
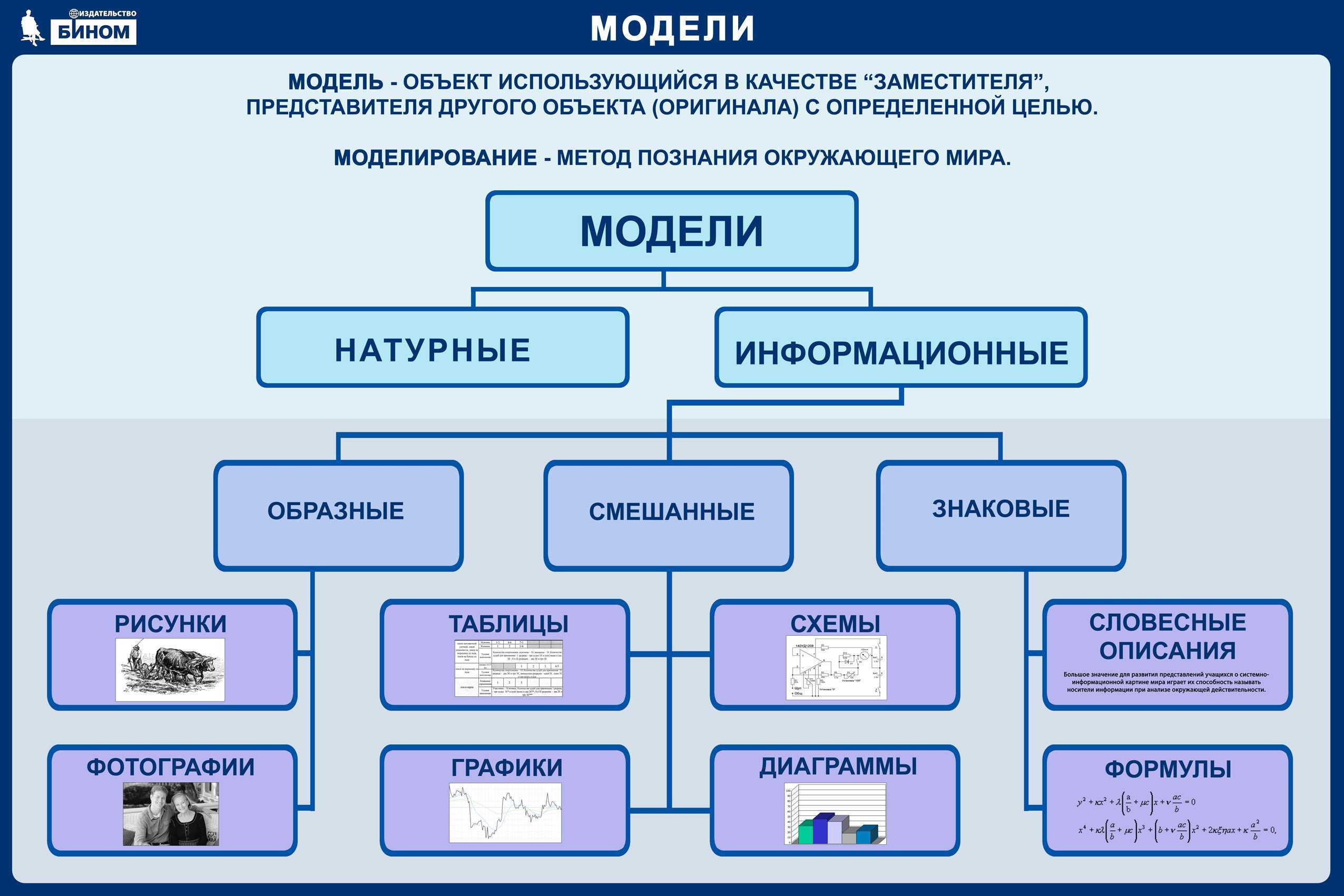
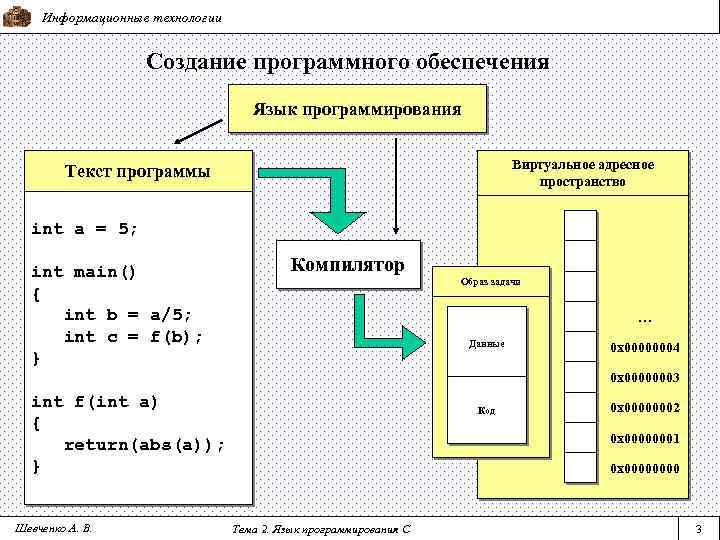
Введение
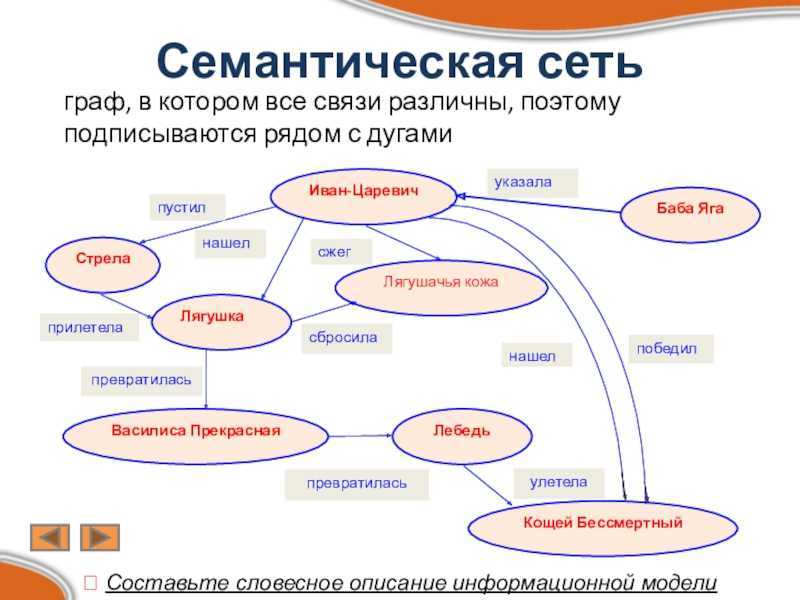
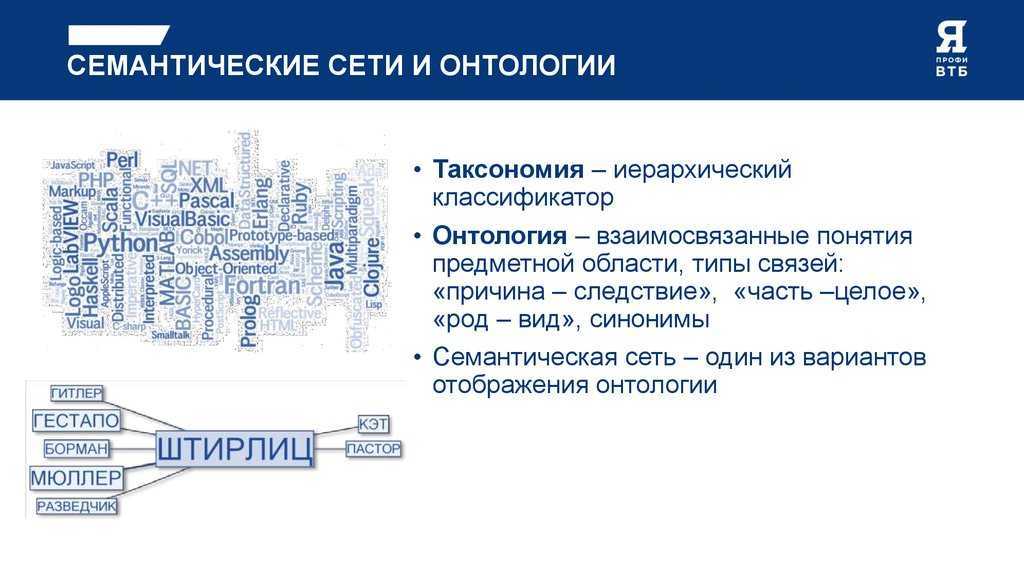
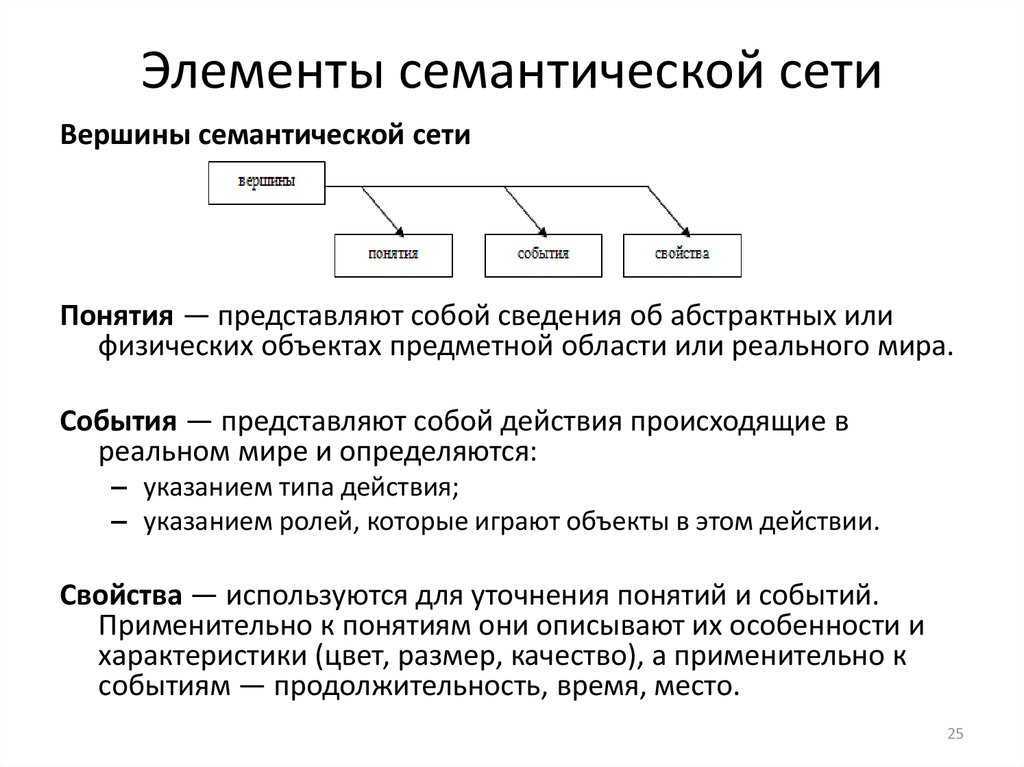
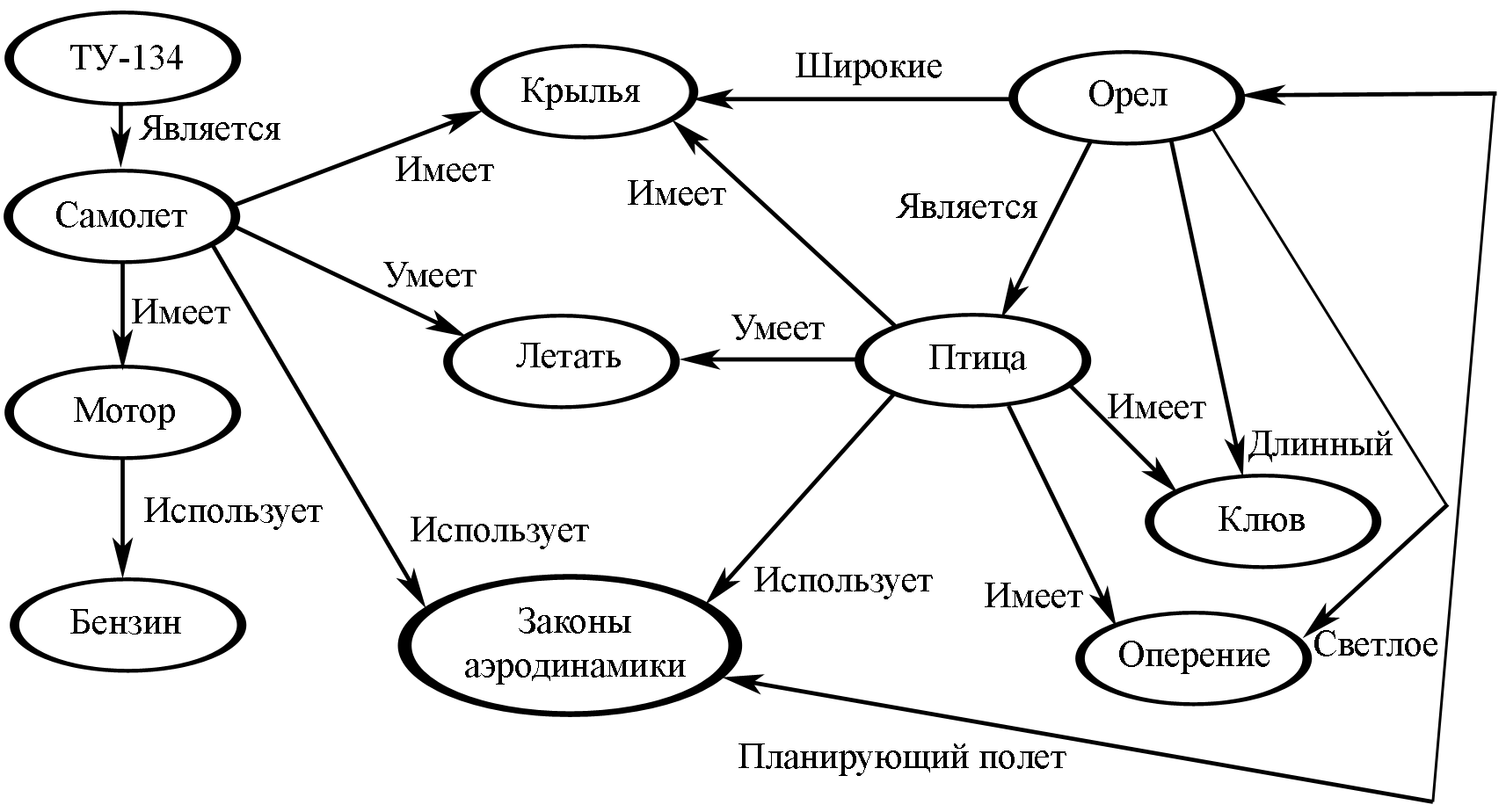
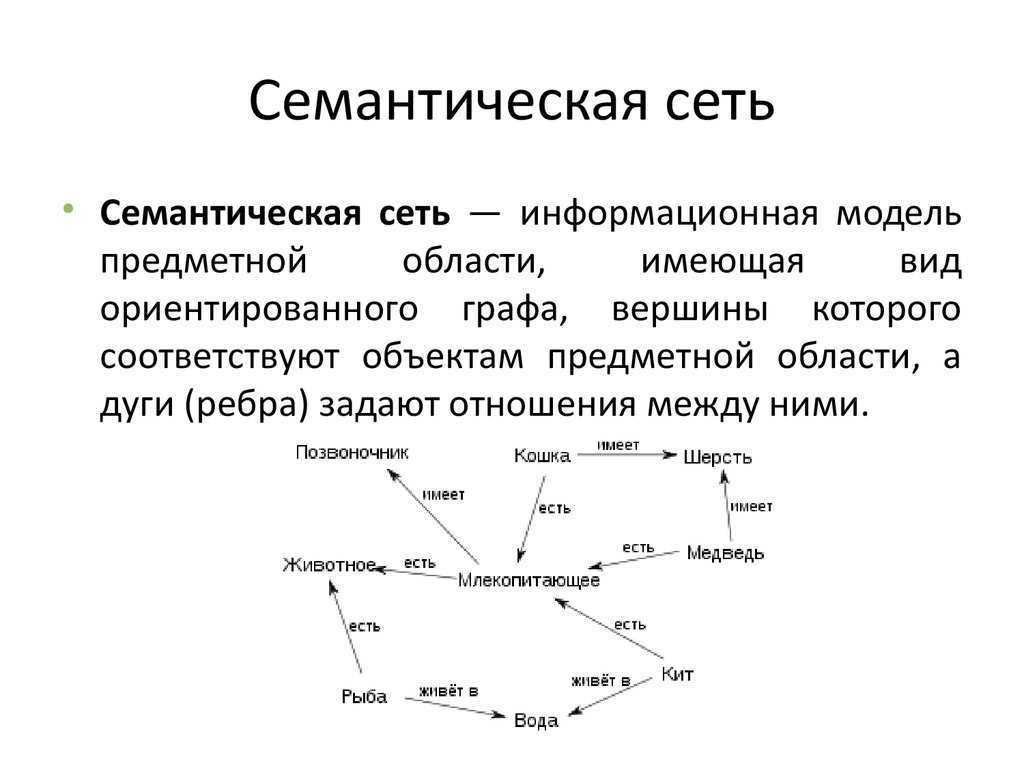
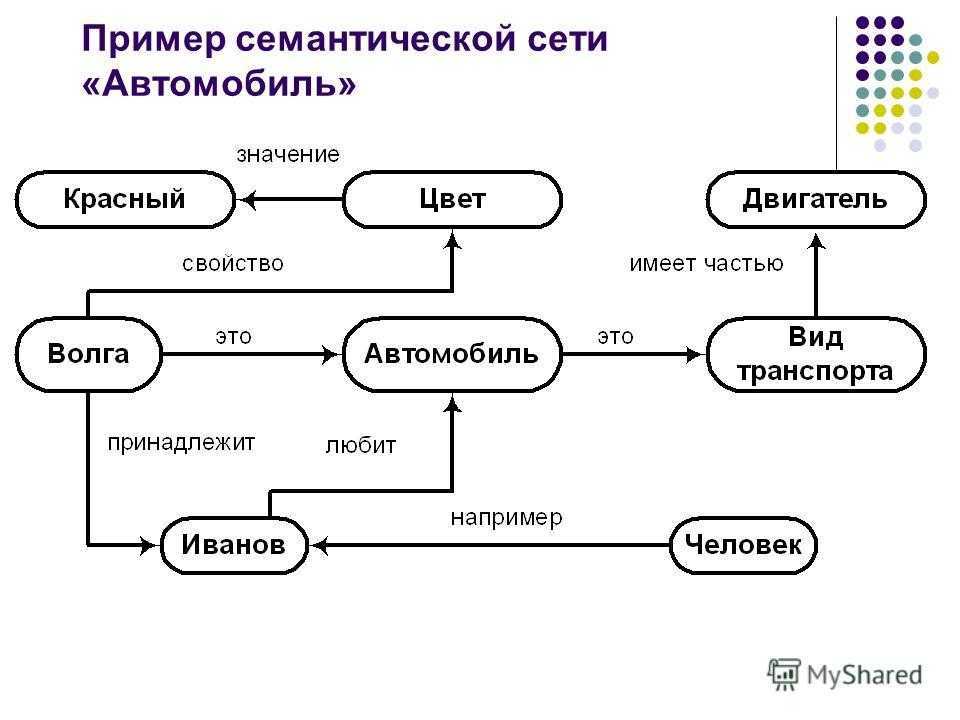
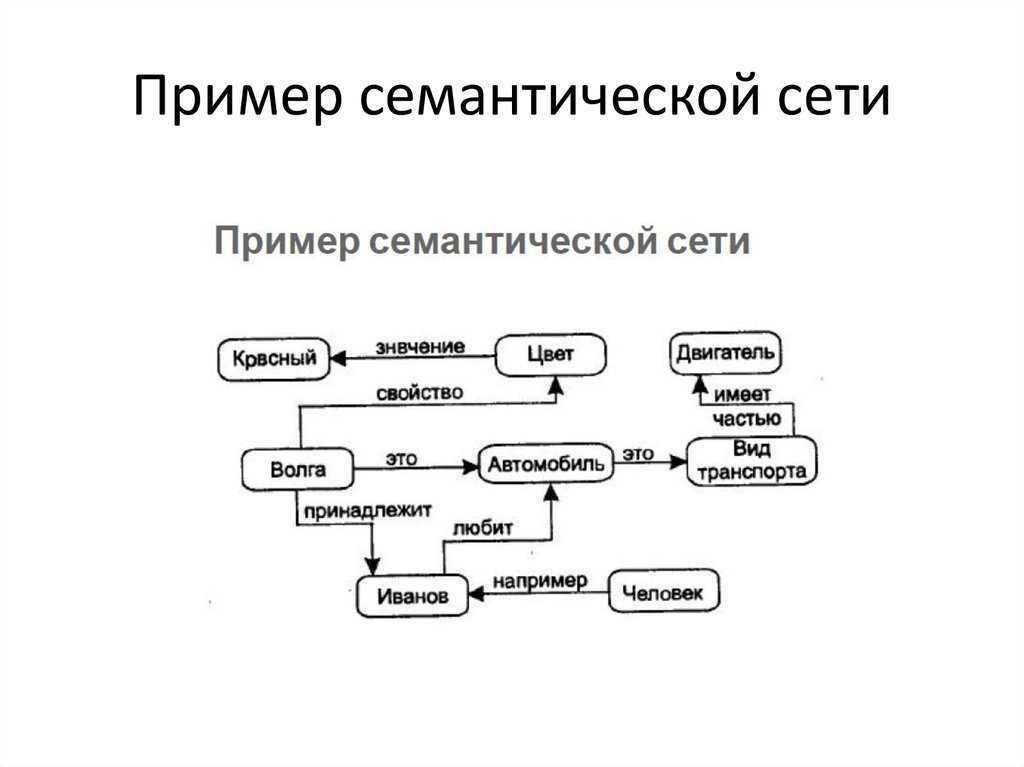
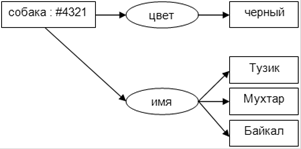
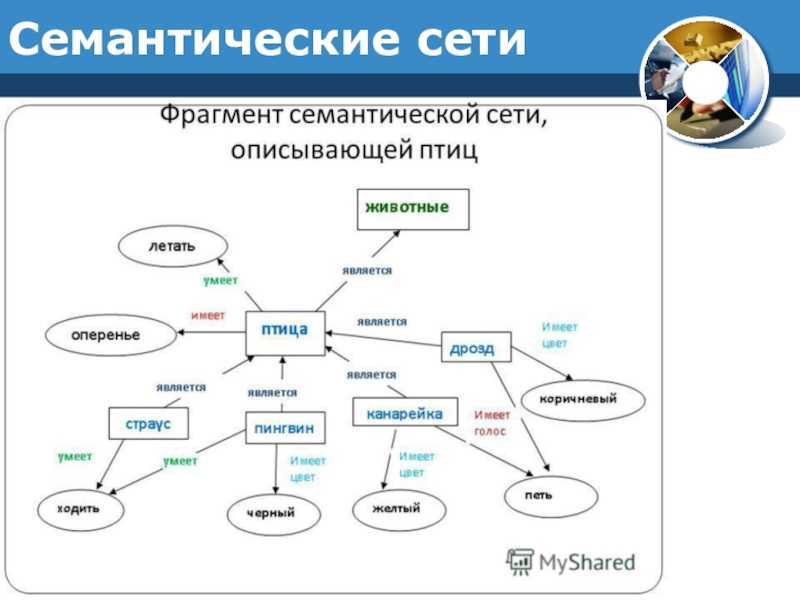
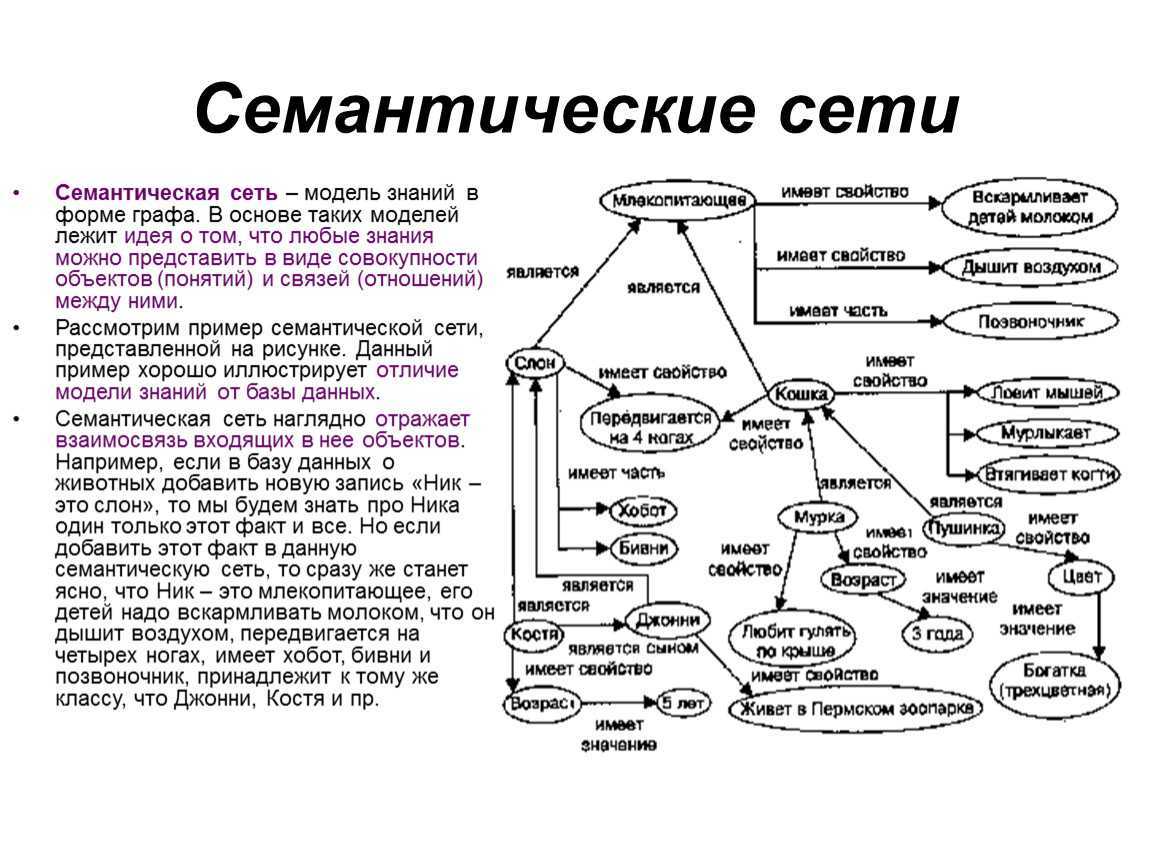
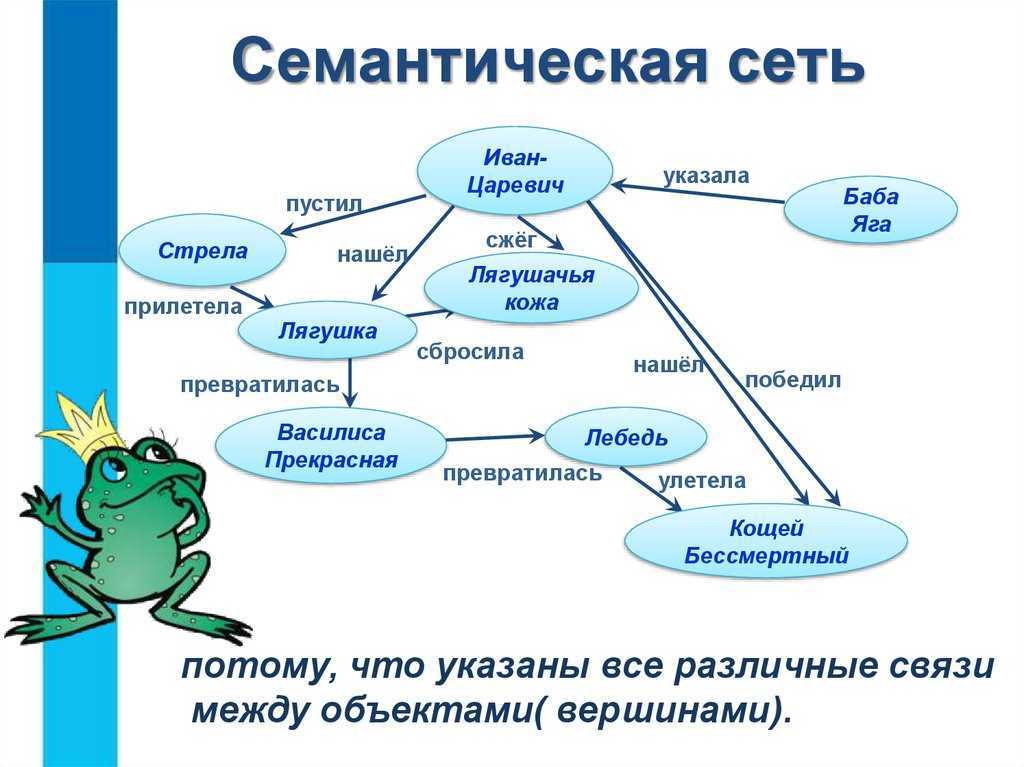
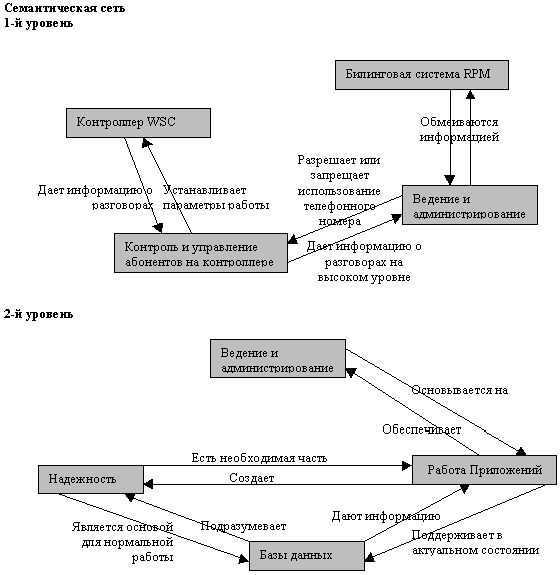
Семантическая сеть — это граф, в узлах которого находятся сущности, их свойства и действия.
Направленные рёбра между узлами имеют различные типы и играют роль бинарных отношений.
Семантическую сеть мы рассматриваем как промежуточный этап между естественным языком и моделью мира.
Фактически — это текст, записанный однозначным образом.
Одним из критериев выразительности отношений между узлами семантической сети служит возможность её трансляции на
естественный язык,
с максимальным сохранением заложенного в неё «смысла».
Перевод в обратную сторону (из текста в сеть) существенно более сложная
задача, часто требующая параллельного построения модели текста (его понимания).
При помощи семантической сети описываются обыденные знания об окружающем мире
или знания из специализированной предметной области.
Одним из узлов сети может быть сама интеллектуальная система.
Связь этого узла с другими узлами сети формирует самосознание системы.
Введение
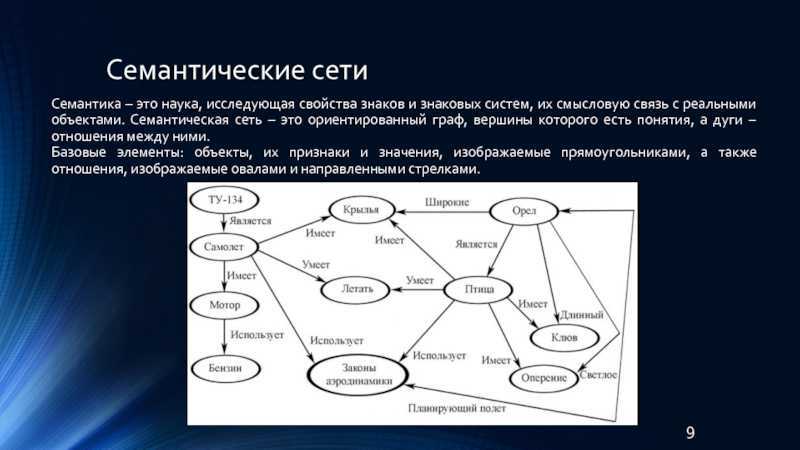
Семантическая сеть — структура для представления знаний в виде узлов, соединенных дугами. Самые первые семантические сети были разработаны в качестве языка-посредника для систем машинного перевода, а многие современные версии до сих пор сходны по своим характеристикам с естественным языком. Однако последние версии семантических сетей стали более мощными и гибкими и составляют конкуренцию фреймовым системам, логическому программированию и другим языкам представления.
Начиная с конца 50-ых годов были создано и применены на практике десятки вариантов семантических сетей. Несмотря на то, что терминология и их структура различаются, существуют сходства, присущие практически всем семантическим сетям:
- узлы семантических сетей представляют собой концепты предметов, событий, состояний;
- различные узлы одного концепта относятся к различным значениям, если они не помечено, что они относятся к одному концепту;
- дуги семантических сетей создают отношения между узлами-концептами (пометки над дугами указывают на тип отношения);
- некоторые отношения между концептами представляют собой лингвистические падежи, такие как агент, объект, реципиент и инструмент (другие означают временные, пространственные, логические отношения и отношения между отдельными предложениями;
- концепты организованы по уровням в соответствии со степенью обобщенности так как, например, сущность, живое существо, животное, плотоядное.
Однако существуют и различия: понятие значения с точки зрения философии; методы представления кванторов общности и существования и логических операторов; способы манипулирования сетями и правила вывода, терминология. Все это варьируется от автора к автору. Несмотря не некоторые различия, сети удобны для чтения и обработки компьютером, а также достаточно мощны, чтобы представить семантику естественного языка.
Программные инструменты
Существуют также тщательно продуманные типы семантических сетей, связанные с соответствующими наборами программных инструментов, используемых для лексический инженерия знаний, например, система обработки семантической сети (SNePS ) Стюарта С. Шапиро или MultiNet парадигма Германа Хельбига, особенно подходит для семантического представления выражений естественного языка и используется в нескольких НЛП Приложения.
Семантические сети используются в специализированных задачах поиска информации, таких как обнаружение плагиата. Они предоставляют информацию об иерархических отношениях, чтобы использовать семантическое сжатие чтобы уменьшить языковое разнообразие и дать системе возможность подбирать значения слов независимо от набора используемых слов.
Сеть знаний, предложенная Google в 2012 году, на самом деле представляет собой приложение семантической сети в поисковой системе.
Моделирование реляционных данных, таких как семантические сети, в низкоразмерных пространствах с помощью форм встраивание имеет преимущества в выражении отношений сущностей, а также в извлечении отношений из таких носителей, как текст. Существует много подходов к изучению этих встраиваний, в частности, с использованием байесовских кластерных структур или энергетических структур, а в последнее время TransE (НИПС 2013). Применения встраивания данных базы знаний включают: Анализ социальных сетей и Извлечение отношений.
Что такое обработка естественного языка
Обработка естественного языка (далее NLP — Natural language processing) — область, находящаяся на пересечении computer science, искусственного интеллекта и лингвистики. Цель заключается в обработке и “понимании” естественного языка для перевода текста и ответа на вопросы.
С развитием голосовых интерфейсов и чат-ботов, NLP стала одной из самых важных технологий искусственного интеллекта. Но полное понимание и воспроизведение смысла языка — чрезвычайно сложная задача, так как человеческий язык имеет особенности:
- Человеческий язык — специально сконструированная система передачи смысла сказанного или написанного. Это не просто экзогенный сигнал, а осознанная передача информации. Кроме того, язык кодируется так, что даже маленькие дети могут быстро выучить его.
- Человеческий язык — дискретная, символьная или категориальная сигнальная система, обладающая надежностью.
- Категориальные символы языка кодируются как сигналы для общения по нескольким каналам: звук, жесты, письмо, изображения и так далее. При этом язык способен выражаться любым способом.
Где применяется NLP
Сегодня быстро растет количество полезных приложений в этой области:
- поиск (письменный или устный);
- показ подходящей онлайн рекламы;
- автоматический (или при содействии) перевод;
- анализ настроений для задач маркетинга;
- распознавание речи и чат-боты,
- голосовые помощники (автоматизированная помощь покупателю, заказ товаров и услуг).
Глубокое обучение в NLP
Существенная часть технологий NLP работает благодаря глубокому обучению (deep learning) — области машинного обучения, которая начала набирать обороты только в начале этого десятилетия по следующим причинам:
- Накоплены большие объемы тренировочных данных;
- Разработаны вычислительные мощности: многоядерные CPU и GPU;
- Созданы новые модели и алгоритмы с расширенными возможностями и улучшенной производительностью, c гибким обучением на промежуточных представлениях;
- Появились обучающие методы c использованием контекста, новые методы регуляризации и оптимизации.
Большинство методов машинного обучения хорошо работают из-за разработанных человеком представлений (representations) данных и входных признаков, а также оптимизации весов, чтобы сделать финальное предсказание лучше.
В глубокомобучении алгоритм пытается автоматически извлечь лучшие признаки или представления из сырых входных данных.
Созданные вручную признаки часто слишком специализированные, неполные и требуют время на создание и валидацию. В противоположность этому, выявленные глубоким обучением признаки легко приспосабливаются.
Глубокое обучение предлагает гибкий, универсальный и обучаемый фреймворк для представления мира как в виде визуальной, так и лингвистической информации. Вначале это привело к прорывам в областях распознавания речи и компьютерном зрении. Эти модели часто обучаются с помощью одного распространенного алгоритма и не требуют традиционного построения признаков под конкретную задачу.
Недавно я закончил исчерпывающий курс по NLP с глубоким обучением из Стэнфорда.
Этот курс — подробное введение в передовые исследование по глубокому обучению, примененному к NLP. Курс охватывает представление через вектор слов, window-based нейросети, рекуррентные нейросети, модели долгосрочной-краткосрочной памяти, сверточные нейросети и некоторые недавние модели с использованием компонента памяти. Со стороны программирования, я научился применять, тренировать, отлаживать, визуализировать и создавать собственные нейросетевые модели.
Замечание: доступ к лекциям из курса и домашним заданиям по программированию находится в этом репозитории.
Произвольные отношения
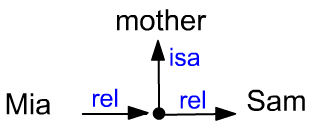
Смыслы могут вступать в различные парные отношения:
(Толстой автор «Война и мир») или (Mия мать Сэма).
Так как подобных отношений очень много и они могут выстраиваться в иерархию,
следует их реализовывать через фиктивные узлы (точка):
Tolstoy rel { isa author; rel War_and_Peace }.
Маша rel { isa sister; rel Саша }.
Саша rel { isa brother; rel Маша }.
Маша rel { isa mother; rel Миша, Гриша, Лиза; }.
Родственные отношения между людьми могут быть самыми разнообразными. Базовыми для данного человека
являются связи с его отцом (father) и его матерью (mather).
Остальные родственные отношения — производные.
Семья — это группа людей (по крови или по жизни?).
family ako group.
Mia isa woman.
Bob isa man.
Mia, Bob pof { isa family }.
wifehusband
Голосовые помощники
Много статей написано о “разговорном” искусственном интеллекте (ИИ), большинство разработок фокусируется на вертикальных чат-ботах, мессенджер-платформах, возможностях для стартапов (Amazon Alexa, Apple Siri, Facebook M, Google Assistant, Microsoft Cortana, Яндекс Алиса). Способности ИИ понимать естественный язык пока остаются ограничены, поэтому создание полноценного разговорного ассистента остается открытой задачей. Тем не менее, представленные ниже работы — отправная точка для людей, заинтересованных в прорыве в области голосовых помощников.
Исследователи из Монреаля, Технического Института Технологий Джорджии, Microsoft и Facebook создали нейросеть, способную создавать чувствительные к контексту ответы в разговоре. Эта система может тренироваться на большом количестве неструктурированных диалогов в Twitter. Архитектура рекуррентной нейросети используется для ответов на разреженные вопросы, которые появляются при интегрировании контекстной информации в классическую статистическую модель, что позволяет системе учесть сказанное ранее. Модель показывает уверенное улучшение результата над контент-чувствительной и контент-нечувствительной базовой линией машинного перевода и поиска информации.
Разработанная в Гонконге нейронная машина для ответов (далее NRM — Neural Responding Machine) — генератор ответов для коротких текстовых бесед. NRM использует общий кодер-декодер фреймворк. Сначала формализуется создание ответа, как процесс расшифровки на основе скрытого представления входного текста, пока кодирование и декодирование реализуется с помощью рекуррентных нейросетей. NRM обучен на больших данных с односложными диалогами, собранными из микро-блогов. Эмпирическим путем установлено, что NRM способен генерировать правильные грамматические и уместные в данном контексте ответы на 75% поданных на вход текстов, опережая в результативности современные модели с теми же настройками.
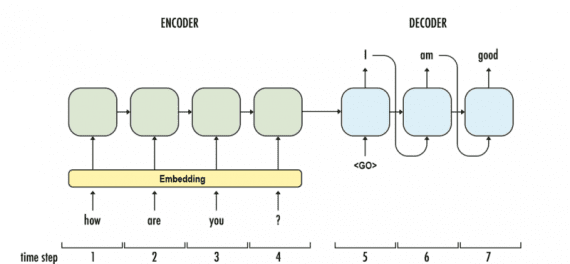
Последняя модель — Google’s Neural Conversational Model предлагает простой подход к моделированию диалогов, используя sequence-to-sequence фреймворк. Модель поддерживает беседу благодаря предсказанию следующего предложения, используя предыдущие предложения из диалога. Сильная сторона этой модели — способность к сквозному обучению, из-за чего требуется намного меньше рукотворных правил.
Модель способна создавать простые диалоги на основе обширного диалогового тренировочного сета, способна извлекать знания из узкоспециализированных датасетов, а также больших и зашумленных общих датасетов субтитров к фильмам. В узкоспециализированной области справочной службы для ИТ-решений модель находит решения технической проблемы с помощью диалога. На зашумленных датасетах транскриптов фильмов модель способна делать простые рассуждения на основе здравого смысла.
Примеры
В Лиспе
В следующем коде показан пример семантической сети в Язык программирования Лисп используя список ассоциаций.
(setq *база данных*'((канарейка (это птица) (цвет желтый) (размер маленький)) (пингвин (это птица) (движение плавать)) (птица (это позвоночное животное) (часть крылья) (воспроизведение кладка яиц))))
Чтобы извлечь всю информацию о типе «канарейка», можно использовать функция с ключом «канарейка».
WordNet
Пример семантической сети: WordNet, а лексический база данных английский. Он группирует английские слова в наборы синонимов, называемых синсеты, дает краткие общие определения и записывает различные семантические отношения между этими наборами синонимов. Определены некоторые из наиболее распространенных семантических отношений: меронимия (A является меронимом B, если A является частью B), холонимия (B является холонимом A, если B содержит A), гипонимия (или же тропонимия ) (A подчиняется B; A является разновидностью B), гипернимия (A выше B), синонимия (A означает то же, что и B) и антонимия (A означает противоположность B).
Свойства WordNet были изучены с теория сети перспективы и по сравнению с другими семантическими сетями, созданными из Тезаурус Роже и словесная ассоциация задачи. С этой точки зрения трое из них — структура маленького мира.
Другие примеры
Также возможно представить логические описания с использованием семантических сетей, таких как экзистенциальные графы из Чарльз Сандерс Пирс или связанные концептуальные графики из Джон Ф. Сова. Они обладают выразительной силой, равной или превышающей стандартную. логика предикатов первого порядка. В отличие от WordNet или других лексических сетей или сетей просмотра, семантические сети, использующие эти представления, могут использоваться для надежного автоматического логического вывода. Некоторые автоматизированные средства рассуждений используют теоретико-графические особенности сетей во время обработки.
Другие примеры семантических сетей: Gellish модели. Gellish English с этими Gellish English Dictionary, это формальный язык это определяется как сеть отношений между концептами и названиями концептов. Gellish English является формальным подмножеством естественного английского языка, так же как Gellish Dutch — формальным подмножеством голландского языка, тогда как несколько языков разделяют одни и те же концепции. Другие сети Gellish состоят из моделей знаний и информационных моделей, которые выражаются на Gellish языке. Сеть Gellish — это сеть (бинарных) отношений между вещами. Каждое отношение в сети является выражением факта, классифицируемого по типу отношения. Каждый тип отношения сам по себе является понятием, которое определено в словаре гелльского языка. Каждая связанная вещь — это либо понятие, либо отдельная вещь, которая классифицируется понятием. Определения понятий созданы в форме моделей определений (сетей определений), которые вместе образуют Gellish Dictionary. Сеть Gellish может быть задокументирована в базе данных Gellish и интерпретируется компьютером.
SciCrunch это совместно редактируемая база знаний для научных ресурсов. Он предоставляет однозначные идентификаторы (идентификаторы исследовательских ресурсов или RRID) для программного обеспечения, лабораторных инструментов и т. Д., А также предоставляет возможности для создания связей между RRID и сообществами.
Еще один пример семантических сетей, основанный на теория категорий, является ologs. Здесь каждый тип — это объект, представляющий набор вещей, а каждая стрелка — это морфизм, представляющий функцию. Коммутативные диаграммы также предписаны для ограничения семантики.
В социальных науках люди иногда используют термин семантическая сеть для обозначения сети совместного возникновения. Основная идея состоит в том, что слова, которые одновременно встречаются в единице текста, например предложения, семантически связаны друг с другом. Связи, основанные на совместной встречаемости, затем могут использоваться для построения семантических сетей.
Иерархия типов
Иерархия типов и подтипов является стандартной характеристикой семантических сетей. Иерархия может включать сущности: ТАКСА<СОБАКА<ПЛОТОЯДНОЕ<ЖИВОТНОЕ<ЖИВОЕ СУЩЕСТВО<ФИЗИЧЕСКИЙ ОБЪЕКТ<СУЩНОСТЬ. Они также могут включать в себя события: ЖЕРТВОВАТЬ<ДАВАТЬ<ДЕЙСТВИЕ<СОБЫТИЕ или состояния: ЭКСТАЗ<СЧАСТЬЕ<ЭМОЦИОНАЛЬНОЕ СОТОЯНИЕ<СОСТОЯНИЕ. Иерархия Аристотеля включала в себя 10 основных категорий: субстанция, количество, качество, отношение, место, время, состояние, активность и пассивность. Некоторые учение дополнили его своими категориями.
Символ < между более общим и более частным символом читается как: «Х-тип/подтип У».
Термин «иерархия» обычно обозначает частичное упорядочение, где одни типы являются более общими, чем другие. Упорядочение является частичным, потому, что многие типы просто не подлежат сравнению между собой. Сравним HOUSE<DOG и DOG<HOUSE бессмысленны, если их сравнивать, однако слово DOGHOUSE является подтипом HOUSE, но не DOG. Рассмотрим некоторые виды графов:
Ацикличный граф. Любое частичное упорядочение может быть изображено, как граф без циклов. Такой граф имеет ветви, которые расходятся и сходятся вместе опять, что позволяет некоторым узлам иметь несколько узлов-родителей. Иногда такой тип графа называют путанным.
Деревья. Самым распространенным видом иерархии является граф с одной вершиной. В такого рода графах налагаются ограничения на ацикличные графы: вершина графа представляет собой один общий тип, и каждый другой тип Х имеет лишь одного родителя У.
Решетка. В отличие от деревьев узлы в решетке могут иметь несколько узлов родителей. Однако здесь налагаются другие ограничения: любая пара типов Х и У как минимум должна иметь общий гипертип ХиУ и подтип ХилиУ. Вследствие этого ограничения решетка выглядит, как дерево, имеющее по главной вершине с каждого конца. Вместо всего одной вершины решетка имеет одну вершину, которая является гипертипом всех категорий, и другую вершину, которая является подтипом всех типов.
Customisation
Mobile operators can define the kinds of categories they want an AI to sort messages into. Using guided machine learning the system will learn what kinds of pattern in a text will correspond with the categories it has been given and react according to the rules given to it.
For example, spam is just another category, and when the system recognises certain patterns it has learned are associated with spam it can flag those messages for review, or simply block them.
The same thing applies to fraud, giving operators another tool for protecting their subscribers. Other rules and categories can be defined, as needed by an operator, and the AI can be trained to use these by being shown examples of the type of message in question.
This flexibility and ability to learn extends to the languages that can be used. Because in this case we are not particularly interested in teaching the machine to understand the messages, all it needs to do is recognise the patterns. This makes the job a lot easier than if one were training the machine to give a coherent response to a question or comment.

While it comes pre-trained in English and Chinese, almost any language can be taught to the machine in this sense. Given enough examples (about 50,000 unique messages for each category the MNO wants to define) the AI can be trained to recognise the patterns necessary to have “learned” any particular language that the operator’s subscribers and enterprise customers use.
GMS is committed to finding new methods and technologies to enhance its partners’ networks. Artificial intelligence offers new ways to optimise and improve network security. Get in touch with our experts to find out how GMS can use cutting-edge technology to bring progress to your business.
История
Примеры использования семантических сетей в логике, ориентированных ациклических графов как мнемонического инструмента насчитывают столетия. Самое раннее задокументированное использование — это комментарий греческого философа Порфирия к категориям Аристотеля в третьем веке нашей эры.
В истории вычислительной техники «семантические сети» для исчисления высказываний были впервые реализованы для компьютеры к Ричард Х. Риченс Кембриджского отделения языковых исследований в 1956 году как «интерлингва » за машинный перевод из естественные языки
Хотя важность этой работы и CLRU была осознана лишь с опозданием
Семантические сети были также независимо реализованы Робертом Ф. Симмонсом. и Шелдон Кляйн, использующий в качестве основы исчисление предикатов первого порядка, вдохновленный демонстрацией Виктора Ингве. Это направление исследований было инициировано первым президентом Ассоциации Виктором Ингве, который в 1960 году опубликовал описания алгоритмов использования грамматики фразовой структуры для генерации синтаксически правильных бессмысленных предложений. Шелдон Кляйн и Примерно в 1962-1964 годах я был очарован этой техникой и обобщил ее до метода контроля смысла того, что было создано, путем соблюдения семантических зависимостей слов в том виде, в котором они встречаются в тексте ». Другие исследователи, в первую очередь М. Росс Куиллиан и другие на Корпорация системного развития помогли внести свой вклад в их работу в начале 1960-х годов в рамках проекта SYNTHEX. Именно из этих публикаций в SDC большинство современных производных от термина «семантическая сеть» цитируют как основу. Позже выдающиеся работы были выполнены Аллан М. Коллинз и Куиллиан (например, Коллинз и Куиллиан; Коллинз и Лофтус Quillian). Еще позже, в 2006 году, Герман Хельбиг полностью описал MultiNet.
В конце 1980-х годов два Нидерланды университеты, Гронинген и Твенте, совместно начали проект под названием Графики знаний, которые являются семантическими сетями, но с дополнительным ограничением, заключающимся в том, что ребра должны быть из ограниченного набора возможных отношений, чтобы упростить алгебры на графе. В последующие десятилетия различие между семантическими сетями и графики знаний было размыто. В 2012, дали своему графу знаний имя Сеть знаний.
Сеть семантических ссылок систематически изучалась как метод социальной семантической сети. Его базовая модель состоит из семантических узлов, семантических связей между узлами и семантического пространства, которое определяет семантику узлов и ссылок, а также правила рассуждения о семантических связях. Систематическая теория и модель были опубликованы в 2004 году. Это направление исследований восходит к определению правил наследования для эффективного поиска модели в 1998 г. и Active Document Framework ADF. С 2003 года исследования развиваются в направлении социальных семантических сетей. Эта работа является систематическим нововведением в эпоху всемирной паутины и глобальных социальных сетей, а не приложением или простым расширением семантической сети (сети). Его цель и объем отличаются от семантической сети (или сети). Правила рассуждений, эволюции и автоматического обнаружения неявных ссылок играют важную роль в сети семантических ссылок. Недавно он был разработан для поддержки киберфизического и социального интеллекта. Он был использован для создания общего метода реферирования. Самоорганизующаяся сеть семантических ссылок была интегрирована с многомерным пространством категорий, чтобы сформировать семантическое пространство для поддержки продвинутых приложений с многомерными абстракциями и самоорганизующимися семантическими ссылками. Было подтверждено, что сеть семантических связей играет важную роль в понимании и представлении посредством приложений реферирования текста. Чтобы исследовать особую социальную семантику, отношения конкуренции и отношения симбиоза, а также их роли в развивающемся обществе были изучены в новой теме: киберфизический социальный интеллект.
Для конкретного использования созданы более специализированные формы семантических сетей. Например, в 2008 году докторская диссертация Фоси Бендека формализовала Сеть семантического сходства (SSN), который содержит специализированные отношения и алгоритмы распространения для упрощения семантическое сходство представление и расчеты.
Examples of natural language processing
NLP is not a particularly new field. While techniques and technologies have changed, the overall goal – allowing a machine to “read” some text or “hear” a sentence — is almost as old as AI research itself.
It was key to the earliest chatbots, like Eliza, aimed at creating dialogic interfaces for interacting with machines, although Eliza itself was built to mimic the role of a psychotherapist.
There are, broadly speaking, two kinds of NLP task: syntactic and semantic.
Syntax describes the grammatical ordering of a sentence. In natural language processing its analysis involves identifying the parts of speech (verb, noun, and so on) and inflected forms of words (recognising “running” and “ran” as forms of “run”, for example) as well as how these grammatical features work together. It aids interpretation of meaning and sentence function by understanding grammatical rules, roles, and conventions.
Semantic analysis focuses more directly on extracting the meaning or significance of words, and therefore of whole sentences. It covers things like recognising nouns denoting “named entities” such as people or places, and identifying positive or negatives sentiments, or even sarcasm.
Semantic tasks are critical for creating truly useful, modern chatbots, since these techniques are what allow the machine to formulate and express a meaning in response to the linguistic input it receives. (Although, as we shall see, they are not so critical from an operator’s perspective.)
 Example of Amazon Alexa command. Source: Chatbots Magazine
Example of Amazon Alexa command. Source: Chatbots Magazine
Modern “smart home” devices and mobile assistants like Siri or Google use these techniques to determine what is being asked of them. In their case they don’t so much distinguish between verbs and nouns, as between commands and services (or as it is termed in the example here, the “invocation name”).
NLP is also used to sort and organise information for security purposes, distinguishing between threats and ordinary correspondence.
As early as the 1990s a team at America’s NSA was developing NLP-based approaches to try and avoid the agency “drowning in data.” And at least one cybersecurity company is proposing caused by human error and extortion.
Островной мир
Эти сущности важны для жителей двух затерянных островов в бескрайнем океане:
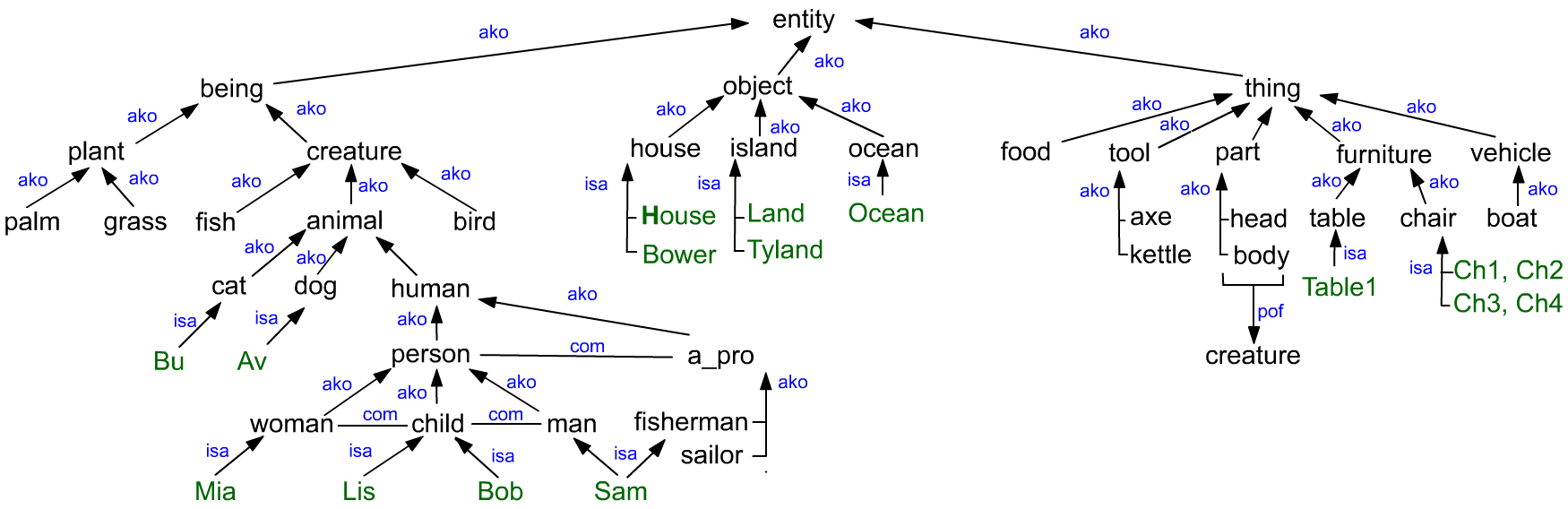
Они различают следующие свойства сущностей:

Описание соответствующей семантической сети имеет вид:
# Иерархия атрибутов:
gender, age, size, color ako attribute.
male, female ako gender.
young, old ako age.
small, normal, large, huge ako size.
black, white,
blue, yellow, red, green ako color.
yellow, green ako banana_color { ako color }.
# ako-иерархия сущностей:
being, object, thing ako entity.
plant, creature ako being.
animal, fish, bird ako creature.
human, cat, dog ako animal.
food, tool, vehicle, furniture, part ako thing.
house, island, ocean ako object.
axe, kettle ako tool.
table, chair ako furniture.
boat ako vehicle.
a_pro { ako human; com person }.
fisherman, sailor ako a_pro.
person { ako human }.
woman { ako person; att female; }.
man { ako person; att male; }.
child { ako person; com woman, man }.
head { ako part; pof creature; }.
h_head { ako head; pof human; }.
ocean { ako object; att huge, blue }.
island { ako object; }.
grass { ako plant; att green }.
palm { ako plant; att large, green }.
banana { ako food; pof palm; att banana_color; }.
# Конкретные объекты:
Mia { isa woman }.
Sam { isa man, fisherman }.
Lis { isa child; att { isa female}; }.
Bob { isa child; att { isa male }; }.
Bu { isa cat; att { isa small }}.
Av { isa dog }.
Ocean isa ocean.
Land, Tyland isa island.
House, Bower isa house.
Table1 isa table.
Ch1,Ch2,Ch3,Ch4 isa chair.
$X { isa human; att female } -> $X isa woman.
$X pof $Y { isa human; loc $Z } -> $X loc $Z.
senses.ancestors('Sam') # fisherman, man, professional, human,
# animal, creature, being, entity, person
senses.isa('Mia', 'human') # 1.0 : Mia является элементом множества human
senses.isa('Mia', 'ocean') # 0.0 : Mia не является элементом множества ocean
senses.isa('Mia', 'sailor') # 0.5 : Mia может быть элементом множества sailor
senses.set_pof('Mia') # создать части объекта и вывести всё с ним связанное:
senses.sense ('Mia') # Mia { isa woman; }.
# body_Mia { pof Mia; isa body; }.
# head_Mia { pof Mia; isa head; }.
senses.query( '$X { isa head; pof Mia }.')
# 1.0, $X = head_Mia < Есть ли голова у Мии?
senses.query( 'Mia att $X { isa gender }.')
# 1.0, $X = female < Какого пола Мия?
senses.query( 'Ocean att $X { isa color }.')
# 1.0, $X = blue < Какого цвета океан Ocean?
senses.query('Mia loc House. $X { isa head; pof Mia; loc $Y }.')
# 1.0, $X = head_Mia, $Y: House < Где голова Мии, если Мия в доме?
senses.query( 'Lis isa woman.' )
# 1.0 < потому, что Lis att female (!)
senses.query( 'Tyland loc Land.' )
# 0.0 < Находится ли остров Tyland на острове Land
Следующие вопросы требуют действий и знаний о них:
- Мия находится на острове Land. Какой инструмент ей нужен, чтобы попасть на остров Tyland (лодка).
- Для чего Боб каждый день ездит по Океану на лодке? (видимо, чтобы ловить рыбу).
- Зачем рыба Бобу?
- Ест ли Бу рыбу?
следующем документе
Пропозиционные сети
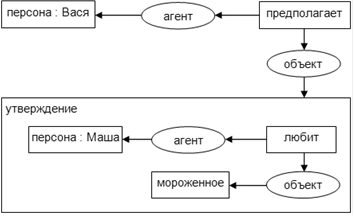
В пропозиционных сетях узлы представляют целые предложения. Эти узлы являются точками соприкосновения для отношений между отдельными предложениями связанного текста. С другой стороны они определяют время и модальность для всего контекста. Представленные ниже примеры иллюстрируют отношения, для записи которых необходимы пропозиционные узлы:
Sue thinks that Bob believes that a dog is eating a bone.
If a dog is eating a bone, it is unwise to try to take it away from him.
В первом предложении для глаголов «think» и «believe» целое предложение является дополнением: Боб считает, что «А dog is eating a bone», то, что думает Сью представляет собой более сложное предложение-«Bob believes that a dog is eating a bone». Такое гнездование предложений внутри других предложений может повторятся сколь угодно большое количество раз. Чтобы изобразить такое предложение, необходимо использовать пропозиционные узлы, которые содержат гнездящиеся графы. На рисунке 4 изображена пропозиционная сеть для этого предложения. Отметим, что (EXP) — experiencer, то есть тот кто испытывает, соединяет THINK с Сью, а BELIEVE с Бобом, однако EAT и DOG соединены между собой агентивным отношением (AGNT). Причиной разного типа отношений является тот факт, что думать и считать-это состояния, испытываемые людьми, а поедание-это действие осуществляемое агентом.
Во втором примере представлены два предложения, находящиеся в отношении условия. Антецедентом является предложение «А dog is eating a bone», а консеквентом предложение «It is unwise to try to take it away from him». Инфинитивы «to try» и «to take» указывают на другие, гнездящиеся предложения. На гнездящиеся предложения также указывает оборот «it is unwise». Для этого предложения также необходимо указать соответствие между «it», «him» и «bone» и «dog». Связи соответствия обозначены пунктиром. Для формальной записи этого предложения также используются кванторы общности и существования и некоторые элементы логики.
Все реляционные графы и графы с центром в глаголе имеют много общего. Однако среди них существуют также и отличия:
- Включение контекста или всего лишь его условное обозначение с отсылкой на схеме.
- Строгое гнездование: один и тот же концепт может или не может встречаться в двух разных контекстах, ни один из которых не гнездиться в другом.
- Указание связей соответствия. При перекрещивающемся контексте, то есть когда они один и тот же концепт встречается в двух разных контекстах, эти связи не указываются.
Однако это всего лишь стилистические расхождения, которые не влияют существенно на логику построения.
Примение на практике
Семантические сети могут быть записаны практически на любом языке программирования на любой машине. Самые популярные в этом отношении языки LISP и PROLOG. Однако многие версии были созданы и на FORTRANе, PASCALе, C и других языках программирования. Для хранения всех узлов и дуг необходима большая память, хотя первые системы были выполнены в 60-х годах на машинах, которые были гораздо меньше и медленнее современных компьютеров.
Один из самых распространенных языков, разработанных для записи естественного языка в виде сетей, — это PLNLP (Programming Language for Natural Language Processing) Язык Программирования для Обработки Естественного Языка, созданный Хайдерном. Этот язык используется для работы с большими грамматиками с обширным покрытием. PLNLP работает с двумя видами правил:
- с помощью правил декодирования производится синтаксический анализ линейной языковой цепочки и строится сеть.
- с помощью правил кодирования сканируется сеть порождается языковая цепочка или другая трансформированная сеть.
Помимо специальных языков для семантических сетей было также разработано специальное аппаратное обеспечение. На обычных компьютерах могут быть успешно выполнены операции с языками синтаксического анализа и операции сканирования сетей. Однако для больших баз знаний нахождение нужных правил или доступ к предзнаниям может потребоваться очень много времени. Чтобы позволить различным процессам поисках проходить одновременно Фальман разработал систему NETL, которая представляет собой семантическую сеть, которая может использоваться с параллельным аппаратным обеспечением. Таким образом он хотел создать модель человеческого мозга, в котором сигналы могут двигаться по различным каналам одновременно. Другие ученые разработали параллельное программное обеспечение для поиска наиболее вероятной интерпретации двусмысленных фраз естественного языка.



