
Системный взгляд на эволюцию ИТ:
Фаза 1: Ручная обработка информации.
В течение 6 тыс. лет (с 4000 г. до н.э. – 1900г.) наблюдалась эволюция носителей информации (от глиняных таблиц к папирусу, а затем к бумаге), информация обрабатывалась вручную.
Наиболее значимые достижения этого периода связаны с появлением книгопечатания (1445г.).
Фаза 2: Технология перфокарт.
Технология перфокарт (1900-1955 гг.), когда запись данных производилась в двоичной системе счисления, а для их сбора и обработки использовались электромеханические устройства и компьютеры (первый компьютер появился в 1946г.).
Фаза 3: Технология магнитных лент.
Технология магнитных лент (1955-1980 гг.) использовала программируемое оборудование обработки информации – электронные компьютеры с хранимыми программами.
- Особенности технологии:
- Последовательная организация наборов данных.
- Пакетная обработка транзакций.
Фаза 4: Технология оперативных БД на магнитных дисках и барабанах.
Технология оперативных БД на магнитных дисках и барабанах (1965-1980 гг.) связана с внедрением оперативного доступа к данным (доли секунды для доступа к любому элементу) в интерактивном режиме, с использованием систем БД с оперативными транзакциями.
- Особенности технологии:
- Интерактивное подключение к компьютеру.
- Прямая и индексно-последовательная организация наборов данных.
- Модели БД (от простых иерархических – к сетевым и простейшим реляционным).
- Виды схем для независимости данных в БД.
- Логическая;
- Физическая;
- Подсхема для программных приложений
Проблема – отсутствие навигационного программного интерфейса.
Фаза 5: Технология реляционной БД с архитектурой «клиент-сервер».
Технология реляционных БД с архитектурой «клиент-сервер» (1980-1995гг.) явилась откликом на проблему низкоуровневого интерфейса и широким распространением технологий компьютерных сетей.
- Характерной особенностью таких БД является наличие унифицированного языка SQL – стандарта для:
- определения данных,
- навигации по данным,
- манипулирования данными.
- Реляционная модель вместе с повышением продуктивности и простотой использования оказалась очень удобной для ее использования:
- в архитектуре «клиент-сервер»,
- в параллельной обработке данных,
- в разработке графических пользовательских интерфейсов.
Эволюция критериев разработки ПО.
- «Машинные ресурсы» (до середины 60-ых годов): экономия времени и памяти, фаза «кустарного производства» программ и пакетной обработки.
- «Программирование» (до начала 80-ых годов): экономия человеческих ресурсов, появление БИС и СБИС, микропроцессоров, систем программирования и операционных систем типа ОС UNIX.
- «Формализация знаний»(до 90-ых годов): расширение сферы применения, появление систем автоматизации (САПР, АСУ, АСУ ТП, ГАП) для непрограммистов-профессионалов.
- «Интернет-технологии» (н.вр.): приложения для широкого круга пользователей-непрограммистов.
Сервера приложений (#B Application servers)
Преимущества: Место веб-сервера занимает сервер приложений, т.е. не приложение запускается под управлением веб-сервера, а веб-сервер встраивается в приложение или сервер приложений. Более того, для повышения эффективности, HTTP/HTTPS могут быть заменены специализированными протоколами на базе TCP/TLS. Особенно это актуально для мобильных и десктопных приложений, что дает возможность строить RPC, шину событий, синхронизацию БД.
Недостатки: Такие приложения пока не имеют универсальных облачных решений, но все идет к тому, что они скоро появятся. А до этого, нужно изобретать свой стек технологий и самим строить приватное облако. Это сложно поддерживать и обслуживать. Кроме того, синхронизация БД на сервере и клиенте делается вручную, через приложение, обычно сверхусилями разработчиков, а использовать такие решения повторно обычно не удается.
Вывод: Это направление сейчас доступно только крупным компаниям, имеющим потребность в обслуживании миллионов пользователей, создании интерактивных приложений или R&D лабораториям, готовящим подобные решения для массового пользователя.
Обслуживание высоких нагрузок облаком (#A Cloud Highload)
Преимущества: Облака прекрасно справляются с масштабированием, используя принцип REST, приложения могут обслуживать десятки миллионов абонентов, если отказываются от состояния, т.е. серверные процессы не хранят состояния в памяти, все сетевые вызовы независимы и не переводят сессию ни в какое состояние.
Недостатки: В реальных приложениях часто отходят от REST именно потому, что для решения задачи нужно состояние. Получается псевдо-REST, не масштабируемый, но с кучей ограничений. А главное, совершенно не подходящий для приложений, интерактивно взаимодействующих с пользователем или обеспечивающих взаимодействие между пользователями.
Вывод: Во многих случаях это оптимальное решение: публикация контента, информационные ресурсы, СМИ, могут быть эффективно построены в облаке, но для сложных приложений с базами данных и интерактивностью, это шаг назад от архитектуры #8.
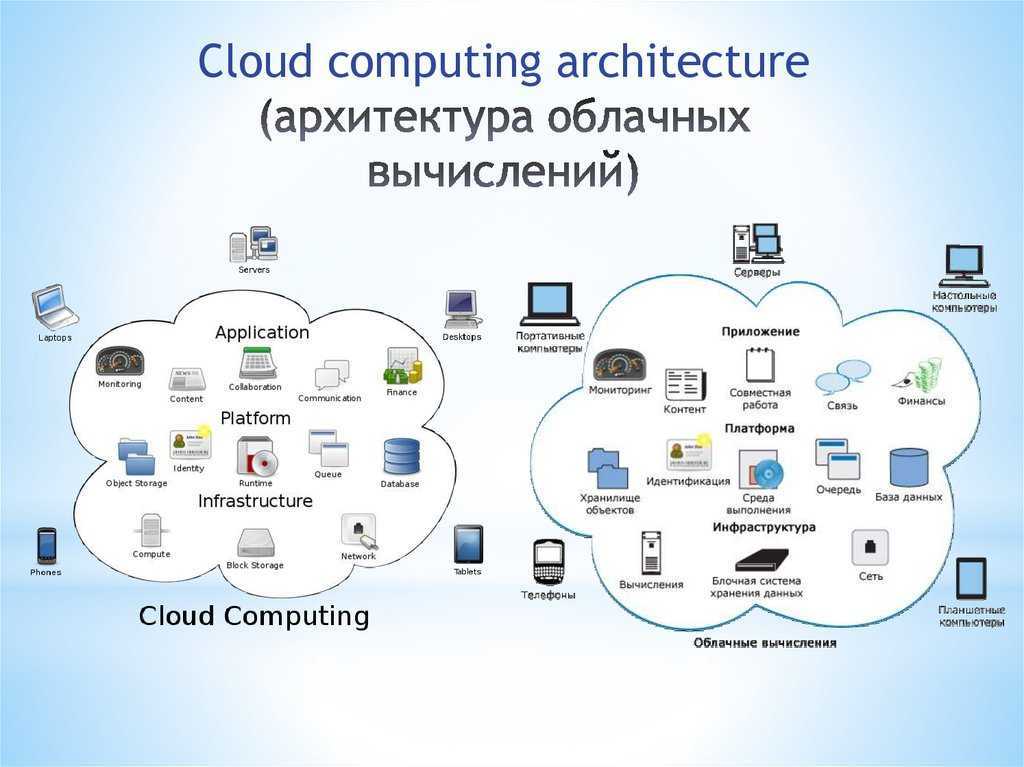
Структура Data Access Layer
Данный раздел описывает принципиальное устройство программного обеспечения DAL, реализующего концепцию унифицированного доступа к данным. В описании структуры DAL рассматриваются в том числе и вопросы выбора и применения конкретных технологий и программных продуктов.
Принципы, применяющиеся при проектировании DAL
- Не ставится задача автоматического, безостановочного, не требующего затрат или мгновенного переключения работающей АС с одного средства хранения на другое. Проектировочные решения должны не полностью исключать (что долго и сложно), а существенно снижать зависимость логики приложения от средства хранения таким образом, чтобы значительно облегчить возможный переход. Нужно рассчитывать на разумный подход проектировщиков АС и понимание ими архитектурных принципов и целей, а потому не пытаться выстроить суперзащищенную техническую систему.
- При проектировании должны максимально использоваться готовые, уже существующие на рынке и стандартизованные средства и компоненты. Если предприятие хочет обеспечить максимальную независимость от вендоров, то предпочтительно использование Open Source продуктов и технологий, но только достаточно зрелых, с подобающим размером сообщества и примерами внедрений на ответственных предприятиях.
- Следует стремиться к простоте перевода существующих АС на DAL.
- Лучше наращивать возможности реализуемого DAL постепенно, итерационно. Первый шаг должен быть простым, дешевым и быстрым, направленным на решение наиболее актуальных задач (в частности, переносимость реляционных СУБД).
- Новый подход к управлению хранением может не ограничиваться техническими средствами, а включать, например, изменения в организационных механизмах предприятия в части управления инфраструктурой, а также в процессах проектирования и технического аудита АС.
Варианты размещения компонентов структуры DAL
Рис. 6. Варианты размещения компонентов структуры DAL
- В виде библиотеки, включаемой в состав приложения. В этом варианте необходима разработка разных видов модулей доступа для разных технологий разработки АС.
- В виде сетевого сервиса. Этот вариант предназначен для тех случаев, когда по каким-то причинам невозможна или нежелательна работа сервиса доступа к данным в виде библиотеки (например, ИС разработана на платформе, у которой нет библиотеки для работы с DAL). В таком варианте DAL доступен для любого приложения, способного работать с сетевыми сервисами по протоколу HTTP. Для этого способа размещения набор предоставляемых интерфейсов доступа к данным может быть ограничен.
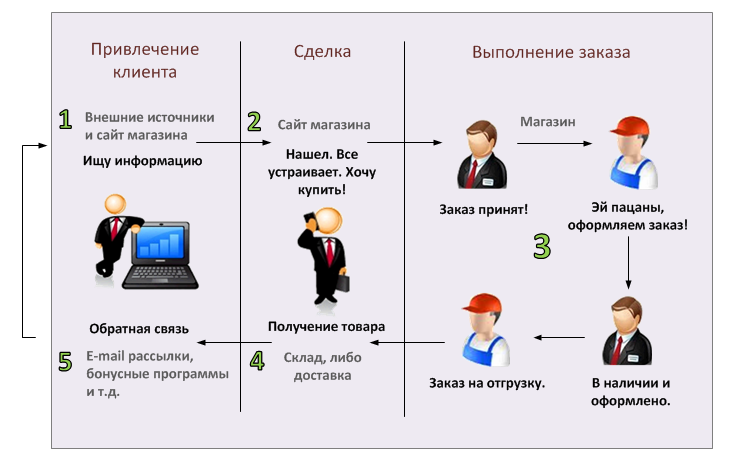
Что такое компьютерная сеть?
Компьютерная сеть (Computer NetWork: net – сеть, work –работа) – это система обмена информацией между компьютерами.
Главная цель – обеспечение доступа для пользователя к локальным ресурсам любого из компьютеров сети.
- Основные компоненты компьютерной сети
- Компьютеры: ПК, ноутбуки, мэйнфреймы…
- Телекоммуникационное оборудование: коммутаторы, маршрутизаторы, линии связи…
- Операционные системы – WinNT, Novell NetWare, Unix…
- Сетевые приложения – сетевые принтеры и диски, базы данных…
Классификация компьютерных сетей
- …по «географии» распространения:
- Локальные сети LAN (Local Area Network)
- Глобальные сети WAN(Wide Area Network)
- Городские сети MAN(Metropolitan Area Network)
- …по масштабу производственного подразделения:
- Сети отделов
- Сети кампусов
- Корпоративные сети
- …по способу управления:
- Сети «клиент-сервер»: сервер– поставщик услуг, клиент– потребитель услуг.
- Одноранговые сети.
- …по структуре (топологии) связей:
- С топологией «Общая шина»;
- С топологией «Звезда»;
- С топологией «Кольцо»;
- С древовидной топологией
- Со смешанной топологией
Наиболее распространенные виды сетей.
Интернет (Internet) – сообщество международных и национальных компьютерных сетей.
Интранет (Intranet) – внутренняя сеть организации, использующая протоколы, службы и технологии интернета.
Экстранет (Extranet) – корпоративная интранет, имеющая доступ к части ресурсов извне только для ограниченного числа пользователей.
Модуль доступа к РСУБД для приложений Java
Интерфейсы доступа к реляционным данным
- доступ напрямую к реляционным данным через интерфейс JDBC и язык SQL;
- доступ посредством объектной модели через объектно-реляционный адаптер JPA (Java Persistence API).
Конструктивная реализация модуля DAL для Java
JBoss TeiidРис. 8. Конструктивная реализация модуля DAL для Java



- предоставление интерфейса JPA для приложений Java;
- предоставление интерфейса JDBC для приложений Java;
- использование собственного унифицированного диалекта SQL (на основе стандарта SQL-99);
- трансляция собственного диалекта SQL в специфические диалекты поддерживаемых БД;
- наличие коннекторов к большинству используемых РСУБД и простая расширяемость;
- возможность работы как в режиме встроенного модуля, так и в режиме сетевого сервиса;
- открытые исходные коды (Open Source), возможность бесплатного использования в коммерческих целях, развитое сообщество и примеры внедрения в крупных предприятиях.
- объединение баз данных путем создания так называемой «виртуальной БД» (virtual DB, VDB) в настройках с помощью визуального дизайнера. Подобная «виртуальная БД» ассоциируется с реальными средствами хранения (не только реляционными);
- эффективное выполнение «кросс-запросов» — SQL-запросов к «виртуальной БД», которые автоматически транслируются в SQL-запросы к реальным БД;
- кеширование результатов запросов к «виртуальной БД».
Модуль доступа к РСУБД для приложений Java
Интерфейсы доступа к реляционным данным
- доступ напрямую к реляционным данным через интерфейс JDBC и язык SQL;
- доступ посредством объектной модели через объектно-реляционный адаптер JPA (Java Persistence API).
Конструктивная реализация модуля DAL для Java
JBoss TeiidРис. 8. Конструктивная реализация модуля DAL для Java
- предоставление интерфейса JPA для приложений Java;
- предоставление интерфейса JDBC для приложений Java;
- использование собственного унифицированного диалекта SQL (на основе стандарта SQL-99);
- трансляция собственного диалекта SQL в специфические диалекты поддерживаемых БД;
- наличие коннекторов к большинству используемых РСУБД и простая расширяемость;
- возможность работы как в режиме встроенного модуля, так и в режиме сетевого сервиса;
- открытые исходные коды (Open Source), возможность бесплатного использования в коммерческих целях, развитое сообщество и примеры внедрения в крупных предприятиях.
- объединение баз данных путем создания так называемой «виртуальной БД» (virtual DB, VDB) в настройках с помощью визуального дизайнера. Подобная «виртуальная БД» ассоциируется с реальными средствами хранения (не только реляционными);
- эффективное выполнение «кросс-запросов» — SQL-запросов к «виртуальной БД», которые автоматически транслируются в SQL-запросы к реальным БД;
- кеширование результатов запросов к «виртуальной БД».
Концепция Data Access Layer
В данном разделе описывается общая концепция и принципы DAL, с помощью которых можно решить вышеупомянутые проблемы. Здесь концепция описана абстрактно и пока не связана с применением тех или иных технологий или программных продуктов.
Принцип управляемого специализированного хранения данных
- обеспечивать возможность использования специализированных БД в ИТ-архитектуре предприятия одновременно с сохранением управляемости (например, за счет контроля их разнообразия и применения);
- подготавливать бизнес-приложения к плавной и технологичной смене СУБД в случае обострения отношений с поставщиком СУБД или, возможно, из соображений технологической модернизации и технологического развития.
Рис. 2. Принцип управляемого специализированного хранения данных
Понятия
Этот раздел уточняет и детализирует модель объектов описания DAL, коротко введенную в предыдущем разделе.Рис. 4. Понятийная модель концепции DAL
- класс данных;
- средство хранения;
- характеристика средства хранения;
- класс средств хранения;
- группа данных;
- контейнер данных.
Класс данных
- абстрактную («логико-математическую») модель самих данных (например, «набор реляционных отношений» или «набор пар ключ-значение»);
- модель (или несколько моделей) доступа к данным и вычисления над данными (например, «реляционная алгебра» или MapReduce);
- модель безопасности (например, «именованные контейнеры», «пользователи» и «права»);
- модель структуры данных (например, «схема с описанием таблиц» или «перечень групп атрибутов»).
- производительность чтения/записи;
- масштабируемость;
- работа в памяти (in-memory);
- ограничения;
- специализация (например, Big Data или Fast Data);
- поддержка ACID-транзакций и т. д.
Обобщение тенденций
Какой гибрид выйдет в итоге слияния этих направлений, пока не ясно, но уже можно построить несколько предположений и, как минимум, выделить тенденции.
Уже очевидно, что ветвление архитектур на этом этапе будет происходить, в первую очередь, за счет встраивания системных компонентов в само приложение:
- Встраиваемые в приложение коммуникационного сервера: HTTP/WS, HTTPS/WSS, TCP/TLS и т.д.
- Встраиваемые в приложение СУБД с автоматической синхронизацией.
- По аналогии можно вспомнить и про еще одну функцию ИС, это обработка данных или вычисления. Так что, встраиваемые в приложения систем распределенных вычислений рано или поздно тоже произойдет. Ведь пользовательские устройства в наше время обладают большой вычислительной мощностью и не использовать их для распределенной обработки данных, это непозволительное архитектурное упущение.
Лично я хочу объединить Data-centric архитектуру (которая, по принципу Парето, накроет 80% потребностей полной автоматизацией) с сервером приложений (который даст возможность сделать интеграцию на уровне API или шины событий для оставшихся 20% случаев). Для этого протокол взаимодействия ИС должен поддерживать одновременно 5 типов взаимодействия: RPC, REST, Event BUS, DB Sync, Binary streaming. Над таким комплексным решением и работает сейчас наша команда.
Кроме четырех крупных архитектур можно строить гибриды из комбинации отдельных возможностей:
- Synchronization — синхронизация структур данных между приложениями в распределенных системах в режиме времени, приближенном к реальному;
- Offline — возможность работать с частью данных, сохраненных в локальном хранилище в браузере или мобильном приложении, а при выходе в онлайн синхронизировать;
- Interactivity — возможность двустороннего обмена событиями с сервером и построение реактивных компонентов: UI, курсоров баз данных, логики приложения, обмена по сети и т.д.;
- Low latency (или High availability) — характеристика готовности обработки запросов и оптимизация времени отклика сервера (не путать с пропускной способностью);
- Highload — обработка интенсивного потока запросов (request per second), что включает их частоту, размер, приоритет, время ожидания в очереди, время жизни и ресурсы для обслуживания;
- High connectivity — большое количество конкурентных (одновременных и долгоживущих) соединений клиентов к серверу с возможностью двустороннего обмена данными по инициативе любой из сторон;
- High interconnection — характеристика интенсивности взаимодействия между конкурентными соединениями, а также размер взаимодействующих групп соединений;
- Scalability — группа характеристик горизонтального и вертикального масштабирования, обеспечивающих прозрачность масштабирования для программных и аппаратных средств (без переписывания кода);
- Big data — возможность обрабатывать большие объемы данных, например потоковая обработка данных или построение запросов к распределенным хранилищам;
- Big memory и in-memory DB — высокая утилизация объемов памяти или перенос баз данных полностью в оперативную память с дополнительными индексами для быстрого исполнения запросов;
- Integration flexibility — характеристика гибкости и простоты интеграции решений, на базе интроспекции, автоматического связывания интерфейсов, скаффолдинга и динамической интерпретации метамоделей.
Для того, чтобы мы все понимали тенденции, предлагаю ответить на вопросы, а так же, буду благодарен за конструктивную критику и комментарии.
Отчет Duo об удаленном доступе
Cisco Безопасность Duo с его современной безопасностью доступа, предназначен для защиты всех пользователей, устройств и приложений. Он предлагает безопасный доступ и масштабируемое, простое в развертывании решение SaaS, которое изначально защищает все приложения. Кроме того, он обеспечивает интуитивно понятную аутентификацию для пользователей. В с помощью удаленного доступа можно было получить некоторые интересные факты об эволюции удаленной работы. Таким образом, мы знаем, что 78% опрошенных рабочих не менее 60% времени работали из дома в марте этого года.
Еще одним заслуживающим внимания фактом стало увеличение на 72% количества многофакторных удаленных технологий аутентификации и на 85% увеличение использования политик, запрещающих аутентификацию по SMS. Что касается iOS устройств, они в четыре раза чаще получали и устанавливали обновления, чем Android устройств. Кроме того, использование биометрических устройств увеличилось на 64%. Ежедневная аутентификация в облачных приложениях также увеличилась на 40% в первые месяцы пандемии Covid-19. В то время целью этих компаний было продолжить работу и гарантировать безопасный доступ к своим услугам.
Обслуживание высоких нагрузок облаком (#A Cloud Highload)
Преимущества: Облака прекрасно справляются с масштабированием, используя принцип REST, приложения могут обслуживать десятки миллионов абонентов, если отказываются от состояния, т.е. серверные процессы не хранят состояния в памяти, все сетевые вызовы независимы и не переводят сессию ни в какое состояние.
Недостатки: В реальных приложениях часто отходят от REST именно потому, что для решения задачи нужно состояние. Получается псевдо-REST, не масштабируемый, но с кучей ограничений. А главное, совершенно не подходящий для приложений, интерактивно взаимодействующих с пользователем или обеспечивающих взаимодействие между пользователями.
Вывод: Во многих случаях это оптимальное решение: публикация контента, информационные ресурсы, СМИ, могут быть эффективно построены в облаке, но для сложных приложений с базами данных и интерактивностью, это шаг назад от архитектуры #8.
Отраслевые методы многофакторной аутентификации
Теперь мы посмотрим, как методы многофакторной аутентификации развиваются в двух секторах промышленности, с помощью некоторых графиков. Это то, что делает финансовый сектор.
Это график технологического сектора.
Как видно, в обоих секторах использование SMS-аутентификации очень мало из-за того, что применяются более современные и безопасные методы. По этой причине мы ранее упоминали, что его использование значительно сократилось. Беспокоит тот факт, что более 30% Windows устройства в медицинских организациях по-прежнему использовали Windows 7, хотя их поддержка уже закончилась.
Что касается перехода к удаленной работе, то он вызывает ряд изменений. Использование приложений в облаке постепенно превосходит использование локальных приложений. Таким образом, приложения в облаке составляют 13.2% всех аутентификаций Duo, что на 5.4% больше, чем в прошлом году. Что касается местных заявок, то они составляют 18.5% от общего числа, и их количество снизилось на 1.5% по сравнению с прошлым годом. В этом смысле неудивительно, если облачные приложения вскоре обгонят локальные.






Одноранговое или пиринговое взаимодействие (#D Peer-to-Peer)
Преимущества: Это разгрузит сервера, которые будут выполнять только функцию связывания/брокера. Локальное взаимодействие между пользователями часто более эффективны, чем через удаленный сервер, особенно при больших потоках данных. Дает надежду на анонимность обмена приватными данными.
Недостатки: Вопрос «доверия» в пиринговых сетях все еще полностью не преодолим. Строить распределенные ИС только на P2P не получится, сервера все равно будут в этой схеме. Пока нет распространенных протоколов, библиотек, фреймворков и других программных средств для реализации в объеме, необходимом для построения прикладных ИС.
Вывод: Элементы одноранговых сетей будут встраиваться в централизованные ИС.
Фаза 6: Технология мультимедийных БД.
Технология мультимедийных БД (с 1995 г.) связана с переходом к объектно-реляционным БД.
Название технологии происходит от «мультимедиа» (от англ. multimedia – многие средства).
Технология позволяет хранить, обрабатывать и манипулировать объектами со сложным поведением (карты, видео-ролики и т.п.).
Клиенты и серверы строятся с использованием апплетов и «хелперов», которые сохраняют, обрабатывают и отображают данные того или иного типа (звук, графика, видео, электронные таблицы, графы).
- КОНТРОЛЬНЫЕ ВОПРОСЫ:
- В каких аспектах можно рассматривать эволюцию ИТ?
- Почему сегодня эволюцию ИТ не рассматривают как эволюцию носителей информации?
- Назовите основные этапы в эволюции критериев разработки ПО.
- Сколько этапов (фаз) насчитывает эволюция ИТ с точки зрения смены технологий управления данными?
- Какие фазы эволюции ИТ связаны с эволюцией носителей информации?
- Каким образом осуществлялось управление данными в технологии магнитных лент?
- Каким образом осуществлялось управление данными в технологии оперативных БД на основе магнитных дисков и барабанов?
- Каким образом в этой технологии обеспечивалась независимость данных?
- Какая проблема вызвала переход к следующей фазе в развитии ИТ?
- Что такое «компьютерная сеть» (КС)? Назовите основную цель функционирования КС?
- Назовите основные признаки, используемые для классификации КС.
- Назовите и определите основные виды КС.
- Опишите общую схему взаимодействия в КС по технологии «клиент-сервер».
- Назовите и определите основные понятия технологии «клиент-сервер».
- Каким образом строится приложение «клиент-сервер»?
- Назовите технологии программирования на стороне сервера.
- Назовите технологии программирования на стороне клиента.
- Назовите основные признаки технологии мультимедийных БД.
Обобщение тенденций
Какой гибрид выйдет в итоге слияния этих направлений, пока не ясно, но уже можно построить несколько предположений и, как минимум, выделить тенденции.
Уже очевидно, что ветвление архитектур на этом этапе будет происходить, в первую очередь, за счет встраивания системных компонентов в само приложение:
- Встраиваемые в приложение коммуникационного сервера: HTTP/WS, HTTPS/WSS, TCP/TLS и т.д.
- Встраиваемые в приложение СУБД с автоматической синхронизацией.
- По аналогии можно вспомнить и про еще одну функцию ИС, это обработка данных или вычисления. Так что, встраиваемые в приложения систем распределенных вычислений рано или поздно тоже произойдет. Ведь пользовательские устройства в наше время обладают большой вычислительной мощностью и не использовать их для распределенной обработки данных, это непозволительное архитектурное упущение.
Лично я хочу объединить Data-centric архитектуру (которая, по принципу Парето, накроет 80% потребностей полной автоматизацией) с сервером приложений (который даст возможность сделать интеграцию на уровне API или шины событий для оставшихся 20% случаев). Для этого протокол взаимодействия ИС должен поддерживать одновременно 5 типов взаимодействия: RPC, REST, Event BUS, DB Sync, Binary streaming. Над таким комплексным решением и работает сейчас наша команда.
Кроме четырех крупных архитектур можно строить гибриды из комбинации отдельных возможностей:
- Synchronization — синхронизация структур данных между приложениями в распределенных системах в режиме времени, приближенном к реальному;
- Offline — возможность работать с частью данных, сохраненных в локальном хранилище в браузере или мобильном приложении, а при выходе в онлайн синхронизировать;
- Interactivity — возможность двустороннего обмена событиями с сервером и построение реактивных компонентов: UI, курсоров баз данных, логики приложения, обмена по сети и т.д.;
- Low latency (или High availability) — характеристика готовности обработки запросов и оптимизация времени отклика сервера (не путать с пропускной способностью);
- Highload — обработка интенсивного потока запросов (request per second), что включает их частоту, размер, приоритет, время ожидания в очереди, время жизни и ресурсы для обслуживания;
- High connectivity — большое количество конкурентных (одновременных и долгоживущих) соединений клиентов к серверу с возможностью двустороннего обмена данными по инициативе любой из сторон;
- High interconnection — характеристика интенсивности взаимодействия между конкурентными соединениями, а также размер взаимодействующих групп соединений;
- Scalability — группа характеристик горизонтального и вертикального масштабирования, обеспечивающих прозрачность масштабирования для программных и аппаратных средств (без переписывания кода);
- Big data — возможность обрабатывать большие объемы данных, например потоковая обработка данных или построение запросов к распределенным хранилищам;
- Big memory и in-memory DB — высокая утилизация объемов памяти или перенос баз данных полностью в оперативную память с дополнительными индексами для быстрого исполнения запросов;
- Integration flexibility — характеристика гибкости и простоты интеграции решений, на базе интроспекции, автоматического связывания интерфейсов, скаффолдинга и динамической интерпретации метамоделей.
Для того, чтобы мы все понимали тенденции, предлагаю ответить на вопросы, а так же, буду благодарен за конструктивную критику и комментарии.
Доступ к данным
Существует шесть основных методов доступа к данным:
- Физический последовательный.
- Индексно-последовательный.
- Индексно-произвольный.
- Инвертированный.
- Прямой.
- Доступ через хеширование.
Перечисленные методы отличаются друг от друга по двум признакам:
- Эффективность хранения;
- Эффективность доступа.
Как правило, эти два признака находятся в обратной зависимости. При эффективном хранении доступ усложняется. И наоборот — меры ускоряющие доступ к данным, приводят к увеличению объемов требуемой для хранения памяти.
Другие более сложные методы доступа строятся из перечисленных базовых методов. При этом разработчики программного обеспечения стараются найти оптимальное для конкретных задач соотношение эффективности хранения и доступа.
Одноранговое или пиринговое взаимодействие (#D Peer-to-Peer)
Преимущества: Это разгрузит сервера, которые будут выполнять только функцию связывания/брокера. Локальное взаимодействие между пользователями часто более эффективны, чем через удаленный сервер, особенно при больших потоках данных. Дает надежду на анонимность обмена приватными данными.
Недостатки: Вопрос «доверия» в пиринговых сетях все еще полностью не преодолим. Строить распределенные ИС только на P2P не получится, сервера все равно будут в этой схеме. Пока нет распространенных протоколов, библиотек, фреймворков и других программных средств для реализации в объеме, необходимом для построения прикладных ИС.





Вывод: Элементы одноранговых сетей будут встраиваться в централизованные ИС.
Инвертированный метод доступа
Этот метод предназначен для поиска по значениям произвольных полей и их комбинаций. Произвольные комбинации часто бывают не уникальными, поэтому на каждое значение ключа формируется список указателей на записи. При поиске сначала выбирается нужный индекс, а уже внутри него каким-то иным способом (например, индексно-произвольным) выбирается статья с этим значением. Далее по статье выбирается весь блок ссылок, связанных с данным значением индекса.
У этого метода эффективность доступа не очень высокая, так как для поиска одной записи нужно сделать как минимум два обращения – одно к индексу, другое к базе данных. Эффективность хранения может быть достаточно высокой.
БД-центрический подход (#C Database-centric)
Преимущества: Очень привлекательно поставить БД вперед приложения и настроить синхронизацию (частичную репликацию) между базами данных. Таким образом, мы имеем СУБД встраиваемые в приложения и работаем не с сервером, а с локальной БД. Для этого уже придумано множество методов: optimistic replication, operational transformation, conflict-free replicated data type, ведь СУБД существуют уже достаточно давно и научились масштабироваться.
Недостатки: Общение между приложениями только через данные явно ограничивает наши возможности. Это редукция всего к работе с базой. А как же передача событий, интеграция на уровне API, вызов удаленных процедур? Обо всем этом нужно забыть при БД-центрическом подходе.
Вывод: Для определенного класса задач это шикарное решение, а вместе с интроспекцией и скаффолдингом UI такая архитектура автоматически «раскатает» в очень широкой сфере применения более сложных конкурентов, интегрирующихся при помощи API и требующих все время писать взаимодействие программно.



