
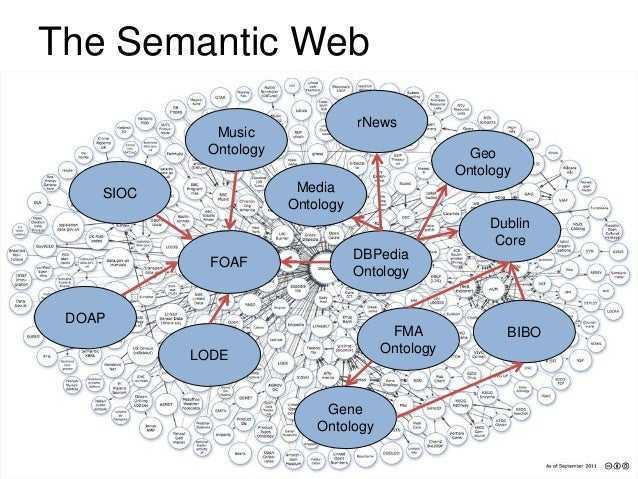
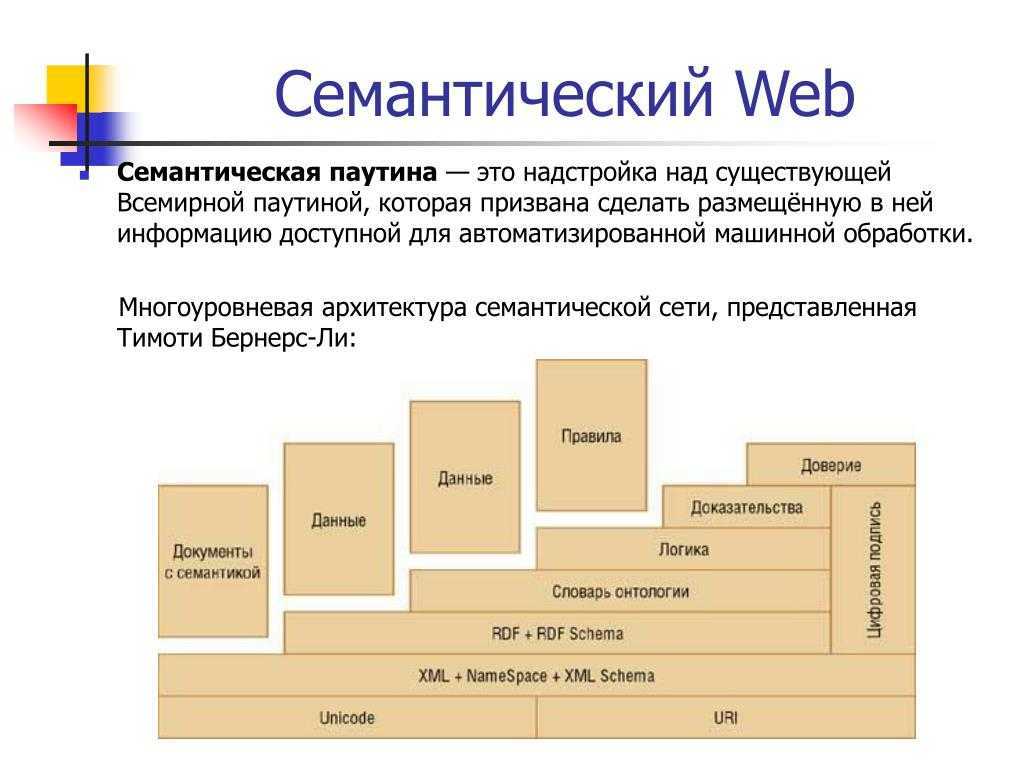
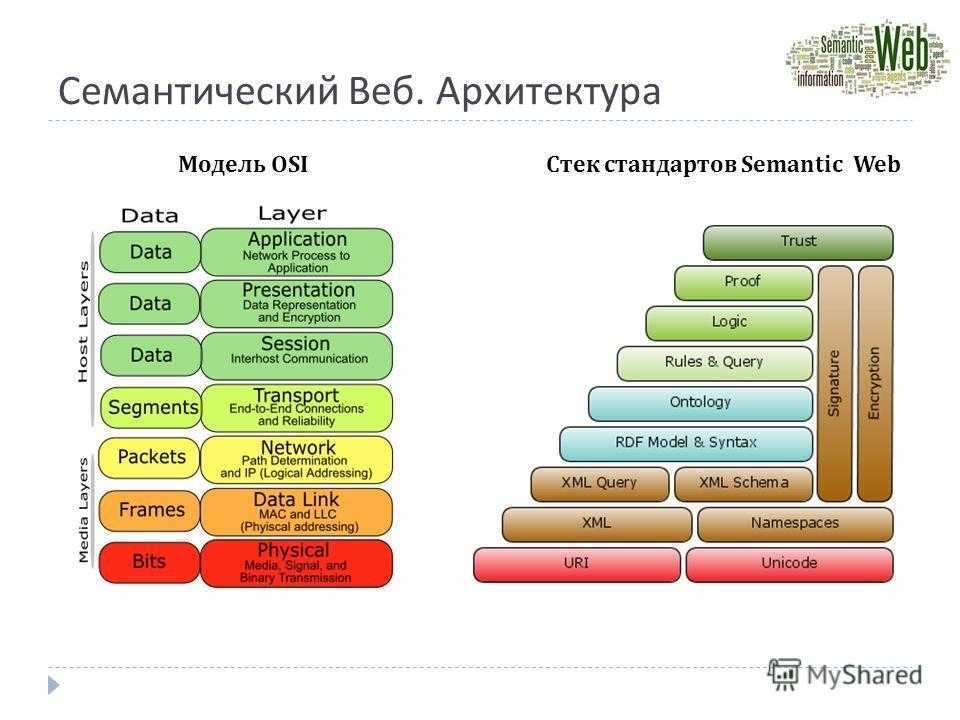
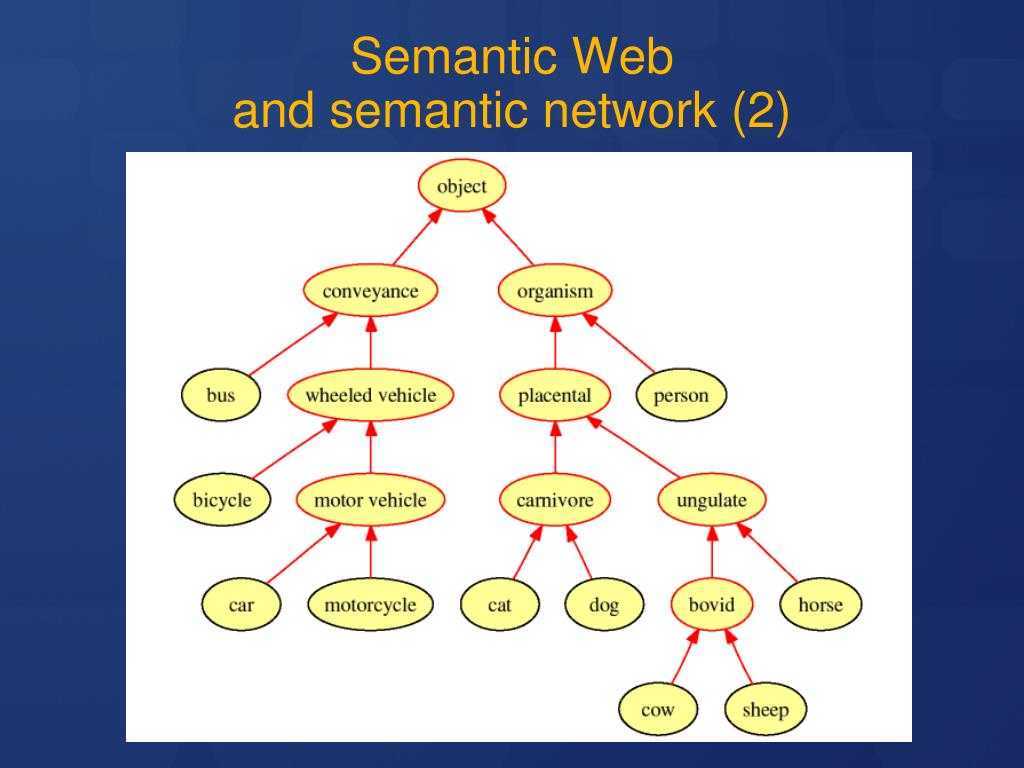
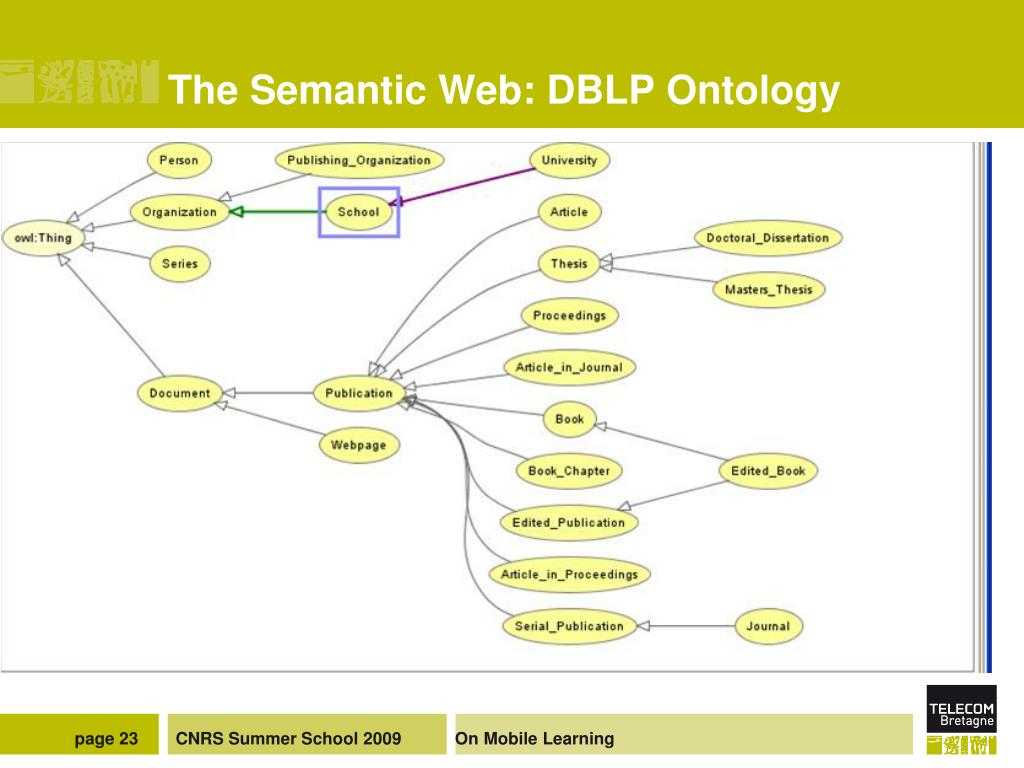
Важнейшие понятия Semantic WEB
Онтологии
экземпляровпонятий, атрибутовотношений
- Экземпляр — элементы самого нижнего уровня. Главной целью онтологий является именно классификация экземпляров, и хотя их наличие в онтологии не обязательно, но как правило они присутствуют. Пример: слова, породы зверей, звёзды.
-
Понятия — абстрактные наборы, коллекции объектов.Пример: Понятие «звёзды», вложенное понятие «солнце». Чем является «солнце», вложенным понятием или экземпляром (светилом) — зависит от онтологии.
Понятие «светило», экземпляр «солнце». -
Атрибуты — каждый объект может иметь необязательный набор атрибутов позволяющий хранить специфичную информацию.Пример: объект солнце имеет такие атрибуты как
• Тип: жёлтый карлик;
• Масса: 1.989 · 1030 кг;
• Радиус: 695 990 км. - Отношения — позволяют задать зависимости между объектами онтологии.
тёмно зелёный, близкий по тональности к хвоеЧасть возможной онтологии адресовOWL-S
Проекты
Дублинское ядро
Одним из первых серьёзных и популярных проектов, основанных на принципах Семантической паутины, стал проект «Дублинское ядро» (англ. Dublin Core), реализуемый инициативной организацией Dublin Core Metadata Initiative (DCMI). Это открытый проект, цель которого — разработать стандарты метаданных, которые были бы независимы от платформ и подходили бы для широкого спектра задач. Конкретнее, DCMI занимается разработкой словарей метаданных общего назначения, стандартизирующих описания ресурсов в формате RDF.
RSS (версий 0.90 и 1.0)
Версии 0.90 и 1.0 формата RSS основаны на RDF. Информация в нём представляется как и в RDF, тройками субъект-отношение-объект. Необходимо отметить, что несмотря на то, что ему присущи многие недостатки Семантической паутины (например, дублирование информации), этот простейший формат быстро стал чрезвычайно популярным за счёт узкой категоризации подмножества используемых метаданных. Отличие RSS от RDF состоит в том, что субъектом тройки всегда является сайт-источник RSS-файла, а в качестве отношений используются самые очевидные свойства документов, имеющие отношение к часто обновляющимся источникам информации: дата написания, автор, постоянная ссылка, и т. д. Другими словами, RSS — узкоспециализированное подмножество RDF.
Заметим, что формат RSS версии 2.0, хотя и не является форматом, основанным на RDF, позволяет внедрение произвольного XML-содержимого, находящегося в собственных пространствах имён XML. Это позволяет использовать RDF-описания также и в нём (используя пространство имён rdf).
FOAF
Проект «Friend of a Friend» («Друг друга») позволяет описывать отношение знакомства с помощью RDF. Любой его участник может идентифицировать себя уникальным образом с помощью URI (например, mailto-адресом электронной почты, адресом блога, и т. п.), создать свой профиль, используя предопределённые для FOAF отношения на языке RDF, и перечислить идентификаторы людей, которых этот участник знает. Это описание может обрабатываться автоматически; на его основе можно строить сети доверия, анализировать структуру социальных групп, и т. д.
DBpedia
DBpedia — проект, направленный на извлечение структурированной информации из данных, созданных в рамках проекта Wikipedia. DBpedia позволяет пользователям запрашивать информацию, основанную на отношениях и свойствах ресурсов Википедии, в том числе ссылки на соответствующие базы данных. Начат группой добровольцев из Свободного университета Берлина и Лейпцигского университета, в сотрудничестве с OpenLink Software, и впервые был опубликован в 2007 году. Проект DBpedia использует Resource Description Framework (RDF) для представления извлеченной информации. По состоянию на апрель 2010, базы данных DBpedia состоят из более чем 1 млрд единиц информации, из которых 257 млн были взяты из английской версии Википедии и 766 млн извлечены из версий на других языках.
Современные языки описания онтологий
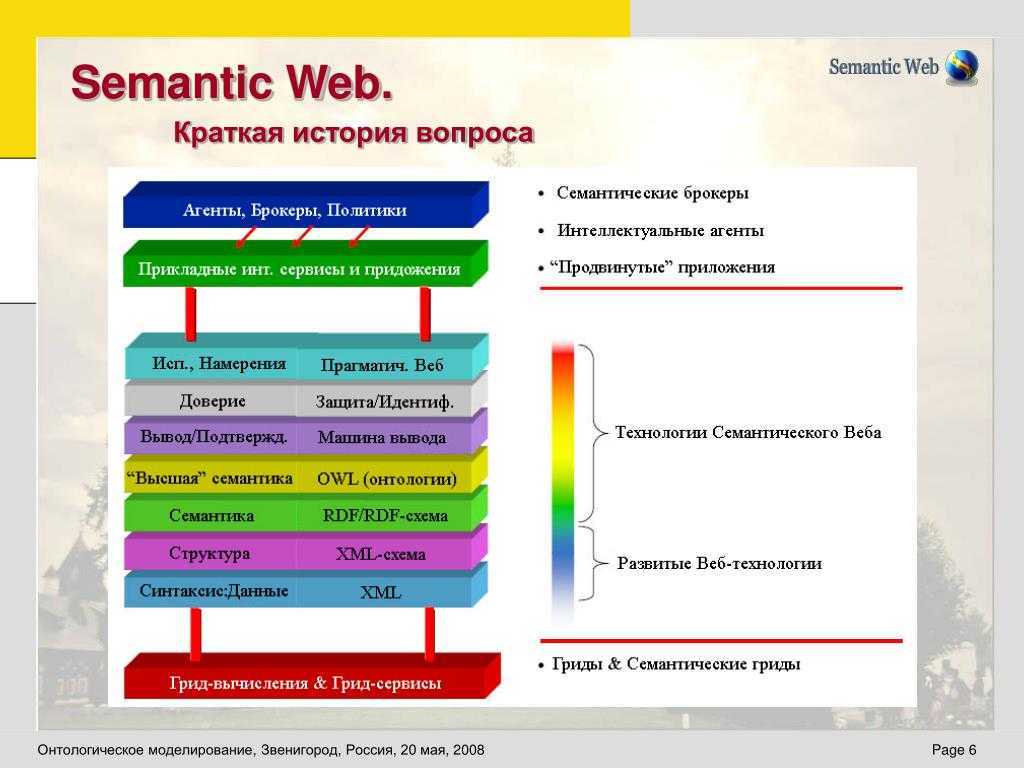
RDFПример таблицы с выделенными параметрамиПример схемы RDI в виде графаOWLМесто OWL в общей структуре Semantic WEB с точки зрения консорциума W3C
- XML — предоставляет возможности создания структурированных документов, но не предъявляет к ним никаких семантических требований;
- XML Schema — определяет структуру XML документов и дополнительно позволяет использовать конкретные типы данных;
- RDF — предоставляет возможность описывать абстрактные модели данных некоторых объектов и отношения между ними. Использует простую семантику на основе XML синтаксиса;
- RDF Schema — позволяет описывать свойства и классы RDF — ресурсов, а также семантику отношений между ними;
- OWL — расширяет описательные возможности предыдущих технологий. Позволяет описывать отношения между классами (к примеру непересекаемость), кардинальность (например «точно один»), симметрия, равенство, перечисляемые типы классов.
- OWL Lite — является подмножеством полной спецификации, предоставляющим минимально достаточные средства описания онтологий. Предназначен для снижения первичного внедрения OWL. А также для упрощения миграции на OWL тезаурусов и прочих таксономий. Гарантируется, что логический вывод на метаданных с выразительностью OWL Lite выполняется за полиномиальное время (сложность алгоритма принадлежит классу Р).
Диалект основан на дескрипционной логике SHLF(D) - OWL DL — с одной стороны предоставляет максимальную выразительность, полноту вычислений (все они будут гарантированно вычисляемыми) и полную разрешаемость (все вычисления завершаются в определённое время). Но в связи с этим имеет строгие ограничения, к примеру на взаимосвязи классов и время выполнения некоторых запросов по таким данным могут требовать экспоненциального времени выполнения.
Диалект основан на дескрипционной логике SHOLN(D) - OWL Full — предоставляет максимальную выразительную свободу, но не даёт никаких гарантий разрешаемости. Все созданные структуры опираются обоснованы только реализуемым алгоритмом. Считается маловероятным, что какое-либо рассудочное программное обеспечение будет в состоянии поддержать полную поддержку каждой особенности OWL Full.
Не соответствует ни одной дескрипционной логике, так — как в принципе является не разрешимым.
Что такое семантика
Эта наука изучает лингвистический и философский смысл языка, языков программирования, формальных логик, семиотики и проводит анализ текста. Она связана отношением:
- с означающими словами,
- словами,
- фразами,
- знаками,
- символами и тем, что они означают, их обозначением.
Проблема понимания была предметом многих запросов в течение длительного периода времени, но этим вопросом занимались большей частью психологи, а не лингвисты. Но только в лингвистике изучается интерпретация знаков или символов, используемых в сообществах при определённых обстоятельствах и контекстах. В этом представлении звуки, мимика, язык тела и проксемика имеют семантический (значимый) контент, и каждый из них включает несколько отделений. На письменном языке такие вещи, как структура абзаца и пунктуация, содержат семантический контент.
Формальный анализ семантики пересекается со многими другими областями исследования, включая:
- лексикологию,
- синтаксис,
- прагматику,
- этимологию и другие.
Само собой разумеется, определение семантики также является чётко определённой областью в своём праве, часто с синтетическими свойствами. В философии языка, семантика и ссылка тесно связаны. Дальнейшие смежные области включают филологию, связь и семиотику.
Семантика контрастирует с синтаксисом, изучением комбинаторики единиц языка (без ссылки на их смысл) и прагматикой, изучением отношений между символами языка, их значением и пользователями языка. Область исследования в этом случае также имеет существенные связи с различными репрезентативными теориями смысла, включая истинные теории смысла, теории связности смысла и теории соответствий смысла. Каждый из них связан с общим философским исследованием реальности и представлением смысла.
История
Автором идеи семантической паутины считается Тим Бернерс-Ли. История концепции уходит корнями в середину 90-х годов XX века, первые детализированные публикации относятся к году. С года проект семантической паутины развивается под эгидой Консорциума Всемирной паутины. В период с 1999 по 2004 год работу над концепцией вела группа разработчиков «RDF Interest Group», в году группа была переименована в «Semantic Web Interest Group».
Первым серьёзным и популярным проектом, основанным на принципах семантической паутины, стал проект «Дублинское ядро» (англ. Dublin Core Metadata Initiative, DCMI). Это открытый проект, цель которого — разработать стандарты метаданных, которые были бы независимы от платформ и подходили бы для широкого спектра задач. Конкретнее, DCMI занимается разработкой специальных словарей метаданных (англ. metadata vocabularies), стандартизирующих описания ресурсов Всемирной паутины в формате RDF.
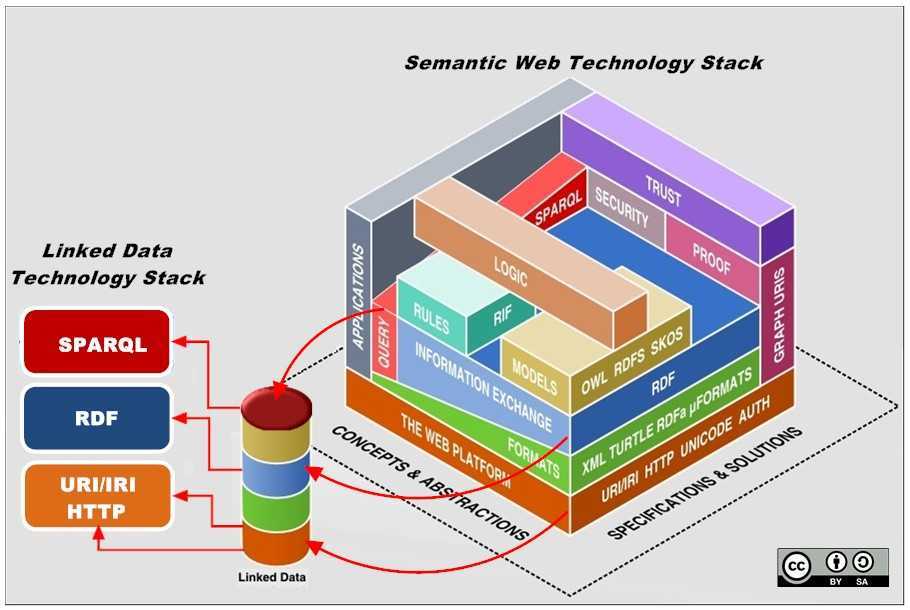
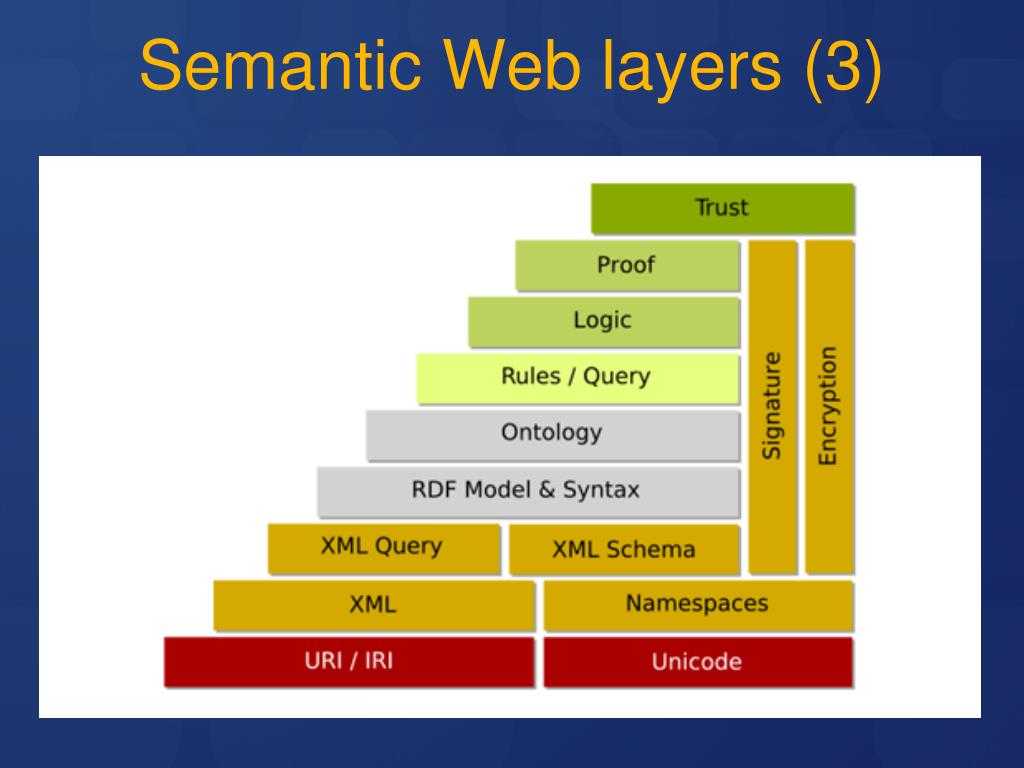
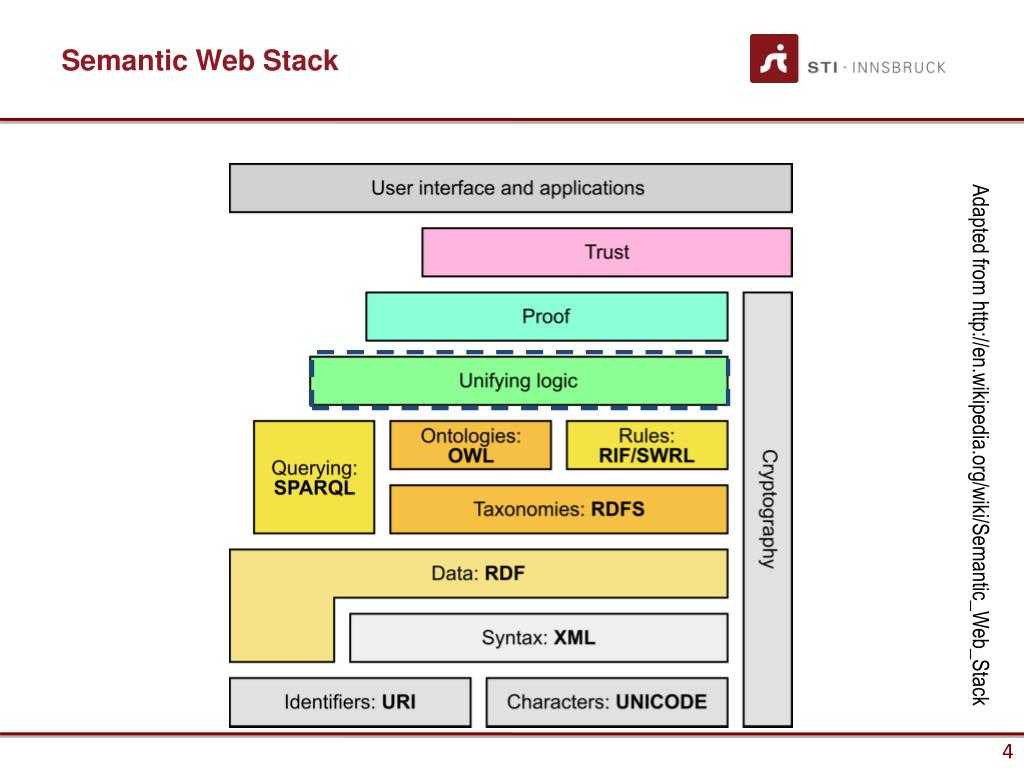
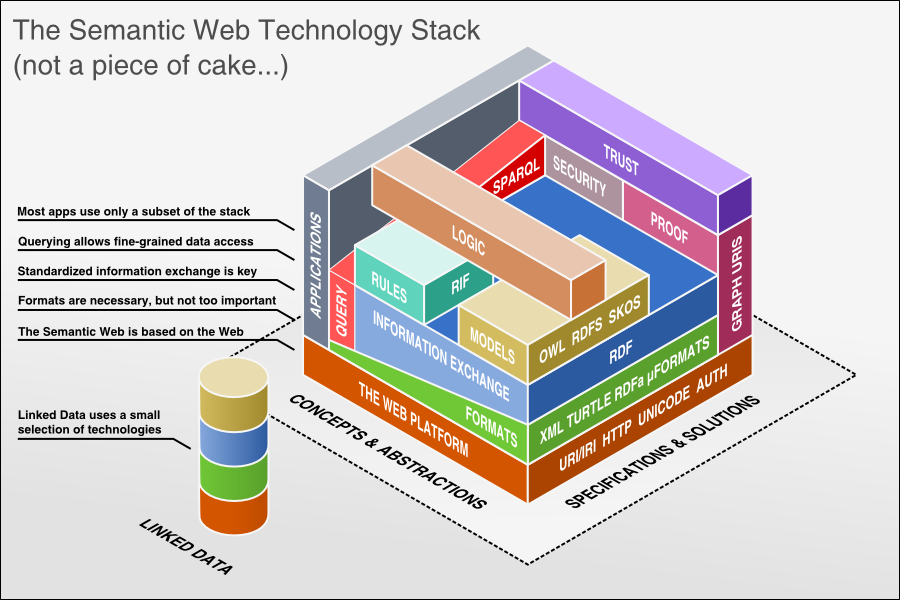
Концепция каждого слоя:
Прежде чем приступить к разработке, давайте поговорим о концепции ресурсов:
Может быть любымСобственный URI (это самое главное)Объекты, люди, объекты, концепции, документы, файлы, аудио и т. Д.
URI: унифицированный идентификатор ресурса
UNICODE: указывает форму кодировки ресурса;
URI определяет уникальный идентификатор для каждого ресурса.
1.2XML
XML определяет содержимое ресурса и его структуру данных (дерево XML, теги для описания), самое важное — отсутствие возможности семантического описания (то есть я не знаю, какова связь между ресурсами). В то же время, теги XML могут быть искусственно определены, что приводит к тому, что компьютер не обрабатывает их должным образом
Для стандартизации тегов и повышения обрабатываемости была введена схема XML для указания тегов в форме
В то же время, теги XML могут быть искусственно определены, что приводит к тому, что компьютер не обрабатывает их должным образом. Для стандартизации тегов и повышения обрабатываемости была введена схема XML для указания тегов в форме
Но поскольку количество тегов уменьшено, легко создать дублирование, которое вводит концепцию пространств имен, xmlns (namespace-ns), в разных пространствах имен теги с одинаковыми именами не затрагиваются. Форма: xmlns: prefix = address. Конкретный код выглядит следующим образом:
1.3 RDF
RDF: Он в основном используется для описания взаимосвязи между ресурсами и принимает форму троек SPO.
Инфраструктура описания ресурсов RDF представляет собой графическую модель, модель данных, а не конкретный тип данных, и состоит в основном из трех частей:
RDF schema
Добавлена семантическая информация в модель данных RDF, которая должна описывать взаимосвязь ресурсов,Способ состоит в том, чтобы увеличить описание атрибута ресурса и класса, к которому принадлежит ресурс.Конкретный метод заключается в следующем:
| концепция | Грамматическая форма | описание |
|---|---|---|
| Класс | C rdf:type rdfs:Class | C (ресурс) является классом RDF |
| Свойство (класс) | P rdf:type rdf:Property | P (ресурс) является атрибутом RDF |
| тип (атрибут) | I rdf:type C | Я (ресурс) является экземпляром C (класс) |
| subClassOf (атрибут) | C1 rdfs:subClassOf C2 | C1 (класс) является подклассом C2 (класс) |
| subPropertyOf (Свойство) | P1 rdfs:subPropertyOf P2 | P1 (атрибут) является податрибутом P2 (атрибут) |
| домен (атрибут) | P rdfs:domain C | Домен P (атрибут) является C (класс) |
| диапазон (атрибут) | P rdfs:range C | Диапазон P (атрибут) — C (класс) |
RDF sytanx
Речь идет о том, как хранить данные RDF на компьютере, что мы называем методом сериализации RDF. Это роль RDF Sytanx. В основном это следующие централизованные методы:


-
JSON-LD: «JSON для связывания данных» использует пары ключ-значение для хранения данных RDF на основе расширенного синтаксиса на основе JSON, хранит RDF в форме пар ключ-значение
-
RDFA: вставлять данные RDF в веб-страницы
-
RDF / XML: XML используется для хранения данных RDF, но из-за длинного формата XML его не удобно читать и не рекомендуется
-
N-трипл, который использует несколько триплетов для представления набора данных RDF, является наиболее интуитивным представлением. В файле каждая строка представляет триплет, что удобно для машинного анализа и обработки. График знаний об открытых доменахDBpediaДанные обычно публикуются в этом формате.
-
Черепаха должна быть наиболее часто используемым методом сериализации RDF. Он более компактен, чем RDF / XML, и более читабелен, чем N-Triples.
Синтаксис черепахи следующий:
1.4 Схема RDF и SPARQL
Схема RDF: в основном для улучшения способности описывать отношения ресурсов (как упомянуто выше),
SPARQL — это граф запросов, а RDF — это граф хранилища, который является языком для запроса данных RDF.
1.5 OWL ,RIF/SWRL
OWL: на основе RDF-схемы добавляются ограничения на атрибуты и классы, то есть свойства добавляются к атрибутам и классам ресурсов, так что могут быть достигнуты две функции: классификация, логический вывод
-
Реализуйте классификацию понятий, потому что в соответствии с ограничениями атрибутов и классов легко определить границы понятий
-
Способствует RIF (обмен правилами) — для достижения вывода, потому что определенные атрибуты содержат определенные свойства, такие как транзитивность.
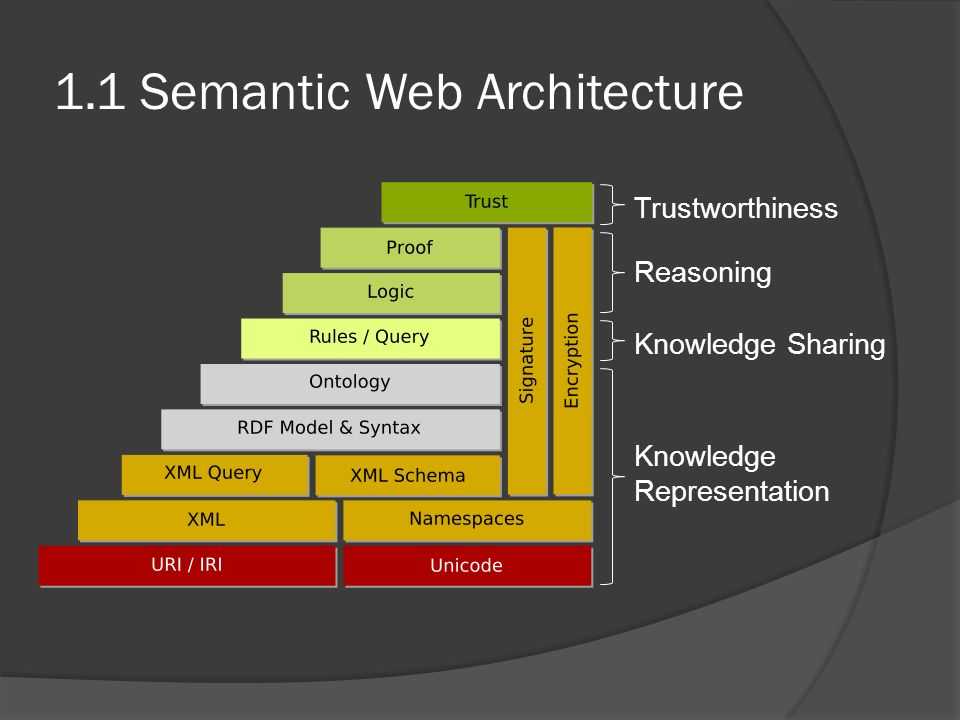
1. 6 Logic + Proof + Trust
Соответствует уровню логики, уровню проверки и уровню доверия соответственно
-
Логический уровень: предоставить аксиомы и правила для реализации логических операций.
-
Уровень проверки: проверка результатов вывода
-
Уровень доверия: создание доверия на основе результатов уровня проверки и некоторых цифровых подписей
Примечания
- The Semantic Web. — www.scientificamerican.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21 Scientific American, 17 мая 2001, русский перевод: Семантическая Сеть — ezolin.pisem.net/logic/semantic_web_rus.html
- Раздел о Семантической паутине на сайте W3C — www.w3.org/standards/semanticweb/ (англ.)
- Resource Description Framework (RDF): Concepts and Abstract Syntax — www.w3.org/TR/2004/REC-rdf-concepts-20040210/ (англ.). Консорциум Всемирной паутины (10 февраля 2004 года). — W3C Recommendation.
- Cool URIs for the Semantic Web — www.w3.org/TR/cooluris/ (англ.). Консорциум Всемирной паутины (3 декабря 2008 года). — W3C Interest Group Note.
- Semantic Web Revisited — eprints.ecs.soton.ac.uk/12614/1/Semantic_Web_Revisted.pdf, IEEE Intelligent Systems, июнь 2006
- Cory Doctorow, Metacrap: Putting the torch to seven straw-men of the meta-utopia, — www.well.com/~doctorow/metacrap.htm август 2001
- Rohit Khare, Tantek Çelik, Microformats: A Pragmatic Path to the Semantic Web, — www.commercenet.com/images/e/ea/CN-TR-06-01.pdf январь 2006
- RDFa Primer — www.w3.org/TR/xhtml-rdfa-primer/
- Ахиллесова пята Семантического Веба — www.computerra.ru/magazine/362912/, Компьютерра
- The Species of OWL in OWL Language Guide — www.w3.org/TR/owl-guide/#OwlVarieties
- OWL Full, OWL DL and OWL Lite in OWL Language Reference — www.w3.org/TR/owl-ref/#Sublanguage-def
- Dublin Core Metadata Initiative (DCMI) — dublincore.org/
- RSS 1.0 Specification — web.resource.org/rss/1.0/spec
- RSS 2.0 Specification — cyber.law.harvard.edu/rss/rss.html#extendingRss
- Friend of a Friend — www.link14
- DBpedia Mappings — mappings.link15
Исследовательская деятельность в области корпоративных приложений
Первой исследовательской группой, явно фокусирующейся на корпоративной семантической сети, была группа ACACIA в INRIA-Sophia-Antipolis, основанная в 2002 году. Результаты их работы включают поисковую систему Corese на основе RDF (S) и применение семантических веб-технологий в сфере электронного обучения.
. Исследовательская группа корпоративной семантической сети, расположенная в Свободном университете Берлина, специализируется на строительных блоках: корпоративном семантическом поиске, корпоративном семантическом сотрудничестве и разработке корпоративных онтологий.
Инженерные исследования онтологий включают этот вопрос о том, как привлекать неопытных пользователей к созданию онтологий и семантически аннотированного контента, а также для извлечения явных знаний из взаимодействия пользователей внутри предприятий.
Будущее приложений
Тим О’Рейли, придумавший термин Web 2.0, предложил долгосрочное видение Семантической паутины как сети данных, в которой сложные приложения манипулируют сетью данных. Сеть данных преобразует World Wide Web из распределенной файловой системы в распределенную систему баз данных.
Реализация
Для создания понятного компьютеру описания ресурса в семантической паутине используется формат RDF (англ. Resource Description Framework), который основан на синтаксисе XML и использует идентификаторы URI для обозначения ресурсов. RDF был утверждён как стандарт W3C в феврале года. RDF — это система описания сетевых ресурсов, понятная компьютеру. Формат RDF предназначен для хранения метаданных (метаданные — это данные о данных). В соответствии с концепцией семантической паутины, описания в формате RDF должны прикрепляться к каждому сетевому ресурсу. Документы RDF должны обрабатываться компьютером автоматически, RDF не предназначен для прочтения и использования человеком. К настоящему времени формат RDF уже устоялся и получил широкое распространение, он служит каркасом для создания семантической паутины.
RDFS (англ. RDF Schema) — это важная надстройка над RDF, позволяющая создавать классы и свойства (как в объектно-ориентированном программировании в рамках конкретного приложения).
Следующим важным направлением концепции семантической паутины является язык OWL (англ. Web Ontology Language, произносится [о́ул]), который стал Рекомендацией W3C в феврале 2004 года. Этот язык построен на форматах RDF и RDFS, он предназначен для обработки информации в сети. Язык OWL имеет 3 степени детализации, что является новым словом в компьютерных технологиях. Он также легко масштабируется и совместим с самыми передовыми сетевыми стандартами.
SPARQL (англ. Protocol And RDF Query Language, произносится [спа́ркл]) — новый язык запросов для быстрого доступа к данным RDF. Используя обычный протокол и язык SPARQL, приложения могут анализировать RDF-описания ресурсов и получать из сети нужную информацию.
Приложения
Цель состоит в том, чтобы повысить удобство использования и полезность Интернета и его взаимосвязанных ресурсы путем создания семантических веб-сервисов, таких как:
. Такие службы могут быть полезны для общедоступных поисковых систем или могут использоваться для управления знаниями в рамках организация. Бизнес-приложения включают:
- Облегчение интеграции информации из смешанных источников
- Устранение двусмысленности в корпоративной терминологии
- Улучшение поиска информации, тем самым уменьшая информационную перегрузку и повышение детализации и точности извлекаемых данных
- Выявление релевантной информации в отношении данного домена
- Обеспечение поддержки принятия решений
В корпорации существует замкнутая группа пользователей и руководство может обеспечить соблюдение руководящих принципов компании, таких как принятие конкретных онтологий и использование семантической аннотации. По сравнению с общедоступной семантической сетью требования к масштабируемости меньше, и в целом можно больше доверять информации, циркулирующей внутри компании; конфиденциальность не является проблемой вне обработки данных клиентов.
Основная идея
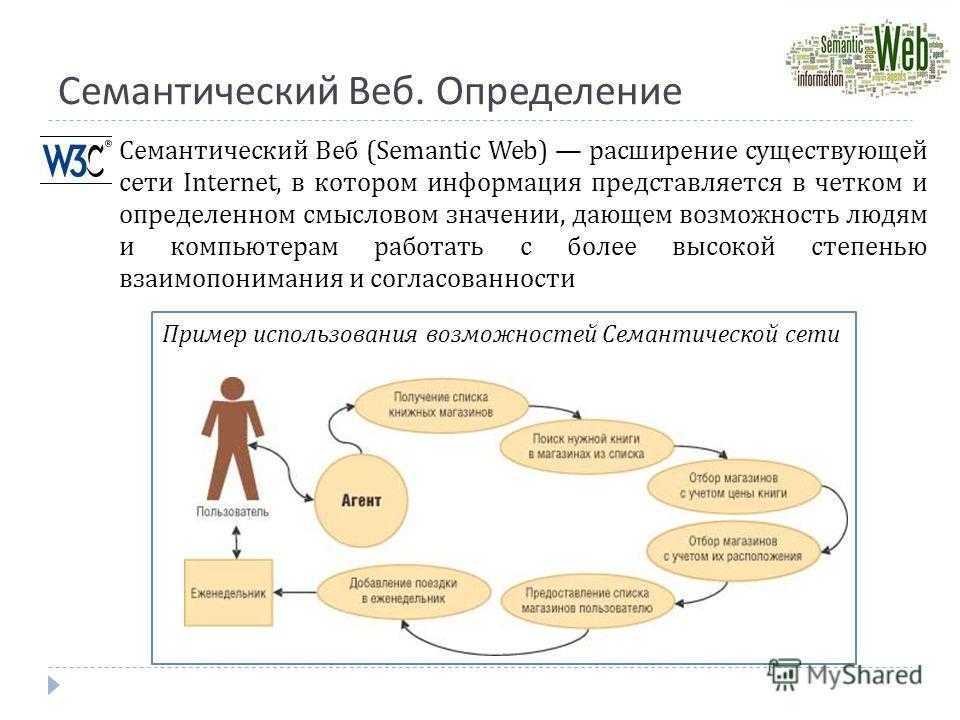
В настоящее время компьютеры принимают довольно ограниченное участие в формировании и обработке информации в сети Интернет. Трудно вообразить, но это так. Функции компьютеров в основном сводятся к хранению, отображению и поиску информации. В то же время создание информации, её оценку, классификацию и актуализацию — всё это по-прежнему выполняет человек. Как включить компьютер в эти процессы? Если компьютер пока нельзя научить понимать человеческий язык, то нужно использовать язык, который был бы понятен компьютеру. То есть, в идеальном варианте вся информация в Интернете должна размещаться на двух языках: на
человеческом языке для человека и на компьютерном языке для понимания компьютера. Семантическая паутина — это концепция сети, в которой каждый ресурс на человеческом языке был бы снабжён описанием, понятным компьютеру.
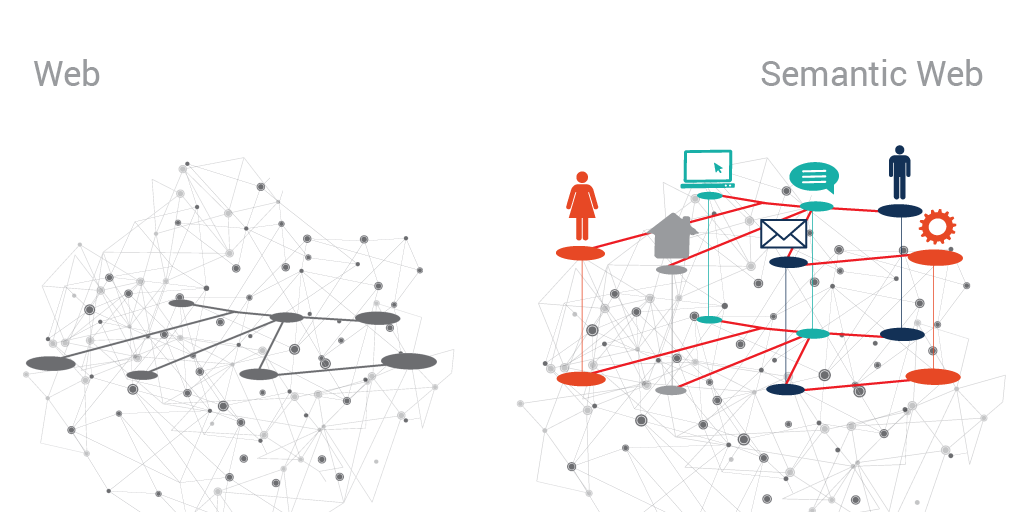
Смысловая паутина и реальность[править | править код]
Web — паутина (страниц) — набор страниц связанных по потоколу HTTP для просмотра людьми. Машина осуществляет процедуру перехода между страницами. Основная единица: текст+URL (URL — по простому ссылка). Пример развитой системы — Интернет — открытая паутина, корпоративная система (условно) закрытая паутина, например IBM, DARPA. Интрига заключается в границе между открытой для публики и закрытой частью. Хакеры — это паразиты злоупотребляющие паутиной?, или же правдолюбцы срывающие маски (см. WikiLeaks ?).
Semantic Web, смысловая паутина — организация больших массивы для принятия (аналитических, промежуточных, исполняемы в реале) решений компьютером, машиной. (Поскольку понятия связанные со смысловой сетью играют принципиальную роль, следует указать на важную проблему: можно ли отождествить компьютер и машину.) Интрига заключается в передаче компьютеру принятия и исполнение в физической реальности действий. Например:
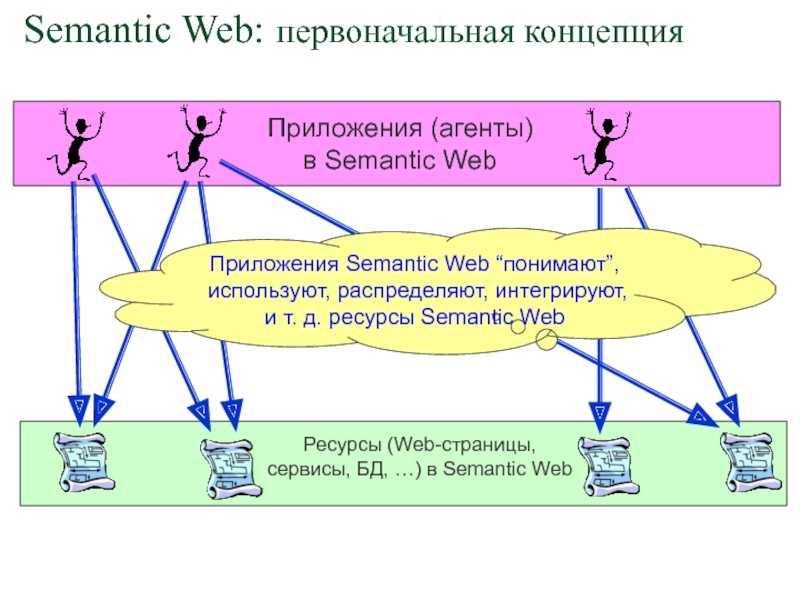
- Роботизированное производство — полностью решенная задача полной автоматизации сферы человеческой детельности (см. дероботизация).
- Сейчас передний край разработок смысловых сетей — военные системы, т.е. полная автоматизация военных действий и поддержания Odnung’а. Типичная задача — создание автоматизированной системы пропаганды на экзотическом языке.
- Предельный случай создание искусственного интеллекта и угроза перехода принятия всех решений … не машине, не компьютеру а искусственной сущности возможно будет создана нанотехногией. Возникает (изначально при создании компьютера возникла) проблема существования человека как вида. Еще одна тема — конкуренция за господство над планетой:
- Открытых государственно-политических структур (Афины — Интернет). Принцип смысловых сетей AAA «Anyone can say Anything about Any topic» — Любой может сказать, что угодно и о чём угодно». Semantic Web for the working ontologist. Dean Allemang, Jim Henler см. Когнитивное радио);
- Закрытых конспирологических, инфернальных структур (Вавилон);
- Искусственных интеллектуальных сущностей. В связи с базированием интеллекта на нелокальности искусственная сущность будет органичной планетарной системой;
не забудем и о
внепланетные сущности, см. MJ-12. Со «Звездных войн» Р.Рейгана вопрос об автономии компьютерных систем перешел в практическую плоскость. (Аналогично различению машина-компьютер, здесь имеет принципиальное, и даже теологическое значение природа пришельцев (alien) — это созданные Господом живые существа для других миров, или же био-роботы, или же небиологические сущности описанные Кастанедой, нечто вне познаваемости человеком — тоже Кастанеда. Плюс американская идиома «Это вам не Калифорния», в данном контексте исследовательские парадигмы NASA и Стенфордский университета.
Философияправить | править код
смысл — внутреннее содержание, значение ч.-л., то, что может быть понято. В семантике логической общее значение языковых выражений расщепляют на две части: предметное значение и смысл.
реальный (от позднелат. realis — вещественный) — действительный, существующий в действительности, в противоположность вымышленному, воображаемому, фантастическому, ирреальному, существующему только в сознании. [Философская энциклопедия. А.А. Ивин]
Как видим реальность находится в положении безнадежно обороняющегося от смысла.
ПО Всемирной паутины
В основе World Wide Web лежат web-серверы. Сегодня их функционал значительно расширен, поэтому достаточно часто они используются в виде шлюзов для серверов различных приложений либо сами способны поддерживать подобный функционал.
По всему миру существует огромное множество IT-инженеров, которые занимаются разработкой программного обеспечения для web-серверов. Наибольшую популярность завоевали такие программные продукты, как Apache Software Foundation, Internet International Services от Microsoft, Google Web Server от Google Incorporation.
Apache представляет собой бесплатное ПО, которое распространяется под совместимой с GPL лицензией. Несколько лет подряд это программное обеспечение держится в мировых лидерах по распространённости и применяемости в сети Интернет благодаря своей надёжности, безопасности, массовой масштабируемости.
Программное обеспечение Internet International Services, разработанное компанией Microsoft, представляет собой группу серверов, созданных для нескольких служб сети Интернет и применяемых совместно с операционными системами Windows, также являющимися ПО, созданным корпорацией Microsoft. В основе этого программного софта лежит web-сервер, который поддерживает такие протоколы, как POP3, NNTP, FTP, SMTP.
Компания Google является создателем ПО на базе Apache, которое называется Google Web Server. Оно было специально разработано для поддержки работы приложений сервиса Google Applications.
Nginx – это специализированный HTTP-сервер, который совмещён с кэширующим прокси-сервером. Первая версия этого программного обеспечения увидела свет в 2004 году, она была разработана программистом Игорем Сысоевым специально для компании Rambler. Сейчас это ПО поддерживается примерно на 9-12 % веб-серверах.
Только до 26.12
Как за 3 часа разбираться в IT лучше, чем 90% новичков и выйти надоход в 200 000 ₽?
Приглашаем вас на бесплатный онлайн-интенсив «Путь в IT»! За несколько часов эксперты
GeekBrains разберутся, как устроена сфера информационных технологий, как в нее попасть и
развиваться.
Интенсив «Путь в IT» поможет:
- За 3 часа разбираться в IT лучше, чем 90% новичков.
- Понять, что действительно ждет IT-индустрию в ближайшие 10 лет.
- Узнать как по шагам c нуля выйти на доход в 200 000 ₽ в IT.
При регистрации вы получите в подарок:
«Колесо компетенций»
Тест, в котором вы оцениваете свои качества и узнаете, какая профессия в IT подходит именно вам
«Критические ошибки, которые могут разрушить карьеру»
Собрали 7 типичных ошибок, четвертую должен знать каждый!
Тест «Есть ли у вас синдром самозванца?»
Мини-тест из 11 вопросов поможет вам увидеть своего внутреннего критика
Хотите сделать первый шаг и погрузиться в мир информационных технологий? Регистрируйтесь и
смотрите интенсив:
Только до 26 декабря
Получить подборку бесплатно
pdf 4,8mb
doc 688kb
Осталось 17 мест
Web-браузер, или web-обозреватель другими словами, – это специальное приложение, разработанное для пользователей для получения доступа к ресурсам сети Интернет. В большинстве случаев это программное обеспечение также поддерживает такие протоколы, как MMS, FTP, POP3, File.


Самые первые версии web-браузеров (такие, как lynx, w3m, links) относились к консольному типу и работали только в текстовом режиме, то есть позволяли только распознавать гипертекст и перемещаться по гиперссылкам.
Сейчас они уже практически не используются обычными пользователями сети Интернет. Однако они сохраняют свою популярность и обеспечивают расширенный функционал для профессиональных web-программистов и web-разработчиков, так как с помощью них можно смотреть на web-ресурсы с позиции поискового робота.

Первым web-браузером, поддерживающим графический интерфейс, и прародителем современного веб-браузера было программное обеспечение NCSA Mosaic, созданное М.Андерисоном и Э.Бином. По своему функционалу эта программа была достаточно упрощённой и ограниченной, но код, лежавший в её основе, стал базой для последующих экспериментов и разработок.
См. Также
- AGRIS
- Управление бизнес-семантикой
- Вычислительная семантика
- Calais (продукт Reuters)
- DBpedia
- Модель сущность – атрибут – значение
- Портал открытых данных ЕС
- Гиперданные
- Интернет вещей
- Связанные данные
- Список новых технологий
- Nextbio
- Согласование онтологий
- Изучение онтологий
- RDF и OWL
- Семантические вычисления
- Семантическая геопространственная сеть
- Семантическая неоднородность
- Семантическая интеграция
- Семантическое сопоставление
- Semantic MediaWiki
- Semantic Sensor Web
- Семантическая социальная сеть
- Семантическая технология
- Семантическая сеть
- Интернет-сообщества с семантическими связями
- Smart-M3
- Социальная семантическая сеть
- Веб-инженерия
- Веб-ресурс
- Веб-наука
1. Основная идея
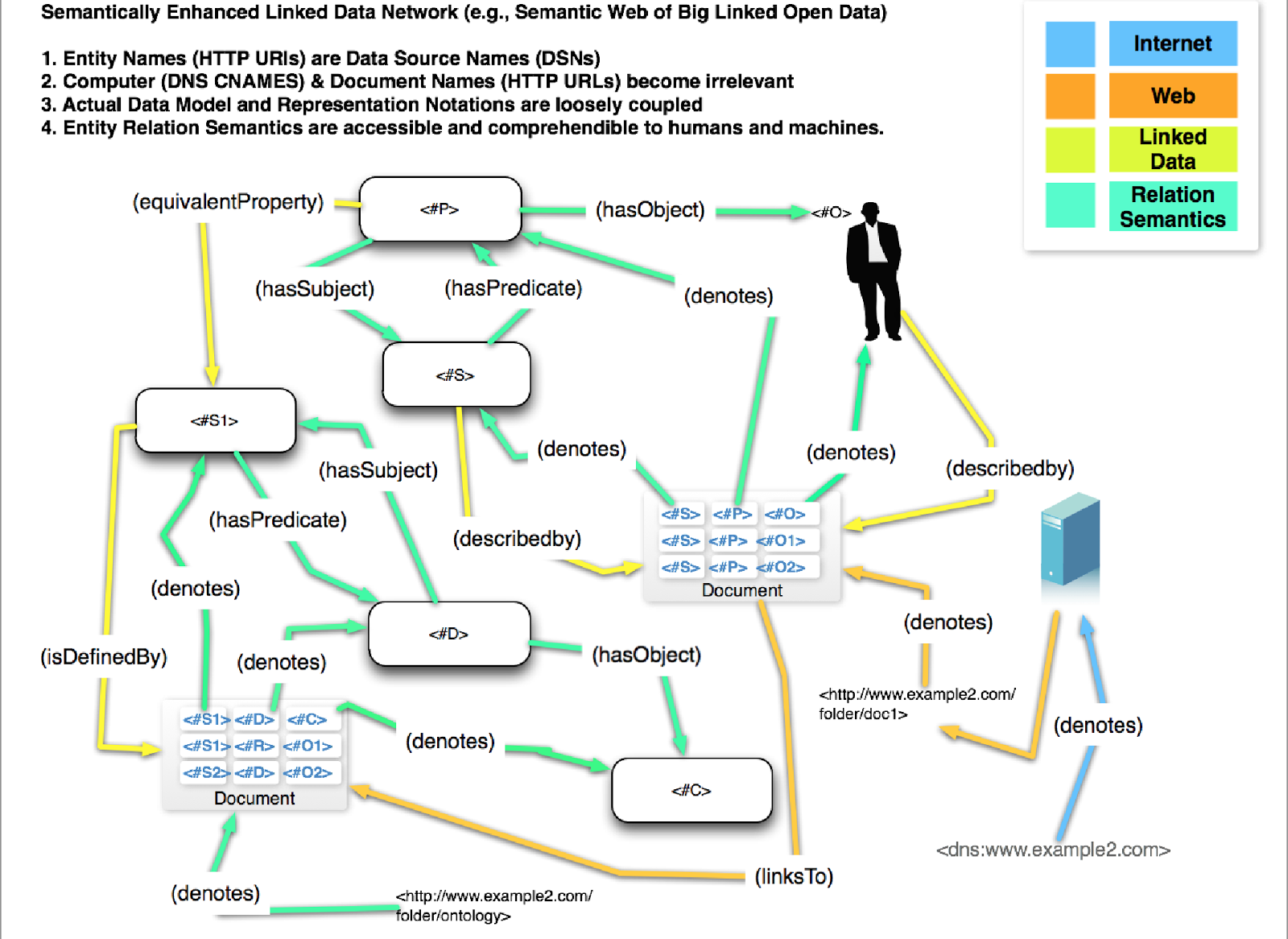
Семантическая паутина — это надстройка над существующей Всемирной паутиной, которая призвана сделать размещённую в ней информацию более понятной для компьютеров. Машинная обработка возможна в семантической паутине благодаря двум её важнейшим характеристикам.
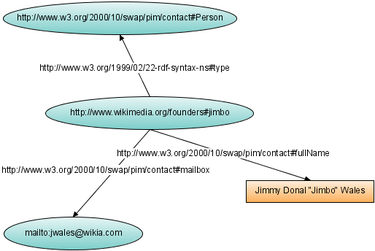
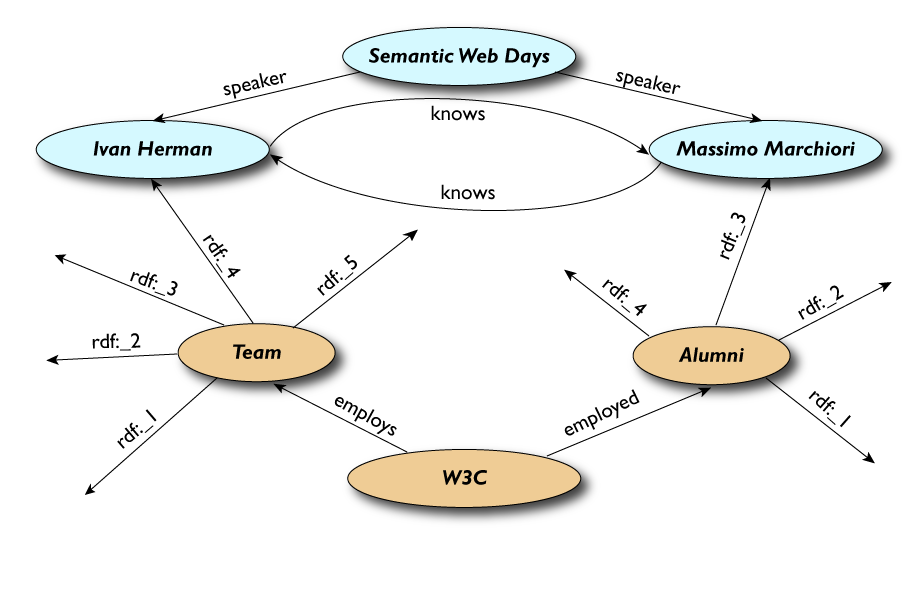
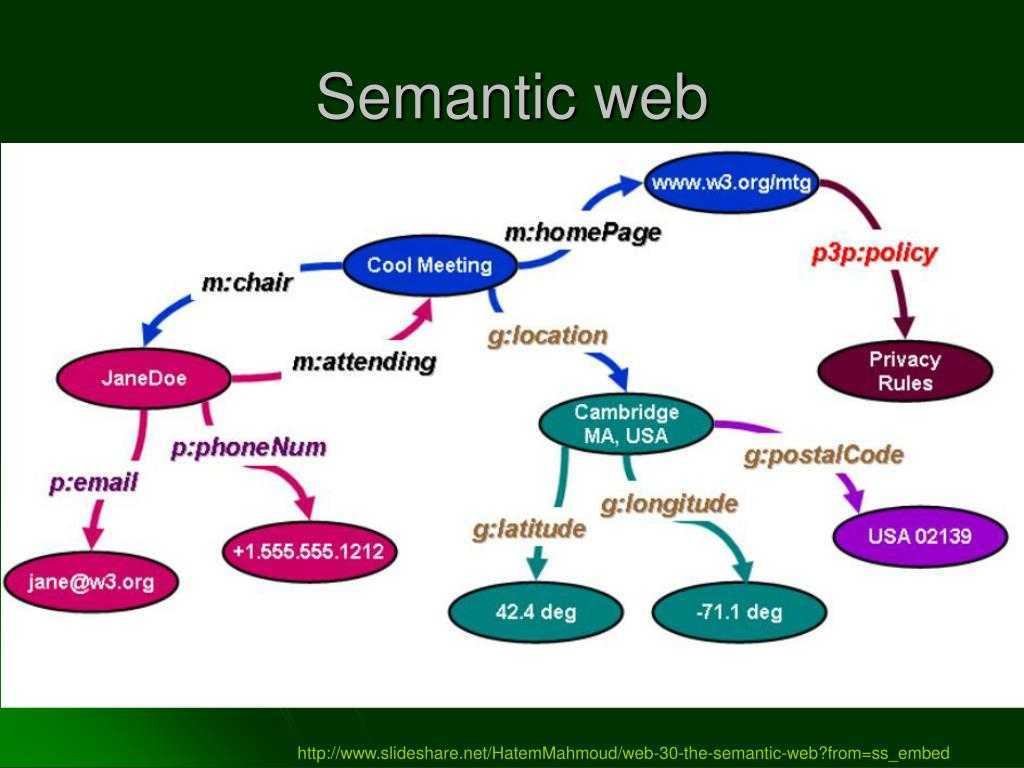
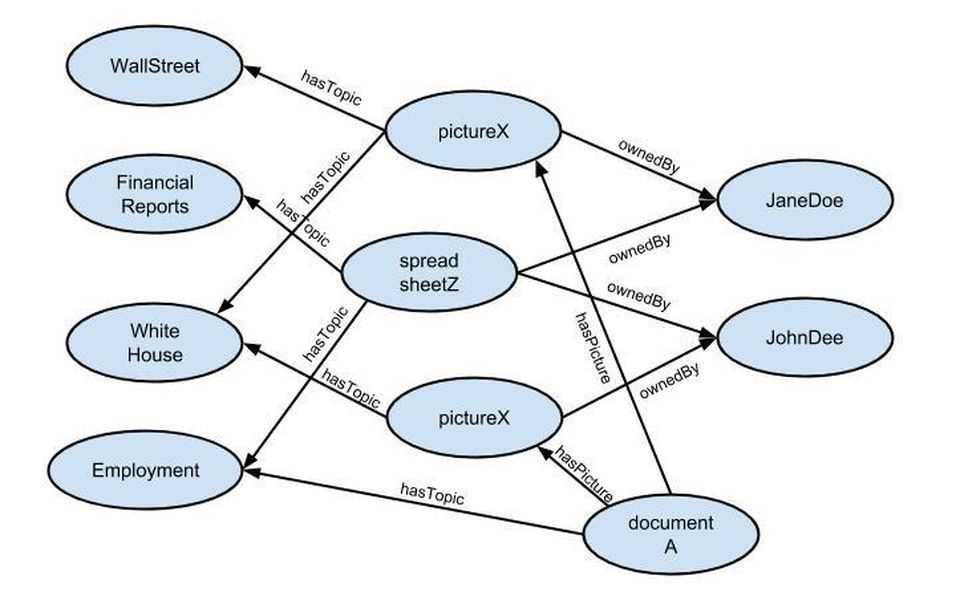
Граф визитной карточки основателя Википедии в формате RDF. Элементы этого графа — как узлы, так и дуги (кроме литерала, изображённого в оранжевом прямоугольнике) — являются URI.
Повсеместное использование унифицированных идентификаторов ресурсов (URI), широко известных как адреса. Традиционно в Интернете эти идентификаторы используются для установки ссылок на адресуемый объект (например, веб-страницу, файл или ящик электронной почты). В семантической паутине URI используются также для именования объектов, то есть каждый URI однозначно называет некоторый объект. Свои URI в семантической паутине есть не только у страниц, но и у объектов реального мира (людей, городов, художественных произведений и так далее), и даже у абстрактных понятий (например, у свойств «имя», «должность», «цвет»). Поскольку URI глобально уникальны, они позволяют называть одни и те же предметы в разных местах в семантической паутине. При этом URI протокола HTTP (то есть начинающиеся с http://) можно одновременно использовать как адреса документов, содержащих машино-читаемые описания этих предметов.
Использование семантических сетей и онтологий. Современные методы автоматической обработки данных, доступных в Интернете, как правило, основаны на частотном и лексическом анализе текстового содержимого, которое прежде всего предназначено для восприятия человеком. В семантической паутине вместо этого используется стандарт RDF, описывающий семантические сети (графы), в которых узлы и дуги имеют URI. Утверждения, кодируемые с помощью RDF, в дальнейшем можно интерпретировать с помощью онтологий, созданных по стандартам RDF Schema и OWL, чтобы получать из них логические заключения. В основе онтологий лежат математические формализмы, называемые дескрипционными логиками.
Примеры и значения современных неологизмов
Итак, чтобы лучше понимать, что представляют собой неологизмы, давайте рассмотрим самые популярные из них и вошедшие в орфографические словари в 2020 году:
- Демо – это слово образовалось путем сокращения слова «демонстрационный». Оно применяется для обозначения пробных версий компьютерных программ (демо-версий), которые доступны пользователю на ограниченный срок. Основная цель предоставления демо – дать попробовать лично протестировать программу, чтобы в дальнейшем клиент приобрел ее полную версию. Данным словом могут обозначаться образцы любой другой продукции.
- Фейк – этот неологизм давно употребляется в речи, но в словарь неологизмов был занесен только в 2020 году. Он обозначает ложную, фиктивную, поддельную информацию, которую разместили в Интернете. Фейки создаются с целью ввести читателей в заблуждение.
- Троллить – слово, которое плотно закрепилось среди пользователей Всемирной паутины. Оно произошло от английского слова troll (ловить блесну) означает «поднимать на смех», «глумиться», «издеваться» или, если ссылаться на корень появления слова, «подлавливать».
- Каршеринг – заимствованный неологизм, образовавшийся от двух английских слов: car – «машина» и share – «делиться». Слово обозначает автопрокат, который предоставляется на короткое время. Такая услуга актуальна для тех, кто временно находится в каком-либо городе и нуждается в личном автомобиле.
- Селфи – слово произошло от возвратного суффикса -self в английском языке и появилось благодаря внедрению новых функций в телефоны, в частности, фронтальной камеры. Конечно, фотографировать сами себя мы все начали раньше, но только это было совсем неудобно. Теперь, когда фронтальные камеры есть на каждом смартфоне, это слово вошло в массовый обиход и является олицетворением самолюбования.
- Репост – это возможность размещать чужую публикацию у себя на странице или пересылать ее кому-то из друзей. Такая функция относится к социальным сетям. При репосте автоматически размещается ссылка на первоначальный источник поста. Эта функция пользуется популярностью, ведь она дает возможность поделиться полезной информацией, новостями и сохранить у себя на странице то, что является важным для пользователя. Слово «репост» тоже пришло из английского языка (repost – «повторить пост») .
Компания «Яндекс» в своем Telegram-канале опубликовала список новых слов, которые чаще остальных пытались растолковать пользователи Интернета через поисковую систему. В 2020 году к таким словам относилось слово «локдаун» – ограничение передвижения людей по причине возникновения чрезвычайных обстоятельств; «френдзона» – термин, обозначающий дружеское отношение между мужчиной и женщиной; «ауф» – молодежное слово, которое обозначает восхищение чем-либо; «падра» – это слово образовалось путем искажения слова «подруга».
А вот самые популярные новые слова в 2019 году, значение которых было интересно пользователям: «вислово» – означает тусовку, вечеринку, место, где можно весело провести время; «фуд-порн» – идеализированное изображение еды; «бумер» – представитель поколения беби-бумеров.
Такие исследования помогают выявить, что сейчас является модным. Например, в 2017 году у людей вырос интерес к рэпу и рэп-батлам, а самым популярным словом, значением которого интересовались в Интернете, являлось «эщкере» – заимствованное от английского языка слово, являющееся неправильным произношением фразы «Let’s gerit (Ler’s get it)» («давай это получим») .
Психология
 В психологии семантическая память — это память для смысла — другими словами, аспект памяти, который сохраняет только суть, общее значение запоминаемого опыта, в то время как эпизодическая память — это память для эфемерных деталей — отдельные особенности или уникальных особенностей опыта. Термин «эпизодическая память» был введён Тулвигом и Шактером в контексте «декларативной памяти», которая включала в себя простое объединение фактической или объективной информации об объекте.
В психологии семантическая память — это память для смысла — другими словами, аспект памяти, который сохраняет только суть, общее значение запоминаемого опыта, в то время как эпизодическая память — это память для эфемерных деталей — отдельные особенности или уникальных особенностей опыта. Термин «эпизодическая память» был введён Тулвигом и Шактером в контексте «декларативной памяти», которая включала в себя простое объединение фактической или объективной информации об объекте.
Воспоминания могут быть переданы поколением или изолированы в одном поколении из-за культурного разрушения. У разных поколений могут быть разные переживания в подобных точках в их собственных временных линиях. Это может создать вертикально разнородную семантическую сеть для определённых слов в однородной культуре.



