
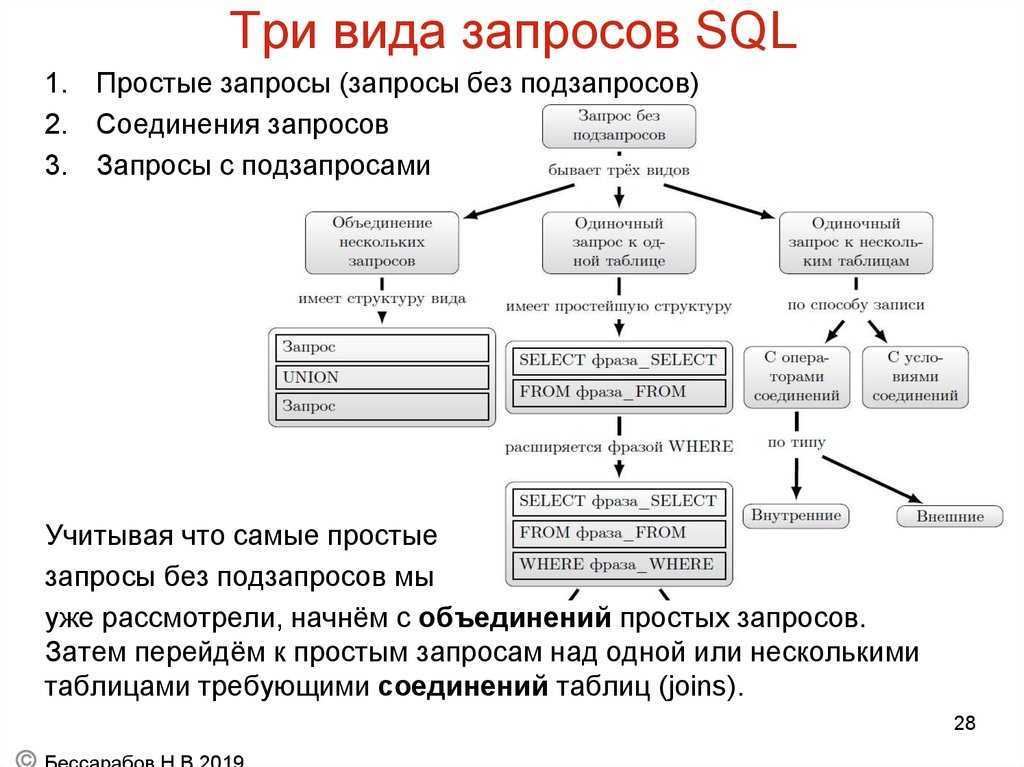
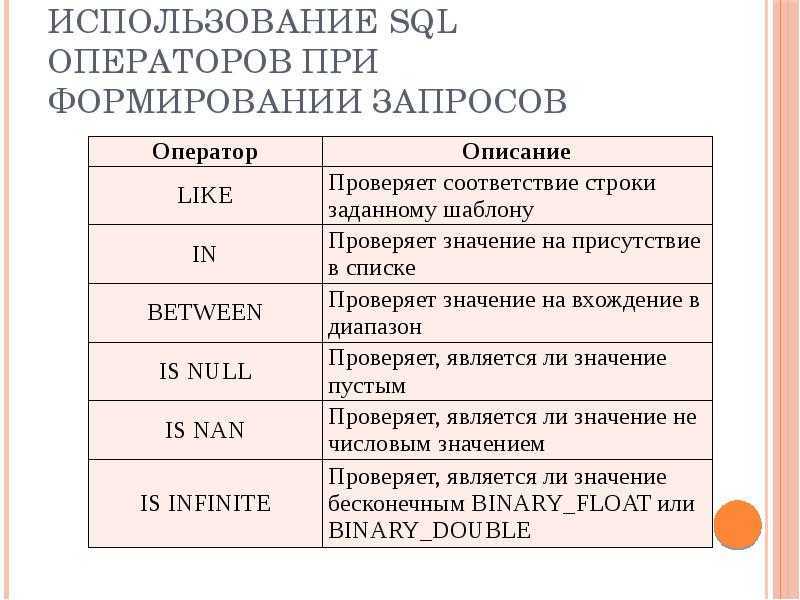
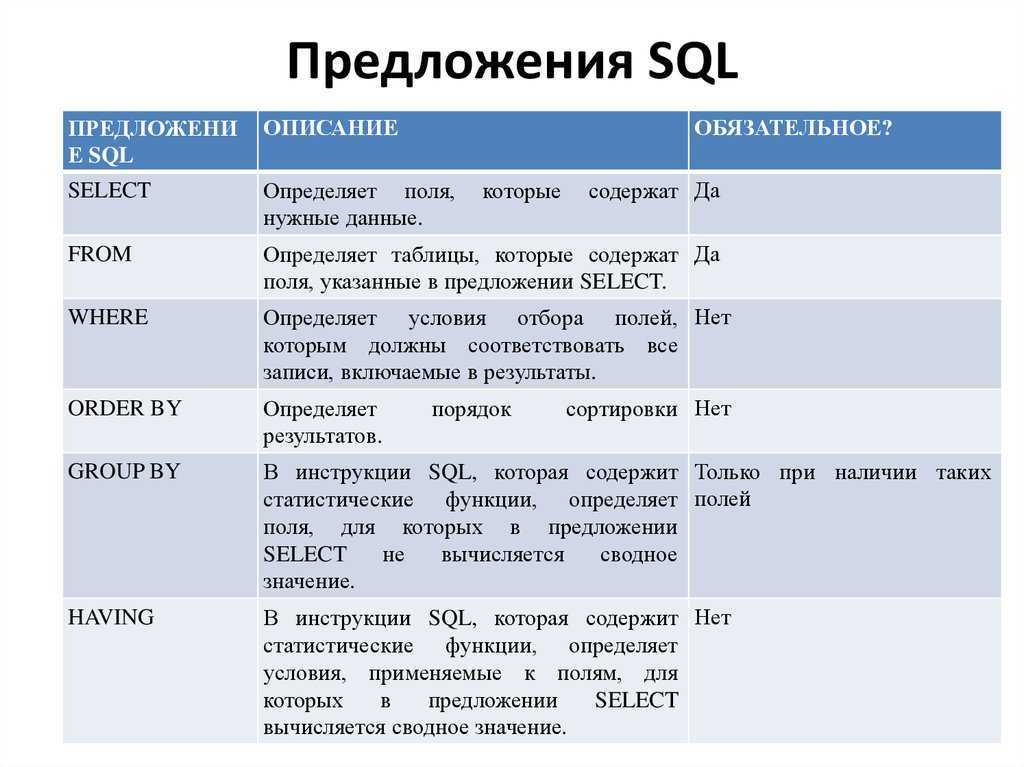
В чем различие между операторами HAVING и WHERE?
Основное отличие ‘WHERE’ от ‘HAVING’ заключается в том, что ‘WHERE’ сначала выбирает строки, а затем группирует их и вычисляет агрегатные функции (таким образом, она отбирает строки для вычисления агрегатов), тогда как ‘HAVING’ отбирает строки групп после группировки и вычисления агрегатных функций. Как следствие, предложение ‘WHERE’ не должно содержать агрегатных функций; не имеет смысла использовать агрегатные функции для определения строк для вычисления агрегатных функций. Предложение ‘HAVING’, напротив, всегда содержит агрегатные функции. (Строго говоря, вы можете написать предложение ‘HAVING’, не используя агрегаты, но это редко бывает полезно. То же самое условие может работать более эффективно на стадии ‘WHERE’.)
Обновление агрегатных функций
Часто — когда вы работаете с базой данных — вы не хотите видеть фактические данные в базе данных. Вместо этого вам может потребоваться информация о данных. Например, вы можете узнать количество уникальных продуктов, которые продаёт ваш бизнес, или максимальный балл в таблице лидеров.
В SQL есть несколько встроенных функций, которые позволяют получить эту информацию. Они называются агрегатными функциями.
Например, предположим, что вы хотите узнать, сколько сотрудников являются торговыми партнёрами, вы можете использовать функцию COUNT. Функция COUNT подсчитывает и возвращает количество строк, соответствующих определённому набору критериев. Другие агрегатные функции включают SUM, AVG, MIN и MAX.
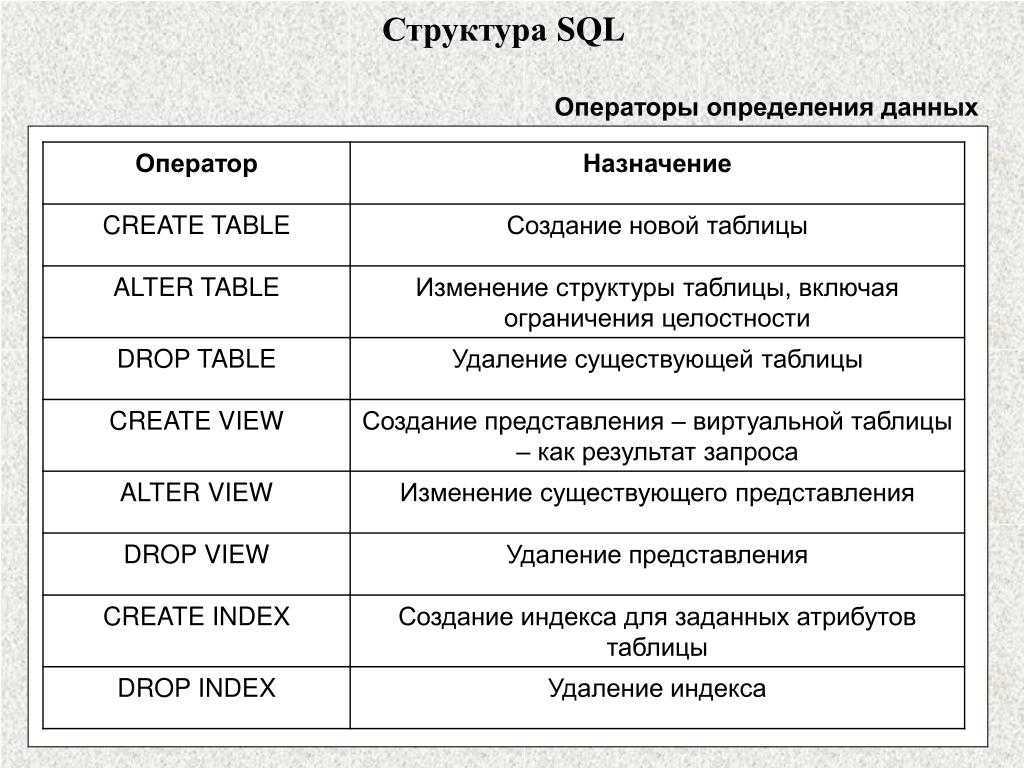
Создание таблицы с данными
Для нашего примера мы создадим таблицу, в которой будут храниться записи о продажах различных продуктов в разных точках.
Таблицу мы назовем sales. Это будет простое представление продаж в магазинах: название локации, название продукта, цена и время продажи.
Если бы мы создавали такую таблицу для настоящего приложения, мы бы использовали внешние ключи к другим таблицам (например, locations или products). Но чтобы показать работу GROUP BY, мы создадим простые TEXT-столбцы.
Давайте создадим нашу таблицу и внесем в нее кое-какие данные о продажах:
CREATE TABLE sales( location TEXT, product TEXT, price DECIMAL, sold_at TIMESTAMP ); INSERT INTO sales(location, product, price, sold_at) VALUES (‘HQ’, ‘Coffee’, 2, NOW()), (‘HQ’, ‘Coffee’, 2, NOW() — INTERVAL ‘1 hour’), (‘Downtown’, ‘Bagel’, 3, NOW() — INTERVAL ‘2 hour’), (‘Downtown’, ‘Coffee’, 2, NOW() — INTERVAL ‘1 day’), (‘HQ’, ‘Bagel’, 2, NOW() — INTERVAL ‘2 day’), (‘1st Street’, ‘Bagel’, 3, NOW() — INTERVAL ‘2 day’ — INTERVAL ‘1 hour’), (‘1st Street’, ‘Coffee’, 2, NOW() — INTERVAL ‘3 day’), (‘HQ’, ‘Bagel’, 3, NOW() — INTERVAL ‘3 day’ — INTERVAL ‘1 hour’);
У нас есть три локации: HQ, Downtown, и 1st Street.
Также у нас есть два продукта: Coffee и Bagel (кофе и бублики). Продажи мы вносим с разными значениями sold_at, чтобы показать, сколько товаров было продано в разные дни и разное время.
У нас были продажи сегодня, вчера и позавчера.
SQL Group By по нескольким столбцам
Если бы мы хотели, мы могли бы выполнить GROUP BY для нескольких столбцов. Например, предположим, что мы хотели получить список сотрудников с определёнными должностями в каждом филиале. Мы могли бы получить эти данные, используя следующий запрос:
Наш набор результатов запроса показывает:
| ответвляться | заглавие | считать |
| Стэмфорд | Сотрудник по продажам | 1 |
| Олбани | Вице-президент по продажам | 1 |
| Сан-Франциско | Сотрудник по продажам | 1 |
| Сан-Франциско | Старший специалист по продажам | 1 |
| Олбани | Директор по маркетингу | 1 |
| Бостон | Сотрудник по продажам | 2 |
(6 рядов)
Наш запрос создаёт список титулов, которыми владеет каждый сотрудник. Мы видим количество людей, обладающих этим титулом. Наши данные сгруппированы по отраслям, в которых работает каждый сотрудник, и их должностям.
3. Группировка и сортировка
Как и при обычной выборке данных, мы можем сортировать группы после группировки оператором HAVING. Для этого мы можем использовать уже знакомый нам оператор ORDER BY. В данной ситуации его применения аналогичное предыдущим примерам. К примеру:
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM(Quantity)>3000 ORDER BY SUM(Quantity)
или просто укажем номер поля по порядку, по которому хотим сортировать:
SELECT Product, SUM(Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM(Quantity)>3000 ORDER BY 2
Видим, что для сортировки сводных результатов нам нужно просто прописать предложения с ORDER BY после оператора HAVING. Однако есть один нюанс. СУБД Access не поддерживает сортировку групп по псевдонимами колонок, то есть в нашем примере, чтобы сортировать значения, мы не сможем в конце запроса прописать ORDER BY Product_num .
SQL-Урок 7. Функции обработки данных
SQL-Урок 9. Подзапросы
Оператор SQL HAVING и сравнение со значением, возвращаемым квантором ALL или ANY (SOME)
Оператор SQL HAVING можно использовать для выборки данных, соответствующим результатам сравнения
не только с заданным числом, но и со значением, возвращаемым квантором ALL или ANY (SOME).
Квантор ALL возвращает из запроса, к которому он применяется, максимальное значение и тогда при помощи
оператора HAVING происходит сравнение с максимальным значением. Например, ALL(10, 15, 20) вернёт 20.
Квантор ANY (и его аналог SOME) возвращает минимальное значение и тогда при помощи
оператора HAVING происходит сравнение с минимальным значением. Синтаксис запроса с оператором SQL HAVING,
определяющий сравнение со значением, возвращаемым квантором ALL или ANY (SOME) выглядит следующим образом:.
SELECT ИМЕНА_СТОЛБЦОВ
FROM ИМЯ_ТАБЛИЦЫ GROUP BY ИМЯ_СТОЛБЦА
HAVING АГРЕГАТНАЯ_ФУНКЦИЯ(ИМЯ СТОЛБЦА)
ОПЕРАТОР_СРАВНЕНИЯ КВАНТОР
(SELECT АГРЕГАТНАЯ_ФУНКЦИЯ(ИМЯ СТОЛБЦА)
FROM ИМЯ_ТАБЛИЦЫ GROUP BY ИМЯ_СТОЛБЦА)
Пример 7. Есть база данных «Театр». В ней есть таблица Play,
содержащая данные о постановках в театре. В этой таблице есть поля PlayID (идентификатор), Name (название),
Genre (жанр), Author (автор), Dir_ID (внешний ключ — идентификатор режиссёра), PremiereDate
(дата премьеры), LastDate (дата окончания). Требуется определить самый популярный жанр театра, то есть
жанр, в котором поставлено наибольшее количество постановок.
Используя операторы SQL HAVING и GROUP BY, пишем первую часть запроса к таблице Play, которая
задаёт сравнение числа строк, сгруппированных по жанру:
SELECT Genre FROM Play GROUP BY Genre HAVING COUNT(*) >=
Теперь нужно определить, с чем сравнивать. Это максимальное число записей в той же
таблице, сгруппированных по жанру. Поэтом нам понадобиться квантор ALL. Пишем вторую часть запроса:



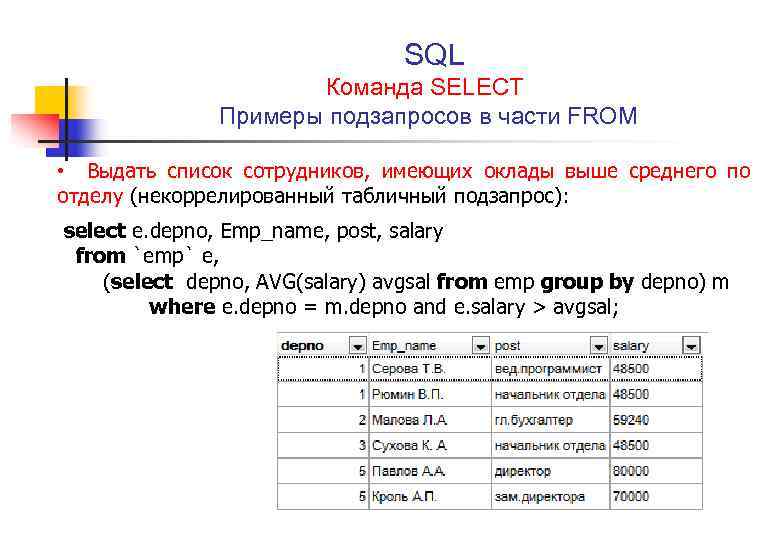



ALL(SELECT COUNT(*) FROM PLAY GROUP BY Genre)
Весь запрос для определения самого популярного жанра в театре будет следующим:
SELECT Genre FROM Play GROUP BY Genre HAVING COUNT(*) >=
ALL(SELECT COUNT(*) FROM PLAY GROUP BY Genre)
Пример
Теперь, зная синткасис команд INSERT и SELECT, можем разобраться как создать из исходного набора данных словари и загрузить данные в БД с учетом внешних ключей
Допустим есть список агентов (данные полученные от заказчика в виде CSV-файла), у которых есть поля название, тип и т.д. (далее по тексту я её называю таблица импорта)
В структуре БД поле «тип агента» создано как внешний ключ на таблицу типов
Заполнение словарей
Для добавления «типов агентов» в таблицу AgentType мы будем использовать альтернативный синтаксис
-
Пишем инструкцию SELECT, которая выбирает уникальные записи из таблицы импорта:
SELECT DISTINCT Тип_агента FROM agents_import- Ключевое слово DISTINCT относится только к топу полю, перед которым написано. В нашем случае выбирает уникальные названия типов агентов.
- Откуда брать поле Image в предметной области не написано и в исходных данных его нет. Но т.к. в целевой таблице это поле не обязательное, то можно его пропустить
Этот запрос можно выполнить отдельно, чтобы проверить что получится
-
После отладки запроса SELECT перед ним допишем запрос INSERT:
INSERT INTO AgentType (Title) SELECT DISTINCT Тип_агента FROM agents_import- Поле ID можно пропустить, оно автоинкрементное и создастся само (по крайней мере в MsSQL)
- Количество вставляемых полей (Title) должно быть равным количеству выбираемых полей (Тип_агента)
Если в таблице есть обязательные поля, а нем неоткуда взять для них данные, то мы можем в SELECT вставить фиксированные значения (в примере пустая строка):
Заполнение основной таблицы
Тоже сначала пишем SELECT запрос, чтобы проверить те ли данные получаются
напоминаю, что порядок и количество выбираемых и вставляемых полей должны быть одинаковыми
в поле AgentTypeID мы должны вставить ID соответсвующей записи из таблицы AgentType, поэтому выборка у нас из двух таблиц и чтобы не писать перед каждым полем полные названия таблиц мы присваиваем им алиасы
SELECT
asi.Наименование_агента,
att.ID,
asi.Юридический_адрес,
asi.ИНН,
asi.КПП,
asi.Директор,
asi.Телефон_агента,
asi.Электронная_почта_агента,
asi.Логотип_агента,
asi.Приоритет
FROM
agents_import asi,
AgentType att
WHERE
asi.Тип_агента=att.Title
Т.е. мы выбираем перечисленные поля из таблицы agents_import и добавляем к ним ID агента у которого совпадает название.
При выборке из нескольких таблиц исходные данные перемножаются. Т.е. если мы не заполним перед этой выборкой словарь, то .
Если же мы не укажем условие WHERE, то выберутся, к примеру, записей (каждый агент будет в каждой категории)
Поэтому важно, чтобы условие WHERE выбирало уникальные значения.
Естественно, количество внешних ключей в таблице может быть больше одного, в таком случае в секции FROM перечисляем все используемые словари и в секции WHERE перечисляем условия для всех таблиц объединив их логическим выражением AND
где алиасы b, c, d — словарные таблицы, а алиас «а» — таблица импорта
Написав и проверив работу выборки (она должна возвращать чтолько же записей, сколько в таблице импорта) дописываем команду вставки данных:
INSERT INTO Agent (Title, AgentTypeID, Address, INN, KPP, DirectorName, Phone, Email, Logo, Priority)
SELECT
asi.Наименование_агента,
att.ID,
asi.Юридический_адрес,
asi.ИНН,
asi.КПП,
asi.Директор,
asi.Телефон_агента,
asi.Электронная_почта_агента,
asi.Логотип_агента,
asi.Приоритет
FROM
agents_import asi,
AgentType att
WHERE
asi.Тип_агента=att.Title
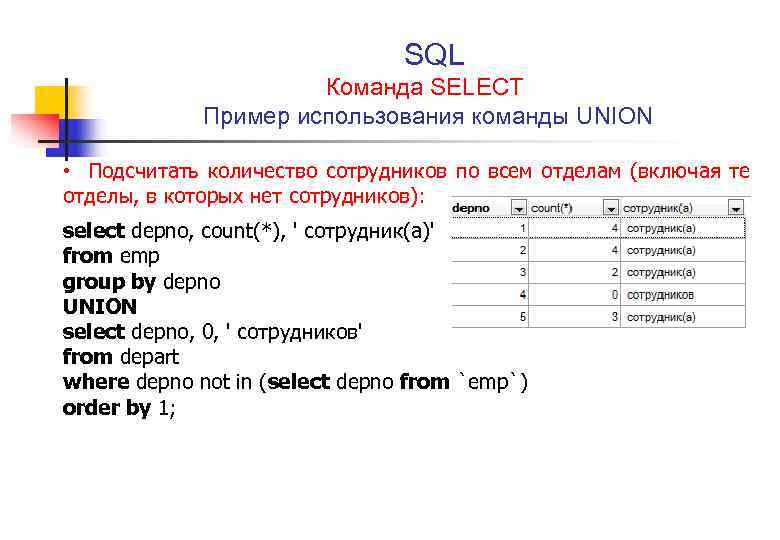
Когда следует использовать GROUP BY в SQL?
Предложение GROUP BY необходимо только тогда, когда вы хотите получить больше информации, чем-то, что возвращает агрегатная функция. Мы обсуждали это чуть раньше.
Если вы хотите узнать количество ваших клиентов, вам нужно всего лишь выполнить обычный запрос. Вот пример запроса, который вернёт эту информацию:
Наш запрос группирует результат и возвращает:
| считать |
| 7 |
(1 ряд)
Если вы хотите узнать, сколько клиентов входит в каждый из ваших планов лояльности, вам нужно будет использовать оператор GROUP BY. Вот пример запроса, который может получить список планов лояльности и количество клиентов по каждому плану:
Наш запрос собирает данные. Затем наш запрос возвращает:
| loyalty_plan | считать |
| Золото | 1 |
| Никто | 3 |
| Серебро | 1 |
| Бронза | 2 |
(4 ряда)
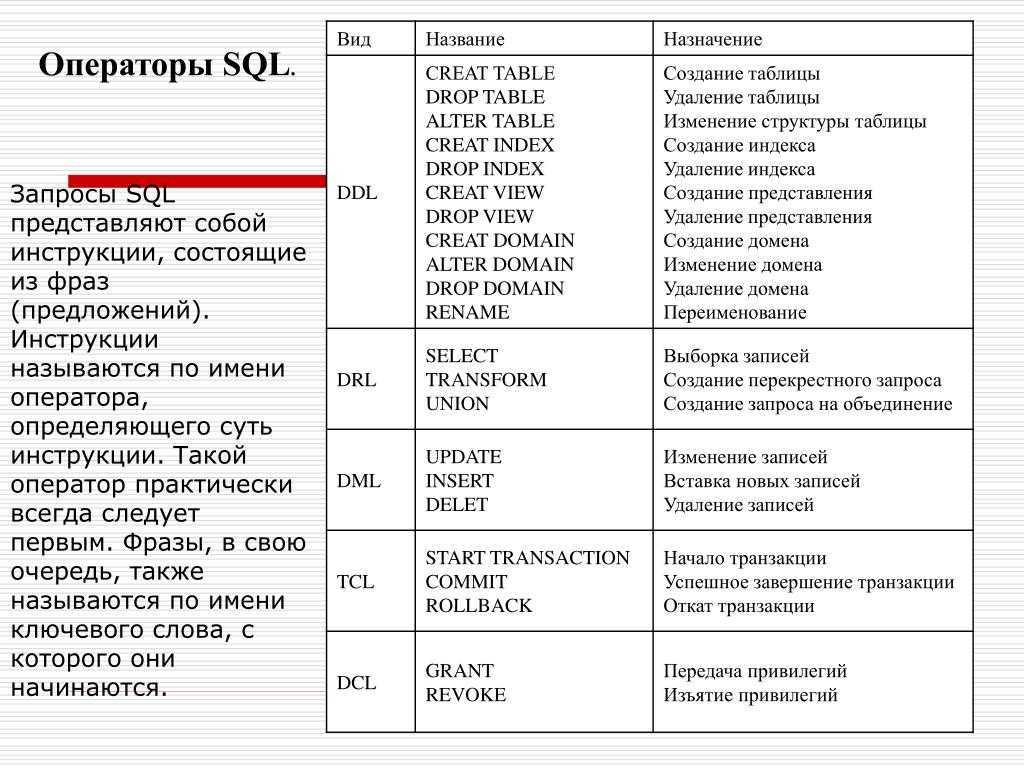
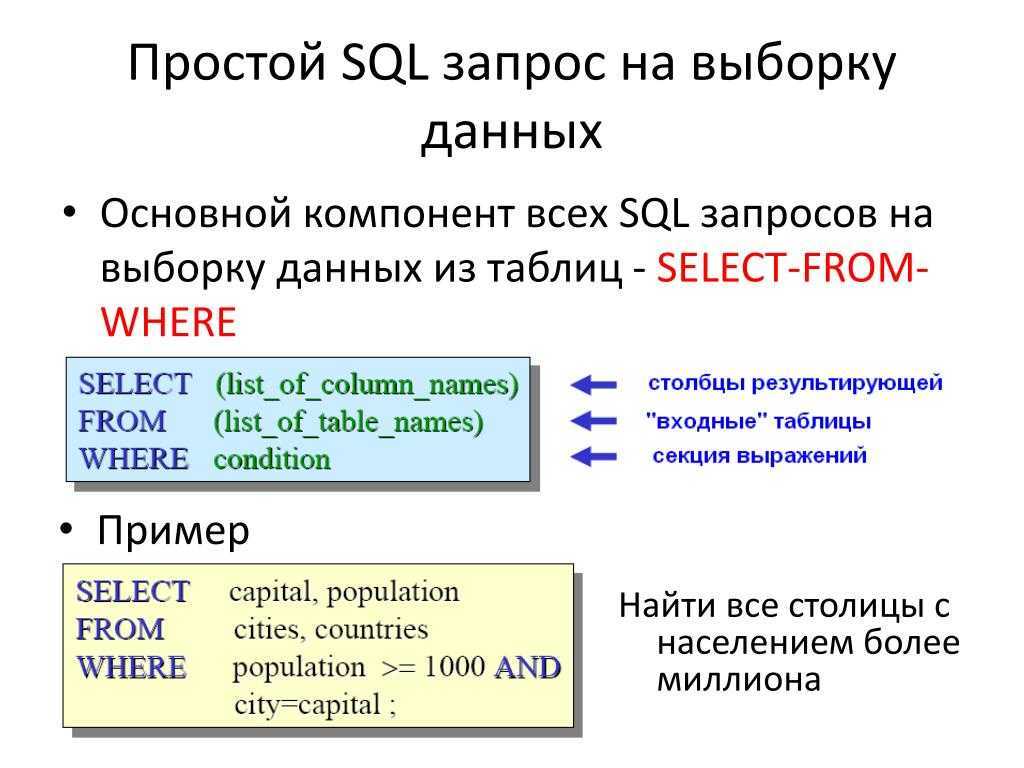
Синтаксис инструкции SELECT.
SELECTALL|DISTINCT*|col1,col2ASname1],...,exprASname2,...FROMtableAStbl WHEREcondition GROUPBYcol|expr|posHAVINGcondition ORDERBYcol|expr|posASC|DESC LIMITcountoffset,count OFFSEToffset
Параметры, принимаемые :
— указание этого символа приведет к выбору всех колонок таблицы. Его использование с другими элементами в списке выбора может привести к ошибке синтаксического анализа. Например, следующий запрос выдаст ошибку:
SELECTAVG(score),*FROMt1…
Указание символа уменьшает производительность базы данных, хорошей практикой считается указание конкретных столбцов для формирования выборки из таблицы.
— колонки таблицы , данные из которых необходимо получить в итоговом запросе.
— необязательное предложение , присваивает колонке таблицы новое имя (псевдоним) . По этому псевдониму можно будет извлечь записи , отобранные в запросе. Например, если таблица с товаром имеет столбцы с ценой за единицу товара и количеством товара то в запросе можно посчитать сумму и извлечь ее по псевдониму:
SELECTproduct,(price*lot)ASamountFROMproducts
При использовании модуля со стандартным классом курсора извлечь данные можно следующим образом:
with closing(db.cursor()) as cursor
# SQL-запрос
sql = «SELECT product, (price * lot) AS amount FROM products WHERE amount > 0»
# выполняем SQL-запрос
cursor.execute(sql)
# извлекаем результаты запроса
for row in cursor.fetchall():
product = row
amount = row1
Этот псевдоним можно также использовать при сортировке () и групповых выражениях (, ).
SELECTproduct,(price*lot)ASamountFROMproducts
WHEREamount>ORDERBYamount
— Выражение может быть строковой функцией, функцией преобразования даты и т.д. Если колонка имеет числовое значение, то может быть простым арифметическим действием (сложение, умножение и т.д.) и/или математической функцией (в выражении могут участвовать несколько числовых колонок). Предложение — присваивает выражению псевдоним , по которому можно будет извлечь итоговые результаты вычисления для каждой отобранной строки в запросе. Этот псевдоним можно также использовать при сортировке () и групповых выражениях (, ). Простой пример объединения колонок и в запросе:
SELECTCONCAT(first_name,last_name`)ASfull_nameFROMstudendORDERBYfull_name
Выражение также может быть подзапросом к другой таблице
Например ниже, к запросу из таблицы успеваемости студентов добавляются их полные имена )`.
— неоптимизированный запрос, представлен в качестве примера
SELECTid_studend,score,
(SELECTCONCAT(first_name,last_name`)
FROMstudendWHEREstudend.id=state.id_studend)ASfull_name
FROMstateWHEREscore>3ORDERBYfull_name
Внимание! Этот неоптимизированный запрос представлен в качестве примера. Для получения аналогичного результата лучше использовать инструкцию объединения таблиц .
Или может быть подзапросом к самой себе (коррелирующий подзапрос)
Например ниже, из таблицы выбираются товары , стоимость которых выше средней цены товаров для данного производителя :
SELECTproduct,factory,price,
(SELECTAVG(price)FROMproductsASSubProds
WHERESubProds.factory=Prods.factory)ASAvgPrice
FROMproductsASProds
WHEREprice>
(SELECTAVG(price)FROMproductsASSubProds
WHERESubProds.factory=Prods.factory);
— указывает таблицу или таблицы, из которых нужно получить выборку строк. Необязательное предложение присваивает таблице новое имя (псевдоним) , которое можно использовать при указании колонок в виде при объединении таблиц инструкцией .
— выражение, которое оценивается как истинное для каждой выбранной строки. Инструкция выбирает все строки, если нет предложения . В условии можно использовать любые функции и операторы, которые поддерживает MySQL, кроме агрегатных (групповых) функций.
— позиции столбцов, выбранные для вывода в инструкции . Позиции столбцов являются целыми числами и начинаются с 1.
— не рекомендуется использовать
SELECTcol1,col2,col3FROMtableORDERBY1,3;
— целое число, количество возвращаемых строк с начала результирующего набора.
— целое число, смещение выборки запроса до конца результирующего набора.
Возвращаемое значение .
строки, включающие в себя значения колонок и выражений, указанных в инструкции SELECT, которые могут быть отобраны по условию (если задано) WHERE или HAVING (в случае с GROUP BY), а их количество ограничено предложением LIMIT.
SELECT и DISTINCT — удаление дубликатов строк
Когда для значений строк таблицы не задано условие уникальности, в результатах запроса могут встретиться
одинаковые строки. Часто требуется вывести лишь уникальные строки. Это делается при помощи выражения
DISTINCT после оператора SELECT.
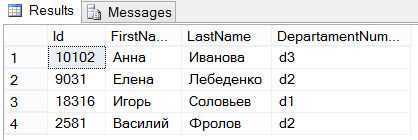
Пример 17. Пусть требуетcя узнать, какие существуют отделы и какие
должности среди отделов, номера которых меньше 30. Это можно сделать при помощи следующего запроса (на MS SQL Server — с предваряющей конструкцией USE company1;):


![Sql [айти бубен]](https://robotrackkursk.ru/wp-content/uploads/3/9/e/39ea1125543678c215b9fb01655ac02c.jpeg)




SELECT DISTINCT Dept, Job
FROM Staff
WHERE DeptORDER BY Dept, Job
Результат выполнения запроса:

- Страница 2 (Группировка вместе с сортировкой в запросе: что ставится раньше — GROUP BY или ORDER BY?)
- Страница 3 (Оператор SELECT для получения выборок из нескольких таблиц)
Модификатор WITH ROLLUP
Модификатор применяется для подсчета подытогов для ключевых выражений. При этом учитывается порядок следования ключевых выражений в списке . Подытоги подсчитываются в обратном порядке: сначала для последнего ключевого выражения в списке, потом для предпоследнего и так далее вплоть до самого первого ключевого выражения.
Строки с подытогами добавляются в конец результирующей таблицы. В колонках, по которым строки уже сгруппированы, указывается значение или пустая строка.
Пример
Рассмотрим таблицу t:
Запрос:
Поскольку секция содержит три ключевых выражения, результат состоит из четырех таблиц с подытогами, которые как бы «сворачиваются» справа налево:
- ;
- (а колонка заполнена нулями);
- (теперь обе колонки заполнены нулями);
- и общий итог (все три колонки с ключевыми выражениями заполнены нулями).
SQL Group By по нескольким столбцам
Если бы мы хотели, мы могли бы выполнить GROUP BY для нескольких столбцов. Например, предположим, что мы хотели получить список сотрудников с определёнными должностями в каждом филиале. Мы могли бы получить эти данные, используя следующий запрос:
Наш набор результатов запроса показывает:
| ответвляться | заглавие | считать |
| Стэмфорд | Сотрудник по продажам | 1 |
| Олбани | Вице-президент по продажам | 1 |
| Сан-Франциско | Сотрудник по продажам | 1 |
| Сан-Франциско | Старший специалист по продажам | 1 |
| Олбани | Директор по маркетингу | 1 |
| Бостон | Сотрудник по продажам | 2 |
(6 рядов)
Наш запрос создаёт список титулов, которыми владеет каждый сотрудник. Мы видим количество людей, обладающих этим титулом. Наши данные сгруппированы по отраслям, в которых работает каждый сотрудник, и их должностям.
Самостоятельная работа для закрепления материала
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2a |
| 2 | L-2b |
| 3 | L-3 |
| 5 | L-5 |
| RCode | RDescr |
|---|---|
| 2 | B-2a |
| 2 | B-2b |
| 3 | B-3 |
| 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2a |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 3 | L-3 | 2 | B-2a |
| 5 | L-5 | 2 | B-2a |
| 1 | L-1 | 2 | B-2b |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 2 | B-2b |
| 5 | L-5 | 2 | B-2b |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2a | 3 | B-3 |
| 2 | L-2b | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2a | 4 | B-4 |
| 2 | L-2b | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Remarks
Учитывая сложность инструкции SELECT, элементы ее синтаксиса и аргументы подробно представлены в предложении:
Порядок предложений в инструкции SELECT имеет значение. Любое из необязательных предложений может быть опущено; но если необязательные предложения используются, они должны следовать в определенном порядке.
Инструкции SELECT разрешено использовать в определяемых пользователем функциях только в том случае, если списки выбора этих инструкций содержат выражения, которые присваивают значения переменным, локальным для функций.
Четырехкомпонентное имя, использующее функцию OPENDATASOURCE в качестве части имени сервера, может служить в качестве исходной таблицы в любом месте инструкции SELECT, где может появляться имя таблицы. Четырехкомпонентное имя не может указываться для База данных SQL Azure.
Для инструкций SELECT, которые задействуют удаленные таблицы, существуют некоторые ограничения на синтаксис.
Предложение ORDER BY
Предложение ORDER BY определяет порядок сортировки строк результирующего набора, возвращаемого запросом. Это предложение имеет следующий синтаксис:
Соглашения по синтаксису
Порядок сортировки задается в параметре col_name. Параметр col_number является альтернативным указателем порядка сортировки, который определяет столбцы по порядку их вхождения в список выборки инструкции SELECT (1 — первый столбец, 2 — второй столбец и т.д.). Параметр ASC определяет сортировку в восходящем порядке, а параметр DESC — в нисходящем. По умолчанию применяется параметр ASC.
Имена столбцов в предложении ORDER BY не обязательно должны быть указаны в списке столбцов выборки. Но это не относится к запросам типа SELECT DISTINCT, т.к. в таких запросах имена столбцов, указанные в предложении ORDER BY, также должны быть указаны в списке столбцов выборки. Кроме этого, это предложение не может содержать имен столбцов из таблиц, не указанных в предложении FROM.
Как можно видеть по синтаксису предложения ORDER BY, сортировка результирующего набора может выполняться по нескольким столбцам. Такая сортировка показана в примере ниже:
В этом примере происходит выборка номеров отделов и фамилий и имен сотрудников для сотрудников, чей табельный номер меньше чем 20 000, а также с сортировкой по фамилии и имени. Результат выполнения этого запроса:
Столбцы в предложении ORDER BY можно указывать не по их именам, а по порядку в списке выборки. Соответственно, предложение в примере выше можно переписать таким образом:
Такой альтернативный способ указания столбцов по их позиции вместо имен применяется, если критерий упорядочивания содержит агрегатную функцию. (Другим способом является использование наименований столбцов, которые тогда отображаются в предложении ORDER BY.) Однако в предложении ORDER BY рекомендуется указывать столбцы по их именам, а не по номерам, чтобы упростить обновление запроса, если в списке выборки придется добавить или удалить столбцы. Указание столбцов в предложении ORDER BY по их номерам показано в примере ниже:
Здесь для каждого проекта выбирается номер проекта и количество участвующих в нем сотрудников, упорядочив результат в убывающем порядке по числу сотрудников.
Язык Transact-SQL при сортировке в возрастающем порядке помещает значения NULL в начале списка, и в конце списка — при убывающем.
Использование предложения ORDER BY для разбиения результатов на страницы
Отображение результатов запроса на текущей странице можно или реализовать в пользовательском приложении, или же дать указание осуществить это серверу базы данных. В первом случае все строки базы данных отправляются приложению, чьей задачей является отобрать требуемые строки и отобразить их. Во втором случае, со стороны сервера выбираются и отображаются только строки, требуемые для текущей страницы. Как можно предположить, создание страниц на стороне сервера обычно обеспечивает лучшую производительность, т.к. клиенту отправляются только строки, необходимые для отображения.








Для поддержки создания страниц на стороне сервера в SQL Server 2012 вводится два новых предложения инструкции SELECT: OFFSET и FETCH. Применение этих двух предложений демонстрируется в примере ниже. Здесь из базы данных AdventureWorks2012 (которую вы можете найти в исходниках) извлекается идентификатор бизнеса, название должности и день рождения всех сотрудников женского пола с сортировкой результата по названию должности в возрастающем порядке. Результирующий набор строк разбивается на 10-строчные страницы и отображается третья страница:
В предложении OFFSET указывается количество строк результата, которые нужно пропустить в отображаемом результате. Это количество вычисляется после сортировки строк предложением ORDER BY. В предложении FETCH NEXT указывается количество удовлетворяющих условию WHERE и отсортированных строк, которое нужно возвратить. Параметром этого предложения может быть константа, выражение или результат другого запроса. Предложение FETCH NEXT аналогично предложению FETCH FIRST.
Основной целью при создании страниц на стороне сервера является возможность реализация общих страничных форм, используя переменные. Эту задачу можно выполнить посредством пакета SQL Server.
Чистая группировка с помощью group by
Представим, что нам необходимо узнать ценность каждой группы, а именно среднее значение рейтинга пользователей в группе и общее число сообщений, оставленных в форуме.
Вначале, небольшое словесное описание, чтобы легче было понимать SQL-запрос. Итак, вам нужно найти вычисляемые значения по группам форума. Соответственно, вам нужно поделить все эти десять строк на три разные группы: admin, moder, user. Чтобы это сделать, нужно в конце запроса добавить группировку по значениям поля forum_group. А так же добавить в select вычисляемые выражения с использованием так называемых агрегатных функций.
Вот как будет выглядеть SQL-запрос
-- Указываем поля и вычисляемые столбцы select forum_group, avg(raiting) as avg_raiting, sum(mess_count) as total_mess_count -- Указываем таблицу from userstat -- Указываем группировку по полю group by forum_group
Обратите внимание, что после того, как вы использовали конструкцию group by в запросе, можно без применения агрегатных функций использовать только те поля в select, которые были указаны после group by. Остальные поля должны быть указаны внутри агрегатных функций
Так же я воспользовался двумя агрегатными функциями. AVG — вычисляет среднее значение. И SUM — вычисляет сумму.
Вот какой получился результат:
| forum_group | avg_raiting | total_mess_count |
|---|---|---|
| admin | 4 | 50 |
| moder | 3 | 50 |
| user | 3 | 150 |
Давайте разберем по шагам, как получился данный результат.
1. Вначале все строки исходной таблицы были разбиты на три группы по значениям поля forum_group. Например, внутри группы admin было три пользователя. Внутри moder так же 3 строки. А внутри группы user было 4 строки (четыре пользователя).
2. Затем для каждой группы применялись агрегатные функции. Например, для группы admin средний рейтинг вычислялся так (2 + 5 + 5)/3 = 4. Количество сообщений вычислялось так (10 + 15 + 25) = 50.
Как видите, ничего сложного. Однако, мы применили всего одно условие группировки и не применяли фильтрацию по группам. Поэтому перейдем к следующему примеру.



