
Пишем код для работы с базой данных
Теперь нам надо написать код для обращения к нашей базе данных. Забираем из этой папки файлы с кодом для каждой из сущностей и помещаем их в свой проект или создаём отдельные файлы и копируем только код. Дальше описываем config для входа в БД напрямую из функции, если вы скопировали весь пакет db. Переделываем обработчик и дополняем рецепт деплоя.
Для проверки вызываем функцию командой:
В результате вызова получаем новую запись в таблице базы данных. Теперь необходимо настроить бизнес-логику приложения при работе с базой данных, для этого создадим два интерфейса.
Интерфейс Repository будет содержать простые методы для работы с базой данных, где каждый метод делает что-то только с одной таблицей.
Второй — более высокоуровневый интерфейс Service. В нём уже есть взаимодействие с авторизацией и с несколькими таблицами сразу. Это уже действие, которое пользователь может делать на сайте или через Алису.
Context is a king
В контексте хранилищ данных очень важна модель данных и приложения. Действительно реляционных данных в мире мало. Реляционная модель (как и любая другая модель) — всего лишь наша попытка представления реальности в цифрах. Есть множество других моделей, которые игнорируются в силу доминирования реляционных баз данных. Например, вот этот текст, который вы сейчас читаете, можно рассматривать по-разному. С точки зрения реляционной модели здесь есть слова, предложения и абзацы, которые составляют текст. А можно рассматривать как последовательность изменений, которые я вносил в текст в течение нескольких вечеров, пока я его писал. Также его можно рассматривать как один целостный документ — «blob», который имеет ссылку в интернете и который имеет смысл только как единое целое. Или можно рассматривать текст как вектор слов на русском языке. Или как массив символов кириллицы. Ну и так далее — текст один, а моделей множество. Все зависит от поставленной задачи. Все задачи решать при помощи реляционной модели данных и SQL — плохая идея.
Как итог написанного, я предлагаю коллегам расширять кругозор, изучать новые хранилища и структуры данных. Учиться моделировать и выбирать правильный инструмент для решения задачи. И постараться перестать видеть все вокруг в реляционной модели с таблицами и связями между ними.
P.S. На моей последней работе вообще нет SQL, и я считаю это приятным бонусом ко всему остальному.
Архитектура YDB
Ключевой элемент YDB — таблетка, предназначенная для хранения небольшого объема данных. Вся система состоит из таких таблеток и теоретически может расти бесконечно. Изначально таблетка маленькая и управляет единицами гигабайт данных. Множество легковесных таблеток внутри единой системы легко перемещаются между узлами кластера, так обеспечивается отказоустойчивость, адаптируемость и легкая масштабируемость — можно почти мгновенно на несколько порядков наращивать ресурсы. В противном случае, когда нагрузки незначительные, можно минимизировать стоимость сервиса.
Фактически база данных становится виртуальным ресурсом — можно сказать, что запущен «мини-контейнер» с базой данных, который находится в облаке и может перемещаться между узлами кластера. Такие микросущности выгодны с точки зрения оплаты, которая производится только за совершенные запросы, а используются лишь ресурсы, необходимые для обработки запросов.
Современная СУБД — сложный программный комплекс, отдельные части которого действуют независимо, взаимодействуют асинхронно, эффективно и прогнозируемо используют доступные ресурсы и физического сервера, и кластера из тысяч узлов. При разработке кода Yandex Database применяются концепция обмена сообщениями и модель акторов. Акторы — это однопоточные конечные автоматы, которые могут обмениваться между собой сообщениями и «живут» на различных серверах кластера. YDB — это распределенная актор-система, которая знает местоположение каждого актора, может быстро «убить» его на одном узле и поднять на другом, например, для балансировки нагрузки или в случае сбоев.
Yandex Database внутри имеет стековую архитектуру и состоит из нескольких слоев.
Надежность хранения состояния таблетки обеспечивает распределенная система хранения (Distributed storage), в которой хранятся все данные таблеток, включая журналы (логи) и снимки (snapshots). По своей природе Distributed storage — это специальное хранилище «блобов» (Binary Large Object — двоичный большой объект), гарантирующее надежную запись, которая успешно завершается, только когда блоб полностью реплицирован и во всех репликах записан на все необходимые диски.
Network Interconnect — слой, который обеспечивает взаимодействие всех других слоев между собой. Это собственная разработка Yandex Database поверх TCP. Интерконнект позволяет передавать сообщения между акторами, которые находятся в разных процессах операционной системы или на разных узлах.
В Yandex Database реализован механизм распределенных транзакций, полностью обеспечивающих требования ACID в запросах, которые могут затрагивать данные из нескольких таблеток (фактически сегментов одной или нескольких таблиц), расположенных на кластере.
Для того, чтобы избежать недостатков, свойственных алгоритму двухфазной фиксации (2PC), связанных с ограничениями пропускной способности и высокой вероятностью отката при конфликте, в Yandex Database реализован механизм планируемых транзакций (deterministic transactions). Они обеспечивают транзакционную изоляцию уровня serializable и основываются на подходе Calvin: когда множество участников должны договориться, как обрабатывать ту или иную транзакцию, то они делают это до того, как поставят блокировки и начнут выполнять транзакцию. Когда транзакция запланирована, она выполняется в соответствии с планом. Так как все узлы договариваются о том, какие транзакции и в каком порядке будут выполняться, то можно отказаться от протоколов распределенной фиксации, уменьшить пересечение конкурирующих транзакций и увеличить пропускную способность системы.
Пользователям Yandex Database доступен язык YQL (Yandex Query Language) — строго типизированный диалект SQL с поддержкой сложных типов: list, tuple, struct, dict. Обычно разработчики приложений для реляционных баз данных ожидают от среды наличия именно диалекта SQL.
Query Processor — это слой обработки YQL-запросов. Компилятор запросов анализирует пришедший в систему запрос на языке YQL и создает на его основе направленный ациклический граф (DAG) с информацией о типах. Оптимизатор запроса переписывает этот граф, основываясь на структуре выражений и свойствах данных. Так создается физический план выполнения запроса.
И наконец — самый верхний слой gRPC proxy. Взаимодействие с базой данных происходит по протоколу gRPC (удаленный вызов процедур с открытым исходным кодом, первоначально предложенный Google). YDB API публично открыт, что позволяет разработать собственные SDK для Yandex Database.
Каковы преимущества бессерверных вычислений?
-
Снижение затрат — бессерверные вычисления, как правило, выгодны, поскольку у многих крупных провайдеров облачных серверных услуг пользователь платит за неиспользуемое пространство или время простоя процессора.
-
Упрощённая масштабируемость — разработчикам, использующим бессерверную архитектуру, не нужно беспокоиться о политиках для масштабирования своего кода. Бессерверный поставщик выполняет все масштабирование по запросу.
-
Упрощённый внутренний код — с помощью FaaS разработчики могут создавать простые функции, которые независимо выполняют одну задачу, например, выполнение вызова API.
-
Более быстрый оборот — бессерверная архитектура может значительно сократить время выхода на рынок. Вместо того, чтобы требовать сложного процесса развёртывания для исправления ошибок и новых функций, разработчики могут добавлять и изменять код по частям.
-
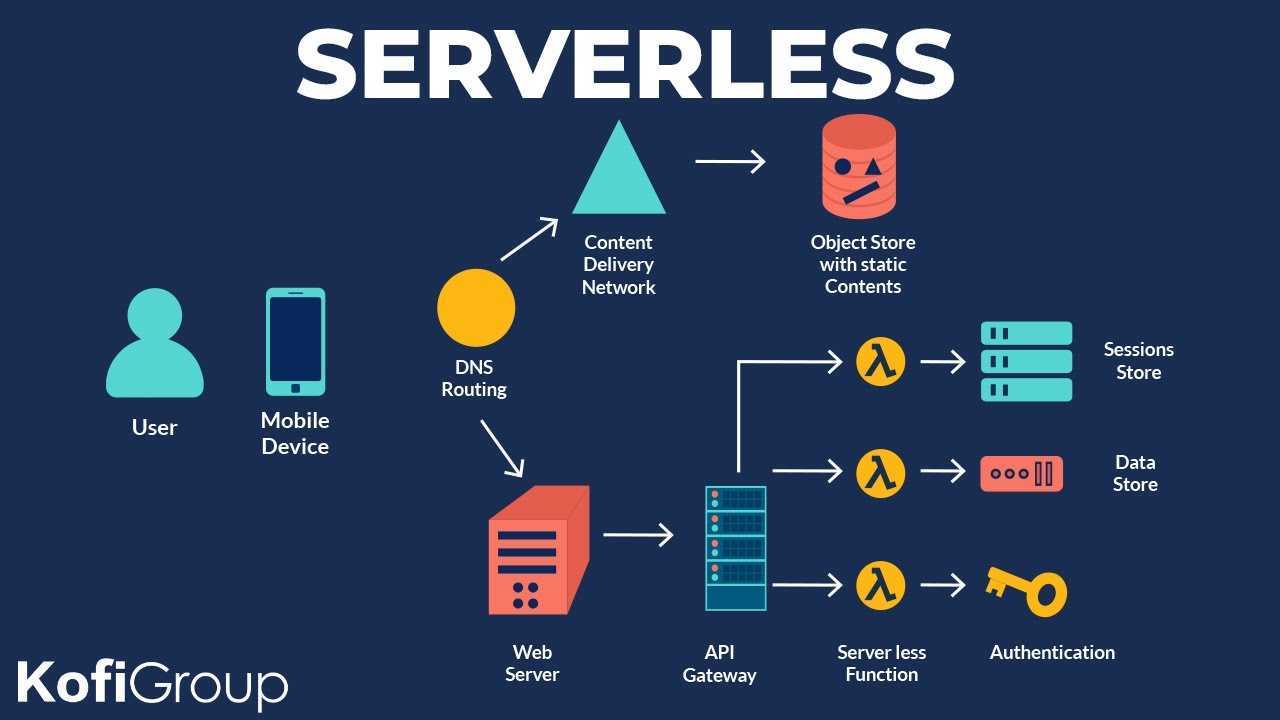


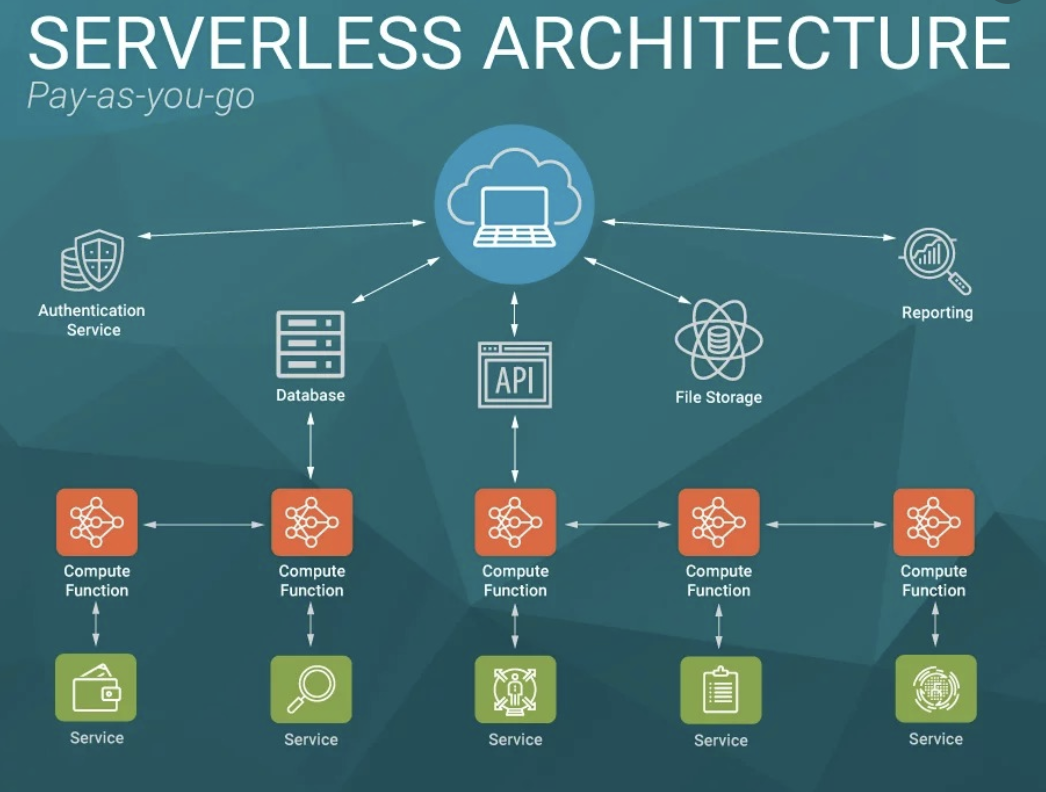

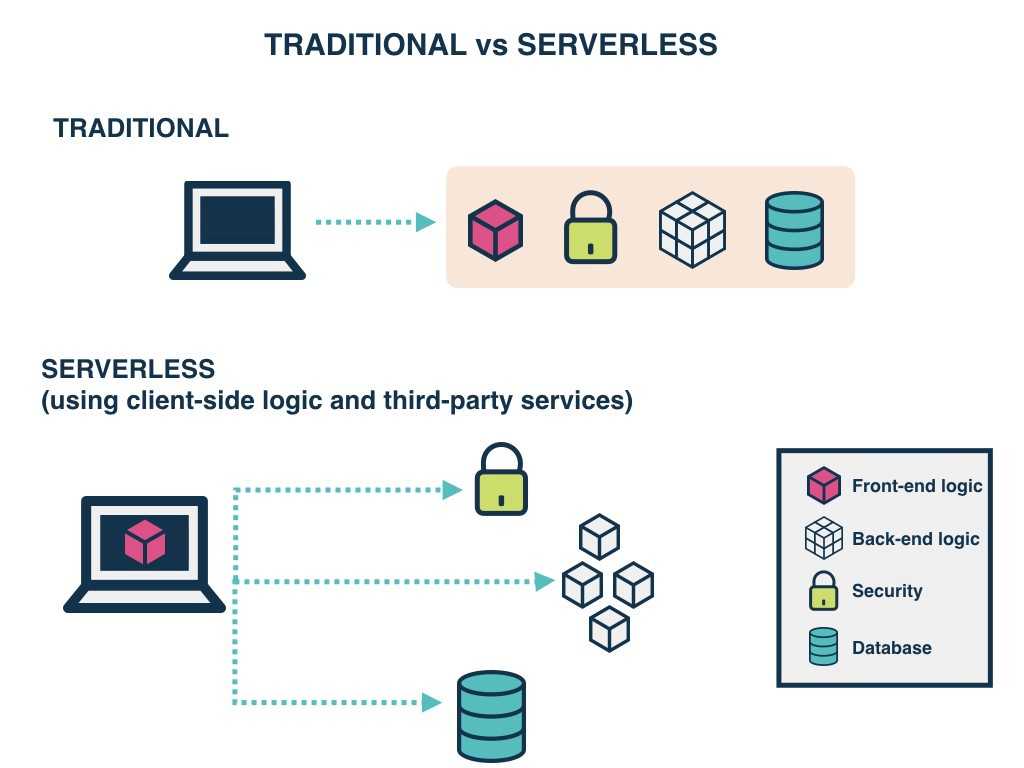



В сравнении с другими моделями облачного сервиса.
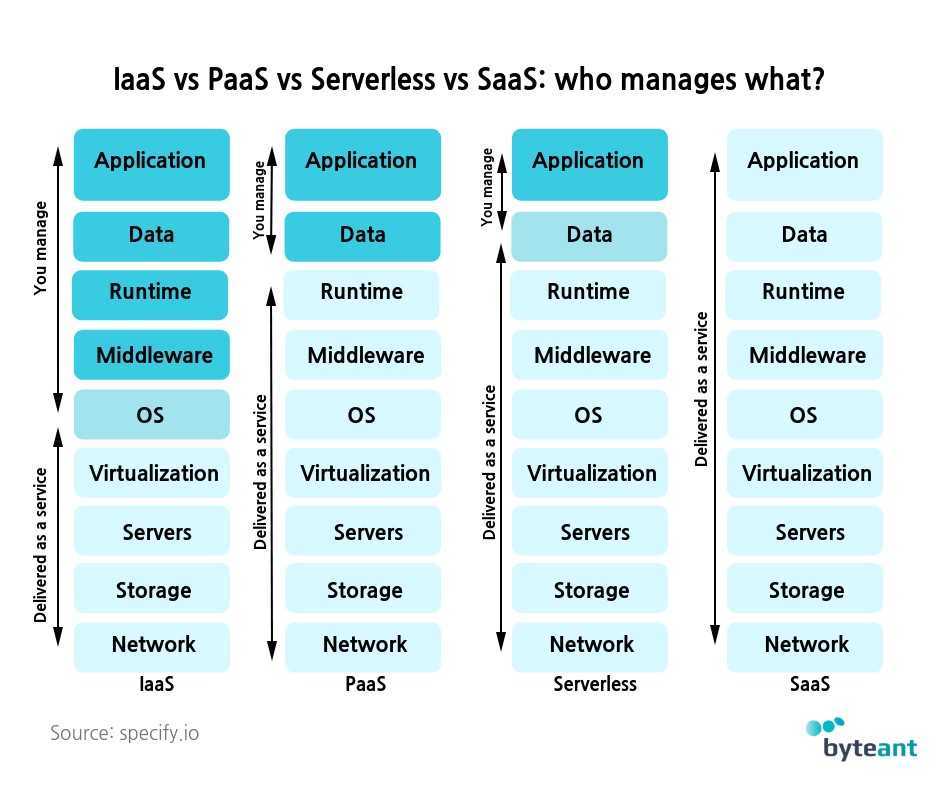
Есть ещё пара технологий, которые часто путают с бессерверными вычислениями — это Backend-as-a-Service и Platform-as-a-Service. Хотя у них есть общие черты, эти модели не обязательно удовлетворяют требованиям бессерверности.
Backend-as-a-service (BaaS) — это модель обслуживания, в которой поставщик облачных услуг предлагает серверные службы (например, хранение данных), чтобы разработчики могли сосредоточиться на написании кода фронтенда. Но хотя бессерверные приложения управляются событиями и работают на периферии, приложения BaaS могут не соответствовать ни одному из этих требований.
Платформа как услуга (PaaS) — это модель, в которой разработчики по сути арендуют все необходимые инструменты для разработки и развёртывания приложений у облачного провайдера, включая такие вещи, как операционные системы и промежуточное ПО. Однако приложения PaaS не так легко масштабируются, как бессерверные приложения. PaaS также не обязательно работает на периферии и часто имеет заметную задержку запуска, которой нет в бессерверных приложениях.
Инфраструктура как услуга (IaaS) — это общий термин для поставщиков облачных услуг, размещающих инфраструктуру от имени своих клиентов. Поставщики IaaS могут предлагать бессерверные функции, но эти термины не являются синонимами.
Развитие бессерверных технологий
Бессерверные вычисления продолжают развиваться, поскольку бессерверные провайдеры предлагают решения, позволяющие преодолеть некоторые из их недостатков. Один из таких недостатков — холодный старт.
Обычно, когда определённая бессерверная функция не вызывалась в течение некоторого времени, провайдер её отключает, чтобы сэкономить энергию и избежать избыточного выделения ресурсов. В следующий раз, когда пользователь запустит приложение, которое вызывает эту функцию, бессерверному провайдеру придётся включить его заново и снова запустить эту функцию. Это добавляет некоторую задержку, известную как «холодный старт».
Как только функция будет запущена, она будет вызываться намного быстрее при следующих запросах (тёплый старт), но если функция опять не будет запрашиваться в течение некоторого времени, она снова перейдёт в неактивное состояние. И следующий пользователь, который запросит эту функцию, столкнётся с некоторой задержкой ответа из-за холодного запуска. Холодный старт — это необходимый компромисс при использовании бессерверных функций.
По мере того как устраняются все больше и больше недостатков использования бессерверных систем, можно ожидать рост популярность подобной модели предоставления вычислений.
Что ещё интересного есть в блоге Cloud4Y
→ В Китае создали настольный квантовый компьютер стоимостью $5000
→ Тим Бернерс-Ли предлагает хранить персональные данные в подах
→ Виртуальные машины и тест Гилева
→ Создание группы доступности AlwaysON на основе кластера Failover
→ Как настроить SSH-Jump Server
Подписывайтесь на наш Telegram-канал, чтобы не пропустить очередную статью. Пишем не чаще двух раз в неделю и только по делу.
Бессерверная альтернатива традиционным базам данных +6
- 15.06.21 06:43
•
olalala
•
#562746
•
Хабрахабр
•
•
5500
Администрирование баз данных, Serverless
Рекомендация: подборка платных и бесплатных курсов 3D-моделирования — https://katalog-kursov.ru/
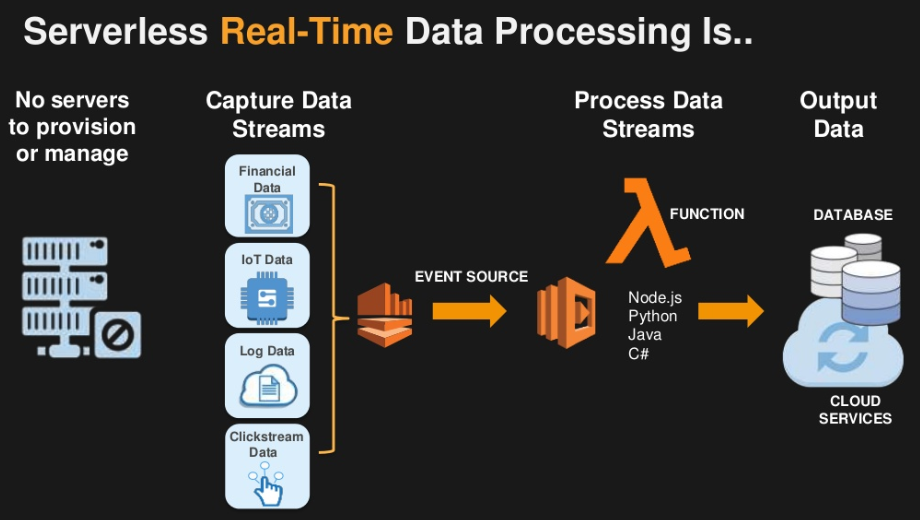
Современная распределенная СУБД должна уметь поддерживать различные типы нагрузки, удовлетворяя запросы совершенно разных пользователей. СУБД Yandex Database позволяет не только хранить петабайты данных, поддерживать обработку миллионов запросов в секунду, но и предоставляет режим бессерверных вычислений. Эта платформа дает возможность обслуживать проекты с различными типами нагрузки: ключ-значение, традиционные веб-приложения на основе реляционной базы, а также документоориентированные базы данных.
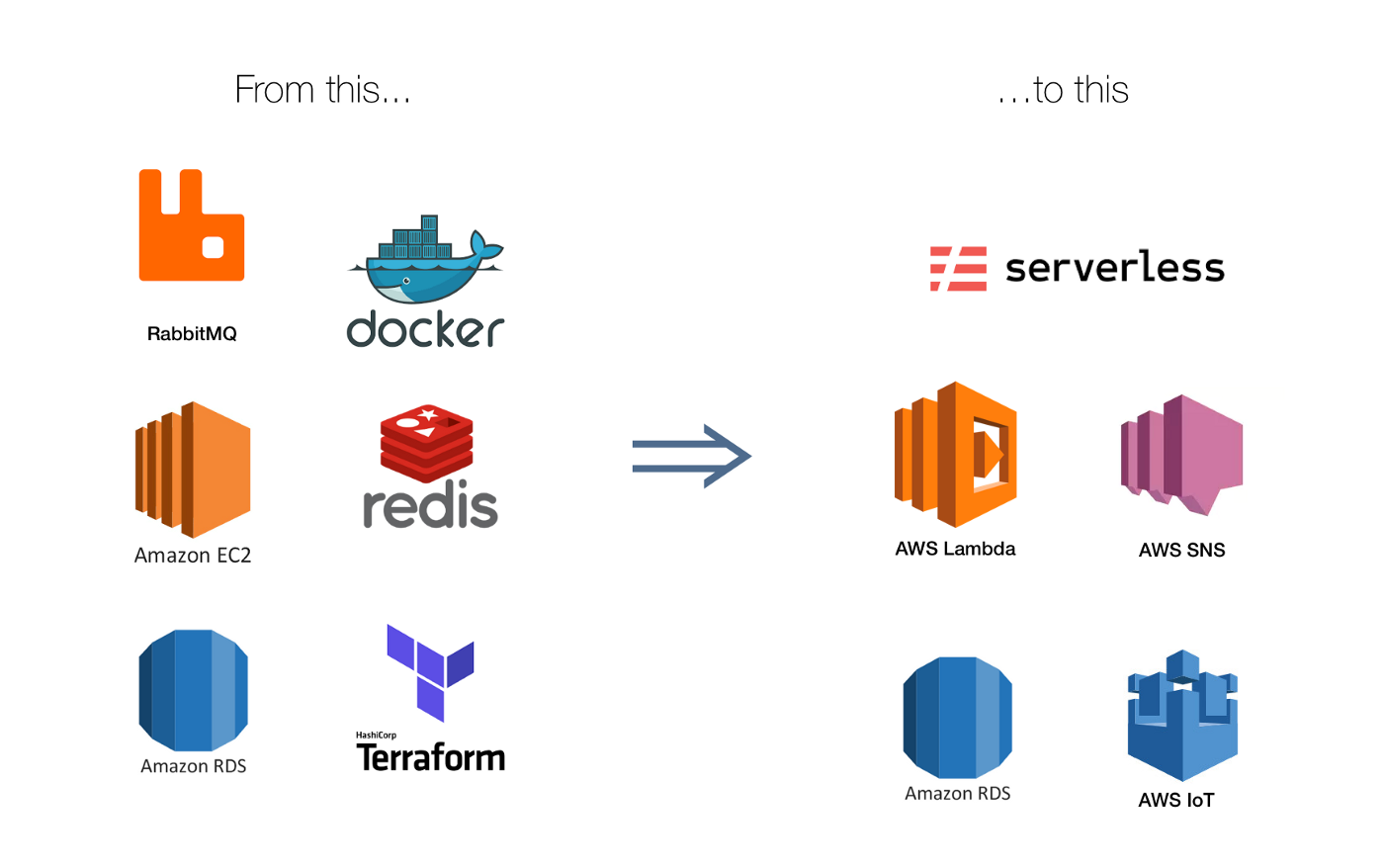
Бессерверные вычисления применяются сейчас в различных сферах — от создания чат-ботов и приложений Интернета вещей до самостоятельных API доступа к сервисам по протоколу HTTP. Платформы для развертывания бессерверных вычислений имеются как у большинства поставщиков облачных решений (Yandex Cloud Functions, Amazon Web Services Lambda, Google Functions), так и у Open Source сообщества.
Переход от «железных» серверов к виртуализации и контейнеризации в свое время привел к появлению культуры DevOps, рождению подходов Infrastructure as Code, предоставив возможность больше времени уделять бизнес-задачам, а не обслуживанию инфраструктуры. Кроме того, был снижен достаточно высокий «налог» на инфраструктуру, который невольно приходилось платить пользователям.
Переход к эпохе бессерверных вычислений (serverless computing) — следующий шаг в направлении дальнейшего снижения налога на инфраструктуру, исключения необходимости ее обслуживания, планирования и оптимизации использования ресурсов, решения задач масштабируемости, а также заботы о системном ПО и среде выполнения. У разработчиков появилась возможность сконцентрироваться только на бизнес-логике. При необходимости обрабатывать больше запросов сервис сам предоставляет возможности по масштабированию. Если, например, приходит рекламный трафик или одновременно происходит множество внешних событий, то облако начинает автоматически увеличивать количество одновременно запускаемых копий функций, выстраивать запросы к ним и обрабатывать ответы в соответствии с настроенными квотами, разворачивая «мини-контейнеры» с функциями. Более того, появилась возможность строить и разворачивать глобальные сервисы, выбирая в какую зону доступности и регион развернуть код для уменьшения задержки между пользователем и приложением. Как следствие, при работе в такой бессерверной среде возникает необходимость в базе данных, способной самостоятельно эластично подстраиваться под нагрузку.
Однако оказалось, что для экосистемы бессерверных вычислений почти нет баз данных, особенно реляционных. Такие системы хранения данных, как S3, не заменяют базу данных, а использование традиционных СУБД слабо совместимо с бессерверной парадигмой. Большинство решений базируются на принципе take or pay: сначала оплачиваются и выделяются ресурсы (обычно впрок), а потом оказывается, что эти ресурсы так и не использовались. Что делать, если нагрузка непредсказуема? Как автоматически менять необходимые ресурсы базы данных вместе с изменением нагрузки и при этом не переплачивать за них?
Быстрая реляционная база данных
А что если нельзя иметь одновременно быстрые чтение и запись в реляционной базе? Компромисс между чтением и записью можно обойти при помощи создания второй базы, которую называют Data Warehouse — ее оптимизируют под чтение данных и создание сложных отчетов. Таким образом, Operational (OLTP) база поддерживает быструю запись и изменение данных, а Data Warehouse (OLAP) поддерживает быстрое чтение и сложные многоэтажные запросы. Но тут вступает в дело CAP теорема — вы не можете иметь все три свойства CAP одновременно в такой конфигурации. Другими словами, вы не можете транзакционно писать одновременно в Operational базу и в Data Warehouse — транзакция будет распределенной и очень медленной. Базы получаются разделены физически, и данные в Data Warehouse попадают с некоторой задержкой. Следовательно, мы приходим к Eventual Consistency на реляционной базе данных — то, что мы пишем в Operational базу, невозможно сразу же прочитать из Data Warehouse. Реляционные базы данных не масштабируются горизонтально. И никакие Shards и Partitions все равно не помогут победить CAP теорему.
Храним сценарии
Сценарий можно описать автоматом. Когда у нас появляется состояние — например, пользователь добавляет что-то в список дел, — надо помнить о том, чтобы он не оказался в тупике, а мог сказать «Отмена» или вернуться в начальное состояние.
Вопрос в том, что делать с этим состоянием. Хранить в базе данных? В платформе Диалогов есть готовая фича — хранить состояние на стороне Диалогов (с ограничением в 1 КБ) и возвращать состояние в ответе. Оно придёт к нам в запросе.



Запрос:
Ответ:
В статье мы с вами рассмотрели основные этапы разработки веб-приложения на Go в serverless-стеке на Yandex.Cloud для навыка Алисы. Подробное руководство и недостающие детали есть в видеозаписи и на GitHub, где весь проект полностью доступен в исходных кодах.
Авторизация и секреты
Так как наше приложение может работать с несколькими пользователями, то для них обязательно должна быть авторизация. Чтобы списки дел оставались приватными, кроме случаев, когда их создатель сам готов ими поделиться.
Воспользуемся инструментами авторизации Яндекса. Для нашего проекта это подходит, потому что мы делаем навык для Алисы. Схема авторизации выглядит так: новый пользователь авторизуется на Яндексе, а мы принимаем его логин как идентификатор пользователя на нашем сайте. Для этого используем Yandex OAuth 2.0 API и API Яндекс ID.
Мы не хотим, чтобы пользователь проходил авторизацию каждый раз, когда совершает какое-то действие на сайте. Поэтому применим механизм HTTP-сессий. Когда пользователь будет авторизовываться, мы запишем ему сессионную куку и положим в неё его Яндекс-логин. В дальнейшем мы будем авторизовывать его по этой куке, минуя API Яндекса. Для работы с куками используем библиотеку Gorilla Sessions.
Кроме этого, нам нужно передавать в приложение секретные значения — secret из Yandex OAuth и ключ шифрования, который используется при работе с HTTP-сессиями. Для шифрования и расшифровки секретов воспользуемся сервисом Yandex KMS. Ключи шифрования в KMS неизвлекаемые — ключ не может утечь, и расшифровать секрет можно только с соответствующим разрешением в Yandex.Cloud.
-
Разрешим сервисному аккаунту нашей функции .
-
наши секреты ключом KMS.
-
в environment-переменные функции.
-
В коде функции расшифруем секреты с помощью Yandex Cloud SDK.
Традиционные (нераспределенные) реляционные СУБД
Один из вариантов масштабирования в реляционных базах — ручное шардирование. То есть при разворачивании нужно настроить несколько экземпляров базы и решить, к какому экземпляру обращаться в приложении. Если нужен одновременный доступ к данным из нескольких экземпляров баз данных, придется самостоятельно заниматься организацией распределенных транзакций. YDB масштабируется на чтение и запись «из коробки», для этого нужно добавить больше оборудования в кластер. «На практике мы работаем с базами размером в сотни терабайт под нагрузкой в миллионы RPS», — указывают авторы статьи.
Архитектура сервиса
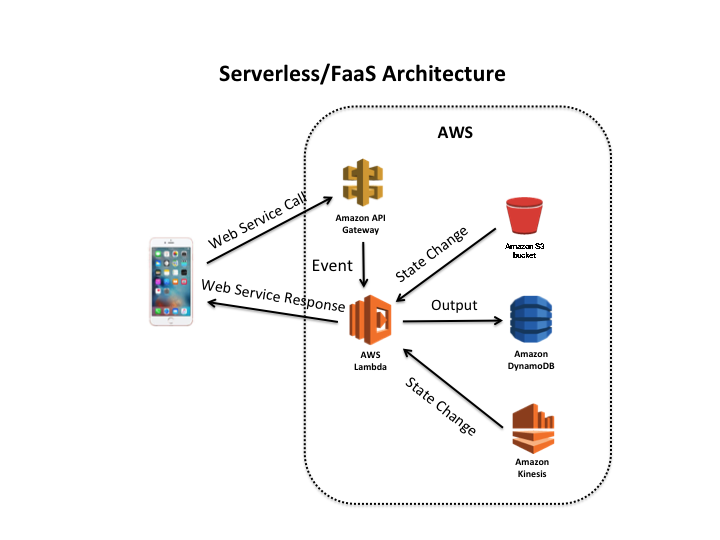
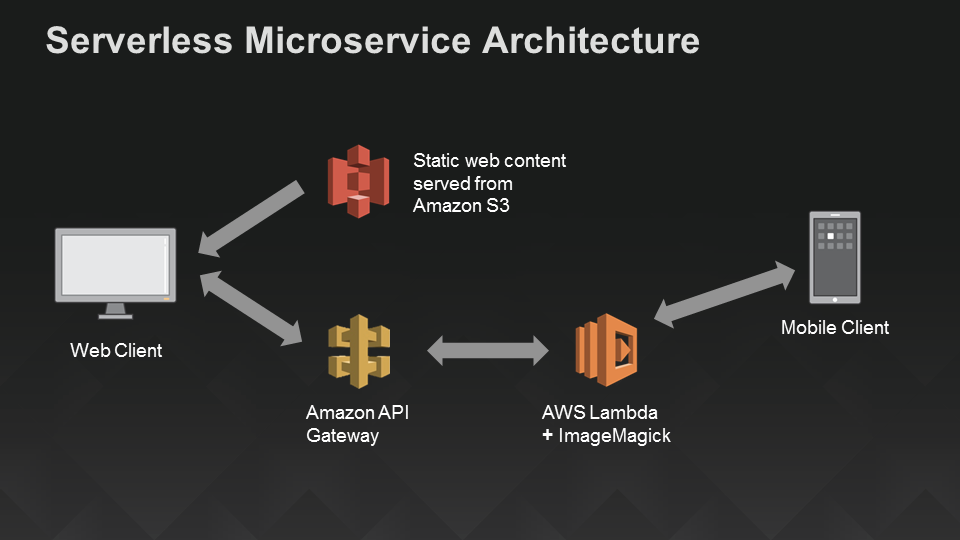
Концептуально архитектура нашего приложения на serverless-стеке не сильно отличается от архитектуры на классическом наборе компонентов. Пользователь приходит или через браузер, или через Алису — платформу Яндекс.Диалоги. В нашем случае платформа выступает как элемент сервиса Cloud Functions, куда можно загрузить свой код.
С начала загрузки код будет доступен для вызова в облаке. В момент вызова экземпляр функции аллоцируется и исполняет запрос пользователя. Чем больше пользователей, тем больше экземпляров аллоцируется.
Экономическую особенность использования serverless можно описать известным выражением — pay-as-you-go. Нет запросов — нет денежных трат, потому что плата взимается за время исполнения функции и за количество вызовов. В этом ключевое отличие serverless от классической архитектуры. Также в serverless-архитектуре отсутствуют компонент load-balancer и масштабирование со стороны разработчика — их предоставляет Yandex.Cloud.
YDB с точки зрения пользователя
Для пользователя YDB представляет древовидную файловую систему: каталоги в нелистовых узлах и объекты различного типа с данными в листовых узлах. Ключевой компонент базы — таблица, в которой хранятся все данные, набор строк, удовлетворяющих схеме данных. Строка — множество значений колонок определенных типов. Некоторые из колонок должны составлять первичный ключ (primary key), по которому отсортирована таблица. Таблицы сегментируются горизонтально, благодаря чему можно хранить таблицы произвольного размера.
Одна из ключевых особенностей Yandex Database — поддержка двух моделей данных (реляционной и «ключ-значение»), что позволяет поддерживать различные типы нагрузки и решать разные задачи.
Для работы с реляционной моделью данных используется YQL API, позволяющий применять YDB как полноценную OLTP-СУБД с транзакциями, SQL-запросами и соединениями (join). Для работы с моделью «ключ-значение» в YDB реализован слой совместимости (Document API) с Amazon DynamoDB API — одной из самых популярных в мире бессерверных СУБД, что позволяет использовать AWS SDK и AWS CLI.
Квазиструктурированные данные обычно трудно отразить в строгой схеме, поэтому для работы с ними все чаще применяются документоориентированные СУБД, предназначенные для хранения и поиска данных, оформленных в виде документов в JSON-подобном формате. В Yandex Database реализована поддержка JsonAPI, а также специальный тип для хранения JSON — JsonDocument, позволяющий обходить документную модель с использованием JsonPath без необходимости разбора всего содержимого. Это дает возможность эффективно выполнять операции из JsonAPI, уменьшая задержки и стоимость пользовательских запросов.
Бессерверные вычисления: ключевые сценарии использования
С того момента, как бессерверная архитектура приняла эстафету у микросервисов, DevOps и прочих модных технологий, она успела завоевать широкую популярность среди компаний малого и среднего бизнеса, а также крупных предприятий. Современные компании останавливают свой выбор на бессерверных решениях, стремясь получить выгоду в результате более быстрого запуска продуктов, снижения операционных затрат и общего роста производительности. При всем их огромном потенциале, который еще предстоит раскрыть в полной мере, уже сформировался ряд областей применения бессерверных вычислений, где их практическая значимость для бизнеса неоспорима.
-
Автоматическая масштабируемость сайтов. После перехода на бессерверную архитектуру предоставление инфраструктурных ресурсов перестанет быть для вас головной болью. Разработчики смогут легко писать код, создавая и развертывая приложения и сайты для бизнеса за меньшее время. Кроме того, такого рода облачные решения предоставят пользователям возможности полноценной автоматизированной масштабируемости при необходимости привлечения дополнительных вычислительных ресурсов.
-
Аналитика больших данных. Бессерверные технологии могут оказаться особенно эффективными при оркестрировании крупных разнородных наборов аналитических данных, которые раньше были разнесены по разным локальным серверам в отсутствие унифицированного разграничения ответственности между командами бэкофиса и фронтофиса. Теперь можно написать отдельное приложение, которое будет вести сбор и обработку информации по всем бизнес-каналам, обращаясь к изолированным наборам данных. Такое бессерверное приложение будет обеспечивать сбор, классификацию и анализ больших данных в рамках единой базы данных.
-
-
Повышение качества взаимодействия между IoT-устройствами. Интегрированные IoT-устройства, включая всевозможные датчики, RFID-метки, смартфоны и другие гаджеты, играют неотъемлемую роль в деятельности большинства компаний. Именно здесь оказываются особенно полезны бессерверные функции: они помогают конечным пользователям избежать неприятных ситуаций с низкой скоростью интернет-трафика в ряде проблемных областей. Более того, возможности автоматического масштабирования позволяют добиться экономии операционных затрат, снизить задержку и, как следствие, существенно повысить удовлетворенность пользователей.

Прописываем подключение в коде
После установки зависимостей мы можем настроить подключение к базе. Я рекомендую открывать/закрывать подключение внутри корневой функции 1 раз и прокидывать подключение внутрь других функций, которые работают непосредственно с командами. Но также можно внутри функций проверять подключение.
Перед написанием кода создадим 3 записи в переменные окружения функции.
Оба KEY у нас беруться из сервисного аккаунта, который мы создали ранее, а ссылку на хранилище мы берем из базы данных (Document API).
Сам ресурс подключается командой:
Здесь мы указываем какой ресурс из boto3 мы используем и его настройки. Тут нас интересуют endpoint_url — адрес базы данных, и два ключа — сервисного аккаунта.
Ура, теперь мы подключили базу данных в программе!
Альтернатива реляционным базам данных
Альтернативные хранилища в основном используют другие структуры данных для хранения, например, LSM, Distributed Hash Table, Inverted Index, Graph или что-то еще более экзотическое. Подробнее про эти структуры данных можно почитать на википедии. По большому счету большинство альтернатив реляционным базам используют разделение записи и чтения в пределах одной базы. Они часто реализуют BASE модель (Basically Available, Soft-state, Eventually-consistent) и жертвуют Consistency в пользу Availability и Partition Tolerance. Если рассмотреть Eventually-consistent хранилище на примере MongoDb — MongoDb выигрывает в производительности записи у SQL, потому что вторичные индексы обновляются не сразу при записи, а асинхронно — через некоторое время. Если у вас несколько партишенов и есть копии данных (реплики), они также обновляются асинхронно через некоторое время. Другими словами, если вы делаете запись и сразу же пытаетесь найти записанный документ — есть шанс, что он не будет найден. Либо вы найдете предыдущую (устаревшую) версию документа. Это и есть отсутствие строгой целостности (strict Consistency). Объяснить все нюансы с Partition Tolerance и Consistency потянет на отдельную статью — кому интересна тема рекомендую почитать NoSQL Distilled — там очень хорошо раскрыта тема CAP теоремы и ее следствий. Стоит упомянуть, что многие из альтернативных хранилищ поддерживают транзакционность в пределах партишена либо глобально по требованию за счет распределенной транзакции, что позволяет писать, используя привычный подход ACID-транзакций.
Пишем спецификацию API 3.0
Cервис API Gateway позволяет декларативно описать HTTP API. В нём используется спецификация OpenAPI 3.0, к ней мы и прибегнем. Эта спецификация позволяет описать пути на вашем сайте и некоторые детали запроса, например форму ответа. В спецификации можно указать пути, по которым нужно идти в функцию или сделать что-то с объектами в хранилище Object Storage. Пользоваться спецификацией — это самый верный способ делать serverless-сайты.
Аналогичным образом производится настройка для всех остальных путей.
Можно сделать API Gateway и на более простой схеме, не указывая все формы ответа и запроса. Но хорошая спецификация, которая подробно описывает ваш API, позволяет генерировать вам клиентский и серверный код, а также документацию. Нам выгодно описывать схему максимально подробно, чтобы потом использовать её.
При создании шлюза создаётся служебный домен, по которому мы уже можем вызывать наш API Gateway, когда он перейдёт в статус running. К спецификации есть много утилит для разных языков, позволяющие генерировать разный код — валидацию, клиентский, серверный. В частности, для этого проекта мы выбрали две библиотеки: для бэкенда go-swagger и для фронтенда restful-react.



