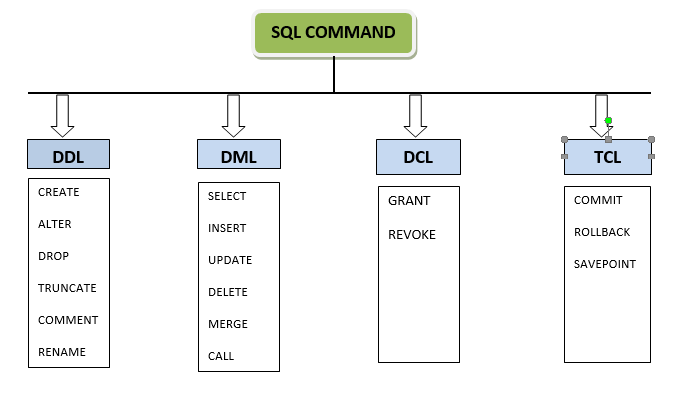
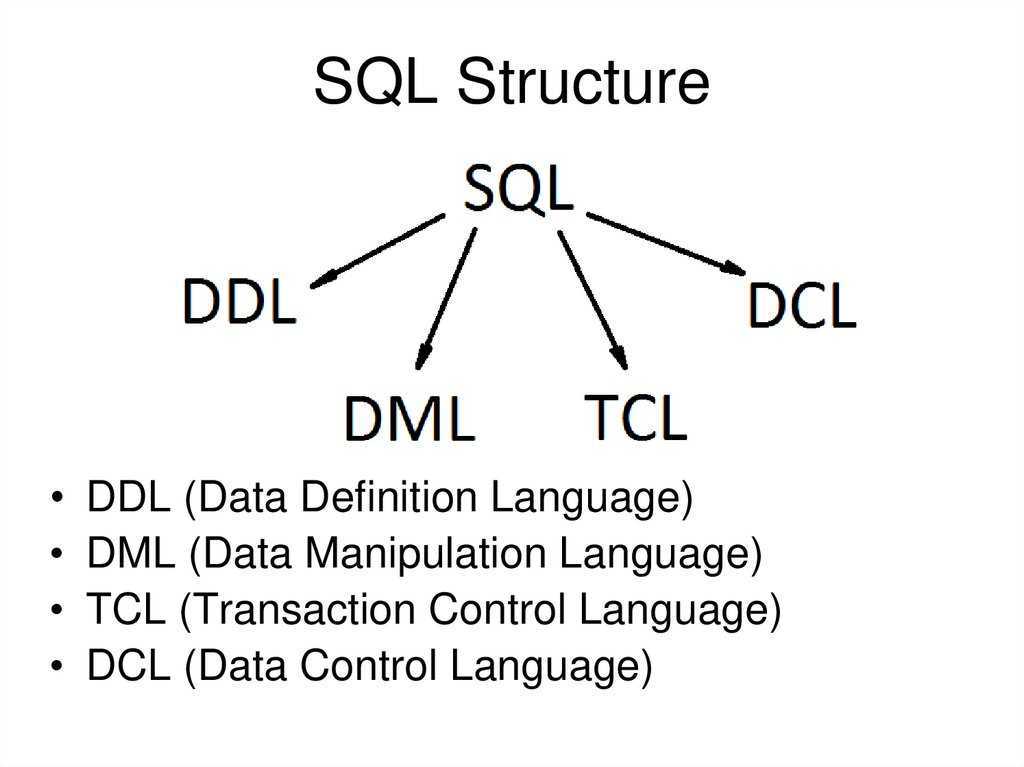
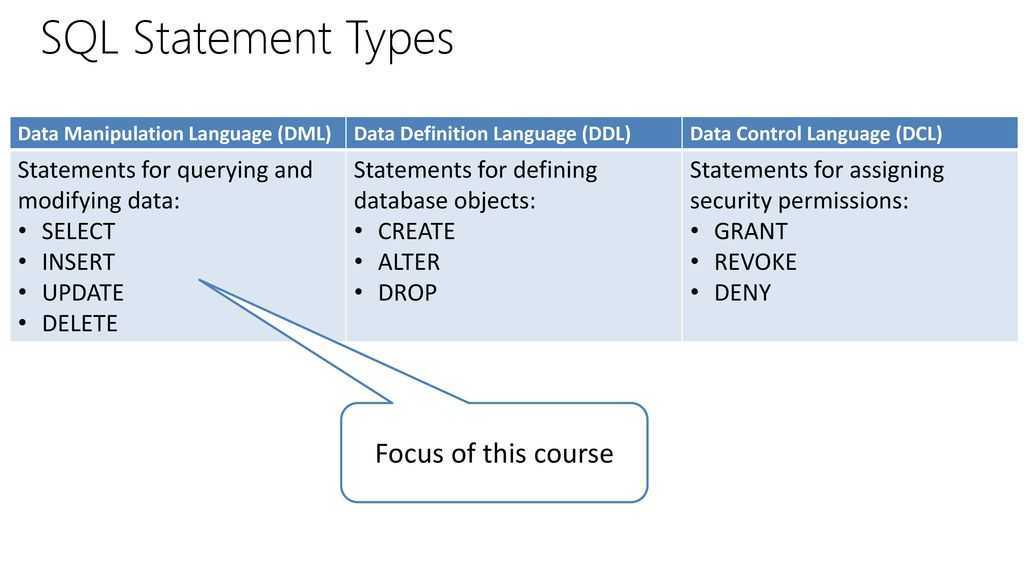
Многотабличные запросы
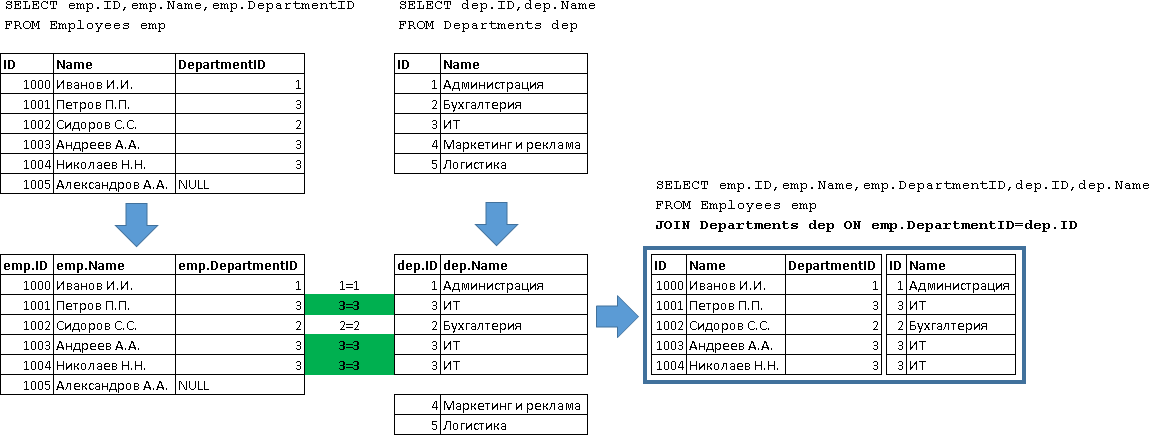
Используя JOIN, можно объединять не только две таблицы, как было описано выше, но и гораздо больше. В MySQL 5.0 на сегодняшний день можно объединить вплоть до 61 таблицы. Помимо объединений разных таблиц, MySQL позволяет объединять таблицу саму с собой. Однако, в любом случае необходимо следить за именами столбцов и таблиц, если они будут неоднозначны, то запрос не будет выполнен.
Так, если таблицу просто объединить саму на себя, то возникнет конфликт имён и запрос не выполнится.
| Код — Объединение таблицы саму на себя |
| mysql> SELECT * FROMnomenclatureJOINnomenclature; ERROR1066 (42000): Notuniquetable/alias: ‘nomenclature’ |
Обойти конфликт имён позволяет использование синонимов (alias) для имён таблиц и столбцов. В следующем примере внутреннее объединение будет работать успешнее:
| Код — Объединение таблицы саму на себя |
| mysql> SELECT * FROMnomenclatureJOINnomenclatureASt2; +—-+————+—-+————+ | id | name | id | name | +—-+————+—-+————+ | 1 | Книга | 1 | Книга | | 2 | Табуретка | 1 | Книга | | 3 | Карандаш | 1 | Книга | | 1 | Книга | 2 | Табуретка | | 2 | Табуретка | 2 | Табуретка | | 3 | Карандаш | 2 | Табуретка | | 1 | Книга | 3 | Карандаш | | 2 | Табуретка | 3 | Карандаш | | 3 | Карандаш | 3 | Карандаш | +—-+————+—-+————+9rowsinset (0.00sec) |
MySQL не накладывает ограничений на использование разных типов объединений в одном запросе, поэтому можно формировать довольно сложные конструкции:
| Код — Пример сложного объединения таблиц |
| mysql> SELECT * FROMnomenclatureASt1JOINnomenclatureASt2LEFTJOINnomenclatureASt3ONt1.id = t3.idANDt2.id = t1.id; +—-+————+—-+————+——+————+ | id | name | id | name | id | name | +—-+————+—-+————+——+————+ | 1 | Книга | 1 | Книга | 1 | Книга | | 2 | Табуретка | 1 | Книга | NULL | NULL | | 3 | Карандаш | 1 | Книга | NULL | NULL | | 1 | Книга | 2 | Табуретка | NULL | NULL | | 2 | Табуретка | 2 | Табуретка | 2 | Табуретка | | 3 | Карандаш | 2 | Табуретка | NULL | NULL | | 1 | Книга | 3 | Карандаш | NULL | NULL | | 2 | Табуретка | 3 | Карандаш | NULL | NULL | | 3 | Карандаш | 3 | Карандаш | 3 | Карандаш | +—-+————+—-+————+——+————+9rowsinset (0.00sec) |
Помимо выборок использовать объединения можно также и в запросах UPDATE и DELETE
Так, следующие три запроса проделывают одинаковую работу:
| Код — Многотаблицные обновления |
| mysql> UPDATEnomenclatureASt1, nomenclatureASt2SETt1.id = t2.idWHEREt1.id = t2.id; QueryOK, 0rowsaffected (0.01sec) Rowsmatched: 3Changed: 0Warnings: 0mysql> UPDATEnomenclatureASt1JOINnomenclatureASt2SETt1.id = t2.idWHEREt1.id = t2.id; QueryOK, 0rowsaffected (0.00sec) Rowsmatched: 3Changed: 0Warnings: 0mysql> UPDATEnomenclatureASt1JOINnomenclatureASt2USING(id) SETt1.id = t2.id; QueryOK, 0rowsaffected (0.00sec) Rowsmatched: 3Changed: 0Warnings: 0 |
Таким же образом работают и многтабличные удаления
| Код — Многотабличные удаления |
| mysql> DELETEt1FROMnomenclatureASt1JOINnomenclatureASt2USING(id) WHEREt2.id > 10; QueryOK, 0rowsaffected (0.02sec) |
Следует помнить, что при использовании многотабличных запросов на удаление или обновление данных, нельзя включать в запрос конструкции ORDER BY и LIMIT. Впрочем, это ограничение очень эффективно обходится при помощи временных таблиц, просто, надо это учитывать при модификации однотабличных запросов.
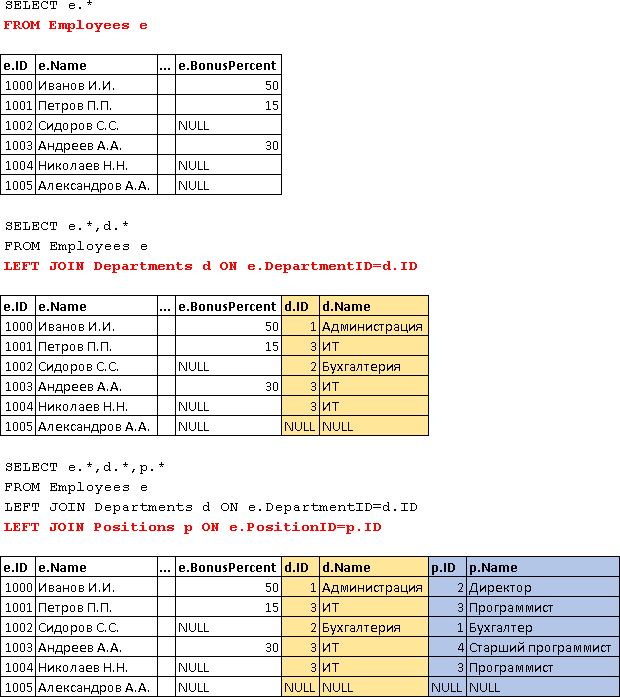
Значения NULL и соединения
Если в столбцах, по которым производится соединение таблиц, есть значение NULL, значения NULL друг с другом совпадать не будут. Наличие таких значений в столбце одной из соединяемых таблиц возможно только при использовании внешнего соединения (если только предложение не исключает значение NULL).
Ниже приведены две таблицы, каждая из которых может содержать NULL в столбце, по которому проводится соединение:
Соединение, сравнивающее значения в столбце a со значениями столбца c, не создает совпадений, если столбцы имеют значение NULL:
Возвращена только одна строка со значением 4 в столбцах a и c:
Значения NULL, возвращаемые из базовой таблицы, также сложно отличить от значений NULL, возвращаемых при внешнем соединении. Например, следующая инструкция выполняет левое внешнее соединение этих двух таблиц.
Результирующий набор:
В результате сложно определить, какие значения NULL получены из данных, а какие означают неуспешное соединение. Если в соединениях данных присутствуют значения NULL, чаще всего желательно исключить их из результатов с помощью обычного соединения.
Основы вложенных запросов
Вложенный запрос по-другому называют внутренним запросом или внутренней операцией выбора, в то время как инструкцию, содержащую вложенный запрос, называют внешним запросом или внешней операцией выбора.
Многие инструкции Transact-SQL, включающие вложенные запросы, можно также сформулировать как соединения. Другие запросы могут быть осуществлены только с помощью подзапросов. В Transact-SQL обычно нет разницы в производительности между инструкцией, которая включает вложенный запрос и семантически эквивалентную версию, которая не отличается. Сведения об архитектуре обработки запросов SQL Server см. в разделе «. Однако в некоторых случаях, когда проверяется существование, соединения показывают лучшую производительность. В противном случае для устранения дубликатов вложенный запрос должен обрабатываться для получения каждого результата внешнего запроса. В таких случаях метод работы соединений дает лучшие результаты.
В следующем примере показаны вложенный запрос и соединение , возвращающие один и тот же результирующий набор и план выполнения:
Вложенный во внешнюю инструкцию SELECT запрос, имеет следующие компоненты:
- обычный запрос , включающий обычные компоненты списка выборки;
- обычное предложение , включающее одно или несколько имен таблиц или представлений.
- Необязательное предложение .
- Необязательное предложение .
- Необязательное предложение .
Запрос SELECT вложенного запроса всегда заключен в скобки. Он не может включать предложение или предложение, и может включать только предложение, если также указано предложение TOP.
Вложенный запрос может быть включен в предложение или внешней инструкции , , или или в другой вложенный запрос. Возможно создавать вложенность до 32-го уровня, хотя ограничения меняются в зависимости от объема доступной памяти и сложности других выражений в запросе. Отдельные запросы могут не поддерживать вложенность до 32-го уровня. Подзапрос может появляться везде, где может использоваться выражение, если он возвращает одно значение.
Если таблица отображается только во вложенном запросе, а не во внешнем запросе, столбцы из этой таблицы не могут быть включены в выходные данные (список выбора внешнего запроса).
Инструкции, включающие вложенные запросы, обычно имеют один из следующих форматов:
В некоторых инструкциях Transact-SQL вложенный запрос можно оценить так, как если бы это был независимый запрос. По сути, результаты вложенных запросов заменяются внешним запросом (хотя это не обязательно, как SQL Server фактически обрабатывает инструкции Transact-SQL с вложенными запросами).
Существуют три основных типа подзапросов, которые:
- работают в списках, указанных с помощью ключевого слова , или тех, которые оператор сравнения изменил с помощью ключевого слова или ;
- вставлены оператором немодифицированных сравнений и должны возвращать одно значение;
- являются проверками на существование, начинающимися с ключевого слова .
FULL OUTER JOIN
Оператор полного внешнего соединенияFULL OUTER JOIN соединяет две таблицы. Порядок таблиц для оператора неважен, поскольку оператор является симметричным.
Заголовок таблицы-результата является объединением (конкатенацией) заголовков соединяемых таблиц.
Тело результата логически формируется следующим образом. Пусть выполняется соединение первой и второй таблиц по предикату (условию) p. Слова «первой» и «второй» здесь не обозначают порядок в записи (который неважен), а используются лишь для различения таблиц.
- В результат включается внутреннее соединение (INNER JOIN) первой и второй таблиц по предикату p.
- В результат добавляются те записи первой таблицы, которые не вошли во внутреннее соединение на шаге 1. Для таких записей поля, соответствующие второй таблице, заполняются значениями NULL .
- В результат добавляются те записи второй таблицы, которые не вошли во внутреннее соединение на шаге 1. Для таких записей поля, соответствующие первой таблице, заполняются значениями NULL .
select * from Person full outer join City on Person.CityId = City.Id
Результат:
| Alex | 1 | 1 | London |
| Michael | 1 | 1 | London |
| John | 2 | 2 | Paris |
| NULL | NULL | 3 | Prague |
| Brad | 4 | NULL | NULL |
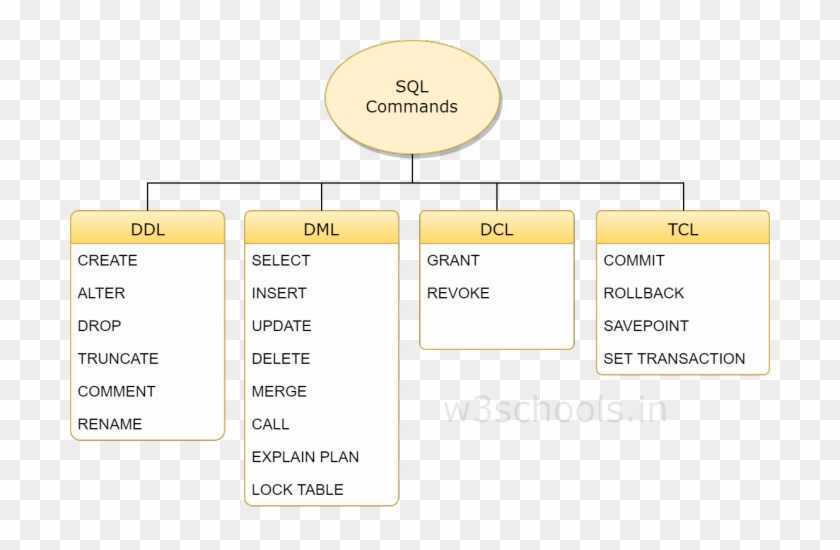
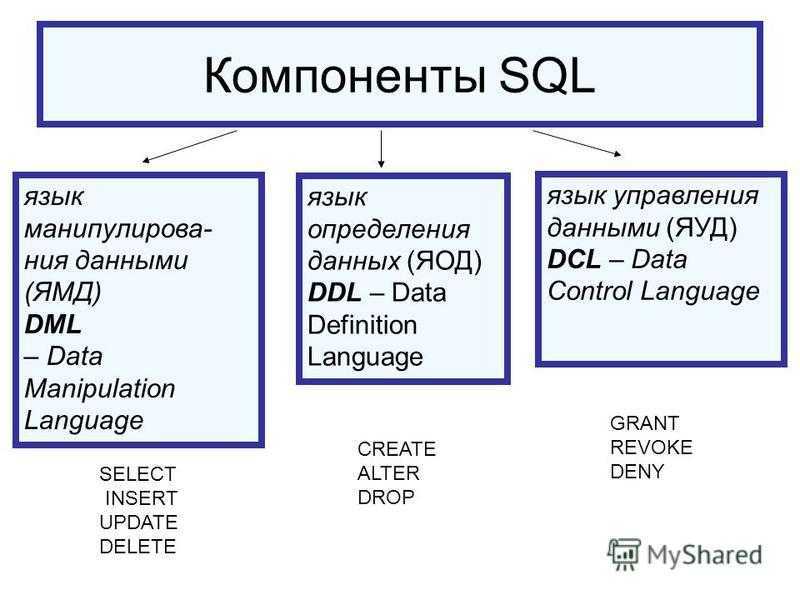
Определение SQL
Чтобы задействовать таблицы в приложениях, играх и прочем контенте, можно использовать SQL. Это – самый распространенный вариант развития событий.
Так называют язык структурированных запросов. Он дает возможность сохранять, управлять и извлекать информацию из реляционных баз данных.
Особенности – что умеет язык
При помощи SQL пользователь/разработчик сможет:
- заполучать доступ к информации в системах управления БД;
- производить описание данных, их структур;
- определять электронные материалы в «табличном хранилище», управляя оными;
- проводить взаимодействие с иными языками при помощи модулей, библиотек и компиляторов SQL;
- создавать новые таблички, удалять старые;
- заниматься созданием представлений, хранимых процедур и функций.
Также при работе с таблицами БД за счет SQL можно настраивать доступ к представлениям, таблицам и процедурам. Главное знать, каким именно образом действовать.
В SQL существуют всевозможные команды, использованием которых удается производить те или иные манипуляции
Далее будет рассказано всего об одном достаточно важном моменте. А именно – как использовать оператор Join
Он пригодится и новичкам, и тем, кто долгое время работает с таблицами и БД.
5 Разница между ON и WHERE
После четкого понимания порядка выполнения JOIN выше, разница между ON и WHERE становится понятной. Например:
Первый случайLEFT JOINПосле выполнения предложения ON второго шага отфильтруйте удовлетворениеi.userid = a.userid and i.userid = 1003Чтобы сгенерировать таблицу vt2, а затем выполнить предложение JOIN третьего шага, добавьте внешнюю строку в виртуальную таблицу, чтобы сгенерировать vt3, что является окончательным результатом:


И второй случайLEFT JOINПосле выполнения предложения ON второго шага отфильтруйте удовлетворениеi.userid = a.useridЧтобы сгенерировать таблицу vt2; затем выполните предложение JOIN третьего шага, чтобы добавить внешние строки для создания таблицы vt3; затем выполните предложение WHERE четвертого шага, а затем отфильтруйте таблицу vt3 для генерации vt4, конечный результат:
Если приведенный выше примерLEFT JOINЗаменитьINNER JOIN, Независимо от условного фильтраONвсе ещеWHEREЗдесь результат тот же, потому чтоINNER JOIN не будет выполнять третий шаг для добавления внешних строк
Возвращенные результаты:
SQL References
SQL Keywords
ADD
ADD CONSTRAINT
ALL
ALTER
ALTER COLUMN
ALTER TABLE
AND
ANY
AS
ASC
BACKUP DATABASE
BETWEEN
CASE
CHECK
COLUMN
CONSTRAINT
CREATE
CREATE DATABASE
CREATE INDEX
CREATE OR REPLACE VIEW
CREATE TABLE
CREATE PROCEDURE
CREATE UNIQUE INDEX
CREATE VIEW
DATABASE
DEFAULT
DELETE
DESC
DISTINCT
DROP
DROP COLUMN
DROP CONSTRAINT
DROP DATABASE
DROP DEFAULT
DROP INDEX
DROP TABLE
DROP VIEW
EXEC
EXISTS
FOREIGN KEY
FROM
FULL OUTER JOIN
GROUP BY
HAVING
IN
INDEX
INNER JOIN
INSERT INTO
INSERT INTO SELECT
IS NULL
IS NOT NULL
JOIN
LEFT JOIN
LIKE
LIMIT
NOT
NOT NULL
OR
ORDER BY
OUTER JOIN
PRIMARY KEY
PROCEDURE
RIGHT JOIN
ROWNUM
SELECT
SELECT DISTINCT
SELECT INTO
SELECT TOP
SET
TABLE
TOP
TRUNCATE TABLE
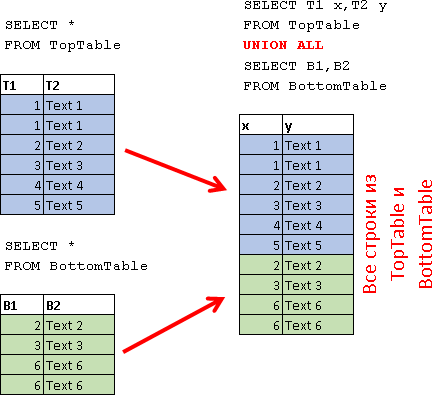
UNION
UNION ALL
UNIQUE
UPDATE
VALUES
VIEW
WHERE
MySQL Functions
String Functions:
ASCII
CHAR_LENGTH
CHARACTER_LENGTH
CONCAT
CONCAT_WS
FIELD
FIND_IN_SET
FORMAT
INSERT
INSTR
LCASE
LEFT
LENGTH
LOCATE
LOWER
LPAD
LTRIM
MID
POSITION
REPEAT
REPLACE
REVERSE
RIGHT
RPAD
RTRIM
SPACE
STRCMP
SUBSTR
SUBSTRING
SUBSTRING_INDEX
TRIM
UCASE
UPPER
Numeric Functions:
ABS
ACOS
ASIN
ATAN
ATAN2
AVG
CEIL
CEILING
COS
COT
COUNT
DEGREES
DIV
EXP
FLOOR
GREATEST
LEAST
LN
LOG
LOG10
LOG2
MAX
MIN
MOD
PI
POW
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SUM
TAN
TRUNCATE
Date Functions:
ADDDATE
ADDTIME
CURDATE
CURRENT_DATE
CURRENT_TIME
CURRENT_TIMESTAMP
CURTIME
DATE
DATEDIFF
DATE_ADD
DATE_FORMAT
DATE_SUB
DAY
DAYNAME
DAYOFMONTH
DAYOFWEEK
DAYOFYEAR
EXTRACT
FROM_DAYS
HOUR
LAST_DAY
LOCALTIME
LOCALTIMESTAMP
MAKEDATE
MAKETIME
MICROSECOND
MINUTE
MONTH
MONTHNAME
NOW
PERIOD_ADD
PERIOD_DIFF
QUARTER
SECOND
SEC_TO_TIME
STR_TO_DATE
SUBDATE
SUBTIME
SYSDATE
TIME
TIME_FORMAT
TIME_TO_SEC
TIMEDIFF
TIMESTAMP
TO_DAYS
WEEK
WEEKDAY
WEEKOFYEAR
YEAR
YEARWEEK
Advanced Functions:
BIN
BINARY
CASE
CAST
COALESCE
CONNECTION_ID
CONV
CONVERT
CURRENT_USER
DATABASE
IF
IFNULL
ISNULL
LAST_INSERT_ID
NULLIF
SESSION_USER
SYSTEM_USER
USER
VERSION
SQL Server Functions
String Functions:
ASCII
CHAR
CHARINDEX
CONCAT
Concat with +
CONCAT_WS
DATALENGTH
DIFFERENCE
FORMAT
LEFT
LEN
LOWER
LTRIM
NCHAR
PATINDEX
QUOTENAME
REPLACE
REPLICATE
REVERSE
RIGHT
RTRIM
SOUNDEX
SPACE
STR
STUFF
SUBSTRING
TRANSLATE
TRIM
UNICODE
UPPER
Numeric Functions:
ABS
ACOS
ASIN
ATAN
ATN2
AVG
CEILING
COUNT
COS
COT
DEGREES
EXP
FLOOR
LOG
LOG10
MAX
MIN
PI
POWER
RADIANS
RAND
ROUND
SIGN
SIN
SQRT
SQUARE
SUM
TAN
Date Functions:
CURRENT_TIMESTAMP
DATEADD
DATEDIFF
DATEFROMPARTS
DATENAME
DATEPART
DAY
GETDATE
GETUTCDATE
ISDATE
MONTH
SYSDATETIME
YEAR
Advanced Functions
CAST
COALESCE
CONVERT
CURRENT_USER
IIF
ISNULL
ISNUMERIC
NULLIF
SESSION_USER
SESSIONPROPERTY
SYSTEM_USER
USER_NAME
MS Access Functions
String Functions:
Asc
Chr
Concat with &
CurDir
Format
InStr
InstrRev
LCase
Left
Len
LTrim
Mid
Replace
Right
RTrim
Space
Split
Str
StrComp
StrConv
StrReverse
Trim
UCase
Numeric Functions:
Abs
Atn
Avg
Cos
Count
Exp
Fix
Format
Int
Max
Min
Randomize
Rnd
Round
Sgn
Sqr
Sum
Val
Date Functions:
Date
DateAdd
DateDiff
DatePart
DateSerial
DateValue
Day
Format
Hour
Minute
Month
MonthName
Now
Second
Time
TimeSerial
TimeValue
Weekday
WeekdayName
Year
Other Functions:
CurrentUser
Environ
IsDate
IsNull
IsNumeric
SQL Quick Ref
SQL JOIN
A clause is used to combine rows from two or more tables, based on
a related column between them.
Let’s look at a selection from the «Orders» table:
| OrderID | CustomerID | OrderDate |
|---|---|---|
| 10308 | 2 | 1996-09-18 |
| 10309 | 37 | 1996-09-19 |
| 10310 | 77 | 1996-09-20 |
Then, look at a selection from the «Customers» table:
| CustomerID | CustomerName | ContactName | Country |
|---|---|---|---|
| 1 | Alfreds Futterkiste | Maria Anders | Germany |
| 2 | Ana Trujillo Emparedados y helados | Ana Trujillo | Mexico |
| 3 | Antonio Moreno Taquería | Antonio Moreno | Mexico |
Notice that the «CustomerID» column in the «Orders» table refers to the
«CustomerID» in the «Customers» table. The relationship between the two tables above
is the «CustomerID» column.
Then, we can create the following SQL statement (that contains an ),
that selects records that have matching values in both tables:
Example
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDateFROM OrdersINNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;
and it will produce something like this:
| OrderID | CustomerName | OrderDate |
|---|---|---|
| 10308 | Ana Trujillo Emparedados y helados | 9/18/1996 |
| 10365 | Antonio Moreno Taquería | 11/27/1996 |
| 10383 | Around the Horn | 12/16/1996 |
| 10355 | Around the Horn | 11/15/1996 |
| 10278 | Berglunds snabbköp | 8/12/1996 |
Внешнее соединение
Внешнее соединение позволяет в отличие от внутреннего извлечь не только строки с одинаковыми значениями соединяемых столбцов, но и строки без совпадений из одной или обеих таблиц.
Выделяют три вида внешних соединений:
-
левое внешнее соединение — в результирующий набор попадают все строки из таблицы с левой стороны оператора сравнения (независимо от того имеются ли совпадающие строки с правой стороны), а из таблицы с правой стороны — только строки с совпадающими значениями столбцов. При этом если для строки из левой таблицы нет соответствий в правой таблице, значениям строки в правой таблице будут присвоены NULL
Transact-SQL
SELECT employee_enh.*, department.location
FROM employee_enh LEFT OUTER JOIN department
ON domicile = location;1
2
3SELECTemployee_enh.*,department.location
FROMemployee_enhLEFTOUTERJOINdepartment
ONdomicile=location;
-
правое внешнее соединение — аналогично левому внешнему соединению, но таблицы меняются местами
Transact-SQL
SELECT employee_enh.domicile, department.*
FROM employee_enh RIGHT OUTER JOIN department
ON domicile =location;1
2
3SELECTemployee_enh.domicile,department.*
FROMemployee_enhRIGHTOUTERJOINdepartment
ONdomicile=location;
- полное внешнее соединение — композиция левого и правого внешнего соединения: результирующий набор состоит из всех строк обеих таблиц. Если для строки одной из таблиц нет соответствующей строки в другой таблице, всем ячейкам строки второй таблицы присваивается значение NULL.
SQL RIGHT OUTER JOIN JOIN
Другой тип соединения называется SQL RIGHT OUTER JOIN. Этот тип соединения возвращает все строки из таблиц с правосторонним соединением, указанным в условии ON, и только те строки из другой таблицы, где объединяемые поля равны (выполняется условие соединения).
Синтаксис
Синтаксис для RIGHT OUTER JOIN в SQL:
SELECT columns
FROM table1
RIGHT JOIN table2
ON table1.column = table2.column;
В некоторых базах данных ключевое слово OUTER опущено и записывается просто как RIGHT JOIN.
Рисунок
На этом рисунке SQL RIGHT OUTER JOIN возвращает затененную область:
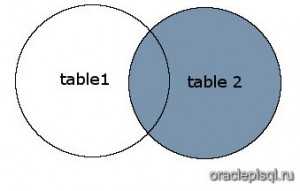
SQL RIGHT OUTER JOIN возвращает все записи из table2 и только те записи из table1, которые пересекаются с table2.
Пример
Теперь давайте рассмотрим пример, который показывает, как использовать RIGHT OUTER JOIN в операторе SELECT.
| customer_id | first_name | last_name | favorite_website |
|---|---|---|---|
| 4000 | Justin | Bieber | google.com |
| 5000 | Selena | Gomez | bing.com |
| 6000 | Mila | Kunis | yahoo.com |
| 7000 | Tom | Cruise | oracle.com |
| 8000 | Johnny | Depp | NULL |
| 9000 | Russell | Crowe | google.com |
И таблицу orders со следующими данными:
| order_id | customer_id | order_date |
|---|---|---|
| 1 | 7000 | 2019/06/18 |
| 2 | 5000 | 2019/06/18 |
| 3 | 8000 | 2019/06/19 |
| 4 | 4000 | 2019/06/20 |
| 5 | NULL | 2019/07/01 |
Введите следующий SQL оператор:
PgSQL
SELECT customers.customer_id,
orders.order_id,
orders.order_date
FROM customers
RIGHT OUTER JOIN orders
ON customers.customer_id = orders.customer_id
ORDER BY customers.customer_id;
|
1 |
SELECTcustomers.customer_id, orders.order_id, orders.order_date FROMcustomers RIGHT OUTER JOINorders ONcustomers.customer_id=orders.customer_id ORDERBYcustomers.customer_id; |
Будет выбрано 5 записей. Вот результаты, которые вы должны получить:
| customer_id | order_id | order_date |
|---|---|---|
| NULL | 5 | 2019/07/01 |
| 4000 | 4 | 2019/06/20 |
| 5000 | 2 | 2019/06/18 |
| 7000 | 1 | 2019/06/18 |
| 8000 | 3 | 2019/06/19 |
Этот пример RIGHT OUTER JOIN вернул бы все строки из таблицы orders и только те строки из таблицы customers, где объединенные поля равны.
Если значение customer_id в таблице orders не существует в таблице customers, то все поля в таблице customers будут отображаться как NULL в наборе результатов. Как видите, строка, где order_id равен 5, будет включена в RIGHT OUTER JOIN, но в поле customer_id отображается NULL.
Булевы операторы и простые операторы сравнения
| AND | логическое И. Ставится между двумя условиями (условие1 AND условие2). Чтобы выражение вернуло True, нужно, чтобы истинными были оба условия |
|---|---|
| OR | логическое ИЛИ. Ставится между двумя условиями (условие1 OR условие2). Чтобы выражение вернуло True, достаточно, чтобы истинным было только одно условие |
| NOT | инвертирует условие/логическое_выражение. Накладывается на другое выражение (NOT логическое_выражение) и возвращает True, если логическое_выражение = False и возвращает False, если логическое_выражение = True |
| Условие | Значение |
|---|---|
| = | Равно |
| < | Меньше |
| > | Больше |
| <= | Меньше или равно |
| >= | Больше или равно |
| <> != |
Не равно |
| IS NULL | Проверка на равенство NULL |
|---|---|
| IS NOT NULL | Проверка на неравенство NULL |
Соединения слиянием.
Если два входа соединения достаточно велики, но отсортированы по соединяемым столбцам (например, если они были получены просмотром отсортированных индексов), то наиболее быстрой операцией соединения будет соединение слиянием. Если оба входа соединения велики и имеют сходные размеры, соединение слиянием с предварительной сортировкой и хэш-соединение имеют примерно одинаковую производительность. Однако операции хэш-соединения часто выполняются быстрее, если два входа значительно отличаются по размеру.
Соединение слиянием требует сортировки обоих наборов входных данных по столбцам слияния, которые определены предложениями равенства (ON) предиката объединения. Оптимизатор запросов обычно просматривает индекс, если для соответствующего набора столбцов такой существует, или устанавливает оператор сортировки под соединением слиянием. В редких случаях может быть несколько предложений равенства, но столбцы слияния берутся только из некоторых доступных предложений равенства.
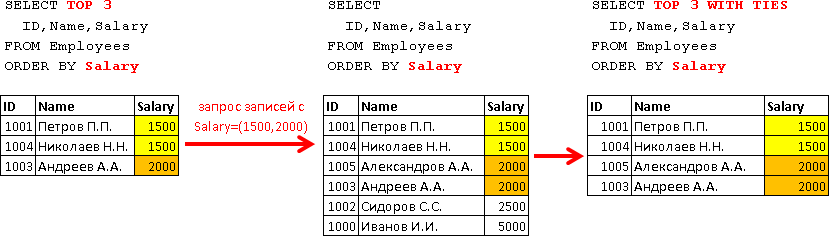

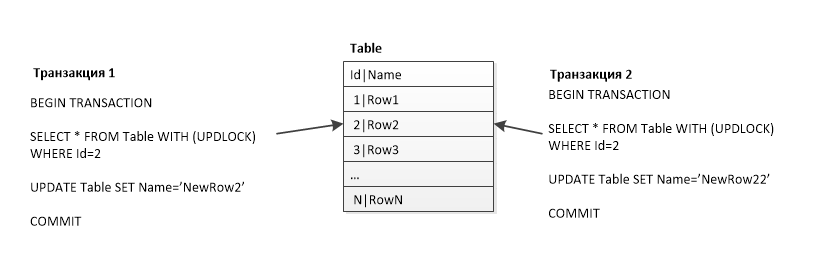
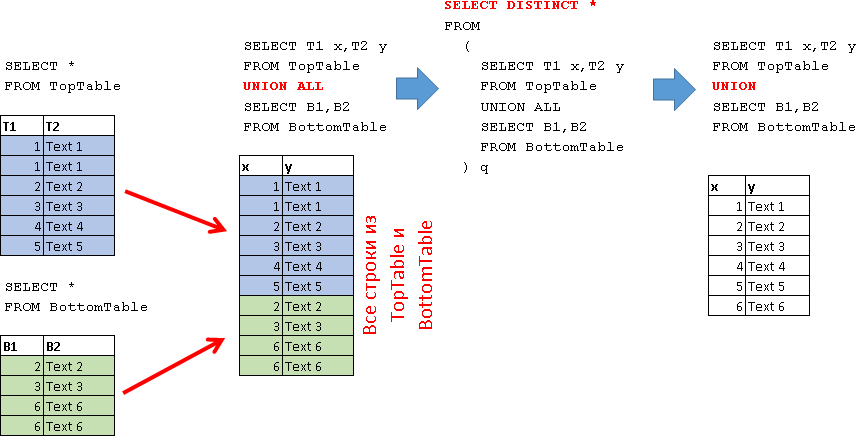
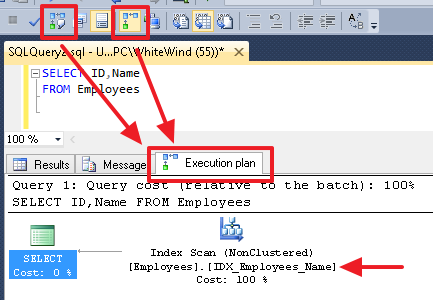
Так как каждый набор входных данных сортируется, оператор Merge Join получает строку из каждого набора входных данных и сравнивает их. Например, для операций внутреннего соединения строки возвращаются в том случае, если они равны. Если они не равны, строка с меньшим значением не учитывается, и из этого набора входных данных берется другая строка. Этот процесс повторяется, пока не будет выполнена обработка всех строк.
Операция соединения слиянием может быть как обычной, так и операцией типа «многие ко многим». Соединение слиянием «многие ко многим» использует временную таблицу для хранения строк. При наличии дублирующих значений из каждого набора входных данных один из наборов должен будет сбрасываться на начало дубликатов по мере обработки каждого дубликата из другого набора данных.
При наличии остаточного предиката все строки, удовлетворяющие предикату слияния, определяют остаточный предикат, и возвращаются только те строки, которые ему соответствуют.
Соединение слиянием — очень быстрая операция, но она может оказаться ресурсоемкой, если требуется выполнение операций сортировки. Однако если том данных имеет большой объем, и необходимые данные могут быть получены из существующих индексов сбалансированного дерева с выполненной предварительной сортировкой, соединение слиянием является самым быстрым из доступных алгоритмов соединения.
Основы вложенных запросов
Вложенный запрос по-другому называют внутренним запросом или внутренней операцией выбора, в то время как инструкцию, содержащую вложенный запрос, называют внешним запросом или внешней операцией выбора.
Многие инструкции Transact-SQL, включающие вложенные запросы, можно также сформулировать как соединения. Другие запросы могут быть осуществлены только с помощью подзапросов. В Transact-SQL обычно нет разницы в производительности между инструкцией, которая включает вложенный запрос и семантически эквивалентную версию, которая не отличается. Сведения об архитектуре обработки запросов SQL Server см. в разделе «. Однако в некоторых случаях, когда проверяется существование, соединения показывают лучшую производительность. В противном случае для устранения дубликатов вложенный запрос должен обрабатываться для получения каждого результата внешнего запроса. В таких случаях метод работы соединений дает лучшие результаты.
В следующем примере показаны вложенный запрос и соединение , возвращающие один и тот же результирующий набор и план выполнения:
Вложенный во внешнюю инструкцию SELECT запрос, имеет следующие компоненты:
- обычный запрос , включающий обычные компоненты списка выборки;
- обычное предложение , включающее одно или несколько имен таблиц или представлений.
- Необязательное предложение .
- Необязательное предложение .
- Необязательное предложение .
Запрос SELECT вложенного запроса всегда заключен в скобки. Он не может включать предложение или предложение, и может включать только предложение, если также указано предложение TOP.
Вложенный запрос может быть включен в предложение или внешней инструкции , , или или в другой вложенный запрос. Возможно создавать вложенность до 32-го уровня, хотя ограничения меняются в зависимости от объема доступной памяти и сложности других выражений в запросе. Отдельные запросы могут не поддерживать вложенность до 32-го уровня. Подзапрос может появляться везде, где может использоваться выражение, если он возвращает одно значение.
Если таблица отображается только во вложенном запросе, а не во внешнем запросе, столбцы из этой таблицы не могут быть включены в выходные данные (список выбора внешнего запроса).
Инструкции, включающие вложенные запросы, обычно имеют один из следующих форматов:
В некоторых инструкциях Transact-SQL вложенный запрос можно оценить так, как если бы это был независимый запрос. По сути, результаты вложенных запросов заменяются внешним запросом (хотя это не обязательно, как SQL Server фактически обрабатывает инструкции Transact-SQL с вложенными запросами).
Существуют три основных типа подзапросов, которые:
- работают в списках, указанных с помощью ключевого слова , или тех, которые оператор сравнения изменил с помощью ключевого слова или ;
- вставлены оператором немодифицированных сравнений и должны возвращать одно значение;
- являются проверками на существование, начинающимися с ключевого слова .
Соединения слиянием.
Если два входа соединения достаточно велики, но отсортированы по соединяемым столбцам (например, если они были получены просмотром отсортированных индексов), то наиболее быстрой операцией соединения будет соединение слиянием. Если оба входа соединения велики и имеют сходные размеры, соединение слиянием с предварительной сортировкой и хэш-соединение имеют примерно одинаковую производительность. Однако операции хэш-соединения часто выполняются быстрее, если два входа значительно отличаются по размеру.
Соединение слиянием требует сортировки обоих наборов входных данных по столбцам слияния, которые определены предложениями равенства (ON) предиката объединения. Оптимизатор запросов обычно просматривает индекс, если для соответствующего набора столбцов такой существует, или устанавливает оператор сортировки под соединением слиянием. В редких случаях может быть несколько предложений равенства, но столбцы слияния берутся только из некоторых доступных предложений равенства.
Так как каждый набор входных данных сортируется, оператор Merge Join получает строку из каждого набора входных данных и сравнивает их. Например, для операций внутреннего соединения строки возвращаются в том случае, если они равны. Если они не равны, строка с меньшим значением не учитывается, и из этого набора входных данных берется другая строка. Этот процесс повторяется, пока не будет выполнена обработка всех строк.
Операция соединения слиянием может быть как обычной, так и операцией типа «многие ко многим». Соединение слиянием «многие ко многим» использует временную таблицу для хранения строк. При наличии дублирующих значений из каждого набора входных данных один из наборов должен будет сбрасываться на начало дубликатов по мере обработки каждого дубликата из другого набора данных.
При наличии остаточного предиката все строки, удовлетворяющие предикату слияния, определяют остаточный предикат, и возвращаются только те строки, которые ему соответствуют.
Соединение слиянием — очень быстрая операция, но она может оказаться ресурсоемкой, если требуется выполнение операций сортировки. Однако если том данных имеет большой объем, и необходимые данные могут быть получены из существующих индексов сбалансированного дерева с выполненной предварительной сортировкой, соединение слиянием является самым быстрым из доступных алгоритмов соединения.
3 Примеры
Создайте таблицу информации о пользователе:
Создайте еще одну таблицу баланса пользователя:
Не стесняйтесь импортировать некоторые данные:
Всего 8 пользователей имеют имена пользователей, а 4 пользователя имеют остатки на счетах.Получите имя и баланс пользователя с идентификатором пользователя 1003, SQL выглядит следующим образом:
Шаг 3: ПРИСОЕДИНЯЙТЕСЬ, чтобы добавить внешние строки
LEFT JOINСтроки левой таблицы, которых нет в vt2, будут вставлены в vt2, а остальные поля каждой строки будут заполнены NULL,RIGHT JOINТакой же В этом примереLEFT JOIN, Итак, левая таблицаuser_infoДобавьте оставшиеся строки для создания таблицы vt3:
Шаг 5: ВЫБРАТЬ
SELECT i.name, a.money генерирует vt5:
Виртуальная таблица vt5 возвращается клиенту в качестве окончательного результата
После знакомства с процессом объединения таблиц давайте взглянем на наиболее часто используемыеJOINРазличия
Использование JOIN
Использование синтаксиса SQL JOINS при работе с базами данных достаточно популярно, без них не обходится любой серьезный SQL запрос.
Предположим, что у нас есть две следующие таблицы. Слева Таблица A, и таблица B справа. Поместим в каждой из них по 4 записи (строки).
Давайте соединим эти таблицы с помощью SQL join по столбцу «name» несколькими способами и посмотрим, как это будет выглядеть на диаграммах Венна.
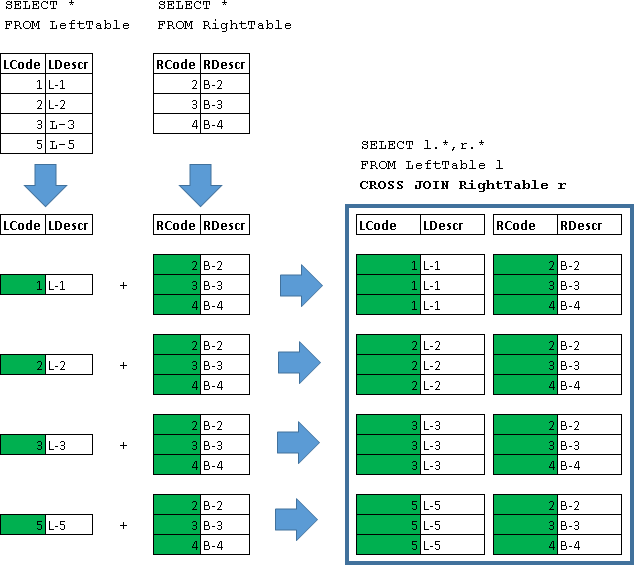
Inner join(внутреннее присоединение) производит выбор только строк, которые есть и в таблице А, и в таблице В.
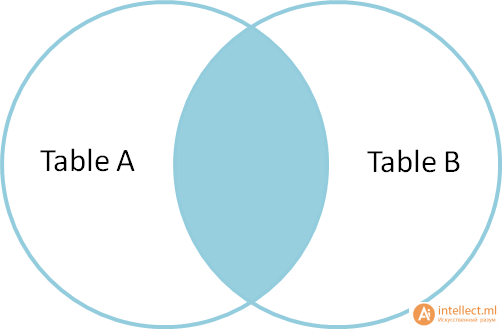
SELECT * FROM TableA
INNER JOINTableB ON TableA.name = TableB.name
Full outer join (полное внешнее соединение — объединение) производит выбор всех строк из таблиц А и В, причем со всеми возможными вариантами. Если с какой-либо стороны не будет записи, то недостающая запись будет содержать пустую строку (null значения).


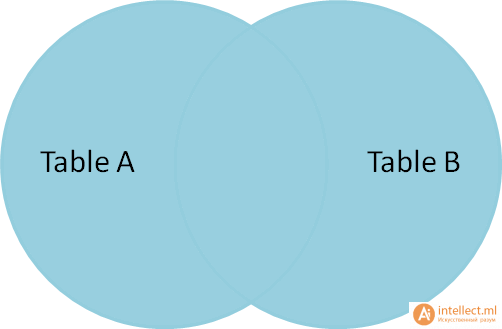
SELECT * FROM TableA
FULL OUTER JOIN TableB ON TableA.name = TableB.name
Left outer join(левое внешнее соединение) производит выбор всех строк таблицы А с доступными строками таблицы В. Если строки таблицы В не найдены, то подставляется пустой результат (null).
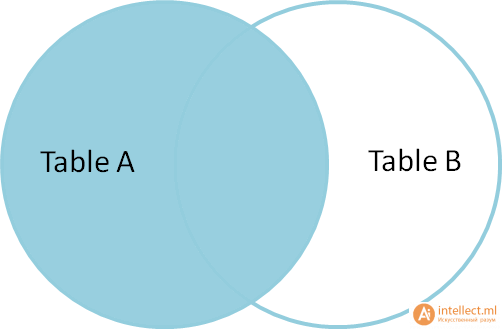
SELECT * FROM TableA
LEFT OUTER JOINTableB ON TableA.name = TableB.name
Чтобы произвести выбор строк из Таблицы A, которых нет в Таблице Б, мы выполняем тот же самый LEFT OUTER JOIN, затем исключаем строки, которые заполнены в Таблице Б. То есть выбрать все записи таблицы А, которых нет в Таблице В, мы выполняем тоже jeft outer join, но исключаем пустые записи таблицы В.
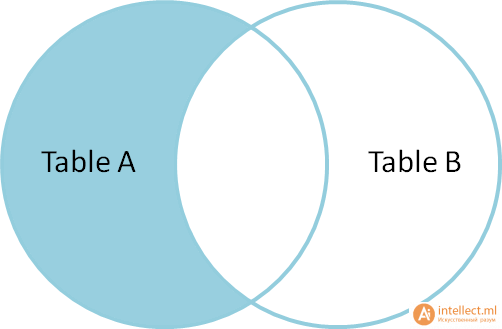
С добавлением условия получаем:
SELECT * FROM TableA
LEFT OUTER JOINTableB ON TableA.name = TableB.name
WHERE TableB.id IS null
Чтобы выбрать уникальные записи таблиц А и В, мы выполняем FULL OUTER JOIN, а затем исключаем записи, которые принадлежат и таблице А, и таблице Б с помощью условия WHERE.
SELECT * FROM TableA
FULL OUTER JOINTableB ON TableA.name = TableB.name
WHERE TableA.id IS null OR TableB.id IS null