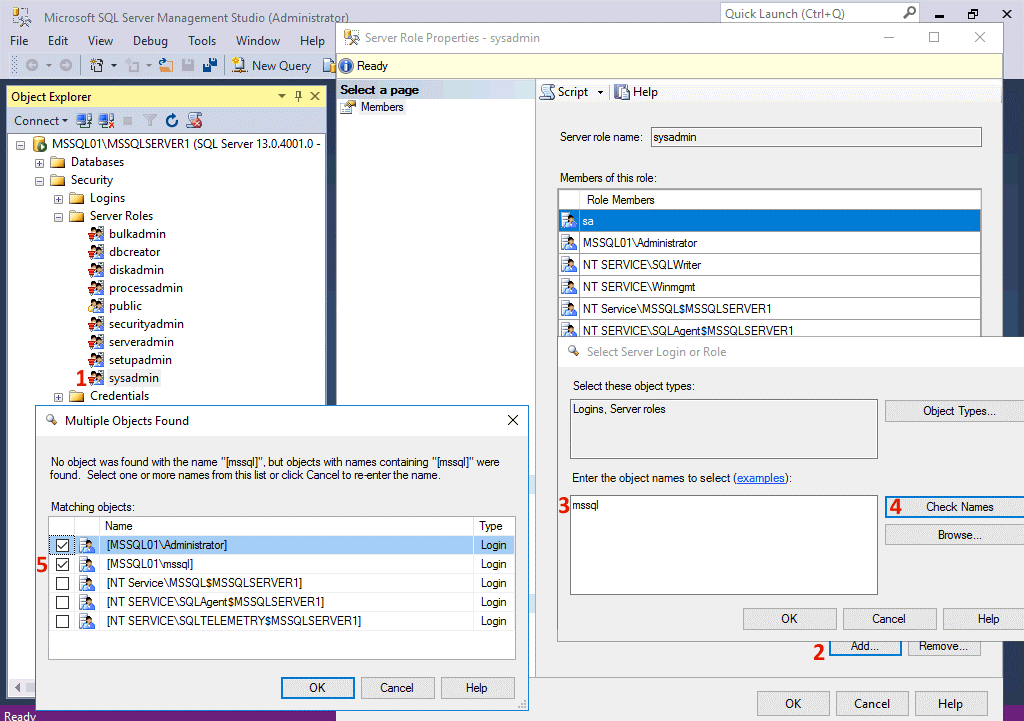
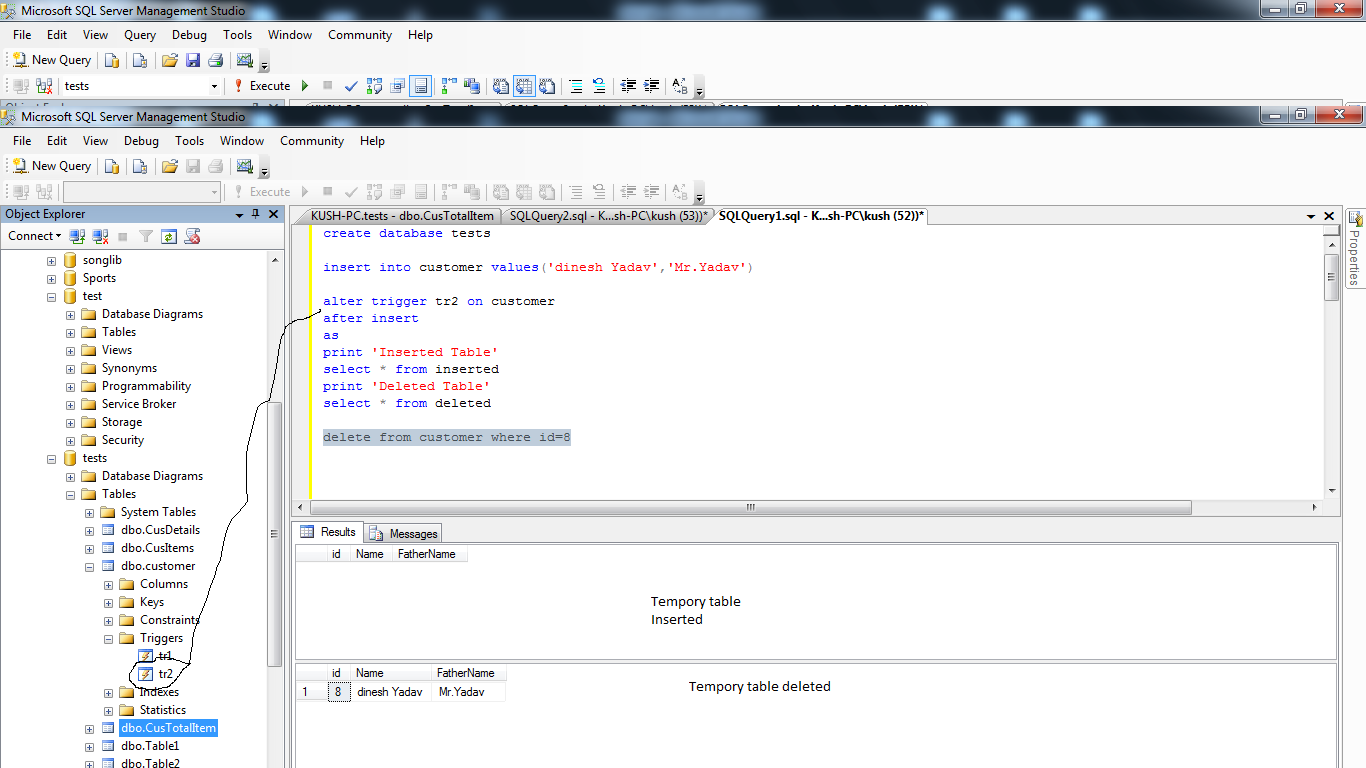
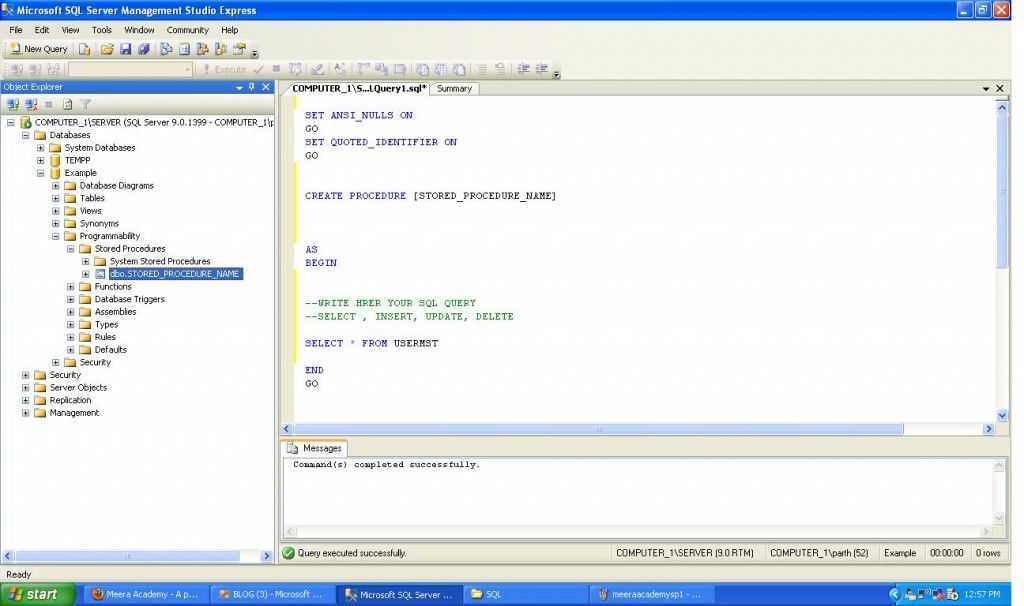
Шаг 6. Изучение и устранение проблем с SARGability
Предикат в запросе поддерживает поиск SARG (поиск с поддержкой аргумента), если ядро SQL Server может использовать индекс для поиска, чтобы ускорить выполнение запроса. Многие макеты запросов делают поиск по аргументам невозможным, что приводит к сканированию таблицы или индекса и высокой загрузке ЦП. Рассмотрим следующий запрос к базе данных AdventureWorks, где необходимо получить каждый элемент и применить к нему функцию, после чего сравнить его с буквенным значением строки. Как видите, перед началом сравнения необходимо получить все строки таблицы, а затем применить к ним функцию. Получение всех строк таблицы — это сканирование таблицы или индекса, что приводит к повышению загрузки ЦП.
Применение любой функции или вычисления к одной или нескольким строкам в предикате поиска обычно приводит к тому, что запрос не поддерживает поиска по аргументам и повышению загрузки ЦП. Решения этой проблемы обычно связаны с творческим редактированием запросов, чтобы добавить им поддержку поиска по аргументам. Возможным решением проблемы в этом примере являются следующие правки с удалением функции из предиката запроса и поиском в другой строке, что дает идентичный результат:
Рассмотрим еще один пример, в котором менеджеру по продажам необходимо взыскать комиссионный сбор в размере 10% от суммы продаж для больших заказов, и проверить заказы, для которых комиссия составила больше 300 долларов США. Ниже приведен логический способ без поддержки поиска по аргументам.
Ниже приведено менее интуитивное решение запроса с поддержкой поиска по аргументам, в котором вычисление перенесено в другую часть предиката.
Поиск по аргументам применим не только к условию , но и к условиям , , и . Часто невозможность использования поиска по аргументам происходит из-за использования функций , , и с условиями и , что приводит к сканированию столбцов. При использовании условий с преобразованием типа данных ( или ) для решения проблемы можно перейти к сравнению одинаковых типов данных. Ниже приведен пример, в котором столбец преобразуется в тип данных в условии Преобразование не позволяет использовать индекс в столбце соединения. Та же проблема возникает при , когда типы данных отличаются, и SQL Server преобразовывает один из них для выполнения соединения.
Чтобы избежать сканирования таблицы , можно изменить базовый тип данных столбца после надлежащего планирования и проектирования, а затем присоединить два столбца без использования функции преобразования .
Другим решением является создание вычисляемого столбца , в котором используется та же функция , а затем создание индекса на нем. Это позволит оптимизатору запросов использовать этот индекс без необходимости изменять запрос.
В некоторых случаях запросы нельзя легко переписать, чтобы обеспечить возможность SARGability. В таких случаях вы можете проверить, может ли вычисляемый столбец с индексом помочь, или нужно сохранить запрос так, как это было, с учетом того, что он может привести к более высоким сценариям ЦП.
Проверка непрерывности сбора данных по запросам хранилищем запросов
Хранилище запросов может без предупреждения изменять режим работы. Постоянно наблюдайте за состоянием хранилища запросов, чтобы знать, что оно работает, и предпринимать действия для исключения сбоев по предотвращаемым причинам. Выполните следующий запрос, чтобы определить режим работы и просмотреть наиболее актуальные параметры.
Разница между и показывает, что произошло автоматическое изменение режима работы. Самое частое изменение — автоматическое переключение хранилища запросов в режим «только чтение». В исключительно редких случаях хранилище запросов может оказаться в из-за внутренних ошибок.
Если фактическое состояние является режимом только чтения, используйте столбец для определения основной причины. Скорее всего, вы обнаружите, что хранилище запросов перешло в режим «только чтение» из-за превышения квоты на размер. В этом случае в столбце будет значение 65536. Другие причины см. в разделе sys.database_query_store_options (Transact-SQL).
Рассмотрите следующие действия, чтобы переключить хранилище запросов в режим чтения и записи и активировать сбор данных.
-
Увеличение максимального размера хранилища с помощью параметра MAX_STORAGE_SIZE_MB инструкции .
-
Очистка данных в хранилище запросов с помощью следующей инструкции.
Можно применить одно или оба этих действия, выполнив следующую инструкцию, которая явно изменяет режим работы обратно на режим чтения и записи:
Выполните следующие упреждающие действия.
- Вы можете предотвратить автоматические изменения режима работы, применяя рекомендации. Если размер хранилища запросов всегда будет меньше максимально допустимого значения, это существенно уменьшит вероятность перехода в режим «только чтение». Активируйте политику на основе размера, как описано в разделе , чтобы хранилище запросов автоматически очищало данные при достижении предельного размера.
- Чтобы обеспечить сохранение последних данных, настройте политику на основе времени для регулярного удаления устаревшей информации.
- Наконец, следует рассмотреть возможность установки автоматическогорежима записи запросов, так как в нем отфильтровываются запросы, которые обычно меньше всего соответствуют вашей рабочей нагрузке.
Состояние ошибки
Чтобы восстановить хранилище запросов, попробуйте явно установить режим чтения и записи и проверьте фактическое состояние еще раз.
Если проблема сохраняется, это означает повреждение данных в хранилище запросов, сохраненных на диске.
В версии SQL Server 2017 (14.x); и выше хранилище запросов можно восстановить, выполнив хранимую процедуру в соответствующей базе данных. Прежде чем пытаться выполнять операцию восстановления, необходимо отключить хранилище запросов. Ниже приведен пример запроса для использования или изменения с целью проверки согласованности и восстановления QDS:
В версии SQL Server 2016 (13.x); необходимо очистить данные в хранилище запросов, как показано ниже.
Если восстановление выполнить не удалось, можно попробовать очистить хранилище запросов перед включением режима чтения и записи.
Группа показателей «Запросы»
- «Суммарное время выполнения запросов»
- «Максимальное время выполнения запросов»
- «Среднее время выполнения запросов»
- «Количество выполняемых запросов»
При первом получении данных производится подключение к агенту сервера 1С. Далее при каждом такте обновления показателей (частота обновления задана в параметрах) происходит получение списка соединений с выбранной информационной базой. Для каждого соединения анализируется свойство durationCurrentDBMS (Время текущего вызова СУБД), измеряется в миллисекундах. Это же значение можно посмотреть в консоли кластера серверов в разделе сеансы, колонка «Время вызова СУБД (текущее)». Но здесь время измеряется уже в секундах. Если свойство больше 0, тогда оно попадет в нашу выборку.
Количество выполняемых запросов вычисляется как количество соединений, выполняющих запросы к СУБД в данный момент. Иными словами, количество соединений, у которых в данный момент свойство durationCurrentDBMS > 0.
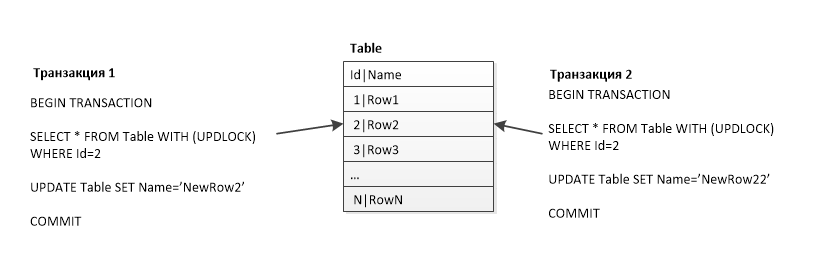
Блокирующее чтение остатков в начале транзакции
Режим разделения итогов эффективно решает задачу исключения блокировки при записи остатков регистров бухгалтерии и накопления. Однако для решения некоторых задач необходимо выполнять блокирующее чтение итогов. Классическим примером такой задачи является контроль остатков при проведении документа. Если в результате проведения документа остатки станут отрицательными, то транзакция должна быть отменена (проводить такой документ нельзя).
Операция чтения остатков должна быть блокирующей, то есть необходимо запретить двум пользователям одновременно читать один и тот же остаток. Если чтение будет неблокирующим, то возможна ситуация, при которой два пользователя одновременно прочитают один и тот же остаток (например 10 единиц) и примут решение о возможности списания части этого остатка. Если сумма списаний двух пользователей будет больше 10, то в итоге остаток получится отрицательным. Например, первый пользователь спишет 8 единиц (8 меньше 10, следовательно, операция разрешена), а второй пользователь спишет 6 единиц (на таком же основании). Результатом будет -4 единицы остатка, что недопустимо с точки зрения прикладной логики системы.
Итак, существуют задачи, для решения которых необходимо выполнять блокирующее чтение остатков. Эта блокировка не может быть устранена, т. к. это привело бы к нарушению логики работы системы. Однако можно уменьшить ее влияние на интегральную производительности системы. Для этого рекомендуется изменить стандартный подход к контролю остатков. Обычно для контроля остатков используется запрос в модуле набора записей регистра, который идет перед записью набора. При этом возможны следующие проблемы:
- Разработчик, как правило, не контролирует порядок записи движений в разные регистры — запись обычно осуществляется автоматически платформой «1С:Предприятие». Запрос контроля остатков реализуется в модуле набора записей и вызывается при записи движений регистра. Если этот регистр будет записываться в начале транзакции (например, первым), то установленная блокировка будет мешать работе других пользователей в течение длительного периода времени (пока будут записываться все остальные регистры), и ее влияние на производительность системы может оказаться неоправданно большим.
- В некоторых случаях, возможно, нет необходимости в контроле остатков, поскольку записываемые движения заведомо не могут привести к получению отрицательных остатков.
Для того чтобы минимизировать влияние блокирующего чтения остатков на производительность системы, необходимо:
Проанализировать, какие именно остатки нуждаются в блокирующем чтении и при каких обстоятельствах. Например, контроль остатков не требуется при проведении приходного документа, поскольку он может только увеличить остатки. Также не требуется контролировать остатки при перепроведении документа, который списывает в этот раз не больше остатков чем при первом проведении (этот контроль уже проводился). И так далее.
В начале транзакции (например, в обработчике «ОбработкаПроведения» документа) в явном виде записать движения по всем регистрам, которые в данном случае не требуют контроля остатков. Следует всегда придерживаться одинакового порядка записи регистров (например, алфавитного)
Обратите внимание на то, что у всех записываемых регистров накопления и бухгалтерии должен быть включен разделитель итогов, а у наборов записей опция «БлокироватьДляИзменения» должна быть установлена в значение ЛОЖЬ. Выполнить все остальные действия, которые должны быть выполнены в рамках этой транзакции
В самом конце транзакции в явном виде записать движения по тем регистрам, которые требуют контроля остатков. Для наборов записей этих регистров следует установить опцию «БлокироватьДляИзменения» в значение ИСТИНА. Это необходимо для предотвращения взаимоблокировки. Именно в этот момент времени будет установлена блокировка остатков регистра по данному набору значений измерений.
Для каждого регистра выполнить запрос контроля остатков. Обратите внимание, что в данном случае нет необходимости использовать опцию «ДЛЯ ИЗМЕНЕНИЯ» (в автоматическом режиме) или явную управляемую блокировку (в управляемом режиме), поскольку проверяемые остатки уже заблокированы их записью на предыдущем шаге. Запрос должен считывать только отрицательные остатки по заданному набору значений измерений. Если такие записи имеются, то транзакция должна быть отменена. Если запрос вернул пустой результат, то транзакция должна быть зафиксирована.
Пример решения проблемы блокировок
Как еще можно избавиться от излишних ожиданий?
Допустим, у вас есть торговые представители, которые после окончания рабочего дня (в 6 часов вечера), отправляют документы в базу. А там, как только эти документы через мобильный интернет приходят, они сразу пытаются загрузиться и провестись. В результате, если торговые представители заказали один и тот же товар с одного и того же склада, возникает ожидание, потому что они обращаются к одним и тем же данным, и поскольку там есть контроль остатков, разделитель итогов не поможет и кому-то кого-то придется ждать.
Как этого можно избежать? Можно при загрузке документы создавать, но не проводить, а потом написать механизм, который, например, реализует это дальнейшее проведение в многопоточном режиме, где каждый поток будет проводить документы по своему складу. Разнести, таким образом, эти процессы во времени: первый поток проводит документы по одному складу, второй поток – по второму складу и т.д. Тогда проблема будет решена.
Экспертный кейс. Расследование фатального замедления времени расчета себестоимости в 1С:ERP 2
При выполнении нагрузочного тестирования информационной системы на базе 1С:ERP для одного из клиентов с целью оценки возможности миграции системы на PostgreSQL и Astra Linux мы столкнулись с неприемлемым увеличением времени выполнения расчета себестоимости.
Строго говоря, сценарий тестирования закрытия месяца не был выполнен вообще – он не укладывался в таймаут выполнения теста, 24 часа. По прошествии 18 часов всё ещё шло выполнение операции «Распределение затрат и расчет себестоимости». Более 16 часов выполнялся подэтап “Расчет партий и себестоимости. Этап. Расчет себестоимости: РассчитатьСтоимость”. Всё это время выполнялся запрос, который в текущей инфраструктуре клиента (СУБД MS SQL Server) выполняется чуть более 3 минут на аналогичных данных.
Способы создания индексов
Предусмотрено создание индексов ms sql server с помощью двух инструментов. В этом помогут:
- SSMS (MSSQL Management Studio);
- специальный язык Transact-SQL (T-SQL, поддерживающий Paging Queries).
Как создать кластеризованный индекс
Как отмечалось выше, создание кластеризованного индекса sql сервером происходит автоматически, когда определенный столбец выбирается в качестве первичного ключа (PRIMARY KEY). Когда такого не происходит, следует создать кластерный индекс своими руками.
Чтобы создать Clustered index воспользуемся Management Studio. Для этого следует:
- Открыть SSMS.
- Воспользовавшись обозревателем выбрать соответствующую таблицу.
- Остановившись на пункте «Индексы» кликнуть мышкой.
- Выбрать «Создать индекс» и соответствующий тип (выбираем «Кластеризованный»).
- В новом окне появится форма «Новый индекс». Здесь потребуется вписать наименование нового создаваемого индекса (в рамках одной таблицы требуется, чтобы оно было уникальным). Поставить галочку, что он уникальный.
- Выбрать столбец, который будет являться ключом индекса. Он ляжет в основу создаваемого Clustered index. Провести сортировку строк табличных данных кнопкой «Добавить».
- После ввода всех необходимых параметров кликнуть «ОК».
Результатом действий станет кластерный индекс.
Он может быть создан и с помощью инструкций Transact-SQL CREATRE INDEX.
Создание Nonclustered index с включенными столбцами
Коснемся вопроса, как создать Nonclustered index с условием, что в индекс включены столбцы, которые не являются ключевыми. Такой индекс принято использовать в тех случаях, когда индекс создается под конкретный запрос. К примеру, чтобы индексом покрывался запрос полностью, т.е. включал все столбцы. Вследствие того, что запрос покрыт, увеличивается производительность. Это становится возможным благодаря тому, что оптимизатор запросов может получить все значения столбцов в индексе без обращения к табличным данным. Это ведет к уменьшению числа операций ввода-вывода на диске.
Однако стоит учитывать, что с включением в индекс неключевых столбцов размер его увеличивается. А значит, для его хранения понадобится больше дискового пространства. Это также может снизить производительность операций INSERT, UPDATE, DELETE и MERGE в базовой таблице данных.
Для его создания также воспользуемся Management Studio:
- Открыть SSMS.
- Воспользовавшись обозревателем выбрать требуемую таблицу и щелкнуть мышкой по пункту «Индексы».
- Выбрать «Создать индекс», а затем «Некластеризованный» (не ставить галочку на уникальности).
- В открывшейся форме «Новый индекс» вписать наименование нового индекса, добавить один или несколько ключевых столбцов, воспользовавшись кнопкой «Добавить».
- Перейти во вкладку «Включено столбцы». Добавить все столбцы, которые должны быть включены в индекс, воспользовавшись кнопкой «Добавить».
- Когда введены все нужные параметры кликнуть «ОК».
Все готово!
При необходимости, можно легко создать фильтруемый Nonclustered index. Для этого следует воспользоваться T-SQL и в операторе CREATE NONCLUSTERED INDEX в WHERE указать условие фильтрации. Так можно отфильтровать практически любые данные, не важные в запросах.
Сведения о хранилище запросов
Планы выполнения для любого специального запроса в SQL Server обычно меняются со временем по разным причинам, например из-за изменения статистики, схемы, создания и удаления индексов и т. д. В кэше процедур (где хранятся кэшированные планы запросов) хранится только последний план выполнения. Планы исключаются из кэша планов из-за нехватки памяти. В результате устранение проблем со снижением производительности запросов, вызванным изменениями планов выполнения, может оказаться сложным и требующим много времени.
Так как хранилище запросов сохраняет несколько планов выполнения на запрос, оно может принудительно применить политики, чтобы заставить процессор запросов использовать конкретный план выполнения для запроса. Это называется принудительным выполнением плана. Принудительное выполнение плана в хранилище запросов обеспечивается с использованием механизма, аналогичного указанию запроса USE PLAN , но не требует изменений в приложениях пользователей. Принудительное выполнение плана может решить проблему со снижением производительности запросов, вызванным изменением плана за очень короткий период времени.
Примечание
Хранилище запросов собирает планы для инструкций DML, в частности для SELECT, INSERT, UPDATE, DELETE, MERGE и BULK INSERT.
Хранилище запросов по умолчанию не собирает данные для скомпилированных в собственном коде хранимых процедур. Чтобы включить сбор данных для скомпилированных в собственном коде хранимых процедур, используйте хранимую процедуру sys.sp_xtp_control_query_exec_stats.
Статистика ожидания является другим источником сведений, помогающим устранять неполадки с производительностью в Компонент Database Engine. Довольно долго статистика ожидания была доступна только на уровне экземпляра, что затрудняло обратное отслеживание до определенного запроса. Начиная с SQL Server 2017 (14.x); и База данных SQL Azure, в хранилище запросов есть измерение, отслеживающее статистику ожидания. В следующем примере в хранилище запросов активируется сбор статистики ожидания.
Ниже перечислены стандартные сценарии использования хранилища запросов.
- Быстрый поиск и устранение снижения производительности планов путем принудительного выполнения предыдущего плана запроса. Исправление запросов, производительность которых была недавно снижена из-за изменений в планах выполнения.
- Определение количества выполнений запросов за заданный период времени и помощь DBA в устранении неполадок с производительностью ресурсов.
- Определение первых n запросов (по времени выполнения, потреблению памяти и т. д.) за последние x часов.
- Аудит журнала планов запросов для указанного запроса.
- Анализ шаблонов использования ресурсов (ЦП, операций ввода-вывода и памяти) для определенной базы данных.
- Определение первых n-запросов, ожидающих ресурсы.
- Понимание характера ожидания для определенного запроса или плана.
Хранилище запросов содержит три хранилища:
- хранилище планов для сохранения сведений о планах выполнения;
- хранилище статистики времени выполнения для сохранения статистических сведений о выполнении;
- хранилище статистики ожидания для сохранения статистических сведений об ожидании.
Количество уникальных планов, которые можно сохранить для запроса в хранилище планов, ограничено параметром конфигурации max_plans_per_query . Для повышения производительности сведения записываются в хранилища асинхронно. Для уменьшения использования свободного места статистические данные времени выполнения в хранилище вычисляются для фиксированного интервала времени. Сведения в этих хранилищах доступны посредством запросов к представлениям каталога в хранилище запросов.
Приведенный ниже запрос возвращает сведения о запросах и планах в хранилище запросов.
Старайтесь не использовать запросы без параметров
Использовать запросы без параметров не рекомендуется за исключением случаев, когда этого никак нельзя избежать. Примером такой ситуации может служить динамический анализ. Кэшированные планы не могут использоваться повторно, что заставляет оптимизатор запросов компилировать запросы для каждого уникального текста запроса. См. .
Кроме того, хранилище запросов может быстро превысить квоту на размер из-за потенциально большого количества разных текстов запросов и, следовательно, большого количества разных планов выполнения с аналогичной формой. В результате производительность рабочей нагрузки может стать неудовлетворительной и хранилище запросов может перейти в режим «только чтение» или постоянно удалять данные в попытке справиться с входящими запросами.
Следуйте приведенным ниже рекомендациям.
- Параметризуйте запросы везде, где это возможно. Например, заключайте запросы в хранимую процедуру или . См. дополнительные сведения о .
- Используйте параметр Оптимизировать для нерегламентированной рабочей нагрузки
Сравните число уникальных значений query_hash с общим числом записей в sys.query_store_query. Если их соотношение близко к 1, ваша нерегламентированная рабочая нагрузка создает разные запросы.
, если рабочая нагрузка содержит много нерегламентированных пакетов для однократного использования с разными планами запроса.
- Применяйте для базы данных или подмножества запросов, если количество разных планов запроса невелико.
- Используйте структуру плана, чтобы применить принудительную параметризацию только в выбранном запросе.
- Настройте принудительную параметризацию с помощью параметра базы данных , если в рабочей нагрузке существует небольшое число разных планов запроса. Примером является ситуация, когда отношение числа разных query_hash к общему числу записей в намного меньше 1.
- Установите параметр QUERY_CAPTURE_MODE в значение AUTO, чтобы динамические запросы с небольшим потреблением ресурсов отфильтровывались автоматически.
Совет
При использовании решения объектно-реляционного сопоставления (ORM), такого как Entity Framework (EF), запросы приложений, такие как деревья запросов LINQ, отправляемых вручную, или определенные необработанные запросы SQL, могут не параметризоваться. Это влияет на повторное использование плана и возможность отслеживать запросы в хранилище запросов. Дополнительные сведения см. в статьях Кэширование и параметризация запросов EF и Необработанные запросы SQL EF.
Поиск непараметровизованных запросов в хранилище запросов
Чтобы узнать количество планов, сохраненных в хранилище запросов с помощью приведенного ниже запроса, можно использовать динамические административные представления хранилища запросов, SQL Server, управляемый экземпляр SQL Azure или базу данных SQL Azure:
В следующем примере создается сеанс расширенных событий для записи события , что может быть пригодиться при диагностике потребления ресурсов запросов. В SQL Server такой сеанс расширенных событий по умолчанию создает файл событий в папке журналов SQL Server. Например, при установке SQL Server 2019 (15.x) в Windows по умолчанию файл событий (XEL-файл) создается в папке . Для управляемого экземпляра SQL Azure укажите вместо этого расположение хранилища BLOB-объектов Azure. Дополнительные сведения см. в статье . Событие qds.query_store_db_diagnostics для базы данных SQL Azure недоступно.
С помощью этих данных можно узнать количество планов в хранилище запросов, а также многие другие статистические сведения. Чтобы понять объем используемой памяти и количество планов, отслеживаемых хранилищем запросов, изучите столбцы , , и . Если количество планов больше обычного, это может указывать на увеличение числа непараметризованных запросов. Используйте приведенный ниже запрос динамических административных представлений хранилища запросов для проверки параметризованных запросов и непараметризованных запросов в хранилище запросов.
Для параметризованных запросов:
Для непараметризованных запросов:
Управляемые блокировки
Технологический журнал
Наличие управляемых блокировок определяется режимом управления блокировками в свойствах конфигурации. Для того чтобы получить информацию об управляемых блокировках необходимо настроить технологический журнал на сбор событий TLOCK. Определить наличие ожиданий при конфликтах блокировок можно отобрав события TLOCK по не пустому значению поля WaitConnections. Для того чтобы получить общее время ожидания системы на блокировках, необходимо просуммировать их длительности за соответствующий период. При этом следует не забыть правильно интерпретировать результат: в технологическом журнале до версии 8.3 записывалось время в сотнях микросекунд, начиная с 8.3 – в микросекундах.
Настройка технологического журнала
<log location=»Z:\Locks» history=»8″>
<event>
<eq property=»Name» value=»TLOCK»/>
<eq property=»p:processName» value=»MyBase»/>
<ne property=»WaitConnections» value=»»/>
</event>
<property name=»all»/>
</log>
|
1 |
<log location=»Z:\Locks»history=»8″> <event> <eq property=»Name»value=»TLOCK»/> <eq property=»p:processName»value=»MyBase»/> <ne property=»WaitConnections»value=»»/> </event> <property name=»all»/> </log> |
Ниже приведена визуализация данных технологического журнала смоделированных ожиданий на блокировках. Как видно по рисунку, за время анализа произошло 7 попыток установки блокировки, при которых имели место ожидания. Общее время ожидания системы на этих блокировках составило около 10 секунд (данные на рисунке представлены для платформы 8.3). Для самостоятельного моделирования и анализа ожиданий можно воспользоваться обработкой из статьи «Методика расследования конфликтов на управляемых блокировках 1С:Предприятие».
 Визуализация ожиданий на блокировках из данных технологического журнала
Визуализация ожиданий на блокировках из данных технологического журнала
Центр управления производительностью (ЦУП)
Так же на интересующие нас вопросы можно ответить воспользовавшись «Центром Управления Производительностью» (ЦУП) из комплекта поставки «Корпоративный Инструментальный Пакет» (КИП). В данном инструменте нам будут полезны статистические показатели «Среднее время ожидания на блокировках 1С», «Суммарное время ожидания на блокировках 1С», «Максимальное время ожидания на блокировках 1С», «Количество текущих ожиданий на блокировках 1С».
Использование хранилища запросов в активной георепликации Базы данных SQL Azure
Хранилище запросов на вторичной активной геореплике База данных SQL Azure будет доступным только для чтения копии действия на первичной реплике.
Избегайте несоответствия уровней с георепликацией База данных SQL Azure. База данных-получатель должна иметь такой же или практически такой же объем вычислительных ресурсов, что и база данных-источник, и находиться на том же уровне службы, что и база данных-источник. Взгляните на тип ожидания HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO в sys.dm_db_wait_stats, который указывает на регулирование скорости журнала транзакций на первичной реплике из-за задержки на вторичной реплике.
Дополнительные сведения об оценке и настройке размера Базы данных-получателя SQL Azure с активной георепликацией см. в разделе .
Обязательные параметры SET для индексированных представлений
Если при выполнении запроса активны разные параметры SET, выполнение одного и того же выражения может дать разные результаты в Компонент Database Engine . Например, если параметр SET равен ON, выражение возвращает значение . Однако если параметр равен OFF, то же самое выражение дает результат .
Для правильной поддержки представлений и получения согласованных результатов некоторые параметры SET индексированных представлений должны иметь определенные значения. В приведенных ниже случаях параметрам SET из следующей таблицы нужно присвоить значения, указанные в столбце Обязательное значение :
- Будет создано представление с соответствующими индексами в нем.
- Базовые таблицы, на которые ссылается представление в момент создания представления.
- С любой из таблиц, используемых в индексированном представлении, выполняется операция вставки, обновления или удаления. Это требование охватывает такие операции, как массовое копирование, репликация и распределенные запросы.
- Индексированное представление используется оптимизатором запросов для создания плана запроса.
| Параметры SET | Обязательное значение | Значение сервера по умолчанию | По умолчаниюЗначение OLE DB и ODBC | По умолчаниюЗначение DB-Library |
|---|---|---|---|---|
| ANSI_NULLS | ON | ON | ON | OFF |
| ANSI_PADDING | ON | ON | ON | OFF |
| ANSI_WARNINGS1 | ON | ON | ON | OFF |
| ARITHABORT | ON | ON | OFF | OFF |
| CONCAT_NULL_YIELDS_NULL | ON | ON | ON | OFF |
| NUMERIC_ROUNDABORT | OFF | OFF | OFF | OFF |
| QUOTED_IDENTIFIER | ON | ON | ON | OFF |
1 Если параметру присвоить значение ON, то для параметра будет неявно задано значение ON.
Если используется соединение с сервером через интерфейсы OLE DB или ODBC, достаточно изменить параметр . Все DB-Library значения должны быть правильно заданы на уровне сервера с помощью или из приложения с помощью команды.
Важно!
Настоятельно рекомендуется задать для пользователя параметр на уровне сервера сразу после создания первого индексированного представления или индекса вычисляемого столбца в любой базе данных на сервере.