Классификация методов автоматического реферирования
По возможности использовать новые слова:
- Извлекающие (экстрактивные, экстрагирующие, квазиреферативные, extractive)
- Генерирующие (абстрактивные, абстрагирующие, реферативные, abstractive)
В первом варианте реферат собирается исключительно из предложений первичного документа. Во втором же варианте компьютерная программа может по своему усмотрению добавлять в реферат новые слова, заменять существующие, создавая текст, которого не было в первичном документе. Извлекающие алгоритмы проще в разработке, но при этом во многих случаях выделившиеся предложения могут бы не связаны между собой, и в целом подход сильно ограничен. Генерирующие алгоритмы потенциально могут создавать идеальные тексты, и, в отличие от извлекающих, не имеют теоретических ограничений. Но на практике их сложнее разрабатывать, и итоговый текст может быть несвязными даже на уровне слов.
По необходимости наличия эталонных рефератов:
- С учителем
- Без учителя
Некоторым моделям для обучения нужны эталонные рефераты
Их использование позволяет модели адаптироваться под нужную предметную область, определить, что важно при составлении реферата, а что не важно. Составление таких рефератов — нетривиальная задача, довольно дорогая с точки зрения стоимости разметки
Поэтому очень часто используются именно методы без учителя, либо каким-то образом перенесённые в другую предметную область методы с учителем.
PEGASUS
PEGASUS — модель со специально подобранной под автоматическое реферирование задачей предобучения. С точки зрения архитектуры это обычный sequence-to-sequence Трансформер, как и предыдущие две модели. Но вместо восстановления случайных кусков текста предлагается использовать задачу генерации пропущенных предложений. Она заключается в том, что мы выбираем самые важные предложения из документа, заменяем их на токен-маску, формируем из них квазиреферат, и пытаемся этот квазиреферат сгенерировать. Эту задачу можно решать одновременно в паре с маскированным языковым моделированием.
Авторы предлагают 3 основных стратегии выбирать важные предложения: случайно; брать первые несколько предложений; брать несколько предложения по некой мере важности. В качестве меры важности можно брать похожесть предложений на оставшийся текст по ROUGE или даже жадно набирать квазиреферат аналогично методу «оракула» из предыдущей статьи
PEGASUS выигрывает у BART и T5 на всех основных наборах данных, особенно при использовании другого корпуса для предобучения, HugeNews, который составляли сами авторы, и который состоит из 1.5 миллиардов новостных документов.
К сожалению, никаких адаптаций этой модели для русского языка нет и пока не предвидится.
Система автоматического реферирования для трех языков +12
- 26.11.15 12:40
•
AlexanderButakov
•
#271771
•
Хабрахабр
•
Из песочницы
•
•
2800
Алгоритмы
Рекомендация: подборка платных и бесплатных курсов таргетированной рекламе — https://katalog-kursov.ru/
Я хочу рассказать о разработанном мной сервисе реферирования новостных текстов на английском, русском и немецком языках.
Системы автоматического реферирования (резюмирования) (САР) — тема довольно специфическая и будет интересна в основном тем, кто занимается автоматической обработкой языка. Хотя идеально исполненный саммарайзер мог бы стать полезным помощником в сферах, где необходимо преодолеть информационный перегруз и быстро принять решение о том, какая информация стоит дальнейшего рассмотрения.
Презентация на тему: » Говоря о двух последних «умениях» компьютера, необходимо помнить, что почти во всех существующих системах автоматического реферирования в качестве основных.» — Транскрипт:
1
Говоря о двух последних «умениях» компьютера, необходимо помнить, что почти во всех существующих системах автоматического реферирования в качестве основных смысловых единиц реферата выступают ключевые предложения или ключевые словосочетания и слова исходного текста.

2
Первые в их последовательной совокупности (в том порядке, в котором они идут в исходном тексте) образуют текст (квазитекст) реферата. Второй тип смысловых единиц (ключевые словосочетания и слова) используется компьютером для построения так называемых табличных рефератов.

3
При составлении с помощью компьютера аннотации также используются как ключевые предложения (в том виде, что и при составлении реферата), так и ключевые слова и словосочетания. Последние перечисляются вслед за реляторами вида: «В статье рассматриваются следующие вопросы:…», «Книга посвящена следующим проблемам:…», «Статья раскрывает следующие понятия:…» и т.д.

4
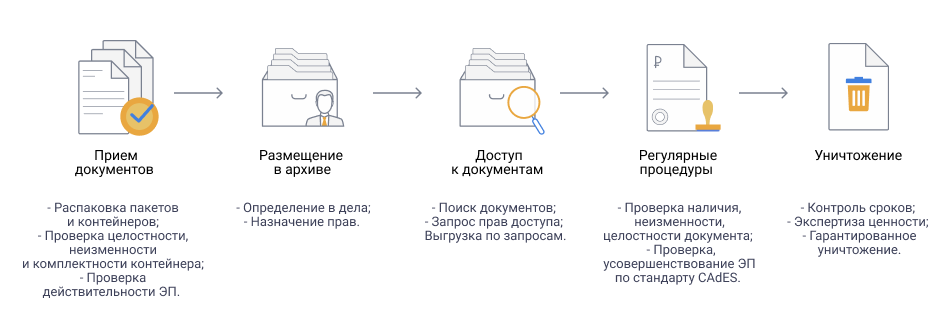
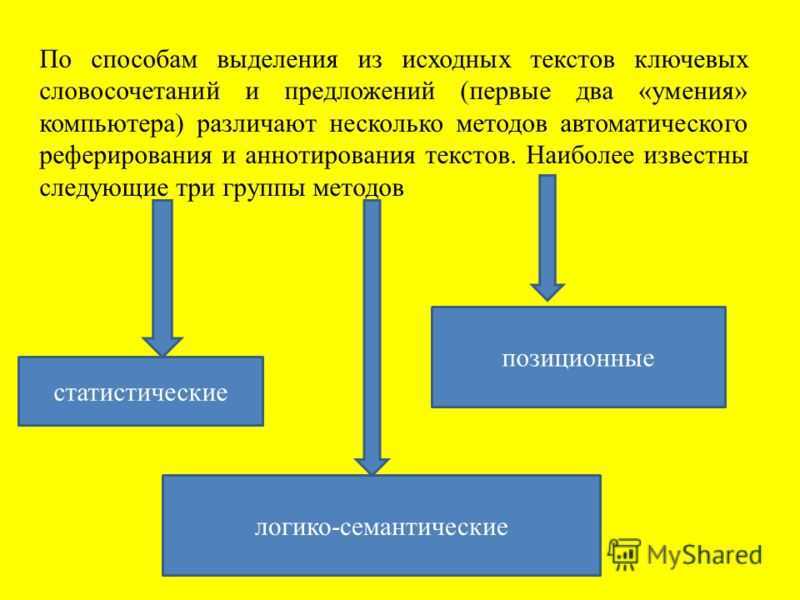
По способам выделения из исходных текстов ключевых словосочетаний и предложений (первые два «умения» компьютера) различают несколько методов автоматического реферирования и аннотирования текстов. Наиболее известны следующие три группы методов статистические логико-семантические позиционные
5
Суть статистической группы методов заключается в том, что ключевыми словами считаются такие знаменательные слова текста, которые с учетом всех синонимов встречаются в тексте наибольшее число раз ключевым предложением считается предложение текста, которое имеет несколько ключевых слов содержит ключевые слова на небольшом расстоянии друг от друга
6
Принадлежность слова, словосочетания или предложения к числу ключевых определяется специальными статистическими коэффициентами.

7
В позиционных методах автоматического реферирования и аннотирования ключевым предложением считается предложение, входящее в заголовок, подзаголовок, начало или конец какой-то части текста или всего текста. Такие предложения, как правило, содержат информацию о целях, методах, выводах и результатах исследования, описанного в первичном документе
Важность тех или иных предложений с указанной точки зрения определяется экспертами путем изучения семантической структуры первичных документов определенного типа
8
Логико-семантические методы опираются на исследование структуры и семантики текстов. Существует несколько вариантов этих методов, но цель их одна выделить из конкретного текста предложения с наибольшим функциональным весом. Величина эта зависит от многих факторов: наличия в исследуемом предложении специальных семантически значимых слов, связи этого предложения с другими предложениями текста, синтаксического типа самого предложения и т.д.











9
Формулируя задачу построения системы автоматического аннотирования и реферирования текста, необходимо четко указать метод, который используется для выделения ключевых слов предложения способ определения ключевых словосочетаний предложения критерий выделения ключевых предложений текста тип подготавливаемой аннотации: текстовая, в виде релятора с последующими ключевыми словами и словосочетаниями, или табличная тип формируемого реферата: текстовый или табличный

10
Учитывая все сказанное, сформулируем задачу автоматического реферирования и аннотирования текста следующим образом

11
На устройстве внешней памяти (например, дискете или винчестере) находится английский научно-технический текст. Начало каждого абзаца в нем обозначено знаком*
Используя для выделения ключевых (опорных) слов текста один из вариантов статистического метода, а именно коэффициент важности слова В формуле для К важ буквы означают следующее: F частота словоупотреблений в тексте; т число абзацев текста, в которых встретилось слово; N общее число словоупотреблений в тексте; п общее число абзацев в тексте
12
Это позволяет получить

Стратегии декодирования
С генерацией слева направо связана одна фундаментальная проблема, а именно проблема поиска оптимального пути в пространстве состояний. Эта проблема касается всех вышеописанных моделей. Она описывается формулой ниже, где — все возможные генерируемые последовательности, — исходная последовательность, — последовательность с максимальной вероятностью.
На каждом шаге декодировщика выдаётся распределение вероятностей для следующего токена. Самая простая стратегия — наивная жадная, то есть такая, в которой мы на каждом шаге мы выбираем максимально вероятный токен. Такая стратегия выбирает локально-оптимальный путь, а значит общая вероятность выбранной последовательности не обязательно минимальна.
Для этой задачи без дополнительных ограничений глобально-оптимальный путь можно найти перебором. Однако, на практике его невозможно использовать: его сложность , где — количество токенов на выходе, а — размер словаря.
Поэтому приходится использовать эвристики, которые выдают результат хуже перебора, но лучше наивного жадного алгоритма. Главная эвристика называется лучевым поиском. Её суть в том, что мы берём топ-N вероятных состояний на каждом шаге и высчитываем продолжения только для них. При это в точности наивный жадный алгоритм, а при — перебор. На рисунке ниже изображён лучевой поиск с . На каждом шаге, кроме первого, генерируется вариантов, из которых отбирается лучших. Отбор можно делать за линейное время без сортировки. Сложность всего алгоритма: .
Пример использования лучевого поиска с в transformers:
Кроме детерминированных алгоритмов поиска, также возможны различные методы семплирования, в которых мы выбираем случайное продолжение либо из лучших K токенов по вероятности, либо из набора токенов, покрывающего P% вероятности.
Пример использования семплирования с в transformers:
Возможно ещё и изменение температуры генерации в softmax-функции. Температура — это в формуле ниже. Чем выше температура, тем сглаженнее распределение. При , распределение превращается в равномерное. При распределение превращается в вырожденное: топ-1 токен имеет вероятность 1, а остальные — 0. С точки зрения людей, чем выше температура, тем «новее» выглядит текст.
Пример использования температуры в transformers:
Заключение
После выхода BERT в 2018 году, все последующие значимые модели для обработки естественного языка используют Трансформеры в том или ином виде. BERT, BART, T5, GPT, PEGASUS — все основаны на Трансформерах. Ещё две недели назад я бы написал «они точно с нами надолго», но после прорыва на LRA я уже не так в этом уверен.
PEGASUS является прекрасным примером успешного подбора и использования специализированной задачи предобучения под автоматическое реферирование. Кажется, что если улучшить механизм отбора маскируемых предложений, можно получить результаты ещё лучше. Жалко только, что для русского таких моделей пока нет.
Вы можете сравнить некоторые из моделей для русского языка на своих задачах:
- mBART, реферирование, Gazeta: mbart_ru_sum_gazeta
- ruT5-base, реферирование, Gazeta: rut5_base_sum_gazeta
- ruT5-base, генерация заголовков, Telegram contest: rut5_base_headline_gen_telegram
- ruT5-base, реферирование, составной корпус: rut5-base-absum
- ruGPT3-medium, реферирование, Gazeta: rugpt3medium_sum_gazeta
- mT5-base, реферирование, XLSum: mT5_multilingual_XLSum
Что осталось за кадром? Другой древний механизм копирования, CopyNet. Модель на основе N-граммных предсказаний, ProphetNet. Трансформеры для длинных текстов, такие как LED или BigBird. Основанная на них модель для сводного реферирования, PRIMER.
В следующих статьях будет обзор на метрики и обзор на доступные наборы данных. Надеюсь, какие-то из моделей выше пригодятся. Удачи!
Задача
В общем случае задача реферирования такова: по одному или нескольким документам на входе нужно составить краткий и беглый реферат, содержащую самую важную информацию из входных документов. В этом определении «краткий» означает, что рефераты должны быть меньше входных документов, «беглый» означает, что они должны быть грамматически корректными и связными
«Важность» информации определяется из контекста и предметной области
Автоматическое реферирование — сложная задача, потому что в процессе своей работы программе, делающей реферирование, необходимо понимать, какие из фрагментов оригинального документа важны, а какие не важны, а в некоторых случаях реорганизовывать и изменять оригинальные тексты. Даже для людей это нетривиальная задача, особенно когда дело касается реферирования нескольких документов одновременно.










Существует путаница, касающаяся названия задачи. Некоторые работы называют этот процесс автоматическим аннотированием или суммаризацией. По ГОСТ 7.9-95 «Реферат и аннотация. Общие требования» правильное название задачи — автоматическое реферирование, этого названия я и буду придерживаться.
За рубежом существовало несколько конференций по проблемам автоматического реферирования, самая известная из которых — DUC, Document Understanding Conferences. Сейчас основное специализированное место для обсуждения исследований по автоматическому реферированию — это семинар NewSum, New Frontiers in Summarization, в рамках конференции EMNLP.
Кроме того, регулярно проводятся дорожки по разным смежным задачам. Во-первых, с 2014 по 2019 проводилась дорожка CL-SciSumm по автоматическому реферированию научных документов. Во-вторых, в 2017 и 2020 проводилась дорожка WebNLG по преобразованию триплетов RDF в тексты и наоборот. Это можно рассматривать как специфический тип автоматического реферирования. В-третьих, в 2021 году была дорожка AutoMin в рамках конференции Interspeech, посвящённая автоматическому реферированию расшифровок аудиозаписей встреч.
Существуют задачи, которые тоже могут считаться автоматическим реферированием и требуют специфических методов, а именно:
- Генерация заголовков новостей
- Генерация текстов по таблицам или триплетам
- Реферирование стенограмм встреч
- Реферирование под поисковый запрос
- Реферирование книг
- Подбор ключевых слов для текстов
Кроме того, есть очень похожая задача: симплификация, упрощение текстов. По этой задаче на конференции Диалог-2021 была отдельная дорожка, RuSimpleSentEval. Её суть в том, что нужно упростить предложение с помощью удаления ненужных подробностей или упрощения лексики.
Seq2seq
Sequence-to-sequence — семейство подходов для перевода одной последовательности в другую. В случае задачи реферирования в качестве входа служит набор токенов исходного документа, а в качестве выхода — набор токенов реферата. Входную последовательность обрабатывает кодировщик, а выходную генерирует декодировщик.
На каждом своём шаге декодировщик предсказывает распределение вероятностей для следующего генерируемого слова, . При обучении мы считаем функцию потерь как кросс-энтропию между предсказанным распределением вероятностей и унитарным кодом настоящего токена.
Первые версии sequence-to-sequence моделей использовали кодировщики и декодировщики из рекуррентных сетей. При этом начальным скрытым состоянием декодировщика было последнее скрытое состояние кодировщика. Подобная модель для задачи машинного перевода схематично изображена ниже.
Механизм внимания
Проблема такой архитектуры — «узкое горлышко» в виде контекста из кодировщика , который фиксирован для всех шагов декодировщика. На разных шагах декодировщика мы хотели бы менять учитываемый контекст. Именно с этой целью и был создан механизм внимания. Его идея в том, чтобы на разных шагах декодировщика по-разному взвешивать выходы кодировщика. При этом веса для этих выходов считаются на основе предыдущего выхода декодировщика и всех выходов кодировщика.
Вариант механизма внимания представлен на рисунке ниже. Есть и вариант, в котором мы считаем веса внимания на основе текущего, а не предыдущего выхода декодировщика, и подаём итоговый вектор контекста сразу в предсказатель распределения токенов.
Pointer-Generator Network
В дотрансформерную эпоху было несколько модификаций рекуррентных seq2seq моделей для автоматического реферирования. Самая интересная из них — Pointer-Generator Network, указательно-генеративная сеть.
Основная её идея заключается в том, чтобы наравне с генерацией новых токенов позволить модели копировать токены из исходной последовательности. Выбор между генерацией и копированием делается через шлюз , который вычисляется по формуле ниже.
При формировании итогового предсказания словарь искусственно расширяется на количество неизвестных слов во входной последовательности. Вероятности копируемых токенов берутся из весов внимания по этим токенам. Вероятности токенов из словаря домножаются на , а токенов из исходной последовательности — на . Схематично это представлено на рисунке ниже.
Кроме того, в этой модели использовался механизм покрывающего внимания, но я не буду на нём останавливаться.
Мне когда-то довелось написать собственную PGN в рамках фреймворка AllenNLP. Её реферат нашей новости представлен ниже. Модель пыталась скопировать первые два предложения исходного текста, но не совсем удачно.
Какое качество саммари?
ROUGEDUCздесьcosine similarityJensen–Shannon divergence
- Open Text Summarizer, который работает с выбранными мною тремя языками и по словам самих разработчиков “Several academic publications have benchmarked it and praised it”;
- TextRank, популярный сегодня алгоритм в реализации Sumy;
- Random – справделиво сравнить алгоритм со случайно выбранными предложениями статьи.
| Cosine Similarity (—>1) | Jensen–Shannon divergence (—>0) | |||||||
| t-CONSP | OTS | Textrank | Random | t-CONSP | OTS | Textrank | Random | |
| popsci | 0.7981 | 0.7727 | 0.8227 | 0.5147 | 0.5253 | 0.4254 | 0.3607 | 0.4983 |
| environ | 0.9342 | 0.9331 | 0.9402 | 0.7683 | 0.3742 | 0.3741 | 0.294 | 0.4767 |
| politics | 0.9574 | 0.9274 | 0.9394 | 0.5805 | 0.4325 | 0.4171 | 0.4125 | 0.5329 |
| social | 0.7346 | 0.6381 | 0.5575 | 0.1962 | 0.3754 | 0.4286 | 0.5516 | 0.8643 |
| IT | 0.8772 | 0.8761 | 0.9218 | 0.6957 | 0.3539 | 0.3425 | 0.3383 | 0.5285 |
| Cosine Similarity (—>1) | Jensen–Shannon divergence (—>0) | |||||||
| t-CONSP | OTS | Textrank | Random | t-CONSP | OTS | Textrank | Random | |
| popsci | 0.6707 | 0.6581 | 0.6699 | 0.4949 | 0.5009 | 0.461 | 0.4535 | 0.5061 |
| envir | 0.7148 | 0.6749 | 0.7512 | 0.2258 | 0.4218 | 0.4817 | 0.4028 | 0.6401 |
| politics | 0.7392 | 0.6279 | 0.6915 | 0.4971 | 0.4435 | 0.4602 | 0.4103 | 0.499 |
| social | 0.638 | 0.5015 | 0.5696 | 0.6046 | 0.4687 | 0.4881 | 0.456 | 0.444 |
| IT | 0.4858 | 0.5265 | 0.6631 | 0.4391 | 0.5146 | 0.537 | 0.4269 | 0.485 |
| Cosine Similarity (—>1) | Jensen–Shannon divergence (—>0) | |||||||
| t-CONSP | OTS | Textrank | Random | t-CONSP | OTS | Textrank | Random | |
| popsci | 0.6005 | 0.5223 | 0.5487 | 0.4789 | 0.4681 | 0.513 | 0.5144 | 0.5967 |
| environ | 0.8745 | 0.8100 | 0.8175 | 0.7911 | 0.382 | 0.4301 | 0.4015 | 0.459 |
| politics | 0.5917 | 0.5056 | 0.5428 | 0.4964 | 0.4164 | 0.4563 | 0.4661 | 0.477 |
| social | 0.6729 | 0.6239 | 0.5337 | 0.6025 | 0.3946 | 0.4555 | 0.4821 | 0.4765 |
| IT | 0.84 | 0.7982 | 0.8038 | 0.7185 | 0.5087 | 0.4461 | 0.4136 | 0.4926 |
здесьЗдесьздесь
BART
BART — sequence-to-sequence Трансформер, который предобучается реконструкции испорченного зашумлённого текста. Разработка Facebook AI Research. На входе у модели каким-то образом испорченный текст, а на выходе ей надо сгенерировать его оригинальную версию.
BERT использует только кодировщик, GPT использует только декодировщик, а вот BART — полноценная sequence-to-sequence модель. Схематично это изображено на рисунке ниже.
Как зашумляется текст:
- Маскировка токенов (аналогично BERT)
- Удаление токенов
- Маскировка нескольких подряд идущих токенов одной маской
- Перемешивание предложений
- «Вращение» документа относительно случайного токена. То есть мы делаем этот токен началом документа, а всё, что было до него — переносим в конец.
BART предобучался на том же корпусе, что и RoBERTa, то есть на составном корпусе из 4 частей: книг, новостей, документов по ссылкам из постов Reddit, кусочка Common Crawl.
Важно, что в отличие от BERT, эта модель сразу предобучается на генерации текста, и поэтому лучше подходит для автоматического реферирования. Наличие в задачах предобучения перемешиваний предложений и «вращений» документов также помогает при дальнейшем дообучении
Кроме английской версии BART, была обучена ещё и многоязычная версия этой модели, mBART. Она обучалась на многоязычном корпусе CC25, подмножестве Common Crawl из 25 языков. При предобучении использовались одноязычные части корпуса, то есть никаких переводов не модель не видела.






Русский язык там второй по степени представленности после английского. Это позволяет использовать эту модель и для русского языка тоже. Вот моя модель на основе mBART для автоматического реферирования на русском языке: mbart_ru_sum_gazeta. Модель довольно хороша, и с реферированием новостей может справляться не хуже некоторых людей, что подтверждается в этой статье.
Её реферат нашего примера представлен ниже. Модель отлично отработала и выделила самое главное. Единственная проблема — «уже упомянутые» болезни, которые в реферате до этого упомянуты не были.
Заключение
Все методы, описанные выше, довольно старенькие, но от того не менее полезные. Многие из них позволяют доработку с помощью современных моделей. Например, можно заменить подсчёт схожести в TextRank на косинусное сходство между любыми текстовыми эмбеддингами вроде USE или LaBSE.
Что ещё важнее, они не требует значительной адаптации под предметную область! У большинства современных моделей автоматического реферирования с этим трудности: им требуется корпус для обучения, и за рамками предметной области этого корпуса они уже плохо работают.
Сопроводительный код в Colab: ссылка.
В следующих статьях цикла мы рассмотрим намного более хайповые вещи: рекуррентные сети, модели на основе трансформеров: кодировщики, декодировщики и sequence-to-sequence модели, такие как BERT, GPT, BART, T5 и PEGASUS, а также обязательно затронем вопросы об оценке качества автоматического реферирования. Надеюсь, что этот мини-обзор был полезен, увидимся в следующих статьях!