Соединения слиянием.
Если два входа соединения достаточно велики, но отсортированы по соединяемым столбцам (например, если они были получены просмотром отсортированных индексов), то наиболее быстрой операцией соединения будет соединение слиянием. Если оба входа соединения велики и имеют сходные размеры, соединение слиянием с предварительной сортировкой и хэш-соединение имеют примерно одинаковую производительность. Однако операции хэш-соединения часто выполняются быстрее, если два входа значительно отличаются по размеру.
Соединение слиянием требует сортировки обоих наборов входных данных по столбцам слияния, которые определены предложениями равенства (ON) предиката объединения. Оптимизатор запросов обычно просматривает индекс, если для соответствующего набора столбцов такой существует, или устанавливает оператор сортировки под соединением слиянием. В редких случаях может быть несколько предложений равенства, но столбцы слияния берутся только из некоторых доступных предложений равенства.
Так как каждый набор входных данных сортируется, оператор Merge Join получает строку из каждого набора входных данных и сравнивает их. Например, для операций внутреннего соединения строки возвращаются в том случае, если они равны. Если они не равны, строка с меньшим значением не учитывается, и из этого набора входных данных берется другая строка. Этот процесс повторяется, пока не будет выполнена обработка всех строк.
Операция соединения слиянием может быть как обычной, так и операцией типа «многие ко многим». Соединение слиянием «многие ко многим» использует временную таблицу для хранения строк. При наличии дублирующих значений из каждого набора входных данных один из наборов должен будет сбрасываться на начало дубликатов по мере обработки каждого дубликата из другого набора данных.
При наличии остаточного предиката все строки, удовлетворяющие предикату слияния, определяют остаточный предикат, и возвращаются только те строки, которые ему соответствуют.
Соединение слиянием — очень быстрая операция, но она может оказаться ресурсоемкой, если требуется выполнение операций сортировки. Однако если том данных имеет большой объем, и необходимые данные могут быть получены из существующих индексов сбалансированного дерева с выполненной предварительной сортировкой, соединение слиянием является самым быстрым из доступных алгоритмов соединения.
Допустим, что вы дошли до этого момента
- Выбирать детальные данные по условию WHERE из одной таблицы
- Умеете пользоваться агрегатными функциями и группировкой из одной таблицы
| ID | Name | Birthday | … | Salary | BonusPercent | DepartmentName | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | 5000 | 50 | Администрация | Директор | |
| 1001 | Петров П.П. | 03.12.1983 | 1500 | 15 | ИТ | Программист | |
| 1002 | Сидоров С.С. | 07.06.1976 | 2500 | NULL | Бухгалтерия | Бухгалтер | |
| 1003 | Андреев А.А. | 17.04.1982 | 2000 | 30 | ИТ | Старший программист | |
| 1004 | Николаев Н.Н. | NULL | 1500 | NULL | ИТ | Программист | |
| 1005 | Александров А.А. | NULL | 2000 | NULL | NULL | NULL |
| ID | Name | Birthday | … | Salary | BonusPercent | DepartmentName | PositionName |
|---|---|---|---|---|---|---|---|
| 1000 | Иванов И.И. | 19.02.1955 | 5000 | 50 | Администрация | Директор | |
| 1001 | Петров П.П. | 03.12.1983 | 1500 | 15 | ИТ | Программист | |
| 1002 | Сидоров С.С. | 07.06.1976 | 2500 | NULL | Бухгалтерия | Бухгалтер | |
| 1003 | Андреев А.А. | 17.04.1982 | 2000 | 30 | ИТ | Старший программист | |
| 1004 | Николаев Н.Н. | NULL | 1500 | NULL | ИТ | Программист | |
| 1005 | Александров А.А. | NULL | 2000 | NULL | NULL | NULL |
| DepartmentName | PositionCount | EmplCount | SalaryAmount | SalaryAvg |
|---|---|---|---|---|
| NULL | 1 | 2000 | 2000 | |
| Администрация | 1 | 1 | 5000 | 5000 |
| Бухгалтерия | 1 | 1 | 2500 | 2500 |
| ИТ | 2 | 3 | 5000 | 1666.66666666667 |
| ID | Name | Salary |
|---|---|---|
| 1005 | Александров А.А. | 2000 |
| 1003 | Андреев А.А. | 2000 |
| 1000 | Иванов И.И. | 5000 |
| 1004 | Николаев Н.Н. | 1500 |
| 1001 | Петров П.П. | 1500 |
| 1002 | Сидоров С.С. | 2500 |
Значения NULL и соединения
Если в столбцах, по которым производится соединение таблиц, есть значение NULL, значения NULL друг с другом совпадать не будут. Наличие таких значений в столбце одной из соединяемых таблиц возможно только при использовании внешнего соединения (если только предложение не исключает значение NULL).
Ниже приведены две таблицы, каждая из которых может содержать NULL в столбце, по которому проводится соединение:
Соединение, сравнивающее значения в столбце a со значениями столбца c, не создает совпадений, если столбцы имеют значение NULL:
Возвращена только одна строка со значением 4 в столбцах a и c:
Значения NULL, возвращаемые из базовой таблицы, также сложно отличить от значений NULL, возвращаемых при внешнем соединении. Например, следующая инструкция выполняет левое внешнее соединение этих двух таблиц.
Результирующий набор:
В результате сложно определить, какие значения NULL получены из данных, а какие означают неуспешное соединение. Если в соединениях данных присутствуют значения NULL, чаще всего желательно исключить их из результатов с помощью обычного соединения.
Операторы сравнения (Transact-SQL)
Операторы сравнения позволяют проверить, одинаковы ли два выражения. Операторы сравнения можно применять ко всем выражениям, за исключением выражений типов text, ntext и image. Операторы сравнения Transact-SQL приведены в следующей таблице:

Тип данных Boolean
Результат выполнения оператора сравнения имеет тип данных Boolean. Он может иметь одно из трех значений: TRUE, FALSE и UNKNOWN. Выражения, возвращающие значения типа Boolean, называются «логическими выражениями». В отличие от других типов данных SQL Server, тип Boolean не может быть типом столбца или переменной и не может быть возвращен в результирующем наборе.
Условный оператор WHERE
Ситуация, когда требуется сделать выборку по определенному условию, встречается очень часто. Для этого в операторе SELECT существует параметр WHERE, после которого следует условие для ограничения строк. Если запись удовлетворяет этому условию, то попадает в результат, иначе отбрасывается.
Общая структура запроса с оператором WHERE
SELECT поля_таблиц FROM список_таблиц WHERE условия_на_ограничения_строк ;
В описанной структуре запроса необязательные параметры указаны в квадратных скобках.
В условном операторе применяются операторы сравнения, специальные и логические операторы.
Операторы сравнения
Операторы сравнения служат для сравнения 2 выражений, их результатом может являться ИСТИНА (1), ЛОЖЬ (0) и NULL.
| Оператор | Описание |
|---|---|
| = | Оператор равенство |
| <=> | Оператор эквивалентностьАналогичный оператору равенства, с одним лишь исключением: в отличие от него, оператор эквивалентности вернет ИСТИНУ при сравнении NULL <=> NULL |
| <>или!= | Оператор неравенство |
| < | Оператор меньше |
| <= | Оператор меньше или равно |
| > | Оператор больше |
| >= | Оператор больше или равно |
Специальные операторы
-
— позволяет узнать равно ли проверяемое значение NULL.
Для примера выведем всех членов семьи, у которых статус в семье не равен NULL:
SELECT * FROM FamilyMembers WHERE status IS NOT NULL; -
— позволяет узнать расположено ли проверяемое значение столбца в интервале между min и max.
Выведем все данные о покупках с ценой от 100 до 500 рублей из таблицы Payments:
SELECT * FROM Payments WHERE unit_price BETWEEN 100 AND 500; -
— позволяет узнать входит ли проверяемое значение столбца в список определённых значений.
Выведем имена членов семьи, чей статус равен «father» или «mother»:
SELECT member_name FROM FamilyMembers WHERE status IN ('father', 'mother'); -
— позволяет узнать соответствует ли строка определённому шаблону.
Например, выведем всех людей с фамилией «Quincey»:
SELECT member_name FROM FamilyMembers WHERE member_name LIKE '% Quincey';
Трафаретные символы
В шаблоне разрешается использовать два трафаретных символа:
- символ подчеркивания (_), который можно применять вместо любого единичного символа в проверяемом значении
- символ процента (%) заменяет последовательность любых символов (число символов в последовательности может быть от 0 и более) в проверяемом значении.
| Шаблон | Описание |
|---|---|
| never% | Сопоставляется любым строкам, начинающимся на «never». |
| %ing | Сопоставляется любым строкам, заканчивающимся на «ing». |
| _ing | Сопоставляется строкам, имеющим длину 4 символа, при этом 3 последних обязательно должны быть «ing». Например, слова «sing» и «wing». |
ESCAPE-символ
ESCAPE-символ используется для экранирования трафаретных символов. В случае если вам нужно найти строки, содержащие проценты (а процент — это зарезервированный символ), вы можете использовать ESCAPE-символ.
Например, вы хотите получить идентификаторы задач, прогресс которых равен 3%:
SELECT
job_id
FROM
Jobs
WHERE
progress LIKE '3!%'
ESCAPE '!';
Если бы мы не экранировали трафаретный символ, то в выборку попало бы всё, что начинается на 3.
Логические операторы
Логические операторы необходимы для связывания нескольких условий ограничения строк.
- Оператор NOT — меняет значение специального оператора на противоположный
- Оператор OR — общее значение выражения истинно, если хотя бы одно из них истинно
- Оператор AND — общее значение выражения истинно, если они оба истинны
- Оператор XOR — общее значение выражения истинно, если один и только один аргумент является истинным
Выведем все полёты, которые были совершены на самолёте «Boeing», но, при этом, вылет был не из Лондона:
SELECT
*
FROM
Trip
WHERE
plane = 'Boeing' AND NOT town_from = 'London';
Обзор синтаксиса выражения SQL
Выражение SQL содержит комбинацию одного или нескольких значений, операторов и функций SQL, которые можно использовать для запроса или выбора подмножества объектов и записей таблиц в ArcGIS.
Все запросы SQL выражаются с помощью ключевого слова SELECT.
SELECT * FROM формирует первую часть выражения SQL и автоматически предоставляется вам в большинстве диалоговых окон ArcGIS. Например, когда вы , оператор SELECT используется для выбора полей из слоя или таблицы и предоставляется вам.
Следующая часть выражения SQL, которая приходит после SELECT * FROM <Layer_name> — это предложение WHERE. Предложение WHERE используется для получения записей, соответствующих определенным критериям, и является частью выражения, которое вы должны построить.
Подсказка:
Звездочка (*) в выражении SQL используется для запроса всех столбцов.
Вот базовая форма предложения WHERE SQL-выражения:
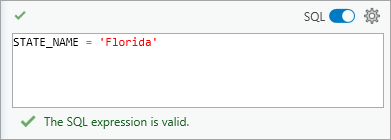
Например, STATE_NAME = ‘Florida’. Это выражение содержит одно предложение и выбирает все объекты, содержащие слово ‘Florida’ в поле STATE_NAME.








Для составных выражений используется следующая форма:
…
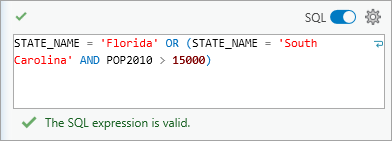
Например, STATE_NAME = ‘Florida’ OR (STATE_NAME = ‘South Carolina’ AND POP2010 > 15000). Это составное выражение состоит из нескольких предложений, связанных логическим оператором И или ИЛИ, и выбирает все объекты, содержащие Florida в поле STATE_NAME, и все объекты, которые содержат как South Carolina в поле STATE_NAME, так и имеют значение больше 15000 в поле с именем POP2010.
Подсказка:
По желанию, круглые скобки () могут использоваться для определения порядка операций в составных выражениях.
Поскольку вы выбираете столбцы в целом, вы не можете ограничить SELECT возвратом только некоторых столбцов в соответствующей таблице, поскольку синтаксис SELECT * жестко запрограммирован. По этой причине ключевые слова, такие как DISTINCT, ORDER BY и GROUP BY, нельзя использовать в выражении SQL в ArcGIS, за исключением случаев использования подзапросов. Подробнее см. в разделе .
Значения NULL и соединения
Если в столбцах, по которым производится соединение таблиц, есть значение NULL, значения NULL друг с другом совпадать не будут. Наличие таких значений в столбце одной из соединяемых таблиц возможно только при использовании внешнего соединения (если только предложение не исключает значение NULL).
Ниже приведены две таблицы, каждая из которых может содержать NULL в столбце, по которому проводится соединение:
Соединение, сравнивающее значения в столбце a со значениями столбца c, не создает совпадений, если столбцы имеют значение NULL:
Возвращена только одна строка со значением 4 в столбцах a и c:
Значения NULL, возвращаемые из базовой таблицы, также сложно отличить от значений NULL, возвращаемых при внешнем соединении. Например, следующая инструкция выполняет левое внешнее соединение этих двух таблиц.
Результирующий набор:
В результате сложно определить, какие значения NULL получены из данных, а какие означают неуспешное соединение. Если в соединениях данных присутствуют значения NULL, чаще всего желательно исключить их из результатов с помощью обычного соединения.
Как читать чужой код? Часть 3. Разбор и доработка запросов
Во всех вакансиях есть требование — умение читать чужой код. Но ни на одних курсах специально этому не учат.
Чтобы устранить это противоречие, пишу данную статью. Рассмотрю случаи, в которых нам необходимо разбирать чужой код, поймём, чей код мы пытаемся разобрать, зачем и, главное, как. В статье описан личный опыт длиною в 18 лет начиная с версии платформы 7.7. Статья будет большой, набираемся терпения). Статья содержит в себе описание сценариев разбора кода, т.е. набор шагов. В статье не получится показать это на практике. Для этого планирую сделать онлайн или оффлайн курс, где на примерах будет показан разбор незнакомого кода. Статья разбита на 4 публикации для удобства изучения.
Основные сведения о соединениях вложенных циклов
Если один вход соединения имеет небольшой размер (менее десяти строк), а другой вход сравнительно большой и индексирован по соединяемым столбцам, индексное соединение вложенных циклов является самой быстрой операцией соединения, так как для нее потребуется наименьшее количество операций сравнения и ввода-вывода.
Соединение вложенных циклов, называемое также вложенной итерацией, использует один ввод соединения в качестве внешней входной таблицы (на графической схеме выполнения она является верхним входом), а второй в качестве внутренней (нижней) входной таблицы. Внешний цикл использует внешнюю входную таблицу построчно. Во внутреннем цикле для каждой внешней строки производится сканирование внутренней входной таблицы и вывод совпадающих строк.
В простейшем случае во время поиска целиком просматривается таблица или индекс; это называется упрощенным соединением вложенных циклов. Если при поиске используется индекс, то такой поиск называется индексным соединением вложенных циклов. Если индекс создается в качестве части плана запроса (и уничтожается после завершения запроса), то он называется временным индексным соединением вложенных циклов. Все эти варианты учитываются оптимизатором запросов.
Соединение вложенных циклов является особенно эффективным в случае, когда внешние входные данные сравнительно невелики, а внутренние входные данные велики и заранее индексированы. Во многих небольших транзакциях, работающих с небольшими наборами строк, индексное соединение вложенных циклов превосходит как соединения слиянием, так и хэш-соединения. Однако в больших запросах соединения вложенных циклов часто являются не лучшим вариантом.
Если для атрибута OPTIMIZED оператора соединения вложенными циклами задано значение True, это означает, что оптимизированные соединения вложенными циклами (или пакетная сортировка) используются для уменьшения количества операций ввода-вывода, когда внутренняя таблица имеет большой размер, независимо от того, выполняется ли ее параллельная обработка. Такая оптимизация в этом плане выполнения может быть не слишком очевидна при анализе плана, если сама сортировка выполняется как скрытая операция. Но изучив XML-код плана для атрибута OPTIMIZED, можно обнаружить, что соединение вложенными циклами, возможно, попытается изменить порядок входных строк, чтобы повысить производительность операций ввода-вывода.
Глоссарий
SQL: Язык структурированных запросов, язык структурированных запросов, представляет собой разновидность управления данными в реляционной базе данных.Стандартный язык. SQL — это декларативный язык программирования, что означает, что вам нужно только указать, что необходимо, не обращая внимания на детали реализации (то же самое верно и для LINQ в C #).
Диалект SQL:Другие языки, основанные на стандарте SQL, такие как T-SQL, используемый в SQL Server
Обратите внимание, что диалекты SQL могут не полностью поддерживать все стандарты SQL
T-SQL:Transact-SQL, диалект (расширение) SQL, предоставляемый Microsoft для базы данных SQL Server.
Дополнительные варианты фильтрации
Как вы помните, различные элементы определения окна (секционирование, упорядочение и кадрирование) по сути являются различными вариантами фильтрации. Существуют другие потребности в фильтрации, которые эти определения не в состоянии удовлетворить. Некоторые из этих потребностей удается удовлетворить с помощью предложения FILTER, которое не было реализовано в SQL Server 2012. Есть также попытки решить эту проблему за счет внесения предложений по расширению стандарта, которые, я надеюсь, так или иначе появятся в стандарте и SQL Server.
Начну с предложения FILTER. В стандарте определено, что в функциях агрегирования это предложение позволяет фильтровать набор строк, к которому применяется агрегирование, с использованием предиката, формат этого предложения выглядит так:
<функция агрегирования>(<входное выражение>) FILTER (WHERE <условие поиска>)
В качестве примера приведу запрос, вычисляющий разницу между текущим количеством и среднемесячным количеством для сотрудника до текущей даты (не месяца текущей строки):
SQL Server 2012 пока не поддерживает предложение FILTER. Честно говоря, я не знаю СУБД, которая поддерживала его. Если вам нужна такая возможность, существует довольно простое альтернативное решение — использовать в качестве входных данных для функции агрегирования выражение CASE:
<функция агрегирования>(CASE WHEN <условие поиска> THEN <входное выражение> END)
Вот полный запрос, который решает ту же задачу:
Чего все еще не хватает в стандарте (начиная с версии SQL 2008) и SQL Server 2012, так это возможности ссылаться на элементы текущей строки для целей фильтрации. Это можно было бы применять в предложении FILTER, в альтернативном решении с использованием выражения CASE, а также в других случаях, в которых нужна фильтрация.
Для демонстрации этой потребности представьте на секундочку, что на элемент текущей строки можно ссылаться с помощью префикса $current_row. А теперь представим себе, что нужно написать запрос представления Sales.OrderValues, который бы вычислял для каждого заказа разницу между значением текущего заказа и средним значением для определенного сотрудника для всех клиентов кроме того клиента, которому принадлежит этот заказ. Эта задача решается следующим запросом с предложением FILTER:
В качестве альтернативы можно воспользоваться выражением CASE:
Ещё раз напомню, что это всего лишь мои выдумки для иллюстрации того, чего не хватает в стандарте языка, поэтому, как говорится, «не пытайтесь повторить это у себя дома».
Предложение по улучшению
Есть очень интересные предложения по расширению стандарта для удовлетворения этой и других потребностей. Одним из примеров являются сравнительные оконные функции. Подробнее о предложении можно узнать из блога Тома Кайта по адресу Comparative Window Functions.
Принцип сравнительных оконных функций выглядит интересно. Он довольно простой и позволяет удовлетворить потребность ссылаться на элементы из текущей строки. Но что действительно заставит вас пошевелить мозгами, так этого исключительно крутое предложение по расширению стандарта, которое называется «распознавание паттернов в строках» и решает задачу обращения к элементам из текущей строки, а также многие другие задачи.
Паттерны в последовательностях строк определяются с применением семантики, похожей на регулярные выражения. Этот механизм может применяться для определения табличного выражения, а также для фильтрации строк в определении окна. Он также может использоваться в технологиях потоковой передачи данных, например с StreamInsight в SQL Server, а также в запросах, которые работают с неперемещаемыми данными. Вот ссылка на предоставленный для всеобщего доступа документ: http://www.softwareworkshop.com/h2/SQL-RPR-review-paper.pdf. Прежде чем читать этот документ, я предлагаю освободить голову от лишних мыслей и хорошенько взбодриться кофе. Это непросто чтение, но идея исключительно интересна и я надеюсь, что она пробьет себе путь в стандарт SQL и будет использоваться не только для данных в движении, но и для неактивных данных.
Примеры использования предикатов
Предикаты представляют собой выражения, принимающие истинностное значение. Они могут представлять собой как одно выражение, так и любую комбинацию из неограниченного количества выражений, построенную с помощью булевых операторов AND, OR или NOT. Кроме того, в этих комбинациях может использоваться SQL-оператор IS, а также круглые скобки для конкретизации порядка выполнения операций
Предикат в языке SQL может принимать одно из трех значений TRUE (истина), FALSE (ложь) или UNKNOWN (неизвестно). Исключение составляют следующие предикаты: NULL (отсутствие значения), EXISTS (существование), UNIQUE (уникальность) и MATCH (совпадение), которые не могут принимать значение UNKNOWN.
Правила комбинирования всех трех истинностных значений легче запомнить, обозначив TRUE как 1, FALSE как 0 и UNKNOWN как 1/2 (где то между истинным и ложным).
AND с двумя истинностными значениями дает минимум этих значений. Например, TRUE AND UNKNOWN будет равно UNKNOWN.
OR с двумя истинностными значениями дает максимум этих значений. Например, FALSE OR UNKNOWN будет равно UNKNOWN.
Отрицание истинностного значения равно 1 минус данное истинностное значение. Например, NOT UNKNOWN будет равно UNKNOWN.
Помимо этого, используются предикаты сравнения.
Предикат сравнения представляет собой два выражения, соединяемых оператором сравнения. Имеется шесть традиционных операторов сравнения: =, >, <, >=, <=, <>.






Данные типа NUMERIC (числа) сравниваются в соответствии с их алгебраическим значением.
Данные типа CHARACTER STRING (символьные строки) сравниваются в соответствии с их алфавитной последовательностью. Если a1a2…an и b1b2…bn — две последовательности символов, то первая «меньше» второй, если а1<b1, или а1=b1 и а2<b2 и т.д. Считается также, что а1а2…аn<b1b2…bm, если n<m и а1а2…аn=b1b2…bn, т.е. если первая строка является префиксом второй. Например, ‘folder'<‘for’, т.к. первые две буквы этих строк совпадают, а третья буква строки ‘folder’ предшествует третьей букве строки ‘for’. Также справедливо неравенство ‘bar’ < ‘barber’, поскольку первая строка является префиксом второй.
Данные типа DATETIME (дата/время) сравниваются в хронологическом порядке.
Данные типа INTERVAL (временной интервал) преобразуются в соответствующие типы, а затем сравниваются как обычные числовые значения типа NUMERIC.
Пример. Получить информацию о компьютерах, имеющих частоту процессора не менее 500 Мгц и цену ниже $800:
SELECT * FROM PC
WHERE speed >= 500 AND price < 800;
Запрос возвращает следующие данные (Таблица 6.):
Таблица 6. – Пример информационного запроса.
Существуют так же и другие предикаты, например, BETWEEN, IN, LIKE.
Имена столбцов, указанных в предложении SELECT, можно переименовать. Это делает результаты более читабельными, поскольку имена полей в таблицах часто сокращают с целью упрощения набора. Ключевое слово AS, используемое для переименования, согласно стандарту можно и опустить, т.к. оно неявно подразумевается.
Например, запрос:
SELECT ram AS Mb, hd Gb
FROM PC
WHERE cd = ’24x’;
переименует столбец ram в Mb (мегабайты), а столбец hd — в Gb (гигабайты). Этот запрос возвратит объемы оперативной памяти и жесткого диска для тех компьютеров, которые имеют 24-скоростной CD-ROM (Таблица 7.):
Таблица 7. – Пример запроса SELECT AS.
Получение итоговых значений:
Существует возможность получения итоговых (агрегатных) функций. Стандартом предусмотрены следующие агрегатные функции (Таблица 8.):
Таблица 8 .– Описание (агрегатных) функций.
Все эти функции возвращают единственное значение. При этом, функции COUNT, MIN и MAX применимы к любым типам данных, в то время как SUM и AVG используются только для числовых полей. Разница между функцией COUNT(*) и COUNT() состоит в том, что вторая при подсчете не учитывает NULL-значения.
Пример. Найти минимальную и максимальную цену на персональные компьютеры:
SELECT MIN(price) AS Min_price, MAX(price) AS Max_price
FROM PC;
Результатом будет единственная строка, содержащая агрегатные значения (таблица 9.):
Таблица 9. – Строка содержащая (агрегатные) значения.
Для просмотра данных наиболее удобно использовать совместно значения оператора COUNT — счетчик (позволяет узнать количество записей в запросе), и оператора CURSOR — позволяет принимать не все записи сразу, а по одной (указанной пользователем).
Вызов определяемой пользователем функции
Определенную пользователем функцию можно вызывать с помощью инструкций Transact-SQL, таких как SELECT, INSERT, UPDATE или DELETE. Вызов функции осуществляется, указывая ее имя с парой круглых скобок в конце, в которых можно задать один или несколько аргументов. Аргументы — это значения или выражения, которые передаются входным параметрам, определяемым сразу же после имени функции. При вызове функции, когда для ее параметров не определены значения по умолчанию, для всех этих параметров необходимо предоставить аргументы в том же самом порядке, в каком эти параметры определены в инструкции CREATE FUNCTION.
В примере ниже показан вызов функции ComputeCosts в инструкции SELECT:
Инструкция SELECT в примере отображает названия и номера всех проектов, бюджеты которых меньше, чем общие дополнительные расходы по всем проектам при заданном значении процентного увеличения.
В инструкциях Transact-SQL имена функций необходимо задавать, используя имена, состоящие из двух частей: schema name и function name, поэтому в примере мы использовали префикс схемы dbo.
Логическая обработка запросов
Логическая обработка запросов описывает принципы оценки запроса SELECT в соответствии с логической системой языка. Она описывает процесс, состоящий из нескольких этапов, или фаз, которые начинаются входными таблицами запроса и заканчиваются результирующим набором запроса.
Заметьте, что под логической обработкой запросов я подразумеваю концепцию оценки запроса, которая не обязательно совпадает с физическим процессом обработки запроса сервером SQL Server. В рамках оптимизации SQL Server может сокращать путь, менять порядок некоторых этапов и делать все, что ему заблагорассудится. Но все это только при условии, что он возвращает тот же результат, который должен получиться при логической обработке запроса при декларативном его определении.
Каждый этап логической обработки запроса работает с одной или несколькими таблицами (наборами строк), которые являются входными данными, и возвращает в качестве результата таблицу. Результирующая таблица одного этапа становится входной для следующего этапа.
На следующем рисунке представлена схема логической обработки запроса в SQL Server 2012:
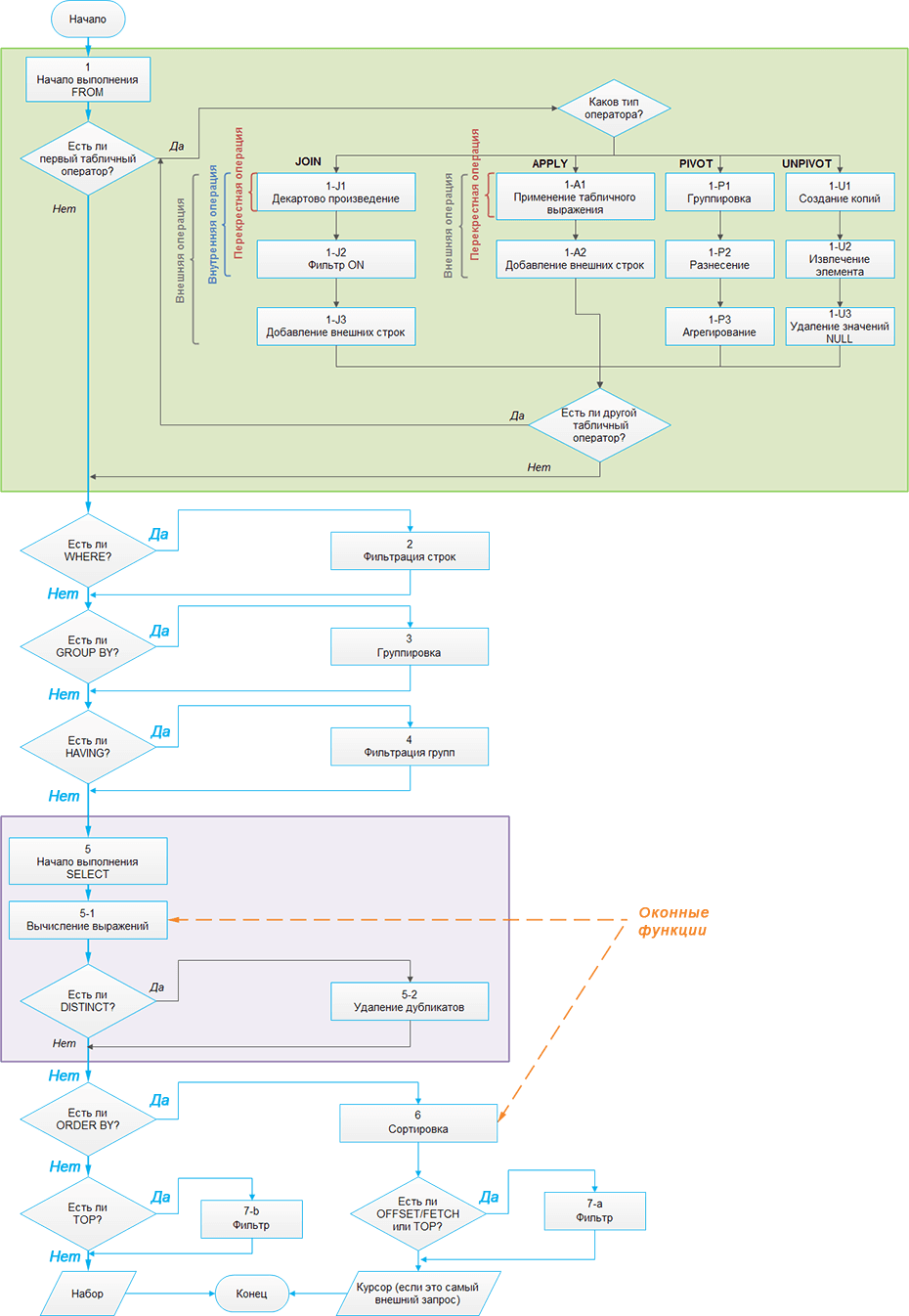
Заметьте, что при написании запроса предложение SELECT всегда пишется первым, но в процессе логической обработки оно находится практически в самом конце — непосредственно перед обработкой предложения ORDER BY.
Логической обработке запросов можно посвятить целую книгу, но для нашей цели достаточно более лаконичного изложения
Для целей нашей дискуссии важно заметить порядок, в которой обрабатываются разные предложения. Следующий список представляет этот порядок (фазы, в которых разрешены оконные функции, выделены цветом):
-
FROM
-
WHERE
-
GROUP BY
-
HAVING
-
SELECT
-
Вычисление выражений
-
Удаление дубликатов
-
-
ORDER BY
-
OFFSET-FETCH/TOP
Понимание процедуры и порядка логической обработки запросов позволяет понять, почему использование оконных функций разрешили только в определенных предложениях.
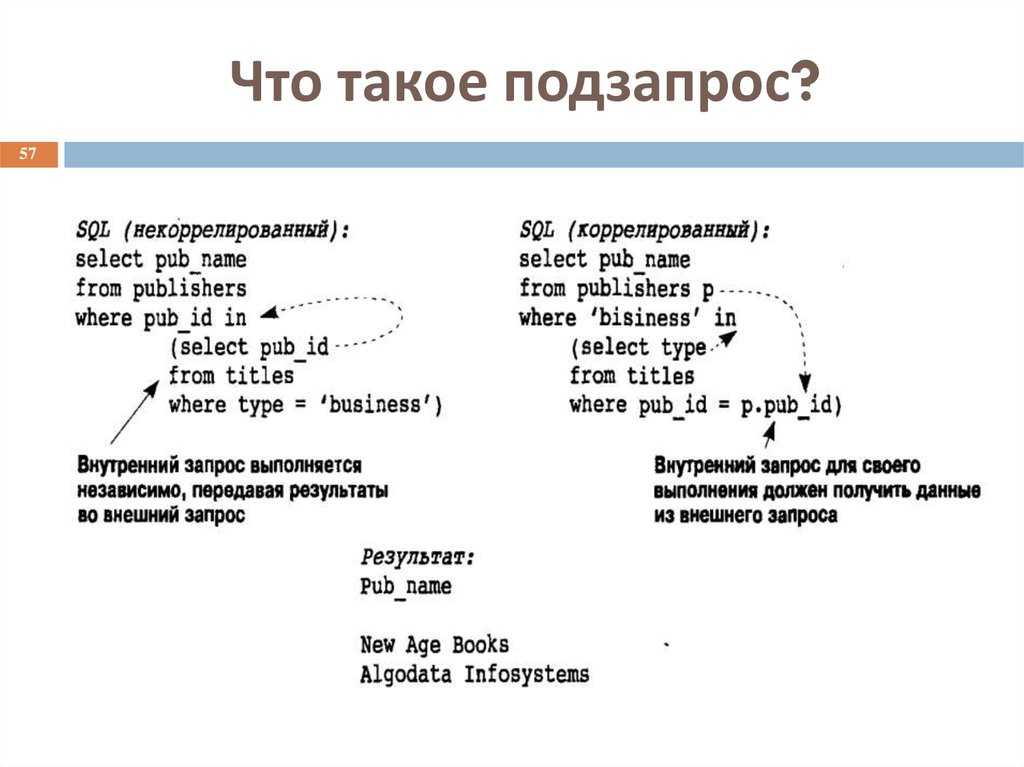
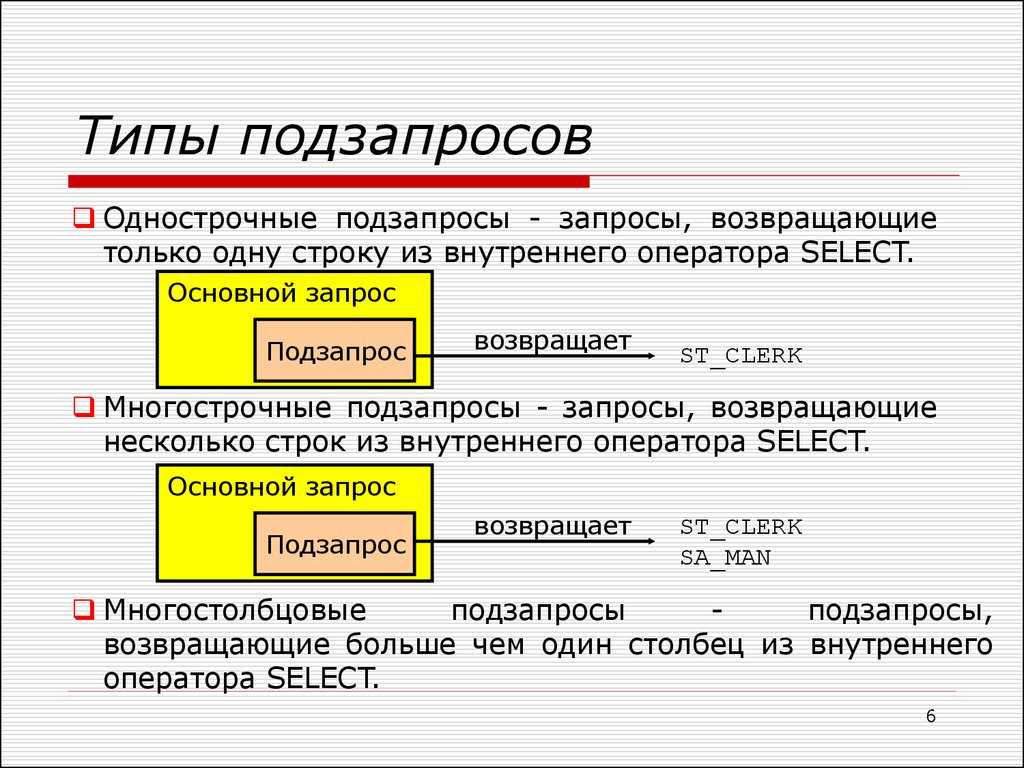
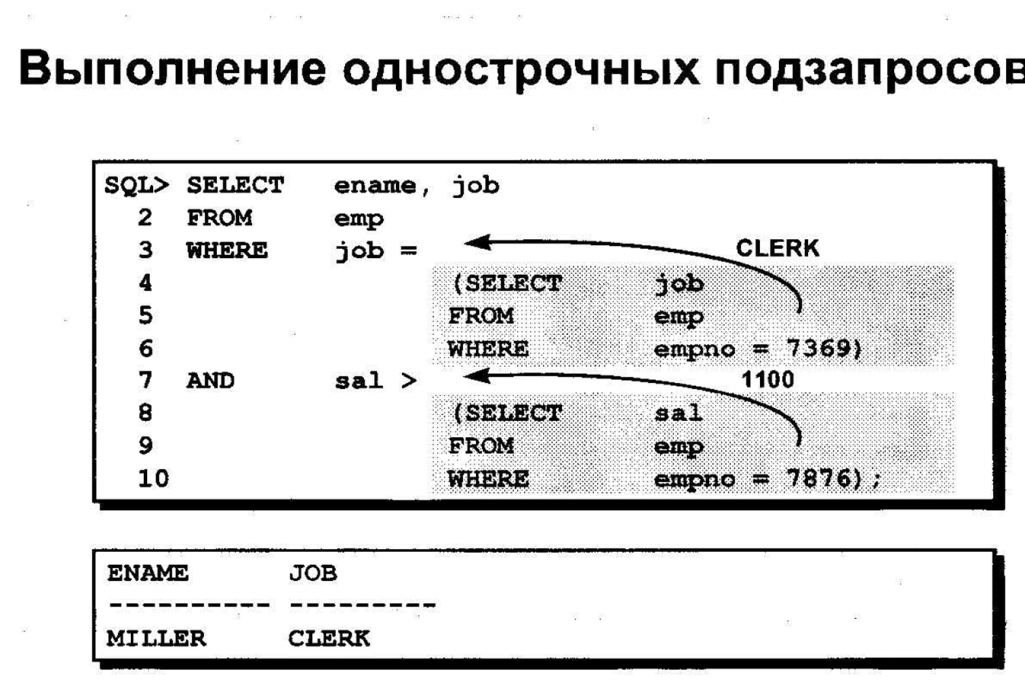
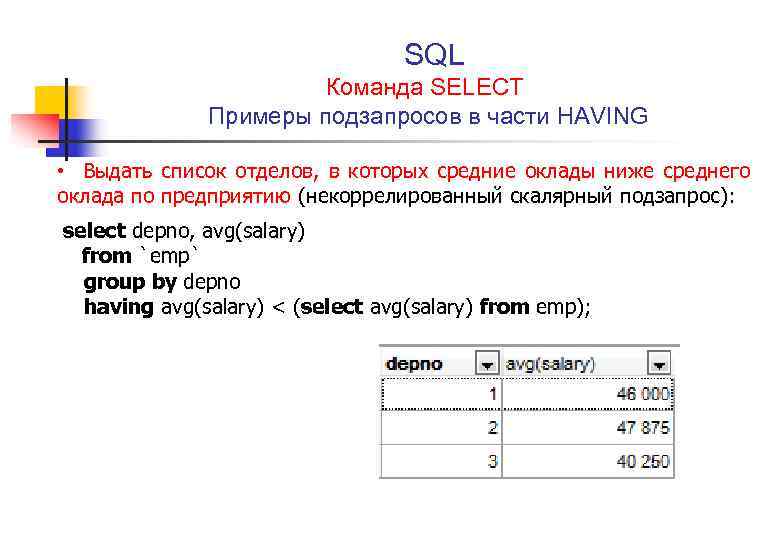
Подзапросы
Подзапрос – это запрос, вложенный в другой запрос и поддерживаемый только в базах геоданных. Подзапросы могут использоваться в SQL-выражении для применения предикативных или агрегирующих функций, или для сравнения данных со значениями, хранящимися в другой таблице и т.п. Это может быть сделано с помощью ключевых слов IN или ANY. Например этот запрос выбирает только те страны, которых нет в таблице indep_countries:




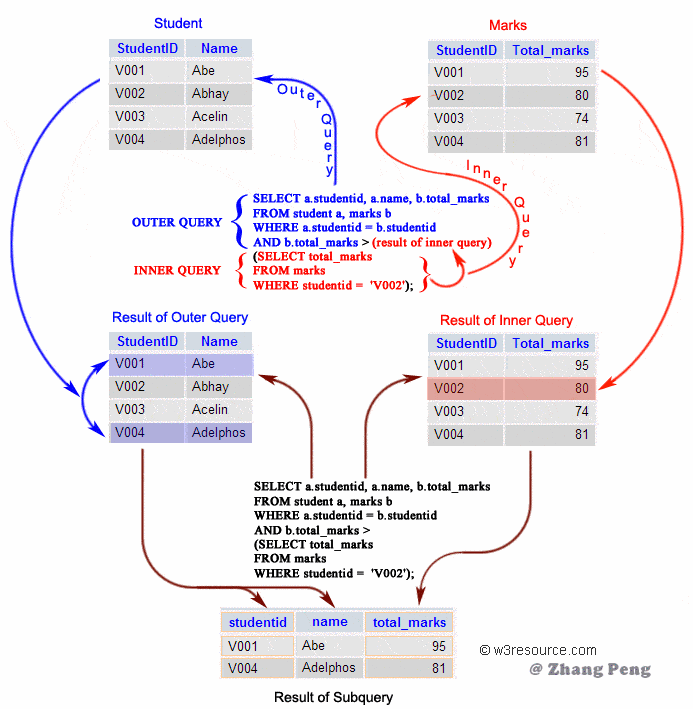



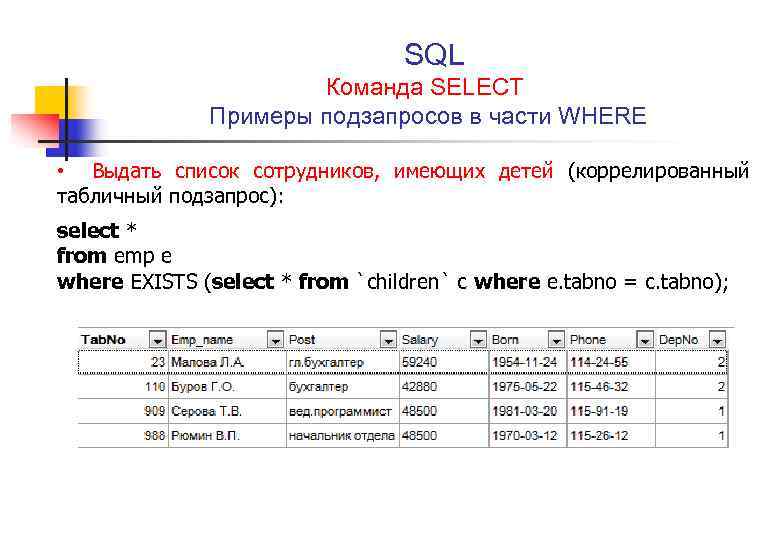
COUNTRY_NAME NOT IN (SELECT COUNTRY_NAME FROM indep_countries)
Шейп-файлы и прочие файловые источники данных, не относящиеся к базам геоданных, не поддерживают подзапросы. Подзапросы, выполняемые на версионных многопользовательских классах объектов и таблицах, не возвращают объекты, которые хранятся в дельта-таблицах. Файловые базы геоданных имеют ограниченную поддержку подзапросов, описанных в данном разделе, в то время, как многопользовательские базы геоданных поддерживают их полностью. Информацию обо всех возможностях подзапросов к многопользовательским базам геоданных смотрите в документации по своей СУБД.
Этот запрос возвращает объекты, где GDP2006 больше, чем GDP2005 любых объектов, содержащихся в countries (странах):
GDP2006 > (SELECT MAX(GDP2005) FROM countries)
Поддержка подзапросов в файловых базах геоданных ограничена следующим:
Возвращаемся к таблицам Employees и Departments
Запрос
Резюме
По сути данный запрос вернет только сотрудников, у которых указано значение DepartmentID.
Т.е. мы можем использовать данное соединение, в случае, когда нам нужны данные по сотрудникам числящихся за каким-нибудь отделом (без учета внештаткиков).
Вернет всех сотрудников
Для тех сотрудников у которых не указан DepartmentID, поля «dep.ID» и «dep.Name» будут содержать NULL.
Вспоминайте, что NULL значения в случае необходимости можно обработать, например, при помощи ISNULL(dep.Name,’вне штата’).
Этот вид соединения можно использовать, когда нам важно получить данные по всем сотрудникам, например, чтобы получить список для начисления ЗП.
Здесь мы получили дырки слева, т.е. отдел есть, но сотрудников в этом отделе нет.
Такое соединение можно использовать, например, когда нужно выяснить, какие отделы и кем у нас заняты, а какие еще не сформированы
Эту информацию можно использовать для поиска и приема новых работников из которых будет формироваться отдел.
Этот запрос важен, когда нам нужно получить все данные по сотрудникам и все данные по имеющимся отделам. Соответственно получаем дырки (NULL-значения) либо по сотрудникам, либо по отделам (внештатники).
Данный запрос, например, может использоваться в целях проверки, все ли сотрудники сидят в правильных отделах, т.к. может у некоторых сотрудников, которые числятся как внештатники, просто забыли указать отдел.
В таком виде даже сложно придумать где это можно применить, поэтому пример с CROSS JOIN я покажу ниже.
| ID | Name | ID | Name |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1001 | Петров П.П. |
| 3 | ИТ | 1003 | Андреев А.А. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
| ID | Name | ID | Name |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
| MaxEmployeeID |
|---|
| 1005 |
| 1000 |
| 1002 |
| 1004 |
Часто используемые выражения: поиск чисел
Точка (.) всегда используется в качестве десятичного разделителя, независимо от региональных настроек. В выражениях в качестве разделителя десятичных знаков нельзя использовать запятую.
Вы можете запрашивать цифровые значения, используя операторы равно (=), не равно (<>), больше (>), меньше (<), больше или равно (>=) и меньше или равно (<=), а также BETWEEN (между), например:
POPULATION >= 5000
Числовые функции можно использовать для форматирования чисел. Например функция ROUND округляет до заданного количества десятичных знаков данные в файловой базе геоданных:
ROUND(SQKM,0) = 500
6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
Что дает нам:
| avg |
|---|
| 3.000 |
И это можно использовать в качестве скалярной величины .
Теперь, наконец, можно написать весь запрос:
Это то же самое, что:
И результат:
| bookid | title | author | published | stock |
|---|---|---|---|---|
| 3 | Who Will Cry When You Die? | Robin Sharma | 2006-06-15 00:00:00 | 4 |