
«Что есть реальность?» В виртуальной среде
Утром первым делом посмотрел на результаты, они были странные – замедление 60% на виртуальном кластере. Даже ФИФО который параллелится только по бумагам и не создает большой нагрузке посчитался медленней на 30%
Кликайте на картинки для большего разрешения!
Хорошо, что мне есть с чем сравнивать, и я могу просто сказать «А вот на железном кластере с той же конфигурацией гораздо быстрее» или сравнить счетчики MS SQL на быстром и медленном кластере. Но допустим, кому-то дали облако под проект с якобы заявленными параметрами, как ему понять что кластер (1С MSSQL Hardware) работает на полную мощность?
Тут можно обратится к принципу непротиворечивости логичной системы аксиом
В логике предикатов это изложено детально, но по простому можно сказать: Вы можете построить любую систему аксиом для своей алгебры, геометрии, теории множеств – важно чтобы она была непротиворечивой при выводе теорем и утверждений. Там, где есть противоречие 2 варианта либо система аксиом плоха, либо вы что-то не знаете и не учитываете и именно там истина
Математика, физические постоянные существуют в мире не просто так любые противоречия разрушили бы вселенную. Напр путешествие во времени назад вызывает кучу противоречий, значит оно невозможно, а вот в будущее без возврата в прошлое вполне возможно.
Значит решено — снимаем показатели и ищем противоречия. ИТ технологии сложны, но это гораздо проще тензорного исчисления J. Производительность какого-то компонента кластера снижается по одной из трех причин.
-
Ресурс перегружен, это сразу видно на счетчиках производительности.
-
Ресурс частично свободен, но ждет снятия какой-то блокировки (Это может быть блокировка строк в СУБД, ресурсов памяти Latch, и т.д.).
-
Ресурс частично свободен, но у него скопилась очередь (Это может быть очередь к дисковой системе, минимально необходимые задержки на передачу пакета по сети).
Комбинация этих причин приводит к тому что все утыкается в бутылочное горлышко и остальные ресурсы просто не нагружаются.
Настроил счетчики, я не будут описывать нужные — так как в разных ситуациях нужно искать разные. Принцип простой – из всех счетчиков ищите счетчики очередей, ожиданий, миллисекунд на трансфер. Счетчики на % загрузки как правило не дают сделать выводы напр. Передача по сети множества мелких пакетов не создает 100% траффика, но за счет задержек сети упирается в потолок производительности ()
Для оборудования настроил Perfomance Monitor с записью, то что называется Data collection set. Странно, но оно работало только после перезагрузки сервера.
Для SQL Server сбросил счетчики статистики и кэши:
Анализ перегруженности ресурсов не показал ничего критичного.
На кластере 1С за счет горизонтального маштабирования, загрузка плотная больше 50% (что считается с точки зрения Microsoft значительной нагрузкой).
Небольшая странность, бывают очереди на процессор (Processor queue length).
На сервере базы данных нагрузка небольшая, значит можно увеличить еще, но видны противоречия:
Видны всплески очередей на диск (Current disk queue length больше 100), когда активность превышает 10 тыс IOPS . Причем видно что очередь держится по несколько секунд. Это странно, ведь SSD должен переваривать такой траффик легко.
Попросил администраторов проверить со стороны гипервизора, получил ответ.
«В данной конфигурации Ваш виртуальный сервер может спокойно потреблять до 50k iops при минимальном latency. Разумеется, если от него этого требуют.
На Ваших графиках видно, что нагрузка почти нулевая с периодическими кратковременными скачками. Я посмотрел — в эти пиковые моменты сервер потреблял всего до 20k iops. Latency в эти моменты достигала 15-20 мс, что безусловно не мало, но и не катастрофично, учитывая, что эти всплески длятся доли секунды.
Latency растет, т.к. Вы периодически упираетесь в одно единственно ограничение — одновременное количество потоков данных от виртуального сервера к дисковой системе (максимум 64) в текущей конфигурации.
Параметр queue lentgh и все его производные имеет смысл рассматривать только на однодисковых десктопах. На серверах и в виртуализации он не показывает абсолютно ничего. »
Вот первый звоночек оказывается VMWare ограничивает одновременное количество потоков данных от сервера к дисковой подсистеме, неужели придется еще VWWare изучать J чтобы знать ее узкие места. Про очереди не согласен, если они возникают значит что-то не так. А так «Все хорошо прекрасная маркиза, все хорошо, все хорошо».
Дополнительные сведения
Корпорация Майкрософт предоставляет техническую поддержку SQL Server 2008 и более поздних версий для следующих поддерживаемых сред виртуализации оборудования:
-
Windows Server 2008 и более поздних версий с Hyper-V
-
Microsoft Hyper-V Server 2008 и более поздних версий
-
Конфигурации, которые проверяются с помощью программы проверки виртуализации сервера (SVVP).
Дополнительные сведения о сертифицированных поставщиках и конфигурациях для SVVP см. в разделе http://windowsservercatalog.com/svvp.aspx?svvppage=svvp.htm.
Примечание.
Решение SVVP должно работать на оборудовании, сертифицированном для Windows Server 2008 R2 или более поздней версии, чтобы считаться допустимой конфигурацией SVVP.
Корпорация Майкрософт предоставляет техническую поддержку SQL Server 2008 и более поздних версий для следующих поддерживаемых сред виртуализации оборудования:
Службы инфраструктуры Azure, включаемые в azure Виртуальные машины и Azure виртуальная сеть (дополнительные сведения см. в разделе «Часто задаваемые вопросы»).
Корпорация Майкрософт может предоставлять ограниченную техническую поддержку или не предоставлять техническую поддержку для следующих сред:
- Любая версия SQL Server более ранней, чем SQL Server 2008 (например, SQL Server 2005), которая работает на любом поставщике или конфигурации виртуализации.
- Любое программное обеспечение виртуализации сторонних разработчиков, не являющееся конфигурацией, которая проверяется с помощью программы SVVP.
Эта политика ограниченной поддержки основана на следующей статье базы знаний Майкрософт:
Virtual Networking
VM admins will have virtual networks that can be assigned to virtual machines already mapped and available to assign . The networks align with VLANs or network segments, and are as simple as selecting a virtual network adapter and selecting the target network from a drop down list (Figure 11). Your VM administrator will tell you the right virtual network to assign to the network adapter.
Figure 11
If you expand the ‘New Network’ option, ensure that the ‘Connect at Power On’ checkbox is checked, and that the type ‘VMXNET 3’ is selected. The other types of virtual network adapters available for Windows Server 2012 and above (E1000E and E1000) are present for backwards compatibility, as they are built into the operating system. VMware created the VMXNET3 custom virtual network adapter and driver for their virtual machines that provides a more stable and performant connection to the physical network.
This driver is installed for free with the VMware Tools package. Once the VMware Tools package is installed, just after the operating system is installed, any virtual hardware tied to VMware-specific drivers in this package will appear and become usable. This network adapter type should be used for all Windows VMs, regardless of version.
Figure 12
Add a network adapter for each virtual network segment that this virtual machine should have access to. Assign each adapter to the appropriate virtual network, shown above in Figure 12.
Разнести файлы данных mdf и файлы логов ldf на разные физические диски.
В этом случае работа с файлами может идти не последовательно, а практически параллельно, что повышает скорость работы дисковых операций. Лучше всего для этих целей подходят диски SSD.
Для переноса файлов необходимо:
-
Запустить Management Studio и подключиться к нужному серверу
-
Открыть свойства нужной базы и выбрать закладку Файлы
-
Запомнить имена и расположение файлов
-
Отсоединить базу, выбрав через контекстное меню Задачи – Отсоединить
-
Поставить флаг Удалить соединения и нажать Ок
-
Открыть Проводник и переместить файл данных и файл журнала на нужные носители
-
В Management Studio открыть контекстное меню сервера и выбрать пункт Присоединить базу
-
Нажать кнопку Добавить и указать файл mdf с нового диска
-
В нижнем окне сведения о базе данных в строке с файлом лога нужно указать новый путь к файлу журнала транзакций и нажать Ок
Локальное и удаленное хранение снимков данных
| Тип снимка | CLI | UI | REST | |||
|---|---|---|---|---|---|---|
| Вручную | По расписанию | Вручную | По расписанию | Вручную | По расписанию | |
| Локальный | 1 год | 1 год | 5 лет | 4 недели | 100 лет | Без ограничений |
| Удаленный | 5 лет | 255 недель | 5 лет | 255 недель | 5 лет | 255 недель |
- Все компоненты базы данных SQL Server должны быть защищены как набор данных. Когда файлы данных и журналов находятся на разных LUN, эти LUN должны быть частью консистентной группы. Консистентная группа гарантирует, что моментальный снимок будет сделан одновременно на всех LUN в группе. Когда файлы данных и журналов находятся на нескольких общих файловых ресурсах SMB, общие ресурсы должны находиться в одной файловой системе.
- При восстановлении базы данных SQL Server из моментального снимка на основе блоков, если экземпляр SQL Server должен оставаться подключенным, используйте присоединение к хосту Unisphere. Для восстановления на основе файлов создается дополнительный общий ресурс SMB с использованием снимка в качестве источника. После подключения томов базу данных можно присоединить под другим именем или заменить существующую базу данных восстановленной.
- При выполнении восстановления с использованием метода восстановления моментальных снимков Snapshot Restore в Unisphere переведите инстанс SQL Server в автономный режим. SQL Server не знает об операциях восстановления. Перевод инстанса в автономный режим гарантирует, что тома не будут повреждены при операциях записи в базу данных перед восстановлением. Как только инстанс будет перезапущен, аварийное восстановление SQL Server приведёт базы данных в согласованное состояние.
- Разрешите моментальные снимки для нескольких объектов хранения одновременно, а затем, прежде чем включать дополнительные снимки, при мониторинге системы убедитесь, что она находится в рекомендованных рабочих режимах.
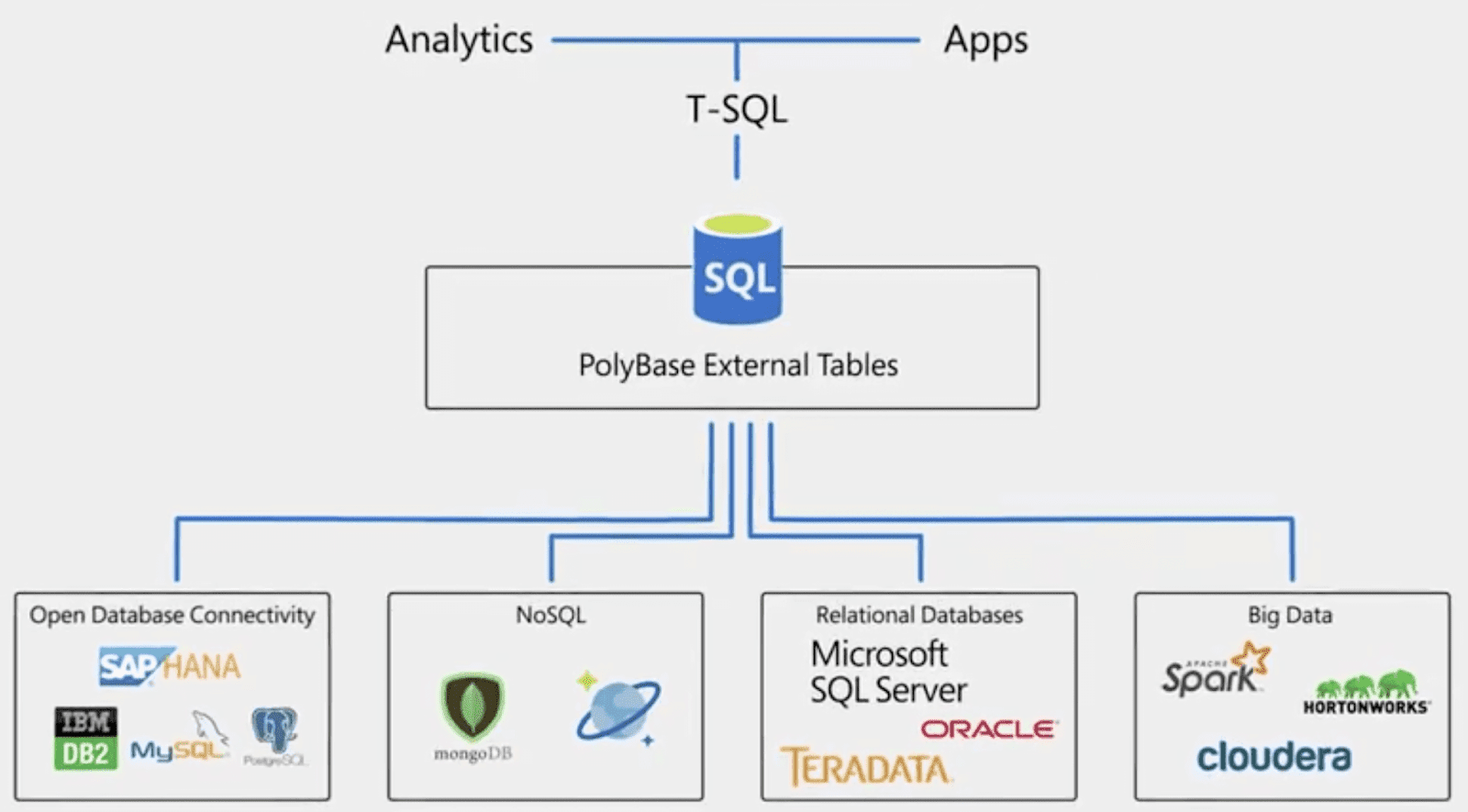
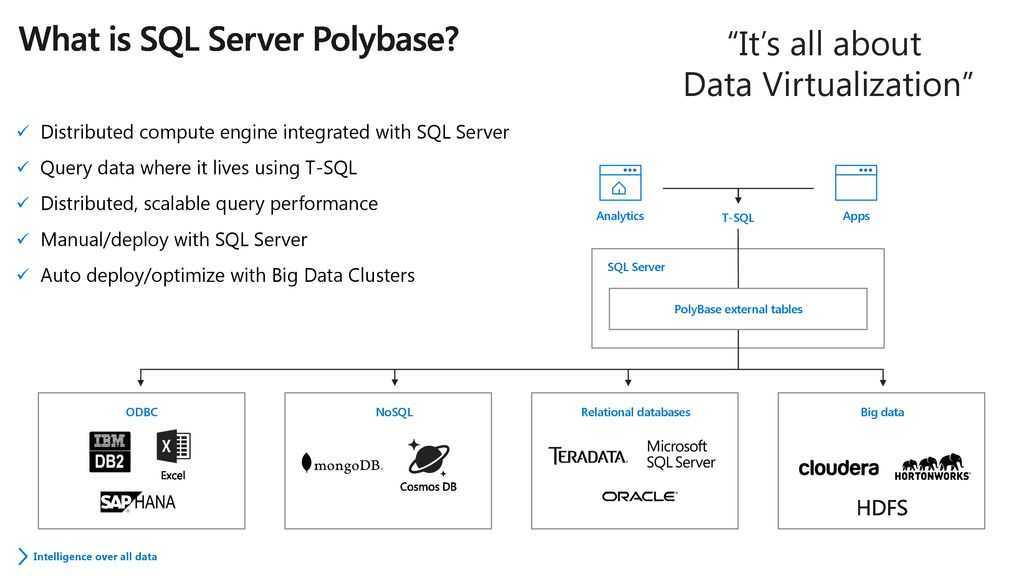
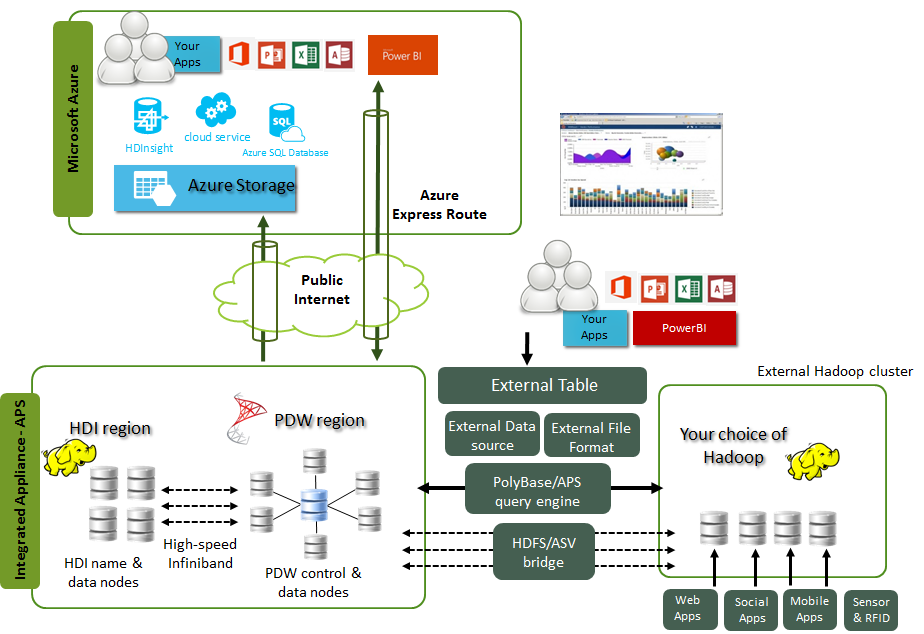
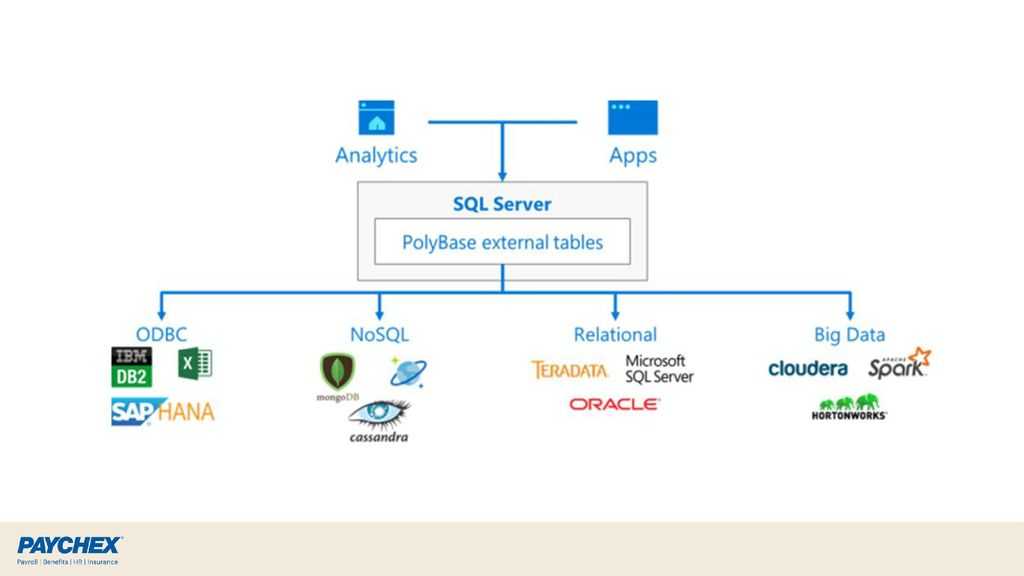
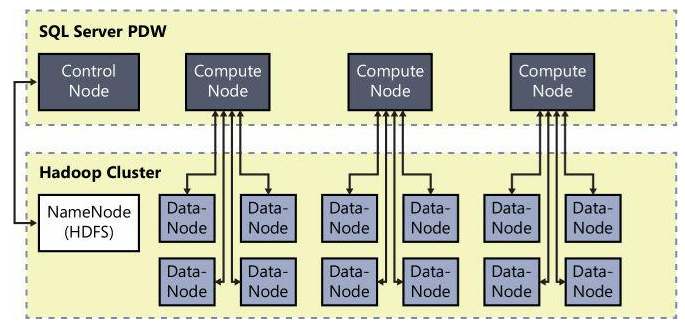
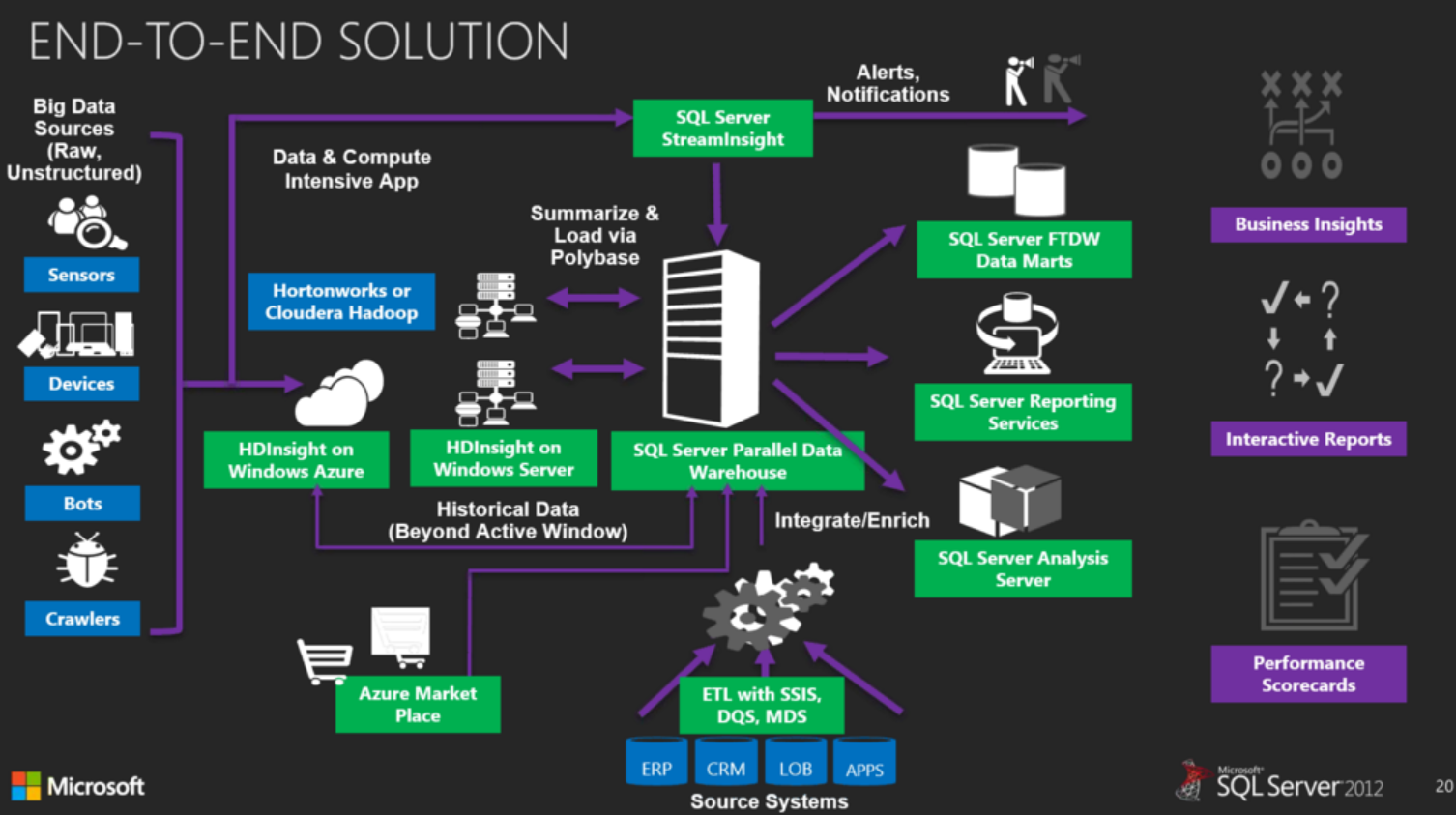
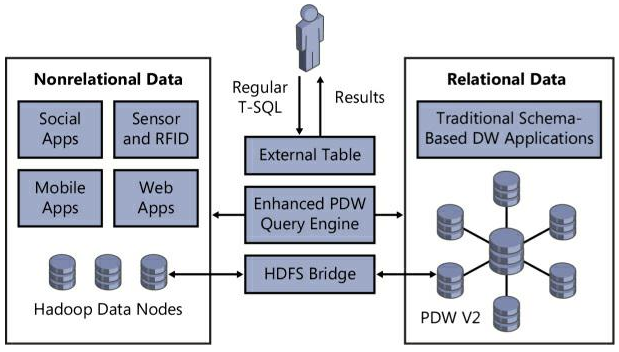
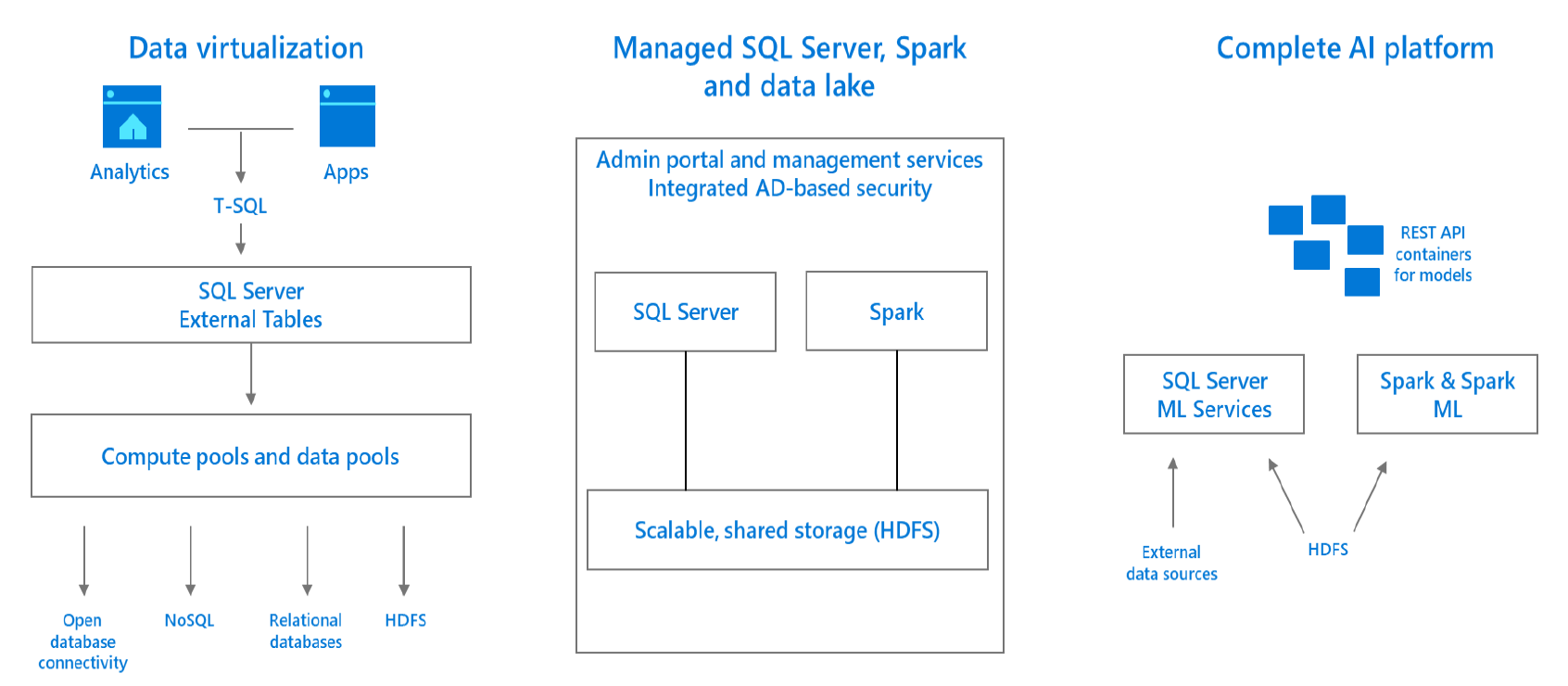
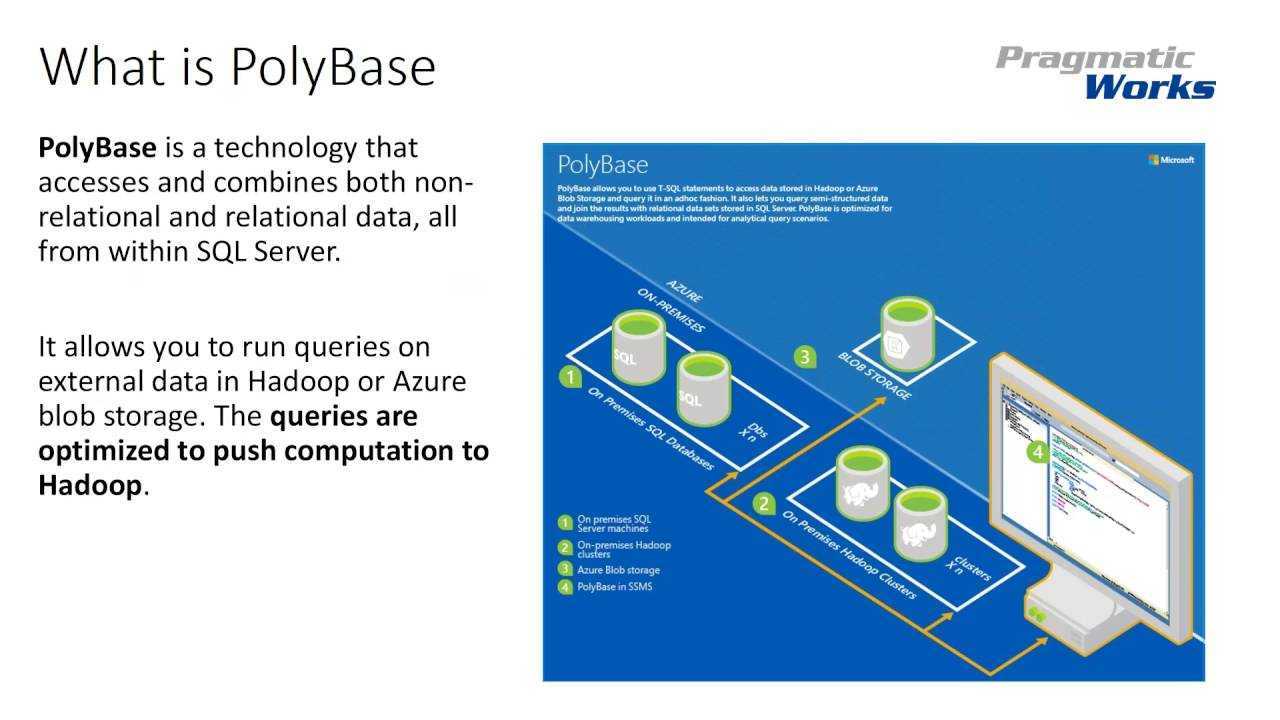
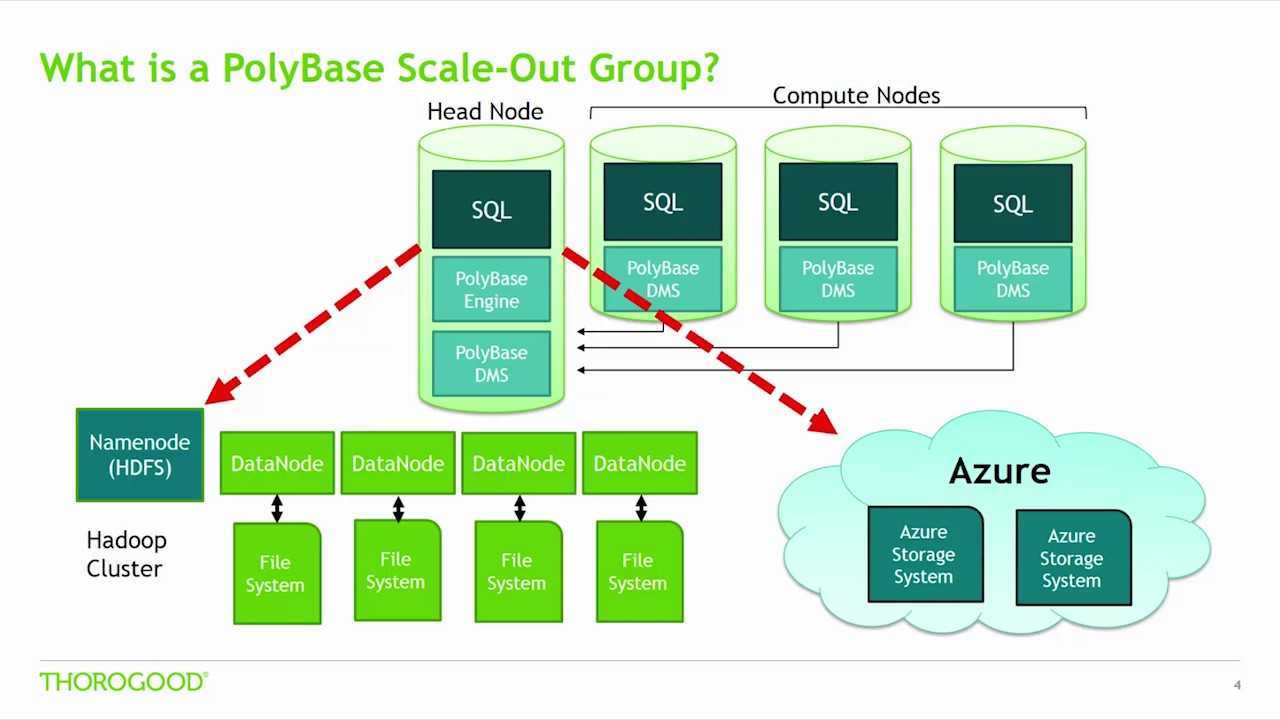
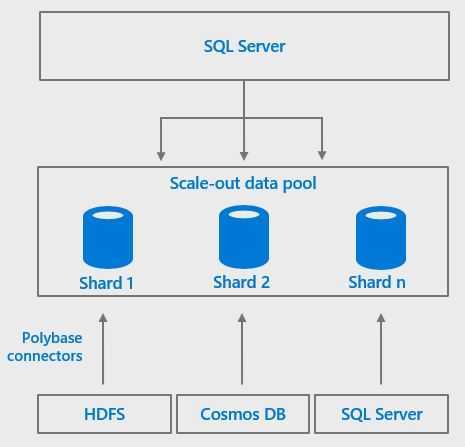
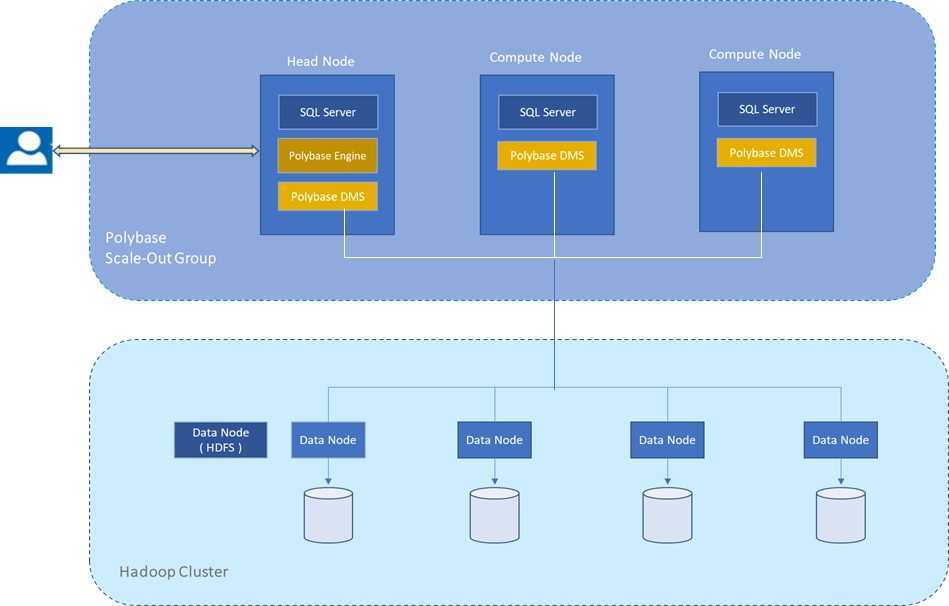
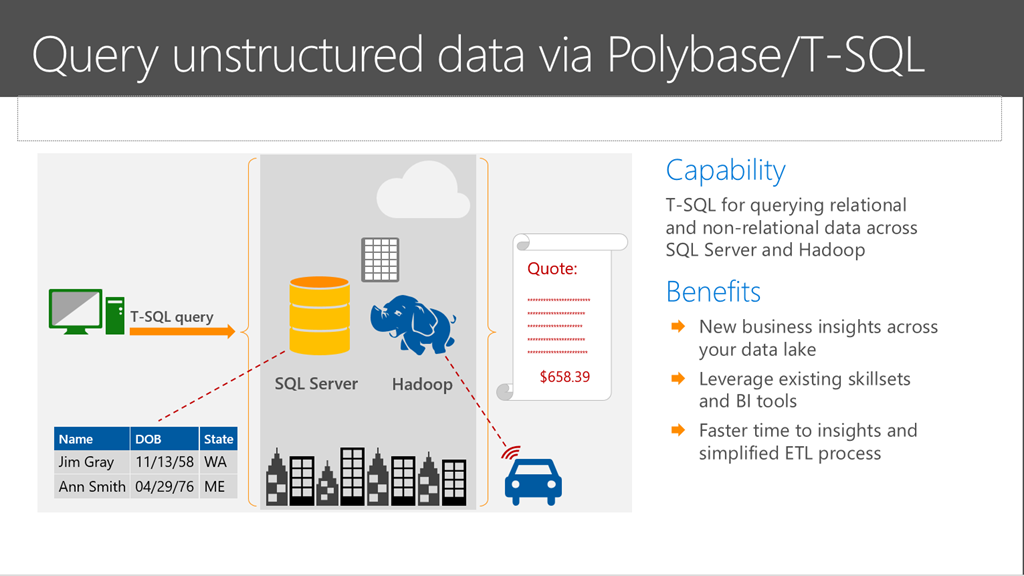
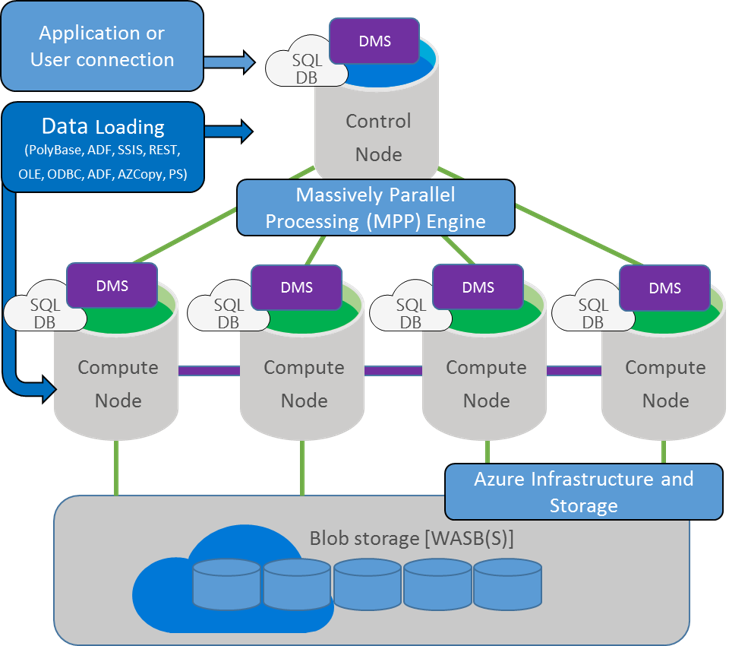
Зачем нужна технология PolyBase
PolyBase позволяет объединять данные из экземпляра SQL Server с внешними данными. Прежде чем PolyBase объединит данные во внешних источниках, можно выполнить одно из следующих действий:
- передать часть данных, чтобы все они находились в одном месте;
- запросить данные из двух источников, а затем написать пользовательскую логику запроса для объединения и интеграции данных на уровне клиента.
PolyBase позволяет легко объединять данные, используя Transact-SQL.
PolyBase не требует установки дополнительного программного обеспечения в среде Hadoop. При запросе внешних данных используется такой же синтаксис T-SQL, как и при запросе таблицы базы данных. Все вспомогательные действия, реализуемые PolyBase, выполняются прозрачно. Автору запроса не требуется знать, как работает внешний источник.
Варианты использования PolyBase
PolyBase поддерживает следующие сценарии в SQL Server:
-
Запрашивать данные, хранящиеся в Хранилище BLOB-объектов Azure. Хранилище BLOB-объектов Azure — это удобное место для хранения данных для использования службами Azure. PolyBase позволяет легко обращаться к данным с помощью T-SQL.
-
Запрашивание данных, хранящихся в Hadoop, из экземпляра SQL Server или PDW. Пользователи хранят данные в более экономичных распределенных и масштабируемых системах, таких как Hadoop. PolyBase позволяет легко запрашивать данные с помощью T-SQL.
-
Импорт данных из Hadoop, хранилища BLOB-объектов Azure или Azure Data Lake Store. Используйте скорость технологии Microsoft SQL columnstore и возможности анализа, импортируя данные из Hadoop, хранилища BLOB-объектов Azure или Azure Data Lake Store в реляционные таблицы. Нет необходимости в отдельном средстве ETL или импорта.
-
Экспорт данных в Hadoop, Хранилище BLOB-объектов Azure или Azure Data Lake Store. Архивация данных в Hadoop, хранилище BLOB-объектов Azure или Azure Data Lake Store позволяет создать экономичное хранилище и обеспечить его подключение к сети для удобного доступа к данным.
-
Интегрироваться со средствами бизнес-аналитики. Можно использовать PolyBase со средствами бизнес-аналитики и стеком технологий анализа Майкрософт, а также применять любые сторонние средства, совместимые с SQL Server.
vSphere storage considerations for SQL Server workloads ^
One of the main reasons for bad performance is and always was storage. As SQL Server workloads consume a huge number of input/output operations per second (IOPS), it’s crucial to select your datastore accordingly.
VMware recommends placing SQL Server workloads on Virtual Machine File System 6 (VMFS6) formatted datastores. (vSphere 6.5 and 6.7). You should definitely avoid placing a VM hosting SQL Server on a VMFS3 or VMFS3-upgraded datastore. It will negatively affect disk performance and thus the overall VM performance.
For the most critical databases where performance requirements are the top priority, you should have a one-to-one mapping between Virtual Machine Disks (VMDKs) and logical unit numbers (LUNs). This means one VMDK per datastore.
Note that supported storage types include Network File System (NFS) and raw device mapping (RDM) in physical compatibility mode. vSphere version 6.0 and later support vMotion of a VM with an RDM disk in physical compatibility mode.
SSD backed-up datastores are necessary for high-performance SQL Server workloads, so consider using all-flash storage.
Ограничить максимальный объем памяти сервера MS SQL Server.
Необходимо ограничить максимальный объем памяти, потребляемый MS SQL Server, особенно это критично, если роли сервера 1С и сервера СУБД совмещены. Максимальный объем памяти, рекомендуемый для MS SQL Server, можно рассчитать по следующей формуле:
Память для MS SQL Server = Память всего – Память для ОС – Память для сервера 1С
Например, на сервере установлено 64 ГБ оперативной памяти, необходимо понять, сколько памяти выделить серверу СУБД, чтобы хватило серверу 1С.
Для нормальной работы ОС в большинстве случаев более чем достаточно 4 ГБ, обычно – 2-3 ГБ.
Чтобы определить, сколько памяти требуется серверу 1С, необходимо посмотреть, сколько памяти занимают процессы кластера серверов в разгар рабочего дня. Этими процессами являются ragent, rmngr и rphost, подробно данные процессы рассматриваются в разделе, который посвящен кластеру серверов. Снимать данные нужно именно в период пиковой рабочей активности, когда в базе работает максимальное количество пользователей. Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Чтобы установить максимальный объем памяти, используемый MS SQL Server, необходимо:
-
Запустить Management Studio и подключиться к нужному серверу
-
Открыть свойства сервера и выбрать закладку Память
-
Указать значение параметра Максимальный размер памяти сервера
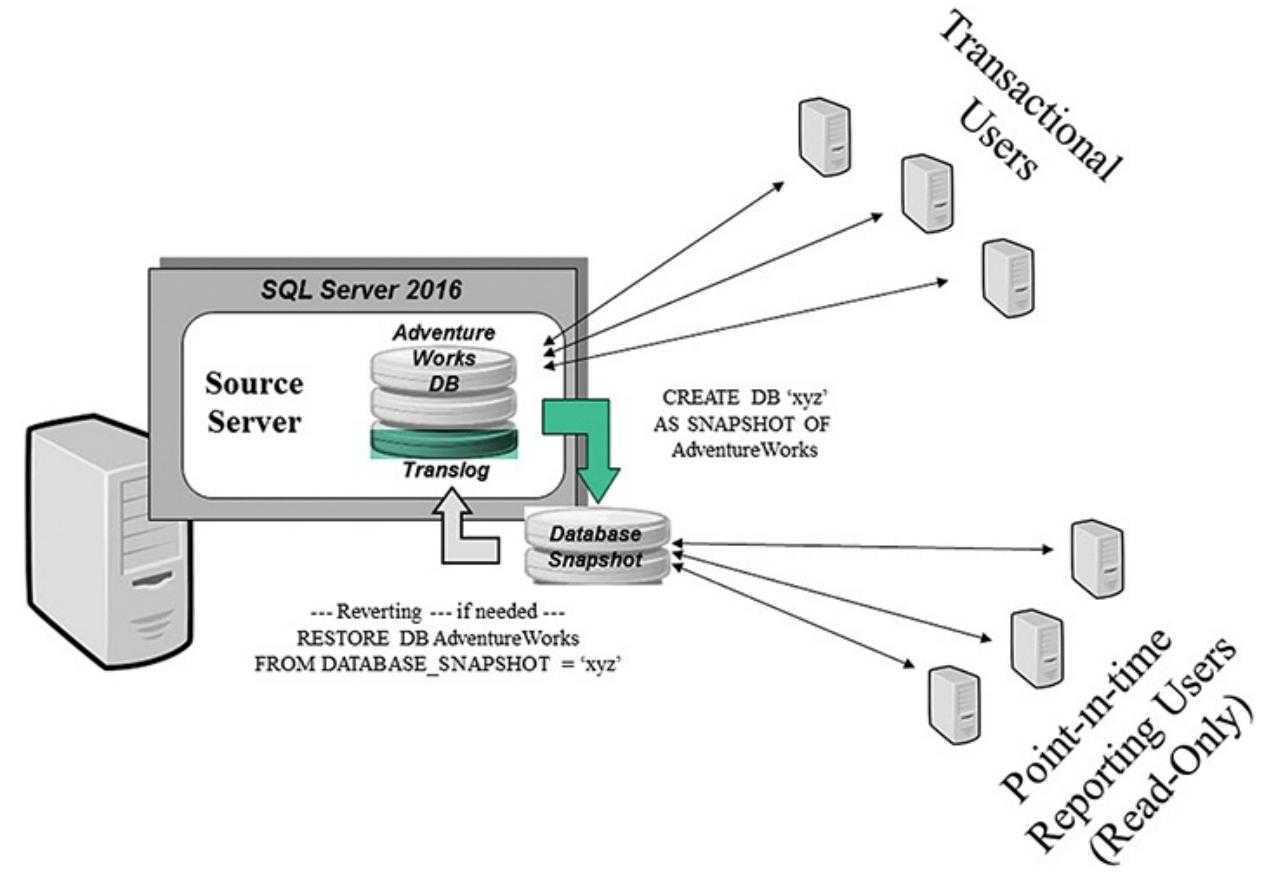
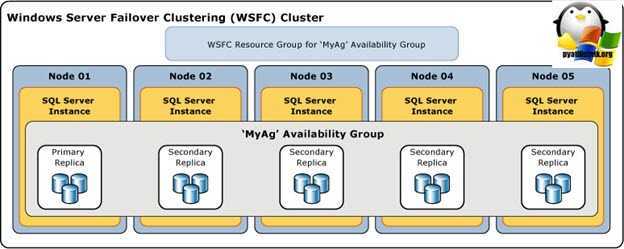
Что такое AlwaysOn в SQL Server 2016
Группы доступности AlwaysOn — это мощнейшее средство в составе дистрибутива SQL, дающее возможность для администраторов баз данных, реализовать очень высокий уровень доступности (HA, high availability) с помощью кластерных технологий и не обязательно иметь общую файловую область (Shared Storage), уменьшить время восстановления (disaster recovery, DR) после аварии или сбоя оборудования. Данная технология, является в моем понимании заменой предыдущей технологии по зеркалированию базы данных (Database Mirroring). Если вы ее уже пробовали на практике, то знаете, что это не синхронная репликация логов транзакций и базы данных.
AlwaysOn умеет в автоматическом или ручном режиме, переводить базу данных или даже группы баз данных на запасной (резервный) ресурс, есть поддержка до 4 вторичных реплик и автоматическое восстановление страниц при ошибках. В рамках этой технологии, можно производить создание кластеров БД, в разных подсетях или же сайтах, есть примеры реализации и между дата центрами.
Модель защиты AlwaysOn
Для того, чтобы что-то развернуть и управлять этим, необходимо разобраться в функциональных возможностях и тонкостях технологии, давай посмотрим за счет чего обеспечивается высокая доступность и отказоустойчивость БД в SQL Server 2016:
Первое на что следует обратить внимание, это на уровень серверов (физическое железо + операционная система Windows Server 2012 R2), тут отказоустойчивость реализована, с помощью кластера WSFC (Windows Server Failover Cluster — отказоустойчивый кластер Windows). Именно данная технология мониторит состояние членов кластера и принимает решение о координации при отказе.
Далее следует уровень SQL Server 2016, тут отказоустойчивость реализовывается возможностями отказоустойчивых кластерных экземпляров AlwaysOn (их еще называют инстансами)
Он разворачивается на нужном количестве узлов кластера Windows Server, и в случае недоступности одного из узлов, будет производится переключение.
Технология групп доступности AlwaysOn — реализуется на уровне баз данных, состоит из одной и более БД, которые будут переведены на дублирующий SQL Server в случае отказа.
Еще хочу отметить уровень, на котором подключаются клиенты, тут соединение возможно, как напрямую к экземпляру SQL Server, либо же используя virtual network name (VNN, виртуального сетевого имени), оно служит для скрытия уровней отказоустойчивого кластера Windows Server и групп доступности AlwaysOn, так же делает перенаправление запросов клиентов на нужные экземпляры SQL Server 2016 и реплику БД
Что входит в группы доступности AlwaysOn
Если обратиться к сайту Microsoft, то там можно обнаружить вот такие вещи, AlwaysOn легко взаимодействует со средой баз данных доступности, данные группы доступности содержат набор баз данных получателей и источников. Реплики доступности, как раз и размещают базы данных доступности. Реплики доступности бывают вот такие:
- Так называемая, первичная реплика, она содержит БД, являющиеся источником реплик
- И вторая реплика, которая содержит набор БД получателей, напоминаю, их может быть до 4, о чем я уже писал выше.
Когда клиент обращается к данным, их доступность реализуется ну уровне БД, и если по какой-то причине происходит сбой на ее уровне, это не может быть причиной переключиться на другую реплику. Если рассмотреть первичную реплику, то в ней все присутствующие базы данных-источники предоставляются клиентам как на чтение, так и на запись. Когда идет синхронизация данных, то запускается механизм передачи журнала транзакций из БД-источника во все базы получателей. Там журнал будет закэширован и лишь, когда будет осуществлена передача, будет выполнена транзакция в БД-получателей. Из чего видно, что обмен осуществляется независимо, и сбои не затрагивают остальные базы данных получателей.
Как я и писал выше, вам потребуется развернуть отказоустойчивый кластер Windows Server Failover Cluster на Windows Server 2012 R2 и выше. Ваши реплики будут располагаться на разных его узлах, но в рамках одного Windows Server Failover Cluster, в группах доступности отсутствует роль следящего.
Additional Configuration
On the next step is the option to select an operating system installation media from an ISO file. I recommend selecting the bootable ISO image file now instead of later. By selecting an image now, the wizard will add the virtual optical drive for you automatically versus having to manually adding it later.
Figure 8
Your VM administrator should have the appropriate ISO containing the Windows version and edition required made accessible to the host. You will need the path to the ISO for this step. Specify the appropriate ISO and continue, as shown in Figure 9.
Figure 9
The final step presents a summary of your initial configuration options. Select ‘Finish’ to have Hyper-V construct this empty VM. At this point, we are not finished quite yet, but your VM should now appear in the list of virtual machines on this host.
Figure 10
We now need to refine the virtual hardware configuration, and add additional virtual disks. After selecting your VM, select Settings on the Actions column on the right as shown in Figure 10.
Under the Firmware section, select the box to enable Secure Boot.
Figure 11
Secure Boot enables the UEFI firmware for the operating system, which helps improve the boot time of the VM, and enables drive-level encryption technologies.
Не думай о миллисекундах с высока
Поскольку все были озадачены такими результатами, были подключены администраторы СУБД по другим системам. Две головы как говорится лучше двух и была найдено еще одно противоречие с реальностью.
Странно, Avg Disk sec \ Transfer сильно отличалось от Service Time которое регистрирует VMWare при обращениях к диску
Ниже Вы видите 2 мс Service time против 20 мс Avg Disk sec / transfer в счетчиках Windows over VMWare!
Поиск в сети вывел на статью
How Windows performance counters are affected by running under VMware ESX где подробно изложена проблема VMWare приводящая к “неточностям “ измерений в Windows. Не знаю когда это исправят, но такие «неточности» приводят к логической проблеме
Исходные данные кривые & Алгоритм анализа верен = Результат анализа кривой
Поскольку данный факт не объяснял отставание производительности виртуального кластера от реального, исследования продолжили. Было ясно что, что-то еще душит связку процессор, память , взаимодействие с устройствами. Диски\Контроллеры пока можно было исключить
Сокращение данных в Unity (все модели) и расширенная поддержка дедупликации
| Версия Unity OE | Технология | Поддерживаемый тип пула | Поддерживаемые модели |
|---|---|---|---|
| 4.3 / 4.4 | Сокращение объема данных | Пул флэш-памяти — традиционный или динамический | 300, 400, 500, 600, 300F, 400F, 500F, 600F, 350F, 450F, 550F, 650F |
| 4.5 |
Сокращение объема данных | 300, 400, 500, 600, 300F, 400F, 500F, 600F, 350F, 450F, 550F, 650F | |
| Сокращение объема данных и расширенная дедупликация* | 450F, 550F, 650F | ||
| 5 |
Сокращение объема данных | 300, 400, 500, 600, 300F, 400F, 500F, 600F, 350F, 450F, 550F, 650F, 380, 480, 680, 880, 380F, 480F, 680F, 880F | |
| Сокращение объема данных и расширенная дедупликация | 450F, 550F, 650F, 380, 480, 680, 880, 380F, 480F, 680F, 880F |
* Сокращение объема данных по умолчанию отключено, и его нужно включить до того, как расширенная дедупликация станет доступной опцией. После включения сокращения объема данных расширенная дедупликация доступна, но по умолчанию она отключена.
Обновление до SQL Server 2022
Начиная с SQL Server 2022 (16.x) Hortonworks Data Platform (HDP) и Cloudera Distributed Hadoop (CDH) больше не поддерживаются. Из-за этих изменений перед миграцией на SQL Server 2022 (16.x) необходимо вручную удалить внешние источники данных PolyBase, созданные в предыдущих версиях SQL Server, которые используют службу хранилища Azure. Для удаления внешних источников данных также требуется удалить связанные объекты базы данных, такие как учетные данные для базы данных и внешние таблицы.
Соединители службы хранилища Azure необходимо изменить на основе приведенной ниже справочной таблицы:
| Внешний источник данных | Исходный тип | Кому |
|---|---|---|
| хранилище BLOB-объектов Azure | wasb(s) | abs |
| ADLS 2-го поколения | abfs(s) | adls |
Подключение к виртуальной машине Linux
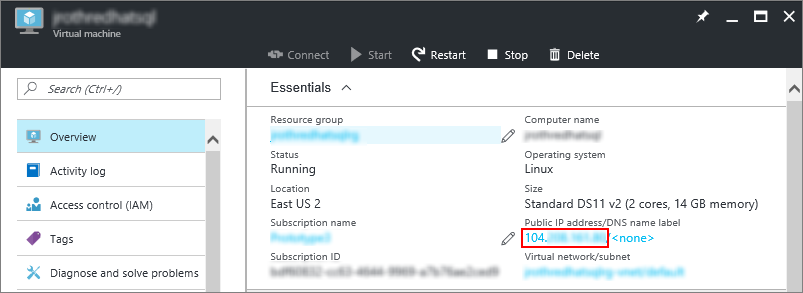
Если вы уже используете оболочку BASH, подключитесь к виртуальной машине Azure с помощью команды SSH. В следующей команде замените имя пользователя и IP-адрес виртуальной машины, чтобы подключиться к виртуальной машине Linux.
IP-адрес виртуальной машины можно найти на портале Azure.
Если вы используете Windows и у вас нет оболочки BASH, установите клиент SSH, например PuTTY.
-
Запустите PuTTY.
-
На экране настройки PuTTY введите общедоступный IP-адрес виртуальной машины.
-
Выберите Открыть и введите имя пользователя и пароль при появлении запросов.
Дополнительные сведения о подключении к виртуальным машинам Linux см. в статье Создание виртуальной машины Linux с помощью портала Azure.
Примечание
Если вы видите оповещение системы безопасности PuTTY о том, что ключ узла сервера не кэшируется в реестре, выберите один из следующих параметров. Если вы доверяете этому узлу, выберите Да, чтобы добавить ключ в кэш PuTTy и продолжить подключение. Если вы хотите продолжить подключение один раз, не добавляя ключ в кэш, выберите Нет. Если вы не доверяете этому узлу, выберите Отмена, чтобы прервать подключение.
Virtual Networking
Virtual machines need a way to connect to a network segment on a physical network. The hypervisor accomplishes this is by creating a named virtual network. This network is mapped to a virtual switch, essentially a traffic routing engine inside the hypervisor. The virtual switch is then connected to one or more physical network adapters on the physical host. When a virtual network adapter on a virtual machine is assigned to a particular named virtual network, the traffic routes out to the physical network through these layers.
Multiple virtual networks can be created. Traffic can be segregated or directed in a number of directions, usually through the extension of a VLAN. A VLAN allows traffic to be isolated or routed in a certain manner, all while multiple VLANs can share a physical network adapter port. A virtual network can be assigned a VLAN tag, which assigns that traffic to a particular VLAN.
Describe your networking requirements to your VM administrators and they should be able to configure the networking layer for you.
For example, let’s say you wanted to configure Availability Groups in virtual machines, and you want to isolate Availability Group communication and backup traffic. In this diagram, three virtual networks, represented by the colored lines, are present for use for virtual machine traffic.
Figure 3- Example of a virtual network
The two SQL Servers that are part of the Availability Group (SQLAG01 and SQLAG02 shown above) contain three virtual network adapters. The third stand-alone instance (SQL09) just contains two. Each of these adapters is connected to an individual virtual network. Each virtual network is configured to use a separate VLAN tag, or VLAN assignment. If the networking underneath is set to not route traffic across VLANs, one server’s network adapter on one VLAN would not be able to “see” the network adapters on other VMs that are not assigned to the same VLAN.
For example, in the above diagram, SQL09 would not be able to access the Availability Group replica traffic taking place on VLAN61.
The flexibility that this presents is limitless. Availability Group traffic can be isolated to allow for the maximum performance without worrying about network congestion from other virtual machines. Backup traffic can be isolated for security purposes. Virtual firewalls can be used to further enhance security, all while eliminating complex physical cabling nightmares or having many network adapters on each physical machine.



