Настройка общей конфигурации IIS на всех узлах кластера
Примечание.
Возникла проблема с общей конфигурацией IIS в Windows 2008 Server из-за отсутствия привилегий для . Для работы общей конфигурации необходимо выполнить следующие действия при настройке общей конфигурации IIS в Windows 2008 Server.
-
Откройте командную команду администратора.
-
Выполните следующую команду:
-
Выполните следующую команду:
-
Выполните следующую команду:
После выполнения этих действий на каждом сервере Windows 2008 в кластере продолжайте настройку общей конфигурации IIS, как описано в этом разделе.
На одном из узлов кластера экспортируйте общую конфигурацию в общую папку:
- Перейдите к разделу «Администрирование» и выберите диспетчер служб IIS.
- В левой области выберите узел имени сервера.
- Дважды щелкните значок общей конфигурации .
- На странице «Общая конфигурация» выберите «Экспорт конфигурации» в области действий (справа), чтобы экспортировать файлы конфигурации с локального компьютера в другое расположение.
- В диалоговом окне «Конфигурация экспорта» введите путь к общей папке () в поле «Физический путь «.
- Выберите «Подключить как», а затем введите имя пользователя и пароль для учетной записи пользователя, которая имеет доступ к общей папке, в которой хранится общая конфигурация, а затем нажмите кнопку «ОК». Эта учетная запись будет использоваться для доступа к общей папке. Следует использовать ограниченную учетную запись Active Directory, которая не является администратором домена.
- В диалоговом окне «Экспорт конфигурации» введите пароль, который будет использоваться для защиты ключей шифрования, а затем нажмите кнопку «ОК».
- На странице «Общая конфигурация » установите флажок «Включить общую конфигурацию».
- Введите физический путь, учетную запись пользователя и пароль, введенные ранее, а затем выберите «Применить » в области действий.
- В диалоговом окне «Пароль ключей шифрования» введите пароль ключа шифрования, который вы настроили ранее, а затем нажмите кнопку «ОК «.
- В диалоговом окне «Общая конфигурация» нажмите кнопку «ОК».
- Нажмите кнопку ОК.
На каждом из других узлов кластера используйте общую конфигурацию, которую вы только что экспортируете в общую папку:
- Перейдите к разделу «Администрирование» и выберите диспетчер служб IIS.
- Выберите узел имени сервера.
- Дважды щелкните значок общей конфигурации .
- На странице «Общая конфигурация » установите флажок «Включить общую конфигурацию».
- Введите физический путь к общей папке (), учетную запись пользователя и пароль, введенные ранее, а затем выберите «Применить» в области действий.
- В диалоговом окне «Пароль ключей шифрования» введите пароль ключа шифрования, который вы настроили ранее, а затем нажмите кнопку «ОК «.
- В диалоговом окне «Общая конфигурация» нажмите кнопку «ОК».
- Нажмите кнопку ОК.
Примечание.
Дополнительные сведения о настройке общих конфигураций в IIS см. в разделе «Общая конфигурация».
Компоненты WWW¶
Функционирование сервиса обеспечивается четырьмя составляющими:
Адресация веб-ресурсов. URL, URN, URI
URL (RFC 1738) — унифицированный локатор (указатель) ресурсов, стандартизированный способ записи адреса ресурса в www и сети Интернет. Адрес URL имеет гибкую и расширяемую структуру для максимально естественного указания местонахождения ресурсов в сети. Для записи адреса используется ограниченный набор символов ASCII. Общий вид адреса можно представить так:
<схема>://<логин>:<пароль>@<хост>:<порт>/<полный-путь-к-ресурсу>
Где:
схема
схема обращения к ресурсу: http, ftp, gopher, mailto, news, telnet, file, man, info, whatis, ldap, wais и т.п.
логин:пароль
имя пользователя и его пароль, используемые для доступа к ресурсу
хост
доменное имя хоста или его IP-адрес.
порт
порт хоста для подключения
полный-путь-к-ресурсу
уточняющая информация о месте нахождения ресурса (зависит от протокола).
Примеры URL:
http://example.com #запрос стартовой страницы по умолчанию
http://www.example.com/site/map.html #запрос страницы в указанном каталоге
http://example.com:81/script.php #подключение на нестандартный порт
http://example.org/script.php?key=value #передача параметров скрипту
ftp://user:pass@ftp.example.org #авторизация на ftp-сервере
http://192.168.0.1/example/www #подключение по ip-адресу
file:///srv/www/htdocs/index.html #открытие локального файла
gopher://example.com/1 #подключение к серверу gopher
mailto://user@example.org #ссылка на адрес эл.почты
В августе 2002 года RFC 3305 анонсировал устаревание URL в пользу URI (Uniform Resource Identifier), еще более гибкого способа адресации, вобравшего возможности как URL, так и URN (Uniform Resource Name, унифицированное имя ресурса). URI позволяет не только указавать местонахождение ресурса (как URL), но и идентифицировать его в заданном пространстве имен (как URN). Если в URI не указывать местонахождение, то с его помощью можно описывать ресурсы, которые не могут быть получены непосредственно из Интернета (автомобили, персоны и т.п.). Текущая структура и синтаксис URI регулируется стандартом RFC 3986, вышедшим в январе 2005 года.
Язык гипертекстовой разметки HTML
HTML () — стандартный язык разметки документов во Всемирной паутине. Большинство веб-страниц созданы при помощи языка HTML. Язык HTML интерпретируется браузером и отображается в виде документа, в удобной для человека форме. HTML является приложением SGML (стандартного обобщённого языка разметки) и соответствует международному стандарту ISO 8879.
HTML создавался как язык для обмена научной и технической документацией, пригодный для использования людьми, не являющимися специалистами в области вёрстки. Для этого он представляет небольшой (сравнительно) набор структурных и семантических элементов — тегов. С помощью HTML можно легко создать относительно простой, но красиво оформленный документ. Изначально язык HTML был задуман и создан как средство структурирования и форматирования документов без их привязки к средствам воспроизведения (отображения). В идеале, текст с разметкой HTML должен единообразно воспроизводиться на различном оборудовании (монитор ПК, экран органайзера, ограниченный по размерам экран мобильного телефона, медиа-проектор). Однако современное применение HTML очень далеко от его изначальной задачи. Со временем основная идея платформонезависимости языка HTML стала жертвой коммерциализации www и потребностей в мультимедийном и графическом оформлении.
Протокол HTTP
HTTP () — протокол передачи гипертекста, текущая версия HTTP/1.1 (RFC 2616). Этот протокол изначально был предназначен для обмена гипертекстовыми документами, сейчас его возможности существенно расширены в сторону передачи двоичной информации.
HTTP — типичный клиент-серверный протокол, обмен сообщениями идёт по схеме «запрос-ответ» в виде ASCII-команд. Особенностью протокола HTTP является возможность указать в запросе и ответе способ представления одного и того же ресурса по различным параметрам: формату, кодировке, языку и т. д. Именно благодаря возможности указания способа кодирования сообщения клиент и сервер могут обмениваться двоичными данными, хотя данный протокол является символьно-ориентированным.
HTTP — протокол прикладного уровня, но используется также в качестве «транспорта» для других прикладных протоколов, в первую очередь, основанных на языке XML (SOAP, XML-RPC, SiteMap, RSS и проч.).
История Всемирной паутины
Так выглядит самый первый веб-сервер, разработанный Тимом Бернерс-Ли
Изобретателями всемирной паутины считаются Тим Бернерс-Ли и в меньшей степени, Роберт Кайо. Тим Бернерс-Ли является автором технологий HTTP, URI/URL и HTML. В 1980 году он работал в Европейском совете по ядерным исследованиям (фр. Conseil Européen pour la Recherche Nucléaire, CERN) консультантом по программному обеспечению. Именно там, в Женеве (Швейцария), он для собственных нужд написал программу «Энквайр» (англ. Enquire, можно вольно перевести как «Дознаватель»), которая использовала случайные ассоциации для хранения данных и заложила концептуальную основу для Всемирной паутины.
В 1989 году, работая в CERN над внутренней сетью организации, Тим Бернерс-Ли предложил глобальный гипертекстовый проект, теперь известный как Всемирная паутина. Проект подразумевал публикацию гипертекстовых документов, связанных между собой гиперссылками, что облегчило бы поиск и консолидацию информации для учёных CERN. Для осуществления проекта Тимом Бернерсом-Ли (совместно с его помощниками) были изобретены идентификаторы URI, протокол HTTP и язык HTML. Это технологии, без которых уже нельзя себе представить современный Интернет. В период с 1991 по 1993 год Бернерс-Ли усовершенствовал технические спецификации этих стандартов и опубликовал их. Но, всё же, официально годом рождения Всемирной паутины нужно считать 1989 год.
В рамках проекта Бернерс-Ли написал первый в мире веб-сервер httpd и первый в мире гипертекстовый веб-браузер, называвшийся WorldWideWeb. Этот браузер был одновременно и WYSIWYG-редактором (сокр. от англ. What You See Is What You Get — что видишь, то и получишь), его разработка была начата в октябре 1990 года, а закончена в декабре того же года. Программа работала в среде NeXTStep и начала распространяться по Интернету летом 1991 года.
Первый в мире веб-сайт был размещён Бернерсом-Ли 6 августа 1991 года на первом веб-сервере доступном по адресу http://info.cern.ch/, (здесь архивная копия). Ресурс определял понятие Всемирной паутины, содержал инструкции по установке веб-сервера, использования браузера и т. п. Этот сайт также являлся первым в мире интернет-каталогом, потому что позже Тим Бернерс-Ли разместил и поддерживал там список ссылок на другие сайты.









Первая фотография во Всемирной паутине — группа Les Horribles Cernettes
На первой фотографии во Всемирной паутине была изображена пародийная филк-группа Les Horribles Cernettes. Тим Бернес-Ли попросил их отсканированные снимки у лидера группы после CERN Hardronic Festival.
И всё же теоретические основы веба были заложены гораздо раньше Бернерса-Ли. Ещё в 1945 году Ванна́вер Буш разработал концепцию Memex — вспомогательных механических средств «расширения человеческой памяти». Memex — это устройство, в котором человек хранит все свои книги и записи (а в идеале — и все свои знания, поддающиеся формальному описанию) и которое выдаёт нужную информацию с достаточной скоростью и гибкостью. Оно является расширением и дополнением памяти человека. Бушем было также предсказано всеобъемлющее индексирование текстов и мультимедийных ресурсов с возможностью быстрого поиска необходимой информации. Следующим значительным шагом на пути ко Всемирной паутине было создание гипертекста (термин введён Тедом Нельсоном в 1965 году).
С 1994 года основную работу по развитию Всемирной паутины взял на себя консорциум Всемирной паутины (англ. World Wide Web Consortium, W3C), основанный и до сих пор возглавляемый Тимом Бернерсом-Ли. Данный консорциум — организация, разрабатывающая и внедряющая технологические стандарты для Интернета и Всемирной паутины. Миссия W3C: «Полностью раскрыть потенциал Всемирной паутины путём создания протоколов и принципов, гарантирующих долгосрочное развитие Сети». Две другие важнейшие задачи консорциума — обеспечить полную «интернационализа́цию Сети́» и сделать Сеть доступной для людей с ограниченными возможностями.
W3C разрабатывает для Интернета единые принципы и стандарты (называемые «рекомендациями», англ. W3C Recommendations), которые затем внедряются производителями программ и оборудования. Таким образом достигается совместимость между программными продуктами и аппаратурой различных компаний, что делает Всемирную сеть более совершенной, универсальной и удобной. Все рекомендации консорциума Всемирной паутины открыты, то есть не защищены патентами и могут внедряться любым человеком без всяких финансовых отчислений консорциуму.
Как устроена всемирная паутина
Конечно, сам процесс просмотра веб-страницы описан очень примитивно, но алгоритм верный. Примитивно, потому что серверов с веб-страницами — миллионы. А это значит, что браузер не может сразу же найти необходимый веб-сервер, на котором расположен искомый сайт. Поиск нужного сервера происходит ступенчато:
- сначала браузер отправляет запрос на локальный сервер провайдера интернета;
- тот сервер отправляет запрос браузера на «головной сервер»;
- «головной сервер» не может ответить на запрос, но определяет к какой доменной зоне принадлежит искомый сайт;
- сервер доменной зоны не может ответить на запрос браузера, но знает на каком сервере может располагаться искомая веб-страница, поэтому отправляет туда запрос;
- если он точно определяет адрес сервера, на котором расположен искомый сайт, тогда он возвращает этот адрес браузеру;
- и браузер отправляет запрос найденному серверу по поводу искомой страницы и получает ответ.
На словах этот процесс описывается долго, но на деле это происходит за доли секунд, что пользователь не успевает понять, сколько работы было проделано, чтобы показать ему сайт.
В чем отличие новой концепции Веб 3.0 от предыдущих?
Web 3.0 — портируемый (переносной) персональный веб.
- Сфокусированность — на индивиде.
- Структура данных – принцип лайфстрим (lifestream): «жизненный поток» — контент в форме дневника-календаря.
- Концепция данных – динамическое объединение в структурной взаимосвязи.
- Основной источник информации и знаний – Интернет.
- Технологии – «drag and drop» (перетаскивание) и mashups (коллажи из данных любого формата).
- Классификация информации – поведенческая (полностью зависящая от предпочтений конкретного пользователя).
- Поисковый механизм — iGoogle, NetVibes.
- Стоимость рекламы – определяется активностью пользователей.
- Продвижение – advertainment (ненавязчивая косвенная реклама, облеченная в форму представлений, развлекательных акций).
- Сервисы, продвигающие концептуальные положения технологии Web 3.0:
- универсальная поисковая система Google, которая сохраняет историю поиска пользователя и учитывает его предпочтения (в последнее время в этом же направлении движется и Яндекс);
- FOAF (friend of a friend),
- Социальная поисковая система Wink,
- Империя микроблогов Twitter, multi-touch — технология для сенсорных дисплеев Surface;
- система, обеспечивающая единую авторизацию пользователя во все мировой Сети – OpenID.
ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ: WEB 1.0, WEB. 2.0, WEB 3.0
«Что такое Web 2.0, Web 3.0?» – вопрос, который нам неоднократно задавали, и, вероятно, у него столько же ответов, сколько людей использует этот термин. Однако, после того как начались разговоры о Web 3.0 и даже Web 4.0, наступила новая ситуация. Чтобы помочь людям понять идеи таких умных слов, как Web 2.0 и Web 3.0, в данной статье мы постараемся рассмотреть, что именно означают эти термины, и как они относятся, в частности, к бизнесу электронной торговли.
Стандарты Всемирной паутины
Веб-стандарты состоят из множества зависящих друг от друга технологических стандартов и спецификаций, часть из которых регулирует только WWW, а часть – весь Интернет в целом. Все эти стандарты оказывают влияние на создание и управление всеми сайтами и сервисами, находящимися внутри сети Интернет. Благодаря web-стандартам использование всех web-ресурсов принимает понятный, доступный и удобный характер.
ТОП-30 IT-профессий 2022 года с доходом от 200 000 ₽
Команда GeekBrains совместно с международными специалистами по развитию карьеры
подготовили материалы, которые помогут вам начать путь к профессии мечты.
Подборка содержит только самые востребованные и высокооплачиваемые специальности
и направления в IT-сфере. 86% наших учеников с помощью данных материалов определились
с карьерной целью на ближайшее будущее!
Скачивайте и используйте уже сегодня:

Александр Сагун
Исполнительный директор Geekbrains
Топ-30 самых востребованных и высокооплачиваемых профессий 2022
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Получить подборку бесплатно
pdf 3,7mb
doc 1,7mb
Уже скачали 16912
Веб-стандарты Всемирной паутины WWW включают в себя следующие компоненты:
- список рекомендаций, утверждённый Консорциумом Всемирной паутины (World Wide Web Consortium);
- документы запроса комментариев (Request for Comments), утверждённые Инженерной группой Интернета (Internet Engineering Task Force);
- официальные стандарты, утверждённые Международной организацией по стандартизации (International Organization for Standardization);
- официальные стандарты, утверждённые Организацией по стандартизации информационных и коммуникационных технологий (Ecma International);
- стандарты и технические отчёты Unicode, утверждённые консорциумом Unicode (Unicode –стандарт кодирования символов, который содержит знаки практически всех письменных языком мира);
- реестры имён и номеров, утверждённые Управлением по присвоению номеров Интернета (Internet Assigned Numbers Authority).
Важно отметить, что web-стандарты не являются фиксированным, неизменным набором правил, которому подчиняются абсолютно все ресурсы в сети Интернет. Они представляют собой постоянно меняющийся и усовершенствующийся набор технических стандартов и спецификаций, над разработкой которых работают специализированные и признанные по всём мире организации и консорциумы по стандартизации

Эти объединения часто ведут конкурентную борьбу друг с другом, но имеют общую заинтересованность к приведению всех ресурсов к единым стандартам и правилам. Ещё один важный момент: необходимо чётко различать те стандарты и спецификации, которые ещё только находятся на этапе разработки и усовершенствования, от тех, которые уже признаны и получили статус финальной разработки.









Алгоритмы обхода графа: поиск в ширину и в глубину
Поиск в глубину
Существует два классических алгоритма обхода графов. Первый — простой и мощный — алгоритм называется поиск в глубину (Depth-first search, DFS). В его основе лежит рекурсия, и он представляет собой следующую последовательность действий:
- Помечаем текущую вершину обработанной.
- Обрабатываем текущую вершину (в случае поискового робота обработкой будет просто сохранение копии).
- Для всех вершин, в которые можно перейти из текущей: если вершина еще не обработана, рекурсивно обрабатываем и ее тоже.
Код на Python, имплементирующий данный подход буквально дословно:
Приблизительно таким же образом работает, например, стандартная линуксовая утилита wget с параметром -r, показывающим, что нужно выкачивать сайт рекурсивно:
Метод поиска в глубину целесообразно применять для того, чтобы обойти веб-страницы на небольшом сайте, однако для обхода всего Интернета он не очень удобен:
- Содержащийся в нем рекурсивный вызов не очень хорошо параллелится.
- При такой реализации алгоритм будет забираться все глубже и глубже по ссылкам, и в конце концов у него, скорее всего, не хватит места в стеке рекурсивных вызовов и мы получим ошибку stack overflow.
В целом обе эти проблемы можно решить, но мы вместо этого воспользуемся другим классическим алгоритмом — поиском в ширину.
Поиск в ширину
Поиск в ширину (breadth-first search, BFS) работает схожим с поиском в глубину образом, однако он обходит вершины графа в порядке удаленности от начальной страницы. Для этого алгоритм использует структуру данных «очередь» — в очереди можно добавлять элементы в конец и забирать из начала.
- Алгоритм можно описать следующим образом:
- Добавляем в очередь первую вершину и в множество «увиденных».
- Если очередь не пуста, достаем из очереди следующую вершину для обработки.
- Обрабатываем вершину.
- Для всех ребер, исходящих из обрабатываемой вершины, не входящих в «увиденные»:
- Добавить в «увиденные»;
- Добавить в очередь.
- Перейти к пункту 2.
Код на python:
Понятно, что в очереди сначала окажутся вершины, находящиеся на расстоянии одной ссылки от начальной, потом двух ссылок, потом трех ссылок и т. д., то есть алгоритм поиска в ширину всегда доходит до вершины кратчайшим путем.
Еще один важный момент: очередь и множество «увиденных» вершин в данном случае используют только простые интерфейсы (добавить, взять, проверить на вхождение) и легко могут быть вынесены в отдельный сервер, коммуницирующий с клиентом через эти интерфейсы. Эта особенность дает нам возможность реализовать многопоточный обход графа — мы можем запустить несколько одновременных обработчиков, использующих одну и ту же очередь.
Robots.txt
Прежде чем описать собственно имплементацию, хотелось бы отметить, что хорошо ведущий себя краулер учитывает запреты, установленные владельцем веб-сайта в файле robots.txt. Вот, например, содержимое robots.txt для сайта lenta.ru:
Видно, что тут определены некоторые разделы сайта, которые запрещено посещать роботам яндекса, гугла и всем остальным. Для того чтобы учитывать содержимое robots.txt в языке python, можно воспользоваться реализацией фильтра, входящего в стандартную библиотеку:
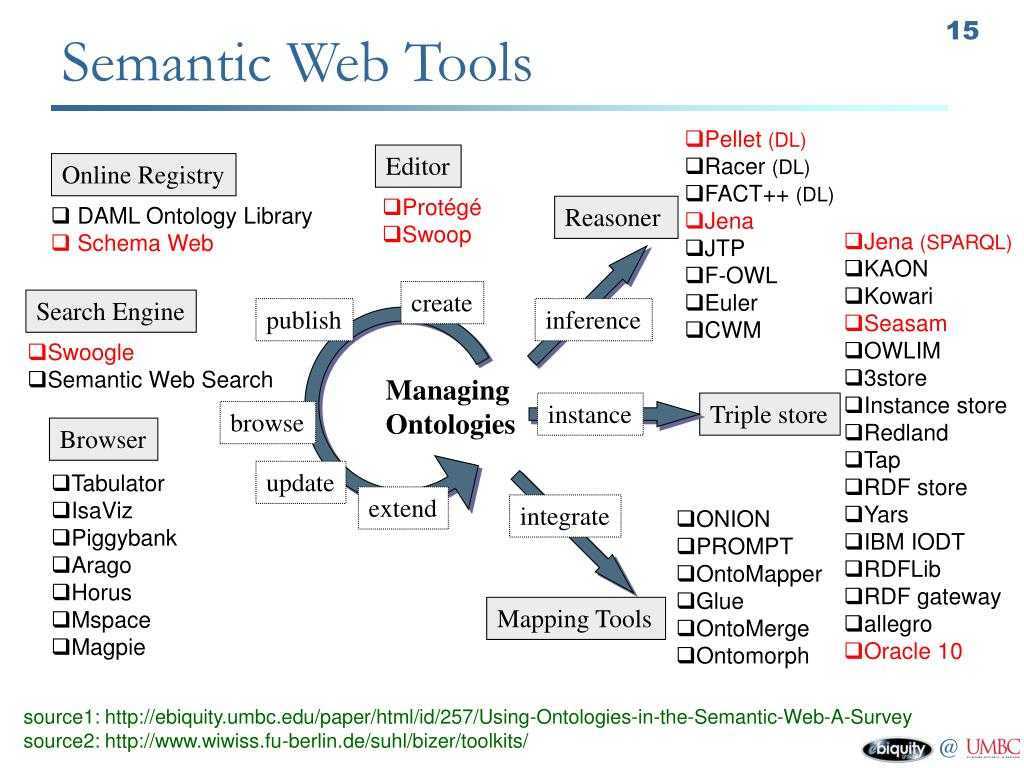
Важнейшие понятия Semantic WEB
Онтологии
экземпляровпонятий, атрибутовотношений
- Экземпляр — элементы самого нижнего уровня. Главной целью онтологий является именно классификация экземпляров, и хотя их наличие в онтологии не обязательно, но как правило они присутствуют. Пример: слова, породы зверей, звёзды.
-
Понятия — абстрактные наборы, коллекции объектов.Пример: Понятие «звёзды», вложенное понятие «солнце». Чем является «солнце», вложенным понятием или экземпляром (светилом) — зависит от онтологии.
Понятие «светило», экземпляр «солнце». -
Атрибуты — каждый объект может иметь необязательный набор атрибутов позволяющий хранить специфичную информацию.Пример: объект солнце имеет такие атрибуты как
• Тип: жёлтый карлик;
• Масса: 1.989 · 1030 кг;
• Радиус: 695 990 км. - Отношения — позволяют задать зависимости между объектами онтологии.
тёмно зелёный, близкий по тональности к хвоеЧасть возможной онтологии адресовOWL-S
Веб — это граф
Та часть Интернета, которая нам интересна, состоит из веб-страниц. Для того чтобы поисковая система смогла найти ту или иную веб-страницу по запросу пользователя, она должна заранее знать, что такая страница существует и на ней содержится информация, релевантная запросу. Пользователь обычно узнает о существовании веб-страницы от поисковой системы. Каким же образом сама поисковая система узнает о существовании веб-страницы? Ведь никто ей не обязан явно сообщать об этом.
К счастью, веб-страницы не существуют сами по себе, они содержат ссылки друг на друга. Поисковый робот может переходить по этим ссылкам и открывать для себя все новые веб-страницы.
На самом деле структура страниц и ссылок между ними описывает структуру данных под названием «граф». Граф по определению состоит из вершин (веб-страниц в нашем случае) и ребер (связей между вершинами, в нашем случае — гиперссылок).
Другими примерами графов являются социальная сеть (люди — вершины, ребра — отношения дружбы), карта дорог (города — вершины, ребра — дороги между городами) и даже все возможные комбинации в шахматах (шахматная комбинация — вершина, ребро между вершинами существует, если из одной позиции в другую можно перейти за один ход).
Графы бывают ориентированными и неориентированными — в зависимости от того, указано ли на ребрах направление. Интернет представляет собой ориентированный граф, так как по гиперссылкам можно переходить только в одну сторону.
Для дальнейшего описания мы будем предполагать, что Интернет представляет собой сильно связный граф, то есть, начав в любой точке Интернета, можно добраться до любой другой точки. Это допущение — очевидно неверное (я могу легко создать новую веб-страницу, на которую не будет ссылок ниоткуда и соответственно до нее нельзя будет добраться), но для задачи проектирования поисковой системы его можно принять: как правило, веб-страницы, на которые нет ссылок, не представляют большого интереса для поиска.
Небольшая часть веб-графа:
Результаты
Скачивание habrahabr и geektimes у меня заняло три дня.
Можно было бы скачать гораздо быстрее, увеличив количество экземпляров воркеров на каждой рабочей машине, а также увеличив количество воркеров, но тогда нагрузка на сам хабр была бы очень большой — зачем создавать проблемы любимому сайту?
В процессе работы я добавил пару фильтров в краулер, начав фильтровать некоторые явно мусорные страницы, нерелевантные для разработки поискового движка.
Разработанный краулер, хоть и является демонстрационным, но в целом масштабируется и может применяться для сбора больших объемов данных с большого количества сайтов одновременно (хотя, возможно, в продакшне есть смысл ориентироваться на существующие решения для краулинга, такие как heritrix. Реальный продакшн-краулер также должен запускаться периодически, а не разово, и реализовывать много дополнительного функционала, которым я пока пренебрег.
За время работы краулера я потратил примерно 60 $ на облако amazon. Всего скачано 5.5 млн страниц, суммарным объемом 668 гигабайт.
В следующей статье цикла я построю индекс по скачанным веб-страницам при помощи технологий больших данных и спроектирую простейший движок собственно поиска по скачанным страницам.
От Web 1.0 к Web 3.0 — три десятилетия Интернет
Картинка стоит тысячи слов. С учетом сказанного, приведем следующие изображения для объяснения различий между Web 2.0 и Web 3.0 иначе известного как семантического веба. Но, прежде чем сравнивать Web 2.0 и Web 3.0, полезно сравнить с Web 1.0 Web 2.0 в первую очередь.
Ниже приведено визуальное сравнение Web 1.0, Web 2.0 и Web 3.0.
И, наконец, приведем изображение, которое показывает развитие от Web 1.0 до 4.0!









Таким образом, к концу первого десятилетия XXI в. можно рассматривать следующие этапы развития сети:
Web 1.0 — контент (содержание) интернет-ресурсов формирует сравнительно небольшая группа профессионалов, а подавляющее большинство пользователей сети Интернет фигурирует в качестве простых «читателей». В первом десятилетии сети Интерент, или Web 1.0, была разработана сама основа Интернет, которая позволила дать доступ к огромным объемам информации широкому кругу пользователей сети.
Web 2.0 — в создание контента активно включаются пользователи сети. Сейчас мы находимся в конце второго десятилетия — Web 2.0 — были развиты различные пользовательские интерфейсы, которые позволяли пользователям уже управлять содержимым сети Интерент и связаться друг с другом.
Web 3.0 — мы на пороге третьей декады — Web 3.0. Семантического Веб (Semantic Web). Семантическая паутина (Semantic Web) – «часть глобальной концепции развития сети Интернет, целью которой является реализация возможности машинной обработки информации, доступной во Всемирной паутине. Основной акцент концепции делается на работе с метаданными, однозначно характеризующими свойства и содержание ресурсов Всемирной паутины, вместо используемого в настоящее время текстового анализа документов» (Википедия).То есть — это некая сеть над Сетью, содержащая метаданные о ресурсах Всемирной паутины и существующая параллельно с ними.
Важно понимать, что, давая определения и используя понятия различных концепций построения сайтов Web 1.0, Web 2.0, Web 3.0, если сайт использует особенности Web 2.0, это не делает его устаревшим. В конце концов, у небольшого веб-сайта электронной торговли, пытающегося продать продукцию в какой-либо нише, возможно, нет никакой потребности в предоставлении содержимого пользователями или возможности взаимодействия пользователей друг с другом
Следует понимать,создание сайтов — дорогостоящий и времязатратный процесс, и, чтоб ваш Интерент-проект был удачен, уже на самых первых этапах проектирования, продумывания концепции сайта, важно четко знать существующие тенденции современных Интернет-технологий.
Очевидно одно: Интернет не перестает развиваться и будущее Интернет-технологий чрезвычайно интересно!
Литература
http://www.e-xecutive.ru/wiki/index.php/%D0%92%D0%B5%D0%B1_3.0
http://abcblog.ru/web-3-0/
http://www.creasol.ru/index2.php?ob=articles_one&id=8