
Введение
Объектно-ориентированное программирование (ООП) стало революционным
подходом в 1980-е годы []. В 1990-х годах применение ООП стало
важнейшей областью исследований и разработок применительно к реляционным системам
управления базами данных (СУБД) . В 1996
г. была выпущена объектно-реляционная СУБД Informix Universal Server
Несмотря на
важность и актуальность классической реляционной и объектно-реляционной моделей,
тем не менее остается много нерешенных проблем
В данной статье кратко описаны основные ограничения реляционных
и объектно-реляционных технологий, и для их разрешения предложена структура данных
в виде дерева объектов.
Ограничения реляционных баз данных
В реляционной модели каждая запись об объекте
находится в отношении с некоторым набором атрибутов. Количество атрибутов
(полей) в таблице может измеряться десятками и даже сотнями. С увеличением длины
записи (количества и размера атрибутов) падает производительность, поскольку требуется
больше дисковых операций ввода/вывода. Разбиение широкой таблицы на несколько узких
с меньшим числом атрибутов потребует операций соединения (join) и во многих случаях
является неэффективным.
Индексирование тоже не всегда эффективно, а только на больших
наборах данных, т. к. скорость поиска по индексу экспоненциально зависит
от количества записей:
exp (vi) ~ n (1)
или
vi ~ ln (n) , (2)
в то время как зависимость между скоростью последовательного
перебора и размером выборки пропорциональная:
v ~ n · k , (3)
где v — скорость последовательного перебора,
vi — скорость поиска с использованием индекса
i, n — количество записей в таблице,k — количество колонок в таблице.
Применение индексов наиболее эффективно при большом количестве
узких записей, а не широких []. Вдобавок, индексы имеют свои
недостатки:
- Чем больше атрибутов (колонок в таблице), тем больше индексов нужно создавать.
- Для каждого индекса требуется дополнительное дисковое пространство (которое
на практике может даже превышать размер индексируемой таблицы). - После модификации данных необходимо обновлять статистику или перестраивать
все индексное дерево.
Еще одним ограничением реляционной модели является «плоская»
организация атрибутов объектов. Это означает, что в реляционном отношении нельзя
группировать или структурировать атрибуты — все они находятся на одном уровне иерархии.
А на практике не все атрибуты объекта одинаково значимы и поэтому должны принадлежать
разным уровням вложенности.
Конечно, есть дополнительные типы данных, определяемые пользователем,
а также большие двоичные BLOB и текстовые CLOB-объекты. Однако, и у них есть свои
ограничения. Например, поля BLOB и CLOB не могут быть упорядочены или проиндексированы
и должны обрабатываться на стороне клиента.
Использование преимуществ объектно-реляционных технологий
Informix Universal Server
— это СУБД объектно-реляционного типа, созданная путем внедрения технологии ООП
в популярную СУБД Informix Dynamic Server. Она обладает следующими свойствами ООП:
- абстрактные типы данных,
- наследование,
- иерархии данных и типов.
На практике встречается много примеров, когда набора стандартных
типов недостаточно. Хотя абстрактные типы данных дают определенные преимущества,
описание новых типов в СУБД не совсем приемлемо — в дальнейшем всегда может возникнуть
потребность добавить еще один тип.
К тому же определение новых типов в СУБД Informix Universal
Server может вызвать отрицательные последствия, т. к. потребуются навыки опытных
программистов по разработке на языке C процедур и методов хранения, доступа и индексирования
данных.
Свойство наследования не может полностью решить проблему иерархии
большого набора атрибутов. Иногда потребность добавления нового атрибута возникает
на этапе эксплуатации базы данных, вынуждая модифицировать структуру таблицы.
И наконец, один атрибут может потребовать использования набора
других атрибутов. Если попытаться создать несколько таблиц, то это слишком усложнит
структуру базы данных, ухудшит производительность выполнения запросов и повысит
в них вероятность ошибок.
Сценарии использования
HSM часто используется для глубокого архивного хранения данных с целью долгосрочного хранения и невысокой стоимости. Автоматизированные ленточные роботы могут эффективно хранить большие объемы данных с низким энергопотреблением.
Некоторые программные продукты HSM позволяют пользователю помещать части файлов данных в кэш высокоскоростного диска, а остальные — на ленту. Это используется в приложениях, которые транслируют видео через Интернет — начальная часть видео сразу же доставляется с диска, в то время как робот находит, монтирует и передает остальную часть файла конечному пользователю. Такая система значительно снижает стоимость диска для больших систем предоставления контента.
Реализации
- Alluxio
- Амазонский ледник
- IBM 3850 IBM 3850 Mass Storage Facility
- IBM Tivoli Storage Manager для управления пространством (HSM доступен на UNIX (IBM AIX, HP UX, Солярис ) & Linux )
- IBM Tivoli Storage Manager HSM для Windows ранее OpenStore для файловых серверов (OS4FS) (HSM доступен в Microsoft Windows Server )
- Бесконечный диск, ранняя система ПК (несуществующая)
- ЭМС DiskXtender, ранее Legato DiskXtender, ранее OTG DiskXtender
- Moonwalk для Windows, NetApp, OES Linux
- Oracle SAM-QFS (Открытый исходный код под Opensolaris, затем проприетарный)
- Oracle HSM (Собственная, переименованная из SAM-QFS)
- Диспетчер хранилища Versity для Linux, открытая модель лицензия
- Dell Compellent Прогресс данных
- Зарафа Архиватор (компонент ZCP, решение для архивирования для конкретного приложения, продаваемое как решение HSM)
- HPE Структура управления данными (DMF, ранее SGI Data Migration Facility) для SLES и RHEL
- Квантовые StorNext
- яблоко Fusion Drive за macOS
- Microsoft начиная с версии, поставляемой с . Более старый продукт Microsoft был , в комплекте с Windows 2000 и Windows 2003.
Сценарии использования
HSM часто используется для глубокого архивного хранения данных с целью долгосрочного хранения и невысокой стоимости. Автоматизированные ленточные роботы могут эффективно хранить большие объемы данных с низким энергопотреблением.
Некоторые программные продукты HSM позволяют пользователю помещать части файлов данных в кэш высокоскоростного диска, а остальные — на ленту. Это используется в приложениях, которые транслируют видео через Интернет — начальная часть видео сразу же доставляется с диска, в то время как робот находит, монтирует и передает остальную часть файла конечному пользователю. Такая система значительно снижает стоимость диска для больших систем предоставления контента.
Иерархическая структура объектов
Дерево объектов [] представляет собой информационную
систему для хранения иерархической структуры объектов. Задача усложняется тем, что
у объектов допускается произвольное количество атрибутов — десятки, сотни и более,
каждый из которых может быть в Informix любого типа (целый, вещественный, десятичный,
строковый, дата/время и т. д.). Все это предусмотрено в представленной структуре
данных.
Система иерархических таблиц и расширенных типов данных построена
на базе Informix Universal Server и Informix Web DataBlade. Но при этом используются
стандартные методы доступа, т. е. нет необходимости программировать обработчики.
Поэтому данная структура данных может быть реализована как на платформе Informix
Universal Server, так и Informix Dynamic Server.
Структура данных () создана в СУБД
Informix посредством SQL и состоит из таблиц, описанных ниже. Для их модификации
разработаны хранимые процедуры. Пример создания таблиц и процедур их модификации
приведен в отдельном файле ().
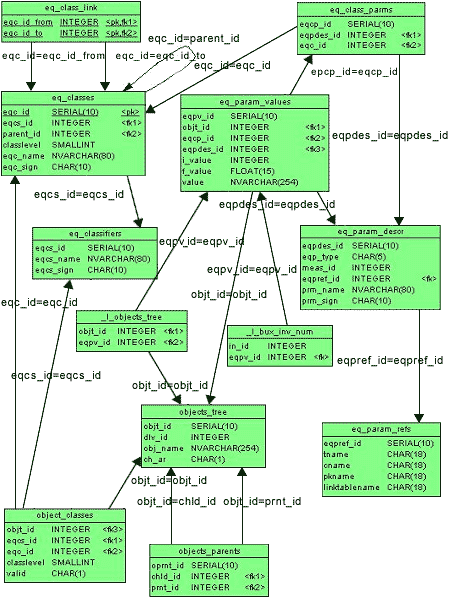
Рис. 1. Структура данных для хранения иерархических объектов
Таблица objects_tree
Таблица objects_tree содержит информацию как об объектах-родителях,
так и объектах-потомках иерархического дерева.
Атрибуты (колонки) таблицы objects_tree:
obt_id — ID записи об объекте,dlv_id — ссылка на ID в таблице подразделений,obj_name — любой текст,ch_ar — символ-признак архивности записи, используемый для хранения информации
об удаленных объектах.
Для добавления, модификации и удаления объектов используются
хранимые процедуры. При удалении объекта не производится рекурсивное удаление всех
его потомков. Иначе говоря, если у объекта есть потомки, он не может быть удален.
Если потомки объекта не удалены, процедура возвращает код ошибки SQL. Это сделано
в целях безопасности данных. Реализация рекурсивного удаления потомков в хранимой
процедуре повысит вероятность случайного удаления целой ветви дерева объектов.
Таблица objects_parents
Каждая запись в таблице objects_parents () содержит ссылку на объект-родитель и соответствующий ему объект-потомок в
таблице objects_tree.
Оба поля — ID предка и ID потомка — ссылаются на таблицу objects_tree.
Новые отношения родитель-потомок добавляются посредством хранимой процедуры. Для
улучшения производительности родительский и дочерний объекты назначаются совместно.
Но модификации не допускаются, для этого соответствующая запись должна быть удалена
прямым вызовом SQL оператора а затем новая запись
добавляется путем вызова хранимой процедуры.




![[клякс@.net][информатика и икт в школе. компьютер на уроках.][[экзамен по информатике][билет №21]]](https://robotrackkursk.ru/wp-content/uploads/a/d/f/adfc88075b64634ee66ca0b6df6885e5.jpeg)


Каждый объект в структуре базы данных может иметь произвольное
количество потомков и предков, как показано в .
Пример 1. Примером иерархической структуры
является университет, в котором факультет является дочерним подразделением института
и в то же время родительской структурой для входящих в него лабораторий (, ).
3 популярных реляционных базы данных для веб-разработки
MySQL
Данную открытую систему управления базами данных американская корпорация Oracle приобрела в комплекте с Sun Microsystems. Опрос, проведенный порталом StackOverflow.com два года назад, в котором приняли участие 65 000 пользователей, показал, что около 55,6 % разработчиков работают с MySQL.
Такая популярность обусловлена высокой скоростью управления данными и возможностью бесплатного использования. MySQL изначально разрабатывалась, чтобы обрабатывать огромные информационные базы в промышленных объемах. Впоследствии, когда разработчики оценили ее быстродействие и бесплатность, эта СУБД покорила мировой Интернет. Пока MySQL остается наиболее удобной системой управления данными для работы и веб-приложениями, и страницами.
При этом, данная СУБД получает серьезную поддержку от разработчиков языков программирования. Сегодня практически все популярные языки имеют интерфейс для работы с MySQL.
SQLite
В этой системе управления реляционными базами данных применяется много всего, что входит в стандартный язык SQL.
Основным ее достоинством считается встраиваемость, которая обусловлена тем, что SQlight в отличие от остальных СУБД является не приложением на подобие «клиент-сервер», а подключаемой библиотекой.
О популярности SQLite может говорить тот факт, что она присутствует во всех смартфонах. В гаджетах на Андроид в этой базе данных хранятся медиафайлы и контакты. В смартфонах на iOS СУБД SQLite используется большинством приложений.
PostgreSQL
Это наиболее продвинутая система управления реляционными базами данных. PostgreSQL является свободной объектно-реляционной СУБД.
Популярные статьи
Высокооплачиваемые профессии сегодня и в ближайшем будущем
Дополнительный заработок в Интернете: варианты для новичков и специалистов
Востребованные удаленные профессии: зарабатывайте, не выходя из дома
Разработчик игр: чем занимается, сколько зарабатывает и где учится
Как выбрать профессию по душе: детальное руководство + ценные советы
Уникальность данной СУБД состоит в том, что кроме стандартных типов данных, поддерживаемых другими реляционными системами, она может работать с финансовой информацией, сетевыми адресами, JSON, XML и геометрическими данными. Более того, PostgreSQL может создавать свои типы данных.
OSD vs NAS. Или вместе лучше?
Призвана ли концепция объектных хранилищ заменить современные сетевые хранилища на основе файловых систем? Конечно же, нет. Технологии эти находятся в разных весовых категориях, и каждая из них по-своему эффективна.
Технологически для пользователей, привыкших к работе с файловыми системами, возможно создание гибридной модели, скрывающей свою объектную сущность
Объектные хранилища наиболее эффективны в случаях действительно массового (сотни миллионов, миллиарды) единиц неструктурированной информации. В этом случае работа традиционных файловых систем создает непроизводительные издержки, существенно снижающие эффективность поиска и управления данными.
Кроме того, работа с объектами эффективна в случае относительно статичных данных — например, тех, что хранятся в архивах. Исследования показали, что после создания более 70 процентов неструктурированной информации не подвергается модификации и доступ к ней осуществляется относительно редко, 20 процентов составляют «золотую середину» и только 10 активно используется и модифицируется. Именно с последним типом данных наиболее эффективно справляются файловые системы и поддерживающие их сетевые хранилища.
Области использования объектных хранилищ и традиционных файловых систем
Кроме масштабируемости, эффективность объектных хранилищ дополнительно связана с интеллектуальным управлением данными. Богатая метаинформация объектов позволит оптимизировать процесс хранения и минимизировать затраты на него.
Ну а стремительный рост социальных сервисов и облачных хранилищ — кладезей неструктурированной информации, скорее всего, стимулирует прогресс в области стандартизации OSD и совершенствования парадигмы объектно-ориентированной памяти.
Циркулярно связанные списки в Python
Основным недостатком стандартного связного списка является то, что вам всегда нужно начинать с узла Head.
Циклический связанный список устраняет эту проблему, заменяя nullуказатель узла Tail указателем на узел Head. При обходе программа будет следовать указателям, пока не достигнет узла, на котором она была запущена.
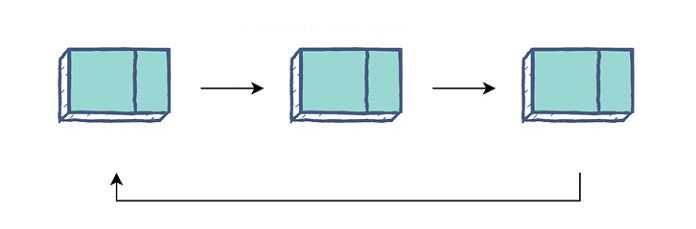
Преимущество этой настройки заключается в том, что вы можете начать с любого узла и пройти по всему списку. Это также позволяет вам использовать связанные списки в качестве зацикленной структуры, задав желаемое количество циклов через структуру.
Списки с круговой связью отлично подходят для процессов, которые зацикливаются в течение длительного времени, например, распределение ЦП в операционных системах.
Преимущества:
- Может просматривать весь список, начиная с любого узла.
- Делает связанные списки более подходящими для циклических структур.
Недостатки:
Сложнее найти узлы Head и Tail списка без nullмаркера.
Приложения:
- Регулярно зацикливающиеся решения, такие как планирование ЦП.
- Решения, в которых вам нужна свобода начать обход с любого узла.
Общие вопросы собеседования со связным списком в Python
- Обнаружить петлю в связанных списках.
- Перевернуть круговой связанный список.
- Обратный круговой связанный список в группах заданного размера.
Основные свойства типа hierarchyid
Значение типа данных hierarchyid представляет позицию в древовидной иерархии. Значения hierarchyid обладают следующими свойствами.
-
Исключительная компактность
Среднее число бит, необходимое для представления узла в древовидной структуре с n узлами, зависит от среднего количества потомков у узла. Для небольших уровней ветвления (0 — 7) этот размер равен 6*logAn бит, где A — средний уровень ветвления. Для представления узла в иерархии организации, насчитывающей 100 000 человек со средним уровнем ветвления 6, необходимо около 38 бит. Эта величина округляется до 40 бит (5 байт), которые необходимы для хранения.
-
Сравнение проводится в порядке приоритета глубины
Если заданы два значения hierarchyid — a и b, a<b означает, что значение a появляется раньше значения b, если проходить по дереву с приоритетным направлением в глубину. Индексы для типов данных hierarchyid располагаются в порядке приоритета глубины, а узлы, встречающиеся рядом при проходе по дереву с приоритетным направлением глубины, хранятся рядом друг с другом. Например, потомки некоторой записи хранятся рядом с этой записью.
-
Поддержка произвольных вставок и удалений
С помощью метода GetDescendant можно в любой момент создать одноуровневый элемент, расположенный справа от заданного узла, слева от заданного узла или между любыми двумя другими одноуровневыми элементами. Свойство сравнения сохраняется, если произвольное число узлов вставляется в иерархию или удаляется из нее. Большинство операций вставки и удаления сохраняют свойство компактности. Однако операции вставки между двумя узлами приводят к созданию значений hierarchyid, обладающих менее компактным представлением.
-








Выполнение
В типичном сценарии HSM файлы данных, которые часто используются, хранятся на дисках, но в конечном итоге мигрировал записать на пленку, если они не используются в течение определенного периода времени, обычно несколько месяцев. Если пользователь повторно использует файл, который находится на ленте, он автоматически перемещается обратно в дисковое хранилище. Преимущество состоит в том, что общий объем хранимых данных может быть намного больше, чем емкость доступного дискового хранилища, но поскольку на ленте находятся только редко используемые файлы, большинство пользователей обычно не замечают замедления.
HSM иногда называют .
HSM (первоначально DFHSM, теперь DFSMShsm) был первым[нужна цитата ] реализовано IBM на их мэйнфреймы для снижения стоимости хранения данных и упрощения извлечения данных с более медленных носителей. Пользователю не нужно знать, где хранятся данные и как их вернуть; компьютер получит данные автоматически. Единственная разница для пользователя заключалась в скорости возврата данных.
Австралийское подразделение компьютерных исследований CSIRO внедрило HSM в свою операционную систему DAD (барабаны и дисплей) с областью документов в 1960-х годах, при этом копии документов записывались на 7-дорожечную ленту и автоматически извлекались при доступе к документам.
HSM в форме IBM 3850 Mass Storage Facility был (согласно IBM) объявлен в 1974 году.
Позже IBM перенесла HSM на свой Операционная система AIX, а затем к другим Unix-подобный операционные системы, такие как Солярис, HP-UX и Linux.
HSM также был реализован на DEC VAX / VMS системы и системы Alpha / VMS. Дата первого внедрения должна быть легко определена из Руководств по внедрению системы VMS или брошюр с описанием продуктов VMS.
В последнее время разработка Последовательный ATA (SATA) диски создали значительный рынок для трехступенчатого HSM: файлы переносятся из высокопроизводительных Fibre Channel сеть хранения данных устройства несколько медленнее, но намного дешевле SATA дисковые массивы всего несколько терабайты или больше, а затем, в конце концов, с дисков SATA на ленту.
Новейшая разработка HSM с жесткие диски и флэш-память, причем флеш-память более чем в 30 раз быстрее дисков, но диски значительно дешевле.
Концептуально HSM аналогичен тайник найден в большинстве компьютеров Процессоры, где небольшие суммы дорогих SRAM память, работающая на очень высоких скоростях, используется для хранения часто используемых данных, но наименее недавно использованный данные перемещаются в более медленный, но гораздо больший основной DRAM память, когда необходимо загрузить новые данные.
На практике HSM обычно выполняется с помощью специального программного обеспечения, такого как IBM Tivoli Storage Manager, Oracle SAM-QFS, Диспетчер хранилища Versity, Квантовая, Технология динамического хранения Novell (DST) на платформе Open Enterprise Server (OES) Linux, HPE Структура управления данными (DMF, ранее SGI Средство переноса данных), StorNext, или же ЭМС Легато OTG DiskXtender.
Удаление файлов с более высокого уровня иерархии (например, с магнитного диска) после того, как они были перемещены на более низкий уровень (например, оптический носитель), иногда называют обработка файлов.
Многоуровневое хранилище
Многоуровневое хранилище это хранилище данных среда, состоящая из двух или более типов хранилищ, различающихся по крайней мере одним из этих четырех атрибутов: цена, производительность, емкость и функция.
Любое существенное различие в одном или нескольких из четырех определяющих атрибутов может быть достаточным, чтобы оправдать отдельный уровень хранения.
Примеры:
- Диск и Лента: два отдельных уровня хранения, идентифицируемых по различиям во всех четырех определяющих атрибутах.
- Диск старой технологии и диск новой технологии: два отдельных уровня хранения, идентифицируемых по различию в одном или нескольких атрибутах.
- Высокопроизводительное дисковое хранилище и менее дорогой, более медленный диск той же емкости и функции: два отдельных уровня.
- Идентичный диск корпоративного класса, настроенный для использования различных функций, таких как RAID уровень или репликация: отдельный уровень хранения для каждого набора уникальных функций.
Примечание. Уровни хранилища нет определяется различиями в поставщиках, архитектуре или геометрии, за исключением случаев, когда эти различия приводят к явным изменениям цены, производительности, емкости и функций.
Алгоритмы
Ключевым фактором HSM является политика миграции данных, которая контролирует передачу файлов в системе. Точнее, политика определяет, на каком уровне должен храниться файл, чтобы вся система хранения могла быть хорошо организована и имела кратчайшее время ответа на запросы. Существует несколько алгоритмов, реализующих этот процесс, например, замена наименее недавно использованных (LRU), Замена размера-температуры (STP), эвристический порог (STEP) и т. д. В исследованиях последних лет также было выявлено несколько интеллектуальных политик с использованием технологий машинного обучения.
Алгоритмы
Ключевым фактором HSM является политика миграции данных, которая контролирует передачу файлов в системе. Точнее, политика определяет, на каком уровне должен храниться файл, чтобы вся система хранения могла быть хорошо организована и имела кратчайшее время ответа на запросы. Существует несколько алгоритмов, реализующих этот процесс, например, замена наименее недавно использованных (LRU), Замена размера-температуры (STP), эвристический порог (STEP) и т. д. В исследованиях последних лет также было выявлено несколько интеллектуальных политик с использованием технологий машинного обучения.
Как всё начиналось
В 60-х годах прошлого столетия появилась необходимость в надежной модели хранения и обработки данных. В первую очередь эти данные генерировались банками и финансовыми организациями. В то время не существовало единых стандартов работы с данными и моделями, да и работа как таковая заключалась в ручном упорядочении и организации хранящейся информации.
У банков худо-бедно получалось записывать информацию о транзакциях в виде файлов в заранее подготовленную структуру. У каждой организации было собственное понимание того, как все это должно выглядеть и работать. Не было таких понятий, как консистентность (англ. data consistency), целостности данных (англ. data integrity). В файлах часто встречались дубликаты данных клиентов и их транзакций, которые необходимо было каким-то образом уточнять и приводить в порядок, делалось это в основном вручную. В целом все проблемы того времени в отношении работы с данными можно разделить на несколько основных видов:
-
Представление структуры в каждом файле было различным.
-
Необходимо было согласовывать данные в разных файлах, чтобы обеспечить непротиворечивость информации.
-
Сложность разработки и поддержки приложений, работающих с конкретными данными, и их обновления при изменении структуры файла.
По сути, здесь мы видим антипаттерн «чистой архитектуры», который был описан Робертом Мартином (Robert C. Martin).
Следует отметить, что были попытки создания моделей, позволяющих навести порядок в данных и их обработке. Одна из таких попыток — иерархическая модель, в которой данные были организованы в виде древовидной структуры. Иерархическая модель была востребованной, но не гибкой. В ней каждая запись могла иметь только одного «предка», даже если отдельные записи могли иметь несколько «потомков». Из-за этого базы данных представляли только отношения «один к одному» или «один ко многим». Невозможность реализации отношения «многие ко многим» могла привести к проблемам при работе с данными и усложняла модель. Более того, вопросы консистентности данных и отсутствия дублирования информации здесь вообще не стояли. Первая иерархическая СУБД называлась IMS от IBM.
На помощь иерархической пришла сетевая модель данных, и уже новая концепция реализовала отношение «многие ко многим». Данный подход был предложен как спецификация модели CODASYL в рамках рабочей группы DBTG (Data Base Task Group).
Но всё это модели, которые сложно было поддерживать. Упростить задачу сбора и обработки данных смог Франк Кодд (Edgar F. Codd). Его фундаментальная работа привела к появлению реляционных баз данных, которые нужны практически всем отраслям. Кодд предложил язык Alpha для управления реляционными данными. Коллеги Кодда из IBM — Дональд Чемберлен (Donald Chamberlin) и Рэймонд Бойс (Raymond Boyce) — создали один из языков под влиянием работы Кодда. Они назвали свой язык SEQUEL (Structured English Query Language), но изменили название на SQL из-за существующего товарного знака.
Массивы (списки) в Python
Python не имеет встроенного типа массива, но вы можете использовать списки для всех тех же задач. Массив — это набор значений одного типа, сохранённых под тем же именем.
Каждое значение в массиве называется «элементом», и индексирование соответствует его положению. Вы можете получить доступ к определённым элементам, вызвав имя массива с индексом желаемого элемента. Вы также можете получить длину массива с помощью len()метода.
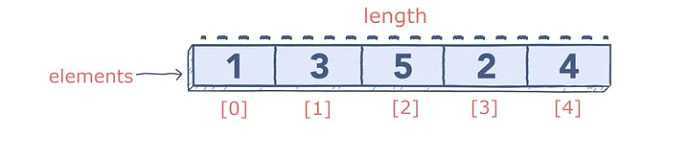
В отличие от языков программирования, таких как Java, которые имеют статические массивы после объявления, массивы Python автоматически увеличиваются или уменьшаются при добавлении / вычитании элементов.
Например, мы могли бы использовать этот append()метод для добавления дополнительного элемента в конец существующего массива вместо объявления нового массива.
Это делает массивы Python особенно простыми в использовании и адаптируемыми на лету.
Преимущества:
- Простота создания и использования последовательностей данных.
- Автоматическое масштабирование в соответствии с меняющимися требованиями к размеру.
- Используется для создания более сложных структур данных.
Недостатки:
- Не оптимизирован для научных данных (в отличие от массива NumPy).
- Может управлять только крайним правым концом списка.
Приложения:
- Совместное хранилище связанных значений или объектов, т.е. myDogs.
- Коллекции данных, которые вы будете просматривать.
- Коллекции структур данных, например, список кортежей.
Общие вопросы собеседования с массивами в Python
- Удалить чётные числа из списка.
- Объединить два отсортированных списка.
- Найдите минимальное значение в списке.
- Подсписок максимальной суммы.
- Печать продукции всех элементов.
Что такое структуры данных?
Структуры данных — это структуры кода для хранения и организации данных, которые упрощают изменение, навигацию и доступ к информации. Структуры данных определяют способ сбора данных, функциональные возможности, которые мы можем реализовать, и отношения между данными.






Структуры данных используются практически во всех областях информатики и программирования, от операционных систем до интерфейсной разработки и машинного обучения.
Структуры данных помогают:
- Управляйте большими наборами данных и используйте их.
- Быстрый поиск определённых данных в базе данных.
- Создавайте чёткие иерархические или реляционные связи между точками данных.
- Упростите и ускорьте обработку данных.
Структуры данных являются жизненно важными строительными блоками для эффективного решения реальных проблем. Структуры данных — это проверенные и оптимизированные инструменты, которые дают вам удобную основу для организации ваших программ. В конце концов, вам не нужно переделывать колесо (или конструкцию) каждый раз, когда это нужно.
У каждой структуры данных есть задача или ситуация, для решения которой она наиболее подходит. Python имеет 4 встроенных структуры данных, списки, словари, кортежи и наборы. Эти встроенные структуры данных поставляются с методами по умолчанию и негласной оптимизацией, которая упрощает их использование.
Большинство структур данных в Python являются их модифицированными формами или используют встроенные структуры в качестве основы.
- Список: структуры, похожие на массивы, которые позволяют сохранять набор изменяемых объектов одного и того же типа в переменную.
- Кортеж: кортежи — это неизменяемые списки, то есть элементы не могут быть изменены. Он объявлен в круглых скобках вместо квадратных.
- Набор: наборы — это неупорядоченные коллекции, что означает, что элементы неиндексированы и не имеют установленной последовательности. Они объявляются фигурными скобками.
- Словарь (dict): Подобно хэш-карте или хеш-таблицам на других языках, словарь представляет собой набор пар ключ / значение. Вы инициализируете пустой словарь пустыми фигурными скобками и заполняете его ключами и значениями, разделёнными двоеточиями. Все ключи — уникальные неизменяемые объекты.
Теперь давайте посмотрим, как мы можем использовать эти структуры для создания всех сложных структур, которые ищут интервьюеры.
Стеки в Python
Стеки представляют собой последовательную структуру данных, которая действует как версия очередей «последний пришёл — первым ушёл» (LIFO). Последний элемент, вставленный в стек, считается верхним в стеке и является единственным доступным элементом. Чтобы получить доступ к среднему элементу, вы должны сначала удалить достаточное количество элементов, чтобы нужный элемент находился на вершине стека.
Многие разработчики представляют стопки как стопку обеденных тарелок; вы можете добавлять или убирать тарелки в верхнюю часть стопки, но вам нужно переместить всю стопку, чтобы разместить одну внизу.
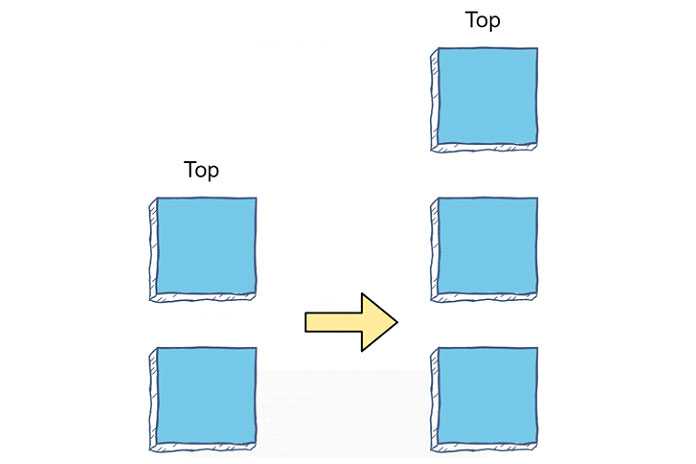
Добавление элементов называется выталкиванием, а удаление элементов — всплывающим сообщением. Вы можете реализовать стеки в Python, используя встроенную структуру списка. При реализации списка в операциях push используется append()метод, а в операциях pop — pop().
Преимущества:
- Предлагает управление данными LIFO, которое невозможно с массивами.
- Автоматическое масштабирование и очистка объекта.
- Простая и надёжная система хранения данных.
Недостатки:
- Память стека ограничена.
- Слишком много объектов в стеке приводит к ошибке переполнения стека.
Приложения:
- Используется для создания высокореактивных систем.
- Системы управления памятью используют стеки для обработки в первую очередь самых последних запросов.
- Полезно для таких вопросов, как сопоставление скобок.
Общие вопросы собеседования по стекам в Python
- Реализуйте очередь, используя стеки.
- Вычислить выражение Postfix с помощью стека.
- Следующий по величине элемент, использующий стек.
- Создать min()функцию с использованием стека.



