повторно запрос придёт, например, через 5 или 10 минут. Задержку можно задать с точностью до одной секунды.
DLQ нужно настраивать в конфигурационном файле app.toml, отдельно для каждого сервиса.
Пример сервиса «item.landed.on.mars», у которого есть три отложенные очереди: на 5, 10 и 30 минут
Если сервис из примера на иллюстрации получит сообщение и ответит на него DEFER, то оно попадёт сначала в первую отложенную очередь. Через 5 минут сообщение будет отправлено повторно. Если сервис снова ответит DEFER, то сообщение переходит во вторую очередь, и так далее.
В Queues можно отправлять батчи сообщений и отвечать на них DEFER. Сервис, который получил батч, ответит на него счётчиком processed, так же как и в Data Bus. Если после счётчика сервис отправит DEFER, то одно сообщение попадёт в конец очереди или в отложенную очередь, если она есть. Все остальные сообщения будут считаться необработанными.
Батч сообщений в Queues: три успешно обработаны, одно отправлено в конец очереди
и одно не обработано
В примере на иллюстрации сервис получил пять сообщений из Queues. Первые три из них обработал и вернул processed=3. Потом сервис отправил DEFER на сообщение m4, оно будет переложено в очередь. Ответ на сообщение m5 будет NACK.
Механика доставки сообщений Queues реализована таким образом, что сообщение m5 будет отправлено сразу после обработки этого батча.
Обработка сообщений при асинхронном обмене
Асинхронный обмен подразумевает, что сервис-отправитель сообщения не ждёт ответ на него, а продолжает работу в обычном режиме. Но когда сообщение доходит до сервиса-получателя, он сообщает об этом шине данных.
Если сервис получает от шины данных Data Bus одно сообщение, то возвращает для него один из двух ответов:
-
ACK (acknowledgement);
-
NACK (negative acknowledgement).
Результат ACK означает, что сообщение обработано и отправлять его повторно не нужно. То есть сервис-получатель должен отправлять ACK только тогда, когда выполнит все действия с сообщением и зафиксирует их. Например, этот ответ нужно отправлять после того, как закоммитили транзакцию в базу данных.
Результат NACK означает, что сообщение не может быть обработано. В этом случае шина данных отправит его повторно тому же получателю. То есть через заданный шиной промежуток времени то же самое сообщение придёт снова.
Если после отправки NACK получатель отключится, то шина данных отправит сообщение следующему получателю.
Сервис может получить несколько сообщений, то есть батч. В этом случае он отправляет шине данных значение счётчика processed. Это количество успешно обработанных сообщений, если считать от начала батча. Все остальные сообщения из этого батча будут считаться необработанными, как если бы сервис отправил для них значение NACK.
Батч сообщений, в котором три успешно обработаны, а последние два нет
Например, вы получили в батче пять сообщений, успешно обработали три из них. Затем произошёл какой-то сбой, и последние два сообщения сервис не обработал. На шину данных нужно отправить processed, который равен трём: сообщения m1, m2, m3 закоммичены как успешно обработанные. Сообщения m4 и m5 не обработаны, поэтому шина данных отправит их повторно.
Для асинхронных очередей внутри одного сервиса (Queues) есть ещё один вариант ответа на сообщение.
DEFER означает, что сообщение нужно не просто повторно отправить, а переложить в конец очереди. DEFER не блокирует получение всех последующих сообщений.
Перекладывать сообщения можно в отложенную очередь (DLQ). То есть повторно запрос придёт, например, через 5 или 10 минут. Задержку можно задать с точностью до одной секунды.
DLQ нужно настраивать в конфигурационном файле app.toml, отдельно для каждого сервиса.
Пример сервиса «item.landed.on.mars», у которого есть три отложенные очереди: на 5, 10 и 30 минут
Если сервис из примера на иллюстрации получит сообщение и ответит на него DEFER, то оно попадёт сначала в первую отложенную очередь. Через 5 минут сообщение будет отправлено повторно. Если сервис снова ответит DEFER, то сообщение переходит во вторую очередь, и так далее.
В Queues можно отправлять батчи сообщений и отвечать на них DEFER. Сервис, который получил батч, ответит на него счётчиком processed, так же как и в Data Bus. Если после счётчика сервис отправит DEFER, то одно сообщение попадёт в конец очереди или в отложенную очередь, если она есть. Все остальные сообщения будут считаться необработанными.
Батч сообщений в Queues: три успешно обработаны, одно отправлено в конец очереди
и одно не обработано
В примере на иллюстрации сервис получил пять сообщений из Queues. Первые три из них обработал и вернул processed=3. Потом сервис отправил DEFER на сообщение m4, оно будет переложено в очередь. Ответ на сообщение m5 будет NACK.
Механика доставки сообщений Queues реализована таким образом, что сообщение m5 будет отправлено сразу после обработки этого батча.
Как можно организовать связь между сервисами
Для передачи данных из одного сервиса в другой есть четыре способа:
-
Опубликовать файл с данными. Для этого нужно общее хранилище данных, в которое один сервис записывает файл, а второй его считывает. Этот способ удобно использовать, если нужно, например, передать несколько сотен ГБ данных.
-
Загрузить данные в единую базу. Вся выходная информация из всех сервисов в системе публикуется в общей базе. Каждый сервис, когда ему нужно, подключается к базе и забирает данные. Этот способ подходит для ситуаций, когда в системе сложная схема взаимодействия сервисов.
-
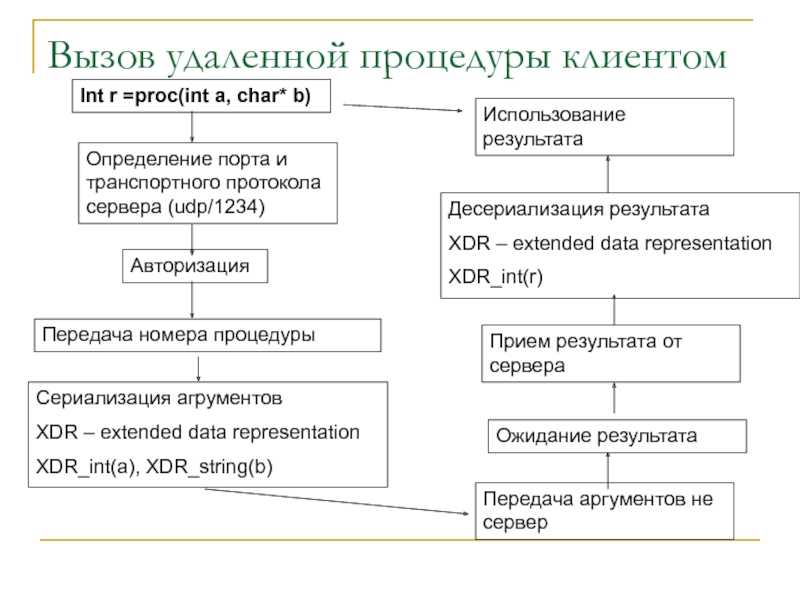
Использовать механизм удалённого вызова процедур. RPC позволяет отправить из одного сервиса запрос в другой и получить ответ с нужными данными. Это удобно, когда сервисы нужно связать друг с другом напрямую.
-
Отправить асинхронное сообщение через общую шину данных. В этом случае сервис не ждёт ответ на запрос, а продолжает работать в обычном режиме.
Первые два способа сложно масштабировать, они не подходят для такой крупной системы, как платформа Авито с сотнями сервисов. Поэтому мы используем только RPC и отправку сообщений — более современные и гибкие способы взаимодействия.


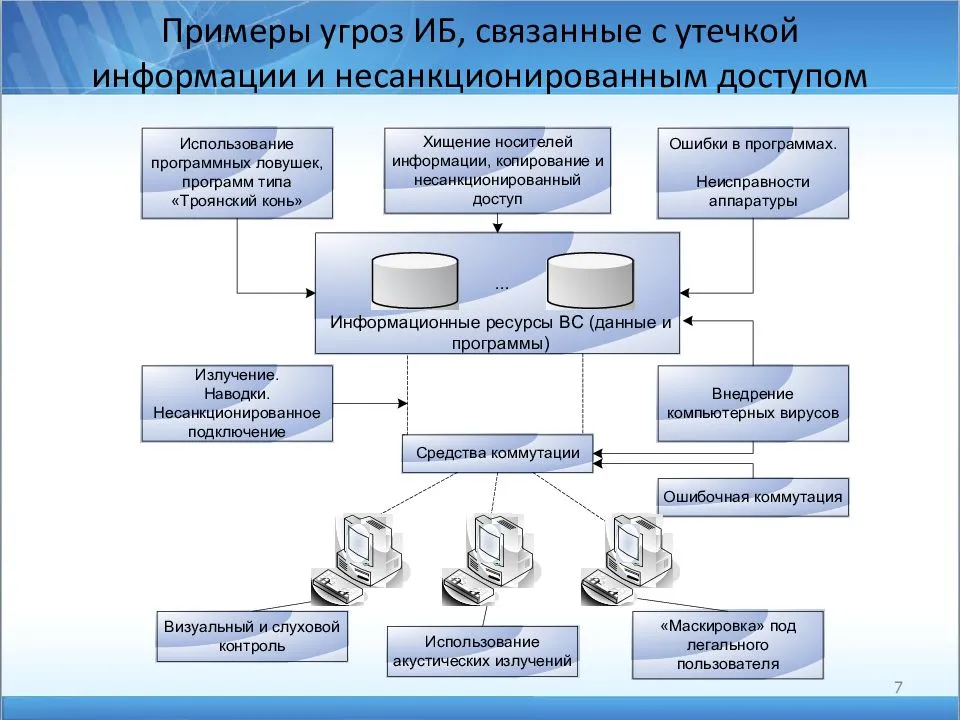
RPC и обмен сообщениями: в чём разница
Главное отличие удалённого вызова процедур и обмена сообщениями — синхронность процессов и связанность системы.
Сервис А удалённо вызывает процедуру из B и получает в ответ данные
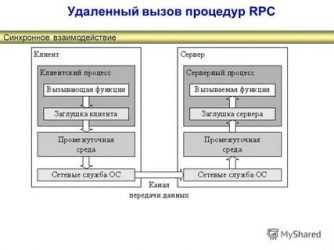
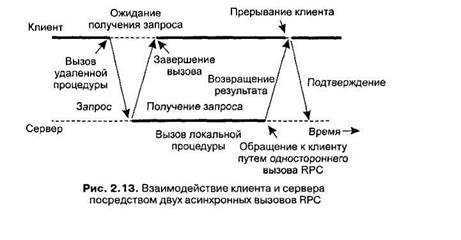
Удалённый вызов процедур подразумевает, что один сервис обращается к другому и ждёт ответ. Отправитель запроса приостанавливает работу и ожидает в течение ограниченного времени. Сервис получает ответ и обрабатывает его, затем продолжает работу. Между отправкой запроса и получением ответа не происходит никаких операций. Такой процесс можно считать синхронным: если запрос отправлен, на него должны ответить.
С точки зрения сервиса, вызов удалённой процедуры не отличается от обычного вызова функции внутри сервиса. Но разработчику нужно учитывать, что сервис-получатель может быть недоступен. Например, он отключён или удалён. Если запрос уйдёт к такому сервису, отправитель не сможет продолжить работу, потому что никогда не получит ответ.
Использовать RPC нужно, если точно известны отправитель и получатель запроса. Это делает систему очень связанной. Если из одного сервиса убрали вызываемый метод, то нужно переписать все другие сервисы, которые могут обращаться к этому методу. Иначе запросы будут оставаться без ответа, сервисы не смогут работать, и вся система рискует сломаться.
Производительности системы может не хватить для обработки всех запросов, если нужно делать много вызовов, а обмен данными происходит медленно. Поэтому RPC сложно масштабировать: чем больше запросов, тем дольше отвечает система.
Сервисы посылают запросы на шину данных.
Каждый может читать все сообщения независимо от других
Обмен сообщениями подразумевает, что сервис отправляет запрос через шину данных, не ждёт ответ и продолжает работать. Сервис может даже не знать, кто будет получателем сообщения. Для его работы это не имеет значения. Например, это может быть сервис для сбора данных от клиентов, который просто публикует их на шине для других сервисов.
Обмен сообщениями — это асинхронный процесс: запрос отправлен, но отвечать на него не обязательно. Это может быть нужно для того, чтобы другие сервисы могли в будущем прочитать сообщение с шины данных и каким-то образом его обработать
Для сервиса-отправителя это неважно. Использовать обмен сообщениями можно почти в любых ситуациях, если нет причин выбрать RPC.
Асинхронный обмен сообщениями позволяет легко масштабировать систему. Для шины данных нет большой разницы, два получателя у сообщения или сто. Поэтому через неё можно связывать любое число источников и получателей.
Асинхронный обмен не влияет на работу системы. Даже если ни один из получателей не доступен, сервис, который отправил запрос, продолжит работу. По этой же причине система становится менее связанной. Это значит, что изменения одного сервиса не влияют на работоспособность других.
Асинхронный обмен сообщениями на платформе Авито реализован через шину данных Data Bus — специальную систему передачи данных между сервисами. Шина данных позволяет любому сервису в любой момент читать какое угодно сообщение. По сути это лог всех сообщений внутри системы.
Иногда сервису нужно отправить сообщение самому себе. В этом случае асинхронный обмен реализован через Queues, или очередь. Такой способ подходит, если, например, сервис хочет оставить отложенные сообщения. К очереди нельзя подключиться из другого сервиса.
Заключение
В последние десятилетия SOA сильно эволюционировала. Благодаря неэффективности прежних решений и развитию технологий сегодня мы пришли к микросервисной архитектуре.
Эволюция шла по классическому пути: сложные проблемы разбивались на более мелкие, простые в решении.
Проблему сложности кода можно решать так же, как мы разбиваем монолитное приложение на отдельные доменные компоненты (разграниченные контексты). Но с разрастанием команд и кодовой базы увеличивается потребность в независимом развитии, масштабировании и развёртывании. SOA помогает добиться такой независимости, упрочняя границы контекстов.
Повторюсь, что всё дело в слабой взаимозависимости и высокой связности, причём размер компонентов должен быть больше прежнего. Необходимо прагматично оценить свои потребности: используйте SOA, лишь когда это необходимо, поскольку она сильно увеличивает сложность. И если на самом деле вы можете обойтись без SOA, то лучше выберите микросервисы подходящего размера и количества, не больше и не меньше.



