
The uptime options
The command doesn’t have many options. In fact, there are only four, and one of those is the help option to view the other three. That option is .
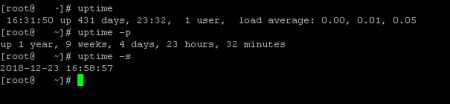
First, use the option to organize the output into a «pretty» format. Using this option results in just the system’s running time being displayed on the screen.
Image
Redirect it into your documentation file like this:
Next, display the system date and time since the system started by using the option.
Image
SCREEN uptime -s
Redirect it into your documentation file like this:
Finally, the option displays the version information for the command.
Image
Wrap up
I think it’s worth pointing out that the results are also displayed in the first line of the command’s output. That’s pretty handy information when troubleshooting performance issues using . In that case, knowing the system load averages over the five and fifteen-minute ranges is good as related to the current information dynamically displayed in . For a reminder on how to use and customize , see this article here on Enable Sysadmin.
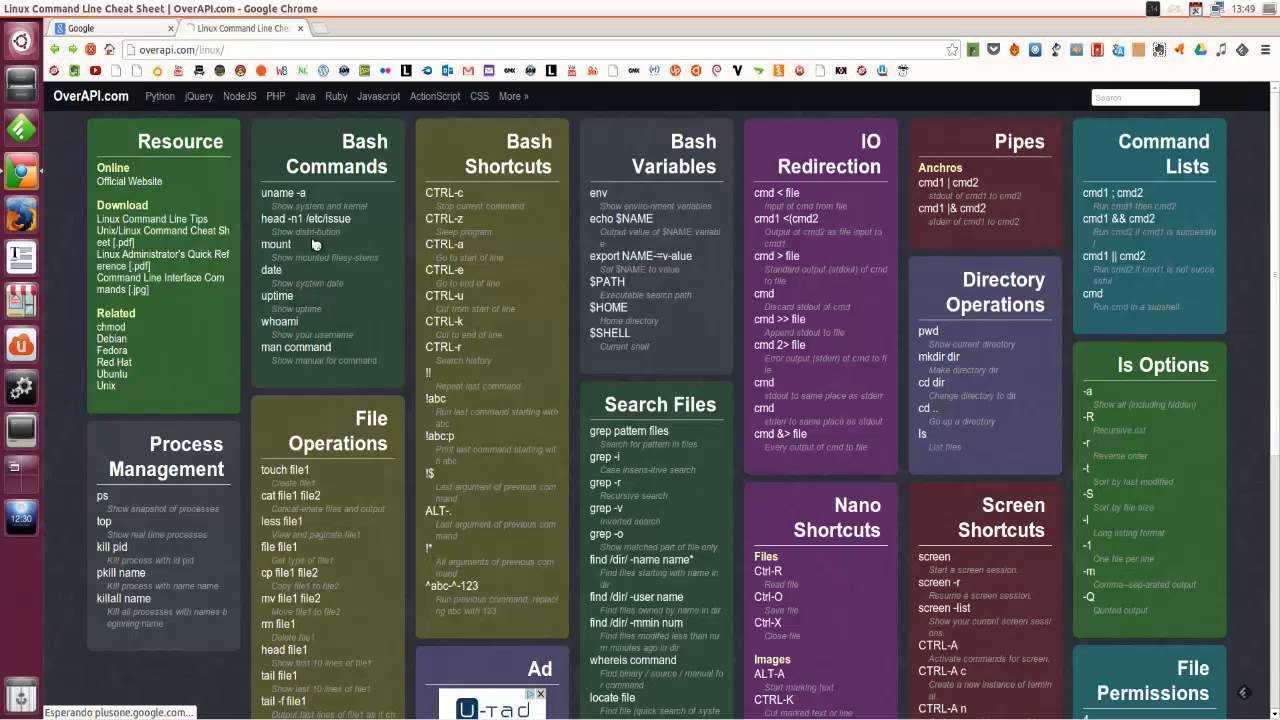
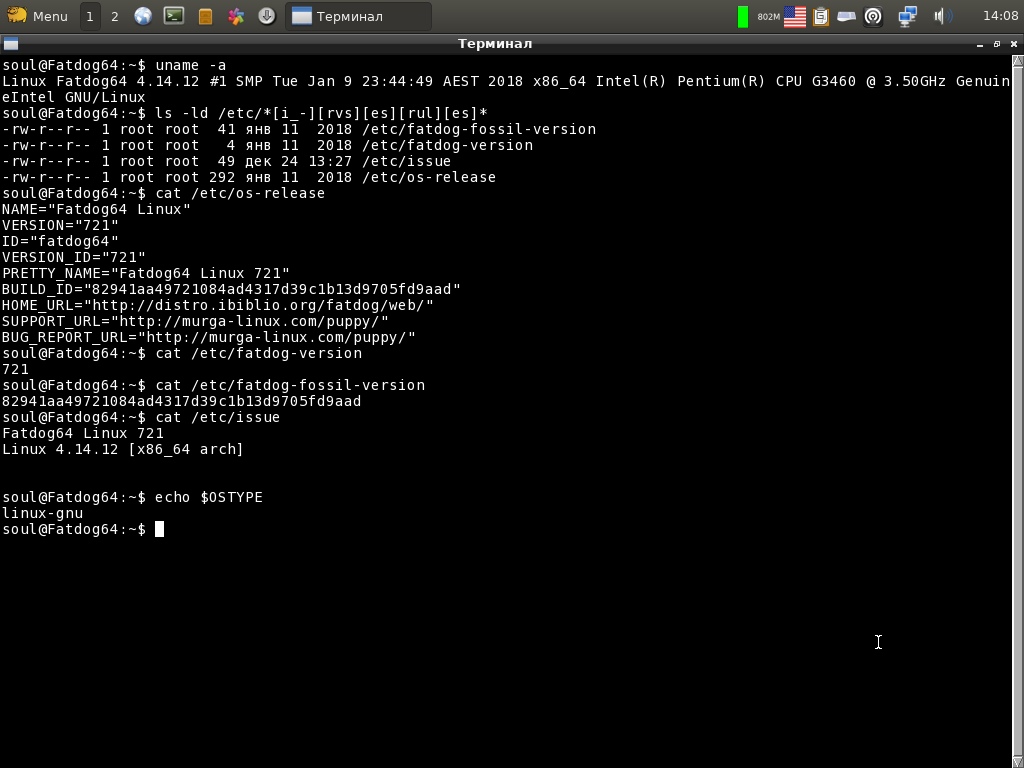
Как узнать время работы операционной системы Linux?
Определение времени работы Linux при помощи команды Uptime
Команду uptime можно запускать без параметров, так и с параметрами
Где, Options: -p, –pretty Показывает время работы ОС -h, –help Показывает помощь -s, –since Показывает время старта ОС -V, –version Отображение версии
результат запуска как с параметрами, так и без показан ниже на скриншоте:
Определение времени работы Linux при помощи команды w
Для определения времени работ ОС Linux можно также воспользоваться командой w. Результат ее выполнения показан на скриншоте ниже:

Определение времени работы Linux при помощи команды top
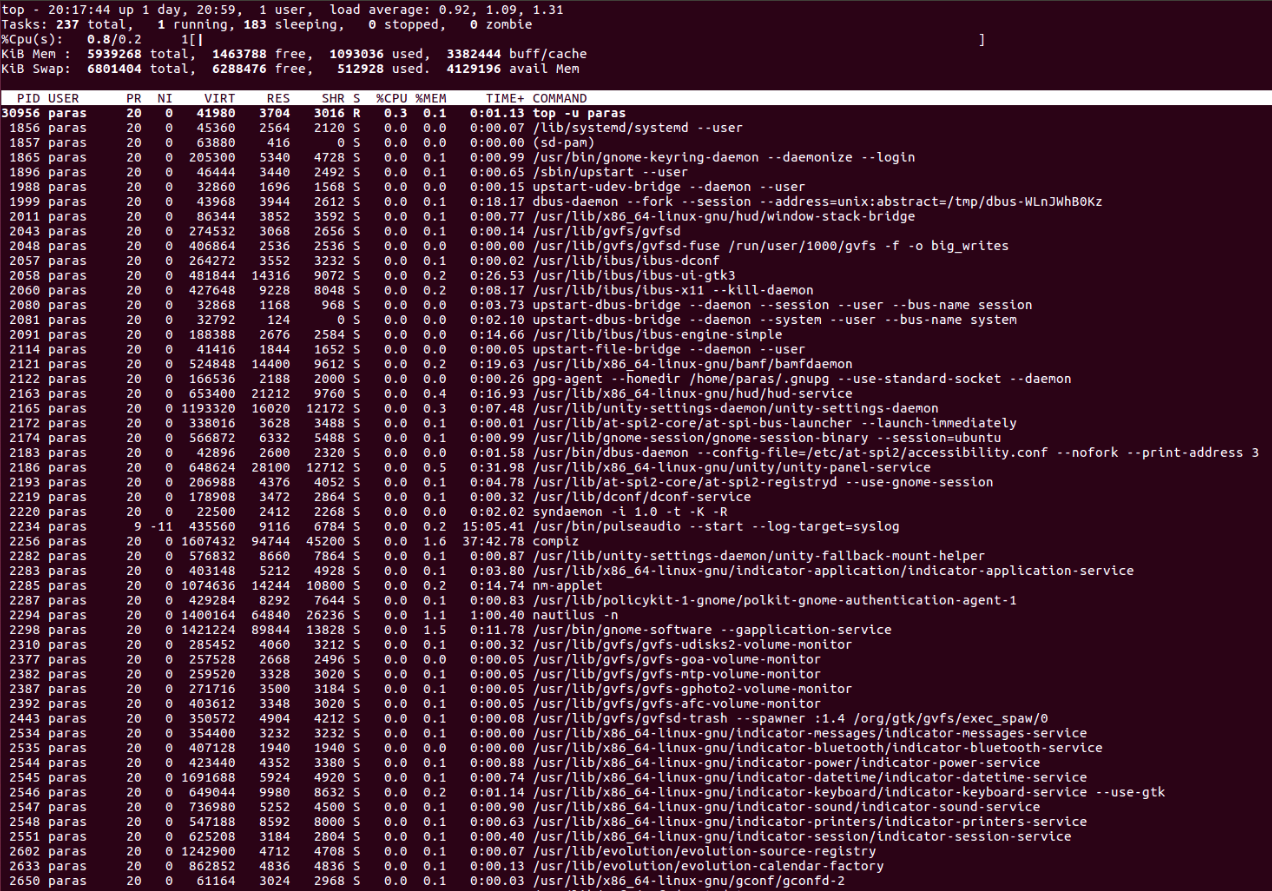
Для определения времени работ ОС Linux можно также воспользоваться командой top. результат ее выполнения показан на скриншоте ниже, время работы ОС с момент запуска можно увидеть в левом верхнем углу.
Системные команды Linux
Эти команды используются для просмотра информации и управления, связанной с системой Linux.
1. uname
Команда Uname используется в Linux для поиска информации об операционных системах. В Uname существует много опций, которые могут указывать имя ядра, версию ядра, тип процессора и имя хоста.
Следующая команда uname с опцией отображает всю информацию об операционной системе.
2. uptime
Информация о том, как долго работает система Linux, отображается с помощью команды uptime. Информация о времени безотказной работы системы собирается из файла ‘/proc/uptime‘. Эта команда также отобразит среднюю нагрузку на систему.
Из следующей команды мы можем понять, что система работает в течение последних 36 минут.
Полное руководство команды Uptime
3. hostname
Вы можете отобразить имя хоста вашей машины, введя в своем терминале. С помощью опции вы можете просмотреть ip-адрес компьютера. А с помощью параметра вы можете просмотреть доменное имя.
4. last
Команда last в Linux используется для определения того, кто последним вошел в систему на вашем сервере. Эта команда отображает список всех пользователей, вошедших (и вышедших) из «/var/log/wtmp » с момента создания файла.
Вам просто нужно ввести «last» в своем терминале.
5. date
В Linux команда date используется для проверки текущей даты и времени системы. Эта команда позволяет задать пользовательские форматы для дат.
Рекомендуем статью Команда Date (Дата) в Linux с примерами использования
Например, используя «date +%D«, вы можете просмотреть дату в формате «ММ/ДД/ГГ«.
6. cal
По умолчанию команда cal отображает календарь текущего месяца. С помощью опции вы можете просмотреть календарь на весь год.
9. reboot
Команда reboot используется для перезагрузки системы Linux. Вы должны запустить эту команду из терминала с правами суперпользователя sudo.
10. shutdown
Команда shutdown используется для выключения или перезагрузки системы Linux. Эта команда позволяет планировать завершение работы и уведомлять пользователей сообщениями о выключении и перезагрузке.
По умолчанию компьютер (сервер) выключится через 1 минуту. Вы можете отменить расписание, выполнив команду:
Немедленное отключение тоже возможно, для этого используется опция «now»
Сам себе Большой Брат
Что вообще такое «мониторинг»? Поскольку я в свое время оканчивал химический университет, у меня это понятие четко ассоциируется с системами управления технологическими производствами. По сути, у нас есть ряд параметров сложной системы, которые мы отслеживаем, а по результатам можем, если необходимо, выполнить управляющее воздействие. Например, понизить давление в реакторе. Кроме того мы можем отправить уведомление оператору, который уже независимо примет то или иное управляющее решение.
У тех, кто далек от химии, но близок к IT, ассоциация немного другая, но в целом похожая — обычно это экран с кучей графиков, на которых творится какая-то магия, как в голливудских сериалах. Для многих администраторов так оно и выглядит — Graphite/Icinga/Zabbix/Prometheus/Netdata (нужное подчеркнуть) как раз рисуют красивый интерфейс, в который можно задумчиво глядеть, почесывая бороду и гладя свитер.
Большинство этих систем работают одинаково: на конечные ноды, за которыми мы хотим наблюдать, устанавливаются так называемые агенты, или коллекторы, а дальше все происходит по методике push или pull. То есть либо мы указываем этому агенту мастер-ноду, и он начинает периодически отсылать туда отчеты и heartbeat, либо же, наоборот, мы добавляем ноду в список для мониторинга на мастере, а тот уже, в свою очередь, сам ходит и опрашивает агенты о текущей ситуации.
Нет, я не буду рассказывать в подробностях, как настраивать подобные системы. Вместо этого мы голыми руками докопаемся до того, что вообще происходит в системе.
vmstat
Вы можете использовать команду , в основном, для контроля того, что происходит с виртуальной памятью. Для того, чтобы получить наилучшую производительность системы хранения данных, Linux постоянно обращается к виртуальной памяти.
Если ваши приложения занимают слишком много памяти, вы получите чрезмерное значение затрат страниц памяти (page-outs) — программы перемещаются из оперативной памяти в пространство подкачки вашей системы, которое находится на жестком диске. Ваш сервер может оказаться в таком состоянии, когда он тратит больше времени на управление памятью подкачки, а не на работу ваших приложений; это состояние называемое пробуксовкой (thrashing). Когда компьютер находится в состоянии пробуксовки, его производительность падает очень сильно. Команда , которая может отображать либо усредненные данные, либо фактические значения, может помочь вам определить программы, которые занимают много памяти, прежде, чем из-за них ваш процессор перестанет шевелиться.
Использование командной строки для уничтожения процесса в Windows
Если вы предпочитаете инструменты командной строки, вы также можете убить процесс с помощью CMD. Командная строка дает доступ ко многим полезным утилитам, в том числе к Taskkill.
Как следует из названия, вы можете использовать Taskkill, чтобы убить любую запущенную задачу или процесс. Если вы запустите CMD от имени администратора, вы даже можете убить защищенные задачи.
- Чтобы использовать Taskkill, сначала откройте командную строку. Введите cmd в поле поиска и щелкните Запуск от имени администратора на правой панели.
- Прежде чем вы сможете использовать Taskkill, вам необходимо знать имя или PID рассматриваемой задачи. Введите список задач, чтобы получить список всех запущенных процессов на вашем компьютере.
- Теперь вы можете использовать команду Taskkill двумя способами. Чтобы использовать PID, введите taskkill / F / PID x, где x — это PID процесса, который вы хотите убить. Вы получите уведомление, если операция прошла успешно.
- Если вы хотите вместо этого ввести имя, используйте taskkill / IM «x» / F, где x — это имя рассматриваемого процесса.
Может показаться нелогичным использовать инструмент командной строки, когда диспетчер задач может делать то же самое без необходимости ввода команд. Это потому, что мы коснулись только самого простого способа использования Taskkill. Есть много других способов отфильтровать процессы, не просматривая их вручную.
sar
Программа является инструментальным средством мониторинга, столь же универсальным как швейцарский армейский нож. Команда , на самом деле, состоит из трех программ: , которая отображает данные, и и , которые собирают и запоминают данные. После того, как программа установлена, она создает подробный отчет об использовании процессора, памяти подкачки, о статистике сетевого ввода/вывода и пересылке данных, создании процессов и работе устройств хранения данных. Основное отличие между и в том, что первая команда лучше при долгосрочном мониторинге системы, в то время, как я считаю, лучше для того, чтобы мгновенно получить информацию о состоянии моего сервера.
№ 5: ps – список процессов
Команда ps выдаст краткий список текущих процессов. Для того, чтобы выбрать все процессы, используете параметр -A или –e:
# ps -A
Пример вывода данных:
PID TTY TIME CMD
1 ? 00:00:02 init
2 ? 00:00:02 migration/0
3 ? 00:00:01 ksoftirqd/0
4 ? 00:00:00 watchdog/0
5 ? 00:00:00 migration/1
6 ? 00:00:15 ksoftirqd/1
....
.....
4881 ? 00:53:28 java
4885 tty1 00:00:00 mingetty
4886 tty2 00:00:00 mingetty
4887 tty3 00:00:00 mingetty
4888 tty4 00:00:00 mingetty
4891 tty5 00:00:00 mingetty
4892 tty6 00:00:00 mingetty
4893 ttyS1 00:00:00 agetty
12853 ? 00:00:00 cifsoplockd
12854 ? 00:00:00 cifsdnotifyd
14231 ? 00:10:34 lighttpd
14232 ? 00:00:00 php-cgi
54981 pts/0 00:00:00 vim
55465 ? 00:00:00 php-cgi
55546 ? 00:00:00 bind9-snmp-stat
55704 pts/1 00:00:00 ps
Команда ps подобна команде top, но выдает больше информации.
Показать больше данных
# ps -Al
Для того, чтобы включить режим максимальной выдачи данных (будут показаны аргументы командной строки, переданные в процесс):
# ps -AlF
Настроить выдачу данных в формате, определенном пользователем
# ps -eo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,wchan:14,comm # ps axo stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,pcpu,comm # ps -eopid,tt,user,fname,tmout,f,wchan
# ps -C lighttpd -o pid=
или
# pgrep lighttpd
или
# pgrep -u vivek php-cgi
Настройка сервера времени ntp в Linux
Для этого, чтобы ваша система могла автоматический регулировать время, вам нужно установить програмку ntp. Получите ее из репозитария. После того, как она будет установлена, вы можете настроить ее следующим образом. Однократно хронируем время:





Если получили что-то вроде the NTP socket is in use, exiting — значивает ntpd демон уже запущен. В этом случае остановим его:
Налаживаем работу ЧРВ в BIOS на время по UTC:
Этой бригадой мы присвоили значение времени аппаратных часов равным системному времени. Как вы помните, целые часы мы синхронизировали командами выше. Проверим содержимое файла /etc/sysconfig/clock дабы система после загрузки правильно выставляла местное время.
Теперь целые и аппаратные часы вашего сервера будут автоматически синхронизироваться с эталонными серверами и постоянно показывать точное время. Теперь вы знаете как выполняется установка времени linux. Как видите, это очень просто, вы можете использовать различные способы, в зависимости от того, что вам будет спокойнее.
№ 10: pmap – использование процессами оперативной памяти
# pmap -d PID
# pmap -d 47394
47394: /usr/bin/php-cgi Address Kbytes Mode Offset Device Mapping 0000000000400000 2584 r-x-- 0000000000000000 008:00002 php-cgi 0000000000886000 140 rw--- 0000000000286000 008:00002 php-cgi 00000000008a9000 52 rw--- 00000000008a9000 000:00000 0000000000aa8000 76 rw--- 00000000002a8000 008:00002 php-cgi 000000000f678000 1980 rw--- 000000000f678000 000:00000 000000314a600000 112 r-x-- 0000000000000000 008:00002 ld-2.5.so 000000314a81b000 4 r---- 000000000001b000 008:00002 ld-2.5.so 000000314a81c000 4 rw--- 000000000001c000 008:00002 ld-2.5.so 000000314aa00000 1328 r-x-- 0000000000000000 008:00002 libc-2.5.so 000000314ab4c000 2048 ----- 000000000014c000 008:00002 libc-2.5.so ..... ...... .. 00002af8d48fd000 4 rw--- 0000000000006000 008:00002 xsl.so 00002af8d490c000 40 r-x-- 0000000000000000 008:00002 libnss_files-2.5.so 00002af8d4916000 2044 ----- 000000000000a000 008:00002 libnss_files-2.5.so 00002af8d4b15000 4 r---- 0000000000009000 008:00002 libnss_files-2.5.so 00002af8d4b16000 4 rw--- 000000000000a000 008:00002 libnss_files-2.5.so 00002af8d4b17000 768000 rw-s- 0000000000000000 000:00009 zero (deleted) 00007fffc95fe000 84 rw--- 00007ffffffea000 000:00000 ffffffffff600000 8192 ----- 0000000000000000 000:00000 mapped: 933712K writeable/private: 4304K shared: 768000K
- mapped: 933712K общее количество памяти, отведенного под файлы
- writeable/private: 4304K общее количество приватного адресного пространства
- shared: 768000K общее количество адресного пространства, которое данный процесс использует совместно другими процессами.
Использование команды pmap для определения распределения памяти по программам / процессам в Linux
От чего зависит uptime сайта и как его улучшить
Uptime зависит от двух аспектов: качества хостинга и оптимизированности сайта.
Если хостинг слишком слаб, то нагрузка, которую на него оказывает сайт, может выбить его из строя на некоторое время. И это приведёт к недоступности сайта, то есть он будет в дауне.
Если же сайт стоит на хорошем хостинге, то он всё равно может оказаться недоступным из-за высокой нагрузки, которую оказывает в связи плохой оптимизацией. Оптимизация сайта – дело долгое и тонкое, и необходимо добиваться наименьшей нагрузки и наибольшей скорости загрузки.
Помните, что даже самый дорогой хостинг и самый оптимизированный сайт не имеет uptime 100%. Приемлемый показатель — не менее 99%.
И ещё одна причина, когда сайт выпадает в даун – это технические работы на нём. Но, как правило, вебмастер в курсе их и контролирует ситуацию, так что это не показательно.
Устанавливаем образ RaveOS на носитель: SSD, HDD, M.2 или флешку
Прежде чем устанавливать RaveOS, нам нужно добавить Worker. Это нужно для того, что бы установленную систему RaveOS привязать к созданному воркеру. Так при загрузке RaveOS с носителя, мы увидим запущенную систему в Web интерфейсе.
В web интерфейсе RaveOS заходим во вкладку Dashboard или Workers и добавляем Worker нажав Add Worker.
Добавление Worker через Dashboard
Так же Worker можно добавить через вкладку Workers.
Добавление Worker через вкладку Workers
При добавлении воркера, заполните следующие поля:
Создание worders в RaveOS
- Name — имя воркера.
- Description — описание воркера.
- Password — пароль воркера, на случай передачи доступ другим людям.
- Card quantity — кол-во карт которое будет в воркере.
После скачивания образа RaveOS на ПК, нужно его установить на носитель. Носитель должен быть как минимум на 16Gb. Крайне рекомендуем использовать SSD накопители, т.к. они работают гораздо быстрее чем флешки и стабильнее. Если есть возможность, можете использовать SSD M.2, но данный порт в материнской плате можно использовать под дополнительную видеокарту, а в качестве носителя выбрать SSD.
Если вы все таки остановитесь на флешке, обязательно убедитесь что она имеет интерфейс минимум USB 3.0 и вставлена в порт материнской платы, который поддерживает USB 3.0, а так же убедитесь что флешка имеет хотя бы 16Gb памяти.
Для записи образа, нам понадобиться разархивированный образ RaveOS. Установить утилиту HDD Raw Copy Tool.
Через HDD Raw Copy Tool записываем образ RaveOS.
Запускаем программу, в поле FILE выбираем образ RaveOS.
HDD Raw Copy Tool
В следующем окне открываем в поле ATA выбираем носитель на который будем записывать образ.
HDD Raw Copy Tool
Далее нажимаем Continue и подтверждаем запись.
После записи образа, нужно прописать токен нашего рига в конфигурационный файл, это свяжет нашу систему с ригом на котором будет запущен RaveOS.
Выбираем Edit, входим в настройки воркера и ищем вкладку SYSTEM INFO. Нас интересует поле Worker Token.
Worker token
Копируем Worker token.
Нам его нужно вставить в файл ОС (диск с операционной системой RaveOS):/config/token.txt, вставьте Worker’s token и сохраните его. Все, этим действием вы соединили ваш воркер в RaveOS с образом, теперь при запуске этого образа в ферме, вы увидите это через панель управления (web интерфейс) RaveOS.
После записи образа, настраиваем bios материнской платы под майнинг, делая наш носитель с образом приоритетным для записи в том числе.
Linux команды консоли для работы с текстом
19. more / less
Это две простенькие команды терминала для просмотра длинных текстов, которые не вмещаются на одном экране. Представьте себе очень длинный вывод команды. Или вы вызвали cat для просмотра файла, и вашему эмулятору терминала потребовалось несколько секунд, чтобы прокрутить весь текст. Если ваш терминал не поддерживает прокрутки, вы можете сделать это с помощью less. Less новее, чем more и поддерживает больше опций, поэтому использовать more нет причин.
20. head / tail
Ещё одна пара, но здесь у каждой команды своя область применения. Утилита head выводит несколько первых строк из файла (голова), а tail выдает несколько последних строк (хвост). По умолчанию каждая утилита выводит десять строк. Но это можно изменить с помощью опции -n. Ещё один полезный параметр -f, это сокращение от follow (следовать). Утилита постоянно выводит изменения в файле на экран. Например, если вы хотите следить за лог файлом, вместо того, чтобы постоянно открывать и закрывать его, используйте команду tail -nf.
21. grep
Grep, как и другие инструменты Linux, делает одно действие, но делает его хорошо: она ищет текст по шаблону. По умолчанию она принимает стандартный ввод, но вы можете искать в файлах. Шаблон может быть строкой или регулярным выражением. Она может вывести как совпадающие, так и не совпадающие строки и их контекст. Каждый раз, когда вы выполняете команду, которая выдает очень много информации, не нужно анализировать всё вручную — пусть grep делает свою магию.
22. sort
Сортировка строк текста по различным критериям. Наиболее полезные опции: -n (Numeric), по числовому значению, и -r (Reverse), которая переворачивает вывод. Это может быть полезно для сортировки вывода du. Например, если хотите отсортировать файлы по размеру, просто соедините эти команды.
24. diff
Показывает различия между двумя файлами в построчном сравнении. Причём выводятся только строки, в которых обнаружены отличия. Измененные строки отмечаются символом «с», удалнные — «d», а новые — «а». Подробнее — здесь.
Кстати, я подготовил ещё одну подробную статью, в которой описан именно просмотр содержимого текстового файла в Linux c помощью терминала.
Многооконный режим top (как в top включить несколько вкладок)
Программа top поддерживает работу с несколькими окнами — до четырёх. Причём в каждом из них можно сделать совершенно разные настройки и наблюдать за различными характеристиками системы.
Многооконный вид top называется альтернативным режимом отображения. Для его включения нажмите A. Чтобы последовательно переключаться между окнами нажимайте a (переход к следующему) или w (возврат к предыдущему). Чтобы узнать, какое именно окно является открытым в данный момент, посмотрите на самую верхнюю строчку (если вы не отключили её кнопкой l) — там будет содержаться номер и название активного окна.
С помощью интерактивной команды g можно быстро переключаться между окнами. После её нажатия нужно будет ввести цифры от 1 до 4. Кстати, команда g работает как в многооконном режиме, так и в режиме одного окра. В последнем случае также происходит переключение на другое окно.
Вы можете установить имя окна (которое отображается в самом верху, для этого используйте команду G. После её отправки вам нужно будет ввести новое имя текущего окна.
Для каждого окна можно установить свой собственный набор полей, независимый от других окон, настроить сортировку и отображение.
4. dmidecode
Утилита dmidecode собирает подробную информацию об оборудовании системы на основе данных DMI в BIOS. Отображаемая информация включает производителя, версию процессора, доступные расширения, максимальную и минимальную скорость таймера, количество ядер, конфигурацию кэша L1/L2/L3 и т д. Здесь информация о процессоре Linux намного легче читается чем у предыдущей утилиты.
5. hardinfo
Hardinfo это графическая утилита которая позволяет получить информацию о процессоре и другом оборудовании в системе в графическом интерфейсе. Утилиту надо установить:
Запуск
6. i7z
Утилита i7z — монитор параметров процессора в реальном времени для процессоров Intel Core i3, i5 и i7. Он отображает информацию по каждому ядру в реальном времени, такую как состояние TurboBoost, частота ядер, настройки управления питанием, температура и т д. У i7z есть консольный интерфейс основанный на Ncurses, а также графический на базе библиотек Qt.
7. inxi
Команда inxi — это bash скрипт, написанный для сбора информации о системе в удобном и понятном для человека виде. Он показывает модель процессора, размер кэша, скорость таймера и поддерживаемые дополнительные возможности процессора. Для установки используйте:




Для запуска:
8. likwid-topology
Likwid (Like I Knew What I’m Doing) — это набор инструментов командной строки для измерения, настройки и отображения параметров оборудования компьютера. Информация о процессоре может быть выведена с помощью утилиты likwid-topology Она показывает модель и семейство процессора, ядра, потоки, кэш, NUMA. Установка:
9. lscpu
Команда lscpu отображает содержимое /proc/cpuinfo в более удобном для пользователя виде. Например, архитектуру процессора, количество активных ядер, потоков, сокетов.
10. lshw
Команда lshw — универсальный инструмент для сбора данных об оборудовании. В отличии от других инструментов для lshw необходимы права суперпользователя так как утилита читает информацию из DMI в BIOS. Можно узнать общее количество ядер, и количество активных ядер. Но нет информации об кэше L1/L2/L3.
11. lstopo
Утилита lstopo входит в пакет hwloc и визуализирует топологию системы. Сюда входит процессор, память, устройства ввода/вывода. Эта команда полезна для идентификации архитектуры процессора и топологии NUMA. Установка:
12. numactl
Первоначально разрабатываемая для настройки планировки NUMA и политик управления памятью в Linux numactl также позволяет посмотреть топологию NUMA:
13. x86info
x86info — инструмент командной строки для просмотра информации о процессорах архитектуры x86. Предоставляемая информация включает модель, количество ядер/потоков, скорость таймера, конфигурацию кэша, поддерживаемые флаги и т д. Установка в Ubuntu:
14. nproc
Утилита просто выводит количество доступных вычислительных потоков. Если процессор не поддерживает технологию HyperThreading, то будет выведено количество ядер:
15. hwinfo
Утилита hwinfo позволяет выводить информацию о различном оборудовании, в том числе и о процессоре. Программа отображает модель процессора, текущую частоту, поддерживаемые расширения. Наверное, это самый простой способ узнать частоту процессора Linux:
×
Файлы, которых нет
Если говорить совсем откровенно, в Linux основным источником информации как о процессах, так и о железе служит именно файловая виртуальная файловая система
procfs(/proc), а также
sysfs(/sys). И у них довольно богатая и интересная история.
Дело в том, что одно из официальных положений идеологии UNIX гласит: «Всё есть файл», то есть взаимодействие с любым системным компонентом теоретически должно вестись через реальный или виртуальный файл, доступный через обычное дерево каталогов. Эту идею до абсолюта довели в наследнике UNIX под названием Plan 9, где все процессы превратились в каталоги и взаимодействовать с ними можно было даже посредством команд
cat и
ls, поскольку они были текстовыми. Именно так появилась файловая система procfs, которая позже перекочевала в Linux и BSD.
Но, как и в случае с load average, конкретно в Linux есть свои тонкости (это я так политкорректно называю адскую кашу-малашу). Например, линуксовый
/proc, вопреки названию, с самого начала был универсальным интерфейсом получения информации от ядра в целом, а не только от процессов. Более того, именно взаимодействовать с процессами через эту систему практически не получается, только извлекать информацию по их PID’ам.
С течением времени в
/proc появлялось все больше и больше файлов, содержащих информацию о самых разных подсистемах ядра, железе и многом другом. В конечном итоге он превратился в помойку, и разработчики решили вынести информацию хотя бы о железе в отдельную файловую систему, которую к тому же можно было бы использовать для формирования каталога
/dev. Так и появилась
/sys со своей странной структурой каталогов — ее трудно разгребать вручную, но она очень удобна для автоматического анализа другими приложениями (такими как udev, который и формирует содержимое каталога
/dev на основе информации из
/sys).
В итоге куча информации до сих пор дублируется в
/proc и
/sys просто потому, что, если выкинуть файлы из
/proc, можно сломать некоторые фундаментальные системные компоненты (легаси!), которые до сих пор не переписаны.
Ну а еще есть
/run, конечно же. Это файловая система, которая монтируется одной из первых и служит перевалочным пунктом для данных рантайма основных системных демонов, в частности udev и systemd (о нем поговорим отдельно чуть позже). Кстати, сам проект udev в 2012 году влился в systemd и дальше развивается как его часть.
В общем, как писал Льюис Кэрролл, «все чудесатее и чудесатее».
Но вернемся к нашим замерам. Для того чтобы смотреть, какие PID присвоены процессам, есть команды
pidstat и
htop (из одноименного пакета, более продвинутая версия top, заодно показывает чертову прорву всего, аналог графического диспетчера задач).
Кроме того, команда time позволяет запустить процесс, попутно измерив время его выполнения, точнее, целых три времени:
|
1 |
$time python3-c»import time; time.sleep(1)» python3-c»import time; time.sleep(1)»0.04suser0.01ssystem4%cpu1.053total |
Как выше я уже проговорился, любая программа может проводить разное время в kernel space и user space, то есть выполняя вызовы в ядро или свой собственный код. Поэтому при базовом взгляде на эти цифры можно в некоторых случаях уже сделать вывод об узком месте в программе: если первый показатель сильно выше, то, вполне возможно, затык в I/O, а если второй — то, возможно, в коде есть неэффективно написанные куски, которые стоит запрофилировать подробнее.
А вот третье время, total time, оно же wall clock time или real time, — это время, которое реально заняло выполнение программы с момента запуска до момента возврата управления. Кстати, user time может быть сильно больше real time, потому что оно рассчитывается как сумма по всем ядрам CPU. Если такое происходит — значит, программа неплохо параллелится.
Ну и напоследок, чтобы посмотреть загрузку для каждого ядра в отдельности, можно использовать вот такую команду:
| 1 | $mpstat-PALL1 |
Если будут сильные перекосы в загрузке ядер — значит, какая-то из программ, напротив, параллелится крайне плохо. А единичка значит «обновляй-ка раз в секунду».
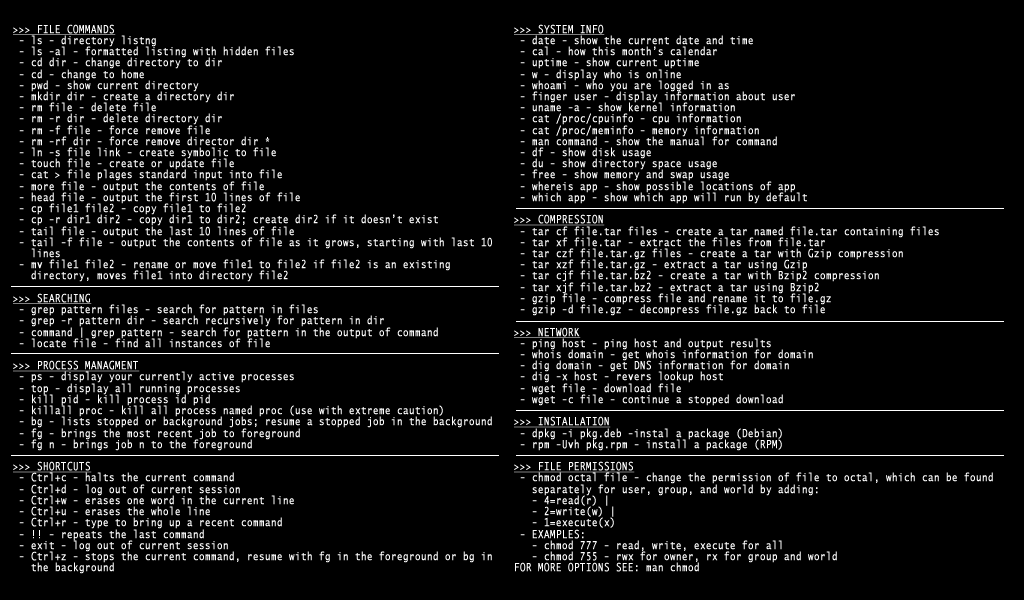
Команды Linux, для работы с файлами
Эти команды используются для обработки файлов и каталогов.
33. ls
Очень простая, но мощная команда, используемая для отображения файлов и каталогов. По умолчанию команда ls отобразит содержимое текущего каталога.
34. pwd
Linux pwd — это команда для показывает имя текущего рабочего каталога. Когда мы теряемся в каталогах, мы всегда можем показать, где мы находимся.
Пример ример ниже:
35. mkdir
В Linux мы можем использовать команду mkdir для создания каталога.
По умолчанию, запустив mkdir без какой-либо опции, он создаст каталог в текущем каталоге.
36. cat
Мы используем команду cat в основном для просмотра содержимого, объединения и перенаправления выходных файлов. Самый простой способ использовать cat— это просто ввести » имя_файла cat’.
В следующих примерах команды cat отобразится имя дистрибутива Linux и версия, которая в настоящее время установлена на сервере.
37. rm
Когда файл больше не нужен, мы можем удалить его, чтобы сэкономить место. В системе Linux мы можем использовать для этого команду rm.
38. cp
Команда Cp используется в Linux для создания копий файлов и каталогов.
Следующая команда скопирует файл ‘myfile.txt» из текущего каталога в «/home/linkedin/office«.
39. mv
Когда вы хотите переместить файлы из одного места в другое и не хотите их дублировать, требуется использовать команду mv. Подробнее можно прочитать ЗДЕСЬ.
40.cd
Команда Cd используется для изменения текущего рабочего каталога пользователя в Linux и других Unix-подобных операционных системах.
41. Ln
Символическая ссылка или программная ссылка — это особый тип файла, который содержит ссылку, указывающую на другой файл или каталог. Команда ln используется для создания символических ссылок.
Команда Ln использует следующий синтаксис:
42. touch
Команда Touch используется в Linux для изменения времени доступа к файлам и их модификации. Мы можем использовать команду touch для создания пустого файла.
44. head
Команда head используется для печати первых нескольких строк текстового файла. По умолчанию команда head выводит первые 10 строк каждого файла.
45. tail
Как вы, возможно, знаете, команда cat используется для отображения всего содержимого файла с помощью стандартного ввода. Но в некоторых случаях нам приходится отображать часть файла. По умолчанию команда tail отображает последние десять строк.
46. gpg
GPG — это инструмент, используемый в Linux для безопасной связи. Он использует комбинацию двух ключей (криптография с симметричным ключом и открытым ключом) для шифрования файлов.


50. uniq
Uniq — это инструмент командной строки, используемый для создания отчетов и фильтрации повторяющихся строк из файла.
53. tee
Команда Linux tee используется для связывания и перенаправления задач, вы можете перенаправить вывод и/или ошибки в файл, и он не будет отображаться в терминале.
54. tr
Команда tr (translate) используется в Linux в основном для перевода и удаления символов. Его можно использовать для преобразования прописных букв в строчные, сжатия повторяющихся символов и удаления символов.
Команды Linux для управления сетью
39. ip
Если список команд Linux для управления сетью вам кажется слишком коротким, скорее всего вы не знакомы с утилитой ip. В пакете net-tools содержится множество других утилит: ipconfig, netstat и прочие устаревшие, вроде iproute2. Всё это заменяет одна утилита — ip. Вы можете рассматривать её как швейцарский армейский нож для работы с сетью или как непонятную массу, но в любом случае за ней будущее. Просто смиритесь с этим.
40. ping
Ping — это ICMP ECHO_REQUEST дейтаграммы, но на самом деле это неважно. Важно то, что утилита ping может быть очень полезным диагностическим инструментом
Она поможет быстро проверить, подключены ли вы к маршрутизатору или к интернету, и дает кое-какое представление о качестве этой связи.
41. nethogs
Если у вас медленный интернет, то вам, наверное, было бы интересно знать, сколько трафика использует какая-либо программа в Linux или какая программа потребляет всю скорость. Теперь это можно сделать с помощью утилиты nethogs. Для того чтобы задать сетевой интерфейс используйте опцию -i.
×
42. traceroute
Это усовершенствованная версия ping. Мы можем увидеть не только полный маршрут сетевых пакетов, но и доступность узла, а также время доставки этих пакетов на каждый из узлов. Подробнее — тут.
w — узнайте, кто вошел в систему и какие действия производит
Команда who (w) отображает информацию о пользователях, находящихся в данный момент в системе, и их процессах.
Примеры выводов:
4. uptime — узнайте, сколько уже работает система Linux
Команда uptime используется, чтобы узнать, как долго, с момента последней перезагрузки, работает после сервер. Текущее время, сколько времени система работает, сколько пользователей в системе на данный момент и средняя загрузка системы за последние 1, 5 и 15 минут.
Вывод:
1 пользователь в системе считается оптимальным значением нагрузки. Нагрузка может меняться от системы к системе. Для систем с одним ЦП приемлемо значение нагрузки 1–3, для систем SMP — 6–10.
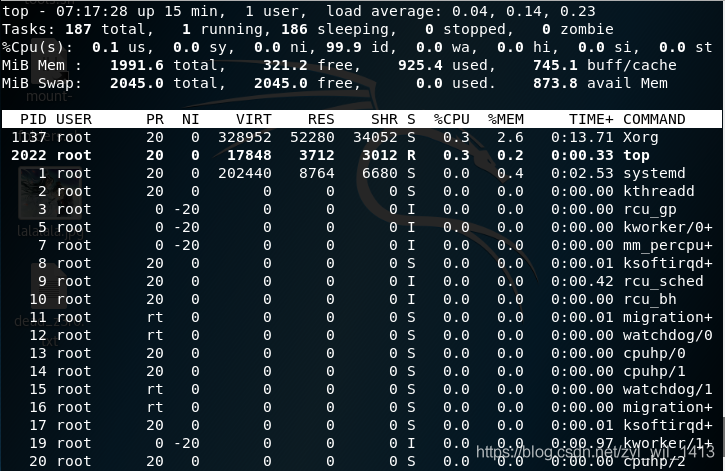
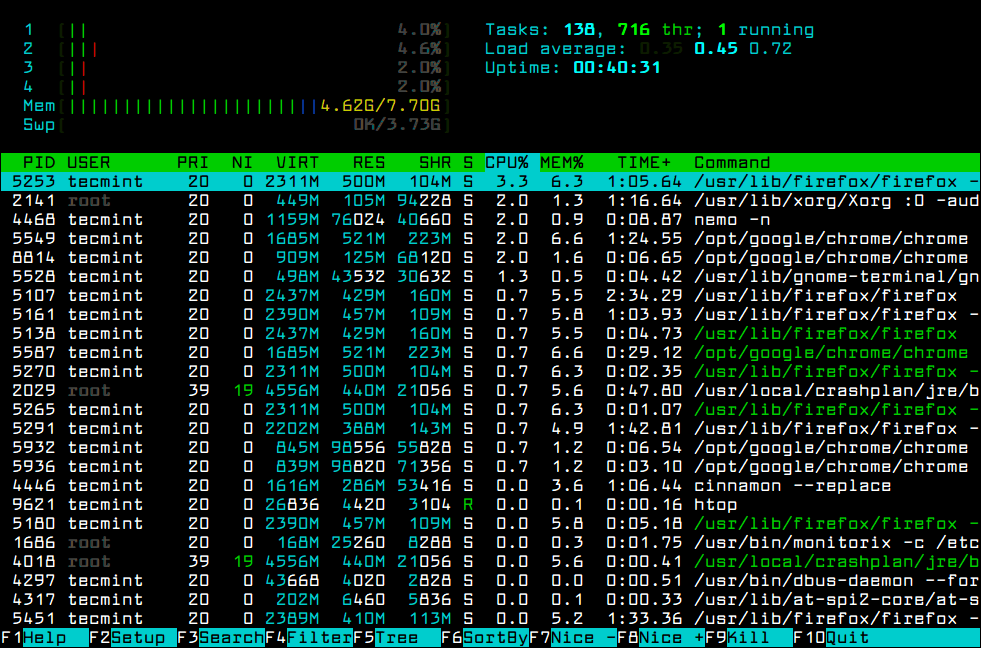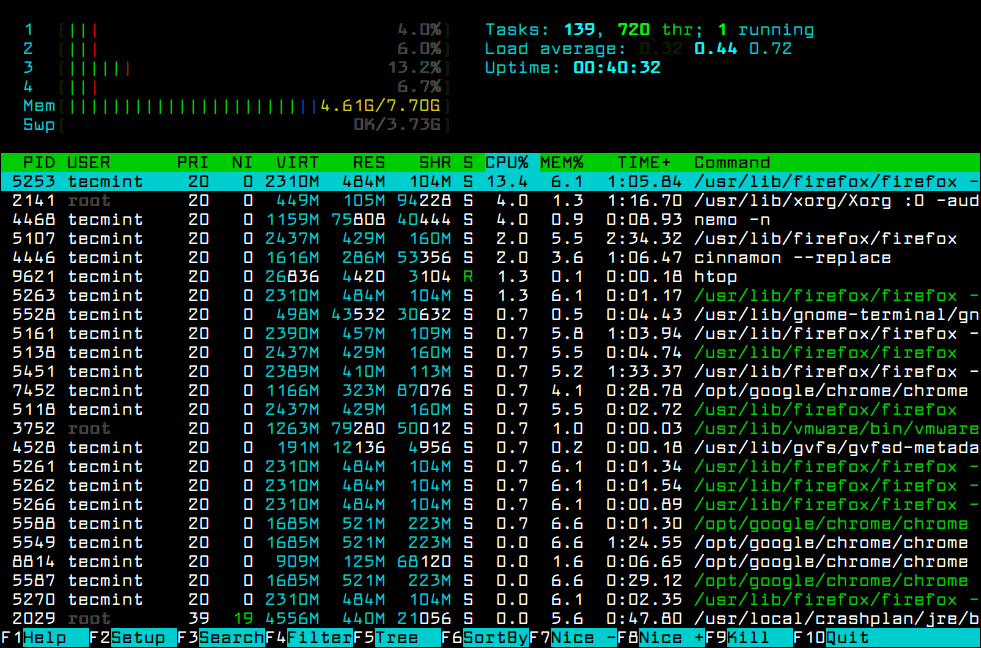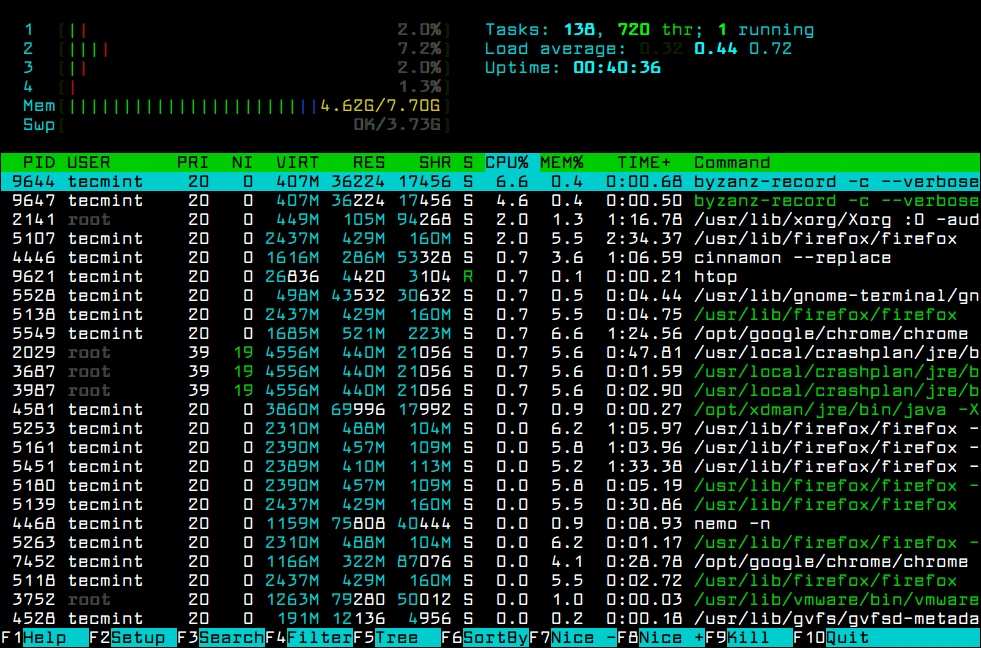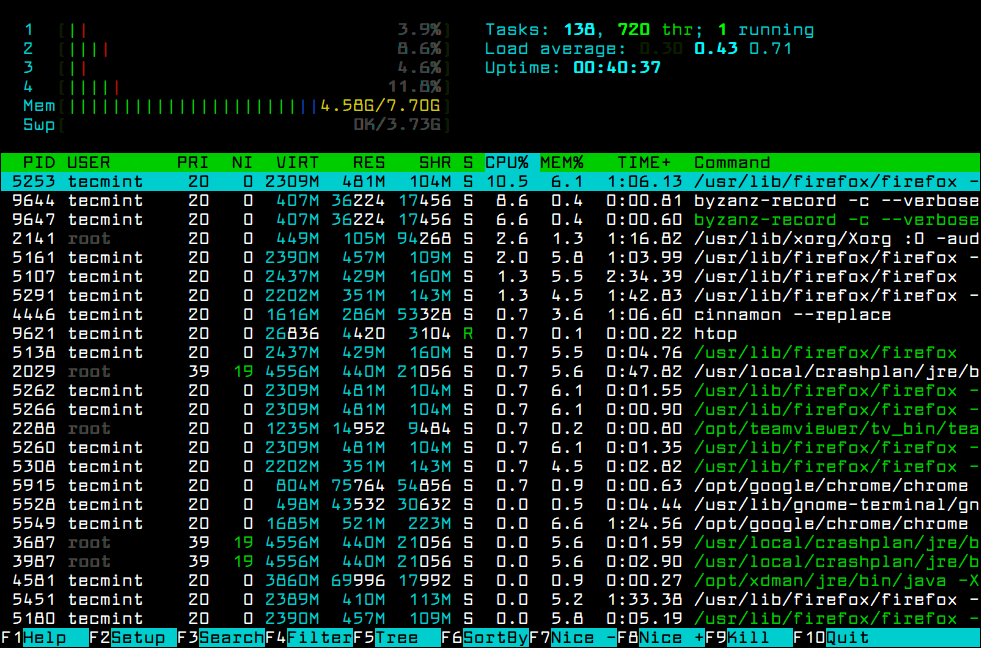
Что означают цифры в top (как понимать вывод top)
Начнём с краткой характеристики стандартного интерфейса top. Как уже было сказано, его можно почти полностью сконфигурировать под свои предпочтения.
Верхняя часть программы показывает краткую обобщённую информацию об использовании процессора и оперативной памяти системы.
В самой верхней строке показано: текущее время в системе, аптайм (время работы после загрузки), общее количество пользователей и средняя нагрузка за последние 1, 5 и 15 минут.
Далее идут строки с информацией о:
- задачах
- процессоре
- оперативной памяти
- разделе подкачки
Далее идёт перечень запущенных процессов. По умолчанию выводиться следующая информация:
PID — уникальный идентификатор процесса
USER — имя пользователя, являющегося владельцем задачи
PR — приоритет задачи в расписании. Если вы в этом поле видите «rt», это означает, что задача запущена в расписании приоритетов в реальном времени (это самый высокий приоритет).
NI — значение nice задачи. Негативное значение означает более высокий приоритет, а положительное значение nice означает более низкий приоритет
VIRT — общее количество используемой задачей виртуальной памяти, включает все коды, данные, совместные библиотеки, плюс страницы, которые были перенесены в раздел подкачки, и страницы, которые были размечены, но не используются
RES — используемая оперативная память, является подмножеством VIRT, представляет физическую память, не помещённую в раздел подкачки, которую в текущий момент использует задача. Также является суммой полей RSan, RSfd и Rssh.
SHR — размер совместной памяти, подмножество используемой памяти RES, которая может использоваться другими процессами
S — статус процесса. Может быть:
- D = бесперебойный сон
- I = простой (не работает)
- R = запущен
- S = спит
- T = остановлен сигналом управления работой
- t = остановлен отладчиком во время трассировки
- Z = зомби
%CPU — использование центрального процессора, доля задачи в потреблённом процессорном времени с момента последнего обновления экрана, выражается в процентах от общего времени CPU
%MEM — доля задачи в использовании памяти (RES)
TIME+ — общее время центрального процессора, которое использовала задача с момента запуска
COMMAND — Имя команды или Строка команды. Показывает строку команды, используемую для запуска задачи или имя ассоциированной программы



